modelação de conceitos económicos em programação matemática · capítulo 1 introdução ......
TRANSCRIPT

Modelação de conceitos económicos em programaçãomatemática
Maria Mafalda de Lancastre e Távora Ceyrat
Dissertação para a obtenção do Grau de Mestre em
Matemática e Aplicações
Orientadores: Prof. Doutor Carlos José Santos AlvesProf. Doutor José Rui de Matos Figueira
Júri
Presidente: Prof.a Doutora Adélia da Costa Sequeira dos Ramos SilvaOrientador: Prof. Doutor José Rui de Matos FigueiraVogal: Prof.a Doutora Ana Leonor Mestre Vicente Silvestre
dezembro 2015

ii

Resumo
Nesta tese analisa-se a escolha e a combinação de funções multi-objetivo num problema de programação
matemática. O estudo baseia-se no artigo de J.N.Hooker e H.P.Williams [18], pretendendo dar resposta
a uma questão deixada em aberto em [18], relativamente a um problema de distribuição de recursos
escassos em saúde para certas classes de pacientes.
O objetivo consiste em analisar a escolha de uma nova função de equidade e modelar duas funções
combinadas, uma de utilidades e outra de equidade. Existem várias definições de equidade, assim como
várias abordagens e modelações, e o seu inverso pode ser visto como uma questão de iniquidade. Neste
caso, queremos encontrar a combinação que maximiza o problema de otimização.
Considera- se a programação matemática linear e alguns métodos de resolução de um problema multi-
objetivo. Mostramos como a escolha de uma função objetivo mais adequada ao problema de distribuição
de recursos, assim como de um método para a resolução de um problema PLIM alternativo, permitem
alargar o leque de possíveis soluções e encontrar melhores resultados.
Palavras Chave: Programação matemática, Programação multi-objetivo, Modelos de otimi-
zação
iii

iv

Abstract
In this work we analyze the choice and the combination of multi-objective functions in a mathemati-
cal programming problem. The study is motivated and based on the article “Combining Equity and
Utilitarianism in a Mathematical Programming Model” of J.N.Hooker and H.P.Williams [18].
The goal is to model two combined functions in the mathematical programming problem: the utility
function and the equity function. There are many definitions of equity, as well as approaches and models
to this concept, and the inverse can be seen as an inequality problem. Here, we search the combination
that maximizes the optimization problem.
Addressing a question raised by Hooker and Williams in [18], we analyze the choice of a new equity
function for the problem of healthcare policy in allocating scarce resources to classes of patients. It
is shown that the choice of a more appropriate function as well as the choice of an alternative MILP
resolution method, allows extending the range of possible solutions and lead to better results for this
problem.
Keywords: Mathematical programming, Multi-objective programing, Optimization models
v

vi

Agradecimentos
Agradeço ao Professor Carlos José Santos Alves e ao Professor José Rui de Matos Figueira, pelo seu
apoio, dedicação e disponibilidade na orientação assim como na revisão deste trabalho.
Agradeço ao Instituto Superior Técnico, pelos conhecimentos que adquiri e que me permitiram concluir
a dissertação e à Professora Ana Leonor Silvestre pela sua ajuda na adaptação e planeamento do mestrado.
Por último quero agradecer também à minha família e aos meus amigos pelo apoio e incentivo, e em
especial à minha mãe, ao meu pai, aos meus irmãos e ao Manuel Catarino por estarem presentes ao longo
do meu percurso académico.
vii

viii

Conteúdo
Resumo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . iii
Abstract . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . v
Lista de Tabelas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xiii
1 Introdução 1
1.1 Objetivos da dissertação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Estrutura e metodologia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2 Conceitos e definições 3
2.1 Programação matemática . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.1.1 Programação linear . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.1.2 Programação linear inteira mista (PLIM) . . . . . . . . . . . . . . . . . . . . . . . 4
2.1.3 Softwares usados para resolver problemas de programação lineares inteira mista . . 5
2.1.4 Programação não linear . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.5 Programação linear multi-objetivo . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.1.6 Otimização de problemas multi-objetivo . . . . . . . . . . . . . . . . . . . . . . . . 9
2.1.7 Objectivos max min . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.1.8 Conclusão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3 A matemática na economia 12
3.1 Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.2 O modelo de Hooker e Willimas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.3 Exemplos de modelos equitativos e comparação com os utilitaristas . . . . . . . . . . . . . 14
3.3.1 Negociação de Nash . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.3.2 Solução igualitarista . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.4 Exemplos de modelos de iniquidade e comparação com os utilitaristas . . . . . . . . . . . 17
3.4.1 Índice de Atkinson . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.4.2 Índice de Gini . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.4.3 O índice de Theil . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.4.4 Modelos utilitaristas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.5 Conclusão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
ix

4 Modelo alternativo 26
4.1 Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.2 Modelo inicial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.3 Alterações no modelo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.4 Modelo generalizado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.5 Análise dos dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.6 Implementação do modelo PLIM do artigo . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
4.7 Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
4.7.1 Abordagem estatística . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.7.2 Gráficos resultantes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.8 Conclusões . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5 Conclusões 47
6 Apêndice 49
6.1 Teoremas provados no artigo de J.N.Hooker e H.P. Williams . . . . . . . . . . . . . . . . . 49
x

Lista de Figuras
2.1 Ótimos globais e locais da função não linear . . . . . . . . . . . . . . . . . . . . . . . . . . 6
3.1 Função da negociação de Nash com u0 = 0 e u0 = 1 . . . . . . . . . . . . . . . . . . . . . 14
3.2 Corte do gráfico tridimensional da função da negociação de Nash com u0 = 0 e u0 = 1 . . 15
3.3 Combinação da função da negociação de Nash com a função utilitarista . . . . . . . . . . 15
3.4 Corte do gráfico tridimensional da função da negociação de Nash com a função utilitarista 15
3.5 Exemplo de uma função igualitarista . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.6 Exemplo de uma função combinada de igualdade com utilidade . . . . . . . . . . . . . . . 17
3.7 Função de Atkinson com ε = 1 e com ε 6= 1 . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.8 Função de Atkinson com ε = 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.9 Função de Atkinson com ε 6= 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.10 Corte do gráfico tridimensional da função de Atkinson com ε = 1 e com ε 6= 1 . . . . . . . 19
3.11 Função do índice de Gini . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.12 Combinação do índice de Gini com a função utilitarista . . . . . . . . . . . . . . . . . . . 21
3.13 Índice de Theill . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.14 Corte do gráfico tridimensional da função do índice de Theill . . . . . . . . . . . . . . . . 22
3.15 Combinação do índice de Theil com o utilitarismo . . . . . . . . . . . . . . . . . . . . . . 22
3.16 Corte do gráfico tridimensional da função do índice de Theil com o utilitarismo . . . . . 22
4.1 Resultados do modelo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
4.2 Resultados do modelo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.3 Resultados do modelo com variação na variável M . . . . . . . . . . . . . . . . . . . . . . 35
4.4 Resultados do modelo com variação na variável M . . . . . . . . . . . . . . . . . . . . . . 36
4.5 Resultados do modelo sem a variável M . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.6 Resultados do modelo com variação nas variáveis ci . . . . . . . . . . . . . . . . . . . . . . 38
4.7 Simulação 1 e 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.8 Simulação 3 e 4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.9 Simulação 5 e 6 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.10 Simulação 7 e 8 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
4.11 Simulação 9 e 10 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
4.12 Simulação 11 e 12 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
xi

4.13 Simulação 13 e 14 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.14 Simulação 15 e 16 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.15 Simulação 17 e 18 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.16 Simulação 19 e 20 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
4.17 Simulação 21 e 22 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
4.18 Simulação 23 e 24 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
4.19 Simulação 25 e 26 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.20 Simulação 27 e 28 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.21 Simulação 29 e 30 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
xii

Lista de Tabelas
2.1 Condições necessárias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
4.1 Dados do exemplo da saúde . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.2 Resultados das simulações . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.3 Resultados das simulações CPU . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
xiii

xiv

Capítulo 1
Introdução
Os modelos matemáticos começaram a aparecer na economia por volta do século XVIII. Com a revolução
industrial surge a necessidade de compreender e prever alterações económicas, nomeadamente, o compor-
tamento de agentes, questões de distribuições de bens e serviços, impostos, tarifas a atribuir e a melhoria
de processos industriais. A economia rege-se principalmente por análises estatísticas de comportamentos
e situações passadas, derivadas de modelos, de modo a compreender reacções e poder realizar previsões
[6].
A programação matemática é um suporte na modelação de problemas reais desde que os modelos
escolhidos estejam não só bem adaptados como também sejam consistentes. Caso contrário, pode levar a
análises erradas com conclusões que não se adaptam às situações. Mesmo após a escolha e implementação
de um método específico, que descreve certas propriedades da situação em estudo é construtivo analisar
o comportamento de modelos alternativos para o mesmo problema.
1.1 Objetivos da dissertação
Nesta dissertação pretende-se apresentar uma análise e fazer a implementação de modelos de programação
matemática para o problema de distribuição de recursos tratado no artigo de J.N.Hooker e H.P.Williams
“Combining Equity and Utilitarianism in a Mathematical Programming Model” [18].
São realizadas duas abordagens com diferentes objetivos. Em primeiro lugar, procura-se aprofundar
e acrescentar valor ao artigo e identificar objetivos para um trabalho futuro, conforme sugerido pelos
autores de [18]. Além disso, implementa-se um novo modelo de programação matemática e um novo
método para a sua resolução, como abordagem alternativa ao modelo de Hooker e Williams. O modelo e
o método alternativos são sugeridos no âmbito de uma resolução mais eficiente do problema. Realiza-se
uma análise estatística sobre os resultados obtidos com esta nova abordagem. A ferramenta usada para a
formulação do novo modelo, e implementação do novo método, é o programa CPLEX. Este é um trabalho
complementar, com o objetivo de enriquecer o trabalho já realizado no artigo mencionado.
1

1.2 Estrutura e metodologia
A dissertação incide na análise do modelo de programação matemática apresentado por J.N.Hooker
e H.P.Williams em [18] e na combinação de uma função de equidade com uma função de utilidade
adequadas, seguidas por uma investigação sobre possíveis modelos alternativos para um problema de
distribuição de recursos. O que se segue divide-se em três capítulos de desenvolvimento com a estrutura
que a seguir se descreve.
O Capítulo 2 consiste num levantamento dos conceitos e definições matemáticas referentes à progra-
mação linear e métodos de otimização que auxiliarão o estudo em causa.
No terceiro capítulo, faz-se uma enumeração de várias funções de equidade como possíveis substitutas
da função usada em [18], entre elas a solução clássica da negociação de Nash e a solução igualitarista.
Apresentam-se ainda alguns modelos iniquidade tais como o índice de Atkinson, o índice de Gini e o
índice de Theil. O capítulo termina com uma análise de modelos utilitaristas. Este capítulo visa preparar
o capítulo seguinte, ilustrando o problema para o caso de duas pessoas.
Por último, no Capítulo 4, considera-se a formulação matemática do problema para o caso de n pessoas.
Apresenta-se um modelo alternativo, com a sugestão de uma nova função de equidade, mais adequada
para a resolução do problema da distribuição de recursos em saúde. Usando o programa CPLEX, realiza-
se uma série de simulações com os dados fornecidos em [18]. Segue-se uma análise comparativa dos
resultados dos dois modelos testados e as conclusões obtidas neste estudo.
2

Capítulo 2
Conceitos e definições
Neste capítulo faz-se uma revisão de conceitos importantes em Programação Matemática de problemas
lineares e não lineares.
Começa-se por uma breve explicação da programação matemática e das suas variantes - programação
linear, linear inteira mista, não linear - e métodos de linearização de problemas com múltiplos objetivos. A
seguir, faz-se a descrição do método usado na dissertação para a otimização de problemas multi-objetivo.
2.1 Programação matemática
A programação matemática é frequentemente usada na modelação de problemas de Engenharia, Econo-
mia, Gestão, Biologia e outras ciências. Os modelos de programação matemática têm presente o conceito
de otimização (maximização ou minimização) de um ou múltiplos objetivos ( ver [19]). Na resolução de um
problema multi-objetivo usam-se técnicas, tais como a programação por objetivo, o método lexicográfico,
a otimização min max, a combinação linear por pesos e o método da restrição - ε [9].
2.1.1 Programação linear
A programação linear, regra geral, é o caso mais simples de resolver em programação matemática. Um
problema de programação linear é descrito por funções lineares das variáveis de decisão. O problema
geral pode ser expresso da seguinte forma (cf. [13]):
maximizar∑nj=1 cjxj
sujeito a:∑nj=1 aijxj ≤ bi, i = 1, ...,m
xj ≥ 0, j = 1, ..., n,
(2.1)
ou adicionando as variáveis de folga, xn+1, ..., xn+i, ..., xn+m:
3

maximizar∑nj=1 cjxj
sujeito a:∑nj=1 aijxj + xn+i = bi, i = 1, ...,m
xj ≥ 0, j = 1, ..., n
xn+i ≥ 0, i = 1, ...,m
(2.2)
onde bi e aij são restrições fixas e xi as variáveis de decisão.
Um problema de programação linear que não se encontre nesta forma pode ser convertido através
de modelos de linearização para, a partir daí, se aplicar os métodos de resolução correntes em funções
lineares. As funções lineares têm propriedades desejadas como a convexidade. Estas propriedades podem
ser encontradas no livro de Luenberger (2008) “Linear and Nonlinear Programming” [25].
2.1.2 Programação linear inteira mista (PLIM)
A programação linear inteira mista é um caso particular de programação matemática. Um problema
de programação linear inteira pode tomar várias formas, entre elas a programação linear inteira mista
(PLIM), a programação linear inteira pura (PLIP) e a programação linear inteira binária (PLIB).
A formulação padrão da programação linear inteira mista é representada e definida da forma (cf. [13]):
maxx,y,z{cTx+ dT y + vT z : Ax+Dy + Ez 6 b, x ∈ Rn1
+ , y ∈ Zn2+ , z ∈ {0, 1}n3} (2.3)
onde n1 é a dimensão do espaço vetorial das variáveis reais, n2 é a dimensão do espaço vetorial das
variáveis inteiras e n3 é o número de variáveis binárias, A ∈ Rm×n1 , D ∈ Rm×n2 , E ∈ Rm×n3 , e b ∈ Rm.
Definição 2.1.1. Considere-se o conjunto de desigualdades lineares e de variáveis contínuas e inteiras
da forma:
Ax+Dy + Ez 6 b,
x ∈ Rn1+ ,
y ∈ Zn2+ ,
z ∈ {0, 1}n3 .
(2.4)
Diz-se que a desigualdade é uma formulação PLIM para um conjunto Z ⊆ Rn1 se a projeção de (2.4) nas
variáveis x é exatamente Z. Ou seja, se x ∈ Z se e só se existirem y ∈ Zn2 e z ∈ Zn3 tais que (x, y, z)
satisfaz (2.4) [27].
Definição 2.1.2. A relaxação contínua é uma técnica de modelação que no caso do problema (2.4)
consiste em eliminar as restrições de integralidade y ∈ Zn2+ , z ∈ {0, 1}n3 de modo a que as variáveis y e
z possam assumir valores em Rn2+ e [0, 1] por exemplo, mantendo a mesma função objetivo do problema
PLIM [27].
4

No que se segue, designamos por conv(Z) de um conjunto discreto Z o conjunto de todas as combi-
nações convexas dos seus pontos (|Z| = p):
conv(Z) = {p∑i=1
λizi :
p∑i=1
λi = 1, λi > 0, i = 1, ..., p}.
Definição 2.1.3. Uma formulação PLIM do conjunto Z ⊂ Rn1+ é uma formulação afinada se, e só se, a
projeção nas variáveis x da sua relaxação contínua for exatamente conv(Z) [27].
2.1.3 Softwares usados para resolver problemas de programação lineares in-
teira mista
Os problemas PLIM podem ser resolvidos através de software atualmente desenvolvidos. Hillier e
Lieberman[17] referem exemplos como o Excel, LINGO/LINDO, e MPL/CPLEX os quais incluem um
algoritmo para a resolução de modelos puros ou mistos, uns mais complexos que outros, da programa-
ção inteira binária, assim como algoritmos para resolver modelos de programação inteira gerais (pura
ou mista) onde as variáveis são inteiras mas não binárias. Nesta dissertação irá ser usado o programa
CPLEX da IBM.
2.1.4 Programação não linear
A programação não linear é muito comum nos casos práticos. Em geral, é composta por uma função
objetivo, restrições gerais e variáveis, onde pelo menos uma função é não linear a qual pode ser a função
objetivo ou uma das restrições [7].
Nestes problemas o ótimo não está restrito aos pontos extremos, o que torna difícil distinguir o ótimo
global do ótimo local. A programação não linear pode aparecer em diversos formatos não existindo um
único algoritmo para resolver todos os casos [17]. De forma geral, o problema de programação não linear
está em encontrar x = (x1, x2, ..., xn) tal que:
max f(x)
sujeito a: gi(x) 6 bi , para i = 1, 2, ..., n
(2.5)
onde f(x) e g(x) são funções com n variáveis de decisão.
Geometricamente, problemas não lineares comportam-se de forma diferente dos lineares. Nestes pro-
blemas uma solução ótima local não é necessariamente o ótimo global.
Definição 2.1.4 (Máximo global e Máximo local). Seja x = (x1, x2, ..., xn) uma solução dentro da região
admissível para um problema de maximização com a função objetivo f(x). x é:
• Um máximo global se f(x) > f(y) para qualquer ponto y = (y1, y2, ..., yn) dentro da região admis-
sível;
• Um máximo local se f(x) > f(y) para qualquer ponto y = (y1, y2, ..., yn) dentro da região admissível
suficientemente perto de x. Ou seja, se existir um número ε > 0 tal que, sempre que cada variável
5

yj esteja entre: xj − ε 6 yj 6 xj + ε e y na região admissível, então f(x) > f(y).
Figura 2.1: Ótimos globais e locais da função não linear
Na figura 2.1 os pontos a vermelho são os ótimos globais e os pontos a azul são os ótimos locais. O
caso mais simples de otimização não linear tem apenas uma função objetivo não linear sem restrições e
envolve uma única variável. Onde a função f(x) a ser maximizada é côncava. As condições necessárias
para uma solução particular x = x∗ ser ótima (máximo global), são:
∇f = (∂f
∂x1,∂f
∂x2, ...,
∂f
∂xn) = 0 em x = x∗ (2.6)
Assume-se que a função objetivo f(x) é diferenciável, ou seja, possui um gradiente ∇f(x) a cada ponto
x.
Não existe um algoritmo que resolva todos os problemas específicos da programação não linear, con-
tudo, certos casos podem ser resolvidos ao criar hipóteses sobre as funções não lineares [17]. As condições
necessárias para o ótimo variam com o tipo de problema:
Problema com uma variável sem restrições ∂f∂x = 0
Problema com multiplas variáveis sem restrições: ∂f∂xj
= 0 , (j = 1, 2, ..., n)
Problema com restrições gerais: condições Karush-Kuhn-Tucker
Tabela 2.1: Condições necessárias
As condições suficientes que consideramos são a da convexidade de gi(x), i = 1, ...,m e a concavidade
de f(x).
Considerando o problema de encontrar o mínimo ou o máximo da função f(x), sujeita à restrição de
x satisfazer todas as seguinte equações:
6

g1(x) = b1
g2(x) = b2
.
.
.
gm(x) = bm,
(2.7)
onde m < n. Um método clássico de resolução deste problema é o método dos multiplicadores de
Lagrange. O processo começa com a formulação da função de Lagrange [17]:
h(x, λ) = f(x)−m∑i=1
λi[gi(x)− bi], (2.8)
onde as variáveis λ = (λ1, λ2, ..., λm) são os multiplicadores de Lagrange. De notar que para os valores
admissíveis de x,
gi(x)− bi = 0 , para todo o i, (2.9)
então h(x, λ) = f(x). Assim, pode ser mostrado que se (x, λ) = (x∗, λ∗) for um mínimo local ou global,
ou um máximo local ou global da função sem restrições h(x, λ), então x∗ é o ponto crítico correspondente
ao problema original (ponto onde gradiente iguala a zero). Como resultado, o método reduz-se à análise
de h(x, λ) pelo processo de análise de funções sem restrições da Tabela 2.1. Assim, as derivadas parciais
m+ n tomaram o valor de zero
∂h∂xj
= ∂f∂xj−∑mi=1 λi
∂gi∂xj
= 0 , para j = 1, 2, ..., n
∂h∂λj
= −gi(x) + bi = 0, para i = 1, 2, ...,m
(2.10)
os pontos críticos são obtidos ao resolver a equações para (x, λ). Verifica-se que as últimas m equações
são equivalentes às restrições no problema original, assim apenas soluções dentro da região admissível são
consideradas. Após a análise para identificar o mínimo ou o máximo global de h(·), o valor resultante de
x é a solução desejada do problema original.
As condições para o caso geral são as condições de Karush-Kuhn-Tucker (condições KKT). O seu
resultado está incorporado no seguinte teorema:
Teorema 2.1.1. Assume-se que f(x), g1(x), g2(x), ..., gm(x) são funções diferenciáveis que satisfazem
certas condições de regularidade. Então:
x∗ = (x∗1, ..., x∗n)
pode ser a solução ótima para o problema de programação não linear apenas se existirem m números
λ1, λ2, ..., λm tal que todas as seguintes condições de KKT sejam satisfeitas:
7

