manual_rb
TRANSCRIPT

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 1/344
1
Introducción al R
Juan Carlos Correa Morales y Nelfi González
Posgrado en Estadística
Universidad Nacional-Sede Medellín
2002

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 2/344
2
PREFACIO 8
CAPÍTULO 1: INTRODUCCIÓN 9
1.1. OPERANDO R 91.1.1 I NICIACIÓN DE UNA SESIÓN EN R 91.1.2 TERMINACIÓN DE UNA SESIÓN EN R 101.2. EJECUCIÓN DE COMANDOS DESDE UN ARCHIVO EXTERNO 10 1.3. EJECUCIÓN DE FUNCIONES ESPECIALES 11
CAPÍTULO 2: MANEJO DE DATOS EN R 14
2.1. ENTRADA Y LECTURA DE DATOS 14 2.1.1 FUNCIÓN SCAN 14 2.1.2 FUNCIÓN READ.TABLE 27 2.1.3 FUNCIÓN READ.FWF 35 2.1.4 E NTRANDO DATOS DESDE EL TECLADO 41 2.2. DATOS FALTANTES 47 2.3. FUNCIONES DE ESCRITURA Y EXPORTACIÓN DE DATOS QUE ESTÁN EN R 492.3.1 FUNCIÓN DUMP 49 2.3.2 FUNCIÓN WRITE (ESCRIBIENDO UNA MATRIZ A UN ARCHIVO EXTERNO) 54
2.3.3 FUNCIÓN SINK (E NVIANDO RESULTADOS A UN ARCHIVO DE TEXTO) 562.4. CONSTRUCCIÓN, LECTURA Y ESCRITURA DE TABLAS DE CONTINGENCIA
CATEGÓRICAS 59 2.4.1 FUNCIÓN FTABLE 59
CAPÍTULO 3: MANIPULACIÓN DE DATOS 74
3.1. OPERADORES 74 3.1.1 FUNCIONES QUE PRODUCEN ESCALARES 79 3.1.2 FUNCIONES PARA REDONDEO DE NÚMEROS 81
3.1.3 FUNCIONES RELACIONADAS CON DISTRIBUCIONES 83 3.2. EJECUCIONES CONDICIONALES Y LOOPS (FLUJOS DE CONTROL) 893.2.1 CÓMO PARAR CICLOS: LA FUNCIÓN STOP() 99 3.3. OBJETOS EN R 1003.3.1 FUNCIÓN APPEND 100 3.3.2 FUNCIÓN MATRIX, IS.MATRIX, AS.MATRIX 105 3.3.3 FUNCIÓN DATA.MATRIX 110

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 3/344
3
3.3.4 FUNCIÓN LIST 112 3.3.5 FUNCIÓN UNLIST 117
3.3.6 FUNCIÓN DATA.FRAME 120 3.3.7 R EMOVIENDO OBJETOS 124
CAPÍTULO 4: CREACIÓN DE NUEVAS FUNCIONES EN R 125
4.1. PROBLEMAS DE MEMORIA EN R 132
CAPÍTULO 5: MATRICES 133
5.1. OPERACIONES BÁSICAS CON MATRICES 133
5.2. TRANSPOSICIÓN DE UNA MATRIZ 134 5.3. PRODUCTOS CRUZADOS 135 5.4. DESCOMPOSICIÓN SVD 135 5.5. DESCOMPOSICIÓN QR 136 5.6. PEGANDO MATRICES 141 5.7. DESCOMPOSICIÓN DE CHOLESKY 143 5.8. CÁLCULO DE VALORES Y VECTORES PROPIOS 143 5.9. CREACIÓN DE MATRICES DIAGONALES 145 5.10. PRODUCTO K RONECKER 146 5.11. INVERSA DE UNA MATRIZ 147 5.12. ORDENANDO UN VECTOR 148
5.13. APLICANDO FUNCIONES SOBRE LAS COMPONENTES DE UNA MATRIZ 149 5.14. FUNCIONES COLSUMS, ROW SUMS, COL M EANS, ROW M EANS 156
CAPÍTULO 6: INTRODUCCIÓN 160
6.1. FUNCIONES PARA ESPECIFICAR DEVICES 160 6.2. ALGUNOS PARÁMETROS PARA GRAFICAR EN R 1606.3. GRÁFICOS UNIDIMENSIONALES 161 6.4. GRÁFICOS BIDIMENSIONALES 161 6.5. GRÁFICOS TRIDIMENSIONALES 161
6.6. MÚLTIPLES GRÁFICOS POR PÁGINA (EJEMPLOS) 1626.7. FUNCIÓN PERSP 163 6.8. FUNCIÓN CONTOUR 167 6.9. FUNCIÓN IMAGE 171 6.10. FUNCIÓN MATPLOT 175 6.11. IMPRIMIENDO GRÁFICOS 178

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 4/344
4
CAPÍTULO 7: GRÁFICOS PARA UNA VARIABLE 179
7.1. FUNCIÓN HIST: HISTOGRAMAS 179 7.2. FUNCIÓN BOXPLOT 185 7.3. FUNCIÓN STEM 189 7.4. FUNCIÓN QQNORM : GRÁFICOS CUANTIL - CUANTIL 191
CAPÍTULO 8: GRÁFICOS MULTIVARIABLES 194
8.1. FUNCIÓN PAIRS : MATRICES DE DISPERSIÓN 194 8.2. FUNCIÓN PLOT : GRÁFICOS DE DISPERSIÓN 197 8.3. FUNCIÓN STARS: GRÁFICO DE ESTRELLAS 199
8.4. GRÁFICAS TRELLIS (DE R EJILLA) 205
CAPÍTULO 9: MODELOS ESTADÍSTICOS EN R 211
9.1. ESTADÍSTICA BÁSICA 211 9.1.1 MEAN(): 2119.1.2 WEIGHTED.MEAN(): 2129.1.3 COR(), VAR() Y COV(): 2139.1.4 MEDIAN(): 2159.1.5 MAX(), MIN(): 216
9.1.6 PMAX(), PMIN(): 2169.1.7 QUANTILE(): 2179.1.8 RANGE(): 2189.1.9 RANK(): 2189.1.10 SUMMARY(): 2199.2. FÓRMULAS EN R 2219.2.1 I NTERACCIÓN Y E NCAJAMIENTO 222 9.2.2 FUNCIÓN FORMULA 223 9.3. FUNCIONES PARA PRUEBAS ESTADÍSTICAS 227 9.3.1 TEST DE NORMALIDAD: FUNCIÓN SHAPIRO.TEST 228 9.4. R EGRESIÓN LINEAL CLÁSICA 229 9.4.1 FUNCIÓN LM: 2309.4.2 FUNCIÓN LSFIT: 2349.4.3 FUNCIÓN LS.DIAG: 2359.4.4 FUNCIÓN STEP: 2419.4.5 MEDIDAS DE I NFLUENCIA 246 9.5. MÍNIMOS CUADRADOS NO LINEALES: FUNCIÓN NLS 249

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 5/344
5
9.6. ANÁLISIS MULTIVARIABLE 253 9.6.1 DISCRIMINACIÓN, FUNCIÓN: LDA 254
9.6.2 FUNCIÓN MAHALANOBIS 258 9.6.3 FUNCIÓN COV.WT 260 9.6.4 FUNCIÓN PRCOMP 261 9.6.5 FUNCIÓN BIPLOT.PRINCOMP 266 9.6.6 FUNCIÓN BIPLOT 267 9.6.7 FUNCIÓN SCREEPLOT 270 9.6.8 FUNCIÓN FACTANAL 271 9.6.9 FUNCIÓN CANCOR 277 9.6.10 FUNCIÓN DIST 281 9.6.11 FUNCIÓN KMEANS 283 9.6.12 FUNCIÓN HCLUST 287 9.6.13 FUNCIÓN CUTREE 292 9.7. ANÁLISIS DE DATOS CATEGÓRICOS 306 9.7.1 FUNCIÓN CUT: 3069.7.2 FUNCIÓN TABLE: 3099.7.3 FUNCIÓN LEVELS 309 9.7.4 FUNCIÓN FACTOR 309 9.7.5 FUNCIÓN BINOM.TEST: 3119.7.6 FUNCIÓN LOGLIN 3159.7.7 FUNCIÓN SPLIT 319 9.8. MODELO LINEAL GENERALIZADO: FUNCIÓN GLM 323
9.8.1 FUNCIÓN FAMILY 331 9.9. ANÁLISIS DE VARIANZA: FUNCIÓN AOV 333
CAPÍTULO 10: APÉNDICE: DATOS 338
10.1. DATOS DE VELOCIDADES DE AUTOS 338 10.2. DATOS DE PRECIOS DE CARROS R EANULT 4 Y 12 338 10.3. DATOS DE LAS PRUEBAS NACIONALES DEL ICFES 339
CAPÍTULO 11: REFERENCIAS 344

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 6/344
6
Prefacio
Estas notas son para uso local en la Universidad Nacional-Sede Medellín y se realizaron
para motivar el uso del programa R entre los estudiantes del posgrado de estadística. El
programa R es una versión del programa S creado en los laboratorios ATT-Bell. Ha tenido
la ventaja de contar con el apoyo de famosos estadísticos y científicos tales como Hastie,
Tibshirani, Friedman, Ripley, Venables, etc. Muchos han contribuído con nuevas y
novedosas rutinas para implementar nueva metodología estadística, lo que lo coloca como
uno de los programas de avanzada para investigadores en estadística. Fué escrito básicamente en Scheme con la implementación de algunas rutinas provenientes de Fortran.
La filosofía de programación es muy similar a la del lenguaje C.
Más que un programa de estadística R puede ser considerado un lenguage de alto nivel. Es
completamente estructurado. La programación es dinámica ya que el uso de la memoria y
el dimensionamiento de matrices es ejecutado automáticamente. Permite definir funciones
que pasan a ser parte del sistema automáticamente y pueden ser llamadas en posterioressesiones sin tener que definirlas nuevamente. R puede pensarse, aunque es mucho más,
como un lenguage matricial. Las siguientes son unas ventajas:
Opera con objetos,
Posee una amplia base de operadores,
Usa operadores que se aplican a matrices completas, por ejemplo, si A y B son matrices
las siguientes operaciones son posibles: A B+ , etc.
Es interactivo,
Produce gran variedad de gráficos de excelente calidad.
R es un paquete estadístico de dominio público, pero esto no quiere decir que su calidad
sea baja, por el contrario, su calidad es muy superior a muchos paquetes estadísticos que

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 7/344
7
cuestan una pequeña fortuna. Este paquete ha tenido un desarrollo vertiginoso debido al
entusiasmo de un grupo de personas que trabajan en estadística, que no solo son
estadísticos prestantes sino que también aportan sus conocimientos a la comunidad. El
programa se puede obtener, para diferentes plataformas, de la siguiente dirección en
Internet
http cran r project org: // . .
Los orígenes de este programa se remontan a finales de la década de los 80, cuando salió el
programa S + y las versiones comerciales de él, en especial el S-Plus. Realmente se trataba
de una emulación escrita en Scheme que no tuvo un desarrollo grande en sus primeros años.
A mediados de los 90 se realiza una transacción comercial que generó cierto resquemor
entre la comunidad de usuarios del S-Plus, StatSci Inc. fue vendida a Mathsoft Inc. Esta
última empresa se ha caracterizado por su agresividad comercial y StatSci se caracterizó
por ser una empresa abierta a la comunidad científica. Esto motivó que algunos miraran
hacia otro lado. En Internet se conseguía R (versión 0.6), un programa altamente inestable,
pero estaba disponible y además era de código abierto y altamente compatible con S-Plus
(versión 3.1). La migración fue inmediata y en término de dos meses se habían liberadovarias modificaciones del programa empujadas por Brian Ripley, un profesor de Oxford,
experto en simulación y estadística espacial, cuyos aportes al S-Plus habían sido
significativos. En la versión de R 0.64 el programa ya era bastante estable y prácticamente
era igual al S-Plus 3.1.
Una de las características que hizo que la comunidad estadística en la década de los 80
mirara el S-Plus, era su capacidad gráfica. Los gráficos producidos por este programa son
de altísima calidad (calidad de publicación) y se pueden realizar gráficos de una manera
muy simple. Otra característica es su orientación a objetos. Los creadores de S + en los
laboratorios de la AT&T siempre defendieron la idea que este era un lenguaje para realizar
análisis de datos y no un paquete estadístico.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 8/344
8
Parte IManejo de Datos

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 9/344
9
Capítulo 1: Introducción
1.1. Operando R
1.1.1 Iniciación de una sesión en R
En el ícono de R oprima la tecla derecha del mouse dos veces. El programa ejecuta y
aparece la pantalla de comandos encabezada por lo siguiente:
R : Copyright 2001, The R Development Core Team
Version 1.3.1 (2001-08-31)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type `license()' or `licence()' for distribution details.
R is a collaborative project with many contributors.
Type `contributors()' for more information.
Type `demo()' for some demos, `help()' for on-line help, or
`help.start()' for a HTML browser interface to help.
Type `q()' to quit R.
[Previously saved workspace restored]
>
y el cursor se ubicará en esa línea. El programa espera que usted le dé los comandos
respectivos. El símbolo $>$ que aparece al lado izquierdo es el prompt. Ud. no lo tiene que

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 10/344
10
escribir y lo seguiremos escribiendo para conservar uniformidad con los otros textos sobre
R.
1.1.2 Terminación de una sesión en R
Para finalizar una sesión en R selecciona en la ventana el comando de terminar o escriba el
siguiente comando:
> q()
Nota: Es importante notar que para el programa las mayúsculas son diferentes a las
minúsculas, y el comando q() es diferente del comando Q(). Una vez ud. decide
terminar su sesión en R el programa le presenta una ventana en la cual le pregunta si desea
guardar el trabajo ralizado (los comandos, archivos usados y las funciones creadas), si ud.
le responde que no, todo el trabajo realizado se pierde, en caso contrario, su trabajo se
guarda y puede retomarlo en el mismo punto donde lo deja.
Consejo: Una buena alternativa es abrir un editor de textos e ir guardando los comandos
que ud. ha ido utilizando. Guardarlos como un archivo plano o de texto nos permite replicar
el trabajo en caso necesario. Usted también puede ir salvando su espacio de trabajo, cosa
que puede ser útil cuando se trabaja con varios proyectos que manejen diferentes conjuntos
de funciones y datos.
1.2. Ejecución de comandos desde un archivo externo
Cuando el análisis que vamos a realizar requiere muchos comandos, es conveniente
editarlos y guardarlos primero en un archivo ASCII, digamos comandos.txt , la extensión

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 11/344
11
.txt es solo con el fin de enfatizar que el archivo es en ASCII, ellos pueden ser ejecutados
en cualquier momento en una sesión de R simplemente escribiendo el comando
> source(“comandos.txt”)
Obviamente, deberá indicar la ruta completa del archivo que contiene la función. También
podemos ir a la barra menú FILE y seleccionar la opción “Source R code” con la cual se
abre la ventana presentada en el gráfico 1.1; all\'\i\ seleccionamos la ruta y archivo
particular en donde se encuentran objetos R tales como funciones, tablas, matrices, etc.
Figura 1.1: Ventana Source R code: Podemos llamar a través deesta ventana,
disponible en la barra menú FILE, cualquier archivo en donde previamente se
han guardado objetos R
1.3. Ejecución de Funciones Especiales
En R las funciones están organizadas en librerías o paquetes. Por defecto R inicializa en el
paquete denominado “ base” en el cual encontramos las funciones generales para el manejo

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 12/344
12
de datos y graficación. Existen otros paquetes en los cuales se encuentran herramientas de
análisis más especializadas, las cuales pueden ser utilizadas cargando previamente la
librería que las contiene. Una librería o paquete puede cargarse mediante la función
library() o bien a través de la barra menú PACKAGE del R, ilustrada en la figura 1.2.
Una descripción de estas librerias puede obtenerse con:
> library()
Lo que produce la siguiente información:
Packages in library `C:/ARCHIV~1/R/rw1031/library':
base The R base package
boot Bootstrap R (S-Plus) Functions (Canty)
class Functions for classification
cluster Functions for clustering (by Rousseeuw et al.)
ctest Classical Tests
eda Exploratory Data Analysis
foreign Read data stored by Minitab, SAS, SPSS, ...KernSmooth Functions for kernel smoothing for Wand & Jones (1995)
lqs Resistant Regression and Covariance Estimation
MASS Main Library of Venables and Ripley's MASS
mgcv Multiple smoothing parameter estimation and GAMs by GCV
modreg Modern Regression: Smoothing and Local Methods
mva Classical Multivariate Analysis
nlme Linear and nonlinear mixed effects models
nls Nonlinear regression
nnet Feed-forward neural networks and multinomial log-linearmodels
rpart Recursive partitioning
spatial functions for kriging and point pattern analysis
splines Regression Spline Functions and Classes
stepfun Step Functions, including Empirical Distributions

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 13/344
13
survival Survival analysis, including penalised likelihood.
tcltk Interface to Tcl/Tk
ts Time series functions
Figura 1.2: Cargando paquetes de R a través de la barra menú

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 14/344
14
Capítulo 2: Manejo de Datos en R
El manejo de datos en R puede parecer complejo. El programa cuenta confunciones
poderosas tanto para la lectura como la escritura de datos.
Comando Función
scan() Lectura de datos. Especial para datos unestructurados.
read.table() Lectura de matrices de datos
read.fwf() Lectura de datos en formato fijo.
sink() Desvía la salida de información.
write() Escribe una matriz en un archivo de texto.
xtable() Escribe una matriz en formato Latex. Es
necesario cargar la librería xtable.
ftable() Permite presentar decentemente un arreglo
multidimensional.
2.1. Entrada y Lectura de Datos
La entrada de datos puede hacerse desde teclado y la lectura través de un archivo en
ASCII. Una vez los datos han sido leidos estos quedan en forma permanente en el disco
duro en formato R. Estos datos en formato especial pueden usarse repetidamente en
diferentes sesiones y quedan grabados en el directorio .Data, si estamos bajo UNIX o en
cambiarse.
2.1.1 Función scan
La función scan() puede usarse para leer datos desde un archivo de texto o
interactivamente desde el teclado; es de notar la similaridad con el lenguaje C. Su sintaxis
es como sigue:

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 15/344
15
scan(file = "", what = double(0), nmax = -1,
n = -1, sep = "",quote = if (sep=="\n") "" else "'\"",dec = ".",skip = 0, nlines = 0, na.strings = "NA",
flush = FALSE, fill = FALSE, strip.white = FALSE,
quiet = FALSE,blank.lines.skip = TRUE,
multi.line = TRUE)
Los argumentos son:
• file: Nombre del archivo, desde el cual se leerán los datos. Si en su lugar seespecifica `” “ ', entonces la entrada será tomada desde el teclado y en este caso la
entrada puede ser terminada por una línea en blanco. Por ejemplo, es posible entrar
datos por teclado asignados a un objeto R (vector, matriz, lista) mediante la
instrucción scan() luego de dar enter digitar los correspondientes valores. El
nombre del archivo es interpretado en relación al directorio de trabajo actual (dado
por `getwd()' , a no ser que se especifique una ruta completa. También `file' puede
ser una `connection' (ver funciónconnetion
) la cual será abierta cuando es
necesaria y se cerrará al final del llamado de la función. `file' puede ser también un
URL completo.
• what: Indica el tipo de datos (numérico o carácter) a ser leídos. Cuando los datos a
leer están en un arreglo rectangular de filas y columnas (filas para observaciones y
columnas para variables) en los cuáles un número de variables son de tipo numérico y
otras son alfanuméricas, entonces `what' es una lista, cuya longitud corresponde al
número de variables o items.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 16/344
16
• nmax: El número máximo de valores a ser leídos, o si `what' es una lista, entonces
indica el número máximo de registros a ser leídos. Si se omite y `nlines' no está
ajustado a un valor positivo, scan leerá todo el archivo.
• n: El máximo número de valores a ser leídos, por defecto no tiene límite.
• sep: Por defecto, scan espera leer los campos de entrada delimitados (separados)
por espacios en blanco. Alternativamente, `sep' puede usarse para especificar un
carácter con el cual se han delimitado los campos. Un campo siempre es delimitado
por una nueva línea a menos que esté entre comillas (esto es posible cuando el campo
es definido como alfanumérico).
• quote: el conjunto de caracteres entre comillas como una sola cadena de caracteres.
• dec: carácter para punto decimal.
• skip: El número de líneas del archivo de entrada a omitir antes de comenzar a leer los datos.
• nlines: El número máximo de líneas de datos a ser leídos.
• na.strings: Vector de caracteres. Los elementos de este vector son interpretados
como valores faltantes (`NA').
• flush: Argumento lógico. Si es TRUE', scan activará el final de la línea después
de leer el último campo requerido. Esto permite colocar comentarios después del
último campo de una línea, pero preclude colocar más de un registro en una línea.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 17/344
17
• fill: Argumento lógico. Si es `TRUE', scan implícitamente agregará campos
vacíos a todas las líneas con menos campos que los implicados por `what'.
• strip.white: Un vector de valores lógicos correspondiendo a los items en el
argumento `what'. Se usa únicamente cuando `sep' ha sido especificado, y permite el
desmantelamiento de espacios en blanco del principio y final de campos `character'
(esta función siempre es aplicada sobre campos numéricos). Si la longitud de este
argumento es 1, entonces es aplicada a todos los campos; de lo contrario si
`strip.white[i]' es `TRUE' y el i-ésimo campo de tipo caracter, entonces el espacio en
blanco al inicio y final de éste campo es quitado.
• quiet: Argumento lógico. si es `FALSE' (valor por defecto) scan() imprimirá una
línea diciendo cuantos items han sido leídos.
• blank.lines.skip: Argumento lógico. Si es `TRUE' las líneas en blanco en la entrada
son ignoradas, excepto cuando se cuentan con `nlines'.
• multi.line: Argumento lógico. Sólo es usado si `what' es una lista. Si es `FALSE', la
totalidad de un registro debe aparecer en una línea, pero más de un registro puede
aparecer en una sóla línea. Notar que usar `fill = TRUE' implica que un registro
terminará al final de una línea.
Detalles:
• El valor de `what' puede ser una lista de tipos de caracter, en cuyo caso scan devuelve una lista de vectores con los tipos dados por los tipos de los elementos en
`what'. Esto proporciona una manera de leer datos en columnas.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 18/344
18
• Campos numéricos vacíos son siempre considerados como valores faltantes. Campos
de tipo caracter vacíos son escaneados como vectores de caracter vacíos, a menos que
`na.strings' contenga “ “ cuando ellos son considerados como valores faltantes.
• Si `sep' está ajustado al valor por defecto, el carácter '\' en una cadena entre comillas
escapa al carácter siguiente, así que las comillas pueden incluirse en la cadena y
pasarlas por alto.
• Si `sep' no está ajustado al valor por defecto, los campos pueden estar entre comillas
en el estilo de archivos `.csv' en donde separadores entre comillas (sencillas o dobles)
son ignorados y las comillas pueden ser colocadas dentro de las cadenas
duplicándolas. Pero si ‘sep = “\n” ’ es asumido por defecto entonces se desea leer
líneas completas tal cual.
• Para leer un registro por línea usar `flush = TRUE' y `multi.line = FALSE'.
• Las cadenas de longitud mayor que 8190 caracteres serán truncadas con unaadvertencia.
• Cuando no se especifica el número de items, el mecanismo interno reubica memoria
en potencias de dos y por tanto podría usar hasta tres veces más de la memoria
necesaria. Siempre que se pueda, especifique bien sea `n' o `nmax' mientras esté
ingresando un vector grande, y `nmax' o `nlines' cuando esté ingresando una lista
grande.
Ver también: read.table, readLines, write .
Ejemplos:

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 19/344
19
Uso del argumento n: La función scan() permite leer parte del archivo de datos con la
opción n , por ejemplo,
datos<-scan(“c:/miarchivo”,what=list(“ “,0,0),n=5)
El anterior comando nos permite leer cinco elementos del archivo.
Si tenemos una matriz de datos con d columnas y n filas, por el momento suponemos
que solo contiene elementos numéricos, en un archivo llamado “misdatos”, los cuales se
encuentran grabados en un disquete que se coloca en el drive a. El comando es
datos<-matrix(scan("a:misdatos"),ncol=d,byrow=T)
Aquí tenemos una función nueva: matrix() . Esta nos permite crear un objeto que es una
matriz. Si los datos estuvieran separados por comas se coloca una opción adicional de la
siguiente forma:
datos<-matrix(scan("a:misdatos",sep=","'),ncol=d,byrow=T)
Uso del argumento `what': Vamos a leer el siguiente conjunto de datos ubicado en la ruta
“c:/graficosr/datosgraficos/renault.dat”:
Tipo devehículo
Modelo
Precio enmillones
r4 85 4.00r4 88 4.30r4 81 2.85
r4 80 2.95r4 70 2.20r4 77 2.45r4 71 2.00r4 88 4.90r4 74 1.78r4 73 1.70r4 80 2.90

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 20/344
20
Tipo devehículo
Modelo
Precio enmillones
r12 80 4.60r12 76 3.80r12 78 4.80r12 79 4.70r12 76 3.60r12 78 4.50r12 74 3.50r12 74 3.50
Los datos en el correspondiente archivo no tienen encabezados de columna; la lectura se
hace así:
a<-scan(file="c:/graficosr/datosgraficos/renault.dat",
what=list("",1,1))
Read 19 records
>a
[[1]]
[1] "r4" "r4" "r4" "r4" "r4" "r4" "r4" "r4" "r4" "r4" "r4" "r12"
[13] "r12" "r12" "r12" "r12" "r12" "r12" "r12"
[[2]]
[1] 85 88 81 80 70 77 71 88 74 73 80 80 76 78 79 76 78 74 74
[[3]]
[1] 4.00 4.30 2.85 2.95 2.20 2.45 2.00 4.90 1.78 1.70 2.90 4.60 3.80 4.80 4.70
[16] 3.60 4.50 3.50 3.50
El objeto creado `a', tiene tres componentes, puede llamarse una cualquiera como se indica
a continuación:
> a[1]
[[1]]
[1] "r4" "r4" "r4" "r4" "r4" "r4" "r4" "r4" "r4" "r4" "r4" "r12" "r12" "r12"
[15] "r12" "r12" "r12" "r12" "r12"

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 21/344
21
En el apéndice A se presentan unos datos sobre los resultados de unos estudiantes en las
pruebas del ICFES. Los datos los tenemos en un archivo de texto en un diskette. Los
queremos leer en R. La instrucción será:
icfes<-scan("c:/graficosr/datosgraficos/icfes.dat",
what=list(" ",1, 1, 1, 1, 1, 1, 1, 1, 1, 1," "))
Supongamos ahora que se quiere construir por teclado, un objeto con dos campos por
registro: sexo (M ó F) y puntaje, y 10 registros, podemos hacerlo como sigue:
notas<-scan(what=list(character(0),double(0)))
1: F 55
2: M 78
3: M 56
4: F 87
5: F 65
6: M 80
7: F 57
8: F 79
9: M 90
10: M 82
11:
Read 10 records
Nota: Los números al comienzo de cada registros seguidos por dos puntos aparecen
automáticamente, y nos indica el número de la siguiente observación a ser entrada desde el
teclado. La entrada de datos se finaliza pulsando la tecla enter dos veces seguidas.
> notas
[[1]]
[1] "F" "M" "M" "F" "F" "M" "F" "F" "M" "M"
[[2]]
[1] 55 78 56 87 65 80 57 79 90 82

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 22/344
22
En los dos ejemplos anteriores el correspondiente objeto creado con scan usando
`what=list(...)', crea listas con las cuales no se pueden operar directamente, hay que
aplicarles una función denominada unlist :
sexo<-unlist(notas[1])
nota<-unlist(notas[2])
#grafica boxplot de notas por sexo en el mismo gráfico:
boxplot(split(nota,sexo))
Observe ahora el uso de comillas para considerar lo que está entre ellas como un solo stringde caracteres:
> b<-scan(what=character(0))
1: 'ciudad
1: de medellin'
2: cali
3: bogota
4:
Read 3 items
> b
[1] "ciudad \nde medellin" "cali" "bogota"
uso del argumento `sep': (Observe el efecto de diferentes especificaciones de este
argumento cuando las entradas de datos son por teclado)
#Por ejemplo si estamos leyendo dato
#por línea entonces el comando es:
datos<-scan(“miarchivo”,sep=“\n”)
#Si tenemos datos separados con
#tabulador entonces el comando es
datos<-scan(“miarchivo”,sep=“\t”)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 23/344
23
#un objeto con dos registros de caracteres:
>a<-scan(sep="\n",what=character(0))
1: a b c
2: d e f
3:
Read 2 items
> a
[1] "a b c" "d e f"
#un objeto con dos registros numéricos
> a<-scan(sep="\n")
1: 1 2 3
2: 4 5 6
3:
Read 2 items
> a
[1] 123 456
#un objeto con cuatro registros numéricos
a<-scan(sep="*")
1: 23*12
3: 4*8
5:
Read 4 items
> a
[1] 23 12 4 8
#un objeto con tres registros numéricos y un valor faltante
a<-scan(sep="*")
1: 23 34 *
3: 12
4: 45
5:
Read 4 items

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 24/344
24
> a
[1] 2334 NA 12 45
#un objeto con dos registros numéricos y dos valores faltantes:
> a<-scan(sep="*")
1: *
3: 23
4: 34
5:
Read 4 items
> a
[1] NA NA 23 34
Uso del argumento `flush': Observe como la expresión entre comillas al final del primer
registro no es tenido en cuenta si `flush=TRUE', en cambio si flush=FALSE', observe el
error que nota el sistema:
> a<-scan(flush=TRUE)
1: 2 "fin"
2: 33: 2
4:
Read 3 items
> a
[1] 2 3 2
> a<-scan(flush=FALSE)
1: 2 "fin"
1: 3
Error in scan(flush = FALSE) : "scan" expected a real, got ""fin""
Ahora observe que sucede cuando `flush=TRUE' y cuando `flush=FALSE':
a<-scan(sep="*",flush=TRUE)
1: 23 34*32

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 25/344
25
2: 12
3: 23
4:Read 3 items
> a
[1] 2334 12 23
> a<-scan(sep="*",flush=FALSE)
1: 23 34*32
3: 12
4: 23
5:
Read 4 items
> a
[1] 2334 32 12 23
> a<-scan(flush=TRUE)
1: 1 2 3
2: 4 5 6
3:
Read 2 items
> a
[1] 1 4
> a<-scan(flush=FALSE)
1: 1 2 3
4: 4 5 6
7:
Read 6 items
> a
[1] 1 2 3 4 5 6
Uso del argumento `strip.white': Observe como en las cadenas de caracteres
`strip.white=TRUE' elimina los espacios en blanco en el inicio y final de éstas:

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 26/344
26
> a<-scan(sep="\n",what=character(0),strip.white=TRUE)
1: SER FRT2: DRT ASE
3:
Read 2 items
> a
[1] "SER FRT" "DRT ASE"
> a<-scan(sep="\n",what=character(0))
1: ser frt
2: drt ase
3:
Read 2 items
> a
[1] " ser frt " "drt ase "
Uso del argumento `multi.line': Observe como en una sola línea es posible escribir dos
registros:
> a<-scan(what=list(1,1,""),multi.line =TRUE)1: 2 1 A 3 4 B
3: 5 6 C 7 8 D
5:
Read 4 records
> a
[[1]]
[1] 2 3 5 7
[[2]][1] 1 4 6 8
[[3]]
[1] "A" "B" "C" "D"

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 27/344
27
La función read.table() permite leer archivos en ASCII y crear un marco de datos.
Esta función tiene la siguiente sintaxis:
2.1.2 Función read.table
Cuando debemos manejar un archivo de datos relativamente grande y que contiene
variables tanto numéricas como alfanuméricas podemos utilizar la función
read.table() , la cual nos permite leer archivos externos en ASCII, como los que crea
una hoja electrónica. Lo que debemos tener en cuenta con esta función es la estructura de
datos, la cual se conoce como data frame, lo traduciremos como marco de datos, estaestructura crea un arreglo de datos en forma matricial, donde las filas corresponden a las
observaciones y las columnas o campos a las variables. Cuando deseamos restringir un
marco de datos a una matriz, o sea que solo deseamos considerar las columnas de tipo
numérico, utilizamos la función data.matrix(). Su desventaja es que consume mucha
memoria para archivos extensos y puede requerir una memoria mayor.
Como un ejemplo consideremos la base de datos sobre municipios de Antioquia, la cual
fue creada en una hoja electrónica y exportada como un archivo ASCII.
antioquia.marco<-read.table("a:antioq.txt",header=FALSE)
antioquia.dat<-data.matrix(antioquia.marco)
La sintaxis de esta función es como sigue:
read.table(file, header = FALSE, sep = "", quote = "\"'", dec = ".",
row.names, col.names, as.is = FALSE, na.strings = "NA",
skip = 0, check.names = TRUE, fill = FALSE,
strip.white = FALSE, blank.lines.skip = TRUE)
read.csv(file, header = TRUE, sep = ",", quote="\"", dec=".",
fill = TRUE, ...)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 28/344
28
read.csv2(file, header = TRUE, sep = ";", quote="\"", dec=",",
fill = TRUE, ...)
read.delim(file, header = TRUE, sep = "\t", quote="\"", dec=".",
fill = TRUE, ...)
read.delim2(file, header = TRUE, sep = "\t", quote="\"", dec=",",
fill = TRUE, ...)
Argumentos:
• file: Nombre del archivo a ser leído. Las filas de la tabla corresponden a las líneas
del archivo. Cuando no se especifica una ruta para el archivo, se asume el directorio
actual de trabajo. Este argumento también puede ser un `connection', o un URL.
• header: Argumento lógico para indicar si la primera línea del archivo contiene
nombres para las variables o columnas. Cuando no se especifica, su valor es ajustado
según el formato del archivo: Se ajustará a `TRUE' si la primera fila contiene menos
campos que el número de columnas.
• sep: Caracter para indicar separación entre campos. Debe corresponder al caracter
que en el el archivo se utilice para separar los valores en una misma línea. Si `sep = "
" ' (El valor por defecto para este argumento) el separador corresponde a uno o más
espacios en blanco, tabuladores o líneas nuevas.
• quote: Conjunto de caracteres entre comillas. Para desabilitarlo usar `quote=" " '.
• dec: El caracter usado en el archivo a leer, para indicar puntos decimales.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 29/344
29
• row.names: Un vector de nombres para las filas. Puede ser un vector que dé los
nombres actuales de las filas, o un sólo número que indique la columna de la tabla
que contiene los nombres de las filas, o una cadena de caracteres que dé el nombre de
la columna de la tabla que contiene los nombres de las filas. Si hay un encabezado y
la primera fila contiene un campo menor que el número de las columnas, la primera
columna en la entrada es usada es usada para el nombre de las filas. De lo contrario,
si `row.names' no existe, entonces las filas son numeradas. `row.names = NULL'
produce dicha numeración de las filas.
• col.names: Un vector de nombres opcionales para las variables. Su valor por defecto
es usar `"V"' seguido del número de la columna.
• as.is: La acción por defecto de `read.table' es convertir las variables no numéricas en
factores. `as.is' controla esta acción. Su valor puede ser un vector lógico o un vector
de índices numéricos que especifican cuales columnas deben ser tratadas como
cadenas de caracteres.
• na.strings: Un vector de caracteres para valores faltantes, interpretados como `NA'
• skip: El número de líneas del arhivo de datos a omitir antes de comenzar a leer
datos.
• check.names: Argumento lógico. Si es `TRUE' entonces de las variables en el
marco de datos son chequeados para asegurar que ellos son sintáticamente nombres
de variables válidos. Si es necesario ajustarlos, ellos lo serán.
• fill: Argumento lógico. Si es `TRUE', si las filas tienen longitud desigual, campos en
blanco son adicionados implícitamente.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 30/344
30
• strip.white: Argumento lógico. Es usado sólo cuando `sep' ha sido especificado, y
permite eliminar los epacios en blanco al principio y al final de campos tipo
`character' (esta acción siempre es aplicada sobre campos numéricos).
• blank.lines.skip: Argumento lógico. Si es `TRUE' líneas en blanco en la entrada son
ignoradas.
• ...: Argumentos adicionales.
Detalles:
• Si no se especifica `row.names' y la línea de encabezado tiene una entrada
• menos que el número de columnas, la primera columna es tomada como el nombre de
las filas. Si `row.names' es especificado y no se refiere a la primera columna, esa
columna es descartada del archivo.
• El número de columnas es determinada a partir de las primeras cinco líneas de la
entrada o de toda la fila si tiene menos de cinco líneas, o de la longitud de `col.names'
si éste ha sido especificado. Esto puede ser erróneo si `fill' o `blank.lines.skip' son
TRUE.
• `read.csv' y `read.csv2' son funciones idénticas a read.table' excepto en los valores
por defecto. Estas están especificadas para leer archivos con valores separados por
coma (`.csv') o la variante usada en algunas regiones que usan la coma como punto
decimal y un punto y coma como separador de campo. De forma similar, `read.delim'
y `read.delim2' son archivos de lectura delimitada, por defecto usan el caracter TAB

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 31/344
31
para el delimitador. Notar que por defecto en estas últimas cuatro funciones `header =
TRUE' y `fill = TRUE'.
• Adicionalmente, también es posible leer datos guardados bien sea en el disco duro del
computador o en alguna unidad de memoria externa con read.table usando el
comando file.choose() , lo cual permite navegar por el sistema de archivos y
abrir aquel que deseamos trabajar:
> read.table(file.choose())
V1 V2 V31 r4 85 4.00
2 r4 88 4.30
3 r4 81 2.85
4 r4 80 2.95
5 r4 70 2.20
6 r4 77 2.45
7 r4 71 2.00
8 r4 88 4.90
9 r4 74 1.7810 r4 73 1.70
11 r4 80 2.90
12 r12 80 4.60
13 r12 76 3.80
14 r12 78 4.80
15 r12 79 4.70
16 r12 76 3.60
17 r12 78 4.50
18 r12 74 3.5019 r12 74 3.50
Los datos anteriores corresponden a “c:/graficosr/datosgraficos/renault.dat”

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 32/344
32
Ver también: `read.fwf' para leer archivos de formato de lectura de ancho fijo,
`read.table.url' para leer archivos de internet, `write.table', `data.frame'. count.fields' es una
función que puede ser útil para determinar problemas con la lectura de archivos para los
cuales el programa reporta incorrectas longitudes de los registros.
Ejemplos: A diferencia de scan, read.table nos permite una lectura más apropiada
de los archivos con campos de tipo caracter y numéricos, de modo que quedan disponibles
para una posterior y directa operación con todos ellos.
a<-read.table(file="c:/graficosr/datosgraficos/renault.dat",header=FALSE,
row.names=NULL, as.is=FALSE)
> a
V1 V2 V3
1 r4 85 4.00
2 r4 88 4.30
3 r4 81 2.85
4 r4 80 2.95
5 r4 70 2.206 r4 77 2.45
7 r4 71 2.00
8 r4 88 4.90
9 r4 74 1.78
10 r4 73 1.70
11 r4 80 2.90
12 r12 80 4.60
13 r12 76 3.80
14 r12 78 4.8015 r12 79 4.70
16 r12 76 3.60
17 r12 78 4.50
18 r12 74 3.50
19 r12 74 3.50

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 33/344
33
> a[2]
V21 85
2 88
3 81
4 80
5 70
6 77
7 71
8 88
9 74
10 73
11 80
12 80
13 76
14 78
15 79
16 76
17 78
18 74
19 74
>
> a$V2
[1] 85 88 81 80 70 77 71 88 74 73 80 80 76 78 79 76 78 74 74
Observe en el ejemplo anterior las dos diferentes llamadas de la columna 2 (a[2] y a$V2) de
la tabla y sus respectivos resultados; ¿en qué se diferencian?.
El siguiente archivo de datos
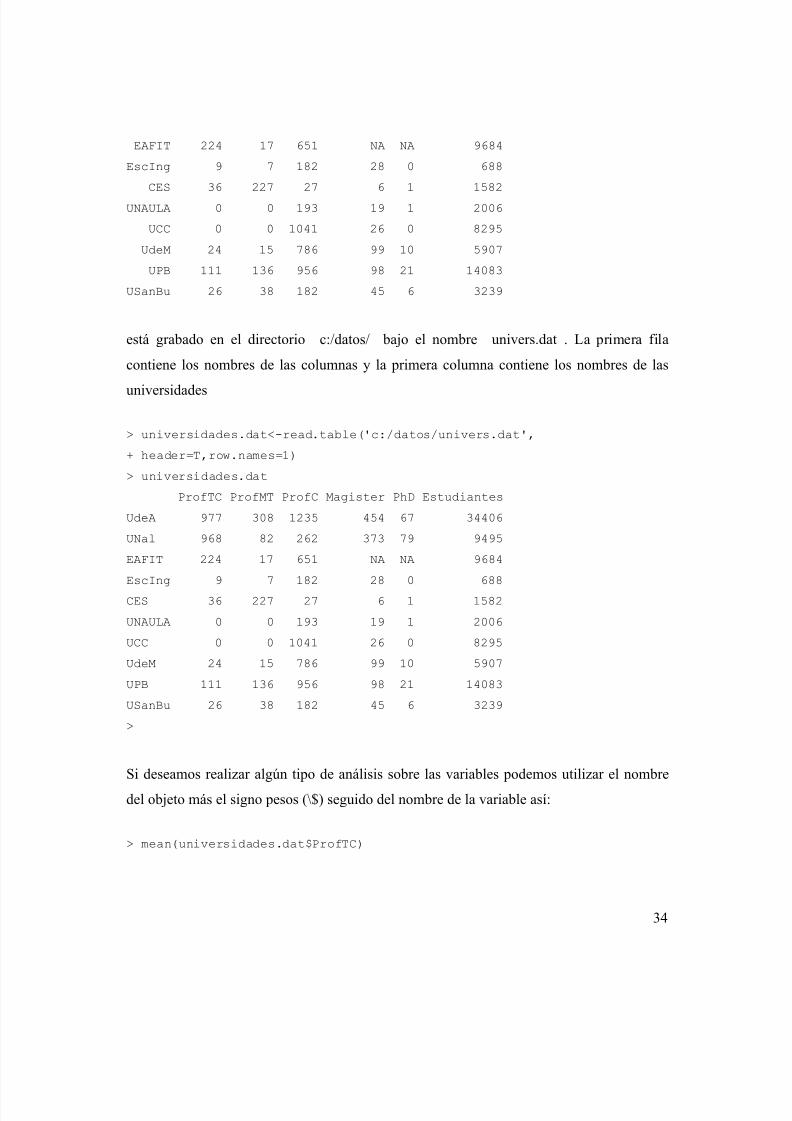
ProfTC ProfMT ProfC Magister PhD Estudiantes
UdeA 977 308 1235 454 67 34406
UNal 968 82 262 373 79 9495
5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 34/344
34
EAFIT 224 17 651 NA NA 9684
EscIng 9 7 182 28 0 688
CES 36 227 27 6 1 1582UNAULA 0 0 193 19 1 2006
UCC 0 0 1041 26 0 8295
UdeM 24 15 786 99 10 5907
UPB 111 136 956 98 21 14083
USanBu 26 38 182 45 6 3239
está grabado en el directorio c:/datos/ bajo el nombre univers.dat . La primera fila
contiene los nombres de las columnas y la primera columna contiene los nombres de las
universidades
> universidades.dat<-read.table('c:/datos/univers.dat',
+ header=T,row.names=1)
> universidades.dat
ProfTC ProfMT ProfC Magister PhD Estudiantes
UdeA 977 308 1235 454 67 34406
UNal 968 82 262 373 79 9495
EAFIT 224 17 651 NA NA 9684EscIng 9 7 182 28 0 688
CES 36 227 27 6 1 1582
UNAULA 0 0 193 19 1 2006
UCC 0 0 1041 26 0 8295
UdeM 24 15 786 99 10 5907
UPB 111 136 956 98 21 14083
USanBu 26 38 182 45 6 3239
>
Si deseamos realizar algún tipo de análisis sobre las variables podemos utilizar el nombre
del objeto más el signo pesos (\$) seguido del nombre de la variable así:
> mean(universidades.dat$ProfTC)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 35/344
35
[1] 237.5
> summary(universidades.dat)ProfTC ProfMT ProfC Magister
Min. : 0.00 Min. : 0.0 Min. : 27.0 Min. : 6.0
1st Qu.: 12.75 1st Qu.: 9.0 1st Qu.: 184.8 1st Qu.: 26.0
Median : 31.00 Median : 27.5 Median : 456.5 Median : 45.0
Mean :237.50 Mean : 83.0 Mean : 551.5 Mean :127.6
3rd Qu.:195.75 3rd Qu.:122.5 3rd Qu.: 913.5 3rd Qu.: 99.0
Max. :977.00 Max. :308.0 Max. :1235.0 Max. :454.0
NA's : 1.0
PhD Estudiantes
Min. : 0.00 Min. : 688
1st Qu.: 1.00 1st Qu.: 2314
Median : 6.00 Median : 7101
Mean :20.56 Mean : 8939
3rd Qu.:21.00 3rd Qu.: 9637
Max. :79.00 Max. :34406
NA's : 1.00
>
2.1.3 Función read.fwf
Esta función permite la lectura de archivos con formato de lectura de ancho fijo dentro de
un `data.frame'. Su valor es un `data.frame'
read.fwf(file, widths, sep="\t", as.is = FALSE,
skip = 0, row.names, col.names, n = -1)
Argumentos:

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 36/344
36
• file: El nombre del archivo (con ruta completa) de lectura de datos.
Alternativamente, v puede ser una `connection', que será abierta cuando sea necesario
y cerrada al final del llamado de la función.
• widths: Un vector de enteros que dan los anchos de los campos de ancho fijo en una
línea.
• sep: Caracter para indicar el separador usado internamente; debe ser un caracter que
no ocurra en la fila y con los cuales se presenta el data frame resultante.
• as.is: Ver read.table'.
• skip: El número de líneas iniciales a omitir; ver `read.table'.
• row.names: Ver read.table'.
• col.names: Ver read.table'.
• n: El número máximo de registros o líneas a ser leídas, por defecto no tiene
limitación.
Nota: Los campos de ancho cero o que están totalmente más allá del extremo de la línea
en `file' son reemplazados por `NA'.
Autor(es): Brian Ripley para la versión R: original `Perl' por Kurt Hornik.
Ver también: `scan' y `read.table'.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 37/344
37
Ejemplo: El siguiente ejemplo aparece en el help `R Documentation'; tres funciones son
invocadas en éste: tempfile, cat y unlink; la primera permite crear nombres para
archivos temporales mediante la creación de un vector de cadena de caracteres usado para
nombrar dichos archivos temporales; la segunda función es una función de concatenación e
impresión de argumentos a un archivo, forzándolos primero a un modo de caracteres; y la
última función permite borrar archivos y directorios específicos:
ff <- tempfile()
cat(file=ff, "123456", "987654", sep="\n")
> ff
[1] "C:\\DOCUME~1\\PROPIE~1\\CONFIG~1\\Temp\\file18467"
read.fwf(ff, width=c(1,2,3))
V1 V2 V3
1 1 23 456
2 9 87 654
unlink(ff)
cat(file=ff, "123", "987654", sep="\n")
read.fwf(ff, width=c(1,0, 2,3))
V1 V2 V3 V4
1 1 NA 23 NA
2 9 NA 87 654
unlink(ff)
El siguiente ejemplo consiste en la lectura de los tiempos de una maratón realizadas por
180 corredores, en donde cada registro consiste de un cifra de cinco dígitos tales que el
primero corresponde a las horas registradas, el segundo y el tercero a los minutos y cuarto y
quinto a los segundos de cada corredor. El objetivo es descomponer el registro en los

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 38/344
38
valores de horas-minutos-segundos y calcular luego el tiempo total en horas de cada
corredor. El archivo de datos presenta la siguiente estructura:
10253 10302 10307 10309 10349 10353 10409 10442 10447 10452 10504 10517
10530 10540 10549 10549 10606 10612 10646 10648 10655 10707 10726 10731
10737 10743 10808 10833 10843 10920 10938 10949 10954 10956 10958 11004
11009 11024 11037 11045 11046 11049 11104 11127 11205 11207 11215 11226
11233 11239 11307 11330 11342 11351 11405 11413 11438 11453 11500 11501
11502 11503 11527 11544 11549 11559 11612 11617 11635 11655 11731 11735
11746 11800 11814 11828 11832 11841 11909 11926 11937 11940 11947 11952
12005 12044 12113 12209 12230 12258 12309 12327 12341 12413 12433 12440
12447 12530 12600 12617 12640 12700 12706 12727 12840 12851 12851 12937
13019 13040 13110 13114 13122 13155 13205 13210 13220 13228 13307 13316
13335 13420 13425 13435 13435 13448 13456 13536 13608 13612 13620 13646
13705 13730 13730 13730 13747 13810 13850 13854 13901 13905 13907 13912
13920 14000 14010 14025 14152 14208 14230 14344 14400 14455 14509 14552
14652 15009 15026 15242 15406 15409 15528 15549 15644 15758 15837 15916
15926 15948 20055 20416 20520 20600 20732 20748 20916 21149 21714 23256
Sin embargo, para leer estos datos con read.fwf es necesario eliminar los espacios
(con un editor de texto esto resulta rápido y fácil) y que el archivo quede como:
102531030210307103091034910353104091044210447104521050410517105301054010549105491060610612106461064810655107071072610731
107371074310808108331084310920109381094910954109561095811004
110091102411037110451104611049111041112711205112071121511226
112331123911307113301134211351114051141311438114531150011501
115021150311527115441154911559116121161711635116551173111735
117461180011814118281183211841119091192611937119401194711952
120051204412113122091223012258123091232712341124131243312440
124471253012600126171264012700127061272712840128511285112937
130191304013110131141312213155132051321013220132281330713316
133351342013425134351343513448134561353613608136121362013646
137051373013730137301374713810138501385413901139051390713912
139201400014010140251415214208142301434414400144551450914552
146521500915026152421540615409155281554915644157581583715916
159261594820055204162052020600207322074820916211492171423256
a<-read.fwf(file="c:/manualr/maraton3.txt",
width=rep(c(1,2,2),12),sep=" ")

