microcomputer systems 1 implementation considerations
TRANSCRIPT

Microcomputer Systems 1
Implementation Considerations

Data Representations & Arithmetic
Fixed-Point Numbers and Arithmetic

April 18, 2023 Veton Këpuska 3
Fixed-Point
There are several different binary number systems. Most notable:
1. Sign Magnitude2. One’s Complement3. Two’s Complement
Example of 4-bit signed numbers in three different formats
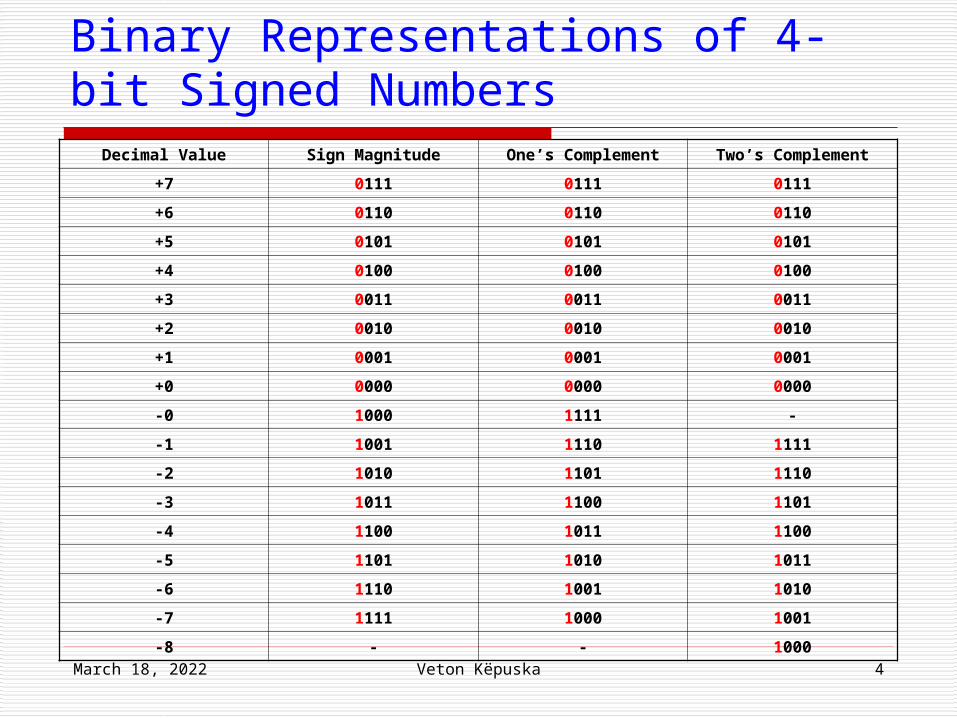
April 18, 2023 Veton Këpuska 4
Binary Representations of 4-bit Signed Numbers
Decimal Value Sign Magnitude One’s Complement Two’s Complement
+7 0111 0111 0111
+6 0110 0110 0110
+5 0101 0101 0101
+4 0100 0100 0100
+3 0011 0011 0011
+2 0010 0010 0010
+1 0001 0001 0001
+0 0000 0000 0000
-0 1000 1111 -
-1 1001 1110 1111
-2 1010 1101 1110
-3 1011 1100 1101
-4 1100 1011 1100
-5 1101 1010 1011
-6 1110 1001 1010
-7 1111 1000 1001
-8 - - 1000

April 18, 2023 Veton Këpuska 5
Fixed-Point Representations
Integers vs. Fractional Numbers Representations Notation: Qm.n Format:
m – Number of bits to the left of the radix point
n – number of bits to the right of the radix point
Let N – total number of bits N=m+n+1 Signed, and
N-bit signed number in Qm.n format with MSB as sign bit (bN-1)
N=m+n Unsigned

April 18, 2023 Veton Këpuska 6
Examples Q16.0 Format is Full unsigned integer number representation Q15.0 Format is Full signed integer number representation
Q15.1 Format represents unsigned 16 bit integer value Q14.1 Format represents signed 15 bit integer value
Q0.16 (or Q.16 or simply Q16) is a 16 bit format that for unsigned number that uses 16 bits for the fractional value.
Q0.15(or Q.15 or simply Q15) is a 15 bit format that for signed number that uses 16 bits for the fractional value.
Fractional Representations (e.g., Q1.15) have the advantage over the Full format representations that results of the multiplication are always smaller than either of the numbers
QX.0 or QY.1 Formats must check for overflow and handle it Q0.X or Q1.Y Formats may lead to underflow but no special handling is
required.

April 18, 2023 Veton Këpuska 7
Fixed-Point Representations Integers vs. Fractional Numbers Representations
Numbers represented as 16/32 bits: 216=65,536 or 232=4,294,967,296 bit patterns.
1. Unsigned Integer Format Stored Value:
16-bit: 0..65,536 or 32-bit: 0..4,294,967,296
2. Signed Integer Format Stored Value:
16-bit: -32,768..32,767 or32-bit: -2,147,483,648..2,147,483647
3. Unsigned Fractional Format Stored Value:
16-bit: 0..1 (65,536 levels) or 32-bit: 0..1 (4,294,967,296 levels)
4. Signed Fractional Format Stored Value:
16-bit: -1..1 (65,536 levels) or 32-bit: -1..1 (4,294,967,296 levels)
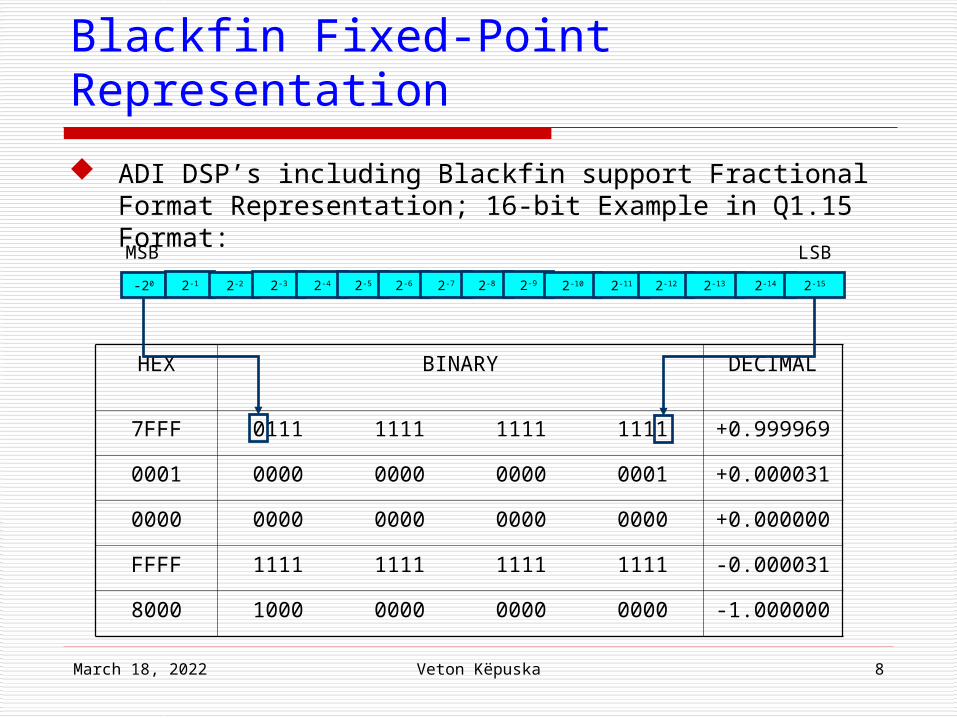
April 18, 2023 Veton Këpuska 8
Blackfin Fixed-Point Representation
ADI DSP’s including Blackfin support Fractional Format Representation; 16-bit Example in Q1.15 Format:
-20 2-1 2-2 2-3 2-4 2-5 2-6 2-7 2-8 2-9 2-10 2-11 2-12 2-13 2-14 2-15
MSB LSB
HEX BINARY DECIMAL
7FFF 0111 1111 1111 1111 +0.999969
0001 0000 0000 0000 0001 +0.000031
0000 0000 0000 0000 0000 +0.000000
FFFF 1111 1111 1111 1111 -0.000031
8000 1000 0000 0000 0000 -1.000000

