learning to interact
TRANSCRIPT

Katja Hofmann
Learning to InteractTowards “Self-learning” Search Solutions Presenting work by various authors,
and own work in collaboration with colleagues at Microsoft and the University of Amsterdam@katjahofmann

Motivation
Example task:Find best news articles based on user context; optimize click-through rate
Example task:Tune ad display parameters (e.g., mainline reserve) to optimize revenue
Example task:Improve ranking of QAC to optimize suggestion usage
Typical approach: lots of offline tuning + AB testing.

AB Testing= controlled experiment (often at
large scale) with (at least) 2 conditions
[Kohavi et al. ’09, ‘12]
Example: which search interface results in higher revenue?

Limitations of AB testingHigh manual effortNeed to carefully design / tune each treatment
Few tested alternativesTypically compare 2-5 options
Large required sample sizeDepending on effect size and variance, thousands to millions of impressions required to detect statistically significant differences
Result: slow development cycles (e.g., weeks)Can any of this be automated to speed up innovation?

Towards “Self-learning” Search SolutionsContextual Bandits
Counterfactual Reasoning
Online Learning to Rank

Image adapted from: https://www.flickr.com/photos/prayitnophotography/4464000634
Contextual bandits

Why bandits?Interactive systems only observe user feedback (reward) on the items (actions) they present to their users.
Exploration – exploitation trade-offFormalized as (contextual) bandit problem
submit query, interact with result lists
generate resultsinterpret feedback

Bandits
Address key challenge: how to balance exploration and exploitation – explore to learn, exploit to benefit from what has been learned.
= Reinforcement learning problem where actions do not affect future states

BanditsExample
Successes so far:100 50 10Arm pulls so far: ?? ?? ??
A B C

BanditsExample
Successes so far: 100 50 10Arm pulls so far:1000 100 20
A B C

BanditsExample
Successes so far: 100 50 10Arm pulls so far:1000 100 20
both arms are promising,higher uncertainty for C
A B C
Bandit approaches balance exploration and exploitation based on expected payoff and uncertainty.

Adding contextGoal: take the best action based on context information (e.g., topics in user history)Contextual ε-greedyIdea 1: Use simple exploration approach (here: ε-greedy)Idea 2: Explore efficiently in a small action space, but use machine learning to optimize over a context space.
[Li et al. ‘12]

Contextual banditsExample application: news recommendation.
[Li et al. ‘12]
Li et al. propose to learn generalized linear models using contextual ε-greedy.
Models:
Example results:
Balancing exploration and exploitation is crucial for good results.

Summary: Contextual BanditsKey ideas1) Balance exploration and exploitation, to ensure
continued learning while applying what has been learned
2) Explore in a small action space, but learn in a large contextual space

Illustrated Sutra of Cause and Effect"E innga kyo" by Unknown - Woodblock reproduction, published in 1941 by Sinbi-Shoin Co., Tokyo. Licensed under Public domain via Wikimedia Commons - http://commons.wikimedia.org/wiki/File:E_innga_kyo.jpg#mediaviewer/File:E_innga_kyo.jpg
Counterfactual Reasoning

