misha bilenko, principal researcher, microsoft at mlconf sea - 5/01/15
TRANSCRIPT

Many Shades of Scale: Big Learning
Beyond Big Data
Misha Bilenko
Principal Researcher
Microsoft Azure Machine Learning

ML ♥ More Data
What we see in production[Banko and Brill, 2001]
What we [used to] learn in school[Mooney, 1996]

ML ♥ More Data
What we see in production[Banko and Brill, 2001]
Is training on more examples
all there is to it?

Big Learning ≠ Learning(BigData)
• Big data: size → distributing storage and processing
• Big learning: scale bottlenecks in training and prediction
• Classic bottlenecks: bytes and cyclesLarge datasets → distribute training on larger hardware (FPGAs, GPUs, cores, clusters)
• Other scaling dimensions
Features Components/People

5
Learning from Countswith
DRACuLaDistributed Robust Algorithm for Count-based Learning
joint work with Chris Meek (MSR)Wenhan Wang, Pete Luferenko (Azure ML)
Scaling to many Features

Learning with relational data
𝑝(𝑐𝑙𝑖𝑐𝑘|𝑎𝑑,𝑐𝑜𝑛𝑡𝑒𝑥𝑡,𝑢𝑠𝑒𝑟) adid = 1010054353adText = K2 ski sale!adURL= www.k2.com/sale
Userid = 0xb49129827048dd9bIP = 131.107.65.14
Query = powder skisQCategories = {skiing, outdoor gear}
6
#𝑢𝑠𝑒𝑟𝑠~109 #𝑞𝑢𝑒𝑟𝑖𝑒𝑠~109+ #𝑎𝑑𝑠~107 # 𝑎𝑑 × 𝑞𝑢𝑒𝑟𝑦 ~1010+
• Information retrieval
• Advertising, recommending, search: item, page/query, user
• Transaction classification
• Payment fraud: transaction, product, user
• Email spam: message, sender, recipient
• Intrusion detection: session, system, user
• IoT: device, location

Learning with relational data
𝑝(𝑐𝑙𝑖𝑐𝑘|𝑢𝑠𝑒𝑟,𝑐𝑜𝑛𝑡𝑒𝑥𝑡,𝑎𝑑)
adid: 1010054353adText: Fall ski sale!adURL: www.k2.com/sale
userid 0xb49129827048dd9bIP 131.107.65.14
query powder skisqCategories {skiing, outdoor gear}
7
• Problem: representing high-cardinality attributes as features• Scalable: to billions of attribute values
• Efficient: ~105+ predictions/sec/node
• Flexible: for a variety of downstream learners
• Adaptive: to distribution change
• Standard approaches: binary features, hashing
• What everyone should use in industry: learning with counts• Formalization and generalization

Standard approach 1: binary (one-hot, indicator)
Attributes are mapped to indices based on lookup tables- Not scalable cannot support high-cardinality attributes- Not efficient large value-index dictionary must be retained- Not flexible only linear learners are practical- Not adaptive doesn’t support drift in attribute values
0010000..00 0..01000000 00000..001 0..00001000
#userIPs #ads #queries #queries x #ads
𝑖𝑑𝑥𝑢 131.107.65.14 𝑖𝑑𝑥𝑞 𝑝𝑜𝑤𝑑𝑒𝑟 𝑠𝑘𝑖𝑠𝑖𝑑𝑥𝑎 𝑘2. 𝑐𝑜𝑚 𝑖𝑑𝑥 𝑝𝑜𝑤𝑑𝑒𝑟 𝑠𝑘𝑖𝑠, 𝑘2. 𝑐𝑜𝑚
8

Standard approach 1+: feature hashing
Attributes are mapped to indices via hashing: ℎ 𝑥𝑖 = ℎ𝑎𝑠ℎ 𝑥𝑖 mod𝑚• Collisions are rare; dot products unbiased
+ Scalable no mapping tables+ Efficient low cost, preserves sparsity- Not flexible only linear learners are practical± Adaptive new values ok, no temporal effects
0000010..0000010000..0000010...000001000
ℎ powder skis + k2. comℎ powder skis
ℎ k2. comℎ 131.107.65.14
𝑚 ∼ 107
[Moody ‘89, Tarjan-Skadron ‘05, Weinberger+ ’08]
9
𝜙(𝑥)

