l2 to off-chip memory interconnects for cmps presented by allen lee cs258 spring 2008 may 14, 2008
Post on 19-Dec-2015
219 views
TRANSCRIPT

L2 to Off-Chip Memory Interconnects for CMPs
Presented by Allen LeeCS258 Spring 2008
May 14, 2008

Motivation In modern many-core systems, there is significant
asymmetry between the number of cores and the number of memory access points Tilera’s multiprocessor has 64 cores and only 4
memory controllers PARSEC benchmarks suggest that off-chip
memory traffic increases with the number of cores for CMPs
We explore mechanisms to lower latency and power consumption for processor-memory interconnect

Tilera Tile64
x5

Tilera Tile64 Five physical mesh networks
UDN, IDN, SDN, TDN, MDN TDN and MDN are used for handling
memory traffic Memory requests transit TDN
Large store requests, small load requests Memory responses transit MDN
Large load responses, small store responses Includes cache-to-cache transfers and off-
chip transfers

Tapered Fat-Tree Good for many-to-few
connectivity Fewer hops Shorter latency Fewer routers Less power,
less area Root nodes directly connect
to memory controller Replace MDN mesh network
with two tapered fat-tree networks One for routing requests up One for routing responses
down

Tile64 with Tapered Fat Tree
Legend
- Level 3 Routers
- Level 2 Routers
- Level 1 Routers(Connect to memory controllers)

Memory Model Directory-based cache coherence Directory cache at every node Off-chip directory controller Tile-to-tile requests and responses transit
the TDN Off-chip memory requests and responses
transit the MDN

TDN and MDN Traffic for L2 Read Misses
Update
Request
Request
Update
Update
Response
Response
MResponseMRequest
MResponse
MRequest
Response
Was off-chip
Was on-chip
Hit
Miss
Miss
Hit
Request
Off-ChipDirectory Controller
Directory Cache
Local Node
Remote Node L2
Memory Controller
Memory Controller
Local Node
Remote Node L2
Local Node
Off-ChipDRAM
Local Node
Local Node
Directory Cache
Directory Cache
Directory Cache
Legend
Sent on TDN
Sent on MDN

Synthetic Benchmarks Statistical simulation
Model benchmarks from PARSEC suite Based on off-chip traffic for 64-byte cache-line for 64 cores
streamcluster0.0266 lines off-chip/cycle
99% are loads
1% are stores
canneal0.0189 lines off-chip/cyc
70% are loads
30% are stores
blackscholes9.38e-5 lines off-chip/cycle
20% are loads
80% are stores
x2640.0025 lines off-chip/cycle
70% are loads
30% are stores
Working Set Size
Sh
arin
g
Small Large
Mo
re
Le
ss

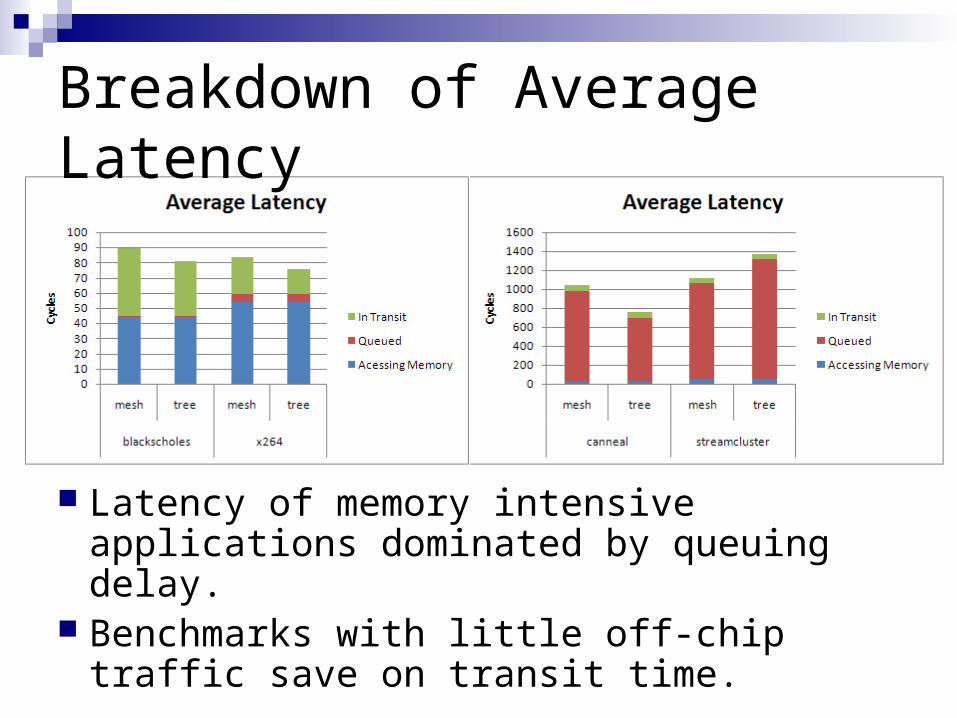
Breakdown of Average Latency
Latency of memory intensive applications dominated by queuing delay.
Benchmarks with little off-chip traffic save on transit time.

Power Modeling Orion power simulator for on-chip routers
from Princeton University Models switching power as sum of
Buffer powerCrossbar powerArbitration power
Specify parametersActivity factor, number of input and output
ports, virtual channels, size of input buffer, etc.

Tilera MDN RoutersRouter Number Inputs Outputs Width
4 3 3 32 bits
24 4 4 32 bits
36 5 5 32 bits
4 4 1 32 bits in
64 bits out
4 1 4 64 bits in
32 bits out
Corner
Edge
Center
Mem Xbar Up
Mem Xbar Down

Router Number Inputs Outputs Width
16 16 4 2 2 4 32 32
8 8 4 4 4 4 32 32
4 4 8 1 1 832 in
64 out
64 in
32 out
Tree Routers
Level 3 Up Level 3 Down
Level 2 Up Level 2 Down
Level 1 Up Level 1 Down

Parameters 100 nm CMOS process VDD = 1.0V Clock Frequency = 750 MHz 32-bit flit width



Conclusion Physical design of the tapered fat-tree is
more difficult The TFT topology can reduce memory
latency and power dissipation for many-core systems