making private user data accessible for information
TRANSCRIPT

Making Private User Data Accessible
for Information Retrieval Research:
Data Sharing with Differential Privacy
Li Xiong
Department of Mathematics and Computer Science
Department of Biomedical Informatics
Emory University
Privacy Preserving IR Workshop (PIR)
Santiago, Chile, August 13, 2015
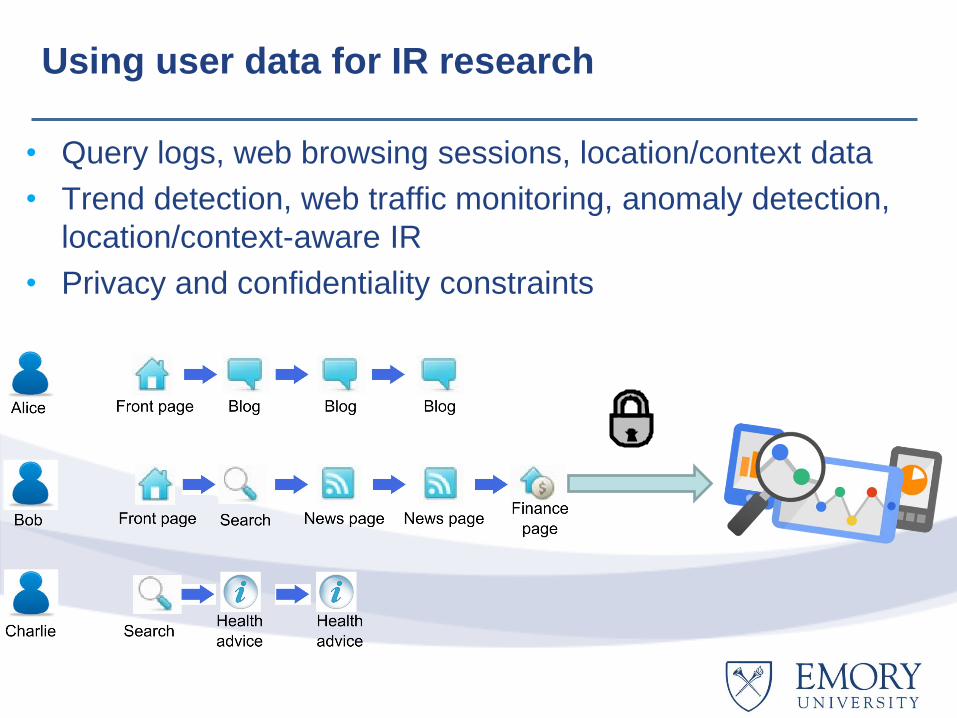
Using user data for IR research
• Query logs, web browsing sessions, location/context data
• Trend detection, web traffic monitoring, anomaly detection,
location/context-aware IR
• Privacy and confidentiality constraints

Original
Data
Sanitized
Records De-identification
anonymization
Traditional De-identification and Anonymization
• Attribute suppression, encoding, perturbation, generalization
• Subject to re-identification and disclosure attacks

The Infamous AOL Incident (2006)

The Genome Hacker (2013)

Original
Data
Statistics/
Models/
Synthetic
Records
Differentially Private
Data Sharing
Data Sharing with Differential Privacy
• More rigorous privacy guarantee
• Macro data (as versus micro data)
• Output perturbation (as versus input perturbation)

Outline
• Preliminaries: differential privacy
• Sharing web browsing data with differential
privacy for IR research
• Aggregated web visits
• Sequential patterns
• Challenges and discussion

