johns hopkins & purdue 1 12 jul 05 scalability, accountability and instant information access...
TRANSCRIPT

Johns Hopkins & Purdue 112 Jul 05
Scalability, Accountability and Instant Information Access for
Network Centric Warfare
Department of Computer ScienceJohns Hopkins University
Yair Amir, Claudiu Danilov, Jon Kirsch, John Lane, Jonathan Shapiro
Chi-Bun Chan, Cristina Nita-Rotaru, Josh OlsenDavid Zage
Department of Computer SciencePurdue University
http://www.cnds.jhu.edu

Johns Hopkins & Purdue 212 Jul 05
Dealing with Insider ThreatsProject goals:
• Scaling survivable replication to wide area networks.– Overcome 5 malicious replicas.
– SRS goal: Improve latency by a factor of 3.
– Self imposed goal: Improve throughput by a factor of 3.
• Dealing with malicious clients.– Compromised clients can inject authenticated but
incorrect data - hard to detect on the fly.
– Malicious or just an honest error? Can be useful for both.
• Exploiting application update semantics for replication speedup in malicious environments.– Weaker update semantics allows for immediate
response.
Today we focus on scaling survivable replication to wide area networks.Introducing Steward: Survivable Technology for Wide Area Replication.
Johns Hopkins & Purdue 312 Jul 05
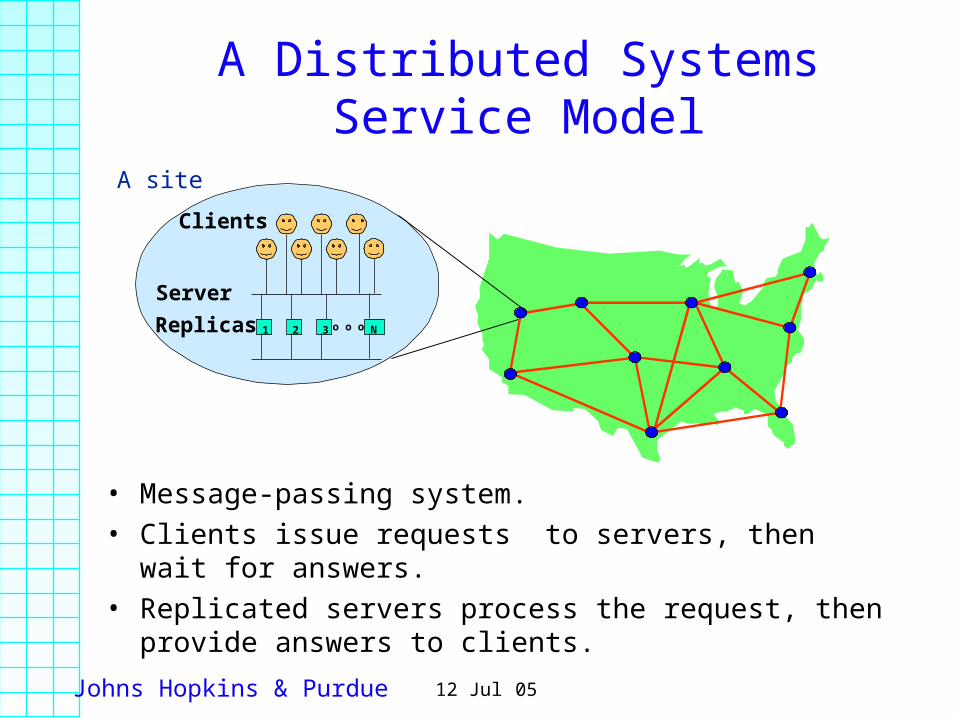
A Distributed Systems Service Model
• Message-passing system.
• Clients issue requests to servers, then wait for answers.
• Replicated servers process the request, then provide answers to clients.
Server
Replicas 1 o o o2 3 N
Clients
A site

Johns Hopkins & Purdue 412 Jul 05
State Machine Replication
• Main Challenge: Ensuring coordination between servers.– Requires agreement on the request to be
processed and consistent order of requests.
• Benign faults: Paxos [Lam98,Lam01]: must contact f+1 out of 2f+1 servers and uses 2 rounds to allow consistent progress.
• Byzantine faults: BFT [CL99]: must contact 2f+1 out of 3f+1 servers and uses 3 rounds to allow consistent progress.
Johns Hopkins & Purdue 512 Jul 05
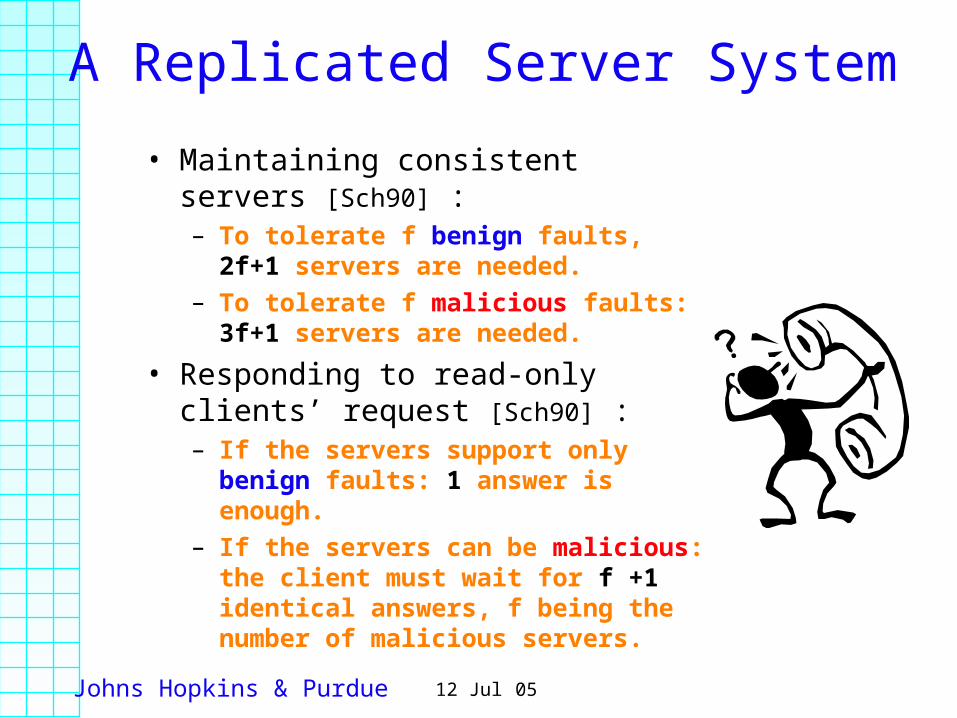
A Replicated Server System
• Maintaining consistent servers [Sch90] :– To tolerate f benign faults, 2f+1
servers are needed.– To tolerate f malicious faults: 3f+1
servers are needed.
• Responding to read-only clients’ request [Sch90] :– If the servers support only benign
faults: 1 answer is enough.– If the servers can be malicious: the
client must wait for f +1 identical answers, f being the number of malicious servers.

