managing incompleteness, complexity and scale in big...
TRANSCRIPT

Managing Incompleteness,
Complexity and Scale in Big Data Nick Duffield
Electrical and Computer Engineering Texas A&M University
http://nickduffield.net/work

Three Challenges for Big Data • Complexity
– Problem: high-dimensional data with complex dependence between variables, difficult to model
– Solution: machine learning dominant relationships • Incompleteness
– Problem: not all quantities can be directly measured – Solution: statistically infer what we want from what we
have • Scale
– Problem: huge datasets: costly to store, slow to compute – Solution: smart data reduction retains ability to answer
most important queries

Big Data Complexity: Customer Experience
• Which objective metrics closely associated with customer dissatisfaction? – If known, remediate and prevent future troubles
• Solution: – (machine) learn metrics (and values), service settings, most associated with
occurrence of customer calls. Set action thresholds. – Monitor metrics, take action when thresholds exceed
• Operational savings – Reduce call volume to customer care center, reduce churn
• Reverse problem – Learn calling patterns and keywords most predictive of network problem
Objective Metrics of Network Performance
Noisy measures of customer experience
Packet loss and delay; line quality; service parameters
Customer care calls; social media; keyword analysis
?

Incompleteness: Internet tomography
• What ISPs want – Origin-Destination (OD) traffic rates
between any two routers • What ISPs have
– Measured traffic rates on each link • Linear relation
– Link_Rates = A . OD_Rates – A = routing matrix
• encodes which links that OD traffic traverses
• Solve? Under-constrained problem – Different possible sets of OD_Rates yield
the same set of measured Link_rates

Internet Tomography • Gravity Model?
– OD_Rate(A à B) =const. × Rate(AàALL) × Rate(ALLàB) – Can measure Rate(AàALL) at links emanating from A
• Problem with gravity! – Gravity model is not a solution of Link_Rates = A . OD_Rates
• Solution: Tomogravity – Use solution closest to gravity model!
• Penalized likelihood solution
– Quick to compute, good accuracy • In daily use in ISPs, Routers
constraint subspace L = A.M
Tomogravity = least square solution
M1
M2
gravity model solution

Big Data Scale • ISP operations generate 100s of Terabytes of usage
measurement data daily • Passive traffic measurements by (core) routers
– Session-level traffic summaries (flow records) – Each flow record reports IP source and destination,
#packets, bytes, timing, .. – Core routers stream flow records to collectors for analysis
• Used widely in network management – timescale from months (planning) to seconds (security)
• Still need tomo-gravity outside core!

Managing Data Scale through Sampling
• Turn Big Data into Smaller Data – Savings in storage, bandwidth; speed up queries
• Reference sampling – Reuse samples over multiple retrospective queries – Know query class in advance, but not specific query
• “Smart” sampling – matches data characteristics to analysis requirements – E.g. uniform sampling is useless on heavy tails
• Streaming constraints – Sample to be computable in small time per item – Big data constraint often not met in classical methods

