l d o e e backpropagation s p o n o redes neurais...
TRANSCRIPT

Unive rsidad e F
ede ral do Espír ito S
a nto – CC
A U
FE
S
Universidade Federal do Espírito SantoCentro de Ciências Agrárias – CCA UFESDepartamento de Computação
Redes Neurais ArtificiaisSite: http://jeiks.net E-mail: [email protected]
Perceptron de Múltiplas Camadase Backpropagation

Unive rsidad e F
ede ral do Espír ito S
a nto – CC
A U
FE
S
2
Perceptron de Múltiplas Camadas
● O Perceptron simples não consegue trabalhar com sistemas não lineares.
● Porém, o Perceptron de Múltiplas Camadas consegue efetuar o mapeamento não linear do espaço de entrada X para o espaço de saída y.
● Para resolver o problema do XOR (ou exclusivo) foi utilizado um Perceptron de uma camada intermediária (oculta) e uma função ed ativação de sinal (sgn).

Unive rsidad e F
ede ral do Espír ito S
a nto – CC
A U
FE
S
3
MLP – XOR● Perceptron de Múltiplas Camadas
(MLP – Multi-Layer Perceptron)
● Vamos trabalhar na implementação de uma Função Discriminativa Não-Linear usando uma camada intermediária que realiza o mapeamento não linear.
x1
x2
XOR
-1 -1 -1
-1 1 1
1 -1 1
1 1 -1

Unive rsidad e F
ede ral do Espír ito S
a nto – CC
A U
FE
S
4
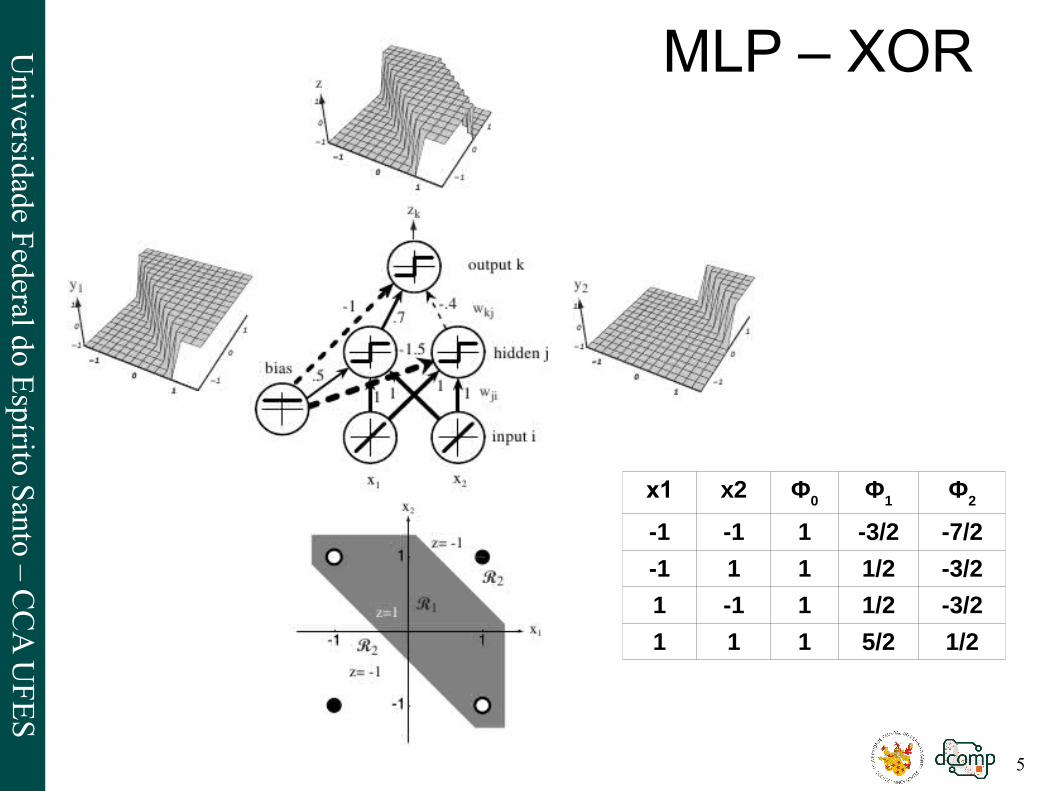
MLP – XOR
y.
X2
X1
X0=1
ɸ1 ɸ
2
Φ0 = 1
Φ(x)=(Φ0(x)Φ1(x)Φ2(x)
)=(Φ0(x0 ; x1 ; x2)
Φ1(x0 ; x1 ; x2)
Φ2(x0 ; x1 ; x2))
Φ0 (x)=1
Φ1(x)=sgn(12 . x0+1. x1+1. x2)Φ2(x)=sgn(−3
2. x0+1. x1+1. x2)
y=sgn (−1.Φ0+0,7.Φ1(x)−0,4.Φ2(x))
Abra o Octave, crie o vetores X, y, y_est, W, W_y, e teste essa RNA e suas sinapses.
Abra o Octave, crie o vetores X, y, y_est, W, W_y, e teste essa RNA e suas sinapses.
Unive rsidad e F
ede ral do Espír ito S
a nto – CC
A U
FE
S
5
MLP – XOR
x1 x2 Φ0
Φ1
Φ2
-1 -1 1 -3/2 -7/2
-1 1 1 1/2 -3/2
1 -1 1 1/2 -3/2
1 1 1 5/2 1/2