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 39/344
39
el data frame resultante tiene 36 columnas dado que cada registro (hora, minutos, segundos)
en descompuesto en tres elementos y en total cada línea posee los registros de los tiempos
de 12 participantes. Pero aún es necesario transformar más estos datos para obtener los
tiempos en horas de los 180 corredores:
#creación de una matriz de 180 filas por 3 columnas
#con columnas correspondiendo a horas, minutos,
#segundos
tiempo<-matrix(t(as.matrix.data.frame(a)),ncol=3,byrow=T)
\end verbatim
Veamos una presentación parcial de esta matriz:
tiempo
[,1] [,2] [,3]
[1,] 1 2 53
[2,] 1 3 2
[3,] 1 3 7
[4,] 1 3 9
[5,] 1 3 49
[6,] 1 3 53
[7,] 1 4 9
[8,] 1 4 42
[9,] 1 4 47
[10,] 1 4 52
[11,] 1 5 4
[12,] 1 5 17
.
.
.
.
[161,] 1 54 6
[162,] 1 54 9

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 40/344
40
[163,] 1 55 28
[164,] 1 55 49
[165,] 1 56 44[166,] 1 57 58
[167,] 1 58 37
[168,] 1 59 16
[169,] 1 59 26
[170,] 1 59 48
[171,] 2 0 55
[172,] 2 4 16
[173,] 2 5 20
[174,] 2 6 0
[175,] 2 7 32
[176,] 2 7 48
[177,] 2 9 16
[178,] 2 11 49
[179,] 2 17 14
[180,] 2 32 56
A continuación calculamos el tiempo de cada corredor en horas:
#Transformación de los tiempos a horas
tiempo<-tiempo[,1]+tiempo[,2]/60+tiempo[,3]/3600
tiempo
[1] 1.048056 1.050556 1.051944 1.052500 1.063611 1.064722 1.069167 1.078333
[9] 1.079722 1.081111 1.084444 1.088056 1.091667 1.094444 1.096944 1.096944
[17] 1.101667 1.103333 1.112778 1.113333 1.115278 1.118611 1.123889 1.125278
[25] 1.126944 1.128611 1.135556 1.142500 1.145278 1.155556 1.160556 1.163611
[33] 1.165000 1.165556 1.166111 1.167778 1.169167 1.173333 1.176944 1.179167
[41] 1.179444 1.180278 1.184444 1.190833 1.201389 1.201944 1.204167 1.207222
[49] 1.209167 1.210833 1.218611 1.225000 1.228333 1.230833 1.234722 1.236944
[57] 1.243889 1.248056 1.250000 1.250278 1.250556 1.250833 1.257500 1.262222
[65] 1.263611 1.266389 1.270000 1.271389 1.276389 1.281944 1.291944 1.293056
[73] 1.296111 1.300000 1.303889 1.307778 1.308889 1.311389 1.319167 1.323889
[81] 1.326944 1.327778 1.329722 1.331111 1.334722 1.345556 1.353611 1.369167

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 41/344
41
[89] 1.375000 1.382778 1.385833 1.390833 1.394722 1.403611 1.409167 1.411111
[97] 1.413056 1.425000 1.433333 1.438056 1.444444 1.450000 1.451667 1.457500
[105] 1.477778 1.480833 1.480833 1.493611 1.505278 1.511111 1.519444 1.520556
[113] 1.522778 1.531944 1.534722 1.536111 1.538889 1.541111 1.551944 1.554444
[121] 1.559722 1.572222 1.573611 1.576389 1.576389 1.580000 1.582222 1.593333
[129] 1.602222 1.603333 1.605556 1.612778 1.618056 1.625000 1.625000 1.625000
[137] 1.629722 1.636111 1.647222 1.648333 1.650278 1.651389 1.651944 1.653333
[145] 1.655556 1.666667 1.669444 1.673611 1.697778 1.702222 1.708333 1.728889
[153] 1.733333 1.748611 1.752500 1.764444 1.781111 1.835833 1.840556 1.878333
[161] 1.901667 1.902500 1.924444 1.930278 1.945556 1.966111 1.976944 1.987778
[169] 1.990556 1.996667 2.015278 2.071111 2.088889 2.100000 2.125556 2.130000
[177] 2.154444 2.196944 2.287222 2.548889
summary(tiempo)Min. 1st Qu. Median Mean 3rd Qu. Max.
1.048 1.202 1.384 1.445 1.625 2.549
Nota: La función as.matrix.data.frame debe aplicarse para transformar las
componentes del data.frame `a' en una matriz, de lo contrario no sería posible hacer uso
de la función matrix con la cual se separaron por filas las horas, minutos y segundos
registrados por cada corredor. Además, la matriz resultante de la función
as.matrix.data.frame debe transpornerse con t(as.matrix.data.frame) para conformar apropiadamente los registros.
2.1.4 Entrando Datos Desde el Teclado
R opera con lo que se conoce como estructura de datos. La más simple de tales
estructuras es el vector , que es una sola entidad consistente de una colección ordenada de
números o caracteres. Para crear un vector llamado x, que tenga seis elementos, digamos
3.6, 2.5, 1.2, 0.6, 1.3, y 2.1, utilizamos el comando
> x<-c(3.6,2.5,1.2,0.6,1.3,2.1)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 42/344
42
Este es un comando de asignación que utiliza la función c() con la cual creamos vectores
y que en este contexto puede tomar un número arbitrario de argumentos. El resultado final
es un vector que concatena los argumentos de la función c() . Esta función combina
valores en un vector o lista. El método por defecto combina los argumentos para formar un
vector. Todos los argumentos son forzados a un tipo común que corresponde al valor
retornado por la función.
c(..., recursive=FALSE)
Argumentos:
• ...: Objetos a ser concatenados.
• recursive: Argumento lógico. si `recursive=TRUE', desciende recursivamente a
través de listas combinanado todos sus elementos en un vector.
• Ver también: `unlist' y `as.vector' para producir vectores libres de atributos.
Ejemplos:
> c(1,7:9)
[1] 1 7 8 9
> c(1:5, 10.5, "s")
[1] "1" "2" "3" "4" "5" "10.5" "s"
> c(list(A=c(B=1)), recursive=TRUE)
A.B
1
> c(list(A=c(B=1)), recursive=FALSE)
$A

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 43/344
43
B
1
> list(A=c(B=1))
$A
B
1
> c(list(A=c(B=1,C=2), B=c(E=7)), recursive=TRUE)
A.B A.C B.E
1 2 7
> c(list(A=c(B=1,C=2), B=c(E=7)), recursive=FALSE)
$A
B C
1 2
$B
E
7
Si tenemos el siguiente conjunto de frutas: pera, manzana, banano, pera, curuba, lo
podemos asignar a un vector así:
frutas<-c("pera","manzana","banano","pera","curuba")
Esto nos crea un vector llamado frutas de caracteres.
El símbolo <- es el de asignación. Lo que está sobre la derecha es asignado al objeto de
la izquierda. Podemos tener asignaciones simples o múltiples. Por ejemplo,
> x <-0
> y <-x<-0

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 44/344
44
Como se mostró previamente, datos pueden también entrarse con la función scan() de
una forma muy simple
> x<-c(scan())
1: 3.6 2.5
2: 1.2 0.6 1.3 2.1
7:
>
Esto nos permite entrar tantos datos por linea como queramos, dejando espacio entre datos
consecutivos. Si queremos ver en pantalla el vector de datos x la instrucción será:
>x
El siguiente ejemplo presenta un caso simple en el cual se analiza un conjunto de datos
referentes a velocidades de autos medidas con radar (en R bajo Windows)
>win.graph()
>velocidades<-c(scan())
1: 48 57 52 45
5: 46 57 38
8: 59 55 53 53 49 46
:
:
66: 40 45
68:>summary(velocidades)
>hist(velocidades)
>stem(velocidades)
>boxplot(velocidades)
>plot(density(velocidades),type=“l”)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 45/344
45
>q()
Si deseamos entrar vectores alfanuméricos entonces la función scan() llevará opciones
adicionales antes vistas.
>ciudades<-scan(what=character(0))
1: Medellin 'Santa Fe de Bogota' Cali Pereira
5: Cartagena Barranquilla
7:
>
Entrando Listas
Si se desea entrar un conjunto de datos que contienen tanto variables numéricas como
alfanuméricas, por ejemplo nombre, peso y edad, se hará como se explicó previamente (ver
función scan ):
> datos<-scan(=list(" ",0,0))
1: Juan 70 25
4: Pedro 65 28
7: Maria 50 22
10: Norma 55 39
13:
>
Generando Sucesiones de Números
R permite crear secuencias de una forma ágil. Por ejemplo 1:5 es equivalente a c(1,2,3,4,5).

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 46/344
46
> s1<-2:10
El anterior comando crea un vector llamado s1 con los elementos 2, 3, 4,..., 10.
> s1<-2:10
> s1
[1] 2 3 4 5 6 7 8 9 10
> s2<-10:2
> s2
[1] 10 9 8 7 6 5 4 3 2
>
Otra forma, aún más poderosa de crear secuencias es usar la función seq() , ya que esta
permite definir un incremento. El símbolo : tiene la más alta prioridad dentro de una
expresión. Un ejemplo de esto es,
s2<-seq(1,2,by=.2)
Este comando crea un vector s2 con los elementos 1.0, 1.2, 1.4, 1.6, 1.8, 2.0.
> s2<-seq(1,2,by=.2)
> s2
[1] 1.0 1.2 1.4 1.6 1.8 2.0
> s2<-seq(2,1,by=-.2)
> s2
[1] 2.0 1.8 1.6 1.4 1.2 1.0
> s2<-seq(2,1,length=6)
> s2
[1] 2.0 1.8 1.6 1.4 1.2 1.0

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 47/344
47
Replicación de una estructura
La función rep() puede usarse para replicar una estructura particular cierto número de
veces. La forma más simple es
s3<-rep(x,times=4)
lo cual nos crea un objeto que es cuatro veces el objeto x.
> x<-c(1,3,2,5)
> s3<-rep(x,times=4)
> s3
[1] 1 3 2 5 1 3 2 5 1 3 2 5 1 3 2 5
>
2.2. Datos Faltantes
Cuando tenemos valores de las variables faltantes debemos denotarlos en R con NA. Sinembargo si tenemos un archivo donde los datos faltantes se denoten con otro carácter
entonces en la opción na.strings = “NA” de la función scan() o de la función
read.table() reemplazamos el NA por el símbolo adecuado.
Tenemos un archivo en el directorio c:/datos/ llamado aptos.txt que es
precio mts2 piezas
120 * 3
175 * 3
* 220 4
95 * 4
* 80 2
120 141 3

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 48/344
48
260 330 4
75 * 3
85 100 3165 235 4
donde los valores faltantes se han denotado por una * . En R le damos el comando
siguiente para su lectura:
> apartamentos.dat<-read.table('c:/datos/aptos.txt',header=T,
na.strings = "*")
> apartamentos.datprecio mts2 piezas
1 120 NA 3
2 175 NA 3
3 NA 220 4
4 95 NA 4
5 NA 80 2
6 120 141 3
7 260 330 4
8 75 NA 39 85 100 3
10 165 235 4
y observamos como el programa reemplaza los símbolos por el adecuado para manejo
interno.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 49/344
49
2.3. Funciones de Escritura y Exportación de Datos que
Están en R
2.3.1 Función dump
Si queremos crear un archivo en ASCII que contenga un objeto usamos la función dump().
Esta función permite realizar representaciones de objetos R tomando un vector de nombres
de dichos objetos y produciendo representaciones textuales de estos en un archivo o
conexión. un archivo `dump' puede ser retomado en una sesión R con la función source.
dump(list, file="dumpdata.R", append=FALSE)
Argumentos:
• list: Argumento tipo caracter. Corresponde a los nombres de uno o más objetos R a
ser descargados.
• file: Corresponde bien sea a una cadena de caracter nombrando un archivo o unaconexión. `" " ' indica salida a la consola (pantalla).
• append: Si es TRUE, la salida será añadida a `file'; de otra forma, sobreescribirá los
contenidos de `file'.
Detalles:
• La implementación actual de dump sólo funciona para arreglos vectoriales, matrices,
tablas y funciones.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 50/344
50
• La función save está diseñada para ser usada para transportar datos R entre
máquinas.
Ver también: `dput', `dget',`write'.\\
Ejemplos: Vamos a guardar dos vectores `x' e `y' en el archivo “c:/result.txt”:
x <- 1
y <- 1:10
dump(c("x","y"),file="c:/result.txt")
Supongamos ahora que estamos iniciando una nueva sesión en R, y queremos utilizar los
objetos `x' e `y' en dicha sesión; para ello, llamamos el archivo “c:/result.txt” con la función
source:
> source("c:/result.txt")
> x
[1] 1
> y
[1] 1 2 3 4 5 6 7 8 9 10
Si un nuevo vector `z' es creado y se desea añadir al archivo
“c:/result.txt”:
#Creación de vector de 100
#valores provenientes de una normal estándar
z<-rnorm(100)
dump("z",file="c:/result.txt",append=TRUE)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 51/344
51
Ahora, crearemos una función llamada `resumen' la cual añadiremos como un objeto R en
“c:/result.txt”:
resumen<-function(x){
media<-mean(x)
desv.std<-sqrt(var(x))
coef.var<-(desv.std/media)*100
mediana<-median(x)
list(media=media,desv.std=desv.std,coef.var=coef.var,mediana=mediana)
}
dump("resumen",file="c:/result.txt",append=TRUE)
Supongamos que necesitamos en una nueva sesión de trabajo algunos de los objetos R
guardados en “c:/result.txt”, podemos llamarlos cargando todos los objetos disponibles en
tal archivo con source("c:/result.txt"); por ejemplo, si requerimos la función `resumen' para
aplicarla a un conjunto de datos `a':
#cargando objetos R disponibles
en "c:/result.txt"
source("c:/result.txt")
#generación de 50 observaciones de una
#normal mu=5, sigma=2:
a<-rnorm(50,5,2)
#aplicación de la función resumen
#sobre el vector a.
resumen(a)
$media
[1] 5.129502

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 52/344
52
$desv.std
[1] 2.066936
$coef.var
[1] 40.29506
$mediana
[1] 5.242943
utilidad de la función dump, pues permite almacenar en otros dispositivos objetos R
(sujetos a las restricciones vistas) y la exportación de estos.
Figura 2.1: Datos en “c:/result.txt”

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 53/344
53
Otro ejemplo: si en el espacio de trabajo R existen ciertos objetos R y deseamos
guardarlos todos en un mismo archivo, podemos hacerlo como sigue:
#creación de tres objetos:
a<-rexp(10)
> b<-rnorm(20)
> c<-a/b
#listado de todos los objetos R
#disponibles en la sesión:
> ls()
[1] "a" "b" "c"
#guardar todos los objetos disponibles
#en "c:/objetos.txt"
> dump(ls(),file="c:/objetos.txt")
#Creación de una matriz la cual
#es añadida a "c:/objetos.txt"
> d<-matrix(b,ncol=4)
> dump("d",file="c:/objetos.txt",append=TRUE)
>
En la figura 2.2 puede observarse el contenido final del archivo "c:/objetos.txt". Las
funciones print(), format(), cat() y paste() pueden usarse para formatear la salida
a ser escrita en un archivo externo. Las funciones data.dump() , dump() y dput() escriben objetos de R a archivos ASCII pero no en formato de texto regular. Ellas se
utilizan para transferir datos entre máquinas.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 54/344
54
Figura 2.2: Datos en “c:/objetos.txt”
2.3.2 Función write (Escribiendo una Matriz a un Archivo Externo)
Para escribir una matriz a un archivo ASCII utilizamos esta función donde los datos que
corresponden a una matriz `x' son escritos al archivo `file'. Cuando `x' es una matriz de dos
o más dimensiones es necesario trasponerla para que las columnas que aparezcan en `file'
coincidan con las de `x'.
write(x, file = "data",
ncolumns = if(is.character(x)) 1 else 5,append = FALSE)
Argumentos:
• x: Corresponde a los datos a ser escritos

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 55/344
55
• file: Una conexión o una cadena de caracteres nombrando el archivo al cual se
escribirán los datos.
• ncolumns: El número de columnas para escribir los datos.
• append: Argumento lógico. Si es TRUE `x' es añadida al archivo `file'.
Ver también: save para escribir cualesquiera objetos R; write.table para data
frames (marcos de datos).
Ejemplos: A continuación guardamos una matrix `x' creada con \tt matrix (ver más
adelante esta función) la cual es guardada en el archivo “c:/manualr/write.txt” (ver figura
2.3):
# crear una matriz de 10x10:
x <- matrix(rnorm(100),ncol=10)
#la matriz creada contiene:
x
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] -0.8558726 1.3148297 -1.38651179 -0.41982265 0.3882958 0.1121742
[2,] -0.8424902 -0.4882481 0.05887779 -0.23149084 -1.5820110 -0.6446336
[3,] 1.1325723 -0.4997801 -0.77362112 -1.02049357 1.3869108 -0.3000436
[4,] -0.6956890 0.7853870 -2.16470421 0.09721843 -0.7354284 0.0783864
[5,] 1.0297177 1.1912180 -0.19048374 0.09899511 -0.7408238 0.1270681
[6,] 0.1915085 -1.1961166 0.39530447 -0.68988096 -0.8448683 0.6209052
[7,] -0.7017792 0.8331557 0.85350462 0.66073701 -0.1763620 0.1802481
[8,] -0.5614818 0.5921645 -0.51038265 -0.29370360 2.2841187 0.3731943
[9,] 0.7775366 0.7954261 -0.38851534 -1.31357741 0.9291928 0.3759094
[10,] 0.5864660 0.3543825 0.25971683 -0.86956602 0.3408166 -0.4886315
[,7] [,8] [,9] [,10]
[1,] 1.3132876 -0.054863632 0.19513390 -0.61315626
[2,] 0.6747525 0.254769398 -1.15391332 -1.04650841

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 56/344
56
[3,] 0.7992131 -0.066703082 0.62109208 -0.28452693
[4,] 2.0775911 0.569413512 2.03562228 3.47638462
[5,] 1.4738575 -0.004902835 1.33584992 -2.14009081[6,] -2.1628119 -1.078721708 -0.06621326 -0.87445892
[7,] -0.3956469 0.285227385 -0.05265089 0.54351961
[8,] 1.2897217 -0.679368675 -0.52699198 0.86417546
[9,] -0.7860005 1.374524963 1.13809830 -0.06029963
[10,] -0.2013117 -1.411422651 -0.60979649 -0.30612573
#copiamos los anteriores datos en
#un archivo de texto:
write(t(x),file="c:/manualr/write.txt")
Figura 2.3: Datos en “c:/manualr/write.txt”
2.3.3 Función sink (Enviando resultados a un archivo de texto)
A veces se requiere tener un archivo ASCII con los resultados que se obtengan en una
sesión para una edición posterior. sink desvía una salida de R a una conexión. Esta nos
redirige la salida de los comandos de la pantalla a un archivo. En la terminal no observamos

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 57/344
57
nada. Es muy útil cuando se ejecutan trabajos como simulaciones (una alternativa obvia
bajo Windows es utilizar las opciones Cortar/Pegar).
sink(file = NULL, append = FALSE, type = c("output", "message"))
Argumentos:
• file: Una conexión o una cadena de caracteres nombrando el archivo al cual se
escribirá la salida, o `NULL' para sinking .
• append: Argumento lógico. Si es `TRUE', la salida será añadido a `file'; de lo
contrario se sobreescribirá los contenidos de `file'.
• type: Caracter. ¿Las salidas o los mensajes?.
Detalles:
• sink desvía la salida de R a una conexión. si `file' corresponde a una cadena de
caracteres, una conexión de archivo con ese nombre será establecida mientras dure la
desviación.
• La salida Normal de R es desviada por defecto a `type = “output” '. únicamente los
apuntadores (prompts) y los mensajes de advertencia/error siguen apareciendo en la
terminal. Estos también puede desviarse por `type = “message” '.
• `sink()' o `sink(file=NULL)' terminan la última desviación (del tipo
especificado). A partir de la versión R 1.3.0 hay una pila de desviaciones para la
salida normal, así que la salida se revierte a la desviación previa (si había alguna). La
pila es hasta 21 conexiones (20 desviaciones).

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 58/344
58
• si `file' es una conexión será abierta cuando sea necesario. switchear a otro archivo o
conexión cierra y destruye el actual sink connection si éste es una conexión archivo
abierta por una llamada anterior a sink.
Advertencia: No usar una conexión que es abierta por sink para cualquier otro
propósito. El programa lo detendrá a usted cerrando tal conexión inadvertidamente. No
aplicar sink al flujo de mensajes a menos que comprenda el código fuente para
implementación y por tanto las trampas.
Ejemplo: El siguiente ejemplo envía al archivo “c:/sink-examp.txt” los resultados de la
función outer (ver más adelante) entre el llamado de sink y el cierre de ésta con
sink(). Si verificamos en en directorio 'C:\' antes de llamar a unlink, veremos que ha
sido creado el archivo de texto (ver figura 2.4); cuando se desea restablecer el modo normal
de operación, esto es, volver a ver los resultados en la terminal, se da el comando
sink(); luego de nuevo se llama el mismo archivo para anexarle las salidas de un objeto
m (una matriz creada con la función matrix; ver más adelante); cerramos nuevamente la
conexión y con la instrucción unlink(“c:/sink-examp.txt”) es borrado:
>sink("c:/sink-examp.txt")
>i <- 1:10
>outer(i,i,"*")
>sink()
>sink("c:/sink-examp.txt", append=TRUE)
>m<-matrix(rnorm(100),ncol=10)>m
>sink()
>unlink("c:/sink-examp.txt")

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 59/344
59
Figura 2.4: Datos en “c:/sink-example”
2.4. Construcción, Lectura y Escritura de Tablas de
Contingencia Categóricas
2.4.1 Función ftable Esta función crea y manipula tablas de contingencias categóricas.
ftable(..., exclude = c(NA, NaN), row.vars = NULL,
col.vars = NULL)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 60/344
60
as.table.ftable(x)
read.ftable(file, sep = "", quote = "\"",
row.var.names, col.vars, skip = 0)write.ftable(x, file = "", quote = TRUE,
digits = getOption("digits"))
Argumentos:
• ...: Los objetos R a ser interpretados como factores (incluyendo cadenas de
caracteres), o una lista o data frame cuyas componentes pueden ser interpretadas, o un
objeto tabla de contingencia de la clase “table” o “ftable”.
• exclude: Valores a usar en argumento exclude de `factor' cuando se interpretan
objetos como no factores.
• row.vars: Un vector de enteros que da los números de las variables, o un vector de
caracteres dando los nombres de las variables a ser usadas por las filas de las tablas
de contingencias categóricas.
• col.vars: Un vector de enteros dando los números de las variables, o un vector de
caracteres dando los nombres de las variables a ser usadas para las columnas de la
tabla de contingencia categórica.
• x: Un objeto R arbitrario.
• file: Puede ser una cadena de caracters nombrando un archivo o conexión desde la
cual los datos van a ser leídos o a donde van a ser escritos. ` ““ 'indica entradas desde
la consola para leer y salidas a la consola para escribir.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 61/344
61
• sep: Cadena separadora de campos. Los valores en cada línea del archivo están
separadas por esta cadena.
• quote: Una cadena de caracteres dando el conjunto de caracteres entre comillas para
read.ftable; para deshabilitar comillas por completo, usar `quote=” ”. Para
write.table es un valor lógico indicando si las cadenas en los datos están entre
comillas dobles.
• row.var.names: Un vector de caracteres con los nombres de las variables fila, en
caso que éstos no puedan ser determinados automáticamente.
• col.vars: Una lista dando los nombres y los niveles de ls variables columna, en caso
que éstos no puedan ser determinados automáticamente.
• skip: El número de líneas en el archivo de datos a ser omitidas antes de comenzar
• la lectura de datos.
• digits: Un entero dando el número de dígitos significativos a ser usados para las
entradas de celda de `x'.
Detalles:
• ftable crea tablas de contingencias categóricas. Como las tablas de contingencias
usuales, éstas contienen los conteos de cada combinación de los niveles de lasvariables (factores) involucrados. Esta información es reordenada como una matriz
cuyas filas y columnas corresponden a la combinaciones únicas de los niveles de las
variables fila y columna (tal como se especificó por `row.vars' y `col.vars'). Las
combinaciones son creadas mediante looping sobre las variables en orden inverso (de

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 62/344
62
modo que los niveles de la variable más a la izquierda varían más lento). Presentando
una tabla de contingencia en esta forma de matriz categórica (por medio de
`print.ftable', que es el método de impresión de los objetos clase “ftable”) es a
menudo preferible para mostrarla como un arreglo un arreglo en alta dimensión.
• ftable es una función genérica. Su método por defecto, ftable.default,
crea primero una tabla de contingencia en forma de arreglo a partir de todos los
argumentos excepto `row.vars' y `col.vars'. Si el primer argumento es de la clase
“table”, representa una tabla de contingencia y es usada como tal; si es una tabla
categórica de clase “ftable”, la información que contiene es convertida a la
representación de arreglo usual usando as.ftable. De lo contrario, los argumentos
deberían ser objetos R los cuales pueden ser interpretados como factores (incluyendo
cadenas de caracteres), o una lista (o data frame) cuyas componentes puedan ser
interpretadas, los cuales son tabulados de forma cruzada usando la función table.
Luego, los argumentos `row.vars' y `col.vars' son usados para plegar la tabla de
contingencia en forma categórica. Si ninguno de estos dos argumentos es dado, la
última variable es usada para las columnas. Si ambos argumentos son dados y suunión es un subconjunto apropiado de todas las variables involucradas, las otras
variables son resumidas.
• La función ftable.formula proporciona método fórmula para crear tablas de
contingencia categóricas.
•
La función as.table.ftable convierte una tabla de contingencia que está en laforma de una matriz categórica a una en la forma de arreglo estándar. Este es un
método para la función genérica as.table.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 63/344
63
• La función write.ftable escribe una tabla categórica a un archivo, lo cual es
útil para generar representaciones ASCII “ pretty” de tablas de contingencias.
• La función read.ftable lee a manera de una tabla de contingencia categórica
desde un archivo. Si el archivo contiene la representación escrita de un tabla
categórica (más precisamente, un encabezado con toda la información de nombres y
niveles de las variables columna, seguidas por una línea con los nombres de las
variables fila) no más argumentos son necesarios. Similarmente, las tablas categóricas
con sólo una variable columna el nombre de la cual es la única entrada en la primera
línea son manipuladas automáticamente. Otras variantes pueden ser tratadas con
omisión de toda información de encabezado usando `skip', y proporcionando los
nombres de las variables fila y los nombres de los niveles de las variables columna
usando row.var.names' y col.vars', respectivamente.
• Notar que las tablas categóricas están caracterizadas por sus presentaciones
recortadas de las etiquetas de filas (puede ser también el caso para las columnas). Si
la “rejilla” completa de los niveles de las variables fila es dado, uno debería usar más bien read.table para leer los datos, y crear la tabla de contingencia usando
xtabs.
Valor: ftable devuelve un objeto de clase “ftable”, el cual es una matriz con conteos en
cada combinación de los niveles de las variables con información sobre los nombres y
niveles de las variables (fila y columnas) guardadas como atributos “row.vars” y”col.vars”.
Referencias: Agresti, A. (1990) Categorical data analysis. New York: Wiley.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 64/344
64
Ver también: ftable.formula para interface de fórmula (la cual permite un argumento
`data = .'); table para tabulación cruzada ordinaria; xtabs para tabulación cruzada basada
en fórmula.
Ejemplo: Los siguientes son ejemplos disponibles en el `R Documentation':
#Llamado de una tabla de contingencia
#disponible en el sistema:
data(Titanic)
> Titanic
, , Age = Child, Survived = No
Sex
Class Male Female
1st 0 0
2nd 0 0
3rd 35 17
Crew 0 0
, , Age = Adult, Survived = No
Sex
Class Male Female
1st 118 4
2nd 154 13
3rd 387 89
Crew 670 3
, , Age = Child, Survived = Yes
Sex
Class Male Female
1st 5 1

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 65/344
65
2nd 11 13
3rd 13 14
Crew 0 0
, , Age = Adult, Survived = Yes
Sex
Class Male Female
1st 57 140
2nd 14 80
3rd 75 76
Crew 192 20
>ftable(Titanic, row.vars = 1:3)
Survived No Yes
Class Sex Age
1st Male Child 0 5
Adult 118 57
Female Child 0 1
Adult 4 140
2nd Male Child 0 11
Adult 154 14
Female Child 0 13
Adult 13 80
3rd Male Child 35 13
Adult 387 75
Female Child 17 14
Adult 89 76
Crew Male Child 0 0
Adult 670 192
Female Child 0 0
Adult 3 20
>ftable(Titanic, row.vars = 1:2, col.vars = "Survived")
Survived No Yes

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 66/344
66
Class Sex
1st Male 118 62
Female 4 1412nd Male 154 25
Female 13 93
3rd Male 422 88
Female 106 90
Crew Male 670 192
Female 3 20
>ftable(Titanic, row.vars = 2:1, col.vars = "Survived")
Survived No Yes
Sex Class
Male 1st 118 62
2nd 154 25
3rd 422 88
Crew 670 192
Female 1st 4 141
2nd 13 93
3rd 106 90
Crew 3 20
#Operando sobre un data frame:
> data(mtcars)
> mtcars
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
Duster 360 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 67/344
67
Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
Merc 280 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4Merc 280C 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4
Merc 450SE 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3
Merc 450SL 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3
Merc 450SLC 15.2 8 275.8 180 3.07 3.780 18.00 0 0 3 3
Cadillac Fleetwood 10.4 8 472.0 205 2.93 5.250 17.98 0 0 3 4
Lincoln Continental 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3 4
Chrysler Imperial 14.7 8 440.0 230 3.23 5.345 17.42 0 0 3 4
Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
Toyota Corona 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
Dodge Challenger 15.5 8 318.0 150 2.76 3.520 16.87 0 0 3 2
AMC Javelin 15.2 8 304.0 150 3.15 3.435 17.30 0 0 3 2
Camaro Z28 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3 4
Pontiac Firebird 19.2 8 400.0 175 3.08 3.845 17.05 0 0 3 2
Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2
Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2
Ford Pantera L 15.8 8 351.0 264 4.22 3.170 14.50 0 1 5 4
Ferrari Dino 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6
Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8
Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2
#Construir tablas de contingencia
#con las variables columna que constituyen
#factores:
x <- ftable(mtcars[c("cyl", "vs", "am", "gear")])
x
gear 3 4 5
cyl vs am
4 0 0 0 0 0

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 68/344
68
1 0 0 1
1 0 1 2 0
1 0 6 16 0 0 0 0 0
1 0 2 1
1 0 2 2 0
1 0 0 0
8 0 0 12 0 0
1 0 0 2
1 0 0 0 0
1 0 0 0
>
ftable(x, row.vars = c(2, 4))
cyl 4 6 8
am 0 1 0 1 0 1
vs gear
0 3 0 0 0 0 12 0
4 0 0 0 2 0 0
5 0 1 0 1 0 2
1 3 1 0 2 0 0 0
4 2 6 2 0 0 0
5 0 1 0 0 0 0
## Agresti (1990), pag. 157, Tabla 5.8.
## Construyendo una tabla pero
##no en la forma estándar:
#Crear un archivo temporal:
file <- tempfile()
#Diseñando la tabla:
cat(" Intercourse\n",
"Race Gender Yes No\n",
"White Male 43 134\n",

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 69/344
69
" Female 26 149\n",
"Black Male 29 23\n",
" Female 22 36\n",file = file)
>file
[1] "C:\\DOCUME~1\\PROPIE~1\\CONFIG~1\\Temp\\file26500"
#Ver en la figura 2.5 el resultado
#del siguiente comando:
file.show(file)
#leyendo el archivo "file"
#como una tabla de contingencia:
ft <- read.ftable(file)
ft
Intercourse Yes No
Race Gender
White Male 43 29
Female 134 23
Black Male 26 22
Female 149 36
#Borrando el archivo "file":
unlink(file)
## Agresti (1990), pag. 297, Tabla 8.16.
## faltan los nombres de las variables fila:
file <- tempfile()
cat(" \"Tonsil Size\"\n",
" \"Not Enl.\" \"Enl.\" \"Greatly Enl.\"\n",

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 70/344
70
"Noncarriers 497 560 269\n",
"Carriers 19 29 24\n",
file = file)file.show(file)
ft <- read.ftable(file, skip = 2,
row.var.names = "Status",
col.vars = list("Tonsil Size" =
c("Not Enl.", "Enl.", "Greatly Enl.")))
ft
Tonsil Size Not Enl. Enl. Greatly Enl.
Status
Noncarriers 497 269 29
Carriers 560 19 24
>
unlink(file)
Figura 2.5: Resultado de “file.show(file)”: Esta función aplicada sobre el
archivo “ file” abre la ventana R Information, en la cual puede observarse la
estructura de los datos guardados en este archivo temporal .

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 71/344
71
A continuación, construiremos una tabla a partir de una base de datos, la cual contiene 12
variables relacionadas con los resultados en las pruebas del ICFES, realizadas durante
varios años, los cuales están disponibles en “BASES DE DATOS", J. C. Correa y J. C.
Salazar, 1997, UNAL. De las 12 variables, hay tres que pueden considerarse como factores,
a saber: sexo (M, F), año en que se tomó la prueba (89,92,93) y tipo de electiva (ABS
(razonamiento abstracto), MET (metalmecánica), CON (contabilidad), ING (inglés), ELE
(eléctrica), MEC (razonamiento mecánico)):
#Lectura de los datos, note que
#las variables columna 1, 2, 12
#son definidas como factores:
icfes<-read.table(file="c:/graficosr/datosgraficos/icfes.dat",
header=FALSE,col.names=c("sexo","ano","biolog","Quim","fisica",
"Soc","AptVerb","EspLIter","AptMat","ConMat","Elect","tipoElect"),
as.is=c(1,2,12))
#Construcción de una tabla de
#contingencia categórica de
#sexo, año versus tipo de electiva:
ftable(icfes[c("sexo","ano","tipoElect")])
>icfes.tabla<-ftable(icfes[c("sexo","ano","tipoElect")])
>icfes.tabla
tipoElect ABS CON ELE ING MEC MET
sexo ano
F 89 0 17 0 1 1 0
92 0 16 0 2 0 093 0 14 0 19 1 3
M 89 3 0 8 1 0 6
92 2 1 2 10 5 2
93 1 0 2 0 7 8
>

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 72/344
72
#Guardando la tabla anterior
#como un objeto R (ver figura 2.6):
dump("icfes.tabla",file="c:/tabla.txt")
#Guardando la misma tabla pero
#sólo como una "pretty table"
"ver figura 2.7:
write.ftable(icfes.tabla,file="c:/tabla2.txt")
Figura 2.6: Datos en “c:/tabla.txt"

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 73/344
73
Figura 2.7: Datos en “c:/tabla2.txt"

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 74/344
74
Capítulo 3: Manipulación de Datos
La manipulación de datos se hace de diferentes formas. Usualmente se toma ventaja de la
vectorización del lenguaje. Esto permite trabajar sobre un conjunto de elementos en lugar
de trabajar elemento a elemento como en lenguajes normales.
3.1. Operadores
• + : Suma
• - : Resta
• * : Multiplicación
• / : División
• ^ : Exponenciación
• %/% : División entera
• %% : Operador módulo
Operadores de comparación
• < : menor
• >: mayor

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 75/344
75
• <= : menor o igual
• >= : mayor o igual
• = = : igual
• != : diferente
Operadores Lógicos
• & : y
• | : ó
• ! : no
• all(...): Todo
• any(...): Ninguno
Operadores de Control
• && : Si el primer operando es cierto se evalúa el segundo operando
• || : Si el primer operando es falso se evalúa el segundo operando.
Operaciones Básicas: Siendo el lenguaje vectorizado, los vectores pueden usarse en
expresiones aritméticas, en cuyo caso las operaciones son ejecutadas elemento a elemento.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 76/344
76
Si x y z son vectores, no necesariamente de la misma dimensión, entonces podemos
ejecutar los siguientes comandos
> y<-x+z
> y2<-x-z
> y3<-2*x+z-3
La dimensión de y , y2 y y3 será igual a la dimensión mayor de los vectores x y z.
> y4<-1/x
El anterior comando produce un vector cuyos elementos corresponden a los inversos de x.
Subíndices
Datos pueden ser extraídos de un objeto de la siguiente forma:
x[ subindice]
La forma del subíndice puede expresarse de varias formas.
• Enteros positivos:
x[1] Solo nos quedamos con el primer elemento de x
x[1:3]
Solo nos quedamos con los tres primeros elementos de x
x[2:5] Solo nos quedamos con elementos 2, 3, 4, y 5 de x
• Valores lógicos:

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 77/344
77
x[x > 0] Sólo tomamos los valores de x que sean positivos.
nombre[estatura > 175 & edad < 30] Nos quedamos con aquellos nombres cuyas
correspondientes esturas sean mayores a 175 y la edad sea menor de 30.
• Enteros negativos:
x[-1] Nos quedamos con todo x pero eliminamos el primer elemento.
Ejemplo: Los siguientes datos corresponden a información tomada del anuario estadístico
de Antioquia de 1996, de los cuales la segunda columna se refiere a la temperatura en las
cabeceras municipales. El objetivo es crear una nueva variable categórica que clasifique
los municipios de acuerdo a rangos de temperatura “Muy Baja”, “Baja”, “Media” y
“Alta”:
>datos.antioquia<-scan()
1: 1 22 1834881 53822 432680 36053 4114 16763 489610 419676 35912 4068 11870 471526 95.316: 1 22 34985 1718 3481 432 14 32 3959 3130 430 14 31 3605 95.9
31: 1 22 293841 9472 63961 2205 266 968 67400 62288 2166 242 849 65545 95
46: 1 19 56488 1825 8481 1119 45 34 9679 8172 1103 45 32 9352 95
61: 1 22 49649 2306 10223 580 57 161 11021 8632 545 45 159 9381 91
76: 1 21 123943 5928 32652 2649 296 299 35896 30951 2619 291 295 34156 97.1
91: 1 22 31168 1662 4662 383 26 54 5125 4298 348 9 52 4707 95.6
106: 1 21 193381 11077 44940 4424 978 575 50917 42700 4366 956 513 48535 98.8
121: 1 20 41592 931 5352 259 95 204 5910 4766 243 89 187 5285 93.7
136: 1 20 29870 1476 6856 771 245 163 8035 6694 762 239 127 7822 97.1
151: 2 28 22362 1068 860 37 0 19 916 667 34 0 17 718 58.6
166: 2 28 54210 1228 8970 776 0 57 9803 3751 286 0 28 4065 39.8181: 2 28 11003 309 1132 109 0 21 1262 38 0 0 0 38 20
.
.
.
1366: 8 21 12356 433 1002 102 1 33 1138 796 68 0 24 888 84.8
1381: 8 20 36194 308 3124 294 0 60 3478 3086 294 0 60 3440 91.6
1396: 8 21 9352 229 1032 77 0 31 1140 758 72 0 23 853 86

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 78/344
78
1411: 8 21 13830 429 1333 123 0 22 1478 989 107 0 16 1112 91.9
1426: 9 28 78019 2403 8868 882 3 70 9823 3662 713 0 28 4403 60
1441: 9 28 23895 677 1380 127 0 32 1539 1008 118 0 31 1157 45
1456: 9 28 44201 1762 3764 337 0 41 4142 2183 275 0 31 2489 44.5
1471: 9 28 2959 81 0 0 0 0 0 0 0 0 0 0 0
1486: 9 28 12670 1354 618 59 0 35 712 NA NA NA NA NA 80
1501: 9 28 99782 2277 5089 343 0 63 5495 NA NA NA NA NA 45
1516: 9 28 9403 96 450 47 0 0 497 0 0 0 0 0 0
1531:
Read 1530 items
datos.antioquia<-matrix(datos.antioquia,ncol=15,byrow=T)
temperatura<-c(datos.antioquia[,2])
tipo<-rep(NA,length(temperatura))
tipo[temperatura<=15]<-'MUy Baja'
tipo[15<temperatura & temperatura<=20]<-'Baja'
tipo[20<temperatura & temperatura<=25]<-'Media'
tipo[25<temperatura]<-'Alta'
> tipo
[1] "Media" "Media" "Media" "Baja" "Media" "Media"
[7] "Media" "Media" "Baja" "Baja" "Alta" "Alta"
[13] "Alta" "Alta" "Alta" "Alta" "Media" "Alta"
[19] "Alta" "Alta" "Media" "Media" "Media" "Media"
[25] "Media" "Baja" "Media" "Media" "Media" "Media"
[31] "Media" "MUy Baja" "Media" "Baja" "Baja" "Baja"
[37] "Baja" "Baja" "Media" "Media" "MUy Baja" "MUy Baja"
[43] "MUy Baja" "Baja" "Media" "MUy Baja" "Baja" "Baja"
[49] "Media" "Media" "Media" "Media" "Media" "Alta"
[55] "Media" "Media" "Baja" "Baja" "Baja" "Baja"
[61] "Media" "Baja" "Baja" "Baja" "Baja" "Baja"
[67] "Baja" "Baja" "Baja" "MUy Baja" "Baja" "Baja"
[73] "Baja" "Media" "Media" "Baja" "MUy Baja" "Media"
[79] "Media" "Baja" "Baja" "Baja" "Media" "Baja"
[85] "Media" "Baja" "Baja" "MUy Baja" "Baja" "Media"
[91] "Baja" "Media" "Baja" "Media" "Media" "Alta"

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 79/344
79
[97] "Alta" "Alta" "Alta"
3.1.1 Funciones que producen escalares
Existen una gran cantidad de funciones que al ser aplicadas a un vector producen como
resultado un escalar. Entre ellas tenemos:
• max(): retorna el máximo del argumento
• min(): retorna el mínimo del argumento
• sum(): retorna la suma de todos los elementos del argumento
• mean(): retorna el promedio aritmético de todos los elementos del argumento.
• var(): retorna la varianza de todos los elementos del argumento, cuando éste es un
vector, o la matriz de varianzas - covarianzas si el argumento es una matriz.
• median(): retorna la mediana del argumento
• quantile(...,probs=c(...)): retorna quantiles del argumento con la proporción o
proporciones indicadas en `probs'.
• prod(): retorna el producto de todos los elementos del argumento
• length(): retorna el número de elementos del argumento si este es una lista o vector.
• ncol(): número de columnas si el argumento es una matriz

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 80/344
80
• nrow(): número de filas si el argumento es una matriz
Ejemplo:
> x<-rexp(20)
> x
[1] 0.65699969 4.38423147 1.39088864 1.82778784 0.07063072 0.16763033 0.26055624 0.13914072
[9] 0.19467512 1.43806059 0.33195089 0.53713890 1.03220040 1.64537448 0.76489143 0.77907097
[17] 0.08561684 0.01892189 0.53475832 2.32819674
> max(x)[1] 4.384231
> min(x)
[1] 0.01892189
> sum(x)
[1] 18.58872
> mean(x)
[1] 0.9294361
> length(x)
[1] 20> median(x)
[1] 0.5970693
> var(x)
[1] 1.102911
> quantile(x,probs=0.75)
75%
1.402682
La función summary nos proporciona los estadísticos básicos del argumento:
> s<-summary(x)
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.01892 0.18790 0.59710 0.92940 1.40300 4.38400

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 81/344
81
> length(s)
[1] 6
#presentando un componente de s:
> s[1]
Min.
0.01892
Transformando a s en un vector:
> c<-as.vector(s)
> c
[1] 0.01892 0.18790 0.59710 0.92940 1.40300 4.38400
3.1.2 Funciones para redondeo de números
En R existen las siguientes seis funciones para el redondeo de números:
• ceiling: Tiene un único argumento: un valor o un vector `x'; devuelve en este
último caso un vector numérico que contiene los enteros más pequeños no menoresque los correspondientes elementos de `x'.
• floor: Costa de un sólo argumento numérico `x' y devuelve un vector numérico
que contiene los enteros más grandes no mayores que los correspondientes elementos
de `x'.
• round: Redondea los valores en su primer argumento al número especificado delugares decimales (por defecto 0). Para completar un 5, se usa el estándar IEEE,
“llevar al dígito par ”. Por tanto, round(0.5) es 0 y round(-1.5) es -2.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 82/344
82
• signif: Redondea los valores en su primer argumento al número especificado de
dígitos significativos.
• trunc: Toma un único argumento numérico `x' y devuelve un vector numérico que
contiene los enteros truncando los valores en `x' hacia 0.
• zapsmall: Determina un argumento `digits' `dr' para llamar a round(x,
digits = dr) tal que los valores cercanos a cero son “zapped”, es decir, tratados
como 0.
ceiling(x)
floor(x)
round(x, digits = 0)
signif(x, digits = 6)
trunc(x)
zapsmall(x, digits= getOption("digits"))
Argumentos:
• x: Un vector numérico.
• digits: Entero que indica la precisión a ser usada.
Ejemplos:
> a<-(.5 + -2:4)
> a
[1] -1.5 -0.5 0.5 1.5 2.5 3.5 4.5
> round(a)
[1] -2 0 0 2 2 4 4
> ceiling(a)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 83/344
83
[1] -1 0 1 2 3 4 5
> floor(a)
[1] -2 -1 0 1 2 3 4> round(a)
[1] -2 0 0 2 2 4 4
> signif(a)
[1] -1.5 -0.5 0.5 1.5 2.5 3.5 4.5
> trunc(a)
[1] -1 0 0 1 2 3 4
> zapsmall(a)
[1] -1.5 -0.5 0.5 1.5 2.5 3.5 4.5
> a<-rexp(6)
> a
[1] 0.9239737 0.1208308 0.2554847 0.1632143 0.1176684 0.7598348
> round(a)
[1] 1 0 0 0 0 1
> ceiling(a)
[1] 1 1 1 1 1 1
> floor(a)
[1] 0 0 0 0 0 0
> round(a,digits=3)
[1] 0.924 0.121 0.255 0.163 0.118 0.760
> signif(a,digits=3)
[1] 0.924 0.121 0.255 0.163 0.118 0.760
> trunc(a)
[1] 0 0 0 0 0 0
> zapsmall(a)
[1] 0.9239737 0.1208308 0.2554847 0.1632143 0.1176684 0.7598348
3.1.3 Funciones relacionadas con distribuciones
En R podemos calcular densidades, probabilidades acumuladas, hallar cuantiles y generar
números aleatorios de la siguiente manera:

