model selection. agenda myung, pitt, & kim olsson, wennerholm, & lyxzen
Post on 21-Dec-2015
215 views
TRANSCRIPT

Model Selection

Agenda
• Myung, Pitt, & Kim
• Olsson, Wennerholm, & Lyxzen

What is a Model?
p(t) = w1 exp(-w2 t)w1 = 1.145w2 = 0.156
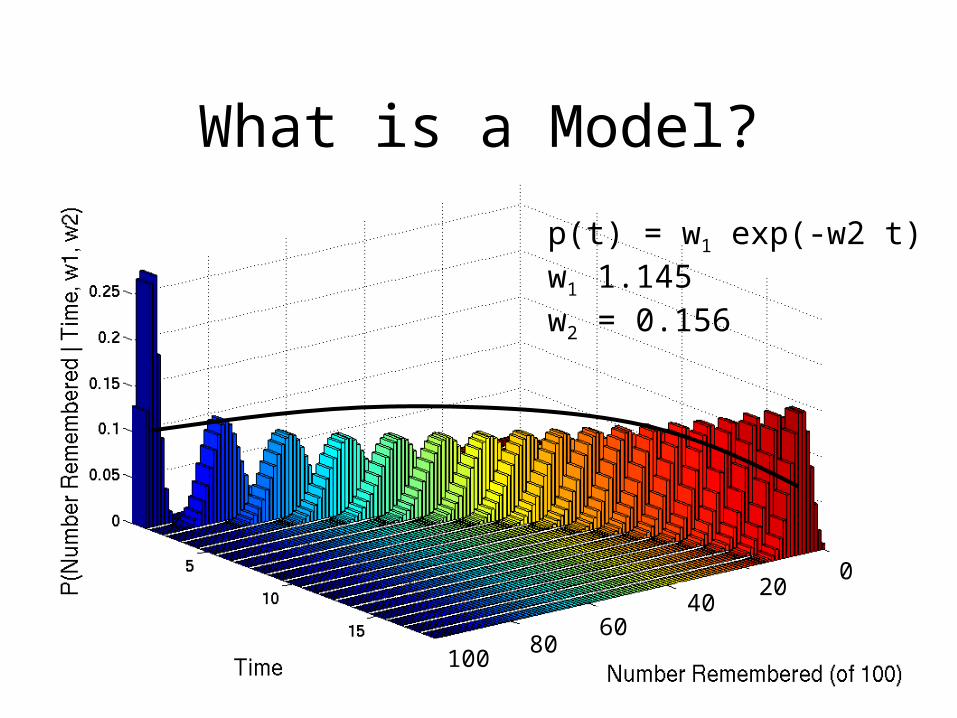
What is a Model?
p(t) = w1 exp(-w2 t)w1 1.145w2 = 0.156
8060
4020
0
100

What is a Model?
p(t) = w1 exp(-w2 t)w1 1.145w2 = 0.156
8060
4020
0
100

What is a Model?
• A model is a parametric family of probability distributions.– Parametric because the distributions
depend on the parameters.– Distributions because they are stochastic
models, not deterministic.
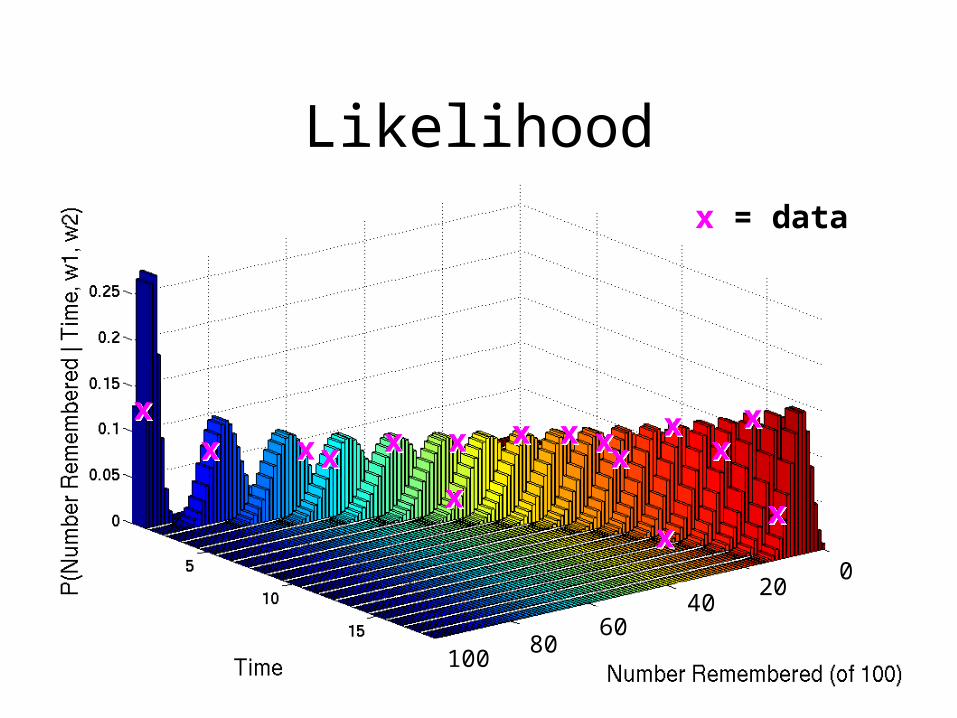
Likelihood
xxxx xx xx xx xx
xx
xx xx xx xxxx
xx
xxxx
xx
x = data
8060
4020
0
100