Unive rsidad e F
ede ral do Espír ito S
a nto – CC
A U
FE
S
6
Perceptron de Múltiplas Camadas
● Em geral, o perceptron com uma camada oculta calcula:
y i(x )=Z i (W i .Φ(x))=Z i(∑k=0
H
W ik .Φk(x))=Z i(∑
k=0
H
W ik . F (W k . x))
=Z i(∑k=0
H
W ik . F (∑j=0
d
W kj . x j))sendo: Z função de saída e F função da camada oculta

Unive rsidad e F
ede ral do Espír ito S
a nto – CC
A U
FE
S
7
Perceptron de Múltiplas Camadas
● No modelo totalmente conectado, a função de ativação é igual para todos os neurônios da mesma camada.
● Características das funções Z e F:– Deve ser não linear em pelo menos uma camada oculta;
– Deve ser diferenciável: Z'(a) deve existir.
● A camada oculta implementa a função de base ϕk(x);
● A função base não é fixa, sendo então adaptável:– Poder de cálculo do MLP.

Unive rsidad e F
ede ral do Espír ito S
a nto – CC
A U
FE
S
8
Backpropagation
● Vamos ver o funcionamento iterativo do backpropagation utilizando a referência de
Mariusz Bernacki, Przemysław Włodarczyk, (2005)
http://home.agh.edu.pl/~vlsi/AI/backp_t_en/backprop.html

