managing xml data dan suciu university of washington
Post on 22-Dec-2015
220 views
TRANSCRIPT

Managing XML Data
Dan Suciu
University of Washington

How the Web is Today
• HTML documents
• often generated by applications
• consumed by humans only
• easy access: across platforms, across organizations

No Application Interoperability
• HTML not understood by applications– screen scraping brittle
• database technology: client-server– still vendor specific
• companies merge, form partnerships; need interoperability fast
people are inventive: send data by fax !

New Universal Data Exchange Format: XML
A recommendation from the W3C
• XML = data
• XML generated by applications
• XML consumed by applications
• easy access: across platforms, organizations
XML data management problems

Paradigm Shift on the Web
• from documents (HTML) to data (XML)
• from information retrieval to data
management

Paradigm shift for databases
• from relational model to semistructured
dat model
• from data processing to data/query
translation
• from storage to transport

What This Tutorial is About
• what the database community has done– semistructured data model– query languages, schemas
• what the Web community has done:– data formats/models: XML– transformation language (XSL), schemas
• where they meet and where they differ

Outline
• Semistructured and XML data models
• Query languages
• Schemas
• Systems issues
• Conclusions

Part 1Semistructured and XML Data
Models

Semistructured Data
Origins:
• integration of heterogeneous sources
• data sources with non-rigid structure
• biological data
• Web data
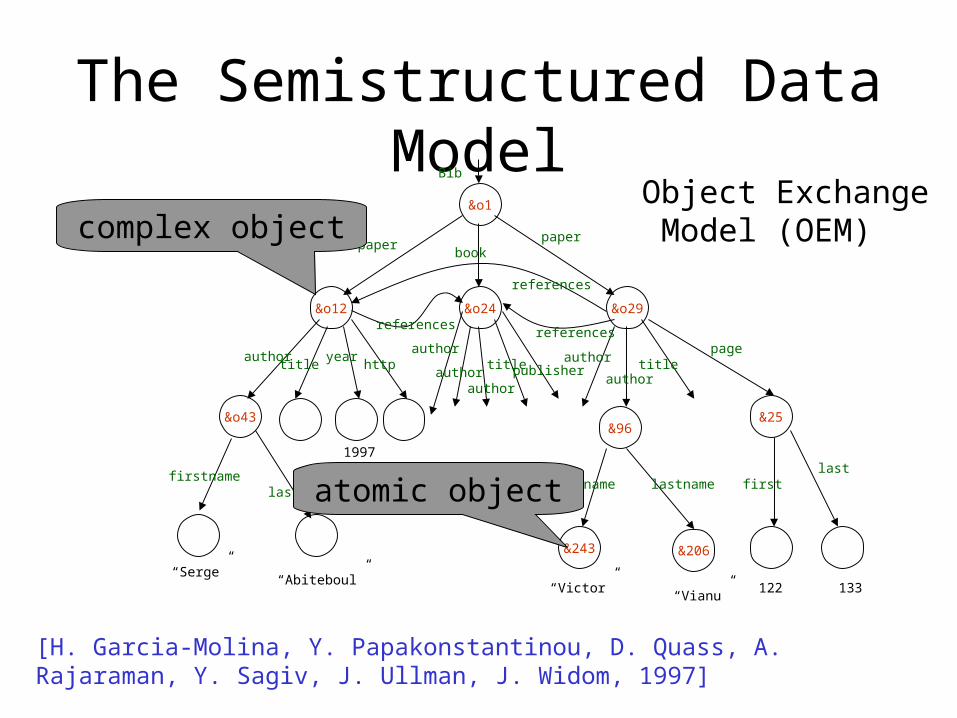
The Semistructured Data Model
&o1
&o12 &o24 &o29
&o43&96
&243 &206
&25
“Serge”“Abiteboul”
1997
“Victor”“Vianu”
122 133
paperbook
paper
references
referencesreferences
authortitle
yearhttp
author
authorauthor
title publisherauthor
authortitle
page
firstnamelastname
firstname lastname firstlast
Bib
Object Exchange Model (OEM) complex object
atomic object
[H. Garcia-Molina, Y. Papakonstantinou, D. Quass, A. Rajaraman, Y. Sagiv, J. Ullman, J. Widom, 1997]

Syntax for Semistructured Data
Bib: &o1 { paper: &o12 { … },
book: &o24 { … },
paper: &o29
{ author: &o52 “Abiteboul”,
author: &o96 { firstname: &243 “Victor”,
lastname: &o206 “Vianu”},
title: &o93 “Regular path queries with constraints”,
references: &o12,
references: &o24,
pages: &o25 { first: &o64 122, last: &o92 133}
}
}

Syntax for Semistructured Data
May omit oid’s:
{ paper: { author: “Abiteboul”,
author: { firstname: “Victor”,
lastname: “Vianu”},
title: “Regular path queries …”,
page: { first: 122, last: 133 }
}
}

Characteristics of Semistructured Data
• missing or additional attributes
• multiple attributes
• different types in different objects
• heterogeneous collections
self-describing, irregular data, no a priori structure

Comparison with Relational Data
{ row: { name: “John”, phone: 3634 },
row: { name: “Sue”, phone: 6343 },
row: { name: “Dick”, phone: 6363 }
}
n a m e p h o n e
J o h n 3 6 3 4
S u e 6 3 4 3
D i c k 6 3 6 3
row row row
name name namephone phone phone
“John” 3634“Sue” “Dick”6343 6363

XML
• a W3C standard to complement HTML
• origins: structured text SGML
• motivation:– HTML describes presentation– XML describes content
• • http://www.w3.org/TR/2000/REC-xml-20001006
(version 2, 10/2000)
SGMLXMLHTML4.0

From HTML to XML
HTML describes the presentation

HTML
<h1> Bibliography </h1>
<p> <i> Foundations of Databases </i>
Abiteboul, Hull, Vianu
<br> Addison Wesley, 1995
<p> <i> Data on the Web </i>
Abiteoul, Buneman, Suciu
<br> Morgan Kaufmann, 1999

XML<bibliography>
<book> <title> Foundations… </title>
<author> Abiteboul </author>
<author> Hull </author>
<author> Vianu </author>
<publisher> Addison Wesley </publisher>
<year> 1995 </year>
</book>
…
</bibliography>XML describes the content

XML Terminology• tags: book, title, author, …• start tag: <book>, end tag: </book>• elements: <book>…<book>,<author>…</author>• elements are nested• empty element: <red></red> abbrv. <red/>• an XML document: single root element
well formed XML document: if it has matching tags

More XML: Attributes
<book price = “55” currency = “USD”>
<title> Foundations of Databases </title>
<author> Abiteboul </author>
…
<year> 1995 </year>
</book>
attributes are alternative ways to represent data

More XML: Oids and References
<person id=“o555”> <name> Jane </name> </person>
<person id=“o456”> <name> Mary </name>
<children idref=“o123 o555”/>
</person>
<person id=“o123” mother=“o456”><name>John</name>
</person>
oids and references in XML are just syntax

XML Data Model
Several competing models:• Document Object Model (DOM):
– http://www.w3.org/TR/2001/WD-DOM-Level-3-CMLS-20010209/ (2/2001)
– class hierarchy (node, element, attribute,…)– objects have behavior– defines API to inspect/modify the document
• XSL data model• Infoset
– PSV (post schema validation)
• XML Query data model (next)

XML Query Data Model
• http://www.w3.org/TR/query-datamodel/2/2001
• Describes XML as a tree, specialized nodes
• Uses a functional-style notation (think ML)

XML Query Data Model
• Node ::= DocNode | ElemNode | ValueNode | AttrNode | NSNode | PINode | CommentNode | InfoItemNode | RefNode

XML Query Data Model
Element node (simplified definition):
• elemNode : (QNameValue, {AttrNode }, [ ElemNode | ValueNode]) ElemNode
• QNameValue = means “a tag name”• {...} = means “set of...”• [...] = means “list of ...”