Statistical Data Sharing
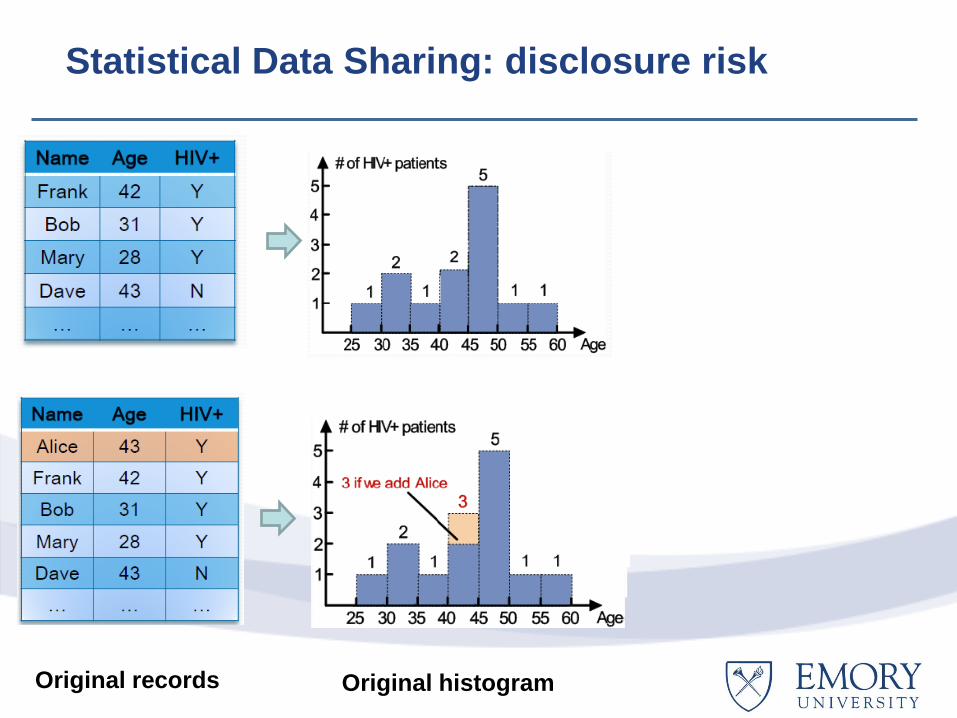
Original records Original histogram
Statistical Data Sharing: disclosure risk
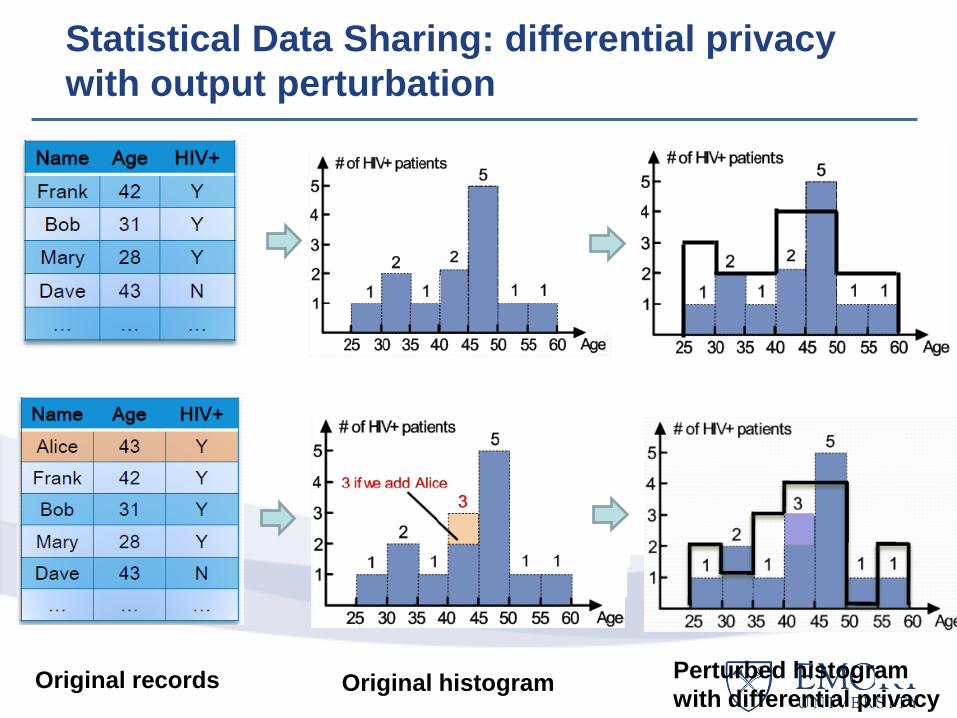
Original records Original histogram Perturbed histogram
with differential privacy
Statistical Data Sharing: differential privacy
with output perturbation

