keyword search in relational databases jaehui park intelligent database systems lab. seoul national...
TRANSCRIPT

Keyword Search in Relational DatabasesKeyword Search in Relational Databases
Jaehui Park
Intelligent Database Systems Lab. Intelligent Database Systems Lab.
Seoul National UniversitySeoul National University
2009. 02. 12.

Copyright 2009 by CEBT
OutlineOutline
Introduction
Bibliography
Fundamental Characteristics
Research Dimensions
Summary
Future Direction
2

Copyright 2009 by CEBT
Data Querying
IntroductionIntroduction
Querying structured data Relational databases
– A repository for a significant amount of data (e.g. enterprise data)
– RDBMS managing an abstract view of underlying data
Structured Query Language (SQL)– Precise and complete
– Difficult for casual users
Querying unstructured data (Web) documents
– Collection of unstructured (natural language) documents available online
– Search engine The most popular application for information discovery
Keyword search– Simple and user-friendly
– Approximating the precise results In statistical and semantic ways
Deep Web Information over the Web comes out of relational databases
3
Structured
Unstructured
Precise
Easy
Easy way of querying structured data

Copyright 2009 by CEBT
IntroductionIntroduction
Enabling casual users to query relational databases with keywords
“casual users”
– Without any knowledge about the schema information
– Without any knowledge of the query language (SQL)
Search system should have the knowledge in behalf of users
Challenges
Inherent discrepancy of data between IR and DB
– Information often splits across the tables (or tuples) in relational databases
Ex) A single retrieval unit of information4
Relational Databases
ResultsSQLkeywords

Copyright 2009 by CEBT
BibliographyBibliography Proximity
[Goldman et al., VLDB, 1998] Proximity Search in Databases
DataSpot [Palmon et al., VLDB, 1998] DTL's DataSpot - Database Exploration Using Plain Language
[Palmon et al., SIGMOD, 1998] DTL's DataSpot- database exploration as easy as browsing the Web
DBXplorer [Agrawal et al., 2002, ICDE] DBXplorer: a system for keyword-based search over relational databases
BANKS [Hulgeri et al., 2001, DEBU] Keeyword Search in Databases
[Hulgeri et al., 2002, ICDE] Keyword Searching and Browsing in Databases using BANKS
[Kacholia et al., 2005, VLDB] Bidirectional Expansion For Keyword Search
DISCOVER [Hristidis et al., 2002, VLDB] DISCOVER: Keyword search in relational databases
[Hristidis et al., 2003, VLDB] Efficient IR-Style Keyword Search over Relational Databases.
[Liu et al., 2006 SIGMOD] Effective Keyword Search in Relational Databases
ObjectRank [Balmin and Hristidis et al., 2004, VLDB] ObjectRank: Authority-Based Keyword Search in Databases
[Balmin and Hristidis et al., 2008, TODS] Authority-based search on databases
5

Copyright 2009 by CEBT
ProximityProximity
Proximity
Measure of how related objects are
Object related by a distance function
– Shortest path computation
K-neighborhood distance look-up table
6
……………………………
document relational database

Copyright 2009 by CEBT
DataSpotDataSpot
Hyperbase
Modeling data graph
Sub-hyperbase as an answer
Best-first searching
7
Customer ID
…
123456 …
Customers
… Customer ID
… 123456
Orders
Record Record
Field
Field Name Field Value
String Key 12345
6
Text “Customer
”
Text “ID”
Stem
Stem “customer
”
Thesaurus
Stem “client”
Relational Databases
Hyperbase
keywords query
convert
SQLquery

Copyright 2009 by CEBT
DBXplorerDBXplorer
Symbol table index for schema entities
Locating objects efficiently
– Granularity
– Compaction
Schema graph
Join tree enumeration
– Joining several tables on the fly
8
Relational Databases
term.
location
… …
… …
… …
keywords
query

Copyright 2009 by CEBT
BANKSBANKS
Directed (data) graph
Backward edge
Graph traversing algorithm
– NP-hard problem
– Heuristics
Backward Expanding search
Bi-directional expanding search
Rich interface
9

Copyright 2009 by CEBT
DISCOVERDISCOVER
High level representation of the architecture for keyword search in relational databases
Top-k join query processing
Pipeline algorithm
– Threshold [Fagin et al. 2001]
IR-style ranking function
TF-IDF based tuple ranking
10

