mda 3
DESCRIPTION
statistikTRANSCRIPT

24/9/2015 dihapus). Sekali Lagi, variabel DENGAN Tingkat signifikansi LEBIH gede Dari 0,05 Dari dikeluarkan
https://translate.googleusercontent.com/translate_f 1/21
Halaman 1
Beberapa Analisis diskriminan
dihapus). Sekali lagi, variabel dengan tingkat signifikansi lebih besar dari 0,05 dikeluarkan daripertimbangan untuk masuk pada langkah berikutnya.
Meneliti perbedaan univariat ditunjukkan pada Tabel 5 mengidentifikasi X17(Harga Fleksibilitas) sebagaivariabel dengan perbedaan yang paling signifikan kedua. Namun proses bertahap tidak menggunakan iniHasil univariat ketika fungsi diskriminan memiliki satu atau lebih variabel dalam diskriminan yangfungsi. Ini menghitung D 2nilainilai dan tes signifikansi statistik dari perbedaan kelompok setelahpengaruh variabel (s) dalam model dihapus (dalam hal ini hanya X13adalah dalam model).
Seperti yang ditunjukkan pada bagian terakhir dari Tabel 6, tiga variabel (X6, X11, Dan X17) Jelas bertemukriteria tingkat 0,05 signifikansi untuk dipertimbangkan pada tahap berikutnya. X17tetap yang terbaik berikutnyakandidat untuk masuk model karena memiliki tertinggi Mahalanobis D 2(4,300) dan larg yangst F untuk memasukkan nilai. Namun, variabel lain (misalnya X11) Memiliki pengurangan substansial dalam merekatingkat signifikansi dan Mahalanobis D 2dari yang ditunjukkan pada Tabel 5 karena satu varia ledalam model (X13).
Bertahap Estimasi: Menambahkan Variabel KeduaXu. Pada langkah 2 (lihat mampu 7), X17memasukimodel seperti yang diharapkan. Model keseluruhan signifikan(F =31,129) dan meningkatkan di dis yangdakwa antara kelompok yang dibuktikan dengan penurunan lambda Wilks '0,6450,478.Selain itu, kekuatan diskriminatif dari kedua variabel termasuk titik ini juga statistikpenting (F nilai 20,113 untuk X 13dan 19,863 untuk X17). Wi kedua variabel statistik signifikan, prosedur bergerak untuk meneliti variabel tidak dalam persamaan untuk potensial kandidattanggal untuk dimasukkan dalam fungsi diskriminan berdasarkan diskriminasi inkremental merekaantara kelompok.
x 11adalah pertemuan variabel berikutnya persyaratan atau inklusi, namun tingkat signifikansi dankemampuan membedakan telah berkurang substantiall b penyebab multikolinearitas dengan X13dan X17sudah dalam fungsi diskriminan. Kebanyakan noticea le adalah peningkatan malt di Mahalanobis D2dari hasil univariat dimana setiap variabel dianggap secara terpisah. Dalam kasus X 11ituminimum D2nilai meningkat dari 1,731 (ee Tabel 5) untuk 5,045 (lihat Tabel 7), indikasi dari penyebarandan pemisahan kelompok oleh X 13dan X17sudah dalam fungsi diskriminan. Perhatikan bahwa X18aku shampir identik dalam kekuasaan diskriminasi yang tersisa, tapi X11akan masuk pada langkah ketiga karena yang sedikitKeuntungan.
Bertahap Estimasi: Menambahkan Variabel X Ketiga11. Tabel 8 ulasan hasil ketigalangkah dari bertahap pr c ss, di mana X11tidak memasukkan fungsi diskriminan Hasil keseluruhanmasih nt statistik signific dan terus meningkatkan diskriminasi, sebagaimana dibuktikan oleh penurunannilai lambd yang Wilks '(0,4780,438). Namun perlu dicatat bahwa penurunan itu jauh lebih kecildaripada yang ditemukan saat variabel kedua (X17) Ditambahkan dengan fungsi diskriminan. Dengan X13, X17.dan X11semua sta istically signifikan, prosedur bergerak untuk mengidentifikasi setiap calon yang tersisa untukpenyertaan
Sebagai een di bagian terakhir dari Tabel 8, tidak ada 10 variabel independen yang tersisa luluskriteria entri untuk signifikansi statistik dari 0,05. Setelah X11dimasukkan dalam persamaan, baik ovariabel yang tersisa yang memiliki perbedaan yang signifikan univariat seluruh kelompok (X6dan X12)memiliki relatif sedikit kekuasaan diskriminatif tambahan dan tidak memenuhi kriteria entri. Dengan demikian,proses estimasi berhenti dengan tiga variabel (X 13, X 17, Dan X 11) Yang merupakanfungsi diskriminan.
Ringkasan Proses Stepwise Estimasi. Tabel 9 menyediakan bertahap keseluruhanHasil analisis diskriminan setelah semua variabel signifikan termasuk dalam estimasifungsi diskriminan. Tabel ringkasan ini menjelaskan tiga variabel (X 11, X 13, Danx 17) Yang diskriminator signifikan berdasarkan mereka lambda Wilks 'dan minimumMahalanobis D2nilainilai.
Halaman 2

24/9/2015 dihapus). Sekali Lagi, variabel DENGAN Tingkat signifikansi LEBIH gede Dari 0,05 Dari dikeluarkan
https://translate.googleusercontent.com/translate_f 2/21
MultipleDiscriminantAnalysis
Sejumlah hasil yang berbeda disediakan menangani kedua model keseluruhan fit dandampak variabel tertentu.
Langkahlangkah multivariat model keseluruhan fit dilaporkan di bawah judul "CanonicalFungsi diskriminan. "Perhatikan bahwa fungsi diskriminan sangat signifikan (0,000) danmenampilkan korelasi kanonik 0,749. Kita menafsirkan korelasi ini dengan mengkuadratkan itu (0,749)2=0,561. Dengan demikian, 56,1 persen dari varians dalam variabel dependen (X4) dapat dipertanggungjawabkan(dijelaskan) oleh model ini, yang mencakup hanya tiga variabel independen.
TABEL 7 Hasil dari Langkah 2 dari Stepwise Dua Kelompok diskriminan A
Keseluruhan Model FitNilai F Nilai Derajat Freedo Arti
Wilks 'Lambda 0,478 31,129 2, 57 0,000
Variabel Pemasukan / Dihapus di Langkah 2F
Variabel Dimasukkan Minimum D2Antara
V Lue Arti GrupX17Harga Fleksibilitas 4.300 31,129 0,000 0 dan 1Catatan:Pada setiap langkah, variabel yang memaksimalkan% jarak Mahalanobis antara kedua kelompok terdekatdimasukkan. Variabel dalam Analisis Setelah Langkah 2
Variabel Toleransi F untuk menghapus132 Antara GrupX13 KompetitifHarga 1 000 20,113 2,152 0 dan 1X17Harga Fleksibilitas 1.000 19,863 2,171 0 dan 1
Variabel Tidak dalam Analisis Setelah Langkah 2
Variabel ToleransiMinimumToleransi F memasuki
Minimum132
AntaraGrup
X6Kualitas produk 0,884 0,884 0,681 4.400 0 dan 1X7E Commerce Kegiatan 0,804 0,804 2,486 4,665 0 dan 1X8 Dukungan eknis 0,966 0,966 0,052 4,308 0 dan 1x Resolusi keluhan 0,610 0,610 1,479 4,517 0 dan 1a2,57degreesoffreedom.
Halaman 3
x10Pengiklanan 0,901 0,901 0,881 4,429 0 dan 1x11Product Line 0,848 0,848 5,068 5,045 0 dan 1X12 Salesforce Gambar 0,944 0,944 0,849 4,425 0 dan 1X14Garansi & Klaim 0,916 0,916 0,759 4,411 0 dan 1X15 ProdukProduk Baru 0,986 0,986 0,017 4,302 0 dan 1X16Order & Penagihan 0,625 0,625 0,245 4,336 0 dan 1X18Kecepatan pengiriman 0,519 0,519 4,261 4,927 0 dan 1
Signifikansi Pengujian Perbedaan Kelompok Setelah Langkah 2 'USA / Amerika Utara
Di luar Amerika Utara F 32,129Sig. 0,000

24/9/2015 dihapus). Sekali Lagi, variabel DENGAN Tingkat signifikansi LEBIH gede Dari 0,05 Dari dikeluarkan
https://translate.googleusercontent.com/translate_f 3/21
Halaman 4
Beberapa Analisis diskriminan
TABEL 8 Hasil dari Langkah 3 dari Stepwise Dua Kelompok diskriminan Ana
Keseluruhan Model Fit
Nilai F Nilai Derajat kebebasan Arti
Wilks 'Lambda 0,438 23,923 3, 56 0,000
Variabel Pemasukan / Dihapus di Langkah 3
F
Minimum D2 Nilai Arti Antara Grup
x11Product Line 5,045 23,923 0,000 0 dan 1
Catatan: Pada setiap langkah, variabel yang memaksimalkan jarak Mahalanobis antara dua kelompok terdekat adalah
masuk. Variabel dalam Analisis Setelah Langkah 3
Variabel Toleransi F Hapus D2 Antara GrupX13Harga kompetitif 0,849 7,258 4 015 0 dan 1Xi 7Harga Fleksibilitas 0,999 18,416 2 822 0 dan 1x11Product Line 0,848 5,068 4.300 0 dan 1
Variabel Tidak dalam Analisis Setelah Langkah 3
Variabel ToleransiMinimumToler beras F untuk Masukkan
MinimumD2
AntaraGrup
X6Kualitas produk 0,802 769 0,019 5,048 0 dan 1X7ECommerce Kegiatan 0,801 0,791 2,672 5,482 0 dan 1

24/9/2015 dihapus). Sekali Lagi, variabel DENGAN Tingkat signifikansi LEBIH gede Dari 0,05 Dari dikeluarkan
https://translate.googleusercontent.com/translate_f 4/21
X8Dukungan teknis 0,961 0,832 0,004 5,046 0 dan 1X9Resolusi keluhan 0,233 0,233 0,719 5,163 0 dan 1x10Pengiklanan 900 0,840 0,636 5,149 0 dan 1Xi 2Salesforce Gambar 931 0,829 1,294 5,257 0 dan 1X14Garansi & Klaim 836 0,775 2,318 5,424 0 dan 1X15ProdukProduk Baru 0,981 0,844 0,076 5,058 0 dan 1X16Order & Penagihan 0,400 0,400 1,025 5,213 0 dan 1
X18Kecepatan pengiriman 0,031 0,031 0,208 5,079 0 dan 1
Signifikansi Pengujian Perbedaan Grup Setelah Langkahr
USA / Amerika UtaraDi luar Amerika Utara F 23,923
Sig. 0,000Sebuah3, 56 derajat kebebasan.
Koefisien fungsi diskriminan standar yang disediakan, tetapi kurang disukai untuktujuan interpretasi dari beban diskriminan. The diskriminan unstandardizedkoefisien yang digunakan untuk menghitung nilai Z diskriminan yang dapat digunakan dalam klasifikasi. The beban diskriminan dilaporkan di bawah judul "Struktur Matrix" dandipesan dari tertinggi ke terendah dengan ukuran loading. Loadings dibahaskemudian di bawah fase interpretasi (Tahap 5).
Halaman 5
Koefisien fungsi klasifikasi, juga dikenal sebagai linear diskriminan Fisherfungsi, yang digunakan dalam klasifikasi dan dibahas kemudian.

