keyword search on external memory data graphs bhavana bharat dalvi, meghana kshirsagar, s. sudarshan...
TRANSCRIPT

Keyword Search on External Memory Data Graphs
Bhavana Bharat Dalvi, Meghana Kshirsagar, S. Sudarshan
PVLDB 2008
Reported by: Yiqi Lu

Background: Graph Model Direct graph model for data

Background: Answer Tree Model Answer Tree
Keyword Query

Background: score function A function of the node score and edge score of
answer tree Several score models have been proposed.

Background: keyword search Input: keywords, data graph Output: top-k answer trees Algorithm:
first looking up an inverted keyword index to get the node-
ids of nodes Second
a graph search algorithm is run to find out trees connecting the keyword nodes found above. The algorithm finds rooted answer trees, which should be generated in ranked order.

Example: backward expanding search For each keyword term ki
First find the set of nodes Si that contain keyword ki
Run Dijkstra SP algorithm which provides an interface to incrementally retrieve the next nearest node Traverses the graph To find a common vertex from which a forward path
exists to at least one node in each set Si
Then the answer tree’s root is the common vertex and the keywords are leaves

Background: external memory search Run search algorithm on an external memory
graph representation which clusters nodes into disk pages
Naïve migration will lead to poor performance keyword search algorithms designed for in-
memory search access a lot of nodes, and such node accesses lead to a lot of expensive random IO when data is disk resident.

Background: 2-level graph
Clustering parameters are chosen such that supernode graph fits into the available amount of memory

Background: 2-phase search algorithm

This algorithm lack consideration of time locality

multi-granular graph structure This paper proposes a multi-granular graph
structure to exploit information present in lower-level nodes that are cache-resident at the time a query is executed

MG graph a hybrid graph
A supernode is present either in expanded form (all its innernodes along with their adjacency lists are present in the cache)
Or unexpanded form (its innernodes are not in the cache)

several types of edges

several types of edges
•Supernode answer•Pure answer

ITERATIVE EXPANSION SEARCH Explore phase: Run an in-memory search
algorithm on the current state of the multi-granular graph (the multi-granular graph is entirely in memory)
Expand phase: Expand the supernodes found in top-n results of the (a) and add them to input graph to produce an expanded multi-granular graph

ITERATIVE EXPANSION SEARCH

ITERATIVE EXPANSION SEARCH the stopping criterion:
The algorithm stops at the iteration where all top-k results are pure.
node-budget heuristic: Stop search when

ITERATIVE EXPANSION SEARCH A assumption: the part of graph relevant to
the query fits in cache May fail in some cases
Query has many keywords or algorithm explores a large number of nodes
Have to evict some supernodes from the cache based on a cache replacement policy some parts of the multi-granular graph may shrink
after an iteration Such shrinkage can unfortunately cause a problem
of cycles in evaluation

ITERATIVE EXPANSION SEARCH do not shrink the logical multi-granular graph,
but instead provide a “virtual memory view” of an ever-expanding multi-granular graph. maintain a list, Top-n-SupernodeList, of all
supernodes found in the top-n results of all previous iterations.
Any node present in Top-n-SupernodeList but not in cache is transparently read into cache whenever it is accessed.

INCREMENTAL EXPANSION SEARCH Iterative Expansion algorithm restart
search when supernodes are expanded This can lead to significantly increased CPU time
Incremental expansion algorithm updates the state of the search algorithm

Take BES as example


Heuristics to improve performance stop-expansion-on-full-cache
Intra-supernode-weight heuristic We define the intra-supernode weight of a
supernode as the average of all innernode → innernode edges within that supernode.

Experiment Search Algorithms Compared
Iterative Expanding search Incremental Expanding (Backward) Search with
different heuristics the in-memory Backward Expanding search the Sparse algorithm from “Efficient IR-Style
keyword search in relational databases” A naive approach to external memory search
would be to run in-memory algorithms in virtual memory.
we have implemented this approach on the supernode graph infrastructure, treating each supernode as a page

Data sets DBLP 2003 IMDB 2003 Cluster using EBFS technique Default supernode size is 100 innernodes
corresponding to an average of 7KB on DBLP and 6.8KB on IMDB
Supernode contents were stored sequentially in a single file, with an index for random access within the file to retrieve a specified supernode.

Data sets

Clustering result

Cache Management 3GB RAM, and a 2.4GHz Intel Core 2
processor, and ran Fedora Core 6 All results are taken on a cold cache.
Force linux kernel to drop page cache, inode cache and dentry cache
By excuting sync(flush dirty pages back to disk) then excuting echo 3 > /proc/sys/vm/drop_caches

Queries

Experimental Results first implemented Incremental search without
any of the heuristics did not perform well, and gave poor results, taking
unreasonably long times for many queries. results for this case not presented
two versions of Incremental expansion, one with and one without the intra-supernode-weight heuristic

the intra-supernode-weight heuristic reduces the number of cache misses drasti cally without significantly reducing answer quality.
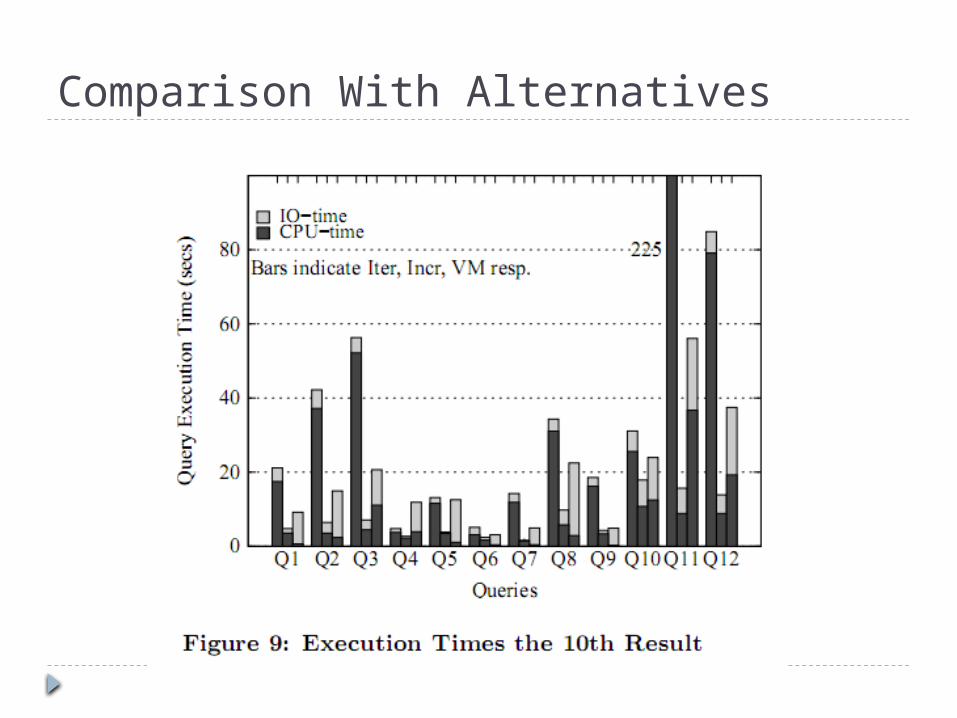
Comparison With Alternatives
