lp : rule induction for information extraction using ... · (lp)2: rule induction for information...
TRANSCRIPT

(LP )2: Rule Induction for Information
Extraction Using Linguistic Constraints
Fabio CiravegnaDepartment of Computer Science,University of Sheffield,
Regent Court, 211 Portobello Street, S1 4DP Sheffield, [email protected]
Technical Report CS-03-07September 29, 2003
Abstract
Machine learning has been widely used in information extraction fromtexts in the last years. Two directions of research can be identified: wrap-per induction (WI) and NLP-based methodologies. WI techniques havehistorically made scarce use of linguistic information and their applicationis mainly limited to rigidly structured documents. NLP-based methodolo-gies tend to be brittle when linguistic information is unreliable and theirapplication to structured web documents has been largely unsuccessful.In this paper we describe (LP )2 , an adaptive algorithm able to cope witha number of document types, from free texts to highly structured webpages. Its main feature is the ability to use both document formattingand linguistic information in the learning phase. In a number of experi-ments on publicly available corpora, (LP )2 reports excellent results withrespect to the state of the art. Also the algorithm has been implemented intwo successful systems which have been used extensively for both researchand application of IE from Web documents. In this paper we describe thealgorithm in details focusing on the role of linguistic information in therule induction process. We also quantify the contribution of linguistic in-formation to the effectiveness and robustness of the analysis, especially incases where it can be unreliable.
Introduction
The classic tasks of Information Extraction from text (IE) include Named En-tity Recognition (NER) and event extraction (template filling). The formerrequires identifying and classifying objects belonging to a limited amount ofvery high-level classes (person, organization, location, etc.), while the latter re-quires capturing more or less complex event structures. The current state of theart includes algorithms using a very limited amount of linguistic features for the
1

former (e.g. via use of statistical methods [MCF+98] or manually written Fi-nite State Grammars [AHB+93]). Systems performing complex event extractiontend to use complex linguistic information manually encoded in system gram-mars [HGA+98a] [AHB+93]. A different kind of task has been defined by thewrapper induction community, requiring the identification of implicit events andrelations. For example Freitag [Fre98b] defines the task of extracting speaker,start-time, end-time and location from a set of seminar announcement. No ex-plicit mention of the event (the seminar) is done in the annotation. Implicitevent extraction is simpler than full event extraction, but has important appli-cations whenever either there is just one event per texts or it is easy to extractstrategies for recognizing the event structure from the document [CL03]. Thewrapper induction community has also changed the focus on the type of textsto be coped with, moving from the free text (i.e. newspaper articles) only sce-narios used in the MUC conferences (e.g. [MUC98]), to ones based on Webdocuments[MMK98]. Web documents can range from free texts (technical re-ports, newspaper-like texts) to (semi)structured marked up texts (e.g. partiallymarked-up or highly structured XML/HTML documents) and even a mixture ofthem. Linguistically based methodologies used for free texts (e.g. [HGA+98b][Gri97]) can be difficult to apply or even ineffective on highly structured texts,such as the Web pages produced by databases. They can’t cope with the vari-ety of extra linguistic structures such as HTML tags, document formatting, andstereotypical language that convey information in such documents. Wrapper in-duction algorithms (e.g. [KWD97], [MMK98]) induce simple regular expressionstesting the HTML structure of the document when highly structured regularpages are analyzed [KWD97, MMK98], moving to more sophisticated learningstrategies when freer documents are analysed [FM99, Fre98b, FK00]. They tendto use pattern matching on strings and structure, without relying on linguisticinformation for generalisation. For example BWI [FK00] uses capitalization in-formation, a wildcard and a gazetteer to generalize. More linguistically orientedmethodologies (including POS tagging, a parser and the use of Wordnet) wereattempted in the past in WHISK [Sod99] and RAPIER [CM97], but these al-gorithms tended to be outperformed by shallower methods. Also Califf showedthat the use of Wordnet did not bring any clear advantage to the algorithm.
In this paper we describe (LP )2 , an algorithm for wrapper induction thatperforms implicit event extraction using linguistic analysis. Linguistic informa-tion is used for generalizing over the flat word sequence, but the algorithm isalso able to exploit the structure of the document (e.g. HTML tags) accordingto the task at hand. We will show that the use of linguistic information is notdisruptive (and in many case pays off) even when unreliable. (LP )2 reportssome excellent results on at least three publicly available corpora and was usedin two systems, LearningPinocchio[CL03] and Amilcare [Cir03]. The former isa commercial system used in a number of real world applications. The latter isdistributed for free for research purposes and was both adopted as support forsemi-automatic annotations by two popular annotation tools for the SemanticWeb and is currently used by a number of researchers as a baseline for furtherexperiments.
2

In the following we will:
• describe the algorithm for rule induction (Sections 1 and 2);
• describe experiments on publicly available corpora (Section 3);
• discuss the role of linguistic generalisation (Section 4);
• draw some conclusion and outline some future work (Section 5).
1 The (LP )2 Algorithm
(LP )2 is an algorithm able to perform implicit event recognition on documentsof different types, including free, structured and mixed ones. It has its rootsin the wrapper induction technology. It induce rules using linguistic informa-tion to generalize over the flat word structure, attempting to use the maximumamount of linguistic information that is reliable for the task at hand, mixingthem with matches on both strings and HTML structure, if necessary. In otherwords, the level of linguistic analysis is one of the parameters that the learnertunes for each task. The linguistic information is provided by generic modulesand resources that are defined once and are not to be modified to specific ap-plication needs by users (which are imagined naive from this point of view).Pragmatically, the measure of reliability used by the learner to tune the levelof linguistic analysis is not linguistic correctness (immeasurable by incompetentusers) but effectiveness in extracting information using linguistic methods asopposed to using shallower approaches. Unlike previous approaches in whichdifferent algorithm versions with different linguistic competence were tested inparallel and the most effective version is chosen [Sod99], (LP )2 learns which isthe best strategy for each information or context separately. For example, itmight decide that parsing is the best strategy for recognizing the speaker ina specific application on seminar announcements but not the best strategy tospot the seminar location or starting time. This is quite useful on mixed typedocuments such as the one in figure 1 where structured and unstructured listsare coexisting with free text.
Rules are learnt by generalising over a set of examples marked via XMLtags identifying the information to be extracted by the system in a trainingcorpus. (LP )2 requires a linguistic preprocessor that analyses documents usinggeneric linguistic modules, for example performing tokenization, morphologicalanalysis, part of speech tagging, gazetteer lookup, generic dictionary lookup,Named Entity Recognition, parsing, ontological reasoning, etc. During ruleinduction, (LP )2 induces rules able to replicate the XML annotation in thecorpus. Input in training mode is a preprocessed annotated training corpus.Output is a set of rules.
The algorithm induces symbolic rules that insert XML tags into texts in twosteps (see Figure 2):
• Sets of annotation rules are induced that insert a preliminary annota-tion.
3

Figure 1: An example of a document containing a mixture of text types: freetext is located in the center, while structured HTML lists can be seen on theleft hand side and a semi structured list on the center right (a list of titles whichare mainly fragmented sentences). A flexible methodology for IE is needed inorder to extract information from the different parts.
4