24/9/2015 dihapus). Sekali Lagi, variabel DENGAN Tingkat signifikansi LEBIH gede Dari 0,05 Dari dikeluarkan
https://translate.googleusercontent.com/translate_f 5/21
Halaman 6
MultipleDiscriminantAnalysis
TABEL 9 Statistik Ringkasan Analisis diskriminan Dua Kelompok
Keseluruhan Fungsi Model Fit Canonical Discriminant
Persen dari VarianceFungsi kumulatif Canonical Wilks '
Fungsi eigen % % Korelasi Lambda ChiSquare df Signifikansi
1 1,282 100 100 0,749 0,438 46,606 3 0,000
Fungsi diskriminan dan Klasifikasi Koefisien Fungsi
Variabel independen
Fungsi diskriminan Dana klasifikasi ons
Unstandardized StandarKelompok 0:
USA / Amerika UtaraKelompok 1:
Di luar Amerika Utarax11Product Line .363 .417 7,725 6,909X13Harga kompetitif 0,398 0,490 6,456 7,349X17Harga Fleksibilitas 0,749 0,664 4.2
1
5,912Konstan 3,752 52 800 60,623
Struktur Matrix Sebuah
Variabel independen Fungsi 1
X13 Competitive Harga 0,656X17Harga Fleksibilitas 0,653x11Product Line .586X7ECommerce Kegiatan * 0,429X6Kualitas produk * .418X14Garansi & Klaim * .329x10Iklan * 0,238X9Keluhan Resolusi * .181X12Salesforce Gambar * 164X16Order & Penagihan * .149X8Dukungan teknis* .136X18Pengiriman Kecepatan * .060X15ProdukProduk Baru* 0,041* Variabel ini tidak digunakan dalam nalysis tersebut.
Sarana Group (centroid) dari Fungsi diskriminan
X4Wilayah Fungsi 1USA / Amerika Utara 1,273Di luar Amerika Utara 0,973'Pooled i hinkelompok korelasi antara variabel diskriminatif dan standar kanonik fungsi diskriminan variabeldiperintahkan oleh Absol ukuran korelasi dalam fungsi.
Grup centroid juga dilaporkan, dan mereka mewakili mean dari diskriminan individuskor fungsi untuk setiap kelompok. Centroid kelompok memberikan ukuran ringkasan dari posisi relatiftion dari masingmasing kelompok pada fungsi diskriminan (s) Dalam hal ini, Tabel 9 menunjukkan bahwa kelompokpusattroid untuk perusahaan di Amerika Serikat / Amerika Utara (kelompok 0) adalah 1,273, sedangkan kelompok massa untuk

24/9/2015 dihapus). Sekali Lagi, variabel DENGAN Tingkat signifikansi LEBIH gede Dari 0,05 Dari dikeluarkan
https://translate.googleusercontent.com/translate_f 6/21
Halaman 7
perusahaan di luar Amerika Utara (kelompok 1) adalah 0,973. lb menunjukkan bahwa ratarata keseluruhan adalah 0, kalikannumberineachgroupbyitscentroidandaddtheresult (misalnya 26x1,273 + 34x.973 = 0,0).
Halaman 8
Beberapa Analisis diskriminan
Hasil keseluruhan model dapat diterima berdasarkan signifikansi statistik dan praktis.Namun, sebelum melanjutkan ke interpretasi hasil, peneliti perlumenilai akurasi klasifikasi dan memeriksa hasil casewise.
MENILAI KLASIFIKASI AKURASI Dengan model keseluruhan signifikan secara statistik danmenjelaskan 56 persen dari variasi antara kelompok (lihat pembahasan sebelumnya dan Tabel 9),kita pindah ke menilai akurasi prediksi dari fungsi diskriminan Dalam contoh ini, kita akanmenggambarkan penggunaan skor diskriminan dan skor pemotongan untuk tujuan klasifikasi. Dalam melakukannya,

24/9/2015 dihapus). Sekali Lagi, variabel DENGAN Tingkat signifikansi LEBIH gede Dari 0,05 Dari dikeluarkan
https://translate.googleusercontent.com/translate_f 7/21
threetasks wemustcomplete:1. Hitung nilai pemotongan, kriteria terhadap yang diskriminan setiap pengamatan iniRataZ dinilai untuk menentukan ke mana kelompok itu harus diklasifikasikan.
2. Klasifikasikan setiap observasi dan mengembangkan matriks klasifikasi untuk kedua lisis sebuahdan sampel ketidaksepakatan.
3. Menilai tingkat akurasi prediksi dari matri klasifikasi es untuk berduasignifikansi statistik dan praktis.
Meskipun pemeriksaan sampel ketidaksepakatan dan akurasi prediktif saya benarbenar dilakukan ditahap validasi, hasil dibahas sekarang untuk kemudahan Compari di antara estimasi dan menahansampel.
Menghitung Cutting Score. Peneliti mu t pertama menentukan bagaimana sebelumprobabilitas dari klasifikasi harus ditentukan, baik berdasarkan n ukuran kelompok yang sebenarnya (dengan asumsimereka iepiesentative dari populasi) atau ditentukan oleh h peneliti, paling sering ditetapkan sebagaisama dengan konservatif dalam proses klasifikasi.
Dalam sampel analisis 60 pengamatan, kita tahu bahwa variabel dependen terdiridari dua kelompok, 26 perusahaan yang berlokasi di Amerika Serikat dan 34 perusahaan di luar Amerika Serikat. Jikakami tidak yakin apakah proporsi populasi yang diwakili oleh sampel, maka kitaharus menggunakan probabilitas yang sama. Namun, karena sampel kami perusahaan secara acak ditarik,kita dapat cukup yakin bahwa sampl ini tidak mencerminkan proporsi populasi. Dengan demikian, inianalisis diskriminan menggunakan proporsi sampel untuk menentukan probabilitas sebelumnya untuktujuan klasifikasi.
Setelah ditentukan probabilitas sebelumnya, skor pemotongan optimum dapat dihitung. Karenadalam situasi ini roups diasumsikan iepiesentative, perhitungannya menjadi ratarata tertimbangc ntroids dua kelompok (lihat Tabel 9 untuk nilainilai kelompok massa):
NSEBUAHZB+ NBZSEBUAH(26 x 0,973) + (34 X 1,273)ZCS = = 0,2997NA± Ng 26 + 34
Dengan substitusi dari nilainilai yang sesuai dalam formula, kita bisa memperoleh kritispemotongan c ulang (dengan asumsi biaya sama kesalahan klasifikasi) dariZ
cs= .2997.
Mengklasifikasikan Pengamatan dan Membangun Klasifikasi Matriks.Setelah pemotonganRata telah dihitung, setiap pengamatan dapat diklasifikasikan dengan membandingkan skor diskriminan untukskor pemotongan.
Prosedur untuk mengklasifikasikan perusahaan dengan skor pemotongan optimal adalah sebagai berikut:
Klasifikasikan sebuah perusahaan sebagai kelompok 0 (Amerika Serikat / Amerika Utara) jika diskriminan nyaRata kurang dari .2997. Klasifikasikan sebuah perusahaan sebagai kelompok 1 (Di luar Amerika Serikat) jika skor diskriminan nyalebih besar dari .2997.
Halaman 9
Beberapa Analisis diskriminan
Matriks klasifikasi untuk pengamatan di kedua analisis dan sampel ketidaksepakatan yangdihitung, dan hasilnya ditunjukkan pada Tabel 10. Tabel 11 berisi skor diskriminan untuk setiapobservasi serta nilainilai keanggotaan kelompok aktual dan prediksi. Perhatikan bahwa kasus denganRata diskriminan kurang .2997 memiliki nilai keanggotaan grup diprediksi 0, sedangkan merekadengan skor di atas .2997 memiliki nilai prediksi 1. Sampel analisis, dengan 86,7 persenakurasi prediksi, sedikit lebih tinggi dari akurasi 85.0 persen dari sampel ketidaksepakatan, sebagaidiantisipasi. Selain itu, sampel lintas divalidasi mencapai akurasi prediksi 83,3 persen.
Mengevaluasi Klasifikasi Akurasi Meraih. Meskipun semua tindakan dari Classiakurasi fikasi cukup tinggi, proses evaluasi membutuhkan dibandingkan dengan lassification yangketepatan dalam serangkaian langkahlangkah berbasis kesempatan. Langkahlangkah ini mencerminkan ement impro dari dis yangModel criminant bila dibandingkan dengan mengklasifikasikan individu tanpa menggunakan fungsi disc iminant.Mengingat bahwa sampel keseluruhan adalah 100 observasi dan kelompok ukuran dalam h ldout / sampel validasiyang kurang dari 20, kita akan menggunakan sampel keseluruhan untuk menetapkan standar anak compar.
Ukuran pertama adalah kriteria kesempatan proporsional, yang sebagai umes bahwa biayakesalahan klasifikasi yang sama (yaitu, kita ingin mengidentifikasi anggota setiap roup sama baiknya). TheKriteria kesempatan proporsional adalah:
CPRO= P2 + (1 P) 2
dimana
CPRO =kriteria kesempatan proporsionalp =propor ion perusahaan dalam kelompok 0 1 p= Proporsi perusahaan dalam kelompok 1

