mmds 7.3 - 7.4
TRANSCRIPT

MMDs 7.3 -‐ 7.4
05-‐03-‐2014 Shota Horii

今回の内容
• ポイント割り当て型クラスタリングの代表的アルゴリズム – K-‐means algorithm
• K-‐meansを大規模データで行うためのアルゴリズム – BFR algorithm
• 大規模データのクラスタリング(複雑な形状のクラスタに対応) – CURE algorithm

k-means algorithm

7.3.1. k-means 概要
• 最も有名なポイント割り当て型クラスタリング
• データについての仮定 – データがユークリッド空間上にある事 – クラスタ数が既知である事 -‐> 未知の場合でもトライ&エラーで推測可
クラスタ数 = 3
e.g.)

7.3.1. k-means 概要
全ての点がクラスタに 割り当てられるまで繰り返す。
異なるクラスタに属するであろう点をk個選び それぞれクラスタ重心とする。
それ以外の点を、最も重心の近いクラスタに割り当てる。
クラスタ重心の位置を修正。

7.3.1. k-means 概要
1. 異なるクラスタに属するであろうK個の点を選び出す。 2. 選ばれたポイントをそれぞれのクラスタの重心とする。 3. step1で選ばれていない全ての点pについて:
I) pに最も近いクラスタ重心を見つける II) pをその重心の属するクラスタに追加する III) pを加えた上でそのクラスタの重心位置を再計算する
4(opConal). 全クラスタの重心を固定し、再度全ての点pについて 最も近いクラスタ重心を探し、そのクラスタに割り当てる。

• 異なるクラスタに属するであろう点を選びたい approach1: できる限り離れたk個の点を選ぶ
approach2: データのサンプルを階層的にk個のクラスタに分割し、 それぞれのクラスタの重心に近い点を選ぶ
7.3.2. k個の初期重心の選び方

7.3.3. クラスタ数が未知のケース
• 正しいクラスタ数を予測したい • クラスタリングの良否を測る基準があれば、様々なクラスタ
数を試して最適なものを選べる。 • (復習) 同一クラスタ内の最も遠い二点間の距離をそのクラス
タの ’直径’ という。 • この直径を利用してクラスタリングの良否を測る。
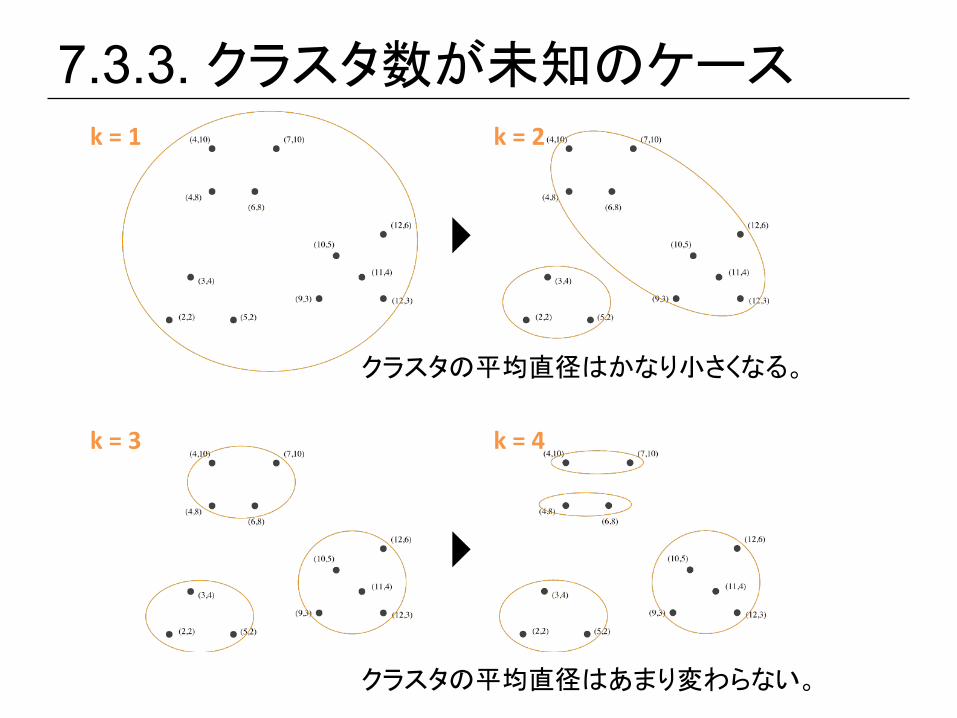
7.3.3. クラスタ数が未知のケース k = 1 k = 2
k = 3 k = 4
クラスタの平均直径はかなり小さくなる。
クラスタの平均直径はあまり変わらない。

