leveling the field for multicore open systems architectures markus levy president, eembc president,...
TRANSCRIPT

Leveling the Field for Multicore Open Systems Architectures
Markus LevyPresident, EEMBC
President, Multicore Association

Analyzing the Multicore Ecosystem
• Embedded Microprocessor Benchmark Consortium® (EEMBC)
• Industry benchmarks since 1997
• Tool for evaluating embedded processors, compilers, systems
• MultiBench for shredding multicore processors

Enabling the Multicore Ecosystem
• Initial engagement began in May 2005
• Industry-wide participation
• Current efforts• Communications APIs• Hypervisors• Multicore Programming Practices• Resource Management

Multicore Issues to Solve
• Concurrent programming • Communications, synchronization, resource
management between/among cores• Performance analysis• Debugging• Distributed power management• OS virtualization• Modeling and simulation• Load balancing• Algorithm partitioning
Multicore Benchmarking Rules
• Do not rely on a single answer
• Match your application requirements– Small or large data sets– Few or many threads– Dependencies– OS overhead

Benchmarking Multicore – What’s Important?
• Measuring scalability
• Memory and I/O bandwidth
• Inter-core communications
• OS scheduling support
• Efficiency of synchronization
• System-level functionality

EEMBC Multicore Strategy• Evaluation and future development of
scalable SMP architectures– Includes multicore and manycore
• Measure impact of parallelization and scalability across both data processing and computationally-intensive tasks
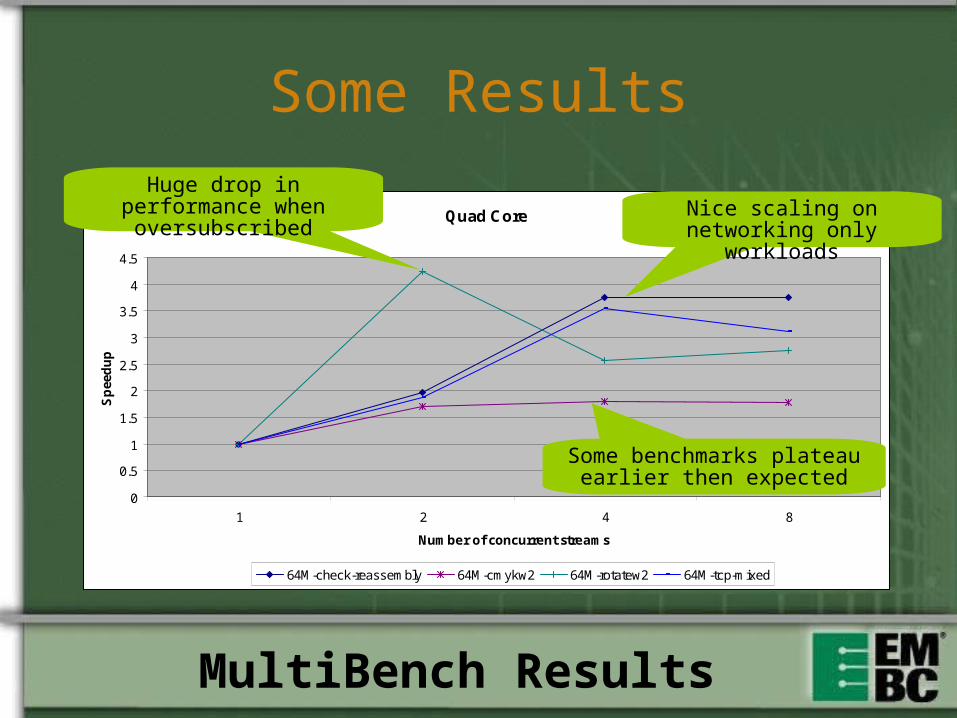
Some Results
Quad Core
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
1 2 4 8
Number of concurrent streams
Sp
eed
up
64M-check-reassembly 64M-cmykw2 64M-rotatew2 64M-tcp-mixed
Huge drop in performance when oversubscribed Nice scaling on networking
only workloads
Some benchmarks plateau earlier then expected
MultiBench Results