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 84/344
84
Distribución Densidad Función Acumulada
Uniforme dunif(x,min=0,max=1,log = FALSE) punif(q,min=0,max=1, lower.tail =
TRUE,log.p = FALSE)
Normal dnorm(x, mean=0, sd=1, log =
FALSE)
pnorm(q, mean=0, sd=1, lower.tail =
TRUE, log.p = FALSE)
Binomial dbinom(x, size, prob, log = FALSE) pbinom(q, size, prob, lower.tail =
TRUE, log.p = FALSE)
Lognormal dlnorm(x, meanlog = 0, sdlog = 1,
log = FALSE)
plnorm(q, meanlog = 0, sdlog = 1,
lower.tail = TRUE, log.p = FALSE)
Beta dbeta(x, shape1, shape2, ncp=0,
log = FALSE)
pbeta(q, shape1, shape2, ncp=0,
lower.tail = TRUE, log.p = FALSE)
Geométrica dgeom(x, prob, log = FALSE) pgeom(q, prob, lower.tail = TRUE,
log.p = FALSE)
Gamma dgamma(x, shape, scale=1, log =
FALSE)
pgamma(q, shape, scale=1, lower.tail =
TRUE, log.p = FALSE)
Ji cuadrado dchisq(x, df, ncp=0, log = FALSE) pchisq(q, df, ncp=0, lower.tail =
TRUE, log.p = FALSE)
Exponencial dexp(x, rate = 1, log = FALSE) pexp(q, rate = 1, lower.tail = TRUE,
log.p = FALSE)
F df(x, df1, df2, log = FALSE) pf(q, df1, df2, ncp=0, lower.tail =
TRUE,log.p = FALSE)
Hipergeom. dhyper(x, m, n, k, log = FALSE) phyper(q, m, n, k, lower.tail = TRUE,
log.p = FALSE)
t dt(x, df, log = FALSE) pt(q, df, ncp=0, lower.tail = TRUE,
log.p = FALSE)
Poisson dpois(x, lambda, log = FALSE) ppois(q, lambda,lower.tail = TRUE,
log.p = FALSE)
Weibull dweibull(x, shape, scale = 1, log
= FALSE)
pweibull(q, shape, scale = 1,
lower.tail = TRUE, log.p = FALSE)
Binom. Neg. dnbinom(x, size, prob, mu, log =
FALSE)
pnbinom(q, size, prob, mu, lower.tail
= TRUE, log.p = FALSE)
Donde:
• x, q: Es un vector de cuantiles.
• p: Vector de probabilidades.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 85/344
85
• log, log.p: Argumentos lógicos; si son TRUE, las probabilidades p son dadas como
log(p).
• lower.tail: Argumento lógico; si es TRUE (por defecto), las probabilidades
corresponden a P[X <= x], de lo contrario, P[X > x].
• min,max: En la distribución uniforme corresponde a los límites inferior y superior
de la distribución. Por defecto son 0 y 1.
• size: En la binomial, corresponde al número de intentos; en la binomial negativa
corresponde al número de intentos exitosos (o número de éxitos) objetivo.
• prob: En la binomial, binomial negativa y en la geométrica, corresponde a la
probabilidad de éxito en cada intento.
• meanlog, sdlog: En la Log normal, media y desviación estándar de la distribución
en escala log con valores por defecto de 0 y 1 respectivamente.
• shape1, shape2: Parámetros positivos de la distribución Beta.
• shape, scale: En las distribuciones Gamma y Weibull, parámetros de forma y
escala.
•
ncp: En las distribuciones Ji cuadrado, F y t, corresponde a parámetro de nocentralidad.
• rate: En la distribución exponencial, es un vector de tasas . Su valor por defecto es
1.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 86/344
86
• df: En las distribuciones t y Ji son los grados de libertad.
• df1, df2: Grados de libertad del numerador y del denominador en la distribución F.
Detalles:
• La Hazard acumulada de la distribución log normal H(t) = - log(1 - F(t))
se calcula con -plnorm(t, r,lower = FALSE, log = TRUE)
• La distribución geométrica tiene densidad p(x) = p(1-p)x para x = 0, 1, 2, ...
donde X corresponde al número de fracasos antes de que ocurra el primer éxito.
• La densidad de la distribución Beta es de la forma (((( ))))(((( )))) (((( ))))
(((( ))))11 1
baa b
x x a b
+ + + +
• La distribución Gamma tiene densidad de la forma (((( ))))(((( ))))
1 /1 a x s
a f x x e
s a
====
, shape =
a y scale = s. Para x>0, a>0, s>0. La media y la varianza son E(X) =
as y Var(X) = as2
• La Hazard acumulada H(t)=-log(1-F(t)) se calcula con -pgamma(t, ...,lower =
FALSE, log = TRUE) .
• La distribución Ji cuadrado con df=n grados de libertad tiene densidad
(((( ))))(((( ))))
/ 2 1 / 2/ 2
1
2 / 2n x
n n f x x e
n
====
para x>0, con media y varianza n y 2n respectivamente.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 87/344
87
• La distribución Ji cuadrado con df=n grados de libertad y parámetro de no
centralidad ncp= tiene densidad (((( ))))(((( ))))
(((( ))))/ 2
0
/ 2, 2!
r
r f x e dchisq x df r r
===== += += += + para x 0.
Esta es la distribución de la suma de los cuadrados de n normales cada una con
varianza 1, donde es la suma de los cuadrados de las medias de las normales.
• La distribución exponencial con tasa tiene densidad (((( )))) f x e
==== para x0.
• La Hazard acumulada de la distribución exponencial H(t)=-log(1-F(t)) se
calcula con -pexp(t,r,lower.tail=FALSE,log=TRUE).
• La distribución F es la distribución de la razón de los cuadrados medios de n1 y n2
normales estándar independientes y por tanto es la razón de dos variables aleatorias Ji
cuadrados cada una dividida por sus grados de libertad. De aquí que la razón de una
normal y la raíz del cuadrado medio de m normales independientes tiene una
distribución Student'sm
t .
• La distribución F no central es la razón de los cuadrados medios de normales
independientes de varianza unitaria, pero las que están en el numerador pueden tener
medias no nulas y el ncp corresponde a la suma de los cuadrados de las medias.
• La densidad de la distribución hipergeométrica con parámetros m, n y k es
(((( ))))m n m n
p x
x k x k
++++ ====
para max(0,k-n) x min(m,k)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 88/344
88
• La distribución t no central con parámetros (df, ncp) es definida como la
distribución de(((( )))) (((( )))) (((( )))), /
U ncp
T df ncp df df
++++====
, donde U y X(df) son variables aleatorias
independientes, con U~N(0,1) y X2(df)~2.
• La densidad de la distribución Weibull con parámetros de forma shape=a y de
escala scale=b corresponde a (((( )))) (((( )))) (((( )))) (((( ))))1 // /aa x b
f x a b x b e
==== para x>0. La Hazard
acumulada H(t)=-log(1-F(t)) se calcula con -
pweibull(t,a,b,lower=FALSE, log=TRUE) la cual corresponde a
H(t)=(t/b)a.
• La distribución binomial negativa con size=n y prob=p tiene densidad
(((( )))) (((( )))) (((( ))))(((( )))) (((( ))))/ ! 1x n p x x n n x bp p = + = + = + = + para x = 0, 1, 2, .... Esta representa el
número de fallas las cuales ocurren en una secuencia de intentos bernoullis antes de
que un número de éxitos objetivo sea alcanzado. Una distribución binomial negativa
se deriva como una mezcla de distribuciones poisson con media distribuída como una
gamma con parámetro de escala (1 - prob)/prob y de forma size (esta
definición permite valores no enteros para size ). En este modelo
prob=scale/(1+scale) y la media es size*(1 - prob)/prob).
Distribución Cuantiles Números Aleatorios
Uniforme qunif(p; min=0; max=1;lower.tail = TRUE;log.p
= FALSE)
runif(n; min=0; max=1)
Normal qnorm(p; mean=0; sd=1; lower.tail =
TRUE;log.p = FALSE)
rnorm(n; mean=0; sd=1)
Binomial qbinom(p; size; prob; lower.tail = TRUE;
log.p = FALSE)
rbinom(n; size; prob)
Lognormal qlnorm(p; meanlog = 0; sdlog = 1; lower.tail
= TRUE; log.p = FALSE)
rlnorm(n; meanlog = 0; sdlog
= 1)Beta qbeta(p; shape1; shape2; lower.tail = TRUE;
log.p = FALSE)
rbeta(n; shape1; shape2)
Geométrica qgeom(p; prob; lower.tail = TRUE; log.p =
FALSE)
rgeom(n; prob)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 89/344
89
Distribución Cuantiles Números Aleatorios
Gamma qgamma(p; shape; scale=1; lower.tail = TRUE;
log.p = FALSE)
rgamma(n; shape; scale=1)
JI cuadrado qchisq(p; df; ncp=0; lower.tail = TRUE; log.p
= FALSE)
rchisq(n; df; ncp=0)
Exponencial qexp(p; rate = 1; lower.tail = TRUE; log.p =
FALSE)
rexp(n; rate = 1)
F qf(p; df1; df2;lower.tail = TRUE; log.p =
FALSE)
rf(n; df1; df2)
Hipergeom. qhyper(p; m; n; k; lower.tail = TRUE; log.p =
FALSE)
rhyper(nn; m; n; k)
t qt(p; df;lower.tail = TRUE; log.p = FALSE) rt(n; df)
Poisson qpois(p; lambda; lower.tail = TRUE; log.p =
FALSE)
rpois(n; lambda)
Weibull qweibull(p; shape; scale = 1; lower.tail =
TRUE; log.p = FALSE)
rweibull(n; shape; scale =
1)Binom.Neg. qnbinom(p; size; prob; mu; lower.tail = TRUE;
log.p = FALSE)
rnbinom(n; size; prob; mu)
Donde:
• p: Es un vector de probabilidades (acumuladas).
• n: Número de observaciones, excepto para la hipergeométrica, donde nn corresponde a tal. Si la longitud de n es mayor que 1, la longitud es tomada como el
número requerido.
3.2. Ejecuciones Condicionales y Loops (Flujos de
Control)
El lenguaje permite la construcción de condiciones para el control del flujo como cualquier
lenguaje de programación. Son las construcciones de flujo de control básicos del lenguaje
R. Son similares a los argumentos de control de cualquier lenguaje algorítmico:
if(cond) expr

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 90/344
90
if(cond) cons.expr else alt.expr
for(var in seq) expr
while(cond) exprrepeat expr
break
next
if....else
El uso de este condicional es el siguiente:
> if(expresion 1) expresion 2 else expresion 3
donde si la expresión 1 es cierta se evalúa la expresión 2. En caso contrario se evalúa la
expresión 3. Si la expresión 2 ó expresión 3 son complejas, esto es, tienen más de un
comando entonces deben encerrarse entre llaves:
> if(expresion 1) {
...comandos R... }else {
...comandos R... }
Cuidado:
En lenguajes vectorizados se pueden cometer errores que son difíciles de detectar. Por
ejemplo supongamos que tenemos la variable sexo codificada como (1, 2) y supongamos
que deseamos recodificarla a (1, 0). La siguiente instrucción, que en su estructura es similar
a la que utilizan muchos lenguajes, produce un error:
>if(sexo==2) sexo<-0 else sexo<-1

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 91/344
91
Una solución es la siguiente:
> sexo1<-rep(NA, length(sexo))> sexo1[sexo==2]<-0
> sexo1[sex!=2]<-1
Otra solución es utilizar la función ifelse()
> sexo<-ifelse(sexo==2,0,1)
Si el conjunto de acciones a realizar mientras se cunpla la condición de if(....)
son
complejas (o también para el caso alterno else (...) ), procedemos como sigue:
if(...){
.
.
.
}
else{
.
.
.
}
Colocando entre llaves los pasos u operaciones requeridas en cada caso.
Ejemplo:
Supongamos que se lanza un dado cargado de forma que los pares son dos veces más
probables que los impares (de donde probabilidad de cada impar es 1/9 y de cada par es
2/9). Simulemos 100 lanzamiento de dicho dado:

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 92/344
92
#Creación de una función
#para simular el resultado
#del lanzamiento de un dado#cargado con prob(par):2(impar)
lanzamiento1<-function(n=1){
#generar un numero entre
#0 y 1 (las cdf observadas):
F<-runif(n)
#Definir las cdf:
F1<-1/9
F2<-3/9
F3<-4/9
F4<-6/9
F5<-7/9
F6<-1
#Determinar el resultado
#con base en el valor
#cdf observado:
if(F<=F1)result<-1 else
if(F<=F2)result<-2 else
if(F<=F3)result<-3 else
if(F<=F4)result<-4 else
if(F<=F5)result<-5 else
if(F<=F6) result<-6
res<-c(F,result)
}
#Generar resultados en 1000
#lanzamientos:
> muestra<-matrix(rep(1,1000),ncol=1)
> result<-t(apply(muestra,1,lanzamiento1))
> result
[,1] [,2]
[1,] 0.709534370 5
[2,] 0.164301291 2

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 93/344
93
[3,] 0.088355489 1
[4,] 0.244265059 2
[5,] 0.197429391 2[6,] 0.491711938 4
[7,] 0.739780114 5
[8,] 0.078908737 1
[9,] 0.389658087 3
[10,] 0.957607416 6
.
.
.
[992,] 0.091973664 1
[993,] 0.020980510 1
[994,] 0.128269766 2
[995,] 0.854701702 6
[996,] 0.127352686 2
[997,] 0.478872951 4
[998,] 0.290334604 2
[999,] 0.442169692 3
[1000,] 0.716538823 5
#Construir tabla de frecuencias:
> a<-table(result[,2])
> a
1 2 3 4 5 6
120 237 108 202 121 212
#Graficar frecuencias:
> barplot(a,space=0)
Función ifelse
Como ya se dijo previamente, el uso de if está limitado a expresiones que no sean
vectores. Si estamos evaluando vectores o matrices entonces lo indicado es hacerlo con

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 94/344
94
ifelse devuelve un valor con la misma forma que el argumento `test' el cual es llenado
con elementos seleccionados bien sea del argumento `yes' o del argumento `no'
dependiendo de si el elemento de `test' es `TRUE' O `FALSE'. si los argumentos `yes' `no'
son muy cortos, entonces sus elementos son reciclados.
ifelse(test, yes, no)
Argumentos:
• test: Es un vector lógico o condición lógica a ser evaluada.
• yes: Devuelve valores para los elementos ciertos de `test'.
• no: Devuelve valores para los elementos falsos de `test'.
Ejemplos:
x <- c(6:-4)
>sqrt(x)#Produce advertencia
[1] 2.449490 2.236068 2.000000 1.732051 1.414214 1.000000 0.000000 NaN
[9] NaN NaN NaN
Warning message:
NaNs produced in: sqrt(x)
> sqrt(ifelse(x >= 0, x, NA))#No produce advertencia
[1] 2.449490 2.236068 2.000000 1.732051 1.414214 1.000000 0.000000 NA
[9] NA NA NA
> ifelse(x >= 0, sqrt(x), NA)#produce advertencia
[1] 2.449490 2.236068 2.000000 1.732051 1.414214 1.000000 0.000000 NA

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 95/344
95
[9] NA NA NA
Warning message:
NaNs produced in: sqrt(x)
Generar 100 observaciones de una distribución normal estándar y determinar cuántas están
dentro de dos desviaciones estándar de la muestra:
x<-rnorm(100)
media<-mean(x)
desv.est<-sqrt(var(x))
desv<-abs(x-media)cuenta<-ifelse(desv<(2*desv.est),1,0)
cuenta
[1] 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
[38] 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
[75] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1
sum(cuenta)
[1] 95
mean(cuenta)[1] 0.95
for
Para loops el R proporciona varias formas. La más usada es
> for( nombre in expresion1) expresion 2
nombre es una variable de control del loop. expresión1 es un vector, por ejemplo del
tipo 1:20; y expresión2 usualmente es un conjunto agrupado de instrucciones a ser
repetidas a medida que cambie la variable que controla el loop.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 96/344
96
En lenguajes vectorizados, como el R, el uso de loops no es recomendado y en versiones
viejas del programa se presentaban grandes problemas con su uso. Uno de los problemas
que se presenta es que el programa no libera memoria sino cuando se regresa al prompt. De
esta forma cualquier operación iterativa mucha memoria puede ser utilizada (no
necesariamente por un número grande de iteraciones, con números tan pequeños como 10
puede ocurrir). Esto causa que el computador se quede sin memoria o que se presente un
uso intensivo del disco duro. Otro síntoma, cuando se trabaja en estaciones con posibilidad
de realizar múltiples tareas simultáneamente o con varios usuarios, es que el sistema se
vuelva en extremo lento. Algunos remedios pueden ser los siguientes:
1. Evite las iteraciones tanto como sea posible utilizando los arreglos y las operaciones
sobre listas (ejemplos: apply, lapply; además de las operaciones matriciales
corrientes).
x<-rnorm(100000)
media.1<-function(x){
temp<-0
for(i in 1:length(x)){ temp<-temp[i]media<-temp/length(x)
media}
}
media.2<-function(x) sum(x)/length(x)
media.3<-function(x) mean(x)
#Determinación del tiempo de
#uso de la cpu o procesamiento:
system.time(media.1(x))
[1] 0.45 0.00 0.45 NA NA
system.time(media.2(x))
[1] 0 0 0 NA NA
system.time(media.3(x))

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 97/344
97
[1] 0.01 0.00 0.01 NA NA
El tiempo gastado por el programa para calcular la media es 10 veces mayor utilizando el
for que utilizando la función mean() o con sum() .
2. Codifique la iteración básica en Fortran o C y llámela desde el programa. Esto
requiere un esfuerzo extra de programación y puede no funcionar en algunas
plataformas.
Otras funciones para controlar loops son
>repeat expresion
y el comando
> while(condicion) expresion
En el siguiente ejemplo, se estima el número de unidades de reserva a emplear en unsistema compuesto por una unidad principal y n de reserva (las reservas se utilizan una a
una a medida que vayan fallando) cada una con un tiempo Ti, i=1,2,...,Tn+1 de vida
distribuído weibull con parámetro de forma a y de escala b, de manera que la probabilidad
de que el sistema opere por más de “t” unidades de tiempo sea al menos cierta cantidad
0<<1; es decir P(>t). El tiempo de vida del sistema es =T1 +T2 +...+Tn+1
con Ti~weibull(a,b), Supongamos que t=2, a=2, b=0.5, =0.9:
#iniciar un contador en 0
k<-0
#Definir valores para

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 98/344
98
#los parámetros
t<-2
a<-2b<-0.5
gamma<-0.9
#inicializar la probabilidad
#buscada, con un valor de cero.
p.est.n<-0
#Determinar por simulación
#valores aleatorios de la variable tau
#para nro. de reservas=0,1,2,...hasta
#el primer valor de n que cumpla la condición
#de p(tau>t)>=gamma. A partir de 1000
#muestras de tamaño 100 :
nsim<-1000
ksim<-100
while(p.est.n<gamma){
k<-k+1
conta<-0
#Repetir nsim veces la generación de
#ksim valores aleatorios de tau para el valor
#actual de k:
for(i in 1:nsim){
tau.obs<-c(rep(0,ksim))
}
#Generar ksim valores de tau que
#corresponde a la suma de k weibulls(a,b)
#y guardarlos en el vector tau.obs previamente
#inicializado con ceros:
for(j in 1:ksim){

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 99/344
99
T<-rweibull(k,shape=a,scale=b)
tau.obs[j]<-sum(T)
}#Conteo por cada muestra de tamaño ksim
#de los valores generados de tau mayores
#que el valor t considerado, y almacenamiento
#de estos conteos en un vector ("conta" cuyo
#primer valor será siempre 0 para poder usar
#luego la función append) cuyos elementos
# se van incrementado hasta que el valor de k
# es tal que la propoción muestral "p.est.n" de
# valores de (tau >t) es mayor o igual a gamma:
cont<-length(tau.obs[tau.obs>t])
conta<-append(conta,cont)
}
p.est.n<-sum(conta)/(ksim*nsim)
res<-list(nro.reserv=k-1,p.est.n=p.est.n)
}
> res
$nro.reserv
[1] 6
$p.est.n
[1] 0.97
De acuerdo a lo anterior, se requieren 6 unidades de reserva para garantizar que la
probabilidad de que el sistema opere más de 2 unidades de tiempo.
3.2.1 Cómo parar ciclos: La función stop()
La función stop() sirve para abortar un procedimiento para el que se cumpla alguna
condición particular. Detiene la ejecución de la expresión actual, imprime el mensaje dado
como argumento, y luego ejecuta una acción de error.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 100/344
100
stop(message = NULL, call. = TRUE)
Argumentos:
• message: un vector de caracteres de longitud 1 o `NULL'.
• call.: Argumento lógico que indica si la llamada será parte del mensaje de error.
Ejemplo:
> for(i in 1:100){
+ temp<-rnorm(1)
+ if(temp>2) stop('Se logra un numero mayor que 2')
+ }
Error: Se logra un numero mayor que 2
>
3.3. Objetos en R
La información es manipulada en R es en forma de objetos. Ejemplos de objetos son
vectores de valores numéricos (reales) o valores complejos, vectores de valores lógicos y
vectores de caracteres. Estos son conocidos como estructuras “atómicas” ya que sus
componentes son todos del mismo tipo o modo. Las mismas funciones del R son objetos. R
también opera con objetos llamados listas, que son del modo lista. Estos son secuencias
ordenadas de objetos que individualmente pueden ser de cualquier tipo.
3.3.1 Función append
Esta función permite agregar elementos a un vector o unir vectores.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 101/344
101
append(x, values, after=length(x))
Argumentos:
• x: El vector a ser modificado.
• values: Valores a ser incluídos en el vector modificado.
• after: Un subíndice, después del cual los valores van a ser agregados.
• Valor: Esta función genera un vector que contiene los valores en `x' con los
elementos de `values' agregados después del elemento de `x' especificado.
Ejemplos:
> a<-c(rnorm(10))
> a
[,1]
[1,] -1.2961701
[2,] -0.9220065
[3,] -1.1227425
[4,] -3.1331096
[5,] -1.3215306
[6,] 0.4399376
[7,] -1.6406378
[8,] -0.6781794
[9,] 2.1854698
[10,] -0.8711059
> b<-c(rexp(10))
> b
[,1]
[1,] 0.6752021
[2,] 0.9485898

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 102/344
102
[3,] 3.8524993
[4,] 1.8882795
[5,] 1.1236463[6,] 1.3654229
[7,] 0.7593380
[8,] 0.3170737
[9,] 1.9335677
[10,] 1.1592543
#Formar un nuevo vector con
#los vectores a y b
> t<-append(a,b)
> t[1] 0.750172910 -0.626747997 0.776044312 1.054390254 -0.093146289
[6] -0.435600090 -0.327977143 1.589835229 0.431930587 0.812786494
[11] 0.206826698 0.615974670 0.357283118 0.290794746 0.342937697
[16] 0.105532442 0.088188337 0.006005927 1.176917191 0.215131458
#Generar valores de
#una variable aleatoria poisson
#de lambda=1 hasta hallar el primero
#que sea mayor o igual a 2:
> t<-rpois(1,1)> t
[1] 1
> p<-t
> while(p<2){
+ p<-rpois(1,1)
+ t<-append(t,p)
+
> x<-length(t)
> x
[1] 19> t
[1] 1 0 1 1 0 1 0 1 0 1 0 0 1 1 0 1 0 1 2
#repitamos 100 veces este proceso
#veamos la distribución de la
#variable x: No. de valores de una poisson

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 103/344
103
#generados hasta hallar el primer
#valor mayor o igual a 2:
#definir un valor arbitrario para#el vector x para poder invocar
#posteriormente a la función append
x<--100
for(i in 1:1000){
t<-rpois(1,1)
p<-t
while(p<2){
p<-rpois(1,1)
t<-append(t,p)
}x<-append(x,length(t))
}
#Eliminar el primer elemento
#del vector de conteos que fuera
#definido arbitrariamente
x<-x[-1]
#construcción de una tabla
#de frecuencias para x:
table(x)x
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 18 20 21 22
269 186 139 109 74 51 47 25 33 19 10 14 8 5 3 3 1 1 1 1
27
1
#Construcción de un diagrama de
#barras para la distribución de
#frecuencias de x:
> barplot(table(x),space=0,main="Distribución muestral de X\nNúmero de
valores poisson generados\nhasta el primer valor >=2",
xlab="X",ylab="Frecuebcias")
>

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 104/344
104
La distribución de frecuencias de la variable x del último experimento está representada en
la figura.3.1.
Figura 3.1: La variable aleatoria X de este experimento tiene una distribución
geométrica.
Un tipo de objeto importante en R es el arreglo de doble entrada, u objeto matriz . Para
crear una matriz usamos la función matrix(). Toma como argumentos un vector y dos
números que especifican las filas y las columnas. Por ejemplo:
> matrix(1:16,nrow=4,ncol=4)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 105/344
105
crea una matrix de 4 × 4 con los enteros desde el 1 hasta el 16. Si queremos llenar la
matriz “ por filas”, usamos la opción byrow=T en matrix . En el ejemplo
anterior pudimos haber escrito
> matrix(1:16,ncol=4,byrow=T)
3.3.2 Función matrix, is.matrix, as.matrix
En R es posible crear matrices y convertir data frames en matrices utilizando:
• matrix Crea una matriz desde un conjunto de valores dado.
• as.matrix Intenta convertir su argumento en una matriz.
• is.matrix Prueba si su argumento es una matriz (estricta).
matrix(data = NA, nrow = 1, ncol = 1,byrow = FALSE, dimnames = NULL)
as.matrix(x)
is.matrix(x)
Argumentos:
• data: Un vector opcional de datos.
• nrow: El número deseado de filas.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 106/344
106
• ncol: El número deseado de columnas.
• byrow: Argumento lógico. Si es FALSE (valor por defecto), la matriz es llenada por
columnas (es decir los objetos en `data' son colocados en secuencia llenando la
primera columna, luego la siguiente, etc.) de lo contrario la matriz es llenada por
filas.
• dimnames: Un atributo `dimnames' para la matriz, es decir, una lista (`list') de
longitud 2 dando los nombres de la dimensión correspondiente a las filas y de la
dimensión correspondiente a las columnas (no son los nombres de los niveles de cada
una de estas dos dimensiones).
• x: Un objeto R.
Detalles:
• Si `nrow' o `ncol' no es dado, el programa intenta inferirlo a partir de la longitud de`data' y el otro parámetro.
• is.matrix devuelve `TRUE' si `x' es una matriz (es decir, si no es una
`data.frame' y tiene un atributo `dim' de longitud 2) y `FALSE' en caso contrario.
Ver también: data.matrix .
Ejemplos:
is.matrix(as.matrix(1:10))
[1] TRUE
data(warpbreaks)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 107/344
107
> warpbreaks
breaks wool tension
1 26 A L2 30 A L
3 54 A L
4 25 A L
5 70 A L
6 52 A L
7 51 A L
8 26 A L
9 67 A L
10 18 A M
11 21 A M12 29 A M
13 17 A M
14 12 A M
15 18 A M
16 35 A M
17 30 A M
18 36 A M
19 36 A H
20 21 A H
21 24 A H22 18 A H
23 10 A H
24 43 A H
25 28 A H
26 15 A H
27 26 A H
28 27 B L
29 14 B L
30 29 B L
31 19 B L32 29 B L
33 31 B L
34 41 B L
35 20 B L
36 44 B L
37 42 B M

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 108/344
108
38 26 B M
39 19 B M
40 16 B M41 39 B M
42 28 B M
43 21 B M
44 39 B M
45 29 B M
46 20 B H
47 21 B H
48 24 B H
49 17 B H
50 13 B H51 15 B H
52 15 B H
53 16 B H
54 28 B H
#Determinando la estructura del objeto R
> str(warpbreaks)
`data.frame': 54 obs. of 3 variables:
$ breaks : num 26 30 54 25 70 52 51 26 67 18 ...
$ wool : Factor w/ 2 levels "A","B": 1 1 1 1 1 1 1 1 1 1 ...$ tension: Factor w/ 3 levels "L","M","H": 1 1 1 1 1 1 1 1 1 2 ...
#usando as.matrix.data.frame(.) method:
> str(as.matrix(warpbreaks))
chr [1:54, 1:3] "26" "30" "54" "25" "70" "52" "51" "26" "67" "18" "21" ...
- attr(*, "dimnames")=List of 2
..$ : chr [1:54] "1" "2" "3" "4" ...
..$ : chr [1:3] "breaks" "wool" "tension"
> a<-matrix(as.matrix(warpbreaks),ncol=3)> a
[,1] [,2] [,3]
[1,] "26" "A" "L"
[2,] "30" "A" "L"
[3,] "54" "A" "L"
[4,] "25" "A" "L"

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 109/344
109
[5,] "70" "A" "L"
[6,] "52" "A" "L"
[7,] "51" "A" "L"[8,] "26" "A" "L"
[9,] "67" "A" "L"
[10,] "18" "A" "M"
[11,] "21" "A" "M"
[12,] "29" "A" "M"
[13,] "17" "A" "M"
[14,] "12" "A" "M"
[15,] "18" "A" "M"
[16,] "35" "A" "M"
[17,] "30" "A" "M"[18,] "36" "A" "M"
[19,] "36" "A" "H"
[20,] "21" "A" "H"
[21,] "24" "A" "H"
[22,] "18" "A" "H"
[23,] "10" "A" "H"
[24,] "43" "A" "H"
[25,] "28" "A" "H"
[26,] "15" "A" "H"
[27,] "26" "A" "H"[28,] "27" "B" "L"
[29,] "14" "B" "L"
[30,] "29" "B" "L"
[31,] "19" "B" "L"
[32,] "29" "B" "L"
[33,] "31" "B" "L"
[34,] "41" "B" "L"
[35,] "20" "B" "L"
[36,] "44" "B" "L"
[37,] "42" "B" "M"[38,] "26" "B" "M"
[39,] "19" "B" "M"
[40,] "16" "B" "M"
[41,] "39" "B" "M"
[42,] "28" "B" "M"
[43,] "21" "B" "M"

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 110/344
110
[44,] "39" "B" "M"
[45,] "29" "B" "M"
[46,] "20" "B" "H"[47,] "21" "B" "H"
[48,] "24" "B" "H"
[49,] "17" "B" "H"
[50,] "13" "B" "H"
[51,] "15" "B" "H"
[52,] "15" "B" "H"
[53,] "16" "B" "H"
[54,] "28" "B" "H"
3.3.3 Función data.matrix
Permite construir una matriz convirtiendo todas las variables en un data frame a un modo
numérico y entonces pegarlos juntos como las columnas de una matriz. Los factores y los
factores ordenados son reemplazados por sus códigos.
data.matrix(frame)
Argumentos:
• frame: Un data frame cuyos componentes son bien sea vectores lógicos, factores o
vectores numéricos.
Ver también: as.matrix, codes, data.frame, matrix.
Ejemplo:
> data.matrix(warpbreaks)
breaks wool tension
1 26 1 2

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 111/344
111
2 30 1 2
3 54 1 2
4 25 1 25 70 1 2
6 52 1 2
7 51 1 2
8 26 1 2
9 67 1 2
10 18 1 3
11 21 1 3
12 29 1 3
13 17 1 3
14 12 1 315 18 1 3
16 35 1 3
17 30 1 3
18 36 1 3
19 36 1 1
20 21 1 1
21 24 1 1
22 18 1 1
23 10 1 1
24 43 1 125 28 1 1
26 15 1 1
27 26 1 1
28 27 2 2
29 14 2 2
30 29 2 2
31 19 2 2
32 29 2 2
33 31 2 2
34 41 2 235 20 2 2
36 44 2 2
37 42 2 3
38 26 2 3
39 19 2 3
40 16 2 3

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 112/344
112
41 39 2 3
42 28 2 3
43 21 2 344 39 2 3
45 29 2 3
46 20 2 1
47 21 2 1
48 24 2 1
49 17 2 1
50 13 2 1
51 15 2 1
52 15 2 1
53 16 2 154 28 2 1
3.3.4 Función list
Otro objeto con el que trabaja R es el objeto lista , es el más general y flexible para
guardar datos. Una lista es una colección ordenada de componentes. Estos componentes
pueden ser de diversas clases. Podemos tener una lista con dos componentes: un vector de
caracteres y una matriz de números. Se puede crear una lista con la función list().
Existe una serie de funciones en R que permiten construir listas, convertir toda clase de
objetos R en listas y para chequear si lo son.
list(...)
pairlist(...)
as.list(x, ...)
as.list.default(x, ...)
as.pairlist(x)
is.list(x)
is.pairlist(x)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 113/344
113
alist(...)
Argumentos:
• ...: Objetos.
• x: Objeto R a ser forzado o probado como lista.
Detalles:
• La mayoría de las listas en R internamente son vectores genéricos, mientras que las
listas de pares punteadas tradicionales (como en LISP) están aún disponibles.
• Los argumentos para list o pairlist son de la forma `value' o `tag=value'.
Las funciones devuelven una lista compuesta de sus argumentos con cada valor ya
sea etiquetadas o no etiquetadas, dependiendo de cómo fue especificado el
argumento.
• alist es como list , excepto en la manipulación de los argumentos etiquetados
sin valor. Estos son manejados como si ellos describieran los argumentos de una
función sin valor por defecto. En tanto que list simplemente los ignora.
• as.list intenta forzar su argumento al tipo lista. Para funciones, ésta devuelve la
concatenación de la lista de los argumentos formales y el cuerpo de la función. Para
expresiones, la lista de llamadas componentes es devuelta.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 114/344
114
• is.list devuelve un `TRUE' si y sólo sí su argumento es un `list' o un `pairlist' de
longitud mayor que 0, mientras que is.pairlist sólo retorna un `TRUE' en el
último caso.
• Un pairlist vacío, pairlist() es igual a `NULL'. Esto es diferente de list().
Ver también: vector(., mode="list") , c para concatenación; formals.
Ejemplos:
> x<-list(a=1:10, b=c(“manzana”, “pera”))
nos crea una lista, llamada x , que tiene componentes a y b. a es un vector de números
y b es un vector de caracteres. Observe que los componentes tienen un número diferente
de componentes. Si queremos hacer referencia al componente a del objeto x escribimos
x$a.
> x$a
nos mostrará los elementos de a . Veamos otros ejemplos:
data(cars)
#Crear una estructura
#para graficación
pts <- list(x=cars[,1], y=cars[,2])
#graficar los valores de
#cars[,2] vs. cars[,1]
plot(pts)
#Listar Argumentos
> f <- function(x,y)sin(x)*exp(-y)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 115/344
115
>list(f)
[[1]]
function(x,y)sin(x)*exp(-y)
> t<-pairlist(f)
>t
[[1]]
function(x,y)sin(x)*exp(-y)
#Forzar un objeto R como lista
> as.list(f)
$x
$y
[[3]]
sin(x) * exp(-y)
#Verificar si un objeto R es una lista
> is.list(as.list(f))
[1] TRUE
> is.list(f)
[1] FALSE
#creando listas con objetos R
> a<-c("manzanas","naranjas","peras")
> b<-c(100,140,50)
> n<-list(frutas=a,cantidad=b)
>n
$frutas
[1] "manzanas" "naranjas" "peras"
$cantidad[1] 100 140 50
> m<-pairlist(frutas=a,cantidad=b)
> m
$frutas
[1] "manzanas" "naranjas" "peras"

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 116/344
116
$cantidad
[1] 100 140 50
#invocando una componente de una lista
> n$cantidad
[1] 100 140 50
> n[1]
$frutas
[1] "manzanas" "naranjas" "peras"
#Forzando a ser lista
> as.list(c(a,b))
[[1]]
[1] "manzanas"
[[2]]
[1] "naranjas"
[[3]]
[1] "peras"
[[4]]
[1] "100"
[[5]]
[1] "140"
[[6]]
[1] "50"
> as.pairlist(c(a,b))
[[1]]
[1] "manzanas"
[[2]]
[1] "naranjas"

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 117/344
117
[[3]]
[1] "peras"
[[4]]
[1] "100"
[[5]]
[1] "140"
[[6]]
[1] "50"
> alist(c("manzanas","naranjas","peras"))
[[1]]
c("manzanas", "naranjas", "peras")
> list(c("manzanas","naranjas","peras"))
[[1]]
[1] "manzanas" "naranjas" "peras"
Muchas funciones en R cuando son ejecutadas entregan un objeto. Este objeto debe ser
manipulado en la forma descrita para obtener los resultados deseados.
3.3.5 Función unlist
Dada una estructura `x' tipo lista, esta función la simplifica para producir un vector que
contiene todos los componentes atómicos que ocurren en `x'.
unlist(x, recursive = TRUE, use.names = TRUE)
Argumentos:
• x: Una lista o vector.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 118/344
118
• recursive: Argumento lógico. ¿Debería unlisting ser aplicado para listar las
componentes de `x'?
• use.names: Argumento lógico. ¿Deberían preservarse los nombres?.
Detalles:
• Si `recursive = FALSE', la función no se repite más allá de los items de
primer nivel en `x'.
• `x' puede ser un vector, pero entonces unlist no hace nada útil, ni siquiera quita
los nombres.
• Por defecto, unlist intenta retener información de denominación presente en `x'.
Si `use.names = FALSE' toda la información de denominación es quitada.
• Donde es posible los elementos de la lista son forzados a un modo común durante el
unlisting, y así a menudo terminan como un vector de caracteres.
• Una lista es un vector genérico, y el vector simplificado debe aún ser una lista (y debe
ser incambiable). Elementos no vectoriales de la lista (tales como nombres, fórmulas)
no son forzados, y así una lista contiene uno o más de estos restos de una lista.
Ver también: `c', `as.list'.
Ejemplos:
>a<-c("manzanas","naranjas","peras")
>b<-c(100,140,50)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 119/344
119
> n<-list(frutas=a,cantidad=b)
#Descomponiendo la lista#note que en este caso la función
#forza a todos los elementos
#a ser caracteres
> unlist(n)
frutas1 frutas2 frutas3 cantidad1 cantidad2 cantidad3
"manzanas" "naranjas" "peras" "100" "140" "50"
#Eliminando los nombres de
#las componentes
> unlist(n,use.names=FALSE)[1] "manzanas" "naranjas" "peras" "100" "140" "50"
#Otro ejemplo:
> tiempo1<-rexp(10)
> tiempo2<-rexp(10,rate=0.5)
> tiempos<-list(llegadas=tiempo1,servicio=tiempo2)
> tiempos
$llegadas
[1] 0.03234987 0.48611757 0.13446453 1.10649004 0.33979095 1.34478218[7] 0.12969581 1.43734645 4.08248358 0.32642360
$servicio
[1] 3.19001640 0.19896770 1.13467186 14.93080135 3.84831055 0.23845463
[7] 0.14711193 0.89396062 0.34205063 0.08852118
> unlist(tiempos)
llegadas1 llegadas2 llegadas3 llegadas4 llegadas5 llegadas6
0.03234987 0.48611757 0.13446453 1.10649004 0.33979095 1.34478218
llegadas7 llegadas8 llegadas9 llegadas10 servicio1 servicio20.12969581 1.43734645 4.08248358 0.32642360 3.19001640 0.19896770
servicio3 servicio4 servicio5 servicio6 servicio7 servicio8
1.13467186 14.93080135 3.84831055 0.23845463 0.14711193 0.89396062
servicio9 servicio10
0.34205063 0.08852118

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 120/344
120
3.3.6 Función data.frame
Estas funciones crean o manipulan data frames, colecciones de variables conectadas
fuertemente las cuales comparten muchas de las propiedades de las matrices y listas, usados
como la estructura fundamental de datos por la mayoría del software de modelación de R.
data.frame(..., row.names = NULL, check.rows = FALSE,
check.names = TRUE)
as.data.frame(x, row.names = NULL, optional)is.data.frame(x)
row.names(x)
row.names(x) <- names
print(x, ..., digits = NULL, quote = FALSE, right = TRUE)
plot (x, ...)
Argumentos:
• ...: Estos argumentos son o de la forma `value' o de la forma tag=value'. Los
nombres de las componentes son creados con base en la etiqueta (si existe) o del
argumento suministrado por sí mismo.
• row.names: Un vector de caracteres dando los nombres de las filas para el data
frame.
• check.rows: Argumento lógico. Si es `TRUE' entonces las filas son revisadas para
verificar la consistencia de la longitud y los nombres.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 121/344
121
• check.names: rgumento lógico. Si es `TRUE' entonces los nombres de las variables
en el data frame son revisados para asegurar que son nombres de variables
sintácticamente válidos. Si es necesario ellos son ajustados (por medio de
`make.names') para que lo sean.
• data.frame.obj: Objetos de clase `data.frame'.
• ...: Argumentos opcionales para los métodos `print' o `plot'.
• optional: Argumento lógico. Si es `TRUE', ajustar los nombres de fila es opcional.
Detalles:
• Variables no numéricas sometidas a data.frame son convertidas a columnas
factor a menos que sean protegidas por `I' (ver función `I'). Esta aplica a variables
caracter y variables lógicas, en particular. También aplica para agregar columnas a
un data frame.
• Si una lista, data frame o una matriz es pasada a data.frame esto resulta como si
cada columna hubiese sido pasada como un argumento separado, con la excepción de
matrices de la clase `model.matrix'.
Valor:
• Para `data.frame(.)' un data frame, una estructura como matricial cuyas
columnas pueden ser de diferentes tipos (numéricos, tipo factor y caracteres).

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 122/344
122
• `as.data.frame' es una función genérica con muchos métodos. Intenta forzar
su argumento para que sea un data frame.
• `is.data.frame' devuelve un `TRUE' si su argumento es un data frame y un
valor de `FALSE' de lo contrario.
• `row.names' puede ser usado para ajustar y retroalimentar los nombres de fila de
un data frame, similarmente a `rownames' para arreglos (y es una función genérica
que llama a `rownames' para algún argumento de array .
Ejemplos:
#creación de un data frame
#que contiene tres variables
#x, y, fac
>L3 <- LETTERS[1:3]
> d <- data.frame(cbind(x=1, y=1:10), fac=sample(L3, 10, repl=TRUE))
> d
x y fac
1 1 1 A
2 1 2 A
3 1 3 C
4 1 4 C
5 1 5 A
6 1 6 C
7 1 7 C
8 1 8 C
9 1 9 C
10 1 10 A
#llamada de una variable componente
#del dataframe
> d$x

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 123/344
123
[1] 1 1 1 1 1 1 1 1 1 1
#manipulación de datos#en variables numéricas del
#dataframe
> mean(d$x)
[1] 1
> mean(d$y)
[1] 5.5
#Creación de un dataframe con nombres de
#columnas automáticos
> e<-data.frame(cbind( 1, 1:10),sample(L3, 10, repl=TRUE))> e
X1 X2 sample.L3..10..repl...TRUE.
1 1 1 C
2 1 2 B
3 1 3 A
4 1 4 A
5 1 5 A
6 1 6 C
7 1 7 B
8 1 8 B9 1 9 A
10 1 10 C
#forzando un objeto R a data frame
> as.data.frame((cbind(x=1, y=1:10)))
x y
1 1 1
2 1 2
3 1 3
4 1 45 1 5
6 1 6
7 1 7
8 1 8
9 1 9
10 1 10

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 124/344
124
3.3.7 Removiendo Objetos
Si objetos viejos no son removidos, eventualmente, el sistema podría copar el disco duro
con estos objetos y colapsar. Por esto es necesario hacer una labor de limpieza
regularmente. Dentro de una sesión R se deben eliminar los objetos que no se utilizarán
nuevamente. Para hacer esto se usa la función rm() . El argumentos de esta función es la
lista de objetos, separados por comas, que se quieren eliminar. Si se quiere saber que
objetos hay en el sistema se usa la función objects() ó ls(), cuyo resultado es una
lista de los objetos presentes.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 125/344
125
Capítulo 4: Creación de Nuevas Funciones
en R
Una de las mayores ventajas del programa R es la facilidad que le deja al usuario de crear
nuevas funciones que se integran automáticamente al sistema y que pueden seguir siendo
usadas posteriormente. En R se dispone de function, return las cuales
proporcionan los mecanismos de base para definir nuevas funciones en lenguaje R.
function( arglist ) expr
return(value)
Argumentos:
• arglist: Vacío o uno o mas nombres separados por comas indicando los argumentos
de la función o términos del tipo nombre=expresión.
• value: Una expresión o una serie de expresiones separadas por comas.
Detalles
• En R los nombres en una lista de argumentos no pueden estar entre comillas ni ser
nombres estándar.
• Si `value' es una serie de expresiones, el valor devuelto es una lista de las expresiones
evaluadas, con los conjuntos de nombres para las expresiones donde éstas son los
nombres de objetos R.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 126/344
126
Ver también: args y body para accesar a los argumentos y al cuerpo de una función.
Más detalladamente, La sintaxis para escribir funciones es la siguiente:
> mi.funcion<-function(argumento1,argumento2,...)
...Instrucciones en R...
Si sólo tenemos una línea de instrucciones las llaves no son necesarias. Por ejemplo si
queremos crear una función que nos entregue el coeficiente de kurtosis, podemos entrar el
siguiente comando.
> kurtosis<-function(x)
> mean(((x-mean(x))/sqrt(var(x)))^4)-3
Así mismo si queremos definir una función que calcule el coeficiente de asimetría podemos
entrar el siguiente comando
> asimetria<-function(x)mean(((x-mean(x))/sqrt(var(x)))^3)
Las anteriores funciones quedan integradas al R y pueden seguir siendo utilizadas sin
necesidad de definirlas. Si queremos ver cómo está definida una función damos su nombre
simplemente sin paréntesis.
En caso de tener más de una línea las llaves son necesarias para distinguir la función de los
otros comandos. Una vez la función es definida pasa a ser parte integral del R y puede
llamarse en otras ocasiones.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 127/344
127
Por ejemplo, para calcular la media geométrica de un vector x podemos definir la siguiente
función:
> media.geometrica<-function(x) prod(x)^(1/length(x))
Si queremos usarla posteriormente para calcular la media geométrica de un vector y
simplemente escribimos el comando
> media.geometrica(y)
Otro ejemplo es la siguiente función que permite hacer un rápido análisis exploratorio
gráfico de una variable:
> forma.aed<-function(x){
par(mfrow=c(2,2))
hist(x)
boxplot(x)
dic<-summary(x)[5]-summary(x)[2]
plot(density(x,width=2*dic), xlab="x", ylab=" ", type="l")qqnorm(x)
qqline(x)}
Esta es una función que produce cuatro gráficas: un histograma, una caja de Tukey, una
estimación de la densidad y un gráfico q-q (cuantil vs. cuantil), y le adiciona una línea que
pasa por el primer y tercer cuartil.
Retomando el ejemplo presentado previamente sobre el cálculo del número de unidades dereservas necesarias para que la probabilidad opere por un periódo mayor que cierto t sea
mayor o igual que un valor dado, asumiendo que los tiempos de vida de las reservas y de
la unidad principal se distribuyen weibull con los mismos parámetros. Una función para
este fin nos permitiría hacer este cálculo para cualquier conjunto de parámetros:

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 128/344
128
reservas.weibull<-function(a,b,t,gamma,nsim,ksim){
k<-0
p.est.n<-0while(p.est.n<gamma){
k<-k+1
conta<-0
for(i in 1:nsim){
tau.obs<-c(rep(0,ksim))
for(j in 1:ksim){
T<-rweibull(k,shape=a,scale=b)
tau.obs[j]<-sum(T)
}
cont<-length(tau.obs[tau.obs>t])
conta<-append(conta,cont)
}
p.est.n<-sum(conta)/(ksim*nsim)
res<-list(nro.reserv=k-1,p.est.n=p.est.n)
}
res
}
#Una aplicación de la función:
> reservas.weibull(2,0.5,2,0.9,1000,100)
$nro.reserv
[1] 6
$p.est.n
[1] 0.97237
Una función para el ejemplo previo donde se simuló los valores de una variable aletatoria X
que contaba el número de variables poisson () a generar hasta obtener un número de
eventos mayor o igual a cierto valor:

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 129/344
129
geometrica<-function(lambda,nsim){
x<--100
for(i in 1:nsim){
t<-rpois(1,lambda)
p<-t
while(p<2){
p<-rpois(1,1)
t<-append(t,p)
}
x<-append(x,length(t))
}
x<-x[-1]
x
}
#Una aplicación:
res<-geometrica(1,1000)
Algunas reglas para escribir funciones en R
• Utilice nombres completos tanto para definir funciones como para los argumentos.
Aunque el nombre de los argumentos puede ser abreviado, el nombre completo puede
dar mayor claridad. Existen muchas funciones en R, por lo tanto la selección de un
buen nombre es importante.
• Escoja defaults razonables para los argumentos.
• Comience de una forma simple, chequeando inmediatamente y agregue capacidades y
complejidad gradualmente e interactivamente.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 130/344
130
• Trate de pensar en términos de “todo el problema”. ¿Qué es lo que se pretende
conseguir al final?. No trate de escribir las instrucciones secuencialmente como se
hace en un programa de Fortran.
• Trate con la situación más general, si es posible. Por ejemplo, qué hacer con NA's
(datos faltantes), con datos de tipo caracter, listas, argumentos de longitud 0. De otra
parte, recuerde que es fácil complicarse demasiado. Un programa corto es preferible
si funciona bien el 90% de las veces a un programa extremadamente largo que
considera todos los casos posibles.
• Haga los apropiados chequeos de errores.
• Sea especialmente cuidadoso en la construcción de un vector elemento a elemento en
loops. Es preferible crear un objeto completo y reemplazar sus partes poco a poco que
tener que aumentar un objeto cada vez.
• Utilice líneas de comentario. Escriba buena documentación.
• Utilice on.exit() para hacer limpieza final: cambios en parámetros en gráficos,
remover archivos temporales, etc.
Las funciones cat() y readline() son de gran utilidad cuando trabajamos con
funciones. La función cat() permite imprimir en pantalla valores que tienen variables y
mensajes. Esto es útil en el momento de depurar una función. Un ejemplo sencillo es elsiguiente:
y <- NULL
for(i in 1:3){
y <- y+i

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 131/344
131
cat("i es ",i,"\n")
}
i es 1i es 2
i es 3
La función readline() regresa un conjunto de caracteres entrados por pantalla. La
entrada termina luego de pulsar la tecla enter. Consideremos el siguiente ejemplo que nos
permite escoger una de dos distribuciones para generar una muestra de tamaño 10:
> ejemplo <- function(){
cat("Escriba el nombre de la distribución para generar","\n")
cat("una muestra de 10 observaciones","\n")
cat("Normal o Uniforme?")
distrib <- readline()
switch(distrib,Normal=rnorm(10),Uniforme=runif(10),
stop("Seleccion invalida"))
}
Ejemplo:
> ejemplo()
Escriba el nombre de la distribución para generar
una muestra de 10 observaciones
Normal o Uniforme?Normal
[1] 0.03739638 0.51370761 0.93633222 -0.96063739 -1.40418324 1.32700988
[7] 1.21586688 -0.23684435 1.04664870 -0.34162372
> ejemplo()
Escriba el nombre de la distribución para generar
una muestra de 10 observaciones

