metody optymalizacji kodu wynikowego uwzględniając kryterium
TRANSCRIPT

POZNAŃSKIE CENTRUM SUPERKOMPUTEROWO SIECIOWE
METODY OPTYMALIZACJI KODU WYNIKOWEGO UWZGLĘDNIAJĄC
KRYTERIUM CZASU WYKONYWANIA OBLICZEŃ, ZA POMOCĄ KOMPILATORA I TECHNIK PROGRAMISTYCZNYCH.
Wykorzystanie przełączników kompilatora GCC i ICC, wielowątkowości, MPI oraz OpenMP.
Autor: Arkadiusz Mądrawski Prowadzący: dr inż. Marcin Lawenda Data: 19.08.2011 Miejsce: Poznań.
Niniejsza praca dotyczy wykorzystywania technik programistycznych i dostępnych narzędzi do optymalizacji kodu w kryterium czasu wykonywania kompilatu. W pracy porównane zostały dwa kompilatory: GCC oraz ICC z dostępnymi przełącznikami optymalizacyjnymi. Porównano również techniki programistyczne takie jak: wielowątkowość, MPI oraz OpenMP. Wykazano zależności czasowe czasu wykonywania obliczeń od zastosowanych technik i narzędzi, dla wybranych eksperymentów.

1 | S t r o n a
1 WPROWADZENIE 4
2 ZASADY EFEKTYWNEGO PROGRAMOWANIA 6
2.1 WSTĘP 6 2.2 OBLICZANIE STAŁYCH 6 2.3 DOPASOWANIE TYPÓW DO WARTOŚCI 6 2.4 WYRZUCANIE NIEZMIENNIKÓW PĘTLI POZA CIAŁO 7 2.5 UPRASZCZANIE WYRAŻEŃ LOGICZNYCH I ALGEBRAICZNYCH 7 2.6 ŁĄCZENIE INSTRUKCJI 8 2.7 ŁĄCZENIE PĘTLI 8 2.8 PĘTLA O MALEJĄCYM ITERATORZE 9 2.9 OPERACJE NA SZYBSZYCH OPERANDACH 10 2.10 SPŁASZCZANIE PĘTLI 10 2.11 ELIMINACJA ZBĘDNYCH WYRAŻEŃ 10 2.12 WYKONANE OBLICZENIA 11 2.13 SPRAWDZANIE WARUNKÓW 11 2.14 ZWIĘKSZENIE SKOKU PĘTLI 12 2.15 PRZEKAZYWANIE DUŻYCH DANYCH 12 2.16 KONSTRUKCJA WZAJEMNEGO WYKLUCZANIA 12 2.17 WARTOŚCI LENIWE 13 2.18 PODSUMOWANIE ZASAD EFEKTYWNEGO PROGRAMOWANIA 13
3 PRZEŁĄCZNIKI WYBRANYCH KOMPILATORÓW 14
3.1 KOMPILATOR GCC 14 3.1.1 PRZEŁĄCZNIKI TYPU –O[X] 14 3.1.2 FLAGI OPTYMALIZACYJNE OBLICZENIOWE 15 3.1.3 FLAGI OPTYMALIZACYJNE ARCHITEKTURALNE 15
3.2 KOMPILATORA ICC 15 3.2.1 PRZEŁĄCZNIKI TYPU –O[X] 15 3.2.2 FLAGI OPTYMALIZACYJNE OBLICZENIOWE 16 3.2.3 FLAGI OPTYMALIZACYJNE ARCHITEKTURALNE 16
4 WIELOWĄTKOWOŚĆ PROGRAMÓW 17
5 OPENMP 18
5.1 WSTĘP DO OPENMP 18 5.2 PRAGMY W OPENMP 19
5.2.1 PRAGMA PARALEL 19 5.2.2 PRAGMA FOR 19 5.2.3 KLAUZULA ORDERED 19 5.2.4 KLAUZULA SCHEDULE 19

2 | S t r o n a
5.2.5 KONSTRUKCJA BARIER 20 5.2.6 KONSTRUKCJA MASTER 20 5.2.7 KONSTRUKCJA CRITICAL 20 5.2.8 KONSTRUKCJA ATOMIC 21 5.2.9 DYREKTYWA FLUSH 21
6 MPI 21
6.1 WSTĘP DO MPI 21 6.2 OPTYMALNA KOMUNIKACJA W MPI 22 6.3 ANALIZA KOMUNIKACJI W MPI NA PODSTAWIE PROGRAMU VAMPIR 25
6.3.1 ANALIZA PRZEPROWADZONEGO TESTU 25
7 EKSPERYMENTY 31
7.1 TEST PRZEZNACZONY DLA KOMPILATORÓW GCC I ICC 31 7.2 TEST PRZEZNACZONY DLA WIELOWĄTKOWOŚCI 31 7.3 TEST PRZEZNACZONY DLA OPENMP 31 7.4 TEST PRZEZNACZONY DLA MPI 31
8 ŚRODOWISKO EKSPERYMENTÓW 32
8.1 MASZYNA NO.1 32 8.2 MASZYNA NO.2 32
9 WYNIKI TESTÓW PRZY UŻYCIU KOMPILATORÓW GCC I ICC 33
9.1 PRZEŁĄCZNIKI PODSTAWOWE KOMPILATORÓW 33 9.1.1 EKSPERYMENT PIERWSZY 33 9.1.2 EKSPERYMENT DRUGI 36
9.2 FLAGI ROZSZERZAJĄCE KOMPILATORÓW 39 9.2.1 EKSPERYMENT PIERWSZY 40
9.3 SZYBKOŚĆ VS. JAKOŚĆ 42 9.4 PODSUMOWANIE PORÓWNANIA KOMPILATORÓW 44
10 WYNIKI TESTÓW PRZY UŻYCIU WIELOWĄTKOWOŚCI 45
10.1 OPTYMALNE ZARZĄDZANIE WĄTKAMI W EKSPERYMENCIE 45 10.2 EKSPERYMENT PIERWSZY 46 10.3 EKSPERYMENT DRUGI 50 10.4 PODSUMOWANIE PROGRAMU WIELOWĄTKOWEGO 55 10.5 PORÓWNANIE PROGRAMU WIELOWĄTKOWEGO I SEKWENCYJNEGO 55

3 | S t r o n a
11 WYNIKI TESTÓW PRZY UŻYCIU OPENMP ORAZ MPI 56
11.1 OPENMP 56 11.1.1 ZARZĄDZANIE PRAGMAMI 56 11.1.2 EKSPERYMENT PIERWSZY 57 11.1.3 EKSPERYMENT DRUGI 60 11.1.4 SZYBKOŚĆ ZA JAKOŚĆ 68 11.1.5 PODSUMOWANIE 69
11.2 MPI 69 11.2.1 EKSPERYMENT PIERWSZY 69 11.2.2 MPI+OPENMP 73 11.2.3 PODSUMOWANIE 74
12 WNIOSKI 74
13 SPIS 75
BIBLIOGRAFIA 75 RYSUNKÓW 75 RÓWNAŃ 75 SPIS TABEL 76 WYKRESÓW 76 FIGURE 78

4 | S t r o n a
1 Wprowadzenie W systemie, w którym program musi wykonać szereg obliczeń numerycznych, obok
poprawności wyników, istotnym elementem jest czas pozyskania wyników. Uzyskanie większej
szybkości wykonywania obliczeń, co za tym idzie, szybszego przetwarzania danych, odgrywa
kluczowe znaczenie w miejscu, gdzie danych do obróbki jest dużo. Takimi danymi zazwyczaj są
przekazy wizyjne. Mogą być one dynamiczne lub quasi-statyczne. Obróbka takiej liczby danych
zazwyczaj zajmuje więcej czasu niż ich pozyskanie. Polepszenie szybkości działania programu,
przy zachowaniu jego zgodności, co do poprawności wyznaczanych danych, jest pożądanym
efektem. Również, gdy danych do przetworzenia jest niewiele, lecz na danych tych trzeba
wykonać czasochłonne obliczenia numeryczne. Jest kilka możliwości, które pozwalają
zwiększyć szybkość działania programu. Są to metody, począwszy od zastosowania
odpowiedniego kompilatora i jego przełączników. Takie postępowanie nie wymusza pisania
kodu programu od początku, czy też jakąkolwiek zmianę strukturalną kodu wykonaną przez
programistę. Następne metody polegają na zmianie struktury kodu, w celu wykorzystania
największej ilość mocy obliczeniowej, która może być wykorzystana przez pracujący program.
Takimi technikami są np. wątki, OpenMP oraz MPI.
Postępowanie optymalizacyjne zależy głównie od tego, co ma wykonywać program.
Generalnie, optymalizację rozpoczyna się od programisty, który odpowiada na pytanie: „Czy
zmieniając tą linię kodu uzyskam szybsze wyniki działania małym nakładem sił na zmianę linii
kodu?”. Te pytanie odnosi się do podstawowych zasad programistycznych, których główną ideą
jest: „nie wykonuj obliczeń niepotrzebnie.”
Następnie, gdy programista stwierdził, że nie ma sobie nic do zarzucenia, można
spróbować wykonać optymalizację wykorzystując podstawowe narzędzia, jakimi są
kompilatory języka. Kompilatory, prócz tego, iż przetwarzają język zrozumiały dla człowieka, na
język zrozumiały dla maszyny, posiadają gamę przełączników, lub też flag, które można ustawić
podczas kompilacji programu. Flagi te mają za zadanie optymalizować kod w kategoriach: czas
wykonywania obliczeń lub wielkość zajmowanego miejsca. Typy flag określa się, jako: ogólną
optymalizację lub też na specyficzną technikę obliczeń. W pracy tej wybrano dwa kompilatory:
GCC oraz ICC, wraz z kilkoma przykładowymi przełącznikami, celem pokazania, jak posługiwać
się przełącznikami, aby kompilat być wydajniejszy w czasowym kryterium.
Kroki powyższe posiadają niezwykła zaletę. Nie trzeba dużo manipulować przy kodzie,
aby osiągnąć lepsze wyniki w wybranym kryterium. Jednak posiadają wadę, iż przy tych
technikach nie uzyska się maksymalnego efektu. Efekt taki, można uzyskać, wtedy, gdy
wykorzysta się całą dostępną moc obliczeniową. Jednak takie podejście, wymaga zazwyczaj
pisania kodu od podstaw, z użyciem zaawansowanych technika przetwarzania danych. Taki
technikami mogą być programy wielowątkowe, wielordzeniowe, rozproszone, czyli
podpadające pod zasadę: „im więcej mocy mogę wykorzystać, tym lepiej.”
Warto podkreślić, iż wybór odpowiedniego podejścia optymalizacyjnego, zależy głównie
od chęci zmiany, możliwych nakładów przeznaczonymi na wykonanie optymalizacji oraz
rzeczywistym zyskiem czasowym. Dlatego nie trzeba wykorzystywać wszystkich tych technik i
zwyczajów. Można spróbować dowolnej gałęzi optymalizacyjnej, dopasowanej do swoich
potrzeb.
W celu pokazania, jakie przyspieszenia czasowe można osiągnąć wykonano po dwa
eksperymenty dla każdego zestawu przełączników kompilatorów, oraz zmiany struktury kodu z
sekwencyjnego na wydajniejsze, kolejno: wielkowątkowe, OpenMP oraz MPI. Przeprowadzone
eksperymenty to:

5 | S t r o n a
1. Mnożenie dwóch macierzy kwadratowych o elementach
całkowitoliczbowych.
2. Mnożenie dwóch macierzy kwadratowych o elementach
zmiennoprzecinkowych.
Warto zaznaczyć, że poniższa analiza nie musi mieć charakteru globalnego.
Wartości poszczególnych przyspieszeń mogą zależeć od maszyny a przede wszystkim
od umiejętności algorytmicznych i numerycznych programisty.

6 | S t r o n a
2 Zasady Efektywnego Programowania
2.1 Wstęp Zasady przedstawione w tym rozdziale mają na celu przyspieszenie wykonywania kody
wynikowego, zaczynając od poprawy techniki programowania autora kodu. Zasady te zostały
wybrane według reguły: kilka z wielu. Pozwalają one na efektywniejsze zagospodarowanie
jednostki obliczeniowej oraz przyszykowanie kodu do lepszej optymalizacji w przyszłości.
Warto zaznaczyć, że korzystanie z poniższych zasad nie przyspieszy znacząco działania
programu na liczbę instrukcji optymalizowanych. Jednak optymalizacja przez te zasady może
przynieść znaczący skutek, gdy operacji wykonywanych w miejscach newralgicznych, jest dużo,
czyli gdy liczba iteracji jest znacząca dla miejsca optymalizacji.
Poniższe zasady zostały wybrane i opisane bez technologii know-how, więc nie trzeba
posiadać wiedzy informatycznej, aby jest stosować i zrozumieć.
W celu polepszenia swojej techniki programowania warto zajrzeć do dodatkowej
literatury, opisującej głębsze relacje między kodem pisanym a wynikowym.
2.2 Obliczanie stałych Obliczenie wartości wyrażenia, gdy jest ono długie, warto wykonać osobno i wpisać do
zmiennej gotowy wynik.
Nieoptymalnie: long x = 12*72+13*923-32687+286+12*(57+65-213) + 735*67835 + 7835-759*765-
643*76532;
Optymalnie: //12*72+13*923-32687+286+12*(57+65-213)+735*67835+7835-759*765-43*76532
long x = 55219;
2.3 Dopasowanie typów do wartości Jeżeli wiadomo, jakie wartość będą przyjmowane przez określone zmienne, warto
dopasować określony typ do rozpatrywanej zmiennej tak, aby dopasowanie było jak najlepsze,
w kryterium wykorzystania wszystkich liczb z zakresu typu do zakresu wartości zmiennej.
Mamy kilka liczb: 17;-73;[-500,200];[0,100]; -58309; -9.23;
Nieoptymalnie: int x1=17;
int x2=-73;
int x3a=-500;
int x4a=0;
int x5 = -58309;
double x6 = -9.23;
Optymalnie: unsigned char x1=17;
signed char x2=-73; //char x2=-73
signed short x3a = -500; //short x3a = -500 // for(x3a=-500;x3a<200;x3a++)
unsigned char x4a=0; // for(x4a=0;x4a<100;x4a++)
signed int x5 = -58309; //int x5 = -58309
signed float x6 = -9.23; //float x6 =-9.23

7 | S t r o n a
2.4 Wyrzucanie niezmienników pętli poza ciało Przy wykonywaniu instrukcji w pętli, warto zastanowić się, czy niektóre zmienne są stałe
względem tej pętli. Jeżeli jakaś zmienna jest stała względem tej pętli, to można ją wyrzucić poza
ciało pętli. Wtedy program wykona mniej przypisań, więc wykonanie będzie szybsze.
Nieoptymalnie: int tab[1000];
for(int i=0;i<1000;i++)
{
int s=5*8+9-(3+12*5-7*127)-111*3-541; //można również wyliczyć wartość.
tab[i]=s;
}
Optymalnie: unsigned short tab[1000]; //dopasowanie zakresu do wartości
unsigned char s=1; //wyliczona wartość oraz dopasowanie zakresu do wartości
for(unsigned short i=0; i<1000; i++)
tab[i]=s;
2.5 Upraszczanie wyrażeń logicznych i algebraicznych Często warunki, które zamieszczane są w programie są warunkami prostymi,
jednoargumentowymi. Zdarzą się niekiedy, że sprawdzany warunek jest w bardzo
rozbudowanej formie. Warto wtedy zastosować upraszczanie wyrażeń arytmetycznych i
logicznych, korzystając z praw logiki, algebry.
Nieoptymalnie: /*przykład 1*/ float licz(int x)
{
return ((5*8+9-(3+12*5-7*127)-111*3-539)*x+2*5+2-(7+9*4-8*183)-215*6-
121)/(3*x+11);
}
/*przykład 2*/ bool test(bool spr1, bool spr2, bool spr3)
{
if((spr1 AND (spr2 OR spr3)) OR spr1 OR (spr2 AND (spr1 OR spr3)) AND (spr3 OR
(spr1 AND spr2)) OR spr2 OR spr3)
return true;
else
return false;
}
Optymalnie: /*przykład 1*/ float licz(int x)
{
return 1+11/(3*x+11);
}
/*przykład 2*/

8 | S t r o n a
bool test(bool spr1, bool spr2, bool spr3)
{
if(spr1 OR spr2 OR spr3) return true;
else return false;
}
2.6 Łączenie instrukcji Gdy kolejne instrukcje wykonują podobne operacje, może je połączyć w jedną.
Nieoptymalnie: int tab[10];
int x=10;
for(int i=0;i<10;i++)
{
x=x+10;
x=x-i;
x=3*x+5;
x=x+i;
x=2*x+9;
tab[i]=x;
}
Optymalnie: int tab[10];
int x=10;
for(int i=0;i<10;i++)
tab[i]=-4*i+6*x+79;
2.7 Łączenie pętli Jeżeli pętle posiadają ten sam warunek iteracyjny, można je połączyć w jedną pętle.
Niekiedy można połączyć kilka pętli, które nie posiadają tego samego warunku iteracyjnego.
Nieoptymalnie: /*przykład 1*/ int tab1[100];
int tab2[100];
int tab3[100];
int s=10;
int w=11;
for(int i=0;i<100;i++)
tab1[i]=1;
for(int j=0;j<100;j++)
tab2[j]=tab1[j]+j+w; //tab2[j]=1+j+w;
for(int k=0;k<100;k++)
tab3[k]=k+s;
/*przykład 2*/ int tab1[100];
int tab2[200];

9 | S t r o n a
int tab3[50];
int s=10;
int w=11;
for(int i=0;i<100;i++)
tab1[i]=1;
for(int j=0;j<200;j++)
tab2[j]=3*j+w;
for(int k=0;k<50;k++)
tab3[k]=k+s;
Optymalnie: /*przykład 1*/ int tab1[100];
int tab2[100];
int tab3[100];
int s=10;
int w=11;
for(int i=0;i<100;i++)
{
tab1[i]=1;
tab2[j]=tab1[j]+j+w; //tab2[j]=1+j+w;
tab3[k]=k+s;
}
/*przykład 2*/ int tab1[100];
int tab2[200];
int tab3[50];
int s=10;
int w=11;
for(int i=0;i<200;i++)
{
if(i<50)
{
tab1[i]=1;
tab3[i]=i+s;
}
else if(i<100)
tab1[i]=1;
// zawsze wykonaj przypisanie dla tab2
tab2[i]=3*i+w;
}
2.8 Pętla o malejącym iteratorze Można stosować iterator i++ (++i) lub również i--(--i). Iterator drugi jest szybszy,
bowiem warunek sprawdzający komputer wykonuje w jednym rozkazie (i>0) a nie w dwóch (i-
100>0).
Nieoptymalnie:

10 | S t r o n a
for(int i=0;i<100;i++)
tab[i]=3;
Optymalnie: for(int i=100;i>0;i--)
tab[i]=3;
2.9 Operacje na szybszych operandach Maszynie trudniej jest wykonać potęgowanie niż mnożenie czy dzielenie. Szybciej radzi
sobie z dodawaniem i odejmowaniem. Jednak najszybciej wykonuje przesuniecie bitowe.
Zamiast mnożyć/dzielić dwie liczby, można wykorzystać z przesunięcia bitowego i dodawania.
Nieoptymalnie: long licz(int podaj)
{
return podaj*199;
}
Optymalnie: long licz(int podaj)
{
return (podaj<<0) + (podaj<<1) + (podaj<<2) + (podaj<<6) + (podaj<<7);
}
2.10 Spłaszczanie pętli Zastępowanie kilku zagnieżdżonych pętli w jedną dłuższą.
Nieoptymalnie: int tab[100][100];
for(int i=0;i<100;i++)
for(int j=0;j<100;j++)
tab[i][j]=i+j;
Optymalnie: unsigned char tab[10000]; //bo 100*100
unsigned short it=0;
unsigned char w=0;
unsigned char k=0;
for(it=0;it<10000;it++)
{
if(w==100) {w=0; k++;}
tab[it]=w+k;
w++;
}
2.11 Eliminacja zbędnych wyrażeń Pomijanie instrukcji, dla których ich wynik będzie miał taką samą wartość. Zazwyczaj są
to instrukcje pisane przez programistę w celu odszukania błędu w programie i kontrolowaniu
poszczególnych wartości na każdym etapie algorytmu. Niekiedy jednak takie instrukcje nie są
pisane w określonym celu, jakim jest np. szukanie błędu. Czasami programista pisze dwie

11 | S t r o n a
funkcje, które mają właściwie takie same ciała i dają identyczne wyniki. Zdarza się czasami, iż
używa ich naprzemiennie. Warto wtedy pozostać przy jednej.
2.12 Wykonane obliczenia Najlepiej widać to w rozwinięciach w szereg Taylora. Załóżmy, że trzeba policzyć kolejne
wyrazy dla skończonego rozwinięcia, w zwiniętym szeregu:
���∙���
�!�
���
Ideą takiego postępowania jest, iż jeżeli obliczona została potęgę dla x^7 to aby obliczyć
x^9 nie trzeba ponownie obliczyć dla x^7. Więc, aby przyspieszyć obliczenia odszukano
zależność między i-tym oraz (i+1)-szym wyrazem i skorzystano z tej zależności. Warto zwrócić
uwagę, iż w takim podejściu można zredukować liczbę funkcji dodatkowych potrzebnych do
obliczeń. Niekiedy zredukowane funkcje są czasochłonne.
Nieoptymalnie: double wyraz(int pozycja, int x)
{
return potega(x,2*pozycja+1)/silnia(pozycja);
//nie zagłębiam się jak wyglądają funkcje: potęga(…) oraz silnia(…)
}
Optymalnie: double wyraz(double poprzednik, int x, int pozycja)
{
return poprzednik*potega(x,2)/(pozycja+1);
//nie zagłębiam się jak wygląda funkcja potega(…)
}
2.13 Sprawdzanie warunków Stosując instrukcje if, zdarza się czasami, iż warunek do sprawdzenia jest długi i
skomplikowany. Zdarza się czasami, iż warunek zawiera odwołanie od funkcji, której obliczenia
są czasochłonne. Warto wiedzieć, iż komputer sprawdza warunki od lewej strony do prawej.
Można wtedy skorzystać z faktu, iż najpierw niech sprawdzi warunki, które sprawdza się
szybko lub które często będą nieprawdziwe i stopniowo przechodzić do warunków bardziej
czasochłonnych. Warto również spróbować najpierw uprościć wyrażenie, natomiast później
zamieścić je w odpowiedniej kolejności.
W tym przypadku funkcja Licz(arg) jest funkcją czasochłonną w obliczeniach.
Nieoptymalnie: /*przykład 1*/ if(test1==true AND Licz(arg)==true OR test2==true)
/*przykład 2*/ if(Licz(arg))==true AND test2=false AND test1==true)
Optymalnie: /*przykład 1*/ if(test2==true OR test1==true AND Licz(arg)==true)
/*przykład 2*/ if(test2=false AND test1==true OR Licz(arg))==true)

12 | S t r o n a
2.14 Zwiększenie skoku pętli Dla wielkich pętli, gdzie iterator przebiega od 0 do >10�, warto zwiększyć skok pętli.
Przy skoku równym 1 komputer sprawdzi 10� warunek zakończenia pętli. Warto wówczas
zaoszczędzić ten czas i przeznaczyć go na coś efektywniejszego.
Nieoptymalnie: for(unsigned long i=0;i<10000000;i++)
{
tab[i]=i;
}
Optymalnie: for(unsigned long i=0;i<10000000;i+=5)
{
tab[i]=i;
tab[i+1]=i+1;
tab[i+2]=i+2;
tab[i+3]=i+3;
tab[i+4]=i+4;
}
2.15 Przekazywanie dużych danych Jeżeli jakaś funkcja posiada, jako argument strukturę, to nie opłaca się przekazywać całej
struktury. Warto przekazywać argument, jako wskaźnik/referencje, która jest czasami znacznie
lżejsza niż przekazanie całej struktury.
struct moja
{ double a,b,c,d,e,f,g,h,i,j; };
Nieoptymalnie: void obliczenia(moja dane)
Optymalnie: void obliczenia(moja &dane)
2.16 Konstrukcja wzajemnego wykluczania Warto zastępować konstrukcje if, konstrukcja if else if… Chodzenie po tak
stworzonej strukturze warunków jest znaczenie szybsze oraz nie zastają sprawdzane
wielokrotnie warunki, które pośrednio zostały sprawdzone i są one nieprawdziwe.
Nieoptymalnie: /*przykład 1*/ if(test1<10) {/*instrukcja1*/}
if(test1>=10 AND test1<100) {/*instrukcja2*/}
/*przykład 2*/ if(test1<10 AND test2<60) {/*instrukcja3*/}
if(test1>=10 AND test1<100 AND test2<60)
{/*instrukcja4*/}
if(test1>=100 AND test1<200 AND test2>=60 AND
test2<75) {/*instrukcja5*/}
Optymalnie: /*przykład 1*/ if(test1<10) {/*instrukcja1*/}

13 | S t r o n a
else if(test1<100) {/*instrukcja2*/}
/*przykład 2*/ if(test2<60){
if(test1<10) {/*instrukcja3*/}
else if(test1<100) {/*instrukcja4*/}
}
else if(test2<75)
if(test1>=100 AND test1<200) {/*instrukcja5*/}
2.17 Wartości leniwe Strategia wyznaczania wartości argumentów funkcji na żądanie. Podczas próby
wykonywania obliczeń sprawdzamy czy już takie obliczenia były wykonane i czy wartości z tych
obliczeń są aktualne. Jeżeli wynik obliczeń jest nieaktualny wracamy do obliczenia danych na
nowo. Zazwyczaj uzyskiwanie tych informacji i przetrzymywanie wiąże się z niewielkim
narzutem czasowym i pamięciowym.
2.18 Podsumowanie Zasad Efektywnego Programowania Zasady, które zostały przytoczone powyżej, nie wyczerpują po trosze tematu
efektywnego programowania. Pokazują, w jaki sposób można rozpocząć efektywne
programowanie, w kryterium czasu wykonywania kompilatu. Zasady te warto stosować i
przetestować na dużych liczbach iteracji, aby całkowity uzysk czasowy był miły dla oka. Warto
zwrócić szczególną uwagę na to, że programy składają się z pętli, które niekiedy z rzędem
licznika milion. Warto wtedy zwrócić swoją uwagę na te pętle i skupić całą optymalizację w ich
obrębie. Warto również rozważyć instrukcje warunkowe, czy warunki są w najprostszej postaci
oraz czy nie następuje sprawdzanie warunku, który z góry będzie niespełniony.

14 | S t r o n a
3 Przełączniki wybranych kompilatorów Wybrane do testowania kompilatory posiadają 2 typy podstawowych przełączników
optymalizacyjnych. Pierwszy typ odpowiada za wielkość kodu wynikowego, natomiast drugi typ
odpowiada za szybkość działania kompilatu. W niniejszym rozdziale skupiono się na typem
optymalizacyjnym względem czasu wykonywania kompilatu. Są cztery tego typu przełączników.
Kompilatory również posiadają flagi optymalizacyjne, które można podzielić na:
obliczeniowe, architektoniczne, precyzji, inne. Skupiono się na flagach obliczeniowych oraz
architektonicznych, bowiem te flagi mają bezpośredni wpływ na optymalizację w wybranym
kryterium. Flagi precyzji, są to flagi, które pozwalają na zmniejszenie precyzji obliczeń. Flagi te
nie będą przedmiotem niniejszej pracy, bowiem praca dotyczy optymalizacji bez straty precyzji
prowadzonych obliczeń.
3.1 Kompilator GCC
3.1.1 Przełączniki typu –O[x] -O0:
Brak optymalizacji. Przełącznik domyślnie aktywny.
-O1:
Kompilator stara się zmniejszyć rozmiar kodu i czas realizacji, bez wykonywania
żadnych optymalizacji, które mogą powodować problem przy uruchamianiu kompilatu na
innym sprzęcie, lub mogące powodować zmianę struktury kodu. W zależności od jądra systemu,
ten przełącznik włącza następujące flagi:
-fauto-inc-dec, -fcprop-registers, -fdce, -fdefer-pop, -fdelayed-branch, -fdse, -fguess-branch-
probability, -fif-conversion2, -fif-conversion, -fipa-pure-const, -fipa-reference, -fmerge-
constants, -fshrink-wrap, -fsplit-wide-types, -ftree-builtin-call-dce, -ftree-ccp, -ftree-ch, -ftree-
copyrename, -ftree-dce, -ftree-dominator-opts, -ftree-dse, -ftree-forwprop, -ftree-fre, -ftree-
phiprop, -ftree-sra, -ftree-pta, -ftree-ter, -funit-at-a-time.
-O2:
Kompilator stara się zwiększyć szybkość działania kodu wynikowego, dopasowując się
do rodziny sprzętowej, jak analizując kod pod względem typowych przekształceń
numerycznych i algorytmicznych. W zależności od jądra systemu, ten przełącznik włącza
następujące dodatkowe względem przełącznika –O1 flagi:
-fthread-jumps, -falign-functions, -falign-jumps, -falign-loops, -falign-labels, -fcaller-saves –
crossjumping, -fcse-follow-jumps, -fcse-skip-blocks, -fdelete-null-pointer-checks, -fexpensive-
optimizations, -fgcse, -fgcse-lm, -finline-small-functions, -findirect-inlining, -fipa-sra, -foptimize-
sibling-calls, -fpeephole2, -fregmove -freorder-blocks, -freorder-functions, -frerun-cse-after-
loop, -fsched-interblock, -fsched-spec, -fschedule-insns, -fschedule-insns2, -fstrict-aliasing, -
fstrict-overflow, -ftree-if-to-switch-conversion, -ftree-switch-conversion, -ftree-pre -ftree-vrp.
-O3:

15 | S t r o n a
Kompilator stara się zwiększyć szybkość działania kodu wynikowego, dopasowując się
do konkretnej architektury system. Program taki może nie wykonać się na innej klasie jednostki
obliczeniowej. W zależności od jądra systemu, ten przełącznik włącza następujące dodatkowe
względem przełącznika –O2 flagi:
-finline-functions, -funswitch-loops, -fpredictive-commoning, -fgcse-after-reload, -ftree-
vectorize, -fipa-cp-clone options.
Możliwości optymalizacyjnych, jakie oferuje kompilator GCC jest więcej, co za tym idzie,
zaleca się przeczytanie dokumentacji kompilatora, w celu jak najlepszego dopasowania swojej
optymalizacji do użytku programu.
3.1.2 Flagi optymalizacyjne Obliczeniowe Są to flagi kompilatora, które pozwalają dopasować się do konkretnych obliczeń, które
wykonywane są w programie. Jeżeli wykonywane są obliczenia modulo dla pewnego pierścienia
można przyspieszyć obliczenia ze względu na włączenia flagi, która przyspieszy takie
obliczenia. W celu dopasowania specyficznych obliczeń do konkretnej flagi zaleca się
zapoznanie z dokumentacją kompilatora. Przykładowe flagi, które zostały wybrane:
-fipa-pure-const, -fipa-reference, -fmerge-constants, -fshrink-wrap, -fsplit-wide-types, -ftree-
builtin-call-dce, -ftree-copyrename, -ftree-dce, -ftree-dominator-opts, -ftree-dse, -ftree-
forwprop, -ftree-fre, -ftree-phiprop, -ftree-sra, -ftree-pta, -ftree-ter, -funit-at-a-time, -fkeep-
inline-functions, -fkeep-static-consts, -fmerge-constants, -fmodulo-sched, -fgcse, -fdce, -fdse, -
fexpensive-optimizations, -fipa-cp-clone, -fipa-matrix-reorg, -ftree-loop-linear, -floop-
interchange, -floop-strip-mine, -floop-block, -ftree-loop-distribution, -ffast-math, -fassociative-
math, -freciprocal-math, -funroll-all-loops, -fpeel-loops,
3.1.3 Flagi optymalizacyjne Architekturalne Są to flagi kompilatora, które pozwalają dopasować się do kontentej maszyny liczącej,
wykorzystując jej najlepsze cechy, rozkład rejestrów. Wykorzystują architekturę tak aby jak
najlepiej dopasować się pod względem szybkości wykonywanych obliczeń. Przykładowe flagi,
które zostały wybrane:
-mmangle-cpu. -mcpu=cpu, -mcpu=name, -mtune=name, -march=name, -mfpu=name, -
mfpe=number, -mfp=number, -mstructure-size-boundary=n, -mtp=name, -mcpu=cpu[-
sirevision], -mmulticore.
3.2 Kompilatora ICC
3.2.1 Przełączniki typu –O[x] -O0:
Wyłącza wszystkie optymalizacje. Przełącznik domyślnie aktywny.
-O1:
Kompilator poprzez ten przełącznik nie dopasowuje się do architektury maszyny.
Kompilator próbuje optymalizować kod poprzez wykorzystanie ogólnodostępnych narzędzi
komunikacji między poszczególnymi fragmentami kodu wynikowego. Przełącznik ten oferuje

16 | S t r o n a
najmniejszy stopień optymalizacji. W zależności od architektury maszyny, przełącznik ten może
aktywować flagi, o których użytkownik może nie wiedzieć1.
-O2:
Zalecany poziom optymalizacji. Przełącznik ten umożliwia lepsze dostosowanie się do
rodziny sprzętowej, przez globalne zarządzanie rejestrami. Dopasowuje się również do
optymalnego zarządzania wyjątkami, optymalizuje wybrany fragment kodu przez rozwinięcie
pętli oraz zmianę warunków w pętli. Przełącznik ten może włącz inne flagi optymalizacyjne w
celu zwiększenia prędkości działania kompilatu, jednak włączenie ich zależy od systemu i
architektury, na jakiej kompilator działa. W celu zwiększenia działania swojego kodu, zalecane
jest zapoznanie się z dokumentacją kompilatora z sekcją: Optymalizacja.
-O3:
Kompilator agresywniej podchodzi do kompilacji, stosując pewne techniki
optymalizacyjne, przez co kompilat może być niestabilny. Kompilator próbuje bardziej
dostosować się do architektury komputera, co może uniemożliwić działanie kodu na innej
maszynie. Przełącznik ten aktywuje flaga, w zależności od parametrów technicznych maszyny,
na której kompilator pracuje. Optymalizacja tym przełącznikiem jest niezalecana, w kryterium
bardzo dokładnych obliczeń oraz mobilności kodu wynikowego. W celu zapoznania się z
przełącznikiem, warto przeczytać dokumentacje kompilatora.
Przełączników kompilatora ICC jest więcej. Głównie flagi, które są zawarte w
dokumentacji kompilatora, mają za zadanie dopasowanie się do architektury firmy prowadzącej
kompilator.
3.2.2 Flagi optymalizacyjne Obliczeniowe -fast, -fast-transcendentals, -fpie, -funroll-all-loops, -funsigned-bitfields, -parallel, -opt-matmul, -
fmath-errno, -fp-model keyword, -fp-speculation=mode.
3.2.3 Flagi optymalizacyjne Architekturalne -auto-p32, -axcode, -fomit-frame-pointer.
1 Jeżeli kompilator odszuka sprzyjający sprzęt firmy Intel, kompilator aktywuje flagi związane z
dostosowaniem się do rodziny jednostki obliczeniowej.