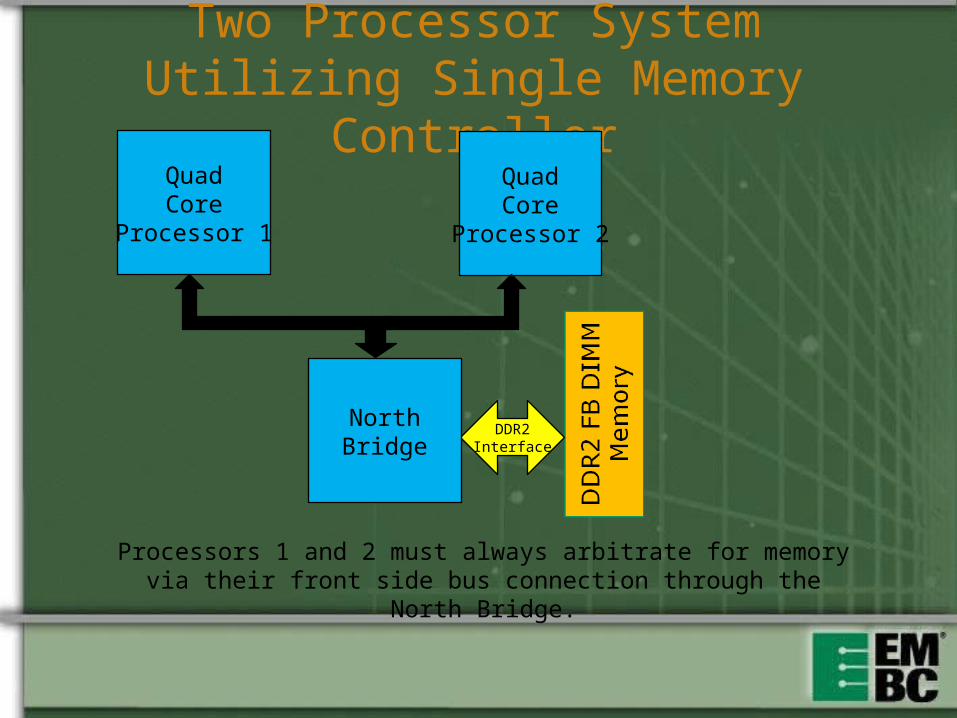
Two Processor System Utilizing Single Memory Controller
QuadCore
Processor 1
QuadCore
Processor 2
DDR2Interface
Processors 1 and 2 must always arbitrate for memory via their front side bus connection through the North Bridge.
NorthBridge
Intel Front Side Bus
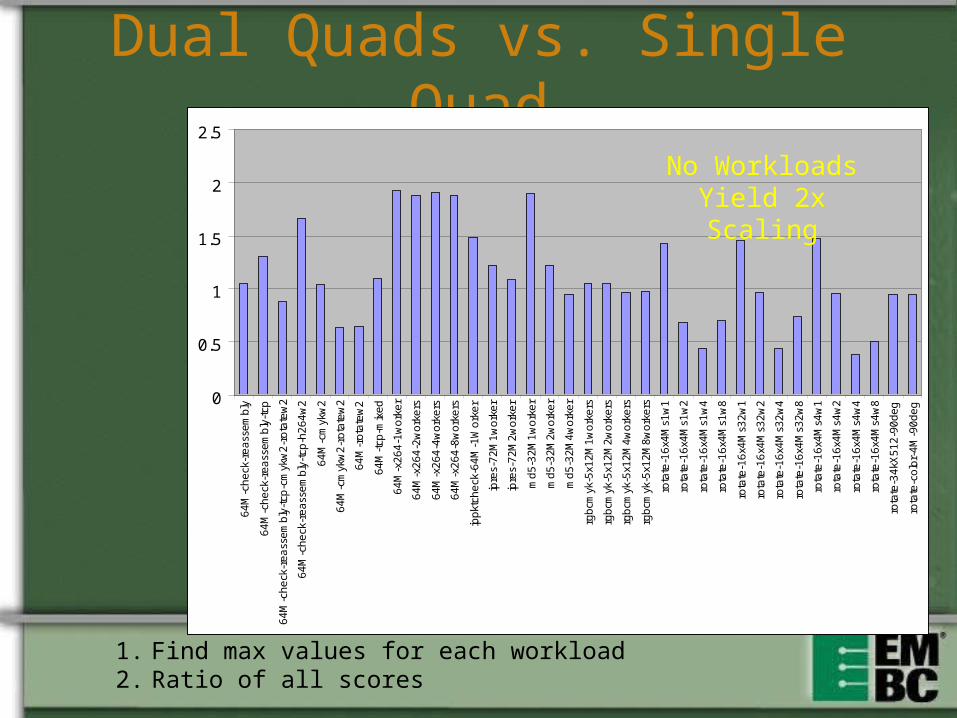
Dual Quads vs. Single Quad
1. Find max values for each workload2. Ratio of all scores
0
0.5
1
1.5
2
2.5
64
M-c
he
ck-r
ea
sse
mb
ly
64
M-c
he
ck-r
ea
sse
mb
ly-t
cp
64
M-c
he
ck-r
ea
sse
mb
ly-t
cp-c
myk
w2
-ro
tate
w2
64
M-c
he
ck-r
ea
sse
mb
ly-t
cp-h
26
4w
2
64
M-c
myk
w2
64
M-c
myk
w2
-ro
tate
w2
64
M-r
ota
tew
2
64
M-t
cp-m
ixe
d
64
M-x
26
4-1
wo
rke
r
64
M-x
26
4-2
wo
rke
rs
64
M-x
26
4-4
wo
rke
rs
64
M-x
26
4-8
wo
rke
rs
ipp
ktch
eck
-64
M-1
Wo
rke
r
ipre
s-7
2M
1w
ork
er
ipre
s-7
2M
2w
ork
er
md
5-3
2M
1w
ork
er
md
5-3
2M
2w
ork
er
md
5-3
2M
4w
ork
er
rgb
cmyk
-5x1
2M
1w
ork
ers
rgb
cmyk
-5x1
2M
2w
ork
ers
rgb
cmyk
-5x1
2M