XML Query Data Model
• Reads: “give me a tag, a set of attributes, a list of elements/values, and I will return an element”

XML Query Data Model
Example
<book price = “55”
currency = “USD”>
<title> Foundations … </title>
<author> Abiteboul </author>
<author> Hull </author>
<author> Vianu </author>
<year> 1995 </year>
</book>
<book price = “55”
currency = “USD”>
<title> Foundations … </title>
<author> Abiteboul </author>
<author> Hull </author>
<author> Vianu </author>
<year> 1995 </year>
</book>
book1= elemNode(book, {price2, currency3}, [title4, author5, author6, author7, year8])
price2 = attrNode(…) /* next */currency3 = attrNode(…)title4 = elemNode(title, string9)…
book1= elemNode(book, {price2, currency3}, [title4, author5, author6, author7, year8])
price2 = attrNode(…) /* next */currency3 = attrNode(…)title4 = elemNode(title, string9)…

XML Query Data Model
Attribute node:
• attrNode : (QNameValue, ValueNode) AttrNode

XML Query Data Model
Example
<book price = “55”
currency = “USD”>
<title> Foundations … </title>
<author> Abiteboul </author>
<author> Hull </author>
<author> Vianu </author>
<year> 1995 </year>
</book>
<book price = “55”
currency = “USD”>
<title> Foundations … </title>
<author> Abiteboul </author>
<author> Hull </author>
<author> Vianu </author>
<year> 1995 </year>
</book>
price2 = attrNode(price,string10) string10 = valueNode(…) /* next */currency3 = attrNode(currency, string11)string11 = valueNode(…)
price2 = attrNode(price,string10) string10 = valueNode(…) /* next */currency3 = attrNode(currency, string11)string11 = valueNode(…)

XML Query Data Model
Value node:• ValueNode = StringValue |
BoolValue | FloatValue …
• stringValue : string StringValue• boolValue : boolean BoolValue• floatValue : float FloatValue

XML Query Data Model
Example
<book price = “55”
currency = “USD”>
<title> Foundations … </title>
<author> Abiteboul </author>
<author> Hull </author>
<author> Vianu </author>
<year> 1995 </year>
</book>
<book price = “55”
currency = “USD”>
<title> Foundations … </title>
<author> Abiteboul </author>
<author> Hull </author>
<author> Vianu </author>
<year> 1995 </year>
</book>
price2 = attrNode(price,string10)string10 = valueNode(stringValue(“55”))currency3 = attrNode(currency, string11)string11 = valueNode(stringValue(“USD”))
title4 = elemNode(title, string9)string9 = valueNode(stringValue(“Foundations…”))
price2 = attrNode(price,string10)string10 = valueNode(stringValue(“55”))currency3 = attrNode(currency, string11)string11 = valueNode(stringValue(“USD”))
title4 = elemNode(title, string9)string9 = valueNode(stringValue(“Foundations…”))

XML Namespaces
• http://www.w3.org/TR/REC-xml-names (1/99)
• name ::= [prefix:]localpart
<book xmlns:isbn=“www.isbn-org.org/def”>
<title> … </title>
<number> 15 </number>
<isbn:number> …. </isbn:number>
</book>
<book xmlns:isbn=“www.isbn-org.org/def”>
<title> … </title>
<number> 15 </number>
<isbn:number> …. </isbn:number>
</book>

<tag xmlns:mystyle = “http://…”>
…
<mystyle:title> … </mystyle:title>
<mystyle:number> …
</tag>
<tag xmlns:mystyle = “http://…”>
…
<mystyle:title> … </mystyle:title>
<mystyle:number> …
</tag>
XML Namespaces
• syntactic: <number> , <isbn:number>
• semantic: provide URL for schema
defined here

XML v.s. Semistructured Data
• both described best by a graph
• both are schema-less, self-describing

Similarities and Differences
<person id=“o123”>
<name> Alan </name>
<age> 42 </age>
<email> ab@com </email>
</person>
{ person: &o123
{ name: “Alan”,
age: 42,
email: “ab@com” }
}
person
name age email
Alan 42 ab@com
person
name age email
Alan 42 ab@com
father father
<person father=“o123”> …</person>
{ person: { father: &o123 …}}
similar on trees, different on graphs

More Differences
• XML is ordered, ssd is not
• XML can mix text and elements: <talk> Making Java easier to type and easier to type
<speaker> Phil Wadler </speaker>
</talk>
• XML has lots of other stuff: entities, processing instructions, comments
Very important:these differences make XML data management harder

Summary of Data Models
• semistructured data, XML
• data is self-describing, irregular
• schema embedded with the data

Part 2Query Languages
• Semistructured and XML data models
• Query languages
• Schemas
• Systems issues
• Conclusions

Query Languages: Outline
• Path expressions:– XPath
• Declarative languages (query languages)– XML-QL– Quilt– XQuery
• Recursive languages– structural recursion– XSL

XPath• http://www.w3.org/TR/xpath (11/99)
• Building block for other W3C standards:– XSL Transformations (XSLT) – XML Link (XLink)– XML Pointer (XPointer)– XML Query
• Was originally part of XSL

Example for XPath Queries<bib>
<book> <publisher> Addison-Wesley </publisher> <author> Serge Abiteboul </author> <author> <first-name> Rick </first-name> <last-name> Hull </last-name> </author> <author> Victor Vianu </author> <title> Foundations of Databases </title> <year> 1995 </year></book><book price=“55”> <publisher> Freeman </publisher> <author> Jeffrey D. Ullman </author> <title> Principles of Database and Knowledge Base Systems </title> <year> 1998 </year></book>
</bib>
<bib><book> <publisher> Addison-Wesley </publisher> <author> Serge Abiteboul </author> <author> <first-name> Rick </first-name> <last-name> Hull </last-name> </author> <author> Victor Vianu </author> <title> Foundations of Databases </title> <year> 1995 </year></book><book price=“55”> <publisher> Freeman </publisher> <author> Jeffrey D. Ullman </author> <title> Principles of Database and Knowledge Base Systems </title> <year> 1998 </year></book>
</bib>

XPath: Simple Expressions
/bib/book/year
Result: <year> 1995 </year>
<year> 1998 </year>
/bib/paper/year
Result: empty (there were no papers)

XPath: Restricted Kleene Closure
//author
Result:<author> Serge Abiteboul </author> <author> <first-name> Rick </first-name> <last-name> Hull </last-name> </author> <author> Victor Vianu </author> <author> Jeffrey D. Ullman </author>
/bib//first-nameResult: <first-name> Rick </first-name>

Xpath: Text Nodes
/bib/book/author/text()
Result: Serge Abiteboul
Jeffrey D. Ullman
Rick Hull doesn’t appear because he has firstname, lastname

Xpath: Wildcard
//author/*
Result: <first-name> Rick </first-name>
<last-name> Hull </last-name>
* Matches any element

Xpath: Attribute Nodes
/bib/book/@price
Result: “55”
@price means that price is has to be an attribute

Xpath: Qualifiers
/bib/book/author[firstname]
Result: <author> <first-name> Rick </first-name>
<last-name> Hull </last-name>
</author>

