latent rating regression for aspect analysis of user ...fmi.stat.unipd.it/pdf/bellio_pd2019.pdf ·...
TRANSCRIPT

Latent Rating Regression for Aspect Analysis ofUser-Generated Content
Ruggero Bellio
Department of Economics & Statistics, University of Udine(Italy)
PRIN 2019, Padova 1/ 27

My co-authors at &
PRIN 2019, Padova 2/ 27

Outline
Background and motivation
Methodology
An Illustration
Conclusion and Ongoing
PRIN 2019, Padova 3/ 27

Setting of interest
We are interested in (online) reviews of products or services,each with an overall rating.
Imaginary Boston Hotel
Reviewer 1:”Clean and comfortable”
Coming from the convention center, it was not imme-
diately obvious how to enter the building, esp sinceGoogle maps hasn’t yet updated to include the littleside street with the main entrance yet. The hotel it-self is clean, comfortable, and the rooms had lots ofoutlets with bliss spa toiletries, which was nice. Quietlocation although a bit of a hike (20 min walk fromSouth Station) from the nearest T. Would stay thereagain.
Reviewer 2:”Great affordable Hotel”
Everything from Check-in, atmosphere, cleanliness,
bar, staff and amenities exceeded expectations. Acrossstreet from convention center. Beer liquor store andDunkins next door. A new Boston Seaport Favourite.Also collect Starwood points.
PRIN 2019, Padova 4/ 27

Aspect ratings and weights
The aim is to infer the rating of a set of aspects, plus theweights placed on each aspect by reviewer
Imaginary Boston Hotel
Reviewer 1:”Clean and comfortable”
Coming from the convention center, it was not imme-
diately obvious how to enter the building, esp sinceGoogle maps hasn’t yet updated to include the littleside street with the main entrance yet. The hotel it-self is clean, comfortable, and the rooms had lots ofoutlets with bliss spa toiletries, which was nice. Quietlocation although a bit of a hike (20 min walk fromSouth Station) from the nearest T. Would stay thereagain.
INFER
Value 39%Room 25%Location 17%Service 19%
Reviewer 2:”Great affordable Hotel”
Everything from Check-in, atmosphere, cleanliness,
bar, staff and amenities exceeded expectations. Acrossstreet from convention center. Beer liquor store andDunkins next door. A new Boston Seaport Favourite.Also collect Starwood points.
INFER
Value 38%Room 25%Location 9%Service 28%
PRIN 2019, Padova 5/ 27

Our proposal
• Aspect Rating Analysis was first proposed by Wang et al.(2010, 2011) in the Machine Learning literature
• We build upon their methods, re-interpreting and extendingthem from a statistical perspective to obtain moresatisfactory inferences and predictions
PRIN 2019, Padova 6/ 27

A two-step approach
Our proposal consists of a two-step approach
1. Sentence-based LDA to build a word-frequency matrix
2. Application of a novel Latent Rating Regression (LRR)model
The focus here is mostly on the second step.
PRIN 2019, Padova 7/ 27

Step 1: Sentence-based LDA
Notation
→ Set of documents indexed by d = 1, . . . , D
→ rd overall rating
→ Vocabulary of the entire set of documents, mapped to the set1, . . . , V
• Starting point is the identification of a set of K aspects,performed by Latent Dirichlet Allocation (LDA) (Blei et al.,2003).
• The crucial twist is to adopt Sentence-based LDA providesa good generative model for reviews, overcoming thebag-of-words assumption (Buschken and Allenby, 2016)
PRIN 2019, Padova 8/ 27

Step 1: Word-frequency matrix
• Based on the output of Sentence-based LDA, for eachdocument d a word-frequency matrix Wd is built.
• Wd, d = 1, . . . , D contains the (processed) frequency of eachword of document d for each of the K aspects.
• The collection of Wd, d = 1, . . . , D is a three-dimensionalextension (D ×K × V array) of a classical document termmatrix ⇒ very sparse object
PRIN 2019, Padova 9/ 27

Step 2: Latent Rating Regression
Starting point is a linear model for rd
rd = sTdαd + εd , εd ∼ N (0, δ2) ,
with independence assumed across reviews.
→ sd (K × 1) aspect ratings, with sdk =∑V
v=1 βkv wdkv
→ βkv is the (k, v) element of the matrix of sentimentpolarities β (K × V )
→ αd (K × 1) aspect weights, withK∑k=1
αdk = 1 , on which we
make some distributional assumptions
PRIN 2019, Padova 10/ 27

Distributional assumption on aspect weights
We assume a logistic normal distribution on the simplex for αd
(Atchinson, 1986). More precisely
• The 1:1 transformation αd ↔ ηd is defined, where
αdk =exp{ηdk}∑Kk=1 exp{ηdk}
, k = 1, . . . ,K ,
with∑K
k=1 αdk = 1 and∑K
k=1 ηdk = 0.
• A singular multivariate normal distribution (Rao, 1973) isassumed for ηd
ηd ∼ NK (µ,Σ)
where∑K
k=1 µk = 0 and Σ has (K − 1) positive eigenvaluesand one zero eigenvalue.
• Note that each aspect is treated symmetrically.
PRIN 2019, Padova 11/ 27