Johns Hopkins & Purdue 612 Jul 05
Peer Byzantine Replication Limitations
• Construct consistent total order.• Limited scalability due to 3 round all-peer
exchange.• Strong connectivity is required.
– 2f+1 (out of 3f+1) to allow progress and f+1 to get an answer.
• Partitions are a real issue.• Clients depend on remote information.
– Bad news: Provably optimal.• We need to pay something to get something else.
Johns Hopkins & Purdue 712 Jul 05
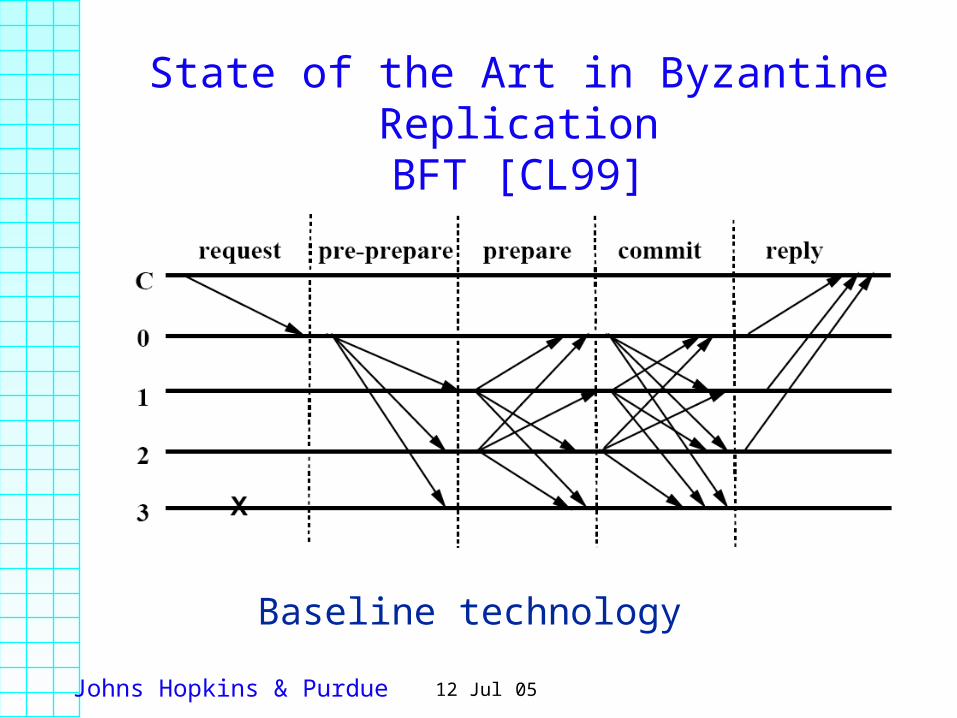
State of the Art in Byzantine ReplicationBFT [CL99]
Baseline technology
Johns Hopkins & Purdue 812 Jul 05
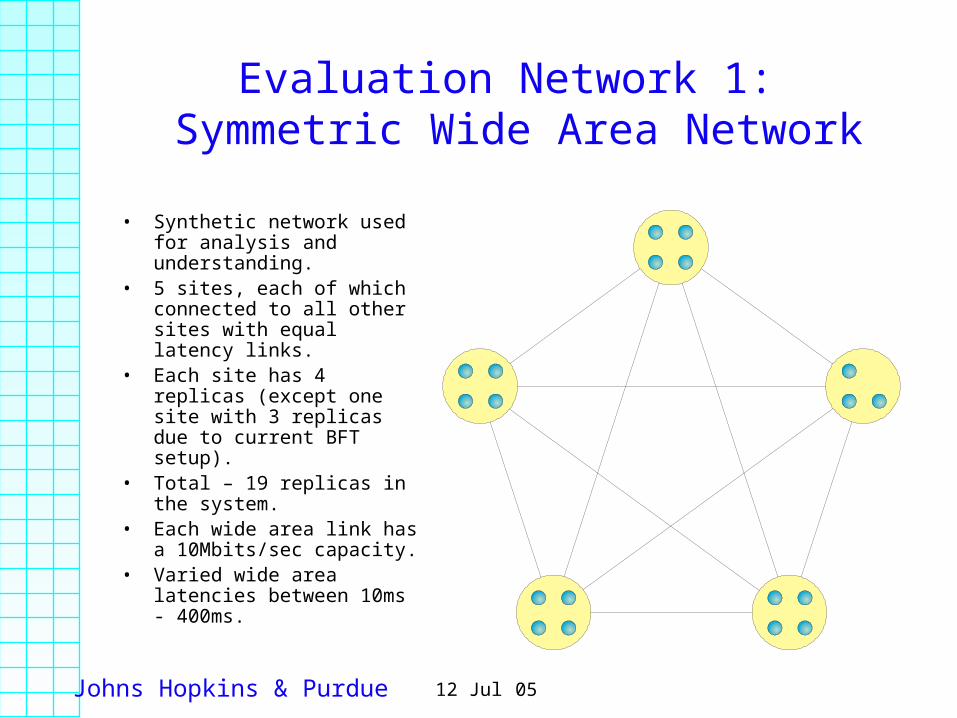
Evaluation Network 1: Symmetric Wide Area Network
• Synthetic network used for analysis and understanding.
• 5 sites, each of which connected to all other sites with equal latency links.
• Each site has 4 replicas (except one site with 3 replicas due to current BFT setup).
• Total – 19 replicas in the system.
• Each wide area link has a 10Mbits/sec capacity.
• Varied wide area latencies between 10ms - 400ms.
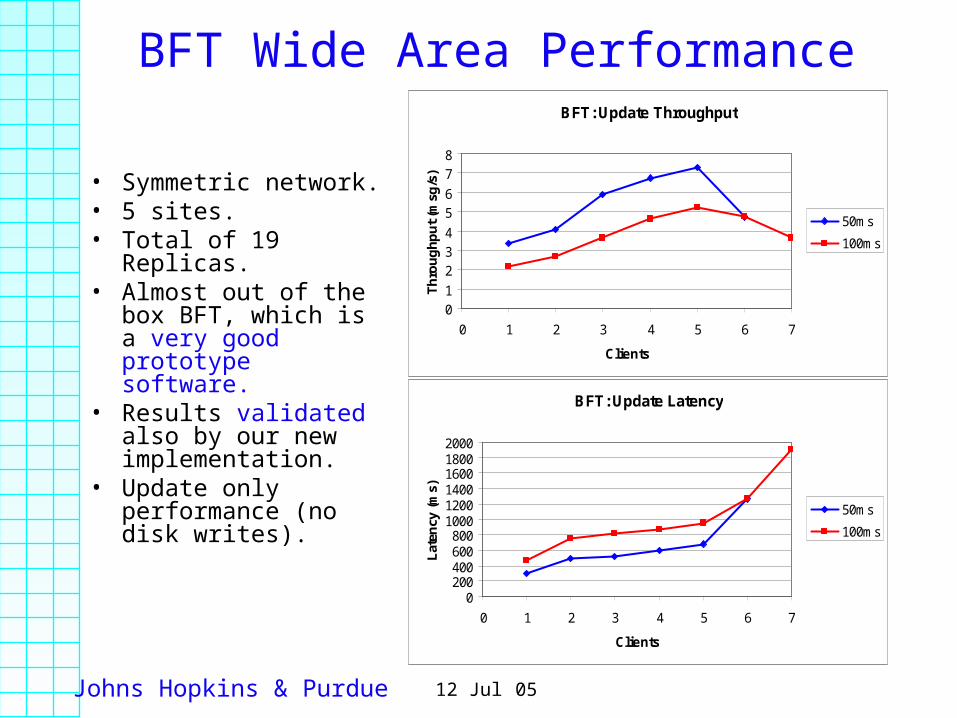
Johns Hopkins & Purdue 912 Jul 05
BFT Wide Area Performance
• Symmetric network.• 5 sites. • Total of 19 Replicas.• Almost out of the box
BFT, which is a very good prototype software.
• Results validated also by our new implementation.
• Update only performance (no disk writes).
BFT: Update Throughput
01
234
56
78
0 1 2 3 4 5 6 7
Clients
Th
rou
gh
pu
t (m
sg/s
)
50ms
100ms
BFT: Update Latency
0200400600800
100012001400160018002000
0 1 2 3 4 5 6 7
Clients
Lat
ency
(m
s)
50ms
100ms
Johns Hopkins & Purdue 1012 Jul 05
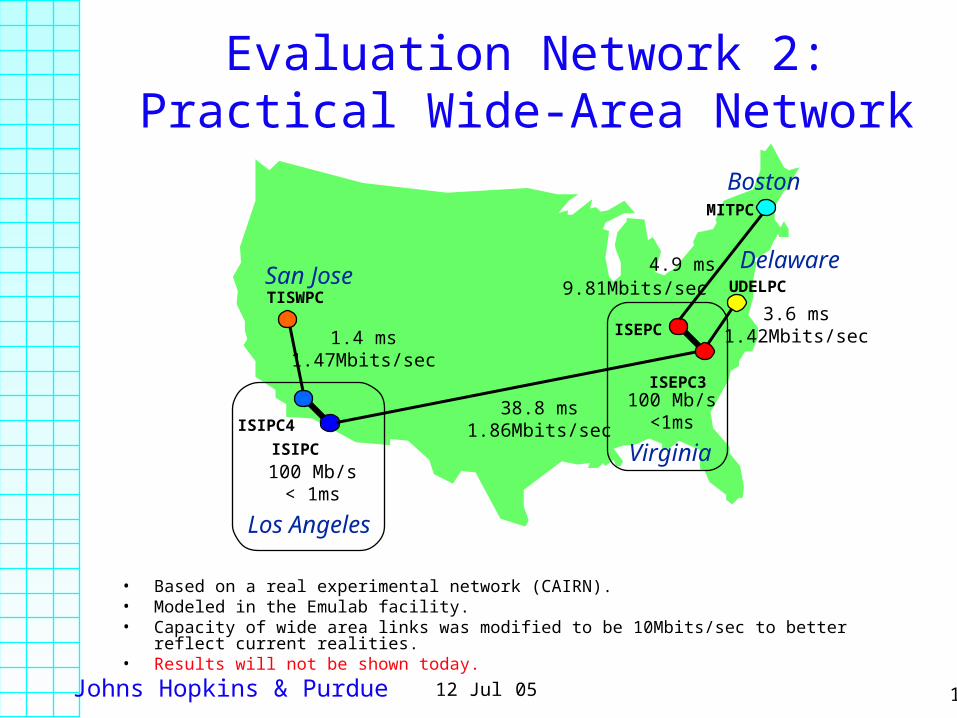
Evaluation Network 2:Practical Wide-Area Network
• Based on a real experimental network (CAIRN). • Modeled in the Emulab facility.• Capacity of wide area links was modified to be 10Mbits/sec to better reflect current realities.• Results will not be shown today.
ISIPC
ISIPC4
TISWPC
ISEPC3
ISEPC
UDELPC
MITPC
38.8 ms1.86Mbits/sec
1.4 ms1.47Mbits/sec
4.9 ms9.81Mbits/sec
3.6 ms1.42Mbits/sec
100 Mb/s< 1ms
100 Mb/s<1ms
Virginia
Delaware
Boston
San Jose
Los Angeles