Figure 2: Rule induction steps.
• Correction rules are induced that refine the annotation by correctingmistakes and imprecision.
1.1 Inducing Annotation Rules
An annotation rule is composed of a left hand side, containing a pattern ofconditions on a sequence of adjacent words, and a right hand side that is anaction inserting an XML tag in the texts. Each rule inserts a single XMLtag, e.g. <speaker>. This makes (LP )2 different from many adaptive IEalgorithms, whose rules recognize whole slot fillers (i.e. insert both <speaker>and </speaker> [CM97, Fre98a]) or even multiple slots [Sod99, FM99]. Theinduction algorithm uses positive examples from the training corpus for learningrules. Positive examples are the XML tags inserted by the user. All the restof the corpus is considered a pool of negative examples. For each positiveexample the algorithm: (1) builds an initial empty rule, (2) progressively addsconstraints to the rule (3) keeps the k best rules. In particular (LP )2 ’s mainloop starts by selecting a tag in the training corpus and extracting from thetext a window of w words to the left and w words to the right. Each pieceof information stored in the 2*w word window is transformed into a condition,e.g. if the third word in the window is “seminar”, the condition is added to thepool of possible conditions that Word3="seminar". Conditions are not limitedto word matching, but include linguistic information associated with each word.For example, the condition Word3.POS="noun" checks if the third word is anoun. Such information is provided by the linguistic preprocessor. Each inducedrule is tested on the training corpus and an error rate L=wrong/matched iscalculated. generalisations are accepted when they fall into one of the twogroups described in the rest of the section: best rules and contextual rules.
5
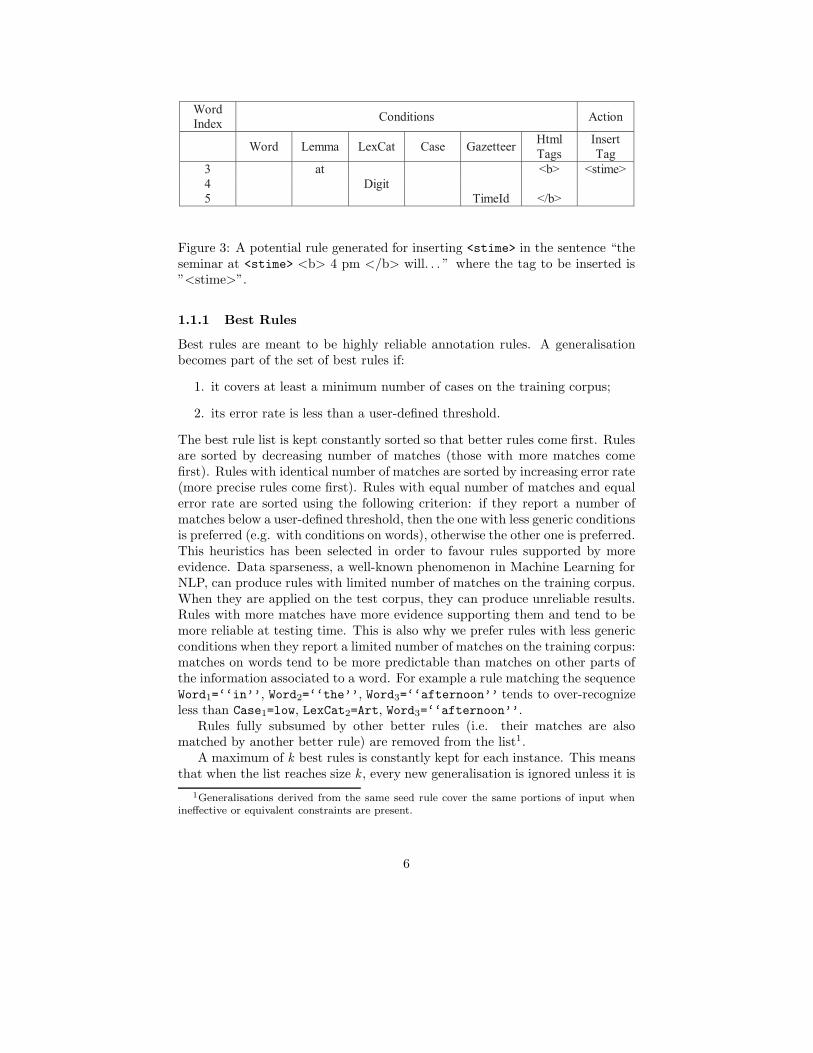
Figure 3: A potential rule generated for inserting <stime> in the sentence “theseminar at <stime> <b> 4 pm </b> will. . . ” where the tag to be inserted is”<stime>”.
1.1.1 Best Rules
Best rules are meant to be highly reliable annotation rules. A generalisationbecomes part of the set of best rules if:
1. it covers at least a minimum number of cases on the training corpus;
2. its error rate is less than a user-defined threshold.
The best rule list is kept constantly sorted so that better rules come first. Rulesare sorted by decreasing number of matches (those with more matches comefirst). Rules with identical number of matches are sorted by increasing error rate(more precise rules come first). Rules with equal number of matches and equalerror rate are sorted using the following criterion: if they report a number ofmatches below a user-defined threshold, then the one with less generic conditionsis preferred (e.g. with conditions on words), otherwise the other one is preferred.This heuristics has been selected in order to favour rules supported by moreevidence. Data sparseness, a well-known phenomenon in Machine Learning forNLP, can produce rules with limited number of matches on the training corpus.When they are applied on the test corpus, they can produce unreliable results.Rules with more matches have more evidence supporting them and tend to bemore reliable at testing time. This is also why we prefer rules with less genericconditions when they report a limited number of matches on the training corpus:matches on words tend to be more predictable than matches on other parts ofthe information associated to a word. For example a rule matching the sequenceWord1=‘‘in’’, Word2=‘‘the’’, Word3=‘‘afternoon’’ tends to over-recognizeless than Case1=low, LexCat2=Art, Word3=‘‘afternoon’’.
Rules fully subsumed by other better rules (i.e. their matches are alsomatched by another better rule) are removed from the list1.
A maximum of k best rules is constantly kept for each instance. This meansthat when the list reaches size k , every new generalisation is ignored unless it is
1Generalisations derived from the same seed rule cover the same portions of input whenineffective or equivalent constraints are present.
6