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 132/344
132
Normal o Uniforme?Uniforme
[1] 0.4946902 0.3232580 0.7835886 0.5212327 0.6081415 0.5861348 0.6357172
[8] 0.9553567 0.7956487 0.5185195
4.1. Problemas de Memoria en R
Cuando se requiere el uso del R para ayudar a resolver ciertos problemas, como puede ser
el caso de simulaciones, a veces aparece un problema con la memoria disponible. El
problema es grave cuando se utilizan 'loops', por ejemplo for, while y repeat, ya que el
programa no libera memoria hasta que no se termina y vuelve a aparecer el prompt. En este
caso lo mejor es vectorizar. Soluciones, al menos parciales pueden ser:
1. Re-utilice las variables temporales si puede.
2. Evite ir creciendo un objeto
3. No asigne nombres a pasos intermedios si no es absolutamente necesario
4. Puede ser aconsejable que los cálculos mas complejos sean codificados en C o
FORTRAN

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 133/344
133
Capítulo 5: Matrices
R es un programa con una gran base de funciones que permiten resolver problemas de
álgebra lineal. Aquí mencionamos unas cuantas:
5.1. Operaciones básicas con matrices
Si A y B son matrices entonces podemos usar los operadores *, %*%. El primero es la
operación producto elemento a elemento, obviamente las matrices deben tener la misma
dimensión. El segundo operador corresponde a la multiplicaciónde matrices.
> A<-matrix(1:20,ncol=4,byrow=T)
> A
[,1] [,2] [,3] [,4]
[1,] 1 2 3 4
[2,] 5 6 7 8
[3,] 9 10 11 12
[4,] 13 14 15 16
[5,] 17 18 19 20
> B<-matrix(2:21,ncol=4,byrow=T)
> B
[,1] [,2] [,3] [,4]
[1,] 2 3 4 5
[2,] 6 7 8 9
[3,] 10 11 12 13
[4,] 14 15 16 17
[5,] 18 19 20 21
> c<-A*B
> c

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 134/344
134
[,1] [,2] [,3] [,4]
[1,] 2 6 12 20
[2,] 30 42 56 72[3,] 90 110 132 156
[4,] 182 210 240 272
[5,] 306 342 380 420
> d<-A%*%t(B)
> d
[,1] [,2] [,3] [,4] [,5]
[1,] 40 80 120 160 200
[2,] 96 200 304 408 512
[3,] 152 320 488 656 824
[4,] 208 440 672 904 1136
[5,] 264 560 856 1152 1448
5.2. Transposición de una matriz
t(): Esta función retorna la matriz transpuesta del argumento:
> B<-matrix(c(1,2,8,3),ncol=2)
> B
[,1] [,2]
[1,] 1 8
[2,] 2 3
> t(B)
[,1] [,2][1,] 1 2
[2,] 8 3
>

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 135/344
135
5.3. Productos cruzados
crossprod(): Dadas las matrices `x' y `y' como argumentos crossprod retorna la
matriz del producto cruzado, es decir XTY. Si sólo se da un argumento, digamos X,
entonces devuelve XTX.
> A
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 2 4 5[3,] 3 5 2
> crossprod(A)
[,1] [,2] [,3]
[1,] 14 25 19
[2,] 25 45 36
[3,] 19 36 38
>
> t(A)%*%A[,1] [,2] [,3]
[1,] 14 25 19
[2,] 25 45 36
[3,] 19 36 38
>
5.4. Descomposición SVD
svd(): produce la descomposición en valores singulares de una matriz rectangular:
> A
[,1] [,2] [,3]

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 136/344
136
[1,] 1 2 3
[2,] 2 4 5
[3,] 3 5 2> desc<-svd(A)
desc
$d [1] 9.51206040 2.55323549 0.04117509
$u
[,1] [,2] [,3]
[1,] -0.3789216 -0.3931549 -0.83776349
[2,] -0.6934136 -0.4788893 0.53837038
[3,] -0.6128589 0.7849168 -0.09115742
$v
[,1] [,2] [,3]
[1,] -0.3789216 0.3931549 -0.83776349
[2,] -0.6934136 0.4788893 0.53837038
[3,] -0.6128589 -0.7849168 -0.09115742
U<-desc$u
D<-diag(desc$d)
V<-desc$v
U%*%D%*%t(V)
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 2 4 5
[3,] 3 5 2
5.5. Descomposición QR
qr(): Produce la descomposición QR de una matriz:

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 137/344
137
qr(x, tol=1e-07) qr.coef(qr, y) qr.qy(qr, y) qr.qty(qr, y)
qr.resid(qr, y) qr.fitted(qr, y, k = qr$rank) qr.solve(a, b, tol =1e-7)
is.qr(x)as.qr(x)
Argumentos:
• x: La matriz sobre la cual se hará la descomposición.
• tol: La tolerancia para detectar dependencias lineales entre las columnas de `x'.
• qr: Una descomposición del tipo calculada por qr.
• y, b: Un vector o matriz de los lados derechos de sistemas de ecuaciones.
• a: Una matriz o descomposición QR.
Detalles
• La descomposición QR puede ser usada para resolver el sistema Ax = b, es útil para
calcular los coeficientes de regresión y aplicar el algoritmo de Newton-Raphson.
• Las funciones qr.coef, qr.resid, y qr.fitted devuelven los
coeficientes, los residuales y los valores ajustados obtenidos cuando se ajusta `y' a la
matriz que tiene `qr' como su descomposición QR. qr.qy y qr. qty devuelvenla matriz Qy y Q
T y, con Q siendo la matriz Q de la descomposición.
• qr.solve resuelve sistemas de ecuaciones mediante la descomposición QR.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 138/344
138
• is.qr devuelve un `TRUE' si `x' es una lista con componentes denominados `qr',
`rank' y `qraux' y `FALSE' en caso contrario.
• No es posible forzar objetos al modo `"qr"'. Los objetos son o no descomposiciones
QR.
Valor: Una lista que contiene los siguientes objetos:
• qr: Una matriz con la misma dimensión de `x'. El triángulo superior contiene el R de
la descomposición y el triángulo superior contiene información del Q de la
descomposición.
• qraux: Un vector de longitud `ncol(x)' que contiene información adicional de Q.
• rank: El rango de `x' calculado por la descomposición. Siempre esl rango completo
en el caso complejo.
• pivot: Información sobre la estrategia de pivoteo usada durante la descomposición.
Nota:
• Para calcular el determinante de una matriz la descomposición QR es mucho más
eficiente que usar los valores propios (`eigen'). Ver `det'
• El caso complejo usa pivoteo sobre columna y no intenta detectar matrices deficientes
en rango.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 139/344
139
Ver también: qr.Q, qr.R, qr.X para reconstrucción de las matrices. solve.qr,
lsfit, eigen, svd.
Ejemplos:
A<-cbind(c(1,2,3),c(2,4,5),c(3,5,2))
> A
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 2 4 5
[3,] 3 5 2
descQR<-qr(A)
descQR
$qr
[,1] [,2] [,3]
[1,] -3.7416574 -6.6815310 -5.0779636
[2,] 0.5345225 -0.5976143 -3.4661630
[3,] 0.8017837 -0.8244771 -0.4472136
$rank
[1] 3
$qraux
[1] 1.2672612 1.5658953 0.4472136
$pivot
[1] 1 2 3
#Reconstruyendo las matrices de la
#descomposición
Q<-qr.Q(descQR)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 140/344
140
Q
[,1] [,2] [,3]
[1,] -0.2672612 -0.3585686 -8.944272e-01[2,] -0.5345225 -0.7171372 4.472136e-01
[3,] -0.8017837 0.5976143 -5.551115e-16
R<-qr.R(descQR)
R
[,1] [,2] [,3]
[1,] -3.741657 -6.6815310 -5.0779636
[2,] 0.000000 -0.5976143 -3.4661630
[3,] 0.000000 0.0000000 -0.4472136
#Reconstruyendo la matriz original
#Observe que X es la
#matriz inicial A:
X<-qr.X(descQR)
X
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 2 4 5
[3,] 3 5 2
#Resolviendo un sistema de
#ecuaciones de la forma Ax=y:
y<-c(-1,-1,3.5)
x<-qr.solve(A,y,tol = 1e-10)
x
[1] 1.0 0.5 -1.0
#o bien:
x<-qr.coef(descQR,y)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 141/344
141
x
[1] 1.0 0.5 -1.0
#Otro ejemplo:
y<-c(-1,-1,3.2)
x<-qr.coef(descQR,y)
x
[1] 0.4 0.8 -1.0
#o bien
x<-qr.solve(descQR, y)
x
[1] 0.4 0.8 -1.0
residuos<-qr.resid(descQR,y)
residuos
[1] 0 0 0
qr.fitted(descQR,y)
[1] -1.0 -1.0 3.2
5.6. Pegando matrices
cbind(): Esta función junta dos matrices por filas (o sea, una al lado de la otra)
> A<-matrix(c(1,3,5,7),ncol=2)> A
[,1] [,2]
[1,] 1 5
[2,] 3 7
> B<-matrix(c(0,3,2,1,4,7),nrow=2)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 142/344
142
> B
[,1] [,2] [,3]
[1,] 0 2 4[2,] 3 1 7
> C<-cbind(A,B)
> C
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 0 2 4
[2,] 3 7 3 1 7
>
rbind(): Junta dos matrices por columna (una matriz sobre la otra)
> A<-matrix(c(1,3,5,7),ncol=2)
> A
[,1] [,2]
[1,] 1 5
[2,] 3 7
> B<-matrix(c(0,3,2,1,4,7),ncol=2)
> B
[,1] [,2]
[1,] 0 1
[2,] 3 4
[3,] 2 7
> C<-rbind(A,B)
> C
[,1] [,2]
[1,] 1 5
[2,] 3 7
[3,] 0 1
[4,] 3 4
[5,] 2 7
>

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 143/344
143
5.7. Descomposición de Cholesky
chol(): produce la descomposición de Cholesky de una matriz simétrica definida
positiva, devolviendo el factor correspondiente a la matriz triangular superior:
> A<-matrix(c(5,2,3,2,4,2,3,2,7),ncol=3)
> A
[,1] [,2] [,3]
[1,] 5 2 3
[2,] 2 4 2
[3,] 3 2 7
> B<-chol(A)
> B
[,1] [,2] [,3]
[1,] 2.236068 0.8944272 1.3416408
[2,] 0.000000 1.7888544 0.4472136
[3,] 0.000000 0.0000000 2.2360680
> t(B)%*%B
[,1] [,2] [,3]
[1,] 5 2 3
[2,] 2 4 2
[3,] 3 2 7
>
5.8. Cálculo de valores y vectores propios
eigen(): produce los valores y vectores propios de una matriz cuadrada.
eigen(x, symmetric, only.values = FALSE)
La.eigen(x, symmetric, only.values = FALSE)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 144/344
144
Argumentos:
• x: La matriz cuya descomposición espectral va a ser calculada.
• symmetric: Si es `TRUE', se asume que la matriz es simétrica o hermitiana si es
compleja, y sólo su triángulo inferior es usado. Si `symmetric' no es especificado, la
matriz es inspeccionada para simetría.
• only.values: Si es `TRUE', sólo son calculados los valores propios, de lo contrario
tanto los valores como los vectores propios son devueltos.
La descomposición espectral de `x' es devuelta como las componentes de una lista:
• values: Un vector con los p valores propios de `x', ordenados en orden decreciente,
de acuerdo a `Mod(values)' si son complejos.
• vectors: Una matriz de dimensión p× p cuyas columnas contienen los vectores propios de of `x', o `NULL' si `only.values' es `TRUE'.
> A<-matrix(c(1,2,3,2,4,5,3,5,2),ncol=3)
> A
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 2 4 5
[3,] 3 5 2
> eigen(A)
$values
[1] 9.51206040 0.04117509 -2.55323549
$vectors
[,1] [,2] [,3]

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 145/344
145
[1,] 0.3789216 -0.83776349 0.3931549
[2,] 0.6934136 0.53837038 0.4788893
[3,] 0.6128589 -0.09115742 -0.7849168
5.9. Creación de matrices diagonales
diag(): crea una matriz diagonal si el argumento es vectorial o retorna la matriz
diagonal de una matriz
> diag(c(1,2,3,4))[,1] [,2] [,3] [,4]
[1,] 1 0 0 0
[2,] 0 2 0 0
[3,] 0 0 3 0
[4,] 0 0 0 4
> A<-matrix(c(1,2,3,2,4,5,3,5,2),ncol=3)
> A
[,1] [,2] [,3][1,] 1 2 3
[2,] 2 4 5
[3,] 3 5 2
> diag(A)
[1] 1 4 2
> diag(diag(A))
[,1] [,2] [,3]
[1,] 1 0 0[2,] 0 4 0
[3,] 0 0 2
>

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 146/344
146
5.10. Producto Kronecker
kronecker(): Producto kronecker entre matrices. Calcula el producto kronecker
generalizado de dos arreglos, `X' e `Y'. kronecker(X, Y) devuelve un arreglo `A'
con dimensiones `dim(X) * dim(Y)'.
kronecker(X, Y, FUN = "*", make.dimnames = FALSE, ...)
X %x% Y
• X: Un vector o arreglo.
• Y: Un vector o arreglo.
• FUN: Una función; puede estar entre comillas.
• make.dimnames: Proporciona los nombres de las dimensiones que son el producto
de `X' e `Y'.
• ...: Argumentos opcionales para `FUN'.
> A<-matrix(c(1,2,3,2,4,5,3,5,2),ncol=3)
> A
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 2 4 5
[3,] 3 5 2
> B<-matrix(c(1,2,2,3),ncol=2)
> B
[,1] [,2]
[1,] 1 2

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 147/344
147
[2,] 2 3
>
> kronecker(A,B)
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 1 2 2 4 3 6
[2,] 2 3 4 6 6 9
[3,] 2 4 4 8 5 10
[4,] 4 6 8 12 10 15
[5,] 3 6 5 10 2 4
[6,] 6 9 10 15 4 6
> kronecker(B,A)
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 1 2 3 2 4 6
[2,] 2 4 5 4 8 10
[3,] 3 5 2 6 10 4
[4,] 2 4 6 3 6 9
[5,] 4 8 10 6 12 15
[6,] 6 10 4 9 15 6
>
> kronecker(c(1,2,3),c(5,6))
[1] 5 6 10 12 15 18
> kronecker(c(5,6),c(1,2,3))
[1] 5 10 15 6 12 18
5.11. Inversa de una matriz
La matriz inversa no se encuentra directamente sino a través de la función solve() Esta
función resuelve para `x' el sistema Ax=b donde `b' puede ser un vector o una matriz.
solve(a, b, tol = 1e-7)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 148/344
148
Argumentos:
• a: Una matriz numérica con los coeficientes del sistema lineal.
• b: Un vetor numérico o matriz dando el (los) lado (s) derecho del sistema lineal. Si
se omite, se asume la matriz identidad y por tanto solve devolverá la inversa de `a'.
• tol: La tolerancia para detectar las dependencias lineales en las columnas de `a'.
Ver también: `backsolve', qr.solve'.
> A<-matrix(c(1,2,3,2,4,5,3,5,2),ncol=3)
> A
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 2 4 5
[3,] 3 5 2
> solve(A)
[,1] [,2] [,3]
[1,] 17 -11 2.000000e+00
[2,] -11 7 -1.000000e+00
[3,] 2 -1 1.117140e-15
>
> b<-c(2,1,3)
> solve(A,b)
[1] 29 -18 3
>
5.12. Ordenando un vector
sort(): ordena en forma ascendente el vector dado como argumento.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 149/344
149
> sort(c(-1,5,-2,4,3,9))
[1] -2 -1 3 4 5 9
5.13. Aplicando funciones sobre las componentes de
una matriz
Las siguientes funciones simplifican los cálculos que operan de forma iterada sobre
columnas o filas de una matriz. Si tenemos arreglos tridimensionales opera sobre las
matrices en caso requerido.
Función Argumentos Lo que hace
apply apply(X,MARGIN,FUN,...) Devuelve un vector o arreglo o lista
de valores obtenidos aplicando una
función a las márgenes de un arreglo
X: El arreglo a ser usado MARGIN: Un
vector con los subíndices sobre los
cuales la función será aplicada 1 indica
filas, 2 indica columnas, `c(1,2)' indica
filas y columnas.
...: Argumentos opcionales para `FUN'
tapply tapply(X,INDEX,FUN = NULL,..., simplify =
TRUE)
Aplica una función a cada celda de
un arreglo “Ragged”,es decir, a cada
grupo de valores (no vacíos) dados
por una única combinación de los
niveles de ciertos factores.
X: Típicamente un vector INDEX: Lista de
factores, cada uno de la misma longitud
de `X' FUN: La función a ser aplicada
...: Argumentos opcionales para `FUN'
simplify: Si es `FALSE',`tapply' siempre
devuelve un arreglo del tipo lista. Si es
`TRUE' (por defecto) y `FUN' siempre
produce un escalar, entonces `tapply'

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 150/344
150
Función Argumentos Lo que hace
devuelve un arreglo del modo escalar
lapply lapply(X,FUN,...) Devuelve una lista de la misma
longitud de `X'. Cada elemento de
ésta resulta de aplicar `FUN' al
correspondiente elemento de `X'.
sapply sapply(X,FUN,...,simplify = TRUE,
USE.NAMES = TRUE)
Es una versión más amigable de
`lapply' también trabaja sobre
vectores y devuelve un vector o
arreglo.
X: Lista o vector a ser usado.
FUN: La función a aplicar
...: Argumentos opcionales para `FUN'
simplify: Argumento lógico. ¿debería el
resultado ser simplificado a un vector
cuando sea posible?
USE.NAMES: Argumento lógico, si es `TRUE'
y si `X' es caracter,usa a `X' como
`names' para los resultados a menos que
ya se tengan nombres.
Por ejemplo si deseamos calcular las medias de las columnas de una matriz X damos el
comando
medias.col<-apply(X,2,mean)
Otros ejemplos:
#Generando tres muestras bivariadas#de tamaño 10:
library(mass)
mu<-c(0,0)
Sigma<-matrix(c(1,0,0,1),ncol=2)
a<-matrix(rep(10,3),ncol=3)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 151/344
151
b<-array(apply(a,2,mvrnorm,mu,Sigma),dim=c(10,2,3))
b, , 1
[,1] [,2]
[1,] -0.9546754 -0.9788744
[2,] 0.3951823 -0.1284428
[3,] 1.0079476 -0.5692264
[4,] 0.1308736 0.4990434
[5,] 0.6154087 0.8054497
[6,] 0.8264678 -0.6473254
[7,] -0.4329034 0.8565902
[8,] 0.3916516 0.7230044
[9,] -0.8908572 0.5820368
[10,] -0.8976308 -0.6085847
, , 2
[,1] [,2]
[1,] 0.03365421 0.01812461
[2,] -0.66313500 2.31526069
[3,] -0.92103077 2.21952089
[4,] -0.97599197 1.39551295
[5,] -0.55824010 0.15656623
[6,] 0.77337990 0.52407043
[7,] -1.62980628 0.26459324
[8,] -1.01363258 -1.74454949
[9,] -0.32201918 -0.07920861
[10,] -1.40875243 -0.77490633
, , 3
[,1] [,2]
[1,] -0.9856771 -1.69944802

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 152/344
152
[2,] 0.6159202 1.01835201
[3,] 0.8225232 0.83393529
[4,] 0.7533535 0.01518407[5,] 0.5899308 -0.46316405
[6,] 1.6388345 -1.30981318
[7,] 1.4050816 -0.35261864
[8,] -0.3563772 -0.94868464
[9,] -1.6126299 1.67723448
[10,] 0.4840092 -1.00325728
#estimación de localización y
#matriz de covarianza clásicas
c<-apply(b, c(3, 2), mean)
d<-apply(b, c(3), var)
c
[,1] [,2]
[1,] 0.01914649 0.05336708
[2,] -0.66855742 0.42949846
[3,] 0.33549690 -0.22322799
d
[,1] [,2] [,3]
[1,] 0.56654836 0.49486624 1.0488130
[2,] 0.02954414 0.07806947 -0.2243212
[3,] 0.02954414 0.07806947 -0.2243212
[4,] 0.50585323 1.60101998 1.2107389
apply(b[,,1],2,mean)
[1] 0.01914649 0.05336708
var(b[,,1])
[,1] [,2]
[1,] 0.56654836 0.02954414
[2,] 0.02954414 0.50585323

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 153/344
153
Ejemplo: Datos Antropométricos
La siguiente tabla contiene mediciones realizadas en el pie derecho de 10 estudiantes.
Cinco variables fueron medidas:
• Longitud máxima de la huella (en cm)
• Amplitud máxima de la huella (en cm)
• Amplitud máxima del talón (en cm)
• Longitud máxima del dedo mayor (en cm)
• Amplitud máxima del dedo mayor (en cm)
• Sexo (1: Hombre; 0: Mujer)
Observación
Número
Longitud
Máxima
Ancho
Máximo
Ancho
del
Talón
Longitud
del Dedo
Mayor
Ancho del
Dedo
mayor
Sexo
1 24.20 9.40 5.50 3.00 3.20 1
2 21.70 8.50 6.10 3.20 2.60 0
3 25.40 9.60 5.50 4.00 3.10 14 25.00 10.10 5.30 3.50 2.70 1
5 22.00 8.50 5.70 3.10 2.70 0
6 25.90 9.30 6.10 4.30 3.30 1
7 22.20 8.60 5.20 3.90 2.90 0
8 21.70 8.40 5.00 3.20 2.30 0
9 25.50 9.20 6.10 3.30 3.20 1
10 24.40 9.40 4.70 3.60 2.80 1
Los datos fueron leídos en forma de matriz desde un archivo de texto:
> pies.dat <- matrix(scan('c:/datos/pies.txt'),ncol=6,byrow=T)
> pies.dat
V1 V2 V3 V4 V5 V6
1 24.2 9.4 5.5 3.0 3.2 1

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 154/344
154
2 21.7 8.5 6.1 3.2 2.6 0
3 25.4 9.6 5.5 4.0 3.1 1
4 25.0 10.1 5.3 3.5 2.7 15 22.0 8.5 5.7 3.1 2.7 0
6 25.9 9.3 6.1 4.3 3.3 1
7 22.2 8.6 5.2 3.9 2.9 0
8 21.7 8.4 5.0 3.2 2.3 0
9 25.5 9.2 6.1 3.3 3.2 1
10 24.4 9.4 4.7 3.6 2.8 1
Si queremos trabajar con los hombres y mujeres separadamente podemos usar los
siguientes comandos
> hombres.pies<-pies.dat[pies.dat[,6]= =1,]
> hombres.pies
V1 V2 V3 V4 V5 V6
1 24.2 9.4 5.5 3.0 3.2 1
3 25.4 9.6 5.5 4.0 3.1 1
4 25.0 10.1 5.3 3.5 2.7 1
6 25.9 9.3 6.1 4.3 3.3 19 25.5 9.2 6.1 3.3 3.2 1
10 24.4 9.4 4.7 3.6 2.8 1
> mujeres.pies<-pies.dat[pies.dat[,6]= =0,]
> mujeres.pies
V1 V2 V3 V4 V5 V6
2 21.7 8.5 6.1 3.2 2.6 0
5 22.0 8.5 5.7 3.1 2.7 0
7 22.2 8.6 5.2 3.9 2.9 0
8 21.7 8.4 5.0 3.2 2.3 0>

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 155/344
155
lo cual genera dos matrices hombres.pies y mujeres.pies. Para propósitos
ilustrativos vamos a seleccionar las tres primeras variables: largo del pie, ancho del pie y
ancho del talón. Procedemos así:
> hombres.pies<-hombres.pies[,1:3]
> mujeres.pies<-mujeres.pies[,1:3]
> hombres.pies
V1 V2 V3
1 24.2 9.4 5.5
3 25.4 9.6 5.5
4 25.0 10.1 5.36 25.9 9.3 6.1
9 25.5 9.2 6.1
10 24.4 9.4 4.7
> mujeres.pies
V1 V2 V3
2 21.7 8.5 6.1
5 22.0 8.5 5.7
7 22.2 8.6 5.2
8 21.7 8.4 5.0>
Si queremos calcula las matrices de dispersión (varianzas y covarianzas) y correlación por
sexo, procedemos así:
> dispersion.hombres<-var(hombres.pies)
> dispersion.hombres
V1 V2 V3
V1 0.4386667 -0.030 0.2613333
V2 -0.0300000 0.104 -0.0680000
V3 0.2613333 -0.068 0.2786667
> dispersion.mujeres<-var(mujeres.pies)
> dispersion.mujeres

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 156/344
156
V1 V2 V3
V1 0.06000000 0.016666667 -0.030000000
V2 0.01666667 0.006666667 0.006666667V3 -0.03000000 0.006666667 0.246666667
> correlacion.hombres<-cor(hombres.pies)
> correlacion.hombres
V1 V2 V3
V1 1.0000000 -0.1404550 0.7474549
V2 -0.1404550 1.0000000 -0.3994383
V3 0.7474549 -0.3994383 1.0000000
> correlacion.mujeres<-cor(mujeres.pies)
> correlacion.mujeres
V1 V2 V3
V1 1.0000000 0.8333333 -0.2465985
V2 0.8333333 1.0000000 0.1643990
V3 -0.2465985 0.1643990 1.0000000
5.14. Funciones colSums, rowSums,
colMeans, rowMeans
Calculan sumas y medias de filas y columnas en arreglos numéricos. Es equivalente a usar
apply con `FUN = mean' o `FUN = sum' pero es mucho más rápida.
colSums(x, na.rm = FALSE, dims = 1)
rowSums(x, na.rm = FALSE, dims = 1)
colMeans(x, na.rm = FALSE, dims = 1)
rowMeans(x, na.rm = FALSE, dims = 1)
Argumentos:

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 157/344
157
• x: Un arreglo de dos o más dimensiones con valores numéricos, complejos, enteros,
o lógicos, o un data frame.
• na.rm: Argumento lógico para especificar si se omiten los valores faltantes de los
cálculos.
• dims: Cuáles dimensiones son consideradas como “rows” o “columns” para la suma
total. Para `col*', la suma o la media es sobre la dimensión total `dims+1, ...'; para
`row*' es sobre las dimensiones `1:dims'.
Ejemplos:
x <- cbind(x1 = 3, x2 = c(4:1, 2:5))
x
x1 x2
[1,] 3 4
[2,] 3 3
[3,] 3 2
[4,] 3 1
[5,] 3 2
[6,] 3 3
[7,] 3 4
[8,] 3 5
> rowSums(x)
[1] 7 6 5 4 5 6 7 8
> colSums(x)
x1 x224 24
> rowMeans(x)
[1] 3.5 3.0 2.5 2.0 2.5 3.0 3.5 4.0
> colMeans(x)
x1 x2

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 158/344
158
3 3
##Caso complejo:
x <- cbind(x1 = 3 + 2i, x2 = c(4:1, 2:5) - 5i)
x[3, ] <- NA; x[4, 2] <- NA
> x
x1 x2
[1,] 3+2i 4-5i
[2,] 3+2i 3-5i
[3,] NA NA
[4,] 3+2i NA
[5,] 3+2i 2-5i
[6,] 3+2i 3-5i
[7,] 3+2i 4-5i
[8,] 3+2i 5-5i
> rowSums(x)
[1] 7-3i 6-3i NA NA 5-3i 6-3i 7-3i 8-3i
> colSums(x)
x1 x2
NA NA
> rowMeans(x)
[1] 3.5-1.5i 3.0-1.5i NA NA 2.5-1.5i 3.0-1.5i 3.5-1.5i 4.0-1.5i
> colMeans(x)
x1 x2
NA NA
rowSums(x, na.rm = TRUE); colSums(x, na.rm = TRUE)
[1] 7-3i 6-3i 0+0i 3+2i 5-3i 6-3i 7-3i 8-3i
x1 x2
21+14i 21-30i

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 159/344
159
Parte IIGráficos

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 160/344
160
Capítulo 6: Introducción
Una de las ventajas mayores del programa R es su capacidad de producir gráficos de alta
calidad. Posee un gran número de funciones que son fáciles de usar y de modificar para
ajustarlas a nuestras necesidades.
6.1. Funciones para Especificar Devices
postscript(archivo, comando, horizontal=F, width,height, rasters,
pointsize=14, font=1,preamble=ps.preamble, fonts=ps.fonts)
printer(width=80, height=64, file=“ “, command=“ “)
show()
6.2. Algunos Parámetros para Graficar en R
log='<x|y|xy>' Ejes Logarítmicos
main='título'&
new=<logical> Adiciona sobre el gráfico actual
sub='título de abajo'
type='<l|p|b|n>' Línea, puntos, ambos, ninguno
lty=n Tipo de Línea
pch='.' Caracter de dibujo\xlab='Nombre del eje x'
ylab='Nombre del eje y'
xlim=c(x_ minimo ,x_ maximo )ylim=c(y_ minimo ,y_ maximo )

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 161/344
161
6.3. Gráficos Unidimensionales
barplot(Estaturas)
barplot(Estaturas,amplitud, nombres, space=.2, inside=TRUE,beside=FALSE,
horiz=FALSE, legend, angle,density, col, blocks=TRUE)
boxplot(..., rango, amplitud, varwidth=FALSE,notch=FALSE, names,
plot=TRUE)
hist(x, nclass, breaks, plot=TRUE, angle,density, col, inside)
6.4. Gráficos Bidimensionales
lines(x, y, type="l")
points(x, y, type="p"))
plot(x, y, type="p", lty=1:5, pch=, col=1:4)
points(x, y, type="p", lty=1:5, pch=, col=1:4)
lines(x,y, type="l", lty=1:5, pch=, col=1:4)
plot(x, y, type="p", log="")
abline(coef)
abline(a, b)abline(reg)
abline(h=a)
abline(v=a)
qqplot(x, y, plot=TRUE)
qqnorm(x, datax=FALSE, plot=TRUE)
6.5. Gráficos Tridimensionales
contour(x, y, z, v, nint=5, add=FALSE, labels)
interp(x, y, z, xo, yo, ncp=0, extrap=FALSE)
persp(z, eye=c(-6,-8,5), ar=1)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 162/344
162
6.6. Múltiples Gráficos por Página (Ejemplos)
Cuatro gráficos en una misma página, y un título general:
par(mfrow=c(2,2), oma=c(0, 0, 4, 0))
plot(rnorm(50),main="Muestra normal estándar",cex.main=0.8)
plot(rexp(50),main="Muestra exponencial(1)", cex.main=0.8)
plot(rweibull(50,3,2),main="Muestra weibul(3,2)", cex.main=0.8)
plot(rnorm(50,mean=1),main="Muestra normal(1,1)", cex.main=0.8)
mtext(side=3, line=0, cex=1, outer=T,"Este es un Titulo para Toda la
Página")
Tres gráficos: uno centrado en la parte superior, y los otros dos
abajo:
nf <- layout(rbind(c(0,1,1,0), c(2,2,3,3)))
plot(1:10)
plot(rnorm(10,0,1))
plot(rlnorm(10,0,1))
Otra presentación, en la cual dos gráficos son presentados en columna, y centrados en la
ventana graficadora, es posible de la forma siguiente:
nf <- layout(rbind(c(0,1,1,0), c(0,2,2,0)))
plot(rnorm(10))
plot(rlnorm(10))
Entre las funciones para graficar de más uso están:

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 163/344
163
6.7. Función persp
Esta función permite realizar gráficos tridimensionales de perspectiva de superficies sobre
el plano x-y.
persp(x, ...)
persp.default(x = seq(0, 1, len = nrow(z)),
y = seq(0, 1, len = ncol(z)),
z, xlim = range(x), ylim = range(y),
zlim = range(z, na.rm = TRUE), xlab = NULL,ylab =NULL, zlab = NULL, main = NULL, sub = NULL, theta = 0,
phi = 15, r = sqrt(3), d = 1,
scale = TRUE, expand = 1, col = NULL, border = NULL,
ltheta = -135, lphi = 0, shade = NA,
box = TRUE, axes = TRUE, nticks = 5, ticktype = "simple",...)
Argumentos:
• x, y: Ubicación de las lineas de la rejilla sobre la cual los valores en 'z' son medidos.
éstas deben estar en orden ascendente. Por defecto, se usan valores igualmente
espaciados en el intervalo de 0 a 1. Si x es una lista, sus componentes x$x y x$y
son usados para x e y respectivamente.
• z: Una matriz que contiene los valores a ser graficados (valores 'NA' son
permitidos). Notar que 'x' puede ser usada en ves de 'z' por conveniencia.
• xlim, ylim, zlim: Límites x, y y z para el gráfico. El gráfico es producido de
manera que el volumen rectangular definido por estos límites sea visible.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 164/344
164
• xlab, ylab, zlab: Títulos para los ejes. Estos deben ser cadenas de caracteres; no se
permiten expresiones.
• main, sub: Título y subtítulo.
• theta, phi: ángulos que definen la dirección de las vistas. 'theta' da la dirección
azimutal y 'phi' la colatitud.
• r: La distancia del eyepoint desde el centro de la caja de graficación.
• d: Un valor que puede usarse para variar la longitud de la transformación de la
perspectiva. Valores mayores que 1 reducirán el efecto perspectiva y valores menores
o iguales a 1 lo exagerarán.
• scale: Antes de visualizar las coordenadas x, y y z de los puntos que definen la
superficie, éstas son transformadas al intervalo [0,1]. Si 'scale' es TRUE las
coordenadas son transformadas separadamente. Si es FALSE las coordenadas sonescaladas de manera que el aspecto de las razones son mantenidas. Esto es útil para
representar cosas como información DEM.
• expand: Un factor de expansión aplicado a las coordenadas z. A menudo es usado
con 'expand' entre (0,1) para contraer el gráfico en la dirección z.
• col: El color de las facetas de la superficie.
• border: El color de la linea dibujada alrededor de las facetas de la superficie. Un
valor de 'NA' inhabilitará el trazo de bordes. Esto resulta útil cuando la superficie es
sombreada.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 165/344
165
• ltheta, lphi: Si se especifican valores finitos para estos, la superficie es sombreada
como si fuera iluminada desde la dirección especificada por el azimut 'ltheta' y la
colatitud 'lphi'.
• shade: La sombra en un faceta de la superficie es calculada como
((1+d)/2)shade, donde 'd' es el producto punto de un vector unitario normal a la
faz y un vector unitario en la dirección de un fuente de luz. Los valores de 'shade'
cercanos a 1 producen sombreado similar a un modelo de fuente de luz puntual y
valores cercanos a 0 no producen sombra. Valores en el rango de 0.5 a 0.75
proporcionan una aproximación a la iluminación diurna.
• box: Traza un caja para la superficie. Por defecto e 'TRUE'.
• axes: Agrega ticks y etiquetas a la caja. Por defecto es 'TRUE'. Si 'box' es 'FALSE'
las etiquetas y los ticks no son dibujados.
• ticktype: Caracter: “simple” dibuja un flecha paralela al eje para indicar la direcciónde aumento; “detailed” dibuja los ticks normales como en gráficos 2D
• nticks: El número aproximado de marcas ticks a dibujar en los ejes. No tiene efecto
si 'ticktype' es “simple”.
• ...: Parámetros gráficos adicionales.
Ejemplo 1: Graficación de normales bivariadas
x<-seq(-4,4,len=50)
y<-seq(-4,4,len=50)
normal.bivariada<-function(x,y,rho,mu1,sigma1,mu2,sigma2){

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 166/344
166
1/(2*pi*sigma1*sigma2*sqrt(1-rho^2))*exp(-1/(2*(1-rho^2))*(((x-
mu1)/sigma1)^2-2*rho*((x-mu1)/sigma1)*((y-mu2)/sigma2)+((y-
mu2)/sigma2)^2))}
nf<-layout(matrix(c(1,2,3,4),ncol=2,byrow=T),
widths=c(rep(10,4)),heights=c(rep(10,4)),respect=T)
f<-outer(x,y,normal.bivariada,rho=0.85,mu1=0,sigma1=1,mu2=0,sigma2=1)
par(mar=c(1,1,4,1))
persp(x,y,f,theta = 30, phi = 30, col = "lightblue",xlab = "X", ylab =
"Y", zlab ="Z",main="rho=0.85",cex.main=0.8)
f<-outer(x,y,normal.bivariada,rho=0.5,mu1=0.5,sigma1=1,mu2=0,sigma2=1)
par(mar=c(1,1,4,1))
persp(x,y,f,theta = 30, phi = 30, col = "lightblue",xlab = "X", ylab =
"Y", zlab ="Z",main="rho=0.5",cex.main=0.8)
f<-outer(x,y,normal.bivariada,rho=0.0,mu1=0,sigma1=1,mu2=0,sigma2=1)
par(mar=c(1,1,4,1))
persp(x,y,f,theta = 30, phi = 30, col = "lightblue",xlab = "X", ylab =
"Y", zlab ="Z",main="rho=0.0",cex.main=0.8)
f<-outer(x,y,normal.bivariada,rho=-0.85,mu1=0,sigma1=1,mu2=0,sigma2=1)
par(mar=c(1,1,4,1))
persp(x,y,f,theta = 30, phi = 30, col = "lightblue",xlab = "X", ylab =
"Y", zlab ="Z",main="rho=-0.85",cex.main=0.8)
par(oma=c(1,1,1,1),new=T,font=2,cex=1)
mtext(outer=T,"Distribución Normal
Bivariada",side=3,cex=0.8)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 167/344
167
Figura 6.1: visualización de las superficies normales bivariadas para unos
parámetros específicos es posible gracias a la función `persp' .
6.8. Función contour
Esta función permite realizar gráficos de contornos, tales como los contornos de
verosimilitud en dos parámetros o también en la graficación de regiones de confianza,
mapas topográficos, etc. Dichos contornos pueden ser agregados a un gráfico previo, por
ejemplo a un gráfico de dispersión:
contour(x = seq(0, 1, len = nrow(z)),y = seq(0, 1, len = ncol(z)), z,
nlevels = 10,levels = pretty(zlim, nlevels), labels = NULL,
xlim = range(x, finite = TRUE),ylim =range(y, finite = TRUE),
zlim = range(z, finite = TRUE),labcex = 0.6, drawlabels = TRUE,

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 168/344
168
method = "flattest",vfont = c("sans serif", "plain"),axes = TRUE,
frame.plot = axes, col= par("fg"), lty = par("lty"), lwd = par("lwd"),
add = FALSE, ...)
Argumentos:
• x,y: Ubicación de las lineas de la rejilla sobre la cual los valores en 'z' son medidos.
éstas deben estar en orden ascendente. Por defecto, se usan valores igualmente
espaciados en el intervalo de 0 a 1. Si x es una lista, sus componentes x$x y $x$y
son usados parax
ey
respectivamente. Si la lista tiene componente 'z' ésta es usada
para 'z'.
• z: Una matriz que contiene los valores a ser graficados (son permitidos valores
'NA'). Notar que 'x' puede ser usada en ves de 'z' por conveniencia.
• nlevels: El número de niveles de contorno deseados si 'levels' no es especificado.
• levels: Vector numérico que da los niveles en los cuales se desea dibujar las lineas
de contorno.
• labels: Un vector que proporciona etiquetas para las lineas de contorno. Si es
'NULL' entonces los niveles son usados como etiquetas.
• labcex: Factor de expansión de caracter 'cex' para la etiquetación de los contornos.
• drawlabels: Argumento lógico. Si es 'TRUE' los contornos son etiquetados.
• method: cadena de caracteres que especifica dónde se ubicarán las etiquetas. Los
valores posibles son (entre comillas) “simple”, “edge” y “flattest” (por defecto). El

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 169/344
169
primero dibuja la etiqueta en el borde del gráfico, sobreponiéndola a la linea de
contorno; el segundo dibuja la etiqueta en el borde del gráfico , incrustado en la linea
de contorno, sin superponerlas; y el tercero dibuja sobre la sección más plana del
contorno, incrustando la etiqueta en la linea de contorno sin superposición. El
segundo y tercer método pueden no dibujar un etiqueta en cada linea de contorno.
• vfont: Si se especifica un vector de caracteres de longitud 2, entonces vector de
fuentes Hershey son usados para las etiquetas de los contornos. El primer elemento
del vector selecciona un estilo o tipo de fuente y el segundo elemento selecciona un
índice de fuente .
• xlim, ylim, zlim: Límites x, y y z para el gráfico.
• axes, frame.plot: Argumento lógico para indicar si ejes o una caja deberían ser
dibujados.
• col: Color de las lineas.
• lty: Tipo de linea.
• lwd: Ancho de linea.
• add: Argumento lógico. Si es 'TRUE', adiciona los contornos a un gráfico.
• ...: Pueden suministrarse parámetros gráficos adicionales y argumentos para 'title'
Ver: 'filled.contour' para contornos con “color-filled”, 'image' y 'demo(graphics).

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 170/344
170
Ejemplo: Mapa topográfico (ejemplo disponible en el Help de R, paquete: base):
data("volcano")
rx <- range(x <- 10*1:nrow(volcano))
ry <- range(y <- 10*1:ncol(volcano))
ry <- ry + c(-1,1) * (diff(rx) - diff(ry))/2
opar <- par(pty = "s")
plot(x = 0, y = 0,type = "n", xlim = rx, ylim = ry,xlab = "", ylab = "")
u <- par("usr")
rect(u[1], u[3], u[2], u[4], border = "black")
contour(x, y, volcano,lty = "solid", add = TRUE,vfont = c("sans serif",
"plain"))
title("Mapa topográfico de Maunga Whau", font = 4)
abline(h = 200*0:4, v = 200*0:4,lty = 2, lwd = 0.1)
par(opar)
Figura 6.2: Aquí observamos una aplicación no estadística pero bastante útil de
la función `contour' en el trazo de mapas topográficos.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 171/344
171
6.9. Función image
Esta función crea un grid de rectángulos en escala de gris o coloreados con los colores
correspondientes a los valores en `z'. Puede usarse para presentar imágenes
de datos aka tridimensionales o espaciales.
Las funciones `heat.colors', `terrain.colors' y `topo.colors' crean el espectro de calor (rojo a
blanco) y esquemas de colores topográficos apropiados para presentar datos ordenados, con
`n' dando el número de colores deseados.
image(x, ...) image.default(x, y, z, zlim, xlim, ylim, col =
heat.colors(12), add = FALSE, xaxs = "i", yaxs = "i", xlab, ylab,
breaks, oldstyle = FALSE, ...)
Argumentos:
• x,y: Ubicaciones de las líneas del grid en las cuáles los valores en `z' son medidos.
Estos deben estar en orden ascendente. Por defecto, son usados valores igualmente
espaciados de 0 a 1. Si `x' es una lista, sus componentes `x$x' y `x$y' son usados para
`x' e `y', respectivamente. Si la lista tiene componente `z' ésta es usada para z'.
• z: Una matriz que contiene los valores a ser graficados (valores faltantes son
permitidos). Notar que `x' puede usarse en vez de `z' por conveniencia.
• zlim: Los valores `z' mínimo y máximo para los cuales los colores van a ser
graficados. Cada uno de los colores dados será usado para colorear un intervalo
igualmente espaciado de este rango. Los puntos medios de los intervalos cubren el
rango, de modo que los valores por fuera del rango serán graficados.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 172/344
172
• xlim, ylim: Rangos para los valores `x' y `y' graficados, por defecto es el rango de
valores finitos de `x' y `y'.
• col: Una lista de colores como los generados por las funciones `rainbow',
`heat.colors', topo.colors', terrain.colors' o similares.
• add: Argumento lógico; si es `TRUE', adiciona al gráfico actual activo (y los
siguientes argumentos son ignorados). Esto es raramente útil debido a que image'
pinta sobre gráficos existentes.
• xaxs, yaxs: Estilo de los ejes `x' y `y'. Por defecto es `"i"' el cual es apropiado para
imágenes. Ver `par'.
• xlab, ylab: Cadena de caracteres dando las etiquetas para los ejes `x' y `y'. Por
defecto usa `call names' de `x' o `y', o `""' si no fue especificado.
• breaks: un conjunto de puntos de corte para los colores: deben darse uno o más puntos de corte que colores.
• oldstyle: Argumento lógico. Si es `TRUE' los puntos medios de los intervalos de
colores están igualmente espaciados, y `zlim[1]' y `zlim[2]' eran tomados como
puntos medios. El valor por defecto actual es tener intervalos de colores de igual
longitud entre los límites.
• ...: Pueden usarsa parámetros gráficos para `plot'.
Detalles: La longitud de `x' debería ser igual a `nrow(x)+1' o `nrow(x)'. En el primer caso
`x' especifica los límites entre celdas; en el segundo caso, `x' especifica los puntos medios

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 173/344
173
de las celdas. Un razonamiento similar se aplica a `y'. Probablemente sólo tenga sentido
especificar los puntos medios de un grid igualmente espaciado. Si se especifica sólo una
fila o columna y la longitud de `x' o `y', el área de usuario completa es llenada en la
dirección especificada.
Si `breaks' es especificado entonces `zlim' no es usado y el algoritmo utiliza `cut', as\'\i\ los
intervalos son cerrados a la derecha y abiertos a la izquierda excepto para el intrvalo
másinferior.
Autor: Basada en una función de Thomas Lumley [email protected].
Ver también: `contour', heat.colors', topo.colors', terrain.colors', rainbow', hsv', par'.
Ejemplos:
x <- y <- seq(-4*pi, 4*pi, len=27)
r <- sqrt(outer(x^2, y^2, "+"))
layout(rbind(c(1,1,2,2),c(0,3,3,0)))
image(z = z <-cos(r^2)*exp(-r/6), col=gray((0:32)/32),
main=expression(paste("Grid de la función",sep=" ",z ==cosr^2 *e^ -r/6 )
))
image(z, main=expression(paste("Grid de la función",sep=" ",z ==cosr^2 *
e^ -r/6 )), xlab="Líneas de Contorno incluidas")
contour(z, add = TRUE, drawlabels = FALSE)
data(volcano)
x <- 10*(1:nrow(volcano))
y <- 10*(1:ncol(volcano))
image(x, y, volcano, col = terrain.colors(100), axes = FALSE)
contour(x, y,volcano,levels=seq(90, 200, by=5),add = TRUE,col = "peru")
axis(1, at = seq(100, 800, by = 100))

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 174/344
174
axis(2, at =seq(100, 600, by = 100))
box()
title(main = "Maunga Whau Volcano\nMapa Topográfico",cex.main=0.9)
Figura 6.3: `image' y `contour' permiten realizar gráficas especiales tanto
estadísticas como de otra índole como se observa en estos tres gráficos

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 175/344
175
6.10. Función matplot
La función matplot grafica las columnas de una matriz contra las columnas de otra, tal que
la primera columna de x es graficada contra la primera columna de y, la segunda columna
de x contra la segunda de y, etc. Sin embargo si una matriz tiene pocas columnas, éstas son
recicladas. El gráfico se obtiene como sigue:
matplot(x, y, type = "p", lty = 1:5, lwd = 1, pch = NULL, col =
1:6, cex = NULL, xlab = NULL, ylab = NULL, xlim = NULL, ylim =
NULL,..., add = FALSE, verbose = getOption("verbose"))
Argumentos:
• x,y: Vectores o matrices de datos a graficar. Es imprescindible que el número de
filas coincida. Si uno de los dos objetos (x o y) falta, el dado es tomado como y, y se
utiliza como x un vector de 1:n. Valores NA son permitidos.
• type: Un vector para indicar el tipo de gráfico para cada columna de y (como se vió
con la función plot), por defecto es p.
• lty,lwd: Vectores para indicar los tipos y anchos de líneas para cada columna de y.
• pch: Caracter o vector de caracteres o enteros para definir los “ plotting characters”,
por cada columna de y second, etc. The default is the digits (1 through 9, 0).
• col: Vector de colores, aunque si no se especifica los colores son usados cíclicamente.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 176/344
176
• cex: Vector de dimensiones del factor de expansión de caracteres, es usado
cíclicamente.
• xlab, ylab: Títulos de ejes x e y.
• xlim, ylim: Rangos para los ejes x e y.
• ...: Parámetros gráficos adicionales (ver “ par ”)
• add: Argumento lógico. Si es TRUE, el gráfico es agregado a un gráfico previo. Se
debe garantizar que los rangos de los ejes en ambos gráficos sean los mismos.
• verbose: Argumento lógico. Si es “TRUE”, escribe una linea de lo que hace la
función, por ejemplo:
matplot: doing 5 plots with col= ("1" "2" "2" "4" "4") pch=("1" "2"
"3" "4" "5") ...
#Supongamos dos series de datos
#de longitud 40:
x1<-1:40
x2<-rnorm(40)
x3<-rexp(40)
aux<-cbind(x2,x3)
#Grafiquemos las dos series en el mismo plano:
matplot(x1,aux,type="l",col=1:2,lty=1:2,xlab="tiempo",
ylab="",yaxt="n",main="Gráfica de dos series
simultáneas\nmediante matplot")
legend(locator(1),c("serie 1","serie 2"),col=1:2,bty="n",lty=1:2)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 177/344
177
Figura 6.4: Podemos graficar varias curvas en un mismo plano utilizando la
función matplot y adicionalmente agregar leyendas mediante la función
legend
Una función de utilidad es par(). Esta permite presentar más de un gráfico en la misma pantalla o en la misma hoja. Su utilización es simple:
> par(mfrow=c(2,2))
Con el anterior comando estamos indicando que hasta cuatro gráficas van a aparecer en la
pantalla o en la hoja.
Ejemplo:
Consideremos el conjunto de datos que hace referencia a las pruebas del ICFES. Si estamos
interesados en una comparación por sexos podemos pensar en un análisis gráfico como el
siguiente. Para obtenerlo asumamos que tenemos nuestro archivo de datos en formato