24/9/2015 dihapus). Sekali Lagi, variabel DENGAN Tingkat signifikansi LEBIH gede Dari 0,05 Dari dikeluarkan
https://translate.googleusercontent.com/translate_f 8/21
TABEL 10 Klasifikasi R s Its untuk Dua Kelompok diskriminan An
Klasifikasi Resultsa • b •
Contoh Grup aktual
Diprediksi Grup Keanggotaan
TotalUSA/
Amerika UtaraDi luar
Amerika Utara
Estimati n Contoh USA / Amerika Utara 25 1 2696,2% 3,8%
Di luar Amerika Utara 7 27 3420,6% 79,4%
Crossdivalidasid USA / Amerika Utara 24 2 2692.3 7.7
Di luar Amerika Utara 8 26 3423,5 76,5
Ketidaksepakatan ContohUSA / Amerika Utara 9 4 1369,2 30,8
Di luar Amerika Utara 2 25 277.4 92.6
Sebuah86,7% dari kasus yang dipilih dikelompokkan asli (sampel estimasi) dengan benar diklasifikasikan.b85,0% dari kasus yang tidak terpilih dikelompokkan asli (sampel validasi) benar diklasifikasikan.`83,3% dari yang dipilih lintasdivalidasi dikelompokkan kasus diklasifikasikan dengan benar.dCrossvalidasi dilakukan hanya untuk kasuskasus dalam analisis (sampel estimasi). Dalam crossvalidasi,setiap kasus diklasifikasikan oleh fungsi yang berasal dari semua kasus selain kasus itu.
Halaman 10
Analisis MultipleDiscriminant
TABEL 11 Grup Prediksi untuk Kasus Individu dalam Analisis Dua Kelompok diskriminan
SebenarnyaDiskriminan Diprediksi SebenarnyaDiskriminan DiprediksiID kasus Kelompok Z Score Kelompok Kasus ID Grup Z Score Kelompok
Analisis Sampel
72 0 2,10690 0 24 1 .60937 014 0 2,03496 0 53 1 .45623 031 0 1,98885 0 32 1 .36094 054 0 1,98885 0 80 1 .1468727 0 1,76053 0 38 1 .04489 129 0 1,76053 0 60 1 .04447 116 0 1,71859 0 65 1 0,09785 161 0 1,71859 0 35 1 0,84464 179 0 1,57916 0 1 1 0,98896 136 0 1,57108 0 4 1 1,10834 198 0 1,57108 0 68 1 1.12 36 158 0 1,48136 0 44 1 1
768
145 0 1,33840 0 17 1 1 35578 12 0 1,29645 0 67 1 1 35578 1
52 0 1,29645 0 33 1 1,42147 150 0 1,24651 0 87 1 1,57544 147 0 1,20903 0 6 1 1,58353 188 0 1,10294 0 46 1,60411 111 0 .74943 0 12 1 1,75931 156 0 .73978 0 69 1 1,82233 195 0 .73978 0 86 1 1,82233 181 0 .72876 0 0 1 1,85847 15 0 .60845 0 30 1 1,90062 1
37 0 .60845 0 15 1 1,91724 163 0 .38398 0 92 1 1,97960 143 0 0,23553 1 7 1 2,09505 13 1 1,65744 0 20 1 2,22839 1
94 1 1,57916 0 8 1 2,39938 149 1 1,04667 0 100 1 2,62102 164 1 .67406 0 48 1 2,90178 1
Ketidaksepakatan Contoh
23 0 22,38834 0 25 1 1,47048 193 0 2,03496 0 18 1 1,60411 159 0 120.903 0 73 1 1,61002 185 0 1 10.294 0 21 1 1,69348 183 0 1,03619 0 90 1 1,69715 191 0 .89292 0 97 1 1,70398 182 0 .74943 0 40 1 1,75931 176 0 .72876 0 77 1 1,86055 1

24/9/2015 dihapus). Sekali Lagi, variabel DENGAN Tingkat signifikansi LEBIH gede Dari 0,05 Dari dikeluarkan
https://translate.googleusercontent.com/translate_f 9/21
96 0 .57335 0 28 1 1,97494 113 0 0,13119 1 71 1 2,22839 189 0 0,51418 1 19 1 2,28652 142 0 0,63440 1 57 1 2,31456 178 0 0,63440 1 9 1 2,36823 122 1 2,73303 0 41 1 2,53652 174 1 1,04667 0 26 1 2,59447 151 1 0,09785 1 70 1 2,59447 162 1 0,94702 1 66 1 2,90178 175 1 0,98896 1 34 1 2,97632 199 1 1,13130 1 55 1 2,97632 184 1 1,30393 1 39 1 3,21116 1
Halaman 11
Beberapa Analisis diskriminan
Kelompok pelanggan yang berlokasi di Amerika Serikat (kelompok 0) merupakan 39,0 persen darisampel analisis (39/100), dengan kelompok yang mewakili pelanggan kedua terletak di luarAmerika Serikat (kelompok 1) membentuk 61,0 persen sisanya (61/100). Proporsional dihitungnilai kesempatan adalah 0,524 (0,3902+ 0,6102= 0,524).
Kriteria kesempatan maksimum hanya persentase benar diklasifikasikan jika semua observasitions ditempatkan dalam kelompok dengan probabilitas terbesar terjadinya. Hal ini mencerminkan paling kamistandar konservatif dan mengasumsikan tidak ada perbedaan dalam biaya kesalahan klasifikasi juga.
Karena kelompok 1 (pelanggan di luar Amerika Serikat) adalah kelompok terbesar di 61,0 persensampel, kita akan benar 61,0 persen dari waktu jika kita ditugaskan semua pengamatan untuk inikelompok. Jika kita memilih kriteria kesempatan maksimal sebagai standar evaluasi, model kami harusmengungguli tingkat 61,0 persen akurasi klasifikasi dapat diterima.
Untuk mencoba meyakinkan signifikansi praktis, klasifikasi acc bersemangat dicapai harusmelebihi standar perbandingan yang dipilih oleh 25 persen. Dengan demikian, kita harus memilih co p risonstandar, menghitung ambang batas, dan membandingkan rasio hit dicapai.
Semua tingkat akurasi klasifikasi (rasio hit) melebihi 85 per ent, yang secara substansiallebih tinggi dari kriteria kesempatan proporsional 52,4 persen dan te kriteria kesempatan maksimum61,0 persen. Semua tiga rasio hit juga melebihi ambang batas yang disarankan dari nilainilai ini (perbandinganstandar ditambah 25 persen), yang dalam hal ini adalah 65,5 p rc nt (52,4% x 1,25 = 65,5%) untukkesempatan proporsional dan 76,3 persen (61,0% x 1,25 = 76% 3) untuk kesempatan maksimal. Dalam semuacontoh (sampel analisis, sampel ketidaksepakatan, dan cros Va idation), tingkat akurasi klasifikasisecara substansial lebih tinggi dari ambang batas ue va, menunjukkan tingkat yang dapat diterima klasifikasiakurasi. Selain itu, rasio hit untuk kelompok individu dianggap memadai juga.
Ukuran akhir akurasi klasifikasi Press Q, yang berbasis statistikmengukur membandingkan akurasi klasifikasi untuk proses acak.
Dari pembahasan sebelumnya, perhitungan untuk sampel estimasi adalah[60 (52 X 2) 12Press Qes Imate sampel 45,07
60 (2 1)Dan perhitungan fo sampel ketidaksepakatan adalah
[40 (34 x 2)]2
Dalam kedua kasus tersebut nilai yang dihitung melebihinilai kritis 6.63. Dengan demikian, akurasi klasifikasi untuk analisis dan, lebih penting,sampel ketidaksepakatan melebihi pada tingkat yang signifikan secara statistik akurasi classif kation diharapkan bychance.
CASEWISE DIAGNOSTIKSelain meneliti hasil keseluruhan, kita bisa memeriksaindividuidual pengamatan untuk akurasi prediksi mereka dan mengidentifikasi secara khusus kasuskasus kesalahan klasifikasi. Di
cara ini, kita dapat menemukan kasuskasus tertentu kesalahan klasifikasi untuk setiap kelompok pada kedua analisis dansampel ketidaksepakatan serta melakukan analisis tambahan profiling untuk kasuskasus kesalahan klasifikasi.
Tabel 11 berisi prediksi kelompok untuk analisis dan ketidaksepakatan sampel dan memungkinkan kita untukmengidentifikasi kasuskasus tertentu untuk setiap jenis kesalahan klasifikasi ditabulasi dalam matriks klasifikasi (lihatTabel 10). Untuk sampel analisis, tujuh pelanggan yang berlokasi di luar Amerika Serikatkesalahan klasifikasi ke dalam kelompok pelanggan di Amerika Serikat dapat diidentifikasi sebagai kasus 3, 94, 49, 64,24, 53, dan 32. Demikian juga, pelanggan tunggal yang terletak di Amerika Serikat, tetapi kesalahan klasifikasi adalahdiidentifikasi sebagai kasus 43. Pemeriksaan serupa dapat dilakukan untuk sampel ketidaksepakatan.
Setelah kasus kesalahan klasifikasi diidentifikasi, analisis lebih lanjut dapat dilakukan untuk memahamialasan untuk kesalahan klasifikasi mereka. Pada Tabel 12, kasus kesalahan klasifikasi digabungkan darianalisis dan sampel ketidaksepakatan dan kemudian dibandingkan dengan kasus diklasifikasikan dengan benar.Upaya ini adalah untuk
PressQ sampel ketidaksepakatan= 40 (2 1) 19,6

