modeling and data analysis of complex systemskahnert/mdacs/lecture_script.pdf · ein system, das...
TRANSCRIPT

Modeling and Data Analysis of Complex Systems
Markus AbelUdo Schwarz, Karsten Ahnert, Carolina Figueras
8th May 2009
Contents
I 1. Vorlesung: Organisation und Motivation 2
1 Organisatorisches 21.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2 Ziel der Vorlesung 3
3 Komplexe Systeme 3
4 Modellierung komplexer Systeme 4
5 Modellierung und Datenalyse komplexer Systeme 6
6 Komplexe Systeme 7
7 Dynamische Systeme 7
8 Ubung: Einfuhrung in R 9
II Zufallsvariablen 10
9 Eine Zufallsvariable 109.1 Wahrscheinlichkeitsdichte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109.2 Mittelwerte und Momente . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119.3 Die charakteristische Funktion und die Kumulanten . . . . . . . . . . . . . . 11
1

10 Mehrdimensionale Zufallsvariablen 1310.1 Wahrscheinlichkeitsdichte, charakteristische Funktion . . . . . . . . . . . . . 1310.2 Summe der Zufallsvariablen, Zentraler Grenzsatz . . . . . . . . . . . . . . . 1510.3 Stabile Wahrscheinlichkeitsverteilungen . . . . . . . . . . . . . . . . . . . . . 15
III Zufallsvariablen 17
11 Schatzung 17
2

Part I
1. Vorlesung: Organisation undMotivation
1 Organisatorisches
Dokumentation
Die Vorlesung wird dokumentiert
• klassich: per Mitschrift
• experimentell, da zum ersten mal: auf Video
• per Skript bzw. Kopie von Folien
• hosted von K.Ahnert: www.stat.physik.uni-potsdam.de/ kahnert/index.php?page=MDACS2009
Termine
Raum und ZeitDo 11-12:30 Vorlesung, R. 2.28.0.104 Mo 11-12:30 Ubung, Computerpool Literatur: s.homepage
Statistik
Die Teilnehmer sind/haben ... ?
• Experimentatoren, Theoretiker?
• interessante Themen?
• Vorbildung?
• Programmierkenntnisse?
Erreichen des Vorlesungsziels
Wie ublichgibt es Ubungen und eine Klausur. An beiden muss erfolgreich teilgenommen worden sein.
Sprache
Wir bieten englisch anStandard ist deutsch. Entscheidung nach Wunsch der Teilnehmer: Deutsch.
3

1.1 Motivation
Thema der Vorlesung
Warum soll man sich mit dem Thema beschaftigen. Wozu dient es?
• Wissenschaftlich: gute Modelle von neuen Systemen sind ein Dauerbrenner der Forschung.Bsp.: Klima
• Industriell: Beispiel Finanzwelt
• Intellektuell: Es ist eine große Herausforderung gegebene Systeme einer Frage gemaßzu abstrahieren und eine entsprechende Beschreibung zu finden.
2 Ziel der Vorlesung
Ziel der VorlesungZiel der Vorlesung ist es, die theoretischen und technischen Kenntnisse zu vermitteln,
die notig sind, ein komplexes System theoretisch zu analysieren, erhobene Daten statis-tisch/dynamisch zu verarbeiten und auf gefordertem Niveau zu modellieren.
3 Komplexe Systeme
Komplexe Systeme (gr. systema, das Gebilde,das Zusammengestellte)
• Was macht ein System komplex?
• Was ist ein System ?
• Was bedeutet komplex ?
• Wechselwirkungen vieler Komponenten
• Ein System ist eine Menge von Elementen oder Komponenten, die miteinander inBeziehung stehen
• viele Komponenten oder nichtlineare Wechselwirkungen oder beides
Komplexe Systeme: Beispiele
• Gekoppelte Oszillatoren: Nichtlineare ODE’s
• Gekoppelte Abbildungen: Integratoren
• Fluid–Dynamik: Turbulenz, Akustik
4

• Plasmaphysik
• Astrophysik: Dynamik von N Himmelskorpern
• Physikalische Chemie: Polymere, Kolloide, Grenzflachen
• Okonomie’: Borsencrash
• Klima, Wetter, Geodynamik
• Netzwerke: Verkehr, WWW, . . .
• Architektur von Computerprogrammen
• Populationsdynamik, Soziologie
• Biologie
4 Modellierung komplexer Systeme
Modellierung (lat. modulus,modus = Art, Weise)
Vereinfachte Beschreibungum ein reales System zu erklaren (Der Art und Weise, wie es funktioniert). Meist in math-ematischer Form anhand von Gleichungen.
Modellierung
Verwirrenderweisein verschiedenem Kontext semantisch verschieden benutzt
• Ingenieure: Nachbildung eines technischen Erzeugnisses in verkleinertem Maßstab,auch als detailliertes Computerprogramm (im Ggs. zur Physik)
• Informatik: Abbild einer Software, bei OO z.B. mit UML
• Klima: Nachbilden z.T. unbekannter Mechanismen durch vernunftige Annahmen oderVergroberung
• Geschaftsprozesse: Abbild (z.T. sehr detailliert) eines Unternehmens oder einer Un-ternehmensidee.
• etc.
5

