mapping genomes onto each other – synteny detection cs 374 aswath manohar
Post on 19-Dec-2015
215 views
TRANSCRIPT

Mapping Genomes onto Mapping Genomes onto each other – Synteny each other – Synteny
detectiondetection
CS 374CS 374
Aswath ManoharAswath Manohar

Necessity is the mother of inventionNecessity is the mother of invention
Genome sequencing has given rise to Genome sequencing has given rise to voluminous amounts of genomic voluminous amounts of genomic data.data.
Human genome has completely been Human genome has completely been sequenced. Rat and mouse genomes sequenced. Rat and mouse genomes have also been completed.have also been completed.
What do we do with all this data?What do we do with all this data?

Necessity…Necessity…
Need to analyze all this data meaningfully.Need to analyze all this data meaningfully. Has given rise to the field of Comparative Has given rise to the field of Comparative
Genomics.Genomics. Identification of functional DNA through Identification of functional DNA through
comparative methods.comparative methods. A large set of functional elements in A large set of functional elements in
Rat/Human/Mouse genomes remains Rat/Human/Mouse genomes remains uncharacterized. (Pash: Kalafus et al)uncharacterized. (Pash: Kalafus et al)

Analysis MethodsAnalysis Methods
Standard Dynamic Programming Standard Dynamic Programming Alignment algorithms – Needleman Alignment algorithms – Needleman Wunsch, Smith-Waterman.Wunsch, Smith-Waterman.
Highly sensitive aligners.Highly sensitive aligners. Computationally prohibitive – Computationally prohibitive –
impossible to apply to analysis of impossible to apply to analysis of multiple mammalian genomes.multiple mammalian genomes.

Methods…Methods… Faster implementations of dynamic Faster implementations of dynamic
programming such as LAGAN (Brudno et al programming such as LAGAN (Brudno et al 2003).2003).
Works well on a megabase level, but Works well on a megabase level, but requires prior information (‘anchors’) on a requires prior information (‘anchors’) on a genomic scale.genomic scale.
Seed and extend methods – a ‘seed’, Seed and extend methods – a ‘seed’, hotspot is determined. Then it is extended hotspot is determined. Then it is extended on either side.on either side.
Again, extension step is computationally Again, extension step is computationally expensive.expensive.

PashPash
So what is the solution?So what is the solution? Use Positional Hashing!!!Use Positional Hashing!!! Pash: Efficient Genome-Scale Pash: Efficient Genome-Scale
Sequence Anchoring by Sequence Anchoring by PPositonal ositonal HHashashing ing
Authors: Ken Kalafus, Andrew Authors: Ken Kalafus, Andrew Jackson and Aleksandar MilosavijevicJackson and Aleksandar Milosavijevic
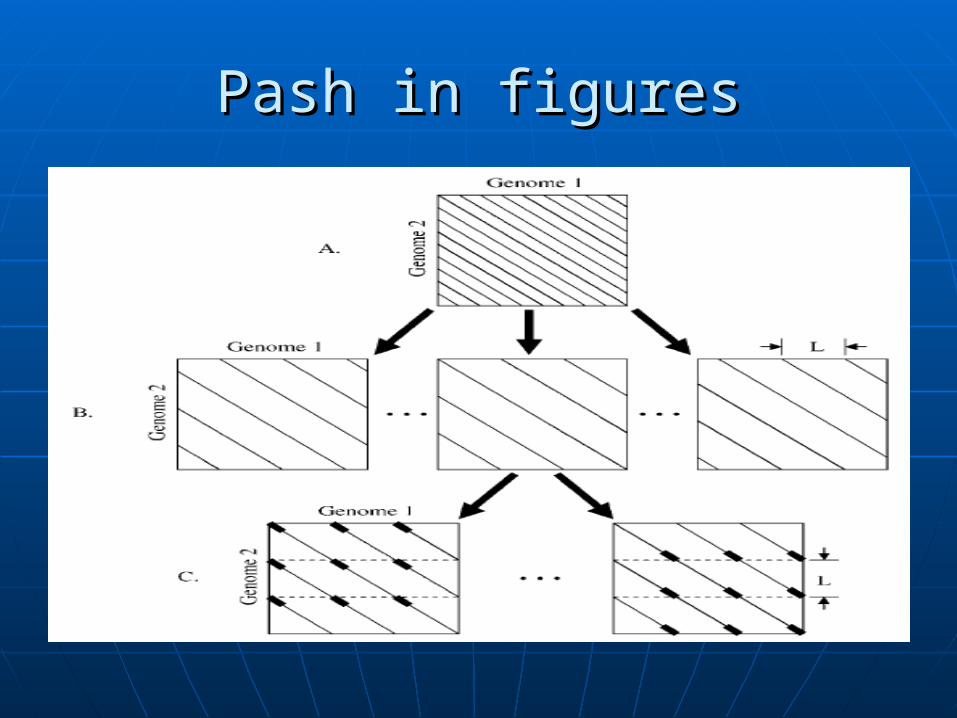
Pash in figuresPash in figures