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 178/344
178
ASCII guardado en el subdirectorio \it datos del disco duro. Una vez estamos en R
corremos los siguientes comandos:
> icfes<-scan(“c:/datos/icfes.dat”,
type=list(“ “,1, 1, 1, 1, 1, 1, 1, 1, 1, 1,” “))
> win.graph()
> par(mfrow=c(2,2))
> boxplot(split(icfes[[3]],split[[1]]))
> boxplot(split(icfes[[4]],split[[1]]))
> boxplot(split(icfes[[5]],split[[1]]))
> boxplot(split(icfes[[6]],split[[1]]))
6.11. Imprimiendo Gráficos
Si queremos imprimir un gráfico generalmente procedemos en dos pasos:
1. Creamos un archivo con el gráfico
2. Posterior a nuestra sesión R imprimes el archivo con el gráfico.
Para crear el archivo con el gráfico, el R posee la función postscript() , esta función
crea un archivo para ser impreso posteriormente en una impresora con lenguaje postscript.
Trabajando bajo Windows la impresión puede realizarse directamente de la pantalla,
escogiendo la opción de impresión.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 179/344
179
Capítulo 7: Gráficos para una variable
Los siguientes son algunas funciones que permiten graficar una variable: boxplot(),hist(), stem(), qqnorm().
7.1. Función hist: Histogramas
Como argumentos esta función recibe un vector con datos. Además, opcionalmente, puedeentrarse como argumento el número de barras a ser graficadas o en su defecto el número de
clases se determina con la fórmula de Sturges.
Nota: Los programas de computador usualmente ajustan los histogramas
automáticamente, pero el programa debe permitirnos variar el histograma. Si usted posee
un programa que no le permita hacer cambios, cambie de programa.
En R el comando básico con el cual se obtiene este tipo de gráfico es “hist”, veamos:
hist(x, ...)
hist.default(x, breaks, freq = NULL, probability = !freq,
include.lowest = TRUE,
right = TRUE, col = NULL, border = par("fg"),
main = paste("Histogram of" , xname),
xlim = range(breaks), ylim = NULL,
xlab = xname, ylab,axes = TRUE, plot = TRUE, labels = FALSE,
nclass = NULL, ...)
Los argumentos de este comando son:

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 180/344
180
• x: Vector de valores para el que se construye el histograma.
• breaks: Puede ser un valor con el cual se indica el número aproximado de clases o
un vector cuyos elementos indican los puntos límites entre las clases o intervalos.
• freq: argumento lógico; si se especifica como “TRUE”, el histograma representará
las frecuencias absolutas o conteo de datos en cada clase; si se especifica
como“FALSE”, se reprentarán las frecuencias relativas. Por defecto, este argumento
toma el valor de “TRUE” siempre y cuando los intervalos sean de igual ancho.
• probability: Especifica un alias para “!freq”, para compatibilidad con S.
• include.lowest: Argumento lógico; si se especifica como “TRUE”, un “x[i]” igual a
los equal a un valor “ breaks” se incluirá en la primera barra, si el argumento “right
=TRUE”, o en la última en caso contrario.
• right: Argumento lógico; si es “TRUE”, los intervalos son abiertos a la izquierda -cerrados a la derecha (a,b]. Para la primera clase o intervalo si
“include.lowest=TRUE” el valor más pequeño de los datos será incluido en éste. Si
es “FALSE” los intervalos serán de la forma [a,b) y el argumento
“include.lowest=TRUE” tendrá el significado de incluir el “más alto”.
• col: Para definir el color de las barras. Por defecto, “ NULL” produce barras sin
fondo.
• border: Para definir el color de los bordes de las barras.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 181/344
181
• plot: Argumento lógico. Por defecto es “TRUE”, y el resultado es el gráfico del
histograma; si se especifica como “FALSE” el resultado es una lista de conteos por
cada intervalo.
• labels: Argumento lógico o carácter. Si se especifica como “TRUE” coloca
etiquetas arriba de cada barra.
• nclass: Argumento numérico (entero). Para compatibilidad con S, “nclass=n” es
equivalente a “ breaks=n”.
• ...: Parámetros gráficos adicionales a “title” y “axis”.
hist(datos)
hist(datos,nclass=5)
Ejemplo: Para los datos de los tiempos de la media maratón de CONAVI:
maraton<-scan()1: 10253 10302 10307 10309 10349 10353 10409 10442 10447 10452 10504 10517
13: 10530 10540 10549 10549 10606 10612 10646 10648 10655 10707 10726 10731
25: 10737 10743 10808 10833 10843 10920 10938 10949 10954 10956 10958 11004
37: 11009 11024 11037 11045 11046 11049 11104 11127 11205 11207 11215 11226
49: 11233 11239 11307 11330 11342 11351 11405 11413 11438 11453 11500 11501
61: 11502 11503 11527 11544 11549 11559 11612 11617 11635 11655 11731 11735
73: 11746 11800 11814 11828 11832 11841 11909 11926 11937 11940 11947 11952
85: 12005 12044 12113 12209 12230 12258 12309 12327 12341 12413 12433 12440
97: 12447 12530 12600 12617 12640 12700 12706 12727 12840 12851 12851 12937
109: 13019 13040 13110 13114 13122 13155 13205 13210 13220 13228 13307 13316121: 13335 13420 13425 13435 13435 13448 13456 13536 13608 13612 13620 13646
133: 13705 13730 13730 13730 13747 13810 13850 13854 13901 13905 13907 13912
145: 13920 14000 14010 14025 14152 14208 14230 14344 14400 14455 14509 14552
157: 14652 15009 15026 15242 15406 15409 15528 15549 15644 15758 15837 15916
169: 15926 15948 20055 20416 20520 20600 20732 20748 20916 21149 21714 23256

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 182/344
182
181:
Read 180 items
horas<-maraton%/%10000min<-(maraton-horas*10000)%/%100
seg<-maraton-horas*10000-min*100
Tiempos<-horas+min/60+seg/3600
> Tiempos
[1] 1.048056 1.050556 1.051944 1.052500 1.063611 1.064722 1.069167 1.078333
[9] 1.079722 1.081111 1.084444 1.088056 1.091667 1.094444 1.096944 1.096944
[17] 1.101667 1.103333 1.112778 1.113333 1.115278 1.118611 1.123889 1.125278
[25] 1.126944 1.128611 1.135556 1.142500 1.145278 1.155556 1.160556 1.163611
[33] 1.165000 1.165556 1.166111 1.167778 1.169167 1.173333 1.176944 1.179167
[41] 1.179444 1.180278 1.184444 1.190833 1.201389 1.201944 1.204167 1.207222[49] 1.209167 1.210833 1.218611 1.225000 1.228333 1.230833 1.234722 1.236944
[57] 1.243889 1.248056 1.250000 1.250278 1.250556 1.250833 1.257500 1.262222
[65] 1.263611 1.266389 1.270000 1.271389 1.276389 1.281944 1.291944 1.293056
[73] 1.296111 1.300000 1.303889 1.307778 1.308889 1.311389 1.319167 1.323889
[81] 1.326944 1.327778 1.329722 1.331111 1.334722 1.345556 1.353611 1.369167
[89] 1.375000 1.382778 1.385833 1.390833 1.394722 1.403611 1.409167 1.411111
[97] 1.413056 1.425000 1.433333 1.438056 1.444444 1.450000 1.451667 1.457500
[105] 1.477778 1.480833 1.480833 1.493611 1.505278 1.511111 1.519444 1.520556
[113] 1.522778 1.531944 1.534722 1.536111 1.538889 1.541111 1.551944 1.554444
[121] 1.559722 1.572222 1.573611 1.576389 1.576389 1.580000 1.582222 1.593333[129] 1.602222 1.603333 1.605556 1.612778 1.618056 1.625000 1.625000 1.625000
[137] 1.629722 1.636111 1.647222 1.648333 1.650278 1.651389 1.651944 1.653333
[145] 1.655556 1.666667 1.669444 1.673611 1.697778 1.702222 1.708333 1.728889
[153] 1.733333 1.748611 1.752500 1.764444 1.781111 1.835833 1.840556 1.878333
[161] 1.901667 1.902500 1.924444 1.930278 1.945556 1.966111 1.976944 1.987778
[169] 1.990556 1.996667 2.015278 2.071111 2.088889 2.100000 2.125556 2.130000
[177] 2.154444 2.196944 2.287222 2.548889
par(mfrow=c(2,2))
hist(Tiempos,nclass=2,main="",xlab='Tiempos-horas',ylab='frecuencias')
mtext("(A)",side=1,line=4,font=1)hist(Tiempos,nclass=4,main="",xlab='Tiempos-horas',ylab='frecuencias')
mtext("(B)",side=1,line=4,font=1)
hist(Tiempos,nclass=8,main="",xlab='Tiempos-horas',ylab='frecuencias')
mtext("(C)",side=1,line=4,font=1)
hist(Tiempos,nclass=16,main="",xlab='Tiempos-horas',ylab='frecuencias')
mtext("(D)",side=1,line=4,font=1)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 183/344
183
puntos<-c(quantile(Tiempos,probs=c(0,0.5,1)))
puntos2<-c(quantile(Tiempos,probs=c(0,0.25,0.5,0.75,1)))
puntos3<-c(quantile(Tiempos,probs=seq(0,1,by=0.10)))puntos4<-c(quantile(Tiempos,probs=seq(0,1,by=0.05)))
puntos
0% 50% 100%
1.048056 1.384306 2.548889
puntos2
0% 25% 50% 75% 100%
1.048056 1.201806 1.384306 1.625000 2.548889
puntos3
0% 10% 20% 30% 40%
1.048056 1.111833 1.168889 1.233556 1.29488950% 60% 70% 80% 90%
1.384306 1.498278 1.580667 1.653778 1.904694
100%
2.548889
puntos4
0% 5% 10% 15% 20% 25% 30% 35%
1.048056 1.081042 1.111833 1.141458 1.168889 1.201806 1.233556 1.260569
40% 45% 50% 55% 60% 65% 70% 75%
1.294889 1.327403 1.384306 1.435458 1.498278 1.539667 1.580667 1.625000
80% 85% 90% 95% 100%1.653778 1.735625 1.904694 2.018069 2.548889
hist(Tiempos,breaks=puntos,freq=FALSE,ylim=c(0,2),labels=TRUE,main="",
ylab="densidad")
mtext("(A)",side=1,line=4,font=1)
hist(Tiempos,breaks=puntos2,freq=FALSE,ylim=c(0,2),labels=TRUE,main="",
ylab="densidad")
mtext("(B)",side=1,line=4,font=1)
hist(Tiempos,breaks=puntos3,freq=FALSE,ylim=c(0,2),main="",
ylab="densidad")
mtext("(C)",side=1,line=4,font=1)hist(Tiempos,breaks=puntos4,freq=FALSE,ylim=c(0,2),main="",
ylab="densidad")
mtext("(D)",side=1,line=4,font=1)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 184/344
184
Nota: En estos histogramas, las alturas corresponden a las intensidades (frec.
relativa/long. intervalo). Por tanto, el área de cada rectángulo da cuenta de las frecuencias
relativas. Para el caso (A) ambos intervalos tienen igual área y cada uno contiene 50 \% de
los datos. esto puede verificarse así:
Intensidad primera clase=1.4869888=0.5/(1.384306-1.048056)
Intensidad segunda clase=0.4293381=0.5/(2.548889-1.384306)
Figura 7.1: Se muestra la distribución del tiempo utilizado por los atletas masculinos
clasificados en el grupo élite en la media maratón de CONAVI. El histograma A tiene solo 2
barras. El gráfico B, con 4 barras,y el C, con 8 barras, muestra más claramente la asimetría
(este es el que la mayoría de los programas produce por defecto, ya que la regla de Sturges,
para este conjunto de datos aproxima a 8 barras). Si consideramos más barras por ejemplo 16,
como tenemos en D, se refina más la información y empezamos a notar multimodalidad.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 185/344
185
Figura 7.2: La selección de histogramas con barras de amplitud variable no es recomendada
por diversos autores, pero si lo hacemos con cuidado podemos obtener gráficos muy
ilustrativos. Se seleccionaron amplitudes de tal forma que cada barra posea el mismo número
de observaciones. El histograma A tiene barras que contienen el 50% de las observaciones, el
B con 25%, el C con 10% y el D con 5%. La multimodalidad es más clara.
7.2. Función boxplot
El boxplot es obtenido mediante la siguiente función:
boxplot(x, ...)
boxplot.default(x,...,range=1.5,width=NULL,varwidth=FALSE,notch=FALSE,
names, boxwex = 0.8, data = parent.frame(), plot = TRUE, border =
par("fg"), col=NULL, log = "", pars =NULL,horizontal=FALSE,add= FALSE)
boxplot.formula(formula, data = NULL, subset, na.action, ...)
Argumentos:

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 186/344
186
• x, ...: Los datos que van a ser graficados con el boxplot. Puede ser un conjunto de
vectores separados, cada uno correspondiendo a un boxplot componente o una lista
que contiene a tales vectores. Alternativamente, una especifiacón de la forma “x ~ g”
puede ser dada para indicar que las observaciones en el vector "x” van a ser
agrupadas de acuerdo a los niveles del factor “g”. En este caso, el argumento “data”
puede usarse para par valores para la variables en la especificación.`NA's son
permitidos en los datos.
• range: Determina la extensión de los “whiskers” de la caja. Si es positivo, “los
whiskers” se extienden hasta el dato más extremo, el cual no es más que el “rango”
por rango intercuartílico de la caja. Un valor de cero hace que los “whiskers” se
extiendan hasta los datos extremos.
• width: Un vector que da los anchos relativos de las cajas.
• varwidth: Si es “TRUE”, las cajas son dibujadas con anchos proporcionales a las
raíces cuadradas del número de observaciones en los grupos.
• notch: Si es “TRUE”, una cuña es dibujada a cada lado de las cajas. Cuando las
cuñas de dos gráficos de caja no se traslapan, entonces las medianas son
significativamente diferentes a un nivel del 5%.
• names: Un grupo de etiquetas a ser impresas debajo de cada boxplot.
• boxwex: Un factor de escala a ser aplicado a todas las cajas. Cuando sólo hay unos
pocos grupos, la apariencia del gráfico puede mejorarse haciendo las cajas más
angostas.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 187/344
187
• data: “data.frame”, “list”, o “environment” en el cual los nombres de las variables
son evaluados cuando “x” es una fórmula.
• plot: Si es “TRUE” (por defecto) entonces se produce el gráfico. De lo contrario, se
producen los resúmenes de los boxplots.
• border: Un vector opcional de colores para las líneas de las cajas y debe ser de
longitud igual al número de gráficos.
• col: Si se especifica, los colores que contiene serán usados en el cuerpo de las cajas.
• log: Para indicar si las coordenadas “x” o “y” o serán graficadas en escala
logarítmica.
• pars: Los parámetros gráficos pueden ser pasados como argumentos para el boxplot.
• horizontal: Si es “FALSE” (por defecto) los boxplots son dibujados verticalmente.
• add: Si es “TRUE” agrega un boxplot al gráfico actual.
• formula: Una fórmula tal como “y ~ x”.
• data: Un data.frame (o lista) del cual las variables en “fórmula” serán tomadas.
• subset: Un vector opcional para especificar un subconjunto de observaciones a ser
usadas en el proceso de ajuste.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 188/344
188
• na.action: Una función la cual indica lo que debería pasar cuando los datos
contienen “ NA's”.
En el siguiente ejemplo, se grafican simultáneamente los datos sobre el número de
pasajeros por viaje registrados entre octubre 1 de 1997 a agosto 30 de 1999, de la ruta
Aranjuez - Anillo, en donde un viaje constituye el recorrido de salida y regreso de un bus
desde la terminal:
viajes97<-matrix(scan('a:/pasaje97.txt'),ncol=4,byrow=T)
viajes98<-matrix(scan('a:/pasaje98.txt'),ncol=4,byrow=T)
viajes99<-matrix(scan('a:/pasaje99.txt'),ncol=4,byrow=T)
pasajeros.viaj97<-matrix((viajes97[,4]/viajes97[,3]),ncol=1)
pasajeros.viaj98<-matrix((viajes98[,4]/viajes98[,3]),ncol=1)
pasajeros.viaj99<-matrix((viajes99[,4]/viajes99[,3]),ncol=1)
anos<-
c(rep(97,nrow(viajes97)),rep(98,nrow(viajes98)),rep(99,nrow(viajes99)))
pasajeros.viaje<-
rbind(pasajeros.viaj97,pasajeros.viaj98,pasajeros.viaj99)
boxplot(split(pasajeros.viaje,anos),main='Promedio de pasajeros transportados\nporviajes- Año',
xlab='años', ylab='número por viaje')
#otraforma:
pasajeros97<-cbind(rep(97,nrow(viajes97)),pasajeros.viaj97)
pasajeros98<-cbind(rep(98,nrow(viajes98)),pasajeros.viaj98)
pasajeros99<-cbind(rep(99,nrow(viajes99)),pasajeros.viaj99)
pasajeros<-rbind(pasajeros97,pasajeros98,pasajeros99)
boxplot(pasajeros[,2]~pasajeros[,1], main='Promedio de pasajerostransportados\npor viajes - Año', xlab='años',ylab='número por viaje')

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 189/344
189
Figura 7.3: Podemos comparar las distribuciones del número de pasajeros por
viaje durante tres años. Se puede apreciar simultáneamente la tendencia y la
dispersión.
7.3. Función stem
Nos permite obtener el gráfico de tallo y hoja. Este gráfico fue propuesto por Tukey (1977)
y a pesar de no ser un gráfico para presentación definitiva se utiliza a la vez que el analista
recoge la información ve la distribución de los mismos. Estos gráficos son fáciles de
realizar a mano y se usan como una forma rápida y no pulida de mirar los datos.
Qué nos muestra?
1. El centro de la distribución.
2. La forma general de la distribución

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 190/344
190
Simétrica Si las porciones a cada lado del centro son imágenes espejos de las otras.
Sesgada a la izquierda Si la cola izquierda (los valores menores) es mucho más larga que
los de la derecha (los valores mayores)
Sesgada a la derecha Opuesto a la sesgada a la izquierda.
3. Desviaciones marcadas de la forma global de la distribución.
Outliers Observaciones individuales que caen muy por fuera del patrón general delos datos.
gaps Huecos en la distribución
Ventajas de gráfico: Muy fácil de realizar y puede hacerse a manos.
Las desventajas son:
1. El gráfico es tosco y no sirve para presentaciones definitivas.
2. Funciona cuando el número de observaciones no es muy grande.
3. No permite comparar claramente diferentes poblaciones.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 191/344
191
7 677 116 8
6 005 56666777899995 0000000112333444444 55555556667777888899994 003343 88----+----+----+----+--
Datos de velocidades registradas con radar
Fecha de observacion: Sept. 10, 1994
7.4. Función qqnorm : Gráficos cuantil - cuantil
Esta es una función genérica que por defecto produce un Q-Q Plot Normal para los valores
en `y'. Adicionalmente, la función qqline agrega una línea al anterior gráfico cuando es
normal, la cual pasa a través del primer y tercer cuartil. La función qqplot produce un
Q-Q Plot de dons conjuntos de datos. En cualquiera de las tres anteriores funciones pueden
especificarse parámetros gráficos (ver par).
qqnorm(y, ...)
qqnorm(y, ylim, main = "Normal Q-Q Plot", xlab ="Theoretical Quantiles",
ylab = "Sample Quantiles", plot.it =TRUE, ...)
qqline(y, ...)
qqplot(x, y, plot.it = TRUE, xlab =deparse(substitute(x)), ylab =
deparse(substitute(y)), ...)
Argumentos:
• x: La primera muestra para `qqplot'.
• y: La segunda o la única muestra.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 192/344
192
• xlab, ylab, main: Etiquetas de ejes y título del gráfico.
• plot.it: Argumento lógico. ¿Debe graficarse el resultado?
• ylim, ...: Parámetros gráficos.
Ver: par
nf<-layout(rbind(c(0,1,1,0),c(0,2,2,0)))
y <- rt(200, df = 5)qqnorm(y)
qqline(y, col = 2)
qqplot(y, rt(300, df = 5),main="Q-QPlot")

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 193/344
193
Figura 7.4: Gráficos obtenidos mediante las funciones qqnorm,
qqline, qqplot

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 194/344
194
Capítulo 8: Gráficos Multivariables
R provee muchas funciones para el caso multivariable. pairs(), plot(),
faces(), stars().
8.1. Función pairs : Matrices de Dispersión
Las matrices de dispersión proporcionan un método simple de presentar las relaciones entre pares de variables, y es la versión múltiple de plot(). Consiste en una matriz donde cada
entrada presenta un gráfico de dispersión sencillo. Un inconveniente es que si tenemos
muchas variables el tamaño de cada entrada se reduce demasiado impidiendo ver con
claridad las relaciones entre los pares de variables.
La celda (i,j) de una matriz de dispersión contiene el scatterplot de la columna i versus la
columna j de la matriz de datos. Este gráfico puede obtenerse mediante:
pairs(x, ...)
pairs.default(x, labels = colnames(x), panel = points, ...,
lower.panel = panel, upper.panel = panel,
diag.panel = NULL, text.panel = textPanel,
label.pos = 0.5 + has.diag/3, cex.labels = NULL,
font.labels = 1, row1attop = TRUE)
Por ejemplo:
pies<-matrix(scan("c:/graficosr/graficos/dedos.dat"),ncol=6,byrow=T)
#x1:longitud max de la huella #x2:amplitud max de la huella
#x3:amplitud max del talon #x4:longitud max del dedo mayor
#x5:amplitud max del dedo mayor #x6:sexo 1: hombre, 0: mujer

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 195/344
195
pairs(pies,labels=c("x1","x2","x3","x4","x5","x6"), main='Matriz
de dispersión\n \npara medidas de pies,cex.main=0.8)
Figura 8.1: Esta gráfica corresponde a los cruces de las variables medidas en los pies de varias personas.
Los argumentos de esta función corresponden a:
• x: Las coordenadas de puntos dados como columnas de una matriz.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 196/344
196
• labels: Un vector para identificar los nombres de las columnas. Por defecto toma los
nombres de columnas de la matriz x.
• panel: Para especificar una función: function(x,y,...), a ser usada para
determinar los contenidos de los paneles o gráaficos componentes. Por defecto es
points, indicando que se graficarán los puntos de los pares de datos. También es
posible utilizar aquí otras funciones prediseñadas.
• ...: Indica que es posible agregar otros parámetros gráficos, tales como pch y col, con
los cuales puede especificarse un vector de símbolos y colores a ser usados en los
scatterplots.
• lower.panel, upper.panel: Para especificar funciones por separado a ser empleados
en los paneles abajo y arriba de la diagonal respectivamente.
• diag.panel: Es opcional. Permite que una función: function(x, ...) sea
empleada para los paneles de la diagonal.
• text.panel: Es opcional. Permite que una función: function(x, y, labels,
cex, font,...) sea aplicada a los paneles de la diagonal.
• label.pos: Para especificar la posición y de las etiquetas en el text panel.
• cex.labels, font.labels: Parámetros para la expansión de caracteres y fuentes a usar en las etiquetas de las variables.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 197/344
197
• row1attop: Parámetro lógico con el cual se especifica si el gráfico para especificar
si el diseño lucirá como una matriz con su primera fila en la parte superior o como un
gráfico con fila uno en la base. Por defecto es lo primero.
Autores:
• Enhancements for R 1.0.0 contributed by Dr. Jens
• Oehlschlaegel-Akiyoshi and R-core members.
8.2. Función plot : Gráficos de Dispersión
Es tal vez el más antiguo de los gráficos multivariables. Está limitado a la presentación de
dos variables, aunque se pueden realizar modificaciones de tal forma que nos permita
incluir más.
En R obtenemos este gráfico mediante la función plot:
plot(x, ...)
plot(x, y, xlim=range(x), ylim=range(y), type="p",main, xlab, ylab, ...)
plot(y ~ x, ...)
Donde:
• x: Objeto que contiene las coordenadas de los puntos del gráfico.
• y: Las coordenadas y de los puntos, sin embargo resulta innecesario cuando el
objeto x tiene la estructura apropiada para dar ambas coordenadas

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 198/344
198
• xlim, ylim: Los rangos para los ejes x e y respectivamente.
• type: Para especificar el tipo de gráfico, así :
1. “ p” para puntos, lo cual es por defecto
2. “l” para trazar líneas entre los puntos
3. “ b” para puntos y líneas
4. “o” para puntos y líneas superpuestos
5. “h” para un histograma pero en vez de rectángulos traza líneas verticales
6. “s” Para gráficos en escala
7. “S” Otros gráficos en escala
8. “n” Para que no aparezca el gráfico.
• main: Para titular al gráfico.
• xlab, ylab: Para etiquetar a los ejes.
• ...: Otros parámetros gráficos.
En el argumento “type” se especifica igual a “ p” para representar las observaciones por
puntos, aunque este es el valor por defecto y por tanto no es necesario especificarlo. En el
siguiente ejemplo se observa el uso de esta función:
preciosr9<-matrix(scan("c:/graficosr/graficos/r9.txt"),ncol=13,byrow=T)
ano<-preciosr9[1,]
valor<-preciosr9[2,]
plot(ano,valor,main='Precio de Oferta Renault 9 vs.
Año',xlab='año',ylab='valor',pch=19)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 199/344
199
Figura 8.2: Esta gráfica presenta información sobre el precio de oferta de
carros Renault 9 vs. el año del carro aparecidos en los avisos clasificados de un
periódico local.
8.3. Función stars: Gráfico de Estrellas
Supóngase un conjunto de datos multivariados ordenados matricialmente, de manera que
las filas corresponden a las observaciones y p columnas, una por cada variable. En dos
dimensiones se pueden construir círculos (uno por cada observación multivariada) de un
radio prefijado, con p rayos igualmente espaciados emanando del centro de cada círculo.
Las longitudes de los rayos son proporcionales a los valores de las variables en cada
observación. Los extremos de los rayos pueden conectarse con segmentos de líneas rectas
para formar una estrella. Con cada observación representada por una estrella, éstas pueden
ser agrupadas según sus similitudes. Es conveniente estandarizar las observaciones, caso
en el cual pueden resultar valores negativos. (Johnson, Wichern (1998)).
En R la función correspondiente es:

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 200/344
200
stars(x, full = TRUE, scale = TRUE, radius = TRUE, labels =
dimnames(x)[[1]], locations = NULL, xlim = NULL, ylim = NULL,
len= 1, colors = NULL, key.loc = NULL, key.labels = NULL, key.xpd =TRUE, draw.segments = FALSE, axes = FALSE, cex = 0.8, lwd = 0.25,...)
Los argumentos son:
• x: La matriz de datos. Un gráfico de estrella será producido por cada fila de “x”.
Los valores faltantes serán tratados como si fueran cero.
• full: Argumento lógico: Si es “TRUE”, Los gráficos ocuparán un círculo completo.
De lo contrario sólo ocuparán un semicírculo superior.
• scale: Argumento lógico: Si es “TRUE”, las columnas de la matriz de datos serán
escaladas independientemente, de modo que el valor máximo en cada columna toma
el valor de 1 y el mínimo de 0. Si es “FALSE”, la presunción es que los datos ya han
sido escalados por algún otro algoritmo al rango [0,1].
• radius: Argumento lógico: Si es “TRUE”, dibujará el radio correspondiente a cada
variable.
• labels: Un vector de caracteres para etiquetar cada gráfico. Por defecto se tiene
especificado que use los nombres de las filas de la matriz de datos.
• locations: Corresponde a una matriz de dos columnas con las coordenadas x e yusadas para ubicar cada gráfico de estrella. Si locations es “ NULL”, es decir, no es
pre especificado, los gráficos son colocados en un arreglo rectangular.
• xlim: Es un vector para especificar el rango de las coordenadas x a graficar.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 201/344
201
• ylim: Es un vector con el rango de coordenadas y a graficar.
• len: Factor de escala para la longitud del radio de los segmentos.
• colors: Vector de valores enteros, cada uno de los cuales especifica un color para
uno de los segmentos. Es ignorado si “draw.segments = FALSE”
• key.loc: Es un vector con las coordenadas x e y para ubicar la unidad que da las
claves que identifican las variables en cada start plot.
• key.labels: Es un vector de caracteres para etiquetar los segmentos de la unidad de
claves que identifica las variables en cada start plot. Si se omite, la segunda
componente de dimnames(x) es usada, si está disponible.
• key.xpd: Anexar un conmutador para la unidad de claves (dibujar y etiquetar), ver
“ par(“xpd”)”.
• draw.segments: Argumento lógico. Si es “TRUE” dibuja un diagrama de segmento.
• axes: Argumento lógico: Si es “TRUE” se agregan ejes al gráfico.
• cex: Factor de expansión de caracter para las etiquetas.
•
lwd: Ancho de línea a ser usado para dibujar.
• ...: Argumentos adicionales, pasadas a la primera llamada de “ plot()” .
Autor: Thomas S. Dye

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 202/344
202
Ejemplos:
datos.Hombres<-matrix(scan('a:/Acoplah.dat'),ncol=12,byrow=T)
datos.Mujeres<-matrix(scan('a:/Acoplam.dat'),ncol=12,byrow=T)
datos<-rbind(datos.Hombres,datos.Mujeres)
colnames(datos.Hombres)<-c("Sexo","Masa Corp","Per muslo
medio","Anch deltoideo","Per Abdom", "Per Cadera","Anch
bideltoideo","Estatura","Alt Acromial Parado", "Pliegue Cutaneo
Sub","Pliegue Cutaneo Trip","edad")
colnames(datos.Mujeres)<-c("Sexo","Masa Corp","Per muslo medio",
"Anch deltoideo","Per Abdom","Per Cadera","Anch bideltoideo",
"Estatura","Alt Acromial Parado","Pliegue Cutaneo Sub","Pliegue
Cutaneo Trip","edad")
nombres1<-c(paste("hombre",1:100,sep=""))
nombres2<-c(paste("mujer",1:100,sep=""))
rownames(datos.Hombres)<-nombres1
rownames(datos.Mujeres)<-nombres2
stars(datos.Hombres[1:12,2:12],key.loc=c(11,3),key.labels =
abbreviate(colnames(datos.Hombres)[2:12]), main='Stars Plots-Datos
antropométricos (hombres)\nPoblación laboral Colombiana')
stars(datos.Mujeres[1:12,2:12],key.loc=c(11,3),key.labels =
abbreviate(colnames(datos.Mujeres)[2:12]), main='Stars Plots-Datos
antropométricos (mujeres)\nPoblación laboral Colombiana')
stars(datos.Hombres[1:12,2:12],key.loc=c(11,3),key.labels =
abbreviate(colnames(datos.Hombres)[2:12]), main='Stars Plots-Datos
antropométricos (hombres)\nPoblación laboral Colombiana',
draw.segments=TRUE,len=0.8)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 203/344
203
Nota: El argumento key.labels = abbreviate(colnames(datos.Hombres)[2:12]), indica
utilizar en el diagrama de claves los nombres de las columnas 2 a 12 de la matriz
datos.hombres. pero abreviándolos, de lo contrario las claves aparecerían completas, pero
por su extensión esto resultaría inadecuado. Algo similar puede hacerse con las etiquetas de
las observaciones (nombres de filas de la matriz), pero de la siguiente forma: labels =
abbreviate(case.names(datos.Hombres))
Figura 8.3: En este gráfico se presentan los primeros 12 datos antropométricos de la base de
datos de hombres. Observe que los hombres 3 y 6 presentan un comportamiento que sobresale
respecto al resto (el número 3 tiene medidas mayores y el 6 tiene medidas más pequeñas).

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 204/344
204
Figura 8.4: En este gráfico se presentan los primeros 12 datos antropométricos de la base de
datos de mujeres. Observe que las mujer 2 y 4 presenta un comportamiento que sobresale
respecto al resto (tienen medidas más pequeñas) y que en las variables pliegue cutáneo
subescapular (PICS) y en pliegue cutáneo triceps (PICT) parece mayor variabilidad (en la
parte inferior de las estrellas observe cómo varíel patrón).
Figura 8.5: En este gráfico se presentan los mismos 12 datos antropométricos de la base de
datos de hombres, pero con una modificación, los gráficos presentan sectores circulares de
radios proporcionales a los valores de cada variable en el respectivo sujeto, además que cada
sector ha sido coloreado. Esto fue posible especificando el argumento draw.segments=TRUE.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 205/344
205
8.4. Gráficas Trellis (de Rejilla)
Las gráficas Trellis (de rejilla) son gráficas que contienen uno o más paneles, arreglados en
forma de rejilla o matriz triangular. Cada panel presenta un gráfico con un subconjunto de
los datos. Todos los paneles presentan el mismo tipo de gráfico. Los subconjuntos de datos
son escogidos con algún criterio uniforme, condicionando en variables continuas o
discretas, proporcionando una serie de vistas en forma de coordenadas.
Las gráficas Trellis representan un paso de mayor importancia en gráficas estadísticas.
Ellos proporcionan una forma general a las gráficas múltiples y condicionales.
La función coplot permite obtener este tipo de gráficos, sus argumentos son:
coplot(formula, data, given.values, panel = points, rows,
columns,show.given = TRUE, col = par("fg"), pch = par("pch"),
xlab = paste("Given :", a.name),ylab = paste("Given :", b.name),
number = 6, overlap = 0.5, ...)
co.intervals(x, number = 6, overlap = 0.5)
• formula: Para definir la forma del gráfico condicional como y~x|a, indicando que
se graficará y versus x condicionados a la variable a. Si la fórmula es de la forma
y~x|a*b entonces los gráficos de y versus x serán condicionados sobre las
variables a y b. x y y deben ser numéricas pero a y b pueden no serlo.
• data: Un marco de datos que contiene los valores para cualquiera de las variables enla fórmula, aunque por defecto coplot usa los datos del ambiente en el cual ha sido
invocado.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 206/344
206
• given.values: Corresponde a un valor o lista de dos valores los cuales determinan
cómo los condicionamientos sobre a y b van a darse. Si sólo se condiciona sobre una
variable, entonces este argumento generalmente corresponde a una matriz con dos
columnas, con cada fila dando un intervalo sobre el cual se condiciona, pero también
puede ser un vector de números o un conjunto de niveles de un factor cuando la
variable sobre la que se condiciona es un factor. En caso de sólo una variable
condicionante, el resultado de co.intervals(..) puede ser usado directamente como el
valor de este argumento.
• panel: Es una función function(x,y, col, pch, ...) que realiza la
acción a ser ejecutada en cada panel del gráfico. Por defecto es “ points”.
• rows: Los paneles del gráfico son puestos en un arreglo de filas por columnas. Este
argumento da el número de filas en el arreglo.
• columns: Corresponde al número de columnas en el arreglo de paneles.
• show.given: Es un argumento lógico, que puede ser de longitud dos cuando se
tienen dos variables condicionantes. Por defecto (TRUE) los gráficos se presentan
para las correspondientes variables condicionantes
• col: Para especificar un vector de colores a ser usados para los puntos. Si es muy
corto los valores son reciclados.
• pch: Para especificar un vector de símbolos de graficación.
• xlab, ylab: Para etiquetar a la primera y segunda variable condicionante
respectivamente.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 207/344
207
• number: Número entero, para indicar el número de intervalos de la variable
condicionante. Puede ser de longitud dos para la dirección x y y.
• overlap: Un valor numérico < 1, con el que se especifica la fracción de
superposición de los intervalos de las variables condicionantes, puede ser de longitud
2 para la dirección x e y. Un valor negativo produce huecos entre tramos de datos.
Ejemplo 1: Ver figura 8.6.
datos.icfes<-read.table('c:/graficos/icfes.dat')sexo<-as.factor(datos.icfes[,1])
conoc.mat<-datos.icfes[,10]
apt.mat<-datos.icfes[,9]
electiva<-as.factor(datos.icfes[,12])
apt.verbal<-datos.icfes[,7]
fisica<-datos.icfes[,5]
coplot(conoc.mat ~ apt.mat | sexo*electiva,
panel=function(x,y,...) panel.smooth(x,y, span= .8, ...))

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 208/344
208
Figura 8.6: Hay paneles vacíos indicando que las mujeres no tomaron las
electivas correspondientes. En cuanto a la influencia del sexo y la electiva sobre
los resultados en matemática no parecen ser determinantes.
Ejemplo 2: Ver figura 8.7.
aux<- fisica ~ conoc.mat | apt.verbal*apt.mat
coplot(aux,number=c(3,4),overlap=c(0,0.1))

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 209/344
209
Figura 8.7: A mayor aptitud matemática y verbal mejores resultados en física y
en matemáticas. también quien tiene buenos resultados en matemáticas logra
buenos resultados en física.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 210/344
210
Parte IIIEstadística en R

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 211/344
211
Capítulo 9: Modelos Estadísticos en R
R posee una amplia gama de funciones que nos permiten resolver asuntos de una forma
eficiente y elegante. Usualmente los resultados de las funciones no son extensos. Realmente
el programa trata de no llenar la pantalla de resultados, sino que el usuario pide lo que
necesita. A veces la combinación de varias funciones produce resultados excelentes. R es
bastante flexible para la creación de modelos altamente complejos.
9.1. Estadística Básica
Cálculos estadísticos básicos se pueden desarrollar de acuerdo con las necesidades
individuales. El R en este sentido es bastante diferente a otros programas que generan un
gran número de estadísticas, muchas inútiles. Si se requiere un análisis en particular se
recomienda crear una función que produzca todos los resultados necesarios en nuestro
problema usando las primitivas proporcionadas por el programa. Las funciones básicas son:
9.1.1 mean():
Permite calcular la media aritmética y medias recortadas de un vector.
mean(x, ...)
mean.default(x, trim = 0, na.rm = FALSE)
Argumentos:
• x: Vector num\'rico cuyos valores van a promediarse. Sólo se permiten vectores
complejos con `trim=0'.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 212/344
212
• trim: Fracción de recorte (de 0 a 0.5) de cada extremo de `x' antes de calcular la
media.
• na.rm: Un valor lógivo para indicar si valores `NA' deberían ser ignorados para los
cálculos.
Ejemplo:
x <- c(0:10, 50)
xm <- mean(x)xm
[1] 8.75
xt<-mean(x, trim = .10)
xt
[1] 5.5
9.1.2 weighted.mean():
Calcula una media ponderada de un vector numérico.
weighted.mean(x, w, na.rm=FALSE)
Argumentos:
• x: Vector num\'rico.
• w: Vector con los pesos para cada valor en `x'.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 213/344
213
• na.rm: Un valor lógivo para indicar si valores `NA' deberían ser ignorados para los
cálculos. si no se especifican, entonces a todos los valores se les da el mismo peso.
Ejemplo
wt <- c(5, 5, 4, 1)/15
x <- c(3.7,3.3,3.5,2.8)
xw <- weighted.mean(x,wt)
xw
[1] 3.453333
9.1.3 cor(), var() y cov():
var calcula la matriz de varianzas y covarianzas de una matriz de datos, cor y cov
calculan respectivamente, la correlación y la covarianza entre dos vectores `x' y `y'
var(x, y = NULL, na.rm = FALSE, use)
cor(x, y = NULL, use = "all.obs")
cov(x, y = NULL, use = "all.obs")
Argumentos:
• x: Un vector o matriz numéricos o un data frame.
• y: `NULL' (por defecto) o un vector, matriz o dataframe compatible con la
dimensión de `x'. el valor por defecto es `y = x'.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 214/344
214
• use: Una cadena de caracteres opcional para indicar el método para calcular
covarianzas en la presencia de valores faltantes. Debe ser una abreviación de las
siguientes cadenas “all.obs”, `"complete.obs"' o “ pairwise.complete.obs”.
• na.rm: Argumento lógico. ¿Deberían removerse los valores faltantes?.
Detalles: Si `use' es “all.obs” entonces si faltan observaciones se producirá un error. Si es
“complete.obs”, entonces las observaciones faltantes son descartadas y si es
“ pairwise.complete.obs”, entonces la correlación entre cada par de variables es calculada
usando todos los pares completos de observaciones de estas variables. Esto último puede
producir matrices de correlación o de covarianzas que no son semidefinidas positivas.
Ejemplos:
x<-rnorm(10)
y<-rnorm(10)
y
[1] -0.9546754 0.3951823 1.0079476 0.1308736 0.6154087 0.8264678[7] -0.4329034 0.3916516 -0.8908572 -0.8976308
var(x)
[1] 0.5058532
var(x,y)
[1] 0.02954414
cov(x,y)
[1] 0.02954414
cor(x,y)
[1] 0.05518748
library(mass)
#Generando una matriz de datos normales bivariados:
x<-matrix(mvrnorm(10,mu=c(0,0),Sigma=matrix(c(1,0,0,1),ncol=2)),ncol=2)
> x
[,1] [,2]

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 215/344
215
[1,] 0.03365421 0.01812461
[2,] -0.66313500 2.31526069
[3,] -0.92103077 2.21952089[4,] -0.97599197 1.39551295
[5,] -0.55824010 0.15656623
[6,] 0.77337990 0.52407043
[7,] -1.62980628 0.26459324
[8,] -1.01363258 -1.74454949
[9,] -0.32201918 -0.07920861
[10,] -1.40875243 -0.77490633
var(x)
[,1] [,2]
[1,] 0.49486624 0.07806947
[2,] 0.07806947 1.60101998
cov(x)
[,1] [,2]
[1,] 0.49486624 0.07806947
[2,] 0.07806947 1.60101998
cor(x)
[,1] [,2]
[1,] 1.00000000 0.08770795
[2,] 0.08770795 1.00000000
cov(x,y)
[,1]
[1,] 0.1037037
[2,] 0.4147815
9.1.4 median():
Calcula la media de un vector de numérico.
median(x, na.rm=FALSE)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 216/344
216
Ejemplo:
library(mass)
x<-matrix(mvrnorm(10,mu=c(0,0),Sigma=matrix(c(1,0,0,1),
ncol=2)),ncol=2)
apply(x,2,median)
[1] -0.7920829 0.2105797
apply(x,1,median)
[1] 0.02588941 0.82606284 0.64924506 0.20976049 -0.20083693 0.648725
[7] -0.68260652 -1.37909104 -0.20061389 -1.09182938
9.1.5 max(), min():
Devuelven el máximo y el mínimo respectivamente, de un vector.
9.1.6 pmax(), pmin():
Toman varios vectores como argumentos y retornan un sólo vector dando el máximo y el
mínimo paralelo respectivamente, de los primeros elementos de todos los argumentos, el
segundo elemento de todos los argumentos, etc. Si los vectores no son de igual longitud, el
más corto es reciclado.
Ejemplo:
library(mass)
x<-matrix(mvrnorm(10,mu=c(0,0),Sigma=matrix(c(1,0,0,1),ncol=2)),ncol=2)
min(x)
[1] -1.744549
max(x)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 217/344
217
[1] 2.315261
apply(x,1,min)
[1] 0.01812461 -0.66313500 -0.92103077 -0.97599197 -0.55824010 0.52407043[7] -1.62980628 -1.74454949 -0.32201918 -1.40875243
pmin(x[,1],x[,2])
[1] 0.01812461 -0.66313500 -0.92103077 -0.97599197 -0.55824010 0.52407043
[7] -1.62980628 -1.74454949 -0.32201918 -1.40875243
apply(x,2,max)
[1] 0.7733799 2.3152607
pmax(x[1,],x[2,])
[1] 0.03365421 2.31526069
9.1.7 quantile():
Produce los cuantiles muestrales correspondientes a las probabilidades dadas. La
observación más pequeña corresponde a una probabilidad de 0 y la más grande a una
probabilidad de 1.
quantile(x, probs = seq(0, 1, 0.25), na.rm = FALSE, names = TRUE)
Argumentos:
• x: Un vector numérico.
• probs: Un vector numérico con valores en $[0,1]$.
•
na.rm: Argumento logico; si es TRUE ningún valor faltante es removido antes decalcular los cuantiles.
• names: Argumento logico; si es TRUE el resultado tiene unos atributos de nombres.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 218/344
218
quantile(x,p) como función de p interpola linealmente los puntos ((i-1)/(n-
1),ox[i]) , donde ox<-order(x) (los estadísticos de orden) y n<-length(x).
De donde quantile(x, p)=(1-f)*ox[i]+f*ox[i+1], donde r<-1+(n-
1)*p, i<-floor(r),f <-r-i y ox[n+1]:= ox[n]
Ejemplos:
quantile(x <- rnorm(1001))
0% 25% 50% 75% 100%
-3.59904264 -0.71189944 -0.02124716 0.59595264 2.82691475quantile(x,probs=1:10/10)
10% 20% 30% 40% 50% 60%
-1.28010254 -0.89459997 -0.57376772 -0.27029481 -0.02124716 0.18551332
70% 80% 90% 100%
0.45891799 0.76740515 1.20626043 2.82691475
9.1.8 range():
Devuelve un vector con los valores mínimo y máximo de todos los argumentos dados.
Ejemplos:
print(r.x <- range(rnorm(100)))
[1] -2.314519 1.967344
diff(r.x) # El rango muestral[1] 4.281863
9.1.9 rank():
Devuelve los rankeos de los valores de un vector numérico, de menor a mayor.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 219/344
219
Ejemplos:
(r1 <- rank(x1 <- c(3,1,4,59,26)))
[1] 2 1 3 5 4
(r2 <- rank(x2 <- c(3,1,4,5,9,2,6,5,3,5))) # ties
[1] 3.5 1.0 5.0 7.0 10.0 2.0 9.0 7.0 3.5 7.0
9.1.10summary():
Con esto obtenemos varias estadísticas de resumen sobre una variable, como lo son los
cuartiles, etc.
summary(x)
Min. 1st Qu. Median Mean 3rd Qu. Max.
-0.6718 -0.3072 0.6527 0.4333 1.2390 1.2540
Veamos ahora un ejemplo en el cual se obtienen estadísticos y gráficos varios univariados:
PROGRAMA PARA OBTENER UN ANALISIS PRELIMINAR DATOS SOBRE EL
CONTENIDO DE ALCOHOL, CALORIAS Y PAIS EN CERVEZAS
LECTURA DE DATOS EN R
> cerveza.dat<-read.table('c:/datos/cerveza.dat')
GRAFICOS
1) HISTOGRAMAS
> hist(cerveza.dat[,2])
> hist(cerveza.dat[,2],col='grey',ylab='Frecuencia',x
lab='% de Alcohol',main=“)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 220/344
220
> title(main='Distribución del Contenido de Alcohol \n
en Diferentes Cervezas')
2) GRAFICO DE CAJA
> boxplot(cerveza.dat[,2],col='grey',y
lab='% de Alcohol',main=“)
> title(main='Distribución del Contenido de Alcohol \n
en Diferentes Cervezas')
> boxplot(split(cerveza.dat[,2],cerveza.dat[,1]),col='grey',
ylab='% de Alcohol',main=“)
> title(main='Distribución del Contenido de Alcohol \n en
Diferentes Cervezas por Países')
3) GRAFICO DE DISPERSION
> plot(cerveza.dat[,2],cerveza.dat[,3],col='grey',x
lab='% de Alcohol',ylab='Calorías',main=“)
> plot(cerveza.dat[,2],cerveza.dat[,3],xlab='% de Alcohol',
ylab='Calorías',main=“)
> title(main='Contenido de Alcohol vs. Calorías \n
en Diferentes Cervezas')
4) MEDIDAS DE RESUMEN
> calcule.todo(cerveza.dat[,2])
Estadisticas Basicas
Medidas de Localizacion
Media= 5.012704
Mediana= 4.96

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 221/344
221
Minimo= 2
Percentil 5%= 4.092
Percentil 10%= 4.27Primer Cuartil= 4.655
Tercer Cuartil= 5.245
Percentil 90%= 5.906
Percentil 95%= 6.322
Maximo= 9.5
Medidas de Dispersion
rango Intercuartil= 0.59
Varianza= 0.6129312
Desviacion Tipica= 0.7828993
Desviacion Media Absoluta= 0.501083
Desv. Media Absoluta Robusta= 0.4972327
Diferencia Media de Gini= 0.7636707
Medidas de Forma
Sesgo= 1.073347
Kurtosis= 7.841771
Prueba de Normalidad Shapiro-Francia: W= 0.8573725
Rechace normalidad si W<0.947 Nivel:5%
>
graficos......histcerv.ps boxpcerv.ps *cerv.ps
9.2. Fórmulas en R
Una fórmula en R es una expresión simbólica que define la forma estructural del modelo y
es utilizada en funciones que ajustan modelos. Un ejemplo de una fórmula es el siguiente:

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 222/344
222
precio ~ modelo + tipo
La expresión al lado izquierdo de “~” es la respuesta, o la variable dependiente. En este
caso la respuesta es el precio. El lado derecho de la fórmula corresponde a la expresión
usada para ajustar la respuesta. En el caso anterior tenemos un modelo aditivo y los
términos están separados por el signo “+”. A pesar de no aparecer explícitamente, se asume
el intercepto.El modelo anterior con la inclusión del intercepto será:
Precio ~ 1 + modelo + tipo
Una fórmula puede llegar a ser bastante compleja. En la fórmula arriba hemos incluído la
variable tipo que es categórica.Los siguientes tipos de datos pueden aparecer en una
fórmula:
1) Un vector numérico, lo cual implica la presencia de un coeficiente;
2) un factor o un factor ordenado, lo cual implica un coeficiente para cada nivel;
3) una matriz, lo que implica un coeficiente por cada columna y
4) cualquier expresión válida en R que evalúe a una variable correspondiente a cualquiera
de los tipos anteriormente descritos. Por ejemplo (modelo>75) evalúa una variable
lógica.
9.2.1 Interacción y Encajamiento
Las fórmulas en R pueden ser bastante compactas. Por ejemplo la fórmula
precio ~ modelo*tipo

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 223/344
223
es equivalente al modelo
precio ~ 1 + modelo + tipo + modelo:tipo
donde el término modelo:tipo representa la interacción entre el modelo y el tipo.
Términos encajados surgen cuando los niveles de un factor dentro de un nivel de algún otro
factor o combinación de factores. Por ejemplo si tenemos datos geográficos y tenemos el
factor departamento y el factor municipio . Obviamente los niveles de municipio dependen
del departamento. En este caso el efecto principal carece de sentido, el modelo debe ajustar un efecto principal para departamento y luego mirar los coeficientes para municipio dentro
de cada nivel de departamento. La fórmula será:
1 + departamento + municipio \%in\% departamento
9.2.2 Función formula
La función genérica formula y sus métodos específicos proporcionan una manera de
extraer fórmulas las cuáles han sido incluidas en otros objetos. as.formula es casi
idéntica pero adicionalmente preserva atributos del objeto. El valor por defecto del
argumento env es usado sólo cuando la fórmula carezca de un ambiente.
y ~ model
formula(x, ...)
as.formula(object, env=parent.frame())
I(x)
Argumentos:

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 224/344
224
• x, object: Un objeto.
• ...: Argumentos adicionales pasados a o desde otros métodos.
• env: El ambiente a asociar con el resultado.
Detalles:
• Los modelos a justar por funciones como lm y glm son especificados en una
forma simbólica compacta. El operador ~ es básico en la formación de tales modelos.
Una expresión de la forma y ~ model es interpretado como una especificación de
que la respuesta `y' es modelada por un predictor lineal especificado simbólicamente
por `model'. Tal modelo consiste de una serie de términos separados por operadores
`+'. Los términos en sí mismos consisten de nombres de variables y factores
separados por operadores `:'. Tal término es interpretado como la interacción de
todas las variables y factores que aparecen en el término.
• Además de `+' y `:', otros operadores son útiles en fórmulas de modelos. El operador
`*' denota cruce de factores. `a*b' es interpretado como `a+b+a:b'. El operador `^'
indica cruzar al grado especificado. Por ejemplo (a+b+c)^2 es idéntico a
(a+b+c)*(a+b+c) en cambio expande a una fórmula que contiene los efectos
principales para a', `b' y `c' junto con sus interacciones de segundo orden. El
operador `%in%' indica que los términos a su izquierda están anidados con aquellos a
su derecha. Por ejemplo a+b%in%a expande a la fórmula a+a:b. El operador -'remueve los términos especificados, de modo que (a+b+c)^2-a:b es idéntico a a+b+c+b:c+a:c. Puede usarse también para remover el término intercepto: y~x-
1 es una recta que pasa por el origen. Un modelo sin intercepto puede especificarse
también como y~x+0 o 0+y~x.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 225/344
225
• Mientras las fórmulas sólo involucren variables y nombres de factores, pueden
también incluir expresiones aritméticas. La fórmula log(y)~a+log(x) es
bastante legal. Cuando tales expresiones aritméticas incluyen operadores que son
también usados simbólicamente en la fórmula del modelo, puede haber confusión
entre el operador aritmético y el simbólico.
• Para evitar esta confución, la función I() puede usarse para encerrar entre paréntesis
aquellas porciones de una fórmula de modelo donde los operadores son usados en su
sentido aritmético. Por ejemplo, en la fórmula y~a+I(b+c) el término `b+c' será
interpretado como la suma de `b' y `c'.
Valor: Todas las funciones anteriores producen un objeto de clase `formula' que
contiene una fórmula de modelo simbólica.
Ambientes: Un objeto fórmula tiene una ambiente asociado, y éste ambiente es usado por
model.frame para evaluar las variables que no son halladas en el argumento data
suministrado. Las fórmulas creadas con as.formula serán usadas en el argumento env
por su ambiente. Fórmulas preexistentes estraidas con as.formula sólo tendrán su
ambiente cambiado si env es dado explícitamente.
Ejemplos:
>class(fo <- y ~ x1*x2)
[1] "formula"
> fo
y ~ x1 * x2
> typeof(fo)
[1] "language"

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 226/344
226
> terms(fo)
y ~ x1 + x2 + x1:x2
attr(,"variables")list(y, x1, x2)
attr(,"factors")
x1 x2 x1:x2
y 0 0 0
x1 1 0 1
x2 0 1 1
attr(,"term.labels")
[1] "x1" "x2" "x1:x2"
attr(,"order")
[1] 1 1 2attr(,"intercept")
[1] 1
attr(,"response")
[1] 1
attr(,".Environment")
<environment: R_GlobalEnv>
> environment(fo)
<environment: R_GlobalEnv>
> environment(as.formula("y~x"))
<environment: R_GlobalEnv>
> environment(as.formula("y~x",env=new.env()))
<environment: 01C8BCA4>
>
#Creación de una fórmula para un modelo
#con muchas variables:
#definiendo nombres de variables:
xnam <- paste("x", 1:25, sep="")
#definiendo fórmula:
>(fmla <- as.formula(paste("y ~ ", paste(xnam, collapse= "+"))))

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 227/344
227
y ~ x1 + x2 + x3 + x4 + x5 + x6 + x7 + x8 + x9 + x10 + x11 +
x12 + x13 + x14 + x15 + x16 + x17 + x18 + x19 + x20 + x21 +
x22 + x23 + x24 + x25
9.3. Funciones para pruebas estadísticas
En R encontramos disponibles en el paquete ctest las siguientes funciones para
diversas pruebas:
ansari.test(ctest) Prueba Ansari-Bradley
bartlett.test(ctest) Prueba de Bartlett para
homogeneidad de varianzas
binom.test(ctest) Prueba Binomial exacta.
chisq.test(ctest) Prueba Chi-cuadrado de Pearson para
datos de conteo
cor.test(ctest) Prueba para asociación entre
muestras pareadas
fisher.test(ctest) Prueba exacta de Fisher para datos
de conteo
fligner.test(ctest) Prueba Fligner-Killeen para
homogeneidad de varianzas
friedman.test(ctest) Prueba Friedman de suma de rangos
kruskal.test(ctest) Prueba de suma rangos Kruskal-Wallis
ks.test(ctest) Prueba Kolmogorov-Smirnov
mantelhaen.test(ctest) Prueba Chi-cuadrado de Cochran-Mantel-Haenszel
para datos de conteo
mcnemar.test(ctest) Prueba Chi-cuadrado de McNemar
para datos de conteo
mood.test(ctest) Prueba de escala Mood para dos muestras
oneway.test(ctest) Prueba de igualdad de medias en
diseño de una vía
pairwise.prop.test(ctest) Comparaciones pareadas de proporciones
pairwise.t.test(ctest) Prueba t datos pareados
pairwise.wilcox.test(ctest) Prueba de suma de rangos Wilcoxon
pareada
power.prop.test(ctest) Cálculos de potencia pruebas de

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 228/344
228
dos muestras para proporciones
power.t.test(ctest) Cálculos de potencia para
pruebas t de una y dos muestrasprint.pairwise.htest(ctest) Método de impresión para
pruebas pareadas
print.power.htest(ctest) Método de impresión para objeto de
cálculo de potencia
prop.test(ctest) Prueba de igualdad o proporciones dadas
prop.trend.test(ctest) Prueba para tendencia en proporciones
quade.test(ctest) Quade Test
shapiro.test(ctest) Test Shapiro-Wilk
t.test(ctest) test t de Student
var.test(ctest) Prueba F para comparar dos varianzaswilcox.test(ctest) Pruebas de suma de rango de Wilcoxon k y
rango con signo
9.3.1 Test de normalidad: Función shapiro.test
En la librería ctest , se encuentra disponible la prueba de normalidad Shapiro-Wilk.
shapiro.test(x)
Argumentos:
• x: Un vector numérico, de longitud entre 3 a 5000.
Valor: Una lista de clase `'htest” que contiene:
• statistic: El valor del estadístico Shapiro-Wilk
• p.value: El valor p de la prueba.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 229/344
229
• method: Cadena de caracteres “Shapiro-Wilk normality test”
• data.name: Una cadena de caractere dando el nombre de los datos.
Referencias:
• Patrick Royston (1982) An Extension of Shapiro and Wilk's W Test for Normality to
Large Samples. Applied Statistics, 31, 115-124.
• Patrick Royston (1982) Algorithm AS 181: The W Test for Normality. Applied
Statistics, 31, 176-180.
• Patrick Royston (1995) A Remark on Algorithm AS 181: The W Test for Normality.
Applied Statistics, 44, 547-551.
Ejemplo
library(ctest)
shapiro.test(rnorm(100, mean = 2, sd = 4))
Shapiro-Wilk normality test
data: rnorm(100, mean = 2, sd = 4)
W = 0.9797, p-value = 0.1265
shapiro.test(rexp(100))
Shapiro-Wilk normality test
data: rexp(100)
W = 0.8524, p-value = 1.458e-08
9.4. Regresión lineal Clásica
La regresión lineal clásica es la herramienta estadística más utilizada. R presenta un
conjunto de funciones que permiten realizar el trabajo de una forma poco tradicional.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 230/344
230
Siguiendo la filosofía del programa, el usuario puede crear sus propias funciones, basadas
en las que el programa provee de tal forma que los resultados que realmente se desean sean
los que se obtengan. Entre las funciones que trae el programa tenemos
1. lm(),
2. lm.influence(),
3 lm.object(),
4. mlm.object(),
5. ls.diag(),
6. ls.summary(),
7. ls.print(),
8. lsfit(),
9. poly(),q
10. stepwise(),
11. hat().
9.4.1 Función lm :
Es usada para ajustar modelos lineales. Puede usarse para realizar regresiones, análisis de
varianza de un solo estrato, y análisis de covarianza (aunque aov puede dar una interface
más conveniente para estas).
lm(formula, data, subset, weights, na.action,method = "qr", model = TRUE,
x = FALSE, y = FALSE, qr = TRUE,singular.ok = TRUE, contrasts = NULL,
offset = NULL, ...)
Argumentos:
• formula: Una descripción simbólica del modelo a ser especificado.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 231/344
231
• data: Marco de datos opcional que contiene las variables en el modelo. por defecto
las variables son tomadas de `environment(formula)' , típicamente el
ambiente del cual lm es llamada.
• subset: Un vector opcional para especificar un subconjunto de observaciones usadas
en el proceso de ajuste.
• weights: Un vecto opcional con pesos a ser usados en el proceso de ajuste. Si es
especificado, mínimo cuadrados ponderados es usado con los pesos especificados, es
decir, se minimiza sum(w*e^2); de lo contrario se usa mínimos cuadrados
ordinarios.
• na.action: Una función que indica lo que debería hacerse cuando hay datos faltantes
`NA's. El valor por defecto es el ajustado por na.action'.
• method: El método a ser usado para el ajuste. Actualmente sólo es soportado el
método `qr' ; `method='model.frame’ ' devuelve el marco del modelo.
• model, x, y, qr: Argumentos lógicos. Si son iguales a `TRUE' los componentes
correspondientes del ajuste (el marco del modelo, la matriz del modelo, la respuesta,
la descomposición QR) son devueltos.
• singular.ok: Argumento lógico, por defecto es `TRUE'. `FALSE' no está
implementado.
• contrasts: Una lista opcional. Ver `contrasts.arg' de
`model.matrix.default'.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 232/344
232
• offset: Puede usarse para especificar una componente conocida anterior a ser
incluida en el predictor lineal durante el ajuste. Un término `offset' puede ser
incluido en la fórmula en vez o también, y si ambos son especificados su suma es
usada.
• ...: Argumentos adicionales.
Detalles: Los modelos para lm se especifican simbólicamente. El modelo usual tiene la
forma respuesta~términos donde respuesta es el vector de respuesta y
términos es una serie de predictores lineales. Estos términos se especifican de la forma
`primero+segundo' indica todos los términos en `primero' junto con todos los
términos en `segundo' con duplicaciones removidas. Una especificación de la forma
`primero:segundo' indica el conjunto de términos obtenidos tomando las interacciones
de todos los términos en `primero' con todos los términos en `segundo'. La
especificación `primero*segundo' indica el cruce de `primero' y `segundo' . Esto
es lo mismo que primero+segundo+primero:segundo'.
Las funciones summary y anova son usadas para obtener e imprimir un resumen y una
tabla de análisis de varianzas de los resultados. Las funciones genéricas extractoras
coefficients, effects, fitted.values y residuals extraen varias
características útiles de los valores retornados por lm.
Un objeto de clase “lm” es una lista con los siguientes componentes, entre otros:
• coefficients: Un vector con los coeficientes
• residuals: Los residuales, es decir la respuesta menos valores ajustados.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 233/344
233
• fitted.values: Los valores ajustados.
• rank: El grado del modelo lineal ajustado.
• weights: Pesos si se hizo ajuste ponderado.
• df.residual: Grados de libeertad de los residuales.
• formula: La fórmula dada.
• terms: El objeto `terms' usado.
• contrasts: Sólo donde son relevantes, los contrastes usados.
• xlevels: Sólo si son relevante, un registro de los niveles de los factores usados en el
ajuste.
• y: Si es requerido, la respuesta usada.
• x: Si es requerido, la matriz modelo usada.
• model: El marco de modelo usado.
Nota: los offsets especificados por `offset' no serán incluidas las predicciones por
predict.lm mientras aquellas especificadas por un término offset en formula si será
incluido.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 234/344
234
Ver también: summary.lm, anova.lm, coefficients, effects, residuals,
fitted.values, predict.lm (para predicción e intervalos de predicción),
lm.influence (para diagnósticos de regresión) y glm (para modelos lineales
generalizados).
9.4.2 Función lsfit:
Halla los estimadores mínimo cuadrados del modelos y=X b + e.
lsfit(x, y, wt=NULL, intercept=TRUE, tolerance=1e-07, yname=NULL)
Argumentos
• x: Una matriz cuyas filas corresponden a los casos y las columnas a las variables.
• y: Las respuestas. Puede ser una matriz de valores si se quiere múltiple ajuste en el
lado izquiedo.
• wt: Un vector opcional de pesos para mínimos cuadrados ponderados.
• intercept: Para indicar si o no será usado un término de intercepto.
• tolerance: La tolerancia a usar en la descomposición de la matriz.
• yname: Un parámetro no usado para compatibilidad.
Detalles: Las observaciones con campos faltantes son omitidas antes del análisis.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 235/344
235
Valor: Una lista con los siguientes componentes:
• coef: Las estimaciones mínimo cuadráticas de los coeficientes.
• residuals: Los residuales del ajuste.
• intercept: Indica si un intercepto fue hallado.
• qr: La descomposición QR de la matriz de diseño.
9.4.3 Función ls.diag:
Calcula diagnósticos para resultados de regresión con lsfit, estadísticos básicos
incluyendo errores estándar, valores t y valores p, para los coeficientes de regresión.
ls.diag(ls.out)
Argumentos:
• ls.out: El resultado de lsfit().
Valor: Una lista con los siguientes componentes:
• std.dev: La desviación estándar de los errores, una estimación de sigma.
• hat: Entradas hii de la matriz hat.
• std.res: Residuales estandarizados.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 236/344
236
• stud.res: Residuaes estudentizados.
• cooks: Distancias Cook's.
• dfits: Estadísticos DFITS.
• correlation: Matriz de correlación.
• std.err: Errores estándar de los coeficientes de la regresión.
• cov.scaled: Matriz de covarianza de los coeficientes escala.
• cov.unscaled: Matriz de covarianza de los coeficientes no escalada.
Como un ejemplo de lsfit() tenemos el siguiente programa que hace referencia a los precios
de oferta de carros Renault que aparecen en el apéndice. Dediquemos un momento a
plantear el modelo que podría explicar el precio de oferta de carros Renault. Una variableque explica el precio de oferta es el año del carro. Obviamente esperamos que un carro
viejo sea más barato que un carro más nuevo, asimismo el modelo o tipo del carro, si es R4
esperamos tenga un menor valor que un R12 del mismo año. Preguntas interesantes pueden
ser: Cuál es el cambio en el precio de oferta entre dos carros de años consecutivos? La
diferencia en precios entre R4 y R12 se conserva para diferentes años? etc. Dado que en el
conjunto de datos tenemos una variable alfanumérica no podemos utilizarla directamente en
la función lsfit(). Podemos crear una función como la siguiente que nos crea una variable
binaria a partir de una variable alfanumérica y luego la usamos con apply() para resolver
este inconveniencia:
> binaria<-function(a,texto,b)
> if(a==texto) b<-0

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 237/344
237
> else b<-1
> modelo<-matrix(renault$modelo,ncol=1)
> tipo<-apply(modelo,1,binaria,”r4”,tipo)> renault.reg<-lsfit(cbind(renault$ano,tipo),
renault$precio,intercept=T)
El objeto que se produce es el siguiente:
$coef:
Intercept tipo
-9.846147 0.1618658 1.527716
$residuals:
[1] 0.08755707 -0.09804023 -0.41497986
[4] -0.15311409 0.71554359 -0.16751679
[7] 0.35367782 0.50195977 -0.35191948
[10] -0.27005371 -0.20311409 -0.03083053
[13] -0.18336745 0.49290101 0.23103524
[16] -0.38336745 0.19290101 -0.15963592
[19] -0.15963592
$intercept:
[1] T
$qr:
$qr$qt:
[1] -14.91890517 -2.85727082 3.22552976
[4] -0.10954689 0.76553080 -0.12202358
[7] 0.40302303 0.54039095 -0.30450028
[10] -0.22199251 -0.15954689 -0.16348059
[13] -0.31344951 0.36153495 0.09902718
[16] -0.51344951 0.06153495 -0.28843397
[19] -0.28843397

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 238/344
238
$qr$qr:
Intercept tipo
[1,] -4.3588989 -339.99411760 -1.83532587[2,] 0.2294157 -21.58703314 0.41691695
[3,] 0.2294157 0.07846199 2.11134062
[4,] 0.2294157 0.03213788 0.15397011
[5,] 0.2294157 -0.43110317 0.27275040
[6,] 0.2294157 -0.10683443 0.18960420
[7,] 0.2294157 -0.38477907 0.26087237
[8,] 0.2294157 0.40273073 0.05894589
[9,] 0.2294157 -0.24580675 0.22523828
Intercept tipo
[10,] 0.2294157 -0.29213086 0.2371163
[11,] 0.2294157 0.03213788 0.1539701
[12,] 0.2294157 0.03213788 -0.3196626
[13,] 0.2294157 -0.15315854 -0.2721505
[14,] 0.2294157 -0.06051033 -0.2959066
[15,] 0.2294157 -0.01418622 -0.3077846
[16,] 0.2294157 -0.15315854 -0.2721505
[17,] 0.2294157 -0.06051033 -0.2959066
[18,] 0.2294157 -0.24580675 -0.2483944
Intercept tipo
[19,] 0.2294157 -0.2458068 -0.2483944
$qr$qraux:
[1] 1.229416 1.402731 1.142092
$qr$rank:
[1] 3
$qr$pivot:
[1] 1 2 3
$qr$tol:
[1] 1e-007

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 239/344
239
Un resumen mejor del objeto anterior se obtiene con la función print.ls()
> print.ls(renault.reg)
Residual Standard Error = 0.3477, Multiple R-Square = 0.9057
N = 19, F-statistic = 76.8016 on 2 and 16 df, p-value = 0
coef std.err t.stat p.value
Intercept -9.8461 1.2982 -7.5844 0
0.1619 0.0164 9.8596 0
tipo 1.5277 0.1647 9.2772 0
Si se desea realizar diagnósticos entonces podemos utilizar la función ls.summary() . Esta
función cuando es aplicada al objeto creado por lsfit() produce los bien conocidos
resultados de Belsey et al. Por ejemplo en el caso de los carros Renault:
> renault_diagnosticos<-ls.summary(renault.reg)
> renault_diagnostico
$std.dev:[1] 0.3476825
$hat:
[1] 0.17611290 0.27887709 0.10152271
[4] 0.09402316 0.26428336 0.09827966
[7] 0.22719096 0.27887709 0.14266893
[10] 0.16638374 0.09402316 0.14677342
[13] 0.12670704 0.12782183 0.13506803
[16] 0.12670704 0.12782183 0.14342902
[19] 0.14342902
$std.res:
[1] 0.27744351 -0.33206026 -1.25918828

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 240/344
240
[4] -0.46267263 2.39937436 -0.50738731
[7] 1.15714808 1.70012741 -1.09316629
[10] -0.85071535 -0.61376018 -0.09599883[13] -0.56436423 1.51800887 0.71450367
[16] -1.17991973 0.59408571 -0.49609647
[19] -0.49609647
$stud.res:
[1] 0.26928206 -0.32262958 -1.28450956
[4] -0.45100806 2.90355461 -0.49527634
[7] 1.17044941 1.81858216 -1.10034238
[10] -0.84298733 -0.60139245 -0.09297725
[13] -0.55196483 1.58865147 0.70312350
[16] -1.19565489 0.58167223 -0.48408083
[19] -0.48408083
$cooks:
[1] 0.0054846808 0.0142139930 0.0597195059
[4] 0.0074053247 0.6893408505 0.0093529744
[7] 0.1312125795 0.3726020444 0.0662875629
[10] 0.0481495248 0.0130314846 0.0005284375
[13] 0.0154041759 0.1125711756 0.0265740826
[16] 0.0673324542 0.0172415693 0.0137367722
[19] 0.0137367722
$dfits:
[1] 0.12449994 -0.20063466 -0.43178286
[4] -0.14529249 1.74024190 -0.16350968
[7] 0.63461754 1.13092734 -0.44886760
[10] -0.37661135 -0.19373890 -0.03856277
[13] -0.21024796 0.60817498 0.27785417
[16] -0.45543482 0.22267848 -0.19808643
[19] -0.19808643
$correlation:

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 241/344
241
Intercept tipo
Intercept 1.0000000 -0.9967344 -0.2444971
-0.9967344 1.0000000 0.1937247tipo -0.2444971 0.1937247 1.0000000
$std.err:
[,1]
Intercept 1.29820431
0.01641709
tipo 0.16467379
$cov.unscaled:
Intercept
Intercept 13.9418531 -0.175732854
-0.1757329 0.002229598
tipo -0.4323900 0.004332514
tipo
Intercept -0.432389977
0.004332514
tipo 0.224327954
Si queremos un gráfico Cuantil-Cuantil para ver si los residuales studentizados se
aproximan a la normal podemos dar los siguientes comandos:
win.graph()
titulo<-”Grafico QQ de los Residuales Studentizados”
qqnorm(renault\_diagnosticos\$stud.res, main=titulo,
xlab=“Grafico QQ con la Normal”,
ylab=“Residuales Studentizados”)
9.4.4 Función step:
Elige un modelo con el criterio AIC en un algoritmo Stepwise

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 242/344
242
step(object,scope,scale=0,direction=c("both","backward","forward"),
trace=1,keep=NULL,steps=1000,k=2,...)
Argumentos:
• object: Un objeto representando un modelo de una clase apropiada (principalmente
“lm” y “glm”). Este es usado como el modelo inicial en la búsqueda stepwise.
• scope:
Define el rango de los modelos examinados en la búsqueda stepwise. Debe
ser ya sea una fórmula, o una lista que contiene las componentes `upper' y `lower',
ambas fórmulas.
• scale: Usada en la definición del estadístico AIC para seleccionar los modelos,
actualmente, sólo para los modelos lm.aov y glm.
• direction: El modo de búsqueda, puede ser uno de los siguientes: `'both”,
`'backward”, o `'forward”, siendo por defecto `'both”. Si el argumento `scope' no es
especificado (o el modelo inicial es el modelo superior) el valor por defecto para
`direction' es 'backward”.
• trace: Si es positivo, la información es impresa durante la corrida de step . Valores
grandes pueden dar información más detallada.
• keep: Una función filtro cuya entrada es un objeto modelo ajustado y el estadísticoAIC asociado, y cuya salida es arbitraria. Típicamente este argumento selecciona un
subconjunto de las componentes del objeto y las retorna. El valor por defecto es no
guardar nada.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 243/344
243
• steps: El número máximo de pasos a ser considerado. Por defecto es 1000.
• k: El múltiplo de los grados de libertad usado para penalización. Sólo `k = 2' da el
genuino AIC: `k = log(n)' es algunas veces referido como BIC o SBC.
• ...: Cualesquier argumentos adicionales para `extractAIC'.
Hay un problema potencial al usar ajustes glm con una variable de escala, ya que en ese
caso el deviance no está relacionado simplemente al log de verosimilitud maximizado. La
función extractAIC.glm hace el ajuste apropiado para una familia gaussiana, pero
pueden ser necesarias correciones para otros casos.
Valor: El modelo seleccionado stepwise es devuelto, con hasta dos componentes
adicionales. Hay una componente `'anova” correspondiente a los pasos tomados en la
búsqueda, como también una componente `'keep” si el argumento `keep=' fue
proporcionado. La columna `'Resid. Dev” de la tabla de análisis del deviance se refiere a
una constante menos dos veces el log de verosimilitud maximizado: Será un deviance sóloen los casos donde un modelo saturado sea bien definido.
Los modelos ajustados deben ser aplicados al mismo conjunto de datos. Esto puede ser un
problema si hay valores faltantes y el valor por defecto de R, `na.action = na.omit' es usado.
Se sugiere remover antes las observaciones con valores faltantes.
Esta función tiene una implementación mínima. Usar la función stepAIC de la librería
MASS para un rango de objetos más amplio.
Autor: B. D. Ripley.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 244/344
244
Ver también: `stepAIC' (en librería MASS), `add1', `drop1'
Ejemplo: Tomado Directamente de R:
data(swiss)
summary(lm1 <- lm(Fertility ~ ., data = swiss))
Call:
lm(formula = Fertility ~ ., data = swiss)
Residuals:Min 1Q Median 3Q Max
-15.2743 -5.2617 0.5032 4.1198 15.3213
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 66.91518 10.70604 6.250 1.91e-07 ***
Agriculture -0.17211 0.07030 -2.448 0.01873 *
Examination -0.25801 0.25388 -1.016 0.31546
Education -0.87094 0.18303 -4.758 2.43e-05 ***Catholic 0.10412 0.03526 2.953 0.00519 **
Infant.Mortality 1.07705 0.38172 2.822 0.00734 **
---
Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1
Residual standard error: 7.165 on 41 degrees of freedom
Multiple R-Squared: 0.7067, Adjusted R-squared: 0.671
F-statistic: 19.76 on 5 and 41 DF, p-value: 5.594e-10
slm1 <- step(lm1)
Start: AIC= 190.69
Fertility ~ Agriculture + Examination + Education + Catholic +
Infant.Mortality

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 245/344
245
Df Sum of Sq RSS AIC
- Examination 1 53.0 2158.1 189.9
<none> 2105.0 190.7- Agriculture 1 307.7 2412.8 195.1
- Infant.Mortality 1 408.8 2513.8 197.0
- Catholic 1 447.7 2552.8 197.8
- Education 1 1162.6 3267.6 209.4
Step: AIC= 189.86
Fertility ~ Agriculture + Education + Catholic + Infant.Mortality
Df Sum of Sq RSS AIC
<none> 2158.1 189.9
- Agriculture 1 264.2 2422.2 193.3
- Infant.Mortality 1 409.8 2567.9 196.0
- Catholic 1 956.6 3114.6 205.1
- Education 1 2250.0 4408.0 221.4
> summary(slm1)
Call:
lm(formula = Fertility ~ Agriculture + Education + Catholic +
Infant.Mortality, data = swiss)
Residuals:
Min 1Q Median 3Q Max
-14.6765 -6.0522 0.7514 3.1664 16.1422
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 62.10131 9.60489 6.466 8.49e-08 ***
Agriculture -0.15462 0.06819 -2.267 0.02857 *
Education -0.98026 0.14814 -6.617 5.14e-08 ***
Catholic 0.12467 0.02889 4.315 9.50e-05 ***
Infant.Mortality 1.07844 0.38187 2.824 0.00722 **
---

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 246/344
246
Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1
Residual standard error: 7.168 on 42 degrees of freedomMultiple R-Squared: 0.6993, Adjusted R-squared: 0.6707
F-statistic: 24.42 on 4 and 42 DF, p-value: 1.717e-10
slm1$anova
Step Df Deviance Resid. Df Resid. Dev AIC
1 NA NA 41 2105.043 190.6913
2 - Examination 1 53.02656 42 2158.069 189.8606
9.4.5 Medidas de Influencia
El siguiente conjunto de funciones permiten calcular algunos de los diagnósticos de
regresión discutidos en Belsley, Kuh and Welsch(1980), y en Cook and Weisberg (1982).
influence.measures(lm.obj)
rstandard(lm.obj,
infl = lm.influence(lm.obj),res = weighted.residuals(lm.obj),
sd = sqrt(deviance(lm.obj)/df.residual(lm.obj)))
rstudent (lm.obj, infl = ..., res = ...)
dffits (lm.obj, infl = ..., res = ...)
dfbetas (lm.obj, infl = ...)
covratio (lm.obj, infl = ..., res = ...)
cooks.distance(lm.obj, infl = ..., res = ..., sd = ...)
hat(x, intercept = TRUE)
Argumentos:
• lm.obj: El objeto resultante devuelto por lm.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 247/344
247
• infl: Estructura de influencia como la retornada por la función lm.influence.
• res: Residuales, posiblemente ponderados.
• sd: Desvaición estándar a usar.
• x: X o la matriz de diseño.
• intercept: Debería una columna intercepto ser pre anexada a X?
Detalles: La función principal es influence.measures que produce un objeto
tabular de clase “infl” mostrando los DFBETAS para cada variable del modelo, DFFITS,
covariance ratios, Cook's distances y los elementos de la diagonal de la matriz Hat. Los
casos que son influenciales para cualquiera de estas medidas son marcados con asterisco.
Las funciones dfbetas, dffits, covratio y cooks.distance proporcionan
acceso directo a las correspondientes cantidades de diagn'ostico. Las funcionesrstandard y rstudent dan respectivamente, los residuales estandarizados y
estudentizados.
Los argumentos opcionales `infl', `res' y `sd' están allí para el uso de estas funciones de uso
directo, cuando por ejemplo, las medidas subyacentes de influencia básicas (de
lm.influence) ya están disponibles.
Referencias.
• Belsley, D. A., Kuh, E. and Welsch, R. E. (1980) Regression Diagnostics. New York:
Wiley.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 248/344
248
• Cook, R. D. and Weisberg, S. (1982) Residuals and Influence in Regression. London:
Chapman and Hall.
Ejemplo:
data(LifeCycleSavings)
#ajustando un modelo:
lm.SR <- lm(sr ~ pop15 + pop75 + dpi + ddpi, data = LifeCycleSavings)
#obteniendo sólo las observaciones potencialmente
#influyentes:
summary(inflm.SR <- influence.measures(lm.SR))
Potentially influential observations of
lm(formula = sr ~ pop15 + pop75 + dpi + ddpi, data = LifeCycleSavings) :
dfb.1_ dfb.pp15 dfb.pp75 dfb.dpi dfb.ddpi dffit cov.r cook.d
Chile -0.20 0.13 0.22 -0.02 0.12 -0.46 0.65_* 0.04
United States 0.07 -0.07 0.04 -0.23 -0.03 -0.25 1.66_* 0.01
Zambia 0.16 -0.08 -0.34 0.09 0.23 0.75 0.51_* 0.10
Libya 0.55 -0.48 -0.38 -0.02 -1.02_* -1.16_* 2.09_* 0.27
hat
Chile 0.04
United States 0.33_*
Zambia 0.06
Libya 0.53_*
#o bien:
which(apply(inflm.SR$is.inf, 1, any))
Chile United States Zambia Libya
7 44 46 49
#Obteniendo una medida específica:
covratio(lm.SR)
Australia Austria Belgium Bolivia Brazil
1.1928303 1.2678392 1.1761879 1.2238199 1.0823332
Canada Chile China Colombia Costa Rica
1.3283009 0.6547098 1.1498637 1.1666845 0.9681384
Denmark Ecuador Finland France Germany
0.9344047 1.1393880 1.2031561 1.2262654 1.2256855

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 249/344
249
Greece Guatamala Honduras Iceland India
1.1396174 1.0852720 1.1855450 0.8658808 1.2024438
Ireland Italy Japan Korea Luxembourg1.2680432 1.1624611 1.0845999 0.8695843 1.1961844
Malta Norway Netherlands New Zealand Nicaragua
1.1282611 1.1680616 1.2285315 1.1336998 1.1742677
Panama Paraguay Peru Philippines Portugal
1.0667255 0.8732040 0.8312741 0.8177726 1.2331038
South Africa South Rhodesia Spain Sweden Switzerland
1.1945449 1.3130954 1.2081541 1.0864869 1.1471125
Turkey Tunisia United Kingdom United States Venezuela
1.1003557 1.1314365 1.1886236 1.6554816 1.0945955
Zambia Jamaica Uruguay Libya Malaysia0.5116454 1.1995171 1.1872025 2.0905736 1.1126445
9.5. Mínimos cuadrados no lineales: Función nls
En el paquete nls se halla la función nls que permite hallar estimaciones de los
parámetros en modelos no lineales.
nls(formula, data, start, control = nls.control(),
algorithm = "default", trace = FALSE, subset,
weights, na.action)
Argumentos:
• formula: Fórmula de un modelo no lineal que incluye variables y parámetros.
• data: Un data frame opcional en el cual se hallen las variables en `formula'.
• start: Una lista de denominación o vector numérico de estimaciones iniciales.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 250/344
250
• control: Una lista opcional de ajustes de control.
• algorithm: Cadena de caracteres especificando algoritmo a usar. Por defecto es el
algoritmo Gauss-Newton. Puede ser también “ plinear ”, el algoritmo Golub-Pereyra
para modelos mínimo cuadrados parcialmente lineales.
• trace: Argumento lógico para solicitar traza de las iteraciones. Por defecto es
`FALSE'.
• subset: Vector opcional para especificar un subconjunto de observaciones a ser
usados en el ajuste.
• weights: Vector opcional de pesos. Si se da, la función objetivo es de mínimos
cuadrados ponderados. No está implementada.
• na.action: Función de acción para valores `NA's.
Valor: Una lista con:
• m: Un objeto `nlsModel'.
• data: Los datos sobre los que se ajustó.
Autor: Douglas M. Bates and Saikat DebRoy
Ejemplos:
library(nls)
data( DNase )

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 251/344
251
DNase1 <- DNase[ DNase$Run == 1, ]
## Usando un modelo de autoarranque
fm1DNase1<- nls( density ~ SSlogis( log(conc), Asym, xmid, scal ),DNase1 )
>fm1DNase1
Nonlinear regression model
model: density ~ SSlogis(log(conc), Asym, xmid, scal)
data: DNase1
Asym xmid scal
2.345180 1.483090 1.041455
residual sum-of-squares: 0.004789569
summary( fm1DNase1 )
Formula: density ~ SSlogis(log(conc), Asym, xmid, scal)
Parameters:
Estimate Std. Error t value Pr(>|t|)
Asym 2.34518 0.07815 30.01 2.16e-13 ***
xmid 1.48309 0.08135 18.23 1.22e-10 ***
scal 1.04146 0.03227 32.27 8.50e-14 ***
---
Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1
Residual standard error: 0.01919 on 13 degrees of freedom
Correlation of Parameter Estimates:
Asym xmid
xmid 0.9868
scal 0.9008 0.9063
## usando linealidad condicional
> fm2DNase1 <- nls( density ~ 1/(1 + exp(( xmid - log(conc) )/scal ) ),
data = DNase1,start = list( xmid = 0, scal = 1 ),

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 252/344
252
alg = "plinear", trace = TRUE )
0.7139315 : 0.000000 1.000000 1.453853
0.1445295 : 1.640243 1.390186 2.4617540.008302152 : 1.620899 1.054228 2.478388
0.004794192 : 1.485226 1.043709 2.347334
0.004789569 : 1.483130 1.041468 2.345218
0.004789569 : 1.483090 1.041455 2.345180
> summary( fm2DNase1 )
Formula: density ~ 1/(1 + exp((xmid - log(conc))/scal))
Parameters:
Estimate Std. Error t value Pr(>|t|)
xmid 1.48309 0.08135 18.23 1.22e-10 ***
scal 1.04145 0.03227 32.27 8.50e-14 ***
.lin 2.34518 0.07815 30.01 2.16e-13 ***
---
Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1
Residual standard error: 0.01919 on 13 degrees of freedom
Correlation of Parameter Estimates:
xmid scal
scal 0.9063
.lin 0.9868 0.9008
##Sin linealidad condicional:
fm3DNase1 <- nls( density ~ Asym/(1 + exp(( xmid - log(conc) )/scal ) ),
data = DNase1,
start = list( Asym = 3, xmid = 0, scal = 1 ),
trace = TRUE )
14.32279 : 3 0 1
0.4542698 : 2.1152456 0.8410193 1.2000640
0.05869601 : 2.446376 1.747516 1.189515

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 253/344
253
0.005663523 : 2.294087 1.412198 1.020463
0.004791528 : 2.341429 1.479688 1.040758
0.004789569 : 2.345135 1.483047 1.0414390.004789569 : 2.345179 1.483089 1.041454
>
> summary( fm3DNase1 )
Formula: density ~ Asym/(1 + exp((xmid - log(conc))/scal))
Parameters:
Estimate Std. Error t value Pr(>|t|)
Asym 2.34518 0.07815 30.01 2.16e-13 ***
xmid 1.48309 0.08135 18.23 1.22e-10 ***
scal 1.04145 0.03227 32.27 8.50e-14 ***
---
Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1
Residual standard error: 0.01919 on 13 degrees of freedom
Correlation of Parameter Estimates:
Asym xmid
xmid 0.9868
scal 0.9008 0.9063
9.6. Análisis Multivariable
El análisis multivariable trata con datos que contienen observaciones con dos o más
variables obtenidas por cada sujeto. Vamos a suponer que nuestra matriz de datos se llamaDATOS y que es numérica. Cada fila representa las variables observadas a cada sujeto y
cada columna representa el conjunto de observaciones para una variable.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 254/344
254
9.6.1 Discriminación, Función: lda
El problema de clasificación consiste en clasificar un individuo en una de k poblaciones P 1 ,
P 2 , ... ,P k . Para ello se utiliza una regla construida teniendo como base las mediciones de d
variables de n individuos, digamos x1 , x2 , ... , xn, los cuales sabemos a cuales poblaciones
pertenecen con certeza. La técnica para construir la regla se conoce como discriminación.
La función R Disponible en el paquete mass, lda permite realizar análisis discriminante
lineal.
lda(formula, data, prior = proportions, tol = 1.0e-4,
subset, na.action = na.fail,
method, CV = FALSE, nu)
lda(x, grouping, prior = proportions, tol = 1.0e-4,
subset, na.action = na.fail,
method, CV = FALSE, nu)
Argumentos:
• formula: Una fórmula de la forma `groups~x1+x2+...' , es decir la respuesta
es el factor de agrupamiento y el lado derecho especifica los discriminadores.
• data: Data frame dese el cual se toman las variables especificadas en fórmula.
• x: Se requiere si no se da ninguna fórmula. Es una matriz de datos o data frame ouna matriz con las variables explicatorias.
• grouping: Se requiere si no de da ninguna fórmula. Es un factor que especifica la
clase de cada observación.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 255/344
255
• prior: Las probabilidades previas de los miembros de clase. Si no se especifican, las
proporciones de clase para el conjunto de entrenamiento son usadas. Si son dadas,
deben ser especificadas en el orden de los niveles de factor.
• tol: Una tolerancia para determinar si una matriz es singular. Rechazará variables y
combinaciones lineales de variables de varianza unitaria cuyas varianza es menor que
`tol2'.
• subset: Un vector índice que especifica los casos a ser usados en la muestra de
entrenamiento. Este argumento debe ser un nombre del vector.
• na.action: Una función para especificar la acción a tomar con valores `NA's.
• method: “moment” para estimadores estándar de media y varianza, “mle”, para
estimadores MLE, “mve” para usar `cov.mve', o “t” para usar estimaciones robustas
basadas en la distribución t.
• CV: Si es TRUE, devuelve resultados (clases y probabilidades posteriores) para
validación cruzada. Si las probabilidades posteriores son estimadas, las proporciones
en el conjunto total de datos son usadas.
• nu: Grados de libertad para `method = “t” '.
•
...: Argumentos pasados a o desde otros métodos.
Esta función puede ser llamada dando un fórmula y un data frame opcional, o una matriz y
un factor de agrupamiento como los primeros dos argumentos. Los otros argumentos son

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 256/344
256
opcionales, pero `subset=' y `na.action=', si son requeridos, deben ser nombrados
completamente.
Valor: un objeto de clase “lda” que contiene los siguiente componentes:
• prior: Las probabilidades apriori usadas.
• means: Las medias de grupos.
• scaling: Una matriz que transforma las observaciones a funciones discriminantes,
normalizadas de manera que la matriz de covarianza dentro de los grupos es esférica.
• svd: Los valores singulares, los cuales dan la razón de las desviaciones estándar
entre y dentro de los grupos en las variables discriminantes lineales. Sus cuadrados
son los estadísticos F canónicos.
• N: El número de observaciones usadas.
• call: La llamada de la función
• class: La clasificación MAP.
• posterior: Las probabilidades posteriores para las clases.
Ejemplos:
library(mass)
data(iris3)
Iris <- data.frame(rbind(iris3[,,1], iris3[,,2], iris3[,,3]),

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 257/344
257
Sp = rep(c("s","c","v"), rep(50,3)))
train <- sample(1:150, 75)
table(Iris$Sp[train])
z <- lda(Sp ~ ., Iris, prior = c(1,1,1)/3, subset = train)
>z
Call:
lda.formula(Sp ~ ., data = Iris, prior = c(1, 1, 1)/3, subset = train)
Prior probabilities of groups:
c s v
0.3333333 0.3333333 0.3333333
Group means:
Sepal.L. Sepal.W. Petal.L. Petal.W.
c 5.970370 2.777778 4.329630 1.318519
s 4.959091 3.295455 1.472727 0.250000
v 6.719231 3.061538 5.684615 2.053846
Coefficients of linear discriminants:
LD1 LD2
Sepal.L. 0.5831979 -0.3812877Sepal.W. 1.8356729 2.6112610
Petal.L. -2.3052398 -0.7051669
Petal.W. -2.3131828 2.5428727
Proportion of trace:
LD1 LD2
0.9892 0.0108
predict(z, Iris[-train, ])$class
[1] s s s s s s s s s s s s s s s s s s s s s s s s s s s s c c c c c c c c c c[39] c c c c c c c c c c c c c v v v v v v v v v v v v v v v v v v v v v v v v
Levels: c s v

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 258/344
258
9.6.2 Función mahalanobis
Devuelve las distancias de Mahalanobis de todas las filas en una matriz de datos `x' y el
vector mu=`center' con respecto a Sigma=`cov'. Para un vector `y' está definida como
D2=(y-mu)tSigma-1(y - mu).
mahalanobis(x, center, cov, inverted=FALSE)
Argumentos:
• x: Vector o matriz de datos con p columnas.
• center: Vector de medias de la distribución o el segundo vector de datos de longitud
p.
• cov: Matriz de covarianza (p x p) de la distribución.
• inverted: Argumento lógico. Si es `TRUE', se supone que el argumento cov'
contiene la inversa de la matriz de covarianza.
Ejemplo:
library(mass)
mu<-c(0,0)
Sigma<-matrix(c(1,0,0,1),ncol=2)X<-mvrnorm(5,mu,Sigma)
X
[,1] [,2]
[1,] -0.6473254 -0.9788744
[2,] 0.8565902 -0.1284428
[3,] 0.7230044 -0.5692264

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 259/344
259
[4,] 0.5820368 0.4990434
[5,] -0.6085847 0.8054497
T2<-mahalanobis(X,center=mu,cov=Sigma)
T2
[1] 1.3772253 0.7502443 0.8467540 0.5878112 1.0191247
mu<-c(0,0,0)
Sigma<-matrix(c(1,0,0,0,1,0,0,0,1),ncol=3)
X<-mvrnorm(100,mu,Sigma)
Sx <- cov(X)
Sx[,1] [,2] [,3]
[1,] 0.73037799 0.05741202 -0.1222489
[2,] 0.05741202 1.09179799 0.1149610
[3,] -0.12224895 0.11496101 1.0579335
centro<-apply(X,2,mean)
centro
[1] -0.02902490 -0.07151261 0.01496225
D2<-mahalanobis(X,centro,Sx)qqplot(qchisq(ppoints(100), df=3), D2,
main = expression("Q-Q plot de las distancias de Mahalanobis" * ~D^2 *
" vs. cuantiles" * ~ chi[3]^2),xlab=expression("Cuantil"*~chi[3]^2),
ylab=expression(D^2),cex.main=0.8,cex.lab=0.7,cex=0.7,pch=20,cex.axis=0.7)
abline(0, 1, col = 'gray',lty=2)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 260/344
260
Figura 9.1: Gráfico 2
que nos permite evaluar el supuesto de multinormalidad
9.6.3 Función cov.wt
Esta función proporciona una lista que contiene estimaciones de la matriz de covarianza
ponderada y la media de los datos , y opcionalmente, la matriz de correlación ponderada.
cov.wt(x, wt = rep(1/nrow(x), nrow(x)), cor = FALSE, center = TRUE)
Argumentos:
• x: Una matriz o data frame. Las filas son las observaciones y las columnas las
variables.
• wt: Un vector de pesos no nulo y no negativos para cada una de las observaciones.
Debe tener longitud igual al número de filas de `x'.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 261/344
261
• cor: Un argumento lógico para indicar si también deberá retornarse la matriz de
correlación estimada ponderada.
• center: Puede ser un argumento lógico o especificarse como un vector numérico
dando el centro a usar para calcular las covarianzas. Si es TRUE, se usa la media
ponderada de cada variable, ysi es FALSE, se usa cero. Si se especifica un vector, su
longitud debe ser igual al número de variables.
Detalles: La matriz de covarianza es dividida por uno menos la suma de los cuadrados de
los pesos, así si los pesos son (1/n), la estimación usual insesgada de la matriz de
covarianza con divisor (n-1) es retornada.
Valor: Esta función arroja una lista con las siguientes componentes:
• cov: La matriz de covarianza ponderada estimada.
• center: Una estimación para el centro de los datos.
• n.obs: El número de observaciones.
• wt: Los pesos usados en la estimación. Sólo los devuelve cuando sean
especificados.
• cor:
La matriz de correlación estimada. Es devuelta sólo si el argumento
`cor=TRUE'.
9.6.4 Función prcomp

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 262/344
262
Esta función está disponible en el paquete mva, y permite realizar un análisis de
componentes principales sobre una matriz de datos dada y devuelve los resultados como un
objeto de clase `prcomp'.
prcomp(x, retx = TRUE, center = TRUE, scale. = FALSE, tol = NULL)
Argumentos:
• x: Matriz o data frame con los datos.
• retx: Argumento lógico para indicar si deben retornarse las variables rotadas.
• center: Argumento lógico para indicar si las variables deben ser desviadas para
centrarlas en cero. Alternativamente, puede ser un vector de longitud igual al número
de columnas de la matriz de datos. El valor es pasado a scale'.
• scale: Argumento lógico para indicar si las variables deberían ser escaladas para
que tengan varianza unitaria antes de que se realice el análisis. El valor por defecto
es `FALSE' . También puede proporcionarse un vector de longitud igual al número
de columnas de la matriz de datos. El valor es pasado a scale'.
• tol: Un valor para indicar la cantidad por debajo de la cual las componentes deberían
ser omitidas. Las componentes son omitidas si sus desviaciones estándar son
menores o iguales a `tol' por la desviación estándar de la primera componente. Otros
ajustes pueden ser tol = 0' o `tol =sqrt(.Machine$double.eps)', lo cual podría omitir
componentes constantes.
Detalles: El cálculo es realizado mediante la descomposición SVD de la matriz de datos
centrada y escalada. Este es el método preferido por exactitud numérica. El método `print'