able to enter the list in a position p≤k. If it does, the rule previously in positionk is removed from the list. The algorithm is summarized in Figure 4.
Rules retained at the end of the generalisation process of one specific seedrule become part of the global best rules pool. When a rule enters such pool,all the instances covered by this rule are removed from the positive examplespool, i.e. covered instances will no longer be used for rule induction ((LP )2 isa covering algorithm). Rule induction continues by selecting new instances andlearning rules until the pool of positive examples is empty.
1.1.2 Contextual Rules
When applied to the test corpus, the best rules pool provides good results interms of precision, but limited effectiveness in terms of recall. This means thatsuch rules insert few tags (low recall), and that such tags are generally correct(high precision). Intuitively this is because the absolute reliability required forrule selection is strict, thus only a few of the induced rules will match it. In or-der to reach acceptable effectiveness, it is necessary to identify additional rulesable to increase recall without affecting precision. (LP )2 recovers some of therules not selected as best rules and tries to constrain their application to makethem more reliable. Constraints on rule application are derived by exploitinginterdependencies among tags. As mentioned, (LP )2 learns rules for insertingtags (e.g., <speaker>) independently from other tags (e.g., </speaker>). Buttags are not independent. There are two ways in which they can influence eachother: (1) tags represent slots, therefore <tagx> always requires </tagx>; (2)slots can be concatenated into linguistic patterns and therefore the presenceof a slot can be a good indicator of the presence of another, e.g. </speaker>can be used as “anchor tag” for inserting <stime>2. In general it is possibleto use <tagx> to introduce <tagy>. (LP )2 as described so far is not able touse such contextual information, as it induces single tag rules. The context isreintroduced as an external constraint used to improve the reliability of inac-curate rules. In particular, low precision non-best rules are reconsidered forapplication in the context of tags inserted by the best rules. For example somerules will be used only to close slots when the best rules were able to open it,but not to close it (e.g., when the best rules are able to insert <tagx> but not</tagx>). Such rules are called contextual rules. As an example consider a ruleinserting a </speaker> tag between a capitalized word and a lowercase word.This is not a best rule as it reports high recall/low precision on the corpus, butit is reliable if used only to close an open tag <speaker>. Thus it will only beapplied when the best rules have already recognized an open tag <speaker>,but not the corresponding </speaker>. The area of application is the part ofthe text following a <speaker> and within a distance less than or equal to themaximum length allowed for the present slot3. “Anchor tags” used as contextscan be found either to the right of the rule space application (as in the case
2In the following we just make examples related to the first case as it is more intuitive, butthe algorithm effectively uses also the other case.
3The training corpus is used for computing the maximum filler length for each slot.
7

method SelectRule(rule, currentBestPool)if (rule.matches≤MinimumMatchesThreshold)
then return currentBestPool // i.e. reject(rule)if (rule.errorRate≥ErrorRateThreshold)
then return currentBestPool // i.e. reject(rule)insert (rule, currentBestPool)sort(currentBestPool)removeSubsumedRules(currentBestPool)cutRuleListToSize(currentBestPool, k)return currentBestPool
method sort(ruleList)sort by decreasing number of matchesif two rules have equal number of matches
then sort by increasing error rateif two rules have same error rate and number of matches:
then if one rule has more matches than a thresholdthen prefer the one with more generic conditions
else prefer the other onereturn ruleList
method removeSubsumedRules(ruleList)loop for index1 from 0 to ruleList.size-1
rule1=ruleList(index1)loop for index2 from index1+1 to ruleList.size
rule2=ruleList(index2)if (subsumes(rule1, rule2))
then remove (rule2, ruleList)return ruleList
method subsumes(rule1, rule2)return (rule2.matches is a subset of rule1.matches)
method cutRuleListToSize(list, size)return subseq(list, 0, size)
Figure 4: The algorithm for deciding if a generalisation can be considered as abest rule.
8

above when the anchor tag is <speaker>), or to the left as in the opposite case(anchor tag is </speaker>). Acceptability for contextual rules is computed byusing the same algorithm used for selecting best rules, but only matches inconstrained contexts are counted.
In conclusion the sets of annotation rules (LP )2 induces are both the bestrules pool and the contextual rules. Figure 5 shows the whole algorithm forannotation rule induction.
1.2 Inducing Correction Rules
Annotation rules when applied on the training corpus report some imprecisionin slot filler boundary detection. A typical mistake is for example “at <time> 4</time> pm”, where “pm” should be part of the time expression. For this reason(LP )2 induces rules for shifting wrongly positioned tags to the correct position.It learns from the mistakes made on the training corpus. Shift rules consider tagsmisplaced within a distance d from the correct position. Correction rules aresimilar to annotation rules, but (1) their patterns match also the tags insertedby annotation rules and (2) their actions shift misplaced tags rather than addingnew ones. An example of a correction rule for shifting </stime> in “at <stime>4 </stime> pm” is shown in Figure 6. The induction and selection algorithmused for the best annotation rules is also used for shift rules: initial conditionidentification, specialization, test and selection of best k generalisations.
1.3 Extracting Information
In the testing phase information is extracted from the test corpus in four steps(Figure 7): initial annotation, contextual annotation, correction and validation.The best rules pool is initially used to tag the texts. Then contextual rules areapplied in the context of the introduced tags. They are iteratively applied untilno new tags are inserted, i.e. some contextual rules can match also tags insertedby other contextual rules. Then correction rules adjust some misplaced tags.Finally each tag inserted by the algorithm is validated. It is not meaningfulto produce an open tag (e.g. <speaker>) without its corresponding closingtag (</speaker>) and vice versa, therefore uncoupled tags are removed in thevalidation phase.
2 Induction as Specialization and Pruning
The types of rule mentioned above are all induced by the same algorithm. Asmentioned, induced rule patterns contain conditions on word in a window waround each instance. Conditions are either on strings or on information pro-vided by the linguistic preprocessor (e.g. POS tags, Capitalization information,Named Entities, syntactic chunks, etc.). This means that while many similarsuccessful algorithms rely on non-linguistic generalisation (e.g. BWI [FK00]
9

method InduceRules()loop for instance in initial-instances
unless already-covered(instance)loop for rule in generalise(instance)
test(rule)if best-rule?(rule)
then insert(rule, bestrules)cover(rule, initial-instances)
else loop for tag in tag-listif test-in-context(rule, tag, :right)
then select-contxtl(rule, tag, :right)if test-in-context(rule, tag, :left)
then select-contxtl(rule, tag, :left)
method generalise(instance)currentRules={one empty rule}newRules={}loop for lexitem in instance.pattern
generalisations=generalize(lexitem)loop for currentCondition in generalisations
loop for rule in currentRulesnewRule=copyRule(rule)addCondition(newRule, currentCondition)newRules.add(newRule)
currentRules=newRulesnewRules={}
return currentRules
method generalise(lexitem)collect newCondition(lexitem.word)if (lexitem.lemma!=null)
then collect newCondition(lexitem.lemma)if (lexitem.case!=null))then collect newCondition(lexitem.lemma, lexitem.case)
if (lexitem.case!=null)then collect newCondition(lexitem.word, lexitem.case)
collect newCondition(lexitem.case)if (lexitem.lexCat!=null)
then collect newCondition(lexitem.lexCat)if (lexitem.semCat!=null)
then collect newCondition(lexitem.semCat)return collected conditions
Figure 5: The final version of the algorithm for rule annotation induction. Thegeneralise function produces all the possible generalisations for a rule.
10

Figure 6: A correction rule for shifting a misplaced tag in the sentence ”theseminar at <stime> <b> 4 pm </b> will. . . ”. The action shifts the tag fromthe wrong to the correct position, i.e. from before ”pm” to after ”pm”.
Figure 7: The algorithm for extracting information.
11