Unive rsidad e F
ede ral do Espír ito S
a nto – CC
A U
FE
S
9
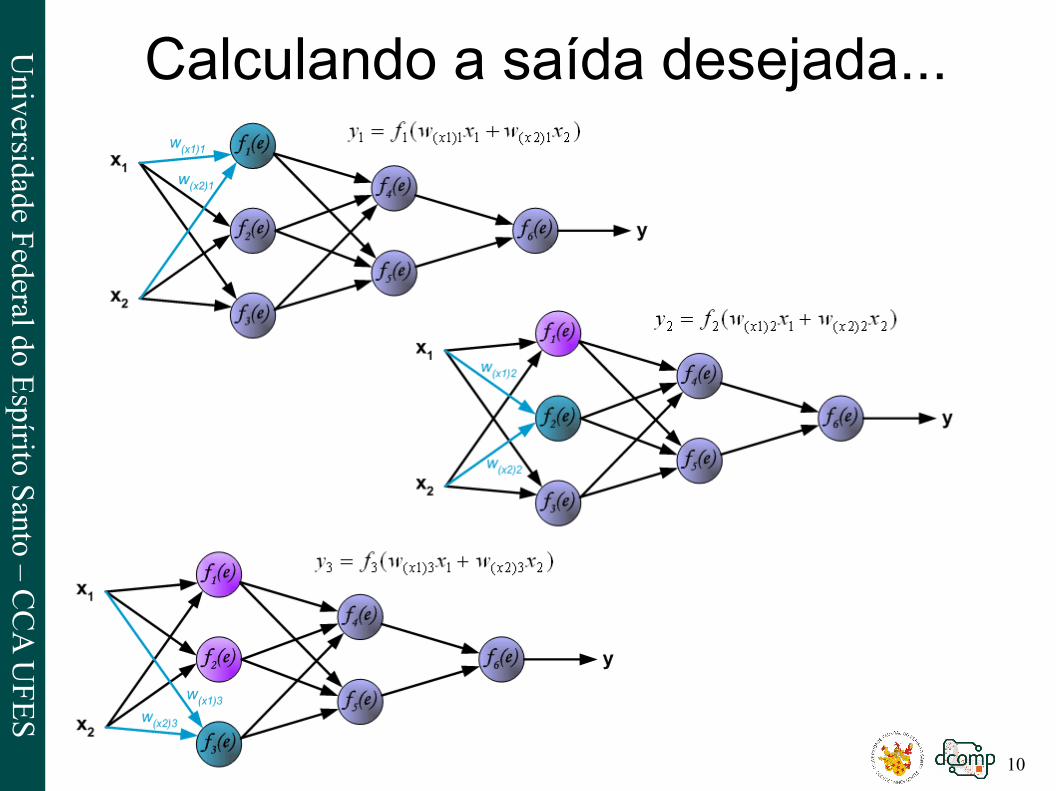
Rede Neural Utilizada
Unive rsidad e F
ede ral do Espír ito S
a nto – CC
A U
FE
S
10
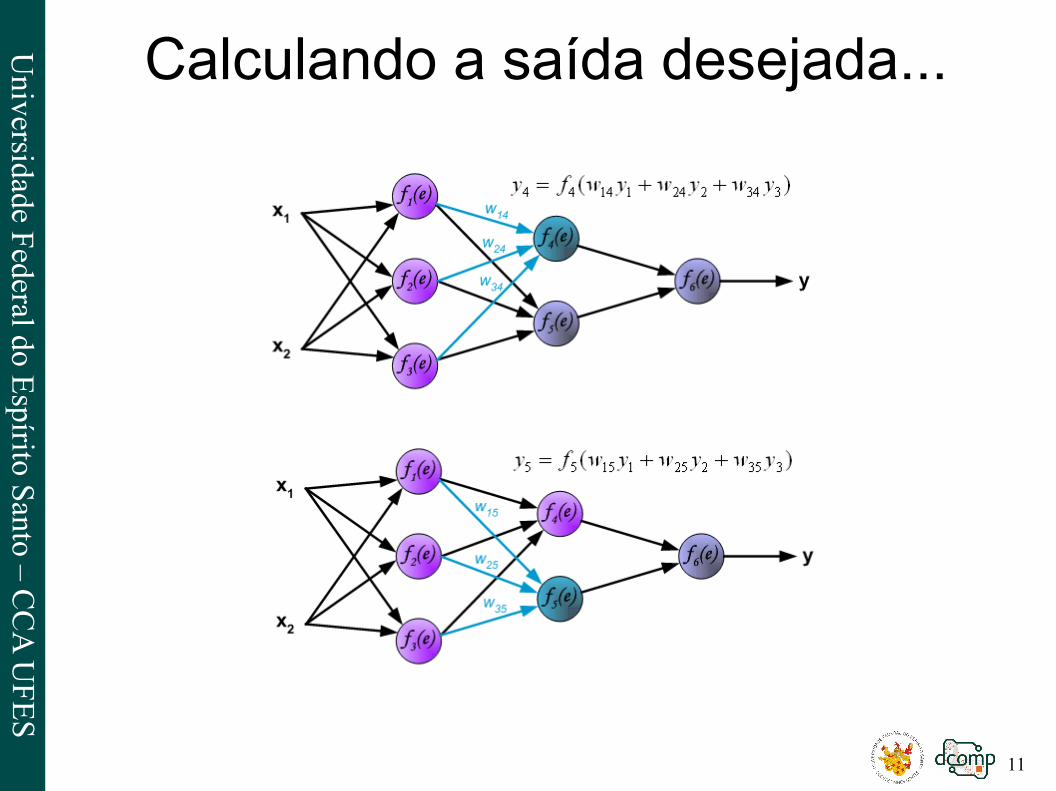
Calculando a saída desejada...
Unive rsidad e F
ede ral do Espír ito S
a nto – CC
A U
FE
S
11
Calculando a saída desejada...

