machine learning zur prognose von besucherzahlen auf ... · kapitel 2 betrachtete...
TRANSCRIPT

Fakultat Wirtschaftsinformatik und AngewandteInformatik
Otto-Friedrich-Universitat Bamberg
Machine Learning zur Prognosevon Besucherzahlen auf Bamberg
Zaubert
Tim Rutermann (Matr.Nr. 1694792)
Simon Josef Schiesser (Matr.Nr. 1725406)
Adrian Schwaiger (Matr.Nr. 1689049)
Projektbericht
SS 2015
26. November 2015
Betreuer: Prof. Dr.Ute Schmid und Prof. Dr.Daniela Nicklas


Inhaltsverzeichnis
1 Einleitung 1
2 Betrachtete Machine-Learning-Verfahren 3
2.1 k-Nachste-Nachbarn . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.1.1 Beschreibung des Algorithmus . . . . . . . . . . . . . . . 3
2.1.2 Parameter . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.2 Lokale Polynomiale Regression . . . . . . . . . . . . . . . . . . . 4
2.3 Support Vector Machine . . . . . . . . . . . . . . . . . . . . . . . 5
2.3.1 Die Idee hinter der Support Vector Machine . . . . . . . . 5
3 Daten 7
3.1 Datenerfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3.1.1 Erfasste Gerate . . . . . . . . . . . . . . . . . . . . . . . . 7
3.1.2 Wetterdaten . . . . . . . . . . . . . . . . . . . . . . . . . 9
3.2 Datenaufbereitung . . . . . . . . . . . . . . . . . . . . . . . . . . 9
4 Anwendung der Machine-Learning-Verfahren 11
4.1 Allgemeines Verfahren . . . . . . . . . . . . . . . . . . . . . . . . 11
4.2 Vorstellung von Rapidminer . . . . . . . . . . . . . . . . . . . . . 12
4.3 Umsetzung in Rapidminer . . . . . . . . . . . . . . . . . . . . . . 13
4.4 k-Nachste-Nachbarn . . . . . . . . . . . . . . . . . . . . . . . . . 13
4.4.1 Parameteroptimierung . . . . . . . . . . . . . . . . . . . . 13
4.4.2 Ergebnisse der Anwendung . . . . . . . . . . . . . . . . . 13
4.5 Lokale Polynomielle Regression . . . . . . . . . . . . . . . . . . . 15
4.5.1 Parameteroptimierung . . . . . . . . . . . . . . . . . . . . 15
4.5.2 Neighbourhood Type . . . . . . . . . . . . . . . . . . . . . 15
4.5.3 Numerical Measure . . . . . . . . . . . . . . . . . . . . . . 16
4.5.4 Degree & Ridge Factor . . . . . . . . . . . . . . . . . . . . 17
4.5.5 Smoothing Kernel . . . . . . . . . . . . . . . . . . . . . . 17
4.6 Support Vector Machine . . . . . . . . . . . . . . . . . . . . . . . 19
4.6.1 Auswahl der Verfahren . . . . . . . . . . . . . . . . . . . . 19
4.6.2 Hyperparameteroptimierung . . . . . . . . . . . . . . . . . 20
4.6.3 Ergebnis der Besuchervorhersage mit der SVM . . . . . . 21
5 Statistische Auswertung 23
5.1 Kurze Wiederholung Statistik . . . . . . . . . . . . . . . . . . . . 23
5.2 Ergebnis und Interpretation . . . . . . . . . . . . . . . . . . . . . 24
i

INHALTSVERZEICHNIS
6 Fazit 27
Literaturverzeichnis 29
A RapidMiner-Prozessgrafiken und -Listings 31
B Arbeiten vor Bamberg Zaubert 35B.1 Ruckblick auf Bamberg Zaubert 2012 . . . . . . . . . . . . . . . . 35B.2 Software fur die Live-Demo auf Bamberg Zaubert . . . . . . . . . 39
B.2.1 Ubertragung der Daten von der Datenbank . . . . . . . . 40B.2.2 Bestimmung der Geratezahl mit Entry- und Leave-Events 40B.2.3 Handhabung von Latenzen . . . . . . . . . . . . . . . . . 40
ii

Tabellenverzeichnis
2.1 Betrachtete Ahnlichkeitsmaße . . . . . . . . . . . . . . . . . . . . 4
3.1 Tabelle zum Lernen . . . . . . . . . . . . . . . . . . . . . . . . . 9
4.1 Kennwerte Metrisch . . . . . . . . . . . . . . . . . . . . . . . . . 124.2 Hyperparameter tabelle . . . . . . . . . . . . . . . . . . . . . . . 20
5.1 Annahme- und Ablehnungsbereiche . . . . . . . . . . . . . . . . . 235.2 Wilcoxon-Vorzeichen-Rang-Test Tabelle . . . . . . . . . . . . . . 245.3 Wilcoxon-Vorzeichen-Rang-Test Ergebnis . . . . . . . . . . . . . 24
iii


Abbildungsverzeichnis
2.1 Bild der Support Vector Machine Generelle Idee . . . . . . . . . 62.2 Bild der Support Vector Machine wahrend der Regression . . . . 6
3.1 Verteilung der Techtypes . . . . . . . . . . . . . . . . . . . . . . . 73.2 Besucherverlauf 2015 . . . . . . . . . . . . . . . . . . . . . . . . . 83.3 Verteilung Besucher gesendet 2015 . . . . . . . . . . . . . . . . . 8
4.1 k-NN Vorhersage nachste 15 Minuten . . . . . . . . . . . . . . . . 144.2 k-NN Vorhersage komplettes Fest . . . . . . . . . . . . . . . . . . 154.3 Polynomielle Regressionskurve . . . . . . . . . . . . . . . . . . . 164.4 Verteilung der Dichtefunktion verschiedener Ansatze . . . . . . . 184.5 Vorhersage Besucherzahlen in 15 Minuten . . . . . . . . . . . . . 184.6 Vorhersage Besucherzahlen fur ganzen Tag . . . . . . . . . . . . . 194.7 Grid Search der Support Vector Machine . . . . . . . . . . . . . . 204.8 Besucherverlauf mit der Support Vector Machine . . . . . . . . . 214.9 Prognose fur die ganze Veranstaltung . . . . . . . . . . . . . . . . 21
A.1 Prozess Parameteroptimierung und Validierung 1 . . . . . . . . . 33A.2 Prozess Parameteroptimierung und Validierung 2 . . . . . . . . . 33A.3 Prozess Parameteroptimierung und Validierung 3 . . . . . . . . . 33A.4 Prozess Prognose fur die nachsten 15 Minuten . . . . . . . . . . . 33A.5 Prozess Prognose fur das restliche Fest 1 . . . . . . . . . . . . . . 34A.6 Prozess Prognose fur das restliche Fest 2 . . . . . . . . . . . . . . 34
B.1 Besuchergesendet 2012 . . . . . . . . . . . . . . . . . . . . . . . . 36B.2 Besucherverlauf 2012 . . . . . . . . . . . . . . . . . . . . . . . . . 36B.3 Laufzeit der Station 1054 . . . . . . . . . . . . . . . . . . . . . . 37B.4 RSSI Verteilung insgesamt . . . . . . . . . . . . . . . . . . . . . . 37B.5 RSSI Werte an der beamzone 1051 . . . . . . . . . . . . . . . . . 38B.6 Stationare Quelle mit der Verteilung an der Beamzone 1055 . . . 38B.7 Stationare Quelle mit der Verteilung an der Beamzone 1059 . . . 39
v


Kapitel 1
Einleitung
Im Rahmen des Projekts”Sensorbasierte Online-Pradiktion von Besucherbewe-
gungen bei Straßenfesten“ wurden auf Bamberg Zaubert 2015 insgesamt sechsSensoren auf dem Festgebiet verteilt, mit welchen WLAN- oder Bluetooth-Gerate erfasst wurden.
Vor der Veranstaltung beschaftigten wir uns vor allem mit der Analyse derDaten von Bamberg Zaubert 2013 und der Entwicklung eines Programms, umdie Daten im Live-Betrieb fur die Visualisierungssoftware aufzubereiten.
Das Projektziel nach Bamberg Zaubert war es, zu analysieren, ob und abwann man bereits wahrend des Fests die Besucherzahlen fur den weiteren Ver-lauf vorhersagen hatte konnen. Dafur haben wir die wahrend Bamberg Zaubertgesammelten Daten aufbereitet und mit RapidMiner insgesamt drei verschiede-ne Machine-Learning-Verfahren auf diese angewendet und evaluiert.
Die nachfolgende Arbeit ist wie folgt gegliedert: Kapitel 2 stellt das allgemei-ne Vorgehen bei den in dieser Arbeit verwendeten Machine-Learning-Verfahrenvor. In Kapitel 3 werden die gesammelten Daten beschrieben und wie sie auf-bereitet wurden. Die konkrete Umsetzung und Auswertung der verwendetenMachine-Learning-Ansatze wird in Kapitel 4 beschrieben, die statistische Aus-wertung der Ergebnisse erfolgt in Kapitel 5. Das Fazit in Kapitel 6 schließt dieArbeit ab. Des Weiteren sind im Anhang noch Beschreibungen der großerenArbeiten vor Bamberg Zaubert.
1