1. ∂f∂xj−∑mi=1 λi
∂gi∂xj
= 0, em x = x∗, para j = 1, 2, ..., n
2. gi(x∗)− bi 6 0 para j = 1, 2, ...,m
3. λi[gi(x∗)− bi] = 0 para j = 1, 2, ...,m
4. λ∗i > 0 para j = 1, 2, ...,m
A condição 3 pode ser combinada com a 2 de modo a serem expressas na forma equivalente:
(2,3) gi(x∗)− bi = 0 (ou 6 0 se λi = 0), para i = 1, 2, ...,m
De notar que satisfazer estas condições não garante que a solução seja ótima, é necessário adicionar
as condições de convexidade para obter tal garantia [17].
Corolário 2.1.1. Assume-se que f(x) é uma função convexa e que g1(x), g2(x), ..., gm(x) são funções
convexas (i.e., é um problema de programação convexa), onde todas estas funções satisfazem as condições
de regularidade. Então x∗ = (x∗1, x∗2, ..., x
∗n) é uma solução ótima se, e só se, todas as condições do
teorema forem satisfeitas [17].
2.1.5 Programação linear multi-objetivo
Na programação linear podem existir problemas multi-objetivo. Existem diversas técnicas de modelação
e estratégias de solução que podem ser aplicadas a tais problemas. O modelo de programação linear
multi-objetivo toma a forma (cf. [13]):
maximizar z1 = c1>x
...
maximizar zl = cl>x
...
maximizar zk = ck>x
sujeito a: Ax ≤ b,
x ≥ 0
(2.11)
onde Rn é o espaço de decisão, n é o número de variáveis de decisão, k é o número de objetivos e Rk é o
espaço de desempenho.
Definição 2.1.5. A X = {x ∈ Rn : Ax ≤ b, x ≥ 0} chama-se região admissível no espaço de decisão e a
Z = {z ∈ Rk : z1 = c1Tx, ..., zk = ckTx, x ∈ X} chama-se a região admissível no espaço de desempenho.
Introduzimos ainda as seguintes definições:
Definição 2.1.6 (Dominância). Seja z′, z′′ ∈ Rk dois vetores de desempenho. Então z′ domina z′′ se, e
só se, z′ ≥ z′′ e z′ 6= z′′. (i.e., z′l > z′′l para todo o l e z′l > z′′l para pelos menos um l ).
Definição 2.1.7 (Dominância forte). Seja z′, z′′ ∈ Rk dois vetores de desempenho. Então z′ domina
fortemente z′′ se, e só se, z′ > z′′ e z′ 6= z′′ (i.e., z′l > z′′l para todo o l ).
8

Definição 2.1.8 (Vetor de desempenho não dominado). Seja z̄ ∈ Z. Então z̄ é não dominado se, e só
se, não existir outro z ∈ Z tal que z ≥ z̄ e z 6= z̄. Caso contrário, z̄ é um vetor de desempenho dominado.
Denota-se por N o conjunto dos vetores de desempenho não dominados.
Definição 2.1.9 (Conjunto de dominância). Seja x̄ ∈ X e C≥ o cone polar semi positivo gerado pelos
gradientes das k funções objetivo definido por:
C≥ = {x ∈ Rn : C>x ≥ 0, C>x 6= 0} ∪ {0 ∈ Rn}.
O conjunto de dominância no ponto x̄ é definido por:
Dx̄ = {x̄} ⊕ C≥
Definição 2.1.10 (Vetores suportados e não dominados). O vetor z̄ ∈ Z é um vetor de desempenho
suportado e não dominado se, e só se, z̄ ∈ N e z̄ ∈ fr(Z≤), ou seja, pertence à fronteira de Z
Definição 2.1.11 (Vetores não suportados e não dominados). O vetor z̄ ∈ Z é um vetor de desempenho
não suportado e não dominado se, e só se, z̄ ∈ N e z̄ ∈ int(Z≤), ou seja, pertence ao interior de Z.
Definição 2.1.12 (Vetores não dominados e suportados no extremo). Seja z̄ ∈ N um vetor de desem-
penho suportado e não dominado. Então z̄ é um vetor de desempenho não dominado e suportado no
extremo se for um ponto no extremo de Z≤. Caso contrário, z̄ é suportado mas não no extremo.
Quando se considera um problema multi-objetivo, o conceito de ótimo é substituído pelo conceito de
eficiência.
Definição 2.1.13 (Ponto (solução) eficiente). Um ponto (solução) x̄ ∈ X é eficiente se e só se não
existir outro x ∈ X tal que CTx ≥ CT x̄ e CTx 6= CT x̄. Caso contrário, x̄ é ineficiente.
Uma solução eficiente pode ser caracterizada da seguinte forma:
Teorema 2.1.2. A solução x̄ é eficiente se, e só se, Dx̄ ∩X = {x̄}.
Definição 2.1.14 (Conjunto de Pareto-ótimo global). O conjunto de soluções não dominadas da região
admissível Z é o conjunto de Pareto-ótimo global. [10]
Definição 2.1.15 (Conjunto de Pareto-ótimo local). Se para cada z num conjunto Z não existir uma
solução z′ (na vizinhança de z tal que ||z′ − z||∞ ≤ ε, onde ε é um número pequeno e positivo) que
domina qualquer elemento do conjunto Z, então as soluções pertencentes ao conjunto de Z constituem
um conjunto de Pareto-ótimo local. [10]
2.1.6 Otimização de problemas multi-objetivo
Nesta dissertação aplica-se um método de otimização combinatória de um problema bi-objetivo. O
método empregue é o da restrição ε em seguida enunciado.
9

Método da restrição - ε
O método da restrição - ε é uma das técnicas aplicadas à otimização e resolução de um problema multi-
objetivo. Este método permite resolver problemas com restrições ao transformar um dos objetivos numa
restrição, tomando a forma (cf. [13]):
maximizar z1
sujeito a:∑nj=1 aijxi ≤ bi, i = 1, ...,m
z1 =∑nj=1 cjxj , j = 1, ..., n
z2 =∑nj=1 djxj , j = 1, ..., n
z2 ≥ ε
xj ∈ {0, 1}
(2.12)
É de grande utilidade para descobrir todas as soluções possíveis incluindo as soluções dominadas, dando às
partes interessadas uma maior variedade de escolhas pois a escolha ótima para um certo indivíduo pode-se
encontrar neste “leque” e não ser necessariamente a solução ótima eficiente do problema. À medida que o
número de objetivos aumenta, as trocas tornam-se complexas e dificilmente quantificáveis. Os requisitos
para uma estratégia de modelação de problemas multi-objetivo são os de permitir, e conseguir, que a
formulação de um problema natural seja fielmente expressa com a capacidade de resolução do problema
e da introdução de preferências no problema modelado [16].
Se algumas das funções, ou restrições, entrarem em conflito, a solução do problema deixa de ser única.
A otimização multi-objetivo está relacionada com a capacidade de gerar e selecionar pontos com soluções
de Pareto.
O método da restrição - ε ultrapassa alguns problemas de convexidade presentes em outros métodos.
Esta abordagem permite identificar um número de soluções de Pareto num conjunto não convexo.
Um problema neste método é, contudo, a escolha certa de ε de modo a garantir uma solução admissível.
O método é resolvido por um algoritmo onde o parâmetro ε assume valores da função objetivo que
não podem ser excedidos. O método começa por minimizar uma das funções objetivo, considerando os
outros objetivos como restrições limitadas pelos valores de ε. Ao variar os valores de ε são obtidas as
soluções do problema [9].
2.1.7 Objectivos max min
Existem situações em que a função objetivo é do tipo:
maximizar (minimo∑i aijxj)
sujeito às convencionais restrições lineares(2.13)
o que pode ser convertido numa forma de programação linear ao introduzir uma variável z que represente
o objetivo acima. Em adição às restrições originais, expressa-se o modelo transformado como:
10

maximizar z
sujeito a: z ≤∑j aijxj para todo o i
(2.14)
As novas restrições garantem que z será maior ou igual a cada∑j aijxj para todo o i. De forma similar,
o problema é também resolvido como maximin. Contudo, um problema maximax ou minimin, devido
às propriedades das suas funções objetivo, não pode ser transformado e resolvido com um problema de
programação linear [15].
2.1.8 Conclusão
A programação matemática pode estar dividida entre um único objetivo e multi-objetivos. Estes podem
ser lineares ou não lineares. Um dos métodos usados em problemas com multi-objetivos é o método da
restrição - ε. Existem softwares que ajudam na implementação e resolução de problemas com grandes
dimensões, diversas funções e variáveis, entre eles o CPLEX.
Os modelos analisados no próximo capítulo são os propostos por Hooker e Williams [18] para a
resolução do problema da distribuição de recursos em saúde, com o propósito de decidir se estes devem
ser distribuídos equitativamente ou de modo a maximizar a utilidade. Assim realizar-se-á o levantamento
de modelos de equidade, iniquidade e utilitaristas, os quais serão usados na análise da otimização do
problema nos capítulos seguintes.
No próximo capítulo estes modelos serão implementados como alternativa aos usados por Hooker e
Williams seguindo uma sugestão dos próprios autores.
11

Capítulo 3
A matemática na economia
3.1 Introdução
Um dos objetivos desta dissertação consiste na modelação de duas funções combinadas: a função de
utilidade com a função de equidade. Neste capítulo abordam-se as questões deixadas em aberto pelos
autores. Hooker e Williams sugerem, como seguimento do seu trabalho [18], a escolha de uma nova função
de equidade, alternativa à definição Rawlsiana utilizada.
Fica em aberto a oportunidade de contribuir para o trabalho realizado por Hooker e Williams de uma
maneira construtiva. Assim serão criadas as novas funções de acordo com os objetivos enumerados. Será
usado o programa Mathematica para a representação gráfica das novas funções sugeridas pelos autores
no problema para duas pessoas. Os modelos de equidade e de iniquidade em análise são:
• Modelos de equidade:
- A Negociação de Nash: os problemas de negociação analisam como dois indivíduos devem coo-
perar quando a ausência de cooperação leva a resultados com soluções ineficientes, é um problema
de seleção de equilíbrio. No caso da negociação de Nash é imposto que a solução satisfaça certos
axiomas como a invariância na escala, otimalidade de Pareto, alternativas independentes e simetria;
- A Solução igualitarista: como na Negociação de Nash, este é um problema de negociação mais
próxima das ideias de John Rawls. Não tem a condição de invariância na escala e tem a condição
da monotonia;
• Modelos de iniquidade:
- O índice de Atkinson: é uma medição de rendimentos não equitativos, determina que parte da
distribuição contribuiu mais para a iniquidade observada;
- O índice de Gini: é uma medida de dispersão estatística que representa a distribuição dos rendi-
mentos de um grupo de indivíduos;
- O índice de Theil: é uma estatística usada para medir a iniquidade económica. É a entropia
maxima dos dados menos a estropia observada. Também pode ser visto como uma medida de re-
12

dundância, falta de diversidade, isolamento, segregação.
3.2 O modelo de Hooker e Willimas
Hooker e Williams discutem o problema da combinação dos objetivos conflituosos da equidade e do uti-
litarismo nas políticas sociais, num único modelo de programação matemática. A definição de equidade
usada por eles é a de Rawls, ”maximizar a utilidade mínima dos indivíduos ou de uma classe de in-
divíduos”. À medida que a disparidade das utilidades aumenta, o objetivo torna-se progressivamente
utilitarista. A criação de um modelo de programação linear inteira mista (PLIM), de acordo com os
autores, levanta questões técnicas devido à não convexidade da função objetivo e do hipografo, na sua
forma inicial, não ser representável de forma PLIM. Contudo, mostram uma formulação sucinta e afinada,
na medida em que a relaxação do problema de programação linear [27] corresponde ao fecho convexo do
conjunto de soluções admissíveis.
O problema consiste numa população de indivíduos (ou classe de indivíduos) e na atribuição das
utilidades por esses indivíduos u1, ..., un. O objetivo combinado é, por um lado, o de maximizar a utilidade
do pior, max min{ui}, caso não tire demasiados recursos a outros e, por outro lado, o de maximizar a
soma de todas as utilidades. No caso para n = 2, o ponto de viragem ocorre quando a inequação exceder
|u1 − u2| > ∆, a função objetivo torna-se numa função utilitarista: u1 + u2.
Uma das principais questões com que J.N.Hooker e H.P. Williams se depararam é o nível a que definem
a variável ∆. Esta é uma situação de juízo e provavelmente um ponto de desacordo, segundo os mesmos.
Contudo, uma vez definido, maximizar a função de bem estar social permite que a mesma política seja
aplicada sempre que seja feita uma decisão orçamental.
Hooker e Williams escrevem a combinação linear dos objetivos utilitaristas e Rawlsianos:
∑i
ui + αmini{ui}
mais fácil de modelar uma vez que é côncava. O parâmetro α permite transformar a combinação linear
numa função contínua, contudo, para Hooker e Williams tal é difícil de justificar. Antes de enunciar
o caso geral, os autores focam-se na formulação do modelo para o caso de duas pessoas, definindo o
parâmetro α com o valor de 2. Assim, o problema fica:
max z
sujeito a :
z 6
2 min{u1, u2}+ ∆ se |u1 − u2| 6 ∆
u1 + u2 caso contrário
u1, u2 > 0
(3.1)
13
3.3 Exemplos de modelos equitativos e comparação com os utili-
taristas
Para a substituição da função de equidade Rawlsiana foram propostas em [18] outras funções de equidade.
De seguida analisam-se duas dessas funções, a função da negociação de Nash e a função da solução
igualitarista.
Definição 3.3.1 (Equidade). A equidade na economia é o tratamento justo entre os indivíduos.
3.3.1 Negociação de Nash
A solução de negociação de Nash é a maximização do produto de Nash [2] :
arg maxu>u0
ΠNi=1(ui − u0
i ) (3.2)
onde o argmaxui f(ui) := {ui|∀uj : f(uj) ≤ f(ui)}, i = 1, .., n e j = 1, ..,m. Após o requisito mínimo ser
satisfeito para todos os indivíduos, os recursos restantes são distribuídos de acordo com as condições de
cada indivíduo. A otimização do problema (2) é equivalente à seguinte otimização:
arg maxu>u0
N∑i=1
log(ui − u0i ). (3.3)
Ao aplicar esta função ao problema para duas pessoas, obtém-se uma função da seguinte forma:
argmaxu>u0(log(u1 − u01) + log(u2 − u0
1)). (3.4)
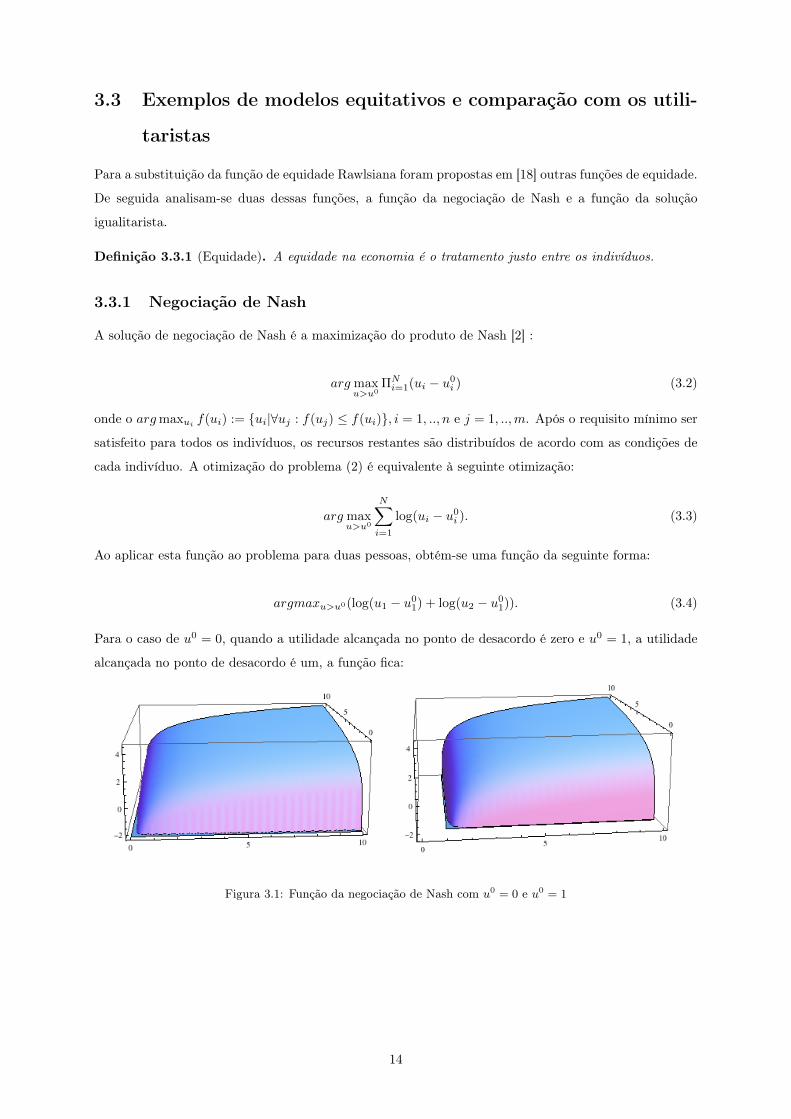
Para o caso de u0 = 0, quando a utilidade alcançada no ponto de desacordo é zero e u0 = 1, a utilidade
alcançada no ponto de desacordo é um, a função fica:
Figura 3.1: Função da negociação de Nash com u0 = 0 e u0 = 1
14
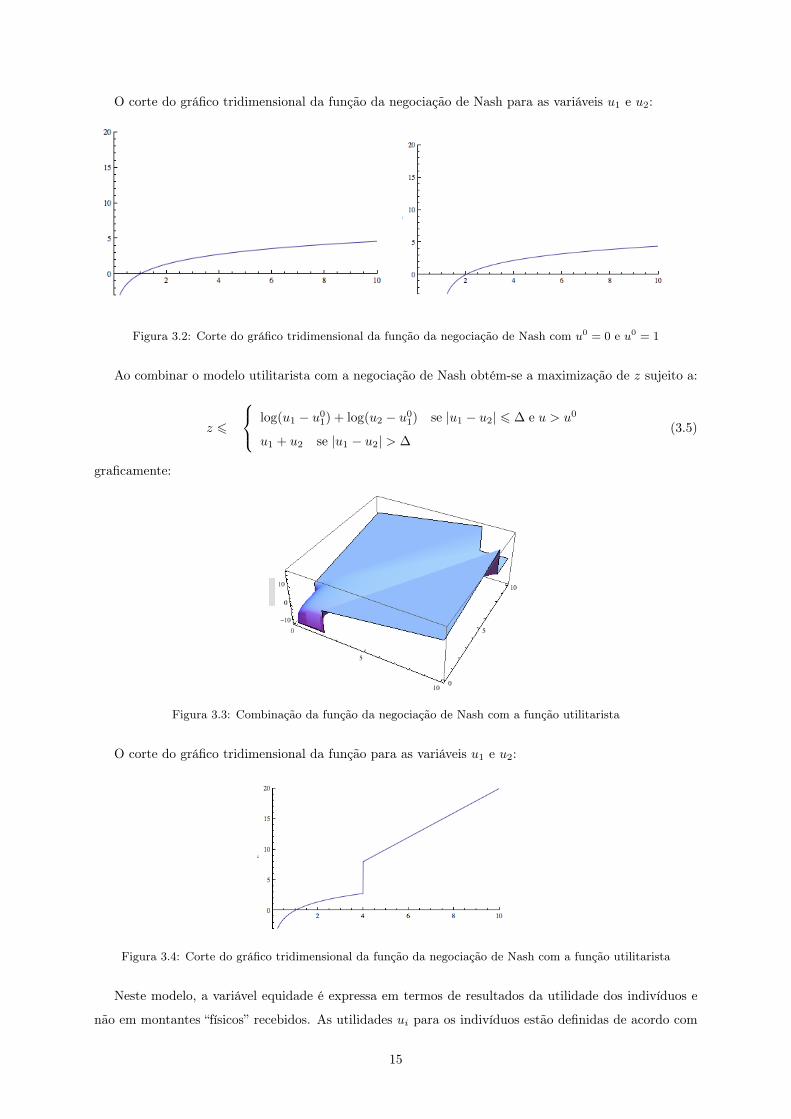
O corte do gráfico tridimensional da função da negociação de Nash para as variáveis u1 e u2:
Figura 3.2: Corte do gráfico tridimensional da função da negociação de Nash com u0 = 0 e u0 = 1
Ao combinar o modelo utilitarista com a negociação de Nash obtém-se a maximização de z sujeito a:
z 6
log(u1 − u01) + log(u2 − u0
1) se |u1 − u2| 6 ∆ e u > u0
u1 + u2 se |u1 − u2| > ∆(3.5)
graficamente:
Figura 3.3: Combinação da função da negociação de Nash com a função utilitarista
O corte do gráfico tridimensional da função para as variáveis u1 e u2:
Figura 3.4: Corte do gráfico tridimensional da função da negociação de Nash com a função utilitarista
Neste modelo, a variável equidade é expressa em termos de resultados da utilidade dos indivíduos e
não em montantes “físicos” recebidos. As utilidades ui para os indivíduos estão definidas de acordo com
15