Learning with counts
• Features are per-label counts [+odds] [+backoff]
𝝓 = [N+ N- log(N+)-log(N-) IsRest]
• log(N+)-log(N-) = log𝒑(+)
𝒑(−): log-odds/Naïve Bayes estimate
• N+, N-: indicators of confidence of the naïve estimate
• IsFromRest: indicator of back-off vs. “real count”
131.107.65.14
𝐶𝑜𝑢𝑛𝑡𝑠(131.107.65.14) 𝐶𝑜𝑢𝑛𝑡𝑠(k2.com)
k2.com
𝐶𝑜𝑢𝑛𝑡𝑠(powder skis)
powder skis
𝐶𝑜𝑢𝑛𝑡𝑠(powder skis, k2.com)
powder skis, k2.com
IP 𝑵+ 𝑵−
173.194.33.9 46964 993424
87.250.251.11 31 843
131.107.65.14 12 430
… … …
REST 745623 13964931
𝝓(𝑪𝒐𝒖𝒏𝒕𝒔 (𝑰𝑷)) 𝝓(𝑪𝒐𝒖𝒏𝒕𝒔 (𝒂𝒅)) 𝝓(𝑪𝒐𝒖𝒏𝒕𝒔 (𝒒𝒖𝒆𝒓𝒚)) 𝝓(𝑪𝒐𝒖𝒏𝒕𝒔 (𝒒𝒖𝒆𝒓𝒚, 𝒂𝒅))

Learning with counts
• Features are per-label counts [+odds] [+backoff]
𝝓 = [N+ N- log(N+)-log(N-) IsRest]
+ Scalable “head” in memory + tail in backoff; or: count-min sketch+ Efficient low cost, low dimensionality+ Flexible low dimensionality works well with non-linear learners+ Adaptive new values easily added, back-off for infrequent values, temporal counts
𝝓(𝑪𝒐𝒖𝒏𝒕𝒔(𝒖𝒔𝒆𝒓)) 𝝓(𝑪𝒐𝒖𝒏𝒕𝒔(𝒂𝒅)) 𝝓(𝑪𝒐𝒖𝒏𝒕𝒔(𝒒𝒖𝒆𝒓𝒚) 𝝓(𝑪(𝒒𝒖𝒆𝒓𝒚 × 𝒂𝒅))
131.107.65.14
𝐶𝑜𝑢𝑛𝑡𝑠(131.107.65.14) 𝐶𝑜𝑢𝑛𝑡𝑠(k2.com)
k2.com
𝐶𝑜𝑢𝑛𝑡𝑠(powder skis)
powder skis
𝐶𝑜𝑢𝑛𝑡𝑠(powder skis, k2.com)
powder skis, k2.com
𝝓(𝑪𝒐𝒖𝒏𝒕𝒔 (𝑰𝑷)) 𝝓(𝑪𝒐𝒖𝒏𝒕𝒔 (𝒂𝒅)) 𝝓(𝑪𝒐𝒖𝒏𝒕𝒔 (𝒒𝒖𝒆𝒓𝒚)) 𝝓(𝑪𝒐𝒖𝒏𝒕𝒔 (𝒒𝒖𝒆𝒓𝒚, 𝒂𝒅))
IP 𝑵+ 𝑵−
173.194.33.9 46964 993424
87.250.251.11 31 843
131.107.65.14 12 430
… … …
REST 745623 13964931

Backoff is a pain. Count-Min Sketches to the Rescue![Cormode-Muthukrishnan ‘04]
Intuition: correct for collisions by using multiple hashes
Featurize: 𝑚𝑖𝑛𝑗 (𝑀[𝑗][ℎ𝑗(𝑖)]) Estimation Time : O(d)
= M (d x w)
Count: for each hash function M[j][hj(i)] ++ Update Time: O(d)

Learning from counts: aggregationAggregate 𝐶𝑜𝑢𝑛𝑡(𝑦, 𝑏𝑖𝑛 𝑥 ) for different 𝑏𝑖𝑛 𝑥
• Standard MapReduce
• Bin function: any projection
• Backoff options: “tail bin”, hashing, hierarchical (shrinkage)
IP 𝑵+ 𝑵−
173.194.33.9 46964 993424
87.250.251.11 31 843
131.253.13.32 12 430
… … …
REST 745623 13964931
query 𝑵+ 𝑵−
facebook 281912 7957321
dozen roses 32791 640964
… … …
REST 6321789 43477252
Query × AdId 𝑵+ 𝑵−
facebook, ad1 54546 978964
facebook, ad2 232343 8431467
dozen roses, ad3 12973 430982
… … …
REST 4419312 52754683
timeTnow
Counting
IP[2] 𝑵+ 𝑵−
173.194.*.* 46964 993424
87.250.*.* 6341 91356
131.253.*.* 75126 430826
… … …
13