Kapitel 2
Betrachtete Machine-Learning-Verfahren
2.1 k-Nachste-Nachbarn
2.1.1 Beschreibung des Algorithmus
Anhand des RapidMiner-Quellcodes1 wird der k-Nachste-Nachbarn-Algorithmusfur Regression beschrieben.
Die Trainingsphase ist hier sehr einfach, es werden lediglich die Trainings-daten abgespeichert (siehe Konstruktor). Die Methode performPrediction() de-finiert, wie ein gesuchter Wert bestimmt wird. Dabei werden zu Beginn die kahnlichsten Beispiele in den Trainingsdaten ermittelt. k ist dabei ein Parameter,welcher manuell gesetzt werden muss. Fur die Bestimmung der Ahnlichkeit zwei-er Beispiele gibt es verschiedene Ahnlichkeitsmaße, in 2.1.2 werden vier Maßevorgestellt.
Zur Bestimmung der Prognose wird dann uber die Werte des gesuchten At-tributs bei den gefunden Beispielen gemittelt. Zusatzlich gibt es mit dem Pa-rameter weighted vote die Moglichkeit, auch noch die Distanz der ermitteltenTrainingsbeispiele zu dem zu prognostizierenden Beispiel zu beachten. Dabeiwird die Gesamtdistanz aller Trainingsbeispiele errechnet und die Distanz ei-nes jeden Trainingsbeispiels durch diese geteilt, um einen Gewichtungsfaktorzu erhalten. Damit haben ahnliche Beispiele einen großeren Einfluss auf dasErgebnis.
Das Verfahren hat den Vorteil, dass es durch seine Einfachheit sehr schnellist. Jedoch hat es den Nachteil, dass die Trainingsdaten den Rahmen fur dieprognostizierten Werte festlegen, da nur uber die Trainingsdaten gemittelt wird.Ist beispielsweise ein Modell fur Besucherzahlen erstellt worden, in welchem inden Trainingsdaten die hochste Besucherzahl 300 und die niedrigste 50 war,so wird dieser Algorithmus keine Werte außerhalb dieses Intervalls bestimmenkonnen.
1https://github.com/rapidminer/rapidminer-5/blob/
3bdfd053cab5f114e724650c7d5cf9a8e8b0c857/src/com/rapidminer/operator/
learner/lazy/KNNRegressionModel.java
3

KAPITEL 2. BETRACHTETE MACHINE-LEARNING-VERFAHREN
2.1.2 Parameter
Bei dem k-NN-Algorithmus gibt es in RapidMiner insgesamt drei Parameter:Erstens k, das heißt wie viele ahnliche Beispiele gesucht werden sollen. Zwei-tens, ob Trainingsbeispiele, die eine hohere Ahnlichkeit zum Vorhersagebeispielhaben, starker ins Gewicht fallen sollen und letztens, welches Ahnlichkeitsmaßverwendet werden soll. Dabei wurden in diesem Projekt vier Maße betrachtet,die in 2.1 aufgelistet sind.
Tabelle 2.1: Betrachtete AhnlichkeitsmaßeMaß Formel Eigenschaften
Euklidischer Abstand
√n∑i=1
(xi − yi)2Attribute mit großeren absolutenWerten und Differenzen zwischenden Werten werden starker ge-wichtet
Kosinus-Ahnlichkeit
n∑i=1
xi∗yi√n∑
i=1
(xi)2∗n∑
i=1
(yi)2
Misst den Winkel zwischen denVektoren, nicht die Große derWerte
Manhattan-Distanzn∑i=1
|xi − yi|Attribute mit großeren absolutenWerten werden starker gewichtet
Canberra-Distanz
Literatur:n∑i=1
|xi−yi||xi|+|yi|
RapidMiner:n∑i=1
|xi−yi||xi+yi|
Der absolute Attributwert falltweniger stark ins Gewicht (imVergleich zu dem EuklidischenAbstand und Manhattan-Distanz). Der Unterschied in derRapidMiner-Implementierungist bei unseren Daten nichtvon Bedeutung, da er nur beinegativen Werten auftritt
2.2 Lokale Polynomiale Regression
Als drittes Verfahren wurde die lokale polynomiellen Regression ausgewahltund soll im Folgenden anhand der RapidMiner Dokumentation zur polynomiel-len Regression2, lokalen polynomiellen Regression3 und dem Github Quellcode4
2http://docs.rapidminer.com/studio/operators/modeling/classification_
and_regression/function_fitting/polynomial_regression.html(RevisionDate:
25.11.2015)3http://docs.rapidminer.com/studio/operators/modeling/classification_
and_regression/function_fitting/local_polynomial_regression.
html(RevisionDate:25.11.2015)4https://github.com/rapidminer/rapidminer-5 (Revision Date: 25.11.2015)
4

2.3. SUPPORT VECTOR MACHINE
erlautert werden. Die lokale polynomielle Regression gehort zu den nichtparame-trischen Regressionsverfahren und ist eine Form der linearen Regression. Hierbeiwird die Beziehung von einer erklarenden Variable X und einer abhangigen Va-riable Y als ein Polynom des Grades n modelliert. Im Kontext von RapidMinerreprasentiert die erklarende Variable X ein Set von Attributen, in unserem Falledie gesammelten Daten wie Wetter, aktuelle und vergangene Besucherzahlen,welches das Label Attribut Y und somit die zukunftigen Besucherzahlen be-stimmen soll. Formal hat ein Polynom folgende Gestalt.
P (x) =
n∑i=0
aixi = a0 + a1x+ a2x
2 + ...+ anxn, n ≥ 0
Ziel der polynomiellen Regression ist es dieses unbekannte Polynom oderauch Funktion bestmoglich zu schatzen um Vorhersagen uber das Label Attri-but treffen zu konnen. Dieses Verfahren wird besonders zur Beschreibung vonnicht-linearen Phanomenen wie Epidemien oder Wachstumsraten eingesetzt undkann als eine Art der multiplen linearen Regression betrachtet werden, da dieFunktion linear abhangig von den Parametern des Datensatzes ist.5 Die Gestaltdieser Funktion wird bei nicht-parametrischen Verfahren ausschließlich anhandder bereitgestellten Datenpunkte hergeleitet, wahrend bei bei parametrischenVerfahren die Form der Funktion vorgegeben wird. Fur die Bestimmung einerFunktion an der Position xP, werden die Distanzen zu den umliegenden Da-tenpunkten durch ein Distanzmaß bestimmt und entsprechend gewichtet. Dadie Nahe der Datenpunkte berucksichtigt wird, handelt es sich um eine lokalepolynomielle Regression.
2.3 Support Vector Machine
2.3.1 Die Idee hinter der Support Vector Machine
Die Idee hinter der Support Vector Machine ist, dass man Mengen in einemniedrigerem Dimensionalen Raum in hoheren Dimensionalen Raum setzt umdie Mengen voneinander Linear zu separieren.
x = (x1, ...xn) 7−→ Φ(x) = (Φ1(x), ...,Φd(x)), d < n
Nachdem dies geschen ist, werden durch Optimierungen der großte Abstand zwi-schen den Punkten erstellt. Diese ermittelten Werte nennt man Stutzvektoren.Somit entsteht die Epsilon Verlust (Epsilon Loss) Funktion 6
Lε(x, y, f) = |y − f(x)|ε = max(0, |y − f(x)|2ε)
Epsilon legt den Toleranzwert fest. Somit sind alle Werte von der Funktion
5https://github.com/rapidminer/rapidminer-5/blob/
3bdfd053cab5f114e724650c7d5cf9a8e8b0c857/src/com/rapidminer/operator/
learner/lazy/KNNRegressionModel.java(RevisionDate:25.11.2015)6Introduciton to Support Vector Machines and other kernel-based learning methods
- Support Vector Regression
5