a percepção de utilidade de cada um. A diferença deste modelo, para o usado no artigo, está no objetivo
de maximizar a soma dos produtos das diferenças da utilidade de cada indivíduo para a utilidade mínima
do conjunto de indivíduos. Deste modo, verificam-se variações crescentes e quando estas atingem uma
diferença de |u1 − u2| 6 ∆, a função passa a ser puramente utilitarista. A equidade passa a ser definida
em termos dos resultados do bem estar da utilidade dos indivíduos e não em níveis de satisfação como os
medidos na função Rawlsiana [29].
3.3.2 Solução igualitarista
A solução igualitarista é o ponto na região admissível onde o conjunto de todos os indivíduos atingem
um aumento da utilidade máxima igual com respeito ao ponto de desacordo (cf. [2]):
max{u > u0|ui − u0i = uj − u0
j ,∀i, j ∈ N} (3.6)
alternativamente pode ser formulada como max−min:
φ(U, u0) = argmaxu∈U
min(u1 − u01, . . . , un − u0
n) (3.7)
onde U é o conjunto de todas as utilidades. De acordo com as condições da definição da solução iguali-
tarista [2], a utilidade para um indivíduo j, pode ser descrita como:
uj = u1 − u01 + u0
j ,∀j ∈ N (3.8)
no problema de duas pessoas tem-se:
u2 = u1 − u01 + u0
2 (3.9)
graficamente:
Figura 3.5: Exemplo de uma função igualitarista
Como foi feito em (3.5), combinada-se a solução igualitarista com o modelo utilitarista. Ao atingir
uma diferença de |u1−u2| 6 ∆, a função a torna-se puramente utilitarista. Ficando assim o novo modelo
a maximizar z sujeito a:
16

z 6
u1 − u01 + u0
2 se |u1 − u2| 6 ∆
u1 + u2 se |u1 − u2| > ∆(3.10)
graficamente:
Figura 3.6: Exemplo de uma função combinada de igualdade com utilidade
O modelo com a solução igualitarista permite analisar o ponto onde todos os indivíduos atingem um
igual aumento da utilidade máxima com respeito ao ponto de desacordo [2]. A desvantagem está na
especificidade deste modelo, tornando-o pouco adaptável. Como na negociação de Nash, estes resultados
são medidos em níveis de bem estar.
3.4 Exemplos de modelos de iniquidade e comparação com os
utilitaristas
Os modelos de iniquidade existentes estão presentes nas análises económicas de problemas atuais. A
escolha do modelo de iniquidade adequado exige uma análise mais detalhada do que a escolha do mo-
delo de equidade. Na ausência de um critério claro, a escolha baseia-se usualmente por conveniência,
familiaridade, fundamentos metodológicos ou nos axiomas da iniquidade [1].
Definição 3.4.1 (Iniquidade). A iniquidade na economia é o tratamento injusto entre os indivíduos.
3.4.1 Índice de Atkinson
O índice de Atkinson é uma das medidas de iniquidade mais referenciadas [3]. Este índice permite a
variação da sensibilidade das iniquidades nas diferentes partes da distribuição dos rendimentos através
de um parâmetro de sensibilidade ε, conhecido como “parâmetro de aversão à iniquidade”, o qual pode
variar entre 0, quando o indivíduo é indiferente à natureza da distribuição dos rendimentos dado que
a distribuição é equitativa, e infinito, quando o indivíduo está preocupado apenas com a posição do
rendimento do grupo que possuí menores rendimentos.
O índice de Atkinson está diretamente relacionado com a classe aditiva das funções de bem estar
social:
17

W =1
N
n∑i=1
f(ui), (3.11)
pois a expressão mostra que o bem estar social é representado pela utilidade média. A forma da função
f , de acordo com Atkinson, é a seguinte:
f(ui) =
1
1−εu1−εi ε 6= 1
log ui ε = 1
ui ε = 0, caso utilitarista
(3.12)
Assim, o modelo depende do valor ε que representa um juízo de valor. Graficamente:
Figura 3.7: Função de Atkinson com ε = 1 e com ε 6= 1
À medida que ε aumenta, atribui-se um peso maior a aumentos, em rendimentos baixos, na produção
do bem estar social. Significa que a função do bem estar social deve ter W ′′ < 0, isto é, deve ser côncava.
Graficamente quando o índice é mais baixo, a distribuição do rendimento é mais equitativa. O índice
de Atkinson é mais eficiente quando usado num problema de comparação entre conjuntos ou grupos. O
índice tem como desvantagem o facto de ser pouco intuitivo [23]. Combinando o caso equitativo com o
caso utilitarista:
z 6
log ui se |u1 − u2| 6 ∆ e ε = 1, i = 1, 2
11−εu
1−εi se |u1 − u2| 6 ∆ e ε 6= 1, i = 1, 2
ui se |u1 − u2| > ∆, i = 1, 2.
(3.13)
Graficamente:
18
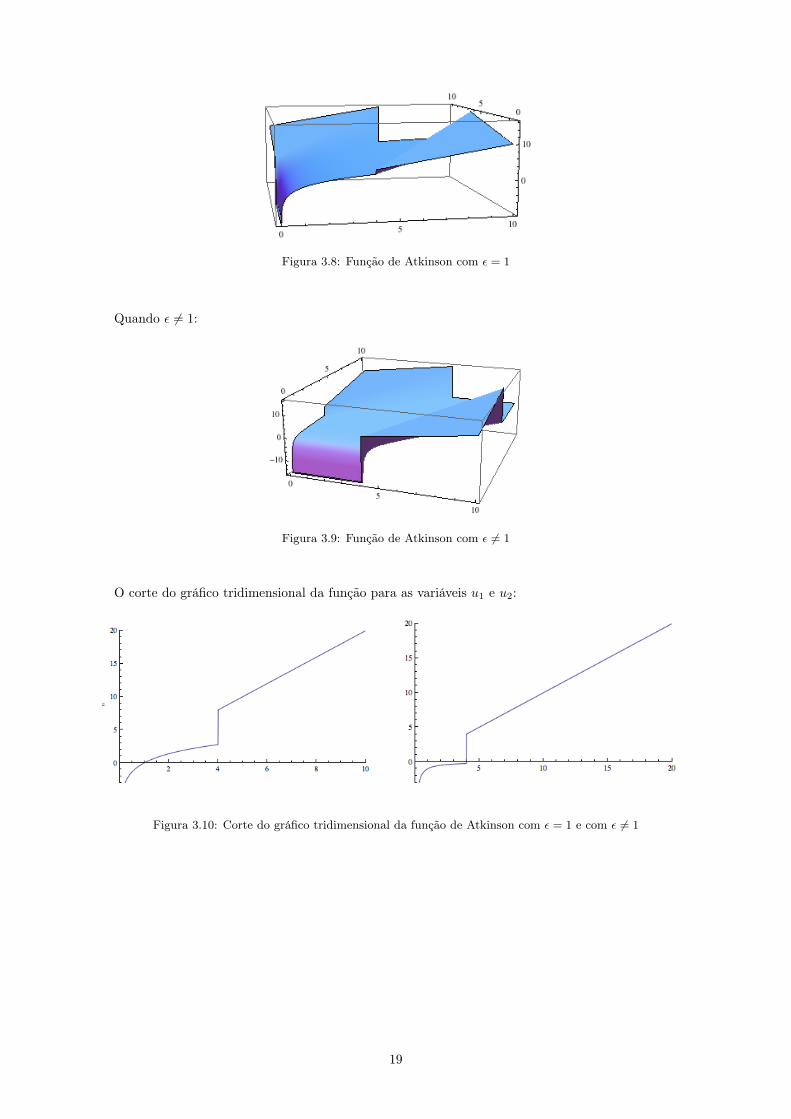
Figura 3.8: Função de Atkinson com ε = 1
Quando ε 6= 1:
Figura 3.9: Função de Atkinson com ε 6= 1
O corte do gráfico tridimensional da função para as variáveis u1 e u2:
Figura 3.10: Corte do gráfico tridimensional da função de Atkinson com ε = 1 e com ε 6= 1
19
3.4.2 Índice de Gini
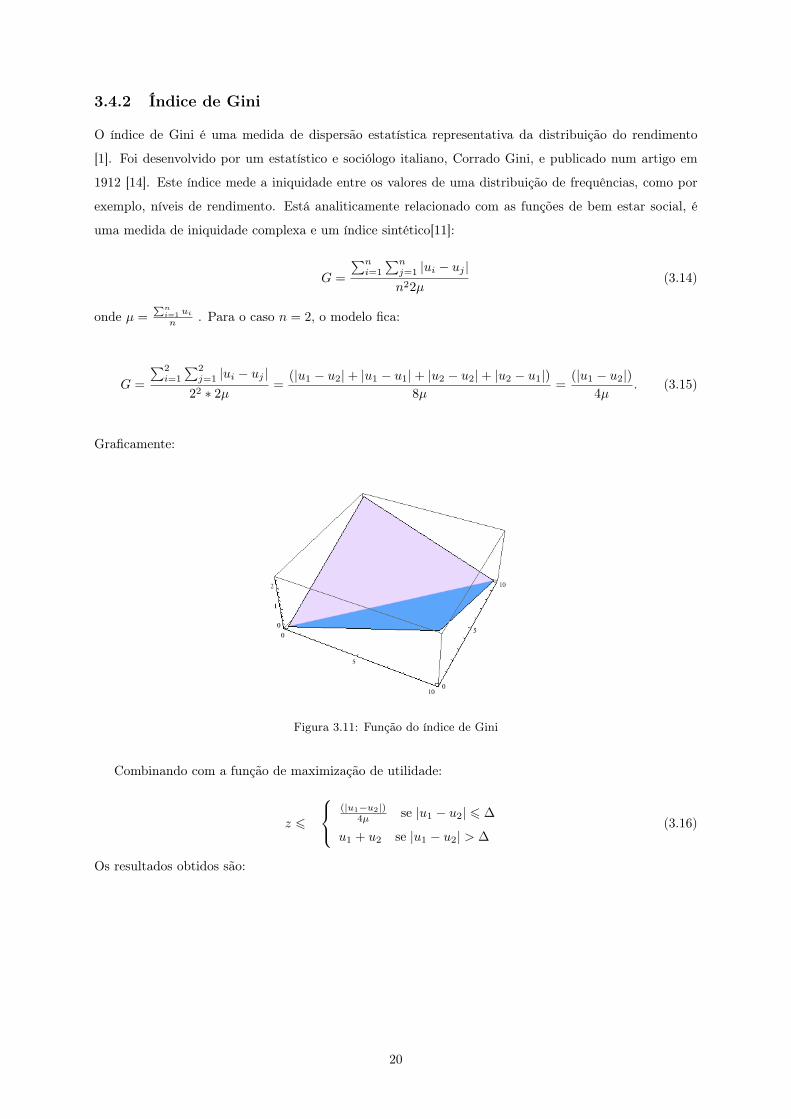
O índice de Gini é uma medida de dispersão estatística representativa da distribuição do rendimento
[1]. Foi desenvolvido por um estatístico e sociólogo italiano, Corrado Gini, e publicado num artigo em
1912 [14]. Este índice mede a iniquidade entre os valores de uma distribuição de frequências, como por
exemplo, níveis de rendimento. Está analiticamente relacionado com as funções de bem estar social, é
uma medida de iniquidade complexa e um índice sintético[11]:
G =
∑ni=1
∑nj=1 |ui − uj |n22µ
(3.14)
onde µ =∑n
i=1 ui
n . Para o caso n = 2, o modelo fica:
G =
∑2i=1
∑2j=1 |ui − uj |
22 ∗ 2µ=
(|u1 − u2|+ |u1 − u1|+ |u2 − u2|+ |u2 − u1|)8µ
=(|u1 − u2|)
4µ. (3.15)
Graficamente:
Figura 3.11: Função do índice de Gini
Combinando com a função de maximização de utilidade:
z 6
(|u1−u2|)
4µ se |u1 − u2| 6 ∆
u1 + u2 se |u1 − u2| > ∆(3.16)
Os resultados obtidos são:
20