Estimation of model parameters
• The word-frequency matrix is treated as fixed by design forthe estimation of the corpus-level parametersθ = (µ,Σ,β, δ2) and the document-level parameters αd.
The aspect weights α = (α1, . . . ,αD), d = 1, . . . , D arerandom effects to be predicted for each document.
• We jointly estimate α and θ, relying on the frequentist theoryof Maximum Posterior Estimation (MPE) (Jiang, 2007) for atheoretical framework.
Following a full Gauss-Seidel approach, the estimationalgorithm iterates between updating α and θ, untilconvergence.
• Could be cast as a Variational Empirical Bayes approach
PRIN 2019, Padova 12/ 27

Update of document-specific parameters
• For updating the document-specific random effects, thefollowing constrained optimization is carried out for fixed θ
ηd = argmaxηd
− 1
2 δ2{rd − s>d αd(ηd)}2 + log p{αd(ηd);µ,Σ}
under the constraint∑
k ηdk = 0, and then αd = αd(ηd).
• Updating of µ and Σ is then straightforward, in spite of thesingularity of Σ (Rao, 1973)
µ =1
D
D∑d=1
ηd , Σ =1
D
D∑d=1
(ηd − µ)(ηd − µ)> .
PRIN 2019, Padova 13/ 27

Update of sentiment polarities and aspect ratings
• By some simple algebra re-express the model for the overallrating for fixed α as
r = X(α)βv + ε ,
where X(α) is a design matrix of size D × (K V ), whose d-throw depends on αd and Wd, and βv = vec(β).
• We endorse ridge regression for regularizing the estimationof the large set of coefficients βv.
We then obtain the estimated aspect ratings
sdk =
V∑v=1
βkv wdkv ,
which are then mapped on the same scale of the overall rating.
PRIN 2019, Padova 14/ 27

Computational aspects
• Everything done in
• The bottleneck is given by Step 1, since our own version ofSentence-based LDA may take several hours on multi-corecomputers for large datasets
• Latent Rating Regression is faster, thanks to two key points:
→ Review-specific update of aspect weights is an embarrassinglyparallel task, carried out in C++ employing the mighty TMB
package (Kristensen et al., 2016)→ Ridge-regression done by the fast library LIBLINEAR
(Helleputte 2017), though we are probably moving to glmnet
(Friedman et al., 2010)
PRIN 2019, Padova 15/ 27

An illustration
• Medium-size dataset of about D = 100, 000 reviews on about4,000 hotels in the US, for the period 2009-2012 (notdisclosed for confidentiality reasons).
• Actual user preferences are available on several aspects, wetake K = 5 aspects: Value for money, Room, Location,Cleanliness, Service.
• The vocabulary size V = 24457, so that X(α) has morecolumns than rows.
PRIN 2019, Padova 16/ 27

Typical output
PRIN 2019, Padova 17/ 27

Estimated sentiment polarities
Word
Aspect
−2
0
2
4
⊕ Polarity = 34% Polarity = 28% %|β| > 0.1 ≈ 40%
PRIN 2019, Padova 18/ 27