17 | S t r o n a
4 Wielowątkowość programów Wątek to jest twór systemowy, który wie, co ma zrobić i próbuje dostać od jednostki
obliczeniowej trochę czasu na wykonanie powierzonego mu zadania.
Wielowątkowość to cecha systemu operacyjnego, która umożliwia w ramach jednego
procesu można wykonywać kilka wątków. Nowe wątki to kolejne instrukcje wykonywane
oddzielnie, pochodzące z tego samego procesu, które współdzielą kod programu oraz dane.
Wielowątkowość można odnieść do procesorów. W takim przypadku, wielowątkowość oznacza
możliwość jednoczesnego wykonywania wielu wątków na pojedynczej jednostce obliczeniowej.
W takim przypadku są to wątki sprzętowe, które zależą od liczby rdzeni procesora i
wykonywane są równolegle. Cechą wielowątkowości jest to, iż wszystkie wątki wykonują się w
ramach procesu głównego.
Wielowątkowość została wprowadzona, w celu przetwarzania współbieżnego.
Przetwarzanie współbieżne może przynieść zwiększenie wydajności programu, jednak mu
istnieć ku temu odpowiednie zasoby sprzętowe. Wielowątkowość może również obniżyć
wydajność, ponieważ potrzeba stworzyć wątek i go obsłużyć. Tworzenie jak i obsługa, np.
synchronizacja wątków zabierają cenny czas procesora.
Wszystkie wątki w obrębie jednego procesu współdzielą tę samą wirtualną przestrzeń
adresową. Komunikacją między wątkami jest skonstruowana dosyć łatwo, bowiem wystarczy
odwołać się do tych zmiennych współdzielonych.

18 | S t r o n a
5 OpenMP
5.1 Wstęp do OpenMP OpenMP jest to standard dla komputerów równoległych (SMP) dostarczony w postaci API
dla programisty. Dostarcza mechanizmów korzystających w sposób jawny z wielowątkowości i
pamięci współdzielonej w trybie równoległym. Standard bazuje na tworzeniu i usuwaniu
wątków dla obszarów równoległych, które wykonują narzucone zadania przez programistę.
Programista ma wpływ na liczbę tworzonych wątków i jakie główne zadanie ma zostać
wykonanie przez grupę wątków. Programista natomiast nie ma wpływu, jakie wątki, co
wykonają, tzn. programista nie przyporządkowuje konkretnemu wątkowi określonego zadania.
Idea działania programu w standardzie OpenMP została ukazana na rysunku poniżej.
Rysunek 1. Idea działania programu ze standardem OpenMP.
Źródło: http://pl.wikipedia.org/w/index.php?title=Plik:Fork_join_pl.svg&filetimestamp=20090913184121
Zawsze startuje pojedynczy proces, który tworzy n wątków dla sekcji równoległej. po
zakończeniu działania w tej sekcji następuje synchronizacja i porządkowanie. Wynikiem tego
wątkiem, który zostaje jest wątek główny. Przechodząc do następnej sekcji równoległej, wątek
główny tworzy n wątków, które wykonują zadanie w sekcji równoległej, po czym kończą
działanie i wątek główny przechodzi dalej.
Tworzenie sekcji równoległych opatrzone jest w kodzie źródłowym w postaci jawnej,
odpowiednia dyrektywą preprocesora w postaci: #pragma omp nazwa_dyrektywy warunki nowa_linia_kodu
Warto zaznaczyć, iż każda dyrektywa posiada jedną nazwę oraz każda dyrektywa dotyczy
najbliższego następującego bloku kodu, czyli np.
#pragma omp parallel shared(sum) private(i,arg)
//miejsce, w którym kodu nie powinno być
{
//instrukcje sekcji równoległej
} //koniec sekcji równoległej automatyczna synchronizacja i zarządzanie watkami

19 | S t r o n a
5.2 Pragmy w OpenMP
5.2.1 Pragma paralel Aby potencjalnie wykorzystać równoległość obliczeń można zastosować pragme
parallel. Po dyrektywnie parallell następuje bezpośrednio blok kodu z jednym wejściem i
jednym wyjściem. Postać konstrukcji parallel jest następujące:
#pragma omp parallel
{
//przetwarzanie równoległe
}
//przetwarzanie sekwencyjne
Wykonanie konstrukcji parrallel jest następujące. Gdy wątek główny programu osiągnie
miejsce określone przez dyrektywę parallel, wówczas tworzona jest grupa wątków. Grupa
wątków stworzona jest pod warunkami, iż nie występuje klauzula if oraz jeśli występuje
klauzula if ma ona wartość różna od zera. Gdy nie wystąpi taka sytuacja, wówczas blok kodu
znajdujący się bezpośrednio pod dyrektywą parallel jest wykonywany przez wątek główny.
Liczba wątków zależy od zmiennej OMP_NUM_THREADS.
5.2.2 Pragma for Warto również zapoznać się z pragmami określającymi dzielenie pracy. Najbardziej
rozpoznawalną konstrukcją jest konstrukcja for. Konstrukcja for umożliwia dzielenie ciała pętli
między wątki w grupie, przy czym każdy obrót pętli będzie wykonywany tylko raz. Konstrukcja
ma postać:
#pragma omp for
for(...,...,...)
{
//ciało pętli for
}
Konstrukcja for wymaga, aby przed jej wykonaniem była znana liczba obrotów pętli.
5.2.3 Klauzula ordered Klauzula ordered umożliwia realizację wybranej części ciała pętli for w takim porządku,
jakby pętla była wykonywana sekwencyjnie.
#pragma omp for ordered
for (i=0; i<32; i++)
{
// intensywne obliczenia
#pragma omp ordered
p r i n t f ( "Watek %d wykonuje:= %d\n",iam,i) ;
}
5.2.4 Klauzula schedule Klauzula schedule specyfikuje sposób podziału wykonań ciała pętli między wątki.
Decyduje o tym parametr rodzaj, który może przybierać następujące wartości:
• static – gdy przyjmuje postać schedule(static,rozmiar), wówczas pula obrotów jest
dzielona na kawałki o wielkości rozmiar, które są cyklicznie przydzielane do wątków;
gdy nie poda się rozmiaru, to pula obrotów jest dzielona na mniej więcej równe części;

20 | S t r o n a
• dynamic – jak wyżej, ale przydział jest dynamiczny; gdy wątek jest wolny, wówczas
dostaje kolejny kawałek; pusty rozmiar oznacza wartość 1;
• guided – jak dynamic, ale rozmiary kawałków maleją wykładniczo, aż liczba obrotów w
kawałku będzie mniejsza niż rozmiar;
• runtime – przydział będzie wybrany w czasie wykonania programu na podstawie
wartości zmiennej środowiskowej OMP SCHEDULE, co pozwala na użycie wybranego
sposobu szeregowania w trakcie wykonania programu, bez konieczności ponownej jego
kompilacji.
Domyślny rodzaj zależy od implementacji. Dodajmy, że w pętli nie może wystąpić instrukcja
break, oraz zmienna sterująca musi być typu całkowitego. Dyrektywy schedule, ordered oraz
nowait mogą wystąpić tylko raz.
5.2.5 Konstrukcja barier Konstrukcja definiuje jawną barierę następującej postaci. Umieszczenie tej dyrektywy
powoduje wstrzymanie wątków, które dotrą do bariery aż do czasu, gdy wszystkie wątki
osiągną to miejsce w programie. Ogólna konstrukcja.
#pragma omp barrier
5.2.6 Konstrukcja master Konstrukcja występuje we wnętrzu bloku strukturalnego po paralleli oznacza, że blok
strukturalny jest wykonywany tylko przez wątek główny. Nie ma domyślnej bariery na wejściu i
wyjściu. Postać konstrukcji jest następująca.
#pragma omp parallel
{
//kod do przetwarzania rownoleglego
#pragma omp master
{
//to co ma wykonać watek glowny
}
5.2.7 Konstrukcja critical Konstrukcja występuje we wnętrzu bloku strukturalnego po parallel i oznacza, że blok
strukturalny jest wykonywany przez wszystkie wątki w trybie wzajemnego wykluczania, czyli
stanowi sekcję krytyczną. Postać konstrukcji jest następująca:
#pragma omp parallel
{
//przetwarzanie równolegle
#pragma omp critical
{
//sekcja krytyczna
}
//przetwarzanie równolegle
}
Możliwa jest również postać z nazwanym regionem krytycznym. Konstrukcja wtedy ma
postać:
#pragma omp parallel
{
//przetwarzanie równolegle

21 | S t r o n a
#pragma omp critical (nazwa)
{
//sekcja krytyczna
}
//przetwarzanie równolegle
}
Wątek czeka na wejściu do sekcji krytycznej aż do chwili, gdy żaden inny wątek nie
wykonuje sekcji krytycznej (o podanej nazwie).
5.2.8 Konstrukcja atomic W przypadku, gdy w sekcji krytycznej aktualizujemy wartość zmiennej, lepiej jest
posłużyć się konstrukcją atomic następującej postaci:
#pragma omp parallel
{
#pragma omp atomic
zmienna=expr;
}
5.2.9 Dyrektywa flush Dyrektywa powoduje uzgodnienie wartości zmiennych wspólnych podanych na liście,
albo, gdy nie ma listy – wszystkich wspólnych zmiennych. Ogólna postać konstrukcji:
#pragma omp parallel
{
#pragma omp f l u s h (lista zmiennych)
}
6 MPI
6.1 Wstęp do MPI Standard MPI zakłada działanie kilku równoległych procesów, w szczególności procesów
rozproszonych, czyli działających na różnych komputerach, połączonych za pomocą sieci. W
praktyce MPI jest najczęściej używany na klastrach komputerów i implementowany, jako
biblioteka funkcji oraz makr, które możemy wykorzystać pisząc programy w językach C/C++
oraz Fortran. Przykładowe implementacje dla tych języków to MPICH oraz OpenMPI.
Oczywiście znajdziemy też wiele implementacji dla innych języków.
Naturalnym elementem każdego programu, w skład, którego wchodzi kilka
równoległych procesów (lub wątków), jest wymiana danych pomiędzy tymi procesami
(wątkami). W przypadku wątków OpenMP odbywa się to poprzez współdzieloną pamięć. Jeden
wątek zapisuje dane do pamięci, a następnie inne wątki mogą tę daną przeczytać. W przypadku
procesów MPI rozwiązanie takie nie jest możliwe, ponieważ nie posiadają one wspólnej
pamięci. Komunikacja pomiędzy procesami MPI odbywa się na zasadzie przesyłania
komunikatów, stąd nazwa standardu. Poprzez komunikat należy rozumieć zestaw danych
stanowiących właściwą treść wiadomości oraz informacje dodatkowe, np. identyfikator
komunikatora, w ramach, którego odbywa się komunikacja, czy numery procesów
komunikujących się ze sobą. Komunikacja może zachodzić pomiędzy dwoma procesami, z
których jeden wysyła wiadomość a drugi ją odbiera, wówczas nazywana jest komunikacją typu

22 | S t r o n a
punkt-punkt, ale może też obejmować więcej niż dwa procesy i wówczas jest określana mianem
komunikacji grupowej.
6.2 Optymalna komunikacja w MPI W tym rozdziale opisano przykład komunikacji w MPI. Wybrana komunikacja to tzw.
Komunikacja nieblokująca. Opisana została na przykładzie mnożenia dwóch macierzy
kwadratowych.
Założenie komunikacji nieblokującej jest takie, że operacja wysyłająca zwraca sterowanie
nie czekając, aż wiadomość zostanie odebrana. Analogicznie przy odbiorze wiadomości może
zostać użyta nieblokująca funkcja receive, której wywołanie jedynie rozpoczyna kopiowanie
danych do bufora, które od tego momentu przebiega jednocześnie z obliczeniami. Do
zakończenia odbioru wiadomości koniecznie jest wywołanie blokującej funkcji, która kończy
odbieranie wiadomości.
Poniżej zamieszczono przykład nieblokującej komunikacji na mnożeniu macierzy
kwadratowych.
/*
Operacja C <- C + AB na kwadratowej siatce proces x proces
Proces P( i , j ) przechowuje bloki A( i , j ) oraz B( i , j ) macierzy
Proces P( i , j ) przechowuje blok C( i , j ) wyniku
Komunikacja nieblokująca
*/
#include "mpi . h"
#include "mkl.h"
#include <stdio.h>
#include <math.h>
int main ( int argc , char * argv [ ] )
{
int myid , myid2d , numprocs , i , j , ndims , newid1 , newid2 ;
double tim ;
MPI_Status stat ;
MPI_Comm cartcom , spl i t com1 , spl i t com2 ;
MPI_Request reqs [ 4 ] ;
int dims [ 2 ] ;
int pers [ 2 ] ;
int coord [ 2 ] ;
int rem [ 2 ] ;
int p , q , n ;
double *a ;
double *b ;
double * c ;
double * a_buff [ 2 ] , *b_buff [ 2 ] ;

23 | S t r o n a
int up , down , left , right , shiftsource , shiftdest ;
char TRANSA=’N’ , TRANSB=’N’ ;
double ALPHA =1.0 , BETA=1.0;
MPI_Init(&argc ,&argv ) ;
MPI_Comm_size(MPI_COMM_WORLD,&numprocs ) ;
MPI_Comm_rank(MPI_COMM_WORLD,&myid ) ;
if (myid==0) scanf ("%d",&n) ;
MPI_Bcast(&n , 1 ,MPI_INT, 0 ,MPI_COMM_WORLD) ;
ndims=2;
dims [0]=0 ; dims[1]=0 ;
pers[0]=1; pers [1]=1 ;
// krok 1 : tworzenie siatki
MPI_Dims_create ( numprocs , ndims , dims ) ;
MPI_Cart_create (MPI_COMM_WORLD, 2 , dims , pers , 1, &cartcom) ;
MPI_Comm_rank( cartcom,&myid2d ) ;
MPI_Cart_coords ( cartcom ,myid2d , 2 , coord ) ;
p=dims [ 0 ] ;
int myrow=coord [ 0 ] ;
int mycol=coord [ 1 ] ;
MPI_Cart_shift ( cartcom ,1 ,-1 ,& right ,&left ) ;
MPI_Cart_shift ( cartcom ,0 ,-1 ,&down ,&up) ;
// alokacja tablic i generowanie danych
q=n/p ;
a=malloc ( q*q* sizeof *a) ;
b=malloc ( q*q* sizeof *b) ;
c=malloc ( q*q* sizeof *c) ;
a_buff [0]=a ;
a_buff [1]= malloc ( q*q* sizeof *a ) ;
b_buff [0]=b ;
b_buff [1]= malloc ( q*q* sizeof *b) ;
for ( i =0; i<q ; i++)
for ( j =0; j<q ; j++){
a [ i*q+j ]= myid ;
b [ i*q+j ]= myid ;

24 | S t r o n a
c [ i*q+j ]=0;
}
if (myid2d==0) tim=MPI_Wtime( );
// krok 2 : przemieszczenie A(i,j),B(i,j)
MPI_Cart_shift ( cartcom ,1 ,-coord [0] ,&shiftsource , &shiftdest) ;
MPI_Sendrecv_replace(a_buff[0],q*q,MPI_DOUBLE,shiftdest,101,shiftsource,101,cartcom,&stat)
;
MPI_Cart_shift ( cartcom ,0 ,-coord [ 1 ] ,&shiftsource,&shiftdest) ;
MPI_Sendrecv_replace(b_buff[0],q*q,MPI_DOUBLE,shiftdest,1,shiftsource,1,cartcom,&stat) ;
// krok 3 : iloczyny lokalne
for ( i =0; i<dims [ 0 ] ; i++){
MPI_Isend ( a_buff [i%2] ,q*q ,MPI_DOUBLE,left,1,cartcom,&reqs[ 0 ]) ;
MPI_Isend ( b_buff [i%2] ,q*q ,MPI_DOUBLE,up,1,cartcom,&reqs[ 1 ]) ;
MPI_Irecv ( a_buff [(i+1)%2] ,q*q ,MPI_DOUBLE,right,1,cartcom,&reqs[2]) ;
MPI_Irecv ( b_buff [(i+1)%2] ,q*q ,MPI_DOUBLE,down,1,cartcom,&reqs[3]) ;
DGEMM(&TRANSA,&TRANSB,&q,&q,&q,&ALPHA,a,&q,b,&q,&BETA,c,&q) ;
for ( j =0; j <4; j++) MPI_Wait(&reqs[j],&stat) ;
}
// krok 4 : rozmieszczenie startowe A(i,j),B(i,j)
MPI_Cart_shift (cartcom,1,+coord[0],&shiftsource,&shiftdest) ;
MPI_Sendrecv_replace(a_buff[i%2],q*q,MPI_DOUBLE,shiftdest,1,shiftsource,1,cartcom,&stat) ;
MPI_Cart_shift (cartcom,0,+coord[1],&shiftsource,&shiftdest) ;
MPI_Sendrecv_replace(b_buff[i%2],q*q,MPI_DOUBLE,shiftdest,1,shiftsource,1,cartcom,&stat) ;
// informacja diagnostyczna
if (myid2d==0){
tim=MPI_Wtime( )-tim ;
printf("Czas:= %lf\n",tim) ;
printf("Mflops:= %lf\n",(2.0*n)*n*(n/1.0e+6.0)/tim) ;
}
MPI_Comm_free(&cartcom) ;
MPI_Finalize ( ) ;
return 0 ;
}
25 | S t r o n a
6.3 Analiza komunikacji w MPI na podstawie programu Vampir Przeprowadzono kilka testów przy użyciu standardu MPI. Testy te posłużyły do jak
wsad dla programu Vampir. Program ten analizuje działanie programu pod względem
czasowym. Monitoruje cały program i pokazuje, co się dzieje w danej chwili, z jaką częścią kodu.
Ukazuje obłożenie jednostek liczących oraz jakiego typu komunikaty zostały przesłane.
Pokazuje, jakie czynności wykonywane są na każdym procesie, po rozesłaniu komunikatu.
Dzięki takim informacją optymalizacja kodu jest znacznie ułatwiona, bowiem wyraźnie widać
jak zachowuje się program na kolejnych etapach działania.
Testy można podzielić na 3 znaczące etapy. Pierwszy z nich można nazwać:
przygotowawcza. W tym etapie następuje zajmowanie pamięci i poinformowanie innych, czym
się zajmuje, czym dysponuję. Rozsyłane są informacje do innych procesów grupowo lub też w
sytuacji punkt-punkt. Drugi etap to wykonywanie właściwego zadania. Polega on na wykonaniu
zadania. Procesy komunikują się w celu ciągłego rozwiązywania problemu. Trzecim etapem jest
zakończenie, gdzie procesy informują, że zakończyły zadanie i potrzeba teraz od nich odebrać
pewne dane i stworzyć w całość.
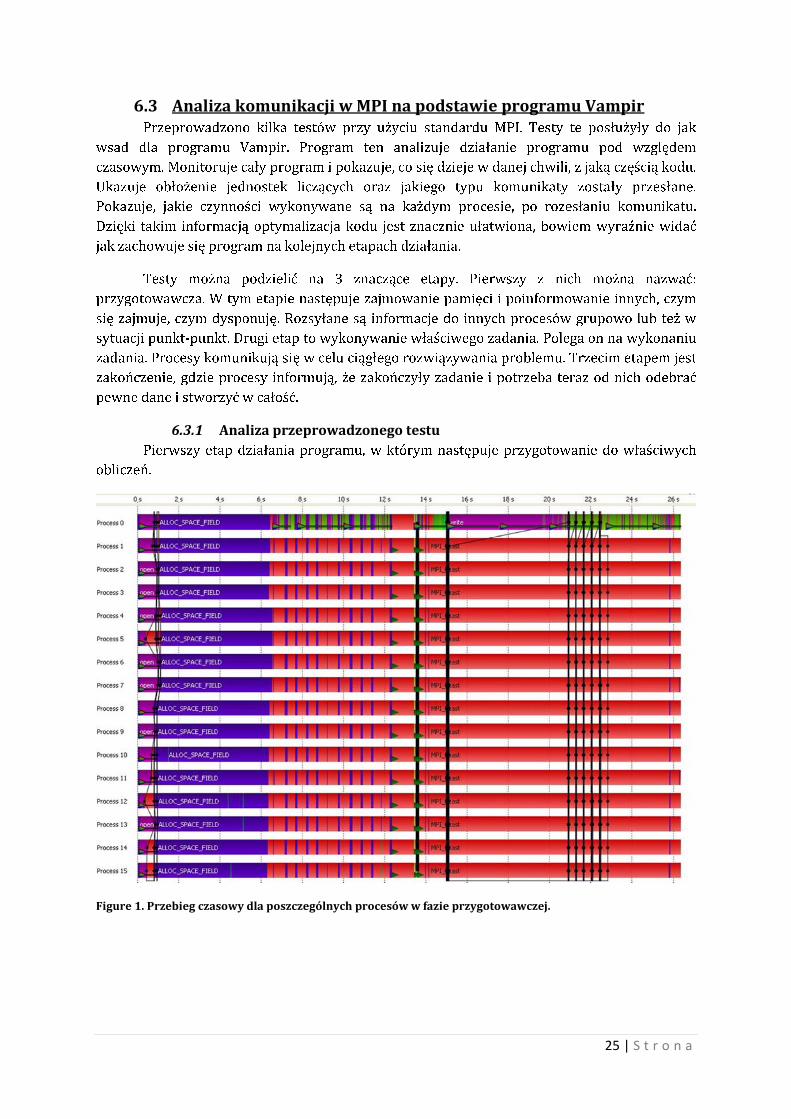
6.3.1 Analiza przeprowadzonego testu
Pierwszy etap działania programu, w którym następuje przygotowanie do właściwych
obliczeń.
Figure 1. Przebieg czasowy dla poszczególnych procesów w fazie przygotowawczej.
26 | S t r o n a
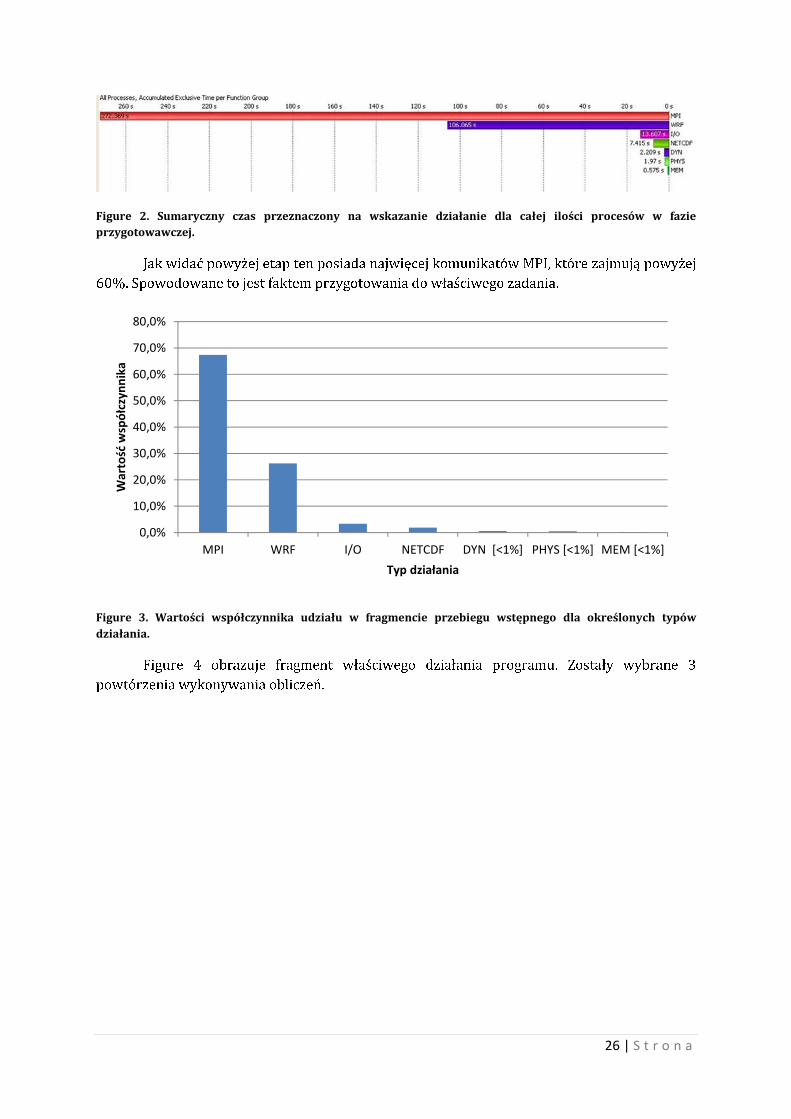
Figure 2. Sumaryczny czas przeznaczony na wskazanie działanie dla całej ilości procesów w fazie przygotowawczej.
Jak widać powyżej etap ten posiada najwięcej komunikatów MPI, które zajmują powyżej
60%. Spowodowane to jest faktem przygotowania do właściwego zadania.
Figure 3. Wartości współczynnika udziału w fragmencie przebiegu wstępnego dla określonych typów działania.
Figure 4 obrazuje fragment właściwego działania programu. Zostały wybrane 3
powtórzenia wykonywania obliczeń.
0,0%
10,0%
20,0%
30,0%
40,0%
50,0%
60,0%
70,0%
80,0%
MPI WRF I/O NETCDF DYN [<1%] PHYS [<1%] MEM [<1%]
War
tość
wsp
ółcz
ynni
ka
Typ działania
27 | S t r o n a
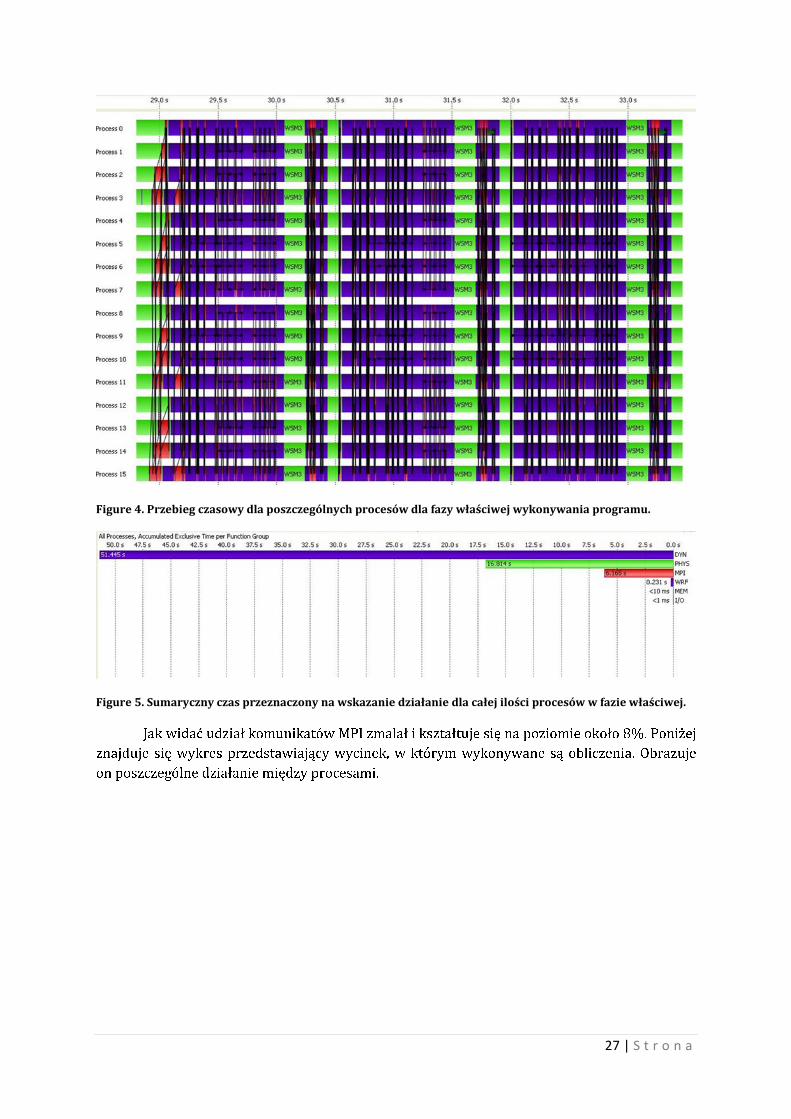
Figure 4. Przebieg czasowy dla poszczególnych procesów dla fazy właściwej wykonywania programu.
Figure 5. Sumaryczny czas przeznaczony na wskazanie działanie dla całej ilości procesów w fazie właściwej.
Jak widać udział komunikatów MPI zmalał i kształtuje się na poziomie około 8%. Poniżej
znajduje się wykres przedstawiający wycinek, w którym wykonywane są obliczenia. Obrazuje
on poszczególne działanie między procesami.