Preliminaries: Differential Privacy
A privacy mechanism A gives ε-differential privacy if
for all neighbouring databases D, D’, and for any
possible output S ∈ Range(A),
Pr[A(D) = S] ≤ exp(ε) × Pr[A(D’) = S]
D D’
• D and D’ are neighboring databases if they differ in one record

• Laplace Mechanism
For example, for a single counting query Q over a dataset
D, returning Q(D)+Laplace(1/ε) gives ε-differential privacy.
Global
Sensitivity
Preliminaries: Differential Privacy

Preliminaries: Differential Privacy
• Composition properties
Sequential composition ∑iεi –differential privacy
Parallel composition max(εi)–differential privacy

Emory AIMS (Assured Information Management
and Sharing)

Outline
• Preliminaries: differential privacy
• Sharing user data with differential privacy for IR
research
• Aggregated user behavior
• Sequential user behavior patterns
• Challenges

Web Browsing Sessions

Web Browsing Sessions

Problem: Aggregated Web Visits
• Individual browsing sessions:
• Aggregation of web visits at time k:
𝑥𝑘𝑓𝑝
, 𝑥𝑘𝑛𝑒𝑤𝑠, …
𝑥𝑘𝑖 : the number of requests of page i at time k
𝑚 : total number of web pages
• Privacy goal: protect the presence of individual sessions
“msnbc.com”
𝒎 aggregates
Liyue Fan, Li Xiong, Vaidy Sunderam. Monitoring web browsing behavior
with differential privacy. WWW 2014

Problem: Single Aggregated Time-series
• A univariate, discrete Time-Series 𝐗 = {𝑥𝑘} with 0 ≤ 𝑘 < 𝑇
• xk: number of web page request at time k
• Other examples: hourly traffic counts at an intersection, daily
flu count
• Problem: Given time series X and differential privacy budget α,
release α-differentially private series R with high utility.
• Utility: relative error
k time
R
X
error

Baseline: Laplace Perturbation Algorithm (LPA)
Laplace Perturbation k time
At each time point k
𝑥𝑘
Aggregate time-series X
Released time-series R
k time • High perturbation error O(T)
𝑟𝑘 = 𝑥𝑘 + 𝜈, 𝜈~𝐿𝑎𝑝(1
𝛼/𝑇)

FAST: Filtering and Adaptive Sampling for Aggregate
Time-series monitoring
• Filtering – model-based posterior estimation
• Adaptive Sampling – feedback-based sampling
•L. Fan, L. Xiong. Real-Time Aggregate Monitoring with Differential Privacy CIKM 2012
•L. Fan, L. Xiong, V. Sunderam. FAST: Differentially Private Real-Time Aggregate Monitor with
Filtering and Adaptive Sampling (demo track). SIGMOD, 2013

Filtering: State-Space Model
• Process Model
𝑥𝑘+1 = 𝑥𝑘 + 𝜔
𝜔~ℕ(0, 𝑄)
• Measurement Model
𝑧𝑘 = 𝑥𝑘 + 𝜈 𝜈~𝐿𝑎𝑝(𝜆)
• Given noisy measurement 𝑧𝑘, how to estimate true state 𝑥𝑘 ?
Process noise
Measurement noise
𝑥𝑘 𝑥𝑘+1
𝑧𝑘 𝑧𝑘+1
Process
Perturbation

Posterior Estimation
• Denote ℤ𝑘 = 𝑧1, … , 𝑧𝑘 - noisy observations up to k
• Posterior estimate:
𝑥 𝑘 = 𝐸(𝑥𝑘|ℤ𝑘)
• Posterior distribution:
𝑓 𝑥𝑘 ℤ𝑘 =𝑓 𝑥𝑘 ℤ𝑘−1 𝑓(𝑧𝑘|𝑥𝑘)
𝑓 𝑧𝑘 ℤ𝑘−1
• Challenge:
𝑓 𝑧𝑘 ℤ𝑘−1 and 𝑓 𝑥𝑘 ℤ𝑘−1 are difficult to compute when
𝑓 𝑧𝑘 𝑥𝑘 = 𝑓𝜈 is not Gaussian

