modern coding in practice - ieee entity web hosting … 2009/modern coding by... · modern coding...
TRANSCRIPT

Mar. 2, 2009TrellisWare Technologies
Modern Coding in Practice
([email protected])TrellisWare Technologies, Inc.16516 Via Esprillo, Suite 300
San Diego, CA 92127
Keith M. Chugg
([email protected])Communication Sciences Institute
Ming Hsieh EE DeptLos Angeles, CA 90089-2565

Mar. 2, 2009TrellisWare Technologies
Talk Summary
•Overview of Modern, Turbo-like Codes-Variations, characteristics-Good, TLC performance
•S-SCP Codes-Systematic RA codes-TrellisWare Codes
•Performance and Complexity-Hardware codec capabilities-Comparisons

Mar. 2, 2009TrellisWare Technologies
Overview of Modern, Turbo-Like Codes

Mar. 2, 2009TrellisWare Technologies
Example Achievable Performance
0
0.5
1
1.5
2
2.5
-2 0 2 4 6 8 10 12
Theoretical Limits for QPSK/AWGN (BPSK/AWGN)
BW E
ffice
ncy
(bits
/sec)
/Hz
Eb/No(dB)
AWGN Capacity
QPSK/AWGN Capacity
Finite Block Size (BLER = 1e-4)
k= 65,536; 16,384; 4096; 2048;1024; 512; 256; 128
(7,4) Hamming soft-in
(7,4) Hamming hard-in
no coding
Conv., 64-state (soft)

Mar. 2, 2009TrellisWare Technologies
A Wrong Turn in Coding?
•(Classic) Coding theorist’s (practitioner's) lament-“All codes are good codes, except those we know
about!”•Is the (7,4) Hamming a bad code?
-Not for it’s size!•To approach capacity, need ~ 2048 input bits

Mar. 2, 2009TrellisWare Technologies
Classic vs. Modern Coding•Classic codes:
- “design bad (small) codes that we can decode optimally”•Modern codes:
-“design good codes that we can decode in a nearly optimal manner”
Pb !!
d!dmin
KdQ"rd
2Eb
N0
#
Obviously, dominated by d_min term
==> look for codes with large min. distance
Hmm... Can we make each Kd decay ~ 1/k or faster?
==> find big codes with “thin” neighborhoods
classic
modern
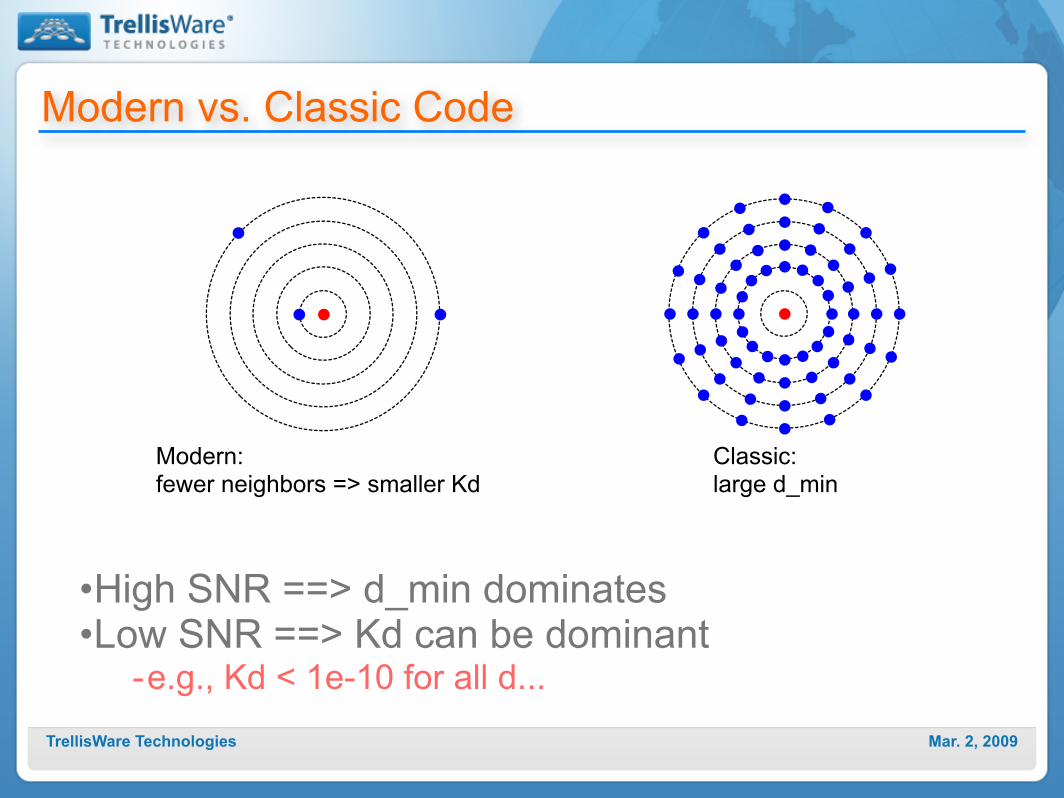
Mar. 2, 2009TrellisWare Technologies
Modern vs. Classic Code
Modern: fewer neighbors => smaller Kd
Classic: large d_min
•High SNR ==> d_min dominates•Low SNR ==> Kd can be dominant
-e.g., Kd < 1e-10 for all d...
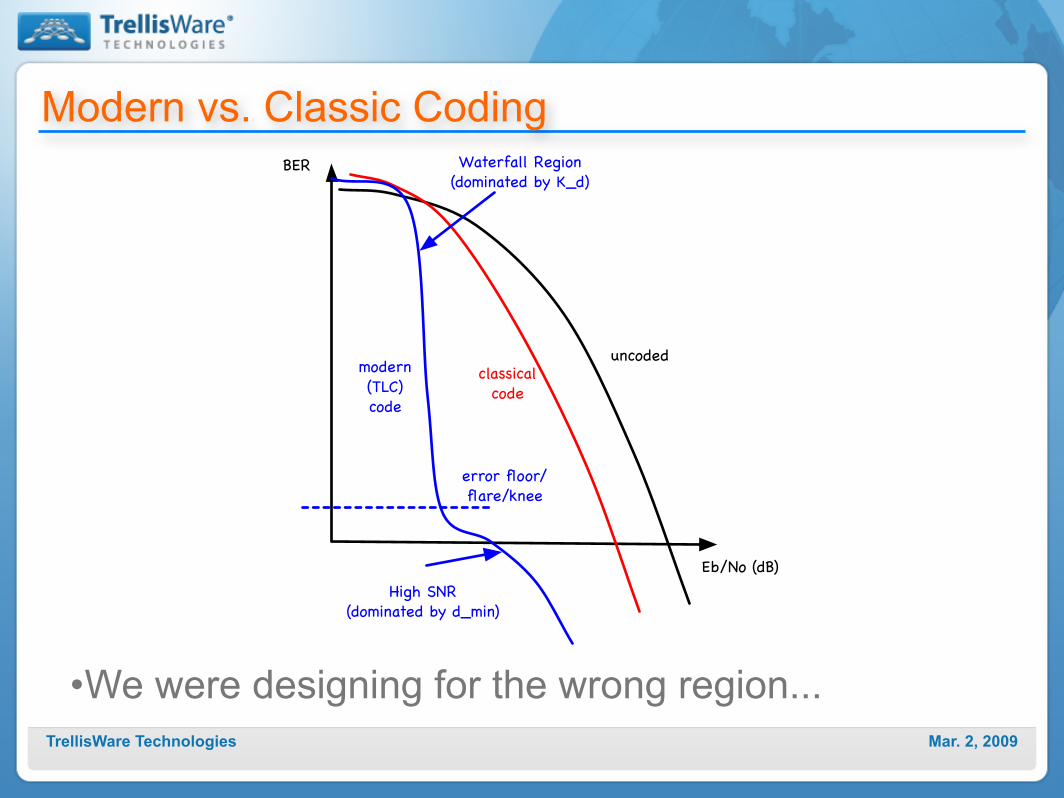
Mar. 2, 2009TrellisWare Technologies
Modern vs. Classic Coding
•We were designing for the wrong region...
Waterfall Region(dominated by K_d)
High SNR (dominated by d_min)
Eb/No (dB)
BER
uncodedclassical
code
modern (TLC) code
error floor/flare/knee