KAPITEL 2. BETRACHTETE MACHINE-LEARNING-VERFAHREN
x 7−→ wx+ b in einem Toleranzfeld zwischen 2.3.1
x 7−→ wx+ b+ ε
und
x 7−→ wx+ b− ε
liegen nun Werte ausserhalb von dem Toleranzfeld werden sie als Schlupf Va-
Abbildung 2.1: Bild der Support Vector Machine Generelle Idee
riablen (margin slack variable) bezeichnet und es entsteht eine neue Funktion.2.2
ξ((xi, yi), f, θ γ) = Lθ −γ(xi, yi, f)
Um Rechnerzeit zu sparen wird der ”Kernel Trickangewandt. Der Rechner
Abbildung 2.2: Bild der Support Vector Machine wahrend der Regression
transformiert die Menge nicht wirklich in ein hoher Dimensionalen Raum, aberer tut so als sei es so.
6

Kapitel 3
Daten
3.1 Datenerfassung
3.1.1 Erfasste Gerate
Um Gerate zu erfassen bedarf es mindestens einem Empfanger und einem Sen-der. Als Empfanger verwendeten wir Flowtracker die in der Stadt verteilt waren.Unter einem Flowtracker versteht man ein Gerat das zwischen festgelegten Fre-quenzen Gerate wahrnimmt und die MAC-Adresse auslesen kann. Eine MAC-Adresse kann eindeutig einem Gerat zugeteilt werden. Fur Bamberg Zaubert2015 haben wir die Moglichkeit gehabt Besucher auf Drei verschiedenen Artenzu erfassen. Die Erfassung fand mittels WLAN, Bluetooth oder als Beacon statt.Als Beacon oder Bluetoothlowenergy versteht man eine bestimmte Art von Blue-tooth. Allerdings wurden nur diejenigen Gerate erfasst welche innerhalb von 100Metern von einem Flowtracker befunden haben. Die Dienste mussten aktiviertsein, zusatzlich durften bei WLAN Gerate diese in keinem WLAN eingeloggtsein. Ein Ubersicht liefern wie haufig die jeweiligen Arten (alternativ Techtypes)auch in den Daten vorkommen. Wie man hier erkennen kann sind die gemesse-nen Werte von Beacons sehr viel hoher als die anderen. Dies liegt daran dassdiese viel haufiger versuchen mit den Flowtracker Kontakt aufzunehmen. 3.1
Abbildung 3.1: Verteilung der Techtypes
Der Aufnahmezeitraum war von 2015-07-09 17:00:00 bis 2015-07-20 10:00:00.Es wurden wahrenddessen 59 691 verschiedene hashmacs gemessen. Unter einerhashmac versteht man in diesem Kontext eine MAC-Adresse die anonymisiert
7

KAPITEL 3. DATEN
wurde. Ausserdem wurden 13 887 verschiedene truncmacs erfasst. Unter einertruncmac versteht man ein model eines Chips. Daraus kann man nun schlussfol-gern, dass pro Vier Besucher sich eine truncmac teilen. Auf der folgenden Grafikkann man erkennen wieviele Besucher pro Stunde an einem Ort waren. 3.2
counts.png
Abbildung 3.2: Besucherverlauf 2015
In der Folgenden Grafik kann man erkennen wieviele Sichtungen ein Besu-cher beziehungsweise eine hashmac hat. Der hochste Wert an Sichtungen ist bei2500 wahrend sie im Jahr 2013 bei 25 000 lag, also um ein 10 Faches hoher. 3.3
Abbildung 3.3: Verteilung Besucher gesendet 2015
Eine Analyse zu Bamberg Zaubert 2013 finden Sie im Anhang.
8

3.2. DATENAUFBEREITUNG
3.1.2 Wetterdaten
Zusatzlich zu den mit den FlowTracks gesammelten Geratedaten wurden furdas Machine Learning auch noch Wetterdaten genutzt, da diese unserer Meinungnach auch einen wesentlichen Einfluss auf das Besucherverhalten haben konnen.So wurden etwa an warmen und trockenen Tagen mehr Besucher erwartet, alsan kalten, regnerischen Tagen. Die Daten stammen von einer Wetterstation inder Nahe der Bamberger Innenstadt und wurden von der Webseite des Deut-schen Wetterdiensts1 heruntergeladen. Bei diesen Wetterdaten handelt es sichum Stundenwerte fur Lufttemperatur, Bodentemperatur, Niederschlagsmenge,Windgeschwindigkeit und Windrichtung.
3.2 Datenaufbereitung
Nachdem die Daten nun erfasst wurden mussen sie in einem Format umge-wandelt werden, welches das System Interpretieren kann. Wir haben nun ZweiTabellen, auf der einen Seite die gemessenen hashmacs mit der Uhrzeit und Ortauf der anderen Seite die Wetterdaten fur das komplette Fest. Die gemessenenhashmacs mit Uhrzeit und Ort mussen nun zusammengefasst werden damit mangleichmaßigere Werte erhalt. Wir haben festgelegt dass wir die Informationenpro Ort in einem Viertelstunden Zeiteinheit zusammenfassen und das Ergebnisdaraus ist die Besucherzahl. Jetzt konnen wir Ausgehend von der neu erstell-ten Tabelle die Wetterinformationen hinzunehmen. Wir haben die Uhrzeit undWissen wie das Wetter ist. Wir konnen also eine Neue Spalte Wetter hinzuneh-men. Dies konnen wir beliebig auch mit anderen Attributen erweitern. Unsereerweiterte Tabelle sieht wie folgt aus.3.1
beamzone visitors visitors-15 visitors-30 date tempbz1078 116 91 120 2015-07-18 11:15:00 28.4
... ... ... ... ... ...
wind temp-15 temp-30 wind-15 wind-30 day time3.5 28.4 26 3.5 3.3 18 1115... ... ... ... ... ... ...
Tabelle 3.1: Tabelle zum Lernen
1http://www.dwd.de/WESTE
9


Kapitel 4
Anwendung der Machine-Learning-Verfahren
4.1 Allgemeines Verfahren
Die Idee des Machine Learning verfahren ist, dass man ein System beziehungs-weise einem Programm beibringt Muster zu erkennen. Es wird hierbei zwischenTrainings- und Testdaten unterschieden. Trainingsdaten werden verwendet ummit einem Machine Learning verfahren ein Model zu erstellen. Ein Model istein Regelwerk fur das System. Mithilfe von den Testdaten kann man nun dieQualitat des gelernten Models Testen.Da nicht immer genug Trainingsdaten vorliegen um valide Aussagen zu treffengibt es die Moglichkeit eine Crossvalidation durchzufuhren. Die Crossvalidationoder Kreuzvalidierung teilt die Menge in n gleich große Teile per Zufall undwendet diese auf die restlichen Daten an. Auf der einen Seite spart uns das ander Stelle kosten und Aufwand weitere Daten erfassen zu mussen. Auf der an-deren Seite ermoglicht dies ein allgemeineres Model zu generieren. Bei MachineLearning kann man das Problem haben, dass man Modele erstellt die nur aufden Testdatensatz gute Resultate liefern. Dieses Problem nennt man Overfittingund sollte vermieden werden, da das Model auch fur die Testdaten gelten soll.Da es sehr viele Machine Learning verfahren gibt muss man schauen welche sichnun fur die Vorhersage von Besucherzahlen eignet. Wir haben im Kontext derProjektarbeit Drei verschiedene Getestet.
Um Machine Learning zu nutzen muss man vorher erkennen ob unsere Da-ten ein klassifikatorisches oder metrisches Merkmal besitzen. Wenn man vonklassifikatorischen Merkmalen spricht, dann kann man diese nicht sinnvoll sor-tieren. Man kann nur sagen dass diese Gleich oder Ungleich sind. Bei metrischenMerkmalen hingegen kann man die Merkmale durchaus sortieren und sogar dieAbstande zueinander interpretieren. Es sind 10 Besucher gerade und spater 20Besucher hier, die Besucherzahl ist großer geworden um 10 Besucher. In unserenDaten finden wir nur metrische Merkmale vor.Nachdem geklart wurde um welche Merkmalsauspragung es sich handelt mussman als nachstes Wissen gegen welches Maßman optimieren mochte. Hier wer-den Drei mogliche Maßzahlen vorgestellt 4.1. Es gibt aber daruber hinaus noch
11