April 18, 2023 Veton Këpuska 9
-21 20
General Qm.n Representation
2
01
03
32
21
1
22
2222N
k
nkk
mN
nNN
NN
NN
bb
bbbbx
bN-1bN-1 bN-2
bN-2 bN-3bN-3 b0
b0
-20 2-1 2-2 2-15
Q0.15
bN-1bN-1 bN-2
bN-2 bN-3bN-3 b0
b0
2-1 2-14
Q1.14
-215 214
bN-1bN-1 bN-2
bN-2 bN-3bN-3 b0
b0
213 20
Q15.0
Sign BitSign Bit
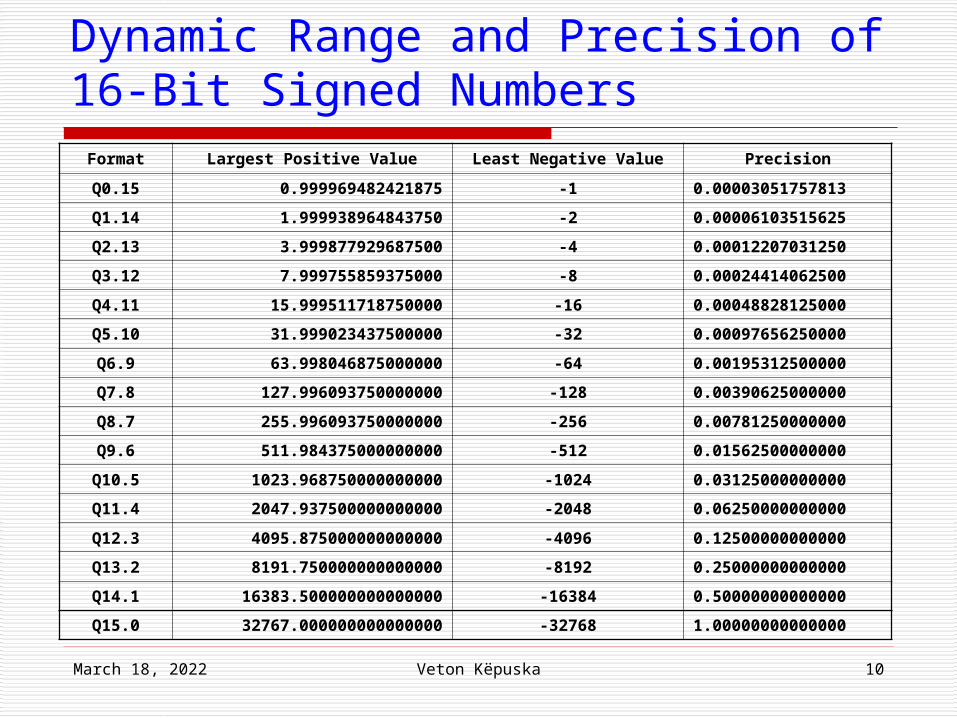
April 18, 2023 Veton Këpuska 10
Dynamic Range and Precision of 16-Bit Signed Numbers
Format Largest Positive Value Least Negative Value Precision
Q0.15 0.999969482421875 -1 0.00003051757813
Q1.14 1.999938964843750 -2 0.00006103515625
Q2.13 3.999877929687500 -4 0.00012207031250
Q3.12 7.999755859375000 -8 0.00024414062500
Q4.11 15.999511718750000 -16 0.00048828125000
Q5.10 31.999023437500000 -32 0.00097656250000
Q6.9 63.998046875000000 -64 0.00195312500000
Q7.8 127.996093750000000 -128 0.00390625000000
Q8.7 255.996093750000000 -256 0.00781250000000
Q9.6 511.984375000000000 -512 0.01562500000000
Q10.5 1023.968750000000000 -1024 0.03125000000000
Q11.4 2047.937500000000000 -2048 0.06250000000000
Q12.3 4095.875000000000000 -4096 0.12500000000000
Q13.2 8191.750000000000000 -8192 0.25000000000000
Q14.1 16383.500000000000000 -16384 0.50000000000000
Q15.0 32767.000000000000000 -32768 1.00000000000000

April 18, 2023 Veton Këpuska 11
Addition of Fractional Numbers Assuming numbers are represented using two’s
complement format. Example:1. Integer Representation Q3.0 of 4 bit numbers:
1. 0100 (4) + 0011 (3) = 0111 (7), no overflow2. 0101 (5) + 0011 (3) = 1000 (-8), overflow3. 1100 (-4) + 0111 (7) = 0011 (3), no overflow4. 1100 (-4) + 1011 (-5) = 0111 (7), overflow
Fractional Representation Q0.3 of 4 bit numbers: 0.100 (0.5) + 0.011 (0.375) = 0.111 (0.875), no overflow 0.101 (0.625) + 0.011 (0.375) = 1.000 (-1), overflow 1.100 (-0.5) + 0.111 (0.875) = 0.011 (0.375), no overflow 1.100 (-0.5) + 1.011 (-0.625) = 0.111 (0.875), overflow

April 18, 2023 Veton Këpuska 12
Multiplication of Fractional Numbers
Example:1. Integer multiplication Q3.0 format of 4 bit numbers:
0111(7) X 0110(6) = 00101010 (42) Note: When storing only the most significant 4-bit number
of the result, e.g., 0010 (2) the error of such representation is 42 - 2 = 40. Therefore, it becomes necessary to store the full 8-bit number to obtain accurate answer. The alternate approach is to scale the resulting numbers loosing at the expense of the precision.
2. Fractional multiplication Q0.3 format of 4 bit numbers: 0.111(0.8775) X 0.110(0.75) = 0.101010 (0.65625)
Note: When storing only the most significant 4-bit number of the result, e.g., 0101 (0.625) the error of such representation is 0.65625 - 0.625 = 0.03125. Thus additional scaling is not required.
BF533 Data Types