More formally…More formally…
The sequences S, T The sequences S, T are conceptually are conceptually divided into sub-divided into sub-sequences of sequences of length L:length L:
Si = [i*L+1,..., Si = [i*L+1,..., (i+1)*L](i+1)*L]
Ti’ = [i’*L+1,..., Ti’ = [i’*L+1,..., (i’+1)*L](i’+1)*L]

HashingHashing
The single scoring matrix is divided The single scoring matrix is divided into L diagonal matrices.into L diagonal matrices.
These are further divided into L These are further divided into L ‘diagonal segment’ matrices.‘diagonal segment’ matrices.
We have L² ‘diagonal segment’ We have L² ‘diagonal segment’ matrices.matrices.
We use a hash table for each We use a hash table for each ‘diagonal segment’ matrix.‘diagonal segment’ matrix.
Therefore Total #Hash tables = L²Therefore Total #Hash tables = L²

Hashing…Hashing…
Each k-mer is Each k-mer is mapped to a bin in mapped to a bin in the hash table.the hash table.
The indices of the The indices of the k-mer are stored in k-mer are stored in one of two linked one of two linked lists (one for each lists (one for each sequence).sequence).
We assume an We assume an efficient hash efficient hash function.function.

Hashing…Hashing…
If both the lists in a If both the lists in a bin are non-empty, bin are non-empty, then the kmer then the kmer corresponding to that corresponding to that bin, is a matching bin, is a matching kmer!kmer!
Collation of matching Collation of matching kmers involves a kmers involves a single traversal of single traversal of each list.each list.

Running timeRunning time
Worst case??Worst case?? When you have to perform an all When you have to perform an all
against all comparisonagainst all comparison O(M*N)O(M*N) Highly unrealisticHighly unrealistic

Running time…Running time…
In practical applications, output size In practical applications, output size is O(M+N).is O(M+N).
If k-mers of sufficient length are If k-mers of sufficient length are used, each of L² hash tables is used, each of L² hash tables is populated with (M+N)/L k-mers.populated with (M+N)/L k-mers.
Hence running time = O(M+N)*L)Hence running time = O(M+N)*L) If you have L nodes, running time = If you have L nodes, running time =
O(M+N).O(M+N).

Significance of SimilaritiesSignificance of Similarities
For each sequence found, Pash For each sequence found, Pash reports both the number of matching reports both the number of matching bases and a bit score that indicates bases and a bit score that indicates significance.significance.
The bit score is calculated according The bit score is calculated according to the Algorithmic Significance to the Algorithmic Significance method.method.

Significance of Similarities…Significance of Similarities…
Based on the number of bits saved in Based on the number of bits saved in a minimal encoding of the target a minimal encoding of the target sequence X=T given that the source sequence X=T given that the source is known.is known.
D = ID = Ioo(X) – I(X)(X) – I(X) IIoo(X) = 2 * n bits(X) = 2 * n bits

Kmer encoding…Kmer encoding…
To encode I(X), one of two options are To encode I(X), one of two options are used on a case by case basis.used on a case by case basis.
A 1 bit flag is used to denote which A 1 bit flag is used to denote which method is used.method is used.
Let w be the number of matching kmers.Let w be the number of matching kmers. Let W be the maximum possible number Let W be the maximum possible number
of kmers in a match.of kmers in a match. Conceptually, W corresponds to the length Conceptually, W corresponds to the length
of the diagonal and is constant.of the diagonal and is constant.