Example: ad placement
Problem: estimate effects of mainline reserve changes.[Bottou et. al ‘13]
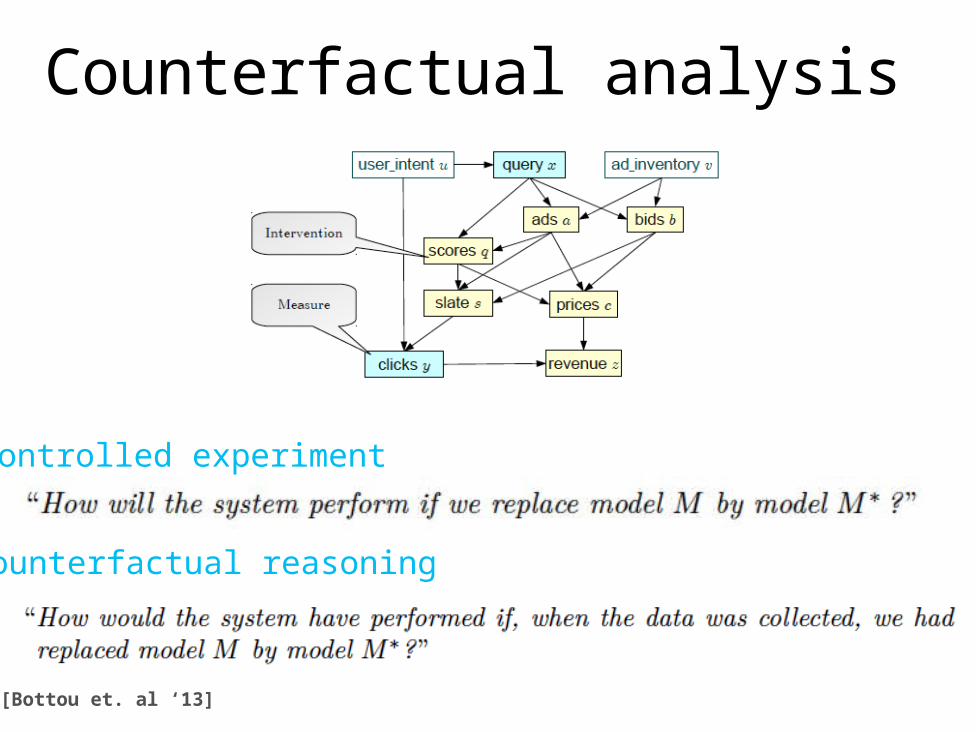
Counterfactual analysis
[Bottou et. al ‘13]
controlled experiment
counterfactual reasoning

Answering “what-if” questionsKey idea: estimate what would have happened if a different
system (distribution over parameter values) had been used, using importance sampling.
Step 1: factorize based on known causal graph
This works because:
[Bottou et. al ‘13]
𝑃 ′ (𝜔 )=𝑃 (𝑢 ,𝑣 )∗…∗𝑃 ′ (𝑞|𝑥 ,𝑎 )∗…𝑃 (𝜔 )=𝑃 (𝑢 ,𝑣 )∗…∗𝑃 (𝑞|𝑥 ,𝑎 )∗…
Step 2: compute estimates using importance sampling
𝑌 ′= 1𝑛∑𝑖=1𝑛
𝑦 𝑖𝑃 ′ (𝑞|𝑥 ,𝑎 )𝑃 (𝑞|𝑥 ,𝑎 )
= =
Example distributions:
𝑃 (𝑞)𝑃 ′(𝑞 )
𝑞
[Precup et. al ‘00]

Example result
[Bottou et. al ‘13]
Counterfactual reasoning allows analysis over a continuous range.

Summary: Counterfactual ReasoningKey ideas1) Leverage known causal structure and importance
sampling to reason about “alternative realities”2) Bound estimator error to distinguish between
uncertainty due to low sample size and exploration coverage

Online Learning to Rank

Compare two rankings:1) Generate interleaved (combined) ranking2) Observe user clicks3) Credit clicks to original rankers to infer
outcome
document 1document 2document 3document 4
document 2document 3document 4document 1
document 1document 2document 3document 4
Interleaved Comparison Methods
[Joachims et al. ’05, Chapelle et al. ‘12, Hofmann et al. ‘13a]
Example: optimize QAC ranking

Learning from relative feedback
Dueling bandit gradient descent (DBGD) optimizes a weight vector for weighted-linear combinations of ranking features.
current best weight vector
sample unit sphere to generate candidate ranker
randomly generated candidate
feat
ure
1
feature 2
Relative listwise feedback is obtained using interleaving
Learning approach
[Yue & Joachims ‘09]

Improving sample efficiency
Idea 1: Generate several candidate rankers, and select the best one by running a tournament on historical dataIdea 2: Use probabilistic interleave and importance sampling for ranker comparisons during the tournament
Estimate comparison outcomes using probabilistic interleave + importance sampling:
generate many candidates and select the most promising one
feat
ure
1
feature 2
[Hofmann et al. ’13c]
Approach: candidate pre-selection (CPS)

Analysis: Speed of Learning
informational click model
[Hofmann et al. ’13b, Hofmann et al. ’13c]
From earlier work: learning from relative listwise feedback is robust to noise. Here: adding structure further dramatically improves performance.