April 18, 2023 Veton Këpuska 14
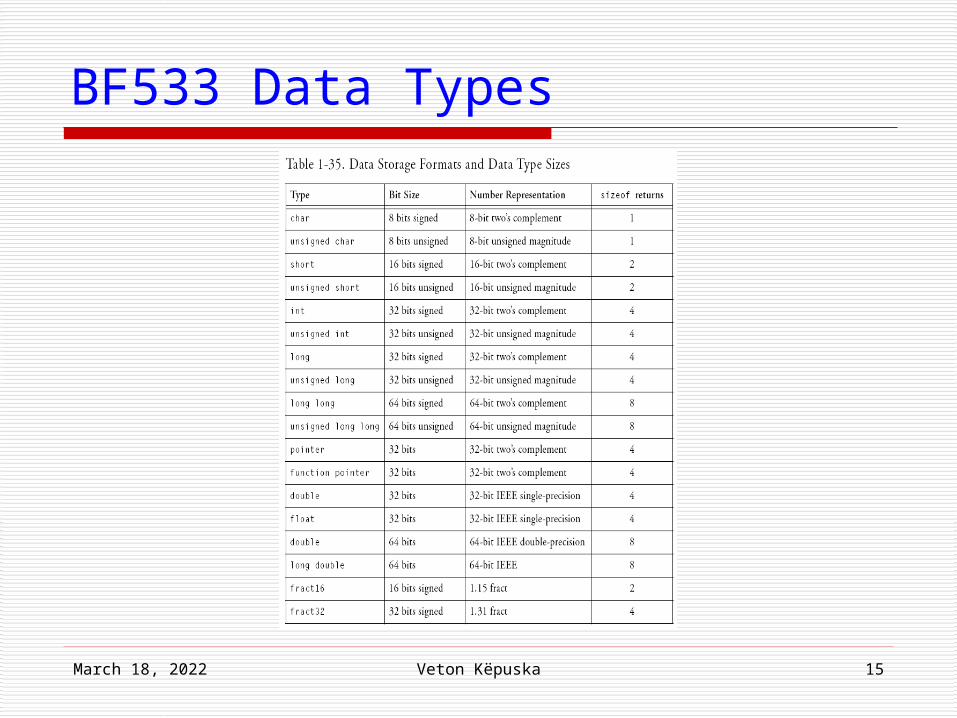
BF533 Data Types The C/C++ run-time environment uses the intrinsic C/C++
data types and data formats that appear in Table 1-35 (next slide).
Important Note: The floating-point and 64-bit data types are implemented using
software emulation, so must be expected to run more slowly than hardware-supported native data types. The emulated data types are float, double, long double, long long and unsigned long long.
The fract16 and fract32 are not actually intrinsic data types— they are typedefs to short and long, respectively. In C, you need to use built-in functions to do basic arithmetic.
(See “Fractional Value Built-In Functions in C++” on page 1-149). You cannot do fract16*fract16 and get the right result.
In C++, for fract data, the classes “fract” and “shortfract” define the basic arithmetic operators.
April 18, 2023 Veton Këpuska 15
BF533 Data Types

April 18, 2023 Veton Këpuska 16
Fractional Arithmetic Support Because fractional arithmetic uses slightly different
instructions for normal arithmetic, you cannot normally use the standard C operators on fract data types and get the right result. Note: Must use the built-in functions described here to work
with fractional data.
The fract.h header file provides access to the definitions for each of the built-in functions that support fractional values. These functions have names with suffixes _fr1x16 for single fract16, _fr2x16 for dual fract16, and _fr1x32 for single fract32.
All the functions in fract.h are marked as inline, so when compiling with the compiler optimizer, the built-in functions are inlined.

April 18, 2023 Veton Këpuska 17
Fractional Arithmetic Support Important Note:
All the 16-bit fractional shift built-in functions without “_clip” in the name ignore all but the least significant five bits of the shift magnitude.
All the 32-bit fractional shift built-in functions without “_clip” in the name ignore all but the least significant 6 bits of the shift magnitude.
The _clip variants of these built-in functions automatically clip the shift magnitude to within a 5- or 6-bit range.
For example, where a 5-bit (-16..+15) range is required, the “_clip” variants would clip the value +63 to be +15, while the non-“_clip” variant would discard the upper bits and interpret bit 5 as the sign bit, giving a value of -1.
To avoid unexpected results, use the “_clip” variants of the functions unless the shift magnitude is known to be within the 5- or 6- bit range.

April 18, 2023 Veton Këpuska 18
fract16 Built-in Functions fract16 add_fr1x16(fract16 f1,fract16 f2)
Performs 16-bit addition of the two input parameters (f1+f2)
fract16 sub_fr1x16(fract16 f1,fract16 f2) Performs 16-bit subtraction of the two input parameters (f1-f2)
fract16 mult_fr1x16(fract16 f1,fract16 f2) Performs 16-bit multiplication of the input parameters (f1*f2).
The result is truncated to 16 bits.
fract16 multr_fr1x16(fract16 f1,fract16 f2) Performs a 16-bit fractional multiplication (f1*f2) of the two
input parameters. The result is rounded to 16 bits. Whether the rounding is biased or unbiased depends on what the RND_MOD bit in the ASTAT register is set to.
April 18, 2023 Veton Këpuska 19
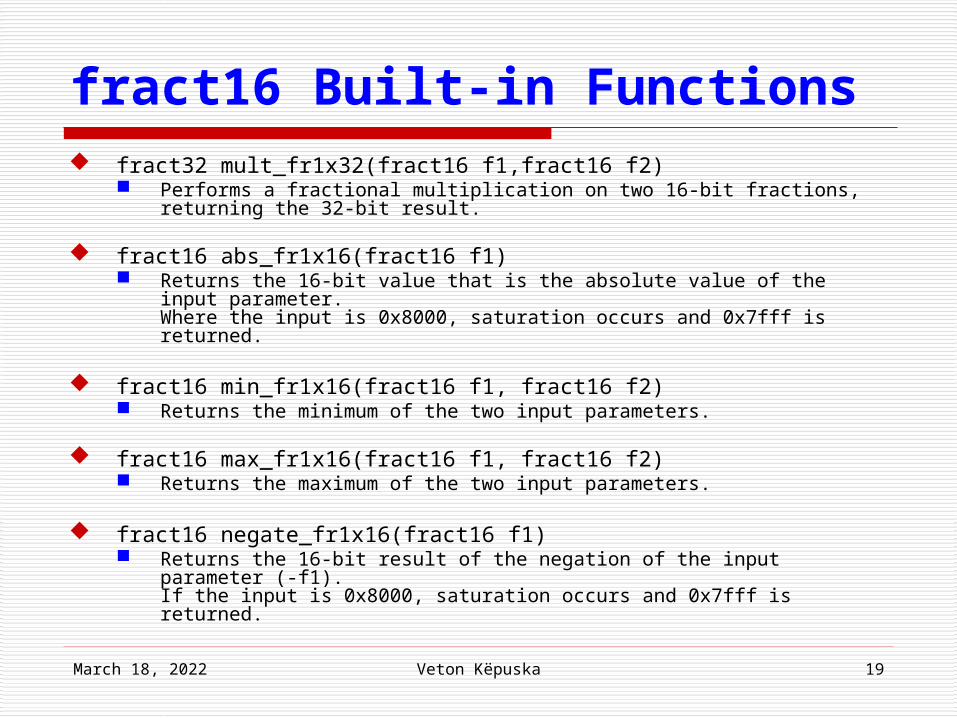
fract16 Built-in Functions fract32 mult_fr1x32(fract16 f1,fract16 f2)
Performs a fractional multiplication on two 16-bit fractions, returning the 32-bit result.
fract16 abs_fr1x16(fract16 f1) Returns the 16-bit value that is the absolute value of the input
parameter.Where the input is 0x8000, saturation occurs and 0x7fff is returned.
fract16 min_fr1x16(fract16 f1, fract16 f2) Returns the minimum of the two input parameters.
fract16 max_fr1x16(fract16 f1, fract16 f2) Returns the maximum of the two input parameters.
fract16 negate_fr1x16(fract16 f1) Returns the 16-bit result of the negation of the input parameter (-f1).
If the input is 0x8000, saturation occurs and 0x7fff is returned.

