machine learning learning... a fundamental aspect of intelligent systems – not just a short-cut to...
TRANSCRIPT

machine learning
learning...
a fundamental aspect of intelligent systems
– not just a short-cut to kn acquisition / complex behaviour

learning
• not well understood by philosophy, psychology, physiology
• AI asks: how can a machine...– generate rules from case histories– reorganise its kn as it expands– generate its own s/w– learn to discriminate diff. phenomenon

learning
• not well understood by philosophy, psychology, physiology
• AI asks: how can a machine...– generate rules – induction– reorganise kn – generalisation & induction– generate s/w – evolution (& others?)– discriminate phenomena – neural nets (etc)

implementation issues
• supervised vs unsupervised – with / without known outputs
• classification vs regression– discrete versus continuous values
• stuff learned “inductive bias” – types of functions learned– algorithms restrict what is learned
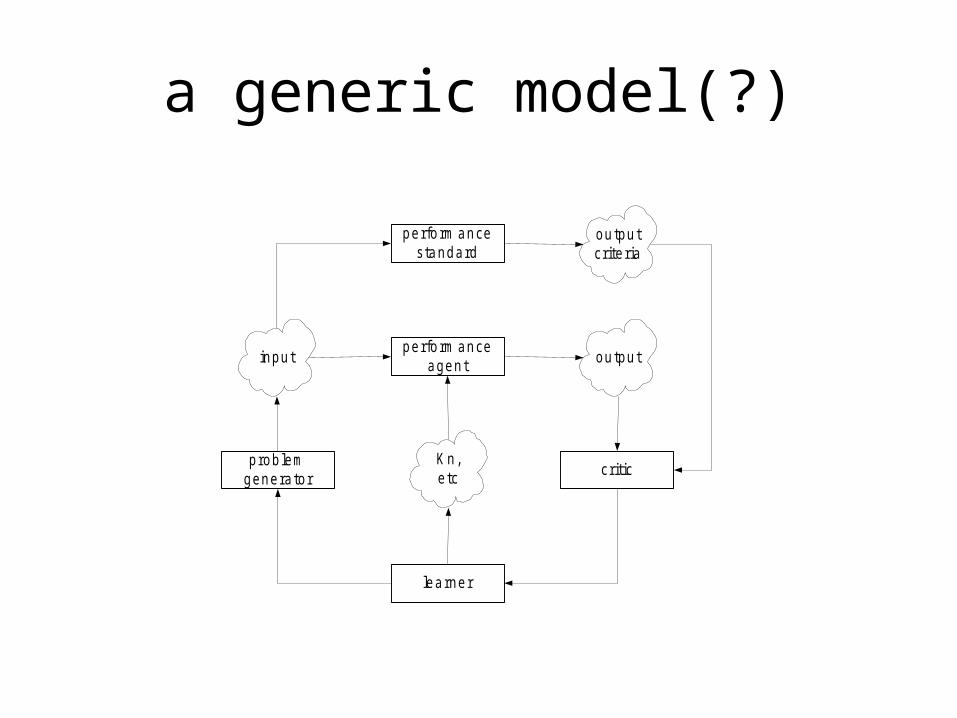
a generic model(?)
perform anceagent
perform ancestandard
prob lemgenera tor
critic
learner
input output
K n,e tc
outputcrite ria

lecture programme
• induction intro• rules from semantic nets (tutorial)• nearest neighbour• splitting feature space• forming decision trees (& then rules)• generalisation (semantic nets)• near-miss• evolution• neural networks

induction #1
• def: “automatically acquire a function from inputs to output values, based on previously seen inputs and output values”
• input: feature values
• output: classification
• eg: speech recognition, object identification

induction #2
• aims: generate rules from examples
• formally:given collection of {x → y}
find hypothesis h : h(x) ≈ y
for (nearly) all x & y

issues
• feature selection• what features to use?• how do they relate to each other?• how sensitive is the technique to feature selection?
(irrelevant, noisy, absent feature; feature types)
• complexity & generalisation• matching training data vs performance on new data
NB: some of following slides are based on examples from Machine learning programme at The University of Chicago Department of Computer Science

