lcslcs 18 september 2002darpa mars pi meeting intelligent adaptive mobile robots georgios...
TRANSCRIPT

18 September 2002 DARPA MARS PI Meeting
LCS
Intelligent Adaptive Mobile Robots
Georgios TheocharousMIT AI Laboratory
with Terran Lane and Leslie Pack Kaelbling (PI)

18 September 2002 DARPA MARS PI Meeting
LCSProject Overview
• Hierarchical POMDP Models• Parameter learning; heuristic action-selection
(Theocharous)• Near-optimal action-selection; Hierarchical
structure learning; (Theocharous, Murphy)• Near-deterministic abstractions for MDPs (Lane)• Near-deterministic abstractions for POMDPs
(Theocharous, Lane)• Visual map building
• Optic flow-based navigation (Temizer, Steinkraus)• Automatic spatial decomposition (Temizer)• Selecting visual landmarks (Temizer)
• Enormous simulated robotic domain (Steinkraus)• Learning low-level behaviors with human training
(Smart)

18 September 2002 DARPA MARS PI Meeting
LCSToday’s talk
• Hierarchical POMDP Models• Parameter learning; heuristic action-selection
(Theocharous)• Near-optimal action-selection; Hierarchical
structure learning; (Theocharous, Murphy)• Near-deterministic abstractions for MDPs (Lane)• Near-deterministic abstractions for POMDPs
(Theocharous, Lane)• Visual map building
• Optic flow-based navigation (Temizer, Steinkraus)• Automatic spatial decomposition (Temizer)• Selecting visual landmarks (Temizer)
• Enormous simulated robotic domain (Steinkraus)• Learning low-level behaviors with human training
(Smart)

18 September 2002 DARPA MARS PI Meeting
LCSThe Problem
How to sequentially select actions in a very large uncertain domain?
• Markov decision processes are a good formalization for uncertain planning
• Optimization algorithms for MDPs are polynomial in the size of the state space
• which is exponential in the number of state variables!!

