julia hirschberg, michiel bacchiani, phil isenhour, aaron rosenberg, larry stead, steve whittaker,...
TRANSCRIPT

Julia Hirschberg, Michiel Bacchiani, Phil Isenhour, Aaron Rosenberg, Larry Stead, Steve Whittaker, Jon Wright, and Gary Zamchick (with
Martin Jansche, Meredith Ringel, and Litza Stark)
SCANMAIL: Audio Browsing and Retrieval in a Voicemail
Domain

2
The Problem: Navigating Audio Data
Increasing amounts of audio data available in corporate, public and private collections (recorded meetings, broadcast news and entertainment, voicemail) – but useless without tools for searching
SCANMail prototype: tool for searching speech data in voicemail domain

3
SCANMail
Inspired by interviews, surveys and usage logs identifying problems of heavy voicemail users: It’s hard to quickly scan through new messages to find
the ones you need to deal with (e.g. during a meeting break)
It’s hard to find the message you want in your archive It’s hard to locate the information you want in any
message (e.g. the telephone number)
SCANMail provides technology to help solve these problems, supporting content-based audio navigation

4
Related Research
Cambridge video mail retrieval by voice (1994)
NIST TREC Spoken Document Retrieval track
IBM voicemail transcription (1998) and information extraction (2001)
AT&T voicemail user studies (1998)
AT&T automatic speaker identification and browsing/search for voicemail (2000, 2001)

SCANMail ArchitectureSCANMail Architecture

6
Training Corpus
Messages collected from 138 AT&T Labs voicemail boxes
100 hr corpus includes ~10K messages from 2500 speakers
Hand-labeled for caller id, gender, age, recording condition, entities (names, dates, telephone numbers)
Gender balanced, ~12% non-native speakers
~10% of calls not from ordinary handsets
Mean message duration 36.4 secs, median 30.0 secs

7
ASR Server: baseline systemTrained on 60 hour training setGender independent, 8k tied states, emission probabilities modeled by 12 component Gaussian mixtures.Uses 14k vocabulary and Katz-style backoff trigram trained on 700k wordsLexicon automatically generated by the AT&T Labs NextGen text to speech systemDecoder uses finite state transducers to construct recognition networkInitial search pass produces lattices used as grammars in all subsequent search passes

8
Accuracy 24.4% wer ~21% with adaptation
Speed 2x real time for first pass Will approach 5-6x real time for final transcription
Details: Bacchiani (HLT2000, ICASSP2000); Hirschberg et al
(Eurospeech2001)


12
Information Retrieval
Uses SMART IR engine (Salton 1971, Buckley 1985)
Generates weighted term vectors for ASR transcripts and queries and computes similarity based on vector inner products
Both ASR transcripts and queries are preprocessed into tokens by removing common words (stop-listing) and stemming


14
Information Extraction
Extracts entities from the ASR transcripts
Old implementation used finite state transducers with hand designed costs
New statistical (trainable) system extracts phone numbers and caller names
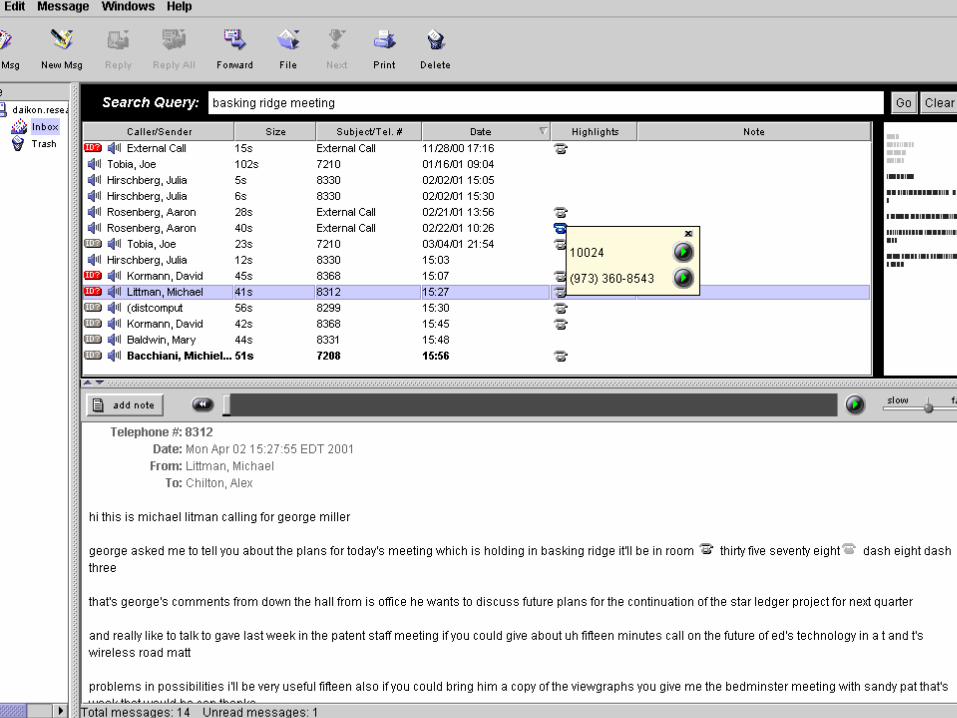

16
Caller Identification
Proposes caller names by matching new incoming messages against existing Text Independent Gaussian Mixture Models (TIGMMs)If no PBX-supplied caller identification, caller ID hypothesis presented to userCaller models trained/adapted based on user feedback Initial model trained after 1 minute of speech collected
from single caller Model updates with each 20sec increment up to 180sec
(mature model)

17
Setting thresholds to keep outgroup acceptance low (2.7%), system had 11.5% ingroup rejection and 1.2% ingroup confusion for 20-caller ingroup.
For more detailed experimental results see Rosenberg (ICSLP 2000, Eurospeech 2001)



20
Email Server
Composes multi-part email message and sends to address specified in user profile ASR transcript Speech file Entity transcriptions and speech segments
Uses time aligned ASR transcript and IE information to include audio excerpts corresponding to entities

21
Evaluation: User Studies
Compared SCANMail with standard over-the-phone interface (Audix)
8 subject performed fact-finding, relevance ranking and summarization tasks
SCANMail Better for fact-finding and ranking tasks in quality/time
measures (p <0.05) Faster solutions for fact-finding task (p<0.01) Rated higher on all subjective measures
Normalized performance scores higher when subject employed successful IR searches (p<0.05)

22
Trials
18 subjects in 2 month field trialUsage: 52% of messages weren’t played completely through Only ~1% of messages deleted
After using SCANMail people thought: “Scanning messages is difficult” (2.84.7) “I frequently replay messages” (1.93.5) “I frequently take notes” (2.64.3) “It’s hard to locate old messages” (2.75.0) “It’s hard to extract info from messages” (2.55.0)

23
Current Status
37 users
Recent improvements More accurate ASR Lighter-weight IR (Lucene) Presentation of information as it becomes available
(e.g. audio only, rough transcript of message) Options for SCANMail email
First versions of phone and Ipaq interfaces built (many interface issues)

24
Research Foci
Additional information extracted from messages (Jansche & Abney) Dates, times Message gisting Message threading
‘Urgent’ and ‘personal’ messages automatically identified (Ringel & Hirschberg)Faster/more accurate ASRMigrate client features to email