Figura 3.12: Combinação do índice de Gini com a função utilitarista
A caraterística do índice de Gini reside no facto de dar informações sobre a distribuição do rendimento
e não sobre as caraterísticas da distribuição do rendimento, como localização e formato. É um bom
indicador para uma análise geral de um problema com uma grande população. A representação gráfica
pode ser também comparada através do tempo, é simples de calcular e interpretar [23]. Contudo o
coeficiente sofre pela desvantagem de ser afetado pelo valor da média, medida através de uma origem
arbitrária [22], e não permite comparações entre e dentro de grupos.
3.4.3 O índice de Theil
O índice de Theil é o índice adequado para dados com um grau de agregação com hierarquia. Toma a
forma (cf. [1]):
T =1
n
n∑i=1
∗(uiµ
) ∗ log(uiµ
) (3.17)
onde n é o número de indivíduos de uma população, ui é o rendimento do indivíduo i e µ é o rendimento
médio da população. No caso do problema de duas pessoas:
T =1
2∗ (u1
µ) ∗ log(
u1
µ) +
1
2∗ (u2
µ) ∗ log(
u2
µ) (3.18)
onde µ = u1+u2
2 . Gráficamente obtém-se:
Figura 3.13: Índice de Theill
O corte do gráfico tridimensional da função para as variáveis u1 e u2:
Quando a função se anula cada indivíduo tem o mesmo rendimento, é o caso de igualdade perfeita. A
função nos extremos opostos representa a situação de iniquidade máxima.
21
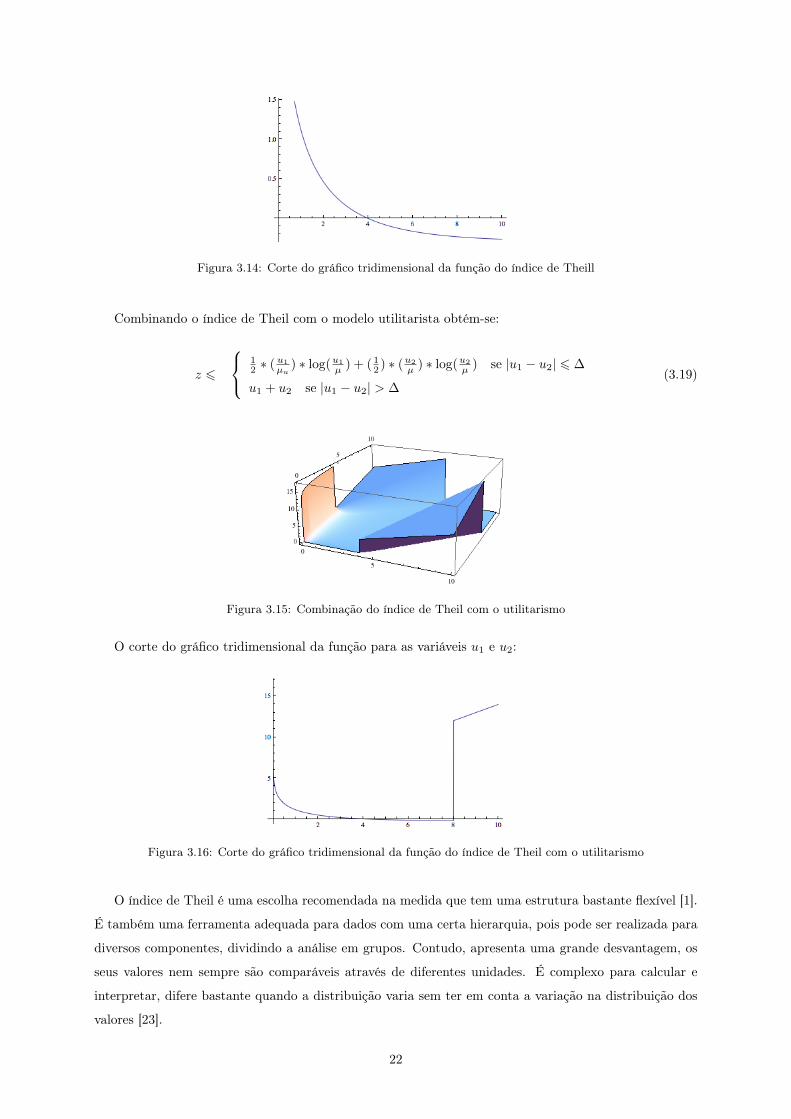
Figura 3.14: Corte do gráfico tridimensional da função do índice de Theill
Combinando o índice de Theil com o modelo utilitarista obtém-se:
z 6
12 ∗ ( u1
µu) ∗ log(u1
µ ) + ( 12 ) ∗ (u2
µ ) ∗ log(u2
µ ) se |u1 − u2| 6 ∆
u1 + u2 se |u1 − u2| > ∆(3.19)
Figura 3.15: Combinação do índice de Theil com o utilitarismo
O corte do gráfico tridimensional da função para as variáveis u1 e u2:
Figura 3.16: Corte do gráfico tridimensional da função do índice de Theil com o utilitarismo
O índice de Theil é uma escolha recomendada na medida que tem uma estrutura bastante flexível [1].
É também uma ferramenta adequada para dados com uma certa hierarquia, pois pode ser realizada para
diversos componentes, dividindo a análise em grupos. Contudo, apresenta uma grande desvantagem, os
seus valores nem sempre são comparáveis através de diferentes unidades. É complexo para calcular e
interpretar, difere bastante quando a distribuição varia sem ter em conta a variação na distribuição dos
valores [23].
22

3.4.4 Modelos utilitaristas
No seu trabalho, Hooker e Williams utilizam o modelo utilitarista combinado com a função de equidade.
Nesta dissertação também será empregue a mesma função. Segue-se uma breve referência ao modelo de
utilidade.
Funções de utilidade
A função representativa da utilidade usada na programação matemática é a de Nicholas Bernoulli (1713)
[4], proposta pelo mesmo e mais tarde resolvida por Daniel Bernoulli (1738). A teoria da utilidade
esperada está presente em análises de escolhas com risco e possíveis resultados multi dimensionais.
A formulação mais conhecida das funções de utilidade é a utilidade aditiva de Von Neumann-Morgenstern
[28], que consiste na aplicação da utilidade esperada de Bernoulli. O seu método de comparação envolve a
consideração de probabilidades. Se um indivíduo consegue escolher entre vários eventos aleatórios, então
é possível compara-los aditivamente.
A função de utilidade esperada depende de quatro axiomas [28], plenitude, transitividade, convexidade
ou continuidade e independência:
Axioma 3.4.1 (Plenitude). Para quaisquer dois eventos aleatórios x e y, uma das situações ocorre:
x ≺ y, y ≺ x, ou x ∼ y
A plenitude assume que um indivíduo tem as suas preferências bem definidas.
Axioma 3.4.2 (Transitividade). Se x � y e y � z, então x � z.
A transitividade assume que as preferências são consistentes entre três opções quaisquer.
Axioma 3.4.3 (Convexidade / Continuidade). Se x � y � z, então existe uma probabilidade p ∈ [0, 1]
tal que px+ (1− p)z ∼ y.
A continuidade assume que existe um ponto entre “estar melhor que” e “estar pior que” com uma
dada opção no meio. Um axioma alternativo à continuidade, e que não envolve uma equidade precisa, é
a propriedade Arquimediana:
Axioma 3.4.4 (Propriedade Arquimediana). Se x ≺ y ≺ z, então existe uma probabilidade ε ∈ (0, 1) tal
que (1− ε)x+ εz ≺ y ≺ εx+ (1− ε)z.
Qualquer separação nas preferências pode ser mantida sob um pequeno desvio nas probabilidades.
Axioma 3.4.5 ( Independência). Se x ≺ y, então para qualquer z e p ∈ (0, 1], px+(1−p)z ≺ py+(1−p)z.
A independência das alternativas irrelevantes assume que uma preferência se mantém independente-
mente da possibilidade de outro resultado.
Teorema 3.4.1. Para qualquer agente racional que satisfaça os quatro axiomas, existe uma função u
que atribui a cada resultado A um número real u(A) tal que para cada dois eventos aleatórios:
x ≺ y se, e só se, E(u(x)) < E(u(y))
23

onde E(u(x)) denota o o valor esperado de u em x onde :
E(u(x)) = p1u(A1) + ...+ pnu(An)⇔ U =∑i
piAi
Teorema 3.4.2 (Utilidade Esperada, von Neumann e Morgenstern 1974). Uma função de utilidade
U : P → R é uma funções de utilidade esperada se existirem números de (u1, ..., un) para cada um dos N
resultados (x1, ..., xn) tal que para cada p ∈ P,U(p) =∑ni=1 pi · ui [24]
Proposição 3.4.1 (Proposição). Supondo que U : P → R é uma representação da utilidade esperada da
relação de preferências � em P . Então V : P → R é uma representação da utilidade esperada de � se e
só se existirem escalares a e b > 0 tal que V (p) = a+ bU(p) para todo o p ∈ P .
Demonstração 3.4.1 (Demonstração). Supondo que U é uma representação da utilidade esperada de
�, e U(p) =∑i piui.
Supondo V = a + bU . Porque b > 0, se U(p′) ≥ U(p), então V (p′) ≥ V (p), e V também representa
�. Assim, V tem uma forma de utilidade esperada pois, se definir-se vi = a+ bui para todo o i = 1, ...n,
tem-se:
V (p) = a+ bU(p) = a+ b ·n∑i=1
piui =
n∑i=1
pi(a+ bui) =
n∑i=1
pivi
(⇒) Supondo que V é uma representação de utilidade esperada de �. Seja p, p ∈ P as lotarias tal que
p � p � p para todo o p ∈ P . (Existe uma melhor e uma pior lotaria porque é assumido que o número
de lotarias é finito). Se p ∼ p , então U e V são constantes sobre P e o resultado é trivial. Assume-se
assim p � p. Então dado p ∈ P , existe um λp ∈ [0, 1] tal que:
U(p) = λpU(p) + (1− λp)U(p).
então:
λp =U(p)− U(p)
U(p)− U(p).
agora, porque p � λpp+ (1− λp)p, tem-se:
V (p) = V (λpp+ (1− λp)p) = λpV (p) + (1− λp)V (p).
definindo :
a = V (p)− U(p)beb =V (p)− V (p)
U(p)− U(p).
é fácil de verificar que V (p) = a+ bU(p) [24].
24

3.5 Conclusão
A economia recorre a teoremas matemáticos para validar conceitos e descreve problemas usando técnicas
de álgebra matricial, cálculo diferencial e integral e equações diferenciais, entre outros. Uma das vantagem
que surge desta abordagem é o facto de se formularem as relações teóricas com rigor, generalização e
simplicidade [6]. Na resolução de problemas de otimização, por vezes, ao contrário de se escolher uma
das medidas de equidade ou de iniquidade, especifica-se uma função de bem estar social e deriva-se uma
função de equidade ou de iniquidade aproximada.
Estes modelos são apenas alguns de entre as muitas possibilidades existentes. Segundo Hooker e
Williams, o estudo e adaptação da função de equidade usada no seu artigo é uma escolha entre diversas
opções, outras poderiam ter sido feitas. Esta escolha depende dos conhecimentos de cada um e de como
cada pessoa interpreta e decide representar o seu modelo equitativo. Depende também do exemplo onde
se aplica o modelo pois as funções são principalmente feitas para se adaptarem, cada uma, a uma área
de eleição.
Deste modo, conclui-se que a função adequada para a abordagem que se segue, a alteração do modelo
de Hooker e Williams, é uma função de equidade adaptada ao problema da distribuição de recursos na área
da saúde. O capítulo seguinte explora os resultados originados pela substituição da função Rawlsiana.
25

Capítulo 4
Modelo alternativo
4.1 Introdução
Após a análise realizada nos capítulos anteriores, aplicam-se agora os conhecimentos ganhos. Em análise
está o artigo de J.N.Hooker e H.P.Williams [18]. Neste capítulo é realizada uma breve introdução e
explicação do modelo usado no artigo, destacando os resultados obtidos no mesmo. Um novo modelo é
então sugerido, alternativamente ao usado por Hooker e Williams assim como um novo método para a
linearização e resolução do problema. Procede-se às transformações consideradas necessárias no modelo
para a aplicação do novo método, o método da restrição - ε, ao exemplo da distribuição dos recursos na
saúde. O algoritmo do novo modelo é implementado no programa CPLEX, seguido de uma análise dos
resultados obtidos.
4.2 Modelo inicial
Hooker e Williams formulam um modelo PLIM para o problema de duas pessoas já referido:
max z
sujeito a :
z 6
2 min{u1, u2}+ ∆ se |u1 − u2| 6 ∆
u1 + u2 caso contrário
u1, u2 > 0
(4.1)
Usando a definição de Jeroslow ([20],[21]) para que o problema seja representado de forma PLIM, o seu
hipografo deve ser a união de um número finito de poliedros com as mesmas direções de recessão. Se
o poliedro não tiver as mesmas direções de recessão, então adicionam algumas restrições para igualar
os cones de recessão. Assim definem o hipografo de (4.1) como a união dos dois poliedros definidos
respetivamente por dois conjuntos disjuntos: {z 6 2u1+δ; z 6 2u2+∆;u1, u2 > 0} e {z 6 u1+u2;u1, u2 >
0}. O primeiro conjunto corresponde ao caso max min e o segundo ao caso utilitariano. Os cones
26

de recessão são definidos por vetores que podem ser combinados no mesmo ao adicionar a restrição
u1−u2 6M e u2−u1 6M . O hipografo fica assim representado pelo método das penalidades. Colocam
também a hipótese de dar aos poliedros o mesmo cone de recessão, impondo limites u1, u2 6 M . O
método das penalidades é uma formulação afinada de (4.1) [27], ou seja, é a relaxação contínua, mais
apertada possível [27], onde foram colocadas restrições para apertar o poliedro das restrições. A relaxação
contínua descreve um poliedro cuja projeção nas variáveis originais é o fecho convexo do hipografo.
O ponto seguinte no artigo é a passagem da formulação do problema de duas pessoas para o caso geral
com n indivíduos. Ao generalizarem, o problema (4.1) passa a ter apenas uma função objetivo. Pode-se
mostrar que a desigualdade anterior é equivalente a:
z 6 ∆ + 2umin + max{0, u1 − umin −∆}+ max{0, u2 − umin −∆} , u1, u2 6 0 (4.2)
onde umin = min{u1, u2}. Cada pessoa i faz uma contribuição utilitarista se ui diferir de umin mais de
∆. As conclusões continuam para o caso de, se u1 > u2 + ∆, o primeiro termo max de (4.2) contribui
com u1 − umin − ∆ e o segundo termo max não contribui, ficando u1 + u2. Similarmente para o caso
u2 > u1 + ∆. Caso contrário ambos os termos max anulam-se.
Chega-se assim à seguinte generalização do modelo de Hooker e Williams:
z 6 (n− 1)∆ + numin +
n∑i=1
max{0, ui − umin −∆} , ui 6 0, para todo o i (4.3)
pegando no método das penalidades já formulado:
uj − ui 6M, para todo o i, j (4.4)
Hooker e Williams formulam o problema como PLIM. Baseando-se numa união de poliedros similar
à usada no caso de n = 2, resultando num problema com soluções binárias exponenciais com muitas
variáveis 0-1. Assim utilizam um modelo mais compacto para maximizar z sujeito a:
z 6 (n− 1)∆ +∑ni=1 vi
ui −∆ 6 vi 6 ui −∆δi, para todo o i
w 6 vi 6 w + (M −∆)δi, para todo o i
ui > 0, δi ∈ {0, 1}, para todo o i
(4.5)
onde δi é 0 quando ui−umin < ∆ e 1 caso contrário. O artigo demonstra, como Teorema 1, que o modelo
(4.5) é uma formulação correta do problema (4.3) com o método das penalidades (4.4) e prova como a
relaxação da programação linear descreve o fecho convexo do conjunto admissível (em anexo).
Contudo, pensam ainda na hipótese frequente das alocações dos recursos serem feitas a grupos ou
classes de beneficiários em vez de atribuídas a indivíduos. As classes geralmente variam em tamanho.
Esta situação pode ser modelada ao introduzir uma variável de utilidade ui para cada indivíduo e impondo
restrições laterais que requerem que os indivíduos, dentro de uma classe, recebam as mesmas distribuições.
27

Pode-se concluir que, se os grupos forem muito grandes, isto resulta num modelo PLIM com uma vasta
dimensão. Como solução constroem um modelo atribuindo utilidades aos grupos e não a indivíduos,
mesmo quando os grupos têm dimensões diferentes.
Supõe-se que existem m grupos de beneficiários e cada grupo i tem uma dimensão ni. Uma vez que
cada membro do grupo recebe a mesma distribuição, separam a utilidade atribuída igualmente por todos
os membros do mesmo grupo. Seja ui a utilidade per capita no grupo i, tal que a utilidade total do grupo
é de niui. O problema de otimização maximiza z sujeito a:
z 6 (∑mi=1 ni − 1)∆ + (
∑mi=1 ni)umin +
∑mi=1 ni(ui − umin −∆)+
uj − ui 6M, para todo o i
ui > 0, para todo o i
(4.6)
onde umin = minj{uj} e (ui − umin −∆)+ são valores positivos.
O problema PLIM para a questão multigrupo é derivado do problema para dois grupos:
max z sujeito a:
z 6 (n1 + n2 − 1)∆ + (n1 + n2)umin + n1(u1 − umin −∆)+ + n2(u2 − umin −∆)+
u1 − u2 6M, u2 − u1 6M
u1, u2 > 0
(4.7)
e fica na forma:
max z sujeito a:z 6 (
∑i ni − 1)∆ +
∑ni=1 nivi (a)
ui −∆ 6 vi 6 ui −∆δi, para todo o i (b)
w 6 vi 6 w + (M −∆)δi, para todo o i (c)
ui > 0, δi ∈ {0, 1}, para todo o i
(4.8)
estes modelos são demonstrados com teoremas que podem ser encontrados em anexo. O modelo (4.8)
foi implementado no CPLEX para melhor compreensão e comparação dos resultado com o novo modelo
sugerido.
Assim termina a breve referência e o resumo do artigo em análise. Hooker e Williams aplicam o
modelo (4.8) no exemplo da saúde referenciado mais à frente. Conclui-se assim que estes modelos foram
bem formulados. A questão está na sua aplicação e se a função representativa do problema de equidade
foi de facto a melhor escolha.
28

4.3 Alterações no modelo
As alterações ao modelo são sugeridas com o propósito de resolver e obter melhores resultados para
o problema proposto. Como Hooker e Williams sugerem ao longo do artigo, há pontos que não estão
completamente esclarecidos ou que poderiam tomar outras formas. Entre eles, está a definição da função
de equidade e uso do parâmetro ∆. É também posto em causa o modo como o artigo lineariza duas
funções através da imposição de um parâmetro α. O objetivo é combinar uma função de equidade
com uma função de utilidade onde a primeira é uma função max min e a segunda um somatório de
valores constantes. O parâmetro α, que para os autores é difícil de justificar, não está medido na mesma
medida que as utilidades. Este processo pode deixar de parte algumas soluções que poderiam estar mais
adequadas na tomada de decisão. O modelo sofre de perda de soluções, mais concretamente, das soluções
dominadas e não suportadas. Esta perda pode levar a más escolhas e a más decisões pois nem sempre o
ideal é a solução ótima, tirando, a quem toma a decisão, a possibilidade de escolher entre um conjunto
mais vasto de soluções. Assim sendo, é importante analisar outras abordagens com diferentes métodos de
otimização. Como concluído no capítulo anterior, a escolha adequada, tendo em conta o exemplo onde
vai ser aplicado o novo modelo, é uma função de equidade adaptada ao problema.
O exemplo escolhido e usado por Hooker e Williams é o da distribuição de recursos na área da saúde.
Dado que esses recursos serão disponibilizados para um número limitado de tratamentos, a principal
questão é quem deve receber o tratamento de entre os grupos de indivíduos, sendo estes indivíduos can-
didatos que podem obter utilidades diferentes. Os tratamentos são: o pacemaker para bloqueio cardíaco
atrioventricular, a substituição da anca, a substituição da válvula para estenose aórtica, a revasculariza-
ção do miocárdio para a doença do principal esquerdo, a revascularização do miocárdio para a doença
tri-arterial, a revascularização do miocárdio para a doença bi-arterial, o transplante de coração, o trans-
plante de rim e a diálise renal. Quem deve receber o tratamento tendo em conta o orçamento disponível?
Dependendo do prognóstico e do benefício tirado dos vários tratamentos, o modelo é construído à volta
do custo por "QALY"(ganho líquido médio de cada indivíduo). Este QALY é providenciado por uma
única fonte, Briggs e Gray [5]. O modelo do artigo varia entre uma atribuição do tratamento equitativa
por todos e uma atribuição utilitarista, ou seja, de modo a maximizar a utilidade obtida na realização
do tratamento dos indivíduos. O que comanda esta variação, a passagem de uma função para outra, é
o já referenciado, parâmetro ∆. A utilidade é aqui o ganho líquido médio, medido em QALYs para um
membro do gruo i quando o tratamento é administrado, mais o ganho quando não o é. Assim a utilidade
per capita de um grupo i é:
ui = qiyi + ai
onde yi é a variável binária que toma o valor de 1 quando o tratamento é atribuído ao indivíduo e 0 caso
contrário. ai é a QALYs média que resulta da gestão médica do tratamento em questão, com ou sem
intervenção. Ficando assim a maximização da função de utilidade, z1:
max z1 =
n∑i
(qiyi + ai)
29