April 18, 2023 Veton Këpuska 20
fract16 Built-in Functions fract16 shl_fr1x16(fract16 src, short shft)
Arithmetically shifts the src variable left by shft places. The empty bits are zero-filled. If shft is negative, the shift is to the right by abs(shft) places with sign extension.
fract16 shl_fr1x16_clip(fract16 src, short shft) Arithmetically shifts the src variable left by shft (clipped to 5 bits)
places.The empty bits are zero filled. If shft is negative, the shift is to the right by abs(shft) places with sign extension.
fract16 shr_fr1x16(fract16 src, short shft) Arithmetically shifts the src variable right by shft places with sign
extension. If shft is negative, the shift is to the left by abs(shft) places, and the empty bits are zero-filled.
fract16 shr_fr1x16_clip(fract16 src, short shft) Arithmetically shifts the src variable right by shft (clipped to 5 bits)
places with sign extension. If shft is negative, the shift is to the left by abs(shft) places, and the empty bits are zero-filled.
April 18, 2023 Veton Këpuska 21
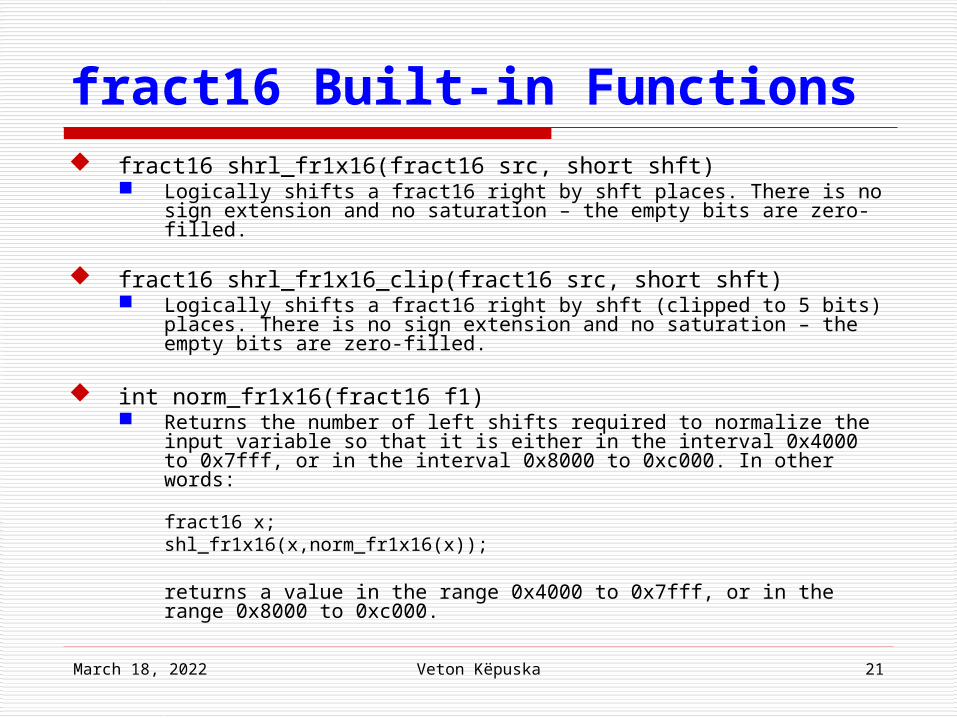
fract16 Built-in Functions fract16 shrl_fr1x16(fract16 src, short shft)
Logically shifts a fract16 right by shft places. There is no sign extension and no saturation – the empty bits are zero-filled.
fract16 shrl_fr1x16_clip(fract16 src, short shft) Logically shifts a fract16 right by shft (clipped to 5 bits) places. There is
no sign extension and no saturation – the empty bits are zero-filled.
int norm_fr1x16(fract16 f1) Returns the number of left shifts required to normalize the input
variable so that it is either in the interval 0x4000 to 0x7fff, or in the interval 0x8000 to 0xc000. In other words:
fract16 x;shl_fr1x16(x,norm_fr1x16(x));
returns a value in the range 0x4000 to 0x7fff, or in the range 0x8000 to 0xc000.

April 18, 2023 Veton Këpuska 22
fract32 Built-in Functions fract32 add_fr1x32(fract32 f1,fract32 f2)
Performs 32-bit addition of the two input parameters (f1+f2).
fract32 sub_fr1x32(fract32 f1,fract32 f2) Performs 32-bit subtraction of the two input
parameters (f1-f2).
fract32 mult_fr1x32x32(fract32 f1,fract32 f2) Performs 32-bit multiplication of the input parameters
(f1*f2). The result (which is calculated internally with an accuracy of 40 bits) is rounded (biased rounding) to 32 bits.