KAPITEL 4. ANWENDUNG DER MACHINE-LEARNING-VERFAHREN
weitere. In unserer Projektarbeit wurde der quadrierte Fehler gewahlt. Dadurchfielen sehr große Abweichungen starker ins Gewicht, das heißt wir mochten keinegroßen Ausreißer. Die Summe uber alle Abweichungen ist nun unsere Kennzahl.Desto kleiner diese ist desto genauer war unsere Vorhersage, es wird also diekleinste Abweichung gewahlt.
Maß Formel Eigenschaft
Quadrierte Fehler∑ni=1(yi − yi)2
Große Abweichungen zwi-schen tatsachlichem undvorhergesagten Wert fal-len sehr stark ins Gewichtdurch die Quadrierung
Relative Fehler∑ni=1
|yi−yi||yi|
Abweichungen zwischentatsachlichem und vor-hergesagten Wert werdenim Verhaltnis gesetzt zumtatsachlichen Zahlenwert
Relative quadratische Fehler∑ni=1( |yi−yi||yi| )2
Wird genauso berechnetwie relative Fehler nurwird der Fehler nochein-mal quadriert, dadurchfallen fehlerhafte Vorher-sagen etwas starker insGewicht.
Tabelle 4.1: Kennwerte Metrisch
4.2 Vorstellung von Rapidminer
Im Rahmen unseres Projektes haben wir uns dazu entschieden RapidMiner1 alsTool fur die Anwendung der Machine-Learning Verfahren zu verwenden. Rapid-Miner stellt Funktionalitat fur viele Machine-Learning Anwendungsgebiete wiedata mining, text mining und business-orientierte Analyseverfahren bereit. Eserlaubt den Nutzern eigene Prozesse zu kreieren und auf diesen eine Vielzahlvon Operatoren, wie Datenimport, Datenmanipulation, Lernen und Anwendenvon Modellen bis hin zum Datenexport anzuwenden.
Im Rahmen des Bamberg Zaubert Projekts haben wir uns dazu entschiedenRapidMiner als Tool fur die Vorhersage fur Besucherzahlen zu verwenden, dadie von uns ausgewahlten Verfahren Support Vector Machine, k-NN und po-lynomielle Regression bereitgestellt werden. Des weiteren ist der Source-Codevon Rapidminer offentlich zuganglich und erlaubte uns somit die verwendetenVerfahren per reverse Engineering besser zu verstehen. Dies ist besonders wich-tig, da die tatsachliche Implementierung sich deutlich von grundlegenden theo-retischen Konzepten der jeweiligen Machine-Learning Verfahren unterscheidenkann. In RapidMiner konnten wir zudem Verfahren wie Cross-Validation undParameter-Optimierungen, welche in spateren Abschnitten erklart werden, an-wenden und verstehen.
1https://rapidminer.com/
12

4.3. UMSETZUNG IN RAPIDMINER
4.3 Umsetzung in Rapidminer
Fur die Anwendung der in den nachfolgenden Kapiteln beschriebenen Verfahrenerstellten wir insgesamt drei Prozesse in RapidMiner:
Der Erste fuhrt eine Parameteroptimierung (es wird auf den relative qua-drierten Fehler hin optimiert) und ein Kreuzvalidierungsverfahren durch.
Beim Zweiten wird mit Daten ab 16:00 Uhr freitags dreimal trainiert (bis11:00 Uhr, 16:00 Uhr und 21:00 Uhr samstags). Mit den drei erhaltenen Model-len wird dann versucht fur den weiteren Verlauf des Fests die Besucherzahlenimmer fur die nachsten 15 Minuten vorherzusagen, ohne das Modell nochmalszu trainieren.
Beim letzten Prozess werden die gleichen Modelle wie beim zweiten Prozesserzeugt, jedoch wird hier versucht die Besucherzahlen fur das gesamte verblei-bende Fest zu prognostizieren, ohne den weiteren Verlauf dieses zu kennen. Furdie drei Machine-Learning-Verfahren unterscheiden sich die Prozesse nur im furdas Lernen verwendeten Operator.
Die Prozesse sind als Grafiken im Anhang (Abbildungen A.1 bis A.6) hin-terlegt, die verwendeten Wetterdaten und Geratedaten des FlowTracks 1078 inder Datei “bigtable.csv
”.
Die in Abbildung A.6 dargestellte Loop wird hier kurz erklart: Als Eingabebekommt sie das trainierte Modell und das ExampleSet fur die zu bestimmendenWerte. Das ExampleSet wird dabei zeilenweise durchlaufen, realisiert mit demLoop-Iterator und dem Operator Filter ExampleSet. Fur jede Zeile wird danndie Besucherzahl prognostiziert. Der Execute Script-Operator (Quellcode sieheListing A.1) aktualisiert dabei das ExampleSet, sodass der vorhergesagte Wertin den nachsten beiden Zeilen als Wert fur Besucher vor 15 beziehungsweise 30Minuten steht. Außerdem gibt er im letzten Durchlauf das ExampleSet mit allenprognostizierten Werten zuruck.
4.4 k-Nachste-Nachbarn
4.4.1 Parameteroptimierung
Zu Beginn wurde eine Parameteroptimierung durchgefuhrt, bei der festgestelltwurde, dass k = 3 und weightedvote = true sein sollten. Als Ahnlichkeitsmaßsollte die Canberra-Distanz verwendet werden. Dies war auch zu erwarten, da beider Kosinus-Ahnlichkeit nur die Winkel betrachtet werden, ein Beispiel mit einerBesucherzahl von 250 und einer Temperatur von 1◦C hatte somit eine Distanzvon 0 zu einem Beispiel mit 25 Besuchern und Temperatur 10◦C. Auch dieManhattan-Distanz und der Euklidische Abstand waren nicht geeignet, da dortdie Besucherunterschiede zu stark ins Gewicht fallen, gegenuber beispielsweiseden Temperaturunterschieden.
4.4.2 Ergebnisse der Anwendung
Abbildung 4.1 zeigt den tatsachlichen Besucherverlauf und die mit k-Nachste-Nachbarn vorhergesagten Werte fur die nachsten 15 Minuten, wenn nur bis zueinem bestimmten Zeitpunkt trainiert wurde. Der graue Bereich ist dabei dieZeit, in der dieser Sensor ausgeschaltet war, fur diesen gibt es keine gemessenenund auch keine vorhergesagten Werte. Bei der Betrachtung der Grafik wird
13

KAPITEL 4. ANWENDUNG DER MACHINE-LEARNING-VERFAHREN
ersichtlich, dass das mit Daten bis 11:00 Uhr trainiert Modell sehr schlechtabschneidet und bis auf den Vormittag des 19. Juli weit unter den gemessenenWerten liegt. Bei dem bis 16:00 Uhr trainierten Modell fallt sofort auf, dasses am Abend des 18. Juli recht stabil bei etwa 290 Geraten bleibt. Dies liegtdaran, dass der maximal gemessene Wert bis zu diesem Zeitpunkt bei 300 lagund somit das schon in der Beschreibung erwahnte Problem auftrat, dass dieTrainingsdaten das Intervall fur die prognostizierten Werte fest vorgeben. Die300 werden dabei nicht erreicht, da k = 3 gesetzt wurde und damit die dreiahnlichsten Beispiel zur Prognose verwendet wurden. Im weiteren Verlauf istdie Prognose bis 18:00 Uhr des nachsten Tages mit der des Modells, welchesbis 21:00 Uhr trainiert wurde, identisch. Beide folgen dem tatsachlichen Verlaufeinigermaßen gut, auch wenn es ab und an einige Ausreißer gibt. Danach tritt wieschon am Abend des 18. Juli der Fall ein, dass keine hoheren Werte vorhergesagtwerden, was sich in diesem Fall sogar gunstig auswirkt. Insgesamt lasst sichsagen, dass dieses Verfahren mit etwas mehr Training ein gutes Potential hatverwendbare Prognosen zu treffen.
Abbildung 4.1: k-NN Vorhersage fur die nachsten 15 Minuten
Der zweite Test (Abbildung 4.2) ist das Training bis zu einem bestimmtenZeitpunkt mit unmittelbar anschließender Vorhersage fur das komplette rest-liche Fest. Dabei zeigt sich, dass keines der drei Modelle sich wirklich fur diePrognose eignet. Das bessere Abbilden des Verlaufs bei den beiden langer trai-nierten Modellen lasst jedoch vermuten, dass mit erheblich langerem Traininggeeignete Prognosen getroffen werden konnten. Die Anwendung auf kurzen Ver-anstaltungen, wie etwa das drei Tage andauernde Bamberg Zaubert, ist dadurchjedoch nicht moglich.
14