Mar. 2, 2009TrellisWare Technologies
Examples of Modern Codes
Recursive
CC
Recursive
CC
=
I
Recursive
CCICC
= = = = =...
permutation
+ + +
=
...
info. bits
p
a
r
it
y
parity p
Parallel Concatenated Convolutional Codes (PCCCs) [Turbo Codes]
Serially Concatenated Convolutional Codes (SCCCs)
Hybrid Concatenated Convolutional Codes (HCCCs)
Low Density Parity Check Codes (LDPCCs)
Turbo Product Codes (TPCs)
Recursive
CCI1
CC
CCI2

Mar. 2, 2009TrellisWare Technologies
Modern Code Analysis/Design
•Uniform Interleaver Analysis-What kind of codes work together?-How does error rate change with block size?
•SNR Threshold Optimization-Try to match specific constituent code properties
to get convergence at lowest SNR‣Irregular structures can improve thresholds

Mar. 2, 2009TrellisWare Technologies
Example ReferencesSNR Threshold Optimization
Uniform Interleaver Analysis
the SPC being s when the input weight is l yields
ACCw,h =
N!
l=0
l!
s=0
pspc(s|l)ACo
w,l !ACis,h"N/J
s
# (17)
where ACow,l and ACi
s,h are the IOWCs for the outer and innerCCs, respectively.
The unique step in this uniform interleaver analysis forthe TW codes is the consideration of the impact of the SPC(i.e., the rest is similar to the analysis of HCCCs in [11]).Define the reduction in weight caused by the SPC as ! = l"s,and note that, since the output weight is reduced when pairsof input ones fall into a parity check for the same output bit,! can only take even values. The number of SPC blocks intowhich one or more the l input ones can fall is at most s + !
2 ,this count coming from the case where s parity checks containa single one and !
2 contain two ones. The probability that all linputs fall within a set of s + !
2 SPC blocks of the N/J SPCblocks times the number of ways to choose those s+ !
2 paritychecks from the N/J total parity checks is then an upperbound on pspc(s|l), as it also includes all output weights thatare smaller than s. This provides the upper bound
pspc(s|l) #$
s + !2
N/J
%l &N/J
s + !2
'(18)
=
$s + l!s
2
N/J
%l &N/J
s + l!s2
'
# (N/J)!l!s2
(s + l!s2 )l
(s + l!s2 )!
$ (N/J)!l!s2
$ N! l!s2
which can be used in (16) to obtain a looser upper bound. Notethat a large N approximation for the binomial coefficient hasbeen used.
Computation of the asymptotic IOWCs for the inner andouter convolutional code in (16) follows the standard develop-ment in [17], [18], [10], [11] and is omitted for brevity. Sub-stituting these asymptotic approximations for the CC IOWCsand the bound in (18) into (16) yields
Pb#Nro!
h=himin
N/J!
w=wmin
N!
l=0
l!
s=0
nomax!
no=1
nimax!
ni=1
Nno+ni! l+s2 !1 (19)
Bw,l,no,ni,h,sQ
$(2r(w + h)
Eb
N0
%
where Bw,l,no,ni,h,s is not a function of the interleaver size N .The number of simple error events (which depart and rejointhe all zero trellis path exactly once) for the inner and outerCCs are ni and no, respectively. For a given input weight wand parity branch output weight h, the maximum exponent ofN in (19) is
"(w, h) = maxl,s
)no + ni " l + s
2" 1
*(20)
In particular, we are interested in the maximum exponent ofN for any possible (w, h) which we denote as "max.
We are interested in comparing recursive and non-recursive(feed-forward) CCs as the constituent codes. The main prop-erty of interest in this context is the minimum input weight tothe CC that will yield a simple non-propagating error pattern.For a non-recursive CC, this minimum value is 1 while itis 2 for a recursive CC. This is important for determining themaximum values of no and ni, which in turn determine "max.
First consider the case when the inner CC is non-recursive.The maximum number of simple error patterns for the innercode is ni
max = s, the number of non-zero inputs to the innerCC, since each can cause a simple error pattern. Also, no
max
is at least %w2 & so that
"(w, h) = maxl,s
)no " l " s
2" 1
*(21)
' 0
so there is no guaranteed interleaver gain when the inner CCis non-recursive.
When the inner code is recursive, nomax = % s
2&, yielding
"(w, h) = maxl
)no +
+s
2
," l + s
2" 1
*(22)
Because the difference between s and l is always even, wecan break l+s
2 into % l+12 &+ % s
2&. Simplifying gives
"(w, l) = maxl
)no "
-l + 1
2
." 1
*(23)
Since nomax # l
dofree
, where dofree is the free distance of the
outer code, we obtain
"max # maxl
)-l
dofree
."
-l + 1
2
." 1
*(24)
which for dofree ' 2, yields
"max # "-
dofree + 1
2
.(25)
For large block size dofree = do
min and this is the result givenin (3).
REFERENCES
[1] C. Berrou, A. Glavieux, and P. Thitmajshima, “Near shannon limit error-correcting coding and decoding: turbo-codes,” in Proc. InternationalConf. Communications, Geneva, Switzerland, May 1993, pp. 1064–1070.
[2] R. G. Gallager, “Low density parity check codes,” IEEE Trans. Infor-mation Theory, vol. 8, pp. 21–28, January 1962.
[3] D. J. C. MacKay, “Good error-correcting codes based on very sparsematrices,” IEE Electronics Letters, vol. 33, pp. 457–458, March 1997.
[4] S. ten Brink, “Convergence of iterative decoding,” IEE ElectronicsLetters, pp. 1117–1119, June 1999.
[5] S. ten Brink, “Convergence behavior of iteratively decoded parallelconcatenated codes,” IEEE Trans. Commununication, pp. 1727–1737,October 2001.
[6] T.J. Richardson and R.L. Urbanke, “The capacity of low-density parity-check codes under message-passing decoding,” IEEE Trans. InformationTheory, vol. 47, pp. 599–618, Feb. 2001.
[7] T.J. Richardson, M.A. Shokrollahi, and R.L. Urbanke, “Design ofcapacity-approaching irregular low-density parity-check codes,” IEEETrans. Information Theory, vol. 47, no. 2, pp. 619–673, February 2001.[8] S. Dolinar, D. Divsalar, and F. Pollara, “Code performance as a functionof block size,” Tech. Rep., JPL-TDA, May 1998, 42–133.
[9] K.M. Chugg and P. Gray, “A simple measure of good modern codeperforamnce,” (in preparation).
[10] S. Benedetto, D. Divsalar, G. Montorsi, and F. Pollara, “Serial concate-nation of interleaved codes: performance analysis, design, and iterativedecoding,” IEEE Trans. Information Theory, vol. 44, no. 3, pp. 909–926,May 1998.
[11] D. Divsalar and F. Pollara, “Hybrid concatenated codes and iterativedecoding,” Tech. Rep., JPL-TDA, August 1997, 42–130.
[12] H. Jin, A. Khandekar, and R. McEliece, “Irregular repeataccumulatecodes,” in Turbo Code Conf., Brest, France, 2000.
[13] K. M. Chugg, “A new class of turbo-like code with desirable practicalproperties,” in IEEE Communication Theory Workshop (no proceedings),Capri Island, May 2004, (recent results session).
[14] “FlexiCodes: A highly flexible FEC solution,” 2004, TrellisWareTechnologies White Paper, available at http://www.trellisware.com.
[15] K.M. Chugg, P. Gray, and R. Ward, “Flexible coding for 802.11n MIMOsystems,” September 2004, IEEE 802.11-04/0953r3, (Berlin, Germany),available at http://www.trellisware.com.
[16] L. Ping, X. Huang, and N. Phamdo, “Zigzag codes and concatenatedzigzag codes,” IEEE Trans. Information Theory, vol. 47, pp. 800–807,Feb. 2001.
[17] S. Benedetto and G. Montorsi, “Design of parallel concatenatedconvolutional codes,” IEEE Trans. Commununication, vol. 44, pp. 591–600, May 1996.
[18] S. Benedetto and G. Montorsi, “Unveiling turbo codes: some resultson parallel concatenated coding schemes,” IEEE Trans. InformationTheory, vol. 42, no. 2, pp. 408–428, March 1996.