Xpath: More Qualifiers
/bib/book/author[firstname][address[//zip][city]]/lastname
Result: <lastname> … </lastname>
<lastname> … </lastname>

Xpath: More Qualifiers
/bib/book[@price < “60”]
/bib/book[author/@age < “25”]
/bib/book[author/text()]

Xpath: Summarybib matches a bib element
* matches any element
/ matches the root element
/bib matches a bib element under root
bib/paper matches a paper in bib
bib//paper matches a paper in bib, at any depth
//paper matches a paper at any depth
paper|book matches a paper or a book
@price matches a price attribute
bib/book/@price matches price attribute in book, in bib
bib/book/[@price<“55”]/author/lastname matches…

Xpath: More Details
• An Xpath expression, p, establishes a relation between:– A context node, and– A node in the answer set
• In other words, p denotes a function:– S[p] : Nodes -> {Nodes}
• Examples:– author/firstname– . = self– .. = parent– part/*/*/subpart/../name = part/*/*[subpart]/name

The Root and the Root
• <bib> <paper> 1 </paper> <paper> 2 </paper> </bib>• bib is the “document element”• The “root” is above bib
• /bib = returns the document element• / = returns the root
• Why ? Because we may have comments before and after <bib>; they become siblings of <bib>
• This is advanced xmlogy
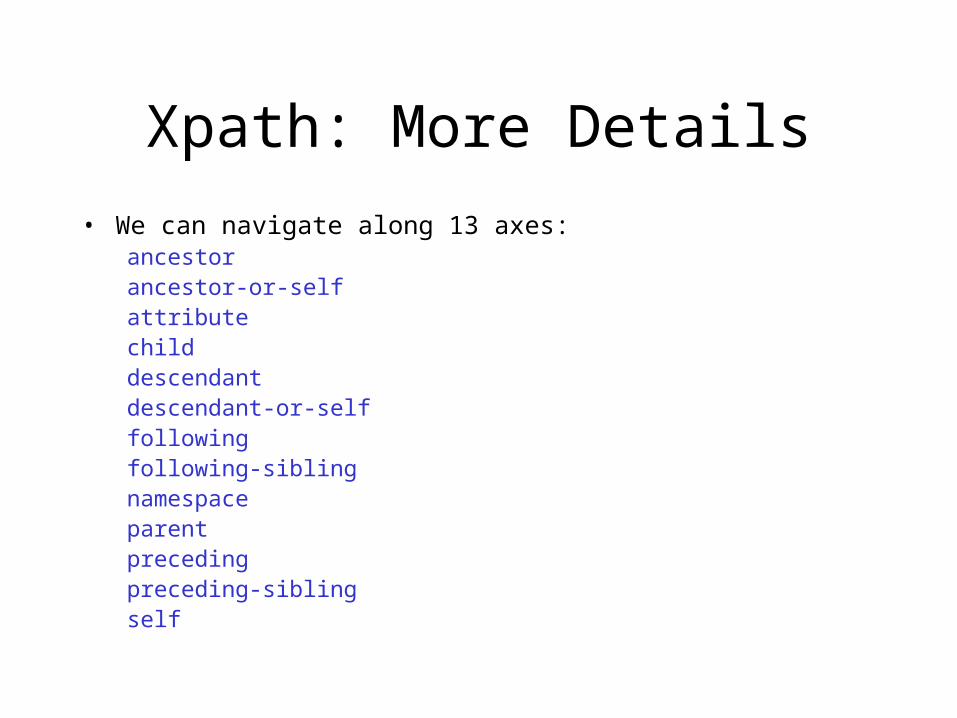
Xpath: More Details
• We can navigate along 13 axes:ancestorancestor-or-selfattributechilddescendantdescendant-or-selffollowingfollowing-siblingnamespaceparentprecedingpreceding-siblingself

Xpath: More Details
• Examples:– child::author/child:lastname =
author/lastname– child::author/descendant::zip = author//zip– child::author/parent::* = author/..– child::author/attribute::age = author/@age

XML-QL: A Query Language for XML
• http://www.w3.org/TR/NOTE-xml-ql (8/98)• Also:
– [Deutsch, Fernandez, Florescu, Levy, Suciu, 99]
• features:– regular path expressions– patterns, templates– Skolem Functions
• based on OEM data model

Pattern Matching in XML-QL
WHERE <book language=“french”> <publisher> <name> Morgan Kaufmann </name> </publisher> <author> $a </author> </book> in “www.a.b.c/bib.xml”CONSTRUCT $a
WHERE <book language=“french”> <publisher> <name> Morgan Kaufmann </name> </publisher> <author> $a </author> </book> in “www.a.b.c/bib.xml”CONSTRUCT $a
$a = a variable

Path Expressions in XML-QL
WHERE <book language=“french”> <publisher/name> Morgan Kaufmann </> <author> $a </> </> in “www.a.b.c/bib.xml”CONSTRUCT $a
WHERE <book language=“french”> <publisher/name> Morgan Kaufmann </> <author> $a </> </> in “www.a.b.c/bib.xml”CONSTRUCT $a
Note: </> abbreviates </book> or </result> or ...
Here: we use Xpath expressions; Original XML-QL: used math syntax

Simple Constructors in XML-QL
WHERE <book language = $l> <author> $a </> </> in “www.a.b.c/bib.xml”CONSTRUCT <result> <author> $a </> <lang> $l </> </>
WHERE <book language = $l> <author> $a </> </> in “www.a.b.c/bib.xml”CONSTRUCT <result> <author> $a </> <lang> $l </> </>
<result> <author>Smith</author><lang>English</lang></result><result> <author>Smith</author><lang>Mandarin</lang></result><result> <author>Doe</author><lang>English</lang></result>

Skolem Functions in XML-QL
WHERE <book language = $l> <author> $a </> </> in “www.a.b.c/bib.xml”CONSTRUCT <result> <author id=F($a)> $a</> <lang> $l </> </>
WHERE <book language = $l> <author> $a </> </> in “www.a.b.c/bib.xml”CONSTRUCT <result> <author id=F($a)> $a</> <lang> $l </> </>
<result> <author>Smith</author> <lang>English</lang> <lang>Mandarin</lang> </result><result> <author>Doe</author> <lang>English</lang> </result>

XQuery
• Based on Quilt (which is based on XML-QL)
• http://www.w3.org/TR/xquery/2/2001
• Xquery = XML-QL – patterns – Skolem + aggregates + duplicates + based on XML data model

XQuery
<result>
FOR $x in /bib/book
WHERE $x/year > 1995
RETURN <newtitle>
$x/title
</newtitle>
</result>

XQuery
• FOR $x in expr -- binds $x to each value in the list expr
• LET $x = expr -- binds $x to the entire list expr– Useful for common subexpressions and for
aggregations

XQuery
<big_publishers> FOR $p IN distinct(document("bib.xml")//publisher) LET $b := document("bib.xml")/book[publisher = $p] WHERE count($b) > 100 RETURN $p
</big_publishers>
distinct = a function that eliminates duplicatescount = a (aggregate) function that returns the number of elms

XQuery
Summary:
• FOR-LET-WHERE-RETURN = FLWR
FOR/LET Clauses
WHERE Clause
RETURN Clause
List of tuples
List of tuples
Instance of Xquery data model

Structural Recursion
Data as sets with a union operator:
{a:3, a:{b:”one”, c:5}, b:4} =
{a:3} U {a:{b:”one”,c:5}} U {b:4}