InduceRuleFromInstance(instance)
RuleSet=startRulesFromEmptyRule(instance);
Loop while notEmpty(RuleSet) {
Loop for rule1 in butLast(RuleSet){
for rule2 in butFirst(RuleSet)
ruleSet=combineRules(rule1, rule2);
add(ruleSet, finalRu leSet);
} }
return finalRuleSet;
}
startRulesFromEmptyRule (instance){
tag=instance.tag
loop for distance from 0 to 2* w {
do word=instance.pattern[distance]
/* w-position is the distance between
the current word and the tag to be
inserte d */
collect generateRule(word,tag, w-position)
} }
Figure 8: The simplified algorithm for non NLP-based rule induction
uses just capitalization, a gazetteer and a wild card), (LP )2 uses linguistic in-formation for generalisation over the flat word level. Linguistic generalisation isimportant in analysing natural language input, because of data sparseness dueto the high flexibility of natural language forms. Avoiding generalisation actu-ally means producing rules covering a limited number of cases each. Such ruleset is very likely to produce excellent results on the training corpus, but obtainvery limited effectiveness on a test corpus. This is the well known problem ofoverfitting the training corpus: on the one hand the system learns a number ofrules for covering unrelated cases: if such cases are not found as they are, therule will not apply at testing time (leading to low recall). On the other hand therule set is sensible to errors in the training data: such errors can either preventsome good rules from being learnt, as they report errors (low recall again duringtest), or can favour acceptance of bad rules producing spurious results at testtime (low precision). It is therefore important to:
• generalise over the plain word surface of the training example in order toproduce rules able to overcome data sparseness;
• prune the resulting rule set in order to reduce overfitting and - possibly -reducing the search space.
12

InduceRuleFromInstance(instance)
RuleSet=startRulesFromEmptyRule(instance);
Loop while notEmpty(RuleSet) {
NewRuleSetS={}
Loop for ruleSet1 in butLast(RuleSet){
for ruleSet2 in butFirst(RuleSet)
ruleSet=combineRuleSet(ruleSet1, ruleSet2);
pruneRuleSet(ruleSet);
add(ruleSet, newRuleSetS);
add(ruleSet, finalRuleSets);
}
RuleSet=NewRuleSetS;
}
PruneRuleSets(finalRuleSets)
}
startRulesFromEmptyRule (instance)
tag=instance.tag
Loop for distance from 0 to 2*w {
word=instance.pattern[distance]
/* w-position is the distance between
the current word and the tag to be
inserted */
generateRuleSet (word, tag, w-position)
}
generateRuleSet(word, tag, position){
Loop for condit in NLPGeneralisations(word)
Collect generateRule(condit, tag, position)
}
PruneRuleSet (ruleSet){
For rule in ruleSet
if (not(subsumedRule(rule, RuleSet)))
collect rule
}
subsumedRule (rule, ruleSet){
loop for ru in ruleSet
if (ru!=rule)
if((ru.score<=rule.score) and
(includes(ru.coverage,rule.coverage)))
return true;
return false;
}
Figure 9: The complete algorithm for NLP-based rule induction
2.1 Rule Specialization
We have implemented different strategies for rule generalisation. The naiveversion of the algorithm [Cir01a] generates all the possible rules in parallel.Each generalisation is then tested separately on the training corpus and anerror score E=wrong/matched is calculated. For each initial rule, the k bestgeneralisations are kept that: (1) report better accuracy; (2) cover more positiveexamples; (3) cover different parts of input. The naive generalisation is quiteexpensive in computational terms. Here we describe a more efficient version ofthe algorithm that uses a general to specific beam search for the best k rules in away similar to AQ [MMJL86]. It starts by modelling a specific instance with themost general rule (the empty rule matching every instance) and specialises it bygreedily adding constraints. Constraints are added by incrementing the lengthof the rule pattern, i.e. by adding conditions on terms, starting from the onesnearest to the tag. Figure 10 shows the search space for an example of this typeof generalisation for the case in which conditions are set only on words4. Thealgorithm is described in Figure 8. The actual algorithm is more complex thanshown, as it also uses linguistic information (see Figure 9). This algorithm is aseffective as the naive one, but it allows a very efficient rule testing. As a matterof fact the matches of a specialised rule can be computed as the intersection of
4Note that we always start adding conditions to elements near the tag and proceed out-wards. One condition is always a wild card that means no conditions on the term. Compu-tationally, this is equivalent to selecting each time the best condition to be added over thebroad spectrum of the window (as for example in CN2), but the implementation for testingthe generated rules is more efficient because it uses intersections on integers, as shown in figure10.
13

the matches of two more general rules, making testing an order of magnitudemore efficient.
2.2 Rule Set Pruning
Pruning is performed both for efficiency reasons (so to reduce the search spaceduring generalisation) and to reduce overfitting. Pruning removes rules thateither are unreliable, or whose coverage fully overlaps with those of other rules.There are two types of unreliable rules: those performing poorly on the trainingcorpus (i.e. with a high error rate) and those reporting a very limited numberof matches on the training corpus, so that it is not easy to foresee what theirbehaviour at test time. In order to prune the final rule set from the first typeof rules, accuracy is tested against a maximum error threshold set by the userbefore running the algorithm. Rules that do not pass the error rate test arediscarded as soon as they are generated and tested. They are no longer con-sidered for IE, but they are considered for further specialisation, as they couldbecome reliable after the addition of more constraints. At the end of trainingthe algorithm tries to optimise the error threshold by restricting the rule selec-tion condition, therefore excluding some other rules. It tests the results of thereduced rule set on the training corpus and stops pruning the moment in whichthere is a reduction of accuracy (seen as the mean of precision and recall).
Rules are also pruned at induction time when they cover too few cases in thetraining corpus and therefore they cannot be safely used at test time because theamount of training data does not guarantees a safe behaviour at run time. Suchrules are detected at generation time and any further specialisation dependingfrom them is stopped. In this way the search space is reduced and the algorithmis more efficient. For example with a threshold on minimum coverage set to 3cases, rules 9 and 10 are not generated in the example in Figure 10. Againthe user can set a priori the minimum coverage threshold and such thresholdwill be optimised at the end of training in a way similar to the error thresholdoptimisation.
There is a further level of pruning based on overlapping rule coverage: allthe rules whose coverage is subsumed by that of others more general ones areremoved from the selected rule set. The goal is to determine the minimumsubset of rules that maximises the accuracy of IE on the training corpus. Ruleswhose coverage is subsumed by those of other rules can be safely removed,as their contribution to the final results is irrelevant. Such type of pruningrequires comparing not only coverage, but also the reliability of the involvedrules (otherwise the algorithm would only produce one rule, i.e. the emptyinitial rule). In general rules subsumed by other rules with the same (or minor)error rate can be safely removed during rule induction. Rules subsumed by oneswith worse error rate are pruned when the final error and covering thresholdhave been determined, as it is necessary to see if the subsuming rule will survivethe final pruning process. A risk of overgeneralisation arises in pruning at everylevel: when two rules cover the same set of examples with the same error rate,choosing the one with the most generic condition when there is limited evidence
14