4w
ork
ers
rgb
cmyk
-5x1
2M
8w
ork
ers
rota
te-1
6x4
Ms1
w1
rota
te-1
6x4
Ms1
w2
rota
te-1
6x4
Ms1
w4
rota
te-1
6x4
Ms1
w8
rota
te-1
6x4
Ms3
2w
1
rota
te-1
6x4
Ms3
2w
2
rota
te-1
6x4
Ms3
2w
4
rota
te-1
6x4
Ms3
2w
8
rota
te-1
6x4
Ms4
w1
rota
te-1
6x4
Ms4
w2
rota
te-1
6x4
Ms4
w4
rota
te-1
6x4
Ms4
w8
rota
te-3
4kX
51
2-9
0d
eg
rota
te-c
olo
r-4
M-9
0d
eg
No Workloads Yield 2x Scaling
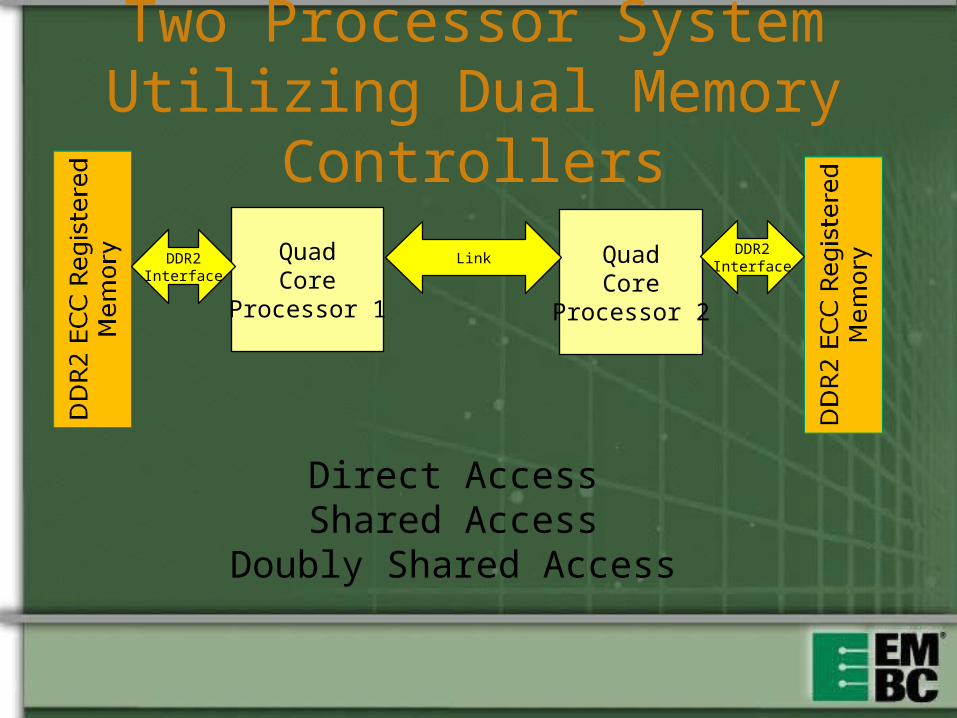
Two Processor System Utilizing Dual Memory Controllers
QuadCore
Processor 1
QuadCore
Processor 2
LinkDDR2Interface
DDR2Interface
Direct AccessShared Access
Doubly Shared Access
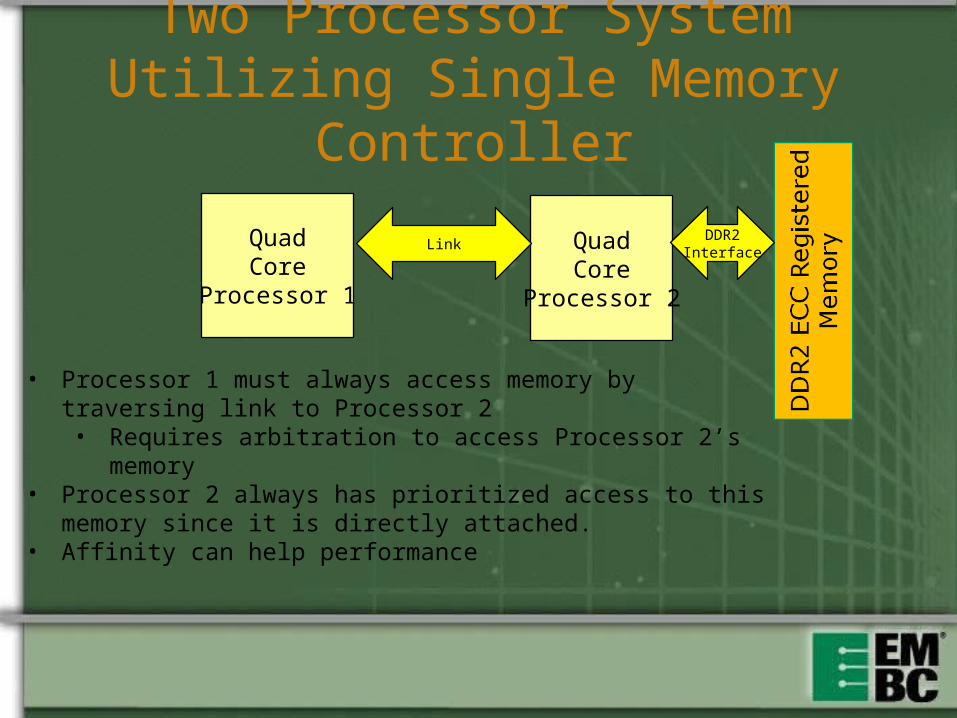
Two Processor System Utilizing Single Memory Controller
QuadCore
Processor 1
QuadCore
Processor 2
LinkDDR2
Interface
• Processor 1 must always access memory by traversing link to Processor 2• Requires arbitration to access Processor 2’s memory
• Processor 2 always has prioritized access to this memory since it is directly attached.