April 18, 2023 Veton Këpuska 23
fract32 Built-in Functions fract32 mult_fr1x32x32NS(fract32 f1, fract32 f2)
Performs 32-bit non-saturating multiplication of the input parameters (f1*f2). This is somewhat faster than mult_fr1x32x32. The result (which is calculated internally with an accuracy of 40 bits) is rounded (biased rounding) to 32 bits.
fract32 abs_fr1x32(fract32 f1) Returns the 32-bit value that is the absolute value of the input
parameter. Where the input is 0x80000000, saturation occurs and 0x7fffffff is returned.
fract32 min_fr1x32(fract32 f1, fract32 f2) Returns the minimum of the two input parameters
fract32 max_fr1x32(fract32 f1, fract32 f2) Returns the maximum of the two input parameters
April 18, 2023 Veton Këpuska 24
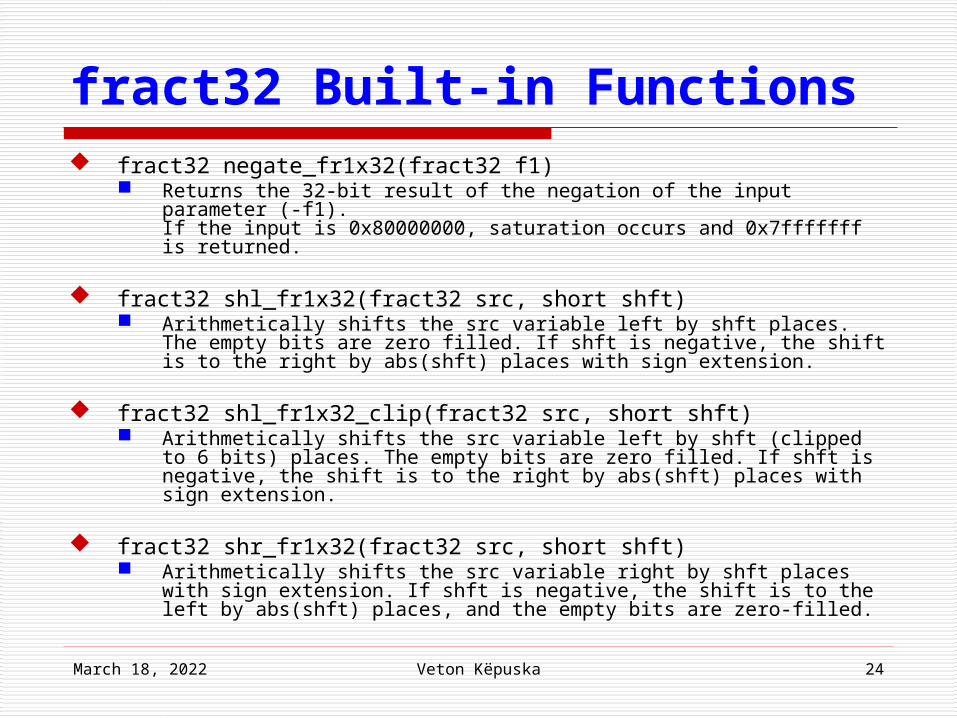
fract32 Built-in Functions fract32 negate_fr1x32(fract32 f1)
Returns the 32-bit result of the negation of the input parameter (-f1).If the input is 0x80000000, saturation occurs and 0x7fffffff is returned.
fract32 shl_fr1x32(fract32 src, short shft) Arithmetically shifts the src variable left by shft places. The empty bits
are zero filled. If shft is negative, the shift is to the right by abs(shft) places with sign extension.
fract32 shl_fr1x32_clip(fract32 src, short shft) Arithmetically shifts the src variable left by shft (clipped to 6 bits)
places. The empty bits are zero filled. If shft is negative, the shift is to the right by abs(shft) places with sign extension.
fract32 shr_fr1x32(fract32 src, short shft) Arithmetically shifts the src variable right by shft places with sign
extension. If shft is negative, the shift is to the left by abs(shft) places, and the empty bits are zero-filled.

April 18, 2023 Veton Këpuska 25
fract32 Built-in Functions fract32 shr_fr1x32_clip(fract32 src, short shft)
Arithmetically shifts the src variable right by shft (clipped to 6 bits) places with sign extension. If shft is negative, the shift is to the left by abs(shft) places, and the empty bits are zero-filled.
fract16 sat_fr1x32(fract32 f1) If f1>0x00007fff (216-1), it returns 0x7fff (216-1). If f1<0xffff8000 -(216-1), it returns 0x8000 -(216-1).
Otherwise, it returns the lower 16 bits of f1.
fract16 round_fr1x32(fract32 f1) Rounds the 32-bit fract to a 16-bit fract using biased
rounding.
April 18, 2023 Veton Këpuska 26
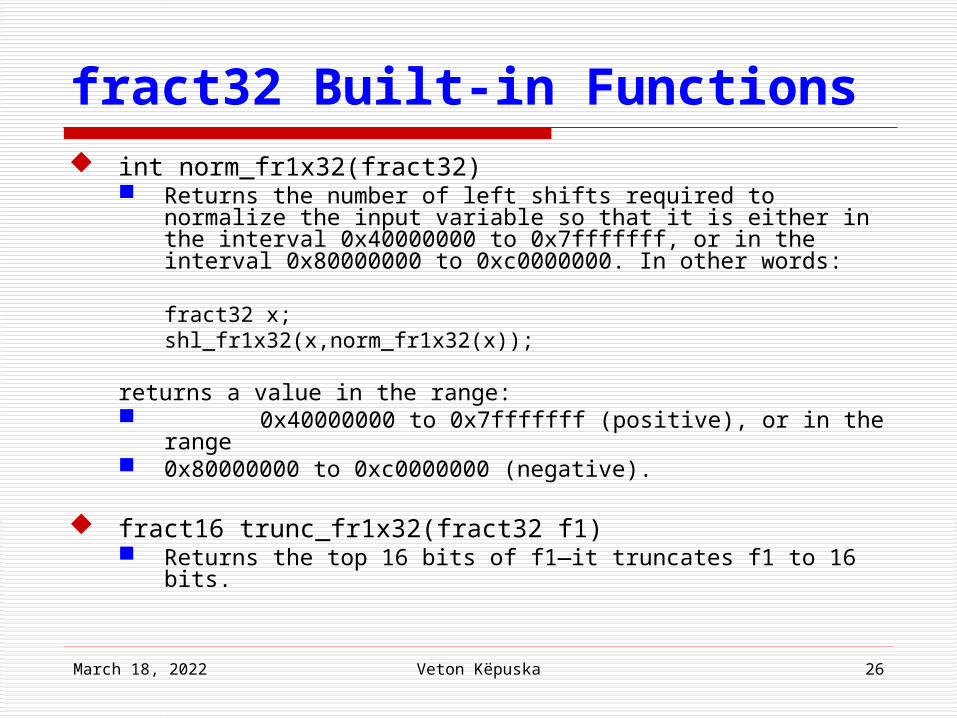
fract32 Built-in Functions int norm_fr1x32(fract32)
Returns the number of left shifts required to normalize the input variable so that it is either in the interval 0x40000000 to 0x7fffffff, or in the interval 0x80000000 to 0xc0000000. In other words:
fract32 x;shl_fr1x32(x,norm_fr1x32(x));
returns a value in the range: 0x40000000 to 0x7fffffff (positive), or in the range 0x80000000 to 0xc0000000 (negative).
fract16 trunc_fr1x32(fract32 f1) Returns the top 16 bits of f1—it truncates f1 to 16 bits.

ETSI Support

April 18, 2023 Veton Këpuska 28
ETSI Support VisualDSP++ 4.5 for Blackfin processors provides European
Telecommunications Standards Institute (ETSI) support routines in the libetsi*.dlb library. It contains routines for manipulation of the fract16 and fract32 data types as stipulated by ETSI.
The routines provide bit-accurate calculations for common operations, and conversions between fract16 and fract32 data types.
To use the ETSI routines, the header file libetsi.h must be included, and all source code must be compiled with the ETSI_SOURCE
macro defined. These routines are:
“32-Bit Fractional ETSI Routines” on page 1-140 “16-Bit Fractional ETSI Routines” on page 1-145
Of the VisualDSP++ 4.5 C/C++ Compiler and Library Manual for Blackfin Processors.