Unive rsidad e F
ede ral do Espír ito S
a nto – CC
A U
FE
S
12
Calculando a saída desejada...
Unive rsidad e F
ede ral do Espír ito S
a nto – CC
A U
FE
S
13
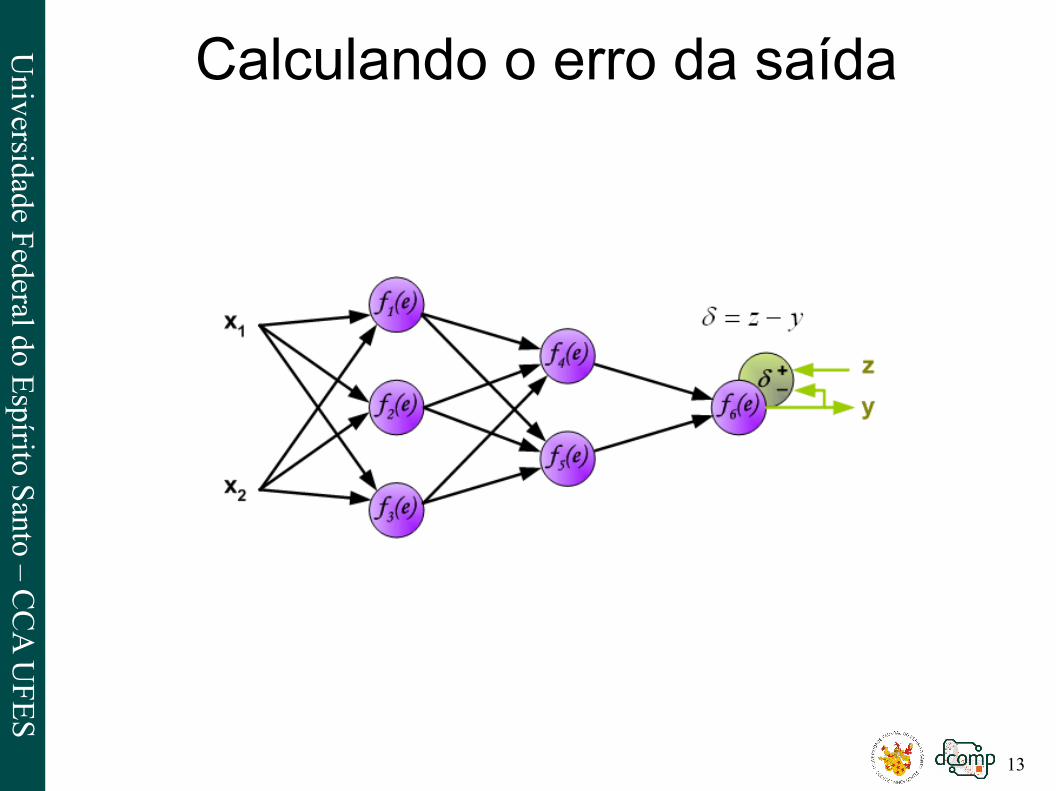
Calculando o erro da saída