Structural Recursion
f(T1 U T2) = f(T1) U f(T2)f({L: T}) = f(T)f({}) = {}f(V) = if isInt(V) then {result: V} else {}
f(T1 U T2) = f(T1) U f(T2)f({L: T}) = f(T)f({}) = {}f(V) = if isInt(V) then {result: V} else {}
Example: retrieve all integers in the data
a a b
b c3
“one” 5
4result result result
3 5 4
standard textbook programming on trees

Structural Recursion
Example: increase all engine prices by 10%
f(T1 U T2) = f(T1) U f(T2)f({L: T}) = if L= engine then {L: g(T)} else {L: f(T)}f({}) = {}f(V) = V
f(T1 U T2) = f(T1) U f(T2)f({L: T}) = if L= engine then {L: g(T)} else {L: f(T)}f({}) = {}f(V) = V
g(T1 U T2) = g(T1) U g(T2)g({L: T}) = if L= price then {L:1.1*T} else {L: g(T)}g({}) = {}g(V) = V
g(T1 U T2) = g(T1) U g(T2)g({L: T}) = if L= price then {L:1.1*T} else {L: g(T)}g({}) = {}g(V) = V
engine body
part price
price price
part price
100
1000
100
1000
engine body
part price
price price
part price
110
1100
100
1000

XSL
• http://www.w3.org/TR/xslt.html11/99
• purpose: stylesheet specification language:– stylesheet: XML -> HTML– in general: XML -> XML

XSL Templates and Rules
• query = collection of template rules
• template rule = match pattern + template
<xsl:template> <xsl:apply-templates/> </xsl:template>
<xsl:template match = “/bib/*/title”> <result> <xsl:value-of/> </result></xsl:template>
<xsl:template> <xsl:apply-templates/> </xsl:template>
<xsl:template match = “/bib/*/title”> <result> <xsl:value-of/> </result></xsl:template>
Retrieve all book titles:

Flow Control in XSL
<xsl:template> <xsl:apply-templates/> </xsl:template>
<xsl:template match=“a”> <A><xsl:apply-templates/></A></xsl:template>
<xsl:template match=“b”> <B><xsl:apply-templates/></B></xsl:template>
<xsl:template match=“c”> <C><xsl:value-of/></C></xsl:template>
<xsl:template> <xsl:apply-templates/> </xsl:template>
<xsl:template match=“a”> <A><xsl:apply-templates/></A></xsl:template>
<xsl:template match=“b”> <B><xsl:apply-templates/></B></xsl:template>
<xsl:template match=“c”> <C><xsl:value-of/></C></xsl:template>
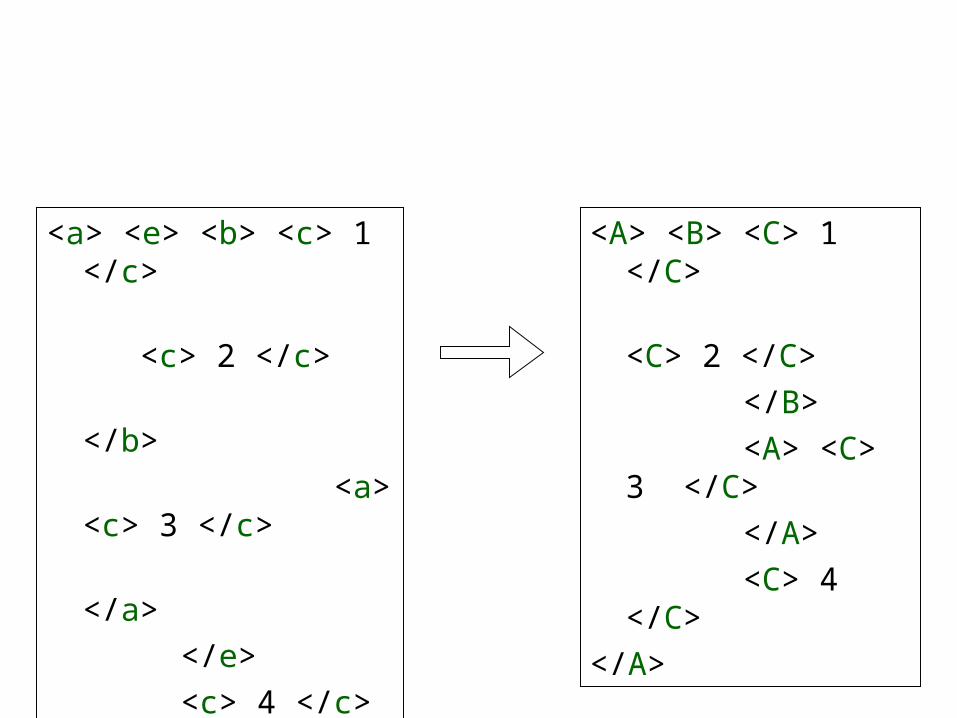
<a> <e> <b> <c> 1 </c>
<c> 2 </c>
</b>
<a> <c> 3 </c>
</a>
</e>
<c> 4 </c>
</a>
<A> <B> <C> 1 </C>
<C> 2 </C>
</B>
<A> <C> 3 </C>
</A>
<C> 4 </C>
</A>

XSL is Structural Recursion
Equivalent to:
f(T1 U T2) = f(T1) U f(T2)f({L: T}) = if L= c then {C: t} else L= b then {B: f(t)} else L= a then {A: f(t)} else f(t)f({}) = {}f(V) = V
f(T1 U T2) = f(T1) U f(T2)f({L: T}) = if L= c then {C: t} else L= b then {B: f(t)} else L= a then {A: f(t)} else f(t)f({}) = {}f(V) = V
XSL query = single functionXSL query with modes = multiple function

XSL and Structural Recursion
XSL:• trees only• may loop
Structural Recursion:• arbitrary graphs• always terminates
<xsl:template match = “e”> <xsl:apply-patterns select=“/”/></xsl:template>
<xsl:template match = “e”> <xsl:apply-patterns select=“/”/></xsl:template>
stack overflow on IE 5.0
add the following rule:

Summary of Query Languages
• Path navigation– Xpath: restricted regular path expressions
• Declarative languages:– XML-QL– Quilt/ Xquery
• Structural recursion:– UnQL– XSLT

Part 3Schemas
• Semistructured and XML data models
• Query languages
• Schemas
• Systems issues
• Conclusions

Schemas
• why ?– XML: to describe semantics– semistructured data: to improve processing
• what ?– semistructured data: foundational – XML: several concrete proposals

Schemas
• when ?– semistructured data, XML: a posteriori– RDBMS: a priori, to interpret binary data
• how ?– semistructured data: schema is independent – XML: schema is hardwired with the data

Outline
• schemas for semistructured data:– foundations– schema extraction
• schemas for XML:– DTD– XML-Schema

