machine learning 12. multilayer perceptrons. neural networks lecture notes for e alpaydın 2004...
TRANSCRIPT

MACHİNE LEARNİNG12. Multilayer Perceptrons

Neural Networks
Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
2
Networks of processing units (neurons) with connections (synapses) between them
Large number of neurons: 1010
Large connectitivity: 105
Parallel processing Distributed computation/memory Robust to noise, failures

Perceptron
Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
3
Learn weight for given task
Td
Td
Td
jjj
x,...,x,
w,...,w,w
wxwy
1
10
01
1
x
w
xw

Perceptron
Weights define a hyperplane (line in 2D) Split space into 2 parts (above/below
hyperplane) Can be used to split data into 2 classes (linear
discriminant) Threshold function
Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
4

K Outputs classification
Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
5
choose if max
Ti i
i i kk
y
C y y
w x

Online Learning
Batch training All data given at once
Online training Sample by Sample Update parameters on each new instance Save memory Data changing in time
Baesed on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
6

Online Learning: Regression Error
Update
Gradually decreasing learning factor
Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
7

Online Learning : Classification Input: (y,r) where y is a data instance and
r=1 if from class C1
Option I: Using threshold function
Difficulties to treat analytically (gradient?)Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press
(V1.1)
8

Online Learning: Classification Replace threshold with
sigmoid Sigmoid output=>probability
of a class True(training) probability is
either 0 or 1 (r) Error measure: Cross-Entropy
Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
9

Online Learning: Classification Reduce cross-entropy error
Gradient descent rule
Update=LearningFactor*(DesiredOutput-ActualOutput)*Input
Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
10

Example: Learning Boolean Function Two Boolean inputs (0 or 1) Single Boolean output (0 or 1) Can be seen as classification problem Not all Boolean function separable (can
be learned)
Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
11

Learning Boolean AND
Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
12
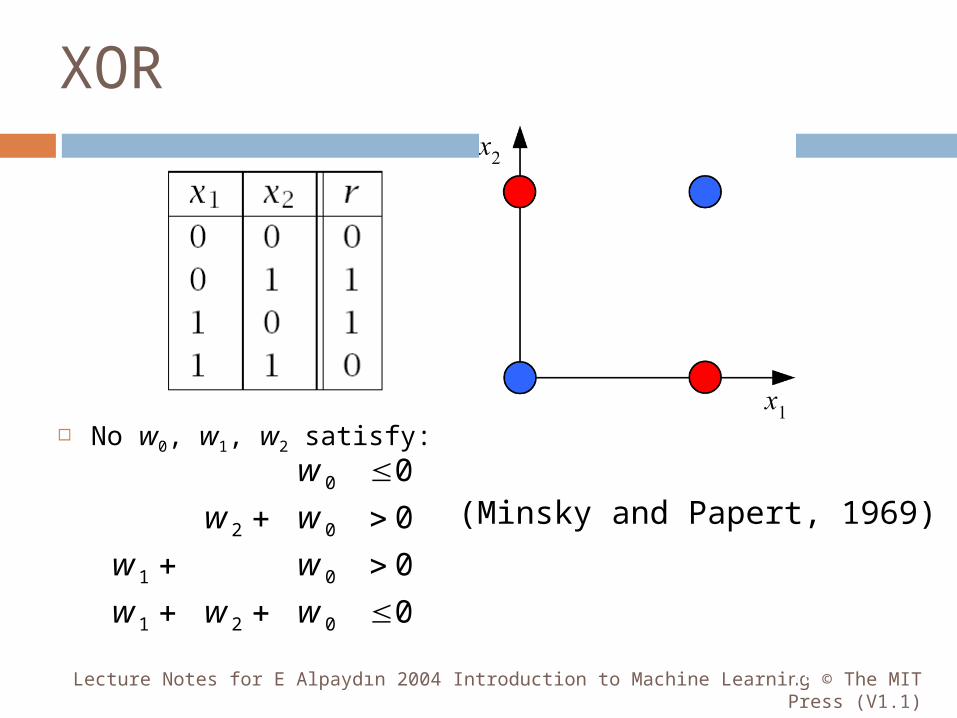
XOR
No w0, w1, w2 satisfy:
0
0
0
0
021
01
02
0
www
ww
ww
w
Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)13
(Minsky and Papert, 1969)

Multilayer Perceptron (MLP)
Can learn only linear discriminant or linear regression
Introduce intermediate/hidden layers
Non linear “activation” function in hidden layers
Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
14

Multilayer Perceptrons
Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
15
d
j hjhj
Thh
H
hihih
Tii
wxw
z
vzvy
1 0
10
exp1
1
sigmoid xw
zv

Multilayer Perceptron
Hidden layer Non-linear transformation from d-
dimensional to H-dimensional
Second output layer implement linear combination of non-linear basis functions
Can add more hidden layers
Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
16

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
17
x1 XOR x2 = (x1 AND ~x2) OR (~x1 AND x2)

Universal Approximator
MLP with one hidden layer and arbitrary number of hidden perceptrons can learn any nonlinear function of input
Baesed on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
18

Backpropagation: Intro
Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
19
hj
h
h
i
ihj
d
j hjhj
Thh
H
hihih
Tii
wz
zy
yE
wE
wxw
z
vzvy
exp1
1
sigmoid
1 0
10
xw
zv

Backpropagation: Regression Model
Error
Update second layer
Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
20
xwThhz sigmoid
H
h
thh
t vzvy1
0
221
| t
tt yr,E XvW
th
t
tth zyrv

Backpropoagation: Regression Use chain rule to obtain first layer
Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
21