Filtering: Solutions
• Option 1: Approximate measurement noise with Gaussian
𝜈~ℕ(0, 𝑅)
→ the Kalman filter
• Option 2: Estimate posterior density by Monte-Carlo method
𝑓 𝑥𝑘 ℤ𝑘 = 𝜋𝑘𝑖 𝛿(𝑥𝑘 − 𝑥𝑘
𝑖 )
𝑁
𝑖=1
where {𝑥𝑘𝑖 , 𝜋𝑘
𝑖 }1𝑁 is a set of weighted samples/particles.
→ particle filters
•Liyue Fan, Li Xiong. Adaptively Sharing Real-Time Aggregates with
Differential Privacy. IEEE TKDE, 2014

FAST: Filtering and Adaptive Sampling for Aggregate
Time-series monitoring
• Filtering – model-based posterior estimation
• Adaptive Sampling – feedback-based sampling

Adaptive Sampling
26
• Fixed sampling – difficult to select sampling rate a priori
• Adaptive sampling - adjust sampling rate based on feedback from
observed data dynamics

Adaptive Sampling: PID Control
• Feedback error: measures how well the data model describes the
current trend
• PID error (Δ): compound of proportional, integral, and derivative errors
• Proportional: current error
• Integral: integral of errors in recent time window
• Derivative: change rate of errors
• Determines a new sampling interval:
𝐼′ = 𝐼 + 𝜃(1 − 𝑒Δ−𝜉𝜉 )
where 𝜃 represents the magnitude of change and 𝜉 is the set point for
sampling process.

• Synthetic Data with 1000 data points:
• Linear: process model
• Logistic: 𝑥𝑘 = 𝐴(1 + 𝑒−𝑘)−1
• Sinusoidal: 𝑥𝑘 = 𝐴 ∗ 𝑠𝑖𝑛(𝜔𝑘 + 𝜑) • Flu: CDC flu data 2006-2010, 209 data points
• Traffic: UW/intelligent transportation systems research 2003-2004,
540 data points
• Unemployment: ST. Louis Federal Reserve Bank, 478 data points
Evaluation: Data Sets
Flu Traffic

Illustration: Original data stream vs. released
data stream
• FAST provides less data volume and higher data utility/integrity with
formal privacy guarantee

Fixed Sampling vs. Adaptive Sampling
• Tradeoff between sampling error and perturbation error
• Adaptive sampling achieves close-to-optimal result without aprior
knowledge
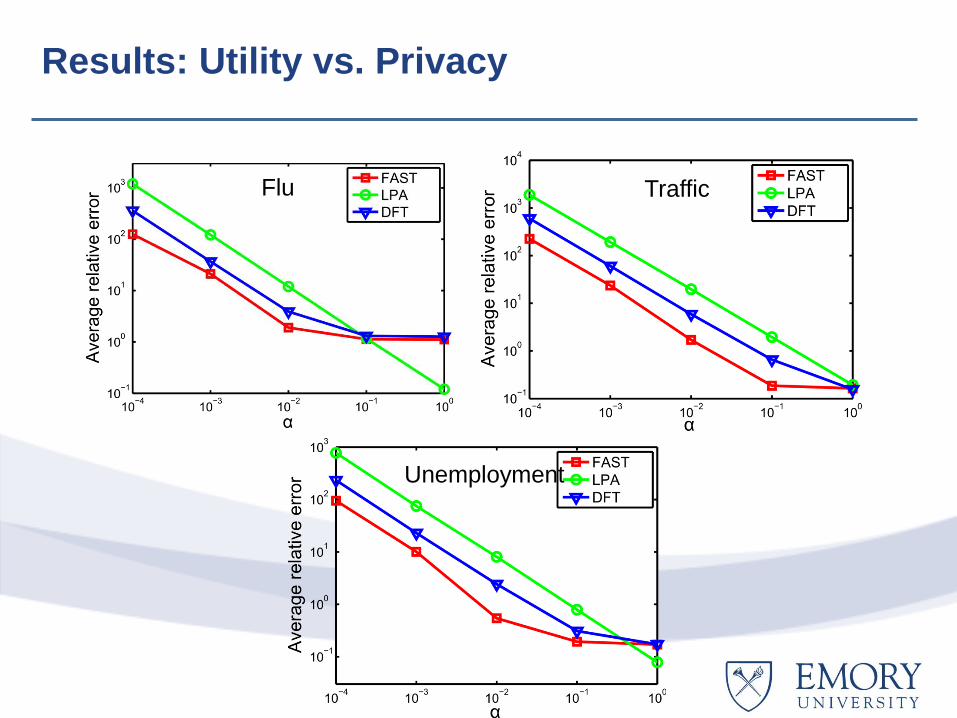
Results: Utility vs. Privacy
31
Flu Traffic
Unemployment