Johns Hopkins & Purdue 1112 Jul 05
Outline• Project goals.• Byzantine replication – current state of the art.• Steward – a new hierarchical approach.• Confining the malicious attack effects to the
local site.– BFT-inspired protocol for the local area site.– Threshold Cryptography for trusted sites.
• Fault tolerant replication for the wide area.– Initial thinking and snags. – A Paxos-based approach.
• Putting it all together.• Evaluation.• Summary.

Johns Hopkins & Purdue 1212 Jul 05
Steward: Survivable Technology for Wide Area Replication
• Each site acts as a trusted logical unit that can crash or partition.
• Effects of malicious faults are confined to the local site.• Between sites:
– Fault-tolerant protocol between sites.– Alternatively – Byzantine protocols also between sites.
• There is no free lunch – we pay with more hardware…
Server
Replicas 1 o o o2 3 3f+1
ClientsA site

Johns Hopkins & Purdue 1312 Jul 05
Steward Architecture
Local AreaByzantine
Replication
Mon
itorWide Area
Fault TolerantReplication
Server Replica 1
Wide area representative
Local AreaByzantine
Replication
Mon
itorWide Area
Fault TolerantReplication
Server Replica 2
Wide area standby
Local AreaByzantine
Replication
Mon
itorWide Area
Fault TolerantReplication
Server Replica 3f+1
Wide area standby
o o o
Wide area network
Local area network
Local SiteClients

Johns Hopkins & Purdue 1412 Jul 05
Outline• Project goals.• Byzantine replication – current state of the art.• Steward – a new hierarchical approach.• Confining the malicious attack effects to the
local site.– BFT-inspired protocol for the local area site.– Threshold Cryptography for trusted sites.
• Fault tolerant replication for the wide area.– Initial thinking and snags. – A Paxos-based approach.
• Putting it all together.• Evaluation.• Summary.