[19] A. Graell, i Amat, S. Benedetto, and G. Montorsi, “Optimal high-rateconvolutional codes for partial response channels,” in Proc. GlobecomConf., Taipei, Taiwan, 2002, pp. CTS–01–4.
[20] L. Ping, “The SPC technique and low complexity turbo codes,” inProc. Globecom Conf., Rio de Janeiro, Brazil, December 1999, pp.2592–2596.
[21] L. R. Bahl, J. Cocke, F. Jelinek, and J. Raviv, “Optimal decoding oflinear codes for minimizing symbol error rate,” IEEE Trans. InformationTheory, vol. IT-20, pp. 284–287, March 1974.
[22] K. M. Chugg, A. Anastasopoulos, and X. Chen, Iterative Detection:Adaptivity, Complexity Reduction, and Applications, Kluwer AcademicPublishers, 2001.
[23] A. Abbasfar, D. Divsalar, and K. Yao, “Accumulate repeat accumulatecodes,” in Proc. Globecom Conf., Dallas, Texas, December 2004, pp.509–513.
[24] A. Abbasfar, D. Divsalar, and K. Yao, “Maximum likelihood decodinganalysis of accumulate-repeat-accumulate codes,” in Proc. GlobecomConf., Dallas, Texas, December 2004, pp. 514–519.
[25] N. Wiberg, Codes and Decoding on General Graphs, Ph.D. thesis,Linkoping University (Sweden), 1996.
[26] S. M. Aji and R. J. McEliece, “The generalized distributive law,” IEEETrans. Information Theory, vol. 46, no. 2, pp. 325–343, March 2000.
[27] F.R. Kschischang, B.J. Frey, and H.-A. Loeliger, “Factor graphs and thesum-product algorithm,” IEEE Trans. Information Theory, vol. 47, pp.498–519, Feb. 2001.
[28] G. D. Forney, Jr., “Codes on graphs: Normal realizations,” IEEETrans. Information Theory, pp. 520–548, February 2001.
[29] J. Dielissen and J. Huisken, “State vector reduction for initialization ofsliding windows MAP,” in 2nd Internation Symposium on Turbo Codes& Related Topics, Brest, France, 2000, pp. 387 – 390.
[30] S. Yoon and Y. Bar-Ness, “A parallel MAP algorithm for low latencyturbo decoding,” IEEE Communications Letters, vol. 6, no. 7, pp. 288– 290, July 2002.
[31] A. Abbasfar and K. Yao, “An efficient and practical architecture for highspeed turbo decoders,” in IEEE 58th Vehicular Technology Conference,October 2003, pp. 337 – 341 Vol.1.
[32] L. Ping, W. K. Leung, and N. Phamdo, “Low density parity check codeswith semi-random parity check matrix,” IEE Electron. Lett., vol. 35, no.1, pp. 38–39, Jan. 1999.
[33] K. R. Narayanan, I. Altunbas, and R. Narayanaswami, “Design ofserial concatenated msk schemes based on density evolution,” IEEETrans. Commununication, vol. 51, pp. 1283 – 1295, Aug. 2003.
[34] D. J. C. MacKay, Information Theory, Inference, and Learning Algo-rithms, Cambridge University Press, 2003.
[35] P. E. McIllree, “Channel capacity calculations for M-ary N-dimensionalsignal sets,” M.S. thesis, The U. South Australia, School of ElectronicEng., Adelaide, February 1995.
[8] S. Dolinar, D. Divsalar, and F. Pollara, “Code performance as a functionof block size,” Tech. Rep., JPL-TDA, May 1998, 42–133.
[9] K.M. Chugg and P. Gray, “A simple measure of good modern codeperforamnce,” (in preparation).
[10] S. Benedetto, D. Divsalar, G. Montorsi, and F. Pollara, “Serial concate-nation of interleaved codes: performance analysis, design, and iterativedecoding,” IEEE Trans. Information Theory, vol. 44, no. 3, pp. 909–926,May 1998.
[11] D. Divsalar and F. Pollara, “Hybrid concatenated codes and iterativedecoding,” Tech. Rep., JPL-TDA, August 1997, 42–130.
[12] H. Jin, A. Khandekar, and R. McEliece, “Irregular repeataccumulatecodes,” in Turbo Code Conf., Brest, France, 2000.
[13] K. M. Chugg, “A new class of turbo-like code with desirable practicalproperties,” in IEEE Communication Theory Workshop (no proceedings),Capri Island, May 2004, (recent results session).
[14] “FlexiCodes: A highly flexible FEC solution,” 2004, TrellisWareTechnologies White Paper, available at http://www.trellisware.com.
[15] K.M. Chugg, P. Gray, and R. Ward, “Flexible coding for 802.11n MIMOsystems,” September 2004, IEEE 802.11-04/0953r3, (Berlin, Germany),available at http://www.trellisware.com.
[16] L. Ping, X. Huang, and N. Phamdo, “Zigzag codes and concatenatedzigzag codes,” IEEE Trans. Information Theory, vol. 47, pp. 800–807,Feb. 2001.
[17] S. Benedetto and G. Montorsi, “Design of parallel concatenatedconvolutional codes,” IEEE Trans. Commununication, vol. 44, pp. 591–600, May 1996.
[18] S. Benedetto and G. Montorsi, “Unveiling turbo codes: some resultson parallel concatenated coding schemes,” IEEE Trans. InformationTheory, vol. 42, no. 2, pp. 408–428, March 1996.
[19] A. Graell, i Amat, S. Benedetto, and G. Montorsi, “Optimal high-rateconvolutional codes for partial response channels,” in Proc. GlobecomConf., Taipei, Taiwan, 2002, pp. CTS–01–4.
[20] L. Ping, “The SPC technique and low complexity turbo codes,” inProc. Globecom Conf., Rio de Janeiro, Brazil, December 1999, pp.2592–2596.
[21] L. R. Bahl, J. Cocke, F. Jelinek, and J. Raviv, “Optimal decoding oflinear codes for minimizing symbol error rate,” IEEE Trans. InformationTheory, vol. IT-20, pp. 284–287, March 1974.
[22] K. M. Chugg, A. Anastasopoulos, and X. Chen, Iterative Detection:Adaptivity, Complexity Reduction, and Applications, Kluwer AcademicPublishers, 2001.
[23] A. Abbasfar, D. Divsalar, and K. Yao, “Accumulate repeat accumulatecodes,” in Proc. Globecom Conf., Dallas, Texas, December 2004, pp.509–513.
[24] A. Abbasfar, D. Divsalar, and K. Yao, “Maximum likelihood decodinganalysis of accumulate-repeat-accumulate codes,” in Proc. GlobecomConf., Dallas, Texas, December 2004, pp. 514–519.
[25] N. Wiberg, Codes and Decoding on General Graphs, Ph.D. thesis,Linkoping University (Sweden), 1996.
[26] S. M. Aji and R. J. McEliece, “The generalized distributive law,” IEEETrans. Information Theory, vol. 46, no. 2, pp. 325–343, March 2000.
[27] F.R. Kschischang, B.J. Frey, and H.-A. Loeliger, “Factor graphs and thesum-product algorithm,” IEEE Trans. Information Theory, vol. 47, pp.498–519, Feb. 2001.
[28] G. D. Forney, Jr., “Codes on graphs: Normal realizations,” IEEETrans. Information Theory, pp. 520–548, February 2001.
[29] J. Dielissen and J. Huisken, “State vector reduction for initialization ofsliding windows MAP,” in 2nd Internation Symposium on Turbo Codes& Related Topics, Brest, France, 2000, pp. 387 – 390.
[30] S. Yoon and Y. Bar-Ness, “A parallel MAP algorithm for low latencyturbo decoding,” IEEE Communications Letters, vol. 6, no. 7, pp. 288– 290, July 2002.
[31] A. Abbasfar and K. Yao, “An efficient and practical architecture for highspeed turbo decoders,” in IEEE 58th Vehicular Technology Conference,October 2003, pp. 337 – 341 Vol.1.
[32] L. Ping, W. K. Leung, and N. Phamdo, “Low density parity check codeswith semi-random parity check matrix,” IEE Electron. Lett., vol. 35, no.1, pp. 38–39, Jan. 1999.
[33] K. R. Narayanan, I. Altunbas, and R. Narayanaswami, “Design ofserial concatenated msk schemes based on density evolution,” IEEETrans. Commununication, vol. 51, pp. 1283 – 1295, Aug. 2003.
[34] D. J. C. MacKay, Information Theory, Inference, and Learning Algo-rithms, Cambridge University Press, 2003.
[35] P. E. McIllree, “Channel capacity calculations for M-ary N-dimensionalsignal sets,” M.S. thesis, The U. South Australia, School of ElectronicEng., Adelaide, February 1995.