24/9/2015 dihapus). Sekali Lagi, variabel DENGAN Tingkat signifikansi LEBIH gede Dari 0,05 Dari dikeluarkan
https://translate.googleusercontent.com/translate_f 10/21
Halaman 12
MultipleDiscriminantAnalysis
TABEL 12 Profiling dengan benar Baris dan Pengamatan kesalahan klasifikasi dalam
Dua Kelompok Analisis diskriminan
Skor ratarata t UjiTergantungVariabel: Kelompok / Profil Benar StatistikX4Wilayah Variabel Diklasifikasikan kesalahan klasifikasiDifferenceSignificance
USA / Amerika Utara (n =34) (n =5)X6Kualitas produk 8,612 9.340 .728 0,000bX7ECommerce Kegiatan 3,382 4.380 .998 0,068bX8Dukungan teknis 5,759 5,280 0,479 0,48X9Resolusi keluhan 5,356 6,140 .784 149x10Pengiklanan 3,597 4.700 1,103 0,022x11Product LineSebuah 6,726 6.540 0,186 0,345bX12Salesforce Gambar 4,459 5.460 1,001 0,018X13Harga kompetitif ' 5,609 8,060 2,45 0,000X14Garansi & Klaim 6,215 6.060 155 0,677X15ProdukProduk Baru 5,024 4.420 0,604 0,391X16Order & Penagihan 4,188 4,540 .352 0,329X17Harga FleksibilitasSebuah 3,568 4.480 .912 0,000bX18Kecepatan pengiriman 3,826 4,160 .334 0,027b
Di luar Amerika Utara (n =52) n =9)X6Kualitas produk 6,906 9,156 2,250 0,000X7ECommerce Kegiatan 3.860 3,289 0,571 159bX8Dukungan teknis 5 085 5,544 .460 0,423X9Resolusi keluhan 5 365 5,822 .457 0,322x10Pengiklanan 0,229 3,922 0,307 0,470x11Product LineSebuah 4,954 6,833 1,879 0,000X12Salesforce Gambar 5,465 5,467 .002 0,998X13Harga kompetitif ' 7,960 5,833 2,126 0,000X14Garansi & CI ims 5,867 6.400 .533 0,007bX15ProdukProduk Baru 5,194 5,778 .584 0,291x16Order & Penagihan 4,267 4,533 .266 0,481
X17Harga FleksibilitasSebuah 5,458 3,722 1,735 0,000X113D Kecepatan livery 3,881 3,989 .108 0,714
Catatan:Kasus dari kedua sampel idation analisis adv termasuk total sampel 100.'Variabel termasuk dalam fungsi inant discri.btTes dilakukan dengan perkiraan tv riance separ daripada perkiraan dikumpulkan karena tes Levene terdeteksi perbedaan yang signifikan dalamvariasi antara kedua kelompok.
dentify perbedaan tertentu pada variabel independen yang mungkin mengidentifikasi baik baruvariabel yang akan ditambahkan atau karakteristik umum yang harus dipertimbangkan.
Lima kasus (baik analisis dan sampel ketidaksepakatan) kesalahan klasifikasi antara Amerika Serikat customers (kelompok 0) menunjukkan perbedaan yang signifikan pada dua dari tiga variabel independen dalam dis yangFungsi criminant (X13dan X17) Serta satu variabel tidak dalam fungsi diskriminan (X6). Untuk ituvariabel tidak dalam fungsi diskriminan, profil kasus kesalahan klasifikasi tidak mirip dengan merekakelompok yang benar; dengan demikian, itu adalah tidak membantu dalam klasifikasi.Demikian juga, sembilan kasus kesalahan klasifikasi kelompok 1(di luar Amerika Serikat) menunjukkan empat perbedaan yang signifikan (X6, X11.X13,dan X17), tapi hanyaX6tidak difungsi diskriminan. Kita bisa melihat bahwa di siniX6bekerja melawan akurasi klasifikasi karena
Halaman 13
kasus kesalahan klasifikasi aremomsimilartotheincorrectgroup lebih thanthe kelompok yang benar.

24/9/2015 dihapus). Sekali Lagi, variabel DENGAN Tingkat signifikansi LEBIH gede Dari 0,05 Dari dikeluarkan
https://translate.googleusercontent.com/translate_f 11/21
Halaman 14
Beberapa Analisis diskriminan
Temuan menunjukkan bahwa kasus kesalahan klasifikasi mungkin merupakan kelompok ketiga yang berbeda,karena mereka berbagi profil sangat mirip di seluruh variabelvariabel ini lebih daripada yang mereka lakukan dengan duaManajemen kelompok yang ada dapat menganalisis kelompok ini pada variabel tambahan atau menilai apakah suatuPola geografis antara kasuskasus kesalahan klasifikasi membenarkan kelompok baru.
Peneliti harus meneliti pola pada kedua kelompok dengan tujuan pemahamankarakteristik umum kepada mereka dalam upaya mendefinisikan alasan untuk kesalahan klasifikasi.
Tahap 5: Interpretasi HasilSetelah memperkirakan fungsi diskriminan, tugas selanjutnya adalah interpretasi. Ini s usia melibatkanmemeriksa fungsi untuk menentukan kepentingan relatif dari masingmasing variabel independen dalammembedakan antara kelompok, menafsirkan diskriminan fungsi bas d atas diskriminasi yangnant beban, dan kemudian profil masingmasing kelompok pada pola variabel nilai ratarata fr diidentifikasisebagai variabel diskriminatif penting.
MENGIDENTIFIKASI VARIABEL diskriminatif PENTINGSeperti dibahas sebelumnya, diskriminanbeban dianggap ukuran yang lebih tepat dari kekuasaan di criminatory, tapi kami juga akanmempertimbangkan bobot diskriminan untuk purpo komparatif es Bobot diskriminan, baik dalamunstandardixed atau bentuk standar, merupakan kontribusi setiap variabel untuk diskriminan yangfungsi. Namun, seperti yang akan kita bahas, multikolinearitas antara variabel independen dapatberdampak interpretasi hanya menggunakan bobot.

24/9/2015 dihapus). Sekali Lagi, variabel DENGAN Tingkat signifikansi LEBIH gede Dari 0,05 Dari dikeluarkan
https://translate.googleusercontent.com/translate_f 12/21
Beban diskriminan dihitung untuk setiap variabel independen, bahkan bagi mereka yang tidaktermasuk dalam fungsi diskriminan. Dengan demikian, d bobot scriminant lepiesent dampak unikmasingmasing variabel independen dan tidak membatasi d hanya dampak bersama karenamultikolinearitas. Selain itu, karena mereka relatif un ffected oleh multikolinearitas, mereka lebihakurat mewakili asosiasi masingmasing variabel dengan te skor diskriminan.
Tabel 13 berisi kumpulan entir tindakan interpretatif, termasuk unstandardized danstandardiskriminan dardized berat s, oadings untuk fungsi diskriminan, lambda Wilks ', danrasio F univariat. Asli 13 variabel independen disaring dengan prosedur bertahap,dan tiga (X11,x 13, Dan X17) Cukup signifikan untuk dimasukkan dalam fungsi. Untuk interpretasitujuan, kita peringkat variabel independen dalam hal beban mereka dan univariat F valueskedua indikator ah variabel daya diskriminatif. Tandatanda bobot atau beban tidak mempengaruhigs ranki; mereka hanya menunjukkan hubungan positif atau negatif dengan variabel dependen.
Menganalisis Wilks 'Lambda dan univariat F. Wilks' lambda dan nilainilai F univariatmenangmengirim efek yang terpisah atau univariat dari setiap variabel, tidak mempertimbangkan multikolinearitasantara variabel independen. Analog dengan korelasi bivariat regresi berganda,mereka indimakan kemampuan masingmasing variabel untuk membedakan antara kelompokkelompok, tetapi hanya secara terpisah.Untukmenginterpretasikan kombinasi dua atau lebih variabel independen memerlukan analisisbobot diskriminan atau beban diskriminan seperti yang dijelaskan di bagian berikut.
Tabel 13 menunjukkan bahwa variabel (X11, X13, Dan X17) Dengan tiga nilai F tertinggi (dantermurah Wilks 'nilainilai lambda) juga variabel masuk ke dalam fungsi diskriminan. Duavariabel lain (X 6 dan X12) Juga memiliki efek diskriminatif signifikan (yaitu, kelompok signifikanperbedaan), tapi tidak dimasukkan oleh proses bertahap dalam fungsi diskriminan. Inikarena multikolinearitas antara kedua variabel dan tiga variabel termasuk dalamfungsi diskriminan. Kedua variabel menambahkan kekuatan diskriminasi tambahan di luarvariabel sudah dalam fungsi diskriminan. Semua variabel yang tersisa harusnilai F tidak signifikan dan Sejalan nilai lambda Wilks tinggi '.
Halaman 15
Beberapa Analisis diskriminan
TABEL 13 Ringkasan Tindakan Interpretasi untuk Analisis Dua Kelompok diskriminan
IndependenVariabel
DiskriminanKoefisien
DiskriminanBeban
Wilks 'Lambda Univariat F Ratio
Terstandarisasid
Standar Memuat Pangkat Nilai F Nilai Sig. Pangkat
X6Kualitas produk NI NI .418 5 0,801 14,387 0,000 4X7ECommerce Kegiatan NI NI 0,429 4 0,966 2,054 0,157 6X8Dukungan teknis NI NI .136 11 0,973 1,598 0,211 7X9Resolusi keluhan NI NI .181 8 0,986 0,849 0,361 8x10Pengiklanan NI NI 0,238 7 0,987 0,775 0,382 9x11Product Line .363 .417 .586 3 0,695 25.500 0,000 3X12Salesforce Gambar NI NI 0,164 9 0,856 9,733 003 5X13 Harga Kompetitif .398 0,490 0,656 1 0,645 31. 92 0,000 1X14 Garansi & Klaim NI NI .329 6 0,992 . 53 0,503 11X15 Produk Baru NI NI 0,041 13 0,990 0,600 0,442 10X16 Order & Penagihan NI NI .149 10 0,999 0,087 0,769 13X17Harga Fleksibilitas 0,749 0,664 0,653 2 0,647 31,699 0,000 2X18Kecepatan pengiriman NI NI .060 12 0,997 0,152 0,698 12
NI = Tidak termasuk estimasi function_ diskriminan
Menganalisis Berat diskriminan. Bobot disc iminant tersedia di unstandardized dan bentuk standar. Bobot terwujud unstandar (ditambah konstan) digunakan untukmenghitung nilai diskriminan, tetapi dapat mempengaruhi d dengan skala variabel independen (hanyaseperti beberapa bobot regresi). Bobot demikian, s andardized lebih benarbenar mencerminkan dampakmasingmasing variabel pada functio diskriminan dan lebih tepat daripada bobot unstandardizedbila digunakan untuk keperluan interpretasi Jika estimasi imultaneous digunakan, multikolinearitas antarasalah satu variabel independen akan mempengaruhi bobot diperkirakan. Namun, dampak dari multicollinearity dapat lebih besar untuk prosedur bertahap, karena multikolinearitas mempengaruhi tidakhanya bobot tetapi mungkin juga pr melampiaskan variabel dari bahkan memasuki persamaan.
Tabel 13 memberikan bobot standar th (koefisien) untuk tiga variabel yang termasuk dalamfungsi diskriminan Dampak multikolinearitas pada bobot dapat dilihat dalam memeriksaX13dan X17.Kedua variabel memiliki kekuatan diskriminatif dasarnya setara bila dilihat dariyang Wilks 'lambda iklan univariatF tes. Bobot diskriminan mereka, bagaimanapun, mencerminkan nyatadampak yang lebih besar untukX17dari X13,yang didasarkan pada bobot sekarang lebih sebanding dengan X11. Iniperubahan relati e pentingnya adalah karena collinearity antara dan X , Yang mengurangi