4.5. LOKALE POLYNOMIELLE REGRESSION
Abbildung 4.2: k-NN Vorhersage fur das restliche Fest
4.5 Lokale Polynomielle Regression
4.5.1 Parameteroptimierung
Bei der Anwendung des RapidMiner Operators Local Polynomial Regressionwurden die Parameter neighbourhood type, ridge factor, degree und numericalmeasure optimiert. Um zu verstehen wie der Operator das Modell lernt, werdenin den folgenden Abschnitten die verschiedenen Parameter erlautert und derAblauf des Verfahrens skizziert.
4.5.2 Neighbourhood Type
Der Neighbourhood Type Parameter bestimmt die Vorgehensweise fur die Aus-wahl von benachbarten Datenpunkten. Fur das Training des Modells wurde derParameter Fixed Distance but at least gewahlt, welcher die zu berucksichtigendenNachbarpunkte festlegt. Diese Datenpunkte werden schließend dazu genutzt umein Polynom mit Hilfe der Methode der kleinsten Quadrate zu finden und an-zupassen. Bei dieser Methode wird mit Hilfe der Summe der quadratischen Ab-weichungen der Datenpunkte genutzt um eine Kurve zu approximieren, welchedie Datenpunktewolke moglichst gut reprasentiert. Im Folgenden sollen die viervon RapidMiner bereitgestellten Neighbourhood Types Fixed Number, FixedDistance, Fixed Distance but at least und Relative Size vorgestellt und erlautertwerden.
Der Typ ’Fixed Number’ erwartet einen integer Wert k mit welchem diek-nachsten beziehungsweise ahnlichsten Datenpunkte ausgewahlt werden. EinVorteil dieses Typs ist, dass immer benachbarte Datenpunkte gefunden werdenkonnen um das Polynom anzupassen. Hierbei konnen allerdings auch bei ei-nem zu großen k-Wert unter Umstanden Punkte berucksichtigt werden, welcheeinen negativen Einfluss auf die Korrektheit des Polynoms haben und deshalbnormalerweise nicht berucksichtigt werden sollten.
Bei ’Fixed Distance’ wird die Große der Nachbarschaft angegeben und nurPunkte, welche innerhalb der angegebenen Distanz liegen berucksichtigt. Dieshat allerdings den Nachteil, dass es unter Umstanden Punkte gibt, deren Di-stanz zu moglichen Nachbarpunkten großer als die angegebene Nachbarschafts-
15

KAPITEL 4. ANWENDUNG DER MACHINE-LEARNING-VERFAHREN
Abbildung 4.3: Polynomielle Regressionskurve
distanz ist und somit nicht berechnet werden konnen. Allerdings werden bei’Fixed Distance’ nur sehr ahnliche Nachbarpunkte berucksichtigt und somit dieVorhersage des Polynoms fur den Wert des Label Attributs verbessert.
Der Nachbarschaftstyp ’Relative Size’ legt die Große der zu betrachtendenNachbarschaft relativ zur Gesamtanzahl der Datenpunkte fest. So werden beieiner ’Relative Size’ von 0,1 die nachsten 10% der totalen Datenpunkte alsNachbarpunkte betrachtet.
Eine Kombination von ’Fixed Distance’ und ’Fixed Number’ stellt der Para-meter ’Fixed Distance but at least’ dar, welcher zu erst Nachbarpunkte inner-halb der angegebenen Distanz berucksichtigt. Sollte die Anzahl der Datenpunk-te innerhalb dieser Nachbarschaft nicht der angegebenen Mindestpunkteanzahlentsprechen, so wird die Distanz der Nachbarschaft vergroßert bis die Minde-stanzahl erreicht ist.
Die Parameteroptimierung ergab fur das Lernen mit dem Gesamtdatensatz,den Parameter ’Fixed Distance But At Least’ als Neighbourhood Type. Diesist wohl darauf zuruckzufuhren, dass dieser Parameter die Vorteile von ’FixedDistance’ und ’Fixed Number’, jedoch nicht uber deren Nachteile, verfugt.
4.5.3 Numerical Measure
Mit dem Parameter Numerical Measure wird das Verfahren fur die Distanzbe-rechnung zwischen benachbarten Datenpunkten ausgewahlt. Fur die im Projektverwendete polynomielle Regression wurde der Jaccard Index als Verfahren aus-gewahlt. Der Jaccard Index ist eine Kennzahl fur die Ahnlichkeit von Mengenund kann als Indiz fur die Distanz von Datenpunkten dienen. Formal wird derJaccard Index als
J(A,B) = |A∩B||A∩B|
16

4.5. LOKALE POLYNOMIELLE REGRESSION
beschrieben. Eine genaue Implementierung des Jaccard-Index in Rapidminerist im Anhang A.2 zu finden.
Rapidminer stellt noch viele weitere Distanzmaße bereit, welche hier nurvollstandigkeitshalber erwahnt werden, da ein Vergleich aller Verfahren als zuaufwendig befunden wurde und einige bereits im Abschnitt zum k-NN Ver-fahren erwahnt wurden. Weitere Verfahren sind: Euclidean Distance, CamberraDistance, Chebychev Distance, Correlation Similarity, Cosine Similarity, DiceSimilarity, Inner Product Similarity, Manhatten Distance, Max Product Simila-rity und Overlap Similarity.
4.5.4 Degree & Ridge Factor
Der Parameter Degree bestimmt den Grad des Polynoms, im Falle der Optimie-rung war er 1 und ist der großte annehmbarer Exponent fur die verschiedenenVariablen. Ein hoherer Grad fuhrt bei der lokalen polynomiellen Regression zuOverfitting und erhoht die Zeit fur die Kalkulation des Wertes des Label Attri-butes erheblich. Obwohl ein hoherer Grad in Bezug auf die Rechenzeit kein Pro-blem darstellen sollte, fuhrt die zu Grunde liegende 10-fache Cross-Validationdazu, dass automatisch ein niedriger Grad gewahlt wird.
Anhand des Parameters Ridge Factor konnen hohe Koeffizienten durch Ge-wichtung bestraft werden um Overfitting zu verhindern. Ahnlich wie bei demGrad des Polynoms fuhrt die Cross-Validation dazu, dass ein relativ hoher RidgeFactor von 0,4 gewahlt wurde, welcher Overfitting reduziert.
4.5.5 Smoothing Kernel
Der Parameter Smoothing Kernel legt den Kernel Typ zur Berechnung der Di-stanzgewichtung von weiter entfernten Datenpunkten fest. Bei dem von uns ver-wendeten Modell wurde der optimale Kernel als ’Triangular’ ermittelt. Kernelwerden bei nicht-parametrischen Regressionsverfahren verwendet um die Wahr-scheinlichkeitsdichtefunktion einer Zufallsvariable zu schatzen. Formal wird die’Triangular’ Kernel Funktion folgendermaßen beschrieben:
K(u) = (1− |u|)1|u| ≤ 1
Weitere von Rapidminer bereitgestellte Kernel sind: Rectangular, Epanech-nikov, Bisquare, McLain, Triweight, Gaussian, Exponential, Tricube. Die zu-gehorigen Dichtefunktionen werden in Abbildung 4.4 der Vollstandigkeit halberdargestellt.
Die Ergebnisse des Lernens mit unterschiedlich großen Subdatensatzen wirdin Figur 4.5 prasentiert. Erwartungsgemaß wurden die vorhergesagten Besucher-zahlen mit Anstieg der Große des Trainingsdatensatzes immer praziser, da mitErhohung des Trainingsdatensatzes mehr Nachbardatenpunkte fur die Modellie-rung der lokalen polynomiellen Regression zur Verfugung stehen. Des Weiterenwurden die Parameter fur einen großen Datensatz optimiert, daher ist die Op-timierung fur kleinere Datensatze weniger geeignet als fur Großere.
Wie der Figur 4.5 zu entnehmen ist konnte die lokale polynomiellen Regres-sion die Besucherzahlen besonders mit dem Trainingsdatensatz bis 21 Uhr sehr
17

KAPITEL 4. ANWENDUNG DER MACHINE-LEARNING-VERFAHREN
Abbildung 4.4: Verteilung der Dichtefunktion verschiedener Ansatze
Abbildung 4.5: Vorhersage Besucherzahlen in 15 Minuten
gute Ergebnisse erzielen. Durch die lokale Betrachtung der Nachbarpunkte an-hand der Distanz sowie einer Mindestnachbarpunktanzahl gibt es keine nennens-werten Ausreißer oder mehrere stark abweichende Vorhersagen hintereinander.Im Rahmen unserer Forschungsfrage muss man ganz klar sagen, dass die vor-hergesagten Werte erstaunlich nah an den aktuellen Besucherzahlen und somitdurchaus realistisch sind. Im Kontrast hierzu stehen die Vorhersagen fur einenganzen Tag, welche sehr stark von den tatsachlich gemessenen Besucherwertenabweichen und in Abbildung 4.6 zu sehen sind. Besonders bei dem ausschließlichbis 16.00 gelernten Modell steigen die Besucherzahlen konstant an ohne einenAbwartstrend zu verzeichnen. Dies ist wohl darauf zuruckzufuhren, dass dasModell keinen Abwartstrend auf Grund mangelnder Datenpunkte erkennt und
18