O modelo proposto sugere uma alteração numa das funções, a função de equidade. Mantendo a função de
utilidade, que já se encontra na forma comum, a função de equidade é alterada para uma mais coerente
com a amostra e representativa das relações equitativas.
A amostra está dividida em 9 tratamentos diferentes que por sua vez estão divididos em subgrupos,
correspondentes a candidatos com mais ou menos necessidades, numa escala que pode ir de 1 a 12. De
acordo com a definição de equidade, todas as intervenções necessitam de pelo menos um subgrupo que
receberá o tratamento. A função anterior, o max min das utilidades, é substituída por uma função de
equidade que selecciona no mínimo um subgrupo de candidatos de entre os diversos subgrupos de pessoas
candidatas aos tratamentos. Após a análise das funções de equidade assim como de iniquidade, a função
ideal obtida é aqui representada por z2 e o objetivo é maximizar o mínimo:
max min z2 =
m∑k=1
Mk
mkn∑j=mki
yj , k = 1, ...,m, j = mki, ...mkn (4.9)
onde M é uma penalização imposta ao modelo, caso este escolha os tratamentos com um custo menor
ou que se limitam a maximizar a utilidade. m = 9 pois representa os tratamentos possíveis e mkn, a
variação dos subgrupos, que pode ir de 1 a 12. As restrições são as utilizadas no modelo inicial (utilidades
positivas ou nulas) com o acréscimo da restrição orçamental e da imposição de, pelo menos, um subgrupo
em cada grupo receber o tratamento:
∑ni (niciyi) 6 B∑mknj=mki yj > 1
(4.10)
onde ci é o custo adicionado por paciente ao administrar o tratamento. O orçamento disponível, B é
correspondente a 3 000 000 libras.
4.4 Modelo generalizado
O modelo proposto surge da adaptação às funções de utilidade e de equidade gerais. Estas tomam uma
forma abstrata de modo a serem flexíveis e maleáveis para se adaptarem a diversas situações. A função
de utilidade original (de Hooker e Williams) é o somatório de todas as utilidades enquanto que a função
de equidade é a maximização da utilidade mínima de entre os indivíduos:
maxU(u) =
∑ni=1 ui
max min{ui} i = 1, ..., n
ui > 0
(4.11)
Nas alterações ao modelo as funções tomam uma forma específica adequada ao problema. A função de
equidade proposta toma a forma:
30

maxU(u) =∑ni=1 ui
max min∑mk=1Mk
∑mknj=mki yj i = 1, ..., n, k = 1, ...,m, j = mki, ...mkn
ui > 0
M > 0
yi ∈ {0, 1}
(4.12)
Mk representa a penalidade atribuída a cada grupo k. Os grupos podem ainda dividir-se em subgrupos
mkn.
O método proposto é o uso do método da restrição - ε. Este método substituí o método de otimização
utilizado no artigo. Vai permitir encontrar soluções que poderão ser melhores que as obtidas pelo método
PLIM, encontrando também soluções que, embora não sejam ótimas, pode ser incluídas na escolha.
O método da restrição - ε para o modelo inicial, o mínimo das utilidades e o somatório das utilidades,
resultam em:
maxα
sujeito a:
α 6 ui, i = 1, ..., n
U(u) =∑ni=1 ui
U(u) > ε
ui > 0, i = 1, ..., n
(4.13)
Com a aplicação do método da restrição - ε, para a linearização das duas funções sugeridas, surge o novo
modelo:
maxα
sujeito a :
α 6 z2
z1 =∑ni (qiyi + ai)
z1 > ε
z2 =∑mk=1Mk
∑mknj=mki yj
ui > 0∑ni (niciyi) 6 B∑mknj=mki yj > 1
(4.14)
O método da restrição - ε permite alcançar um maior conjunto de soluções de Pareto, apanhando também
soluções dominadas e fracamente dominadas. Assim, em vez da escolha do parâmetro ∆ para variação
31

compromisso entre equidade e utilidade, tem-se acesso também a mais soluções e opções de escolha entre
a combinação dos dois objetivos. Isto permite uma análise mais justa do caso e não depende tanto de
juízos pessoais como acontecia na escolha da solução sugerida pelo artigo.
O modelo foi implementado no programa da IBM, CPLEX.
4.5 Análise dos dados
No artigo em estudo, as conclusões tiradas estão de acordo com o modelo (6), com a variação da
multiplicação de ni nos somatórios, permitindo assim uma formulação multigrupo. Os dados usados, e
que também serão os usados no novo modelo, são os da Tabela 1. Existem nove tipos de tratamentos,
como referido, e as dimensões dos grupos são uma aproximação baseada em várias estimativas da frequên-
cia relativa de cada intervenção nos Estados Unidos. Os grupos correspondentes aos pacemakers, e às
substituições da válvula aórtica, estão divididos em três subgrupos, onde o subgrupo B representa o custo
médio por QALY reportado por Briggs e Gray [5] e os grupos A e C refletem desvios da média e permi-
tem aos decisores políticos considerarem diferentes prognósticos entre pacientes com a mesma doença. As
nove categorias de candidatos para CABGs, cirurgias de revascularização miocárdica, são explicitamente
distinguidos por Briggs e Gray, e os custos por QALY reflectem as suas estimativas. Os candidatos à
diálise renal são categorizados por esperança de vida útil enquanto estão em diálise, para refletir o facto
de que, o custo por paciente, assim como a QALY, ganha depende do tempo de previsão de sobrevivência
do paciente. O tamanho relativo de cada categoria é baseado nas taxas de sobrevivência reportadas nos
Estados Unidos pelo "National Kidney and Urologic Diseases Information Clearinghouse"[26]. O custo
anual por paciente é derivado de três fatores. Da estimativa de Briggs e Gray de 14 000 libras por QALY,
de uma média de 0.688 QALYs por ano de diálise, baseado na convenção para uma escala de 0-1 do
Índice de bem estar para os pacientes reportado em Evans et al. [12] que Briggs e Gray citam como fonte,
e por último, uma média de 0.85 anos adicionais de vida obtidos por cada ano gasto em diálise. Isto
resulta num custo de diálise anual per capita de (14000)(0.688)(0.85), ou aproximadamente 8200 libras.
Algumas categorias são ainda subdivididas em prognósticos devido a um alto custo por paciente, pois
caso contrário, financiar uma única categoria iria consumir uma grande fração do orçamento.
A QALY esperada sem intervenção, αi, no novo modelo chamado de ai, depende inteiramente das
características da população, tais como, idade, estado de saúde e ambiente onde vivem. Os dados utiliza-
dos não representam nenhuma população em particular, são selecionados para representar um conjunto
possível de circunstâncias.
32
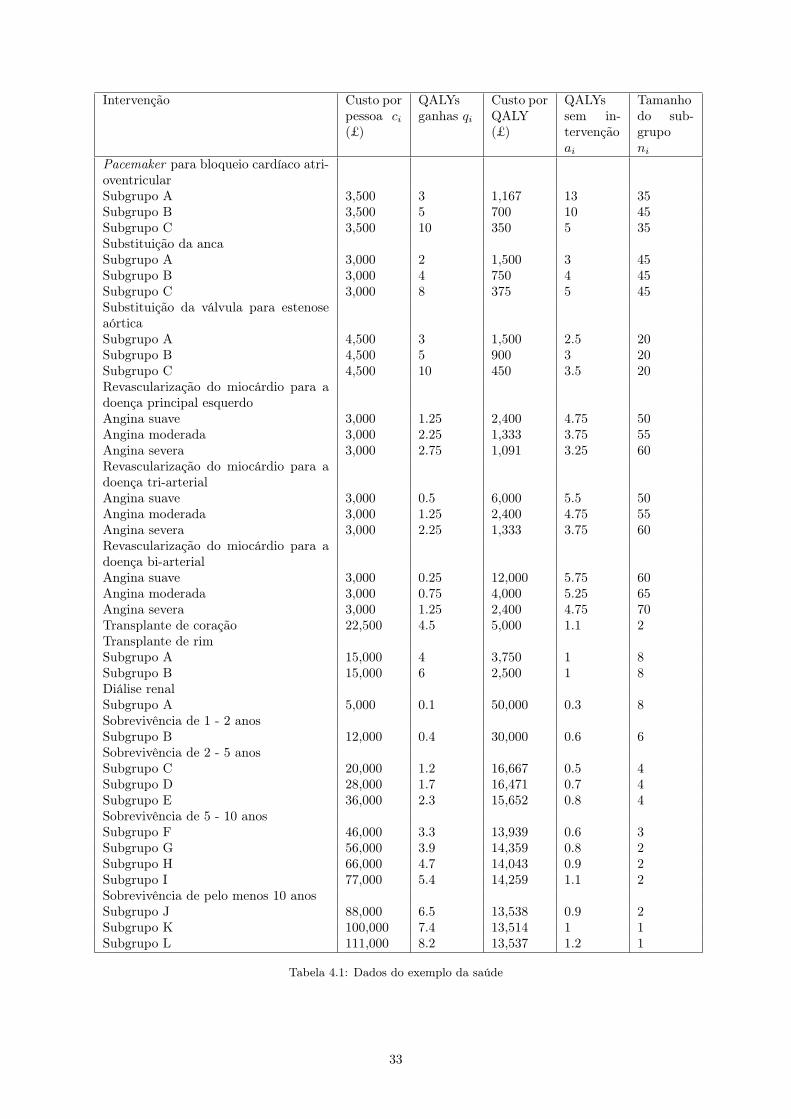
Intervenção Custo porpessoa ci(£)
QALYsganhas qi
Custo porQALY(£)
QALYssem in-tervençãoai
Tamanhodo sub-gruponi
Pacemaker para bloqueio cardíaco atri-oventricularSubgrupo A 3,500 3 1,167 13 35Subgrupo B 3,500 5 700 10 45Subgrupo C 3,500 10 350 5 35Substituição da ancaSubgrupo A 3,000 2 1,500 3 45Subgrupo B 3,000 4 750 4 45Subgrupo C 3,000 8 375 5 45Substituição da válvula para estenoseaórticaSubgrupo A 4,500 3 1,500 2.5 20Subgrupo B 4,500 5 900 3 20Subgrupo C 4,500 10 450 3.5 20Revascularização do miocárdio para adoença principal esquerdoAngina suave 3,000 1.25 2,400 4.75 50Angina moderada 3,000 2.25 1,333 3.75 55Angina severa 3,000 2.75 1,091 3.25 60Revascularização do miocárdio para adoença tri-arterialAngina suave 3,000 0.5 6,000 5.5 50Angina moderada 3,000 1.25 2,400 4.75 55Angina severa 3,000 2.25 1,333 3.75 60Revascularização do miocárdio para adoença bi-arterialAngina suave 3,000 0.25 12,000 5.75 60Angina moderada 3,000 0.75 4,000 5.25 65Angina severa 3,000 1.25 2,400 4.75 70Transplante de coração 22,500 4.5 5,000 1.1 2Transplante de rimSubgrupo A 15,000 4 3,750 1 8Subgrupo B 15,000 6 2,500 1 8Diálise renalSubgrupo A 5,000 0.1 50,000 0.3 8Sobrevivência de 1 - 2 anosSubgrupo B 12,000 0.4 30,000 0.6 6Sobrevivência de 2 - 5 anosSubgrupo C 20,000 1.2 16,667 0.5 4Subgrupo D 28,000 1.7 16,471 0.7 4Subgrupo E 36,000 2.3 15,652 0.8 4Sobrevivência de 5 - 10 anosSubgrupo F 46,000 3.3 13,939 0.6 3Subgrupo G 56,000 3.9 14,359 0.8 2Subgrupo H 66,000 4.7 14,043 0.9 2Subgrupo I 77,000 5.4 14,259 1.1 2Sobrevivência de pelo menos 10 anosSubgrupo J 88,000 6.5 13,538 0.9 2Subgrupo K 100,000 7.4 13,514 1 1Subgrupo L 111,000 8.2 13,537 1.2 1
Tabela 4.1: Dados do exemplo da saúde
33

4.6 Implementação do modelo PLIM do artigo
Foi implementado no CPLEX o modelo PLIM (4.8) do artigo em estudo. Os resultados obtidos foram os
esperados, contudo as variações possíveis no modelo estão apenas em torno da variável ∆. As soluções
eram vastas, existindo não dominadas, suportadas e não suportadas, no entanto o modelo não encontrava
as soluções não dominadas e não suportadas.
4.7 Resultados
Os resultados obtidos no artigo usando o modelo PLIM, são um conjunto de variáveis binárias que de-
terminam quais os grupos que devem receber os tratamentos determinado de forma equitativa, ou de
forma utilitariana, em função de ∆. Concluem que, combinar equidade e eficiência leva a interessantes
e inesperados resultados. O novo modelo apresenta resultados diferentes na medida em que o conjunto
de solução não é composto apenas por variáveis binárias. Este vai variar de acordo com um parâmetro,
a variável M. Defini-la otimamente depende dos resultados obtidos, para tal realizaram-se algumas simu-
lações. A atribuição do parâmetro M é dada em função dos custos por indivíduos, com valores maiores
para tratamentos de um custo menor e valores mais baixos para tratamentos com um custo maior. Deste
modo, permite ao modelo tomar decisões mais justas e não escolher preferencialmente os tratamentos
que minimizam o custo. De notar que as opções para o parâmetro M são múltiplas, tendo-se optado por
começar com uma simulação numa escala de 0 a 10. M toma assim os valores:
M = [9, 10, 7, 10, 10, 10, 1, 2, 5]
Os resultados obtidos gráficamente são:
Figura 4.1: Resultados do modelo
Na Figura 4.1 verificam-se diversas soluções dominadas. Para o valor máximo da função z1, a função
34
de equidade, encontra quatro valores na função de utilidade onde claramente um é melhor que os outros.
Assim sendo eliminando todas as situações em que existe mais do que um valor de z2 para z1, obtém-se:
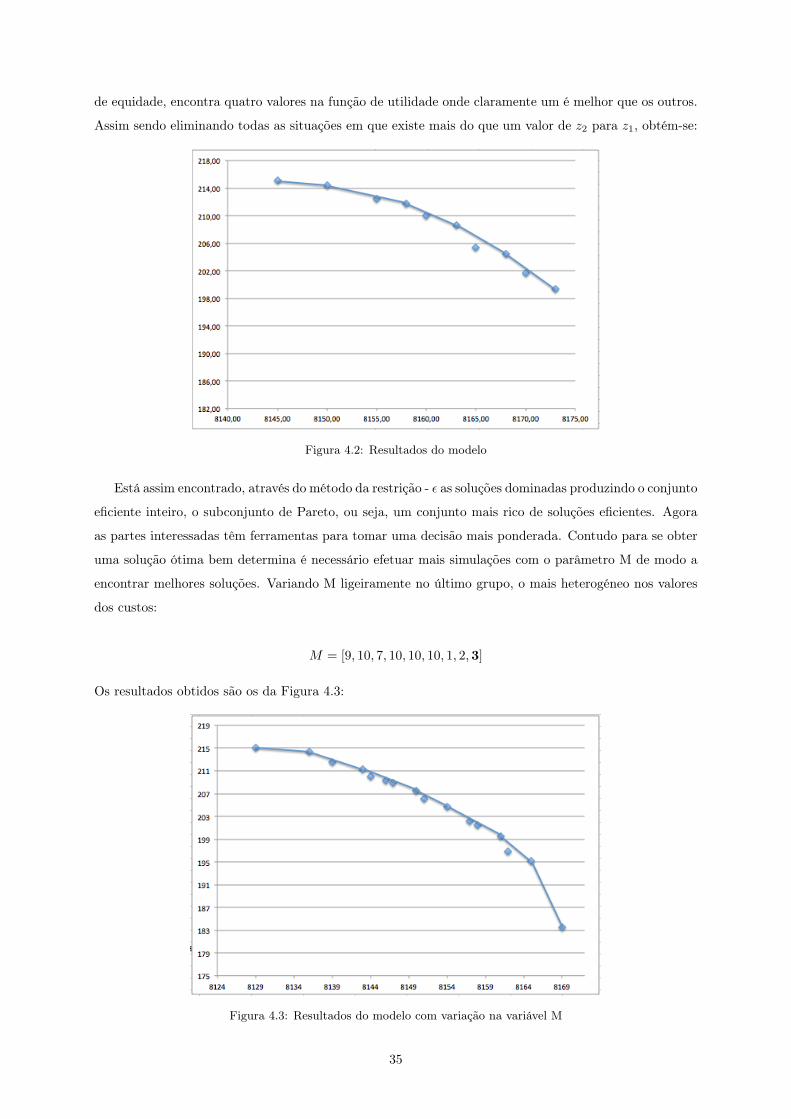
Figura 4.2: Resultados do modelo
Está assim encontrado, através do método da restrição - ε as soluções dominadas produzindo o conjunto
eficiente inteiro, o subconjunto de Pareto, ou seja, um conjunto mais rico de soluções eficientes. Agora
as partes interessadas têm ferramentas para tomar uma decisão mais ponderada. Contudo para se obter
uma solução ótima bem determina é necessário efetuar mais simulações com o parâmetro M de modo a
encontrar melhores soluções. Variando M ligeiramente no último grupo, o mais heterogéneo nos valores
dos custos:
M = [9, 10, 7, 10, 10, 10, 1, 2,3]
Os resultados obtidos são os da Figura 4.3:
Figura 4.3: Resultados do modelo com variação na variável M
35
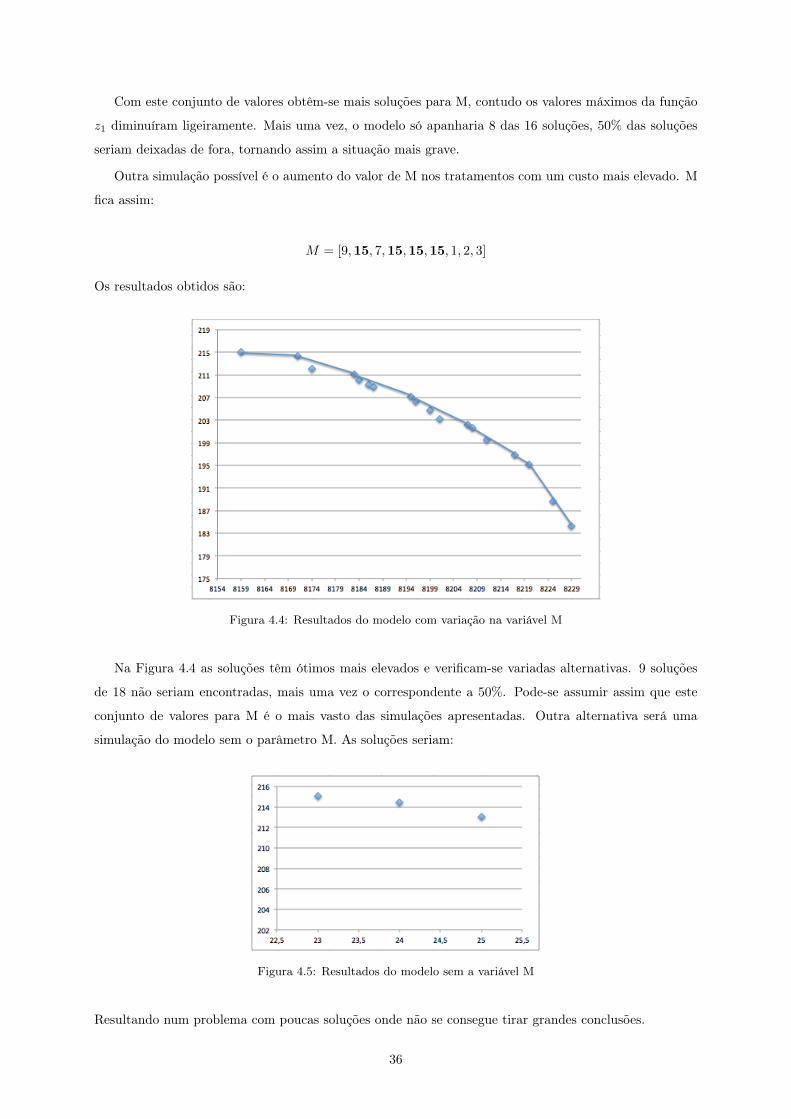
Com este conjunto de valores obtêm-se mais soluções para M, contudo os valores máximos da função
z1 diminuíram ligeiramente. Mais uma vez, o modelo só apanharia 8 das 16 soluções, 50% das soluções
seriam deixadas de fora, tornando assim a situação mais grave.
Outra simulação possível é o aumento do valor de M nos tratamentos com um custo mais elevado. M
fica assim:
M = [9,15, 7,15,15,15, 1, 2, 3]
Os resultados obtidos são:
Figura 4.4: Resultados do modelo com variação na variável M
Na Figura 4.4 as soluções têm ótimos mais elevados e verificam-se variadas alternativas. 9 soluções
de 18 não seriam encontradas, mais uma vez o correspondente a 50%. Pode-se assumir assim que este
conjunto de valores para M é o mais vasto das simulações apresentadas. Outra alternativa será uma
simulação do modelo sem o parâmetro M. As soluções seriam:
Figura 4.5: Resultados do modelo sem a variável M
Resultando num problema com poucas soluções onde não se consegue tirar grandes conclusões.
36

