learning from observations
DESCRIPTION
Learning from Observations. Chapter 18 Through 18.3.5. Outline. Learning agents Inductive learning Decision tree learning. Learning. Learning is essential for unknown environments, i.e., when designer lacks omniscience Learning is useful as a system construction method, - PowerPoint PPT PresentationTRANSCRIPT

Learning from Observations
Chapter 18
Through 18.3.5
1

Outline
• Learning agents• Inductive learning• Decision tree learning
2

Learning
• Learning is essential for unknown environments,– i.e., when designer lacks omniscience
• Learning is useful as a system construction method,– i.e., designer might not know how to solve the
problem
• Learning modifies the agent's decision mechanisms to improve performance over time
3

Learning element
• Design of a learning element is affected by– Which components of the performance element are to
be learned (condition-action rules; relevant properties of the world; results of possible actions; etc.)
– What feedback is available to learn these components– What representation is used for the components (this
chapter: vectors of attribute values)
• Type of feedback:– Supervised learning: correct answers for each
example– Unsupervised learning: correct answers not given– Reinforcement learning: occasional rewards
4

Inductive Learning
• When the output y is one of a finite set of values, the learning problem is called classification
• When y is a number (such as earnings or tomorrow’s temperature), then the learning problem is called regression
5

Inductive learning
• Simplest form: learn a function from examples
f is the target function
An example is a pair (x, f(x))
Problem: find a hypothesis hsuch that h ≈ fgiven a training set of examples
•
•
6

7

Learning decision trees
Problem: decide whether to wait for a table at a restaurant, based on the following attributes:1. Alternate: is there an alternative restaurant nearby?2. Bar: is there a comfortable bar area to wait in?3. Fri/Sat: is today Friday or Saturday?4. Hungry: are we hungry?5. Patrons: number of people in the restaurant (None, Some, Full)6. Price: price range ($, $$, $$$)7. Raining: is it raining outside?8. Reservation: have we made a reservation?9. Type: kind of restaurant (French, Italian, Thai, Burger)10. WaitEstimate: estimated waiting time (0-10, 10-30, 30-60, >60)
8

Attribute-based representations
• Examples described by attribute values (Boolean, discrete, continuous)
• Classification of examples is positive (T) or negative (F)
•9

Decision trees
• One possible representation for hypotheses• E.g., here is the “true” tree for deciding whether to wait:
10
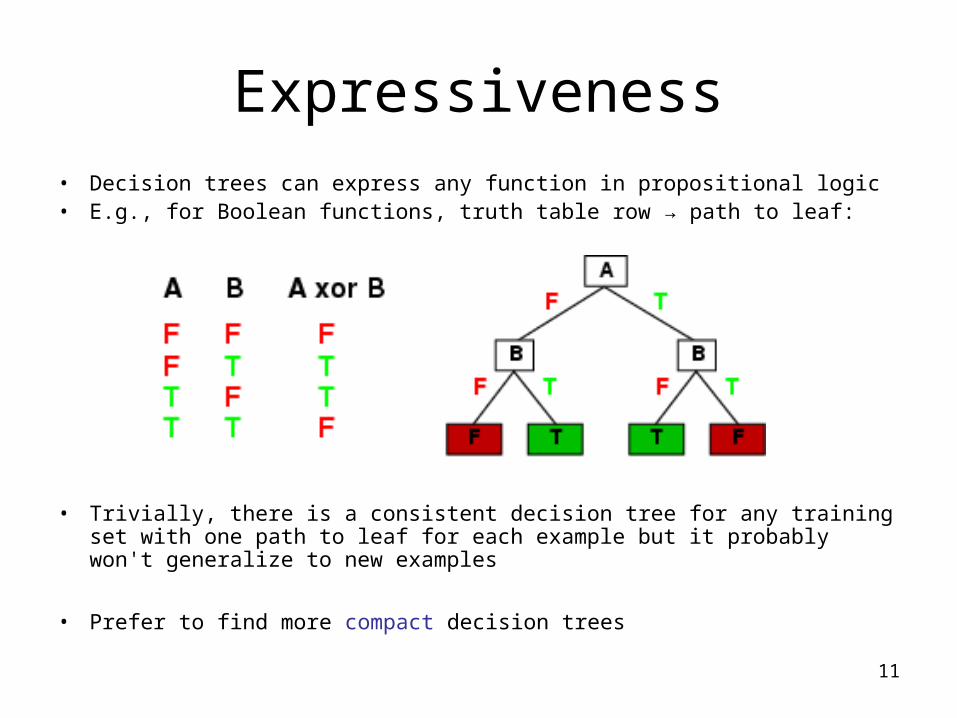
Expressiveness• Decision trees can express any function in propositional logic • E.g., for Boolean functions, truth table row → path to leaf:
• Trivially, there is a consistent decision tree for any training set with one path to leaf for each example but it probably won't generalize to new examples
• Prefer to find more compact decision trees
11