Aggregated Browsing Behavior
• Individual browsing sessions:
• Aggregation of web visits at time k:
𝑥𝑘𝑓𝑝
, 𝑥𝑘𝑛𝑒𝑤𝑠, …
𝑥𝑘𝑖 : the number of requests of page i at time k
𝑚 : total number of web pages
“msnbc.com”
𝒎 aggregates

Univariate Time Series Models
• Individual models for each web page 𝑖
• Little prior knowledge: constant model
• Process Model 𝑥𝑘+1𝑖 = 𝑥𝑘
𝑖 + 𝜔𝑘𝑖 , 𝜔𝑘
𝑖 ~ℕ(0, 𝑄𝑖)
• Measurement Model 𝑧𝑘𝑖 = 𝑥𝑘
𝑖 + 𝜈𝑘𝑖 , 𝜈𝑘
𝑖 ~𝐿𝑎𝑝(0,𝑙𝑚𝑎𝑥
𝛼)
• Gaussian Approx.:
𝜈𝑘𝑖 ~ℕ(0, 𝑅)
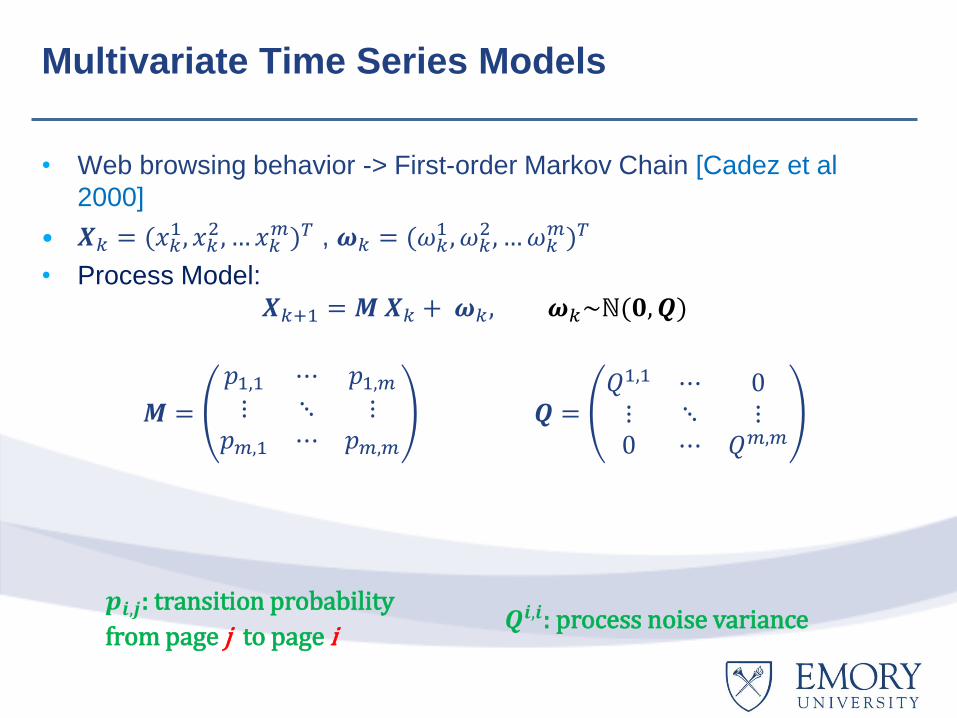
Multivariate Time Series Models
• Web browsing behavior -> First-order Markov Chain [Cadez et al
2000]
• 𝑿𝑘 = (𝑥𝑘1, 𝑥𝑘
2, … 𝑥𝑘𝑚)𝑇 , 𝝎𝑘 = (𝜔𝑘
1 , 𝜔𝑘2 , …𝜔𝑘
𝑚)𝑇
• Process Model:
𝑿𝑘+1 = 𝑴 𝑿𝑘 + 𝝎𝑘, 𝝎𝑘~ℕ(𝟎,𝑸)
𝑴 =
𝑝1,1 ⋯ 𝑝1,𝑚
⋮ ⋱ ⋮𝑝𝑚,1 ⋯ 𝑝𝑚,𝑚
𝑸 =𝑄1,1 ⋯ 0⋮ ⋱ ⋮0 ⋯ 𝑄𝑚,𝑚
𝒑𝒊,𝒋: transition probability
from page j to page i 𝑸𝒊,𝒊: process noise variance