Mar. 2, 2009TrellisWare Technologies
Uniform Interleaver Analysis• Analyze union bound as block size tends toward infinity
- Determine trends in BER, BLER- Determine design rules
Pb!!
d!dmin
KdQ
"#rdEb
2N0
$
Kd " Cd
%
&!
!(d)
N!(d)
'
(
Asymptotic behavior:
Pb ! N!max
Pcw ! N!max+1
!max = maxd
!(d)
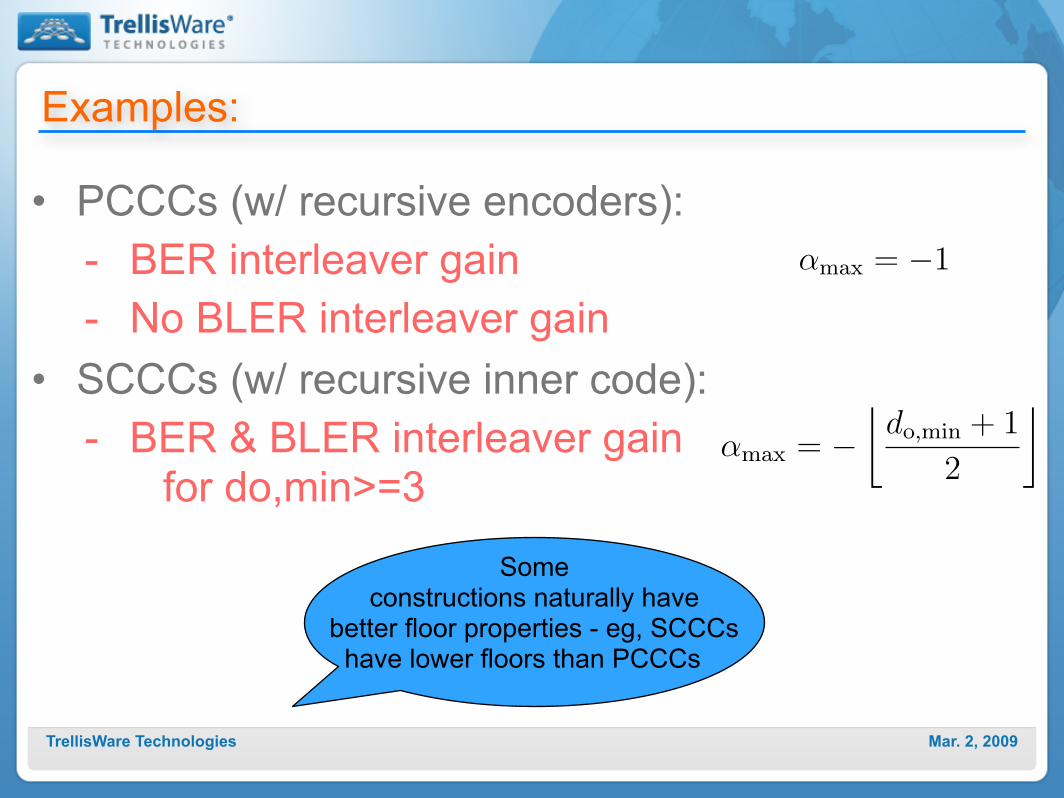
Mar. 2, 2009TrellisWare Technologies
Examples:
!max = !1
• PCCCs (w/ recursive encoders):- BER interleaver gain- No BLER interleaver gain
• SCCCs (w/ recursive inner code):- BER & BLER interleaver gain
for do,min>=3!max = !
!do,min + 1
2
"
Some constructions naturally have
better floor properties - eg, SCCCs have lower floors than PCCCs
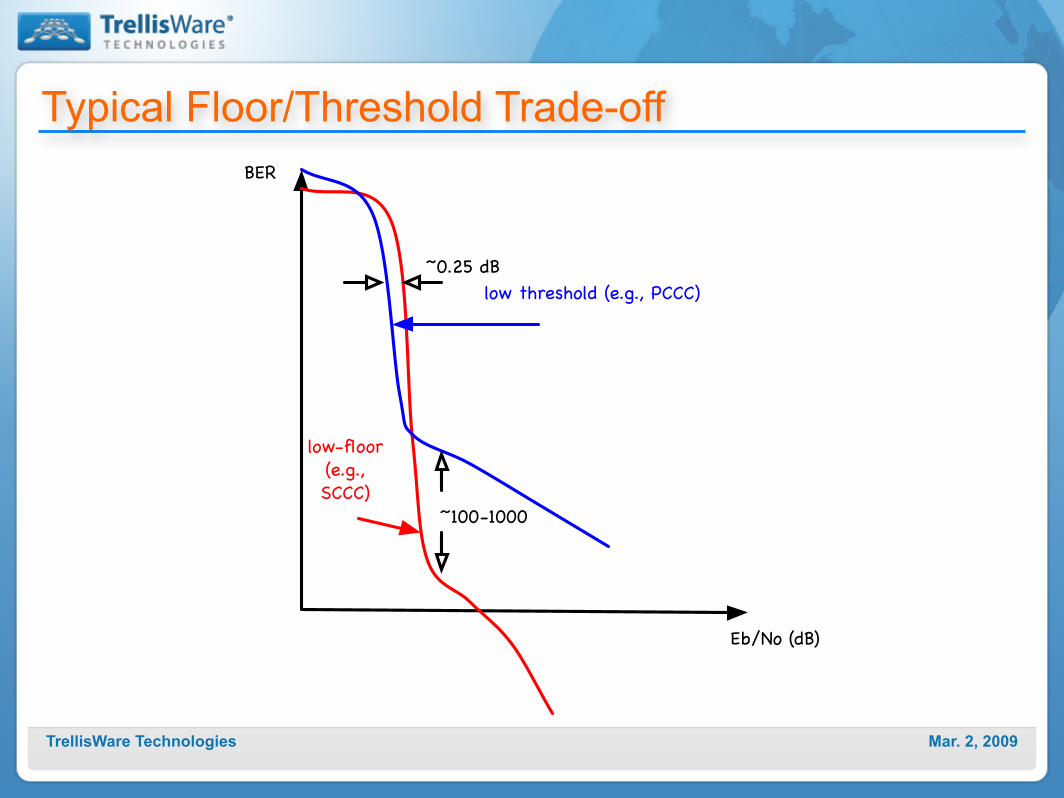
Mar. 2, 2009TrellisWare Technologies
Typical Floor/Threshold Trade-off
low-floor (e.g., SCCC)
low threshold (e.g., PCCC)
Eb/No (dB)
BER
~0.25 dB
~100-1000

Mar. 2, 2009TrellisWare Technologies
Good TLC Performance
• Theoretical bounds- Capacity
‣ Infinite block size, zero error probability- Random coding bound
‣ Upper bound on BLER for ML decoding of random codes- Sphere packing bound
‣ Lower bound on BLER for ML decoding of any code• Nontrivial to evaluate with a modulation constraint• Use a pragmatic guideline