Learning from counts: combiner trainingIP 𝑵+ 𝑵−
173.194.33.9 46964 993424
87.250.251.11 31 843
131.253.13.32 12 430
… … …
REST 745623 13964931
query 𝑵+ 𝑵−
facebook 281912 7957321
dozen roses 32791 640964
… … …
REST 6321789 43477252
timeTnow
Train predictor
….
IsBackoff
ln𝑁+ − ln𝑁−
Aggregatedfeatures
Original numeric features
𝑁−𝑁+
Counting
Train non-linear model on count-based features
• Counts, transforms, lookup properties
• Additional features can be injected
Query × AdId 𝑵+ 𝑵−
facebook, ad1 54546 978964
facebook, ad2 232343 8431467
dozen roses, ad3 12973 430982
… … …
REST 4419312 52754683
14

Prediction with countsIP 𝑵+ 𝑵−
173.194.33.9 46964 993424
87.250.251.11 31 843
131.253.13.32 12 430
… … …
REST 745623 13964931
query 𝑵+ 𝑵−
facebook 281912 7957321
dozen roses 32791 640964
… … …
REST 6321789 43477252
URL × Country 𝑵+ 𝑵−
url1, US 54546 978964
url2, CA 232343 8431467
url3, FR 12973 430982
… … …
REST 4419312 52754683
timeTnow
….
IsBackoff
ln𝑁+ − ln𝑁−
Aggregatedfeatures
𝑁−𝑁+
Counting →
• Counts are updated continuously
• Combiner re-training infrequent
Ttrain
Original numeric features

Where did it come from?
Li et al. 2010
Pavlov et al. 2009
Lee et al. 1998
Yeh and Patt, 1991
16
Hillard et al. 2011
• De-facto standard in online advertising industry
• Rediscovered by everyone who really cares about accuracy

Do we need to separate counting and training?
• Can we use use same data for both counting and featurization
• Bad idea: leakage = count features contain labels → overfitting• Combiner dedicates capacity to decoding example’s label from features
• Can we hold out each example’s label during train-set featurization?
• Bad idea: leakage and bias• Illustration: two examples, same feature values, different labels (click and non-click)
• Different representations are inconsistent and allow decoding the label
Train predictorCounting
Example ID Label N+[a] N-[a]
1 + 𝑁𝑎+ − 1 𝑁𝑎
−
2 - 𝑁𝑎+ 𝑁𝑎
−-1

Solution via Differential privacy
• What is leakage? Revealing information about any individual label
• Formally: count table cT is ε-leakage-proof if same features for ∀𝑥, 𝑇, 𝑇′ = 𝑇\(𝑥𝑖 , 𝑦𝑖)
• Theorem: adding noise sampled from Laplace(k/𝜖) makes counts 𝜖-leakage-proof
• Typically 1 ≤ 𝑘 ≤ 100
• Concretely: N+ = N+ + LaplaceRand(0,10k) N- = N- + LaplaceRand(0,10k)
• In practice: LaplaceRand(0,1) sufficient

Learning from counts: why it works
• State-of-the-art accuracy
• Easy to implement on standard clusters
• Monitorable and debuggable• Temporal changes easy to monitor
• Easy emergency recovery (bot attacks, etc.)
• Error debugging (which feature to blame)
• Modular (vs. monolithic)• Components: learners and count features
• People: multiple feature/learner authors
19
Big Learning: Pipelines and Teams
Ravi: text features in R
Jim: matrix projections
Vera: sweeping boosted trees
Steph: count featureson Hadoop
How to scale up Machine Learning toParallel and Distributed Data Scientists?

AzureML
• Cloud-hosted, graphical environmentfor creating, training, evaluating, sharing, and deployingmachine learning models
• Supports versioning and collaboration
• Dozens of ML algorithms, extensible via R and Python