Modellierung: Beispiel Physikalisches Pendel
Aufgabe:Bestimmung der Periode einer Pendeluhr, mit grober Genauigkeit
Vernunftige Annahmen
• keine Reibung
• Punktmasse
• Achse ohne Masse
• Kraftegleichgewicht
Man erhalt die Gleichung fur das mathematische Pendelmlφ = mg sin(φ) (1)
mit kleiner Auslenkung φ+√
glφ = 0
Modellierung: Beispiel Physikalisches Pendel
Aufgabe:Bestimmung der Periode einer Pendeluhr, mit hoher Genauigkeit
Vernunftige Annahmen
• keine Reibung
• Punktmasse
• Achse ohne Masse
• Kraftegleichgewicht
Man erhalt die Gleichung fur das physikalische PendelIφ+ kφ+ f(φ, φ) +mgl sin(φ) (2)
I ist das Tragheitsmoment, f eine nichtlineare Reibung.
Modellierung: Fazit
Modellierung – eine hohe KunstBei der Modellierung komplexer Systeme ist es unbedingt notig genau nachzudenken, welcheFragen man beantworten will. Je nach Anforderung kann mehr oder weniger genau modelliertwerden. Im Falle komplexer Wechselwirkungen muss identifiziert werden, welche Kompo-nenten fur welche Effekte wichtig sind, Hierarchien oder Skalenprinzipien konnen erstelltwerden.
6

5 Modellierung und Datenalyse komplexer Systeme
Modellierung und Datenanalyse
Bei vollig unbekannter Funktionsweiseeines Systems und der Unterkomponenten kann man meist durch Messung Informationenerhalten.
• Nicht alle Fragen konnen immer beantwortet werden
• Unmoglichkeit der direkten Messung (z.B. bei Zerstorung)
• zu lange Messungen
• zu teure Messungen
• zu komplexe Ausgabe
Modellierung und Datenanalyse
Gezielte Fragenhelfen beim Design einer Messung deren Ausgabe bzw. deren Daten (lat. datum, dasGegebene), analysiert wird und so als Eingabe fur ein Modell dient.
Bei Kenntnis oder Annahme eines Modellsbleibt immer noch die Bestimmung von Parametern, die oft qualitative und quantitative Dy-namik eines Systems bestimmen. Z.B. die genaue Kenntnis einer Spannungs-Dehnungskurveeines Werkstucks, das belastet wird.
Modellierung und Datenanalyse
Datenanalyse (gr. analein, auflosen)bedeutet also im Rahmen dieser Vorlesung die Untersuchung von Daten, die man aus einerMessung erhalt. Die Messung wird an einem System vorgenommen, dessen Funktionsweiseman verstehen will. Mindestens mochte man eine Charakterisierung erhalten, die es ermoglichtverschiedene Klassen von Systemen oder Parametern zu unterscheiden; bestenfalls ist dasErgebnis ein mathematisches Modell, das Vorhersagen uber den Systemzustand erlaubt.
Datenanalyse komplexer Systeme
Datenanalyse – noch eine Kunst
• direkter Zugang: Welche Daten benotige ich, um Frage XY zu beantworten?
• inverser Zugang: Welche Fragen kann man stellen, die mit vorhandenen Daten beant-wortet werden konnen?
7

• Nicht alle Fragen konnen anhand gegebener Daten beantwortet werden
• Welcher Typ von Datenanalyse passt zur Fragestellung?
• Sind die Fragen mit den vorhandenen Resourcen beantwortbar (Rechner, Experimente,Geld, Zeit)?
• Welche Information gibt es in meinen Daten?
• Wieviel Information gibt es in meinen Daten?
Datenanalyse komplexer SystemeEmpfehlung: Werte NIE Daten blind aus, d.h. ohne klare Fragestellung oder Ziele!
6 Komplexe Systeme
Komplexitat
Komplexitat. Lat. complectere, umfassen
Komplexitat. Lat. complectere, umfassen
BeispielLeeres Bild - verrauschtes Bild. Keine Information - zufallige Information Komplexitat kannals globales Maß angesehen werden, das den Zustand des betrachteten Systems beschreibt.Es gibt eine Vielzahl von Komplexitats – Definitionen. Einige werden wir kennenlernen (undnutzen).
Systeme
SystemtheorieIn den 20er Jahren des 20ten Jahrhunderts entstandene Betrachtungsweise von Individuen/Gruppen/Untersystemenals wechselwirkende Einheiten. Erstmals in der Biologie. Sehr erfolgreich in der nichtlinearenDynamik (Synergie)
7 Dynamische Systeme
Dynamische Systeme
Dynamik (gr. dynamos, Kraft)Beschreibt die zeitliche Entwicklung eines Systems, in der Physik meist in Form von Gle-ichungen.
Dynamisches System
8