Likelihood
xxxx xx xx xx xx
xx
xx xx xx xxxx
xx
xxxx
xx
L(w1,w2 | x) = f(xi | w1,w2)ln L(w1,w2 | x) = ln f(xi | w1,w2)
8060
4020
0
100

Likelihood
xxxx
xx
xxxx
xx
xxxx
xx
xxxx
xxxx
xx
xx
xx
L(w1,w2 | x) = f(xi | w1,w2)ln L(w1,w2 | x) = ln f(xi | w1,w2)
8060
4020
0
100

Likelihood
• The w that maximize ln L(w1,w2 | x) = ln f(xi | w1,w2) are the maximum likelihood parameter estimates, w1
* & w2
*.

Falsifiability (Saturation)
• Old rule of thumb: A model is falsifiable if the number of parameters are less than the number of data points.
• New rule of thumb: A model is falsifiable iff the rank of the Jacobian is less than the number of data points.– A model is testable if the probability that a model’s
predictions are right by chance is 0.– Holds under certain smoothness assumptions.

Generalizability
• Generalizability (as defined by Myung) is the ability to generalize to new data from the same probability distribution.
• Data are corrupted by random noise & so goodness of fit reflects the models ability to capture regularities and fit noise.

Generalizability
• Goodness of fit = Fit to regularity (Generalizability) + Fit to noise (Overfitting)
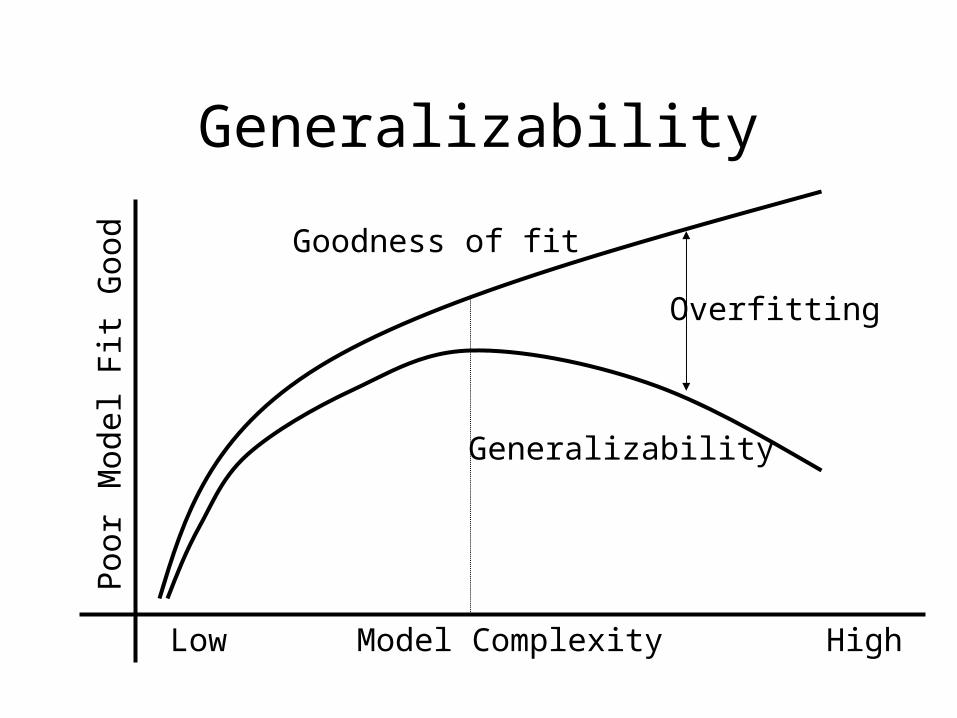
Generalizability
Model ComplexityLow High
Mod
el F
itP
oor
Goo
d Goodness of fit
Generalizability
Overfitting
Generalizability
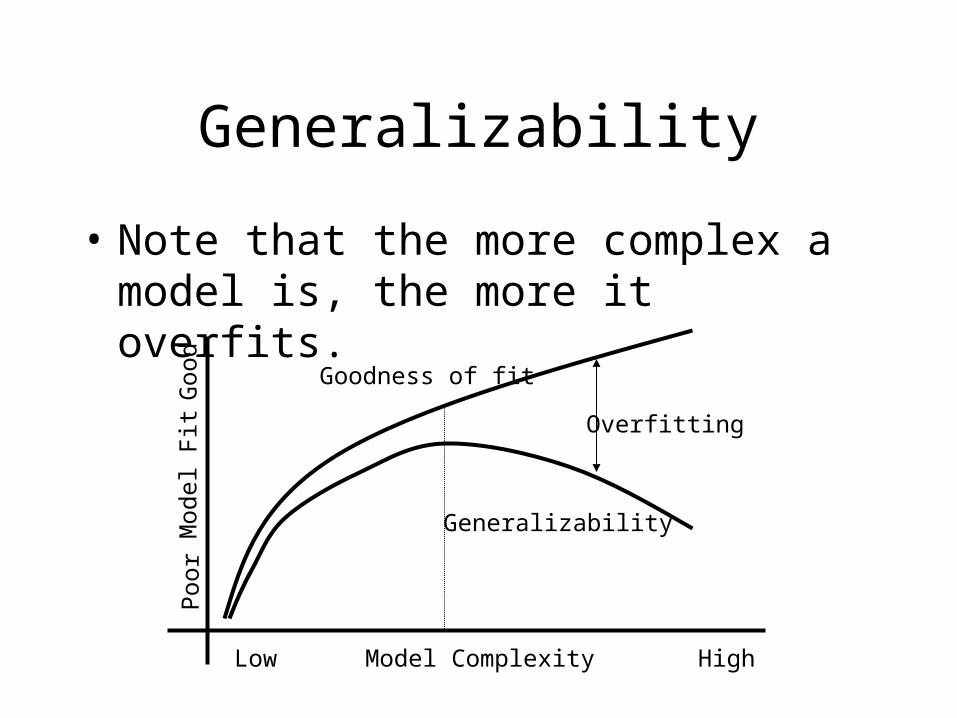
• Note that the more complex a model is, the more it overfits.
Model ComplexityLow High
Mod
el F
itP
oor
Goo
d