Johns Hopkins & Purdue 1512 Jul 05
Constructing a Trusted Entity in the Local Site
No trust between participants in a site:– A site acts as one unit that can only crash if the
assumptions are met.
Main ideas: • Use a BFT-like [CL99, YMVAD03] protocol to
mask local Byzantine replicas.– Every update or acknowledgement from a site will
need to go through some sort of agreement.
• Use threshold cryptography to make sure local Byzantine replicas cannot misrepresent the site. – Every valid message going out of the site will
need to first be signed using at least {f+1 out of n} threshold cryptography.

Johns Hopkins & Purdue 1612 Jul 05
Lessons Learned (1)• Vector HMACs vs Signatures:
– BFT’s good performance in LAN is attributed also to the use of vector HMACs, facilitated by establishing pair-wise secret keys between local replicas.
– Key decision: Use signatures, not HMACs.• Computing power trend works against using HMACs.• Signatures provide non repudiation, while HMACs do not.• Simplifying the protocol during view changes.• Vector HMAC is less scalable (mainly in terms of space).• Steward is designed for 5-10 years from now.
• Not every message out requires a complete BFT invocation:– Acknowledgements require a much lighter protocol
step.

Johns Hopkins & Purdue 1712 Jul 05
Lessons Learned (2)• {f+1 out of n} or {2f+1 out of n} threshold
cryptography:– Performance tradeoff:
• Need f+1 contributing replicas to mask effects of malicious behavior. Need 2f+1 to pass a Byzantine agreement.
• Either use the last round of BFT and create {2f+1 out of n} signature, or add another round after BFT and create {f+1 out of n} signature.
• A complete system requires a complete protocol:– Past research focus on the correctness of ordering, but
not on issues such as generic reconciliation after network partitions and merges, flow control, etc.
– The devil is in the details.

Johns Hopkins & Purdue 1812 Jul 05
Useful By-Product:Threshold Cryptography Library
• We implemented a library providing support for generating Threshold RSA signatures.
• Critical component of the Steward architecture.• Implementation is based on OpenSSL.• Can be used by any application requiring threshold
digital signatures.• We plan to release it as open source.• Let us know if you are interested in such a library.

Johns Hopkins & Purdue 1912 Jul 05
Outline• Project goals.• Byzantine replication – current state of the art.• Steward – a new hierarchical approach.• Confining the malicious attack effects to the
local site.– BFT-inspired protocol for the local area site.– Threshold Cryptography for trusted sites.
• Fault tolerant replication for the wide area.– Initial thinking and snags. – A Paxos-based approach.
• Putting it all together.• Evaluation.• Summary.
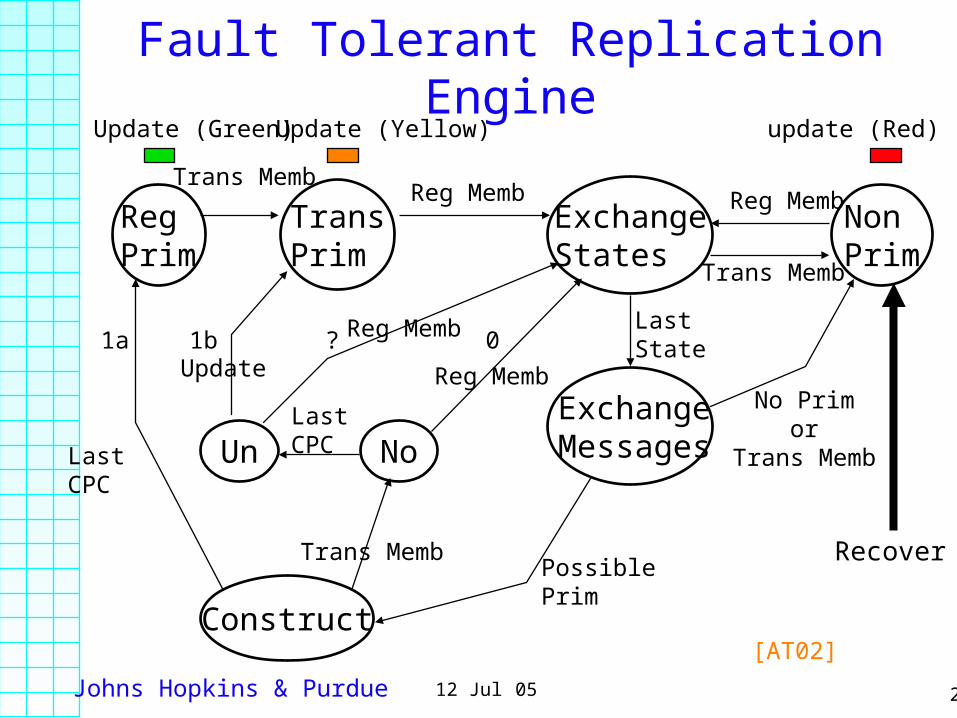
Johns Hopkins & Purdue 2012 Jul 05
Fault Tolerant Replication Engine
RegPrim
TransPrim
ExchangeStates
NonPrim
Construct
Trans Memb
ExchangeMessagesUn No
Last CPCLast
CPC
LastState
PossiblePrim
No Primor
Trans Memb
Recover
Trans Memb
Reg MembReg MembTrans Memb
Reg Memb
Reg MembUpdate
update (Red)Update (Yellow)Update (Green)
1a 1b ? 0
[AT02]
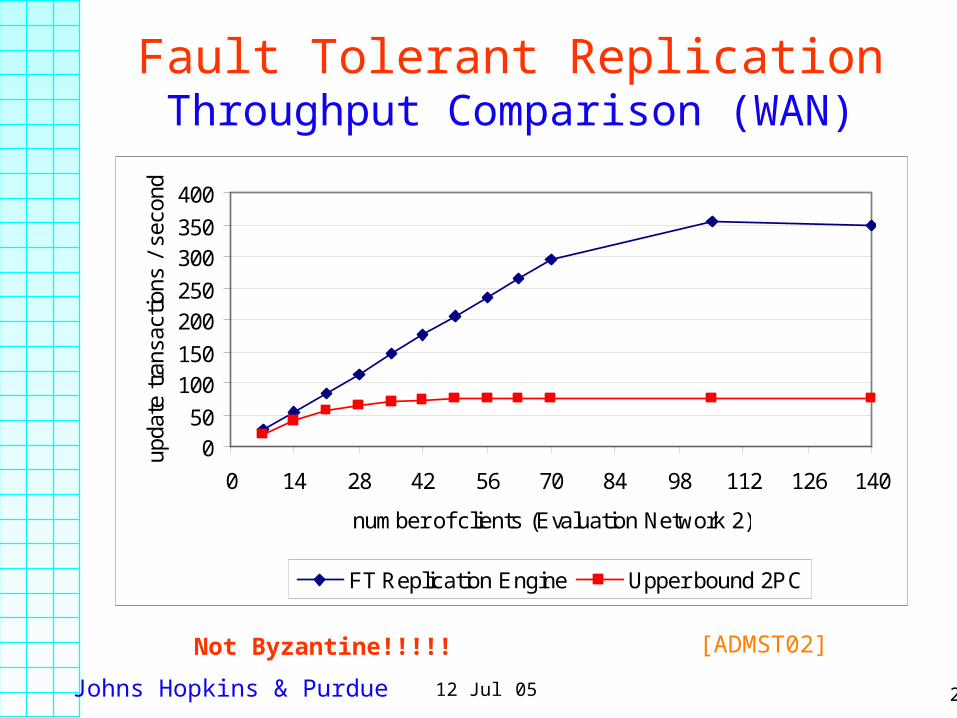
Johns Hopkins & Purdue 2112 Jul 05
Fault Tolerant ReplicationThroughput Comparison (WAN)
050
100150
200250
300350
400
0 14 28 42 56 70 84 98 112 126 140
number of clients (Evaluation Network 2)
upda
te t
rans
actio
ns /
sec
ond
FT Replication Engine Upper bound 2PC
[ADMST02]Not Byzantine!!!!!