Mar. 2, 2009TrellisWare Technologies
Finite Block-Size Performance - Pragmatic Guideline• Symmetric Information Rate (SIR)
- “Modulation constrained capacity”• Use an SNR penalty for finite block size
!Es
N0
"
min,finite,dB
=
!Es
N0
"
min,SIR,dB
+ !dB
!dB =
#20! (2! + 1) [10 log10(1/Pcw)]
k ln(10) (2! ! 1)
[8] S. Dolinar, D. Divsalar, and F. Pollara, “Code performance as a functionof block size,” Tech. Rep., JPL-TDA, May 1998, 42–133.
[9] K.M. Chugg and P. Gray, “A simple measure of good modern codeperforamnce,” (in preparation).
[10] S. Benedetto, D. Divsalar, G. Montorsi, and F. Pollara, “Serial concate-nation of interleaved codes: performance analysis, design, and iterativedecoding,” IEEE Trans. Information Theory, vol. 44, no. 3, pp. 909–926,May 1998.
[11] D. Divsalar and F. Pollara, “Hybrid concatenated codes and iterativedecoding,” Tech. Rep., JPL-TDA, August 1997, 42–130.
[12] H. Jin, A. Khandekar, and R. McEliece, “Irregular repeataccumulatecodes,” in Turbo Code Conf., Brest, France, 2000.
[13] K. M. Chugg, “A new class of turbo-like code with desirable practicalproperties,” in IEEE Communication Theory Workshop (no proceedings),Capri Island, May 2004, (recent results session).
[14] “FlexiCodes: A highly flexible FEC solution,” 2004, TrellisWareTechnologies White Paper, available at http://www.trellisware.com.
[15] K.M. Chugg, P. Gray, and R. Ward, “Flexible coding for 802.11n MIMOsystems,” September 2004, IEEE 802.11-04/0953r3, (Berlin, Germany),available at http://www.trellisware.com.
[16] L. Ping, X. Huang, and N. Phamdo, “Zigzag codes and concatenatedzigzag codes,” IEEE Trans. Information Theory, vol. 47, pp. 800–807,Feb. 2001.
[17] S. Benedetto and G. Montorsi, “Design of parallel concatenatedconvolutional codes,” IEEE Trans. Commununication, vol. 44, pp. 591–600, May 1996.
[18] S. Benedetto and G. Montorsi, “Unveiling turbo codes: some resultson parallel concatenated coding schemes,” IEEE Trans. InformationTheory, vol. 42, no. 2, pp. 408–428, March 1996.
[19] A. Graell, i Amat, S. Benedetto, and G. Montorsi, “Optimal high-rateconvolutional codes for partial response channels,” in Proc. GlobecomConf., Taipei, Taiwan, 2002, pp. CTS–01–4.
[20] L. Ping, “The SPC technique and low complexity turbo codes,” inProc. Globecom Conf., Rio de Janeiro, Brazil, December 1999, pp.2592–2596.
[21] L. R. Bahl, J. Cocke, F. Jelinek, and J. Raviv, “Optimal decoding oflinear codes for minimizing symbol error rate,” IEEE Trans. InformationTheory, vol. IT-20, pp. 284–287, March 1974.
[22] K. M. Chugg, A. Anastasopoulos, and X. Chen, Iterative Detection:Adaptivity, Complexity Reduction, and Applications, Kluwer AcademicPublishers, 2001.
[23] A. Abbasfar, D. Divsalar, and K. Yao, “Accumulate repeat accumulatecodes,” in Proc. Globecom Conf., Dallas, Texas, December 2004, pp.509–513.
[24] A. Abbasfar, D. Divsalar, and K. Yao, “Maximum likelihood decodinganalysis of accumulate-repeat-accumulate codes,” in Proc. GlobecomConf., Dallas, Texas, December 2004, pp. 514–519.
[25] N. Wiberg, Codes and Decoding on General Graphs, Ph.D. thesis,Linkoping University (Sweden), 1996.
[26] S. M. Aji and R. J. McEliece, “The generalized distributive law,” IEEETrans. Information Theory, vol. 46, no. 2, pp. 325–343, March 2000.
[27] F.R. Kschischang, B.J. Frey, and H.-A. Loeliger, “Factor graphs and thesum-product algorithm,” IEEE Trans. Information Theory, vol. 47, pp.498–519, Feb. 2001.
[28] G. D. Forney, Jr., “Codes on graphs: Normal realizations,” IEEETrans. Information Theory, pp. 520–548, February 2001.
[29] J. Dielissen and J. Huisken, “State vector reduction for initialization ofsliding windows MAP,” in 2nd Internation Symposium on Turbo Codes& Related Topics, Brest, France, 2000, pp. 387 – 390.
[30] S. Yoon and Y. Bar-Ness, “A parallel MAP algorithm for low latencyturbo decoding,” IEEE Communications Letters, vol. 6, no. 7, pp. 288– 290, July 2002.
[31] A. Abbasfar and K. Yao, “An efficient and practical architecture for highspeed turbo decoders,” in IEEE 58th Vehicular Technology Conference,October 2003, pp. 337 – 341 Vol.1.
[32] L. Ping, W. K. Leung, and N. Phamdo, “Low density parity check codeswith semi-random parity check matrix,” IEE Electron. Lett., vol. 35, no.1, pp. 38–39, Jan. 1999.
[33] K. R. Narayanan, I. Altunbas, and R. Narayanaswami, “Design ofserial concatenated msk schemes based on density evolution,” IEEETrans. Commununication, vol. 51, pp. 1283 – 1295, Aug. 2003.
[34] D. J. C. MacKay, Information Theory, Inference, and Learning Algo-rithms, Cambridge University Press, 2003.
[35] P. E. McIllree, “Channel capacity calculations for M-ary N-dimensionalsignal sets,” M.S. thesis, The U. South Australia, School of ElectronicEng., Adelaide, February 1995.
Best point-designs TLCs operate within ~0.5 dB of this
limit (software curves)
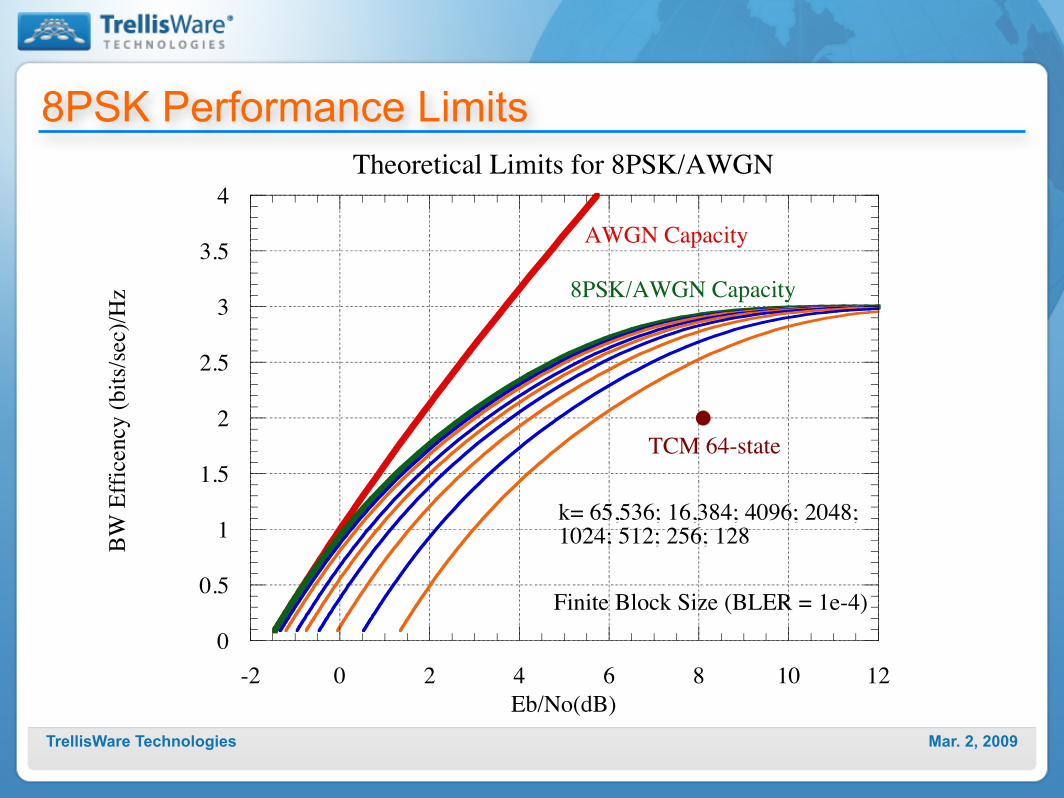
Mar. 2, 2009TrellisWare Technologies
8PSK Performance Limits
0
0.5
1
1.5
2
2.5
3
3.5
4
-2 0 2 4 6 8 10 12
Theoretical Limits for 8PSK/AWGN
BW E
ffice
ncy
(bits
/sec)
/Hz
Eb/No(dB)
AWGN Capacity
8PSK/AWGN Capacity
Finite Block Size (BLER = 1e-4)
k= 65,536; 16,384; 4096; 2048; 1024; 512; 256; 128
TCM 64-state
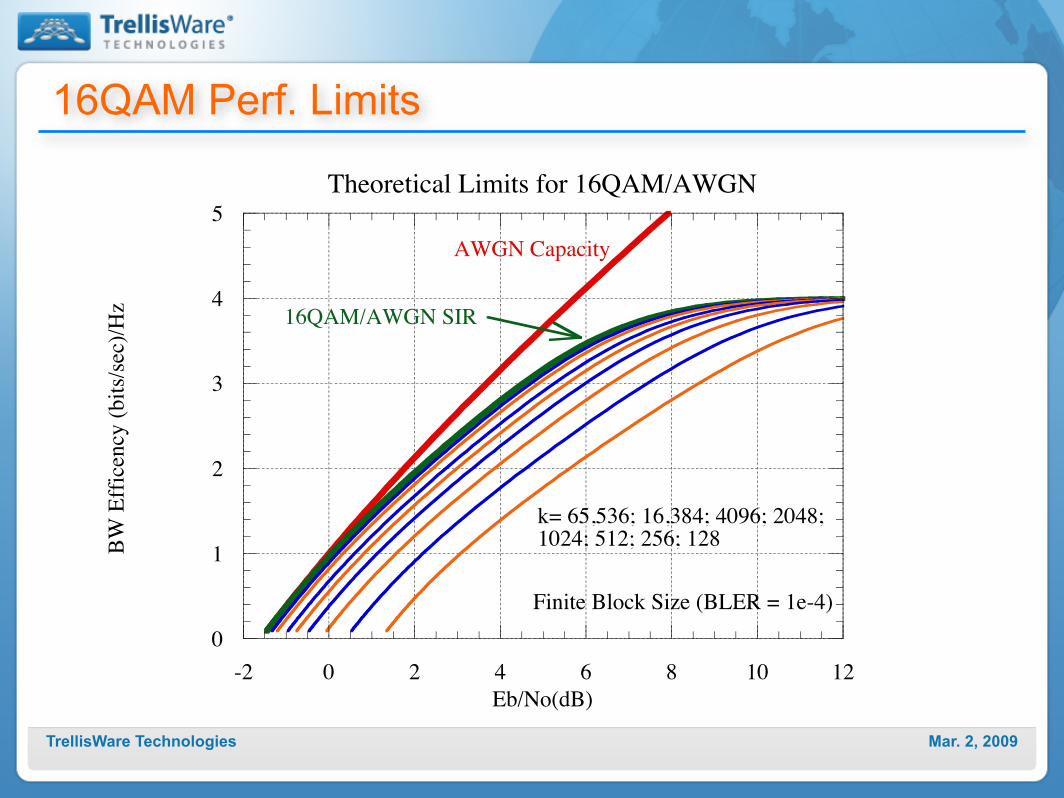
Mar. 2, 2009TrellisWare Technologies
16QAM Perf. Limits
0
1
2
3
4
5
-2 0 2 4 6 8 10 12
Theoretical Limits for 16QAM/AWGN
BW E
ffice
ncy
(bits
/sec)
/Hz
Eb/No(dB)
AWGN Capacity
16QAM/AWGN SIR
Finite Block Size (BLER = 1e-4)
k= 65,536; 16,384; 4096; 2048; 1024; 512; 256; 128
Mar. 2, 2009TrellisWare Technologies
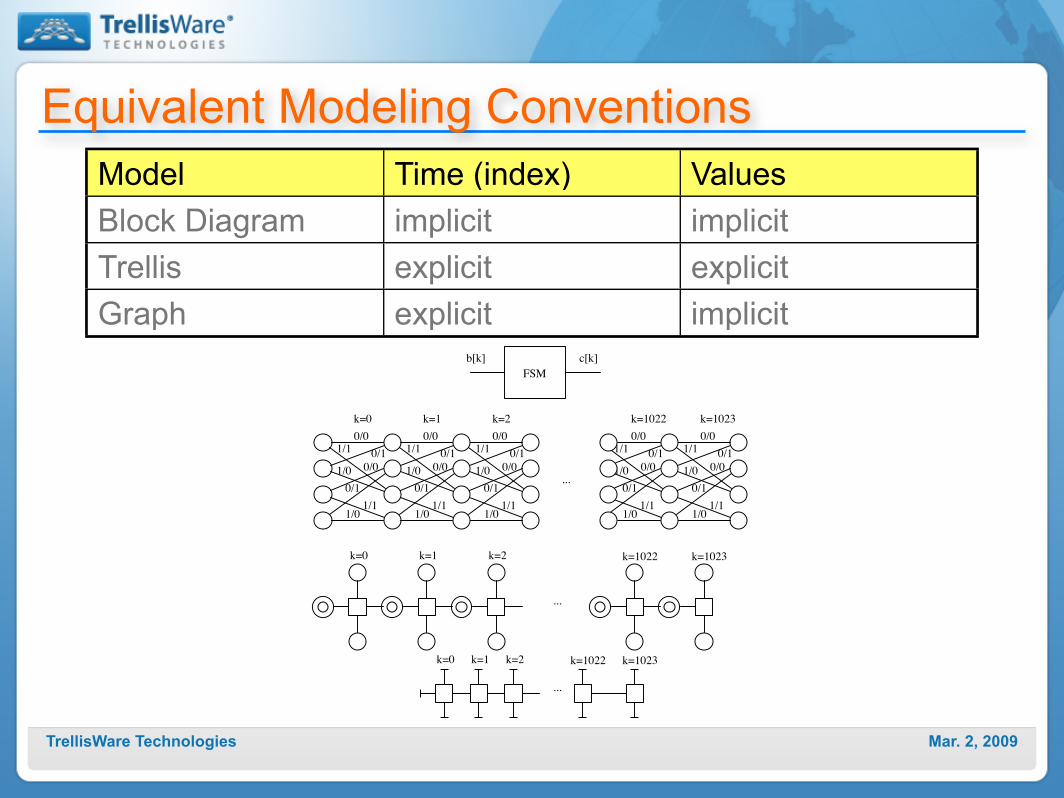
Equivalent Modeling ConventionsModel Time (index) ValuesBlock Diagram implicit implicitTrellis explicit explicitGraph explicit implicit
FSM
b[k] c[k]
0/0
1/1 0/1
0/01/0
1/11/0
0/1
k=0
0/0
1/1 0/1
0/01/0
1/11/0
0/1
k=1
0/0
1/1 0/1
0/01/0
1/11/0
0/1
k=2
0/0
1/1 0/1
0/01/0
1/11/0
0/1
k=1022
0/0
1/1 0/1
0/01/0
1/11/0
0/1
k=1023
k=0 k=1 k=2 k=1022 k=1023
...
...
k=0 k=1 k=2 k=1022 k=1023
...