Goodness of fit
Generalizability
Overfitting

Generalizability
Model M1M2
(TRUE)M3 M4
y =
w1x+e
y =
ln(x + w1) + e
y =
w1 ln(x + w2) + w3 + e
y =
w1x + w2x2 + w3 + e
Training BOF 2.14 1.85 1.71 1.62
Testing BOF 2.29 2.05 6.48 3.44

Generalizability
• A good fit can be achieved simply because a model is more flexible.
• A good fit is necessary, but not sufficient for capturing underlying processes.
• A good fit qualifies the model as a candidate for further consideration.

Generalizability
• The key for many techniques is to find the model that fits future data best, not necessarily the “true” model.– There is rarely enough data to uniquely
identify the true model. – Even if there were, it will probably not be
one of the models under consideration.
• This is not to say that we don’t want to find the “true” model (if there is one).

Model Selection
• The quantity of interest is the lack of generalizability of a model.
• Essentially:• Goodness of fit = Fit to regularity
(Generalizability) + Fit to noise (Overfitting)• Generalizability = GOF - Overfitting• Generalizability = GOF - Complexity• So, -Generalizability = -GOF + Complexity

AIC
• Akaike Information Criterion (AIC)
• AIC is a lack of generalizability measure, so big is bad.

AIC
• AIC = -2 ln L(w*|y) + 2K– y are the data– w* are the MLE estimates– K is the number of model parameters

AIC
• AIC = -2 ln L(w*|y) + 2K
Badness of fit:Decreases with parameters.
Penalty for complexity:Increases with parameters.