April 18, 2023 Veton Këpuska 29
ETSI Built-in Functions
If fract.h is included with ETSI_SOURCE defined, the macros listed below are also defined, mapping from the ETSI fract functions onto the compiler built-in functions. The mappings are done in fract_math.h (included by fract.h).
add() sub() shl() shr() mult() mult_r()
abs_s() saturate() extract_h() extract_l() L_deposit_l() div_s()

April 18, 2023 Veton Këpuska 30
ETSI Built-in Functions
negate() round() L_add() L_sub() L_abs() L_negate() L_shl() L_shr() L_msu() div_l()
norm_s() norm_l() L_Extract() L_Comp() Mpy_32() Mpy_32_16() L_mult() L_mac() L_shr_r()
April 18, 2023 Veton Këpuska 31
ETSI functions that do not map exactly to compiler built-in functions
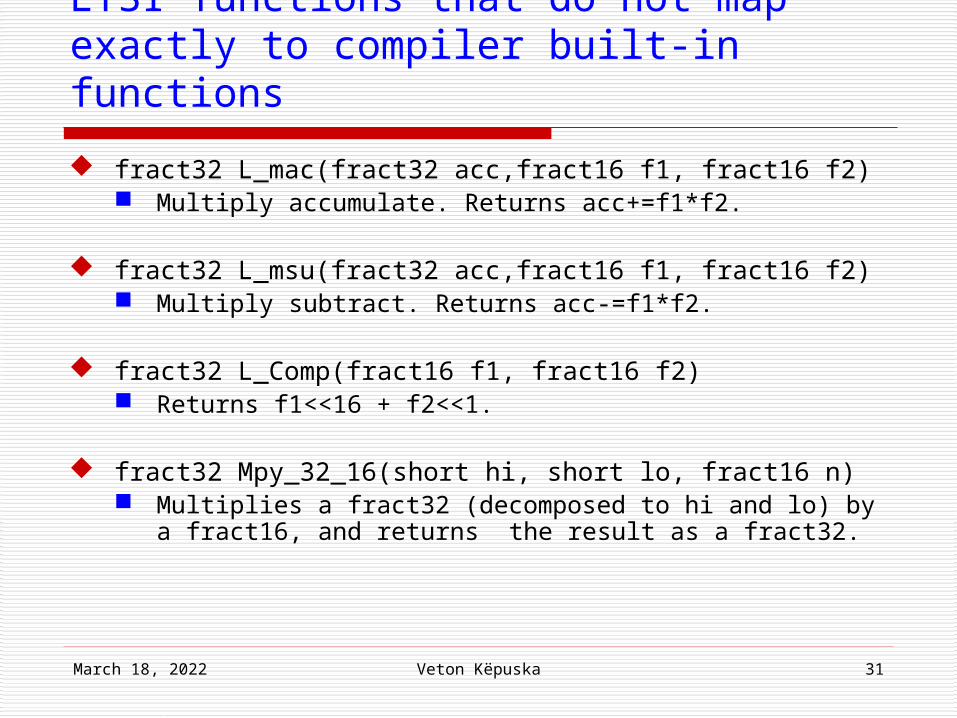
fract32 L_mac(fract32 acc,fract16 f1, fract16 f2) Multiply accumulate. Returns acc+=f1*f2.
fract32 L_msu(fract32 acc,fract16 f1, fract16 f2) Multiply subtract. Returns acc-=f1*f2.
fract32 L_Comp(fract16 f1, fract16 f2) Returns f1<<16 + f2<<1.
fract32 Mpy_32_16(short hi, short lo, fract16 n) Multiplies a fract32 (decomposed to hi and lo) by a
fract16, and returns the result as a fract32.
April 18, 2023 Veton Këpuska 32
ETSI functions that do not map exactly to compiler built-in functions
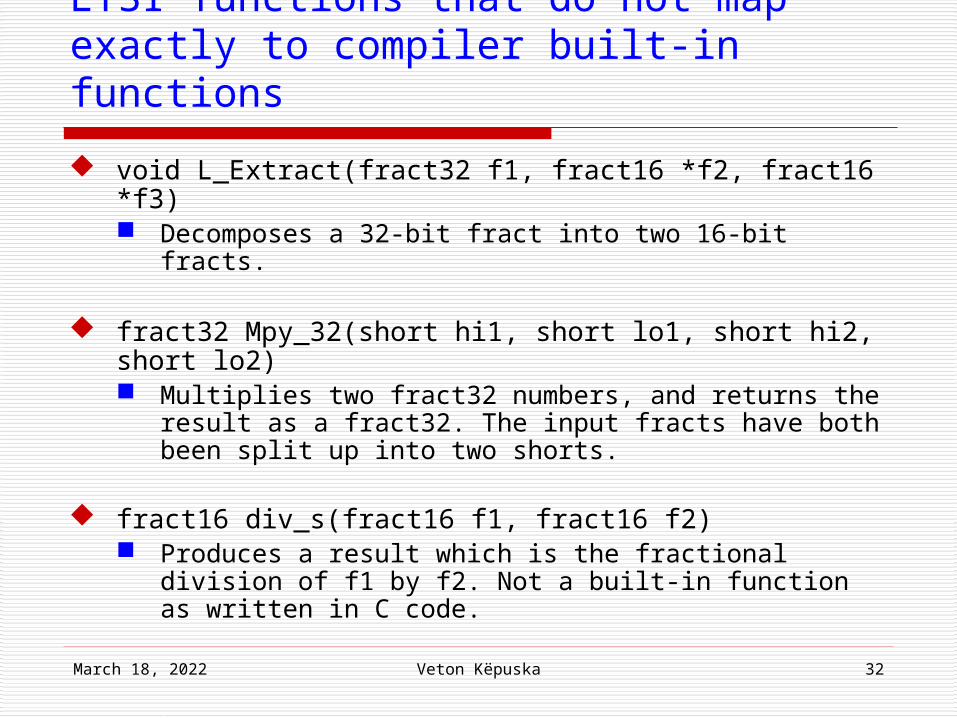
void L_Extract(fract32 f1, fract16 *f2, fract16 *f3) Decomposes a 32-bit fract into two 16-bit fracts.
fract32 Mpy_32(short hi1, short lo1, short hi2, short lo2) Multiplies two fract32 numbers, and returns the result
as a fract32. The input fracts have both been split up into two shorts.
fract16 div_s(fract16 f1, fract16 f2) Produces a result which is the fractional division of f1
by f2. Not a built-in function as written in C code.

April 18, 2023 Veton Këpuska 33
ETSI Functions By default, the ETSI functions
fract16 shl(fract16 _x, short _y); fract16 shr(fract16 _x, short _y); fract32 L_shl(fract32 _x, short _y); fract32 L_shr(fract32 _x, short _y);
map to clipping versions of the built-in fract shifts. To map them to the faster, but non-clipping versions of the built-in fractional shifts, define the macro _ADI_FAST_ETSI, either in your source before you include fract_math.h, or on the compile command line.