Evaluation: web browsing data
• MSNBC data set from UIC repository
• 989,818 browsing sessions
• 17 web page categories
• Longest session: 14,975 page requests
• Average session length: 4.7
• Simulated dynamic browsing sessions
• Poisson arrival model
• Random sample sessions
𝒍𝒎𝒂𝒙 = 𝟐𝟎, longer
sessions are truncated.

Generic Utility Measure
• Average Relative Error (ARE)

Top-k Mining
• Average Precision (AP)
Top-5 popular web pages

Distribution Similarity
• KL-divergence (distance)

Outline
• Preliminaries: differential privacy
• Sharing user data with differential privacy for IR
research
• Aggregated user behavior
• Sequential behavior patterns
• Challenges

Web Browsing Behavior: Sequential Patterns

Sequential Pattern Release: Prefix tree approach
Name Page visited
t1 t2 t3 …
Alice F B B …
Bob F S N …
Charlie S H H …
… … … … …
All: 100
F: 30 S: 70
SH: 40 SN: 30 SF: 0
Original Records
DP Prefix Tree
t1
t2
t3
…
• Accurate for prefix patterns
• Large aggregated error for substring patterns
Luca Bonomi, Li Xiong, Rui Chen, and Benjamin C. M. Fung. Frequent grams
based Embedding for Privacy Preserving Record Linkage. CIKM 2012

Sequential Pattern Release: Two-Phase
Approach
• Prefix tree miner for prefix patterns
• Compute top-k’ frequent patterns (k’>k)
• Transform the dataset to an optimal length-constrained
fingerprint
• Refine the frequency count of the top-k’ frequent patterns
for top-k patterns
A Two-Phase Algorithm For Mining Sequential Patterns with Differential
Privacy. In CIKM 2013

Differentially Private Sequential Pattern Sharing
• Prefix tree based approach
• Retains sequence information, both frequent
and infrequent
• Price: not accurate for frequent (substring)
sequences
• Differentially private frequent pattern mining
• Only care about frequent sequences given a
threshold

Non-private FSM – An Example
ID
100
200
300
400
500
Record
a→c→d
b→c→d
a→b→c→e→d
d→b
a→d→c→d
Database D
Sequence
{a}
{b}
{c}
{d}
Sup.
3
3
4
4
{e} 1
C1: cand 1-seqs
Sequence
{a}
{b}
{c}
{d}
Sup.
3
3
4
4
F1: freq 1-seqs
Sequence
{a→a}
{a→b}
{a→c}
{a→d}
Sup.
0
1
3
3
{b→a}
{b→b}
{b→c}
{b→d}
0
2
2
1
{c→a}
{c→b}
{c→c}
{c→d}
0
0
0
4
{d→a}
{d→b}
{d→c}
{d→d}
0
1
1
0
C2: cand 2-seqs
Sequence
{a→c}
{a→d}
{c→d}
Sup.
3
3
4
F3: freq 2-seqs
Scan D
Scan D
Scan D
Sequence
{a→a}
{a→b}
{a→c}
{a→d}
{b→a}
{b→b}
{b→c}
{b→d}
{c→a}
{c→b}
{c→c}
{c→d}
{d→a}
{d→b}
{d→c}
{d→d}
C2: cand 2-seqs
Sequence
{a→b→c}
C3: cand 3-seqs
Sequence
{a→b→c}
Sup.
3
F3: freq 3-seqs