7.3.3. クラスタ数が未知のケース
• k=1,2,4,8,… とk-‐meansを行う • v, 2vの間で変化が少ないようなvを見つける • 真のkはv/2, vの間にある • v/2とvの間の数をバイナリサーチの要領で真のkを探す • =>最終的に 2logv回のクラスタリングが必要

BFR algorithm

7.3.4. BFRアルゴリズム 概要 • 高次元ユークリッド空間上のデータをクラスタリングするため
に考案されたk-‐meansのバリエーション。
• BFR は著者の名前の頭文字(Bradley, Fayyad and Reina)
• クラスタの形状について厳しい仮定 – クラスタ内の点が、クラスタ重心の周りに正規分布していること
(normally distributed) – 平均と標準偏差は各次元で異なって良いが、各次元がそれぞれ独立
であること -‐> クラスタの軸が次元の軸上に沿っていること

7.3.4. BFRアルゴリズム 概要
• まず通常のk-‐meansと同様にk個の初期重心を設定する。
• その後、データをメインメモリに載るサイズのchunk毎に読み込んでクラスタリングを行っていく。
• chunk毎に読み込んだ点全ての情報をメインメモリに残して
おくことはできない。 -‐> 読み込んだ情報を要約してメインメモリに格納しておく。
• メインメモリには、次に読み込むデータchunk + 読み込み済データの要約情報が格納されることになる。

7.3.4. 3つのオブジェクト
• The Discard Set – k個のクラスタについての情報 – クラスタ情報は保持され、各点の情報は破棄される。
• The Compressed Set – どのクラスタとも近くないが、他の点と近くにある点の集ま
りをミニクラスタと呼ぶ。 – ミニクラスタの情報が保持され、各点の情報は破棄される。
• The Retained Set – どのクラスタとも、他のどの点とも近くない点は、読み込ま
れたままの点の情報としてメインメモリに保持される。
* 近い/近くない の判定基準は後のスライドで

7.3.4. 3つのオブジェクト

7.3.4. クラスタ情報どう保持されるか
• クラスタ情報とミニクラスタ情報はそれぞれ2d+1個の値によって 保持される。
– クラスタ内の点の数 N
– 各次元毎に、全ての点の値の合計。(長さdのベクトル SUM)
– 各次元毎に、全ての点の値の二乗の合計。(長さdのベクトル SUMSQ)
• 最終的には、クラスタ, ミニクラスタを以下の様に表したい。 – クラスタ内の点の数
– クラスタの重心位置
– 各次元の標準偏差
• これらは保持された情報から簡単に求まる。 – クラスタ内の点の数 = N
– ith次元の重心位置 =
– ith次元の標準偏差 =
SUMi / N
SUMSQi / N − (SUMi / N )2

7.3.4. クラスタ情報どう保持されるか
e.g.) 点(5,1), (6, -‐2), (7, 0) から成るクラスタについて考える。
N = 3 SUM = [5+6+7, 1-‐2+0] = [18, -‐1] SUMSQ = [25+36+49, 1+4+0] = [110, 5]
クラスタ重心 = SUM/N = [6, -‐1/3] 各次元の標準偏差: std1 = 110 / 3− (18 / 3)2 = 0.667 = 0.816
std2 = 5 / 3− (−1/ 3)2 = 1.56 =1.25
• なぜ最初からクラスタを重心と標準偏差で保持せずに N, SUM, SUMSQの形で保持するのか?
→ クラスタに新しい点を追加した際、更新の計算が非常に楽に。

7.3.5. BFRアルゴリズム プロセス
1. データchunk中の点で、各クラスタ重心に十分近いものはそのクラスタに追
加される。 2. step1でクラスタに追加されなかった点と、Retained Setの点について、メイン
メモリ上でクラスタリングを行う(階層クラスタリング等)。 ここでクラスタとなったものはCompressed Set(ミニクラスタ)へ。 単一の点として残ったものはRetained Setへ。
3. 既にあるミニクラスタと今回新たに出来たミニクラスタの中で、近くにあるも
のを併合する。 4. クラスタ or ミニクラスタに追加された点はメインメモリからは破棄され、セカ
ンダリメモリに。 5. もし最後のチャンクの場合、Compressed SetとRetained Setを処理。
-‐ どのクラスタにも割り当てない -‐ あるいは、最も近いクラスタに併合する
【ひとつの chunk を読み込んだ時のプロセス】