Unive rsidad e F
ede ral do Espír ito S
a nto – CC
A U
FE
S
14
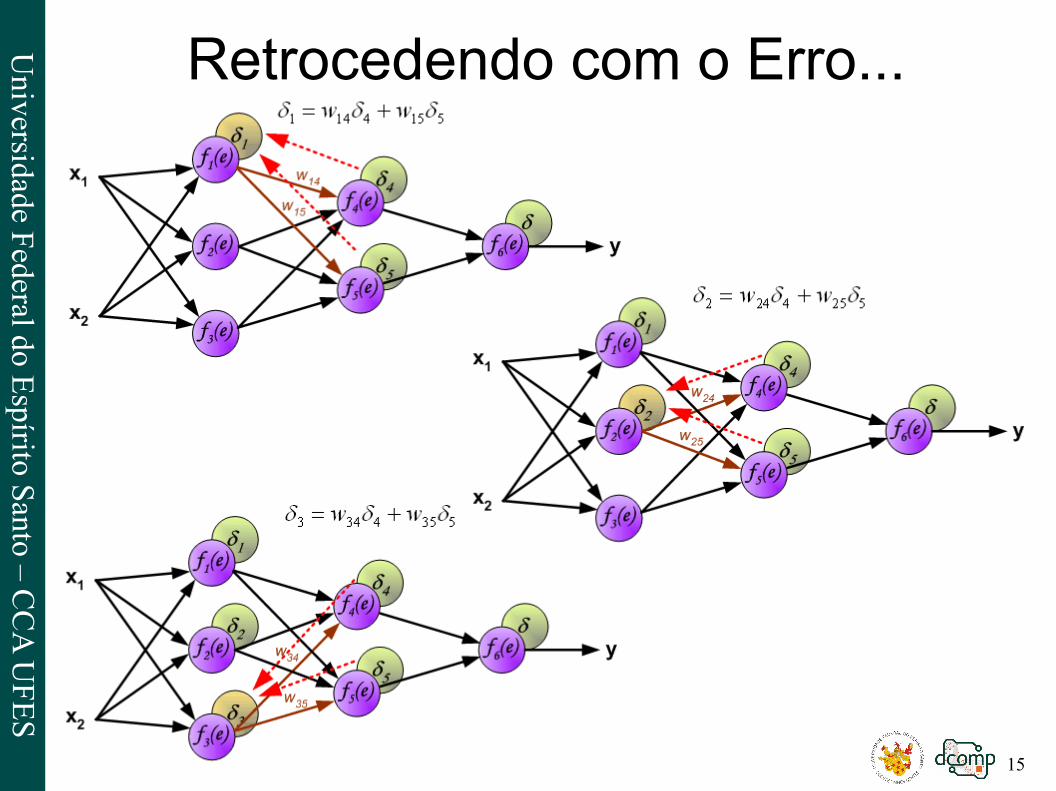
Retrocedendo com o Erro...
Unive rsidad e F
ede ral do Espír ito S
a nto – CC
A U
FE
S
15
Retrocedendo com o Erro...