Johns Hopkins & Purdue 2212 Jul 05
The Paxos ProtocolNormal Case, after leader election
[Lam98]
Key: A simple end-to-end algorithm
C
0
1
2
request proposal accept reply

Johns Hopkins & Purdue 2312 Jul 05
Lessons Learned (1)• Hierarchical architecture vastly reduces the
number of messages sent on the wide area network:– Helps both in throughput and latency.
• Using a fault tolerant protocol on the wide area network reduces the number of mandatory wide area crossings compared with a Byzantine protocol.– BFT-inspired protocols require 3 wide area crossings
for updates generated at leader site, and 4 otherwise.– Paxos-based protocols require 2 wide area crossings
for updates generated at leader site and 3 otherwise.

Johns Hopkins & Purdue 2412 Jul 05
Lessons Learned (2)
• All protocol details have to be specified:– Paxos papers lack most of the details…
• Base operation – specified reasonably well.• Leader election – completely unspecified.• Reconciliation – completely unspecified.• Also not specified (but that is ok) are practical
considerations, such as retransmission handling and flow control.
• The view change / leader election is the most important part, consistency wise:– Determines the liveness criteria of the overall
system.

Johns Hopkins & Purdue 2512 Jul 05
Example: Liveness Criteria• Strong L1:
– If there exists a time after which there is always some set of running, connected servers S, where |S| is at least a majority, then if a server in the set initiates an update, some member of the set eventually executes the update.
• L1:– If there exists a set consisting of a majority of servers, and a time after
which the set does not experience any communication or process failures, then if a server in the set initiates an update, some member of the set eventually executes the update.
• Weak L1:– If there exists a set consisting of a majority of servers, and a time after
which the set does not experience any communication or process failures, AND the members of the set do not hear from any members outside of the set, then if a server in the set initiates an update, some member of the set eventually executes the update.

Johns Hopkins & Purdue 2612 Jul 05
What’s the difference?
• Strong L1:– Allows any majority set– Membership of the set can change rapidly, as long as
cardinality remains at least a majority.
• L1:– Requires a stable majority set, but others (beyond the
majority) can come and go.
• Weak L1:– Requires a stable, isolated majority set.

Johns Hopkins & Purdue 2712 Jul 05
Outline• Project goals.• Byzantine replication – current state of the art.• Steward – a new hierarchical approach.• Confining the malicious attack effects to the
local site.– BFT-inspired protocol for the local area site.– Threshold Cryptography for trusted sites.
• Fault tolerant replication for the wide area.– Initial thinking and snags. – A Paxos-based approach.
• Putting it all together.• Evaluation.• Summary.
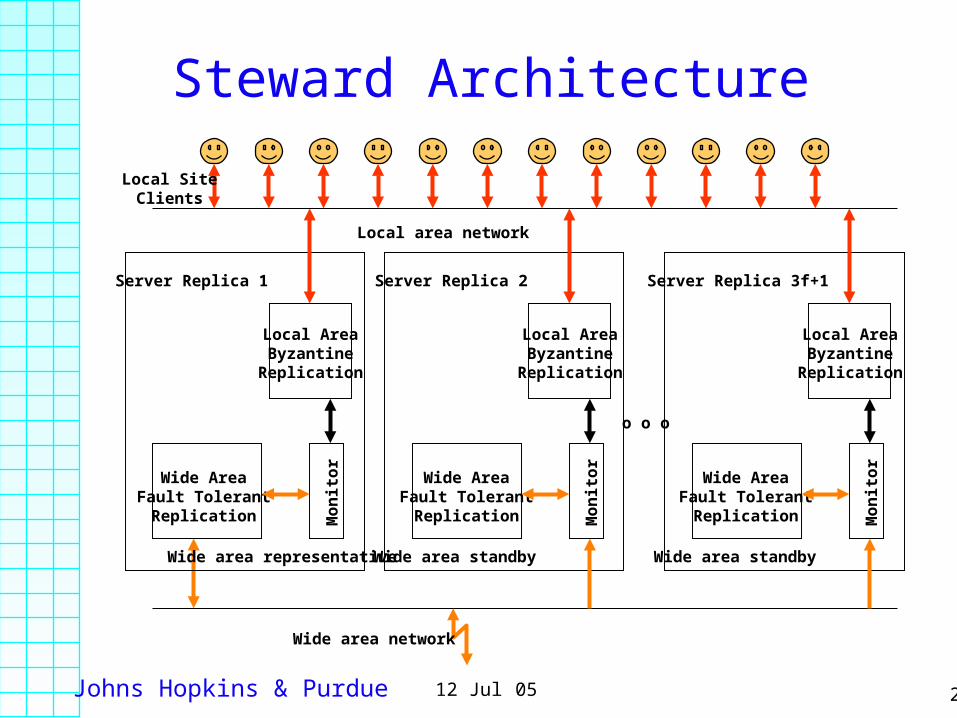
Johns Hopkins & Purdue 2812 Jul 05
Steward Architecture
Local AreaByzantine
Replication
Mon
itorWide Area
Fault TolerantReplication
Server Replica 1
Wide area representative
Local AreaByzantine
Replication
Mon
itorWide Area
Fault TolerantReplication
Server Replica 2
Wide area standby
Local AreaByzantine
Replication
Mon
itorWide Area
Fault TolerantReplication
Server Replica 3f+1
Wide area standby
o o o
Wide area network
Local area network
Local SiteClients