4.6. SUPPORT VECTOR MACHINE
somit immer falsche neue Besucherzahlen vorhersagt, welche dann im nachstenSchritt wieder im Polynom eingesetzt werden.
Abbildung 4.6: Vorhersage Besucherzahlen fur ganzen Tag
4.6 Support Vector Machine
4.6.1 Auswahl der Verfahren
Auswahl SVM typen
In Rapidminer haben wir den svm type epsiolon-SVR (alternativ auch nu-SVR)gewahlt, da diese mit Regression arbeiten konnen von der LibSVM. Unser La-bel, die Besucherzahl, ist numerisch daher mussen wir hier an der Stelle mitder Regression arbeiten. C-SVC oder nu-SVC eignen sich nur zur Klassifikationdaher ist das hier nicht sinnvoll. Der SVM type Epsiolon-SVR nimmt den Wertepsilon entgegen.
Auswahl Kernel typen
Als nachstes wahlen wir einen kernel type. mogliche Kernel sind: Linear, Poly-nomial, Radial Basis Function und Hypberbolic Tangent.Unsere Daten sind nicht Linear separierbar, da die Besucherzahl von fruhs bisabends nicht kontinuierlich steigt. Sie nimmt ab und wieder zu. Der polynomieleKernel dauert sehr lange bis man die passenden Parameter gefunden hat. Daherwird empfohlen zuerst die Radial Basis Funktion, fur den Anfang zu wahlen.Die RBF nimmt die Parameter Cost und Gamma entgegen.
weitere Auswahl
cache size bedeutet wieviel Speicher freigehalten werden soll fur die Berechnungder Hyperebenen.
19

KAPITEL 4. ANWENDUNG DER MACHINE-LEARNING-VERFAHREN
Shrinking wurden aktiviert, d.h. es wird bei jeder 1000 Iteration das Problemverkleinert um Rechenzeit zu sparen, und die Shrinking Herusitic anzuwenden.
4.6.2 Hyperparameteroptimierung
Nachdem wir uns fur einen passenden SVM Typ und Kernel Typ entschiedenhaben, sind wir auf der Suche nach Hyperparameter um unsere Hyperebenenzu erstellen, die notwendig ist fur das lineare separieren.Unsere Werte die wir optimieren wollen sind also Gamma, Cost und der EpsiolonWert. 4.2Als Ergebnis wurde die parameter Cost mit 2511, Gamma 0.001 und epsilon
Tabelle 4.2: Hyperparameter tabelleParameter Bereich Eigenschaft
Cost
Der Mindestwert liegt bei0.001 und geht bis zumMaximum 100000 in Zeh-ner Schritten mit der Ska-lierung Logarithmisch
legt den Strafwert fest
Gamma
Der Mindestwert liegt bei0.001 und geht bis zumMaximum 1.5 in ZehnerSchritten mit der Skalie-rung Logarithmisch 2
verantwortlich fur die Ex-aktheit
Epsilon [0, 0.01, 0.1, 0.5, 1, 2, 4] 3 legt den Toleranzwert fest
ermittelt. Der quadratische Fehler betrug 1722.196 + − 749.876. 4.7die beiden Parameter werden also in dem folgenden Raum gesucht:
Abbildung 4.7: Grid Search der Support Vector Machine4
20

4.6. SUPPORT VECTOR MACHINE
4.6.3 Ergebnis der Besuchervorhersage mit der SVM
Unsere Vorhersagen Mithilfe der SVM fur die nachsten 15 Minuten eignet sichleider nur sehr bedingt. Allerdings sieht man mit zunehmender Datenmenge wirddas Ergebnis zunehmend besser, es fehlen also wahrend des Lernens Daten. 4.8Hier die Prognose fur die ganze Veranstaltung. 4.9
Abbildung 4.8: Besucherverlauf mit der Support Vector Machine
Abbildung 4.9: Prognose fur die ganze Veranstaltung
21


Kapitel 5
Statistische Auswertung
5.1 Kurze Wiederholung Statistik
Da wir nun Modelle erstellt haben fehlt uns noch eine Aussage ob diese richtigsind. Eine Validierung unserer Aussage konnen wir Mithilfe von einem Hypo-thesentest erreichen. Bei Hyptothesentests gibt es Drei unterschiedliche Artenvon Annahme- und Ablehnungsbereiche 5.1
H0 HA
einseitiger Test kleiner gleich großereinseitiger Test großer gleich kleiner
zweiseitiger Test gleich ungleich
Tabelle 5.1: Annahme- und Ablehnungsbereiche
Unsere Behauptung die wir aufstellen ist H0, sollte dies nicht stimmen sogilt HA. Da wir sehen mochten wie gut unsere Vorhersagen ubereinstimmen mitdem tatsachlichen Besuchern prufen wir auf Gleichheit.
Entscheidung fur den richtigen TestDer t-Test ist ein haufig verwendeter Test in der Statistik, allerdings eignet dersich an dieser Stelle nicht. Die Kurve des Besucherverlaufs unterliegt nicht einerNormalverteilung daher kommt der Wilcoxon-Vorzeichen-Rang-Test in Frage.
Als Test Daten wurde die der tatsachliche Besucherzahl und die vorherge-sagten Besucherzahlen der einzelnen Machine Learning verfahren getestet. DerZeitraum war also zwischen Freitag 11:15 Uhr bis Freitag 21:00 Uhr.
Wir mochten wissen ob die Datenreihen sich ahnlich sind und nicht in ei-ne Richtung tendieren daher entscheiden wir uns fur den Parameter alterntai-ve=”two.sided”.
Da die beiden Daten gegen die getestet wird nicht gegeneinander versetztsind, also es ja der selbe Besucherverlauf sein sollte setzen wir den Parametermu = 0.
23

KAPITEL 5. STATISTISCHE AUSWERTUNG
Es handelt sich zwar um die selben Besucher aber die Werte sind dennochunterschiedlichen Ursprungs und dadurch ist der Parameter paired = FALSEzu setzen.
Der Wilcoxon-Vorzeichen-Rang-Test liefert Zwei Ausgabeparameter. Der p-Wert liefert die Wahrscheinlichkeit die Besucheranzahl richtig vorherzusagenund den W-Wert der die Summe der vorzeichenbehafteter Range angibt. DieWerte zwischen vorhergesagten und tatsachlichen Besuchern werden gegenubergestelltund die Differenz gebildet. Nun werden die Zahlen Sortiert dabei wird deren Vor-zeichen aber (vorerst) ignoriert. Jetzt wird abhangig vom Rang der SortierenZahlen ein Wert zugeteilt. Ist an der Stelle der Differenz eine positive Zahl wirdin dem Rang auch ein positives Vorzeichen gegeben, bei einem Negativen Vorzei-chen in der Differenz bekommt der Rang ein negatives Vorzeichen. Anschließendwird in dieser Spalte alles aufsummiert. Das Ergebnis der Aufsummierung istder W-Wert.??
NrTatsachlicheBesucher
VorhergesagteBesucher
Differenz Vorzeichen Rang R
1 250 270 20 - 2 -22 350 340 10 + 1 +13 200 225 25 - 3 -3... ... ... ... ... ... ...N+1 w = ΣNi=1Ri
Tabelle 5.2: Wilcoxon-Vorzeichen-Rang-Test Tabelle
5.2 Ergebnis und Interpretation
Aussage W-Wert p-WertSupport Vector Machine 2373 0.058
k Nearest Neighbors 1640 0.093polynomiell 1940 0.830
Tabelle 5.3: Wilcoxon-Vorzeichen-Rang-Test Ergebnis
Interpretation des Wertes W und pk Nearest Neigbors hat den kleinsten W - Wert, dadurch kann man sagen, dassder Vorzeichenrangtest glucklich fur ihn abgelaufen ist, jedem positiven Rangist ein negativer Rang gefolgt und umgekehrt. Oder es kompensieren sehr großeAusreisser im Positiven eine Reihe von Negativen die vorher mit in den Rangeingeflossen sind. Das heißt das beide vorzeichenbehaftete Range gleich großsind.
w = ∆ = Σ(R+) + Σ(R−)
24

5.2. ERGEBNIS UND INTERPRETATION
Fur die Support Vector Machine und k Neares Neigbors wird H0 abgelehnt.Fur die polynomielle Regression wird H0 nicht abgelehnt. Es wurden 83% derVorhersagen richtig fur die polynomielle Regression vorhergesagt.
Die Daten und das Skript sind im Git-Repository unter: groups - groupdata- willCoxonRangTest zu finden
25