Mar. 2, 2009TrellisWare Technologies
(Iterative) Message Passing Decoding
• Given a model that has constraints and variables- Well-defined standard set of message-passing rules- Locally optimal processing‣ Yields globally optimal results if graphical model
is a tree‣ Good heuristic if cycles are present -- “iterative
message-passing algorithm” (iMPA)✓Modern, TLCs are decoding in this manner
Mar. 2, 2009TrellisWare Technologies
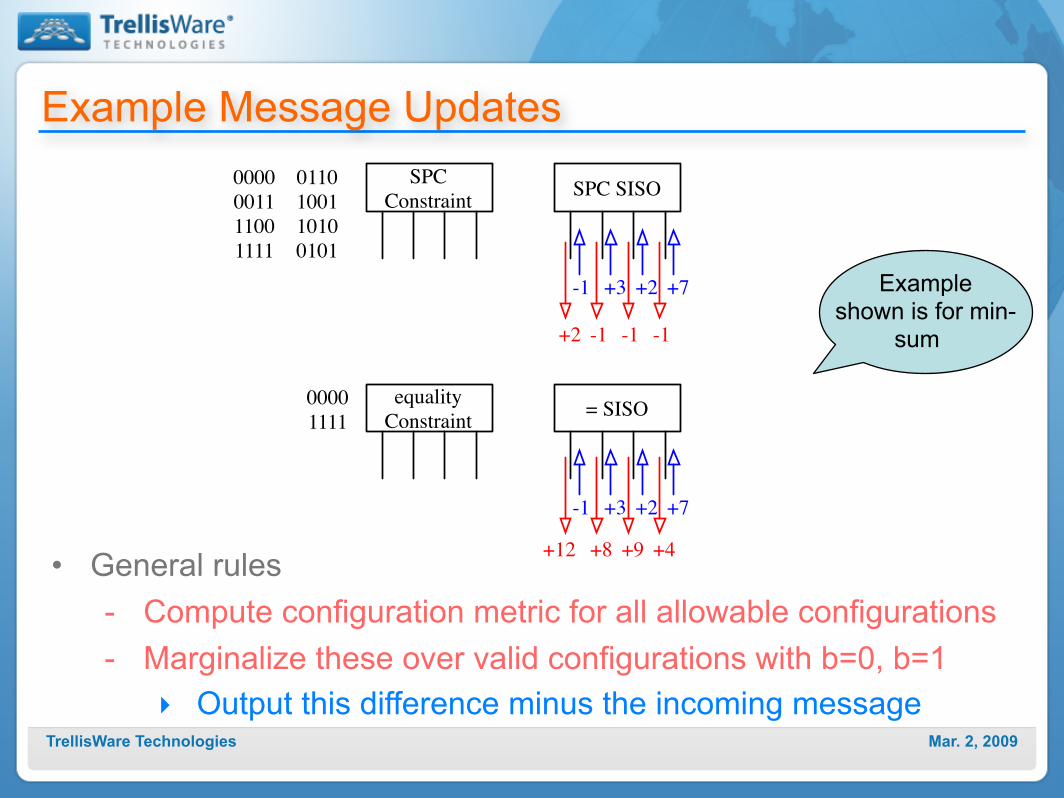
Example Message Updates
• General rules- Compute configuration metric for all allowable configurations- Marginalize these over valid configurations with b=0, b=1
‣ Output this difference minus the incoming message
Example shown is for min-
sum
SPC
Constraint0000
0011
1100
1111
0110
1001
1010
0101
SPC SISO
-1 +3 +2 +7
+2 -1 -1 -1
equality
Constraint0000
1111= SISO
-1 +3 +2 +7
+12 +8 +9 +4