Hypothesis spaces
How many distinct decision trees with n Boolean attributes?
= number of Boolean functions
= number of distinct truth tables with 2n rows = 22n
• E.g., with 6 Boolean attributes, there are 18,446,744,073,709,551,616 trees
• We’ll do a greedy search
12

Decision tree learning
• Aim: find a small tree consistent with the training examples• Idea: (recursively) choose "most significant" attribute as root of
(sub)tree
13

• Example in class
14

Choosing an attribute
• Idea: a good attribute splits the examples into subsets that are (ideally) "all positive" or "all negative"
• Patrons? is a better choice•
15

Using information theory
• To implement Choose-Attribute in the DTL algorithm
• Information Content (Entropy):
I(P(v1), … , P(vn)) = Σi -P(vi) log2 P(vi)
• For a training set containing p positive examples and n negative examples:
np
n
np
n
np
p
np
p
np
n
np
pI
22 loglog),(
16

Information gain
• A chosen attribute A divides the training set E into subsets E1, … , Ev according to their values for A, where A has v distinct values.
• Information Gain (IG) or reduction in entropy from the attribute test:
• Choose the attribute with the largest IG
v
i ii
i
ii
iii
np
n
np
pI
np
npAremainder
1
),()(
)(),()( Aremaindernp
n
np
pIAIG
17

Information gain
For the training set, p = n = 6, I(6/12, 6/12) = 1 bit
Consider the attributes Patrons and Type:
Patrons has the highest IG of all attributes and so is chosen by the DTL algorithm as the root€
IG(Patrons) =1−[2
12I(0,1) +
4
12I(1,0) +
6
12I(
2
6,4
6)] = .541 bits
IG(Type) =1−[2
12I(
1
2,1
2) +
2
12I(
1
2,1
2) +
4
12I(
2
4,2
4) +
4
12I(
2
4,2
4)] = 0 bits
18

Example contd.
• Decision tree learned from the 12 examples:
• Substantially simpler than “true” tree---a more complex hypothesis isn’t justified by small amount of data
19

• Learning algorithm versus classifier (class)
20

Performance measurement
• How do we know that h ≈ f ?1. Use theorems of computational/statistical learning theory
2. Try h on a new test set of examples
Learning curve = % correct on test set as a function of training set size
21

22
Evaluating Inductive Hypotheses
• Accuracy of hypotheses on training data is obviously biased since the hypothesis was constructed to fit this data.
• Accuracy must be evaluated on a separate test set.• Average over multiple train/test splits to get accurate measure of
accuracy.• K-fold cross validation averages over K trials using each example
exactly once as a test case.

23
K-Fold Cross Validation
Randomly partition data D into k disjoint equal-sized subsets P1…Pk
For i from 1 to k do: Use Pi for the test set and remaining data for trainingAverage results over all K folds. Accuracy: % correctFor class C:Precision: #True C & System’s answer is C/#System’s answer is C Recall: #True C & System’s answer is C / # True CF1-measure: 2 * (precision * recall / (precision + recall))

24
K-Fold Cross Validation Comments
• Every example gets used as a test example once and as a training example k–1 times.
• All test sets are independent; however, training sets overlap significantly..
• Standard method is 10-fold.• If k is low, not sufficient number of train/test trials; if k is high, test
set is small and test variance is high and run time is increased.• If k=|D|, method is called leave-one-out cross validation.

Overfitting
• Overfitting can occur with any type of learner• The model describes random error or noise rather than the
underlying pattern• For decision tree induction, “pruning” is use to combat overfitting.• Starting with nodes with only examples as children, eliminate
attributes that fail a significance test. [That’s all you need to know]
25

Summary
• Learning needed for unknown environments, lazy designers• Learning agent = performance element + learning element• For supervised learning, the aim is to find a simple hypothesis
approximately consistent with training examples• Decision tree learning using information gain • Learning performance = prediction accuracy measured on test set
26