• Affinity can help performance
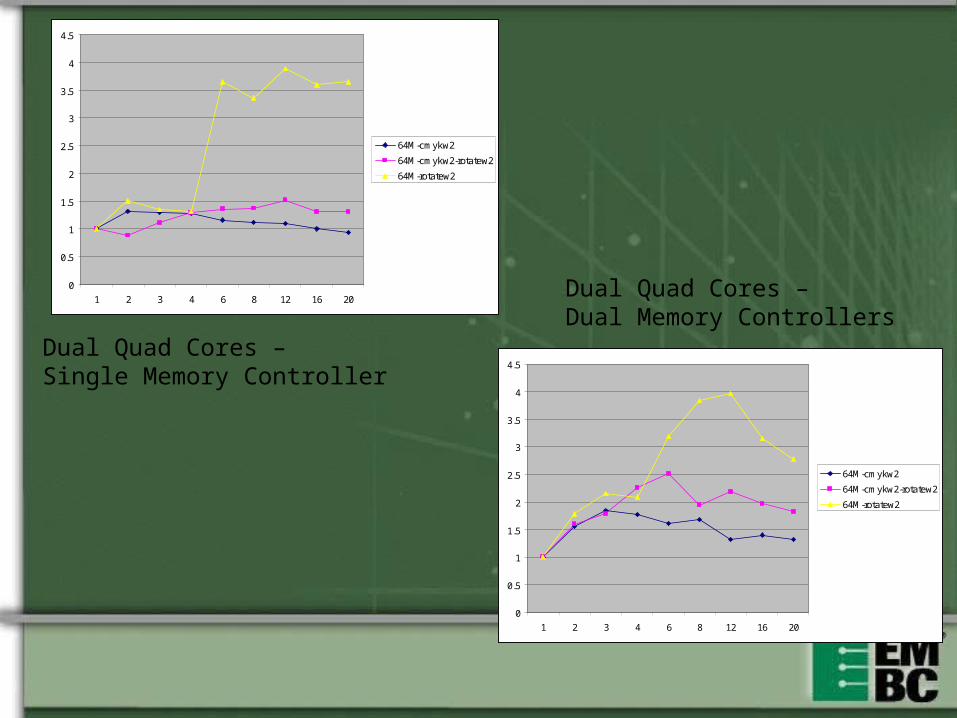
Dual Quad Cores –Single Memory Controller
Dual Quad Cores –Dual Memory Controllers
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
1 2 3 4 6 8 12 16 20
64M-cmykw2
64M-cmykw2-rotatew2
64M-rotatew2
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
1 2 3 4 6 8 12 16 20
64M-cmykw2
64M-cmykw2-rotatew2
64M-rotatew2
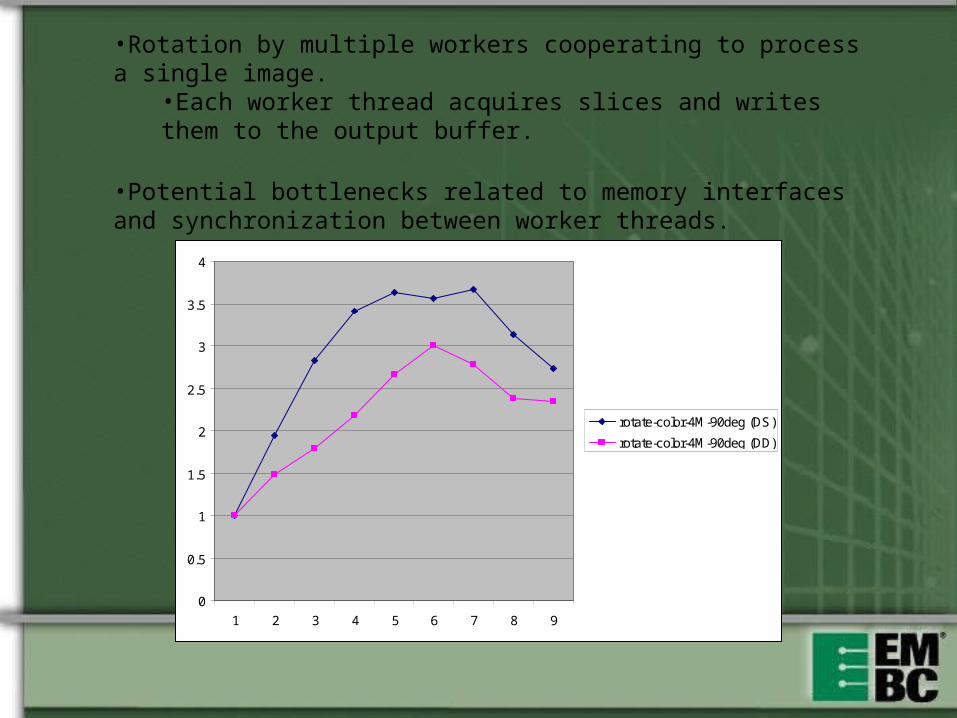
0
0.5
1
1.5
2
2.5
3
3.5
4
1 2 3 4 5 6 7 8 9
rotate-color-4M-90deg (DS)
rotate-color-4M-90deg (DD)
•Rotation by multiple workers cooperating to process a single image.•Each worker thread acquires slices and writes them to the output buffer.