Figure 1: Interaktiv unter http : //www.art − sciencefactory.com/complexity −mapfeb09.html.
9

Ein System, das eine zeitliche Entwicklung hat. Kommt aus der Formulierung durch Krafte-glegewicht.
Deterministische Systeme
Deterministische Systeme
Determinismus (lat. determinare, bestimmen)Vorherbestimmtheit. Druckt aus, dass die zeitliche Entwicklung eines Systems durch An-fangszustand und Entwicklungsvorschrift vollstandig vorherbestimmt ist.
Nichtlineare Systemekonnen chaotisch werden. Dann ist die Bestimmung des Systemzustandes durch Genauigkeits-betrachtungen eingeschrankt. Landlaufiges Argument fur Anti-determinismus: Spatestensim Quantenbereich kann ein Zustand nicht beliebig genau angegeben werden.
Stochastische Systeme
Stochastische Systeme
Stochastik (gr. stochastiki, Vermutens)Lehre vom Zufall, Beschreibung von zeitlichen Ablaufen, die durch zufallige Ereignissebeschrieben werden.
Stochastisches Systemein System, das neben deterministischen Termen auch Zufallsterme beinhaltet. Jede Messungbeinhaltet Zufall, namlich uber die Messgenauigkeit.
8 Ubung: Einfuhrung in R
Geschichte
Community
Wachstum
Installation
Nutzen des Internets
Packages
Dokumentation
Bucher und Tutorien
10

Part II
ZufallsvariablenFur diese Vorlesung danke ich herzlichst Arkadi Pikovski, der sein Skript mit mir geteilt hat.
9 Eine Zufallsvariable
9.1 Wahrscheinlichkeitsdichte
Eine Zufallsvariable x wird durch
• Die Menge aller m”oglichen Werte (z.B. die Menge der Punkte der reelen Achse)
• Die Wahrscheinlichkeitsverteilung auf dieser Menge
gegeben. Die Menge kann sowohl diskret als auch kontinuierlich sein. Zuerst betrachten wirnur skalare Zufallsvariablen.
Die Wahrscheinlichkeit wird entsprechend der Kolmogorov-Axiomatik gegeben. F”urjedes Ereignis A gilt P (A) ≥ 0, und f”ur verschiedene sich ausschliessende Ereignisse
PA1 ∪ A2 ∪ . . . ∪ An =∑
P (Ai)
Ausserdem P (∅) = 0, P (die ganze Menge) = 1.Die Wahrscheinlichkeitsverteilung ist die Funktion W (ξ) = Prob(x ≤ ξ). Diese Funktion
nimmt nie ab und hat die Randbedingungen W (−∞) = 0, W (∞) = 1. Die Wahrschein-
lichkeit, die Variable x in einem Interval a < x ≤ b zu finden ist W (b)−W (a) =∫ badW (x).
Das Integral hier ist ein Stiltjes-Integral. Man sagt, dass damit ein ein Wahrscheinlichkeitsma”sauf der reelen Achse definiert wird. Jedes Ma”s kann in drei Komponenten zergegt werden:
1. Der kontinuierliche differenzierbare Teil dW ∼ dx. Diese Teil hat eine Dichte w(x) =dW/dx.
2. Der diskrete Teil ergibt Spr”unge der Funktion W . Ein Sprung W (x0 +0)−W (x0) = pbedeutet, dass die Zufallsvariable den Wert x0 mit der Wahrscheinlichkeit p annimmt.Die Dichte kann auch geschrieben werden, ist aber eine verallgemeinerte Deltafunktion:w(x) = pδ(x− x0).
3. Der kontinuierliche singul”are Teil, die ein fraktales Ma”s beschreibt. Hier gilt dW ∼(dx)γ, wobei 0 < γ < 1.
Das gesamte Ma”s kann alle drei Komponenten beinhalten.Beispiele:
Kontinuierliche Verteilung: Alle Zahlen auf dem Interval 0 ≤ x ≤ 1 sind gleich wahrschein-lich, w(x) = 1.
11