Word1=at,
action=<stime>
matches: 0,12,15,44,72,134,146,230,250
action=<stime>,
Word1=4
matches: 12,27,72,112,134,230,245
Word1=at,
action=<stime>,
Word2=4
matches: 12,72,134
Word1=seminar,
Word2=at
action=<stime>
matches: 0,12,134
action=<stime>,
Word1=4,
Word2=pm
matches: 12,134
Word1=seminar,
Word2=at,
action=<stime>,
Word3=4
matches: 12,134
Word1=at,
action=<stime>,
Word2=4
Word3=pm
matches: 12,134
Word1=seminar,
Word2=at,
action=<stime>,
Word3=4
Word3=pm
matches: 12,134
action=<stime>
matches: all the corpus
Word1=seminar,
Word2=*
action=<stime>
matches: 0,4,12,134,222,232
action=<stime>,
Word1=*
Word2=pm
matches: 12,27,72,134,245
r0
r1 r2 r3 r4
r5 r6 r7
r8 r9
r10
Figure 10: Pattern specialization for ”the seminar at <stime> 4 pm will” withwindow w=2 (conditions on words only). The rule action is inserted in the partof the pattern where the tag is inserted. For example r6 matches ”at” + ”4”and inserts a tag after ”at”. The ”matches” fields shows positions in the corpuswhere a rule applies.
in the training corpus risks to produce unreliable rules at test time. In this casethe following heuristic is used. If the number of covered cases is limited, thenthe one with most specific conditions is chosen (e.g. one using condition onwords). This is because the training corpus does not provide enough evidencethat the rule is reliable and a rule requiring a sequence of words is less likely toproduce spurious results at test time than one requiring sequences of conditionson the additional knowledge (e.g. on lexical categories). Otherwise, the rulewith the most generic conditions is selected (e.g. testing lexical categories), asit is more likely to provide coverage on the test corpus.
3 Experimental Results
(LP )2 was tested in a number of tasks in two languages: English and Italian.In each experiment the algorithm was trained on a subset of the corpus (somehundreds of texts, depending on the corpus) and the induced rules were tested onunseen texts. In this section we report about results on three standard tasks for
15

Speaker Location Start Time End Time All Slots(LP )2 77.6 75.0 99.0 95.5 86.0SNoW 73.8 75.2 99.6 96.3 85.3Max Entropy 65.3 82.3 99.6 94.5 85.0BWI 67.7 76.7 99.6 93.9 83.9HMM 76.6 78.6 98.5 62.1 82.0SRV 56.3 72.3 98.5 77.9 77.1Rapier 53.0 72.7 93.4 96.2 77.3Whisk 18.3 66.4 92.6 86.0 64.9
Table 1: F-measure (beta =1) obtained on CMU seminars. For (LP )2 theexperiments are obtained as the average results of 10 sessions of experimentsusing a random half of the corpus for training and the rest of the corpus fortesting. We did not use any named entity recognition in the experiments. WithNER, Speaker grows to 80.9% and Location to 79.8%.
Table 2: F-measure (b=1) for misc.jobs.offered using 1/2 corpus for training.Slot (LP )2 Rapier BWI Slot (LP )2 RapierId 100 97.5 100 Platform 80.5 72.5Title 43.9 40.5 50.1 Application 78.4 69.3Company 71.9 69.5 78.2 Area 66.9 42.4Salary 62.8 67.4 Req-years-e 68.8 67.1Recruiter 80.6 68.4 Des-years-e 60.4 87.5State 84.7 90.2 Req-degree 84.7 81.5City 93.0 90.4 des-degree 65.1 72.2Country 81.0 93.2 post date 99.5 99.5Language 91.0 80.6 All Slots 84.1 75.1
adaptive IE: the CMU seminar announcements, the Austin job announcementsand the computer course testbed.
The first task consists of uniquely identifying speaker name, starting time,ending time and location in 485 seminar announcements [Fre98b]. Table 3shows the overall accuracy obtained, and compares it with that obtained byother state of the art algorithms. (LP )2 scores the best overall results in thetask. It definitely outperforms other symbolic NLP-based approaches (+8.7%with respect to Rapier[CM97], +21% w.r.t. to Whisk[Sod99]). Moreover (LP )2
is the only algorithm whose results never go down 75% on any slot (secondbest is SNOW: 73.8%). Please note that most of the papers did not report thecomprehensive ALL SLOTS figure, so we added it as it allows better comparisonamong algorithms. It was computed by:Σslot (F − measure ∗ number of possible slot fillers) ∗ 100/Σslot number of possible slot fillers.For (LP )2 , the results were obtained in ten experiments using a random halfof the corpus for training and the rest for testing. For preprocessing we just
16

Precision Recall F-measureHMM 60.85 62.06 61.45(LP )2 69.74 62.12 65.71
STALKER 19.77 49.55 28.26SRV 74.37 59.74 66.08
Table 3: Experimental results on the Computer Science Course corpus. Theresults show the overall accuracy reached by the different systems using 50% ofthe corpus for training.
used capitalization information and pos tagging. No other algorithm used aNamed Entity Recognizer, so we avoided using it. We will come back to theimportance of the NER later in the paper. F-measure calculated via the MUCscorer [Dou98]. Average training time per run: 5.2 minutes per run on a 2.1GHzPC. Window size w=5. The learning curve is partially shown in figure 11. Notethat the task above (as well as those below) requires implicit relation recognition,not simply Named Entity Recognition, as information is classified using the rolethey play in an implicit event, not in isolation. For example the speaker of aseminar is not the only person name mentioned in the message (e.g. the senderis another one, the secretary organizing the booking may be another one, etc.),the same applies to the time expressions (stime and etime are not the only timeexpressions in the messages. etc.).
A second task concerned IE from 300 Job Announcements [CM97] taken frommisc.jobs.offered. The task consists of identifying for each announcement:message id, job title, salary offered, company offering the job, recruiter, state,city and country where the job is offered, programming language, platform,application area, required and desired years of experience, required and desireddegree, and posting date. The results obtained on such a task are reportedin Table 3. (LP )2 outperforms both Rapier and Whisk (Whisk obtained loweraccuracy than Rapier [CM97]). We cannot compare (LP )2 with BWI as thelatter was tested on a very limited subset of slots.
The third experiment was performed by a group from NCRS ”Demokritos”in Greece [SPSS03] using Amilcare [Cir03]. It consists in extracting informationfrom 101 Web pages describing Computer Science courses collected from differ-ent university sites in the context of the WebKb project. The information to beextracted was course number, title and instructor. Results for four systems arereported in Table 3.
In summary, (LP )2 reaches excellent results in all tasks.
4 Discussion
(LP )2 ’s main features that are most likely to contribute to the excellence in theexperiments are: (1) the use of single tag rules, (2) the use of a correction phase,and (3) rule generalisation via shallow NLP processing. The separate recognitionof tags is an aspect shared by BWI, while HMM, Rapier and SRV recognized
17

Figure 11: The learning curves for the CMU seminar announcement show-ing precision (topmost curve in all graphs), recall (bottom most curve) andf-measure (middle curve)
18