4.7.1 Abordagem estatística
Contudo, não é apenas em torno da variável M que se podem tirar conclusões sobre o novo modelo.
Outra análise realizada é a da variação dos custos ci. Ao variar dentro dos subgrupos, ou seja, dentro de
cada tratamento, realizaram-se 30 simulações obtendo, de acordo com o método da restrição - ε, variáveis
dominadas e não dominadas, ótimas e não ótimas. O objetivo é a realização de uma análise estatística em
torno das variáveis não dominadas e não suportadas. Com esta aplicação aparecem as varáveis dominadas
e fracamente dominadas que não apareceriam noutro método, o novo modelo é mais flexível. O objetivo
agora é, partindo de 30 simulações, verificar quanto se perdia ao ignorar as variáveis não suportadas. A
partir da análise de sensibilidade em torno do exemplo, retiram-se as conclusões:
• quantidade de variáveis não suportadas;
• média das variáveis não suportadas;
• min das variáveis não suportadas;
• max das variáveis não suportadas;
• desvio padrão das variáveis não suportadas;
É de interesse analisar o tempo de processamento do modelo realizando as mesmas estatísticas em
torno da variável CPU:
• tempo de cálculo (CPU);
• tempo médio;
• min CPU
• max CPU;
• desvio padrão do CPU;
Utilizando os valores para a variável M atribuídos numa escala de 0 a 10: M = [9, 10, 7, 10, 10, 10, 1, 2, 5]
é feita uma simulação, por exemplo, em torno das variáveis ci para i = 1, 2, 3. Varia-se os custos para
ci= [5000,3500,4000]. O gráfico com as soluções obtidas é:
37
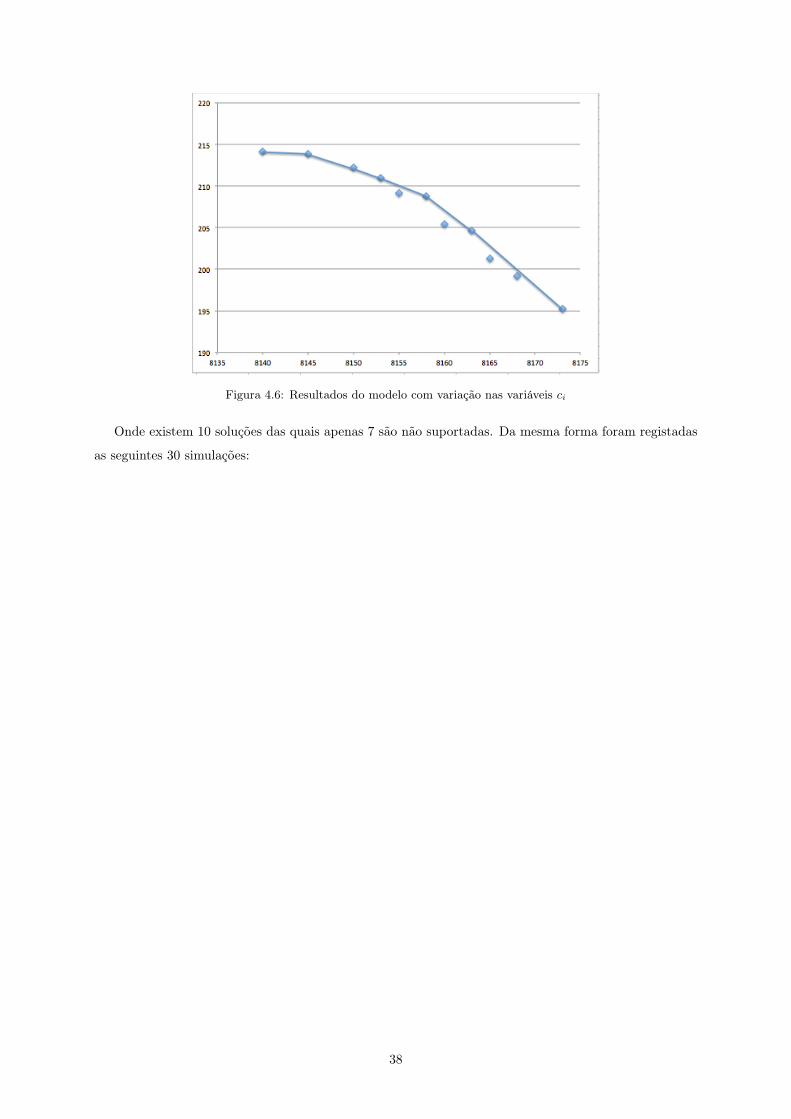
Figura 4.6: Resultados do modelo com variação nas variáveis ci
Onde existem 10 soluções das quais apenas 7 são não suportadas. Da mesma forma foram registadas
as seguintes 30 simulações:
38
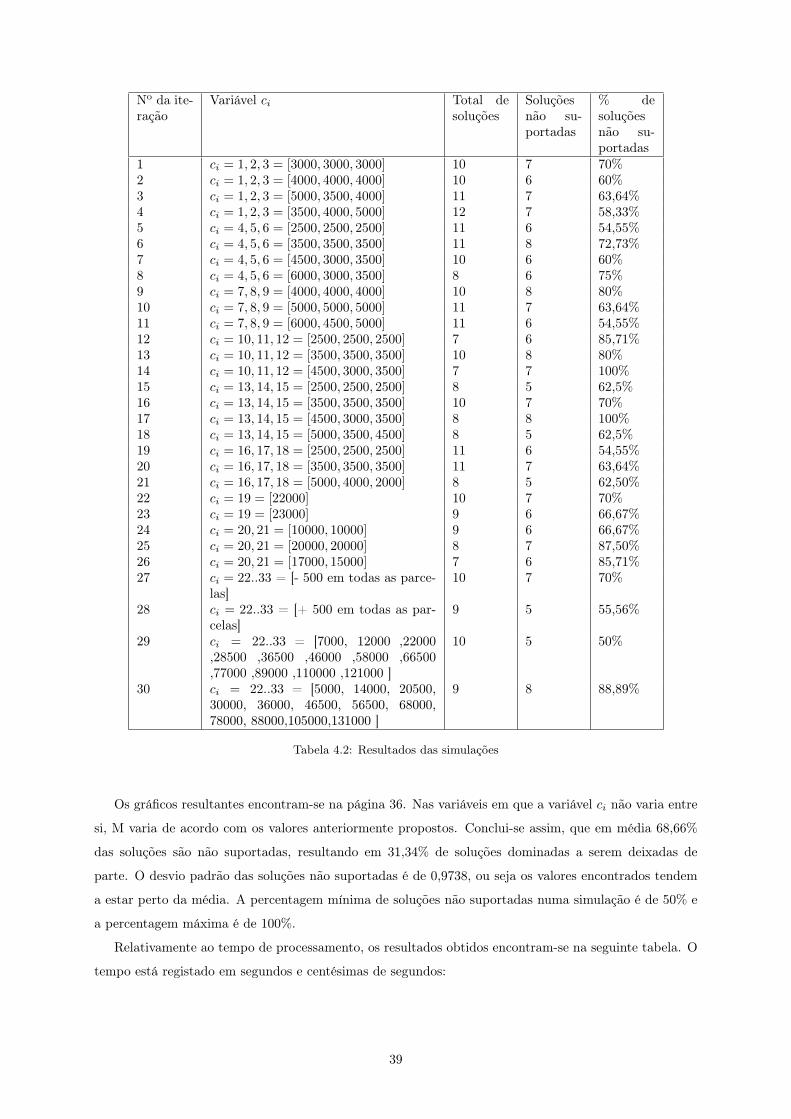
No da ite-ração
Variável ci Total desoluções
Soluçõesnão su-portadas
% desoluçõesnão su-portadas
1 ci = 1, 2, 3 = [3000, 3000, 3000] 10 7 70%2 ci = 1, 2, 3 = [4000, 4000, 4000] 10 6 60%3 ci = 1, 2, 3 = [5000, 3500, 4000] 11 7 63,64%4 ci = 1, 2, 3 = [3500, 4000, 5000] 12 7 58,33%5 ci = 4, 5, 6 = [2500, 2500, 2500] 11 6 54,55%6 ci = 4, 5, 6 = [3500, 3500, 3500] 11 8 72,73%7 ci = 4, 5, 6 = [4500, 3000, 3500] 10 6 60%8 ci = 4, 5, 6 = [6000, 3000, 3500] 8 6 75%9 ci = 7, 8, 9 = [4000, 4000, 4000] 10 8 80%10 ci = 7, 8, 9 = [5000, 5000, 5000] 11 7 63,64%11 ci = 7, 8, 9 = [6000, 4500, 5000] 11 6 54,55%12 ci = 10, 11, 12 = [2500, 2500, 2500] 7 6 85,71%13 ci = 10, 11, 12 = [3500, 3500, 3500] 10 8 80%14 ci = 10, 11, 12 = [4500, 3000, 3500] 7 7 100%15 ci = 13, 14, 15 = [2500, 2500, 2500] 8 5 62,5%16 ci = 13, 14, 15 = [3500, 3500, 3500] 10 7 70%17 ci = 13, 14, 15 = [4500, 3000, 3500] 8 8 100%18 ci = 13, 14, 15 = [5000, 3500, 4500] 8 5 62,5%19 ci = 16, 17, 18 = [2500, 2500, 2500] 11 6 54,55%20 ci = 16, 17, 18 = [3500, 3500, 3500] 11 7 63,64%21 ci = 16, 17, 18 = [5000, 4000, 2000] 8 5 62,50%22 ci = 19 = [22000] 10 7 70%23 ci = 19 = [23000] 9 6 66,67%24 ci = 20, 21 = [10000, 10000] 9 6 66,67%25 ci = 20, 21 = [20000, 20000] 8 7 87,50%26 ci = 20, 21 = [17000, 15000] 7 6 85,71%27 ci = 22..33 = [- 500 em todas as parce-
las]10 7 70%
28 ci = 22..33 = [+ 500 em todas as par-celas]
9 5 55,56%
29 ci = 22..33 = [7000, 12000 ,22000,28500 ,36500 ,46000 ,58000 ,66500,77000 ,89000 ,110000 ,121000 ]
10 5 50%
30 ci = 22..33 = [5000, 14000, 20500,30000, 36000, 46500, 56500, 68000,78000, 88000,105000,131000 ]
9 8 88,89%
Tabela 4.2: Resultados das simulações
Os gráficos resultantes encontram-se na página 36. Nas variáveis em que a variável ci não varia entre
si, M varia de acordo com os valores anteriormente propostos. Conclui-se assim, que em média 68,66%
das soluções são não suportadas, resultando em 31,34% de soluções dominadas a serem deixadas de
parte. O desvio padrão das soluções não suportadas é de 0,9738, ou seja os valores encontrados tendem
a estar perto da média. A percentagem mínima de soluções não suportadas numa simulação é de 50% e
a percentagem máxima é de 100%.
Relativamente ao tempo de processamento, os resultados obtidos encontram-se na seguinte tabela. O
tempo está registado em segundos e centésimas de segundos:
39
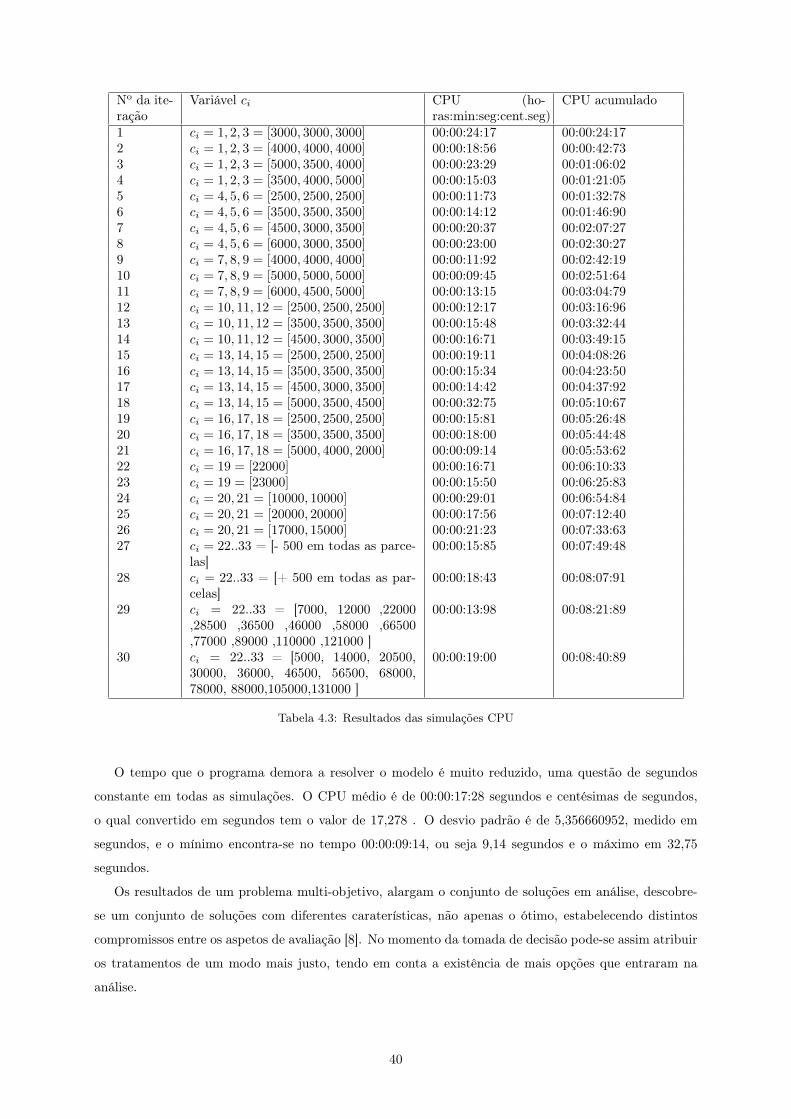
No da ite-ração
Variável ci CPU (ho-ras:min:seg:cent.seg)
CPU acumulado
1 ci = 1, 2, 3 = [3000, 3000, 3000] 00:00:24:17 00:00:24:172 ci = 1, 2, 3 = [4000, 4000, 4000] 00:00:18:56 00:00:42:733 ci = 1, 2, 3 = [5000, 3500, 4000] 00:00:23:29 00:01:06:024 ci = 1, 2, 3 = [3500, 4000, 5000] 00:00:15:03 00:01:21:055 ci = 4, 5, 6 = [2500, 2500, 2500] 00:00:11:73 00:01:32:786 ci = 4, 5, 6 = [3500, 3500, 3500] 00:00:14:12 00:01:46:907 ci = 4, 5, 6 = [4500, 3000, 3500] 00:00:20:37 00:02:07:278 ci = 4, 5, 6 = [6000, 3000, 3500] 00:00:23:00 00:02:30:279 ci = 7, 8, 9 = [4000, 4000, 4000] 00:00:11:92 00:02:42:1910 ci = 7, 8, 9 = [5000, 5000, 5000] 00:00:09:45 00:02:51:6411 ci = 7, 8, 9 = [6000, 4500, 5000] 00:00:13:15 00:03:04:7912 ci = 10, 11, 12 = [2500, 2500, 2500] 00:00:12:17 00:03:16:9613 ci = 10, 11, 12 = [3500, 3500, 3500] 00:00:15:48 00:03:32:4414 ci = 10, 11, 12 = [4500, 3000, 3500] 00:00:16:71 00:03:49:1515 ci = 13, 14, 15 = [2500, 2500, 2500] 00:00:19:11 00:04:08:2616 ci = 13, 14, 15 = [3500, 3500, 3500] 00:00:15:34 00:04:23:5017 ci = 13, 14, 15 = [4500, 3000, 3500] 00:00:14:42 00:04:37:9218 ci = 13, 14, 15 = [5000, 3500, 4500] 00:00:32:75 00:05:10:6719 ci = 16, 17, 18 = [2500, 2500, 2500] 00:00:15:81 00:05:26:4820 ci = 16, 17, 18 = [3500, 3500, 3500] 00:00:18:00 00:05:44:4821 ci = 16, 17, 18 = [5000, 4000, 2000] 00:00:09:14 00:05:53:6222 ci = 19 = [22000] 00:00:16:71 00:06:10:3323 ci = 19 = [23000] 00:00:15:50 00:06:25:8324 ci = 20, 21 = [10000, 10000] 00:00:29:01 00:06:54:8425 ci = 20, 21 = [20000, 20000] 00:00:17:56 00:07:12:4026 ci = 20, 21 = [17000, 15000] 00:00:21:23 00:07:33:6327 ci = 22..33 = [- 500 em todas as parce-
las]00:00:15:85 00:07:49:48
28 ci = 22..33 = [+ 500 em todas as par-celas]
00:00:18:43 00:08:07:91
29 ci = 22..33 = [7000, 12000 ,22000,28500 ,36500 ,46000 ,58000 ,66500,77000 ,89000 ,110000 ,121000 ]
00:00:13:98 00:08:21:89
30 ci = 22..33 = [5000, 14000, 20500,30000, 36000, 46500, 56500, 68000,78000, 88000,105000,131000 ]
00:00:19:00 00:08:40:89
Tabela 4.3: Resultados das simulações CPU
O tempo que o programa demora a resolver o modelo é muito reduzido, uma questão de segundos
constante em todas as simulações. O CPU médio é de 00:00:17:28 segundos e centésimas de segundos,
o qual convertido em segundos tem o valor de 17,278 . O desvio padrão é de 5,356660952, medido em
segundos, e o mínimo encontra-se no tempo 00:00:09:14, ou seja 9,14 segundos e o máximo em 32,75
segundos.
Os resultados de um problema multi-objetivo, alargam o conjunto de soluções em análise, descobre-
se um conjunto de soluções com diferentes caraterísticas, não apenas o ótimo, estabelecendo distintos
compromissos entre os aspetos de avaliação [8]. No momento da tomada de decisão pode-se assim atribuir
os tratamentos de um modo mais justo, tendo em conta a existência de mais opções que entraram na
análise.
40

