ldta’05, edinburgh, april 3, 2005 1/30 inferring context-free grammars for domain-specific...
TRANSCRIPT

LDTA’05, Edinburgh, April 3, 2005 1/30
Inferring Context-Free Grammars for Domain-Specific Languages
Matej Črepinšek, Marjan Mernik University of Maribor, Slovenia
Barrett R. Bryant, Faizan Javed, Alan SpragueThe University of Alabama at Birmingham, USA
UNIVERSITY OF MARIBORFACULTY OF ELECTRICAL ENGINEERING AND COMPUTER SCIENCE

LDTA’05, Edinburgh, April 3, 2005 2/30
Outline of the Presentation
• Motivation • Related Work• Inferring CFG for DSLs• Results• Conclusion

LDTA’05, Edinburgh, April 3, 2005 3/30
Motivation
• Machine learning of grammars finds many applications in– syntactic pattern recognition, – computational biology,– computational linguistic, etc.
• Can be grammatical inference useful also in software engineering?

LDTA’05, Edinburgh, April 3, 2005 4/30
Motivation
• Software engineers would like to recover grammar from legacy systems in order to automatically generate various software analysis and modification tools.
• Currently, this can not be done for real GPL (e.g., Cobol) using grammatical inference.
• Grammar can be semi-automatically recovered from compilers and language manuals [R. Laemmel, C. Verhoef. Semi-automatic Grammar Recovery. SP&E, Vol. 31, No. 15, 2001].

LDTA’05, Edinburgh, April 3, 2005 5/30
Motivation
• What about grammar inference for DSLs (e.g., FDL, VHDL)?– car: all( carBody, Transmission, Engine ) Transmission: one-of( automatic, manual ) Engine: more-of( electric, gasoline )– entity HALFADDER is
port( A, B: in bit; SUM, CARRY: out bit);end HALFADDER;
• Currently, experiments were performed on theoretical sample languages only, such as L={ww | w {a,b}+}, L={w=wR | w {a,b}+}

LDTA’05, Edinburgh, April 3, 2005 6/30
Motivation
• Grammars are found in many applications outside language definition and implementation.
• Grammar-based systems (GBSs) [M. Mernik, M. Črepinšek, T. Kosar, D. Rebernak, V. Žumer. Grammar-based Systems: Definition and Examples. Informatica, 28(3):245-254, 2004]
• In this cases, the grammar needs to be extracted solely from artifacts represented as sentences/programs written in some unknown language.

LDTA’05, Edinburgh, April 3, 2005 7/30
Motivation
Metamodel Model – an instance of Metamodel

LDTA’05, Edinburgh, April 3, 2005 8/30
Motivation
VideoStore ::= MOVIES CUSTOMERSMOVIES ::= MOVIES MOVIE | MOVIEMOVIE ::= title typeCUSTOMERS ::= CUSTOMERS CUSTOMER | CUSTOMER ::= name days RENTALSRENTALS ::= RENTALS RENTAL | RENTALRENTAL ::= MOVIE
• TheRing reg Andy 3 TheRing reg
• TheRing reg Shrek2 child Ann 1 Shrek2 child

LDTA’05, Edinburgh, April 3, 2005 9/30
Motivation
NT15 ::= NT11 NT7 NT15 | NT11 ::= NT10 NT6NT10 ::= NT5 NT10 | NT7 ::= NT5 NT7 | NT6 ::= name daysNT5 ::= title type
NT5titletype
NT6namedays
NT111..*
1..*
1..*
• TheRing reg Andy 3 TheRing reg
• TheRing reg Shrek2 child Ann 1 Shrek2 child

LDTA’05, Edinburgh, April 3, 2005 10/30
Related Work
• Gold Theorem - it is impossible to identify any of the four classes of languages in the Chomsky hierarchy using only positive samples.
• Positive and negative samples are needed.
• So far, grammar inference has been mainly successful in inferring regular languages.