whole slots and Whisk recognizes multi-slots. Separate tag identification allowsreduction of data sparseness, as it better generalizes over the coupling of slotstart/end conditions. For example in order to learn patterns equivalent to theregular expression
(‘at’|‘starting from’)DIGIT(‘pm’|‘am’)
(LP )2 just needs two examples, e.g.,
‘at 4 pm’/‘starting from 9 am’
because the algorithm induces two independent rules for <stime> (‘at’ and‘starting from’) and two for </stime> (‘am’ and ‘pm’). A slot-oriented rulelearning strategy needs four examples:
at 4 pmstarting from 4 pmat 9 amstarting from 9 am.
In a multi-slot approach the problem is worst and the number of training ex-amples needed increases drastically: it is necessary that all the four examplesmentioned above are found in all the multi-slot contexts. This is probably theexplanation for the very low recall obtained by Whisk in the CMU seminar task(about 45% less than (LP )2 ’s on the “speaker” slot). Single tag rules are likelyto provide higher recall, with a potential reduction in precision due to someovergeneration (never registered in the experiments, though).
(LP )2 is the only system that adopts a correction step in order to removesome imprecision in annotation. The idea was inspired by work on Transfor-mation Based Learning.There are many differences between our method forcorrection and the standard TBL approach. On the one hand (LP )2 does notuse any templates for inducing rules, but it uses a very generic algorithm. More-over rules in (LP )2 are independent from each other and the starting seed forrule induction is chosen randomly. In classic TBL rules are ordered and the bestseed for induction is selected at every cycle. Here the difference relies mainly inefficiency in induction, as some authors have shown that it is possible to redefinethe TBL paradigm using rule independence and random seed selection, [Hep00].Finally our correction concerns tag shifting, while Brill’s correction relies on tagidentity change. In our experience correction pays off in recognising slot fillerswith a high degree of variability (e.g., the speaker in the CMU experiment,where it accounts for up to 7% of accuracy), while it has minimum relevance onhighly standardised slot fillers (such as many slots in the Jobs task).
Finally it is interesting to note the way rule pattern length affects accuracy.Some slots are insensible to it (e.g. location), while others definitely need alonger pattern. This is important information to monitor as the window sizestrongly influences training time (see Figure 13).
19

10
20
30
40
50
60
70
80
90
100
100 150 200 243
Speaker Gen Speaker NoGen
etime GEN etime NoGen
Figure 12: Effect of training data quantity in the CMU seminar task.Thegeneralisation-based version converges immediately to the optimal value for<etime> and shows a positive trend for <speaker>. The non NLP based versionshows overfitting on <speaker> and slowly converges on <etime>)
40
50
60
70
80
90
100
4 6 8
speaker stime
etime location
Figure 13: The effect of different window sizes in learning annotation rules.Somefields are not affected (e.g. location), while others (speaker) are sensitive towindow size.
20

Table 4: Comparison between the NLP-based generalisation version (LP)2G withthe version without generalisation (LP)2NG
Slot (LP)2G (LP)2NG
speaker 72.1 14.5location 74.1 58.2stime 100 97.4etime 96.4 87.1
All slots 89.7 78.2
4.1 NLP-based Generalisation
(LP )2 uses shallow NLP processing for generalisation in order to reduce datasparseness: it allows capturing some general aspects beyond the simple flatword structure. Morphology allows overcoming of data sparseness due to num-ber/gender word realisations (an aspect very relevant in morphologically richlanguages such as Italian), while POS tagging information allows generalisationover lexical categories. Gazetteer and Named Entity Recognition informationallow generalizing over some (user-defined) semantic classes, etc.
In principle such types of generalisation produce rules of better quality thanthose matching the flat word sequence; rules that tend to be more effective onunseen cases. This is because they are generic processes performing equallywell on unseen cases; therefore rules relying on their results apply successful onunseen cases. This intuition was confirmed experimentally: we compared therules produced by two versions of (LP )2 , with and without NLP-based general-isation (but with capitalisation information). The latter ((LP)2NG) learned a setof low coverage rules covering sparse data, while the first ((LP)2G) induced quitea number of high quality generic rules covering a large number of cases and areduced number of rules for some exceptions (Figure 14 and Table 5). Moreover(LP)2G definitely outperforms (LP)2NG on the test corpus (Table 4), while havingcomparable results on the training corpus. NLP reduces the risk of overfittingthe training examples. Figure 12 shows experimentally how (LP)2G avoids over-fitting on the speaker field (constant rise in f-measure when the training corpusis increased in size), while (LP)2NG present a clear problem of overfitting (re-duction of effectiveness when more examples are provided). Producing moregeneral rules also implies that the covering algorithm converges more rapidlybecause its rules tend to cover more cases. This means that (LP)2G needs lessexamples in order to be trained, i.e., rule generalisation also allows reducingthe training corpus size. Figure 12 also shows how on etime (LP)2G is able toconverge at optimal values with 100 examples only, while accuracy in (LP)2NG
slowly increases with more training material, even if it is not able to reach thesame accuracy as (LP)2G , even when using half of the corpus for training. Notsurprisingly the role of shallow NLP in the reduction of data sparseness is morerelevant for semi-structured or free texts (e.g. the CMU seminars) than onhighly structured documents (e.g. HTML pages).
21

Table 5: Another Comparison between the NLP-based generalisation version(LP)2G with the version without generalisation (LP)2NG
(LP)2G (LP)2NG
Average rule coverage 10.2 6.2Selected rules 887 1136
Rules covering 1 case 133 (14%) 560 (50%)Rules covering >50 cases 37 15Rules covering >100 cases 19 3
4.2 Robustness
In order to be able to cope with a number of text types (mixed types included),it is necessary to be able to select the reliable level of linguistic analysis forthe specific task at hand. (LP )2 is able to do it at a very sophisticated degree.As a matter of fact the best strategy for each information or context is learntseparately. This is because it is able to decide that using the POS taggerinformation is a good strategy for recognizing - say - the speaker but not the beststrategy to spot the seminar location or starting time. This claim was provenin an experiment where texts written in mixed Italian/English were used. Theywere seminar announcement taken from the ITC’s (www.itc.it) seminar mailinglist; the task was to extract title of seminar, location, date, time and speaker.The texts were mixed in a pseudo-random mixed Italian/English: the bodyannouncing the seminar (containing location, date and time) was generally inItalian, but abstract and title of seminars were generally in English. Otherparts were in either one of the two languages. An example is in Figure 15.We used an English preprocessor that was unreliable on the Italian part of theinput. The preprocessor included a part of speech tagger, a gazetteer and namedentity recogniser. We studied the effectiveness of three different versions of thealgorithm: one using no NLP, one using just the POS tagger and one using thewhole preprocessor. As expected, the more linguistic information is given, thegreater the effectiveness, even if the linguistic information for the Italian partswas unreliable (Table 4.2).
The use of the POS helps consistently in recognising the date (+2.8%) andslightly the speaker (+1.3%); there is also a slight degradation on title (-0.4%),the latter being probably noise due to overgeneralisation in using the POS (asrecall is higher and precision is lower). The improvement on dates is probablydue to the ability to recognise numbers and therefore to generalize over them.As expected the use of gazetteer and NER contributes heavily in recognisingthe speaker (+9%) and there is some gain on both date (where there is somecontributions by the NER) and location, probably a side effect due to the useof contextual rules (the NERC is very unreliable in recognising names of Italianmeeting rooms). The accuracy in recognizing title is quite low; this is due tothe fact that a title is a quite difficult object to recognize. In principlpe it is justa sequence of words, sometimes capitalised, sometimes uppercase and centered
22

Table 6: Comparison of accuracy on mixed Italian English seminar announce-ment (training on 75 texts, test on 73) . The first column refers to the systemusing only information on words and capitalization, the second with words capi-talization and POS tags, the third with the full preprocessor including gazetteerlookup and Named Entity Recognition.
Slot Words POS Fullspeaker 74.1 75.4 84.3
title 62.8 62.4 62.8date 90.8 93.4 93.9time 100.0 100.0 100.0
location 95.0 95.0 95.5
0
50
100
150
200
250
300
350
400
450
500
550
0 2 4 6 8 10 12 14 16 18 20
Cases Covered
Nu
mb
er
of
Ru
les
Generalisation
No Generalisation
Figure 14: The effect of generalisation in reducing data sparseness.Number ofrules (on y) covering number of cases (on X: we show up to 20 cases)
23