Schemas: An Example
&r1
&c1 &c2
&s2 &s3 &s6 &s7
&s10
companycompany
nameaddress name
url
address
“Widget” “Trenton” “Gadget”
“www.gp.fr”
“Paris”
&p2&p1 &p3
&s0 &s1 &s4 &s5 &s8 &s9
personperson
person
“Smith”
nameposition name phonename
position
“Manager” “Jones” “5552121” “Dupont” “Sales”
employeemanages
c.e.o.works-for works-for
works-for
c.e.o.
&a1
&a2 &a3
&a4&a5
&a6&a7
description
description
procurement salesrep
contact
task
eval1997
1998
“on target”
“below target”
Some database:
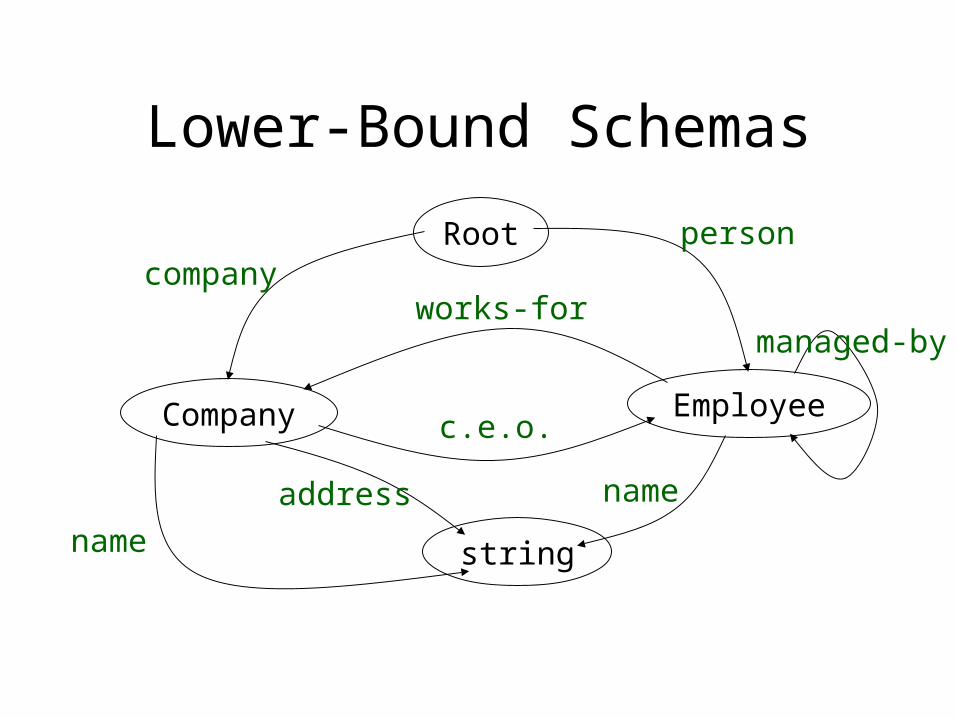
Lower-Bound Schemas
Root
Company Employee
string
companyperson
works-for
c.e.o.
address
name
managed-by
name
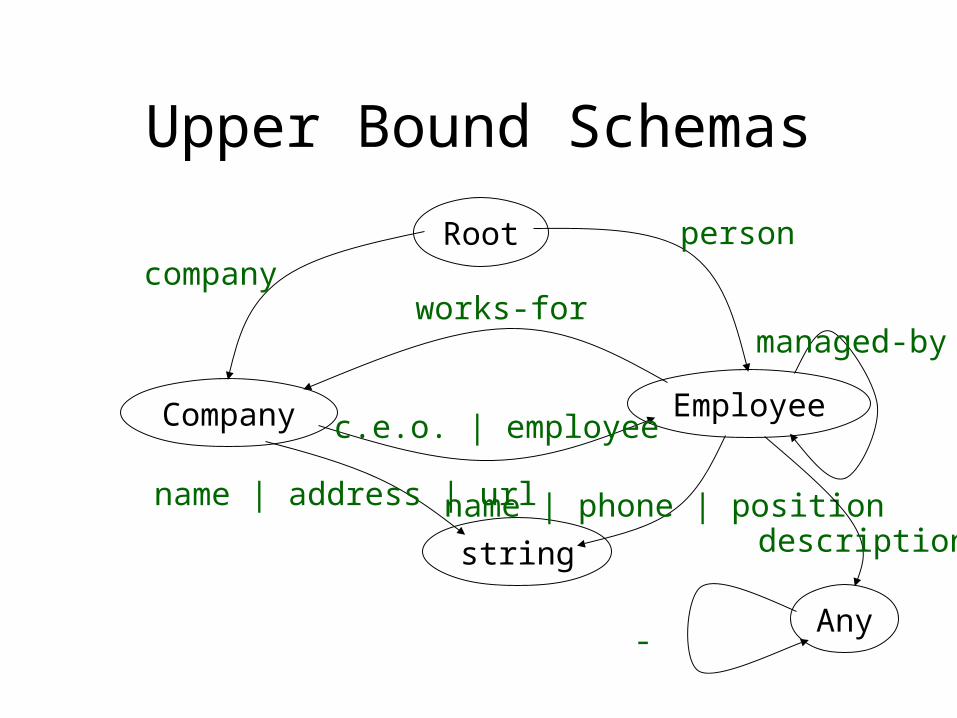
Upper Bound Schemas
Root
Company Employee
string
companyperson
works-for
c.e.o. | employee
name | address | url
managed-by
name | phone | position
Any
description
-

The Two Questions to Ask
Conformance: does that data conform to this schema ?
Classification: if so, then which objects belong to what classes ?

Graph Simulation
Definition Two edge-labeled graphs G1, G2
A simulation is a relation R between nodes:• if (x1, x2) in R, and (x1,a,y1) in G1,
then exists (x2,a,y2) in G2 (same label)
s.t. (y1,y2) in R
x1 x2
a
R
G1 G2
y1
a
Ry2
Note: a simulation can be efficiently computed [Henzinger, et a. 1995]

Using Simulation
Data graph D, schema S
• upper bound schema:– conformance: find simulation R from D to S– classification: check if (x,c) in R
• lower bound schema– conformance: find simulation R from S to D– classification: check if (c,x) in R
[Buneman, Davidson, Fernandez, Suciu 1997]

Example
&r1
&c1 &c2
&s2 &s3 &s6 &s7
&s10
companycompany
nameaddress name
url
address
“Widget” “Trenton” “Gadget”
“www.gp.fr”
“Paris”
&p2&p1 &p3
&s0 &s1 &s4 &s5 &s8 &s9
personperson
person
“Smith”
nameposition namephonename
position
“Manager” “Jones” “5552121” “Dupont” “Sales”
employeemanages
c.e.o.works-for works-for
works-forc.e.o.
&a1
&a2 &a3
&a4&a5
&a6&a7
description
description
procurement salesrep
contact
task
eval1997
1998
“on target”
“below target”
Root
Company Employee
string
company
person
works-for
c.e.o.
address
name
managed-by
name
Root
Company Employee
string
company
person
works-for
c.e.o. | employee
name | address | url
managed-by
name | phone | position
Any
description
-
DatabaseLower Bound Upper Bound
simulation: efficient technique for checking conformance to schema

Application 1: Improve Secondary Storage
Root
Company Employee
string
company
person
works-for
c.e.o.
address
name
managed-by
name
o i d n a m e a d d r e s s c . e . o .… … … …… … … …
Company
o i d n a m e m a n a g e d - b y w o r k s - f o r… … … …… … … …
Employee
Store rest in overflow graph
Lower-bound schema

Application 2: Query Optimization
Bib
paper book
yearjournal
title
int string string
addressauthor
title
zip city street
lastname
firstname
string string string string string
string
select X.titlefrom Bib._ Xwhere X.*.zip = “12345”
select X.titlefrom Bib._ Xwhere X.*.zip = “12345”
select X.titlefrom Bib.book Xwhere X.address.zip = “12345”
select X.titlefrom Bib.book Xwhere X.address.zip = “12345”
Upper-bound schema[Fernandez, Suciu 1998]

Schema Extraction(From Data)
Problem statement
• given data instance D
• find the “most specific” schema S for D
In practice: S too large, need to relax
[Nestorov, Abiteboul, Motwani 1998]