28 | S t r o n a
Figure 6. Fragment wykonywania obliczeń i komunikacji między procesami.
Wykres poniżej obrazuje fazę zakończenia działań wykonywania obliczeń. Następuje
rozgłoszenie do wszystkich procesów, synchronizacja oraz zakończenie i zwrócenie wskazanej
wartości.
Figure 7. Przebieg czasowy dla poszczególnych procesów w fazie zakończeniowej.
29 | S t r o n a
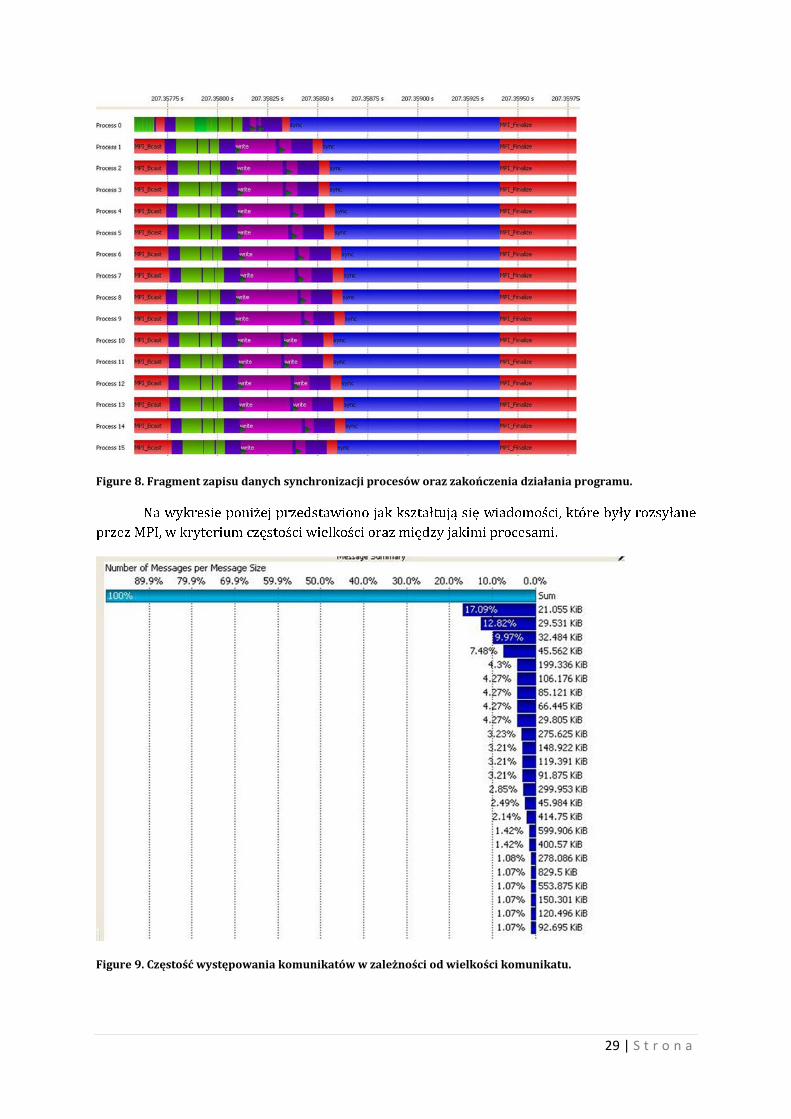
Figure 8. Fragment zapisu danych synchronizacji procesów oraz zakończenia działania programu.
Na wykresie poniżej przedstawiono jak kształtują się wiadomości, które były rozsyłane
przez MPI, w kryterium częstości wielkości oraz między jakimi procesami.
Figure 9. Częstość występowania komunikatów w zależności od wielkości komunikatu.
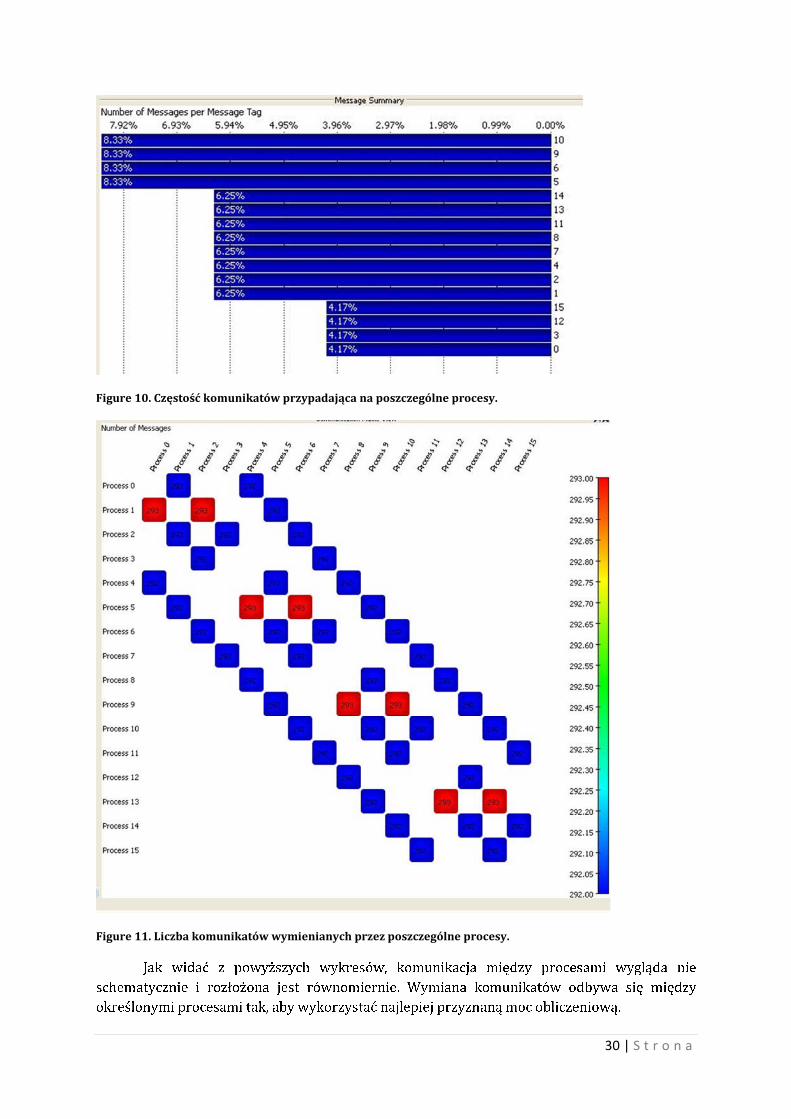
30 | S t r o n a
Figure 10. Częstość komunikatów przypadająca na poszczególne procesy.
Figure 11. Liczba komunikatów wymienianych przez poszczególne procesy.
Jak widać z powyższych wykresów, komunikacja między procesami wygląda nie
schematycznie i rozłożona jest równomiernie. Wymiana komunikatów odbywa się między
określonymi procesami tak, aby wykorzystać najlepiej przyznaną moc obliczeniową.

31 | S t r o n a
7 Eksperymenty
7.1 Test przeznaczony dla kompilatorów GCC i ICC Zadanie polegało na wymnożeniu dwóch kwadratowych macierzy o elementach
całkowitych i zmiennoprzecinkowych. Celem testu jest pokazanie, który z przełączników jest
wydajniejszy oraz jak agresywność działania przełącznika może wpłynąć na końcowy efekt.
7.2 Test przeznaczony dla wielowątkowości Zadanie polegało na wymnożeniu dwóch kwadratowych macierzy o elementach
całkowitych oraz zmiennoprzecinkowych. Celem testu jest porównanie z programem
sekwencyjnym oraz pokazanie jak niebezpieczne jest korzystanie z agresywnego przełącznika,
gdy kod jest „teoretycznie poprawny”.
7.3 Test przeznaczony dla OpenMP Zadanie polegało na wymnożeniu dwóch macierzy o elementach całkowitych oraz
zmiennoprzecinkowych. Celem testu jest pokazanie jak zastosowanie pragm oraz sekcji
krytycznych wpływa na szybkość obliczeń. Również pokazano, jak „teoretycznie poprawny” kod
może zawierać błędy, które kompilator z agresywnym przełącznikiem optymalizacyjnym
wykorzysta w nieodpowiedni sposób.
7.4 Test przeznaczony dla MPI Zadanie polegało na wymnożeniu dwóch macierzy o elementach zmiennoprzecinkowych
uwzględniając komunikację punkt-punkt oraz grupową. Celem testu jest pokazanie jak typ
komunikacji wpływa na czas wykonywanych obliczeń. Również pokazano czas wykonywania
operacji z połączeniem standardów OpenMPI oraz OpenMP.

32 | S t r o n a
8 Środowisko Eksperymentów Eksperymenty przeprowadzono na maszynach i oprogramowaniu o poniższych
parametrach technicznych:
8.1 Maszyna no.1 Laptop o parametrach:
Processor:
Intel Pentium Dual-Core Mobile T2080
Frequency: 1729MHz
Cores: 2
Logical processors: 2
RAM:
Type: DDR2
Frequency: 667MHz
Storage Capacity: 1GB
OS:
Linux Mint Relese 11 (Katya)
Kernel: 2.6.38-8-generic
Compilers:
GCC: 4.5.2
ICC: 12.0.4
8.2 Maszyna no.2 węzeł reef.man.poznan.pl:
Processor:
Quad-core Xeon EM64T 2,5GHz
Frequency: 2,5GHz
Cores: 4
Logical processors: 2
RAM:
Storage Capacity: 12GB
OS:
Red Hat 4.1.2-51
Compilers:
GCC: 4.1.2
ICC: 12.0.4
33 | S t r o n a
9 Wyniki testów przy użyciu kompilatorów GCC i ICC Celem tego rozdziału jest ukazanie zależności między typem kompilatora a czasem
wykonywania obliczeń. Pokazano również jak włączanie przełączników podstawowych oraz
flag kompilatora może wpłynąć na czas wykonywania kompilatu.
Wykonano dwa eksperymenty dla przełączników podstawowych oraz flag kompilatorów.
Przedstawione wyniki ukazano na wykresach.
9.1 Przełączniki podstawowe kompilatorów Wybrano 4 przełączniki podstawowe: -O0, -O1, -O2 oraz –O3. Wartościami kontrolnymi
dla kompilatorów będą wyniki z przełącznika –O0 , czyli kodu nieoptymalizowanego.
9.1.1 Eksperyment pierwszy Przypomnienie: eksperyment dotyczył wymnażania macierzy o elementach
całkowitoliczbowych.
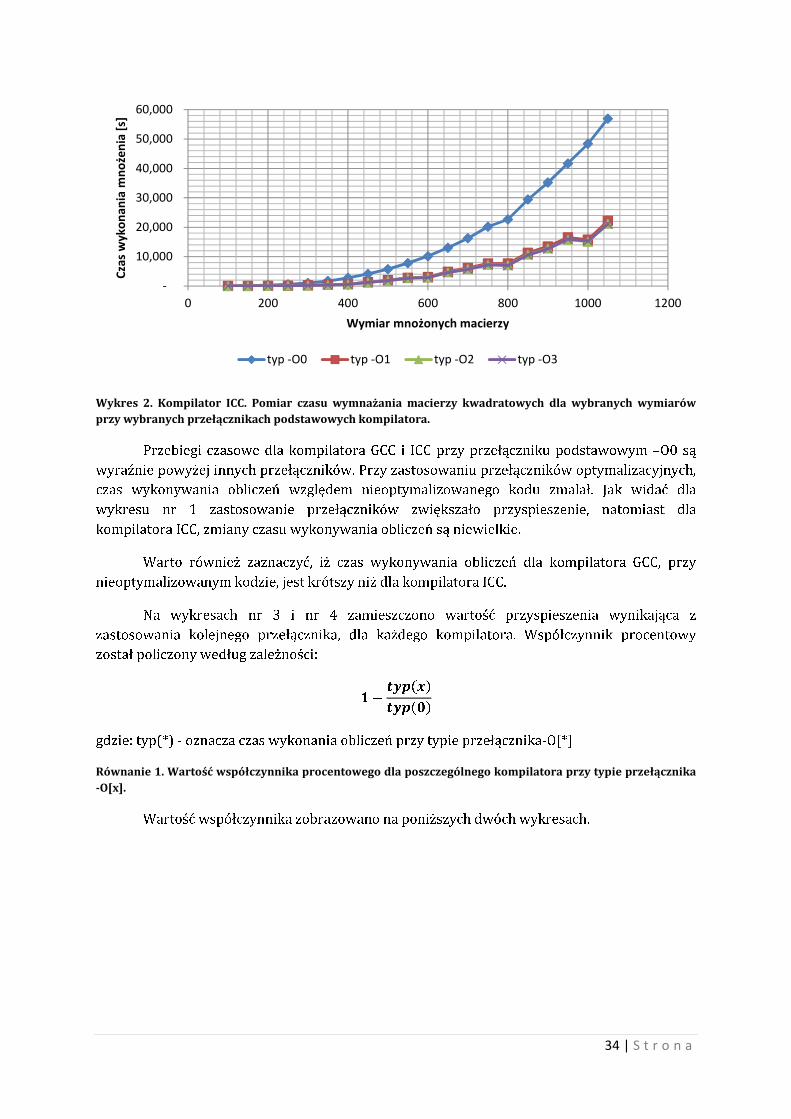
Na wykresie nr 1 i nr 2 pokazano przebiegi czasowe dla poszczególnych kompilatorów,
dla zmieniających się przełączników podstawowych.
Wykres 1. Kompilator GCC. Pomiar czasu wymnażania macierzy kwadratowych dla wybranych wymiarów przy wybranych przełącznikach podstawowych kompilatora.
-
10,000
20,000
30,000
40,000
50,000
60,000
0 200 400 600 800 1000 1200
Czas
wyk
onan
ia m
noże
nia
[s]
Wymiar mnożonych macierzy
typ -O0 typ -O1 typ -O3 typ -O2
34 | S t r o n a
Wykres 2. Kompilator ICC. Pomiar czasu wymnażania macierzy kwadratowych dla wybranych wymiarów przy wybranych przełącznikach podstawowych kompilatora.
Przebiegi czasowe dla kompilatora GCC i ICC przy przełączniku podstawowym –O0 są
wyraźnie powyżej innych przełączników. Przy zastosowaniu przełączników optymalizacyjnych,
czas wykonywania obliczeń względem nieoptymalizowanego kodu zmalał. Jak widać dla
wykresu nr 1 zastosowanie przełączników zwiększało przyspieszenie, natomiast dla
kompilatora ICC, zmiany czasu wykonywania obliczeń są niewielkie.
Warto również zaznaczyć, iż czas wykonywania obliczeń dla kompilatora GCC, przy
nieoptymalizowanym kodzie, jest krótszy niż dla kompilatora ICC.
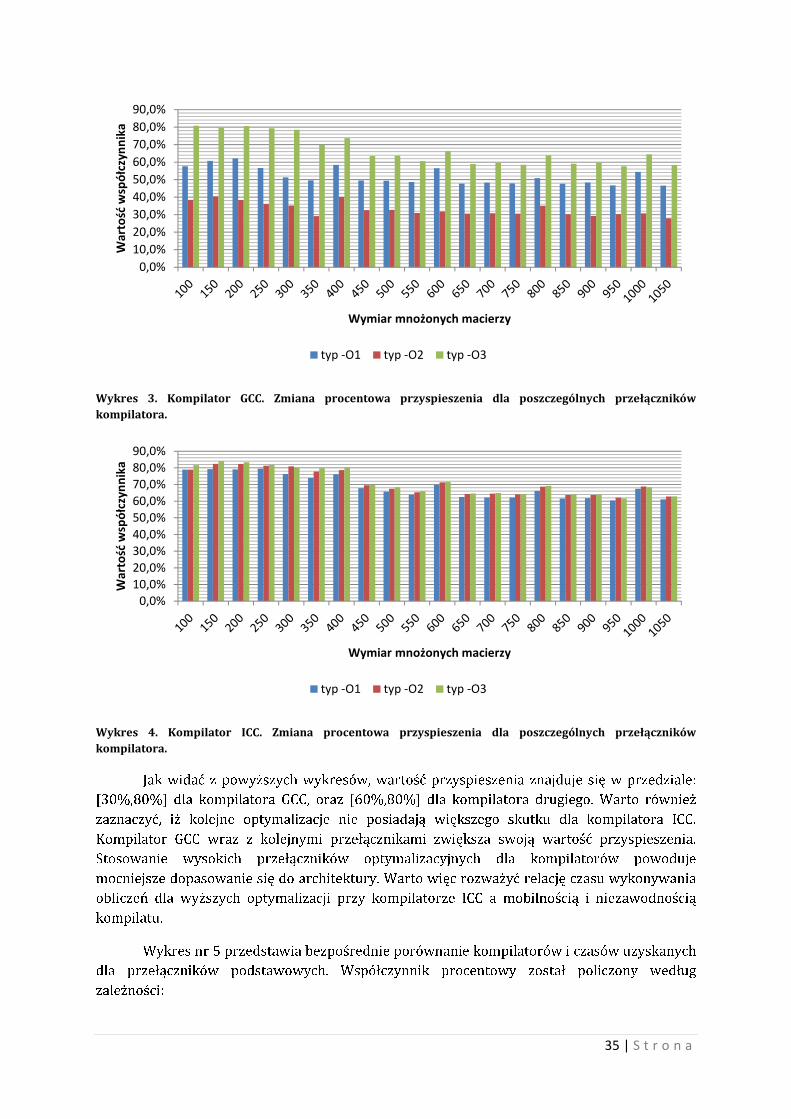
Na wykresach nr 3 i nr 4 zamieszczono wartość przyspieszenia wynikająca z
zastosowania kolejnego przełącznika, dla każdego kompilatora. Współczynnik procentowy
został policzony według zależności:
��������
������
gdzie: typ(*) - oznacza czas wykonania obliczeń przy typie przełącznika-O[*]
Równanie 1. Wartość współczynnika procentowego dla poszczególnego kompilatora przy typie przełącznika -O[x].
Wartość współczynnika zobrazowano na poniższych dwóch wykresach.
-
10,000
20,000
30,000
40,000
50,000
60,000
0 200 400 600 800 1000 1200
Czas
wyk
onan
ia m
noże
nia
[s]
Wymiar mnożonych macierzy
typ -O0 typ -O1 typ -O2 typ -O3
35 | S t r o n a
Wykres 3. Kompilator GCC. Zmiana procentowa przyspieszenia dla poszczególnych przełączników kompilatora.
Wykres 4. Kompilator ICC. Zmiana procentowa przyspieszenia dla poszczególnych przełączników kompilatora.
Jak widać z powyższych wykresów, wartość przyspieszenia znajduje się w przedziale:
[30%,80%] dla kompilatora GCC, oraz [60%,80%] dla kompilatora drugiego. Warto również
zaznaczyć, iż kolejne optymalizacje nie posiadają większego skutku dla kompilatora ICC.
Kompilator GCC wraz z kolejnymi przełącznikami zwiększa swoją wartość przyspieszenia.
Stosowanie wysokich przełączników optymalizacyjnych dla kompilatorów powoduje
mocniejsze dopasowanie się do architektury. Warto więc rozważyć relację czasu wykonywania
obliczeń dla wyższych optymalizacji przy kompilatorze ICC a mobilnością i niezawodnością
kompilatu.
Wykres nr 5 przedstawia bezpośrednie porównanie kompilatorów i czasów uzyskanych
dla przełączników podstawowych. Współczynnik procentowy został policzony według
zależności:
0,0%10,0%20,0%30,0%40,0%50,0%60,0%70,0%80,0%90,0%
War
tość
wsp
ółcz
ynni
ka
Wymiar mnożonych macierzy
typ -O1 typ -O2 typ -O3
0,0%10,0%20,0%30,0%40,0%50,0%60,0%70,0%80,0%90,0%
War
tość
wsp
ółcz
ynni
ka
Wymiar mnożonych macierzy
typ -O1 typ -O2 typ -O3
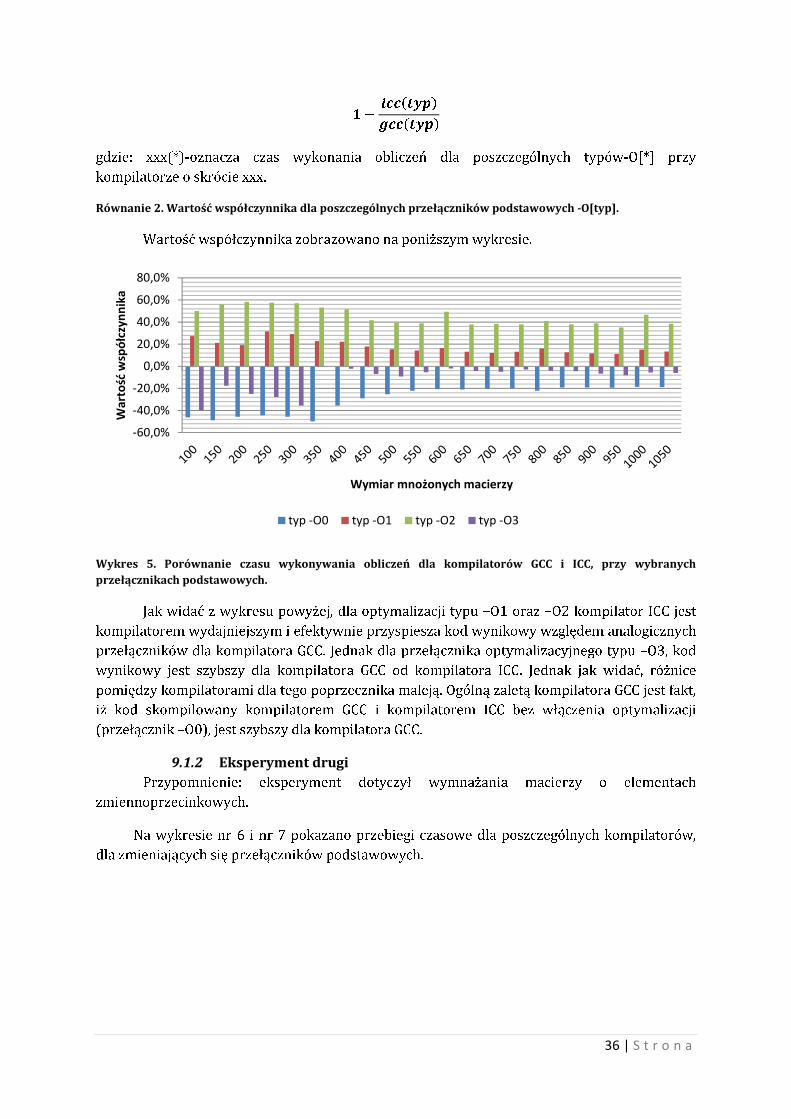
36 | S t r o n a
����������
��������
gdzie: xxx(*)-oznacza czas wykonania obliczeń dla poszczególnych typów-O[*] przy
kompilatorze o skrócie xxx.
Równanie 2. Wartość współczynnika dla poszczególnych przełączników podstawowych -O[typ].
Wartość współczynnika zobrazowano na poniższym wykresie.
Wykres 5. Porównanie czasu wykonywania obliczeń dla kompilatorów GCC i ICC, przy wybranych przełącznikach podstawowych.
Jak widać z wykresu powyżej, dla optymalizacji typu –O1 oraz –O2 kompilator ICC jest
kompilatorem wydajniejszym i efektywnie przyspiesza kod wynikowy względem analogicznych
przełączników dla kompilatora GCC. Jednak dla przełącznika optymalizacyjnego typu –O3, kod
wynikowy jest szybszy dla kompilatora GCC od kompilatora ICC. Jednak jak widać, różnice
pomiędzy kompilatorami dla tego poprzecznika maleją. Ogólną zaletą kompilatora GCC jest fakt,
iż kod skompilowany kompilatorem GCC i kompilatorem ICC bez włączenia optymalizacji
(przełącznik –O0), jest szybszy dla kompilatora GCC.
9.1.2 Eksperyment drugi Przypomnienie: eksperyment dotyczył wymnażania macierzy o elementach
zmiennoprzecinkowych.
Na wykresie nr 6 i nr 7 pokazano przebiegi czasowe dla poszczególnych kompilatorów,
dla zmieniających się przełączników podstawowych.
-60,0%
-40,0%
-20,0%
0,0%
20,0%
40,0%
60,0%
80,0%
War
tość
wsp
ółcz
ynni
ka
Wymiar mnożonych macierzy
typ -O0 typ -O1 typ -O2 typ -O3
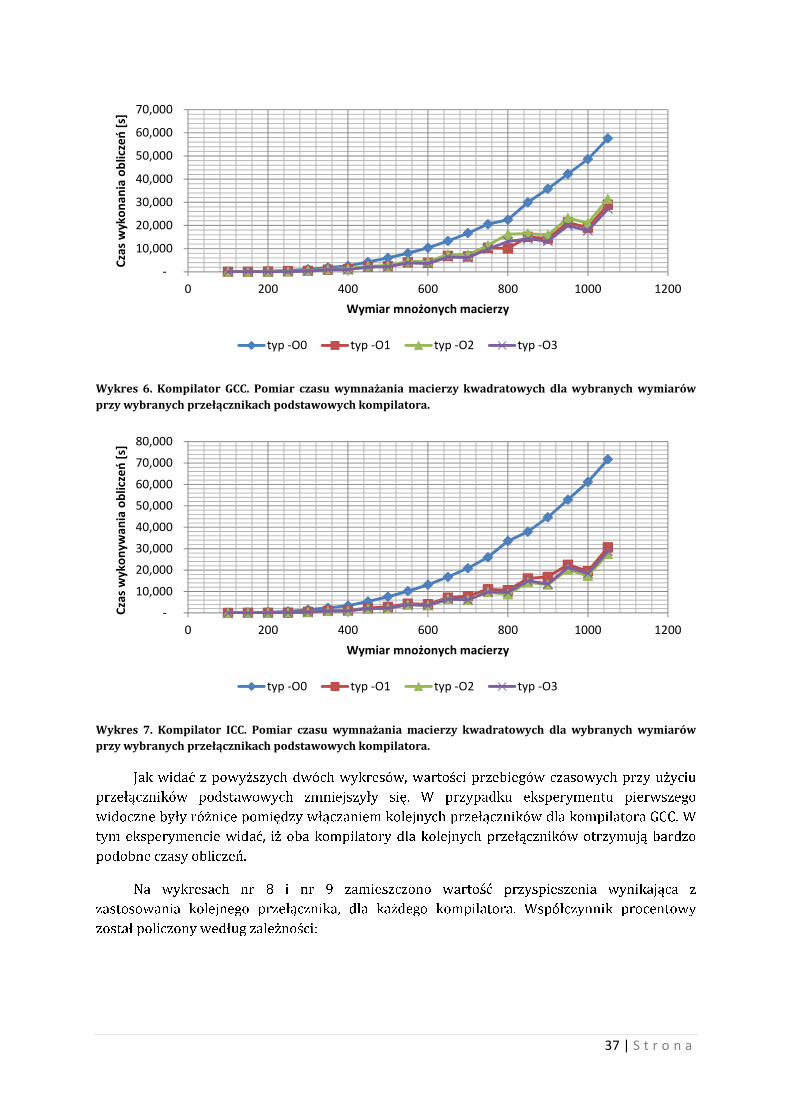
37 | S t r o n a
Wykres 6. Kompilator GCC. Pomiar czasu wymnażania macierzy kwadratowych dla wybranych wymiarów przy wybranych przełącznikach podstawowych kompilatora.
Wykres 7. Kompilator ICC. Pomiar czasu wymnażania macierzy kwadratowych dla wybranych wymiarów przy wybranych przełącznikach podstawowych kompilatora.
Jak widać z powyższych dwóch wykresów, wartości przebiegów czasowych przy użyciu
przełączników podstawowych zmniejszyły się. W przypadku eksperymentu pierwszego
widoczne były różnice pomiędzy włączaniem kolejnych przełączników dla kompilatora GCC. W
tym eksperymencie widać, iż oba kompilatory dla kolejnych przełączników otrzymują bardzo
podobne czasy obliczeń.
Na wykresach nr 8 i nr 9 zamieszczono wartość przyspieszenia wynikająca z
zastosowania kolejnego przełącznika, dla każdego kompilatora. Współczynnik procentowy
został policzony według zależności:
-
10,000
20,000
30,000
40,000
50,000
60,000
70,000
0 200 400 600 800 1000 1200
Czas
wyk
onan
ia o
blic
zeń
[s]
Wymiar mnożonych macierzy
typ -O0 typ -O1 typ -O2 typ -O3
-
10,000
20,000
30,000
40,000
50,000
60,000
70,000
80,000
0 200 400 600 800 1000 1200
Czas
wyk
onyw
ania
obl
iczeń
[s]
Wymiar mnożonych macierzy
typ -O0 typ -O1 typ -O2 typ -O3
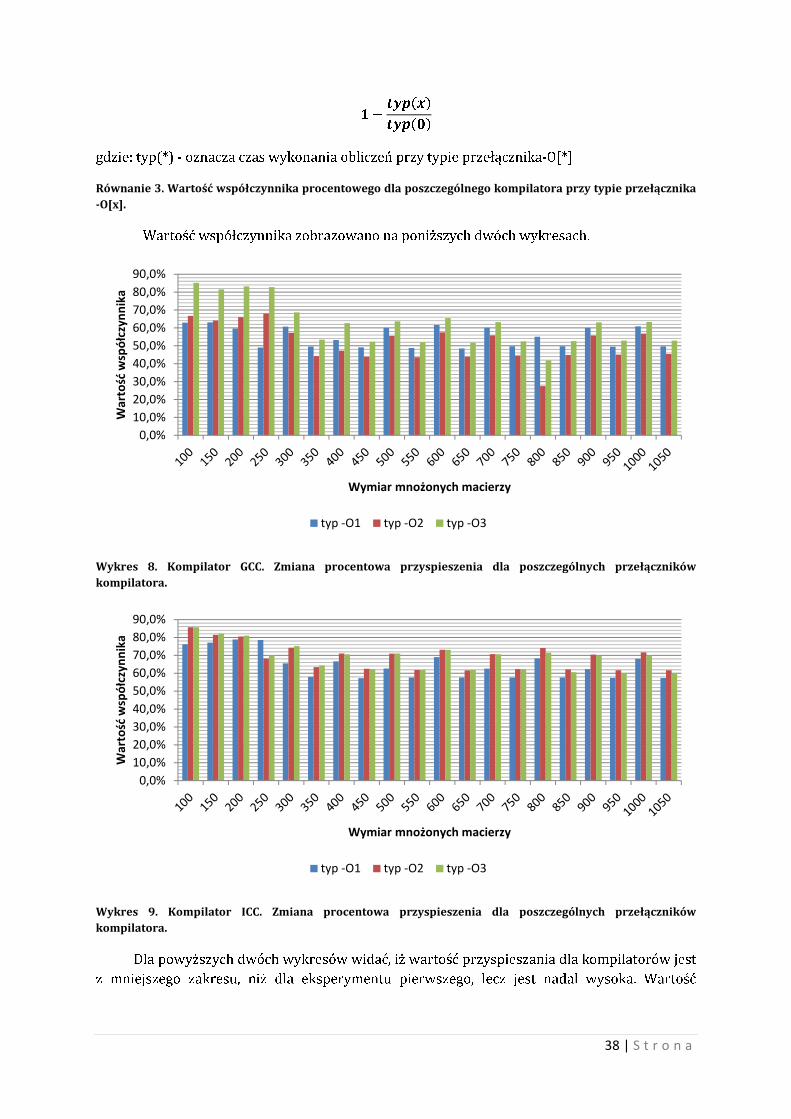
38 | S t r o n a
��������
������
gdzie: typ(*) - oznacza czas wykonania obliczeń przy typie przełącznika-O[*]
Równanie 3. Wartość współczynnika procentowego dla poszczególnego kompilatora przy typie przełącznika -O[x].
Wartość współczynnika zobrazowano na poniższych dwóch wykresach.
Wykres 8. Kompilator GCC. Zmiana procentowa przyspieszenia dla poszczególnych przełączników kompilatora.
Wykres 9. Kompilator ICC. Zmiana procentowa przyspieszenia dla poszczególnych przełączników kompilatora.
Dla powyższych dwóch wykresów widać, iż wartość przyspieszania dla kompilatorów jest
z mniejszego zakresu, niż dla eksperymentu pierwszego, lecz jest nadal wysoka. Wartość
0,0%10,0%20,0%30,0%40,0%50,0%60,0%70,0%80,0%90,0%
War
tość
wsp
ółcz
ynni
ka
Wymiar mnożonych macierzy
typ -O1 typ -O2 typ -O3
0,0%10,0%20,0%30,0%40,0%50,0%60,0%70,0%80,0%90,0%
War
tość
wsp
ółcz
ynni
ka
Wymiar mnożonych macierzy
typ -O1 typ -O2 typ -O3