Kapitel 6
Fazit
Im Rahmen des Projekts haben sich die verschiedenen Verfahren durchaus ak-zeptable Ergebnisse geliefert um die Besucherzahlen fur einen zukunftigen Zeit-punkt vorherzusagen. Hierbei hat sich besonders die lokale polynomiale Regres-sion im Vergleich zur Support Vector Machine und dem k-NN Verfahren als be-sonders zuverlassig erwiesen, wenn nur mit einem sehr kleinen Datensatz gelerntwurde. Bei großeren Datensatzen konnten vor allem das k-NN Verfahren dafurmindestens genauso prazise Vorhersagen machen, dies wird vor allem bei der Be-trachtung der Varianz und dem relativen Fehler deutlich. Moglicherweise erzieltdie Support Vector Machine bei aussagekraftigeren Attributen des Datensatzesoder bei deutlich großeren Datensatzen auch ahnlich gute Fehlermaße wie diebeiden anderen Verfahren. Bei Betrachtung der vorhergesagten Werte fur einenganzen Tag, schneiden sowohl k-NN als auch die SVM wesentlich besser als dielokale polynomiale Regression ab. Hieraus ziehen wir die Schlussfolgerung, dassdie Wahl des Verfahrens stark abhangig von der jeweiligen Aufgabenstellung istund dies vor jeder Anwendung berucksichtigt werden sollte.
Bei zukunftigen Projekten konnten unsere gesammelten Ergebnisse dazu ge-nutzt werden um entweder ein besseres Machine-Learning Verfahren zu findenoder die hier vorgestellten Verfahren in der Praxis einzusetzen um zum BeispielBesucherzahlen live auf Festen oder Einkaufszentren vorherzusagen. Daruberhinaus konnten auch fehlende Daten, wie etwa beim Ausschalten von Flowtracksdurch den Betreiber, mit Hilfe der vorgestellten Verfahren geschatzt werden.Abschließend lasst sich feststellen, dass bei der Wahl eines Machine-LearningVerfahrens, besonders die bereitgestellten Daten und das zu vorhersagende Er-gebnis berucksichtigt werden mussen und es kein optimales Verfahren fur alleDatensatze oder Anwendungsgebiete gibt.
27


Literaturverzeichnis
Mitchell, T. M. (1997). Machine Learning. McGraw-Hill Education.
29


Anhang A
RapidMiner-Prozessgrafiken und-Listings
Listing A.1: Quellcode des ExecuteScript-Operators
// Nummer des aktuellen Durchlaufs
int curIteration =
Integer.parseInt(operator.getProcess().macroHandler.getMacro("iteration"));
// Das originale ExampleSet
ExampleSet orig = input[0];
// Das ExampleSet mit dem prognostizierten Wert
ExampleSet labelled = input[1];
if(curIteration < orig.size()) {
// Schreibe den gerade prognostizierten Wert in die aktuelle
Zeile
orig.getExample(curIteration-1)["curVisitors"] =
labelled.getExample(0).getPredictedLabel();
// Setze den Wert fur prevVisitors der kommenden Zeile
orig.getExample(curIteration)["prevVisitors"] =
labelled.getExample(0).getPredictedLabel();
// Setze den Wert fur prevPrevVisitors der kommenden Zeile
orig.getExample(curIteration)["prevPrevVisitors"] =
orig.getExample(curIteration-1)["prevVisitors"];
}
// Gib das ExampleSet im letzten Durchlauf zuruck
if(curIteration == orig.size()) {
31

ANHANG A. RAPIDMINER-PROZESSGRAFIKEN UND -LISTINGS
orig.getExample(curIteration-1)["curVisitors"] =
labelled.getExample(0).getPredictedLabel();
return orig;
}
Listing A.2: Quellcode des Jaccard-Indexes
// Punkte als Datenarrays, welche die beobachteten Werte
enthalten
public double calculateSimilarity(double[] punkt1, double[]
punkt2) {
// Variable zur Speicherung des Produkts der beiden Punkte
double wxy = 0.0;
// Variable zur Speicherung der Summe der beobachteten Werte von
Punkt 1
double wx = 0.0;
// Variable zur Speicherung der Summe der beobachteten Werte von
Punkt 2
double wy = 0.0;
// Iteriere ueber alle beobachteten Werte
for (int i = 0; i < punkt1.length; i++) {
// Summiere die Werte von Punkt 1 bzw. Punkt 2
wx += value1[i];
wy += value2[i];
// Multipliziere die Werte von Punkt 1 und Punkt 2
wxy += value1[i] * value2[i];
}
// Gib die Distanz zurueck
return wxy / (wx + wy - wxy);
}
32
Abbildung A.1: Prozess Parameteroptimierung und Validierung 1
Abbildung A.2: Prozess Parameteroptimierung und Validierung 1
Abbildung A.3: Prozess Parameteroptimierung und Validierung 1
Abbildung A.4: Prozess Prognose fur die nachsten 15 Minuten
33

ANHANG A. RAPIDMINER-PROZESSGRAFIKEN UND -LISTINGS
Abbildung A.5: Prozess Prognose fur das restliche Fest 1
Abbildung A.6: Prozess Prognose fur das restliche Fest 2
34

Anhang B
Arbeiten vor BambergZaubert
B.1 Ruckblick auf Bamberg Zaubert 2012
Einen Teil im Projekt mochten wir uns mit der Datenaufbereitung beschaftigen.Die teilweise abhangigen Daten soll zunachst einmal interpretiert werden Mit-hilfe von statistischen Methoden. Durch Filten von relevanten zu nicht mehrrelevanten Werten mochte wir die Verrauschung der Daten mindern. Moglichewichtige naherer Betrachtung bedarf es den Faktoren Zeit, IDs und die der Fre-quenzstarke.
Zunachst einmal mochten wir einen Uberblick bekommen uber die Besucher.Wieviele Daten haben einzelne Besucher gesendet? Hierbei kann man erkennen,dass einige Besucher sehr viele Daten gesendet haben und einige nur sehr weni-ge. Dazu spater mehr.
Ein weiterer Punkt von Interesse ist der Besucherverlauf, wieviele Besucherhaben zu einem Zeitpunkt Daten gesendet.
Was man jedoch hier erkennen kann ist, dass die Station 1054 abgeschaltenwurde. Das heißt wir haben Daten von allen 6 Stationen nur vom 2012-07-1210:00:24 bis zum 2012-07-15 20:06:27
Betrachtung aller empfangener RSSI Daten. Hierbei kann man erkennen,dass es in den Signalen sehr starke Ausreisser gibt. Die Ausreisser die in diesemFall bei geringer und großer von sind sind als Fehlmessungen zu interpretieren.Was wir hier zeigen mochte ist, dass keine Normalverteilung vorherrscht.
Hier nochmal die Beamzone 1051 hierbei kann man doch sehr stark erkennendass die Werte sehr unregelmaßig verteilt sind.
Wir haben nun unsere Daten erweitert mit den Wetterdaten von diesemZeitraum. Wir haben die Daten von Temperatur Luft, Temperatur Boden, Nie-derschlag, Windstarke und Windrichtung bekommen. Nun wollen wir naher be-
35