Statistically Optimal Stream Sampling
• Aim: – Sample fraction of flow records – Use to answer queries approximately
• Problem: heavy tails – 10% of the flow records report 90% of bytes – Uniform sampling misses most of the 10%
• Big hit on accuracy • Solution:
– Statistically optimal non-uniform sampling algorithms (minimal estimation variance)
– Computationally feasible for stream sampling – In use in ISPs
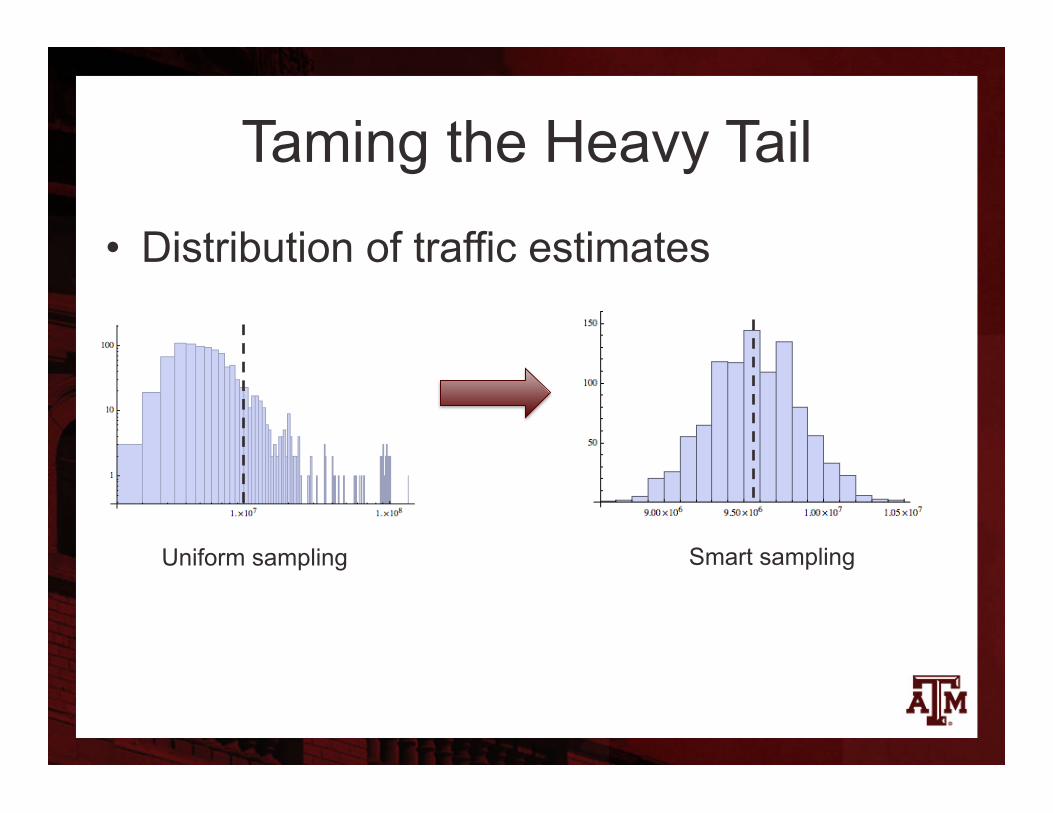
Taming the Heavy Tail
• Distribution of traffic estimates
Uniform sampling Smart sampling

Next: Streaming ISP Graph Data • ISP Communications Graph from Flow Records
– node = IP address; – edge = flow from source to destination
compromise control flooding
• Hard to detect against background • Known attacks:
– Signature matching based on subgraphs, flow features, timing
• Unknown attacks: – exploratory & retrospective analysis
• Smart sampling of subgraphs

Sampling + Knowledge Discovery
• Interplay between sampling and data mining is not well understood – Need to understand how ML/DM algorithms are affected by
sampling – E.g. how big a sample is needed to build an accurate classifier? – E.g. what sampling strategy optimizes cluster quality
• Expect results to be method specific – I.e. “smart samping + k-means”

Sampling and Privacy • Current focus on privacy-preserving data mining
– Opportunity for sampling to be part of the solution • Naïve sampling provides “privacy in expectation”
– Your data remains private if you aren’t included in the sample… • Intuition: uncertainty from sampling contributes to privacy
– This intuition can be formalized with different privacy models • Sampling can be analyzed in the context of differential privacy
– Sampling alone does not provide differential privacy – But applying a DP method to sampled data does guarantee privacy – A tradeoff between sampling rate and privacy parameters
• Understand benefits as well as risks of information flows • Network calculus of risk/reward trade-off from information sharing, joining

Outlook • Big data challenges
– Incompleteness, complexity, scale • Generic problems; transferable solutions
– Find causal relations in high dimensional data • Use machine learning for discovery & prediction
– Big Data Tomography • Solve ill-posed inverse problems with constraints from
models and side data – Smart Sampling
• Speed up computations and save on resources • Tune sampling to mediate between data and queries
– Role of sampling in ML/DM, privacy,…