•Potential bottlenecks related to memory interfaces and synchronization between worker threads.
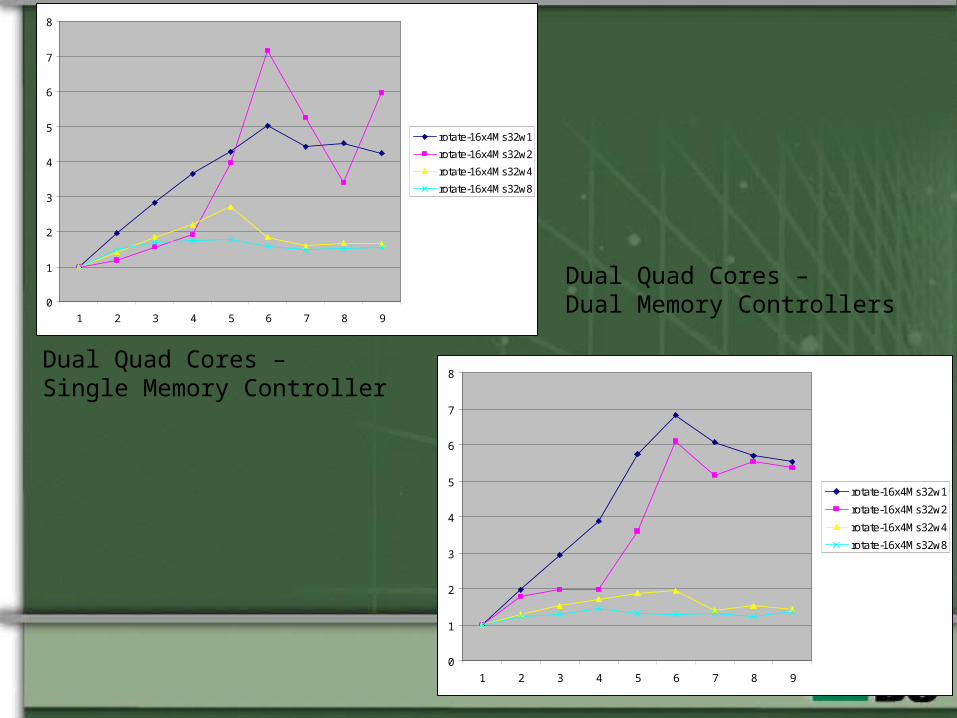
Dual Quad Cores –Single Memory Controller
Dual Quad Cores –Dual Memory Controllers0
1
2
3
4
5
6
7
8
1 2 3 4 5 6 7 8 9
rotate-16x4Ms32w1
rotate-16x4Ms32w2
rotate-16x4Ms32w4
rotate-16x4Ms32w8
0
1
2
3
4
5
6
7
8
1 2 3 4 5 6 7 8 9
rotate-16x4Ms32w1
rotate-16x4Ms32w2
rotate-16x4Ms32w4
rotate-16x4Ms32w8
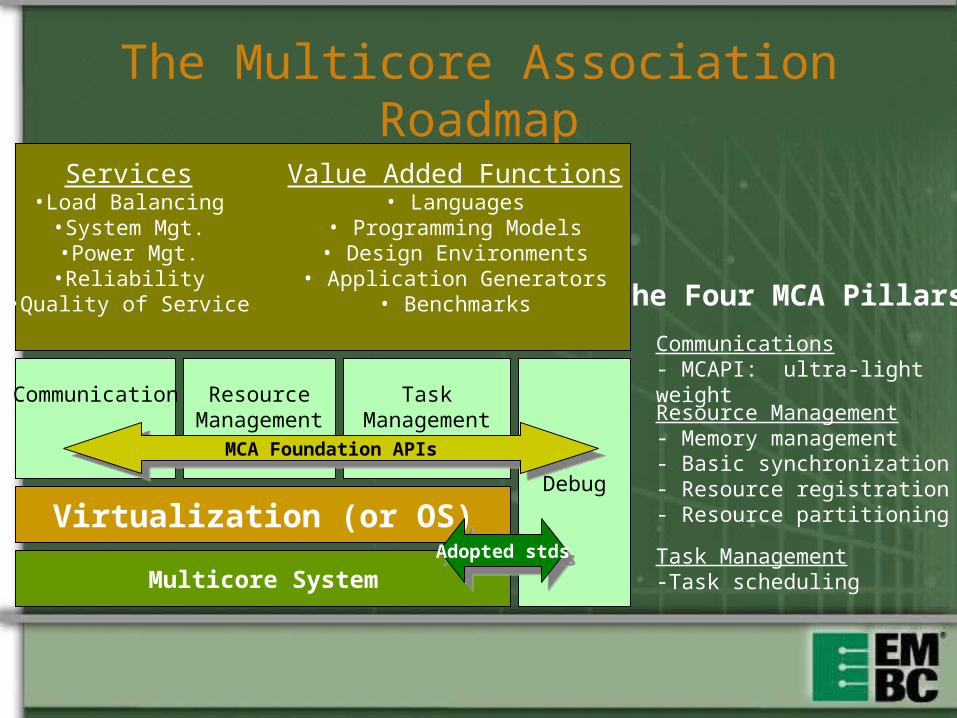
The Multicore Association Roadmap
Communications- MCAPI: ultra-light weight
Resource Management - Memory management- Basic synchronization - Resource registration- Resource partitioning
Task Management-Task scheduling
The Four MCA Pillars
Virtualization (or OS)
Communication ResourceManagement
TaskManagement
Debug
Multicore SystemAdopted stdsAdopted stds
MCA Foundation APIsMCA Foundation APIs
Value Added Functions• Languages
• Programming Models• Design Environments
• Application Generators• Benchmarks
Services•Load Balancing