LDTA’05, Edinburgh, April 3, 2005 11/30
Related Work (Regular Grammars)
A number of algorithms (e.g., RPNI) first construct the maximal canonical automaton (MCA(S+)) or prefix tree acceptor (PTA(+)) from positive samples, and generalize the automaton by using a state merging process.

LDTA’05, Edinburgh, April 3, 2005 12/30
Related Work (Regular Grammars)
The following equation enumerates the search space:
m Em
1 1
2 2
3 5
4 15
5 52
6 203
7 877
8 4140
9 21147
10 115975
11 678570
12 4213597
13 27644437
14 190899322

LDTA’05, Edinburgh, April 3, 2005 13/30
Related Work (CF Grammars)
• Learning context-free grammars G=(V, T, P, S) is more difficult than learning regular grammars.
• Using representative positive samples (that is, positive samples which exercise every production rule in the grammar) along with negative samples did not result in the same level of success as with regular grammar inference.

LDTA’05, Edinburgh, April 3, 2005 14/30
Related Work (CF Grammars)
• Hence, some researchers resorted to using additional knowledge to assist in the induction process (e.g., skeleton derivation trees - unlabelled derivation trees).
num + numnum
num+ num
+

LDTA’05, Edinburgh, April 3, 2005 15/30
Inferring CFG
• What is the search space in the case of CFG inference?
• If we limit ourselves to binary trees (CNF), then all possible unlabelled derivations trees is given by n-th Catalan number:

LDTA’05, Edinburgh, April 3, 2005 16/30
Inferring CFG
• For example, there are 14 different full binary trees when l=5
…

LDTA’05, Edinburgh, April 3, 2005 17/30
Inferring CFG
• For full binary trees to be valid derivation trees, the interior nodes need to be labeled with non-terminals.

LDTA’05, Edinburgh, April 3, 2005 18/30
Inferring CFG
Search space of context-free grammar inference
n Catalan numbers
Catalan numbers * nn Catalan numbers *Bell numbers
1 1 1 1
2 2 8 4
3 5 135 25
4 14 3584 210
5 42 131250 2184
6 132 6158592 26796
7 429 3.532999 E8 376233
8 1430 2.399141 E10 5920200
9 4862 1.883638 E12 1.028167 E8
10 16796 1.679600 E14 1.947916 E9

LDTA’05, Edinburgh, April 3, 2005 19/30
Inferring CFG
• For effective use of an evolutionary algorithm we have to choose a suitable representation of the problem, suitable parameters and genetic operators, and the evaluation function to determine the fitness of chromosomes.
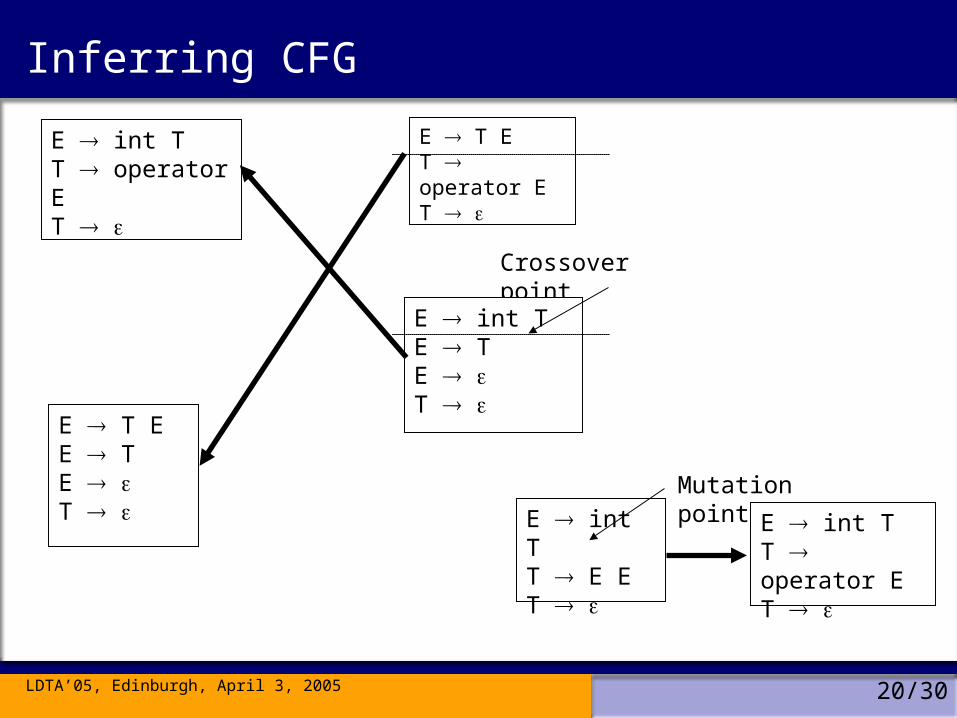
LDTA’05, Edinburgh, April 3, 2005 20/30
Inferring CFG
Crossover point
E int TE TE T
E T ET operator ET
E T EE TE T
E int TT operator ET
E int TT E ET
Mutation point
E int TT operator ET