Diskrete Verteilung: Die ganzen Zahlen x = 1, 2, . . . mit der Dichte w(x) =∑
2−nδ(x− n).Fraktale Verteilung: Wir stellen jede Zahl 0 ≤ x ≤ 1 als einen bin”aren Bruchteil darx = 0, 0110100 . . ., und weisen 0 eine Wahrscheinlichkeit p und 1 die Wahrscheinlichkeitq = 1−p zu. Dann hat jede Menge, die durch einen eindlichen bin”aren Bruchteil dargestelltwird, die Wahrscheinlichkeit pnqm, wobei n und m die Anzahlen von 0 und 1 sind. DasVerh”altnis
∆W
∆x=
pnqm
(1/2)n+m
kann jeden Wert zwischen ∞ und 0 annehmen und hat keinen Grenzwert bei ∆x→ 0.Wir werden hier immer w(x) schreiben und die Dichte als (m”oglicherweise) verallge-
meinerte oder fraktale Funktion betrachten.
9.2 Mittelwerte und Momente
Der Mittelwert einer Funktion der Zufallvariable ist
〈f(x)〉 =
∫f(x)w(x) dx
Aus dieser Definition folgt, dass die Wahrscheinlichkeitsdichte selbst als ein Mittelwertdargestellt werden kann
w(y) = 〈δ(y − x)〉 =
∫δ(y − x)w(x) dx
Die Momente sind die Mittelwerte von Potenzen: Mm = 〈xm〉. Das erste Moment istdabei der Mittelwert
M1 = 〈x〉
F”ur den zweiten Moment M2 = 〈x2〉 k”onnen wir schreiben
〈(x− 〈x〉)2〉 = 〈x2 − 2x〈x〉+ 〈x〉2〉 = M2 −M21 = D
Diese Gr”o”se heisst die Varianz.
9.3 Die charakteristische Funktion und die Kumulanten
Die Fourier-Transformation der Wahrscheinlichkeitsdichte
G(k) = 〈eikx〉 =
∫eikxw(x) dx
ist die charakteristische Funktion. F”ur sie gilt G(0) = 1, |G(k)| ≤ 1. Nach Entwicklung derExponentialfunktion erhalten wir die Momente
G(k) =
∫ ∑ (ik)n
n!xnw(x) dx =
∑ (ik)n
n!Mn
12

Aus dieser Formel folgtMn = (−i)nG(n)(k)
Enwickelt man lnG nach k, so erh”alt man
lnG =∞∑1
(ik)M
m!κm
Man nennt κm die Kumulanten. Wir haben also zwei Darstellungen der charakteristischenFunktion
G(k) =∞∑n=0
(ik)n
n!Mn = e
P∞m=1
(ik)m
m!κm
Nach dem Vergleich
1 + ikM1 −k2
2M2 −
ik3
6M3 . . . = eikκ1− k
2
2κ2...
erhalten wir einen Zusammenhang zwischen Momenten und Kumulanten
κ1 = M1
κ2 = M2 −M21 = D
κ3 = M3 − 3M2M1 + 2M21
κ4 = M4 − 4M3M1 − 3M22 + 12M2M
21 − 6M4
1
Zur Charakterisierung von Verteilungen werden h”aufig folgende Verh”altnisse benutzt:
γ1 =M3
D3/2γ2 =
M4
D2− 3
Hier sind Mn die zentralen Momente Mn = 〈(x − 〈x〉)n〉. γ1 heisst Schiefe und γ2 heisstSteilheit (Kurtosis).
Beispiele.
1. Die Verteilung w(x) = λe−λx, x ≥ 0. Die Momente sind Mn = n!λn
, so dass 〈x〉 =1/λ, D = 1/λ2. Die charakteristische Funktion ist G(k) = λ
λ−ik .
2. Die Gaussische Verteilung
w(x) =1√
2πDexp[−(x− 〈x〉)2
2D]
hat die charakteristische Funktion
G(k) = eik〈x〉−k2D
2
Die Momente sind M2n+1 = 0, M2n = 1 ·3 · · · (2n−1)Dn. Die Schiefe und die Steilheitsind Null.
Es gibt einen Satz: Sei die charakteristische Funktion G(k) = ePn(k), wobei Pn einPolynom n-te Ordnung ist, dann n = 2. Das bedeutet, dass entweder unendlich vieleKumulanten nicht Null sind, oder es ist eine Gaussische Verteilung.
13