induction – principles
• Occam’s razorthe world is inherently simple so the most likely hypothesis is the simplest one which is consistent with observations
• other–use -ve as well as +ve evidence–seek concomitant variation in cause/result–more frequently observed associations are more reliable

rules from semantic nets
• a tutorial problem
• think bicycle, cart, car, motor-bike
• build nets from examples (later)
• build rules from nets

nearest neighbour
• supervised, classification (usually)
• training: record inputs outputs
• use:– find “nearest” trained case & return
associated output value
• +ve: fast, general purpose
• -ve: expensive prediction, definition of distance is complex, sensitive to noise

feature space splitting
• supervised, classification
• training: record inputs outputs
• +ve: fast, tolerant to (some) noise
• -ve: some limitations, issues about feature selection, etc

splitting feature-space
splitting feature-space

splitting feature-space
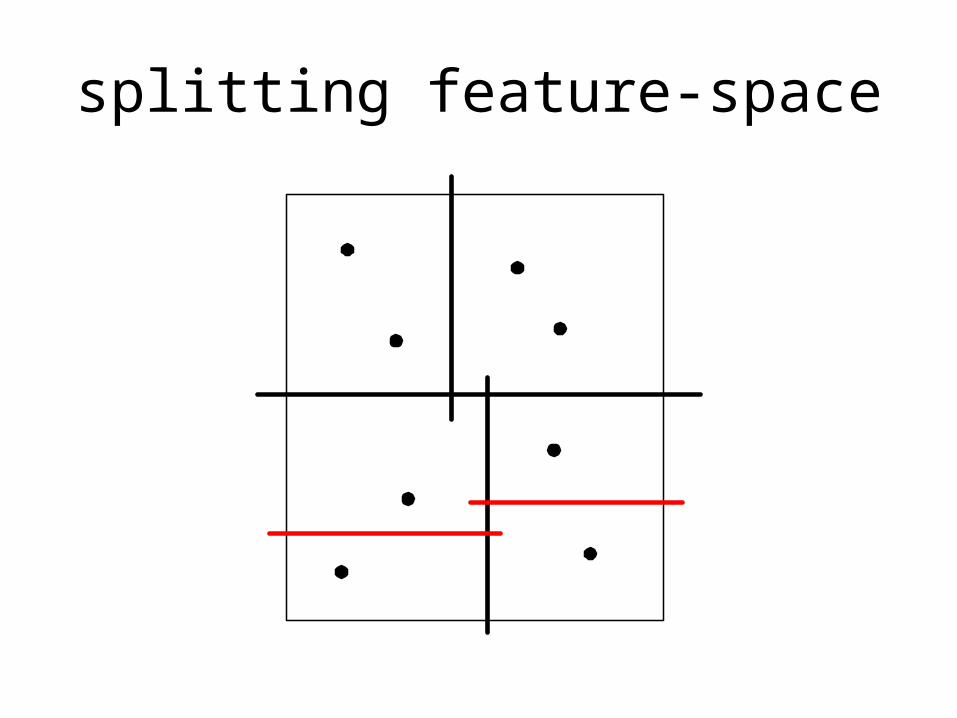
splitting feature-space

splitting feature-space
• real examples have many dimensions
• splitting by clusters can give “better” rules
• wider empty zones between clusters give “better” rules

identification trees
• (aka “decision trees”)
• supervised, classification
• +ve: copes better with irrelevant attributes & noise, fast in use
• -ve: more limited that nearest neighbour(& feature space)

ID trees
• train: build tree by forming subsets of least disorder• use:
– traverse tree based on feature tests & assign leaf node label
– OR: use a ruleset• +ve: robust to irrelevant features & some noise,
fast prediction, readable rules• -ve: poor feature combination, poor handling of feature
dependencies, optimal trees not guaranteed

identification trees
name hair height weight screen resultsarah blonde ave light N burn
dana blonde tall ave Y ok
alex dark tall ave Y ok
annie blonde short ave N burn
emily red ave heavy N burn
pete dark tall heavy N ok
john dark ave heavy N ok
katie blonde short light Y ok