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 263/344
263
para estos objetos imprime los resultado en un buen formato y el método `plot' produce un
scree plot.
Valor: La función devuelve una lista de clase `'prcomp”, que contiene los siguientes
componentes:
• sdev: Las desviaciones estándar de las componentes principales, es decir, las raíces
cuadradas de los valores propios de la matriz de covarianza/correlación.
• rotation: La matriz de los loadings de las variables (es decir, una matriz cuyas
columnas son los vectores propios). La función princomp devuelve esto en el
elemento loadings'.
• x: Si `retx' es TRUE son devueltos los datos rotados (Los datos multiplicados por la
matriz de rotación).
Referencias:
• Mardia, K. V., J. T. Kent, and J. M. Bibby (1979) Multivariate Analysis, London:
Academic Press.
• Venables, W. N. and B. D. Ripley (1997, 9) Modern Applied Statistics with S-PLUS,
Springer-Verlag.
Ver también: `princomp', cor', cov', svd', `eigen'.
Ejemplos:
##Las varianzas en las variables en los datos

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 264/344
264
##USArrests varían por orden de magnitud, por
##tanto, escalar los datos resulta apropiado.
data(USArrests)
USArrests
Murder Assault UrbanPop Rape
Alabama 13.2 236 58 21.2
Alaska 10.0 263 48 44.5
Arizona 8.1 294 80 31.0
Arkansas 8.8 190 50 19.5
California 9.0 276 91 40.6
Colorado 7.9 204 78 38.7
Connecticut 3.3 110 77 11.1Delaware 5.9 238 72 15.8
Florida 15.4 335 80 31.9
Georgia 17.4 211 60 25.8
Hawaii 5.3 46 83 20.2
Idaho 2.6 120 54 14.2
Illinois 10.4 249 83 24.0
Indiana 7.2 113 65 21.0
Iowa 2.2 56 57 11.3
Kansas 6.0 115 66 18.0
Kentucky 9.7 109 52 16.3Louisiana 15.4 249 66 22.2
Maine 2.1 83 51 7.8
Maryland 11.3 300 67 27.8
Massachusetts 4.4 149 85 16.3
Michigan 12.1 255 74 35.1
Minnesota 2.7 72 66 14.9
Mississippi 16.1 259 44 17.1
Missouri 9.0 178 70 28.2
Montana 6.0 109 53 16.4
Nebraska 4.3 102 62 16.5Nevada 12.2 252 81 46.0
New Hampshire 2.1 57 56 9.5
New Jersey 7.4 159 89 18.8
New Mexico 11.4 285 70 32.1
New York 11.1 254 86 26.1
North Carolina 13.0 337 45 16.1

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 265/344
265
North Dakota 0.8 45 44 7.3
Ohio 7.3 120 75 21.4
Oklahoma 6.6 151 68 20.0Oregon 4.9 159 67 29.3
Pennsylvania 6.3 106 72 14.9
Rhode Island 3.4 174 87 8.3
South Carolina 14.4 279 48 22.5
South Dakota 3.8 86 45 12.8
Tennessee 13.2 188 59 26.9
Texas 12.7 201 80 25.5
Utah 3.2 120 80 22.9
Vermont 2.2 48 32 11.2
Virginia 8.5 156 63 20.7Washington 4.0 145 73 26.2
West Virginia 5.7 81 39 9.3
Wisconsin 2.6 53 66 10.8
Wyoming 6.8 161 60 15.6
library(mva)
prcomp(USArrests) # inapropiado
Standard deviations:
[1] 83.732400 14.212402 6.489426 2.482790
Rotation:
PC1 PC2 PC3 PC4
Murder -0.04170432 -0.04482166 0.07989066 0.99492173
Assault -0.99522128 -0.05876003 -0.06756974 -0.03893830
UrbanPop -0.04633575 0.97685748 -0.20054629 0.05816914
Rape -0.07515550 0.20071807 0.97408059 -0.07232502
prcomp(USArrests, scale = TRUE)
Standard deviations:
[1] 1.5748783 0.9948694 0.5971291 0.4164494
Rotation:
PC1 PC2 PC3 PC4
Murder -0.5358995 -0.4181809 0.3412327 -0.64922780
Assault -0.5831836 -0.1879856 0.2681484 0.74340748
UrbanPop -0.2781909 0.8728062 0.3780158 -0.13387773

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 266/344
266
Rape -0.5434321 0.1673186 -0.8177779 -0.08902432
plot(prcomp(USArrests))
summary(prcomp(USArrests, scale = TRUE))
Importance of components:
PC1 PC2 PC3 PC4
Standard deviation 1.57 0.995 0.5971 0.4164
Proportion of Variance 0.62 0.247 0.0891 0.0434
Cumulative Proportion 0.62 0.868 0.9566 1.0000
9.6.5 Función biplot.princomp
Esta función (disponible en librería mva) produce un biplot de los reultados del análisis de
componentes principales realizado con la función princomp.
biplot(x, choices = 1:2, scale = 1, pc.biplot = FALSE, ...)
Argumentos:
• x: Un objeto de clase `'princomp”.
• choices: Vector de longitud 2 para especificar las componentes a graficar.
• scale: Las variables son escaladas por `lambdascale' y las observaciones son
escaladas por `lambda(1-scale)', donde lambda son los valores singulares calculados por
princomp. Normalmente 0 scale 1, y una advertencia se exhibirá si `scale'
especificado está por fuera de rango.
• pc.biplot: Si es TRUE, usa biplot de componente principal, con las observaciones
escaladas por arriba por la raíz cuadrada de n y las variables escaladas por abajo por

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 267/344
267
la misma cantidad . Luego los productos internos de las covarianzas aproximadas de
las variables y las distancias entre la distancia de Mahalanobis aproximada de las
observaciones.
• ...: Argumentos gráficos opcionales.
Referencias:
• Gabriel, K. R. (1971). The biplot graphical display of matrices with applications to
principal component analysis. Biometrika, 58, 453-467.
• Gabriel, K. R. and Odoroff, C. L. (1990). Biplots in biomedical research. Statistics in
Medicine, 9, 469-485.
9.6.6 Función biplot
Realiza un biplot de datos multivariados sobre el dispositivo gráfico actual. Un biplot es un
gráfico que pretende presentar tanto las observaciones y las variables de una matriz de
datos multivariados sobre un mismo gráfico. Hay muchas variaciones de un biplot y quizá
la más ampliamente usada es la implementada en la función biplot.princomp.
biplot(x, ...)
biplot.default(x, y, var.axes = TRUE, col, cex = rep(par("cex"), 2),
xlabs = NULL, ylabs = NULL, expand = 1,
xlim = NULL, ylim = NULL, arrow.len = 0.1, ...)
Argumentos:

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 268/344
268
• x: Para `biplot', es un objeto ajustado. Para `biplot.default' es el primer conjunto de
puntos o una matriz de dos columnas, usualmente asociada con las observaciones.
• y: El segundo conjunto de puntos o una matriz de dos columnas, usualmente
asociada con las variables.
• var.axes: Si es igual a `TRUE' el segundo conjunto de puntos tiene filas
representándolas como ejes.
• col: Un vector de longitus 2 dando los colores para el primer y segundo conjunto de
puntos respectivamente (y de los correspondientes ejes). Si sólo se especifica un
coloreste será usado en ambos conjuntos.
• cex: Factor de expación de caracter usado para etiquetar los puntos. Las estiquetas
pueden ser de diferentes tamaños para los dos conjuntos proporcionando un vector de
longitud 2.
• xlabs: Un vector de cadena de caracteres para etiquetar el primer conjunto de
puntos. Por defecto usa el nombre de dimensión de la fila de `y', o 1:n si la
dimensión es 'NULL'.
• expand: Un factor de expansión para aplicar cuando se traza el segundo conjunto de
puntos en relación al primero. Puede utilizarse para obtener los dos conjuntos sobre
una escala físicamente comparable.
• arrow.len: Las longitudes de las puntas de flechas sobre los ejes en `var.axes'
Pueden suprimirse las puntas de flecha mediante `arrow.len = 0'.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 269/344
269
• xlim, ylim, ...: Parámetros gráficos.
Nota: La función biplot.default proporciona meramente el código subyacente
para graficar dos conjuntos de variables sobre la misma figura.
Autor: B.D. Ripley.
Referencias:
• K. R. Gabriel (1971). The biplot graphical display of matrices with application to
principal component analysis. Biometrika 58, 453-467.
• J.C. Gower and D. J. Hand (1996). Biplots. Chapman \& Hall.
Ejemplo:
data(USArrests)library(mva)
biplot(princomp(USArrests),cex=0.5,expand = 2.5,xlim=c(-0.6,0.4))

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 270/344
270
Figura 9.2: Gráfico Biplot de los datos en data(USArrest), en el análisis de
componentes principales
9.6.7 Función screeplot
Disponible en el paquete mva, realiza gráfico de las varianzas vs. el número de la
componente principal, con el fin de identificar el “codo” para decidir respecto al número de
componentes a dejar.
screeplot(x, npcs = min(10, length(x$sdev)), type = c("barplot",
"lines"), main = deparse(substitute(x)), ...)
Argumentos:
• x: un objeto de clase “ princomp”

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 271/344
271
• npcs: El número de componentes principales a graficar.
• type: El tipo de gráfico.
• main, ...: Parámetros gráficos.
Ejemplo:
library(mva)
data(USArrests)(pc.cr <- princomp(USArrests, cor = TRUE))
screeplot(pc.cr,type="lines")
Figura 9.3: Gráfico screeplot de los datos en data(USArrest), en el análisis de
componentes principales. Nos indica que las dos primeras componentes son
significativas.
9.6.8 Función factanal
Permite realizar análisis de factor mediante máxima verosimilitud, sobre una matriz de
covarianza o una matriz de datos. Disponible en le paquete mva.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 272/344
272
factanal(x, factors, data, covmat = NULL,
n.obs = NA, subset, na.action,
start = NULL, scores = c("none", "regression", "Bartlett"),rotation = "varimax", control = NULL, ...)
Argumentos:
• x: Una fórmula o una matriz numérica o un objeto que puede ser forzado a ser una
matriz numérica. factors: The number of factors to be fitted.
• data: Un data frame.
• covmat: Una matriz de covarianza, o una lista de covarianzas como la producida por
`cov.wt'.
• n.obs: El número de observaciones, usado si `covmat' es una matriz de covarianza.
• subset: Una especificación de los casos a usar, si `x' es usado como una matriz o
fórmula.
• na.action: El `na.action' a usar si `x' es usado como una fórmula.
• start: `NULL' o matriz de valores iniciales, con cada columna dando un conjunto
inicial de unicidades.
• scores: Tipo de scores a producir. Por defecto es ninguno, `'regression” da los
scores Thompson, `'Bartlett” da los scores mínimo cuadrados de Bartlett.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 273/344
273
• rotation: Caracter. `'none” o el nombre de una función a usar para rotar los factores:
será llamada con el primer argumento la matriz de loadings.
• control: Una lista de valores de control:
1. nstart: El número de valores de inicio a ser intentados si `start = NULL', por
defecto es 1.
2. trace logical: ¿Información de seguimiento de la salida? Por defecto es `FALSE'.
3. lower: El límite inferior para las unicidades durante la optimización. Debe ser
positivo, por defecto es 0.005.
4. opt: Una lista de valores de control a pasar al argumento `control' de `optim'.
5. rotate: Una lista de argumentos adicionales para la función de rotación.
• ...: Componentes de `control' pueden suministrarse como argumentos.
Detalles: El modelo de análisis de factor es x=Lambda f+e para un vector fila x de p
elementos, una matriz de loadings p x k un vector de scores de k elementos y un vector
de errores de p elementos. Excepto x ningún otro elemento es observado, los scores son
incorrelacionados y de varianza unitaria, y los errores son independientes con varianza , la
unicidad. Por tanto el análisis de factor en un modelo para la matriz de covarianza de x,
Sigma=Lambda'Lambda+Psi.
Las unicidades están restringidas al intervalo entre cero y 1, pero valores cercanos a cero
son problemáticos por lo que la optimización se hace con un valor frontera de

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 274/344
274
`control$lower'. Los scores pueden producirse si de da una matriz de datos. El primer
método usado es el método de regresión de Thomson (1951), el segundo es del método de
mínimos cuadrados ponderados de Bartlett (1937). Ambo se estiman los scores f no
observados.
Valor: Un objeto de clase “factanal” con los siguientes componentes:
• loadings: Una matriz de loadings, una columna por factor. Los factores se ordenan
en forma decreciente de las sumas de los cuadrados de los loadings, y dando el sigo
que hará que la suma de los loadings sea positiva.
• uniquenesses: Las unicidades calculadas.
• correlation: Matriz de correlación usada.
• criteria: Resultados de la optimización: el valor negativo del log de verosimilitud e
información en las iteraciones usadas.
• factors: El argumento `factors'.
• dof: El número de grados de libertad del modelo de análisis de factor.
• method: Siempre es “mle”.
• scores: Si son requeridos, Una matriz de scores.
• n.obs: El número de observaciones disponibles.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 275/344
275
• call: Coincide la llamada?.
Autor: B. D. Ripley
Ver: `print.loadings', varimax', princomp', `ability.cov'
Ejemplos:
library(mva)
# v2 es como v1 con ruido v2 is just v1 with noise,
# lo mismo para v4 vs. v3 y v6 vs. v5
# los últimos casos en cada vector sólo agregan ruido
# e introducen un múltiplo positivo
v1 <- c(1,1,1,1,1,1,1,1,1,1,3,3,3,3,3,4,5,6)
v2 <- c(1,2,1,1,1,1,2,1,2,1,3,4,3,3,3,4,6,5)
v3 <- c(3,3,3,3,3,1,1,1,1,1,1,1,1,1,1,5,4,6)
v4 <- c(3,3,4,3,3,1,1,2,1,1,1,1,2,1,1,5,6,4)
v5 <- c(1,1,1,1,1,3,3,3,3,3,1,1,1,1,1,6,4,5)
v6 <- c(1,1,1,2,1,3,3,3,4,3,1,1,1,2,1,6,5,4)
m1 <- cbind(v1,v2,v3,v4,v5,v6)
cor(m1)
v1 v2 v3 v4 v5 v6
v1 1.0000000 0.9393083 0.5128866 0.4320310 0.4664948 0.4086076
v2 0.9393083 1.0000000 0.4124441 0.4084281 0.4363925 0.4326113
v3 0.5128866 0.4124441 1.0000000 0.8770750 0.5128866 0.4320310
v4 0.4320310 0.4084281 0.8770750 1.0000000 0.4320310 0.4323259
v5 0.4664948 0.4363925 0.5128866 0.4320310 1.0000000 0.9473451
v6 0.4086076 0.4326113 0.4320310 0.4323259 0.9473451 1.0000000
#Rotación varimax
factanal(m1, factors=3)
Call:
factanal(x = m1, factors = 3)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 276/344
276
Uniquenesses:
v1 v2 v3 v4 v5 v60.005 0.101 0.005 0.224 0.084 0.005
Loadings:
Factor1 Factor2 Factor3
v1 0.184 0.943 0.268
v2 0.236 0.904 0.161
v3 0.210 0.234 0.947
v4 0.243 0.178 0.828
v5 0.881 0.240 0.286
v6 0.959 0.191 0.196
Factor1 Factor2 Factor3
SS loadings 1.889 1.887 1.800
Proportion Var 0.315 0.315 0.300
Cumulative Var 0.315 0.629 0.929
The degrees of freedom for the model is 0 and the fit was 0.4755
#Rotación promax
factanal(m1, factors=3, rotation="promax")
Call:
factanal(x = m1, factors = 3, rotation = "promax")
Uniquenesses:
v1 v2 v3 v4 v5 v6
0.005 0.101 0.005 0.224 0.084 0.005
Loadings:
Factor1 Factor2 Factor3v1 0.984
v2 0.951
v3 1.003
v4 0.867
v5 0.910
v6 1.033

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 277/344
277
Factor1 Factor2 Factor3
SS loadings 1.903 1.876 1.772
The degrees of freedom for the model is 0 and the fit was 0.4755
9.6.9 Función cancor
Esta función permite calcular las correlaciones canónicas entre dos matrices de datos. Está
disponible en el paquete mva. El análisis de correlación canónica busca combinaciones
lineales de las variables `y' las cuales son bien explicadas (lo cual es medido por las
correlaciones) por combinaciones lineales de las variables `x'. La relación es simétrica en
cuanto a que `también son explicadas'.
cancor(x, y, xcenter = TRUE, ycenter = TRUE)
Argumentos:
• x: Una matriz numérica de tamaño n× p1 que contiene las coordenadas x.
• y: Una matriz numérica de tamaño n× p1 que contiene las coordenadas y.
• xcenter: Un argumentológivo o un vector numérco de longitud p1 describiendo
cualquier centramiento a ser hecho sobre los valores de x antes del análisis. Si es
`TRUE' (el valor por defecto), las medias de las columnas son substraidas. Si es
`FALSE', no se ajustan las columnas. Cuando se especifica como un vector, los
valores de éste son substraidos de las columnas.
• ycenter: Semejante a `xcenter', pero sobre los valores de y.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 278/344
278
Valor: Una lista que contiene las siguientes componentes:
• cor: Las correlaciones.
• xcoef: Los coeficientes estimados para las variables `x'.
• ycoef: Los coeficientes estimados para las variables `y'.
• xcenter: Los valores usados para ajustar a las variables `x'.
• ycenter: Los valores usados para ajustar a las variables `y'.
Referencias:
• Hotelling H. (1936). Relations between two sets of variables. Biometrika, 28, 321-
327.
• Seber, G. A. F. (1984). Multivariate Observations. New York: Wiley, p. 506f.
Ejemplo:
data(LifeCycleSavings)
LifeCycleSavings
sr pop15 pop75 dpi ddpi
Australia 11.43 29.35 2.87 2329.68 2.87
Austria 12.07 23.32 4.41 1507.99 3.93
Belgium 13.17 23.80 4.43 2108.47 3.82
Bolivia 5.75 41.89 1.67 189.13 0.22
Brazil 12.88 42.19 0.83 728.47 4.56
Canada 8.79 31.72 2.85 2982.88 2.43
Chile 0.60 39.74 1.34 662.86 2.67

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 279/344
279
China 11.90 44.75 0.67 289.52 6.51
Colombia 4.98 46.64 1.06 276.65 3.08
Costa Rica 10.78 47.64 1.14 471.24 2.80Denmark 16.85 24.42 3.93 2496.53 3.99
Ecuador 3.59 46.31 1.19 287.77 2.19
Finland 11.24 27.84 2.37 1681.25 4.32
France 12.64 25.06 4.70 2213.82 4.52
Germany 12.55 23.31 3.35 2457.12 3.44
Greece 10.67 25.62 3.10 870.85 6.28
Guatamala 3.01 46.05 0.87 289.71 1.48
Honduras 7.70 47.32 0.58 232.44 3.19
Iceland 1.27 34.03 3.08 1900.10 1.12
India 9.00 41.31 0.96 88.94 1.54Ireland 11.34 31.16 4.19 1139.95 2.99
Italy 14.28 24.52 3.48 1390.00 3.54
Japan 21.10 27.01 1.91 1257.28 8.21
Korea 3.98 41.74 0.91 207.68 5.81
Luxembourg 10.35 21.80 3.73 2449.39 1.57
Malta 15.48 32.54 2.47 601.05 8.12
Norway 10.25 25.95 3.67 2231.03 3.62
Netherlands 14.65 24.71 3.25 1740.70 7.66
New Zealand 10.67 32.61 3.17 1487.52 1.76
Nicaragua 7.30 45.04 1.21 325.54 2.48Panama 4.44 43.56 1.20 568.56 3.61
Paraguay 2.02 41.18 1.05 220.56 1.03
Peru 12.70 44.19 1.28 400.06 0.67
Philippines 12.78 46.26 1.12 152.01 2.00
Portugal 12.49 28.96 2.85 579.51 7.48
South Africa 11.14 31.94 2.28 651.11 2.19
South Rhodesia 13.30 31.92 1.52 250.96 2.00
Spain 11.77 27.74 2.87 768.79 4.35
Sweden 6.86 21.44 4.54 3299.49 3.01
Switzerland 14.13 23.49 3.73 2630.96 2.70Turkey 5.13 43.42 1.08 389.66 2.96
Tunisia 2.81 46.12 1.21 249.87 1.13
United Kingdom 7.81 23.27 4.46 1813.93 2.01
United States 7.56 29.81 3.43 4001.89 2.45
Venezuela 9.22 46.40 0.90 813.39 0.53
Zambia 18.56 45.25 0.56 138.33 5.14

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 280/344
280
Jamaica 7.72 41.12 1.73 380.47 10.23
Uruguay 9.24 28.13 2.72 766.54 1.88
Libya 8.89 43.69 2.07 123.58 16.71Malaysia 4.71 47.20 0.66 242.69 5.08
pop <- LifeCycleSavings[, 2:3]
oec <- LifeCycleSavings[, -(2:3)]
library(mva)
cancor(pop, oec)
$cor
[1] 0.8247966 0.3652762
$xcoef
[,1] [,2]
pop15 -0.009110856 -0.03622206
pop75 0.048647514 -0.26031158
$ycoef
[,1] [,2] [,3]
sr 0.0084710221 3.337936e-02 -5.157130e-03
dpi 0.0001307398 -7.588232e-05 4.543705e-06
ddpi 0.0041706000 -1.226790e-02 5.188324e-02
$xcenter
pop15 pop75
35.0896 2.2930
$ycenter
sr dpi ddpi
9.6710 1106.7584 3.7576
Análisis de Agrupamientos (Cluster)
El análisis de agrupamientos tiene como objetivo agrupar objetos similares usando la
información obtenida de los objetos. Veamos algunas funciones.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 281/344
281
9.6.10 Función dist
Esta función calcula y devuelve la matriz de distancias usndo la medida de distancia para
calcular distancias entre las filas de una matriz de datos. Debe llamarse desde el paquete
mva.
dist(x, method = "euclidean", diag = FALSE, upper = FALSE)
print.dist(x, diag = NULL, upper = NULL, ...)
as.matrix.dist(x)
as.dist(m, diag = FALSE, upper = FALSE)
Argumentos:
• x: Una matriz o data frame.
• method: Medida de distancia a usar. “euclidean”(distancia euclidiana), “maximum”
distancia máxima), “manhattan” (distancia absoluta entre vectores), “canberra”
i i i i
i
x y x y + + + +
o “ binary” (aka asymmetric binary). Puede usarse cualquier
sustracción ambigua.
• diag: Argumento lógico que indica si la diagonal de la matriz de distancias deberá
ser impresa por `print.dist'.
• upper: Argumento lógico que indica si el triángulo superior de la matriz de
distancias deberá ser impresa por `print.dist'.
• m: Una matriz de distancias a ser convertida en un objeto “dist”.
• ...: Argumentos adicionale para el método `print'.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 282/344
282
Son permitidos valores faltantes, que son omitidos de los cálculos las filas donde ocurren.
si alguna columna es omitida en los cálculos con Euclidean, Manhattan o Canberra, la suma
es escalada proporcionalmente al número de columnas usadas. Las funciones
as.matrix.dist() y as.dist() se usan para convertir objetos de clase “dist” y
matrices de distancias convencionales.
Valor: Un objeto de clase “dist”: el triángulo inferior de la matriz de distancia guardado
por columnas en un sólo vector.
Referencias: Mardia, K. V., Kent, J. T. and Bibby, J. M. (1979) Multivariate Analysis.
London: Academic Press.
Ejemplos:
library(mva)
x <- matrix(rnorm(100), nrow=5)
dist(x)1 2 3 4
2 6.160498
3 6.626156 5.465186
4 7.123074 6.998268 6.137816
5 6.157322 6.196263 6.196402 6.013627
dist(x, diag = TRUE)
1 2 3 4 5
1 0.000000
2 6.160498 0.0000003 6.626156 5.465186 0.000000
4 7.123074 6.998268 6.137816 0.000000
5 6.157322 6.196263 6.196402 6.013627 0
dist(x, upper = TRUE)
1 2 3 4 5

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 283/344
283
1 6.160498 6.626156 7.123074 6.157322
2 6.160498 5.465186 6.998268 6.196263
3 6.626156 5.465186 6.137816 6.1964024 7.123074 6.998268 6.137816 6.013627
5 6.157322 6.196263 6.196402 6.013627
m <- as.matrix(dist(x))
m
1 2 3 4 5
1 0.000000 6.160498 6.626156 7.123074 6.157322
2 6.160498 0.000000 5.465186 6.998268 6.196263
3 6.626156 5.465186 0.000000 6.137816 6.196402
4 7.123074 6.998268 6.137816 0.000000 6.013627
5 6.157322 6.196263 6.196402 6.013627 0.000000
d <- as.dist(m)
d
1 2 3 4
2 6.160498
3 6.626156 5.465186
4 7.123074 6.998268 6.137816
5 6.157322 6.196263 6.196402 6.013627
print(d, digits = 3)
1 2 3 4
2 6.16
3 6.63 5.47
4 7.12 7.00 6.14
5 6.16 6.20 6.20 6.01
9.6.11 Función kmeans
Realiza clustering K-Means.
kmeans(x, centers, iter.max = 10)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 284/344
284
Argumentos:
• x: Una matrix de datos numérica o un objeto que puede ser forzado a matriz, tal
como un data frame con todas las columnas numéricas.
• centers: Puede ser el número de clusters o un conjunto de los centros de los clusters
iniciales. Si es lo primero, un conjunto aleatorio de filas en `x' son elegidas como los
centros iniciales.
• iter.max: El número máximo de iteraciones permitidas.
Detalles: Los datos dados por `x' son clustered por el algoritmo k-means basado en el
algoritmo de Hartigan and Wong (1979) . Cuando este finaliza, todos los centros de cluster
están en la media de sus conjuntos Voronoi (los conjuntos de puntos que están más cerca al
centro del cluster).
Valor: Una lista con los siguientes componentes:
• cluster: Un vector de enteros indicando el cluster en el cual quedó ubicado cada
punto.
• centers: Una matriz de centros de clusters.
• withinss: La suma de cuadrados dentro de cluster para cada cluster.
• size: El número de puntos en cada cluster.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 285/344
285
Referencias: Hartigan, J.A. and Wong, M.A. (1979). A K-means clustering algorithm.
Applied Statistics 28, 100-108.
Ejemplos:
# Un ejemplo en dos dimensiones
x <- rbind(matrix(rnorm(100, sd = 0.3), ncol = 2),
matrix(rnorm(100, mean = 1, sd = 0.3), ncol = 2))
library(mva)
cl <- kmeans(x, 2, 20)
cl
$cluster
[1] 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2
[38] 2 2 2 2 2 2 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
[75] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
$centers
[,1] [,2]
1 0.97672987 0.91615525
2 -0.05270322 0.03347406
$withinss
[1] 10.69373 7.91773
$size
[1] 52 48
plot(x, col = cl$cluster,pch=cl$cluster)
points(cl$centers, col = 1:2, pch = 20,cex=2)
data(LifeCycleSavings)
cl <- kmeans(LifeCycleSavings,2 , 20)
cl
$cluster
[1] 1 1 1 2 2 1 2 2 2 2 1 2 1 1 1 2 2 2 1 2 2 1 2 2 1 2 1 1 1 2 2 2 2 2 2 2 2 2
[39] 1 1 2 2 1 1 2 2 2 2 2 2

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 286/344
286
$centers
sr pop15 pop75 dpi ddpi
1 10.920556 26.13611 3.636111 2262.3750 3.2644442 8.968125 40.12594 1.537500 456.7241 4.035000
$withinss
[1] 7789032 2763898
$size
[1] 18 32
plot((LifeCycleSavings), col = cl$cluster,pch=cl$cluster)
data(USArrests)
cl <- kmeans(USArrests, 3, 20)
plot(USArrests, col = cl$cluster,pch=cl$cluster)
pairs(USArrests)
Figura 9.4: Clusters con kmeans aplicados sobre datos simulados bivariados

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 287/344
287
Figura 9.5: Gráfico de clusters de los datos en data(USArrest), en
el análisis con kmeans
9.6.12 Función hclust
Esta función (del paquete mva) realiza análisis de clustering jerárquico sobre un conjunto
de disimilaridades para los n objetos a ser clustered. Inicialmente cada objeto es asignado a
su propio cluster y luego el algoritmo procede iterativamente, en cada etapa juntando los
dos cluster más similares, continuando hasta que haya un sólo cluster. En cada etapa las
distancias entre clusters son recalculadas por la fórmula actualizada de disimilaridad de
Lance-Williams de acuerdo al método particular de clustering que se esté usando.
hclust(d, method = "complete", members=NULL)
plot(x, labels = NULL, hang = 0.1,
axes = TRUE, frame.plot = FALSE, ann = TRUE,

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 288/344
288
main = "Cluster Dendrogram",
sub = NULL, xlab = NULL, ylab = "Height", ...)
plclust(tree, hang = 0.1, unit = FALSE, level = FALSE, hmin = 0,square = TRUE, labels = NULL, plot. = TRUE,
axes = TRUE, frame.plot = FALSE, ann = TRUE,
main = "", sub = NULL, xlab = NULL, ylab = "Height")
Argumentos:
• d: Una estructura de disimilaridad como la producida por la función dist.
• method: El método de aglomeración a ser usado. Este podría ser uno de los
siguientes `ward', `single', `complete', `average', `mcquitty', `median' o `centroid'.
• members: `NULL' o un vector con longitud `d'.
• x, tree: Un objeto del tipo producido por `hclust'.
• hang: La fracción de la altura del gráfico par la cual las etiquetas deberían colgar
por debajo del resto del gráfico. Un valor negativo hará que las etiquetas cuelguen
debajo de cero.
• labels: Un vector de caracteres para las etiquetas de las hojas del árbol. Por defecto
toma los nombres de las filas o los números de las filas de los datos originales. Si
`labels=FALSE' no se colocan etiquetas.
• axes, frame.plot, ann: Argumentos lógicos como en `plot.default'.
• main, sub, xlab, ylab: Cadena de caracteres para `title'. `sub' and `xlab'.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 289/344
289
• ...: Argumentos gráficos adicionales. Ver par en ayuda del R.
• unit, level, hmin, square, plot.: Argumentos aún no implementados de `plclust'
para compatibilidad con S-plus.
Detalles:
Diferentes métodos de clustering son proporcionados. El método de mínima varianza de
Ward apunta a hallar clusters esféricos compactos. El método de linkeo completo halla
clusters similares. El método de linkeo único adopta la estrategia de clustering `amigos de
amigos'. Los otros métodos pueden considerarse como apuntando a clusters con
características entre los métodos de linkeo único y completos.
Si `members!=NULL', `d' es tomado como una matriz de disimilaridad entre clusters en
vez de disimilaridades entre individuos y `members' da el número de observaciones por
cluster. De esta forma el algoritmo de cluster jerárquico puede ser iniciado en la mitad del
dendrograma, es decir, con el fin de reconstruir la parte del árbol arriba del corte. Lasdisimilaridades entre cluster pueden calcularse eficientemente sólo para un número limitado
de combinaciones de distancia/linkeo, siendo la más simple de ellas la distancia euclidiana
cuadrada y el linkeo centroide. En este caso las disimilaridades entre clusters corresponden
a las distancias euclidianas cuadradas entre medias de clusters.
El algoritmo usado en hclust ordena los sub árboles de modo que el cluster más
apretado esté a la izquierda (el más reciente, anexo al sub árbol de la izquierda es un valor
inferior que el último anexo al sub árbol derecho). Las observaciones individuales son los
clusters más apretados posibles y las uniones incluyen dos observaciones colocadas en
orden según el número de su la secuencia de observación.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 290/344
290
Valor: La función produce un objeto de clase hclust que describe el árbol producido por el
proceso de clustering. Es una lista con los siguientes componentes:
• merge: Una matriz de n-1 por 2 . La fila de esta componente describe lasuniones de
clusters en el paso i del clustering. Si un elemento j en la fila es negativo, la
observación -j fue unida en esta etapa. Si j es positiva entonces la unión fue con el
cluster formado en la etapa j anterior del algoritmo. Así, entradas negativas en
`merge' indican aglomeraciones de individuos, y entradas positicas indican
aglomeraciones de no individuos.
• height: Un conjunto de of n-1 valores reales no decrecientes. La altura del
clustering, es decir, el valor del criterio asociado con el método de clustering para la
aglomeración particular.
• order: Un vector dando la permutación de las observaciones originales apropiada
para graficar, en el sentido de que un gráfico de cluster usando este ordenamiento y la
matriz `merge' no tendrá cruce de ramas.
• labels: Las etiquetas para cada uno de los objetos que están siendo clustered.
• call: La llamda que produjo el resultado.
• method: El método de cluster que ha sido usado.
• dist.method: La distancia usada para crear a `d' (únicamente es devuelta si el objeto
distancia tiene un atributo `method' ).

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 291/344
291
Hay un método `print' y `plot' para los objetos `hclust' . La función plclust() básicamente es la misma que el método plot, `plot.hclust', principalmente para
compatibilidad con S-plus.
Autor: Esta función está basada en el código fortran contribuido a STATLIB por F.
Murtagh.
Referencias:
• Everitt, B. (1974). Cluster Analysis. London: Heinemann Educ. Books.
• Hartigan, J. A. (1975). Clustering Algorithms. New York: Wiley.
• Sneath, P. H. A. and R. R. Sokal (1973). Numerical Taxonomy. San Francisco:
Freeman.
• Anderberg, M. R. (1973). Cluster Analysis for Applications. Academic Press: NewYork.
• Gordon, A. D. (1999). Classification. Second Edition. London: Chapman and Hall /
CRC
• Murtagh, F. (1985). “Multidimensional Clustering Algorithms”, in COMPSTAT
Lectures 4. Wuerzburg: Physica-Verlag .

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 292/344
292
9.6.13 Función cutree
Disponible en el paquete mva, permite cortar un árbol obtenido previamente con la fucnón
hclust, en varios grupos bien sea mediante la indicación del número de grupos deseados
o la altura del corte.
cutree(tree, k=NULL, h=NULL)
Argumentos:
• tree: Un árbol producido por `hclust'
• k: Un entero o un vector de enteros con el número deseado de grupos.
• h: Un número o vector con las alturas en donde el árbol deberá ser cortado.
Al menos uno de k' o `h' debe ser especificado. Si ambos son dados k' es considerado por encima de `h'.
Valor: Esta función devuelve un vector con los miembros de grupo si `k' o `h' son un
escalar, de otra forma devuelve una matriz con miembros de grupo, donde cada columna
corresponde a los elementos de `k' o `h' , respectivamente (los cuales son usados como
nombres de columna).
Ejemplos:
#require( ) también permite cargar paquetes
#como library( ):
require(mva)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 293/344
293
Loading required package: mva
[1] TRUE
data(USArrests)hc <- hclust(dist(USArrests), "ave")
plot(hc,cex=0.5,main="Dendrograma Cluster data USArrest\nmediante método
'average' ")
plot(hc, hang = -1,cex=0.5,main="Dendrograma Cluster data USArrest\nmediante
método 'average' ")
## Clusters usando el método centroide y la
##distancia euclidiana cuadrada. Corte del árbol
##en 10 clusters y reconstrucción de la parte
##superior del árbol desde los centros de clusters.
hc <- hclust(dist(USArrests)^2, "cen")memb <- cutree(hc, k = 10)
cent <- NULL
for(k in 1:10)
cent <- rbind(cent, colMeans(USArrests[memb == k, , drop = FALSE]))
cent
Murder Assault UrbanPop Rape
[1,] 11.471429 247.57143 74.28571 27.20000
[2,] 13.500000 267.00000 46.66667 28.03333
[3,] 9.950000 288.75000 77.00000 32.87500
[4,] 11.500000 195.33333 66.16667 27.43333[5,] 5.590000 112.40000 65.60000 17.27000
[6,] 15.400000 335.00000 80.00000 31.90000
[7,] 5.300000 46.00000 83.00000 20.20000
[8,] 2.688889 64.55556 50.66667 10.54444
[9,] 5.750000 156.75000 74.00000 19.40000
[10,] 13.000000 337.00000 45.00000 16.10000
hc1 <- hclust(dist(cent)^2, method = "cen", members = table(memb))
opar <- par(mfrow = c(1, 2))
plot(hc, labels = FALSE, hang = -1, main = "Árbol original")
plot(hc1, labels = FALSE, hang = -1, main = "Reinicio desde clusters 10 ")par(opar)
##Obteniendo varios agrupamientos simultáneamente:
hc <- hclust(dist(USArrests))
cutree(hc, k=1:5)#k = 1 es trivial
1 2 3 4 5
Alabama 1 1 1 1 1

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 294/344
294
Alaska 1 1 1 1 1
Arizona 1 1 1 1 1
Arkansas 1 2 2 2 2California 1 1 1 1 1
Colorado 1 2 2 2 2
Connecticut 1 2 3 3 3
Delaware 1 1 1 1 1
Florida 1 1 1 4 4
Georgia 1 2 2 2 2
Hawaii 1 2 3 3 5
Idaho 1 2 3 3 3
Illinois 1 1 1 1 1
Indiana 1 2 3 3 3Iowa 1 2 3 3 5
Kansas 1 2 3 3 3
Kentucky 1 2 3 3 3
Louisiana 1 1 1 1 1
Maine 1 2 3 3 5
Maryland 1 1 1 1 1
Massachusetts 1 2 2 2 2
Michigan 1 1 1 1 1
Minnesota 1 2 3 3 5
Mississippi 1 1 1 1 1Missouri 1 2 2 2 2
Montana 1 2 3 3 3
Nebraska 1 2 3 3 3
Nevada 1 1 1 1 1
New Hampshire 1 2 3 3 5
New Jersey 1 2 2 2 2
New Mexico 1 1 1 1 1
New York 1 1 1 1 1
North Carolina 1 1 1 4 4
North Dakota 1 2 3 3 5Ohio 1 2 3 3 3
Oklahoma 1 2 2 2 2
Oregon 1 2 2 2 2
Pennsylvania 1 2 3 3 3
Rhode Island 1 2 2 2 2
South Carolina 1 1 1 1 1

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 295/344
295
South Dakota 1 2 3 3 5
Tennessee 1 2 2 2 2
Texas 1 2 2 2 2Utah 1 2 3 3 3
Vermont 1 2 3 3 5
Virginia 1 2 2 2 2
Washington 1 2 2 2 2
West Virginia 1 2 3 3 5
Wisconsin 1 2 3 3 5
Wyoming 1 2 2 2 2
#Cortando el árbol en la altura 250:
cutree(hc, h=250)
Alabama Alaska Arizona Arkansas California1 1 1 2 1
Colorado Connecticut Delaware Florida Georgia
2 2 1 1 2
Hawaii Idaho Illinois Indiana Iowa
2 2 1 2 2
Kansas Kentucky Louisiana Maine Maryland
2 2 1 2 1
Massachusetts Michigan Minnesota Mississippi Missouri
2 1 2 1 2
Montana Nebraska Nevada New Hampshire New Jersey2 2 1 2 2
New Mexico New York North Carolina North Dakota Ohio
1 1 1 2 2
Oklahoma Oregon Pennsylvania Rhode Island South Carolina
2 2 2 2 1
South Dakota Tennessee Texas Utah Vermont
2 2 2 2 2
Virginia Washington West Virginia Wisconsin Wyoming
2 2 2 2 2
## Comparando los agrupamientos en 2 y 4:g24 <- cutree(hc, k = c(2,4))
g24
2 4
Alabama 1 1
Alaska 1 1
Arizona 1 1

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 296/344
296
Arkansas 2 2
California 1 1
Colorado 2 2Connecticut 2 3
Delaware 1 1
Florida 1 4
Georgia 2 2
Hawaii 2 3
Idaho 2 3
Illinois 1 1
Indiana 2 3
Iowa 2 3
Kansas 2 3Kentucky 2 3
Louisiana 1 1
Maine 2 3
Maryland 1 1
Massachusetts 2 2
Michigan 1 1
Minnesota 2 3
Mississippi 1 1
Missouri 2 2
Montana 2 3Nebraska 2 3
Nevada 1 1
New Hampshire 2 3
New Jersey 2 2
New Mexico 1 1
New York 1 1
North Carolina 1 4
North Dakota 2 3
Ohio 2 3
Oklahoma 2 2Oregon 2 2
Pennsylvania 2 3
Rhode Island 2 2
South Carolina 1 1
South Dakota 2 3
Tennessee 2 2

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 297/344
297
Texas 2 2
Utah 2 3
Vermont 2 3Virginia 2 2
Washington 2 2
West Virginia 2 3
Wisconsin 2 3
Wyoming 2 2
table(g24[,"2"], g24[,"4"])
1 2 3 4
1 14 0 0 2
2 0 14 20 0
Figura 9.6: Efecto de la función cutree sobre un dendrograma

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 298/344
298
Figura 9.7: Efecto del argumento hang=-1, en el plot del dendrograma: Observe
la organización de las etiquetas debajo de cada rama

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 299/344
299
A continuación presentamos un conjunto de funciones para realizar pruebas corrientes en
análisis multivariable.
#Esta funcion realiza una prueba de Hotelling para Ho:u1=u2
# muestras independientes, normales y con igual dispersion
d2.T2<-function(X, Y, alpha)
{
n1 <- nrow(X)
n2 <- nrow(Y)
if(ncol(X) != ncol(Y))
byrow = T)
cat("\n")
cat("Vector de Medias de la Primera Muestra",
"\n")
cat("======================================",
"\n")
cat(media.x, "\n")
media.y <- matrix(apply(Y, 2, mean), ncol = 1,
byrow = T)
cat("\n")
cat("Vector de Medias de la Segunda Muestra",
"\n")
cat("======================================",
"\n")
cat(media.y, "\n")
cat("\n")
dif <- media.x - media.y
t2.c <- (n1 * n2)/(n1 + n2) * t(dif) %*% solve(
cov.p) %*% dif
cat("T2 calculado", "\n")
cat("============", "\n")
cat(t2.c, "\n")
cat("\n")
t2.critico <- (d * (n1 + n2 - 2))/(n1 + n2 - d -
1) * qf(1-alpha, d, n1 + n2 - d - 1)
cat("T2 critico a un nivel ", alpha, "\n")
cat("==============================", "\n")

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 300/344
300
cat(t2.critico, "\n")
cat("\n")
decision <- "Rechazamos Ho"if(t2.c < t2.critico)
decision <- "No rechazamos Ho"
cat("============DECISION==================",
"\n")
cat(decision, "\n")
cat("======================================",
"\n")
invisible()
}
# Analisis de Perfiles
# ====================
perfiles.grafico<-function(X,Y){
n1 <- nrow(X)
n2 <- nrow(Y)
if(ncol(X) != ncol(Y))
stop("El numero de variables es diferente!!!"
)d <- ncol(X)
win.graph()
media.x <- matrix(apply(X, 2, mean), ncol = 1,
byrow = T)
media.y <- matrix(apply(Y, 2, mean), ncol = 1,
byrow = T)
variables<-1:d
x<-cbind(media.x,media.y)
x1<-min(x)
x2<-max(x)plot(variables,media.x,type="l",ylim=c(x1,x2))
title(main="Grafico de Perfiles",sub="variables")
par(new=T)
plot(variables,media.y,type="l",ylab="",xlab=" ")
}

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 301/344
301
perfiles.paralelo<-function(X,Y,alpha){
n1 <- nrow(X)n2 <- nrow(Y)
if(ncol(X) != ncol(Y))
stop("El numero de variables es diferente!!!"
)
d <- ncol(X)
q<-d-1
cov.p <- ((n1 - 1) * var(X) + (n2 - 1) * var(Y))/(
n1 + n2 - 2)
cat("Matriz de Covarianzas Mezcladas", "\n")
cat("===============================", "\n")cat(cov.p, "\n")
c1<-cbind(matrix(rep(1,d-1),ncol=1),as.matrix(diag(rep(-1,d-1))))
n1 <- nrow(X)
n2 <- nrow(Y)
if(ncol(X) != ncol(Y))
stop("El numero de variables es diferente!!!"
)
d <- ncol(X)
cat("\n")cat("Vector de Medias de la Primera Muestra",
"\n")
cat("======================================",
"\n")
media.x <- matrix(apply(X, 2, mean), ncol = 1,
byrow = T)
cat(media.x, "\n")
media.y <- matrix(apply(Y, 2, mean), ncol = 1,
byrow = T)cat("\n")
cat("Vector de Medias de la Segunda Muestra",
"\n")
cat("======================================",
"\n")
cat(media.y, "\n")

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 302/344
302
cat("\n")
dif <- media.x - media.y
t2.c <- (n1 * n2)/(n1 + n2) * t(c1%*%dif) %*% solve(c1%*%cov.p%*%t(c1)) %*% c1%*%dif
cat("T2 calculado", "\n")
cat("============", "\n")
cat(t2.c, "\n")
cat("\n")
t2.critico <- (q * (n1 + n2 - 2))/(n1 + n2 - q -
1) * qf(1-alpha, q, n1 + n2 - q - 1)
cat("T2 critico a un nivel ", alpha, "\n")
cat("==============================", "\n")
cat(t2.critico, "\n")cat("\n")
decision <- "Rechazamos Ho:Perfiles paralelos"
if(t2.c < t2.critico)
decision <- "No rechazamos Ho:Perfiles paralelos"
cat("============DECISION==================",
"\n")
cat(decision, "\n")
cat("======================================",
"\n")
invisible()}
perfiles.iguales<-function(X,Y,alpha){
n1 <- nrow(X)
n2 <- nrow(Y)
if(ncol(X) != ncol(Y))
stop("El numero de variables es diferente!!!"
)
d <- ncol(X)q<-d-1
cov.p <- ((n1 - 1) * var(X) + (n2 - 1) * var(Y))/(
n1 + n2 - 2)
cat("Matriz de Covarianzas Mezcladas", "\n")
cat("===============================", "\n")
cat(cov.p, "\n")

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 303/344
303
c1<-matrix(rep(1/d,d),nrow=1)
media.x <- matrix(apply(X, 2, mean), ncol = 1,byrow = T)
cat("\n")
cat("Vector de Medias de la Primera Muestra",
"\n")
cat("======================================",
"\n")
cat(media.x, "\n")
media.y <- matrix(apply(Y, 2, mean), ncol = 1,
byrow = T)
cat("\n")cat("Vector de Medias de la Segunda Muestra",
"\n")
cat("======================================",
"\n")
cat(media.y, "\n")
cat("\n")
dif <- media.x - media.y
t2.c <- (n1 * n2)/(n1 + n2) * t(c1%*%dif) %*% solve(
c1%*%cov.p%*%t(c1)) %*% c1%*%dif
cat("T2 calculado", "\n")cat("============", "\n")
cat(t2.c, "\n")
cat("\n")
t2.critico <- (1*(n1 + n2 - 2))/(n1 + n2 - 1-
1) * qf(1-alpha, 1, n1 + n2 - q - 1)
cat("T2 critico a un nivel ", alpha, "\n")
cat("==============================", "\n")
cat(t2.critico, "\n")
cat("\n")
decision <- "Rechazamos Ho:Igual Nivel"if(t2.c < t2.critico)
decision <- "No rechazamos Ho:Igual Nivel"
cat("============DECISION==================",
"\n")
cat(decision, "\n")
cat("======================================",

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 304/344
304
"\n")
invisible()
}
perfiles.promedio<-function(X,Y,alpha){
n1 <- nrow(X)
n2 <- nrow(Y)
if(ncol(X) != ncol(Y))
stop("El numero de variables es diferente!!!"
)
d <- ncol(X)
q<-d-1cov.p <- ((n1 - 1) * var(X) + (n2 - 1) * var(Y))/(
n1 + n2 - 2)
cat("Matriz de Covarianzas Mezcladas", "\n")
cat("===============================", "\n")
cat(cov.p, "\n")
c1<-cbind(matrix(rep(1,d-1),ncol=1),as.matrix(diag(rep(-1,d-1))))
media.x <- matrix(apply(X, 2, mean), ncol = 1,
byrow = T)
cat("\n")cat("Vector de Medias de la Primera Muestra",
"\n")
cat("======================================",
"\n")
cat(media.x, "\n")
media.y <- matrix(apply(Y, 2, mean), ncol = 1,
byrow = T)
cat("\n")
cat("Vector de Medias de la Segunda Muestra",
"\n")cat("======================================",
"\n")
cat(media.y, "\n")
cat("\n")
dif <- media.x + media.y
t2.c <- (n1 * n2)/(n1 + n2) * t(c1%*%dif) %*% solve(