4.7.2 Gráficos resultantes
Figura 4.7: Simulação 1 e 2
Figura 4.8: Simulação 3 e 4
Figura 4.9: Simulação 5 e 6
41
Figura 4.10: Simulação 7 e 8
Figura 4.11: Simulação 9 e 10
Figura 4.12: Simulação 11 e 12
42
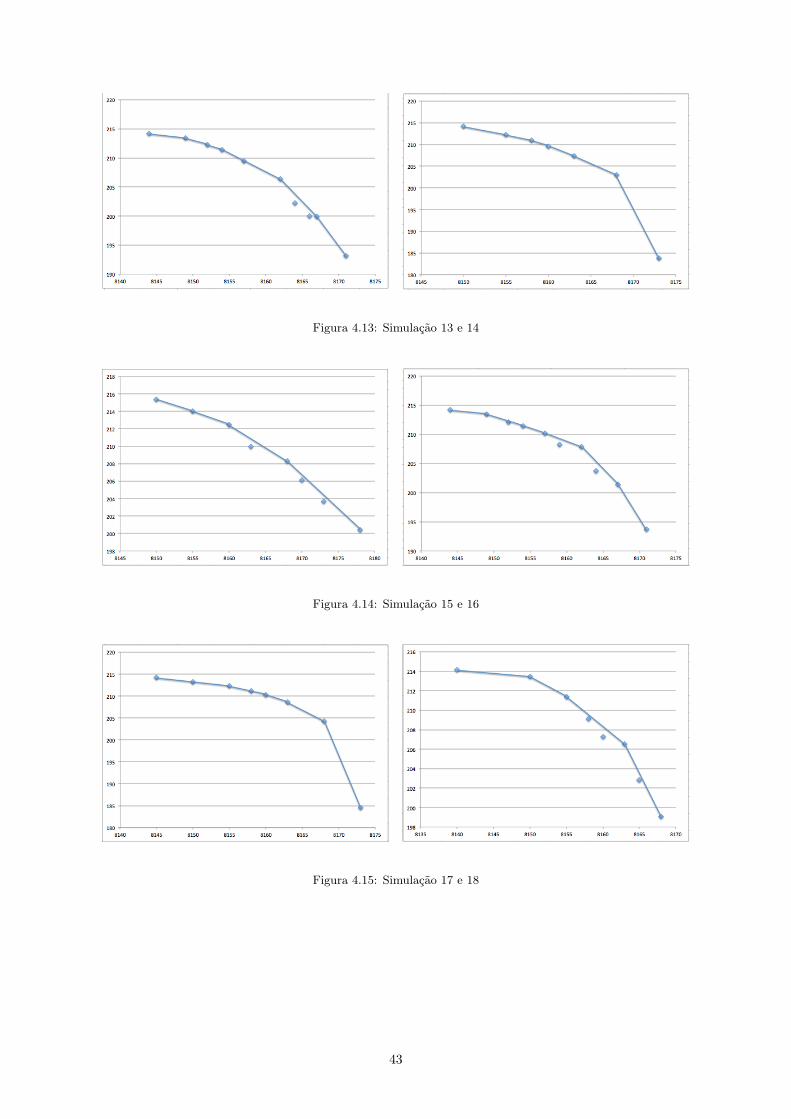
Figura 4.13: Simulação 13 e 14
Figura 4.14: Simulação 15 e 16
Figura 4.15: Simulação 17 e 18
43
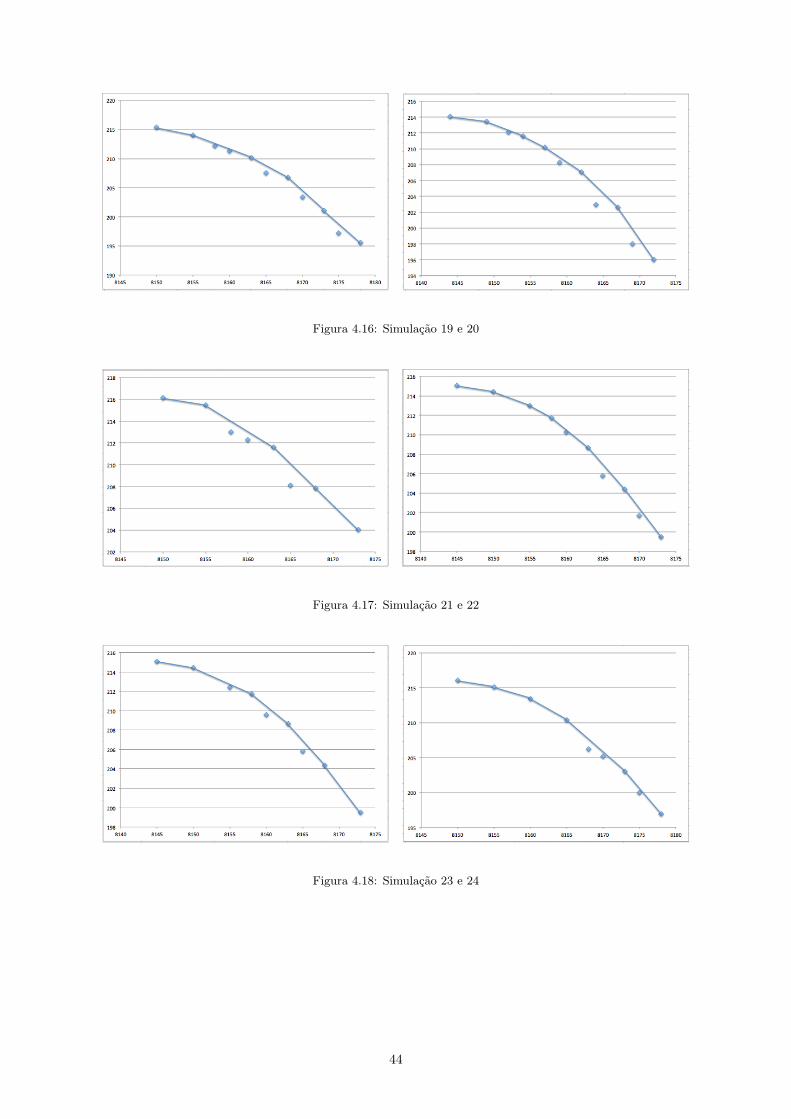
Figura 4.16: Simulação 19 e 20
Figura 4.17: Simulação 21 e 22
Figura 4.18: Simulação 23 e 24
44
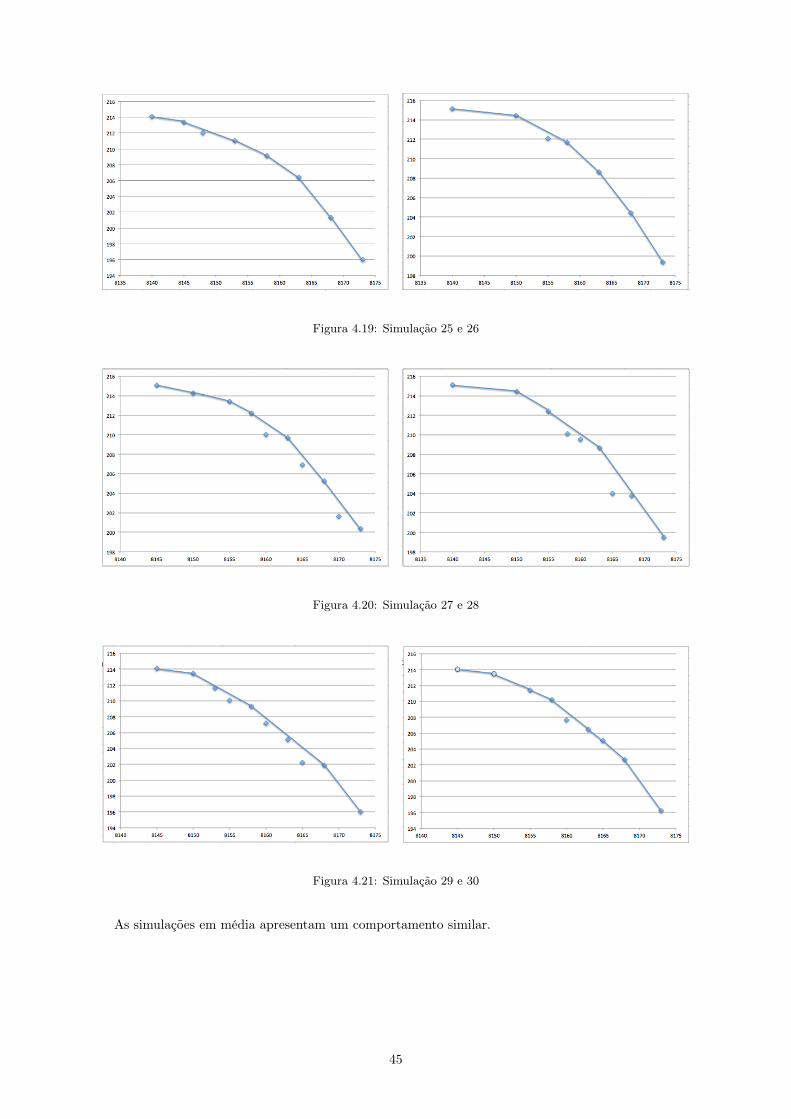
Figura 4.19: Simulação 25 e 26
Figura 4.20: Simulação 27 e 28
Figura 4.21: Simulação 29 e 30
As simulações em média apresentam um comportamento similar.
45

4.8 Conclusões
Após o estudo do artigo de Hooker e Williams, seguiu-se a sugestão de implementação de uma nova função
de equidade para o problema de distribuição de recursos em saúde. Neste sentido, através do estudo nos
capítulos anteriores, chega-se à conclusão que a melhor função de equidade para o problema em questão
é uma função moldada em torno dos dados. A função Rawlsiana foi assim substituída por uma que
seleciona indivíduos de todos os grupos de tratamentos médicos, de modo a que fosse selecionado pelo
menos um de cada tratamento. Para que o modelo não opte pelo grupo que minimize os custos da soma
dos tratamentos, foi adicionada uma variável M, de modo a atribuir pesos adequados aos tratamentos com
custos menores. O problema continuou a ter a forma de um problema min max mas alterou-se o método
usado. Para a resolução do problema conclui-se, após testes com diversos métodos de programação multi-
objetivo, que o método adequado era o da restrição – ε. Os resultados obtidos foram diferentes dos obtidos
anteriormente por Hooker e Williams. Encontram mais soluções que escapam ao modelo dos autores, que
não sendo ótimas, podem ser as ideais na tomada de decisão. Esta análise dos novos resultados permitiu
concluir que existem resultados interessantes dependendo das funções que se escolhem para representação
de uma questão de equidade.
Este capítulo é uma abordagem crítica ao modelo e ao método usado por Hooker e Williams. Os
autores incentivam a continuação e melhoramento do modelo do artigo sugerindo algumas alternativas.
A escolha de uma função de equidade adaptada exclusivamente ao exemplo, revelou-se uma boa opção.
Os resultados mostram uma abordagem diferente à usada por Hooker e Williams, e o método usado, o
da restrição - ε, consegue encontrar mais soluções, sendo assim mais completo.
46

Capítulo 5
Conclusões
Dado os objetivos apresentados anteriormente, isto é, a exploração das alternativas propostas por Hooker
e Williams no seu artigo “Combining Equity and Utilitarianism in a Mathematical Programming Model” e
da implementação de uma nova função e uso de um novo modelo para a questão da otimização, é possível
concluir que, embora os resultados sejam diferentes do modelo tradicional, os objetivos propostos para
esta dissertação foram alcançados. A criação e a exploração da combinação das diferentes funções de
equidade com a função de utilidade proposta por Hooker e Williams, e a implementação de um novo
modelo para o exemplo em questão do artigo "Combining Equity and Utilitarianism in a Mathematical
Programming Model”, obtiveram resultados destacáveis.
A realização do primeiro objetivo permitiu observar que o comportamento da combinação das funções
difere com a variação da definição de equidade. As conclusões tiradas, assim como as interpretações de
cada experimentação, são bastante diferentes, não podendo ser comparadas entre si uma vez que não
concluem o mesmo, pois os resultados não estão na mesma medida. A função usada pelos autores é
medida em níveis de satisfação, a solução dos teoremas de negociação, é medida em níveis de bem estar e,
algumas das medidas de iniquidade, em montantes ”físicos”. A principal missão desta análise é perceber
se estas funções estão aptas para se adaptarem ao exemplo da distribuição dos recursos pela saúde. Nos
exemplos reais, a definição de equidade tem que ser adaptada e escolhida minuciosamente, através de
uma análise exploratória. Assim, conclui-se que a melhor função a usar na segunda parte dos objetivos,
implementação de uma nova função de equidade e implementação de um novo modelo para o problema da
distribuição dos recursos na saúde, é uma função de equidade construída em torno dos dados. O modelo
é um modelo max min com a implementação do método da restrição - ε para a otimização das funções
cominadas (equidade e utilidade).
A concretização do segundo objetivo, permite contribuir para o artigo “Combining Equity and Uti-
litarianism in a Mathematical Programming Model” dando outra hipótese de resolução do problema de
programação matemática seguindo uma abordagem diferente. A escolha do método da restrição - ε foi
feita após tentativas e análises de implementação de outros métodos. Os resultados obtido são mais
completos em termos de soluções encontradas. Acredita-se que ainda existem mais hipóteses consoante
a escolha de outras funções de equidade.
47

Com base na experiência e nas conclusões alcançadas na construção desta dissertação, é possível
afirmar que o caminho para o ótimo é assim difícil e longo. Para alcançar a melhor combinação que
encontre as soluções ótimas do problema de programação é necessário usar uma abordagem de tentativa
e erro.
48

Capítulo 6
Apêndice
6.1 Teoremas provados no artigo de J.N.Hooker e H.P. Williams
Os teoremas provados para a construção e uso dos modelos por J.N.Hooker e H.P. Williams no seu artigo,
são:
Teorema 6.1.1. O modelo PLIM (4.5) é uma formulação correcta do problema (4.3) e (4.4).
Demonstração. Deve-se mostrar que qualquer solução admissível do problema é uma solução de (4.5) e
vice versa. Para o mostrar consideram qualquer solução admissível (u, z). Apresentam valores de v, w, δ
tal que (u, z, v, w, δ) seja uma solução admissível de (4.5). Supondo sem perda de generalidade que
umin = u1, seja:
w = u1, (δi, vi) =
(0, u1) se ui − u1 < ∆
(1, ui −∆) caso contrário(6.1)
Para demonstrar que a segunda e a terceira inequação de (6.1) são satisfeitas, Hooker e Williams
notaram que quando ui − u1 < ∆, estas são satisfeitas devido a (4.5). Quando ui − u1 > ∆, a segunda
inequação de (4.5) e a primeira parte da terceira inequação são satisfeitas devido a (6.1), e a segunda parte
da terceira inequação de (4.5) é satisfeita pois ui− u1 6M é dado. Para provar a primeira inequação de
(4.5), escrevem (4.5) como:
z 6 (n− 1)∆ + nu1 +∑i=i,ui−u1<∆(vi − u1) +
∑i=1,ui−u1>∆(vi − u1)
Substituindo os valores de vi, dado (6.1), a inequação torna-se
z 6 (n− 1)∆ + nu1 +∑i=i,ui−u1<∆(u1 − u1) +
∑i=1,ui−u1>∆(ui − u1 −∆)
que é imposto por (4.3). Supõem de seguida que (u, z, v, w, δ) satisfazem (4.5) e mostram que (u, z)
satisfaz (3) e uj−ui 6M para todo o i, j. Para provar o último, notam que a terceira inequação de (4.5)
implica que vj − (M −∆)δj 6 w 6 vi para qualquer i, j e assim:
vj − vi 6M −∆ (6.2)
49

Contudo, por vj > uj ∆ e vi 6 ui devido à segunda inequação de (4.5), (6.2) implica uj − ui 6M como
foi alegado. Para mostrarem que (u, z) satisfaz (4.3), a primeira inequação de (4.5) é escrita como:
z 6 (n− 1)∆ + nu1 +∑
i=i,δi=0
(vi − u1) +∑
i=1,δi=1
(vi − u1) (6.3)
Cada termo do primeiro somatório satisfaz:
vi − u1 6 w − u1 6 0 6 (ui − u1 −∆)+ (6.4)
onde a primeira desigualdade é devida à segunda inequação de (4.5) e δi = 0. Notam que a partir da
segunda e terceira inequação de (4.5), wi 6 vi 6 ui −∆δi para todo o i, tem-se w 6 u1, de onde vem a
segunda desigualdade em (6.4). Também, cada termo do segundo somatório satisfaz:
vi − u1 6 ui − u1 −∆ 6 (ui − u1 −∆)+
onde a primeira desigualdade vem da segunda inequação de (4.5) e δi = 1. A desigualdade (6.3) implica
assim (4.3) como era desejado.
O artigo continua as suas provas através da demonstração de que o modelo (4.5) é afinado. Defendem
que é devido à projeção da relaxação continua no espaço (z, u) ser o fecho convexo do problema original.
A relaxação continua de (4.5) é:
z 6 (n− 1)∆ +∑ni=1 vj (a)
ui −∆ 6 vi, para todo o i (di)
vi 6 ui −∆δi para todo o i (ei)
w 6 vi, para todo o i (fi)
vi 6 w + (M −∆)δi, para todo o i (gi)
δi > 0, para todo o i (hi)
δi 6 1, ui > 0, para todo o i
(6.5)
Teorema 6.1.2. O modelo (4.5) é uma formulação afinada, no sentido em que a relaxação da progra-
mação linear corresponde ao fecho convexo do conjunto admissível do problema (4.3) - (4.4).
Demonstração. A prova está dividida em duas partes. A primeira mostra que (6.5) implica:
z 6 (n− 1)∆ + (1 + (n− 1) ∆M )ui + (1− ∆
M )∑j 6=i uj , para todo o i (ki)
uj − ui 6M, para todo o i, j (lij)
ui > 0, para todo o i
(6.6)
É necessário mostrar que cada inequação válida para o problema original é implícita por (6.6). Uma vez
que (4.5) é um modelo correto do problema, daí resulta que (6.6) descreve o fecho convexo do conjunto
admissível e (4.5) é um modelo afinado.
Parte 1: Os autores querem provar que (6.5) implica (6.6). A partir da prova do Teorema 1, viu-se que
(6.5) implica (lij) para todo o i, j. Para mostrar que (6.5) implica (ki) para qualquer i, mostram que (ki)
50