C++ Support of Fractional Numbers
April 18, 2023 Veton Këpuska 35
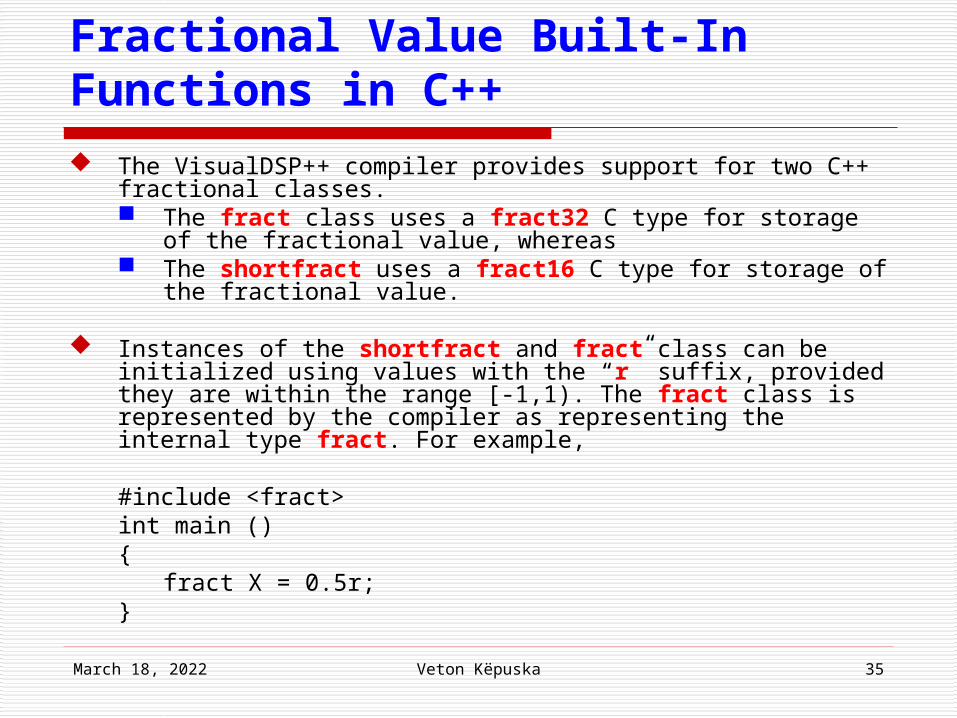
Fractional Value Built-In Functions in C++ The VisualDSP++ compiler provides support for two C++
fractional classes. The fract class uses a fract32 C type for storage of the
fractional value, whereas The shortfract uses a fract16 C type for storage of the
fractional value.
Instances of the shortfract and fract class can be initialized using values with the “r” suffix, provided they are within the range [-1,1). The fract class is represented by the compiler as representing the internal type fract. For example,
#include <fract>int main (){
fract X = 0.5r;}

April 18, 2023 Veton Këpuska 36
Fractional Value Built-In Functions in C++
Instances of the shortfract class can be initialized using “r” values in the same way, but are not represented as an internal type by the compiler. Instead, the compiler produces a temporary fract, which is initialized using the “r” value. The value of the fract class is then copied to the shortfract class using an implicit copy and the fract is destroyed.
The fract and shortfract classes contain routines that allow basic arithmetic operations and movement of data to and from other data types. The example below shows the use of the shortfract class with * and + operators.

April 18, 2023 Veton Këpuska 37
Fractional Value Built-In Functions in C++
The mathematical routines for addition, subtraction, division and multiplication for both fract and shortfract classes are performed using the ETSI-defined routines for the C fractional types (fract16 and fract32).
Inclusion of the fract and shortfract header files implicitly defines the macro ETSI_SOURCE to be 1. This is required for use of the ETSI routines (defined in libetsi.h and located in the libetsi53*.dlb libraries).
Example (next slide)
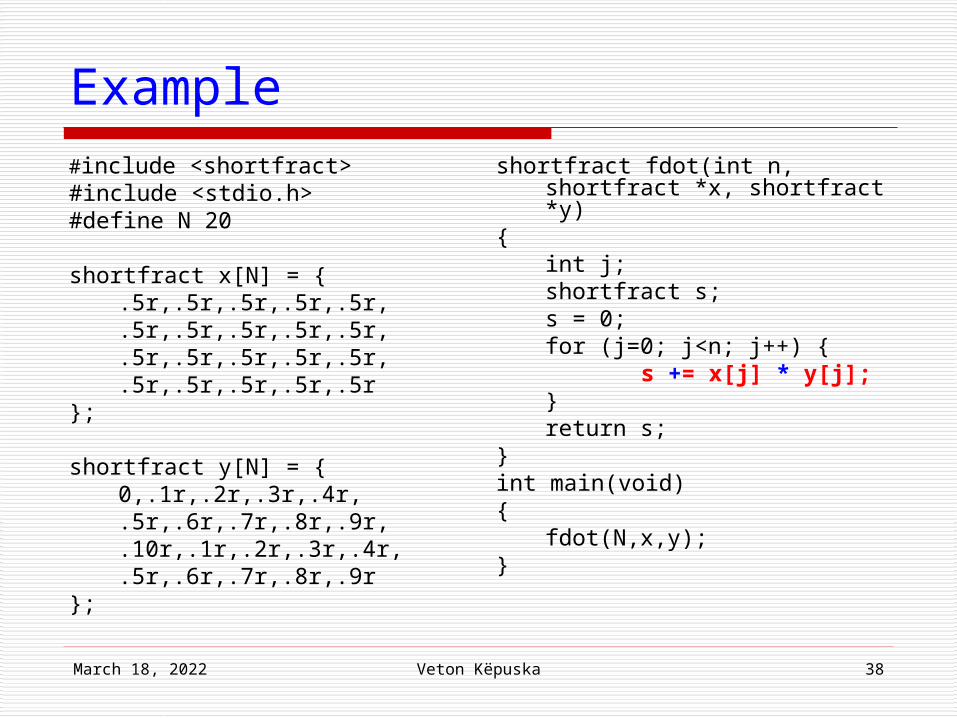
April 18, 2023 Veton Këpuska 38
Example#include <shortfract>#include <stdio.h>#define N 20
shortfract x[N] = {.5r,.5r,.5r,.5r,.5r,.5r,.5r,.5r,.5r,.5r,.5r,.5r,.5r,.5r,.5r,.5r,.5r,.5r,.5r,.5r
};
shortfract y[N] = {0,.1r,.2r,.3r,.4r,.5r,.6r,.7r,.8r,.9r,.10r,.1r,.2r,.3r,.4r,.5r,.6r,.7r,.8r,.9r
};
shortfract fdot(int n, shortfract *x, shortfract *y)
{int j;shortfract s;s = 0;for (j=0; j<n; j++) {
s += x[j] * y[j];}return s;
}int main(void){
fdot(N,x,y);}

April 18, 2023 Veton Këpuska 39
Fractional Literal Values in C
The “r” suffix is not available when compiling in C mode, since “r” literals are instances of the fract class.
However, if a C program is compiled in C++ mode, fract16 and fract32 variables can be initialized using “r” literal values; the compiler automatically converts from the class values to the C types. When adopting this approach, be aware of any
semantic differences between the C and C++ languages that might affect your program.