Copyright 2009 by CEBT
ObjectRankObjectRank
Authority
Measure of how important objects are
– Authority flow graph
Modified Pagerank algorithm
– (Global) ObjectRank algorithm
– Inverse ObjectRank algorithm
11

Copyright 2009 by CEBT
Fundamental CharacteristicsFundamental Characteristics
Identifying schema elements To avoid linearly scanning all the tables
Indexing structure– Inverted index
Processing queries Keyword query processing
– Making the best of the lack of syntax in query keywords
Formalizing internal queries– e.g. SQL
Modeling answers Logical unit of retrieval is not a document
– e.g. Directed Acyclic Graph (DAG)
Ranking answers Assign a single score, which can reflect the semantics of underlying schema, for
each answer
Order the returned answers
12
RDB
RDBMS
Indexing
Processing
Model
Ranking
Search system
k1k2
k3 k4

Copyright 2009 by CEBT
Research DimensionsResearch Dimensions
Model
Processing
Indexing
Ranking
13
Data Representation
Query Representation
Efficient Processing
Top-k query processing
Indexing structure
Ranking
Presentation

Copyright 2009 by CEBT
Data representation (1/4)Data representation (1/4)
Graph model
Data graph
Schema graph
14
Writes
AuthorIDPaperID…
Author
AuthorIDAuthorName…
Paper
PaperIDPaperName…
Cites
CitingCited…
Writes
J.H.Park08
Web Content Summarization Using …
PaperID PaperName
JHParkJ.H.Park08
AuthorID PaperID
SGLeeS.G.Lee08
JHPark Jaehui Park
AuthorID AuthorName
SGLee Sang-goo Lee
Paper
Author

Copyright 2009 by CEBT
Data representation (2/4)Data representation (2/4)
Data graph
Efficient graph traversing
– Search time reducing
Finding an optimal answer
– NP-hard : Steiner tree problem
Heuristics
Size problem
– Too huge to fit into main memory
Maintenance problem
– Not appropriate for update-intensive databases
15
RDB
traversekeywords

Copyright 2009 by CEBT
Data representation (3/4)Data representation (3/4)
Schema graph
Smaller Size
– Scales well for huge database
Utilize underlying RDBMS facilities
– e.g. Database indexes on columns
Exploiting the schema of the underlying database
– Generating optimal internal queries : SQL
– Evaluation for Queries
16
Query keywords : Jaehui Relational Database--------------------------------------------------Candidate join queries:
Tmp1 : select * from Paper, Writes where Paper.PaperName = ‘Relational Database’ AND …
Tmp2 : select * from Tmp1, Author where … Author.AuthorName = ‘Jaehui’ AND …
RDBtraverse Querykeywords

Copyright 2009 by CEBT
Data representation (4/4)Data representation (4/4)
Graph model
A logical unit of information
– Subgraph
A set of multiple nodes joined together
may include some tuples that does not contain any query keywords
Weighting scheme
– Edges
Distance (or Proximity)
Join operations
– Nodes
Importance (or Authority)
17
T1 T2
T3
T4
T5
K2
T6
K3
K3
K1
T1 T2
T3
T4
K2
K3
K1
T1 T2
T3 T5
K2
T6
K3
K1
T1
T3
K2
T6
K3
K1

Copyright 2009 by CEBT
RankingRanking
Relevance Answer size
– Minimal subgraph including all the query keywords
– Distance as the semantics closeness between objects The distance between an entity and its attributes
The distance between tuples in the same table
The distance between tuples related through primary and foreign key
Term frequency– Standard IR weighting method
TF-IDF Text databases (e.g. user complaints, product descriptions, book reviews, etc.)
Importance Authority
– Authority transfer graph Nodes with incoming link with high authority are assumed to have higher importance
– Specificity problem Specific results should be ranked higher than general one
e.g., InverseObjectRank algorithm
18
Writes
AuthorIDPaperID…
AuthorAuthorIDAuthorName…
Paper
PaperIDPaperName…
CitesCitingCited…
0.7
0
0.2 0.2
Writes
JaneTom …
PaperTree Traverse algorithm …Query Evaluation … …
0.20.4
0.8