é uma combinação linear não negativa das desigualdades de (6.5). Primeiro, notam que como resultado
das desigualdades serem combinações lineares positivas de (6.5) para cada i:
vi 6 ∆Mw + (1− ∆
M )ui (pi)
vi 6 ui (qi)
pois (pi) = (1/∆) (ei) +(1/(M − ∆)) (gi) e (qi)= (1/∆)(ei) + (hi). Obtém-se o seguinte resultado
para cada i, j:
vj 6 ∆M vi + (1− ∆
M )uj (rij)
pois (rij) = (M/∆)(pj) + (qi). Finalmente,
(ki) = (a) +∑j 6=i
(rij) + (1 + (n− 1)∆
M)(qi),
que mostra que (ki) é uma combinação linear positiva de (10), como desejado.
Parte 2: Falta mostrar que qualquer desigualdade z 6 au+ b que é valida para o problema é implicada
por (6.6). Para isso, consideram suficiente mostrar que z 6 au+b é dominada por uma combinação linear
positiva de (6.6).
Em primeiro lugar, observa-se que (u1, ..., un, z) = (0, ..., 0, (n − 1)∆) é admissível em (4.3) e deve
assim satisfazer z 6 au+ b. Substituindo estes valores em z 6 au+ b, obtém-se b > (n− 1)∆. Também,
para qualquer t > 0,
(u1, ..., un, z) = (t, ..., t, tn+ (n− 1)∆)
é admissível em (4.3), o que implica
∑i
ai > n− b− (n− 1)∆
t.
Quando t → ∞ , tem-se∑i ai > n. É suficiente mostrar que qualquer z 6 au + b com
∑i ai = n é
dominado por uma combinação linear positiva de (6.6), pois neste caso uma desigualdade com∑i ai > n
pode ser obtida ao adicionar múltiplos de ui > 0 a uma desigualdade com∑i ai = n.
Seja N = {1, ..., n}, os autores definem conjuntos de indíces como:
I = {i ∈ N |1− ∆M 6 ai 6 1}, J = {i ∈ N |ai < 1− ∆
M },
K = N \ (I ∪ J).
De seguida associam os multiplicadores αi com (ki) e βij com (lij), definidos por:
αi =
Mn∆ (ai − 1 + ∆
M ) se i ∈ I1−α[I]n−|I| caso contrário;
(6.7)
51

βi,j =
1|K| (
n−a[I]n−|I| − ai) se i ∈ J, j ∈ K
fij se i, j ∈ K e i 6= j
0 caso contrário,
(6.8)
onde α[I] =∑j∈I αj , e similarmente para a[I] e a[K]. As quantidades fij são fluxos admissíveis e não
negativos nos cantos (i, j) de um grafo completo e direto cujos vértices correspondem aos índices em K,
com um fornecimento liquido de ai−a[K]/|K| a cada vértice i. Tais fluxos existem porque o fornecimento
liquido sobre todos os vértices é de∑i(ai − a[K]/|K|) = 0.
Mostrou-se primeiro que a combinação linear∑i αi(ki) +
∑ij βij (lij) é a desigualdade z 6 au+ (n−
1)∆, dado que∑i ai = n. É facilmente confirmado que
∑i αi = 1, tal que a combinação linear tenha a
forma z 6 du+ (n− 1)∆. Por mostrar que d = a. Tem-se:
di = (1 + (n− 1)∆
M)αi + (1− ∆
M)∑j 6=i
αj +∑j
(βji − βij).
Usando o facto que∑i αi = 1, a equação fica:
di =∆
M(nαi − 1) + 1 +
∑j
(βji − βij). (6.9)
Quando i ∈ I, cada βij = 0 e imediatamente, tem-se a partir de (13), que di = ai. Quando i ∈ J ,
(6.9) fica:
di =n− a[I]
n− |I|−
∑j∈K
1
|K|(n− a[I]
n− |I|− ai) = ai.
Quando i ∈ K, (6.9) fica:
di = n−a[I]n−|I| +
∑j∈J
1|K| (
n−a[I]n−|I| − aj) +
∑j∈K\{i}(fji − fij) =
=(1 + |J||K| )
n−a[I]n−|I| −
a|J||K| +
∑j∈K\{i}(fji − fij).
Usando o facto de que a[J ] = n− a[I]− a[K], isto simplifica para:
di =a[K]
|K|+
∑j∈K\{i}
(fji − fij). (6.10)
Contudo, isto implica que di = ai pois o segundo termo é um fornecimento liquido no vértice i, o qual
é ai − a[K]/|K|.
Conclui-se assim que z 6 au+ (n− 1)∆ é a combinação linear de∑i αi(ki) +
∑ij βij(lij). Por causa
de b > (n − 1)∆, z 6 au + b é dominado por uma combinação linear positiva de (6.6) e assim implícita
por (4.5), mostram agora que os multiplicadores αi e βij são positivos.
Observam primeiro que αi > 0 para i ∈ I porque ai > 1−∆/M dada a definição de I. Para mostrar
que αi > 0 para i 6= I, notam que ai 6 1 para i ∈ I implica αi 6 1/n pela definição de αi. Assim,
α[I] 6 1, o que implica αi > 0 para i /∈ I. Para mostrar que βij > 0 para i ∈ J e j ∈ K, notam que
ai 6 1 para i ∈ I implica que a[I] 6 |I|, de onde:
52

n− a[I]
n− |I|> 1. (6.11)
Contudo, ai < 1−∆/M para i ∈ J \ {j} implica ai 6 1, o que conjuntamente com (15) implica que
βi = fij para i, j ∈ K é por definição um fluxo positivo.
Teorema 6.1.3. O modelo (4.8) é uma formulação correta de (4.6).
A prova é similar à do Teorema 1.
Demonstração. Mostra-se que qualquer solução admissível do problema (4.6) é uma solução de (4.8) e
vice versa. Para o mostrar, consideram qualquer solução admissível (u, z). Apresentam-se valores de
v, w, δ tal que (u, z, v, w, δ) seja uma solução admissível de (4.8). Supondo, sem perda de generalidade
que umin = u1, seja v, w, δ como em (6.1). Mostram como na demonstração do Teorema 1 que (4.8)-b e
(4.8)-c são satisfeitas. Para provar (4.8)-a, escreve-se como:
z 6 (∑i
ni − 1)∆ + (∑i
ni)u1 +∑
i,ui−u1<∆
ni(vi − u1) +∑
i,ui−u1>∆
ni(vi − u1)
Substituindo os valores de vi dados em (6.1), fica:
z 6 (∑i
ni − 1)∆ + (∑i
ni)u1 +∑
i,ui−u1<∆
ni(u1 − u1) +∑
i,ui−u1>∆
ni(ui − u1 −∆)
que é implicada por (4.6).
Supõe-se agora que (u, z, v, w, δ) é admissível em (4.8) e mostra-se que (u, z) é admissível em (4.6).
Pode ser demonstrado como na prova do Teorema 1 que u satisfaz a segunda restrição de (4.6). Para
mostrar que (u, z) satisfaz a primeira restrição, escreve-se (4.8) como:
z 6 (∑i
ni − 1)∆ + (∑i
ni)u1 +∑i,δi=0
ni(vi − u1) +∑i,δi=1
ni(vi − u1) (6.12)
Cada termo do primeiro somatório satisfaz:
ni(vi − u1) 6 ni(w − u1) 6 0 6 ni(ui − u1 −∆)+ (6.13)
onde a primeira desigualdade é devido a (4.8)-b e δi = 0. Note-se que de (4.8)-b e (4.8)-c, w 6 vi 6 ui−∆δi
para todo o i, tem-se que w 6 u1, de onde vem a segunda desigualdade em (6.13). Cada termo do segundo
somatório também satisfaz:
ni(vi − u1) 6 ni(ui − u1 −∆) 6 ni(ui − u1 −∆)+
onde a primeira desigualdade é devida a (4.8)-b e δi = 1. A desigualdade (6.12) implica assim a primeira
restrição de (4.6), como desejado.
53

Teorema 6.1.4. A relaxação do modelo (4.8) corresponde ao fecho convexo do conjunto admissível .
Demonstração. Como anteriormente, esta demonstração foi dividida em duas partes. Primeiro mostraram
que a relaxação continua de (4.8) implica que:
z 6 (∑j nj − 1)∆ + (ni + ∆
M
∑j 6=i nj)ui + (1− ∆
M )∑j 6=i njuj , para todo o i (ki)
uj − ui 6M, para todo o i, j (lij)
ui > 0, para todo o i
(6.14)
Mostram de seguida que cada inequação válida do problema original (4.8) é implicada por (6.14). Como
(4.8) é um modelo correto do problema, daí resulta que (6.14) descreve o fecho convexo e o conjunto
admissível, e (4.8) é um modelo afinado.
Parte I: Mostraram que a relaxação continua de (4.8) implica (6.14). Viu-se na demonstração do
Teorema 3 que isso implica (li) para todo o i, j. Para mostrar que a relaxação continua de (4.8) implica
(ki) para qualquer i, os autores mostraram que (ki) é uma combinação linear positiva da relaxação. As
seguintes combinações lineares positivas são derivadas da prova do Teorema 2:
vi 6 ui (qi)
vj 6 ∆M vi + (1− ∆
M )uj (rij)
agora
(ki) = (a) +∑j 6=i
nj(rij) + (ni +∆
M
∑j 6=i
nj) (qi),
que mostra que (ki) é uma combinação linear positiva, como desejado.
Parte II: Falta mostrar que qualquer desigualdade z 6 au+b que é valida para o problema é implicada
por (6.14). Para isso, é suficiente mostrar que z 6 au+ b é dominada por uma combinação linear positiva
de (6.14).
Em primeiro lugar, observa-se que (u1, ..., un, z) = (0, ..., 0, (n[N ]− 1)∆) é admissível em (4.6) e deve
assim satisfazer z 6 au+b. Substituindo estes valores em z 6 au+b, obtém-se b > (n[N ]−1)∆. Também,
para qualquer t > 0,
(u1, ..., un, z) = (t, ..., t, tn[N ] + (n[N ]− 1)∆)
é admissível em (4.6), o que implica
a[N ] > n[N ]− b− (n[N ]− 1)∆
t.
Quando t→∞ , tem-se a[N ] > n[N ]. É suficiente mostrar que qualquer z 6 au+ b com a[N ] = n[N ] é
dominado por uma combinação linear positiva de (6.14), pois neste caso uma desigualdade com a[N ] >
n[N ] pode ser obtida ao adicionar múltiplos de ui > 0 a uma desigualdade com a[N ] = n[N ].
Definiram os conjuntos de indíces como:
54

I = {i ∈ N |ni(1− ∆M ) 6 ai 6 ni},
J = {i ∈ N |ai < ni(∆M )},
K = N \ (I ∪ J).
De seguida associam-se os multiplicadores com (6.14) como mostrado e definem-se como:
αi =
1n[N ]
M∆ (ai − ni(1− ∆
M )) se i ∈ I1−α[I]m−|I| caso contrário;
(6.15)
βi,j =
1|K| (Si − ai) se i ∈ J, j ∈ K (21)
fij se i, j ∈ K e i 6= j
0 caso contrário,
(6.16)
onde
Si = (1− ∆
M)ni +
n[N ]− (n[N ]− n[I])(1−∆/M)− a[I]
m− |I|.
As quantidades fij são fluxos admissíveis e não negativos nos cantos (i, j) de um grafo completo e directo
cujos vértices correspondem aos índices em K, com um fornecimento liquido de:
si = ai − (ni −n[K]
|K|)(1− ∆
M)− a[K]
|K|
a cada vértice i. Tais fluxos existem porque o fornecimento liquido sobre todos os vértices é de∑i∈K si =
0.
Mostraram primeiro que a combinação linear∑i αi(ki)+
∑ij βij(lij) é a desigualdade z 6 au+(n[N ]−
1)∆, dado que∑i ai = n[N ]. É facilmente confirmado que
∑i αi = 1, tal que a combinação linear tenha
a forma z 6 du+ (n[N ]− 1)∆. Falta mostrar que d = a. Tem-se:
di = (ni +∆
M
∑j 6=i
nj)αi + ni(1−∆
M)∑j 6=i
αj +∑j 6=i
(βji − βij). (6.17)
Usando o facto que∑j αj = 1, a equação implica:
di =∆
M(n[N ]αi) + ni(1−
∆
M) +
∑j 6=i
(βji − βij). (6.18)
Quando i ∈ I, cada βij = 0 e imediatamente, tem-se a partir de (6.18), que di = ai. Quando i ∈ J , (6.18)
fica:
di = Si −∑j∈K
1
|K|(Si − ai) = ai.
Quando i ∈ K, (6.18) fica na forma:
55

di = Si +∑j∈J
1
|K|(Sj − aj) +
∑j∈K\{i}
(fji − fij) = (|K|Si + S|K| − a|J |
|K|) +
∑j∈K\{i}
(fji − fij).
Dada a definição de Si e n[N ] = a[I] + a[J ] + a[K], toma a forma:
di = (1− ∆
M)ni −
1
|K|((n[N ]− n[I]− n[J ])(1− ∆
M)− a[K]) +
∑j∈K\{i}
(fji − fij).
Dado n[N ] = n[I] + n[J ] + n[K]:
di = (1− ∆
M)(ni −
n[K]
|K|) +
a[K]
|K|+
∑j∈K\{i}
(fji − fij) = ai − si +∑
j∈K\{i}
(fji − fij) (6.19)
Como o somatório é o fornecimento liquido si no nó i, tem-se que di = ai, como desejado.
Hooker e Williams concluíram assim que z 6 au+ (n[N ]− 1)∆ é a combinação linear de∑i αi(ki) +∑
ij βij(lij). Por causa de b > (n[N ]− 1)∆, z 6 au+ b é dominado por uma combinação linear positiva
de (6.14) e assim implícita por (4.8), mostrando agora que os multiplicadores em (6.16) são positivos.
Observa-se que αi > 0 para i ∈ I porque ai > ni(1 − ∆/M) dada a definição de I. Para mostrar
que αi > 0 para i 6= I, nota-se que ai 6 ni para i ∈ I implica αi 6 1/n[N ] pela definição de αi. Assim,
α(I) 6 1, o que implica αi > 0 para i /∈ I. Para mostrar que βij > 0 para i ∈ J e j ∈ K, nota-se que
ai 6 ni para i ∈ I implica que a[I] 6 n[I], de onde:
Si > (1− ∆
M)ni +
n[N ]− n[I]
m− |I|> ai +
n[N ]− n[I]
m− |I|> ai. (6.20)
onde a segunda desigualdade vem de ai < (1 − ∆/M)ni para i ∈ J . Contudo, (6.20) e a definição
de βij implicam que βij > 0 para i ∈ J . Finalmente, βij = fij para i, j ∈ K é por definição um fluxo
positivo.
56

Referências
[1] P. D. Allison. Measures of inequality. American Sociological Review, 43, 1978.
[2] G. Araniti, M. Condoluci, A. Iera, L. Militano, and B. A. Pansera. Analytical modeling of bargaining
solutions for multicast cellular services. Electronic Journal of Differential Equations, pages 1–10,
2013.
[3] L. G. Bellù and P. Liberati. Policy impacts on inequality welfare based measures of inequality the
atkinson index. Food and Agriculture Organization of the United Nations, 2006.
[4] Daniel Bernoulli. Exposition of a new theory on the measurement of risk. Econometrica, 22(1):23–36,
1954.
[5] A. Briggs and A. Gray. Using cost effectiveness information. British Medical Journal, 2000.
[6] Alpha C. Chiang and Kevin Wainwright. Fundamentals methods of mathematical economics.
McGraw-Hill Higher Education, 4 edition, 2005.
[7] John W. Chinneck. Practical Optimization: A Gentle Introduction. Carleton University Ottawa,
Systems and Computer Engineering, 2005.
[8] J. N. Clímaco, C. A Antunes, and M. J. G Alves. Programação Linear Multiobjectivo. Do Modelo
de Programação Linear Clássico à Consideração Explícita de Várias Funções Objectivo. Impresa da
Universidade de Coimbra, 2003.
[9] C. Coello, D. A. Van Veldhuizen, and G. B. Lamont. Evolutionary Algorithms for Solving Multi-
Objective Problems. Springer Science and Business Media, 2013.
[10] Kalyanmoy Deb. Multi-Objective Optimization Using Evolutionary Algorithms, volume 16. Wiley
Interscience Series in Systems and Optimization, 2001.
[11] P. Dixon, J. Weiner, T. Mitchell-Olds, and R. Woodley. Bootstrapping the gini coefficient of inequa-
lity. Ecology, 68:1548–1551, 1987.
[12] R. W. Evans, D. L. Manninen, L. P. Garrison, L. G. Hart, C. R. Blagg, R. A. Gutman, A. R. Hill,
and E. G. Lowrie. The quality of life of patients with end-stage renal disease. New England Journal
of Medicine, 312:553–559, 1985.
[13] J. R. Figueira. Optimizations and Applications. Instituto Superior Técnico, 2013.
57

[14] C. Gini. Variabilita e mutabilita. Journal of the Royal Statistical Society, 76(3):326–327, Feb. 1913.
[15] Eiselt H.A and Sandblom C.L. Linear Programming and its Applications. Springer, 2007.
[16] R. T Hafka, J. A. Nachlas, L. T. Watson, T. Rizzo, and R. Desai. Two-point constraint approximation
in structural optimization. Computer Methods in Applied Mechanics and Engineering, 60(3):289–301,
Feb. 1987.
[17] F. S. Hillier and G. J. Lieberman. Introduction to Operations Research. McGraw-Hill Sci-
ence/Engineering/Math, 7 edition, 2002.
[18] J. N. Hooker and Williams H. P. Combining equity and utilitarianism in a mathematical program-
ming model. Management Science, 58(9):1682–1693, May 2011.
[19] Rajgopal J. Principles And Applications Of Operations Researsh. Maynard’s Industrial Engineering
Handbook, 5 edition, 2001.
[20] R. G. Jeroslow. Representability in mixed integer programming, i: Characterization results. Discrete
Applied Mathematics, 17:223–243, 1987.
[21] R. G. Jeroslow. Mixed integer formulation. Logic-Based Decision Support, 40, 1989.
[22] M. Kendall and A. Stuart. The Advanced Theory of Statistics, volume 1. London: Charles Griffen
and Company, 2 edition, 1963.
[23] A. Krol and J. M. Miedema. Measuring income inequality: an exploratory review. Region of Waterloo
Public Health, 451158, 2009.
[24] Jonathan Levin. Choice under uncertainty. Stanford, 2006.
[25] D.G. Luenberger and Y. Ye. Linear and Nonlinear Programming. Springer, 3 edition, 2008.
[26] NKUDIC. Kidney and urologic diseases statistics for the united states. National Kidney and Urologic
Diseases Information Clearing House, 2010.
[27] Juan Pablo Vielma. Mixed integer linear programming formulation techniques. SIAM Review,
57(1):3–57, 2015.
[28] J Von Neumann and Morgenstern O. Theory of Games and Economic Behavior. Princeton University
Press, 2004.
[29] H. P. Young. Equity: In theory and practice. Princeton University Press, 1995.
58