April 18, 2023 Veton Këpuska 40
Fractional Literal Values in C If coding in C mode fractional constants can be used to initialize
the fractional variables. Note that fract16 and fract32 are typedef of short int and long int
built in data types. This is accomplished by normalizing the fractional number to the
range determined by Q format. Example of Q1.15:
Conversion from float to fract16: fract16 x= (0.75 * 32768.0); // fractional representation of 0.75 fract16 float_to_fr16(float) // built in function
fract16 x = float_to_fr16(19571107.945) The number will be saturated to frac16 precision; that is to 32767. This implies that the numbers that are converted must be scaled to fit the data
type range (16 bit or 32 bit).
Conversion from 16 bit signed integer to fract16 No special conversion is needed. Ensure that the proper operators are used since in C mode there is no
operator overloading. Note: Always use fractional functions when using fract variables.
VisualDSP++
Circular Buffer Support

April 18, 2023 Veton Këpuska 42
Circular Buffer Built-In Functions The C/C++ compiler provides the built-in functions that use
the Blackfin processor’s circular buffer mechanisms. These functions provide automatic circular buffer generation, circular indexing, and circular pointer references.
Automatic Circular Buffer Generation If optimization is enabled, the compiler automatically
attempts to use circular buffer mechanisms where appropriate. For example,
void func(int *array,int n,int incr){
int i;for (i = 0;i < n;i++)array [ i % 10 ] += incr;
}

April 18, 2023 Veton Këpuska 43
Circular Buffer Built-In Functions
The compiler recognizes that the “[i % 10 ]” expression is a circular reference, and uses a circular buffer if possible.
There are cases where the compiler is unable to verify that the memory access is always within the bounds of the buffer. The compiler is conservative in such cases, and does not generate circular buffer accesses.
The compiler can be instructed to still generate circular buffer accesses even in such cases, by specifying the -force-circbuf switch. (For more information, see “-force-circbuf” on page 1-33.)

April 18, 2023 Veton Këpuska 44
Explicit Circular Buffer Generation
The compiler also provides built-in functions that can explicitly generate circular buffer accesses, subject to available hardware resources.
The built-in functions provide circular indexing and circular pointer references.
Both built-in functions are defined in the
ccblkfn.h header file.

April 18, 2023 Veton Këpuska 45
Circular Buffer Increment of an Index
The following operation performs a circular buffer increment of an index.
long circindex(long index, long incr, unsigned long nitems);
The operation is equivalent to:
index += incr;if (index < 0)
index += nitems;else if (index >= nitems)
index -= nitems;

April 18, 2023 Veton Këpuska 46
Example Code#include <ccblkfn.h>void func(int *array, int n, int incr, int len){
int i, idx = 0;int *ptr = array;// scale increment and length by size// of item pointed to.incr *= sizeof(*ptr);len *= sizeof(*ptr);for (i = 0; i < n; i++) {
*ptr += incr;ptr = circptr(ptr, incr, array, len);
}}

Block vs. Sample Processing

April 18, 2023 Veton Këpuska 48
Block vs. Sample Processing DSP algorithms usually process signals by
either block processing or sample processing [2].
Block Processing For block processing, data is transferred to a
DSP memory buffer and then processed each time the buffer fills with new data. Examples of such algorithms are: fast fourier transforms and fast convolution.
The processing time requirement is based on the sample rate times the number of locations in the memory buffer.

April 18, 2023 Veton Këpuska 49
Block vs. Sample Processing Sample Processing
In sample processing algorithms, each input sample is processed on a sample-by-sample basis through the DSP routine as each sample becomes available.
Sampled data is usually passed from a peripheral (such as a serial port) and transferred to an internal register or memory location so it is made available for processing.
This is the preferred method when implementing real-time digital filters for infinite duration.
For infinite duration sequences, once the DSP is initialized, it will forever process data coming in and output a result as long as the DSP system is powered .
So for real-time digital IIR/FIR filters and digital audio effects, sample processing will be the method used for most examples to be covered in this paper.
As we will see in the next section, some digital filters and audio effects use sample processing techniques with delay-lines.

April 18, 2023 Veton Këpuska 50
Sample Processing Sample Processing
starts upon the arrival of the input sample x[n] Performs an identical set of operations at each sampling
interval, and Completes the operations before the next sample arrives.
Note: All operations must be completed within one sampling period. Real- time constraint of sample processing.
To achieve this requirement the computational time Ts must satisfy the following relation:
Ts ≤ T-TH
TH is the hardware overhead time that includes both ADC and DAC and the data transfer between the DSP processor and the I/O
devices and where T is the sampling interval.

April 18, 2023 Veton Këpuska 51
Advantages & Disadvantages of the Sample Processing
Advantages:1. All results are kept current within the sampling
period2. Delay between the input and the output is kept
to the theoretical minimum3. Storage of the input and output samples is also
kept to the theoretical minimum.
Disadvantages:1. Overhead of reading and writing each data
sample.

April 18, 2023 Veton Këpuska 52
Block Processing
In block processing, incoming samples x[n] are first stored in a memory buffer.
After N samples have arrived, the entire block of data samples is processed at once to produce the output signal y[n].
Block processing is performed for every NT seconds.

April 18, 2023 Veton Këpuska 53
Block Processing
Inputblock
i
Inputblock
i
Inputblock
i+1
Inputblock
i+1
Processblock
i
Processblock
i
Maximum Block Delay
2NT
Maximum Block Delay
2NT
Inputblock
i+2
Inputblock
i+2
Processblock
i+1
Processblock
i+1
Outputblock
i
Outputblock
i
Inputblock
i+3
Inputblock
i+3
Processblock
i+2
Processblock
i+2
Outputblock
i+1
Outputblock
i+1
Inputblock
i+4
Inputblock
i+4
Processblock
i+3
Processblock
i+3
Outputblock
i+2
Outputblock
i+2
Inputblock
i+5
Inputblock
i+5
Processblock
i+4
Processblock
i+4
Outputblock
i+3
Outputblock
i+3
Inputblock
i+6
Inputblock
i+6
Processblock
i+5
Processblock
i+5
Outputblock
i+4
Outputblock
i+4
Inputblock
i+7
Inputblock
i+7
Processblock
i+6
Processblock
i+6
Outputblock
i+5
Outputblock
i+5

April 18, 2023 Veton Këpuska 54
Real-Time Considerations
Block-Processing In order to meet the real-time constraint
for the computation time for the block processing Tb must satisfy the following:
Tb ≤ NT-T0
T0 - Overhead for block processing.

April 18, 2023 Veton Këpuska 55
Advantages of Block Processing
It allows a slower processor to keep up with input samples. These samples may be buffered and used in computation after all of the input has ceased.
It reduces the overhead of read/write operations to memory. It performs the I/O operations in every NT seconds instead of T seconds for Sample Processing.

April 18, 2023 Veton Këpuska 56
Disadvantages of Block Processing
Introduces 2NT samples delay
Additional memory required.