24/9/2015 dihapus). Sekali Lagi, variabel DENGAN Tingkat signifikansi LEBIH gede Dari 0,05 Dari dikeluarkan
https://translate.googleusercontent.com/translate_f 13/21
X13 11effe unik X13,sehingga mengurangi berat badan diskriminan juga.
MENAFSIRKAN DISKRIMINAN FUNGSI BERBASIS BEBAN DISKRIMINAN Thebeban diskriminan, di contrasttothediscriminantweights, arelessaffectedbymulticollinearitynd sehingga lebih berguna untuk tujuan interpretatif. Juga, karena beban yang dihitung untuk semuavariabel, mereka menyediakan ukuran interpretatif bahkan untuk variabel tidak termasuk dalam diskriminan yangfungsi. Aturan sebelumnya praktis ditunjukkan beban di atas ± 0,40 harus digunakan untuk mengidentifikasi substansialtive variabel diskriminatif.
Loadings dari tiga variabel yang dimasukkan dalam fungsi diskriminan (lihat Tabel 13) adalahtiga tertinggi dan semua melebihi± 0,40,sehingga penjamin inklusi untuk tujuan interpretasi. Duavariabel tambahan (X 6 dan x 7), Namun, juga memiliki beban di atas ± 0,40 ambang batas. TheDimasukkannyaX6tidak terduga, karena itu adalah variabel keempat dengan univariat signifikanmembedakan efek, tetapi tidak termasuk dalam fungsi diskriminan karena multikolinearitas
Halaman 16
Beberapa Analisis diskriminan
X7,Namun, menyajikan situasi lain; tidak memiliki efek yang signifikan univariat. Kombinasi yangtion dari tiga variabel dalam fungsi diskriminan menciptakan efek yang berhubungan denganX7,tapiX7tidak menambahkan kekuatan diskriminasi tambahan. Dalam hal ini,X7dapat digunakan untuk menggambarkanfungsi diskriminan untuk profil tujuan meskipun itu tidak masuk ke dalam estimasifungsi diskriminan.
Menafsirkan fungsi diskriminan dan diskriminasi yang antara kedua kelompok inimengharuskan peneliti mempertimbangkan semua lima variabel tersebut. Sampaisampai mereka mencirikanatau menggambarkan fungsi diskriminan, mereka semua mewakili beberapa komponen fungsi.
Tiga efek terkuat dalam fungsi diskriminan, yang semuanya umumnya sebandingdidasarkan pada nilainilai pemuatan, yangX13 (Harga Kompetitif), X17(Harga Fleksibilitas), dan X11(Product Line).X7(ECommerce Kegiatan) dan efek X6(Kualitas Produk) dapat Ddedketika menafsirkan fungsi diskriminan. Jelas beberapa faktor yang berbeda b ingdikombinasikan untuk membedakan antara kelompok, sehingga membutuhkan lebih profiling dari ps pergi kememahami perbedaan.
Dengan variabel diskriminatif diidentifikasi dan fungsi diskriminan dijelaskan dalam halvariabel dengan beban yang cukup tinggi, peneliti kemudian mulai profil masingmasing kelompok divariabelvariabel ini untuk memahami perbedaan antara mereka
Profiling THE diskriminatif VARIABEL Esearcher yang tertarik dalam interpretasivariabel individu yang memiliki statistik dan p actical signifikansi. Interpretasi sepertidicapai dengan terlebih dahulu mengidentifikasi variabel dengan kekuatan diskriminatif substantif (lihatdiskusi sebelumnya) dan kemudian memahami apa artinya kelompok yang berbeda pada masingmasingvariabel yang ditunjukkan.
Skor yang lebih tinggi pada ariables independen menunjukkan persepsi yang lebih menguntungkan dari pada HBATbahwa atribut (kecuali untukX13,dimana skor yang lebih rendah lebih disukai). Mengacu kembali ke Tabel 5,kita lihat profil bervariasi antara dua kelompok pada lima variabel ini.
Kelompok 0 (pelanggan di Amerika Serikat / Amerika Utara) memiliki persepsi yang lebih tinggi pada tigavariabel: X6(Kualitas Produk),X13(Harga Kompetitif), dan X 11(Product Line). Kelompok 1 (pelanggan di luar Amerika Utara) memiliki persepsi yang lebih tinggi pada sisadua variabel: X7(ECommerce Kegiatan) dan X17(Harga Fleksibilitas).
Dalam melihat ini wo profil, kita dapat melihat bahwa pelanggan USA / Amerika Utara memiliki banyak bertaruhpersepsi ter dari dia HBAT produk, sedangkan para pelanggan di luar Amerika Utara merasa lebih baiktentang masalah harga dan ecommerce. Catat ituX6danX13,keduanya memiliki persepsi yang lebih tinggiantara pelanggan USA / Amerika Utara, membentuk faktor Nilai Produk. Manajemen harus menggunakanHasil pengujian r ini untuk mengembangkan strategi yang menonjolkan kekuatan ini dan mengembangkan kekuatan tambahan untukcomp ement mereka.
Profil rata juga menggambarkan interpretasi tandatanda (positif atau negatif) padabobot diskriminan dan beban. Tandatanda mencerminkan profil relatif ratarata dari dua kelompok.Tandatanda positif, dalam contoh ini, berhubungan dengan variabel yang memiliki skor yang lebih tinggi untuk kelompok 1.Bobot negatif dan beban yang untuk variabelvariabel dengan pola yang berlawanan (yaitu, lebih tingginilaiues dalam kelompok 0). Dengan demikian, tandatanda menunjukkan pola antara kelompok.
Tahap 6: Validasi Hasil
Tahap akhir membahas validitas internal dan eksternal dari fungsi diskriminan. Primercara validasi adalah melalui penggunaan sampel ketidaksepakatan dan penilaian yang prediktifakurasi. Dengan cara ini, validitas didirikan jika fungsi diskriminan melakukan pada diterimatingkat dalam mengklasifikasikan pengamatan yang tidak digunakan dalam proses estimasi. Jika sampel ketidaksepakatan adalahterbentuk dari sampel asli, maka pendekatan ini menetapkan validitas internal dan