Schema Extraction: Sample Data
&r
&p8&p1 &p2 &p3 &p4 &p5 &p6 &p7
&c
company
employeeemployee
employeeemployee employee employee
employeeemployee
worksfor
worksfor
worksforworksforworksfor
worksforworksfor
worksfor
manages
manages
manages
manages
managedby
managedbymanagedby
manages
managedby
managedby

Lower Bound Schema Extraction
Root&r
Bosses&p1,&p4,&p6
Regulars&p2,&p3,&p5,&p7,&p8
Company&c
company employee
manages
managedby
worksfor
worksfor
employee

Upper Bound Schema Extraction: Data Guides
Root&r
Employees&p1,&p1,&p3,P4
&p5,&p6,&p7,&p8
Bosses&p1,&p4,&p6
Regulars&p2,&p3,&p5,&p7,&p8
Company&c
company
employee
managesmanagedby
manages
managedby
worksfor
worksfor
worksfor

Schemas in XML
• Document Type Definition (DTD)
• XML Schema

Document Type Definition: DTD
• part of the original XML specification
• an XML document may have a DTD
• terminology for XML:– well-formed: if tags are correctly closed– valid: if it has a DTD and conforms to it
• validation is useful in data exchange

DTDs as Grammars
<!DOCTYPE paper [ <!ELEMENT paper (section*)> <!ELEMENT section ((title,section*) | text)> <!ELEMENT title (#PCDATA)> <!ELEMENT text (#PCDATA)>]>
<!DOCTYPE paper [ <!ELEMENT paper (section*)> <!ELEMENT section ((title,section*) | text)> <!ELEMENT title (#PCDATA)> <!ELEMENT text (#PCDATA)>]>
<paper> <section> <text> </text> </section> <section> <title> </title> <section> … </section> <section> … </section> </section></paper>

DTDs as Schemas
Not so well suited:• impose unwanted constraints on order
<!ELEMENT person (name,phone)>
• references cannot be constrained
• can be too vague: <!ELEMENT person ((name|phone|email)*)>

XML Schemas
• http://www.w3.org/TR/xmlschema-1/10/2000
• generalizes DTDs• uses XML syntax• two documents: structure and datatypes
– http://www.w3.org/TR/xmlschema-1– http://www.w3.org/TR/xmlschema-2
• XML-Schema is very complex– often criticized– some alternative proposals

XML Schemas<xsd:element name=“paper” type=“papertype”/>
<xsd:complexType name=“papertype”>
<xsd:sequence>
<xsd:element name=“title” type=“xsd:string”/>
<xsd:element name=“author” minOccurs=“0”/>
<xsd:element name=“year”/>
<xsd: choice> < xsd:element name=“journal”/>
<xsd:element name=“conference”/>
</xsd:choice>
</xsd:sequence>
</xsd:element>
DTD: <!ELEMENT paper (title,author*,year, (journal|conference))>

Elements v.s. Types in XML Schema
<xsd:element name=“person”> <xsd:complexType> <xsd:sequence> <xsd:element name=“name” type=“xsd:string”/> <xsd:element name=“address” type=“xsd:string”/> </xsd:sequence> </xsd:complexType></xsd:element>
<xsd:element name=“person”> <xsd:complexType> <xsd:sequence> <xsd:element name=“name” type=“xsd:string”/> <xsd:element name=“address” type=“xsd:string”/> </xsd:sequence> </xsd:complexType></xsd:element>
<xsd:element name=“person” type=“ttt”><xsd:complexType name=“ttt”> <xsd:sequence> <xsd:element name=“name” type=“xsd:string”/> <xsd:element name=“address” type=“xsd:string”/> </xsd:sequence></xsd:complexType>
<xsd:element name=“person” type=“ttt”><xsd:complexType name=“ttt”> <xsd:sequence> <xsd:element name=“name” type=“xsd:string”/> <xsd:element name=“address” type=“xsd:string”/> </xsd:sequence></xsd:complexType>
DTD: <!ELEMENT person (name,address)>

• Types:– Simple types (integers, strings, ...)– Complex types (regular expressions, like in DTDs)
• Element-type-element alternation:– Root element has a complex type– That type is a regular expression of elements– Those elements have their complex types...– ...– On the leaves we have simple types

Local and Global Types in XML Schema
• Local type: <xsd:element name=“person”>
[define locally the person’s type] </xsd:element>
• Global type: <xsd:element name=“person” name=“ttt”/>
<xsd:complexType name=“ttt”> [define here the type ttt] </xsd:complexType>
Global types: can be reused in other elements

Local v.s. Global Elements inXML Schema
• Local element: <xsd:complexType name=“ttt”>
<xsd:sequence> <xsd:element name=“address” type=“...”/>... </xsd:sequence> </xsd:complexType>
• Global element: <xsd:element name=“address” type=“...”/>
<xsd:complexType name=“ttt”> <xsd:sequence> <xsd:element ref=“address”/> ... </xsd:sequence> </xsd:complexType>
Global elements: like in DTDs

Regular Expressions in XML Schema
Recall the element-type-element alternation: <xsd:complexType name=“....”>
[regular expression on elements] </xsd:complexType>
Regular expressions:• <xsd:sequence> A B C </...> = A B C• <xsd:choice> A B C </...> = A | B | C• <xsd:group> A B C </...> = (A B C)• <xsd:... minOccurs=“0” maxOccurs=“unbounded”> ..</...> = (...)*• <xsd:... minOccurs=“0” maxOccurs=“1”> ..</...> = (...)?

Summary of XML Schema
• Formal Expressive Power:– Can express precisely the regular tree
languages (over unranked trees)
• Lots of other stuff– Some form of inheritance– A “null” value– Large collection of data types

Summary of Schemas
• in SS data: – graph theoretic– data and schema are decoupled– used in data processing
• in XML– from grammar to object-oriented– schema wired with the data– emphasis on semantics for exchange

Part 4Systems Issues
• Semistructured and XML data models
• Query languages
• Schemas
• Systems issues
• Conclusions

Systems Issues
• XML publishing (relational XML)
• XML storage (XML relational)
• XML processing (XML XML)
• XML compression (XML )
• XML indexing (XML )

XML Publishing
Today:• legacy data
– fragmented into many flat relations– 3rd normal form– schema is proprietary
• XML data– nested– un-normalized– schema designed by agreement

XML Publishing
• XML = view of Relational/OO/OR sources– Virtual view = mediator based publishing– Materialized view = warehouse based publishing
• Two systems:– SilkRoute
• Virtual [Fernandez, Suciu, Tan, 2000]
• Materialized [Fernandez, Morishima, Suciu, 2001]
– Experanto• Virtual [Shanmugasundaram, Tufte, DeWitt, Naughton, Maier, 2000]
• Materalized [Shanmugasundaram, Shekita, Barr, Carey, Lindsay, Pirahesh, Reinwald, 2000]

XML Publishing in SilkRoute
• relational database:
• virtual XML view:
<store> <name> n1 </name> <book> ... </book> <book> ... </book> ... </store> <store> <name>n2 </name> <book> ... </book> <book> ... </book> …</store>
s i d n a m e… …… …
Stores i d b i d… …… …
SBb i d t i t l e… …… …
Book

XML Publishing in SilkRoute
• specify mediator declaratively (a view):
from Store, SB, Bookwhere Store.sid=SB.sid and SB.bid=Book.bidconstruct <store ID=f(Store.sid)> <name> Store.name </name> <book> Book.title </book> </store>
from Store, SB, Bookwhere Store.sid=SB.sid and SB.bid=Book.bidconstruct <store ID=f(Store.sid)> <name> Store.name </name> <book> Book.title </book> </store>