39 | S t r o n a
współczynnika przyspieszenia przeciętnie wynosi 50%, dla kompilatora GCC, natomiast dla
kompilatora ICC jest ona w granicy około 60%.
Wykres nr 10 przedstawia bezpośrednie porównanie kompilatorów i czasów uzyskanych
dla przełączników podstawowych. Współczynnik procentowy został policzony według
zależności:
����������
��������
gdzie: xxx(*) - oznacza czas wykonania obliczeń dla poszczególnych typów-O[*] przy
kompilatorze o skrócie xxx.
Równanie 4. Wartość współczynnika dla poszczególnych przełączników podstawowych -O[typ].
Wartość współczynnika zobrazowano na poniższym wykresie.
Wykres 10. Porównanie czasu wykonywania obliczeń dla kompilatorów GCC i ICC, przy wybranych przełącznikach.
Wybrano tylko przełączniki typu –O0 oraz –O2, bowiem przełączniki te dobrze
prezentują zależność, iż kompilator kompilatorowi nie równy. Dla przełącznika typu –O2
kompilator ICC jest szybszy, natomiast kompilacja z przełącznikiem typu –O0, czyli bez
optymalizacji w kryterium czasowym, należy się do kompilatora GCC.
9.2 Flagi rozszerzające kompilatorów W aktualnym rozdziale porównano badane kompilatory pod względem czasu
wykonywania obliczeń dla wybranej listy flag optymalizującej obliczenia. Lista została wybrana
z dokumentacji technicznej kompilatorów. Flagi te zostały tak wybrane, aby zoptymalizować
czas wykonywania kompilatu zachowując wysoką mobilność oraz niezawodność kodu
wynikowego.
-80,0%
-60,0%
-40,0%
-20,0%
0,0%
20,0%
40,0%
60,0%
War
tość
wsp
ółcz
ynni
ka
Wymiar mnożonych macierzy
typ -O0 typ -O2
40 | S t r o n a
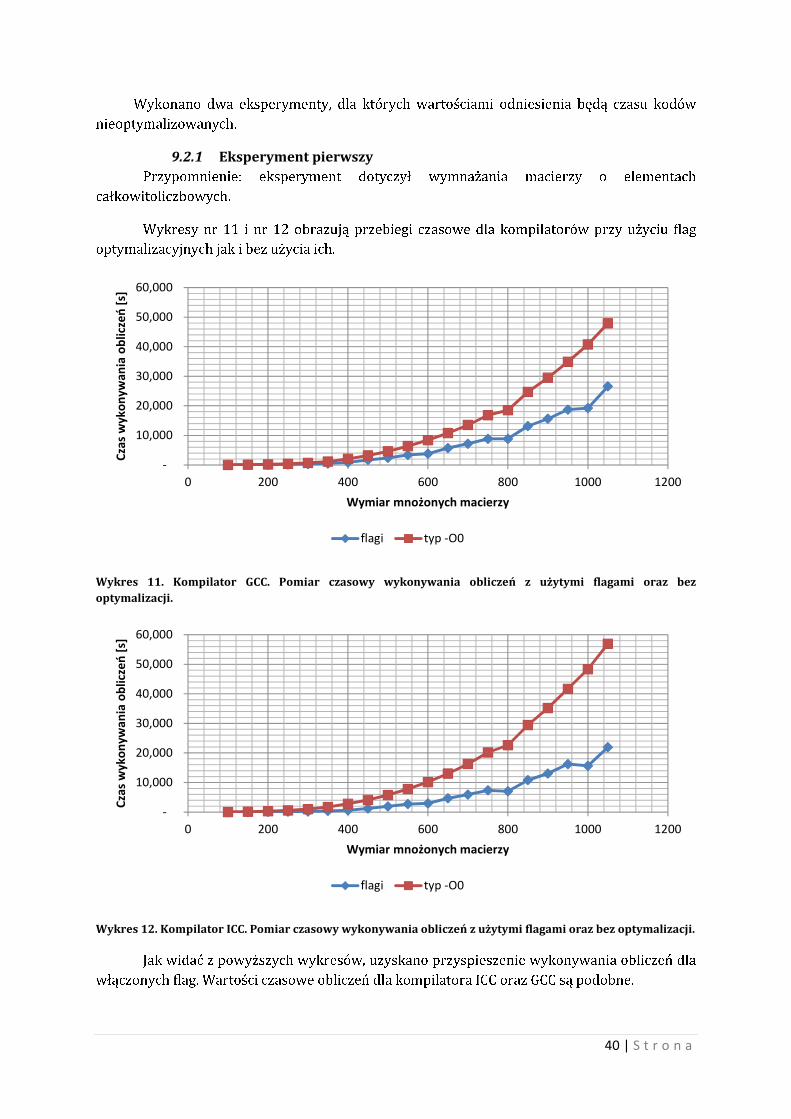
Wykonano dwa eksperymenty, dla których wartościami odniesienia będą czasu kodów
nieoptymalizowanych.
9.2.1 Eksperyment pierwszy Przypomnienie: eksperyment dotyczył wymnażania macierzy o elementach
całkowitoliczbowych.
Wykresy nr 11 i nr 12 obrazują przebiegi czasowe dla kompilatorów przy użyciu flag
optymalizacyjnych jak i bez użycia ich.
Wykres 11. Kompilator GCC. Pomiar czasowy wykonywania obliczeń z użytymi flagami oraz bez optymalizacji.
Wykres 12. Kompilator ICC. Pomiar czasowy wykonywania obliczeń z użytymi flagami oraz bez optymalizacji.
Jak widać z powyższych wykresów, uzyskano przyspieszenie wykonywania obliczeń dla
włączonych flag. Wartości czasowe obliczeń dla kompilatora ICC oraz GCC są podobne.
-
10,000
20,000
30,000
40,000
50,000
60,000
0 200 400 600 800 1000 1200
Czas
wyk
onyw
ania
obl
iczeń
[s]
Wymiar mnożonych macierzy
flagi typ -O0
-
10,000
20,000
30,000
40,000
50,000
60,000
0 200 400 600 800 1000 1200
Czas
wyk
onyw
ania
obl
iczeń
[s]
Wymiar mnożonych macierzy
flagi typ -O0
41 | S t r o n a
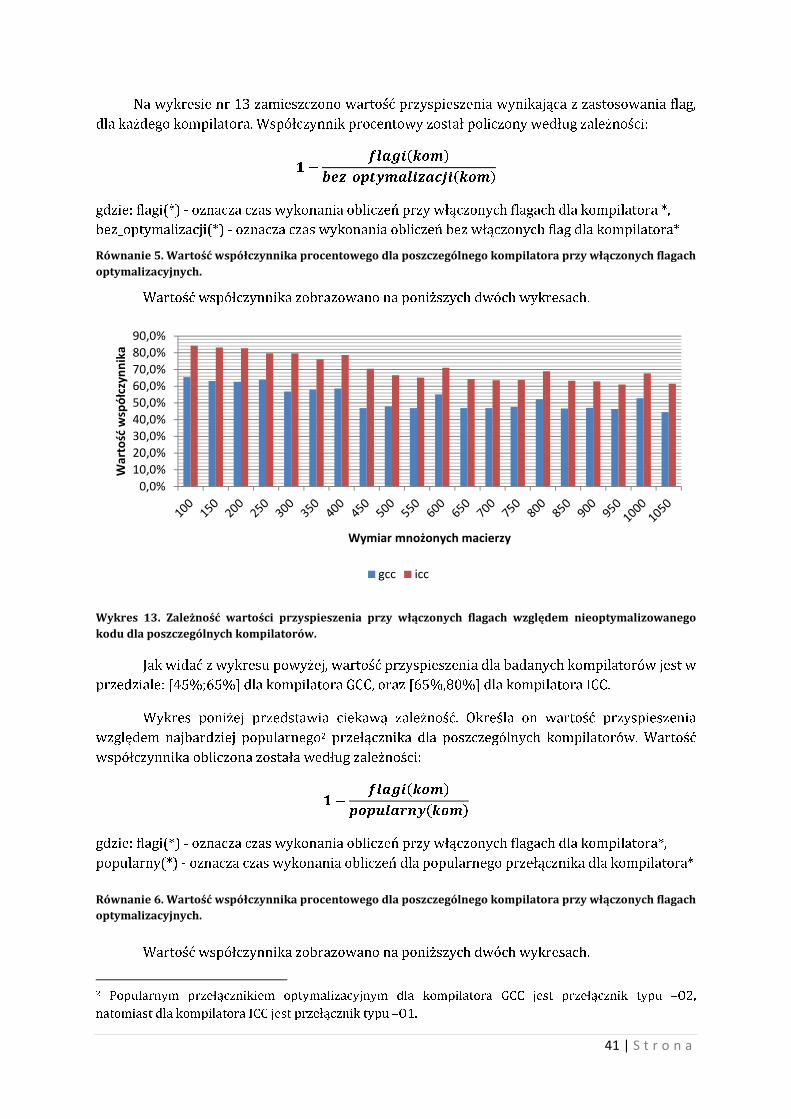
Na wykresie nr 13 zamieszczono wartość przyspieszenia wynikająca z zastosowania flag,
dla każdego kompilatora. Współczynnik procentowy został policzony według zależności:
������������
���_����������������
gdzie: flagi(*) - oznacza czas wykonania obliczeń przy włączonych flagach dla kompilatora *,
bez_optymalizacji(*) - oznacza czas wykonania obliczeń bez włączonych flag dla kompilatora*
Równanie 5. Wartość współczynnika procentowego dla poszczególnego kompilatora przy włączonych flagach optymalizacyjnych.
Wartość współczynnika zobrazowano na poniższych dwóch wykresach.
Wykres 13. Zależność wartości przyspieszenia przy włączonych flagach względem nieoptymalizowanego kodu dla poszczególnych kompilatorów.
Jak widać z wykresu powyżej, wartość przyspieszenia dla badanych kompilatorów jest w
przedziale: [45%;65%] dla kompilatora GCC, oraz [65%,80%] dla kompilatora ICC.
Wykres poniżej przedstawia ciekawą zależność. Określa on wartość przyspieszenia
względem najbardziej popularnego2 przełącznika dla poszczególnych kompilatorów. Wartość
współczynnika obliczona została według zależności:
� �����������
��������������
gdzie: flagi(*) - oznacza czas wykonania obliczeń przy włączonych flagach dla kompilatora*,
popularny(*) - oznacza czas wykonania obliczeń dla popularnego przełącznika dla kompilatora*
Równanie 6. Wartość współczynnika procentowego dla poszczególnego kompilatora przy włączonych flagach optymalizacyjnych.
Wartość współczynnika zobrazowano na poniższych dwóch wykresach.
2 Popularnym przełącznikiem optymalizacyjnym dla kompilatora GCC jest przełącznik typu –O2,
natomiast dla kompilatora ICC jest przełącznik typu –O1.
0,0%10,0%20,0%30,0%40,0%50,0%60,0%70,0%80,0%90,0%
War
tość
wsp
ółcz
ynni
ka
Wymiar mnożonych macierzy
gcc icc

42 | S t r o n a
Wykres 14. Zależność przyspieszenia wykonywania kompilatu przy włączonych flagach względem popularnego przełącznika optymalizującego, dla poszczególnych kompilatorów.
Jak widać z wykresu powyżej wartości przyspieszenia czasu wykonywanych obliczeń dla
włączonych flag przy kompilatorze GCC jest większa niż dla kompilatora ICC, jednak mniejsza
niż 45%. Wartość czasowego uzysku maleje wraz z zwiększaniem wymiaru dla kompilatora ICC,
co może powodować, że dla pewnego wymiaru nie będzie opłacało się stosować samych flag
optymalizacyjnych. Dla kompilatora GCC nie zauważono takiej relacji.
9.3 Szybkość vs. Jakość Przy użyciu przełączników uzyskano szybszy czas obliczeń, jednak dla przełącznika –O3
w kompilatorze GCC i ICC zauważono odstępstwo wyników od wartości kontrolnej.
Wartości kontrolne została przyjęta, jako wartość dla poszczególnego wymiaru i
kompilatora dla przełącznika typu –O0, czyli kompilatu nieoptymalizowanego kompilatorem.
Współczynnikiem, jaki będzie definiował odstępstwo, jest pierwsza cyfra w rozwinięciu
niezgodna z wartością kontrolną, dla każdej komórki. Z tego zbioru wyznaczono wartość
średnią, zaokrągloną w dół. Wyznaczono odchylenie standardowe, które zaokrąglono w górę.
Podano wartość procentową występowania dla reguły trzech sigma.
Macierze, jakie zostały brane pod uwagę to macierze o wymiarach 200, 400, 600 oraz
700. Wyniki współczynnika odstępstwa dla poszczególnych macierzy posiadają następującą
charakterystykę:
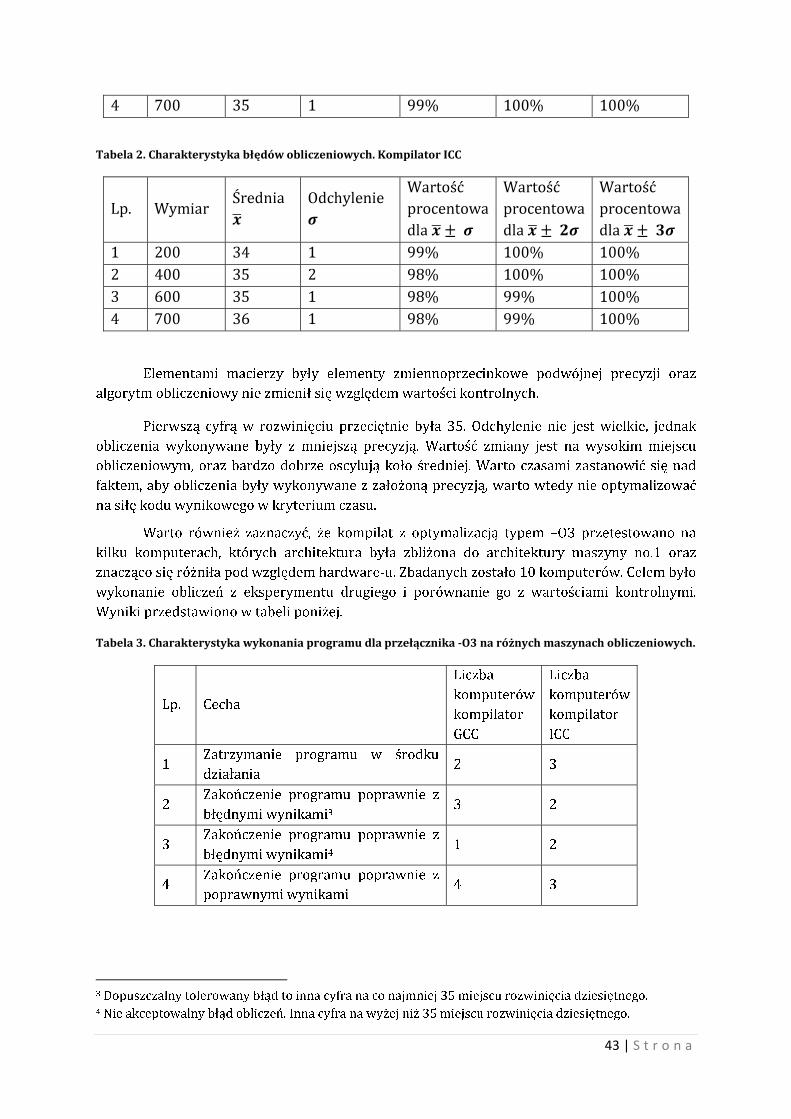
Tabela 1. Charakterystyka błędów obliczeniowych. Kompilator GCC
Lp. Wymiar Średnia
��
Odchylenie
�
Wartość
procentowa dla �� � �
Wartość
procentowa dla �� � ��
Wartość
procentowa dla �� � ��
1 200 35 1 99% 99% 100%
2 400 35 1 98% 99% 100%
3 600 36 2 98% 100% 100%
0,0%5,0%
10,0%15,0%20,0%25,0%30,0%35,0%40,0%45,0%50,0%
War
tość
wsp
ółcz
ynni
ka
Wymiar mnożonych macierzy
gcc icc
43 | S t r o n a
4 700 35 1 99% 100% 100%
Tabela 2. Charakterystyka błędów obliczeniowych. Kompilator ICC
Lp. Wymiar Średnia ��
Odchylenie �
Wartość
procentowa
dla �� � �
Wartość
procentowa
dla �� � ��
Wartość
procentowa
dla �� � ��
1 200 34 1 99% 100% 100%
2 400 35 2 98% 100% 100%
3 600 35 1 98% 99% 100%
4 700 36 1 98% 99% 100%
Elementami macierzy były elementy zmiennoprzecinkowe podwójnej precyzji oraz
algorytm obliczeniowy nie zmienił się względem wartości kontrolnych.
Pierwszą cyfrą w rozwinięciu przeciętnie była 35. Odchylenie nie jest wielkie, jednak
obliczenia wykonywane były z mniejszą precyzją. Wartość zmiany jest na wysokim miejscu
obliczeniowym, oraz bardzo dobrze oscylują koło średniej. Warto czasami zastanowić się nad
faktem, aby obliczenia były wykonywane z założoną precyzją, warto wtedy nie optymalizować
na siłę kodu wynikowego w kryterium czasu.
Warto również zaznaczyć, że kompilat z optymalizacją typem –O3 przetestowano na
kilku komputerach, których architektura była zbliżona do architektury maszyny no.1 oraz
znacząco się różniła pod względem hardware-u. Zbadanych zostało 10 komputerów. Celem było
wykonanie obliczeń z eksperymentu drugiego i porównanie go z wartościami kontrolnymi.
Wyniki przedstawiono w tabeli poniżej.
Tabela 3. Charakterystyka wykonania programu dla przełącznika -O3 na różnych maszynach obliczeniowych.
Lp. Cecha
Liczba
komputerów
kompilator
GCC
Liczba
komputerów
kompilator
ICC
1
Zatrzymanie programu w środku
działania
2 3
2
Zakończenie programu poprawnie z
błędnymi wynikami3 3 2
3
Zakończenie programu poprawnie z
błędnymi wynikami4 1 2
4
Zakończenie programu poprawnie z
poprawnymi wynikami 4 3
3 Dopuszczalny tolerowany błąd to inna cyfra na co najmniej 35 miejscu rozwinięcia dziesiętnego. 4 Nie akceptowalny błąd obliczeń. Inna cyfra na wyżej niż 35 miejscu rozwinięcia dziesiętnego.

44 | S t r o n a
9.4 Podsumowanie porównania kompilatorów Stosowanie przełączników podstawowych w celu przyspieszenia działania pliku
wynikowego jest opłacalne. Opłacalne do tego stopnia, że czas wykonywania obliczeń w
niektórych przypadkach można zredukować, o co najmniej 50%, co za tym idzie, jeżeli program
wykonuje obliczenia przez 30dni, możne je zredukować do 15 dni, bez straty, na jakości
obliczeń. Warto również zaznaczyć, aby samemu przeczytać dokumentacje kompilatora,
szczególnie sekcji Optymalizacja, gdzie zostało dokładnie omówione działanie optymalizacyjne
poszczególnych flag używanych do optymalizacji.
Wykonywanie obliczeń przy włączonych flagach optymalizujących, które nie dokonują
optymalizacji w zakresie dopasowania kodu do architektury maszyny są szybsze w porównaniu
do kodu nieoptymalizowanego kompilatorami. Wartości przyspieszeń są szybsze nawet, gdy
odniesieniem będzie popularny przełącznik dla wybranego kompilatora. Jednak jego wartości
szybko maleją, co świadczą o tym, iż dla większych danych, aby uzyskać efektywne
przyspieszenie trzeba będzie posiłkować się flagami\przełącznikami, które ograniczają
mobilność kodu i dopasowują się do architektury maszyny. Takie działanie prawdopodobnie
będzie wskazane, aby utrzymać wartość przyspieszenia na wybranym poziomie, nie zmieniając
jego struktury.
Jednak w niektórych przypadkach stosowanie przełączników o najwyższym priorytecie
optymalizacyjnym jest niewskazane. W niektórych przypadkach zoptymalizowany kod może
być faktycznie szybszy, jednak jego precyzja obliczeń będzie znacznie mniejsza. Może nawet
dojść do sytuacji, w której program nie będzie wykonywał się na maszynach innych niż, na
której został skompilowany. Co gorsza program będzie działał bez zarzutu, jednak jego wyniki
mogą być niepoprawne, z racji tego, że szybsze działanie będzie kosztem precyzji
jednostkowych operacji. Warto zaznaczyć, iż maszynowa arytmetyka liczb
zmiennoprzecinkowych nie posiada wszystkich aksjomatów, w takim przypadku warto unikać
różnych skali wartości zmiennych, aby uniknąć jeszcze większych rozbieżności.
Warto, zatem poświęcić kilka chwil, w celu przekompilowania swojego kodu pod
różnymi kompilatorami, oraz różnymi przełącznikami. Istnieje, bowiem znacząca możliwość
uzyskania czasowego przyspieszenia, na tyle wysoka, że nie trzeba zmieniać struktury kodu, aby
pomierzyć i sprawdzić, czy ten przełącznik zoptymalizował kod w kryterium czasu
wykonywania kompilatu.

45 | S t r o n a
10 Wyniki testów przy użyciu wielowątkowości W tym rozdziale zostanie porównany program wielowątkowy i program sekwencyjny.
Również zostanie ukazana relacja między liczbą wątków a czasem wykonywania obliczeń.
Porównanie również będzie dotyczyło wielowątkowości pod różnymi typami przełączników.
10.1 Optymalne zarządzanie wątkami w eksperymencie Tworzenie i zarządzanie wątkami jest ważna sprawą dla programu wielowątkowego.
Umiejętność optymalnego tworzenia liczby wątków i zarządzanie tymi bytami jest niezwykle
ciekawym problem. Nieumiejętne zarządzanie wątkami powoduje niekiedy wyraźne straty
czasowe wykonywanych obliczeń. Warto, więc, decydując się na program wielowątkowy
zastanowić się jak tworzyć i co ma robić poszczególny wątek, aby wszystko działało na naszą
korzyść. Biorąc pod uwagę problem mnożenia macierzy oparty na wątkach można
zaproponować kilka rozwiązań. Część z nich to samobójstwo czasowe, natomiast niektóre mogą
dać odczuwalne przyspieszenie programu.
Pierwszą możliwością, jeżeli mamy dwie kwadratowe macierze o wymiarze n, jest
stworzenie takiej liczby wątków, aby każda komórka wynikowa macierzy była obliczana
osobno. Czyli dla wymiaru n, liczba wątków wyniesie ��, co dla przykładu: dla wymiaru 1000
otrzymamy 1 milion wątków.
Taka liczba jest kosmiczna i niestety nieefektywna. Każde tworzenie wątku jest
obarczone narzutem czasowym i pamięciowym. Narzut ten jest nie wielki, jednak dla miliona
wątków, będzie on odczuwalny. Procesor nie będzie wstanie obsłużyć na raz aż tylu wątków,
albo przynajmniej znaczniej liczby z nich. Np. dla cztero rdzeniowego procesora Intel i7 liczba
wątków wykonywanych w jednym czasie wynosi 8, co za tym idzie efektywna liczba wątków nie
może być za duża, bowiem każdy wątek musi w końcu dostać przydział kwantu czasu
procesora. Problem polega na tym, że jeżeli nawet będziemy chcieli stworzyć milion wątków, to
nie stworzymy ich od razu. Dla stworzonej takiej liczby wątków, procesor będzie musiał
przydzielić kwant swojego cennego czasu. Przy takiej liczbie wątków, niektóre wątki dopchają
się częściej od innych, co nie jest korzystne dla działania programu i co może powodować
opóźnienia czasowe wykonywanych obliczeń. Wynika to z tą, iż liczba wątków jest powiązana
relacją z liczbą rdzeni procesora.
Widać, iż tworzenie wątków na siłę, nie przyniesie zamierzonego efektu, bowiem narzut
w kategorii czasu jest dla takiego podejścia znaczący. Trzeba by stworzyć mniejszą liczbę
wątków, taką, aby architektura procesora pozwalała na najlepsze rozdysponowanie jego
czasem. Zazwyczaj liczba ta będzie znacząca mniejsza od wymiaru macierzy. Warto teraz
zastanowić się jak zarządzać wątkami na macierzach, aby wykonać obliczenia poprawnie oraz
komunikacja i rywalizacja między wątkami przebiegała spokojnie. Dobrym pomysłem jest
przydzielenie wątkowi kolejnych numerów kolumn i wierszy macierz według zasady:
����������ó� ∗ � � �������. Zasada ta mówi, iż dobrym przydziałem będzie przydzielenie
wątkowi o numerze 0 kolumn i wierszy 0,8,16,24,…(dla ogólnej stworzonej liczby wątków
wynoszącej 8). Dla następnych wątków te numery są powiększane o wartość 1. Liczba wątków
jest optymalna, oraz nie potrzeba tworzyć wielkiej liczby wątków w celu wymorzenia macierzy.
Warto również zaznaczyć, iż jest to praca współbieżna. Co za tym idzie trzeba pamiętać
o problemach wynikających z współpracy współbieżnej. Problemami taki mogą być dostęp do
zasobu dzielonego, czekanie zwolnienie potrzebnego zasobu, i wiele innych. Zaleca zapoznanie
się z literaturą dotyczącą programowania współbieżnego.
46 | S t r o n a
10.2 Eksperyment pierwszy Przypomnienie: eksperyment dotyczył wymnażania macierzy o elementach
całkowitoliczbowych.
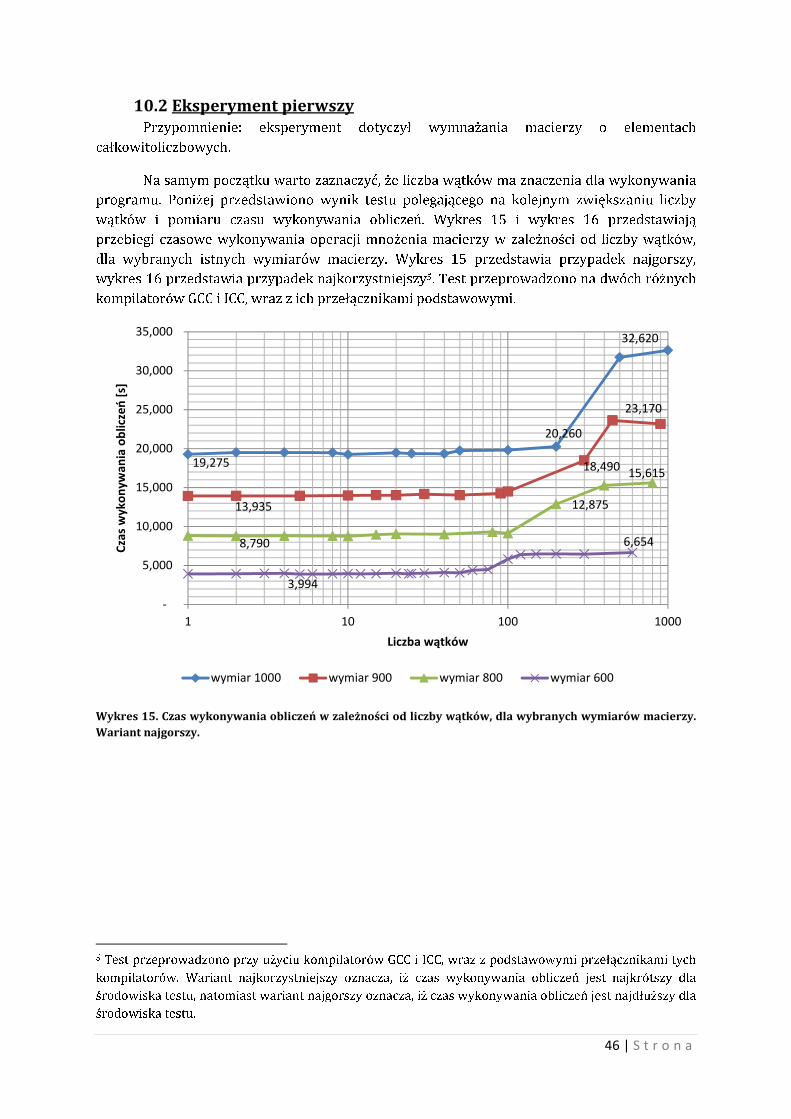
Na samym początku warto zaznaczyć, że liczba wątków ma znaczenia dla wykonywania
programu. Poniżej przedstawiono wynik testu polegającego na kolejnym zwiększaniu liczby
wątków i pomiaru czasu wykonywania obliczeń. Wykres 15 i wykres 16 przedstawiają
przebiegi czasowe wykonywania operacji mnożenia macierzy w zależności od liczby wątków,
dla wybranych istnych wymiarów macierzy. Wykres 15 przedstawia przypadek najgorszy,
wykres 16 przedstawia przypadek najkorzystniejszy5. Test przeprowadzono na dwóch różnych
kompilatorów GCC i ICC, wraz z ich przełącznikami podstawowymi.
Wykres 15. Czas wykonywania obliczeń w zależności od liczby wątków, dla wybranych wymiarów macierzy. Wariant najgorszy.
5 Test przeprowadzono przy użyciu kompilatorów GCC i ICC, wraz z podstawowymi przełącznikami tych
kompilatorów. Wariant najkorzystniejszy oznacza, iż czas wykonywania obliczeń jest najkrótszy dla
środowiska testu, natomiast wariant najgorszy oznacza, iż czas wykonywania obliczeń jest najdłuższy dla
środowiska testu.
19,275
20,260
32,620
13,935
18,490
23,170
8,790
12,875
15,615
3,994
6,654
-
5,000
10,000
15,000
20,000
25,000
30,000
35,000
1 10 100 1000
Czas
wyk
onyw
ania
obl
iczeń
[s]
Liczba wątków
wymiar 1000 wymiar 900 wymiar 800 wymiar 600