sunburn
• goal: predict burn/no burn for new cases
• cannot do exact match (same features) same output (feature space too large)
• nearest neighbour?but: what is close?
which features matter?
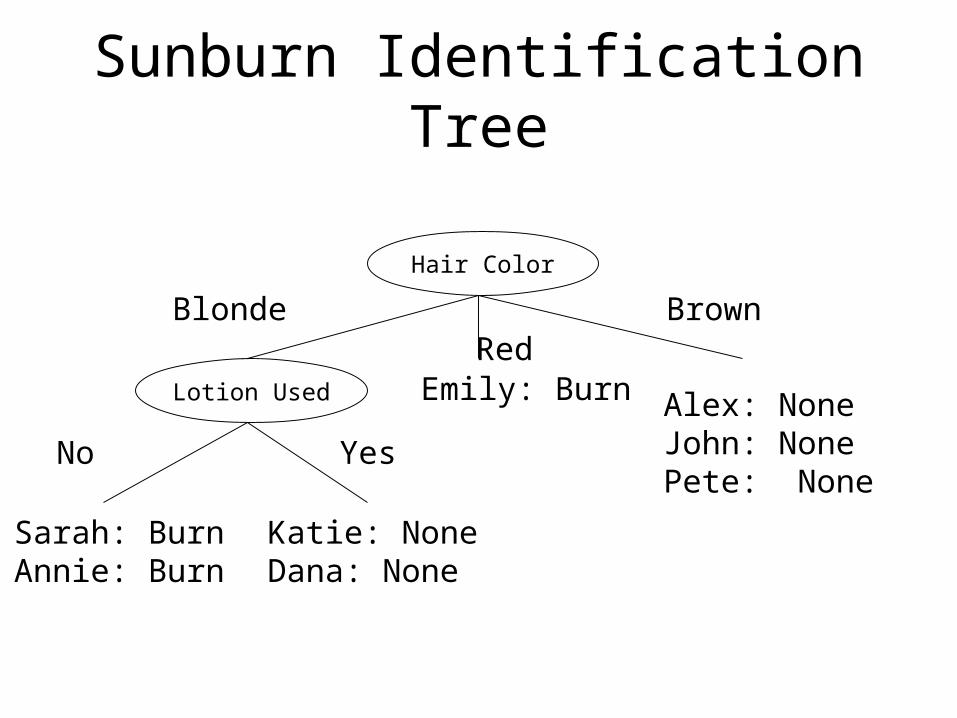
Sunburn Identification Tree
Hair Color
Lotion Used
BlondeRed
Brown
Alex: NoneJohn: NonePete: None
Emily: Burn
No Yes
Sarah: BurnAnnie: Burn
Katie: NoneDana: None

building ID trees
• aim: build a small tree such that all samples at leaves have same label
• at each node, pick tests so branches are closest to having same class– Split into subsets with least “disorder”– (Disorder ~ Entropy)
• find test that minimizes disorder