Johns Hopkins & Purdue 2912 Jul 05
Testing Environment
Platform: Dual Intel Xeon CPU 3.2 GHz 64 bits 1 GByte RAM, Linux Fedora Core 3.
Library relies on Openssl :- Used OpenSSL 0.9.7a 19 Feb 2003.
Baseline operations:- RSA 1024-bits sign: 1.3 ms, verify: 0.07 ms.- Perform modular exponentiation 1024 bits, ~1 ms.- Generate a 1024 bits RSA key ~55ms.
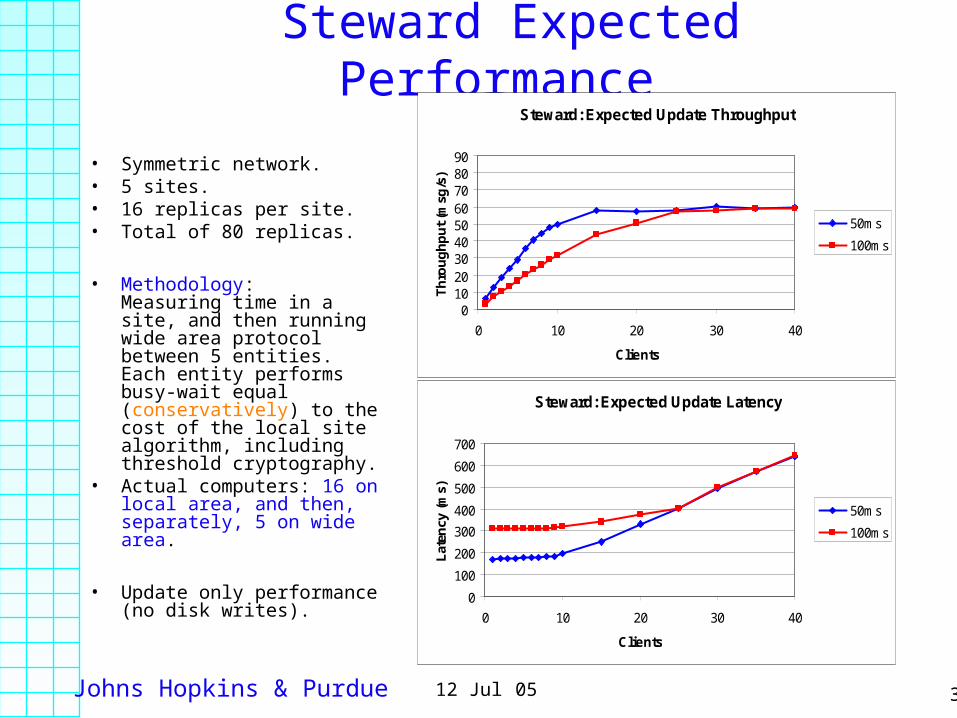
Johns Hopkins & Purdue 3012 Jul 05
Steward Expected Performance
• Symmetric network.• 5 sites.• 16 replicas per site. • Total of 80 replicas.
• Methodology: Measuring time in a site, and then running wide area protocol between 5 entities. Each entity performs busy-wait equal (conservatively) to the cost of the local site algorithm, including threshold cryptography.
• Actual computers: 16 on local area, and then, separately, 5 on wide area.
• Update only performance (no disk writes).
Steward: Expected Update Throughput
0102030405060708090
0 10 20 30 40
Clients
Th
rou
gh
pu
t (m
sg/s
)
50ms
100ms
Steward: Expected Update Latency
0
100
200
300
400
500
600
700
0 10 20 30 40
Clients
Lat
ency
(m
s)
50ms
100ms
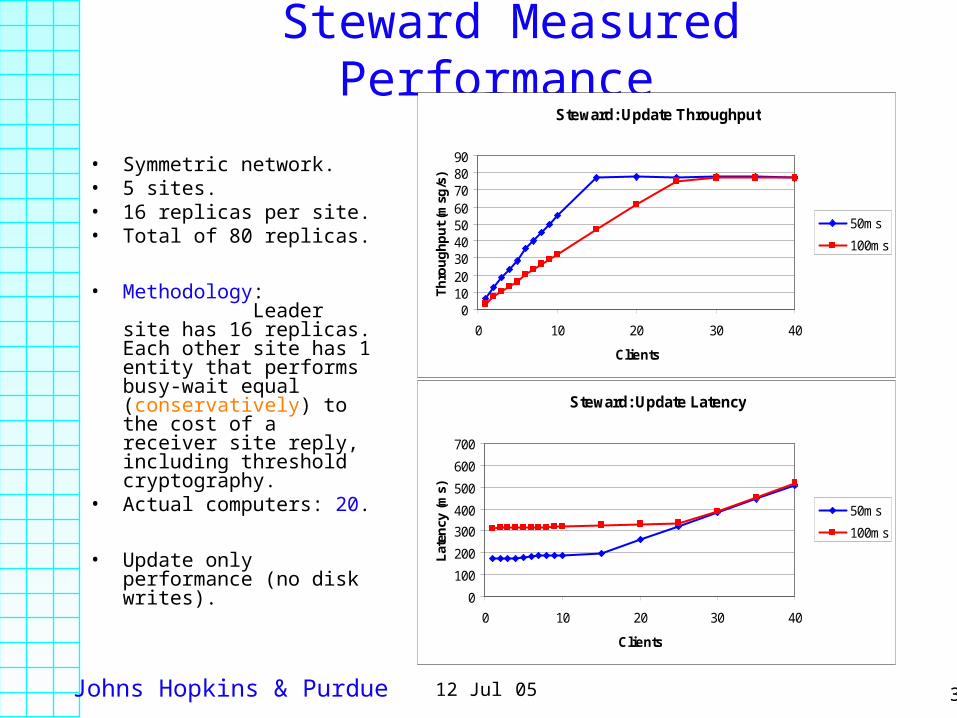
Johns Hopkins & Purdue 3112 Jul 05
Steward Measured Performance
• Symmetric network.• 5 sites.• 16 replicas per site. • Total of 80 replicas.
• Methodology: Leader site has 16 replicas. Each other site has 1 entity that performs busy-wait equal (conservatively) to the cost of a receiver site reply, including threshold cryptography.
• Actual computers: 20.
• Update only performance (no disk writes).
Steward: Update Throughput
0102030405060708090
0 10 20 30 40
Clients
Th
rou
gh
pu
t (m
sg/s
)
50ms
100ms
Steward: Update Latency
0
100
200
300
400
500
600
700
0 10 20 30 40
Clients
Lat
ency
(m
s)
50ms
100ms