Unive rsidad e F
ede ral do Espír ito S
a nto – CC
A U
FE
S
16
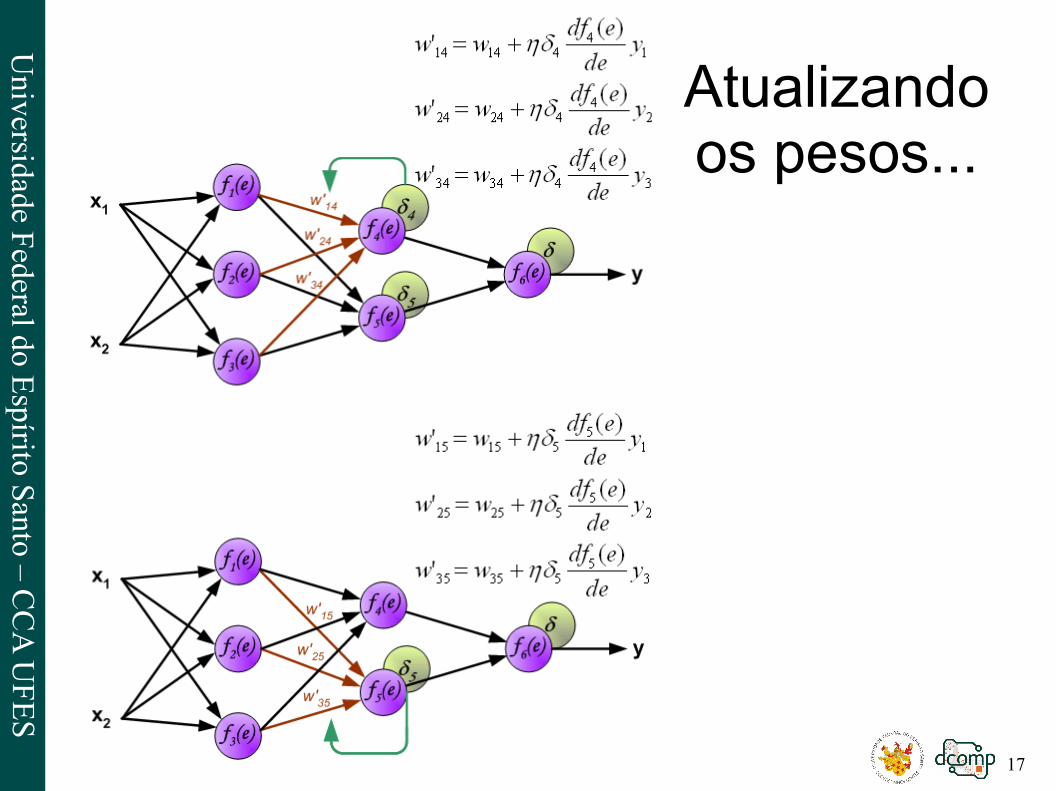
Atualizando os pesos...
Unive rsidad e F
ede ral do Espír ito S
a nto – CC
A U
FE
S
17
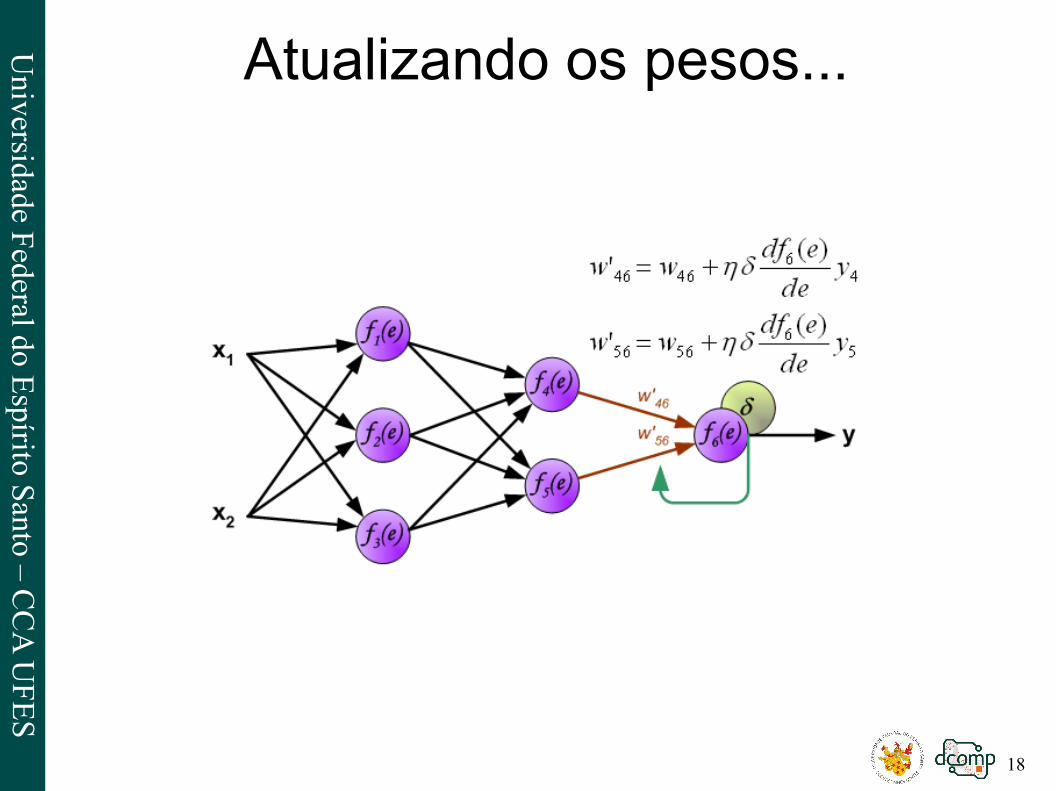
Atualizando os pesos...
Unive rsidad e F
ede ral do Espír ito S
a nto – CC
A U
FE
S
18
Atualizando os pesos...