3. Cauchy-Verteilung
w(x) =λ
π
1
λ2 + (x− α)2
Hier G(k) = eiαk−λ|k|. Man kann sehen, dass M1 nicht existiert, und M2 =∞.
Betrachten wir eine Funktion der Zufallsvariable x: y = f(x). Die Wahrscheinlichkeits-dichte f”ur y ist
wy(y) = 〈δ(y − f(x))〉 =
∫δ(y − f(x))wx(x) dx =
∑alle Wurzeln f(x)=y
wx(xi)
|f ′(xi)|
F”ur eine one-to-one Funktion man kann einfache schreiben |wx(x) dx| = wy(y) dy|.
10 Mehrdimensionale Zufallsvariablen
10.1 Wahrscheinlichkeitsdichte, charakteristische Funktion
Die Wahrscheinlichkeitsverteilung von x1, . . . xn wird durch die Dichte w(x1, . . . xn) gegeben.Ein Teil von Variablen x1, . . . xs wird durch die Randverteilungsdichte
w(x1, . . . , xs) =
∫w(x1, . . . xn) dxs+1 . . . dxn
gegeben. Die bedingte Wahrscheinlichkeit
ws|n−s =w(x1, . . . xn)
w(xs+1, . . . xn)
ist die Wahrscheinlichkeitsdichte, die Werte (x1, . . . , xs) zu beobachten, vorausgesetzt dieVariablen xs+1 . . . xn bestimmte Werte haben. Wenn die bedingte Wahrscheinlichkeit vondie Gruppe xs+1, . . . xn unabh”angig ist, dann
w(x1, . . . xn) = w(x1, . . . xs)w(xs+1, . . . xn).
Im Allgemeinen: Wenn alle Zufallsvariablen unabh”angig sind, ist die Gesamtdichte einProdukt von Einzelndichten:
w(x1 . . . xn) = w1(x1)w2(x2) . . . wn(xn)
Die Momente:
〈xm11 xm2
2 . . . xmnn 〉 =
∫xm1
1 xm22 . . . xmnn w(x1 . . . xn) dx1 . . . dxn
Die charakteristische Funktion
G(k1, k2, . . . kn) = 〈eik1x1+···+iknxn〉
14

Die Kumulanten
lnG =∑ (ik1)m1(ik2)m2 . . . (ikn)mn
m1!m2! . . .mn!〈〈xm1
1 xm22 . . . xmnn 〉〉
Am wichtigsten sind die Momente und Kumulante zweiter Ordnung:
〈xixj〉
〈〈xixj〉〉 = 〈xixj〉 − 〈xi〉〈xj〉 = 〈(xi − 〈xi〉)(xj − 〈xj〉)〉Diese Kumulante heisst die Kovarianz. Wenn man normiert
ρij =〈〈xixj〉〉√DxDy
bekommt man den Korrelationskoeffizient.Wenn zwei Zufallsvariablen unabh”angig sind, dann
1. 〈xm11 xm2
2 〉 = 〈xm11 〉〈xm2
2 〉
2. G(k1, k2) = G1(k1)G2(k2)
3. 〈〈xm11 xm2
2 〉〉 = 0 wenn m1 6= 0 und m2 6= 0
Die Zufallsvariablen heissen unkorelliert, wenn ρ12 = 0.Beispiel:Die Wahrscheinlichkeitsdichte zweier Gaussscher Zufallsvariablen
w(x, y) =1
2π√DxDy(1− ρ2)
exp
[− 1
2(1− ρ2
[(x− 〈x〉)2
Dx
− 2ρ(x− 〈x〉)(y − 〈y〉)√
DxDy
+(y − 〈y〉)2
Dy
]]ist von 5 Parametern 〈x〉, 〈y〉, Dx, Dy, ρ abh”angig. Wenn ρ = 0, sind die Gausssche Variablenunabh”agig.
Im Allgemeinen definiert man f”ur mehere Gausssche Variablen die Kovarianzmatrix
σij = 〈〈xixj〉〉
und schreibt die Dichte in der Form
w(~x) =exp
(− 1
2(~x− 〈~x〉)σ−1(~x− 〈~x〉)
)√
(2π)ndetσ
Die charakteristische Funktion ist
G(~k) = ei~k〈~x〉− 1
2~kσ~k
Alle Momente kann man durch die Elemente der Kovarianzmatrix σ darstellen (sieheAufgabe 1.5).
15