Johns Hopkins & Purdue 3212 Jul 05
Head to Head Comparison (1)
• Symmetric network.• 5 sites.• 50ms distance between
each site.• 16 replicas per site. • Total of 80 replicas.• BFT broke after 6 clients.
• SRS goal: Factor of 3 improvement in latency.
• Self imposed goal: Factor of 3 improvement in throughput.
• Bottom line: Both goals are met once system has more than one client, and considerably excided thereafter.
Steward vs BFT: Update Throughput (50ms net)
0102030405060708090
0 10 20 30 40
Clients
Th
rou
gh
pu
t (m
sg/s
)
BFT
Our Goal
Steward
Steward vs BFT: Update Latency (50ms network)
0
200
400
600
800
1000
1200
1400
0 10 20 30 40
Clients
Lat
ency
(m
s) BFT
SRS Goal
Steward
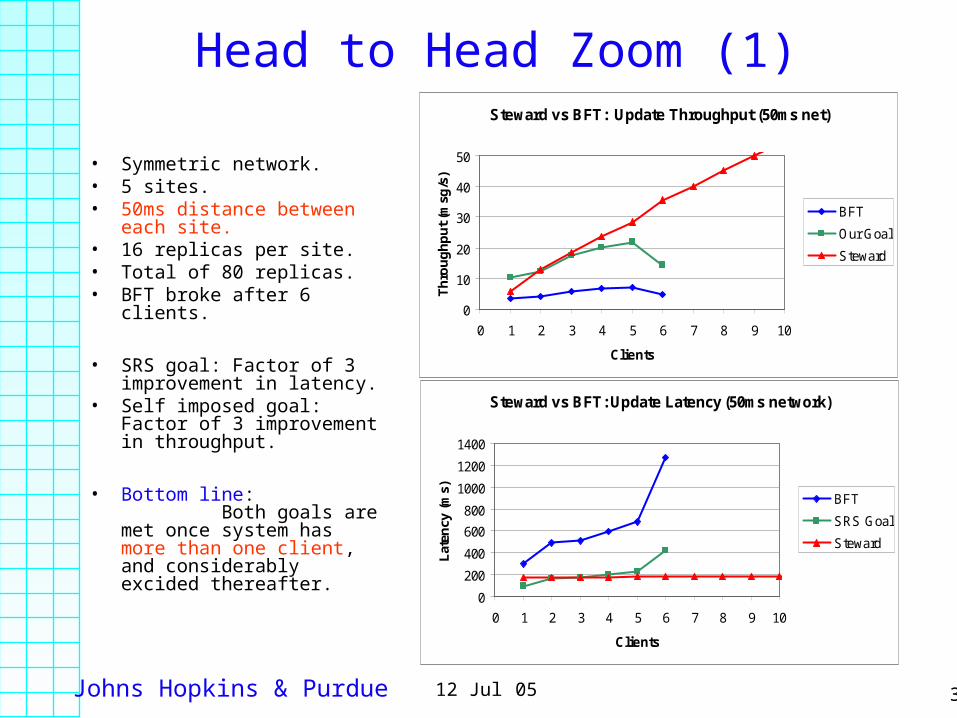
Johns Hopkins & Purdue 3312 Jul 05
Head to Head Zoom (1)
• Symmetric network.• 5 sites.• 50ms distance between
each site.• 16 replicas per site. • Total of 80 replicas.• BFT broke after 6 clients.
• SRS goal: Factor of 3 improvement in latency.
• Self imposed goal: Factor of 3 improvement in throughput.
• Bottom line: Both goals are met once system has more than one client, and considerably excided thereafter.
Steward vs BFT: Update Throughput (50ms net)
0
10
20
30
40
50
0 1 2 3 4 5 6 7 8 9 10
Clients
Th
rou
gh
pu
t (m
sg/s
)
BFT
Our Goal
Steward
Steward vs BFT: Update Latency (50ms network)
0
200
400
600
800
1000
1200
1400
0 1 2 3 4 5 6 7 8 9 10
Clients
Lat
ency
(m
s) BFT
SRS Goal
Steward
Johns Hopkins & Purdue 3412 Jul 05
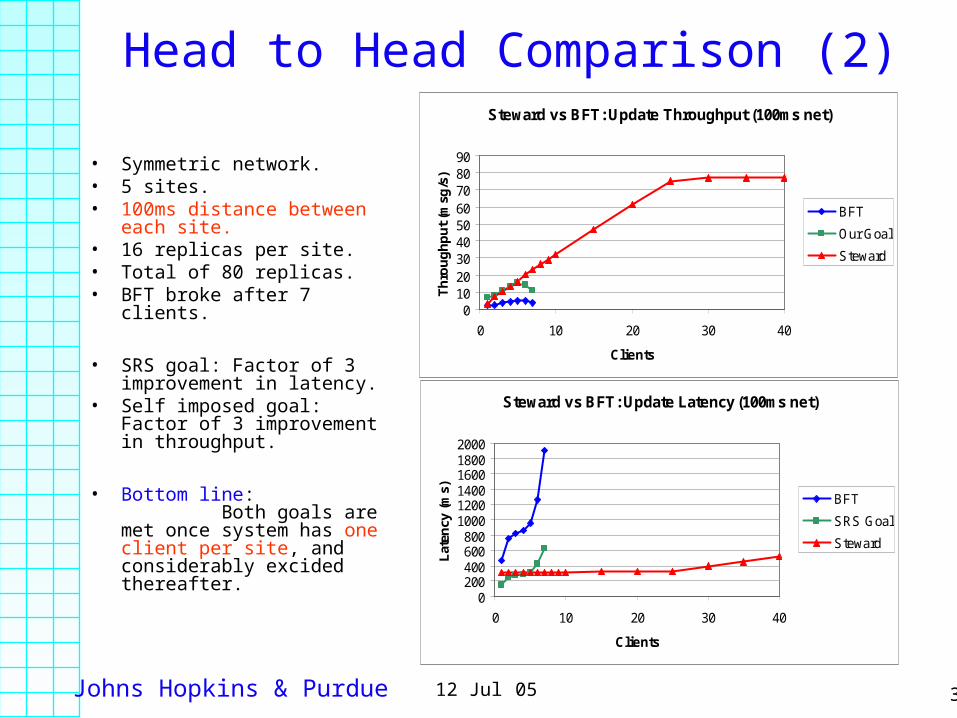
Head to Head Comparison (2)
• Symmetric network.• 5 sites.• 100ms distance between
each site.• 16 replicas per site. • Total of 80 replicas.• BFT broke after 7 clients.
• SRS goal: Factor of 3 improvement in latency.
• Self imposed goal: Factor of 3 improvement in throughput.
• Bottom line: Both goals are met once system has one client per site, and considerably excided thereafter.
Steward vs BFT: Update Throughput (100ms net)
0102030405060708090
0 10 20 30 40
Clients
Th
rou
gh
pu
t (m
sg/s
)
BFT
Our Goal
Steward
Steward vs BFT: Update Latency (100ms net)
0200400600800
100012001400160018002000
0 10 20 30 40
Clients
Lat
ency
(m
s) BFT
SRS Goal
Steward
Johns Hopkins & Purdue 3512 Jul 05
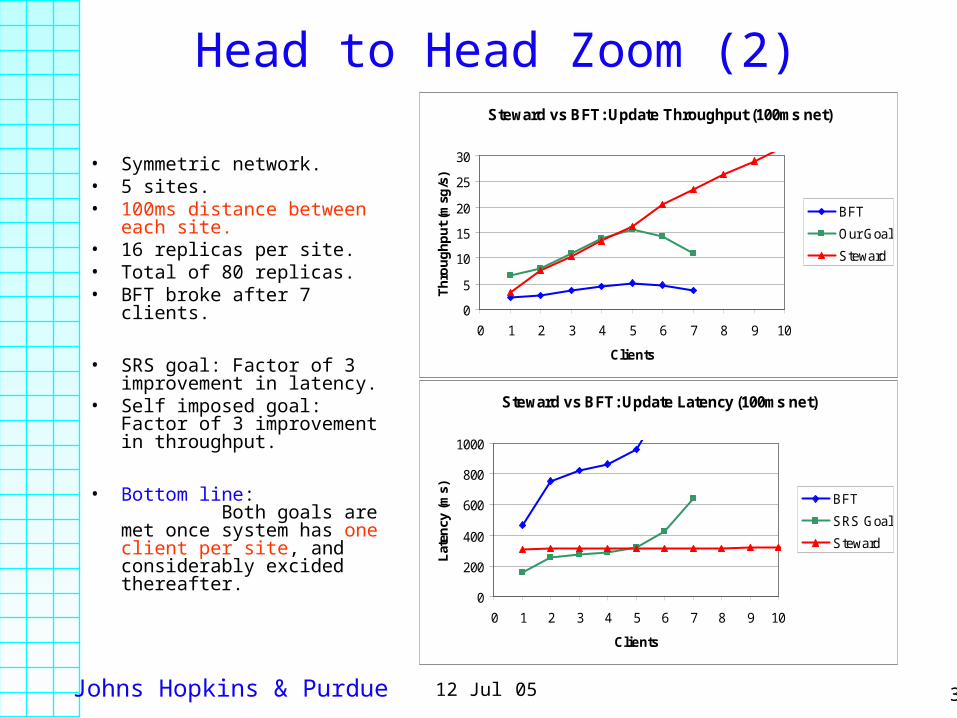
Head to Head Zoom (2)
• Symmetric network.• 5 sites.• 100ms distance between
each site.• 16 replicas per site. • Total of 80 replicas.• BFT broke after 7 clients.
• SRS goal: Factor of 3 improvement in latency.
• Self imposed goal: Factor of 3 improvement in throughput.
• Bottom line: Both goals are met once system has one client per site, and considerably excided thereafter.
Steward vs BFT: Update Throughput (100ms net)
0
5
10
15
20
25
30
0 1 2 3 4 5 6 7 8 9 10
Clients
Th
rou
gh
pu
t (m
sg/s
)
BFT
Our Goal
Steward
Steward vs BFT: Update Latency (100ms net)
0
200
400
600
800
1000
0 1 2 3 4 5 6 7 8 9 10
Clients
Lat
ency
(m
s) BFT
SRS Goal
Steward