ANHANG B. ARBEITEN VOR BAMBERG ZAUBERT
Abbildung B.1: Besuchergesendet 2012
Abbildung B.2: Besucherverlauf 2012
trachten inwiefern sich die Besucheranzahl verandert mithilfe des Korrelations-koeffizienten, und welcher der starksten Zusammenhang aufweist. BetrachteterZeitraum 13.7. 17:00 – 0:00 und 14.7. 11:00 – 0:00 und 15.7. 13:00 – 23:00. DieTemperatur hat wahrend des Zeitraums den großten Einfluss auf den Besuch derVeranstaltung. Die Korrelation betrug hierbei +0.56. Bei Niederschlag betrugdie Korrelation gerade einmal -0.27. Hier im Vergleich vom 13.7. 17:00 bis 15.7.23:00, auf der linken Seite die Anzahl der Besucher insgesamt und zur rechtendie Temperatur.
36
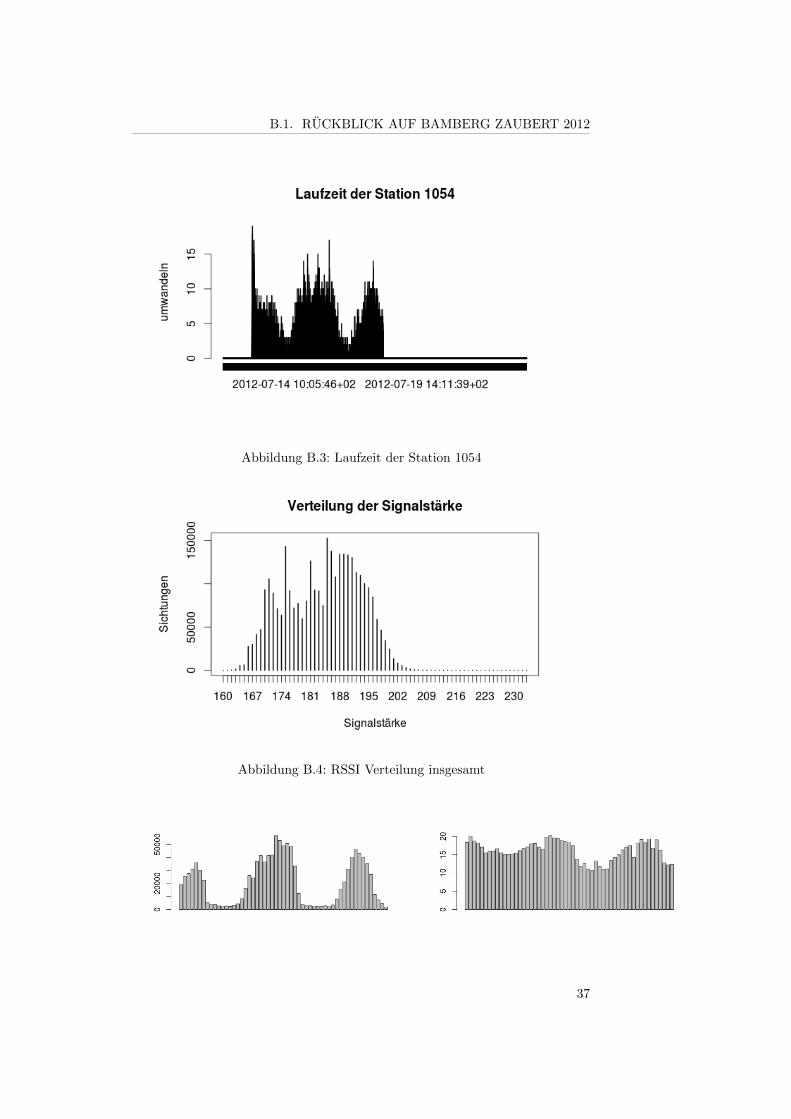
B.1. RUCKBLICK AUF BAMBERG ZAUBERT 2012
Abbildung B.3: Laufzeit der Station 1054
Abbildung B.4: RSSI Verteilung insgesamt
37

ANHANG B. ARBEITEN VOR BAMBERG ZAUBERT
Abbildung B.5: RSSI Werte an der beamzone 1051
Was sind Menschen, was stationare QuellenStationare:Eine Moglichkeit was stationare Quellen sind kann man anhand vom ”passie-ren”von einem oder maximal 2 Empfangerstationen und sich die Strahlung nichtallzu stark verandert. Hier anhand der Adresse “d77fb5a1d4c87008d0525c218a0d064e”
Abbildung B.6: Stationare Quelle mit der Verteilung an der Beamzone 1055
Was hier naher betrachtet werden muss ist ob es keinen Zusammenhang, derFrequenzstarke der beiden Stationen gibt. Also ob der eine Wert steigt und derandere sich nicht groß verandert. Oder ob sich das Objekt tatsachlich bewegt
38

B.2. SOFTWARE FUR DIE LIVE-DEMO AUF BAMBERG ZAUBERT
Abbildung B.7: Stationare Quelle mit der Verteilung an der Beamzone 1059
und sich beim abnehmen der einen Frequenz sich das andere zunimmt, was einenegativer Zusammenhang der Kovarianz deuten wurde.An der Station wurde 1055 im Zeitraum von 2012-07-15 21:13:30+02 - 2012-07-15 23:00:32+02 und in der Station 1059 wurde im Zeitraum 2012-07-1521:13:28+02 - 2012-07-15 23:00:29+02. Es wurden zunachst die Doppelt er-fassten Werte geloscht und danach wurde jeder 5te wert geloscht da die Station1055 20 Prozent mehr werte erfasst hat wahrend dieser Zeit. Die Werte wur-den somit auf 983 werte gekurzt. Die Kovarianz betragt in diesem Zeitraumnur -0.002049487. Es lasst sich somit auf keine Abhangigkeiten der rssi werteschliessen. Somit ist bewiesen, dass die Streuung die auf der Grafik zu erkennenist keine Bewegung ist sondern lediglich auf die Ungenauigkeit der Sensoren be-ziehungsweise des gemessenen Sensors zu erwarten ist.Anmerkung es wurden die 30 am meisten gestrahlten Objekte untersucht ob die-se an 1 oder maximal 2 von Stationen erfasst wurden. Bis zum Hash a8d4efda74b7341ab1220300d29c6b42mit 24146 Datensatzen wurden keine weiteren gefunden.
B.2 Software fur die Live-Demo auf BambergZaubert
Auf Bamberg Zaubert 2015 hatte die Universitat Bamberg einen Stand, aufwelchem die Besucher unter anderem die Anzahl der Gerate an den FlowTrackslive sehen konnten. Dafur wurden zwei Anwendungen entwickelt: Zum eineneine interaktive Visualisierungssoftware, die diese Verteilung darstellte und zumanderen ein Programm, das die dafur benotigten Daten bereitstellte, mit dessenEntwicklung wir uns beschaftigten.
39

ANHANG B. ARBEITEN VOR BAMBERG ZAUBERT
Ziel des Programms war dabei in Echtzeit die FlowTrack-Daten aus derDatenbank zu verarbeiten und aufzubereiten, damit diese visualisiert werdenkonnen. Dabei kann eingestellt werden, wie oft die Datenbank angefragt wird,in welchem Intervall die Daten als csv-Dateien (welche als Schnittstelle zwischenAufbereitung und Visualisierung genutzt wurden) ausgegeben werden und derZeitraum der Daten, die verarbeitet werden sollen. So ist es auch moglich dieAnwendung nicht nur im Live-Betrieb laufen zu lassen, sondern man kann mitihr auch nachtraglich noch die Daten aufbereiten. Im Folgenden soll noch aufdie wichtigsten Bestandteile eingegangen werden.
B.2.1 Ubertragung der Daten von der Datenbank
Zu Beginn war unklar, ob es eine gute Internetverbindung an dem Stand gebenwurde. Deshalb wurden nicht die Observation-Events ubertragen, sondern nurdie Entry- und Leave-Events, da diese deutlich seltener vorkommen und somitweniger Daten ubertragen werden mussen. Damit alle Events verarbeitet wer-den, wurden die trackids genutzt, um neue Daten abzufragen, da die timestampsdurch die unterschiedlichen Pufferzeiten der Sensoren nicht zuverlassig waren.
B.2.2 Bestimmung der Geratezahl mit Entry- und Leave-Events
Da mit Entry- und Leave-Events gearbeitet wurde, wurde fur jede hashmac einObjekt erstellt, das mehrere Sichtungen haben kann. Wurde ein Entry-Eventempfangen, so wurde bei dem entsprechenden Objekt eine neue Sichtung furden Sensor der das Event meldete erstellt. Bei einem Leave-Event wurde dieentsprechende Sichtung beendet. Sollte nun fur einen bestimmten Zeitpunktabgefragt werden, welches Gerat sich wo befanden, so wurde gepruft, welcheSichtungen zu diesem Zeitpunkt stattfanden.
B.2.3 Handhabung von Latenzen
Das großte Problem war der Umgang mit potentiellen Latenzen der Sensoren,bedingt durch die vielen Gerate und der Tatsache, dass die Sensoren ihre Datenuber das Mobilfunknetz sendeten. Dafur wurde nach jeder Abfrage gepruft, wieaktuell die Daten der Sensoren sind. Wurde festgestellt, dass noch keine aktu-ellen Daten vorhanden sind, so wurde fur eine konfigurierbare Zeit gewartet,ansonsten wurden die entsprechenden Sensoren ignoriert. Ein weiterhin beste-hendes Problem ist, dass die FlowTracks nicht die altesten Daten zuerst senden,sondern Gerate mit vielen Sichtungen priorisieren und somit nur teilweise aktu-elle Daten vorliegen konnen. In Zukunft konnte man dies umgehen, indem maneine generelle Verzogerung bei der Ausgabe der Daten implementiert. Weiterhinfiel nach Bamberg Zaubert auf, dass nicht jedes Entry-Event ein Leave-Eventzur Folge hat, da FlowTracks, die ausgeschaltet werden, offene Entry-Eventsnicht schließen. Um dies zu berucksichtigen konnte man entweder jede Sichtungnach einem bestimmten Zeitraum beenden, wodurch jedoch manche Sichtungenzu fruh beendet werden wurden. Eine bessere Moglichkeit ware entweder manu-ell oder automatisch zu erkennen, wann ein Sensor ausgeschaltet wird und imAnschluss die entsprechenden Sichtungen zu beenden.
40