Backpropogation: Regression Update first layer using old values(v) of
the second layer
Update second layer using new values of
Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
22
th
t
tth zyrv
1t t t t thj h h h j
t
w r y v z z x

23

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)24
whx+w0
zh
vhzh

One sigmoid output yt for P(C1|xt) and P(C2|xt) ≡ 1-yt
Two-Class Discrimination
Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
25
t
jth
thh
t
tthj
th
t
tth
t
tttt
H
h
thh
t
xzzvyrw
zyrv
yryr,E
vzvy
1
1 log 1 log |
sigmoid1
0
XvW

Multiple Hidden Layers
Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
26
2
1
1022
21
0212122
11
01111
1sigmoidsigmoid
1sigmoidsigmoid
H
lll
T
H
hlhlh
Tll
d
jhjhj
Thh
vzvy
H,...,l,wzwz
H,...,h,wxwz
zv
zw
xw
MLP with one hidden layer is a universal approximator (Hornik et al., 1989), but using multiple layers may lead to simpler networks

Gradient Descent
Simple Local (change in weight requires only
input and output of single Perceptron) Can be used with online training( data no
storage) Can be implemented in hardware May converge slowly Frequently used techniques to improve
convergenceBased on E Alpaydın 2004 Introduction to Machine
Learning © The MIT Press (V1.1)
27

Momentum At each parameter update, successive
Δw values may be so different that large oscillations may occur and slow convergence
Running average by taking previous value
Based on E Alpaydın 2004 Introduction to Machine
Learning © The MIT Press (V1.1)
28
1
ti
i
tti w
wE
w

Adaptive Learning Rate
Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
29
Keep learning rate increasing when error decrease Going to right direction
Decrease learning rate when error increase Missed the minimum
otherwise
if
b
EEa tt

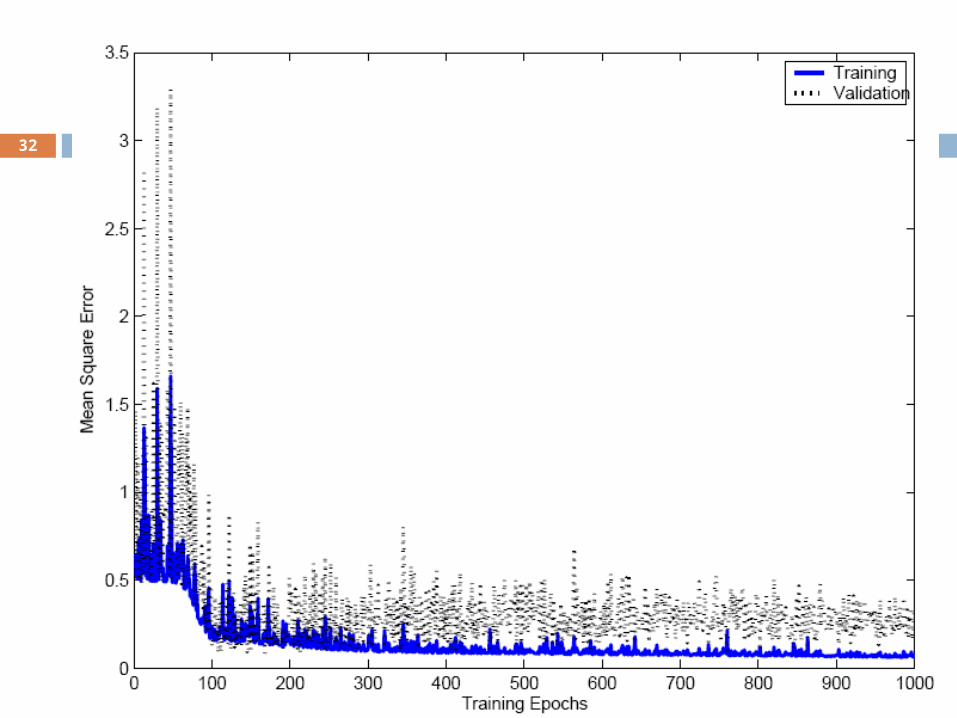
Overfitting/Overtraining
Overfitting: Too many parameters/hidden nodes Fits to the noise present at training sample Poor generalization error Use cross-validation
Overtraining Error function have several minima Most important weights become non-zero first As training continues, more weights move
away from zero, adding more parameters Stop earlier using cross-validation
30

Overfitting31
Number of weights: H (d+1)+(H+1)K
32

Structuring the network
In some applications input has a “local structure” Nearby pixels correlated Speech samples close in time
Hidden units are not connected to all input Define a windows over input Number of parameters is reduced Connect nodes only to a subset of nodes in other
layers Hierarchical cone: features get more complex
Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
33

Structured MLP34

Hints
Have some prior expert knowledge Hint: properties of the target function
known independent of training examples For instance: Invariance to rotation
35

Hints36
Create Virtual examples Generated multiple rotated copies of the
example and feed them to MLP Preprocessing State
Scale and align all inputs Incorporate into structure
Local structure

Tuning Network Size
Networks with unnecessary large number of parameters generalize poorly
Too many possible configuration (nodes/connections) to try for cross-validation
Use structural adaptation Destructive approach: gradually remove
unnecessary nodes and connections Constructive approach: gradually add new
nodes/connections Based on E Alpaydın 2004 Introduction to Machine
Learning © The MIT Press (V1.1)
37

Destructive method: Weight decay Punish for large connection weight Connections with weight close to zero
“disappears”
Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
38
ii
ii
i
wE'E
wwE
w
2
2