Path: itc.it!itc.it!not-for-mail
From: Ileana Collini <[email protected]>
Newsgroups: itc.seminari
Subject: seminario Dr. Stock,26 novembre
Date: 21 Nov 1996 14:43:14 +0100
Organization: Istituto Trentino di Cultura - IRST
Lines: 34
Sender: [email protected]
Distribution: local
Message-ID: <[email protected]>
NNTP-Posting-Host: wonder.itc.it
... QUALCOSA DI DIVERSO .....
SEMINARIO IRST
PASSWORD SWORDFISH: VERBAL HUMOUR IN THE INTERFACE
martedi 26 novembre p.v. ad ore 17.00 in Sala CONFERENZE
Dr. Oliviero Stock
IRST
Povo di Trento
Abstract
Humour will be a necessity in future interfaces, especially in the
area at the crossroads of entertainment and education, so called
edutainment. Some considerations on the state of the art in natural
language processing and on computational humour prospects are
presented, as well as some ideas for the introduction of certain types
of computational humour in seductive interfaces. In doing that,
reference is made to some of the sparkling exchanges of the Marx
Brothers.
*****************************************************************************
Ileana Collini - secretariat tel +39-(0)461-314592
Interactive Sensory Systems Division fax +39-(0)461-314591
IRST e-mail [email protected]
via Sommarive 38050 Povo (Trento) ITALY
{{{
{
{{
I
M
M
E
I
E
Figure 15: An example of mixed Italian/English seminar announcement.”M”marks the parts in mixed language, while ”E” shows the parts in English and”I” those in Italian.
around using spaces. Moreover its length can be quite variable. The only wayto recognize it is using positioning in text and contextual information (it is oftenlocated near the speaker). This is why there is no increase in accuracy in addinglinguistic information to the rules.
In our opinion this shows that the algorithm is able to make the best useof the linguistic information it uses. This means that rules using the unreliableNLP information were automatically discarded when necessary, while those us-ing reliable information where kept. The measure of reliability was - for thelearner - the ability to extract information, not linguistic competence.
5 Conclusion and Future Work
In this paper we have presented (LP )2 , an algorithm for learning to extractimplicit events from documents of different types. We have described the algo-rithm and described experiments where the algorithm reaches excellent results.
24

We have also discussed how the different features of the algorithm contributeto such results. In particular we have focused on the contribution of linguisticinformation, showing that their use is not detrimental to the quality of resultswhen such information is unreliable.
(LP )2 has become the basis for two adaptive IE systems. The first one,called LearningPinocchio, has become a commercial system with applicationsdeveloped and licenses released for further commercial use. Such applicationsare described in details in [CL03]. We have obtained the best experimentalresults on the CMU seminar announcement with it.
Amilcare is a system for information extraction developed as part of theAKT project (www.aktors.org) and has been mainly used for annotation forKnowledge Management and the Semantic Web. Currently it has been adoptedas support to active annotation by two popular annotation tools for the Se-mantic Web: Ontomat, developed at the university of Karlsruhe[HSC02], andMnM, developed at the Open University [VVMD+02]. It has also been inte-grated in Melita, an annotation tool for assisted corpus annotation developedin Sheffield [CDPW02]. In all these tools, Amilcare monitors the tags insertedby a user annotating a corpus and learns how to reproduce it. When the sys-tem has reached a reasonable accuracy in annotation, it starts helping users inthe annotation process by providing every new text with a preliminary anno-tation to be corrected/confirmed by the user. Experiments have shown thatin some cases Amilcare is able to save up to 70% of the user annotation afterhaving trained on 2 or 3 dozens of short texts [CDPW02]. Amilcare is fullydescribed in [Cir03]. Amilcare is also used in the Armadillo system [CDGW03]as support for unsupervised annotation of information on large repositories.Armadillo uses the redundancy of information in large distributed repositories(e.g. the Web) for bootstrapping learning on specific pages; the learner usedis Amilcare. Within Armadillo, Amilcare has been tested on highly structuredpages such as those produced by Google and semi-structured ones, e.g. manu-ally compiled bibliographies. The use of Amilcare increases recall in discoveringnames of people working in a specific computer science department by 100% andincreases the amount of bibliographic references retrieved from personal publi-cation lists by 50% [CDGW03]. Finally Amilcare has been used by membersof the scientific community as baseline for testing further IE algorithms andmethodologies[MK03, FK03, SPSS03]. To date, the system as been released toabout fifty users; half of them are commercial enterprises. Amilcare is freelyavailable for use for research purposes. Instruction for obtaining a copy can befound at http://nlp.shef.ac.uk/amilcare.
Concerning future work, the use of linguistic information has been so farlimited to shallow linguistic analysis, i.e. up to named entity recognition. Wehave also introduced the use of ontological reasoning, so that the system is ableto reason over a hierarchy of semantic types during rule induction. We are cur-rently working to include chunking and the use of Wordnet. The difficulty inusing further level of generalisation is controlling overgeneralisation. In particu-lar the extension to use Wordnet requires a careful monitoring. This is becausethe polysemy is very high in Wordnet and the generalisation derived (i.e. ex-
25

tending the condition in a rule not only to a specific word, but also to all thesynonyms in the synsets) risks to overgeneralise if not kept under control, asexplained in [CM97]. Current strategies under consideration are (1) acceptinga synset only if there is multiple evidence of the reliability of the extension and(2) use a simplified version of Wordnet with reduced polysemy.
Finally, (LP )2 uses a fairly simplistic algorithm from a machine learningpoint of view. More sophisticated algorithm is used, for example, in BWI (whichuses boosting[SS88]). An extension of BWI to using linguistic features as in(LP )2 is under development as part of the dot.kom project (www.dot-kom.org).
Acknowledgments
I developed the naive version of (LP )2 and LearningPinocchio at ITC-Irst, Cen-tro per la Ricerca Scientifica e Tecnologica, Trento, Italy. LearningPinocchio isproperty of ITC-Irst, see http://tcc.itc.it/research/textec/tools-resources/learningpinocchio.html.The advanced version of (LP )2 and Amilcare have been developed at the Uni-versity of Sheffield in the framework of the AKT project (Advanced KnowledgeTechnologies, http://www.aktors.org), an Interdisciplinary Research Collabora-tion (IRC) sponsored by the UK Engineering and Physical Sciences ResearchCouncil (grant GR/N15764/01) (www.aktors.org). The development of Amil-care has been also supported by the dot.kom project (IST-2001-34038) fundedby the European Commission in Framework 5 (www.dot-kom.org).
This paper has been produced using both material from papers I have writtenin the past [Cir01a, Cir01b, CL03], and also some new material. Section 1 andthe first two paragraphs of section 2 were written in cooperation with AlbertoLavelli.
References
[AHB+93] D. Appelt, J. Hobbs, J. Bear, D. Israel, and M. Tyson. FASTUS:A finite-state processor for information extraction from real-worldtext. Proceedings of the Thirteenth International Joint Conferenceon Artificial Intelligence (IJCAI-93), pages 1172–1178, 1993.
[CDGW03] Fabio Ciravegna, Alexiei Dingli, David Guthrie, and Yorick Wilks.Integrating information to bootstrap information extraction fromweb sites. In Proceedings of the IJCAI 2003 Workshop on In-formation Integration on the Web, workshop in conjunction withthe 18th International Joint Conference on Artificial Intelligence(IJCAI 2003), 2003. Acapulco, Mexico, August, 9-15.
[CDPW02] Fabio Ciravegna, Alexiei Dingli, Daniela Petrelli, and YorickWilks. User-system cooperation in document annotation based oninformation extraction. In Proceedings of the 13th International
26