7.3.5. 近さの判定 (方法1)
• 点pに最も重心が近いクラスタを選び出す。
• 今後全ての点を処理し終わった後もそのクラスタが点pから
最も近いクラスタであると考えられる場合、点pを加える。
• そうでない場合、どのクラスタにも加えない。 (Compressed Set 又は Retained Setに加えられることになる)
– 複雑な統計計算が必要。 – アドバンテージ: 点pがどのクラスタとも遠い場合でも、比較的に最も
近いクラスタに追加される。
【点pをクラスタに追加するかどうかの判定 = 点pがクラスタに十分近いかどうかの判定】

• 各次元でクラスタ中の点は軸上に正規分布していると仮定。 • 故に、点pからクラスタ重心までの距離が分かれば、その距
離の点がクラスタに含まれている確率が計算できる。
• マハラノビス距離を計算する。
7.3.5. 近さの判定 (方法2)

7.3.5. マハラノビス距離
• マハラノビス距離 = クラスタの各次元の標準偏差で正規化された、点pからクラスタ重心までの距離。
( pi − ciσ i
)2i=1
d
∑
p = [p1, p2,..., pd ]
c = [c1,c2,...,cd ]
σ i = i番目の次元におけるクラスタの標準偏差
クラスタ重心と点pとの正規化された距離
全てのクラスタとのマハラノビス距離を計算し、これが最も小さいクラスタを選ぶ。 もしこのクラスタとの距離が閾値よりも小さければ、点pをクラスタに加える。

7.3.5. マハラノビス距離
• 例えば閾値を4に設定したとする。
• もしデータが本当に正規分布に従って分布しているならば4標準偏差より離れた点がクラスタに属する確率は1/1000000より小さい。
• すなわち実際にクラスタに属している点を誤って切り捨てる
確率は1/1000000より小さい。

CURE algorithm

7.4. CUREアルゴリズム 概要
• CURE = Clustering Using REpresentaCves • ユークリッド空間上の点を対象
• クラスタの形状について何も制限しない (S字形状やリングなどもOK)
• クラスタの表現に、重心の代わりに複数の代表点を用いる。
e.g.)

7.4.1. CUREアルゴリズム 初期化
1. メインメモリに載るサイズのサンプルを取る 2. それらをメインメモリ上でクラスタリング
-‐ 最も近い点を持つクラスタ同士を併合していくような階層クラスタリングが推奨される。
-‐>複雑な形状のクラスタ に対応できる。
3. 各クラスタから複数の代表点を選ぶ。
-‐ クラスタ内でできる限り離れた点を選択する
4. 各代表点を、一定の割合でクラスタ重心の方へ移動させる。
-‐ 20%が推奨される

7.4.2. CUREアルゴリズム 初期化
1. メインメモリに載るサイズをサンプリング 2. 階層クラスタリング
3. 代表点を選ぶ 4. それぞれクラスタ重心に一定割合寄せる
(最も近い点を持つクラスタ同士を併合する方法で)

7.4.2. CUREアルゴリズム 初期化 • それぞれのクラスタを併合するかどうか判定する必要がある。
各クラスタの代表点同士の距離がある水準よりも小さければ クラスタは併合されるべき。 -‐> この閾値はパラメータとして決定される。

7.4.2. CUREアルゴリズム 完了 • ストレージ上の残りの点について
最も近くに代表点を持つクラスタに併合する。
新しい点 -‐> 内側の円のクラスタに分類される。
new point

まとめ
• k-‐means algorithm – ポイント割り当て型の代表的アルゴリズム – 正しいクラスタ数が未知の場合も予測可能
• BFR algorithm – 大規模データでk-‐meansを行う – クラスタ形状について厳しい仮定 – 読み込んだ情報を要約して保持
• CURE algorithm – 大規模データに対応 – 複雑な形状のクラスタに対応 – クラスタを重心ではなく複数の代表点で表現する