•System Mgt.•Power Mgt.•Reliability
•Quality of Service

Why Virtualize?
• Hardware consolidation
• Migration and hosting of legacy applications
• Resource management and balancing
• Faster provisioning
• Fault tolerance
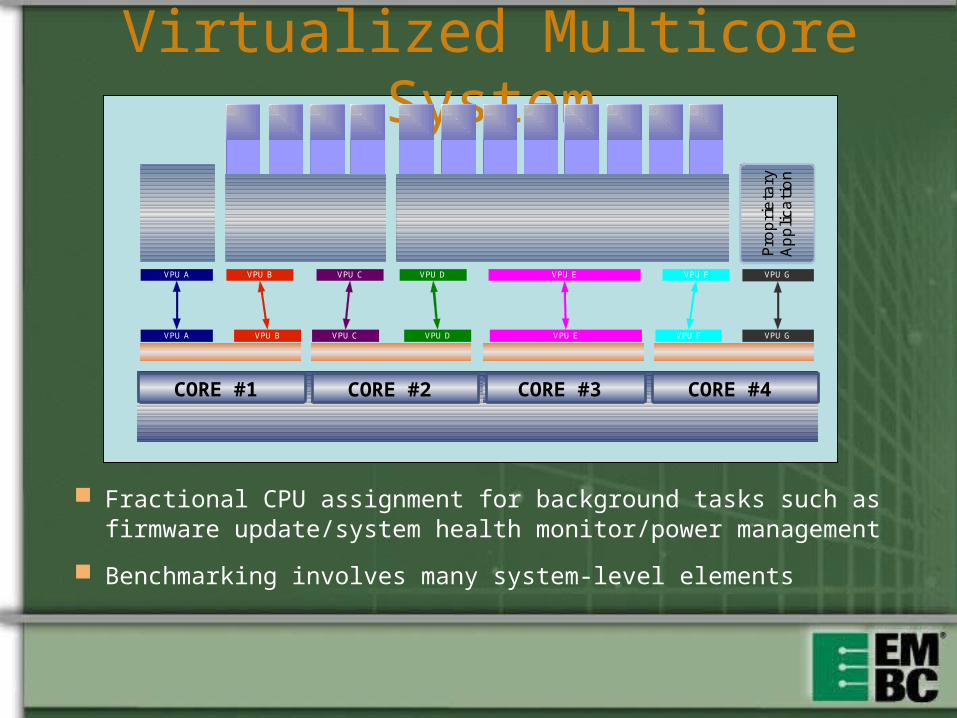
Virtualized Multicore System
Fractional CPU assignment for background tasks such as firmware update/system health monitor/power management
Benchmarking involves many system-level elements
HARDWARE PERIPHERALS
ARM CORE #1
TRANGO #1
ARM CORE #2
TRANGO #2
ARM CORE #3
TRANGO #3
ARM CORE #4
TRANGO #4
Fir
mw
are
Update
AppApp App AppAppApp App App
SMPSMP RTOS
AppApp App App
Pro
pri
eta
ryA
pplica
tion
VPU A VPU B VPU C VPU D VPU E VPU F VPU G
VPU GVPU FVPU A VPU B VPU C VPU D VPU E
CORE #2 CORE #3 CORE #4 CORE #1

EEMBC HypermarkImportant Metrics
• Overall performance overhead of a hypervisor, i.e. CPU loading
• Static footprint (code and data size)
• Jitter
• Interrupt latency
• Comparison to native performance

20
Multicore Programming Practices(MPP)