47 | S t r o n a
Wykres 16. Czas wykonywania obliczeń w zależności od liczby wątków, dla wybranych wymiarów macierzy. Wariant najkorzystniejszy.
Jak widać z powyższych dwóch wykresów zależność ta może zachęcać do efektywniejsze
zarządzania wątkami. Warto zaznaczyć, iż w tym przypadku tworzenie wątków jest
nieprzemyślane, jednak dla każdej takiej liczby wątków autor starał się zagospodarować
zadaniami dla wątków jak najlepiej potrafił. Wartości skrajne zarówno dla wersji
najkorzystniejszej jak i najgorszej są niekiedy prawie dwukrotne.
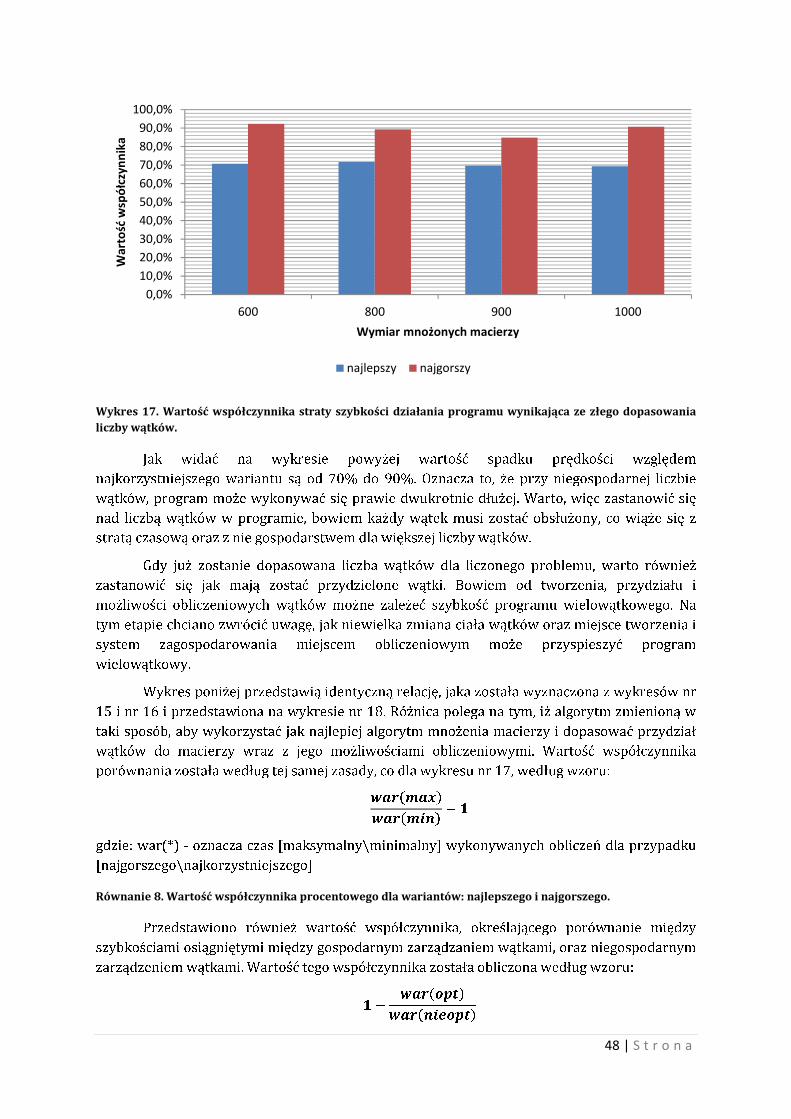
Wykres nr 17 przedstawia wartość procentową straty przyspieszenia działania
programu zarówno dla wersji najkorzystniejsze jak i najgorszej. Wartość współczynnika została
wyznaczona według zależności:
��������
��������� �
gdzie: war(*) - oznacza czas [maksymalny\minimalny] wykonywanych obliczeń dla przypadku
[najgorszego\najkorzystniejszego]
Równanie 7. Wartość współczynnika procentowego dla wariantów: najlepszego i najgorszego.
8,845 9,225
13,790
16,840
6,860 7,080
12,280 12,680
4,160
6,870
7,815 7,635
1,634
3,122
-
2,000
4,000
6,000
8,000
10,000
12,000
14,000
16,000
18,000
1 10 100 1000
Czas
wyk
onyw
nia
oblic
zeń
[s]
Liczba wątków
wymiar 1000 wymiar 900 wymiar 800 wymiar 600
48 | S t r o n a
Wykres 17. Wartość współczynnika straty szybkości działania programu wynikająca ze złego dopasowania liczby wątków.
Jak widać na wykresie powyżej wartość spadku prędkości względem
najkorzystniejszego wariantu są od 70% do 90%. Oznacza to, że przy niegospodarnej liczbie
wątków, program może wykonywać się prawie dwukrotnie dłużej. Warto, więc zastanowić się
nad liczbą wątków w programie, bowiem każdy wątek musi zostać obsłużony, co wiąże się z
stratą czasową oraz z nie gospodarstwem dla większej liczby wątków.
Gdy już zostanie dopasowana liczba wątków dla liczonego problemu, warto również
zastanowić się jak mają zostać przydzielone wątki. Bowiem od tworzenia, przydziału i
możliwości obliczeniowych wątków możne zależeć szybkość programu wielowątkowego. Na
tym etapie chciano zwrócić uwagę, jak niewielka zmiana ciała wątków oraz miejsce tworzenia i
system zagospodarowania miejscem obliczeniowym może przyspieszyć program
wielowątkowy.
Wykres poniżej przedstawią identyczną relację, jaka została wyznaczona z wykresów nr
15 i nr 16 i przedstawiona na wykresie nr 18. Różnica polega na tym, iż algorytm zmienioną w
taki sposób, aby wykorzystać jak najlepiej algorytm mnożenia macierzy i dopasować przydział
wątków do macierzy wraz z jego możliwościami obliczeniowymi. Wartość współczynnika
porównania została według tej samej zasady, co dla wykresu nr 17, według wzoru:
��������
��������� �
gdzie: war(*) - oznacza czas [maksymalny\minimalny] wykonywanych obliczeń dla przypadku
[najgorszego\najkorzystniejszego]
Równanie 8. Wartość współczynnika procentowego dla wariantów: najlepszego i najgorszego.
Przedstawiono również wartość współczynnika, określającego porównanie między
szybkościami osiągniętymi między gospodarnym zarządzaniem wątkami, oraz niegospodarnym
zarządzeniem wątkami. Wartość tego współczynnika została obliczona według wzoru:
����������
�����������
0,0%10,0%20,0%30,0%40,0%50,0%60,0%70,0%80,0%90,0%
100,0%
600 800 900 1000
War
tość
wsp
ółcz
ynni
ka
Wymiar mnożonych macierzy
najlepszy najgorszy

49 | S t r o n a
gdzie: war(*) - oznacza czas [optymalny\nieoptymalny] wykonywanych obliczeń dla przypadku
[najgorszego\najkorzystniejszego]
Równanie 9. Wartość współczynnika procentowego porównującego warianty optymalnego zarządzania wątkami względem nieoptymalnego zarządzania wątkami.
Omawiane dwa współczynniki przedstawiono na wykresie poniżej. Wartość
współczynnika dla wymiaru 500 i 700 nie została policzona, w teście nie były brane pod uwagę
te wymiary.
Wykres 18. Zależność pomiędzy optymalnym zarządzaniem wątkami. Współczynnik porównania dla czasów wykonywania obliczeń dla nieoptymalnego i optymalnego zarządzania wątkami.
Jak widać z wykresu nr 18, przydział optymalny wątków daję rozrzut znacznie mniejszy
niż tworzenie wątków na zasadzie: jakoś to będzie. Wartość współczynnika porównania plasuje
się na poziomie 50%, to znaczy, iż program napisany z dobrą organizacją wątków względem
programu ze złą organizacją wątków jest dwukrotnie szybszy.
Wykresy nr 19 i 20 obrazują jak optymalna liczba wątków przekłada się na szybsze
wykonywanie obliczeń. Wykresy obrazują współczynnik przyspieszenia działania programu.
Wykres nr 19 dla kompilatora GCC i jego przełączników optymalizacyjnych, a wykres nr 20 dla
kompilatora ICC i jego przełączników optymalizacyjnych. Wartość współczynnika została
obliczona według zależności:
� ��������� ������
�
�������� �����
gdzie: kompilator(watki)_x - oznacza czas wykonywania obliczeń dla poszczególnych
kompilatorów programu wielowątkowego przy przełączniku podstawowym -O[x]
Równanie 10. Wartość współczynnika procentowego porównującego program wielowątkowy z programem sekwencyjnym
Omawiane zależności przedstawiono na wykresie poniżej.
0,0%
10,0%
20,0%
30,0%
40,0%
50,0%
60,0%
500 600 700 800 900 1000
War
tość
wsp
ółcz
ynni
ka
najkorzystniejszy najgorszy porównanie
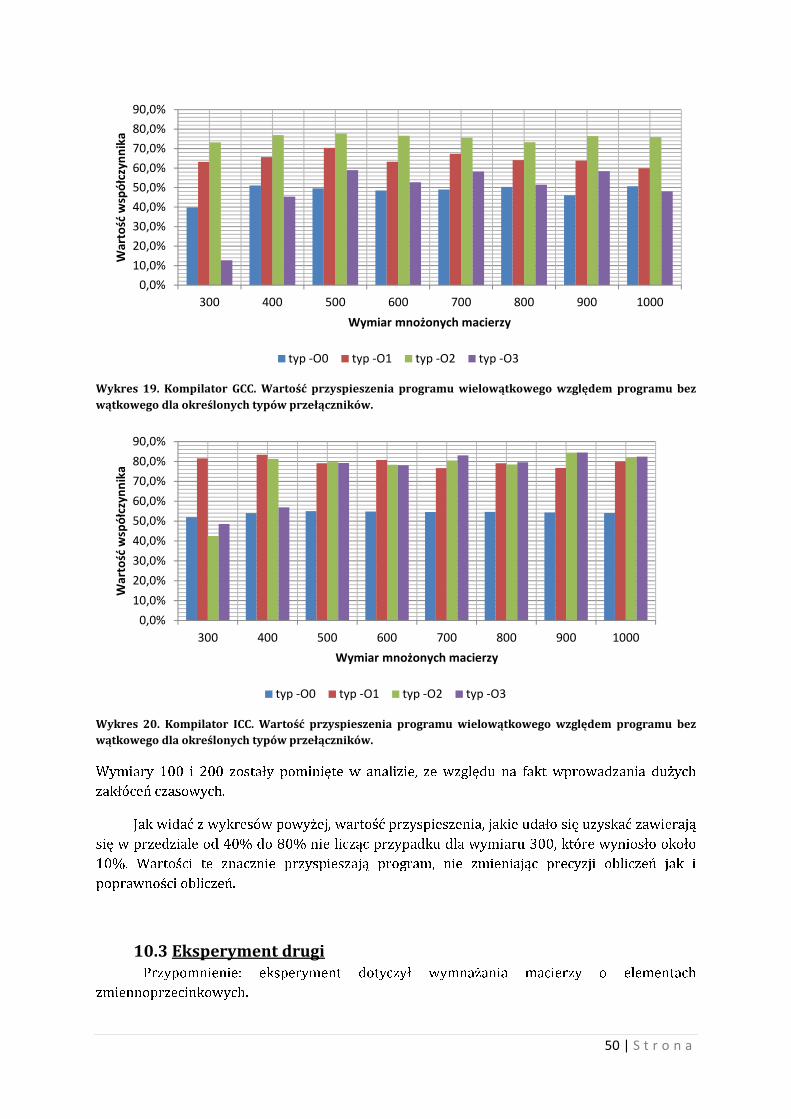
50 | S t r o n a
Wykres 19. Kompilator GCC. Wartość przyspieszenia programu wielowątkowego względem programu bez wątkowego dla określonych typów przełączników.
Wykres 20. Kompilator ICC. Wartość przyspieszenia programu wielowątkowego względem programu bez wątkowego dla określonych typów przełączników.
Wymiary 100 i 200 zostały pominięte w analizie, ze względu na fakt wprowadzania dużych
zakłóceń czasowych.
Jak widać z wykresów powyżej, wartość przyspieszenia, jakie udało się uzyskać zawierają
się w przedziale od 40% do 80% nie licząc przypadku dla wymiaru 300, które wyniosło około
10%. Wartości te znacznie przyspieszają program, nie zmieniając precyzji obliczeń jak i
poprawności obliczeń.
10.3 Eksperyment drugi Przypomnienie: eksperyment dotyczył wymnażania macierzy o elementach
zmiennoprzecinkowych.
0,0%10,0%20,0%30,0%40,0%50,0%60,0%70,0%80,0%90,0%
300 400 500 600 700 800 900 1000
War
tość
wsp
ółcz
ynni
ka
Wymiar mnożonych macierzy
typ -O0 typ -O1 typ -O2 typ -O3
0,0%10,0%20,0%30,0%40,0%50,0%60,0%70,0%80,0%90,0%
300 400 500 600 700 800 900 1000
War
tość
wsp
ółcz
ynni
ka
Wymiar mnożonych macierzy
typ -O0 typ -O1 typ -O2 typ -O3
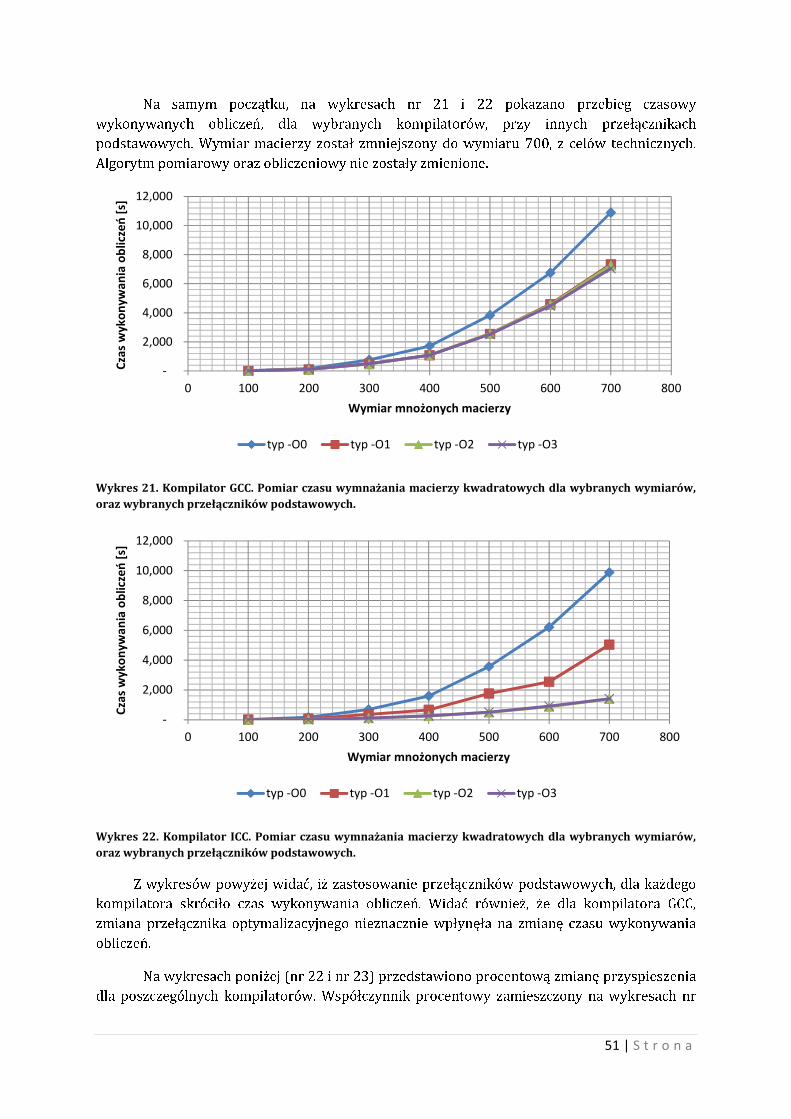
51 | S t r o n a
Na samym początku, na wykresach nr 21 i 22 pokazano przebieg czasowy
wykonywanych obliczeń, dla wybranych kompilatorów, przy innych przełącznikach
podstawowych. Wymiar macierzy został zmniejszony do wymiaru 700, z celów technicznych.
Algorytm pomiarowy oraz obliczeniowy nie zostały zmienione.
Wykres 21. Kompilator GCC. Pomiar czasu wymnażania macierzy kwadratowych dla wybranych wymiarów, oraz wybranych przełączników podstawowych.
Wykres 22. Kompilator ICC. Pomiar czasu wymnażania macierzy kwadratowych dla wybranych wymiarów, oraz wybranych przełączników podstawowych.
Z wykresów powyżej widać, iż zastosowanie przełączników podstawowych, dla każdego
kompilatora skróciło czas wykonywania obliczeń. Widać również, że dla kompilatora GCC,
zmiana przełącznika optymalizacyjnego nieznacznie wpłynęła na zmianę czasu wykonywania
obliczeń.
Na wykresach poniżej (nr 22 i nr 23) przedstawiono procentową zmianę przyspieszenia
dla poszczególnych kompilatorów. Współczynnik procentowy zamieszczony na wykresach nr
-
2,000
4,000
6,000
8,000
10,000
12,000
0 100 200 300 400 500 600 700 800
Czas
wyk
onyw
ania
obl
iczeń
[s]
Wymiar mnożonych macierzy
typ -O0 typ -O1 typ -O2 typ -O3
-
2,000
4,000
6,000
8,000
10,000
12,000
0 100 200 300 400 500 600 700 800
Czas
wyk
onyw
ania
obl
iczeń
[s]
Wymiar mnożonych macierzy
typ -O0 typ -O1 typ -O2 typ -O3
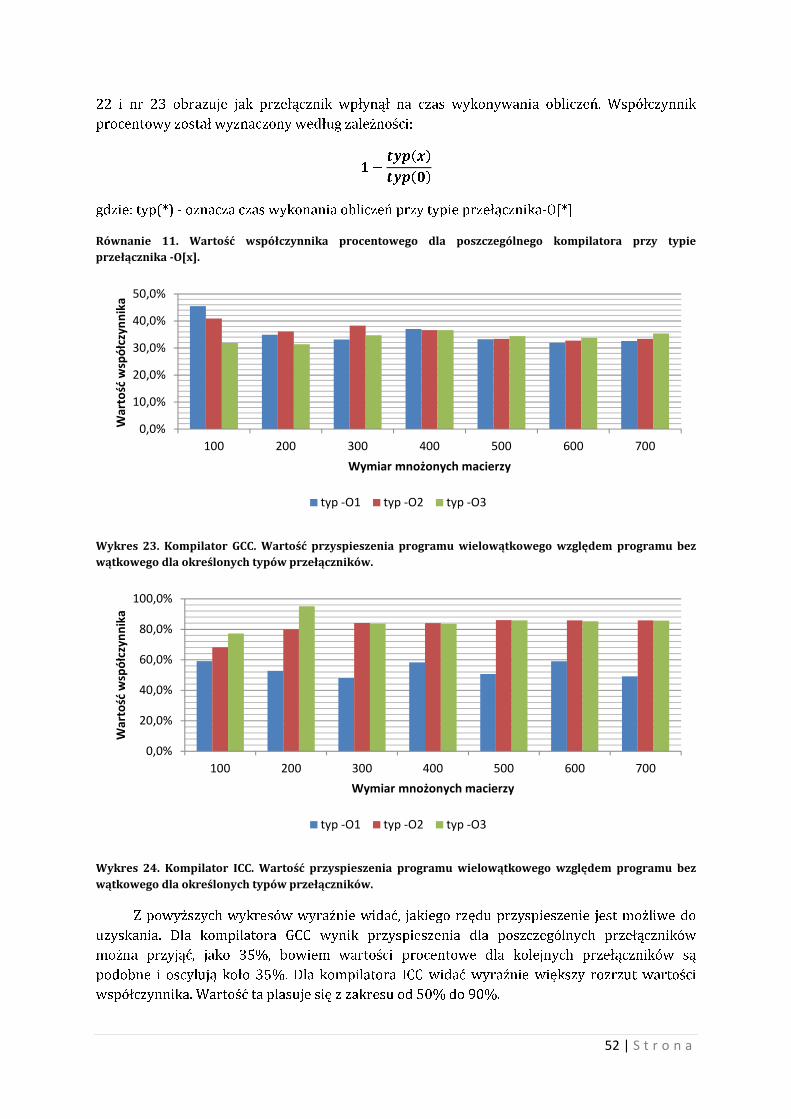
52 | S t r o n a
22 i nr 23 obrazuje jak przełącznik wpłynął na czas wykonywania obliczeń. Współczynnik
procentowy został wyznaczony według zależności:
��������
������
gdzie: typ(*) - oznacza czas wykonania obliczeń przy typie przełącznika-O[*]
Równanie 11. Wartość współczynnika procentowego dla poszczególnego kompilatora przy typie przełącznika -O[x].
Wykres 23. Kompilator GCC. Wartość przyspieszenia programu wielowątkowego względem programu bez wątkowego dla określonych typów przełączników.
Wykres 24. Kompilator ICC. Wartość przyspieszenia programu wielowątkowego względem programu bez wątkowego dla określonych typów przełączników.
Z powyższych wykresów wyraźnie widać, jakiego rzędu przyspieszenie jest możliwe do
uzyskania. Dla kompilatora GCC wynik przyspieszenia dla poszczególnych przełączników
można przyjąć, jako 35%, bowiem wartości procentowe dla kolejnych przełączników są
podobne i oscylują koło 35%. Dla kompilatora ICC widać wyraźnie większy rozrzut wartości
współczynnika. Wartość ta plasuje się z zakresu od 50% do 90%.
0,0%
10,0%
20,0%
30,0%
40,0%
50,0%
100 200 300 400 500 600 700
War
tość
wsp
ółcz
ynni
ka
Wymiar mnożonych macierzy
typ -O1 typ -O2 typ -O3
0,0%
20,0%
40,0%
60,0%
80,0%
100,0%
100 200 300 400 500 600 700
War
tość
wsp
ółcz
ynni
ka
Wymiar mnożonych macierzy
typ -O1 typ -O2 typ -O3
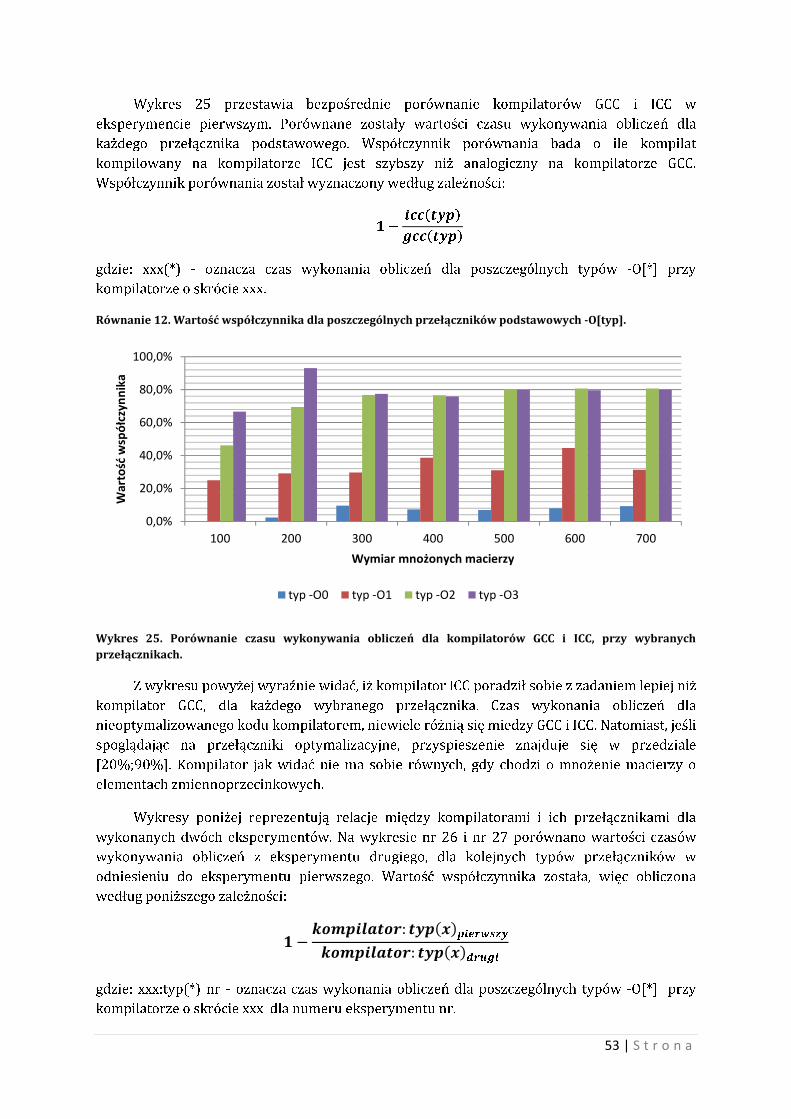
53 | S t r o n a
Wykres 25 przestawia bezpośrednie porównanie kompilatorów GCC i ICC w
eksperymencie pierwszym. Porównane zostały wartości czasu wykonywania obliczeń dla
każdego przełącznika podstawowego. Współczynnik porównania bada o ile kompilat
kompilowany na kompilatorze ICC jest szybszy niż analogiczny na kompilatorze GCC.
Współczynnik porównania został wyznaczony według zależności:
� ���������
��������
gdzie: xxx(*) - oznacza czas wykonania obliczeń dla poszczególnych typów -O[*] przy
kompilatorze o skrócie xxx.
Równanie 12. Wartość współczynnika dla poszczególnych przełączników podstawowych -O[typ].
Wykres 25. Porównanie czasu wykonywania obliczeń dla kompilatorów GCC i ICC, przy wybranych przełącznikach.
Z wykresu powyżej wyraźnie widać, iż kompilator ICC poradził sobie z zadaniem lepiej niż
kompilator GCC, dla każdego wybranego przełącznika. Czas wykonania obliczeń dla
nieoptymalizowanego kodu kompilatorem, niewiele różnią się miedzy GCC i ICC. Natomiast, jeśli
spoglądając na przełączniki optymalizacyjne, przyspieszenie znajduje się w przedziale
[20%;90%]. Kompilator jak widać nie ma sobie równych, gdy chodzi o mnożenie macierzy o
elementach zmiennoprzecinkowych.
Wykresy poniżej reprezentują relacje między kompilatorami i ich przełącznikami dla
wykonanych dwóch eksperymentów. Na wykresie nr 26 i nr 27 porównano wartości czasów
wykonywania obliczeń z eksperymentu drugiego, dla kolejnych typów przełączników w
odniesieniu do eksperymentu pierwszego. Wartość współczynnika została, więc obliczona
według poniższego zależności:
� ���������: ��������������
��������: �����������
gdzie: xxx:typ(*)_nr - oznacza czas wykonania obliczeń dla poszczególnych typów -O[*] przy
kompilatorze o skrócie xxx dla numeru eksperymentu nr.
0,0%
20,0%
40,0%
60,0%
80,0%
100,0%
100 200 300 400 500 600 700
War
tość
wsp
ółcz
ynni
ka
Wymiar mnożonych macierzy
typ -O0 typ -O1 typ -O2 typ -O3
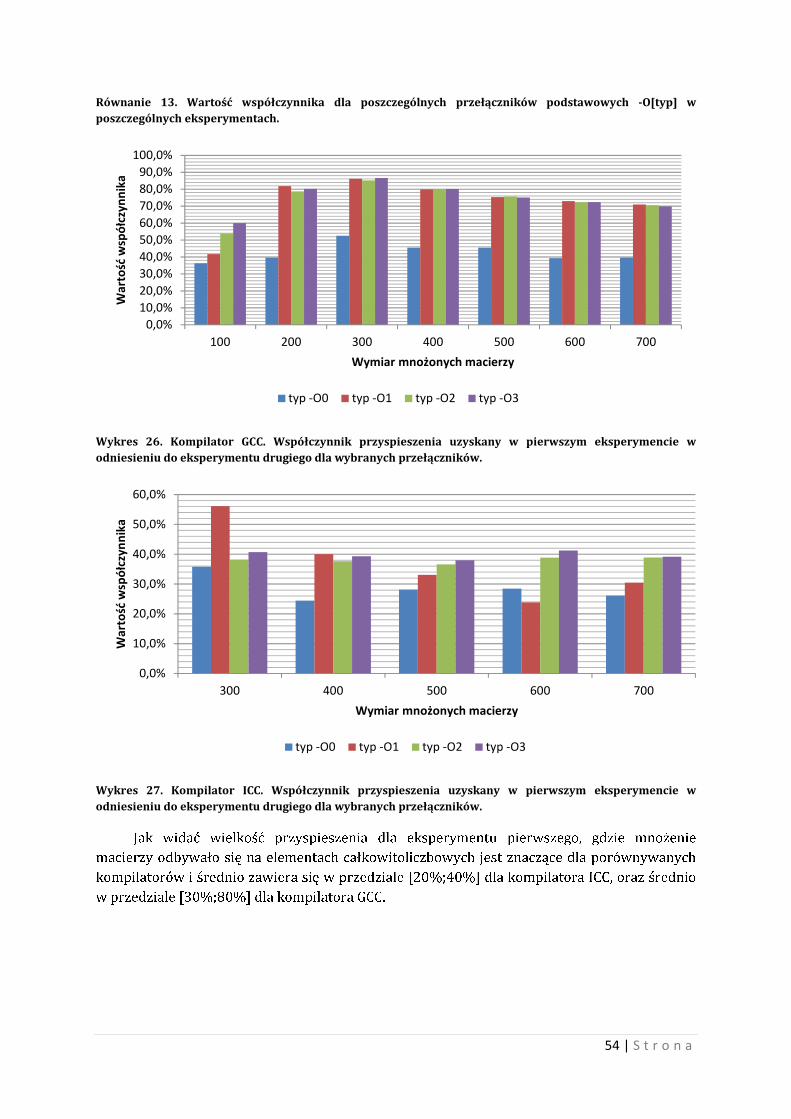
54 | S t r o n a
Równanie 13. Wartość współczynnika dla poszczególnych przełączników podstawowych -O[typ] w poszczególnych eksperymentach.
Wykres 26. Kompilator GCC. Współczynnik przyspieszenia uzyskany w pierwszym eksperymencie w odniesieniu do eksperymentu drugiego dla wybranych przełączników.
Wykres 27. Kompilator ICC. Współczynnik przyspieszenia uzyskany w pierwszym eksperymencie w odniesieniu do eksperymentu drugiego dla wybranych przełączników.
Jak widać wielkość przyspieszenia dla eksperymentu pierwszego, gdzie mnożenie
macierzy odbywało się na elementach całkowitoliczbowych jest znaczące dla porównywanych
kompilatorów i średnio zawiera się w przedziale [20%;40%] dla kompilatora ICC, oraz średnio
w przedziale [30%;80%] dla kompilatora GCC.
0,0%10,0%20,0%30,0%40,0%50,0%60,0%70,0%80,0%90,0%
100,0%
100 200 300 400 500 600 700
War
tość
wsp
ółcz
ynni
ka
Wymiar mnożonych macierzy
typ -O0 typ -O1 typ -O2 typ -O3
0,0%
10,0%
20,0%
30,0%
40,0%
50,0%
60,0%
300 400 500 600 700
War
tość
wsp
ółcz
ynni
ka
Wymiar mnożonych macierzy
typ -O0 typ -O1 typ -O2 typ -O3

55 | S t r o n a
10.4 Podsumowanie programu wielowątkowego Program wielowątkowy, który został przedstawiony dla eksperymentów pierwszego i
drugiego uzyskał przyspieszenie większe niż 20%. Jest to zasługa dobrego zarządzania
wątkami. Głównie liczbą wątków oraz zadaniem do wykonania. Z racji tego ze elementy były
wartościami niezależnymi oraz wsad nie zmieniał można było wykorzystać cały potencjał
programu wielowątkowego.
Warto również zaznaczyć, iż zbadano niezawodności programu wielowątkowego na
innych maszynach przy kompilacji typem –O3. Charakterystyka tego testu podobna jest do
charakterystyka w rozdziale 7.3.
10.5 Porównanie programu wielowątkowego i sekwencyjnego Z powyższych eksperymentów wynika, iż przyspieszenie program wielowątkowego
względem programu wykonywanego sekwencyjne plasuje się około 40%. Jest to wynik
zadowalający, biorąc pod uwagę, iż można uzyskać lepsze przyspieszenie, rzędu 80%,
wybierając przełączniki optymalizacyjne dostępne przy kompilatorach. Programy
wielowątkowe idealnie nadają się na rozpoczęcie strukturalnej optymalizacji, czyli
optymalizacji, którą uzyskujemy dzięki, w tym wypadku niewielkiej zmianie kodu.
Warto również zaznaczyć, iż szybkość działania kody wynikowego, może być w relacji, z
jakością wykonywanych obliczeń. Im większa szybkość tym mniejsza jakoś obliczeń. Często,
kiedy obliczenia mogą być wykonywane z mniejszą precyzją, można iść na takie odstępstwo.
Jednak, jeśli precyzja powinna zostać zachowana, warto tak agresywnie optymalizować kody
wynikowego w kryterium czasu. Niekiedy taka optymalizacja może prowadzić nie tylko do
utraty precyzyjności, lecz również do niestabilnego kodu wynikowego. Taki niestabilny kod
wynikowy może przestać wykonywać powierzone mu czynności w środku działania, co wtedy
spowoduje ogromną stratę czasową. Warto jednak optymalizować z głową i rozważyć pisanie
programu równoległego lub rozproszonego.