Mar. 2, 2009TrellisWare Technologies
Standard Iterative Message Passing References
[8] S. Dolinar, D. Divsalar, and F. Pollara, “Code performance as a functionof block size,” Tech. Rep., JPL-TDA, May 1998, 42–133.
[9] K.M. Chugg and P. Gray, “A simple measure of good modern codeperforamnce,” (in preparation).
[10] S. Benedetto, D. Divsalar, G. Montorsi, and F. Pollara, “Serial concate-nation of interleaved codes: performance analysis, design, and iterativedecoding,” IEEE Trans. Information Theory, vol. 44, no. 3, pp. 909–926,May 1998.
[11] D. Divsalar and F. Pollara, “Hybrid concatenated codes and iterativedecoding,” Tech. Rep., JPL-TDA, August 1997, 42–130.
[12] H. Jin, A. Khandekar, and R. McEliece, “Irregular repeataccumulatecodes,” in Turbo Code Conf., Brest, France, 2000.
[13] K. M. Chugg, “A new class of turbo-like code with desirable practicalproperties,” in IEEE Communication Theory Workshop (no proceedings),Capri Island, May 2004, (recent results session).
[14] “FlexiCodes: A highly flexible FEC solution,” 2004, TrellisWareTechnologies White Paper, available at http://www.trellisware.com.
[15] K.M. Chugg, P. Gray, and R. Ward, “Flexible coding for 802.11n MIMOsystems,” September 2004, IEEE 802.11-04/0953r3, (Berlin, Germany),available at http://www.trellisware.com.
[16] L. Ping, X. Huang, and N. Phamdo, “Zigzag codes and concatenatedzigzag codes,” IEEE Trans. Information Theory, vol. 47, pp. 800–807,Feb. 2001.
[17] S. Benedetto and G. Montorsi, “Design of parallel concatenatedconvolutional codes,” IEEE Trans. Commununication, vol. 44, pp. 591–600, May 1996.
[18] S. Benedetto and G. Montorsi, “Unveiling turbo codes: some resultson parallel concatenated coding schemes,” IEEE Trans. InformationTheory, vol. 42, no. 2, pp. 408–428, March 1996.
[19] A. Graell, i Amat, S. Benedetto, and G. Montorsi, “Optimal high-rateconvolutional codes for partial response channels,” in Proc. GlobecomConf., Taipei, Taiwan, 2002, pp. CTS–01–4.
[20] L. Ping, “The SPC technique and low complexity turbo codes,” inProc. Globecom Conf., Rio de Janeiro, Brazil, December 1999, pp.2592–2596.
[21] L. R. Bahl, J. Cocke, F. Jelinek, and J. Raviv, “Optimal decoding oflinear codes for minimizing symbol error rate,” IEEE Trans. InformationTheory, vol. IT-20, pp. 284–287, March 1974.
[22] K. M. Chugg, A. Anastasopoulos, and X. Chen, Iterative Detection:Adaptivity, Complexity Reduction, and Applications, Kluwer AcademicPublishers, 2001.
[23] A. Abbasfar, D. Divsalar, and K. Yao, “Accumulate repeat accumulatecodes,” in Proc. Globecom Conf., Dallas, Texas, December 2004, pp.509–513.
[24] A. Abbasfar, D. Divsalar, and K. Yao, “Maximum likelihood decodinganalysis of accumulate-repeat-accumulate codes,” in Proc. GlobecomConf., Dallas, Texas, December 2004, pp. 514–519.
[25] N. Wiberg, Codes and Decoding on General Graphs, Ph.D. thesis,Linkoping University (Sweden), 1996.
[26] S. M. Aji and R. J. McEliece, “The generalized distributive law,” IEEETrans. Information Theory, vol. 46, no. 2, pp. 325–343, March 2000.
[27] F.R. Kschischang, B.J. Frey, and H.-A. Loeliger, “Factor graphs and thesum-product algorithm,” IEEE Trans. Information Theory, vol. 47, pp.498–519, Feb. 2001.
[28] G. D. Forney, Jr., “Codes on graphs: Normal realizations,” IEEETrans. Information Theory, pp. 520–548, February 2001.
[29] J. Dielissen and J. Huisken, “State vector reduction for initialization ofsliding windows MAP,” in 2nd Internation Symposium on Turbo Codes& Related Topics, Brest, France, 2000, pp. 387 – 390.
[30] S. Yoon and Y. Bar-Ness, “A parallel MAP algorithm for low latencyturbo decoding,” IEEE Communications Letters, vol. 6, no. 7, pp. 288– 290, July 2002.
[31] A. Abbasfar and K. Yao, “An efficient and practical architecture for highspeed turbo decoders,” in IEEE 58th Vehicular Technology Conference,October 2003, pp. 337 – 341 Vol.1.
[32] L. Ping, W. K. Leung, and N. Phamdo, “Low density parity check codeswith semi-random parity check matrix,” IEE Electron. Lett., vol. 35, no.1, pp. 38–39, Jan. 1999.
[33] K. R. Narayanan, I. Altunbas, and R. Narayanaswami, “Design ofserial concatenated msk schemes based on density evolution,” IEEETrans. Commununication, vol. 51, pp. 1283 – 1295, Aug. 2003.
[34] D. J. C. MacKay, Information Theory, Inference, and Learning Algo-rithms, Cambridge University Press, 2003.
[35] P. E. McIllree, “Channel capacity calculations for M-ary N-dimensionalsignal sets,” M.S. thesis, The U. South Australia, School of ElectronicEng., Adelaide, February 1995.
[8] S. Dolinar, D. Divsalar, and F. Pollara, “Code performance as a functionof block size,” Tech. Rep., JPL-TDA, May 1998, 42–133.
[9] K.M. Chugg and P. Gray, “A simple measure of good modern codeperforamnce,” (in preparation).
[10] S. Benedetto, D. Divsalar, G. Montorsi, and F. Pollara, “Serial concate-nation of interleaved codes: performance analysis, design, and iterativedecoding,” IEEE Trans. Information Theory, vol. 44, no. 3, pp. 909–926,May 1998.
[11] D. Divsalar and F. Pollara, “Hybrid concatenated codes and iterativedecoding,” Tech. Rep., JPL-TDA, August 1997, 42–130.
[12] H. Jin, A. Khandekar, and R. McEliece, “Irregular repeataccumulatecodes,” in Turbo Code Conf., Brest, France, 2000.
[13] K. M. Chugg, “A new class of turbo-like code with desirable practicalproperties,” in IEEE Communication Theory Workshop (no proceedings),Capri Island, May 2004, (recent results session).
[14] “FlexiCodes: A highly flexible FEC solution,” 2004, TrellisWareTechnologies White Paper, available at http://www.trellisware.com.
[15] K.M. Chugg, P. Gray, and R. Ward, “Flexible coding for 802.11n MIMOsystems,” September 2004, IEEE 802.11-04/0953r3, (Berlin, Germany),available at http://www.trellisware.com.
[16] L. Ping, X. Huang, and N. Phamdo, “Zigzag codes and concatenatedzigzag codes,” IEEE Trans. Information Theory, vol. 47, pp. 800–807,Feb. 2001.
[17] S. Benedetto and G. Montorsi, “Design of parallel concatenatedconvolutional codes,” IEEE Trans. Commununication, vol. 44, pp. 591–600, May 1996.
[18] S. Benedetto and G. Montorsi, “Unveiling turbo codes: some resultson parallel concatenated coding schemes,” IEEE Trans. InformationTheory, vol. 42, no. 2, pp. 408–428, March 1996.
[19] A. Graell, i Amat, S. Benedetto, and G. Montorsi, “Optimal high-rateconvolutional codes for partial response channels,” in Proc. GlobecomConf., Taipei, Taiwan, 2002, pp. CTS–01–4.
[20] L. Ping, “The SPC technique and low complexity turbo codes,” inProc. Globecom Conf., Rio de Janeiro, Brazil, December 1999, pp.2592–2596.
[21] L. R. Bahl, J. Cocke, F. Jelinek, and J. Raviv, “Optimal decoding oflinear codes for minimizing symbol error rate,” IEEE Trans. InformationTheory, vol. IT-20, pp. 284–287, March 1974.
[22] K. M. Chugg, A. Anastasopoulos, and X. Chen, Iterative Detection:Adaptivity, Complexity Reduction, and Applications, Kluwer AcademicPublishers, 2001.
[23] A. Abbasfar, D. Divsalar, and K. Yao, “Accumulate repeat accumulatecodes,” in Proc. Globecom Conf., Dallas, Texas, December 2004, pp.509–513.
[24] A. Abbasfar, D. Divsalar, and K. Yao, “Maximum likelihood decodinganalysis of accumulate-repeat-accumulate codes,” in Proc. GlobecomConf., Dallas, Texas, December 2004, pp. 514–519.
[25] N. Wiberg, Codes and Decoding on General Graphs, Ph.D. thesis,Linkoping University (Sweden), 1996.
[26] S. M. Aji and R. J. McEliece, “The generalized distributive law,” IEEETrans. Information Theory, vol. 46, no. 2, pp. 325–343, March 2000.
[27] F.R. Kschischang, B.J. Frey, and H.-A. Loeliger, “Factor graphs and thesum-product algorithm,” IEEE Trans. Information Theory, vol. 47, pp.498–519, Feb. 2001.
[28] G. D. Forney, Jr., “Codes on graphs: Normal realizations,” IEEETrans. Information Theory, pp. 520–548, February 2001.
[29] J. Dielissen and J. Huisken, “State vector reduction for initialization ofsliding windows MAP,” in 2nd Internation Symposium on Turbo Codes& Related Topics, Brest, France, 2000, pp. 387 – 390.
[30] S. Yoon and Y. Bar-Ness, “A parallel MAP algorithm for low latencyturbo decoding,” IEEE Communications Letters, vol. 6, no. 7, pp. 288– 290, July 2002.
[31] A. Abbasfar and K. Yao, “An efficient and practical architecture for highspeed turbo decoders,” in IEEE 58th Vehicular Technology Conference,October 2003, pp. 337 – 341 Vol.1.
[32] L. Ping, W. K. Leung, and N. Phamdo, “Low density parity check codeswith semi-random parity check matrix,” IEE Electron. Lett., vol. 35, no.1, pp. 38–39, Jan. 1999.
[33] K. R. Narayanan, I. Altunbas, and R. Narayanaswami, “Design ofserial concatenated msk schemes based on density evolution,” IEEETrans. Commununication, vol. 51, pp. 1283 – 1295, Aug. 2003.
[34] D. J. C. MacKay, Information Theory, Inference, and Learning Algo-rithms, Cambridge University Press, 2003.
[35] P. E. McIllree, “Channel capacity calculations for M-ary N-dimensionalsignal sets,” M.S. thesis, The U. South Australia, School of ElectronicEng., Adelaide, February 1995.