10.2 Summe der Zufallsvariablen, Zentraler Grenzsatz
Finden wir die Wahrschenlichkeitsdichte der Summe von zwei Zufallsvariablen z = x+ y:
w(z) = 〈δ(z − x− y)〉 =
∫δ(z − x− y)w(x, y) dx dy =
∫w(z − y, y) dy
Wenn die Variablen unabh”angig sind, dann erhalten wir die Faltung
w(z) =
∫wx(z − y)wy(y) dy
F”ur Mittelwerte gilt immer〈z〉 = 〈x〉+ 〈y〉
F”ur Varianz gilt〈〈z2〉〉 = 〈〈x2〉〉+ 〈〈y2〉〉
nur wenn die Zufallsvariablen unkorreliert sind, ρ = 0. F”ur unabh”angige x und y gilt
Gz(k) = Gx(k)Gy(k)
Wir betrachten eine Summe von n unabh”angigen Variablen mit den Mittelwert Null
y = x1 + · · ·+ xn
Die Varianz ist 〈〈y2〉〉 = n〈〈x2〉〉, deshalb normieren wir y mit√n. Dann haben wir
y =x1 + · · ·+ xn√
nGy(k) = [Gx(
k√n
)]n
Wir setzen jetzt
Gx(k) = e−12〈〈x2〉〉k2− ik
3
6〈〈x3〉〉+···
ein und erhalten
Gy(k) = e−12k2〈〈x2〉〉− ik
3
6〈〈x3〉〉n−1/2 ≈ e−
12k2〈〈x2〉〉
Das ergibt die Gausssche Verteilung f”ur die Summe.Bemerkungen:
- Die Variablen xi k”onnen auch verschiedene Verteilungen haben- Die Variablen xi k”onnen auch abh”angig sein, nur die Abh”angigkeit muss schwach sein.
10.3 Stabile Wahrscheinlichkeitsverteilungen
Betrachten wir eine Summe von unabh”angigen gleich verteilten Zufallsvariablen
s = x1 + · · ·+ xn
16

Wenn die Gro”se s nach der Normierung s/cn die selbe Verteilung hat wie x, dann heisstdiese Verteilung stabil. Man kann ”uberlegen, dass der Normierungskoeffizient ein Potenzvon n sein muss: cn = n1/α, 0 < α ≤ 2. Man kann auch ”aquivalent formulieren, dasss1/αx1 + t1/αx2 und (s+ t)1/αx die selbe Verteilung haben.
Die Gauss-Verteilung ist die einzige stabile Verteilung mit einer endlichen Varianz, hierist α = 2.
Beispiele.Die Cauchy-Verteilung w(x) = λ
π(λ2+x2)hat die charakteristische Funktion e−λ|k|. Diese
Verteilung ist stabil mit α = 1: [e−λ|kn|]n = e−λ|k|.
Die Holzmark-Verteilung. Welche Gravitationskraft erzeugt ein Sternsystem? Nehmenwir ein Sternsystem mit der Dichte λ und betrachten die x-Komponente der Kraft im PunktO. Diese Komponente ist eine Zufallsvariable Xλ. Weil die Gravitationskr”afte sich addieren,Xs +Xt und Xs+t haben die selbe Verteilung. Sei X1 die Zufallsvariable im Falle der Dichte1. Bei Dichte t alle Abst”ande verkleinern sich um Faktor t1/3, und die Kraft vergr”ossertsich um Faktor t2/3. Deshalb haben t2/3X1 und Xt die selbe Verteilung. Wir erhalten dieGleichung
s2/3X1 + t2/3X2d= (s+ t)2/3X
Das bedeutet, dass die Kraft die stabile Verteilung mit α = 3/2 hat.
17

Part III
Zufallsvariablen
11 Schatzung
Statistik
lat. status = Zustand
• Zustandsaufnahme einer Population durch Zahlen oder Proporz
• Stichprobe: Messung eines Teils der Gesamtheit
• Experiment → Realisierung von X → N-mal = Stichprobe mit Umfang N
• Bedingung: Reprasentativ, Unabhangigkeit, etc.
• Verteilung ? Parameter ?
Wahrscheinlichkeitsraum
Ein W.-Raumbesteht aus dem Tupel Ω, A, P mit
• Ω eine Algebra
• A die Ergebnismenge (z.B. experimentelle Ergebnisse)
• P die zugeordneten Wahrscheinlichkeiten
Zufallsvariable
Eine Zufallvariable Xbeschreibt die Zuordnung X : A 7→ p, p ∈ R. Wenn A = x ∈ R, dann ist die ZV X(x)
Schatzung
Messung einer ZVenergibt wieder eine ZV! Bsp.: Stichprobenmittel
xN =1
N
N∑i=1
Xi → XN =1
N
N∑i=1
Xi (3)
ist eine ZV. Wo klar, werden Indizes weggelassen.
18

Schatzung
Aussagekraft der Schatzung?
• < X >= E(X)
• V AR(X)
• etc.
Erwartungsttreue Schatzung
geschatzt: Z = ˆf(X)Z ist erwartungstreu, wenn < Z >=< Z >
z.B. < X >= 1N
∑Ni=1 < Xi >=< X >
Sonstige Schatzer fur mittlere Großen
• Median: halbiert eine Verteilung
• Modus: haufigster Wert
Schwankung von X
V AR(X)
V AR(X) =1
N2V AR(
∑Xi) =
1
NV AR(X)
Standardabweichung
σX =√V AR(X) =
σX√V AR(X)
Achtung: Wir kennen nicht < X >, sondern nur eine (evtl. mehr) Realisierung von X. Also
X − σX ≤< X >≤ X + σX
Der wahre MW liegt mit 68% W. im obigen Intervall
Konfidenzintervall
Konfidenzintervall zum Niveau αKonfidenzintervall 68% [
X − σX√N
; X +σX√N
](4)
1− α% -Konfidenzintervall α mit dem q1−α/2-Quantil[X − q1−α/2
σX√N
; X + q1−α/2σX√N
](5)
19