Unive rsidad e F
ede ral do Espír ito S
a nto – CC
A U
FE
S
19
Regra de ajuste do peso
● Considere:
i, ..., c: índice dos neurônios da camada de saída;
h, …, H: índice dos neurônios da camada oculta;
j, …, d: índice dos neurônios da camada de entrada.
● Sensibilidade:– A S (sensibilidade) do neurônio i descreve como o erro
global E(w) muda o valor de neti.
● A regra de ajuste do peso utiliza a sensibilidade de cada neurônio.
● Seu cálculo será adicionado no algoritmo...

Unive rsidad e F
ede ral do Espír ito S
a nto – CC
A U
FE
S
20
Feed Forward: Alimentação Adiante// Entrada para OcultaPara h=0,... , H
neth←0Para j=0, ... , d
neth←neth+W hj X j
Fim ParaΦh←Z (neth)
Fim Para
// Oculta para SaídaPara i=0, ... ,c
net i←0Para h=0, ... , H
net i←net i+W ihΦh
Fim Parayi←Z (neti)
Fim Para

Unive rsidad e F
ede ral do Espír ito S
a nto – CC
A U
FE
S
21
BackpropagationInicialização aleatória dos pesos W' e W, onde ‖W i‖=1 e ‖W h‖=1
Para todos os padrões X(k) , k=1, ... , n , em ordem aleatória :Feedfoward de X(k): ŷ (x(k)
)Para i=1, ... , c :
δi(k)
= yi(k )
− ŷi(x(k)
) // Erro na saída i do padrão k
Si(k)
←2 .δi(k).Z ' (net i
(k)) // Sensibilidade
Para h=0,... , H :w ih
novo←w ih
velho+η.S i
(k) .Z (neth(k)
)
// Adaptar os pesos de entrada para a camada oculta W'Para h=1, ... , H :
aux←0Para i=0, ... , c :
aux←aux+wihvelho .Si
(k)
Para j=0,... , d :whj
novo←whj
velho+η.Sh
(k) . X j(k)
Φh (X(k))

Unive rsidad e F
ede ral do Espír ito S
a nto – CC
A U
FE
S
22
Metodologia de Treinamento● Deve-se realizar a divisão do conjunto de dados dos n
padrões X(k), k=1, …, n em três conjuntos de dados:– Treinar com 75% dos exemplos;
– Validar com 15% dos exemplos;
– Testar com 15% dos exemplos.
Obs.: Essas porcentagens são as padrões do Matlab, mas podem ser alteradas.
● Antes, os dados devem ser normalizados ou estandardizados:– Normalização:
● X = ( X – min(X) ) / ( max(X) – min(X) )
– Estandardização:● X = (X – média(X) ) / σ(X).