56 | S t r o n a
11 Wyniki testów przy użyciu OpenMP oraz MPI Wykorzystanie standardów OpenMP oraz MPI ma na celu zwiększenie wykorzystanie
przyznanej mocy obliczeniowej oraz możliwość łatwego zwiększenia mocy obliczeniowej.
Standard MPI jest standardem stosowanym w przetwarzaniu danych na wielu jednostkach
obliczeniowych z własną pamięcią. Opiera się na wymianie komunikatów wykonawczych i
informacyjnych.
Standard OpenMP jest standardem wykorzystującym, w prosty sposób całą moc
obliczeniową procesora. Pozwala w łatwy sposób zrównoleglić prowadzone w programie
obliczenia. OpenMP opiera się na odpowiednim zarządzaniu liczba wątków oraz ich
obciążeniem.
Opłacalną techniką w kryterium czasu wykonywania zadania i wykorzystanej mocy
obliczeniowej, może być zastosowanie tych standardów w programie.
W tym rozdziale przedstawiono jak stosowanie pragm z OpenMP, wpływa na czas obliczeń
i ich poprawność. Wykazano również zależność między czasem wykonywania obliczeń a
programem zawierającym obydwa standardy.
11.1 OpenMP
11.1.1 Zarządzanie pragmami Standard OpenMP może przyspieszyć działanie programu. Aby uzyskać zadowalający
efekt działania programu w kryterium poprawności wykonania obliczeń, oraz w kryterium
szybszego pozyskania wyników z obliczeń, warto posługiwać się pragmami. Zastosowanie
pragm ze standardu OpenMP pozwala na efektywniejsze wykorzystanie z macy obliczeniowej
komputera. Obliczenia prowadzone są między wieloma procesorami i wieloma rdzeniami, co
wymusza zachowanie pewnych reguł oraz stwarza kilka problemów.
Na samym początku, aby zrównoleglić program, warto przeanalizować fragmenty kodu,
wykonywane są niezależnie względem siebie. Niezależne w tym sensie, że może wykonywać się
jedna część tego kodu i druga w tym samym czasie. Przykładem takim jest uzupełnianie
macierzy danymi. W określonej komórce musi znajdować się określona wartość, ale zupełnie
uzupełnianie macierzy nie musi wykonywać się w określonym porządku. Jeżeli w tablicy
trójelementowej maja znajdować się kolejno elementy 0,5,-2, to nie ważne czy uzupełnione
będzie w kolejności: tab[0]=0, tab[1]=5, tab[2]=-2, czy w kolejności tab[2]=-2, tab[0]=0,
tab[1]=5. Efektem końcowym będzie poprawnie uzupełniona tablica danymi.
W drugiej kolejności warto przeanalizować kod pod względem, gdzie można
zrównoleglić obliczenia, lecz trzeba uważać na niektóre dane. Jeżeli mamy zadanie, polegające
na zsumowaniu elementów tablicy, to można wykorzystać z faktu, że sumowanie jest operacja
przemienna (zakładając, że typu zmiennej na to pozwala), można operację tę zrównoleglić.
Jednakże wartość sumy musi być chroniona, bowiem jest to zasób wspólny dla każdego wątku.
Wątek może ją zapisywać i odczytywać niezależnie od swoich wątkowych kolegów. Zapis i
odczyt wykonuje się bez wiedzy swoich kolegów. Wyobrazić można sobie, że dwa watki bija się
o dostęp do tej sumy. Jeden pobiera wartość sumy, dodaje swoja wartość i przed oddaniem
nowej sumy, watek drugi pobiera wartość starej sumy, dodaje swoją wartość i oddaje. Później
watek pierwszy oddaje wartość sumy, i tym sposobem wartość sumy jest wartością
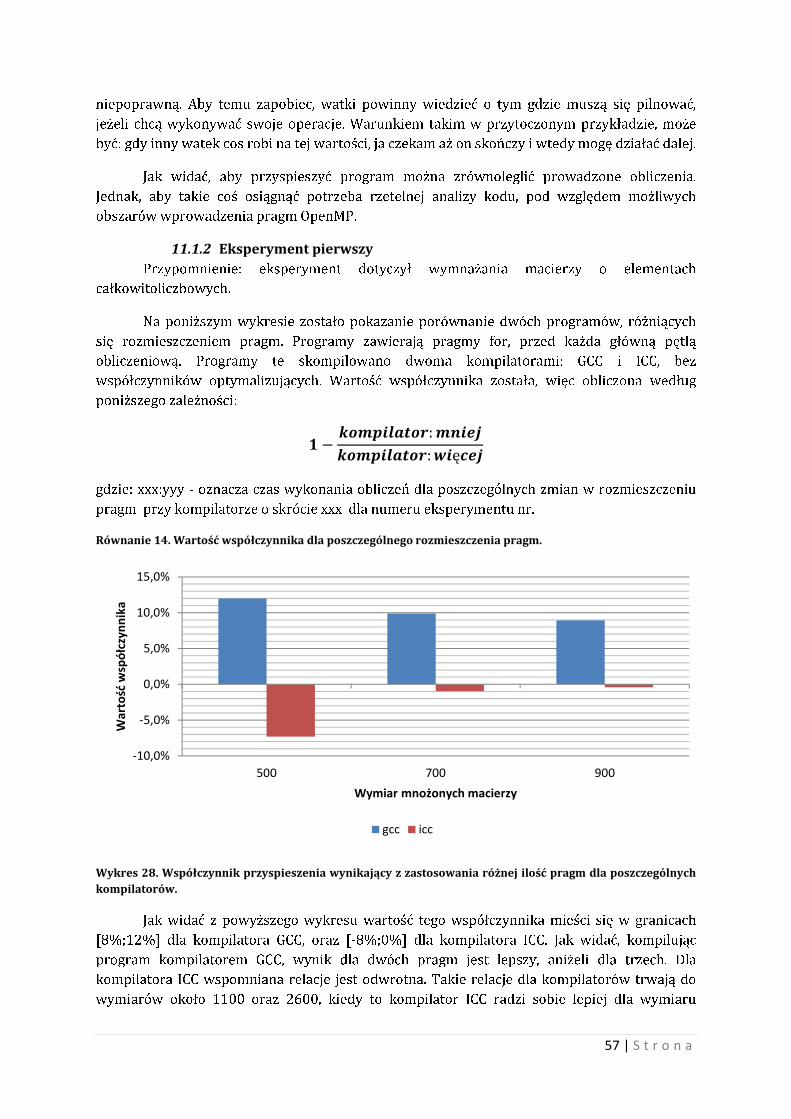
57 | S t r o n a
niepoprawną. Aby temu zapobiec, watki powinny wiedzieć o tym gdzie muszą się pilnować,
jeżeli chcą wykonywać swoje operacje. Warunkiem takim w przytoczonym przykładzie, może
być: gdy inny watek cos robi na tej wartości, ja czekam aż on skończy i wtedy mogę działać dalej.
Jak widać, aby przyspieszyć program można zrównoleglić prowadzone obliczenia.
Jednak, aby takie coś osiągnąć potrzeba rzetelnej analizy kodu, pod względem możliwych
obszarów wprowadzenia pragm OpenMP.
11.1.2 Eksperyment pierwszy Przypomnienie: eksperyment dotyczył wymnażania macierzy o elementach
całkowitoliczbowych.
Na poniższym wykresie zostało pokazanie porównanie dwóch programów, różniących
się rozmieszczeniem pragm. Programy zawierają pragmy for, przed każda główną pętlą
obliczeniową. Programy te skompilowano dwoma kompilatorami: GCC i ICC, bez
współczynników optymalizujących. Wartość współczynnika została, więc obliczona według
poniższego zależności:
� ���������:�����
��������:����
gdzie: xxx:yyy - oznacza czas wykonania obliczeń dla poszczególnych zmian w rozmieszczeniu
pragm przy kompilatorze o skrócie xxx dla numeru eksperymentu nr.
Równanie 14. Wartość współczynnika dla poszczególnego rozmieszczenia pragm.
Wykres 28. Współczynnik przyspieszenia wynikający z zastosowania różnej ilość pragm dla poszczególnych kompilatorów.
Jak widać z powyższego wykresu wartość tego współczynnika mieści się w granicach
[8%;12%] dla kompilatora GCC, oraz [-8%;0%] dla kompilatora ICC. Jak widać, kompilując
program kompilatorem GCC, wynik dla dwóch pragm jest lepszy, aniżeli dla trzech. Dla
kompilatora ICC wspomniana relacje jest odwrotna. Takie relacje dla kompilatorów trwają do
wymiarów około 1100 oraz 2600, kiedy to kompilator ICC radzi sobie lepiej dla wymiaru
-10,0%
-5,0%
0,0%
5,0%
10,0%
15,0%
500 700 900
War
tość
wsp
ółcz
ynni
ka
Wymiar mnożonych macierzy
gcc icc
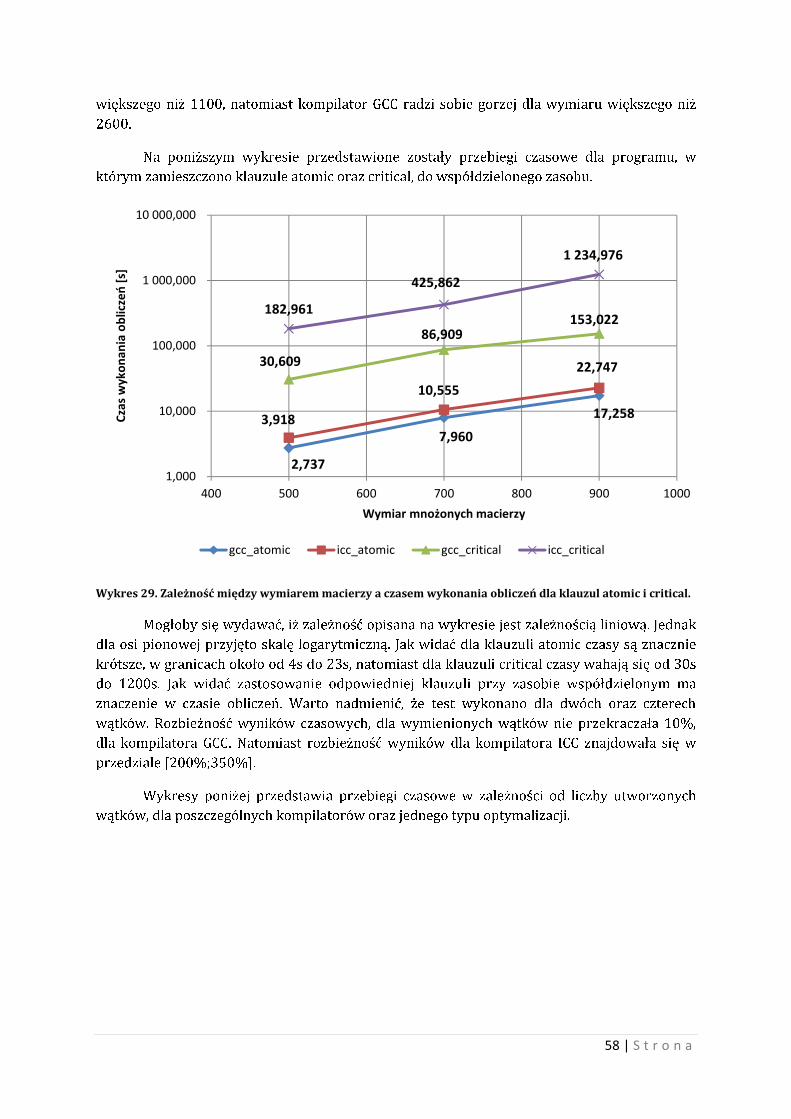
58 | S t r o n a
większego niż 1100, natomiast kompilator GCC radzi sobie gorzej dla wymiaru większego niż
2600.
Na poniższym wykresie przedstawione zostały przebiegi czasowe dla programu, w
którym zamieszczono klauzule atomic oraz critical, do współdzielonego zasobu.
Wykres 29. Zależność między wymiarem macierzy a czasem wykonania obliczeń dla klauzul atomic i critical.
Mogłoby się wydawać, iż zależność opisana na wykresie jest zależnością liniową. Jednak
dla osi pionowej przyjęto skalę logarytmiczną. Jak widać dla klauzuli atomic czasy są znacznie
krótsze, w granicach około od 4s do 23s, natomiast dla klauzuli critical czasy wahają się od 30s
do 1200s. Jak widać zastosowanie odpowiedniej klauzuli przy zasobie współdzielonym ma
znaczenie w czasie obliczeń. Warto nadmienić, że test wykonano dla dwóch oraz czterech
wątków. Rozbieżność wyników czasowych, dla wymienionych wątków nie przekraczała 10%,
dla kompilatora GCC. Natomiast rozbieżność wyników dla kompilatora ICC znajdowała się w
przedziale [200%;350%].
Wykresy poniżej przedstawia przebiegi czasowe w zależności od liczby utworzonych
wątków, dla poszczególnych kompilatorów oraz jednego typu optymalizacji.
2,737
7,960 17,258 3,918
10,555 22,747 30,609
86,909 153,022
182,961
425,862
1 234,976
1,000
10,000
100,000
1 000,000
10 000,000
400 500 600 700 800 900 1000
Czas
wyk
onan
ia o
blic
zeń
[s]
Wymiar mnożonych macierzy
gcc_atomic icc_atomic gcc_critical icc_critical
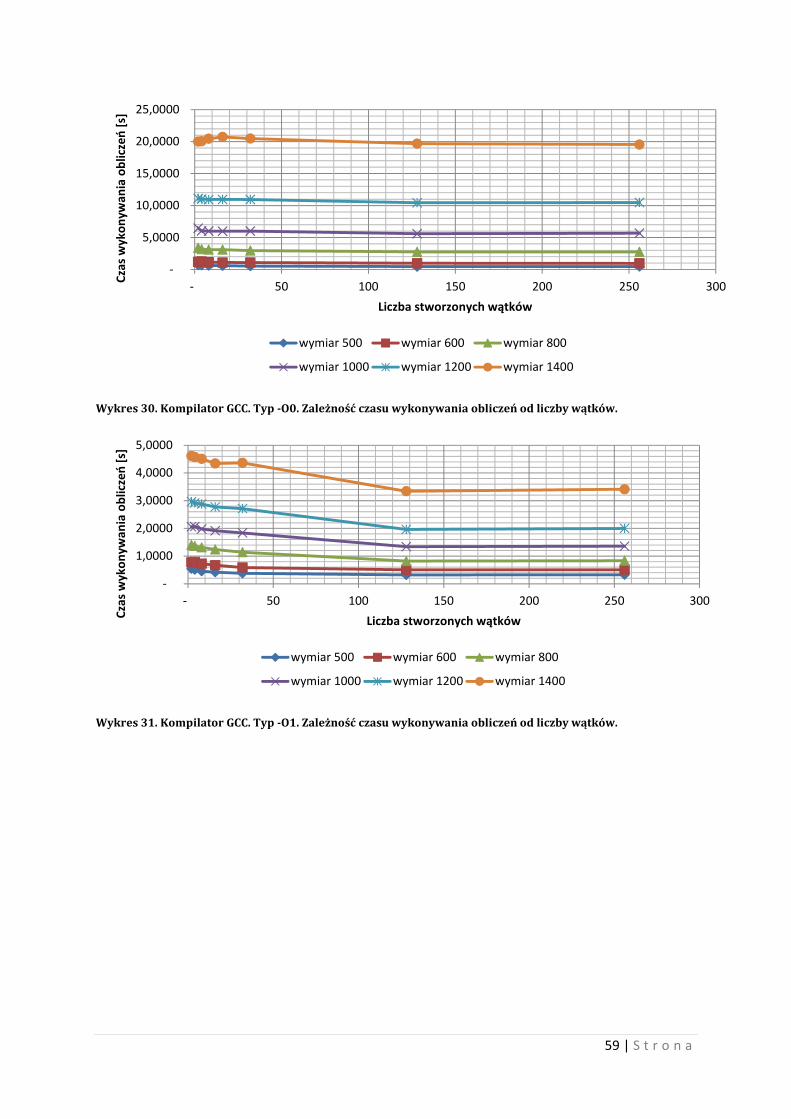
59 | S t r o n a
Wykres 30. Kompilator GCC. Typ -O0. Zależność czasu wykonywania obliczeń od liczby wątków.
Wykres 31. Kompilator GCC. Typ -O1. Zależność czasu wykonywania obliczeń od liczby wątków.
-
5,0000
10,0000
15,0000
20,0000
25,0000
- 50 100 150 200 250 300Czas
wyk
onyw
ania
obl
iczeń
[s]
Liczba stworzonych wątków
wymiar 500 wymiar 600 wymiar 800
wymiar 1000 wymiar 1200 wymiar 1400
-
1,0000
2,0000
3,0000
4,0000
5,0000
- 50 100 150 200 250 300
Czas
wyk
onyw
ania
obl
iczeń
[s]
Liczba stworzonych wątków
wymiar 500 wymiar 600 wymiar 800
wymiar 1000 wymiar 1200 wymiar 1400
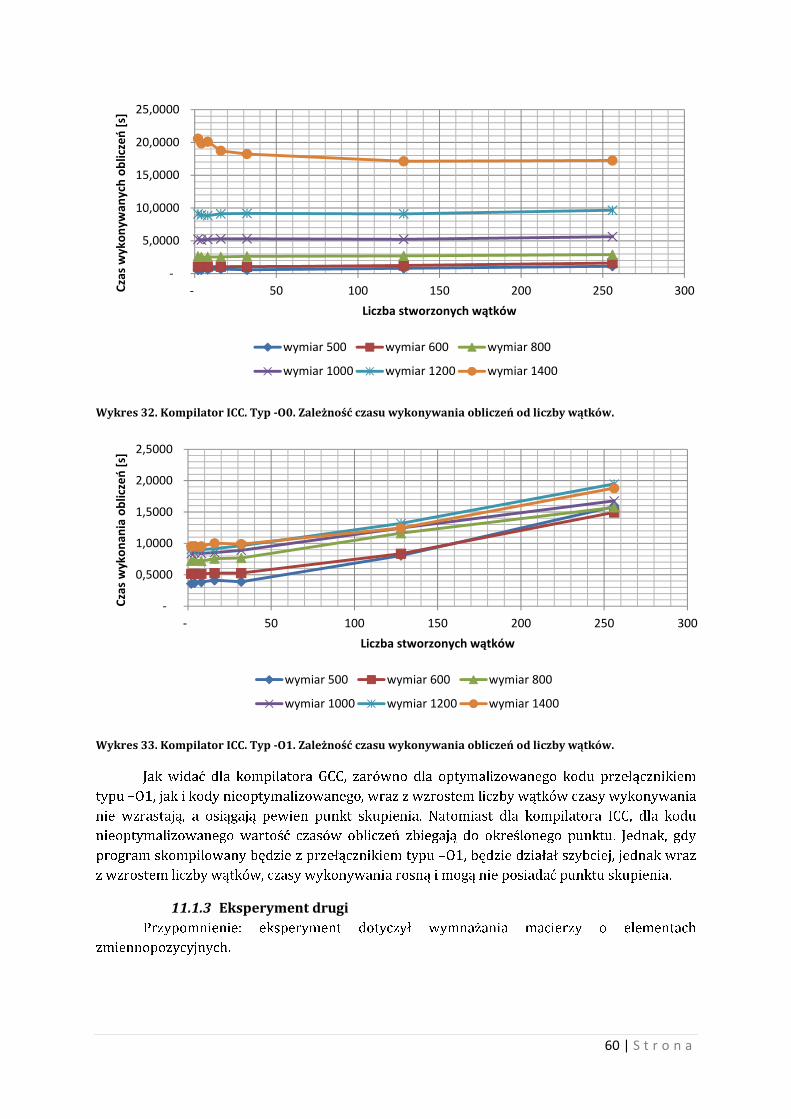
60 | S t r o n a
Wykres 32. Kompilator ICC. Typ -O0. Zależność czasu wykonywania obliczeń od liczby wątków.
Wykres 33. Kompilator ICC. Typ -O1. Zależność czasu wykonywania obliczeń od liczby wątków.
Jak widać dla kompilatora GCC, zarówno dla optymalizowanego kodu przełącznikiem
typu –O1, jak i kody nieoptymalizowanego, wraz z wzrostem liczby wątków czasy wykonywania
nie wzrastają, a osiągają pewien punkt skupienia. Natomiast dla kompilatora ICC, dla kodu
nieoptymalizowanego wartość czasów obliczeń zbiegają do określonego punktu. Jednak, gdy
program skompilowany będzie z przełącznikiem typu –O1, będzie działał szybciej, jednak wraz
z wzrostem liczby wątków, czasy wykonywania rosną i mogą nie posiadać punktu skupienia.
11.1.3 Eksperyment drugi Przypomnienie: eksperyment dotyczył wymnażania macierzy o elementach
zmiennopozycyjnych.
-
5,0000
10,0000
15,0000
20,0000
25,0000
- 50 100 150 200 250 300Czas
wyk
onyw
anyc
h ob
liczeń
[s]
Liczba stworzonych wątków
wymiar 500 wymiar 600 wymiar 800
wymiar 1000 wymiar 1200 wymiar 1400
-
0,5000
1,0000
1,5000
2,0000
2,5000
- 50 100 150 200 250 300
Czas
wyk
onan
ia o
blic
zeń
[s]
Liczba stworzonych wątków
wymiar 500 wymiar 600 wymiar 800
wymiar 1000 wymiar 1200 wymiar 1400
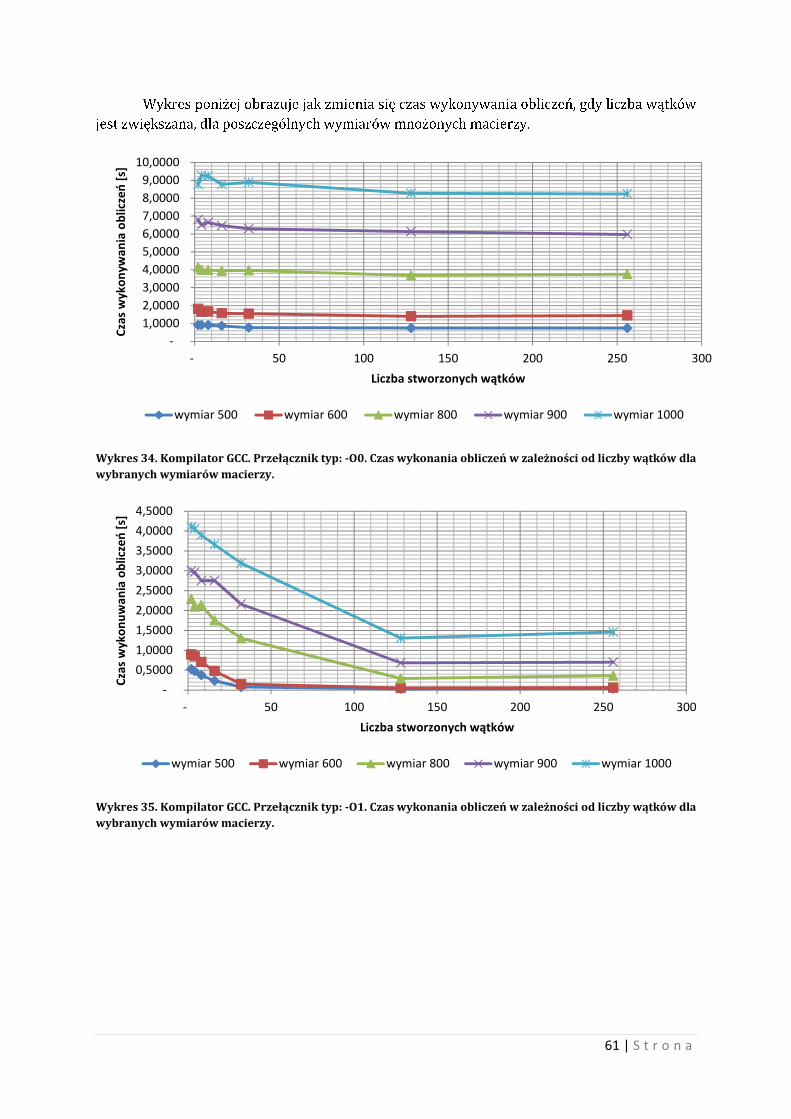
61 | S t r o n a
Wykres poniżej obrazuje jak zmienia się czas wykonywania obliczeń, gdy liczba wątków
jest zwiększana, dla poszczególnych wymiarów mnożonych macierzy.
Wykres 34. Kompilator GCC. Przełącznik typ: -O0. Czas wykonania obliczeń w zależności od liczby wątków dla wybranych wymiarów macierzy.
Wykres 35. Kompilator GCC. Przełącznik typ: -O1. Czas wykonania obliczeń w zależności od liczby wątków dla wybranych wymiarów macierzy.
- 1,0000 2,0000 3,0000 4,0000 5,0000 6,0000 7,0000 8,0000 9,0000
10,0000
- 50 100 150 200 250 300
Czas
wyk
onyw
ania
obl
iczeń
[s]
Liczba stworzonych wątków
wymiar 500 wymiar 600 wymiar 800 wymiar 900 wymiar 1000
- 0,5000 1,0000 1,5000 2,0000 2,5000 3,0000 3,5000 4,0000 4,5000
- 50 100 150 200 250 300
Czas
wyk
onuw
ania
obl
iczeń
[s]
Liczba stworzonych wątków
wymiar 500 wymiar 600 wymiar 800 wymiar 900 wymiar 1000
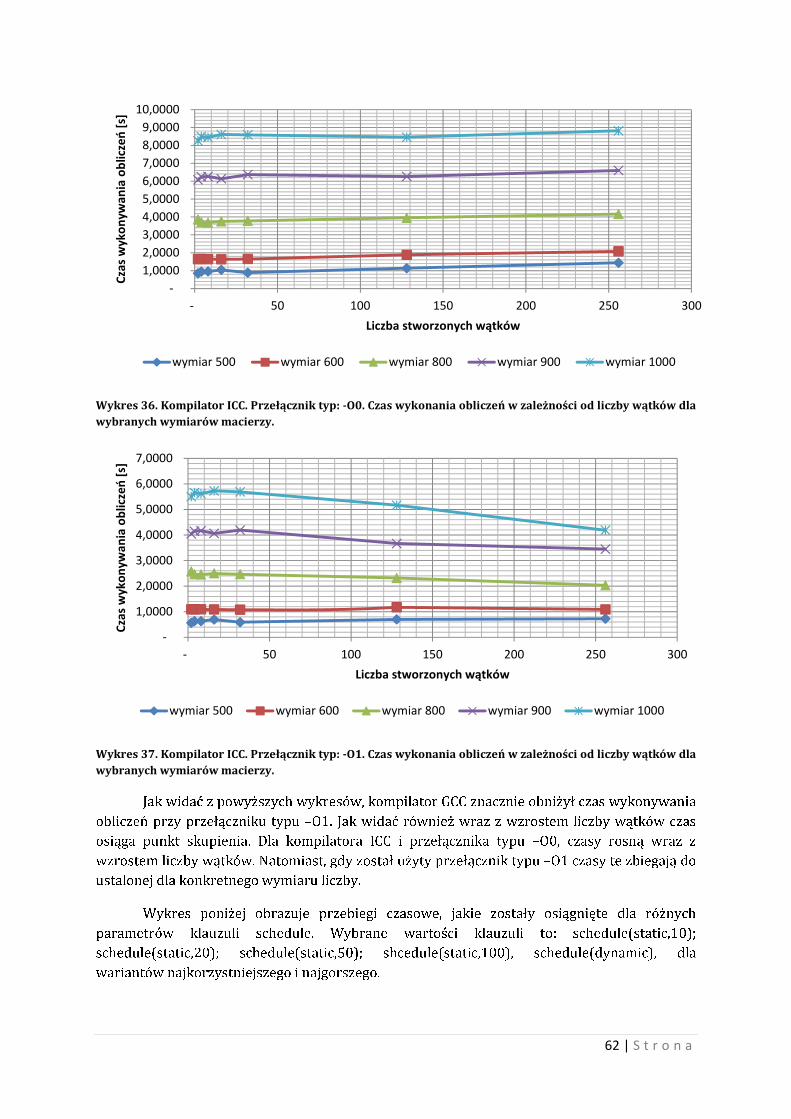
62 | S t r o n a
Wykres 36. Kompilator ICC. Przełącznik typ: -O0. Czas wykonania obliczeń w zależności od liczby wątków dla wybranych wymiarów macierzy.
Wykres 37. Kompilator ICC. Przełącznik typ: -O1. Czas wykonania obliczeń w zależności od liczby wątków dla wybranych wymiarów macierzy.
Jak widać z powyższych wykresów, kompilator GCC znacznie obniżył czas wykonywania
obliczeń przy przełączniku typu –O1. Jak widać również wraz z wzrostem liczby wątków czas
osiąga punkt skupienia. Dla kompilatora ICC i przełącznika typu –O0, czasy rosną wraz z
wzrostem liczby wątków. Natomiast, gdy został użyty przełącznik typu –O1 czasy te zbiegają do
ustalonej dla konkretnego wymiaru liczby.
Wykres poniżej obrazuje przebiegi czasowe, jakie zostały osiągnięte dla różnych
parametrów klauzuli schedule. Wybrane wartości klauzuli to: schedule(static,10);
schedule(static,20); schedule(static,50); shcedule(static,100), schedule(dynamic), dla
wariantów najkorzystniejszego i najgorszego.
- 1,0000 2,0000 3,0000 4,0000 5,0000 6,0000 7,0000 8,0000 9,0000
10,0000
- 50 100 150 200 250 300
Czas
wyk
onyw
ania
obl
iczeń
[s]
Liczba stworzonych wątków
wymiar 500 wymiar 600 wymiar 800 wymiar 900 wymiar 1000
-
1,0000
2,0000
3,0000
4,0000
5,0000
6,0000
7,0000
- 50 100 150 200 250 300
Czas
wyk
onyw
ania
obl
iczeń
[s]
Liczba stworzonych wątków
wymiar 500 wymiar 600 wymiar 800 wymiar 900 wymiar 1000
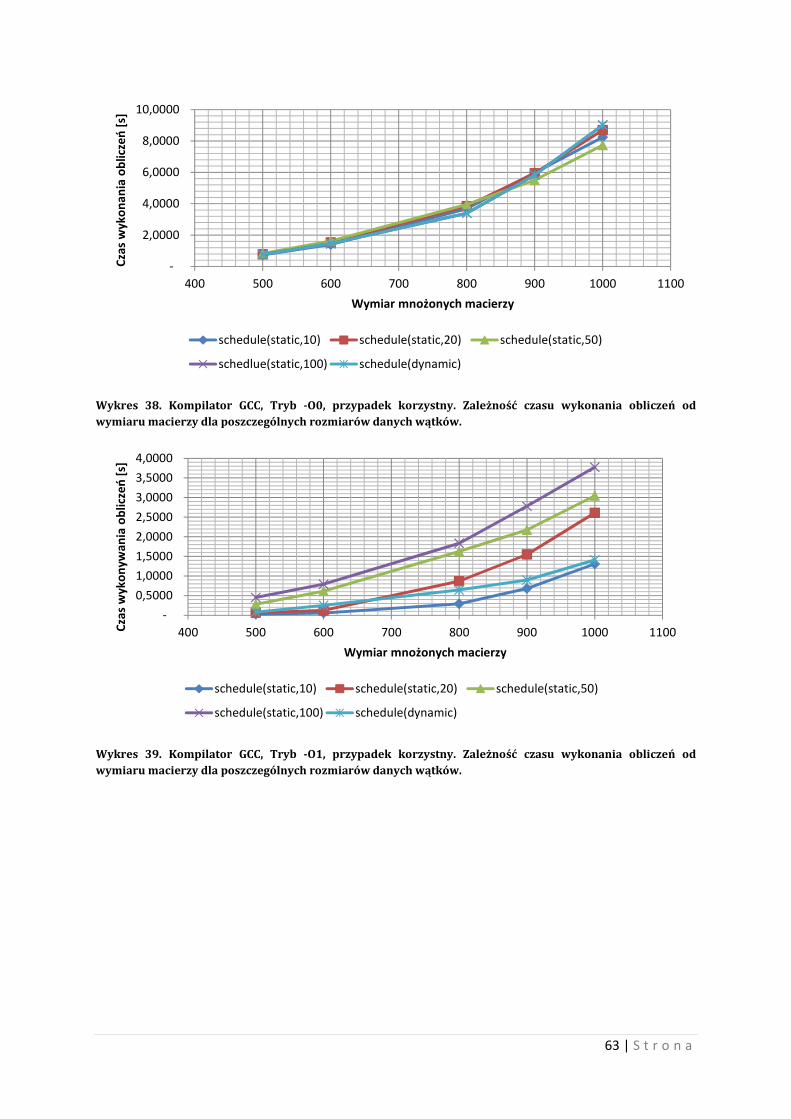
63 | S t r o n a
Wykres 38. Kompilator GCC, Tryb -O0, przypadek korzystny. Zależność czasu wykonania obliczeń od wymiaru macierzy dla poszczególnych rozmiarów danych wątków.
Wykres 39. Kompilator GCC, Tryb -O1, przypadek korzystny. Zależność czasu wykonania obliczeń od wymiaru macierzy dla poszczególnych rozmiarów danych wątków.
-
2,0000
4,0000
6,0000
8,0000
10,0000
400 500 600 700 800 900 1000 1100
Czas
wyk
onan
ia o
blic
zeń
[s]
Wymiar mnożonych macierzy
schedule(static,10) schedule(static,20) schedule(static,50)
schedlue(static,100) schedule(dynamic)
- 0,5000 1,0000 1,5000 2,0000 2,5000 3,0000 3,5000 4,0000
400 500 600 700 800 900 1000 1100Czas
wyk
onyw
ania
obl
iczeń
[s]
Wymiar mnożonych macierzy
schedule(static,10) schedule(static,20) schedule(static,50)
schedule(static,100) schedule(dynamic)
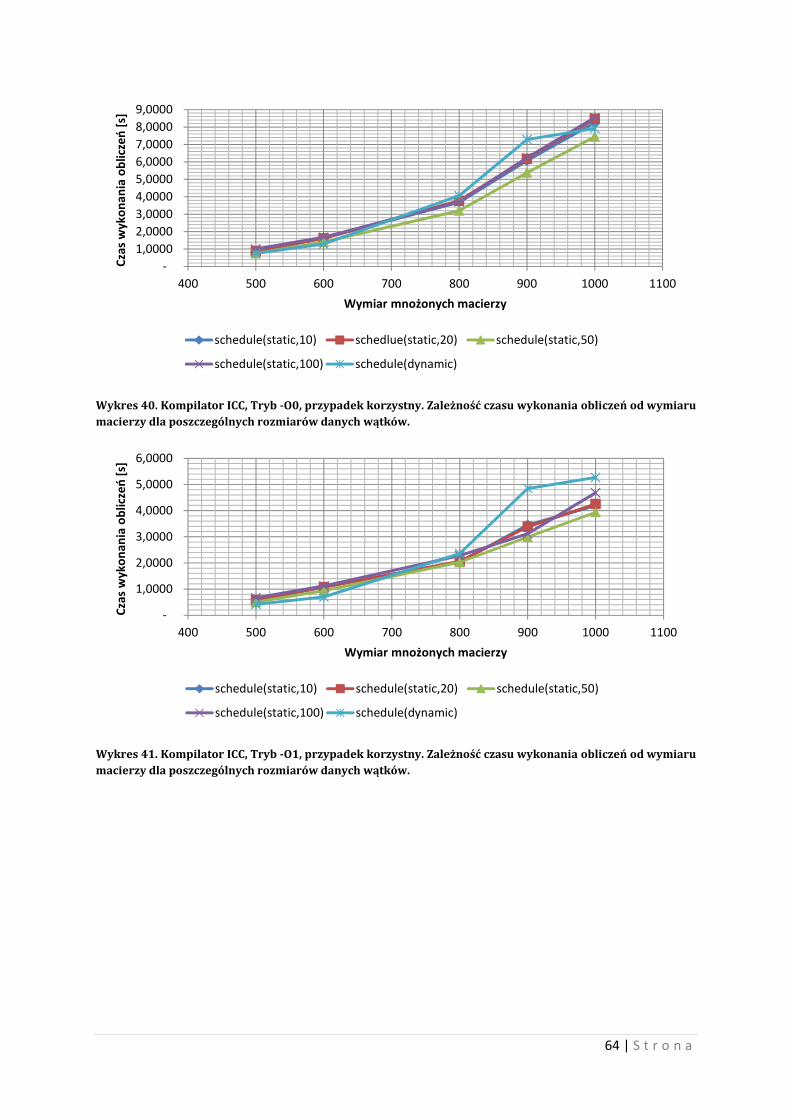
64 | S t r o n a
Wykres 40. Kompilator ICC, Tryb -O0, przypadek korzystny. Zależność czasu wykonania obliczeń od wymiaru macierzy dla poszczególnych rozmiarów danych wątków.
Wykres 41. Kompilator ICC, Tryb -O1, przypadek korzystny. Zależność czasu wykonania obliczeń od wymiaru macierzy dla poszczególnych rozmiarów danych wątków.
- 1,0000 2,0000 3,0000 4,0000 5,0000 6,0000 7,0000 8,0000 9,0000
400 500 600 700 800 900 1000 1100
Czas
wyk
onan
ia o
blic
zeń
[s]
Wymiar mnożonych macierzy
schedule(static,10) schedlue(static,20) schedule(static,50)
schedule(static,100) schedule(dynamic)
-
1,0000
2,0000
3,0000
4,0000
5,0000
6,0000
400 500 600 700 800 900 1000 1100
Czas
wyk
onan
ia o
blic
zeń
[s]
Wymiar mnożonych macierzy
schedule(static,10) schedule(static,20) schedule(static,50)
schedule(static,100) schedule(dynamic)
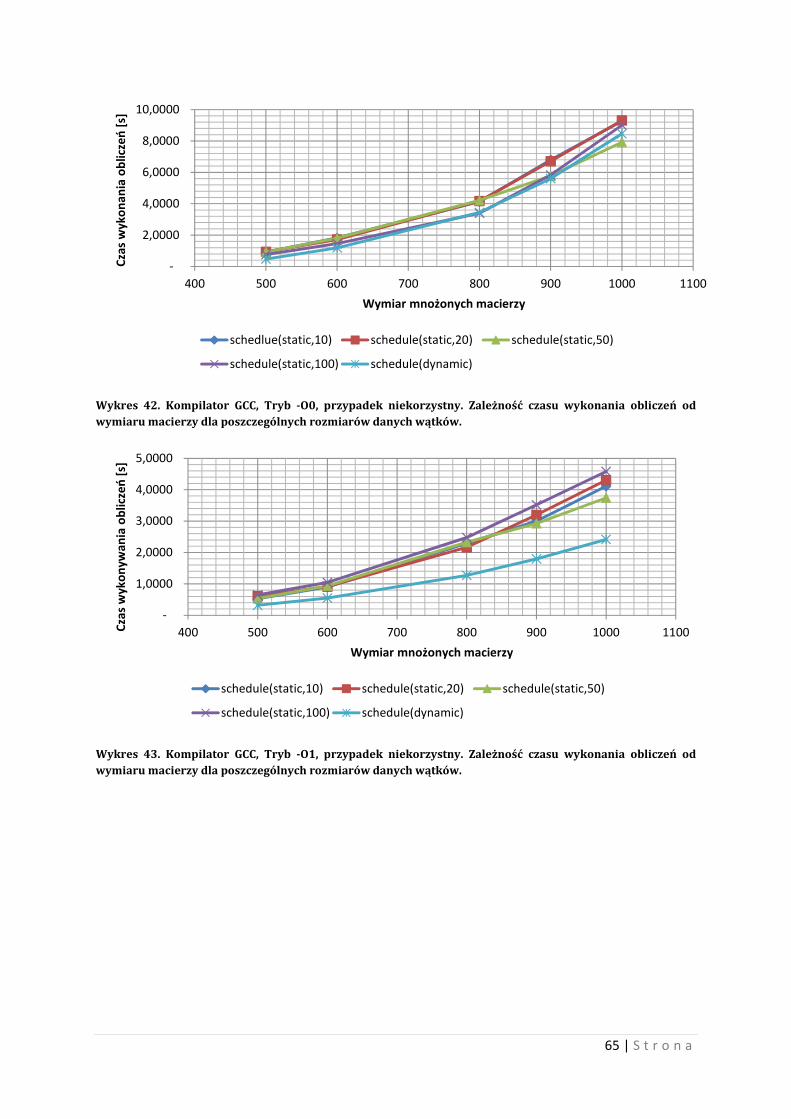
65 | S t r o n a
Wykres 42. Kompilator GCC, Tryb -O0, przypadek niekorzystny. Zależność czasu wykonania obliczeń od wymiaru macierzy dla poszczególnych rozmiarów danych wątków.
Wykres 43. Kompilator GCC, Tryb -O1, przypadek niekorzystny. Zależność czasu wykonania obliczeń od wymiaru macierzy dla poszczególnych rozmiarów danych wątków.
-
2,0000
4,0000
6,0000
8,0000
10,0000
400 500 600 700 800 900 1000 1100
Czas
wyk
onan
ia o
blic
zeń
[s]
Wymiar mnożonych macierzy
schedlue(static,10) schedule(static,20) schedule(static,50)
schedule(static,100) schedule(dynamic)
-
1,0000
2,0000
3,0000
4,0000
5,0000
400 500 600 700 800 900 1000 1100Czas
wyk
onyw
ania
obl
iczeń
[s]
Wymiar mnożonych macierzy
schedule(static,10) schedule(static,20) schedule(static,50)
schedule(static,100) schedule(dynamic)
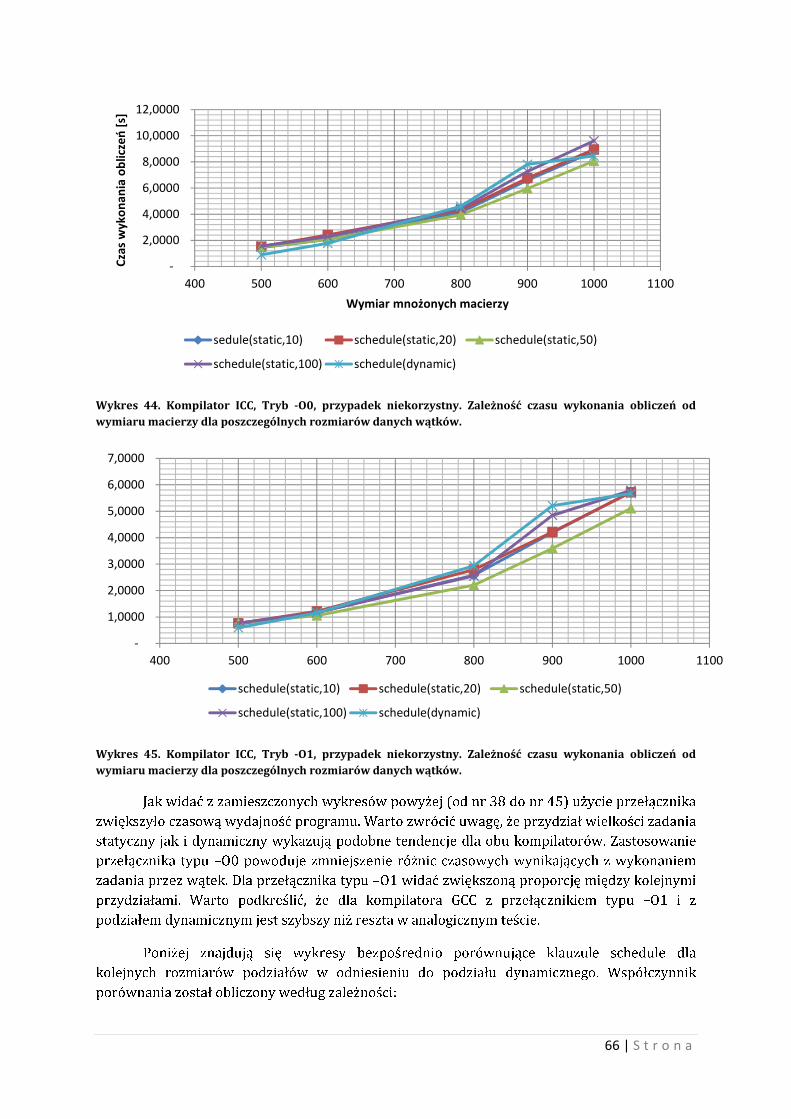
66 | S t r o n a
Wykres 44. Kompilator ICC, Tryb -O0, przypadek niekorzystny. Zależność czasu wykonania obliczeń od wymiaru macierzy dla poszczególnych rozmiarów danych wątków.
Wykres 45. Kompilator ICC, Tryb -O1, przypadek niekorzystny. Zależność czasu wykonania obliczeń od wymiaru macierzy dla poszczególnych rozmiarów danych wątków.
Jak widać z zamieszczonych wykresów powyżej (od nr 38 do nr 45) użycie przełącznika
zwiększyło czasową wydajność programu. Warto zwrócić uwagę, że przydział wielkości zadania
statyczny jak i dynamiczny wykazują podobne tendencje dla obu kompilatorów. Zastosowanie
przełącznika typu –O0 powoduje zmniejszenie różnic czasowych wynikających z wykonaniem
zadania przez wątek. Dla przełącznika typu –O1 widać zwiększoną proporcję między kolejnymi
przydziałami. Warto podkreślić, że dla kompilatora GCC z przełącznikiem typu –O1 i z
podziałem dynamicznym jest szybszy niż reszta w analogicznym teście.
Poniżej znajdują się wykresy bezpośrednio porównujące klauzule schedule dla
kolejnych rozmiarów podziałów w odniesieniu do podziału dynamicznego. Współczynnik
porównania został obliczony według zależności:
-
2,0000
4,0000
6,0000
8,0000
10,0000
12,0000
400 500 600 700 800 900 1000 1100
Czas
wyk
onan
ia o
blic
zeń
[s]
Wymiar mnożonych macierzy
sedule(static,10) schedule(static,20) schedule(static,50)
schedule(static,100) schedule(dynamic)
-
1,0000
2,0000
3,0000
4,0000
5,0000
6,0000
7,0000
400 500 600 700 800 900 1000 1100
schedule(static,10) schedule(static,20) schedule(static,50)
schedule(static,100) schedule(dynamic)
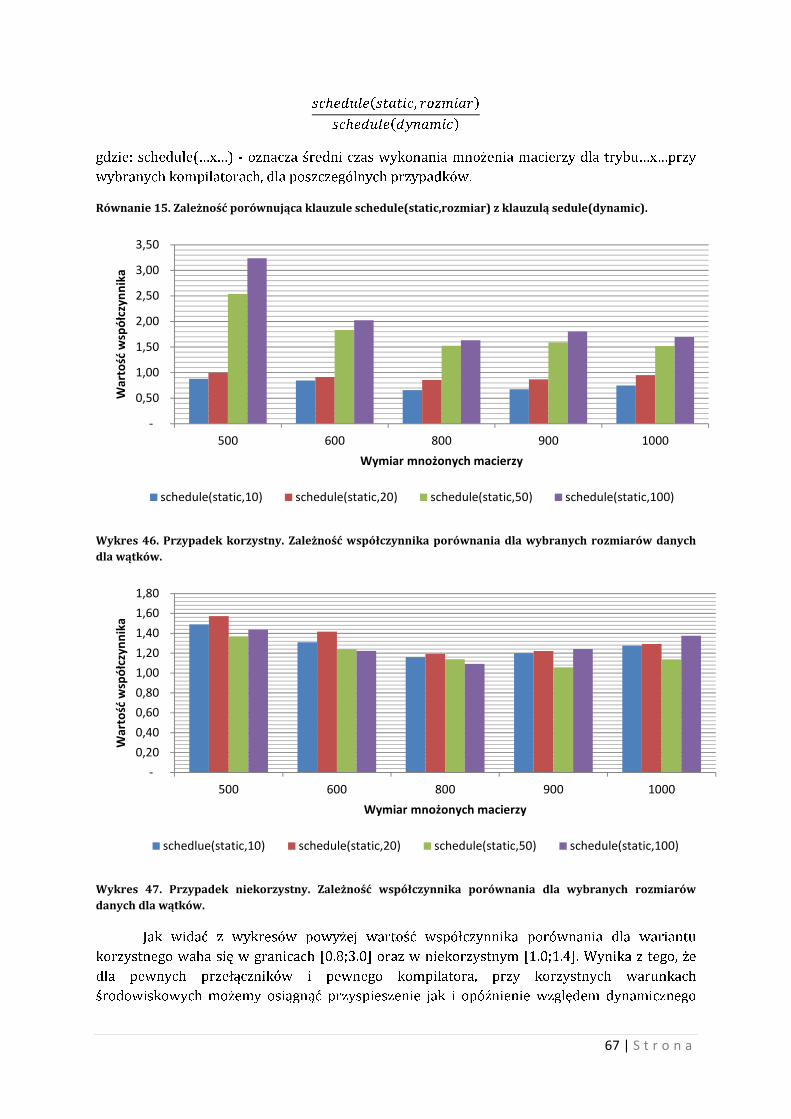
67 | S t r o n a
���������������, ��������
�����������������
gdzie: schedule(…x…) - oznacza średni czas wykonania mnożenia macierzy dla trybu…x…przy
wybranych kompilatorach, dla poszczególnych przypadków.
Równanie 15. Zależność porównująca klauzule schedule(static,rozmiar) z klauzulą sedule(dynamic).
Wykres 46. Przypadek korzystny. Zależność współczynnika porównania dla wybranych rozmiarów danych dla wątków.
Wykres 47. Przypadek niekorzystny. Zależność współczynnika porównania dla wybranych rozmiarów danych dla wątków.
Jak widać z wykresów powyżej wartość współczynnika porównania dla wariantu
korzystnego waha się w granicach [0.8;3.0] oraz w niekorzystnym [1.0;1.4]. Wynika z tego, że
dla pewnych przełączników i pewnego kompilatora, przy korzystnych warunkach
środowiskowych możemy osiągnąć przyspieszenie jak i opóźnienie względem dynamicznego
-
0,50
1,00
1,50
2,00
2,50
3,00
3,50
500 600 800 900 1000
War
tość
wsp
ółcz
ynni
ka
Wymiar mnożonych macierzy
schedule(static,10) schedule(static,20) schedule(static,50) schedule(static,100)
- 0,20 0,40 0,60 0,80 1,00 1,20 1,40 1,60 1,80
500 600 800 900 1000
War
tość
wsp
ółcz
ynni
ka
Wymiar mnożonych macierzy
schedlue(static,10) schedule(static,20) schedule(static,50) schedule(static,100)