Johns Hopkins & Purdue 3612 Jul 05
Factoring Queries In• So far, we only considered updates.
– Worst case scenario from our perspective.• How to factor queries into the game?
– Best answer: Just measure, but we had no time to build the necessary infrastructure and measure.
– Best answer for now: make a conservative prediction. • Steward:
– A query is answered locally after an {f+1 out of n} Threshold Cryptography operation. Cost: ~11ms.
• BFT:– A query requires at least some remote answers in this setup.
Cost: at least 100ms (for 50ms network), 200ms (for 100ms network).
– We could change the setup to include 6 local members in each site (for a total of 30 replicas). That will allow a local answer in BFT with a query cost similar to Steward, but then BFT performance will basically collapse on the updates.
• Bottom line prediction:– Both goals will be met once the system has more than one client,
and will be considerably exceeded thereafter.

Johns Hopkins & Purdue 3712 Jul 05
Impact
New ideas
Scalability, Accountability and Instant Information Access forNetwork-Centric Warfare
ScheduleResulting systems with at least 3 times higher throughput, lower latency and high availability for updates over wide area networks. Clear path for technology transitions intoMilitary C3I systems such as the Army Future Combat System.
http://www.cnds.jhu.edu/funding/srs/
June 04
Dec 04
June05
Dec 05
C3I model, baseline and demo
Componentanalysis & design
ComponentImplement.
System integration & evaluation
Final C3I demoand baseline eval
First scalable wide-area intrusion-tolerant replication architecture.
Providing accountability for authorized but malicious client updates.
Exploiting update semantics to provide instant and consistent information access.
Comp.eval.