24/9/2015 dihapus). Sekali Lagi, variabel DENGAN Tingkat signifikansi LEBIH gede Dari 0,05 Dari dikeluarkan
https://translate.googleusercontent.com/translate_f 14/21
Halaman 17
Beberapa Analisis diskriminan
indikasi awal dari validitas eksternal. Jika sampel lain yang terpisah, mungkin dari populasi lain atausegmen dari populasi, membentuk sampel ketidaksepakatan, maka ini membahas lebih lengkap eksternalkeabsahan hasil diskriminan.
Dalam contoh kita, sampel ketidaksepakatan berasal dari sampel asli. Seperti dibahas sebelumnya,akurasi klasifikasi (rasio hit) untuk kedua sampel ketidaksepakatan dan lintasdivalidasi sampeladalah nyata di atas ambang batas pada semua ukuran akurasi prediksi. Dengan demikian,analisis tidak membangun validitas internal. Untuk tujuan validitas eksternal, sampel tambahan harusdiambil dari populasi yang relevan dan akurasi klasifikasi dinilai dalam banyak situasimungkin.
Peneliti didorong untuk memperpanjang proses validasi melalui profiling diperluaskelompok dan kemungkinan penggunaan sampel tambahan untuk membangun validitas eksternal. Tambahanwawasan dari analisis kasus kesalahan klasifikasi mungkin menyarankan variabel tambahan t di bisameningkatkan bahkan lebih model diskriminan.
Sebuah Tinjauan Manajerial
Analisis diskriminan pelanggan HBAT berdasarkan lokasi geografis (terletak di dalam UtaraAmerika atau di luar) mengidentifikasi satu set perbedaan persepsi yang bisa p Ovide agak ringkas danperbedaan kuat antara kedua kelompok. Beberapa temuan kunci i dude berikut:
Perbedaan ditemukan dalam subset dari hanya lima perceptio s, memungkinkan untuk fokus pada variabel kunciables dan tidak harus berurusan dengan seluruh set ia variabel diidentifikasi sebagai diskriminatifantara kelompok (tercantum dalam urutan impor beras) adalahX13(Harga Kompetitif), X17(HargaFleksibilitas), X11(Product Line),X7(ECommerce Kegiatan), danX6(Kualitas Produk). Hasil juga menunjukkan bahwa perusahaanperusahaan yang berlokasi di Amerika Serikat memiliki persepsi yang lebih baik dari HBATdari rekanrekan internasional mereka saya dari segi nilai produk dan lini produk, sedangkanpersepsi yang lebih menguntungkan Amerika nonUtara pelanggan aea fleksibilitas harga dan ekegiatan perdagangan. Persepsi ini mungkin akibat dari pertandingan yang lebih baik antara Amerika Serikat / UtaraPembeli Amerika, sedangkan pelanggan internasional menemukan kebijakan harga kondusif untukkebutuhan mereka. Hasil yang sangat signifikan, memberikan peneliti kemampuan untuk benar mengidentifikasimembeli strat y sed berdasarkan persepsi ini 85 persen dari waktu. Tingkat tinggi merekakonsistensi memberikan confidenceinthe developmentofstrategiesbasedontheseresults. Analisis perusahaan kesalahan klasifikasi mengungkapkan sejumlah kecil perusahaan yang tampak keluar dari tempat.Mengidentifikasi perusahaan t ese mungkin mengidentifikasi asosiasi tidak ditangani oleh lokasi geografis (misalnya,pasar erved bukan hanya lokasi fisik) atau perusahaan atau pasar karakteristik lain yangadalah sebagai ociated dengan lokasi geografis.
Dengan demikian, mengetahui lokasi geografis suatu perusahaan memberikan wawasan kunci ke persepsi mereka tentangHBAT dan, yang lebih penting, bagaimana dua kelompok pelanggan berbeda sehingga manajemen
dapat menggunakan strategi untuk menonjolkan persepsi positif dalam hubungan mereka dengan orangpelanggan dan diidentifikasi lebih memantapkan posisi mereka.
Sebuah TIGAGROUP CONTOH ILUSTRASI
Untuk menggambarkan aplikasi dari analisis diskriminan tiga kelompok, kami sekali lagi menggunakan HBAT yangDatabase. Dalam contoh sebelumnya, kami prihatin dengan membedakan antara duakelompok, sehingga kita mampu untuk mengembangkan fungsi diskriminan tunggal dan nilai pemotongan untuk membagikedua kelompok. Pada contoh tiga kelompok, perlu untuk mengembangkan dua diskriminan terpisahfungsi untuk membedakan antara tiga kelompok. Fungsi pertama memisahkan satu kelompok dari
Halaman 18
Beberapa Analisis diskriminan
dua lainnya, dan yang kedua memisahkan sisa dua kelompok. Seperti contoh sebelumnya,

24/9/2015 dihapus). Sekali Lagi, variabel DENGAN Tingkat signifikansi LEBIH gede Dari 0,05 Dari dikeluarkan
https://translate.googleusercontent.com/translate_f 15/21
enam tahapan proses model pembangunan yang dibahas.
Tahap 1: Tujuan Analisis diskriminan
Tujuan HBAT dalam penelitian ini adalah untuk mengetahui hubungan antara persepsi perusahaan 'dariHBAT dan lamanya waktu suatu perusahaan telah menjadi pelanggan dengan HBAT.
Salah satu paradigma yang muncul dalam pemasaran adalah konsep hubungan pelanggan, berdasarkanpembentukan kemitraan bersama antara perusahaan atas transaksi berulang Prosesmengembangkan hubungan memerlukan pembentukan tujuan bersama dan nilainilai, yang h uld bertepatan denganpeningkatan persepsi HBAT. Dengan demikian, pembentukan sukses dari ionship rela harus dilihat olehditingkatkan persepsi HBAT dari waktu ke waktu. Dalam analisis ini, perusahaan dikelompokkan pada masa jabatan mereka sebagai HBATpelanggan. Mudahmudahan, jika HBAT telah berhasil lationships gr establishi dengan pelanggan,maka persepsi HBAT akan meningkatkan dengan kepemilikan sebagai pelanggan anHBAT.
Tahap 2: Desain Penelitian untuk Analisis diskriminan
Untuk menguji hubungan ini, analisis diskriminan dilakukan untuk menentukan apakah perbedaanpersepsi ada antara kelompok pelanggan berdasarkan lamanya hubungan ustomer. Jika demikian, HBAT adalahkemudian tertarik melihat apakah dukungan profi membedakan s proposisi yang HBAT memilikiberhasil dalam meningkatkan persepsi antara es blished pelanggan, langkah yang diperlukan dalampembentukan hubungan pelanggan.
PEMILIHAN variabel dependen dan independen Selain nonmetric(kategoris) variabel dependen def ning kelompok kepentingan, analisis diskriminan jugamembutuhkan satu set variabel Tbk metrik yang diasumsikan memberikan dasar untukdiskriminasi atau pembedaan antara kelompok.
Sebuah analisis diskriminan tiga kelompok dilakukan dengan menggunakan X1(Jenis Pelanggan) sebagai dependenvariabel dan persepsi HBAT oleh perusahaanperusahaan ini (X6untuk X18) Sebagai variabel independen. Catatanbahwa X1berbeda dari variabel dependen dalam contoh dua kelompok dalam hal ini memiliki tiga kategori diyang untuk mengklasifikasikan panjang fi m untuk waktu menjadi pelanggan HBAT (1 = kurang dari 1 tahun, 2 = 1 sampai 5tahun, dan 3 = mo Ethan 5 tahun).
CONTOH siz DAN DIVISI SAMPEL Isu mengenai ukuran sampel sangatpenting dengan analisis diskriminan karena fokus pada tidak hanya keseluruhan ukuran sampel, tetapi juga padasampl si e per kelompok. Ditambah dengan kebutuhan untuk pembagian sampel untuk menyediakan validasisampl peneliti harus hatihati mempertimbangkan dampak dari pembagian sampel pada kedua sampel di t rmsdari ukuran sampel secara keseluruhan dan ukuran masingmasing kelompok.
Database HBAT memiliki ukuran sampel 100, yang lagilagi akan dibagi ke dalam analisis dan ketidaksepakatansampel dari 60 dan 40 kasus, masingmasing. Dalam sampel analisis, rasio kasus untuk mandirivariabel hampir 5: 1, yang direkomendasikan batas bawah. Lebih penting lagi, dalam sampel analisis,hanya satu kelompok, dengan 13 pengamatan, turun di bawah tingkat yang direkomendasikan dari 20 kasus per kelompok.Meskipun ukuran kelompok akan melebihi 20 jika seluruh sampel yang digunakan dalam tahap analisis, kebutuhanuntuk validasi didikte penciptaan sampel ketidaksepakatan. Tiga kelompok yang ukuran relatif sama(22, 13, dan 25), sehingga menghindari kebutuhan untuk menyamakan ukuran kelompok. Analisis hasil dengan attentionpaidto yang andinterpretationofthissmallgroupof13observations klasifikasi.
Tahap 3: Asumsi Analisis diskriminan
Seperti halnya dalam contoh dua kelompok, asumsi normalitas, linearitas, dancollinearity dari variabel independen tidak akan dibahas panjang lebar di sini. Sebuah analisismenunjukkan bahwa variabel independen memenuhi asumsi ini di memadai
Halaman 19
Beberapa Analisis diskriminan
tingkat untuk memungkinkan analisis untuk terus tanpa obat tambahan. Kami akan selanjutnyamenganggap kesetaraan varians / kovarians atau matriks dispersi.
Tes M Box menilai kesamaan matriks dispersi dari variabel independendi antara tiga kelompok (kategori). Uji statistik menunjukkan perbedaan pada 0,09 signifikansitingkat. Dalam hal ini, perbedaan antara kelompok yang tidak signifikan dan tidak ada tindakan perbaikan adalahdiperlukan. Selain itu, tidak ada dampak yang diharapkan pada estimasi atau klasifikasi proses.
Tahap 4: Estimasi Model diskriminan dan Menilai keseluruhan Fit
Seperti pada contoh sebelumnya, kita mulai analisis kami dengan meninjau sarana kelompok dan standar dviations untuk melihat apakah kelompok berbeda secara signifikan pada setiap variabel tunggal. Dengan perbedaandalam pikiran, kita kemudian menggunakan prosedur estimasi bertahap untuk menurunkan fungsi diskriminan dan completetheprocessbyassessing accuracyboth klasifikasi overalland withmsewisediagostics.
MENILAI PERBEDAAN GROUPMengidentifikasi van bles paling diskriminatif dengan tiga atau lebihkelompok lebih bermasalah daripada dalam situasi dua kelompok. Untuk thre atau lebih kelompok, khaslangkahlangkah penting untuk perbedaan antar kelompok (yaitu, Wilks '1 MBDA dan F test) hanya menilai