Summary: Online Learning to RankKey ideas1) Avoid combinatorial action space by exploring in
parameter space2) Reduce variance using relative feedback3) Leverage known structures for sample-efficient
learning

SummaryOptimizing interactive systemsSlow with manually designed alternatives and AB testing – how can we automate?
Contextual banditsSystematic approach to balancing exploration and exploitation; contextual bandits explore in small action space but optimize in large context space.Counterfactual reasoningLeverages causal structure and importance sampling for “what if” analyses.
Online learning to rankAvoids combinatorial explosion by exploring and learning in parameter space; uses known ranking structure for sample-efficient learning.

What’s next?ResearchMeasuring reward, low-risk and low-variance exploration schemes, new learning mechanisms
ApplicationsAssess action and solution spaces in a given application, collect and learn from exploration data, increase experimental agilityTry this (at home)Try open-source code samples; Living labs challenge allows experimentation with online learning and evaluation methods
Challenge: http://living-labs.net/challenge/
Code: https://bitbucket.org/ilps/lerot

References and further readingA/B testing[Kohavi et al. ‘09] R. Kohavi, R. Longbotham, D. Sommerfield, R. M. Henne: Controlled experiments on the web:
survey and practical guide (Data Mining and Knowledge Discovery 18, 2009).[Kohavi et al. ‘12] R. Kohavi, A. Deng, B. Frasca, R. Longbotham, T. Walker, Y. Xu: Trustworthy online controlled
experiments: five puzzling outcomes explained (KDD 2012).
Contextual bandits[Li et al. ‘11] L. Li, W. Chu, J. Langford, X. Wang: Unbiased Offline Evaluation of Contextual-bandit-based News Article
Recommendation Algorithms (WWW, 2014).[Li et al. ‘12] L. Li, W. Chu, J. Langford, T. Moon, X. Wang: An Unbiased Offline Evaluation of Contextual Bandit
Algorithms based on Generalized Linear Models, ICML-2011 Workshop on Online Trading of Exploration and Exploitation.
Counterfactual reasoning[Bottou et. al ‘13] L. Bottou, J. Peters, J. Quiñonero-Candela, D.X. Charles, D.M. Chickering, E. Portugaly, D. Ray, P.
Simard, E. Snelson: Counterfactual reasoning and learning systems: the example of computational advertising (Journal of Machine Learning Research 14 (1), 2013).
[Precup et al. ‘00] D. Precup, R. S. Sutton, S. Singh: Eligibility Traces for Off-Policy Policy Evaluation (ICML 2000).
Interleaving[Chapelle et al. ‘12] O. Chapelle, T. Joachims, F. Radlinski, Y. Yue: Large Scale Validation and Analysis of Interleaved
Search Evaluation (ACM Transactions on Information Systems 30(1): 6, 2012).[Hofmann et al. ’13a] K. Hofmann, S. Whiteson, M. de Rijke: Fidelity, Soundness, and Efficiency of Interleaved
Comparison Methods (ACM Transactions on Information Systems 31(4): 17, 2013).[Radlinski et al. ‘08] F. Radlinski, M. Kurup, and T. Joachims: How does clickthrough data reflect retrieval quality?
(CIKM 2008).
Online learning to rank[Yue & Joachims ‘09] Y. Yue, T. Joachims: Interactively optimizing information retrieval system as a dueling bandits
problem (ICML 2009).[Hofmann et al. ’13b] K. Hofmann, A. Schuth, S. Whiteson, M. de Rijke: Reusing Historical Interaction Data for Faster
Online Learning to Rank for IR (WSDM 2013).[Hofmann et al. ’13c] K. Hofmann, S. Whiteson, M. de Rijke: Balancing exploration and exploitation in listwise and
pairwise online learning to rank for information retrieval (Information Retrieval 16, 2013).

© 2013 Microsoft Corporation. All rights reserved. Microsoft, Windows and other product names are or may be registered trademarks and/or trademarks in the U.S. and/or other countries.The information herein is for informational purposes only and represents the current view of Microsoft Corporation as of the date of this presentation. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information provided after the date of this presentation. MICROSOFT MAKES NO WARRANTIES, EXPRESS, IMPLIED OR STATUTORY, AS TO THE INFORMATION IN THIS PRESENTATION.