XML Publishing in SilkRoute
• users ask XML-QL queries:– find stores who sell “The Calculus”
where <store> <name> $n </name> <book> The Calculus </book> <store>construct <result> $n </result>
where <store> <name> $n </name> <book> The Calculus </book> <store>construct <result> $n </result>

XML Publishing in SilkRoute
• system composes query with view:
from Store, SB, Bookwhere Store.sid=SB.sid and SB.bid=Book.bid and Book.title=“The Calculus”construct <result> Store.name </result>
from Store, SB, Bookwhere Store.sid=SB.sid and SB.bid=Book.bid and Book.title=“The Calculus”construct <result> Store.name </result>

XML Storage
• Text file (XML)
• Use generic schema– [Florescu, Kossman 1999]
• Use DTD to derive schema– [Shanmugasundaram, et al. 1999]
• Use data mining to derive schema– [Deutsch, Fernandez, Suciu 1999]
• Build special purpose repository

XML Storage: Text File
• advantages– simple– less space than database !!!– reasonable clustering
• disadvantage– no updates– require special purpose query processor

&o1
&o3
&o2
&o4 &o5
paper
title author authoryear
&o6
“The Calculus” “…” “…” “1986”
XML Stoarge: Ternary Relation
[Florescu, Kossman 1999]
S o u r c e L a b e l D e s t
& o 1 p a p e r & o 2& o 2 t i t l e & o 3& o 2 a u t h o r & o 4& o 2 a u t h o r & o 5& o 2 y e a r & o 6
N o d e V a l u e
& o 3 T h e C a l c u l u s& o 4 …& o 5 …& o 6 1 9 8 6
Ref
Val

XML Storage: DTD to Schema
• DTD:
• Relational schema:Employee(eid, name, address)
Address(aid, eid, street, city, state, zip)
<!ELEMENT employee (name, address, project*)><!ELEMENT address (street, city, state, zip)>
<!ELEMENT employee (name, address, project*)><!ELEMENT address (street, city, state, zip)>
[Christophides, Abiteboul, Cluet, Scholl 1994]
[Shanmugasundaram, Tufte, He, Zhang, DeWitt, Naughton 1999]

XML Storage: Data Mining to Schema
paperpaper paper
paper
authorauthor author author author
titletitle title title
year
fn fn fn fn lnlnlnln
a u t h o r t i t l eX X
f n 1 l n 1 f n 2 l n 2 t i t l e y e a r
X X X X X -X X - - X XX X - - X -
Paper1
Paper2
[Deutsch, Fernandez, Suciu 1999]

Query Evaluation
• Stream XML processing– Xscan
• [Halevy, Ives]
– Niagara • [Shanmugasundaram, Tufte, DeWitt, Naughton, Maier 2000]• [Chen, DeWitt, Tian, Wang, 2000]
• XML updates [Halevy, Ives, Tatarinov, Weld, 2001]
• Query optimization [McHugh, Widom 99]

XScan
• Store and query approach:– Store XML on disk, then index & query – Cannot amortize storage costs
• Streaming data approach (XScan):– Read & parse – Track nodes by ID Index XML graph structure

XScan
• Illustrated here: pattern matching• XML-QL pattern:
• Becomes: $x = (root)/doc/person
$n = $x/name $a = $x/address $s = $a/street $z = $a/zip
<doc/person> <name> $n </> <address> <street> $s </> <zip> $z </> </>
</>
<doc/person> <name> $n </> <address> <street> $s </> <zip> $z </> </>
</>

XScan
• Built a tree of binding tables:$x
elm1
elm2
...
$n $a
$a$n
Saves joinsCan free space when not needed

Compression: The Problem
• XML for exchange (space or time)
• but XML is verbose
• users prefer application specific formats:– Web Server Logs– EMBL– G2
• is XML doomed to fail ?

An Example:Web Server Logs
202.239.238.16|GET / HTTP/1.0|text/html|200|1997/10/01-00:00:02|-|4478|-|-|http://www.net.jp/|Mozilla/3.1[ja](I)202.239.238.16|GET / HTTP/1.0|text/html|200|1997/10/01-00:00:02|-|4478|-|-|http://www.net.jp/|Mozilla/3.1[ja](I)
<apache:entry>
<apache:host> 202.239.238.16 </apache:host>
<apache:requestLine> GET / HTTP/1.0 </apache:requestLine>
<apache:contentType> text/html </apache:contentType>
<apache:statusCode> 200</apache:statusCode>
<apache:date> 1997/10/01-00:00:02</apache:date>
<apache:byteCount> 4478</apache:byteCount>
<apache:referer> http://www.net.jp/ </apache:referer>
<apache:userAgent> Mozilla/3.1$[$ja$]$(I)</apache:userAgent>
</apache:entry>
<apache:entry>
<apache:host> 202.239.238.16 </apache:host>
<apache:requestLine> GET / HTTP/1.0 </apache:requestLine>
<apache:contentType> text/html </apache:contentType>
<apache:statusCode> 200</apache:statusCode>
<apache:date> 1997/10/01-00:00:02</apache:date>
<apache:byteCount> 4478</apache:byteCount>
<apache:referer> http://www.net.jp/ </apache:referer>
<apache:userAgent> Mozilla/3.1$[$ja$]$(I)</apache:userAgent>
</apache:entry>
ASCII File 15.9 MB (gzipped 1.6MB):
XML-ized inflates to 24.2 MB (gzipped 2.1MB):