68 | S t r o n a
rozlokowania wielkości zadnia. Natomiast dla czasów, które odzwierciedlają niekorzystne
warunki otrzymamy przyspieszenie. Wartość tego przyspieszenie nie jest wysoka bo tylko 40%,
ale jednak istnieje one i nie ma wyraźnego trendu malejącego.
11.1.4 Szybkość za Jakość Eksperyment drugi wykonano również dla tego samego programu wraz z
zastosowaniem przy kompilacji przełączników optymalizacyjnych typu –O2 oraz –O3. Wartość
przyspieszenia, jaką udało się uzyskać była rzędu kilkudziesięciu razy. Jednak taka szybkość
została osiągnięta przy zmienionej precyzji obliczeń. Kompilator optymalizował tak agresywnie,
że uzyskane wartości elementów wynikowej macierzy znacząco różniły się od wartości
kontrolnych. Poniżej znajduje się dane pomiarowe wraz z parametrami statystycznymi. Wartość
współczynnika porównania obliczono według wzoru:
����������
������������
gdzie: war_x – oznacza czas wykonywania obliczeń dla wartości sprawdzanej i wartości
kontrolnej.
Równanie 16. Wyznaczenie współczynnika porównania dla typów przełączników podstawowych -O2, -O3.
Liczba powtórzeń testu wyniosła 15 razy. Parametr czas obliczeń, jest wartością średnią
z testu 15 powtórzeń dla wariantów: najlepszego i najgorszego. Wartość współczynnika
porównania jest wartością średnią z liczby powtórzeń testu.
Tabela 3. Charakterystyka błędów dla przełączników –O[x] przy zastosowaniu OpenMP.
Obliczone wartości6
Wymiar
Czas obliczeń [s]
[najlepszy/najgorszy]7
Współczynnik
porównania
∆[%]
Rozrzut
współczynnika
porównania 8[%]
Odchylenie
[s]
Procentowa
zawartość9
dla �̅ ∓ � [%]
Procentowa
zawartość dla
�̅ ∓ 3� Typ –O2 Typ –O3
500
0.00004/
0.01293
0.00001/
0.00927
137,2/81.5 390.5 5.81/6.32 29.0/36.2 83.9/81.5
700
0.00005/
0.01173
0.00003/
0.00763
103.6/120.1 519.7 7.86/5.21 37.9/19.8 89.5/79.3
900
0.00004/
0.01521
0.00004/
0.00918
99.2/171.9 472.8 3.84/7.68 16.0/25.8 91.3/90.6
Analizowanym eksperymentem był eksperyment drugi. Wyniki przedstawione powyżej
mają charakter informacyjny i powinny ukazać, iż optymalizacja kompilatorem przy użyciu
współczynników może i wykazuje polepszenie osiągów czasowych, jednak precyzja
6 Format postaci: [dla –O2\dla –O3], czyli pierwsza liczba oznacza wartość wybranego parametru dla
przełącznika typu –O2, natomiast druga określa wartość wybranego współczynnika dla przełącznika typu
–O3. 7 Test przeprowadzono dla kompilatorów GCC i ICC, wraz z przełącznikami –O2 oraz –O3. Dla wariantu
najgorszego, wybrano wartości maksimum z GCC –O[x] i ICC –O[x], natomiast dla wariantu najlepszego
wybrano wartość minimum z GCC –O[x] i ICC –O[x]. � ∈ �2,3�.
8 Określono w ten sposób długość przedziału [min,max], jako: ��� ���� 9 Określa procentowo, ile danych zawiera się w wybranym przedziale, dla wyznaczonej wartości średniej �̅.
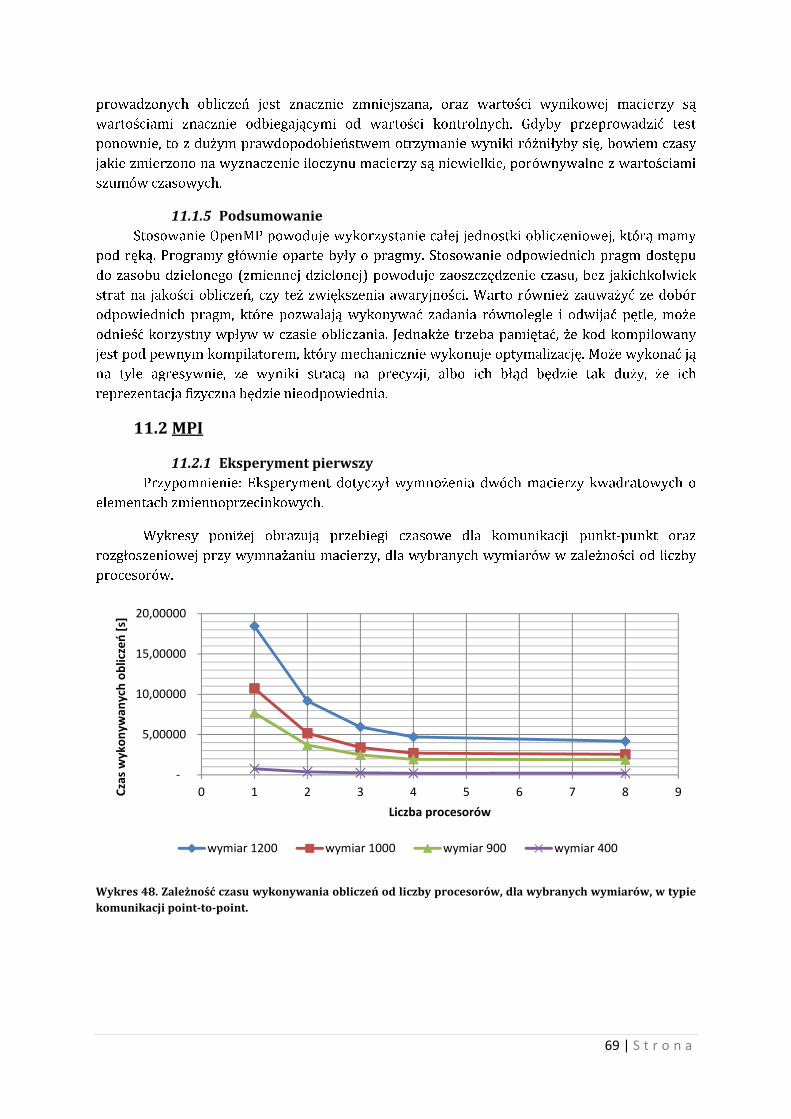
69 | S t r o n a
prowadzonych obliczeń jest znacznie zmniejszana, oraz wartości wynikowej macierzy są
wartościami znacznie odbiegającymi od wartości kontrolnych. Gdyby przeprowadzić test
ponownie, to z dużym prawdopodobieństwem otrzymanie wyniki różniłyby się, bowiem czasy
jakie zmierzono na wyznaczenie iloczynu macierzy są niewielkie, porównywalne z wartościami
szumów czasowych.
11.1.5 Podsumowanie Stosowanie OpenMP powoduje wykorzystanie całej jednostki obliczeniowej, którą mamy
pod ręką. Programy głównie oparte były o pragmy. Stosowanie odpowiednich pragm dostępu
do zasobu dzielonego (zmiennej dzielonej) powoduje zaoszczędzenie czasu, bez jakichkolwiek
strat na jakości obliczeń, czy też zwiększenia awaryjności. Warto również zauważyć ze dobór
odpowiednich pragm, które pozwalają wykonywać zadania równolegle i odwijać pętle, może
odnieść korzystny wpływ w czasie obliczania. Jednakże trzeba pamiętać, że kod kompilowany
jest pod pewnym kompilatorem, który mechanicznie wykonuje optymalizację. Może wykonać ją
na tyle agresywnie, ze wyniki stracą na precyzji, albo ich błąd będzie tak duży, że ich
reprezentacja fizyczna będzie nieodpowiednia.
11.2 MPI
11.2.1 Eksperyment pierwszy Przypomnienie: Eksperyment dotyczył wymnożenia dwóch macierzy kwadratowych o
elementach zmiennoprzecinkowych.
Wykresy poniżej obrazują przebiegi czasowe dla komunikacji punkt-punkt oraz
rozgłoszeniowej przy wymnażaniu macierzy, dla wybranych wymiarów w zależności od liczby
procesorów.
Wykres 48. Zależność czasu wykonywania obliczeń od liczby procesorów, dla wybranych wymiarów, w typie komunikacji point-to-point.
-
5,00000
10,00000
15,00000
20,00000
0 1 2 3 4 5 6 7 8 9Czas
wyk
onyw
anyc
h ob
liczeń
[s]
Liczba procesorów
wymiar 1200 wymiar 1000 wymiar 900 wymiar 400
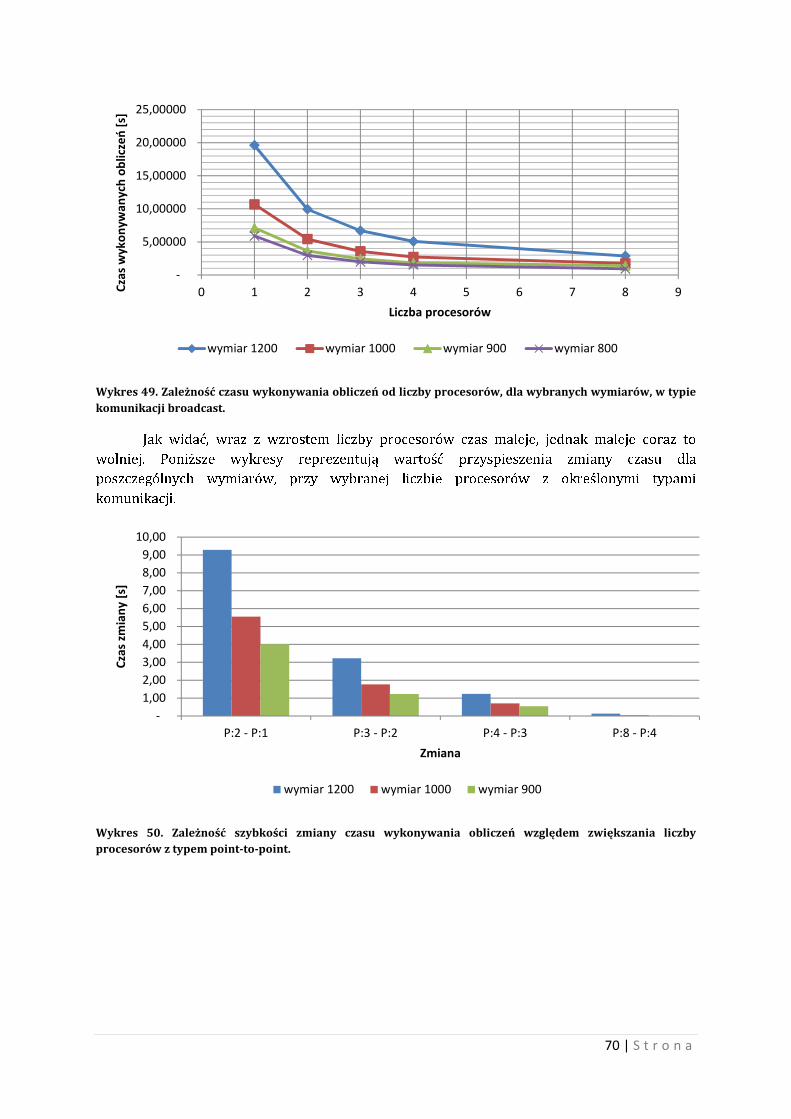
70 | S t r o n a
Wykres 49. Zależność czasu wykonywania obliczeń od liczby procesorów, dla wybranych wymiarów, w typie komunikacji broadcast.
Jak widać, wraz z wzrostem liczby procesorów czas maleje, jednak maleje coraz to
wolniej. Poniższe wykresy reprezentują wartość przyspieszenia zmiany czasu dla
poszczególnych wymiarów, przy wybranej liczbie procesorów z określonymi typami
komunikacji.
Wykres 50. Zależność szybkości zmiany czasu wykonywania obliczeń względem zwiększania liczby procesorów z typem point-to-point.
-
5,00000
10,00000
15,00000
20,00000
25,00000
0 1 2 3 4 5 6 7 8 9Czas
wyk
onyw
anyc
h ob
liczeń
[s]
Liczba procesorów
wymiar 1200 wymiar 1000 wymiar 900 wymiar 800
- 1,00 2,00 3,00 4,00 5,00 6,00 7,00 8,00 9,00
10,00
P:2 - P:1 P:3 - P:2 P:4 - P:3 P:8 - P:4
Czas
zmia
ny [s
]
Zmiana
wymiar 1200 wymiar 1000 wymiar 900
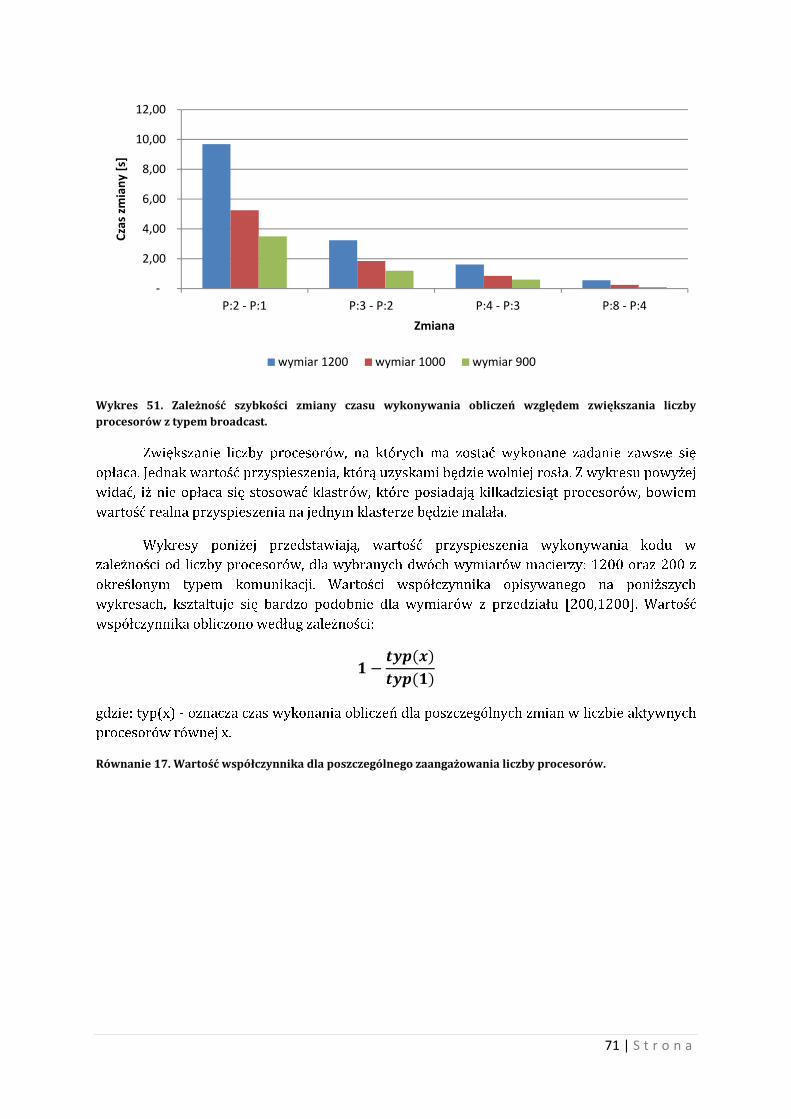
71 | S t r o n a
Wykres 51. Zależność szybkości zmiany czasu wykonywania obliczeń względem zwiększania liczby procesorów z typem broadcast.
Zwiększanie liczby procesorów, na których ma zostać wykonane zadanie zawsze się
opłaca. Jednak wartość przyspieszenia, którą uzyskami będzie wolniej rosła. Z wykresu powyżej
widać, iż nie opłaca się stosować klastrów, które posiadają kilkadziesiąt procesorów, bowiem
wartość realna przyspieszenia na jednym klasterze będzie malała.
Wykresy poniżej przedstawiają, wartość przyspieszenia wykonywania kodu w
zależności od liczby procesorów, dla wybranych dwóch wymiarów macierzy: 1200 oraz 200 z
określonym typem komunikacji. Wartości współczynnika opisywanego na poniższych
wykresach, kształtuje się bardzo podobnie dla wymiarów z przedziału [200,1200]. Wartość
współczynnika obliczono według zależności:
� ������
�����
gdzie: typ(x) - oznacza czas wykonania obliczeń dla poszczególnych zmian w liczbie aktywnych
procesorów równej x.
Równanie 17. Wartość współczynnika dla poszczególnego zaangażowania liczby procesorów.
-
2,00
4,00
6,00
8,00
10,00
12,00
P:2 - P:1 P:3 - P:2 P:4 - P:3 P:8 - P:4
Czas
zmia
ny [s
]
Zmiana
wymiar 1200 wymiar 1000 wymiar 900
72 | S t r o n a
Wykres 52. Zależność wartości współczynnika porównania dla wybranej liczby procesorów aktywnych przy wymiarze 200, z typem point-to-point.
Wykres 53. Zależność wartości współczynnika porównania dla wybranej liczby procesorów aktywnych przy wymiarze 200, z typem broadcast.
0,0%
10,0%
20,0%
30,0%
40,0%
50,0%
60,0%
70,0%
80,0%
2 3 4 8
War
tość
wsp
ółcz
ynni
ka
Liczba procesorów
średnie minimalne maksymalne
0,0%10,0%20,0%30,0%40,0%50,0%60,0%70,0%80,0%90,0%
2 3 4 8
War
tość
wsp
ółcz
ynni
ka
Liczba procesorów
średnie minimalne maksymalne
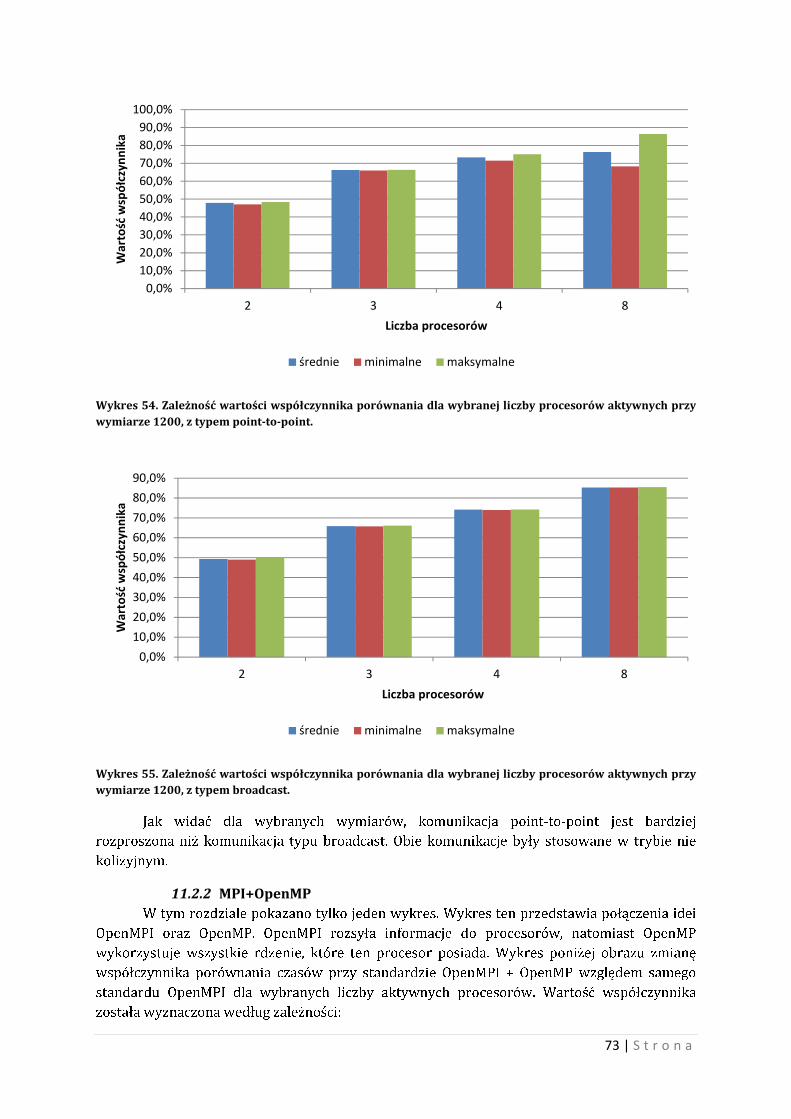
73 | S t r o n a
Wykres 54. Zależność wartości współczynnika porównania dla wybranej liczby procesorów aktywnych przy wymiarze 1200, z typem point-to-point.
Wykres 55. Zależność wartości współczynnika porównania dla wybranej liczby procesorów aktywnych przy wymiarze 1200, z typem broadcast.
Jak widać dla wybranych wymiarów, komunikacja point-to-point jest bardziej
rozproszona niż komunikacja typu broadcast. Obie komunikacje były stosowane w trybie nie
kolizyjnym.
11.2.2 MPI+OpenMP W tym rozdziale pokazano tylko jeden wykres. Wykres ten przedstawia połączenia idei
OpenMPI oraz OpenMP. OpenMPI rozsyła informacje do procesorów, natomiast OpenMP
wykorzystuje wszystkie rdzenie, które ten procesor posiada. Wykres poniżej obrazu zmianę
współczynnika porównania czasów przy standardzie OpenMPI + OpenMP względem samego
standardu OpenMPI dla wybranych liczby aktywnych procesorów. Wartość współczynnika
została wyznaczona według zależności:
0,0%10,0%20,0%30,0%40,0%50,0%60,0%70,0%80,0%90,0%
100,0%
2 3 4 8
War
tość
wsp
ółcz
ynni
ka
Liczba procesorów
średnie minimalne maksymalne
0,0%10,0%20,0%30,0%40,0%50,0%60,0%70,0%80,0%90,0%
2 3 4 8
War
tość
wsp
ółcz
ynni
ka
Liczba procesorów
średnie minimalne maksymalne
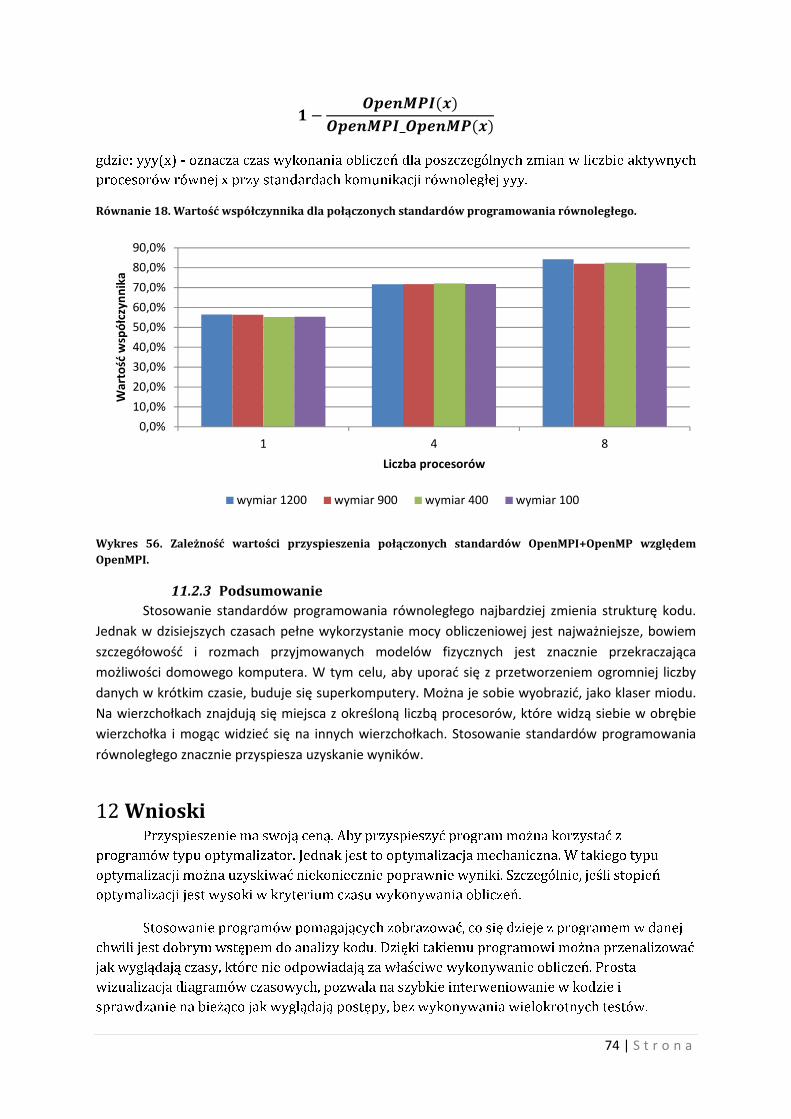
74 | S t r o n a
� ��������
�����_�������
gdzie: yyy(x) - oznacza czas wykonania obliczeń dla poszczególnych zmian w liczbie aktywnych
procesorów równej x przy standardach komunikacji równoległej yyy.
Równanie 18. Wartość współczynnika dla połączonych standardów programowania równoległego.
Wykres 56. Zależność wartości przyspieszenia połączonych standardów OpenMPI+OpenMP względem OpenMPI.
11.2.3 Podsumowanie Stosowanie standardów programowania równoległego najbardziej zmienia strukturę kodu.
Jednak w dzisiejszych czasach pełne wykorzystanie mocy obliczeniowej jest najważniejsze, bowiem szczegółowość i rozmach przyjmowanych modelów fizycznych jest znacznie przekraczająca możliwości domowego komputera. W tym celu, aby uporać się z przetworzeniem ogromniej liczby danych w krótkim czasie, buduje się superkomputery. Można je sobie wyobrazić, jako klaser miodu. Na wierzchołkach znajdują się miejsca z określoną liczbą procesorów, które widzą siebie w obrębie wierzchołka i mogąc widzieć się na innych wierzchołkach. Stosowanie standardów programowania równoległego znacznie przyspiesza uzyskanie wyników.
12 Wnioski Przyspieszenie ma swoją ceną. Aby przyspieszyć program można korzystać z
programów typu optymalizator. Jednak jest to optymalizacja mechaniczna. W takiego typu
optymalizacji można uzyskiwać niekoniecznie poprawnie wyniki. Szczególnie, jeśli stopień
optymalizacji jest wysoki w kryterium czasu wykonywania obliczeń.
Stosowanie programów pomagających zobrazować, co się dzieje z programem w danej
chwili jest dobrym wstępem do analizy kodu. Dzięki takiemu programowi można przenalizować
jak wyglądają czasy, które nie odpowiadają za właściwe wykonywanie obliczeń. Prosta
wizualizacja diagramów czasowych, pozwala na szybkie interweniowanie w kodzie i
sprawdzanie na bieżąco jak wyglądają postępy, bez wykonywania wielokrotnych testów.
0,0%10,0%20,0%30,0%40,0%50,0%60,0%70,0%80,0%90,0%
1 4 8
War
tość
wsp
ółcz
ynni
ka
Liczba procesorów
wymiar 1200 wymiar 900 wymiar 400 wymiar 100