• Long term– Continue research into languages, methodologies, etc
• Short term– How today’s embedded C/C++ code may be written to be
“multicore ready”
• Influence of a group of like-minded methodology experts to ensure completeness, usefulness and industry-wide compatibility
• Creation of a standard “best practices” guide through a recognized, neutral industry body– Based on capturing current best practices
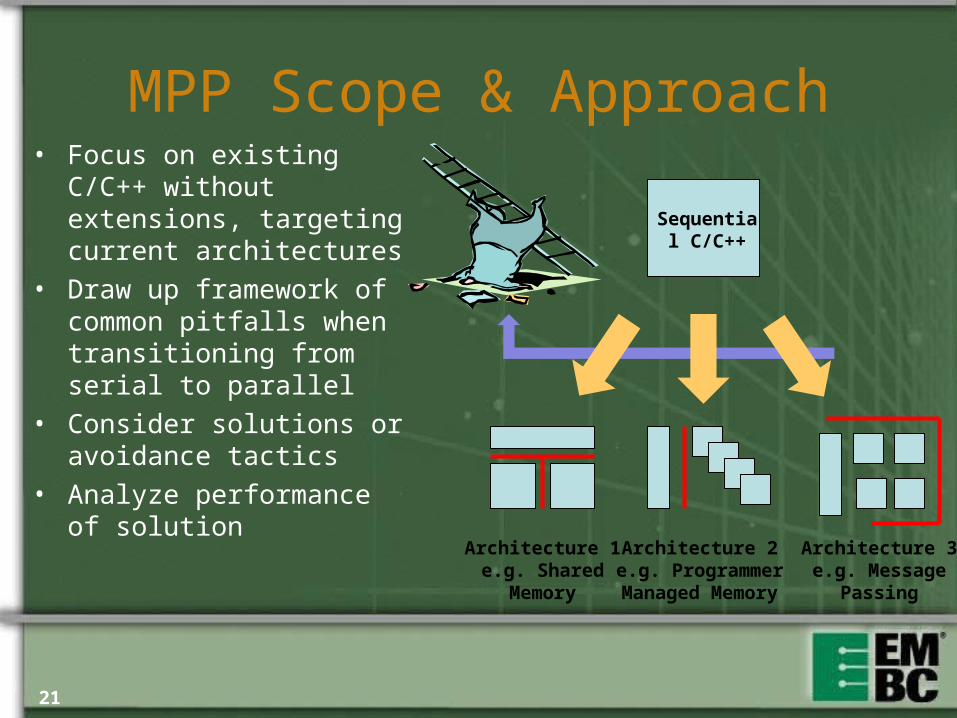
MPP Scope & Approach
21
Sequential C/C++
Architecture 1e.g. Shared
Memory
Architecture 2e.g. Programmer Managed Memory
Architecture 3e.g. Message
Passing
• Focus on existing C/C++ without extensions, targeting current architectures
• Draw up framework of common pitfalls when transitioning from serial to parallel
• Consider solutions or avoidance tactics
• Analyze performance of solution

Summary
• Performance analysis highlights benefits and pitfalls
• EEMBC licensing and membership
• Portability prevents entrapment
• Multicore Association standards and working groups