XMill
• [Liefke and Suciu’2000]
• specialized compressor for XML data
• makes XML look “small”
• www.research.att.com/sw/tools/xmill
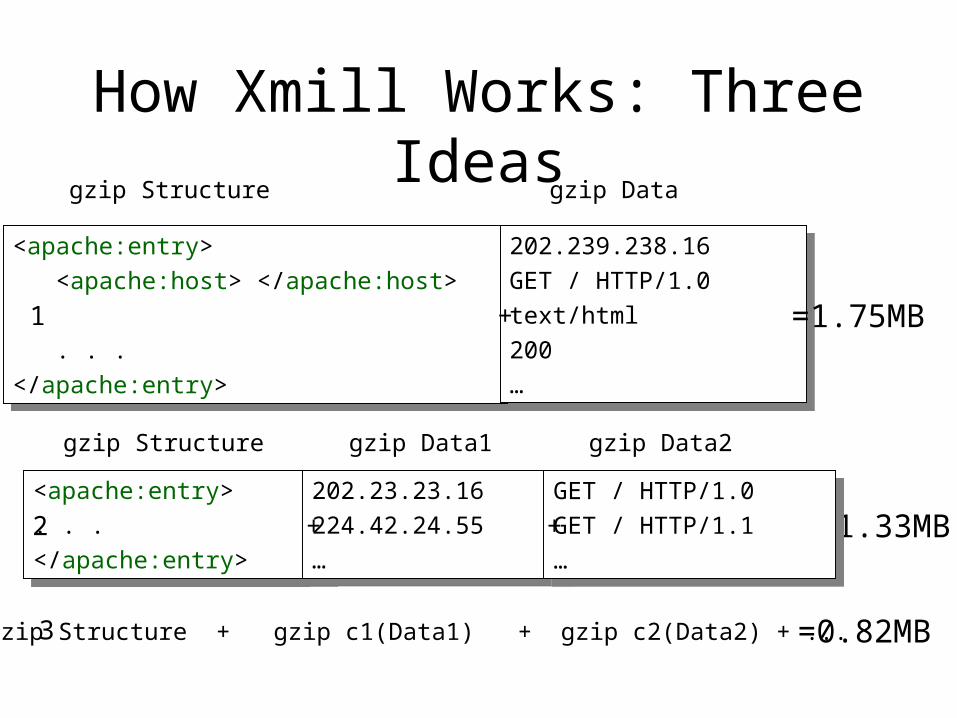
How Xmill Works: Three Ideas
<apache:entry>
<apache:host> </apache:host>
. . .
</apache:entry>
<apache:entry>
<apache:host> </apache:host>
. . .
</apache:entry>
202.239.238.16
GET / HTTP/1.0
text/html
200
…
202.239.238.16
GET / HTTP/1.0
text/html
200
…
gzip Structure gzip Data
=1.75MB+1
<apache:entry>
. . .
</apache:entry>
<apache:entry>
. . .
</apache:entry>
202.23.23.16
224.42.24.55
…
202.23.23.16
224.42.24.55
…
gzip Structure gzip Data1
=1.33MB+2GET / HTTP/1.0
GET / HTTP/1.1
…
GET / HTTP/1.0
GET / HTTP/1.1
…
gzip Data2
+
3 gzip Structure + gzip c1(Data1) + gzip c2(Data2) + ... =0.82MB
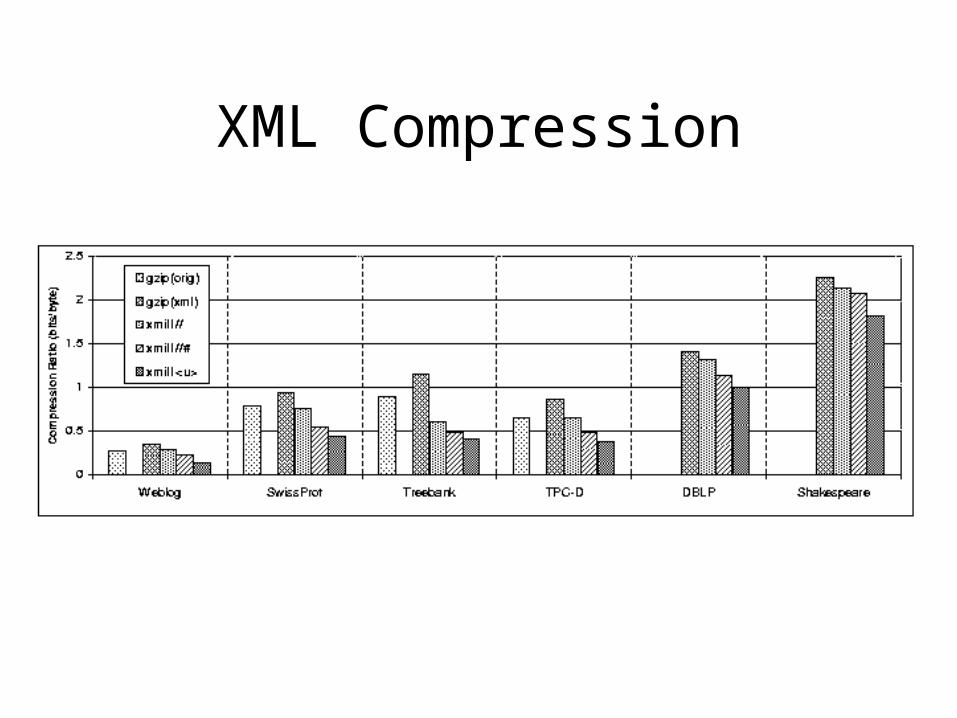
XML Compression
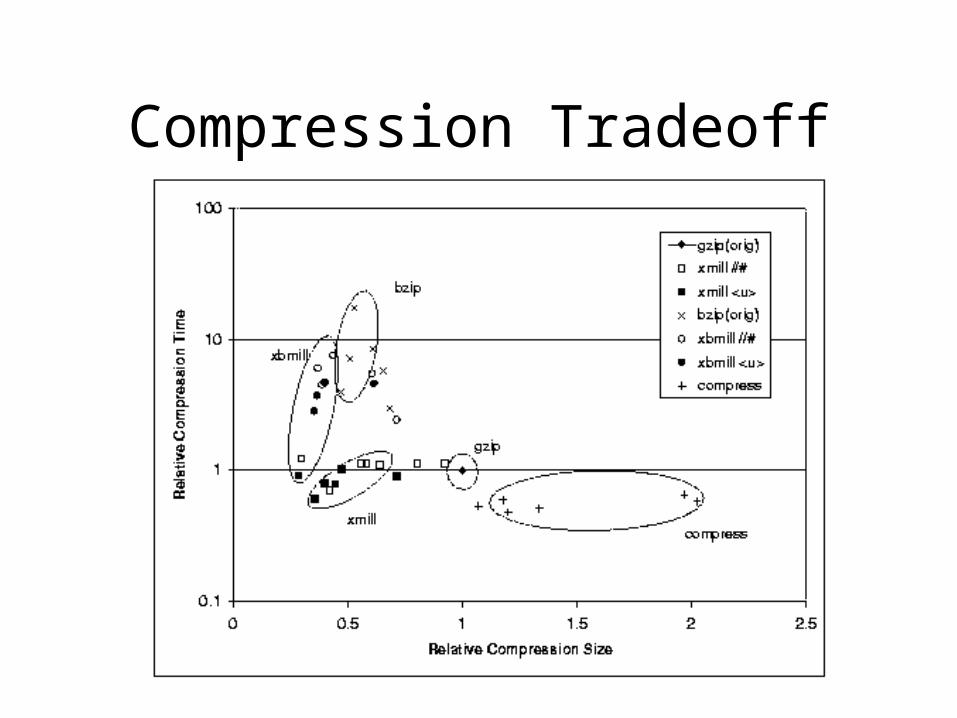
Compression Tradeoff

Indexing Semistructured Data
• coercions: 1995 v.s. “1995”
• regular path expressions– data guides [Goldman, Widom, 1997]– T-indexes [Milo, Suciu, 1999]

Indexing All Paths in the Data1
2 3 4 5 6
7 8 9 10 11 12 13
t t t t t
a b a c a d a a b
Semistructured Data
1
2 3 4 5 6
7 8 10 12 13 7 13 9 11
t
ab c
d
Data Guide
1
2 3 4 5 6
7 13 8 10 12 9 11
t
aa c db
T-Index

Summary of Systems
• XML processing– With relational engines– With XML engines
• Mapping XML to relations is still not well understood
• Indexing work is mostly missing

Part 5Conclusions
• Semistructured and XML data models
• Query languages
• Schemas
• Systems issues
• Conclusions

Summary
• XML = what is out there
• semistructured data = what we can process
• paradigm shift, for both Web and db
• covered in tutorial:– data models, queries, schemas

Current and Future Technologies
• Web applications possible today:– export relational data to XML (e.g. Oracle)– import XML into applications (DOM)
• Web applications in the future:– mediator technology (XML view)– store/process native XML data– mine/analyze XML

Why This Is Cool for Database Researchers
• put to work what you teach in CS101 !– tree traversals (structural recursion, XSL)– automata theory (DTD’s, path expressions)– graph theory (simulation)
• adapt old DB techniques to novel data
• save the trees: from fax to XML
The End

Further Readings
www. w3.org/XML
http://data.cs.washington.edu/xml/
http://cm.bell-labs.com/cm/cs/who/wadler/xml/
http://www.cs.washington.edu/homes/suciu
Abiteboul, Buneman, Suciu
Data on the Web: From Relational to Semistructured to XML
Morgan Kaufmann, 1999