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 305/344
305
c1%*%cov.p%*%t(c1)) %*% c1%*%dif
cat("T2 calculado", "\n")
cat("============", "\n")cat(t2.c, "\n")
cat("\n")
t2.critico <- (q * (n1 + n2 - 2))/(n1 + n2 - q -
1) * qf(1-alpha, q, n1 + n2 - q - 1)
cat("T2 critico a un nivel ", alpha, "\n")
cat("==============================", "\n")
cat(t2.critico, "\n")
cat("\n")
decision <- "Rechazamos Ho:Promedios Iguales"
if(t2.c < t2.critico)decision <- "No rechazamos Ho:Promedios Iguales"
cat("============DECISION==================",
"\n")
cat(decision, "\n")
cat("======================================",
"\n")
invisible()
}
# Determinante de una matrixdeterminante<-function(A){
if(ncol(A)!=nrow(A)) stop("Matriz no es cuadrada!")
y<-eigen(A)
det<-prod(y$values)
det
}
# Pruebas para matrices de covarianzas
independencia.covarianzas<-function(X,c1,c2,alpha){
Sigma<-var(X)Sigma1<-Sigma[c1,c1]
Sigma2<-Sigma[c2,c2]
d<-determinante(Sigma)
if(d==0) stop("Covarianza no singular")
d1<-determinante(Sigma1)
d2<-determinante(Sigma2)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 306/344
306
lambda<-d/(d1*d2)
gl<-nrow(Sigma1)*nrow(Sigma2)
chi.c<- -(nrow(X)-0.5*(nrow(Sigma1)+nrow(Sigma2))-1.5)*log(lambda)chi.critico<-qchisq(1-alpha,gl)
valor.p<-1-pchisq(chi.c,gl)
cat("Matriz de Dispersion Estimada para el Primer Grupo","\n")
cat(" de Variables","\n")
cat(Sigma1,"\n")
cat("\n")
cat("Matriz de Dispersion Estimada para el Segundo Grupo","\n")
cat(" de Variables","\n")
cat(Sigma1,"\n")
cat("\n")cat("Resultados de la Prueba Ho:Los dos bloques de variables","\n")
cat(" son independientes","\n")
cat("*******************************************************","\n")
cat("Chi-cuadrado calculado: ",chi.c,"\n")
cat("Chi-cuadrado critico: ",chi.critico,"\n")
cat("Valor p: ",valor.p,"\n")
}
9.7. Análisis de Datos Categóricos
9.7.1 Función cut:
Nos permite categorizar una variable continua. Acepta tanto un vector de puntos de corte
que definen las categorias o un entero que indica cuantas clases queremos y la función
automáticamente halla los puntos de corte equiespaciados. Esta función permite partir un
vector de datos en grupos con igual amplitud, por ejemplo,
>edad<-c(22,31,37,23,22,35,23,19,42,35,33,36,18)
>cut(edad,breaks=3)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 307/344
307
Si deseamos que los puntos de corte sean con un formato presentable, podemos usar la
función pretty()
>cut(edad,pretty(edad))
La sintaxis general es:
cut(x, ...)
cut.default(x, breaks, labels = NULL,
include.lowest = FALSE, right = TRUE, dig.lab = 3, ...)
Argumentos:
• x: Un vector numérico a ser convertido en factor con cut.
• breaks: Puede ser un vector con puntos de corte o un número indicando el número
de intervalos en los cuales se ha de dividir a `x'.
• labels: Etiquetas para los niveles de la categoría resultante. Por defecto las etiquetas
son de la forma “(a,b]”. Si `labels = FALSE', se usan códigos enteros.
• include.lowest: Argumento lógico. Si s `TRUE', un valor igual al punto de corte es
incluido en el intervalo.
• right: rgumento lógico para indicar si los intervalos deben ser cerrados a la derecha
y abiertos a la izquierda o vice versa.
• dig.lab: Entero usado cuando no se dan etiquetas. Indica el número de dígitos a usar
en el formato de los números de corte.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 308/344
308
• ...: Argumentos adicionales pasados a o desde otros métodos.
Valor: La función devuelve un factor, a menos que `labels = FALSE' en cuyo caso sólo
devuelve los códigos enteros de los niveles.
Nota: `hist(x, br, plot = FALSE)' es más eficiente y usa menos memoria
que `table(cut(x, br))'.
Ver también: `split', factor', tabulate', table'.
Ejemplos:
Z <- round(rnorm(10000),digits=0)
table(cut(Z, br = -3:3))
(-3,-2] (-2,-1] (-1,0] (0,1] (1,2] (2,3]
590 2431 3842 2378 623 76
table(cut(Z, br = -3:3,right = FALSE))
[-3,-2) [-2,-1) [-1,0) [0,1) [1,2) [2,3)56 590 2431 3842 2378 623
## Modificando eqtiquetas:
y <- rnorm(100)
table(cut(y, breaks = pi/3*(-3:3)))
(-3.14,-2.09] (-2.09,-1.05] (-1.05,0] (0,1.05] (1.05,2.09]
1 12 46 31 7
(2.09,3.14]
3
table(cut(y, breaks = pi/3*(-3:3), dig.lab=4))
(-3.142,-2.094] (-2.094,-1.047] (-1.047,0] (0,1.047] (1.047,2.094]1 12 46 31 7
(2.094,3.142]
3

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 309/344
309
9.7.2 Función table:
Esta función permite crear una tabla de contingencia. Por ejemplo,
>edad<-c(22,31,37,23,22,35,23,19,42,35,33,36,18)
>table(cut(edad,breaks=3))
Otro ejemplo un poco más elaborado es el siguiente, en el cual se hace una tabla de doble
entrada contando con el sexo:
>sexo<-factor(c(1,2,1,2,2,1,1,1,2,2,1,1,2),
labels=c(“Mujer”,”Hombre”))
>table(cut(edad,breaks=3),sexo)
9.7.3 Función levels
Proporciona acceso a los atributos de nivel de una variable. La primera devuelve el valor de
los niveles y la segunda ajusta el atributo. La forma de asignación levels<- es unafunción genérica y nuevos métodos pueden ser escritos para éste.
levels(x)
levels(x) <- value
x es un objeto, como un factor.
9.7.4 Función factor
La función factor se usa para codificar un como factor. `is.factor',
`is.ordered', `as.factor' and `as.ordered' son las funciones miembro y de coerción para
estas clases de objetos.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 310/344
310
factor(x, levels = sort(unique(x), na.last = TRUE),
labels = levels,exclude = NA, ordered = is.ordered(x))
ordered(x, ...)is.factor(x)
is.ordered(x)
as.factor(x)
as.ordered(x)
Argumentos:
• x: Un vector de datos (no tiene restricción respecto al tipo).
• levels: Un vector opcional con los valores que debió tomar `x'. El valor por defecto
son los valores de `x', ordenados en forma creciente.
• labels: Un vectro opcioanl de etiquetas para los niveles, en el orden de `levels'
después de remover aquellos en `exclude', o una cadena de caracteres de longitud 1.
• exclude: Vector con valores a excluir cuando se forme el conjunto de niveles. Debe
ser del mismo tipo de `x', y si no será forzado de ser necesario.
• ordered: Argumento lógico para indicar si los niveles deben ser considerados como
ordenados en el orden dado.
• ...: Cualquiera de los anteriores para la función `ordered'.
Debe tenerse en cuenta que los factore y los factores ordenados difieren sólo en sus clase,
pero los métodos y las funciones de ajuste de modelos tratan a ambos de modo muy
diferente.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 311/344
311
Si `factor(x)' es aplicado a un factor no hará nada a menos que hayan niveles no usados, en
este caso es devuelto un factor con nivel reducido.
Valor: `factor' produce un objeto de clase “factor ”, que tiene un conjunto de códigos
numéricos de la misma longitud de `x' con unos atributos “levels” de modo `character'. Si
`ordered' es TRUE, el resultado tiene clase `c(“ordered”, “factor ”)'.
`is.factor' devuelve un TRUE o FALSE dependiendo de si el argumento es o no un factor.
`is.ordered' devuelve un TRUE o un FALSE dependiendo de si el argumento está o no
ordenado.
`as.factor'forza a su argumento a ser un factor.
`as.ordered(x)' devuelve a `x' si este está ordenado, y `ordered(x)' en caso contrario.
Ver también: `gl' para construir factores balanceados y `C' para factores con contrastes
específicos. `levels' y `nlevels' para accesar a niveles y `codes' para ontener códigosenteros.
9.7.5 Función binom.test:
Permite realizar pruebas de hipótesis exactas acerca de (probabilidad de éxito) en una
población dicótoma.
binom.test(x, n, p = 0.5,alternative = c("two.sided", "less",
"greater"),conf.level = 0.95)
Argumentos:

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 312/344
312
• x: Número de éxito o un vector de longitud 2 dando el número de éxitos y fracasos.
• n: Número de ensayos; es ignorado si `x' tiene longitud 2.
• p: Probabilidad de éxito hipotetizada.
• alternative: La hipótesis alternativa y debe ser una de las siguientes “two.sided”,
“greater ”, “less”.
• conf.level: Nivel de confianza para el intervalo devuelto.
Los intervalos de confianza son obtenidos según procedimiento dado en Clopper and
Pearson (1934) que garantizan que el nivel de confianza es al menos el especificado pero
no dan los intervalos de confianza más cortos.
Valor:
Una lista con clase “htest” con los siguientes componentes:
• statistic: El número de éxitos.
• parameter: El número de ensayos.
•
p.value: El valor p de la prueba.
• conf.int: Un intervalo de confianza para la probabilidad de éxito.
• estimate: La probabilidad de éxito estimada.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 313/344
313
• null.value: La probabilidad de éxito bajo la hipótesis nula.
• alternative: Cadena de caracteres que describen la hipótesis alternativa.
• method: La cadena de caracteres “Exact binomial test”.
• data.name: Cadena de caracter que da el nombre de los datos.
Referencias:
• Clopper, C. J. \& Pearson, E. S. (1934). The use of confidence or fiducial limits
illustrated in the case of the binomial. Biometrika, 26, 404-413.
• Conover, W. J. (1971), Practical nonparametric statistics. New York: John Wiley \&
Sons. Pages 97-104.
• Myles Hollander \& Douglas A. Wolfe (1973), Nonparametric statistical inference. New York: John Wiley \& Sons. Pages 15-22.
Ver también: `prop.test' para una prueba general aproximada para igualdad de
proporciones.
Ejemplos:
library(ctest)
#Prueba bilateral
binom.test(42,100,p=0.5)
Exact binomial test
data: 42 and 100
number of successes = 42, number of trials = 100, p-value = 0.1332

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 314/344
314
alternative hypothesis: true probability of success is not equal to 0.5
95 percent confidence interval:
0.3219855 0.5228808sample estimates:
probability of success
0.42
#Solicitando el valor p:
binom.test(42,100,p=0.5)$p.value
#Prueba de cola izquierda:
binom.test(42,100,p=0.5,alt='l')
Exact binomial test
data: 42 and 100
number of successes = 42, number of trials = 100, p-value = 0.0666alternative hypothesis: true probability of success is less than 0.5
95 percent confidence interval:
0.0000000 0.5071585
sample estimates:
probability of success
0.42
#Prueba de cola derecha:
binom.test(42,100,p=0.5,alt='g')
Exact binomial test
data: 42 and 100number of successes = 42, number of trials = 100, p-value = 0.9557
alternative hypothesis: true probability of success is greater than 0.5
95 percent confidence interval:
0.3364797 1.0000000
sample estimates:
probability of success
0.42
#calculando un intervalo de
#confianza del 90%:
binom.test(42,100,p=0.5,conf.level=0.9)$conf.int[1] 0.3364797 0.5071585
attr(,"conf.level")
[1] 0.9
#Intervalo de confianza aproximado
#del 90%:
prop.test(42,100,p=0.5,conf.level=0.9)$conf.int

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 315/344
315
[1] 0.3372368 0.5072341
attr(,"conf.level")
[1] 0.9
9.7.6 Función loglin
Esta función es usada para ajustar modelos log lineales a tablas de contingencia
multidimensionales mediante ajuste proporcional iterativo.
loglin(table, margin, start = rep(1, length(table)), fit = FALSE,
eps = 0.1, iter = 20, param = FALSE, print = TRUE)
Argumentos:
• table: Una tabla de contingencia obtenida típicamente con table.
• margin: Una lista de vectores con los totales marginales a ser ajustados. Los
modelos log lineales pueden especificarse en términos de estos totales marginalesdando los subconjuntos factor “maximal” contenidos en el modelo. Por ejemplo,
`list(c(1, 2), c(1, 3))' especifica, en un modelo de tres factores, que el modelo contiene
parámetros para la gran media en cada factor, y las interaciones 1-2 y 1-3 (un modelo
donde los factores 2 y 3 son independientes dado el factor 1). Pueden usarse los
nombres de los factores.
•
start: Argumento opcional que da una estimación inicial para la tabla ajustada. Esútil para tablas incompletas con estructura de ceros en `table'. En este caso, las
entradas en `start' deberán ser cero y ls otras pueden ser uno.
• fit: Argumento lógico para indicar si los valores ajustados deben ser devueltos.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 316/344
316
• eps: Desviación máxima permitida entre los márgenes observados y ajustados.
• iter: Número máximo de iteraciones.
• param: Argumento lógico para indicar si los valores de los parámetros deben ser
devueltos.
• print: Argumento lógico. Si es `TRUE', el número de iteraciones y la desviación
final son devueltos.
Si no hay ceros estructurales los estadísticos de razón de verosimilitud y el estadístico de
prueba de pearson tiene distribuc\i'on asintótica ji cuadrado.
Valor: Una lista con los siguientes componentes:
• lrt: Estadístico de prueba de razón de verosimilitud.
• pearson: el estadístico de prueba de Pearson.
• df: Los grados de libertad para el modelo ajustado. No hay ajuste para ceros
estructurales.
• margin: Lista de las márgenes que fueron ajustadas. Básicamente las mismas a la
entrada de `margin', pero con los números reemplazados por nombres cuando esto es posible.
• fit: Un arreglo que contiene los valores ajustados. Sólo es devuelto si `fit' es TRUE.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 317/344
317
• param: Una lista con los parámetros estimados del modelo. Sólo es devuelta si
`param' es TRUE.
Ejemplos:
data(HairEyeColor)
>HairEyeColor
, , Sex = Male
Eye
Hair Brown Blue Hazel Green
Black 32 11 10 3
Brown 38 50 25 15
Red 10 10 7 7
Blond 3 30 5 8
, , Sex = Female
Eye
Hair Brown Blue Hazel Green
Black 36 9 5 2
Brown 81 34 29 14
Red 16 7 7 7
Blond 4 64 5 8
## Modelo de la independencia conjunta de
##sexo de cabello y color ojos:
fm <-loglin(HairEyeColor, list(c(1, 2), c(1, 3), c(2, 3)))
fm
$lrt
[1] 8.187009
$pearson
[1] 8.50081
$df
[1] 9
$margin
$margin[[1]]
[1] "Hair" "Eye"

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 318/344
318
$margin[[2]]
[1] "Hair" "Sex"
$margin[[3]][1] "Eye" "Sex"
##El modelo sin interacción
##de los tres factores ajusta bien:
1 - pchisq(fm$lrt, fm$df)
[1] 0.5154158
Considere la siguiente tabla de frecuencias
Factor B
Factor 222 115
A 240 185
y suponga queremos ajustar un modelo log-lineal saturado y obtener los parámetros del
modelo, las instrucciones son:
frecuencias.obs<-matrix(c(222,115,240,185), ncol=2,byrow=T)
loglin(frecuencias.obs,list(1:2),fit=T,param=T)
2 iterations: deviation 0
$lrt
[1] 0
$pearson
[1] 0
$df
[1] 0
$margin
$margin[[1]]
[1] 1 2
$fit
[,1] [,2]

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 319/344
319
[1,] 222 115
[2,] 240 185
$param$param$"(Intercept)"
[1] 5.212151
$param$"1"
[1] -0.1383463 0.1383463
$param$"2"
[1] 0.2295071 -0.2295071
$param$"1.2"
[,1] [,2]
[1,] 0.09936554 -0.09936554
[2,] -0.09936554 0.09936554
la opción fit=T nos presenta la tabla de valores esperados bajo el modelo y param=T nos da los valores estimados del modelo que ajustamos.Si queremos ajustar un modelo de
independencia, la instrucción es
> loglin(frecuencias.obs,list(1,2),fit=T,param=T)
Si queremos un modelo donde no hay efecto de A
> loglin(frecuencias.obs,list(1),fit=T,param=T)
Como se observa con la opción list() nosotros introducimos el modelo a ser estimado.
9.7.7 Función split
Permite dividir los datos de un vector `x' en grupos definidos por `f'. Las formas de
asignación reemplazan los valores correspondientes a tal división. unsplit reversa el
efecto de split.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 320/344
320
split(x, f)
split.default(x, f)
split.data.frame(x, f)split(x, f) <- value
split.default(x, f) <- value
split.data.frame(x, f) <- value
unsplit(value, f)
Argumentos:
• x: Vector o marco de datos con los valores a ser divididos en grupos.
• f: Un factor tal que `factor(f)' define el agrupamiento, o una lista de tales factores
cuyo caso sus interacciones son usadas para el agrupamiento.
• value: Una lista de vectores o data frames compatible con un splitting de `x'.
`unsplit' sólo funciona con listas de vectores. El método data frame puede usarse también
para particionar una matriz en una lista de matrices.
Valor: Esta función produce una lista de vectores que contienen los valores para los
grupos. Los componentes de la lista son denominados por los niveles de factor dados por
`f'. Si `f' es de mayor longitud que `x' algunos de estos valores serán de longitud cero.
Ejemplos:
n <- 10
nn <- 100
##generando un vector, aleatoriamente
##con los números que identifican
##el nivel del factor al que pertenecen cada una de

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 321/344
321
##1000 observaciones. Los niveles
##numerados de 0 a 10.
g <- factor(round(n * runif(n * nn)))
##Definiendo el vector de valores a
##particionar en 11 grupos:
x <- rnorm(n * nn) + sqrt(as.numeric(g))
##Particionando el vector x de acuerdo
##a la asignación de factores en g:
xg <- split(x, g)
boxplot(xg, col = "lavender", notch = TRUE, varwidth = TRUE)sapply(xg, length)
0 1 2 3 4 5 6 7 8 9 10
54 114 74 103 112 107 75 100 103 111 47
sapply(xg, mean)
0 1 2 3 4 5 6
0.8842438 1.4449423 1.7574916 1.9668411 2.2904859 2.4450622 2.5734979
7 8 9 10
2.7544654 2.9478100 3.3161729 3.0368155
##o bien:tapply(x,g,length)
0 1 2 3 4 5 6 7 8 9 10
54 114 74 103 112 107 75 100 103 111 47
tapply(x,g,mean)
0 1 2 3 4 5 6
0.8842438 1.4449423 1.7574916 1.9668411 2.2904859 2.4450622 2.5734979
7 8 9 10
2.7544654 2.9478100 3.3161729 3.0368155
## Calculando scores z por grupo:xgs<-sapply(xg,scale)
z<-unsplit(xgs,g)
tapply(z,g,mean)
0 1 2 3 4
1.015134e-17 -1.186307e-16 4.899422e-17 -6.762895e-17 1.876134e-16
5 6 7 8 9

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 322/344
322
1.426932e-16 -4.121703e-17 1.565588e-18 1.311316e-16 -6.876381e-17
10
1.371354e-16
##o bien:
sapply(xgs,mean)
0 1 2 3 4
1.015134e-17 -1.186307e-16 4.899422e-17 -6.762895e-17 1.876134e-16
5 6 7 8 9
1.426932e-16 -4.121703e-17 1.565588e-18 1.311316e-16 -6.876381e-17
10
1.371354e-16
## Dividir una matriz en una lista por columna
ma <- cbind(x = 1:10, y = (-4:5)^2)
ma
x y
[1,] 1 16
[2,] 2 9
[3,] 3 4
[4,] 4 1
[5,] 5 0
[6,] 6 1[7,] 7 4
[8,] 8 9
[9,] 9 16
[10,] 10 25
split(ma, col(ma))
$"1"
[1] 1 2 3 4 5 6 7 8 9 10
$"2"
[1] 16 9 4 1 0 1 4 9 16 25
##Otro ejemplo:
split(1:10, 1:2)
$"1"
[1] 1 3 5 7 9
$"2"

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 323/344
323
[1] 2 4 6 8 10
Warning message:
argument lengths differ in: split(x, f)
9.8. Modelo Lineal Generalizado: Función glm
Uno de los atractivos de R es su facilidad de manejo para modelos. Entre ellos tenemos el
modelo lineal generalizado con la función glm(). Esta función permite realizar ajuste de
modelos lineales generalizados, mediante la especificación de una fórmula que describe
simbólicamente el predictor lineal y una descripción de la distribucón del error.
glm(formula, family = gaussian, data, weights = NULL, subset =
NULL, na.action, start = NULL, offset = NULL, control =
glm.control(...), model = TRUE, method = "glm.fit", x = FALSE, y =
TRUE, contrasts = NULL, ...)
glm.fit(x, y, weights = rep(1, nrow(x)), start = NULL, etastart =
NULL, mustart = NULL, offset = rep(0, nrow(x)), family =
gaussian(), control = glm.control(), intercept = TRUE)
weights.glm(object, type = c("prior", "working"), ...)
Argumentos:
• formula: Una descripción simbólica del modelo a ser ajustado.
• family: Una descripción de la distribución del error y la función de linkeo a ser
usada en el modelo.
• data: Un data frame opcional con las variables en el modelo. Por defecto las
variables son tomadas de `environment(formula)', generalmente el ambiente desde el
cual es llamada la función glm .

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 324/344
324
• weights: Un vector opcional con pesos a utilizar en el ajuste.
• subset: Un vector opcional especificando un subconjunto de observaciones a ser
usadas en el ajuste.
• na.action: Una función que indica lo que debería pasar cuando los datos tienes
valores faltantes (`NA's). El valor por defecto corresponde al ajuste dado por
`na.action' de `options'.
• start: Valores de inicio para los parámetros en el predictor lineal.
• etastart: Valores de inicio para el predictor lineal.
• mustart: Valores de inicio para el vector de medias.
• offset: Puede utilizarse para especificar una componente conocida apriori a ser
incluida en el predictor lineal durante el ajuste.
• control: Una lista de parámetros para controlar el proceso de ajuste. Ver
`glm.control'.
• model: Un valor lógico que indica si el marco del modelo debe ser incluido como
una componente del valor retornado.
• method: El método a ser usado en el ajuste. Por defecto (y es el único por el
momento) se usa mínimos cuadrados ponderados iterativamente (IWLS ).

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 325/344
325
• x, y: Valores lógicos que indican si el vector de respuesta y la matriz de diseño usada
en el ajuste deben ser devueltos en la salida del procedimiento.
• contrasts: Una lista opcional. Ver `contrasts’ de `model.matrix.default'.
• object: Un objeto de la clase`glm'.
• type: Caracter que indica el tipo de pesos a extraer del objeto modelo ajustado.
• intercept: Argumento lógico para indicar si el modelo incluye intercepto.
• ...: Argumentos adicionales pasados a o desde otros métodos.
Detalles: El modelo típico tiene la forma `respuesta~términos' donde
`respuesta' es el vector respuesta numérico y `términos' es una serie de términos que
especifican un predictor lineal para `respuesta' . En los modelos binomiales (`binomial') la
respuesta puede especificarse como un `factor' (cuando el primer nivel corresponde afracaso y los demás casos son éxitos) o como una matriz de dos columnas con las columnas
dando los números de éxitos y fracasos. Una especificación como `primero+segundo'
indica todos los términos en `primero' junto con todos los términos en `segundo' con las
duplicaciones eliminadas.
Valor:
• glm devuelve un objeto de clase `glm' el cual desciende de la clase lm'. La
función summary (`summary.glm') puede usarse para obtener o imprimir un
resumen de los resultados, y la función anova (`anova.glm') retorna una tabla de
análisis de varianza.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 326/344
326
• Las funciones genéricas coefficients, effects, fitted.values y
residuals pueden utilizarse para extraer estos valores del objeto `glm'.
• La función weights extrae un vector de pesos, para cada caso en el ajuste.
Un objeto de clase `glm' es una lista que contiene los siguientes componentes:
• coefficients: Un vector de coeficientes.
• residuals: Residuales en la iteración final del ajuste IWLS (residuos de trabajo).
• fitted.values: Valores medios ajustados, obtenidos transformando los predictores
lineales por la invers ade la función de linkeo.
• rank: El rango numérico del modelo lineal ajustado.
• family: La familia usada.
• linear.predictors: El ajuste lineal sbre la escala de linkeo.
• deviance: Una constante menos dos veces el log de verosimilitud maximizado.
Donde sea sensible, la constante es elegida de modo que el modelo saturado tenga
deviance igual a cero.
• aic: Criterio de información de Akaike, menos dos veces el log de verosimilitud
maximizado más dos veces el número de coeficientes (asumiendo que la dispersi'on
es conocida).

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 327/344
327
• null.deviance: El deviance para el modelo nulo, comparable con `deviance'. El
modelo nulo incluye el offset, y un intercepto si el modelo lo incluye.
• iter: El número de iteraciones del IWLS.
• weights: De los residuoales de trabajo, es decir los pesos en la iteracción final del
ajuste IWLS.
• prior.weights: Los pesos inicialemtne suminstrados.
• df.residual: Los grados de libertad residuales.
• df.null: Los grados de libertad residuales para el modelo nulo.
• y: El vector `y' usado.
• converged: Argumento lógico para indicar si el algoritmo IWLS convergió.
• boundary: Argumento lógico para indicar si el valor ajustado está sobre la frontera
de los valores alcanzados.
• formula: La fórmula proporcionada.
• terms: El objeto `terms' usado.
• data: El `data argument'.
• offset: El vector offset usado.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 328/344
328
• control: El valor del argumento `control' usado.
• method: El nombre de la función filtro usada. Siempre es `glm.fit'.
• contrasts: El contraste usado.
• xlevels: Un registro de los niveles de los factores usados en el ajuste.
Los ajustes no nulos tendrán componentes `qr', `R' y `effects' en relación al ajuste lineal
ponderado final.
Si un modelo `glm' binomial es especificado mediante una respuesta de dos columnas, los
pesos devueltos por `prior.weights' corresponden al total de casos (factorizado por los pesos
proporcionados) y la componente `y' de los resultados es la proporción de éxitos.
Los offsets especificados en `offset' no se incluirán en las predicciones por `predict.glm',
en tanto que los especificados por un término offset en la fórmula si lo serán.
Referencias:
• McCullagh P. and Nelder, J. A. (1989) Generalized Linear Models. London:
Chapman and Hall.
• Dobson, A. J. (1990) An Introduction to Generalized Linear Models. London:
Chapman and Hall.
• Venables, W. N. and Ripley, B. D. (1999) Modern Applied Statistics withe S-PLUS.
New York: Springer.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 329/344
329
Ver también: `anova.glm', `summary.glm', etc. `anova', `summary', `effects',
`fitted.values', y `residuals'.
Ejemplos:
## Dobson (1990) Pag. 93: Experimentos
##aleatorizados controlados
conteos <- c(18,17,15,20,10,20,25,13,12)
#Generando un factor de 3 niveles con
#1 réplica y resultado de longitud 1,
#para las salidas.
salidas<- gl(3,1,9)
#Generando un factor de 3 niveles con
#3 réplicas para los tratamientos:
tratamiento <- gl(3,3)
print(d.AD <- data.frame(tratamiento, salidas, conteos))
tratamiento salidas conteos
1 1 1 18
2 1 2 17
3 1 3 15
4 2 1 20
5 2 2 10
6 2 3 20
7 3 1 25
8 3 2 13
9 3 3 12
glm.D93 <- glm(conteos~ salidas + tratamiento, family=poisson())
anova(glm.D93)
Analysis of Deviance Table
Model: poisson, link: log
Response: conteos
Terms added sequentially (first to last)
Df Deviance Resid. Df Resid. Dev
NULL 8 10.5814
salidas 2 5.4523 6 5.1291
tratamiento 2 0.0000 4 5.1291
summary(glm.D93)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 330/344
330
Call:
glm(formula = conteos ~ salidas + tratamiento, family = poisson())
Deviance Residuals:1 2 3 4 5 6 7
-0.67125 0.96272 -0.16965 -0.21999 -0.95552 1.04939 0.84715
8 9
-0.09167 -0.96656
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.045e+00 1.709e-01 17.815 <2e-16 ***
salidas2 -4.543e-01 2.022e-01 -2.247 0.0246 *
salidas3 -2.930e-01 1.927e-01 -1.520 0.1285
tratamiento2 1.924e-08 2.000e-01 9.62e-08 1.0000tratamiento3 8.383e-09 2.000e-01 4.19e-08 1.0000
---
Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 10.5814 on 8 degrees of freedom
Residual deviance: 5.1291 on 4 degrees of freedom
AIC: 56.761
Number of Fisher Scoring iterations: 3
#Ejemplo de McCullagh & Nelder (1989, pp. 300-2)
clotting <- data.frame(u = c(5,10,15,20,30,40,60,80,100),
lot1 = c(118,58,42,35,27,25,21,19,18),
lot2 = c(69,35,26,21,18,16,13,12,12))
summary(glm(lot1 ~ log(u), data=clotting, family=Gamma))
Call:
glm(formula = lot1 ~ log(u), family = Gamma, data = clotting)
Deviance Residuals:
Min 1Q Median 3Q Max
-0.04008 -0.03756 -0.02637 0.02905 0.08641
Coefficients:Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.0165544 0.0009275 -17.85 4.28e-07 ***
log(u) 0.0153431 0.0004150 36.98 2.75e-09 ***
---
Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1
(Dispersion parameter for Gamma family taken to be 0.002446013)

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 331/344
331
Null deviance: 3.512826 on 8 degrees of freedom
Residual deviance: 0.016730 on 7 degrees of freedom
AIC: 37.99Number of Fisher Scoring iterations: 3
summary(glm(lot2 ~ log(u), data=clotting, family=Gamma))
Call:
glm(formula = lot2 ~ log(u), family = Gamma, data = clotting)
Deviance Residuals:
Min 1Q Median 3Q Max
-0.05574 -0.02925 0.01030 0.01714 0.06372
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.0239085 0.0013265 -18.02 4.00e-07 ***log(u) 0.0235992 0.0005768 40.91 1.36e-09 ***
---
Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1
(Dispersion parameter for Gamma family taken to be 0.001813340)
Null deviance: 3.118557 on 8 degrees of freedom
Residual deviance: 0.012672 on 7 degrees of freedom
AIC: 27.032
Number of Fisher Scoring iterations: 3
9.8.1 Función family
Permite especificar una familia de distribución para los modelos lineales generalizados en
la función glm.
family(object, ...)
binomial(link = "logit")gaussian(link ="identity")
Gamma(link = "inverse")
inverse.gaussian(link = "1/mu^2")
poisson(link = "log")
quasi(link = "identity", variance = "constant")

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 332/344
332
quasibinomial(link = "logit")
quasipoisson(link = "log")
Argumentos:
• link: Una especificación para la función de linkeo del modelo. La familia
`binomial' admite funciones de linkeo `logit', `probit', `log', and `cloglog' (log–log
complementaria); la familia `Gamma' admite las funciones `identity', `inverse', y
`log'; La familia `poisson', las funciones `identity', `log', y `sqrt'; la familia `quasi'
los links `logit', `probit', `cloglog', `identity', `inverse', `log', `1/mu^2' y `sqrt'. Lafunción `power' puede usarse para crear una función linkeo de potencia para la
familia `quasi' . La familia `gaussian' sólo admite la función `identity' y la familia
`inverse.gaussian' la función 1/mu^2'.
• variance: Para todas las familias excepto la familia `quasi' , la función de varianza
es determinada por la familia. La familia `quasi' aceptará las especificaciones
`constant', `mu(1-mu)', mu', `mu^2' y `mu^3' para la función varianza.
• object: La función family accesa a los objetos `family' que son guardados dentro
de los objetos creado spor las funciones de modelación.
• ...: Argumentos adicionales para los métodos.
Detalles: Las familias `quasibinomial' y `quasipoisson' difieren de las familias `binomial'
y `poisson' respectivamente, en que el parámetro de dispersión no están fijados en uno, por
lo que estos pueden modelar con sobredispersión.
Ejemplos:

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 333/344
333
conteos <- c(18,17,15,20,10,20,25,13,12)
salidas <- gl(3,1,9)
tratamiento <- gl(3,3)d.AD <- data.frame(tratamiento, salidas, conteos)
glm.qD93 <- glm(conteos~ salidas + tratamiento, family=quasipoisson())
anova(glm.qD93, test="F")
summary(glm.qD93)
## Uso de resultados poisson:
anova(glm.qD93, dispersion = 1, test="Chisq")
summary(glm.qD93, dispersion = 1)
## Pruebas de quasi:
x <- rnorm(100)
y <- rpois(100, exp(1+x))glm(y ~x, family=quasi(var="mu", link="log"))
## Es lo mismo que:
glm(y ~x, family=poisson)
glm(y ~x, family=quasi(var="mu^2", link="log"))
y <- rbinom(100, 1, plogis(x))
##Se necesita ajustar un valor inicial
##para el siguiente ajuste:
glm(y ~x, family=quasi(var="mu(1-mu)", link="logit"), start=c(0,1))
9.9. Análisis de Varianza: Función aov
Con esta función podemos ajustar un modelo de análisis de varianza aplicando la función
lm a cada estrato, en diseños balanceados y desbalanceados.
aov(formula, data = NULL, projections = FALSE, qr = TRUE,
contrasts = NULL, ...)
Argumentos:
• formula: Una fórmula que especifica el modelo. Puede especificar respuestas
múltiples.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 334/344
334
• data: Un data frame en el cual se hallan las variables especificadas en la fórmula. Si
no se especifica, las variables son buscadas en el ambiente desde el cual se llamó la
función aov.
• projections: Argumento lógico. ¿Deberá retornarse las proyecciones?
• qr: Argumento lógico. ¿Deberá retornarse la descomposición QR?
• contrasts: Una lista de los contrastes a usar para alguno de los factores en la
fórmula. No son usados para ningún término de `Error'. Proporcional contrastes para
los factores únicamente en el término de `Error' dará una advertencia.
• ...: Argumentos a ser pasados a la función \tt lm , tal como subset', o na.action'.
Si la fórmua contiene sólo un término de `Error', este es usado para especificar los estratos
de errores, y los modelos apropiados son ajustados dentro de cada estrato de error.
Valor: Un objeto de clase `c(“aov”, "lm")', o de clase `c("maov", “aov", "mlm", "lm")' si
hay múltiples respuestas, o de clase “aovlist” para estratos de error múltiples.
Autor: B. D. Ripley
Ejemplo: Para ilustrar un modelo completamente aleatorizado con un factor consideremos
el siguiente ejemplo de Lentner y Bishop, pp. 44: El problema trata del entrenamiento de
unos vendedores. Se dividen en cuatro grupos, cada vendedor es asignado al azar en uno de
los grupos, y a cada grupo se le entrena con un programa diferente. Luego de cinco
semanas se registran las comisiones obtenidas por cada vendedor. Se desea verificar si hay
diferencias entre los programas. El programa en R podría ser el siguiente.

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 335/344
335
programa<-c(1,1,1,1,1,1,2,2,2,2,2,3,3,3,3,3,4,4,4,4,4,4)
comisiones<-c(231,209,226,214,230,218,160,183,210,179,191,
251,246,238,227,240,195,188,204,192,210,197)programa<-as.factor(programa)
aov.comisiones<-aov(comisiones~programa)
summary(aov.comisiones)
Df Sum Sq Mean Sq F value Pr(>F)
programa 3 9513.5 3171.2 23.913 1.677e-06 ***
Residuals 18 2387.1 132.6
---
Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1
Si deseamos hacer un análisis gráfico el programa puede modificarse así:
nf<-layout(rbind(c(0,1,1,0),c(0,2,2,0)))
programa<-c(1,1,1,1,1,1,2,2,2,2,2,3,3,3,3,3,4,4,4,4,4,4)
comisiones<-c(231,209,226,214,230,218,160,183,210,179,191,
251,246,238,227,240,195,188,204,192,210,197)
programa<-as.factor(programa)
comisiones.df<-data.frame(comisiones,programa)
plot(comisiones.df)plot.factor(comisiones.df)
aov.comisiones<-aov(comisiones~programa, comisiones.df)
> aov.comisiones
Call:
aov(formula = comisiones ~ programa, data = comisiones.df)
Terms:
programa Residuals
Sum of Squares 9513.524 2387.067
Deg. of Freedom 3 18
Residual standard error: 11.51585Estimated effects may be unbalanced
summary(aov.comisiones)
Df Sum Sq Mean Sq F value Pr(>F)
programa 3 9513.5 3171.2 23.913 1.677e-06 ***
Residuals 18 2387.1 132.6
---

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 336/344
336
Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1
Un ejemplo de Venables and Ripley (1997) p.210. (tomado de R Documentation)
N <- c(0,1,0,1,1,1,0,0,0,1,1,0,1,1,0,0,1,0,1,0,1,1,0,0)
P <- c(1,1,0,0,0,1,0,1,1,1,0,0,0,1,0,1,1,0,0,1,0,1,1,0)
K <- c(1,0,0,1,0,1,1,0,0,1,0,1,0,1,1,0,0,0,1,1,1,0,1,0)
yield <- c(49.5,62.8,46.8,57.0,59.8,58.5,55.5,56.0,62.8,55.8,69.5,55.0,
62.0,48.8,45.5,44.2,52.0,51.5,49.8,48.8,57.2,59.0,53.2,56.0)
npk <- data.frame(block=gl(6,4), N=factor(N), P=factor(P),
K=factor(K), yield=yield)
( npk.aov <- aov(yield ~ block + N*P*K, npk) )
Call:
aov(formula = yield ~ block + N * P * K, data = npk)
\end verbatim
\scriptsize
\begin verbatim
Terms:
block N P K N:P N:K P:K
Sum of Squares 343.2950 189.2817 8.4017 95.2017 21.2817 33.1350 0.4817
Deg. of Freedom 5 1 1 1 1 1 1
Residuals
Sum of Squares 185.2867
Deg. of Freedom 12
Residual standard error: 3.929447
1 out of 13 effects not estimable
Estimated effects may be unbalanced
summary(npk.aov)
Df Sum Sq Mean Sq F value Pr(>F)
block 5 343.29 68.66 4.4467 0.015939 *
N 1 189.28 189.28 12.2587 0.004372 **
P 1 8.40 8.40 0.5441 0.474904
K 1 95.20 95.20 6.1657 0.028795 *
N:P 1 21.28 21.28 1.3783 0.263165
N:K 1 33.13 33.13 2.1460 0.168648

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 337/344
337
P:K 1 0.48 0.48 0.0312 0.862752
Residuals 12 185.29 15.44
---Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1
coefficients(npk.aov)
(Intercept) block2 block3 block4 block5 block6
51.8250000 3.4250000 6.7500000 -3.9000000 -3.5000000 2.3250000
N1 P1 K1 N1:P1 N1:K1 P1:K1
9.8500000 0.4166667 -1.9166667 -3.7666667 -4.7000000 0.5666667

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 338/344
338
Capítulo 10: Apéndice: Datos
10.1. Datos de Velocidades de Autos
Los siguientes datos representan las velocidades de autos medidas con radar en una calle de
la ciudad.
48 47 49 50 57 44 54 49 52 68 45
77 45 46 51 50 46 47 48 45 57 4056 40 38 48 50 45 59 54 48 55 47
50 53 49 76 53 54 71 56 59 43 49
45 45 46 58 51 56 45 54 59 38 71
47 56 60 53 54 43 59 60 50 57 50
50
10.2. Datos de Precios de Carros Reanult 4 y 12
Los siguientes datos corresponden al modelo (R-4 o R-12), el año del carro y el precio de
oferta de varios carros marca Renault aparecidos en los clasificados del El Colombiano
aparecidos en Noviembre 19/94
r4 85 4.00
r4 88 4.30
r4 81 2.85
r4 80 2.95
r4 70 2.20r4 77 2.45
r4 71 2.00
r4 88 4.90
r4 74 1.78
r4 73 1.70
r4 80 2.90

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 339/344
339
r12 80 4.60
r12 76 3.80
r12 78 4.80r12 79 4.70
r12 76 3.60
r12 78 4.50
r12 74 3.50
r12 74 3.50
10.3. Datos de las pruebas nacionales del ICFES
• La siguiente tabla contiene una muestra de las siguientes variables (por columnas)
relacionadas con los resultados en las pruebas del ICFES realizadas en Colombia
durante varios años.
• 1a. variable: SEXO (Alfanumérica: F:femenino, M:masculino)
• 2a. : Año en que se tomo la prueba
• 3a. : Resultado en Biología
• 4a. :Resultado en Química
• 5a. :Resultado en Física
• 6a. :Resultado en Sociales
• 7a. :Resultado en Aptitud Verbal
• 8a. :Resultado en Español y Literatura

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 340/344
340
• 9a. :Resultado en Aptitud Matemática
• 10a. :Resultado en Conocimientos en Matemáticas
• 11a. :Resultado en Electiva
• 12a. : Electiva (Alfanumérica):
MET: Metalmecánica, CON: Contabilidad ING:Inglés, ELE:Electricidad, MEC:
Razonamiento Mecánico, MET:Metalmecánica
F 89 51 41 40 52 55 49 54 57 47 CON
F 89 46 29 40 40 39 49 50 48 51 CON
F 89 36 32 45 38 51 51 42 40 47 CON
F 92 50 45 54 63 67 65 67 50 57 ING
M 92 50 45 54 63 67 65 67 50 57 ING
F 93 54 50 55 40 55 61 49 44 55 MET
M 89 54 55 53 60 57 50 46 55 48 ABSM 89 52 42 55 51 51 56 50 55 48 MET
F 89 47 44 42 37 50 57 52 51 55 CON
F 89 50 44 42 47 40 54 40 42 56 CON
F 89 46 47 44 39 53 45 48 51 40 CON
F 89 71 65 64 69 66 78 63 67 57 MEC
M 89 62 70 74 66 71 64 69 70 64 ING
M 89 69 58 69 70 69 76 63 67 64 ELE
F 89 54 41 40 55 56 46 56 36 55 CON
F 89 55 44 48 46 57 51 50 46 55 CON
M 93 46 42 56 56 52 54 47 44 61 MECF 93 42 45 47 40 42 50 36 42 41 MEC
M 93 42 50 50 42 59 47 44 48 48 MET
M 93 54 44 51 51 44 47 56 50 60 ABS
M 93 50 50 55 55 53 51 58 48 51 MEC
F 93 37 36 40 36 36 47 36 44 40 CON
F 93 32 42 39 32 45 36 40 36 42 CON

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 341/344
341
F 93 53 53 42 57 59 54 38 40 50 ING
M 93 66 63 64 62 68 59 69 70 69 ELE
M 92 55 49 57 49 61 57 52 60 47 ELEF 92 43 46 45 42 49 58 57 50 56 ING
F 93 40 44 51 36 47 48 44 42 47 ING
F 93 40 41 40 51 45 44 46 44 48 CON
F 93 44 44 45 45 59 54 56 56 56 CON
F 93 36 44 51 39 37 36 44 50 48 CON
F 89 62 35 55 55 58 47 37 46 56 CON
M 89 54 44 58 52 48 62 54 59 42 MET
M 89 54 44 50 45 61 53 48 65 50 ABS
F 89 55 39 47 44 55 56 54 57 56 CON
M 89 47 48 50 49 52 42 71 63 51 ELEF 89 60 45 55 55 61 54 52 48 47 CON
F 89 51 44 52 47 60 65 39 55 60 CON
M 89 56 52 60 53 49 51 52 57 55 MET
F 89 50 45 50 50 61 62 67 57 49 CON
M 89 49 48 53 54 56 51 65 63 55 MET
M 89 59 52 66 58 57 53 58 59 48 ELE
M 89 60 48 58 56 60 49 69 51 55 MET
M 89 56 55 64 55 61 60 67 65 49 ELE
M 89 63 53 60 67 71 60 54 53 46 ELE
M 89 66 48 63 64 66 54 56 57 56 ELEM 89 56 52 58 65 60 58 65 59 57 MET
F 89 58 47 60 55 63 64 56 53 71 CON
M 89 69 55 64 65 64 60 54 55 56 ELE
M 89 58 55 55 57 56 57 67 70 66 ABS
F 89 63 53 50 68 63 62 50 55 68 CON
M 89 59 65 68 57 69 72 65 67 59 ELE
F 89 58 56 58 55 66 62 63 67 77 ING
F 93 42 44 51 45 56 55 36 42 46 ING
F 93 40 41 50 45 56 54 49 32 59 ING
M 93 48 45 58 49 46 51 51 44 53 METF 93 38 35 47 36 43 43 40 40 33 ING
F 93 46 44 48 49 47 55 36 38 56 ING
F 93 28 42 50 39 40 46 51 42 48 CON
M 93 39 33 47 47 41 48 40 28 53 MET
F 93 38 45 40 44 50 51 33 42 50 CON
M 93 55 54 59 50 54 62 64 64 53 MEC

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 342/344
342
M 93 56 44 45 53 59 51 49 36 56 MET
F 93 62 48 58 49 58 61 55 44 62 ING
F 93 54 59 51 50 62 70 55 50 60 INGF 93 38 41 42 35 37 43 35 44 35 CON
F 93 36 51 47 53 61 50 49 46 58 ING
M 93 48 39 50 54 47 48 40 46 63 MET
F 93 34 48 47 38 46 56 36 42 50 ING
M 93 49 39 47 50 54 52 42 40 50 MET
M 93 51 48 58 54 51 52 47 46 63 MET
F 93 57 57 56 57 62 65 60 48 65 ING
F 93 34 41 47 40 43 43 49 32 42 CON
F 93 38 41 43 47 52 47 47 44 63 CON
M 93 61 60 67 67 68 73 66 74 73 MECM 93 53 48 56 51 50 51 60 52 61 MET
M 93 53 41 45 56 43 54 49 48 59 MEC
M 93 67 45 67 64 68 59 69 64 71 MEC
M 92 64 49 61 57 66 54 57 48 46 ING
M 92 65 55 64 64 63 60 59 52 61 ING
M 92 65 59 75 59 65 53 65 66 60 ABS
F 92 54 51 45 46 52 49 41 42 58 CON
F 92 50 48 32 45 50 39 47 46 51 CON
F 92 46 46 37 31 39 41 41 34 43 CON
F 92 43 35 41 45 46 43 54 38 65 CONM 92 54 51 46 54 59 49 57 54 40 MEC
M 92 57 41 54 51 61 52 56 50 53 MET
F 92 38 32 30 39 35 30 36 32 46 CON
F 92 45 32 37 39 42 33 43 44 58 CON
M 92 54 41 45 33 52 50 47 40 53 MEC
F 92 36 41 33 39 31 31 32 32 51 CON
M 92 45 51 51 63 52 54 47 34 54 ING
M 92 54 59 51 46 59 56 52 52 56 ING
M 92 47 49 57 55 63 65 52 54 63 ING
M 92 57 49 62 58 60 70 59 52 66 INGF 92 41 40 43 45 43 48 43 36 42 CON
M 92 55 57 59 42 46 42 48 52 66 ABS
M 92 40 40 48 46 43 45 45 42 46 MET
M 92 64 46 59 60 62 56 45 50 40 MEC
F 93 38 56 51 48 51 50 47 46 55 MET
F 93 59 56 56 49 56 56 53 62 60 CON

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 343/344
343
M 92 63 66 70 64 70 68 68 54 69 ING
M 92 59 57 59 53 59 60 76 68 59 ING
M 92 65 71 72 67 68 66 74 70 66 INGM 92 47 52 41 52 53 46 39 36 43 CON
M 92 56 54 61 64 60 62 61 56 67 MEC
F 92 50 49 51 54 49 56 39 50 65 CON
F 92 63 51 48 57 62 58 50 54 67 CON
F 92 56 45 57 59 65 70 57 50 50 CON
F 92 56 35 53 56 62 64 52 50 58 CON
F 92 56 40 57 61 54 60 52 46 58 CON
F 92 43 51 49 56 61 61 59 66 64 CON
F 92 52 60 54 47 64 57 57 48 64 CON
M 92 55 66 59 57 61 43 57 52 65 ElEM 92 57 48 54 62 58 56 52 56 61 MEC
F 92 46 46 48 50 52 45 47 42 58 CON
F 93 44 50 43 53 45 44 51 44 45 MET
F 93 62 56 58 57 60 56 49 42 78 CON
F 93 31 31 39 28 35 41 44 44 37 CON
F 93 61 47 61 61 66 69 58 56 49 ING
M 93 59 48 64 61 64 65 58 54 56 ElE
F 93 27 50 39 32 42 46 44 38 36 ING
F 93 43 44 55 46 56 59 51 46 66 ING
F 93 46 53 50 56 69 65 47 44 60 INGF 93 34 44 42 38 54 41 42 28 39 ING
F 93 49 48 47 51 51 55 47 52 52 ING
M 93 48 48 53 49 58 50 49 58 54 MEC
F 93 45 53 51 54 55 50 51 50 50 CON
F 93 43 38 42 48 44 44 35 40 52 ING
F 93 38 42 50 41 45 51 46 48 55 ING
F 89 50 39 42 43 49 50 39 36 40 CON
F 89 43 39 31 36 49 32 42 36 41 CON

5/12/2018 MANUAL_Rb - slidepdf.com
http://slidepdf.com/reader/full/manualrb 344/344
Capítulo 11: Referencias
• Becker R. A., Chambers, J. M. y Wilks, A. R. (1988) The New S Language.
Wadsworth & Brooks/Cole Advanced Books & Software.
• Chambers, J. M. y Hastie, T. J. (1992). Statistical Models in S . Wadsworth &
Brooks/Cole Advanced Books & Software.
• Jonhson R.A y Wichern D. W. Applied Multivariate Statistical Análisis. 4ª . Ed.
Prentice may, 1998
• Lentner, M y Bishop, T. (1986) Experimental Design and Analysis . Valley Book
Company: Blacksburg.
• R Documentation (Help R 1.5.0).