APIML STUDIO
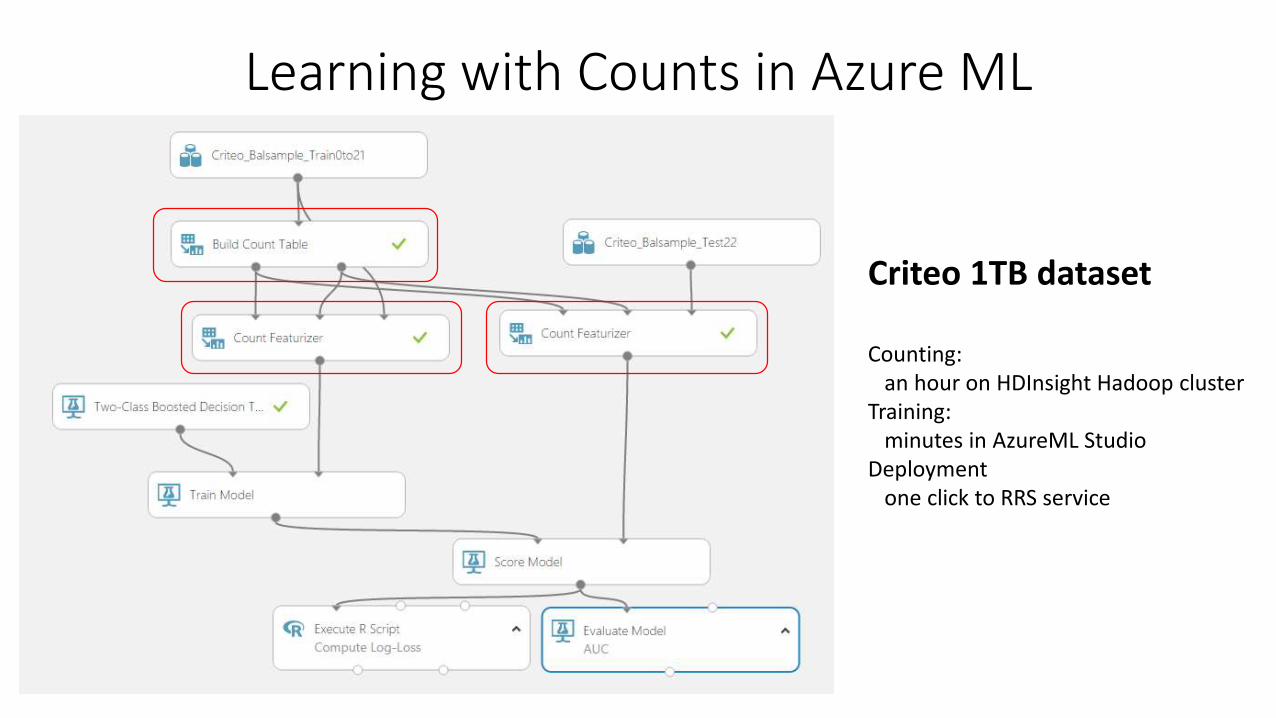
Learning with Counts in Azure ML
Criteo 1TB dataset
Counting:an hour on HDInsight Hadoop cluster
Training: minutes in AzureML Studio
Deploymentone click to RRS service

Maximizing Utilization: Keeping it Asynchronous
• Macro-level: concurrently executing pipelines
• Micro-level: asynchronous optimization (with overwriting updates)• Hogwild SGD [Recht-Re], Downpour SGD [Google Brain]
• Parameter Server [Smola et al.]
• GraphLab [Guestrin et al.]
• SA-SDCA [Tran, Hosseini, Xiao, Finley, B.]

Semi-Asynchronous SDCA: state-of-the-art linear learning
• SDCA: Stochastic Dual Coordinate Ascent [Shalev-Schwartz & Zhang]• Plot: SGD marries SVM and they have a beautiful baby
• Algorithm: for each example: update example’s 𝛼𝑖, then re-estimate weights
• Let’s make it asynchronous, Hogwild-style!
• Problem: primal and dual diverge
• Solution: separate thread for primal-dual synchronization
• Taking it out-of-memory: block pseudo-random data loading
SGD update𝑤𝑡+1 ← 𝑤𝑡−𝛾𝑡 𝜆𝑤𝑡 − 𝑦𝑖𝜙𝑖
′(𝑤𝑡 ⋅ 𝑥𝑖) 𝑥𝑖
SDCA update𝛼𝑖𝑡 ← 𝛼𝑖
𝑡−1 + Δ𝛼𝑖
𝑤𝑡 ← 𝑤𝑡−1 +Δ𝛼𝑖𝜆𝑛
𝑥𝑖

Keeping it asynchronous: it pays off

In closing: Big Learning = Streetfighting
• Big features are resource-hungry: learning with counts, projections… • Make them distributed and easy to compute/monitor
• Big learners are resource-hungry• Parallelize them (preferably asynchronously)
• Big pipelines are resource-hungry: authored by many humans• Run them a collaborative cloud environment