Minimizing Disorder
Hair Color
BlondeRed
Brown
Alex: NPete: NJohn: N
Emily: BSarah: BDana: NAnnie: BKatie: N
Height
WeightLotion
Short AverageTall
Alex:NAnnie:BKatie:N
Sarah:BEmily:BJohn:N
Dana:NPete:N
Sarah:BKatie:N
Light AverageHeavy
Dana:NAlex:NAnnie:B
Emily:BPete:NJohn:N
No Yes
Sarah:BAnnie:BEmily:BPete:NJohn:N
Dana:NAlex:NKatie:N
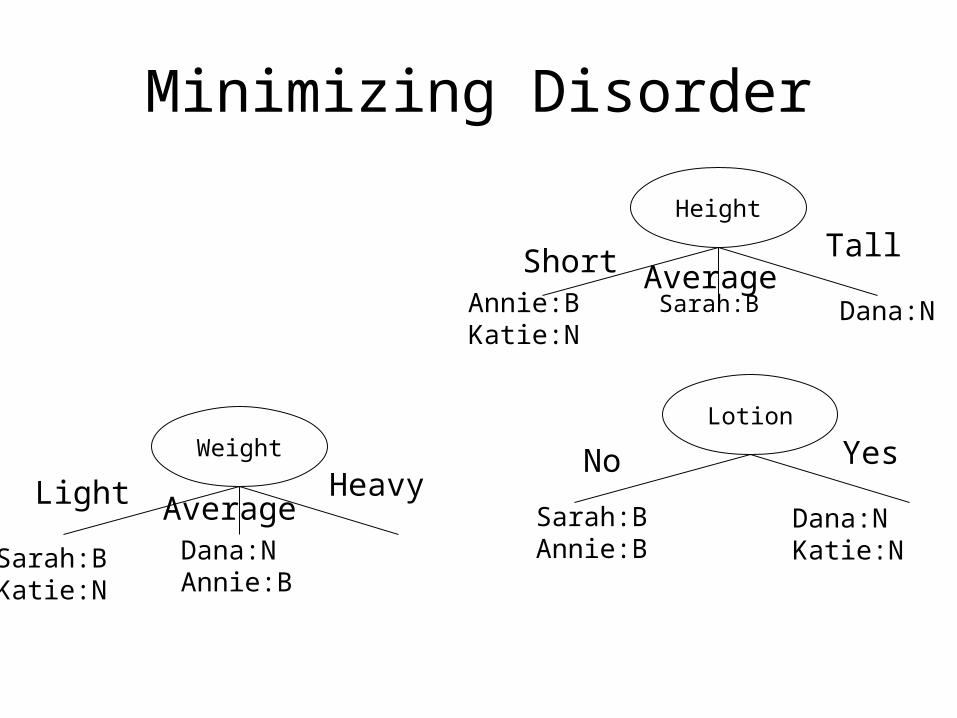
Minimizing Disorder
Height
WeightLotion
Short AverageTall
Annie:BKatie:N
Sarah:B Dana:N
Sarah:BKatie:N
Light AverageHeavy
Dana:NAnnie:B
No Yes
Sarah:BAnnie:B
Dana:NKatie:N

measuring disorder
• Problem: – large DB’s don’t yield homogeneous subsets
• Solution:– IS defines theoretic measure of disorder
• Homogeneous set: least disorder = 0• Even split: most disorder = 1

sunburn entropy #1
k
i i
ci
classc i
ci
t
i
n
n
n
n
n
nrAvgDisorde
1
,2
, log
Hair color = 4/8(-2/4 log 2/4 - 2/4log2/4) + 1/8*0 + 3/8 *0 = 0.5
Height = 0.69Weight = 0.94Lotion = 0.61

sunburn entropy #2
k
i i
ci
classc i
ci
t
i
n
n
n
n
n
nrAvgDisorde
1
,2
, log
Height = 2/4(-1/2log1/2-1/2log1/2) + 1/4*0+1/4*0 = 0.5Weight = 2/4(-1/2log1/2-1/2log1/2) +2/4(-1/2log1/2-1/2log1/2) = 1 Lotion = 0

building ID trees with disorder
• until each leaf is as homogeneous as possible – select a non-homogeneous leaf node– replace node by a test creating subsets with
least average disorder

features in ID Trees: Pros
• Feature selection:– Tests features that yield low disorder
• E.g. selects features that are important!
– Ignores irrelevant features
• Feature type handling:– Discrete type: 1 branch per value– Continuous type: Branch on >= value
• Need to search to find best breakpoint
• Absent features: Distribute uniformly

Features in ID Trees: Cons
• features assumed independent– If want group effect, must model explicitly
• E.g. make new feature AorB
• feature tests conjunctive

From ID Trees to Rules
Hair Color
Lotion Used
BlondeRed
Brown
Alex: NoneJohn: NonePete: None
Emily: Burn
No Yes
Sarah: BurnAnnie: Burn
Katie: NoneDana: None
(if (equal haircolor blonde) (equal lotionused yes) (then None))(if (equal haircolor blonde) (equal lotionused no) (then Burn))(if (equal haircolor red) (then Burn))(if (equal haircolor brown) (then None))

bird
budgie
freddie
sparrow
animal
wings
ako
if has( wings ) flyingelsif has( legs ) walkingelse crawling
ako
color
ako
ako
browncolor
moves_by
generalisation
has
yellow