Naïve Private FSM
ID
100
200
300
400
500
Record
a→c→d
b→c→d
a→b→c→e→d
d→b
a→d→c→d
Database D
Sequence
{a}
{b}
{c}
{d}
Sup.
3
3
4
4
{e} 1
C1: cand 1-seqs
noise
0.2
-0.4
0.4
-0.5
0.8
Sequence
{a→a}
{a→c}
{a→d}
{c→a}
{c→c}
{c→d}
{d→a}
{d→c}
{d→d}
C2: cand 2-seqs
Sequence
{a→a}
{a→c}
{a→d}
Sup.
0
3
3
{c→a}
{c→c}
{c→d}
0
0
4
{d→a}
{d→c}
{d→d}
0
1
0
C2: cand 2-seqs
noise
0.2
0.3
0.2
-0.5
0.8
0.2
0.3
2.1
-0.5
Scan D
Scan D
Sequence
{a→c→d}
C3: cand 3-seqs
{a→d→c}
noise
0
0.3
Sequence
{a→c→d}
Sup.
3
{a→d→c} 1
C3: cand 3-seqs
Scan D
Sequence
{a}
{c}
{d}
Noisy Sup.
3.2
4.4
3.5
F1: freq 1-seqs
Sequence
{a→c}
{a→d}
{c→d}
Noisy Sup.
3.3
3.2
4.2
F2: freq 2-seqs
{d→c} 3.1
Sequence
{a→c→d}
Noisy Sup.
3
F3: freq 3-seqs
Lap(|C2| / ε2)
Lap(|C1| / ε1)
Lap(|C3| / ε3)

Differentially Private Frequent Sequence Mining via
Sampling-based Candidate Pruning
• Observation: most candidate sequences are not frequent
• For k-Sequences
1. Generate candidate k-sequences Ck
2. Use k-th sample DB to prune candidate k-
sequences
3. Compute noisy supports of remaining candidate k-
sequences
Ck
kth
sample database
Prune
Ck’
Original Database
Compute
noisy support
Fk
Laplace
Mechanism
Original Database
mth
sample database2nd
sample database1st sample database
……
Partition
Shengzhi Xu, Sen Su, Xiang Cheng, Zhengyi Li, Li Xiong. Differentially
Private Frequent Sequence Mining via Sampling-based Candidate
Pruning. ICDE 2015

Experiments
• Mining Results vs. Threshold
MSNBC: F-score
MSNBC: RE
BIBLE: F-score
BIBLE: RE
House_Power: F-score
House_Power: RE

Discussions
• Domain knowledge is important
• Web browsing patterns using Markov models
• It is easier if you know what you want
• Aggregated counts vs. sequential patterns
• Frequent sequential patterns vs. all sequential
patterns
• Need user-friendly metrics for understanding
utility and privacy tradeoff
• Need more data and use case studies to evaluate
the feasibility and utility of using DP data for IR
research

Q: The synthetic data has noise, how can I trust
the data?
• In some cases, we can give reasonable utility
guarantees
• It will not replace the raw data, but to speedup
data access

Q: How to set epsilon?
• Understand the privacy risks of data
• Understand the value of data: pricing theory
Figure source: A Theory of Pricing Private Data, ICDT2013, TODS2014

Acknowledgement
• Research support
• Center for Comprehensive Informatics
• Woodrow Wilson Foundation
• Cisco research award
• Students
• James Gardner
• Yonghui Xiao
• Collaborators
• Andrew Post, CCI
• Fusheng Wang, CCI
• Tyrone Grandison, IBM
• Chun Yuan, Tsinghua

Acknowledgement
• Current PhD students
• Recent PhD graduates and visitors
• Funding Supports


Location Cloaking: Challenges
• Road constraints
• Moving patterns

Location Cloaking: Problem Setting
• Users with true (unobservable) locations, share perturbed locations
• Need to guarantee true location is not disclosed even if an adversary
knows the moving patterns and previously released perturbed
locations

Location Cloaking: Proposed Solutions
Extended differential privacy:
• Compute prior probability of the
locations based on Markov
model
• Hide true location among the
probable locations
(indistinguishability set)
Perturbation mechanism:
• Planar Isotrophic Mechanism

Results: Perturbed Trace Illustration

Results: k-Nearest Neighbor Queries