Copyright 2009 by CEBT
Efficient processingEfficient processing
Indexing structure Reducing scan time
– Granularity levels of schema elements Column level vs. Record (or Cell) level
Reducing computation time
– Precomputation edge weights, node weights,
relevance scores, etc.
Query execution technique Top-k query processing
– Avoiding creating all query results Decide which candidate answers will
produce top-k results e.g. Sparse algorithm
Pipeline algorithm
ROWIDb1b2b3
Score905012
… …
ROWIDa1a2a3
Score766015
… …

Copyright 2009 by CEBT
Query representationQuery representation
Logical operators
conjunction, disjunction
Type and condition
Type
– Find type, Near type
Conditional keywords
– e.g. Year > 300
20

Copyright 2009 by CEBT
PresentationPresentation
Visualizing search result
e.g. Tree view
– structural level vs. tuple level
Limiting maximum size of an answer
Limiting maximum number of answer
…
21
Copyright 2009 by CEBT
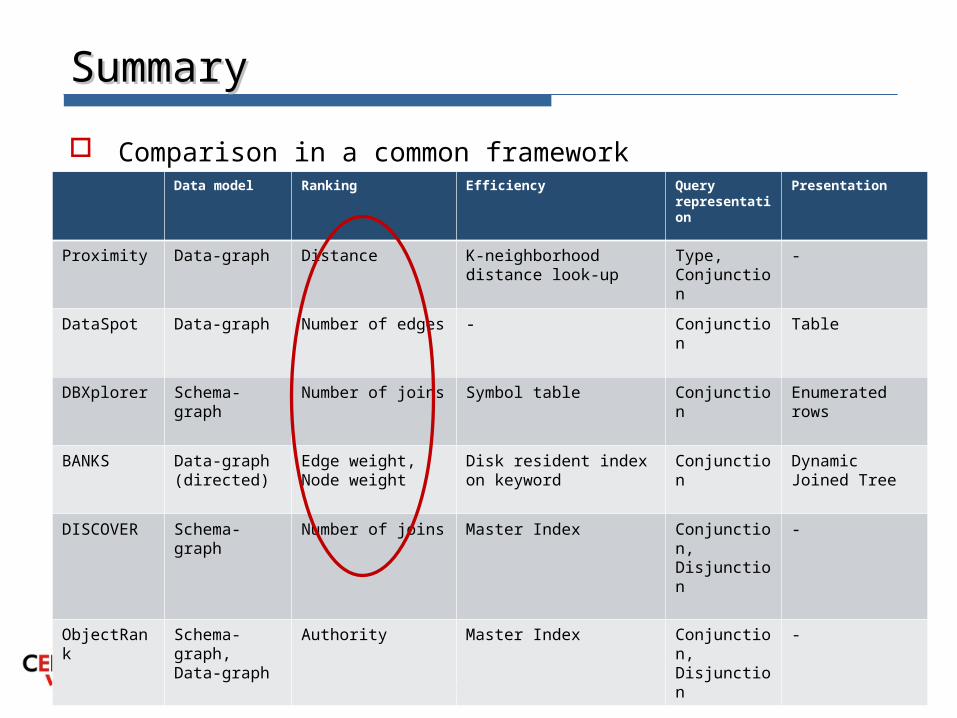
SummarySummary
Comparison in a common framework
22
Data model Ranking Efficiency Query representation
Presentation
Proximity Data-graph Distance K-neighborhood distance look-up
Type, Conjunction
-
DataSpot Data-graph Number of edges - Conjunction Table
DBXplorer Schema-graph
Number of joins Symbol table Conjunction Enumerated rows
BANKS Data-graph (directed)
Edge weight, Node weight
Disk resident index on keyword
Conjunction Dynamic Joined Tree
DISCOVER Schema-graph
Number of joins Master Index Conjunction, Disjunction
-
ObjectRank Schema-graph, Data-graph
Authority Master Index Conjunction, Disjunction
-

Copyright 2009 by CEBT
Future DirectionsFuture Directions
Probabilistic model Naïve approaches
– Rank measures on the answer size Cannot directly estimate the (probability of) relevance between the query and the
retrieved tuples
Heuristic performs well
Probabilistic model– e.g. Bayesian belief network
Term-based approach to approximate optimal answer
Modification for dealing with relational database Dependencies between schema elements
Efficient query processing Top-k query processing have shown a great impact on performance
– Ranking function involves aggregation or grouping operator
– Symbol table design
Conclusion Various approaches are described with our understanding
We envision the above research directions to be important to pursue.
23

Copyright 2009 by CEBT 24
Thank you