24/9/2015 dihapus). Sekali Lagi, variabel DENGAN Tingkat signifikansi LEBIH gede Dari 0,05 Dari dikeluarkan
https://translate.googleusercontent.com/translate_f 16/21
perbedaan keseluruhan dan tidak menjamin bahwa setiap kelompok i signifikan dari yang lain. Dengan demikian,ketika memeriksa variabel perbedaan mereka secara keseluruhan akan Ween kelompok, pastikan untuk juga mengatasiperbedaan kelompok individu.
Tabel 14 memberikan kelompok berarti, Wilks 'lambda, univariat F rasio (ANOVA sederhana), danminimum Mahalanobis D2 untuk masingmasing variabel independen. Ulasan dari langkahlangkah ini dari diskriminatifination mengungkapkan hal berikut:
Secara univariat, sekitar satusetengah (7 dari) dari variabel menampilkan perbedaan yang signifikanantara kelompok berarti. Variabel dengan perbedaan yang signifikan antaraX6, X9, X11, X13,X16, XR7,danX18. Meskipun signific beras statistik lebih besar sesuai dengan diskriminasi keseluruhan yang lebih tinggi (ie., variabel yang paling signifikan memiliki nilai lambda Wilks terendah '), tidakselalu sesuai dengan diskriminasi terbesar antara semua kelompok. pemeriksaan Visual kelompok berarti mengungkapkan bahwa empat variabel dengan berbeda signifikanences(X13, X16, X17,dan X18) Hanya membedakan satu kelompok versus lain dua kelompok [misalnya,X18memiliki perbedaan significa t hanya dalam cara antara kelompok 1 (3,059) versus kelompok 2(4,246) dan 3 (4 288)]. Variabelvariabel ini memainkan peran yang terbatas dalam analisis diskriminan karenamereka penyediaan diskriminasi e antara hanya subset dari kelompok. Tiga variabel (X6, X9,dan X11) Menyediakan beberapa diskriminasi, dalam berbagai derajat, antara semuakelompok hr e secara bersamaan. Satu atau lebih dari variabelvariabel ini dapat digunakan dalam kombinasidengan empat variabel sebelumnya untuk membuat variate dengan diskriminasi maksimal.
The Mahalanobis D2 Nilai memberikan ukuran tingkat diskriminasi antarakelompok. Untuk setiap variabel, minimum Mahalanobis D2 adalah jarak antara keduakelompok terdekat. Misalnya, X11memiliki D tertinggi2nilai, dan itu adalah variabel denganPerbedaan terbesar antara ketiga kelompok. Demikian juga,X18,variabel dengan perbedaan sedikitantara dua kelompok, memiliki D kecil 2nilai. Dengan tiga atau lebih kelompok, minimumMahalanobis D2penting dalam mengidentifikasi variabel yang memberikan perbedaan terbesarantara kedua kelompok paling mirip.
Semua langkahlangkah ini menggabungkan untuk membantu mengidentifikasi set variabel yang membentuk diskriminan yangfunctionsasdescribedinthenextsection.Whenmorethanonefunctioniscreated, eachfunctionprovidesdiskriminasi antara set kelompok. Dalam contoh sederhana dari awal bab ini, salah satukelompok discriminatedbetween variabel 1 vs 2and 3, whereasthe betweengroups2 diskriminasi lainnyaversus3and1.Itisoneoftheprimarybenefitsarisingfromtheuseofdiscriminantanalysis.
Halaman 20
Analisis MultipleDiscriminant
TABEL 14 Grup Statistik Deskriptif dan Pengujian Kesetaraan untuk Contoh Estimasi di
Analisis Tiga Kelompok diskriminanGrup Dependent Variable Berarti:
x/ Jenis pelangganUji KesetaraanGrup Sarana Sebuah
MinimumMahalanobis D2
IndependenVariabel
Kelompok 1:Kurang dari1 tahun(n = 22)
Kelompok 2:Kelompok 3:15 Lebih dariTahun 5 tahun(n = 13) (n = 25)
Wilks ' FLambda Nilai
MinimumArti D2
AntaraGrup
X6Kualitas produk 7,118 6,785 9,000 0,469 32,311 0,000 121 1 dan 2X7ECommerce
Kegiatan 3,514 3,754 3,412 0,959 1,221 0,303 0,025 1 dan 3X8Dukungan teknis 4,959 5,615 5,376 0,973 0,782 0,462 0,023 2 dan 3X9Keluhan
Resolusi 4,064 5.900 6.300 0,414 40,292 . 00 0,205 2 dan 3x10Pengiklanan 3,745 4,277 3,768 0,961 1,147 325 0,000 1 dan 3x11Product Line 4,855 5,577 7,056 0,467 32,583 0,000 0,579 1 dan 2X12Salesforce Gambar 4,673 5,346 4,836 0,943 1,708 0,190 0,024 1 dan 3X13Harga kompetitif 7,345 7,123 5,744 0,751 9 432 0,000 0,027 1 dan 2X14Garansi & Klaim 5,705 6,246 6,072 0,9162 19 0,082 0,057 2 dan 3X15ProdukProduk Baru 4,986 5,092 5,292 0,992 0,216 0,807 0,004 1 dan 2X16Order & Penagihan 3,291 4,715 4.700 532 25,048 0,000 0,000 2 dan 3X17Harga Fleksibilitas 4,018 5,508 4,084 694 12,551 0,000 0,005 1 dan 3X18Kecepatan pengiriman3,059 4,246 4,288 415 40,176 0,000 0,007 2 dan 3
SebuahWilks 'lambda (U statistik) dan univariats F ratio dengan 2 dan 57 derajat freedom_
ESTIMASI THE DISKRIMINAN FUNGSI Prosedur bertahap aku sdilakukanpada bagian yang samacara seperti dalam contoh dua kelompok, dengan semua variabel awalnya dikeluarkan dari model. Sebagaidicatat sebelumnya, jarak Mahalanobis harus digunakan dengan prosedur bertahap untuk memilihvariabel yang memiliki perbedaan yang signifikan tatistically seluruh kelompok sekaligus memaksimalkanMahalanobis distan e (D) Antara kedua kelompok terdekat. Dengan cara ini, secara statistik signifikan

24/9/2015 dihapus). Sekali Lagi, variabel DENGAN Tingkat signifikansi LEBIH gede Dari 0,05 Dari dikeluarkan
https://translate.googleusercontent.com/translate_f 17/21
2variabel sele dengan yang memaksimalkan diskriminasi antara kelompok paling mirip pada setiap tahap.Ini pr ce s terus selama variabel tambahan memberikan diskriminasi signifikan secara statistik
bangsa di luar perbedaan yang sudah dicatat dengan variabel dalam fungsi diskriminan.Sebuah variabl dapat dihapus jika multikolinearitas tinggi dengan variabel independen dalam diskriminan yangmenyenangkan ti n menyebabkan signifikansi jatuh di bawah tingkat signifikansi untuk dihapus (0,10).
Bertahap Estimasi: Menambahkan Variabel Pertama, X11. Data pada Tabel 14 menunjukkan bahwa pertamavariabel untuk memasukkan model bertahap menggunakan jarak Mahalanobis adalah X11(Product Line) karenamemenuhi kriteria perbedaan yang signifikan secara statistik seluruh kelompok dan memiliki terbesarminimum D2nilai (yang berarti telah pemisahan terbesar antara kelompok paling mirip).
Hasil menambahkan X11sebagai variabel pertama dalam proses bertahap ditunjukkan pada Tabel 15.Model keseluruhan fit signifikan dan masingmasing kelompok berbeda secara signifikan, meskipunkelompok 1 (kurang dari 1 tahun) dan 2 (15 tahun) memiliki perbedaan terkecil di antara mereka (lihatBagian bawah merinci perbedaan kelompok).
Dengan perbedaan terkecil antara kelompok 1 dan 2, prosedur diskriminan sekarang akanpilih variabel yang memaksimalkan perbedaan bahwa sementara setidaknya mempertahankan perbedaan lainnya. Jikakita merujuk kembali ke Tabel 14, kita melihat bahwa empat variabel (X9. X16, X17,dan X18) Semua memiliki signifikanperbedaan, dengan perbedaan yang cukup besar antara kelompok 1 dan 2. Mencari pada Tabel 15, kita melihat bahwaempat variabel ini memiliki tertinggi minimum D2nilai, dan dalam setiap kasus itu untuk perbedaanantara kelompok 2 dan 3 (yang berarti bahwa kelompok 1 dan 2 tidak yang paling serupa setelah menambahkan bahwa
Halaman 21
Beberapa Analisis diskriminan
variabel). Dengan demikian, menambahkan salah satu dari variabelvariabel ini yang paling mempengaruhi perbedaan antara kelompok 1dan 2, pasangan yang paling mirip setelah X11ditambahkan pada langkah pertama. Prosedur akan pilihX17karena akan membuat jarak terbesar antara kelompok 2 dan 3.
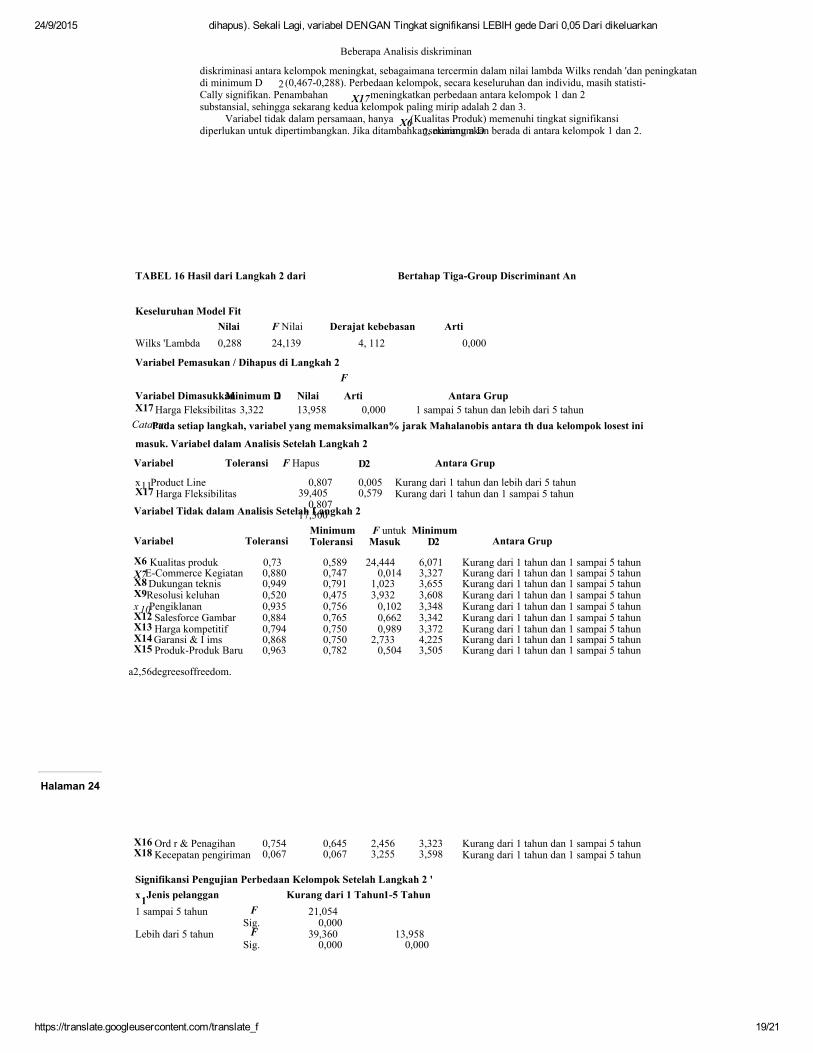
Bertahap Estimasi: Menambahkan Variabel Kedua,Xu.Tabel 16 Rincian langkah keduadari prosedur bertahap: menambahkanX17(Harga Fleksibilitas) ke fungsi diskriminan. The
TABEL 15 Hasil dari Langkah 1 dari Stepwise TigaGrup A diskriminan
Keseluruhan Model FitNilai F Nilai Derajat kebebasan Arti
Wilks 'Lambda 0,467 32,583 2,57 0,000
Variabel Pemasukan / Dihapus pada Langkah 1
F
Variabel DimasukkanMinimum 132 Nilai Arti Grup betweex11Product Line 0,579 4,729 0,000 Kurang dari setahun dan 1 sampai 5 tahun
Catatan:Pada setiap langkah, variabel yang memaksimalkan jarak Mahalanobis antara dua go terdekat pmasuk. Variabel dalam Analisis Setelah Langkah 1Variabel Toleransi F Hapus 132 Antara Grupx11Product Line 1.000 32,583 NA NA
NA = Tidak berlaku.Variabel Tidak dalam Analisis Setelah Langkah 1
Variabel ToleransiMinimumToleransi
F untukMasuk
MinimumD2 Antara Grup
X5Kualitas produk 1.000 000 17,426 0,698 Kurang dari 1 tahun dan 1 sampai 5 tahunX7ECommerce Kegiatan 0,950 0,950 1,171 0,892 Kurang dari 1 tahun dan 1 sampai 5 tahunX8Dukungan teknis 0,959 0,959 0,733 0,649 Kurang dari 1 tahun dan 1 sampai 5 tahunX9Resolusi keluhan 0,84 0,847 15,446 2,455 1 sampai 5 tahun dan lebih dari 5 tahunxioPengiklanan 0,9 8 0,998 1,113 0,850 Kurang dari 1 tahun dan 1 sampai 5 tahunX12Salesforce Gambar 0,932 0,932 3,076 1,328 Kurang dari 1 tahun dan 1 sampai 5 tahunx i 3Harga kompetitif 0,849 0,849 0,647 0,599 Kurang dari 1 tahun dan 1 sampai 5 tahunx i 4Garansi & Klaim 0,882 0,882 2,299 0,839 Kurang dari 1 tahun dan 1 sampai 5 tahunx i 5ProdukProduk Baru 0,993 0,993 0,415 0,596 Kurang dari 1 tahun dan 1 sampai 5 tahun