18 September 2002 DARPA MARS PI Meeting
LCSAbstraction and Decomposition
Our only hope is to divide and conquer
• state abstraction: treat sets of states as if they were the same
• state decomposition: solve restricted problems in sub-parts of the state space
• action abstraction: treat sequences of actions as if they were atomic
• teleological abstraction: goal based abstraction
18 September 2002 DARPA MARS PI Meeting
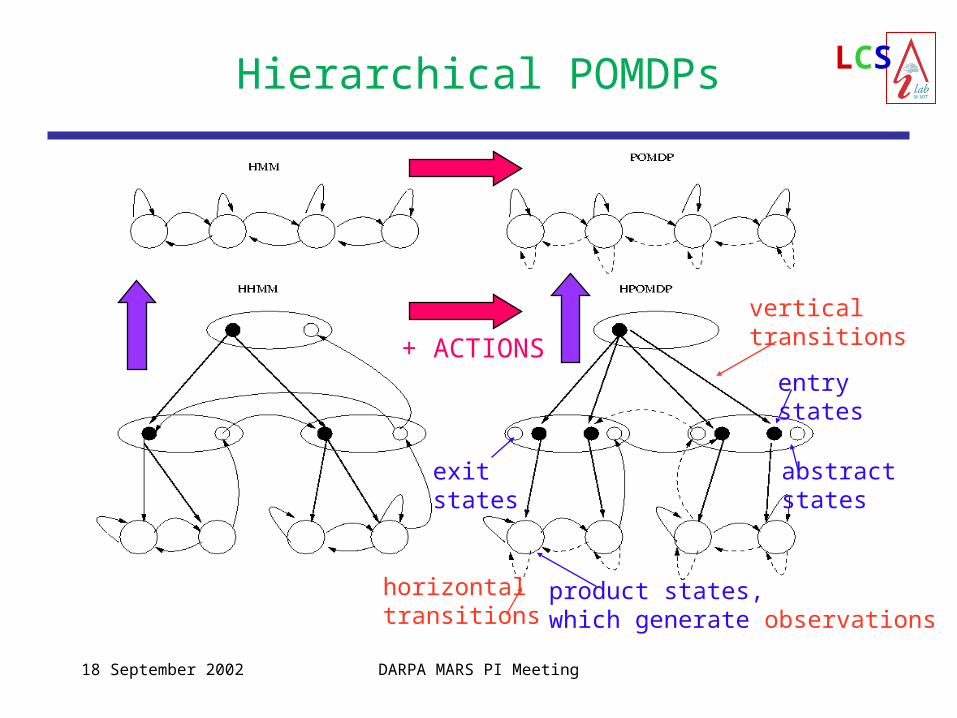
LCSHierarchical POMDPs
+ ACTIONS
abstract states
product states,which generate observations
entry states
exit states
verticaltransitions
horizontaltransitions
18 September 2002 DARPA MARS PI Meeting
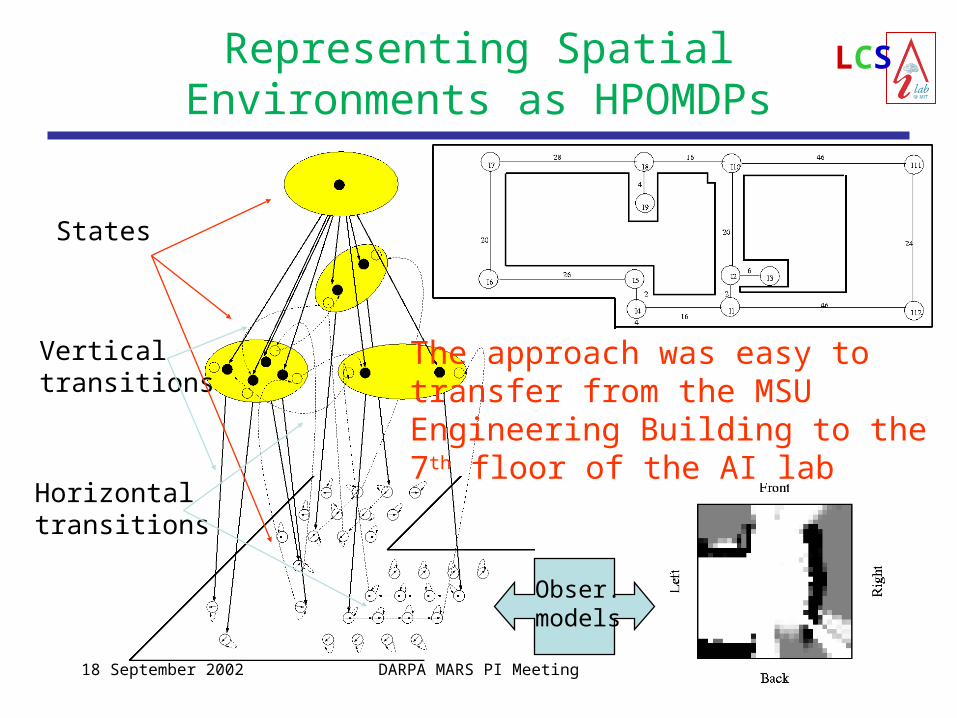
LCSRepresenting Spatial Environments as HPOMDPs
States
Verticaltransitions
Horizontaltransitions
Obser.models
The approach was easy totransfer from the MSU Engineering Building to the 7th floor of the AI lab

18 September 2002 DARPA MARS PI Meeting
LCSHierarchical Learning and Planning in Partially
Observable Markov Decision Processes for Robot Navigation
(Theocharous Ph.D. Thesis MSU 2002)
Derived the HPOMDP model and learning/planning algorithms
Learning HPOMDPs for robot navigation• Exact and approximate algorithms provide:
• Faster convergence/ Less time per iteration/ Better learned models/ Better robot localization /Ability to infer structure
Planning with HPOMDPs for robot navigation• Spatial and temporal abstraction
• Robot computes plans faster /Able to get to locations in the environment starting from unknown location/ Performance scales gracefully to large scale environments

18 September 2002 DARPA MARS PI Meeting
LCSPOMDP macro-actions can be formulated as policy graphs (Theocharous, Terran)
POMDP-macro-actions can be represented as policy graphs with some termination condition
[0,1]M=
Termination condition

18 September 2002 DARPA MARS PI Meeting
LCSReward and transition models of macro-actions
Expected sum of discounted reward for executing controller C from hidden state s and memory state x until termination.
In a similar manner we can compute the transition models
s)(x,CR
z)s,(x,CT
F
corr
else
x1 x2
S2S1 S3
S5
S6
S7