LDTA’05, Edinburgh, April 3, 2005 21/30
Inferring CFG
To enhance the search, the following heuristic operators have been proposed:
• option operator,• iteration* operator, and• iteration+ operator.
E int TT operator FT F EF
Option point
E int TT operator ET

LDTA’05, Edinburgh, April 3, 2005 22/30
Inferring CFG
fitness value
sucessfulness of parsing
parser generation
for each grammar in the population
Test grammars
Crossover and mutation
Selection
Population of grammars
LISA compiler generator
generated parser
fitness cases (positive and negative samples)
run parser on each fitness case

LDTA’05, Edinburgh, April 3, 2005 23/30
Inferring CFG
For the given grammar[i] its fitness fj(grammar[i]) on the j-fitness case is defined as:
fj(grammar[i]) = length(successfully parsed programj)/length(programj)*2
Finally, the total fitness f(grammar[i]) is
defined as:
f(grammar[i])=(Nk=1 fk(grammar[i]))/N

LDTA’05, Edinburgh, April 3, 2005 24/30
Inferring CFG
If a grammar correctly recognized all positive samples than it is tested also on negative samples. Its fitness value is defined as:
f(grammar[i]) = 1.0 -(m/M*2) wherem=number of fully parsed negative samples
M=number of all negative samples

LDTA’05, Edinburgh, April 3, 2005 25/30
Inferring CFG
• Initial population should not be completly randomly generated.
NT8 -> NT7 NT1NT7 -> NT5 NT6NT6 -> NT1 NT3NT5 -> NT4 NT2NT4 -> #idNT3 -> +NT2 -> :=NT1 -> #int
NT7
NT5
NT8
NT3 NT1 NT2
NT6
#int + #int := #id
NT1 NT4

LDTA’05, Edinburgh, April 3, 2005 26/30
Inferring CFG
• Identify sub-languages and construct derivation trees for sub-programs first. But this is as hard as the original problem.
• We can use an approximation: frequent sequences.
• A string of symbols is called a frequent sequence if it appears at least times, where is some preset threshold.

LDTA’05, Edinburgh, April 3, 2005 27/30
Inferring CFG
• GIE-BF tool

LDTA’05, Edinburgh, April 3, 2005 28/30
Results
• Using presented approach we were able to infer grammars for small DSLs (Table 2 in the paper).
• An example of positive/negative samples and control parameters (Table 3 in the paper).
• Comparison of inferred and original grammars (Table 4 and 5 in the paper).

LDTA’05, Edinburgh, April 3, 2005 29/30
Conclusion
• An ongoing research work on context-free grammar inference was presented.
• So far, we have been able to infer grammars for DSLs which are bigger in size and more pragmatic than in other research efforts.
• We are convinced that this approach, when enhanced with other data mining techniques and heuristics, is scalable and feasible to infer grammars of more realistically sized languages.

LDTA’05, Edinburgh, April 3, 2005 30/30
Thank you!
http://www.cis.uab.edu/softcom/GenParse