75 | S t r o n a
Stosowanie dobrych praktyk programistycznych również pomaga na optymalizację
kodu. Warto sobie uświadomić, że pierwsza optymalizacja zaczyna się od weryfikacji
programisty i jego umiejętności. Bowiem stosowanie narzędzi optymalizacyjnych, które
wykonują optymalizację może przynieść nieporządne skutki w działaniu programu.
Stosowanie przełączników oraz wielowątkowości to najprostszy sposób pozwalający na
uzyskanie wymiernego przyspieszenia. Jednak te sposoby nie wykorzystują całkowicie
dostępnej mocy obliczeniowej.
Gdy napotkany problem jest skali makro, wtedy powyższe techniki i narzędzia są
uzupełnieniem optymalizacji kodu. Podstawowymi standardami to programowanie
rozproszone i równoległe. Pozwala to na łączenie komputerów w jeden superkomputer, którego
moc nie jest do kopienia na jeden rzut dla komputera klasy PC.
13 Spis
Bibliografia Dokumentacja kompilatora GCC
Dokumentacja kompilatora ICC
Dokumentacja standardu OpenMP
Dokumentacja standardu OpenMPI
Dokumentacja programu Vampir
Dokumentacja biblioteki VampirTracer
www.vampir.eu
www.nas.nasa.gov
www.icm.edu.pl
www.tu-dresden.de/zih/otf
Open Trace Format (OTF) Tutorial by Wolfgang E. Nagel, Holger Brunst, T.U. Dresden, Germany Sameer Shende, Allen D. Malony, ParaTools, Inc.
NAS Parallel Benchmarks by NASA Advanced Supercomputing (NAS) Division http://tu-dresden.de/
Rysunków Rysunek 1. Idea działania programu ze standardem OpenMP. _____________________________________ 18
Równań Równanie 1. Wartość współczynnika procentowego dla poszczególnego kompilatora przy typie przełącznika -O[x]. ____________________________________________________________________________________ 34 Równanie 2. Wartość współczynnika dla poszczególnych przełączników podstawowych -O[typ]. _________ 36 Równanie 3. Wartość współczynnika procentowego dla poszczególnego kompilatora przy typie przełącznika -O[x]. ____________________________________________________________________________________ 38 Równanie 4. Wartość współczynnika dla poszczególnych przełączników podstawowych -O[typ]. _________ 39 Równanie 5. Wartość współczynnika procentowego dla poszczególnego kompilatora przy włączonych flagach optymalizacyjnych. __________________________________________________________________ 41 Równanie 6. Wartość współczynnika procentowego dla poszczególnego kompilatora przy włączonych flagach optymalizacyjnych. __________________________________________________________________ 41

76 | S t r o n a
Równanie 7. Wartość współczynnika procentowego dla wariantów: najlepszego i najgorszego. __________ 47 Równanie 8. Wartość współczynnika procentowego dla wariantów: najlepszego i najgorszego. __________ 48 Równanie 9. Wartość współczynnika procentowego porównującego warianty optymalnego zarządzania wątkami względem nieoptymalnego zarządzania wątkami. _______________________________________ 49 Równanie 10. Wartość współczynnika procentowego porównującego program wielowątkowy z programem sekwencyjnym _____________________________________________________________________________ 49 Równanie 11. Wartość współczynnika procentowego dla poszczególnego kompilatora przy typie przełącznika -O[x]. _________________________________________________________________________ 52 Równanie 12. Wartość współczynnika dla poszczególnych przełączników podstawowych -O[typ]. ________ 53 Równanie 13. Wartość współczynnika dla poszczególnych przełączników podstawowych -O[typ] w poszczególnych eksperymentach. _____________________________________________________________ 54 Równanie 14. Wartość współczynnika dla poszczególnego rozmieszczenia pragm. ____________________ 57 Równanie 15. Zależność porównująca klauzule schedule(static,rozmiar) z klauzulą sedule(dynamic). ____ 67 Równanie 16. Wyznaczenie współczynnika porównania dla typów przełączników podstawowych -O2, -O3. 68 Równanie 17. Wartość współczynnika dla poszczególnego zaangażowania liczby procesorów. __________ 71 Równanie 18. Wartość współczynnika dla połączonych standardów programowania równoległego. ______ 74
Spis Tabel Tabela 1. Charakterystyka błędów obliczeniowych. Kompilator GCC ________________________________ 42 Tabela 2. Charakterystyka błędów obliczeniowych. Kompilator ICC _________________________________ 43 Tabela 3. Charakterystyka błędów dla przełączników –O[x] przy zastosowaniu OpenMP. _______________ 68
Wykresów Wykres 1. Kompilator GCC. Pomiar czasu wymnażania macierzy kwadratowych dla wybranych wymiarów przy wybranych przełącznikach podstawowych kompilatora. ______________________________________ 33 Wykres 2. Kompilator ICC. Pomiar czasu wymnażania macierzy kwadratowych dla wybranych wymiarów przy wybranych przełącznikach podstawowych kompilatora. ______________________________________ 34 Wykres 3. Kompilator GCC. Zmiana procentowa przyspieszenia dla poszczególnych przełączników kompilatora. ______________________________________________________________________________ 35 Wykres 4. Kompilator ICC. Zmiana procentowa przyspieszenia dla poszczególnych przełączników kompilatora. ______________________________________________________________________________ 35 Wykres 5. Porównanie czasu wykonywania obliczeń dla kompilatorów GCC i ICC, przy wybranych przełącznikach podstawowych. _______________________________________________________________ 36 Wykres 6. Kompilator GCC. Pomiar czasu wymnażania macierzy kwadratowych dla wybranych wymiarów przy wybranych przełącznikach podstawowych kompilatora. ______________________________________ 37 Wykres 7. Kompilator ICC. Pomiar czasu wymnażania macierzy kwadratowych dla wybranych wymiarów przy wybranych przełącznikach podstawowych kompilatora. ______________________________________ 37 Wykres 8. Kompilator GCC. Zmiana procentowa przyspieszenia dla poszczególnych przełączników kompilatora. ______________________________________________________________________________ 38 Wykres 9. Kompilator ICC. Zmiana procentowa przyspieszenia dla poszczególnych przełączników kompilatora. ______________________________________________________________________________ 38 Wykres 10. Porównanie czasu wykonywania obliczeń dla kompilatorów GCC i ICC, przy wybranych przełącznikach. ____________________________________________________________________________ 39 Wykres 11. Kompilator GCC. Pomiar czasowy wykonywania obliczeń z użytymi flagami oraz bez optymalizacji. _____________________________________________________________________________ 40 Wykres 12. Kompilator ICC. Pomiar czasowy wykonywania obliczeń z użytymi flagami oraz bez optymalizacji. _____________________________________________________________________________ 40

77 | S t r o n a
Wykres 13. Zależność wartości przyspieszenia przy włączonych flagach względem nieoptymalizowanego kodu dla poszczególnych kompilatorów. _______________________________________________________ 41 Wykres 14. Zależność przyspieszenia wykonywania kompilatu przy włączonych flagach względem popularnego przełącznika optymalizującego, dla poszczególnych kompilatorów. _____________________ 42 Wykres 15. Czas wykonywania obliczeń w zależności od liczby wątków, dla wybranych wymiarów macierzy. Wariant najgorszy. _________________________________________________________________________ 46 Wykres 16. Czas wykonywania obliczeń w zależności od liczby wątków, dla wybranych wymiarów macierzy. Wariant najkorzystniejszy. __________________________________________________________________ 47 Wykres 17. Wartość współczynnika straty szybkości działania programu wynikająca ze złego dopasowania liczby wątków. ____________________________________________________________________________ 48 Wykres 18. Zależność pomiędzy optymalnym zarządzaniem wątkami. Współczynnik porównania dla czasów wykonywania obliczeń dla nieoptymalnego i optymalnego zarządzania wątkami. _____________________ 49 Wykres 19. Kompilator GCC. Wartość przyspieszenia programu wielowątkowego względem programu bez wątkowego dla określonych typów przełączników. _______________________________________________ 50 Wykres 20. Kompilator ICC. Wartość przyspieszenia programu wielowątkowego względem programu bez wątkowego dla określonych typów przełączników. _______________________________________________ 50 Wykres 21. Kompilator GCC. Pomiar czasu wymnażania macierzy kwadratowych dla wybranych wymiarów, oraz wybranych przełączników podstawowych. _________________________________________________ 51 Wykres 22. Kompilator ICC. Pomiar czasu wymnażania macierzy kwadratowych dla wybranych wymiarów, oraz wybranych przełączników podstawowych. _________________________________________________ 51 Wykres 23. Kompilator GCC. Wartość przyspieszenia programu wielowątkowego względem programu bez wątkowego dla określonych typów przełączników. _______________________________________________ 52 Wykres 24. Kompilator ICC. Wartość przyspieszenia programu wielowątkowego względem programu bez wątkowego dla określonych typów przełączników. _______________________________________________ 52 Wykres 25. Porównanie czasu wykonywania obliczeń dla kompilatorów GCC i ICC, przy wybranych przełącznikach. ____________________________________________________________________________ 53 Wykres 26. Kompilator GCC. Współczynnik przyspieszenia uzyskany w pierwszym eksperymencie w odniesieniu do eksperymentu drugiego dla wybranych przełączników. ______________________________ 54 Wykres 27. Kompilator ICC. Współczynnik przyspieszenia uzyskany w pierwszym eksperymencie w odniesieniu do eksperymentu drugiego dla wybranych przełączników. ______________________________ 54 Wykres 28. Współczynnik przyspieszenia wynikający z zastosowania różnej ilość pragm dla poszczególnych kompilatorów. _____________________________________________________________________________ 57 Wykres 29. Zależność między wymiarem macierzy a czasem wykonania obliczeń dla klauzul atomic i critical. _________________________________________________________________________________________ 58 Wykres 30. Kompilator GCC. Typ -O0. Zależność czasu wykonywania obliczeń od liczby wątków. _________ 59 Wykres 31. Kompilator GCC. Typ -O1. Zależność czasu wykonywania obliczeń od liczby wątków. _________ 59 Wykres 32. Kompilator ICC. Typ -O0. Zależność czasu wykonywania obliczeń od liczby wątków. _________ 60 Wykres 33. Kompilator ICC. Typ -O1. Zależność czasu wykonywania obliczeń od liczby wątków. _________ 60 Wykres 34. Kompilator GCC. Przełącznik typ: -O0. Czas wykonania obliczeń w zależności od liczby wątków dla wybranych wymiarów macierzy. __________________________________________________________ 61 Wykres 35. Kompilator GCC. Przełącznik typ: -O1. Czas wykonania obliczeń w zależności od liczby wątków dla wybranych wymiarów macierzy. __________________________________________________________ 61 Wykres 36. Kompilator ICC. Przełącznik typ: -O0. Czas wykonania obliczeń w zależności od liczby wątków dla wybranych wymiarów macierzy. __________________________________________________________ 62 Wykres 37. Kompilator ICC. Przełącznik typ: -O1. Czas wykonania obliczeń w zależności od liczby wątków dla wybranych wymiarów macierzy. __________________________________________________________ 62 Wykres 38. Kompilator GCC, Tryb -O0, przypadek korzystny. Zależność czasu wykonania obliczeń od wymiaru macierzy dla poszczególnych rozmiarów danych wątków. ________________________________ 63 Wykres 39. Kompilator GCC, Tryb -O1, przypadek korzystny. Zależność czasu wykonania obliczeń od wymiaru macierzy dla poszczególnych rozmiarów danych wątków. ________________________________ 63

78 | S t r o n a
Wykres 40. Kompilator ICC, Tryb -O0, przypadek korzystny. Zależność czasu wykonania obliczeń od wymiaru macierzy dla poszczególnych rozmiarów danych wątków._________________________________________ 64 Wykres 41. Kompilator ICC, Tryb -O1, przypadek korzystny. Zależność czasu wykonania obliczeń od wymiaru macierzy dla poszczególnych rozmiarów danych wątków._________________________________________ 64 Wykres 42. Kompilator GCC, Tryb -O0, przypadek niekorzystny. Zależność czasu wykonania obliczeń od wymiaru macierzy dla poszczególnych rozmiarów danych wątków. ________________________________ 65 Wykres 43. Kompilator GCC, Tryb -O1, przypadek niekorzystny. Zależność czasu wykonania obliczeń od wymiaru macierzy dla poszczególnych rozmiarów danych wątków. ________________________________ 65 Wykres 44. Kompilator ICC, Tryb -O0, przypadek niekorzystny. Zależność czasu wykonania obliczeń od wymiaru macierzy dla poszczególnych rozmiarów danych wątków. ________________________________ 66 Wykres 45. Kompilator ICC, Tryb -O1, przypadek niekorzystny. Zależność czasu wykonania obliczeń od wymiaru macierzy dla poszczególnych rozmiarów danych wątków. ________________________________ 66 Wykres 46. Przypadek korzystny. Zależność współczynnika porównania dla wybranych rozmiarów danych dla wątków. _______________________________________________________________________________ 67 Wykres 47. Przypadek niekorzystny. Zależność współczynnika porównania dla wybranych rozmiarów danych dla wątków. ________________________________________________________________________ 67 Wykres 48. Zależność czasu wykonywania obliczeń od liczby procesorów, dla wybranych wymiarów, w typie komunikacji point-to-point. __________________________________________________________________ 69 Wykres 49. Zależność czasu wykonywania obliczeń od liczby procesorów, dla wybranych wymiarów, w typie komunikacji broadcast. _____________________________________________________________________ 70 Wykres 50. Zależność szybkości zmiany czasu wykonywania obliczeń względem zwiększania liczby procesorów z typem point-to-point. ___________________________________________________________ 70 Wykres 51. Zależność szybkości zmiany czasu wykonywania obliczeń względem zwiększania liczby procesorów z typem broadcast. _______________________________________________________________ 71 Wykres 52. Zależność wartości współczynnika porównania dla wybranej liczby procesorów aktywnych przy wymiarze 200, z typem point-to-point. _________________________________________________________ 72 Wykres 53. Zależność wartości współczynnika porównania dla wybranej liczby procesorów aktywnych przy wymiarze 200, z typem broadcast. ____________________________________________________________ 72 Wykres 54. Zależność wartości współczynnika porównania dla wybranej liczby procesorów aktywnych przy wymiarze 1200, z typem point-to-point. ________________________________________________________ 73 Wykres 55. Zależność wartości współczynnika porównania dla wybranej liczby procesorów aktywnych przy wymiarze 1200, z typem broadcast. ___________________________________________________________ 73 Wykres 56. Zależność wartości przyspieszenia połączonych standardów OpenMPI+OpenMP względem OpenMPI. _________________________________________________________________________________ 74
Figure Figure 1. Przebieg czasowy dla poszczególnych procesów w fazie przygotowawczej. ___________________ 25 Figure 2. Sumaryczny czas przeznaczony na wskazanie działanie dla całej ilości procesów w fazie przygotowawczej. __________________________________________________________________________ 26 Figure 3. Wartości współczynnika udziału w fragmencie przebiegu wstępnego dla określonych typów działania. _________________________________________________________________________________ 26 Figure 4. Przebieg czasowy dla poszczególnych procesów dla fazy właściwej wykonywania programu. ___ 27 Figure 5. Sumaryczny czas przeznaczony na wskazanie działanie dla całej ilości procesów w fazie właściwej. _________________________________________________________________________________________ 27 Figure 6. Fragment wykonywania obliczeń i komunikacji między procesami. _________________________ 28 Figure 7. Przebieg czasowy dla poszczególnych procesów w fazie zakończeniowej. ____________________ 28 Figure 8. Fragment zapisu danych synchronizacji procesów oraz zakończenia działania programu. ______ 29 Figure 9. Częstość występowania komunikatów w zależności od wielkości komunikatu. ________________ 29 Figure 10. Częstość komunikatów przypadająca na poszczególne procesy. ___________________________ 30

79 | S t r o n a
Figure 11. Liczba komunikatów wymienianych przez poszczególne procesy. __________________________ 30