24/9/2015 dihapus). Sekali Lagi, variabel DENGAN Tingkat signifikansi LEBIH gede Dari 0,05 Dari dikeluarkan
https://translate.googleusercontent.com/translate_f 18/21
x i 5Order & Penagihan 0,943 0,943 12,176 2.590 1 sampai 5 tahun dan lebih dari 5 tahunX17Harga Fleksibilitas 0,807 0,807 17,300 3,322 1 sampai 5 tahun dan lebih dari 5 tahun
al, 57degreesoffreedom_
Halaman 22
x i 5Kecepatan pengiriman 0,773 0,773 19,020 2,988 1 sampai 5 tahun dan lebih dari 5 tahun
Signifikansi Pengujian Perbedaan Grup Setelah Langkah lSebuahx1 Jenis Pelanggan Kurang dari 1 Tahun15 Tahun1 sampai 5 tahun F 4,729
Sig. 0,034Lebih dari 5 tahun F 62,893 20,749
Sig. 0,000 0,000
Halaman 23
24/9/2015 dihapus). Sekali Lagi, variabel DENGAN Tingkat signifikansi LEBIH gede Dari 0,05 Dari dikeluarkan
https://translate.googleusercontent.com/translate_f 19/21
Beberapa Analisis diskriminan
diskriminasi antara kelompok meningkat, sebagaimana tercermin dalam nilai lambda Wilks rendah 'dan peningkatandi minimum D 2(0,4670,288). Perbedaan kelompok, secara keseluruhan dan individu, masih statistiCally signifikan. Penambahan X17meningkatkan perbedaan antara kelompok 1 dan 2substansial, sehingga sekarang kedua kelompok paling mirip adalah 2 dan 3.
Variabel tidak dalam persamaan, hanya X6(Kualitas Produk) memenuhi tingkat signifikansidiperlukan untuk dipertimbangkan. Jika ditambahkan, minimum D2sekarang akan berada di antara kelompok 1 dan 2.
TABEL 16 Hasil dari Langkah 2 dari Bertahap TigaGroup Discriminant An
Keseluruhan Model FitNilai F Nilai Derajat kebebasan Arti
Wilks 'Lambda 0,288 24,139 4, 112 0,000
Variabel Pemasukan / Dihapus di Langkah 2F
Variabel DimasukkanMinimum D2 Nilai Arti Antara GrupX17Harga Fleksibilitas 3,322 13,958 0,000 1 sampai 5 tahun dan lebih dari 5 tahunCatatan:Pada setiap langkah, variabel yang memaksimalkan% jarak Mahalanobis antara th dua kelompok losest ini
masuk. Variabel dalam Analisis Setelah Langkah 2
Variabel Toleransi F Hapus D2 Antara Grup
x11Product LineX17Harga Fleksibilitas0,807
39,4050,807
17,300
0,0050,579
Kurang dari 1 tahun dan lebih dari 5 tahunKurang dari 1 tahun dan 1 sampai 5 tahun
Variabel Tidak dalam Analisis Setelah Langkah 2
Variabel ToleransiMinimumToleransi
F untukMasuk
MinimumD2 Antara Grup
X6 Kualitas produk 0,73 0,589 24,444 6,071 Kurang dari 1 tahun dan 1 sampai 5 tahunX7ECommerce Kegiatan 0,880 0,747 0,014 3,327 Kurang dari 1 tahun dan 1 sampai 5 tahunX8Dukungan teknis 0,949 0,791 1,023 3,655 Kurang dari 1 tahun dan 1 sampai 5 tahunX9Resolusi keluhan 0,520 0,475 3,932 3,608 Kurang dari 1 tahun dan 1 sampai 5 tahunx10Pengiklanan 0,935 0,756 0,102 3,348 Kurang dari 1 tahun dan 1 sampai 5 tahunX12 Salesforce Gambar 0,884 0,765 0,662 3,342 Kurang dari 1 tahun dan 1 sampai 5 tahunX13Harga kompetitif 0,794 0,750 0,989 3,372 Kurang dari 1 tahun dan 1 sampai 5 tahunX14Garansi & I ims 0,868 0,750 2,733 4,225 Kurang dari 1 tahun dan 1 sampai 5 tahunX15 ProdukProduk Baru 0,963 0,782 0,504 3,505 Kurang dari 1 tahun dan 1 sampai 5 tahun
a2,56degreesoffreedom.
Halaman 24
X16Ord r & Penagihan 0,754 0,645 2,456 3,323 Kurang dari 1 tahun dan 1 sampai 5 tahunX18Kecepatan pengiriman 0,067 0,067 3,255 3,598 Kurang dari 1 tahun dan 1 sampai 5 tahun
Signifikansi Pengujian Perbedaan Kelompok Setelah Langkah 2 'x1Jenis pelanggan Kurang dari 1 Tahun15 Tahun1 sampai 5 tahun F 21,054
Sig. 0,000Lebih dari 5 tahun F 39,360 13,958
Sig. 0,000 0,000

24/9/2015 dihapus). Sekali Lagi, variabel DENGAN Tingkat signifikansi LEBIH gede Dari 0,05 Dari dikeluarkan
https://translate.googleusercontent.com/translate_f 20/21
Halaman 25
Beberapa Analisis diskriminan
Bertahap Estimasi: Menambahkan Ketiga dan Keempat Variabel,X6dan Xis.Sebagaimana dicatat, dulunyamenerus,X6menjadi variabel ketiga ditambahkan ke fungsi diskriminan. SetelahX6ditambahkan, hanyaX18menunjukkan signifikansi statistik di seluruh kelompok (Catatan: Rincian menambahkanX6pada langkah 3 tidakditampilkan untuk pertimbangan ruang).
Variabel terakhir ditambahkan pada langkah 4 adalahX18(lihat Tabel 17), dengan fungsi diskriminan sekarangtermasuk empat variabel(X11, X17,X6,dan X18). Model keseluruhan signifikan, dengan Wilks '
TABEL 17 Hasil dari Langkah 4 dari Stepwise TigaGroup Discriminant AnKeseluruhan Model Fit

24/9/2015 dihapus). Sekali Lagi, variabel DENGAN Tingkat signifikansi LEBIH gede Dari 0,05 Dari dikeluarkan
https://translate.googleusercontent.com/translate_f 21/21
Nilai F Nilai Derajat kebebasan ArtiWilks 'Lambda 0,127 24,340 8, 108 0,000
Variabel Pemasukan / Dihapus di Langkah 4F
Variabel Memasuki Minimum 132Nilai Signifikansi Antara Grupx18Kecepatan pengiriman6,920 13,393 0,000 Kurang dari 1 kamu r dan 1 sampai 5 tahunCatatan:Pada setiap langkah, variabel yang memaksimalkan% jarak Mahalanobis antara kedua kelompok dos st adalahmasuk. Variabel dalam Analisis Setelah Langkah 4
Variabel Toleransi F Hapus D2 Antara Grup
x11Product Line 0,075 0,918 6,830 Kurang dari 1 tahun dan 1 sampai 5 tahunx17Harga Fleksibilitas 0,070 1,735 6,916 Kurang dari 1 tahun dan 1 sampai 5 tahunx6Kualitas produk 0,680 27,701 3,598 1 sampai 5 tahun dan lebih dari 5 tahunx18DeliverySpeed 0,063 5,387 6,071 Kurang dari 1 tahun dan 1 sampai 5 tahunVariabel Tidak dalam Analisis Setelah Langkah 4
Variabel ToleransiMinimumToleransi
F untukMasuk
Minimum132 Antara Grup
X7 ECommerce Kegiatan 0,870 0,063 0,226 6,931 Kurang dari 1 tahun dan 1 sampai 5 tahuna4, 54 kebebasan degreesof.
Halaman 26