Kmer encoding…Kmer encoding…
There are C(W,w) possible lists of There are C(W,w) possible lists of matching kmers.matching kmers.
To uniquely identify a kmer set we To uniquely identify a kmer set we need logneed log22C(W,w) bitsC(W,w) bits
Therefore Kmer encoding of ITherefore Kmer encoding of Iww(X):(X):
IIww(X) = 1 + log(X) = 1 + log22W + logW + log22C(W,w) bitsC(W,w) bits

Base encodingBase encoding
Base encoding is very similar to kmer Base encoding is very similar to kmer encoding.encoding.
Let b the number of bases defined in Let b the number of bases defined in a match.a match.
Let B be defined as the maximum Let B be defined as the maximum possible number of bases contained possible number of bases contained in a match.in a match.
IIbb(X) = 1 + log(X) = 1 + log22B + logB + log22C(B,b) bits.C(B,b) bits.

Significance of SimilaritiesSignificance of Similarities
Therefore ITherefore Iminmin(X) = min(I(X) = min(Iww(X), I(X), Ibb(X))(X)) I(X) = II(X) = Iminmin(X) + 2*(n-b) bits(X) + 2*(n-b) bits Therefore, after combining and Therefore, after combining and
simplifying,simplifying,
d = 2 * b – Id = 2 * b – Iminmin(X)(X)

ResultsResults
Used in comparing the latest Used in comparing the latest assembly of rat genome to the assembly of rat genome to the human and mouse ones.human and mouse ones.
Each pair-wise comparison took 4 Each pair-wise comparison took 4 days in 6 CPU’s = 24 CPU daysdays in 6 CPU’s = 24 CPU days
Computers were running on 750 MHz Computers were running on 750 MHz Pentium III processorsPentium III processors
Peak Ram usage = 500 MB (approx)Peak Ram usage = 500 MB (approx)
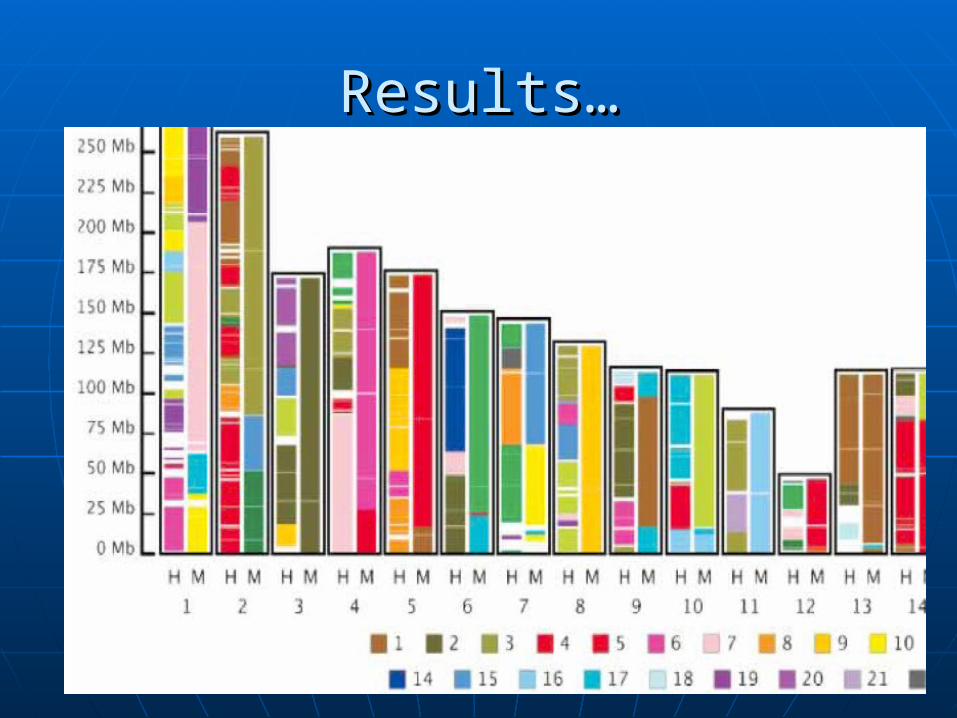
Results…Results…

DiscussionDiscussion
In contrast to seed and extend methods, In contrast to seed and extend methods, Pash represents sequences as short Pash represents sequences as short kmers, rather than bases.kmers, rather than bases.
Efficiently parallizable.Efficiently parallizable. Applications requiring basepair level Applications requiring basepair level
alignments, Pash can be used as an alignments, Pash can be used as an anchoring moduleanchoring module
This can in turn be post processed by This can in turn be post processed by programs like LAGAN, AVID or BLASTZ.programs like LAGAN, AVID or BLASTZ.

AvailiabilityAvailiability
Available free of charge for academic Available free of charge for academic use.use.
http://www.br1.bcm.tmc.eduhttp://www.br1.bcm.tmc.edu

Thanks!Thanks!