A look at the method accuracyAverages of estimated ratings (y) vs averages of actual ratings (x)for 222 hotels with at least 100 reviews
●●
●
●
●
●
●●●
●●
●
●
●
●●
●
●●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●●
●●
●
●●
●●
●
●
●●
●●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●●●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
2.0 2.5 3.0 3.5 4.0 4.5 5.0
2.0
2.5
3.0
3.5
4.0
4.5
5.0
Overall
●●
●●
●
●●●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●●
●
●
●
●
●●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
● ●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●●
●
●
●
●●
●
●●
● ●●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
2.0 2.5 3.0 3.5 4.0 4.5 5.0
2.0
2.5
3.0
3.5
4.0
4.5
5.0
Value
●
●
●
●●
●
●●
●
●●●
●
●
●●
●
● ●
●
●
●
●●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●●
●
● ●
●
●●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●● ●
●●
●
●
●
●●
●
● ●
●
●
●
●
●
●
●
●●
●●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●●
●
2.0 2.5 3.0 3.5 4.0 4.5 5.0
2.0
2.5
3.0
3.5
4.0
4.5
5.0
Room
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●●●
●●
●●●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●●
●
●●
●
●
●
●
●
● ●
●
●
●
●
●
●
●●●
●
●
●
●●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●●●
●
●●
●
●
●●●
●
●
●
●
●●●
●
●
●
●
●
●●
●
●
●
●●
● ●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●●
●●
●
●
●
●
●
●
●●
●
2.0 2.5 3.0 3.5 4.0 4.5 5.0
2.0
2.5
3.0
3.5
4.0
4.5
5.0
Location
●●
●
●
●
●
●●●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●●
●●
●
●
● ●
●
●●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●●
●
●
●
●
2.0 2.5 3.0 3.5 4.0 4.5 5.0
2.0
2.5
3.0
3.5
4.0
4.5
5.0
Cleanliness
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●
●
●
● ●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
2.0 2.5 3.0 3.5 4.0 4.5 5.0
2.0
2.5
3.0
3.5
4.0
4.5
5.0
Service
PRIN 2019, Padova 19/ 27
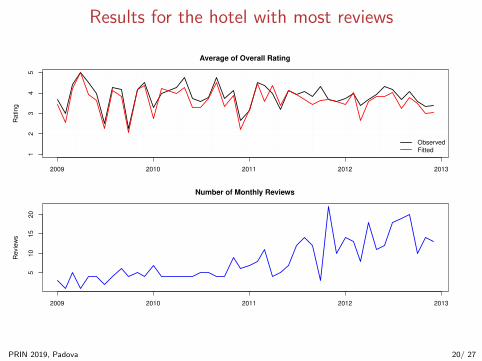
Results for the hotel with most reviews
2009 2010 2011 2012 2013
12
34
5
Average of Overall Rating
date
Rating
Observed
Fitted
2009 2010 2011 2012 2013
510
15
20
Number of Monthly Reviews
Revie
ws
PRIN 2019, Padova 20/ 27
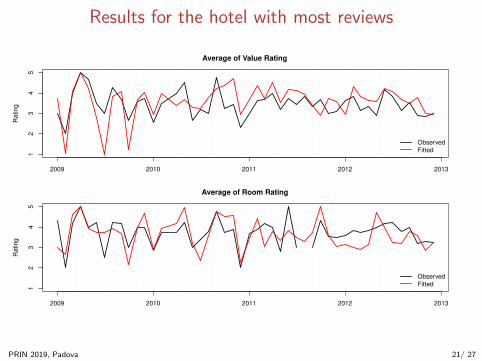
Results for the hotel with most reviews
2009 2010 2011 2012 2013
12
34
5
Average of Value Rating
date
Rating
Observed
Fitted
2009 2010 2011 2012 2013
12
34
5
Average of Room Rating
Rating
Observed
Fitted
PRIN 2019, Padova 21/ 27

Results for the hotel with most reviews: averageaspect weights over time
2009−01−01 2009−07−01 2010−01−01 2010−08−01 2011−02−01 2011−08−01 2012−02−01 2012−08−01
0.0
0.2
0.4
0.6
0.8
1.0
Value
Room
Location
Clean
Service
PRIN 2019, Padova 22/ 27

Discussion
The results obtained seem promising, yet it is essential to validatethe methodology by not relying entirely on observed data expressedby reviewers, since
→ Complete actual ratings are available only seldom
→ In any case, the rating obtained from the text could bemore reliable!
Indeed, the Marketing literature has noted that users tend toevaluate different aspects very similarly, with J-shapeddistributions and carry-over effects across items (Hu et al., 2009).
PRIN 2019, Padova 23/ 27

Ongoing
• Whether inferred ratings better reflect the true underlyingmeaning of quality feedback is an open hypothesis, currentlyunder investigation.
• Evaluation of the estimation algorithm performances are alsounder study, though for a full evaluation some computationalimprovements are also needed.
PRIN 2019, Padova 24/ 27

ReferencesMachine Learning & Marketing
• Blei, D., Ng, A.Y. and Jordan, M.I. (2003). Latent Dirichlet allocation.J. Mach. Learn. Res., 3, 993-1022.
• Buschken, J. and Allenby, G.M. (2016). Sentence-based text analysis forcustomer reviews. Market. Sci., 35, 953-975.
• Hu, N., Pavlou, P.A. and Zhang, J. (2009). Why do online productreviews have a J-shaped distribution? Overcoming biases in onlineword-of-mouth communication. Commun. ACM, 52, 144-147.
• Wang, H., Lu, Y. and Zhai, C. (2010). Latent aspect rating analysis onreview text data: A rating regression approach. In: Proceedings of the16th ACM SIGKDD International Conference on Knowledge Discoveryand Data Mining, 783-792.
• Wang, H., Lu, Y. and Zhai, C. (2011). Latent aspect rating analysiswithout aspect keyword supervision. In: Proceedings of the 17th ACMSIGKDD International Conference on Knowledge Discovery and DataMining, 618-626.
PRIN 2019, Padova 25/ 27

ReferencesStatistics
• Aitchison, J. (1986). The Statistical Analysis of Compositional Data.
• Friedman, J., Hastie, T., and Tibshirani, R. (2010). Regularization pathsfor generalized linear models via coordinate descent. J. Stat. Software,33.
• Helleputte, T. (2017). LiblineaR: linear predictive models based on theLiblinear C/C++ library.
• Kristensen, K., Nielsen, A., Berg, C.W., Skaug, H.J. and Bell, B. (2016).TMB: Automatic differentiation and Laplace approximation. J. Stat.Software, 70.
• Jiang, J. (2007). Linear and Generalized Linear Mixed Models and theirApplications.
• Rao, C.R. (1973). Linear Statistical Inference and its Applications.
PRIN 2019, Padova 26/ 27

Thank you for your attention !
http://people.uniud.it/page/ruggero.bellio
PRIN 2019, Padova 27/ 27