Schwankung
Schatzung der VarianzσX ist i.a. nicht bekannt ⇒ Schatzung
S2 =1
N − 1
N∑i=1
(Xi − X)2 (6)
X aus der gleichen Stichprobe. Erwartungstreu? Berechne
< S2 >= V AR(X) = σ2X
N − 1 konsistent mit N = 1 → < S2 > nicht bestimmt.
Varianz
Schwankung der SchatzungBekannt ist S2, nicht σ2
X =< S2 >. Verteilung von S2? S2 ist Summe von Quadraten vonN N0,1 verteilten VariablenN0,1 (Standardnormalverteilung)
χ2-Verteilung
Verteilungvon Y −
∑X2i ?
p(xi) =1√2πσ
e−x2i
2σ2 (7)
p(Y,N) = ? (8)∫dxNp(x1...xN) =
∫dy
∫dxNδ(y −
∑x2i )p(x1...xN) (9)
Auswertung:
p(Y,N) =1√
(2σ)NΓ(N/2)Y N/2−1e−
Y2σ2 (10)
χ2-Verteilung mit N Freiheitsgraden
chi2 − V erteilung
Zuruck zu S2: Schatzung von V AR(S2)
Y =S2N (N−1)
σ2X
ist χ2 verteilt mit N − 1 Fr.gr.
gemessen: (X− < X >), normalverteilt, bzw. Z =√N
σX(X− < X >) ist N0,1 verteilt.
Ersetzung σX
20

0 2 4 6 8 10
0.00
0.05
0.10
0.15
x
dchi
sq(x
, df =
4)
Figure 2: χ2-Verteilung mit R: dchisq(x,df). Hier df=4
Schatzung von V AR(S2)
Quotient
(X− < X >)√S2N
Abweichung durch Messung (11)
=Z√
Y (N − 1)(12)
Quotient N0,1-verteilt und χ2-verteilter Variablen → t-verteilt: pt(N−1, x). Fast wie Gauss,wichtig fur N . 32
F-Verteilung
Naheres: UbungFur Y1, Y2 χ
2-verteilt mit N1 − 1, N2 − 2 Freiheitsgraden ist Z = Y1(N2−1)Y2(N1−1)
F-verteilt. (z.B.
Yi = SNi,i)
Schatzung von V AR(S2)
Wie nahe liegt σ2 bei S2N
→ (1− α)-Konfidenzintervall[XN − qt,N1−α/2
√S2N√N
; XN + qt,N1−α/2
√S2N√N
]
21
−4 −2 0 2 4
0.0
0.1
0.2
0.3
0.4
x
dt(x
, df =
4)
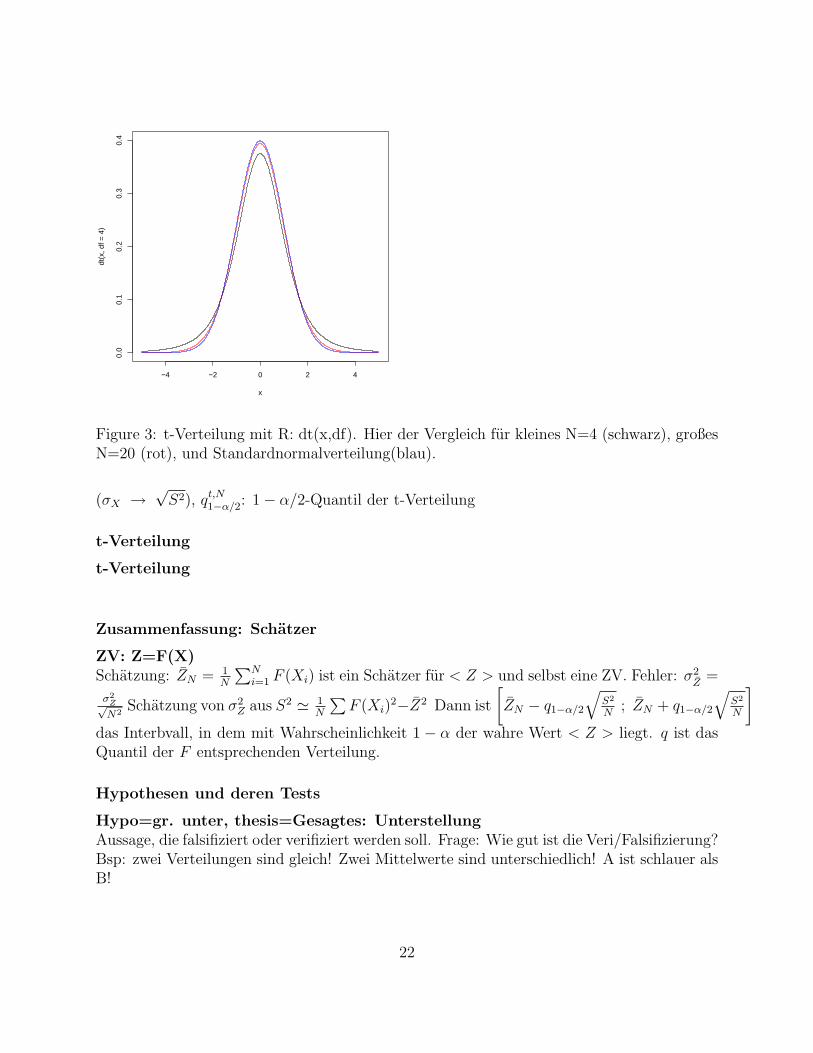
Figure 3: t-Verteilung mit R: dt(x,df). Hier der Vergleich fur kleines N=4 (schwarz), großesN=20 (rot), und Standardnormalverteilung(blau).
(σX →√S2), qt,N1−α/2: 1− α/2-Quantil der t-Verteilung
t-Verteilung
t-Verteilung
Zusammenfassung: Schatzer
ZV: Z=F(X)Schatzung: ZN = 1
N
∑Ni=1 F (Xi) ist ein Schatzer fur < Z > und selbst eine ZV. Fehler: σ2
Z=
σ2Z√N2
Schatzung von σ2Z aus S2 ' 1
N
∑F (Xi)
2−Z2 Dann ist
[ZN − q1−α/2
√S2
N; ZN + q1−α/2
√S2
N
]das Interbvall, in dem mit Wahrscheinlichkeit 1 − α der wahre Wert < Z > liegt. q ist dasQuantil der F entsprechenden Verteilung.
Hypothesen und deren Tests
Hypo=gr. unter, thesis=Gesagtes: UnterstellungAussage, die falsifiziert oder verifiziert werden soll. Frage: Wie gut ist die Veri/Falsifizierung?Bsp: zwei Verteilungen sind gleich! Zwei Mittelwerte sind unterschiedlich! A ist schlauer alsB!
22