18 September 2002 DARPA MARS PI Meeting
LCSPlanning and Execution
Planning: (Solve it as an MDP)States : The hidden statesActions: Pairs of controller, memory states
(C,x)Reward and transition models (as defined
before)
Execution: 1-step look ahead (transition models allow us to predict the belief state far into the future)
Take the actions that maximizes the immediate reward from current belief states plus discounted value of next belief state
18 September 2002 DARPA MARS PI Meeting
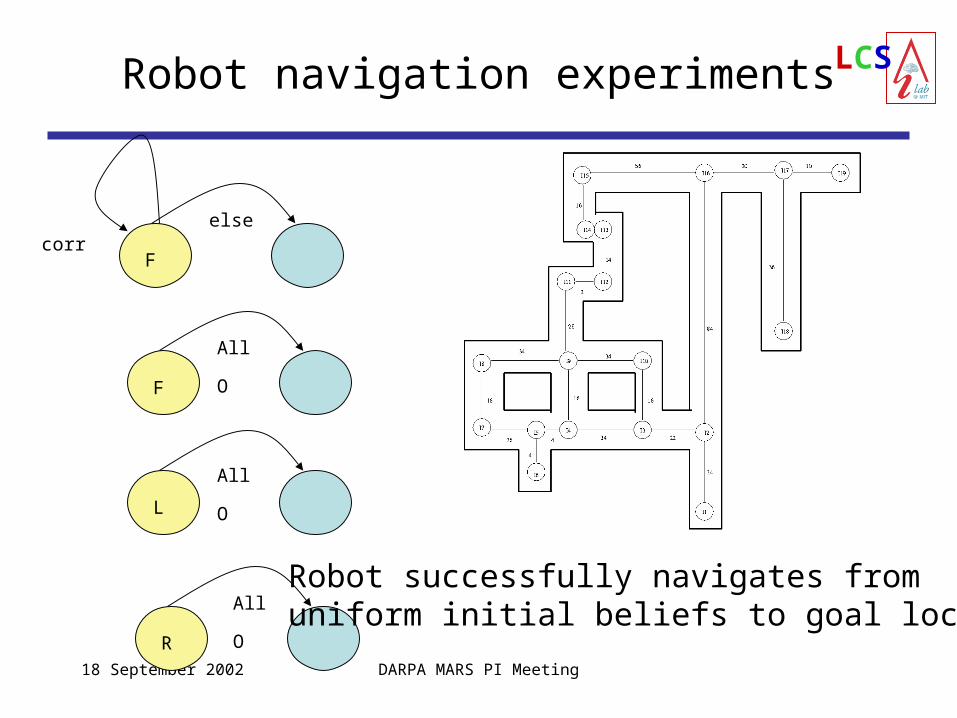
LCSRobot navigation experiments
F
All O
R
All O
L
All O
Fcorr
else
Robot successfully navigates from uniform initial beliefs to goal locations

18 September 2002 DARPA MARS PI Meeting
LCSStructure Learning & DBN
Representations(Theocharous, Murphy)
We are investigating methods for structure learning of HHMM/HPOMDPs (hierarchy depth, number of states, reusable substructures)• Bayesian model selection methods• Approaches for learning compositional hierarchies
(e.g., recurrent neural networks, sparse hierarchical n-grams)
• Other Language acquisition approaches (e.g., Carl de Marcken)
DBN representation of HPOMDPs• Linear time training• Extensions to online-training• Factorial HPOMDPs• Sampling techniques for fast inference

18 September 2002 DARPA MARS PI Meeting
LCSNear Determinism(Lane)
Some common action abstractions• put it in the bag• go to the conference room• take out the trash
What’s important about them?• even if the world is highly stochastic,• you can very nearly guarantee their success
Encapsulate uncertainty at the lower level of abstraction

18 September 2002 DARPA MARS PI Meeting
LCSExample domain
10 Floors~1800 locations per floor45 mail drops per floorLimited battery11 actionsTotal: |S|>2500 states