Conference on Knowledge Engineering and Knowledge Manage-ment, EKAW02. Springer Verlag, 2002.
[Cir01a] Fabio Ciravegna. Adaptive information extraction from text byrule induction and generalisation. In Proceedings of 17th Interna-tional Joint Conference on Artificial Intelligence (IJCAI), 2001.Seattle.
[Cir01b] Fabio Ciravegna. (LP)2, an adaptive algorithm for information ex-traction from web-related texts. In Proceedings of the IJCAI-2001Workshop on Adaptive Text Extraction and Mining held in con-junction with the 17th International Joint Conference on ArtificialIntelligence, 2001. Seattle, http://www.smi.ucd.ie/ATEM2001/.
[Cir03] Fabio Ciravegna. Designing adaptive information extraction forthe Semantic Web in Amilcare. In S. Handschuh and S. Staab,editors, Annotation for the Semantic Web, Frontiers in ArtificialIntelligence and Applications. IOS Press, 2003.
[CL03] Fabio Ciravegna and Alberto Lavelli. Learningpinocchio: Adap-tive information extraction for real world applications. Journal ofNatural Language Engineering, 2003. in press.
[CM97] M. Califf and R. Mooney. Relational learning of pattern-matchrules for information extraction. In Working Papers of the ACL-97 Workshop in Natural Language Learning, pages 9–15, 1997.
[Dou98] A. Douthat. The message understanding confer-ence scoring software user’s manual. In Proceedingsof the 7th Message Understanding Conference, 1998.www.itl.nist.gov/iaui/894.02/relatedprojects/muc/.
[FK00] D. Freitag and N. Kushmerick. Boosted wrapper induction. InR. Basili, F. Ciravegna, and R. Gaizauskas, editors, ECAI2000Workshop on Machine Learning for Information Extraction, 2000.www.dcs.shef.ac.uk/ fabio/ecai-workshop.html.
[FK03] Aidan Finn and Nicholas Kushmerick. Active learning selectionstrategies for information extraction. In Proccedings of the Work-shop on Adaptive Text Extraction and Mining. held in conjunctionwith the 14th European Conference on Machine Learning and the7th European Conference on Principles and Practce of knowledgeDiscovery in Databases, September 2003.
[FM99] D. Freitag and A. McCallum. Information extraction with hmmsand shrinkage. In AAAI-99 Workshop on Machine Learning forInformation Extraction, 1999.
27

[Fre98a] D. Freitag. Information extraction from html: Application of ageneral learning approach. Proceedings of the Fifteenth Conferenceon Artificial Intelligence AAAI-98, pages 517–523, 1998.
[Fre98b] D. Freitag. Multistrategy learning for information extraction. Pro-ceedings of ICML-98, 1998.
[Gri97] Ralph Grishman. Information extraction: Techniques and chal-lenges. In Maria Teresa Pazienza, editor, Information Extraction:a multidisciplinary approach to an emerging technology, 1997.
[Hep00] Mark Hepple. Independence and commitment: Assumptions forrapid training and execution of rule-based part-of-speech taggers.In Proceedings of the 38th Annual Meeting of the Association forComputational Linguistics (ACL-2000), 2000. Hong Kong.
[HGA+98a] K. Humphreys, R. Gaizauskas, S. Azzam, C. Huyck, B. Mitchell,H. Cunningham, and Y. Wilks. Description of the uni-versity of sheffield lasie-ii system as used for muc. InProc. of the 7th Message Understanding Conference, 1998.www.itl.nist.gov/iaui/894.02/relatedprojects/muc/.
[HGA+98b] Kevin Humphreys, Robert Gaizauskas, Saliha Azzam, ChrisHuyck, Brian Mitchell, Hamish Cunningham, and Yorick Wilks.Description of the university of sheffield LaSIE-II system as usedfor muc. In Proc. of the 7th Message Understanding Conference,1998. www.itl.nist.gov/iaui/894.02/relatedprojects/muc/.
[HSC02] S. Handschuh, S. Staab, and F. Ciravegna. S-CREAM - Semi-automatic CREAtion of Metadata. In Proceedings of the 13th In-ternational Conference on Knowledge Engineering and KnowledgeManagement, EKAW02. Springer Verlag, 2002.
[KWD97] N. Kushmerick, D. Weld, and R. Doorenbos. Wrapper inductionfor information extraction. In Proceedings of the InternationalJoint Conference on Artificial Intelligence (IJCAI), 1997., 1997.
[MCF+98] S. Miller, M. Crystal, H. Fox, L. Ramshaw, R. Schwartz,R. Stone, and R. Weischedel. Bbn: Description ofthe SIFT system as used for MUC7. In Proceedingsof the 7th Message Understanding Conference, 1998.www.itl.nist.gov/iaui/894.02/relatedprojects/muc/.
[MK03] David Masterson and Nicholas Kushmerick. Information extrac-tion from multi-document threads. In Proccedings of the Workshopon Adaptive Text Extraction and Mining. held in conjunction withthe 14th European Conference on Machine Learning and the 7thEuropean Conference on Principles and Practce of knowledge Dis-covery in Databases, September 2003.
28

[MMJL86] R. S. Mickalski, I. Mozetic, Hong J., and H. Lavrack. The multipurpose incremental learning system aq15 and its testing applica-tion to three medical domains. In Proceedings of the 5th NationalConference on Artificial Intelligence, 1986. Morgan Kaufmannpublisher.
[MMK98] I. Muslea, S. Minton, and C. Knoblock. Wrapper inductionfor semistructured web-based information sources. In Proceed-ings of the Conference on Automated Learning and Discovery(CONALD), 1998., 1998.
[MUC98] MUC7. Proceedings of the 7th Message Un-derstanding Conference (MUC7). Nist, 1998.www.itl.nist.gov/iaui/894.02/relatedprojects/muc/.
[Sod99] S. Soderland. Learning information extraction rules for semi-structured and free text. Machine Learning, 34(1):233–272, 1999.
[SPSS03] Georgios Sigletos, Georgios Paliouras, Constantine D. Spyropou-los, and Takis Stamatopoulos. Meta-learning beyond classification:A framework for information extraction from the web. In Proc-cedings of the Workshop on Adaptive Text Extraction and Mining.held in conjunction with the 14th European Conference on Ma-chine Learning and the 7th European Conference on Principles andPractce of knowledge Discovery in Databases, September 2003.
[SS88] R. Schapire and Y. Singer. Improved boosting algorithms usingconfidence-rated predictions. In Proceedings of the Eleventh An-nual Conference on Computational Learning Theory, 1988.
[VVMD+02] M. Vargas-Vera, Enrico Motta, J. Domingue, M. Lanzoni,A. Stutt, and F. Ciravegna. MnM: Ontology driven semi-automatic or automatic support for semantic markup. In Proc.of the 13th International Conference on Knowledge Engineeringand Knowledge Management, EKAW02. Springer Verlag, 2002.
29