Gleichheit von Mittelwerten: Test
t-TestHypothese: < X1 >=< X2 > Betrachte Differenz ∆ = X1 − X2 und Schwankung S2
∆ ⇒T =
√N1N2
N1+N2
∆√S2
∆
ist t-verteilt.
Verwerfen der Hypothese mit signifikanz α
wenn T nicht in[−qt1−α/2 ; qt1−α/2
]liegt. Das heisst ∆ liegt nicht in[
−qt1−α/2
√S2
∆
N1 +N2
N1N2
; qt1−α/2
√S2
∆
N1 +N2
N1N2
].
Test auf Gleichheit von Varianzen: F-Test
F-TestBetrachte Y1 =
S21(N1−1)
σ21
, Y2 =S2
2(N2−1)
σ22
. bilde Y1
Y2und untersuche die Verteilung. Es ergibt
sich die F-Verteilung und daraus der F-Test. Ubung.
Gleichheit zweier Verteilungen: χ2-Test
Messung vs. TheorieNull-Hypothese: Messung (Stichprobengroße N) reprasentiert ZV mit Verteilung P (X).Idee: Vergleiche W.-Dichte, mit Histogramm wegen diskreten Werten (Messung)
• Klassenbildung (erfordert Histogramm): K Klassen s, W. ps
• ns = N ps: Theoretische Haufigkeit fur Ergebnis in Klasse s
• ys=Haufigkeit fur Messung in Klasse s
•∑
s p(s) = 1,∑
s Ys = N
• Ys ist poissonverteilt mit < Ys >= ns, V AR(Ys) = ns
Gleichheit zweier Verteilungen: χ2-Test
Kurzherleitung
• Normierung: Zs = Ys−ns√ns
• Zusammenfassung der Abweichungen: V 2 =∑
s Z2s
• V 2 ist Summe von K Quadraten von N0,1-verteilten (N genugend groß) ZVen
• V 2 ist χ2(K − 1)-verteilt
23

• also wird die Hypothese mit Signifikanz α verworfen, wenn V 2 > qχ2
1−α
•
•
Gleichheit zweier Verteillungen: Kolmogorov-Smirnow-Test
Idee: Teste die kumulativen Verteilungen
24