18 September 2002 DARPA MARS PI Meeting
LCSA simple example
State space:• X
• Y
• b (reached goal)Actions:
• N, S, E, W
Transition function:• Noise, walls
Rewards:• -/step until b =1
• 0 thereafterx
y
kYXS 2||

18 September 2002 DARPA MARS PI Meeting
LCSMacros deliver single packages
Macro is a plan over a restricted state space
Defines how to achieve one goal from any <x,y> location
Terminates at any goalCan be found quicklyEncapsulates uncertainty
Goal b2

18 September 2002 DARPA MARS PI Meeting
LCSCombining Macros
Formally: solve semi-MDP over {b}k
• Gets all macro interactions & probs right• Still exponential, though…
These macros are close to deterministic• Low prob. of delivering wrong package
Macros form graph over {b1 … bk}
• Reduce SMDP to graph optimization problem
18 September 2002 DARPA MARS PI Meeting
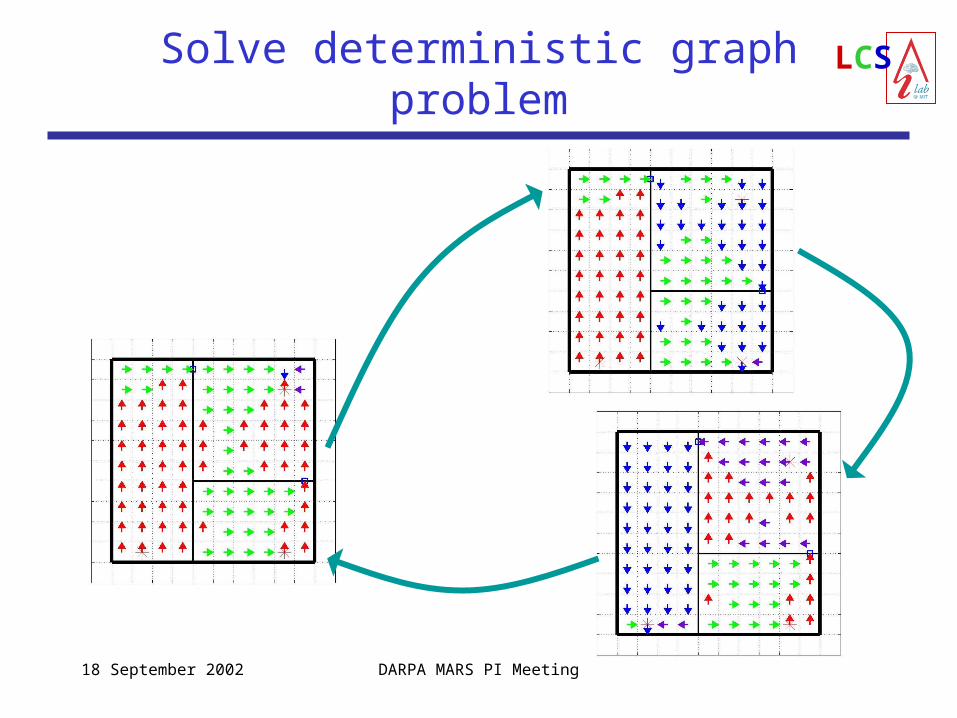
LCSSolve deterministic graph problem

18 September 2002 DARPA MARS PI Meeting
LCSBut does it work?
Yes! (Well, in simulation, anyway…)Small, randomly generated scenarios
• Up to ~60k states ( 6 packages)• Optimal solution directly• 5.8% error on avg
Larger scenarios, based on one-floor building model• Up to ~255 states (~45 packages)• Can’t get optimal solution• 600 trajectories; no macro failures

18 September 2002 DARPA MARS PI Meeting
LCSNear Determinism in POMDPs(Terran, Theocharous)
• Current research project: near-deterministic abstraction in POMDPs
• macros map belief states to actions• choose macros that reliably achieve subsets
of belief states• “dovetailing”

18 September 2002 DARPA MARS PI Meeting
LCSReally Big Domain (Steinkraus)

18 September 2002 DARPA MARS PI Meeting
LCSWorking in Huge Domains
• Continually remap the huge problem to smaller subproblems of current import
• Decompose along lines of utility function; recombine solutions
• Track belief state approximately; devote more bits to currently important aspects of the problem, and those predicted to be important in the future
• Adjust belief representation dynamically