AIC
• AIC measures complexity via number of parameters.
• Functional form is not considered.
QuickTime™ and aTIFF (LZW) decompressor
are needed to see this picture.
QuickTime™ and aTIFF (LZW) decompressor
are needed to see this picture.
1 parameter 2 parameters
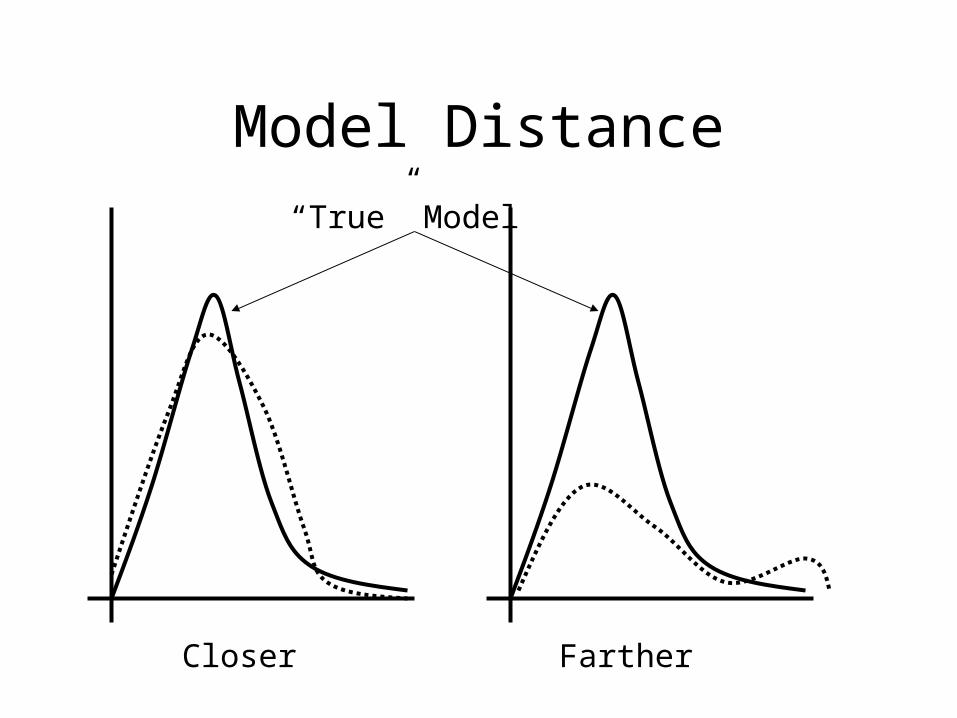
Model Distance
Closer Farther
“True” Model

AIC
• AIC selects a model from a set of models that on average minimizes the distance between the model and the “True” model.
• AIC does not depend on knowing the true model.
• Given certain conditions, K corrects a statistical bias in estimating this distance.

Cross Validation (2-Sample)
Data
Calibration
ModelFindw*
Validation
Usew*
CVI

Cross Validation
• Easy to use.
• Sensitive to functional form of model.
• Not as theoretically grounded as other methods such as AIC.

Cross Validation & AIC
• In single sample CV, the CVI is estimated from the calibration sample.
• Where Ls is the likelihood of the saturated model with 0 df.
€
AIC =N
2CVI − ln Ls( )

Minimum Descriptive Length
• Suppose the following are data described in bits:
– 0001000100010001000100010001
– 0111010011010000101010101011

Minimum Descriptive Length
• The data can be coded as:
– 0001000100010001000100010001• for i=1:7, disp(‘0001’), end
– 0111010011010000101010101011• disp(‘0111010011010000101010101011’)

Minimum Descriptive Length
• Regularity in data can be used to compress the data.
• The more regular the data are, relative to a particular coding method, the simpler the “program”.– The choice of coding method doesn’t
matter so much.

Minimum Descriptive Length
• Think of the ‘program’ as a model.• The model that best captures the
regularities in the data will give the shortest code length.– 0001000100010001000100010001
• for i=1:7, disp(‘0001’), end
– 0111010011010000101010101011• disp(‘0111010011010000101010101011’)

Minimum Descriptive Length
• Capturing data regularities will lead to good prediction of future data, i.e. good generalization.
• By finding the model with the minimum descriptive length, MDL will find the simplest model that predicts the data well.

Minimum Descriptive Length
• Under certain assumptions, MDL is given by:
€
MDL = −ln f (x |w*) +K
2lnn
2π+ ln det I(w)dw∫
Badness of fit.
Penalty for numberof parameters.
Penalty forfunctional form.Doesn’t depend on n.

Minimum Descriptive Length
€
MDL = −ln f (x |w*) +K
2lnn
2π+ ln det I(w)dw∫
Based on I, the Fischer Information Matrix. This term tells you how well the model can fit different data sets by tweaking the parameters.

Other Selection Criterion
• Bayesian model selection
• Bayesian Information Criterion (BIC)
• Generalization Criterion
• Monte Carlo Techniques
• Etc…