Mar. 2, 2009TrellisWare Technologies
S-SCP Codes
Mar. 2, 2009TrellisWare Technologies
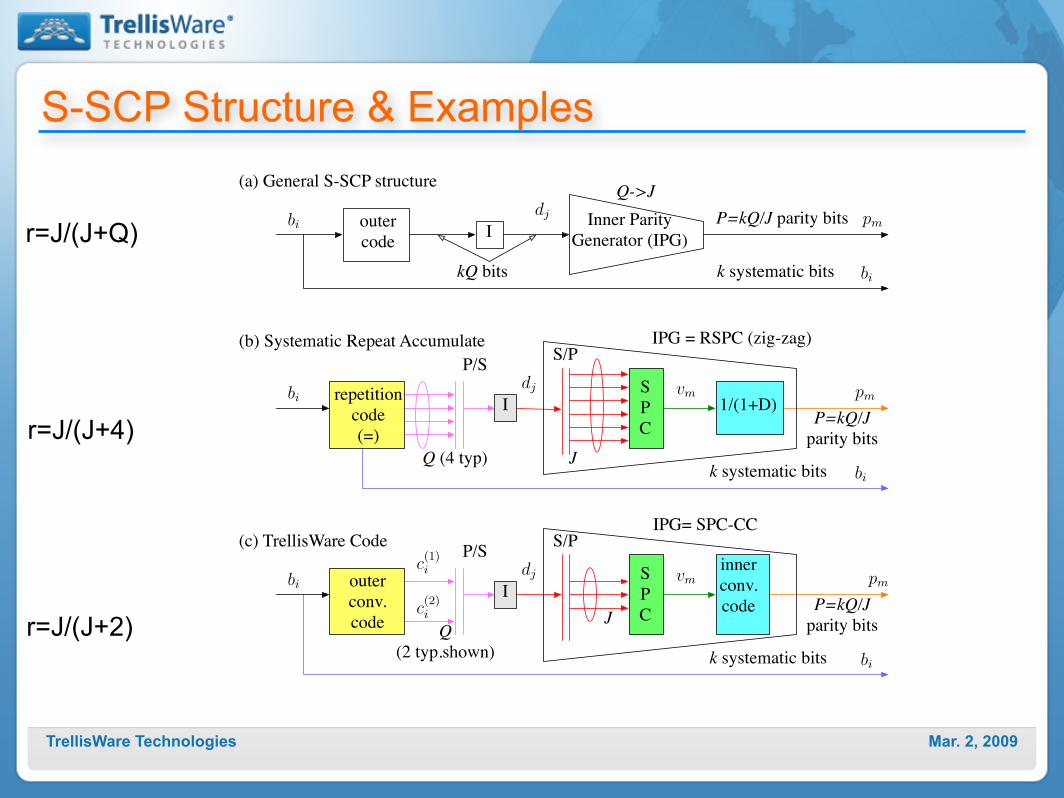
S-SCP Structure & Examples
r=J/(J+2)
r=J/(J+4)
r=J/(J+Q) outer
code
kQ bits
Q->J
k systematic bits
Ibi
dj pm
bi
Inner Parity
Generator (IPG)
P=kQ/J
parity bits
repetition
code
(=)
P/S
Q (4 typ)
S
P
C
1/(1+D)
Jk systematic bits
IPG = RSPC (zig-zag)S/P
Ibi
dj vm pm
bi
P=kQ/J parity bits
(a) General S-SCP structure
(b) Systematic Repeat Accumulate
P=kQ/J
parity bits
outer
conv.
code
P/S
Q
(2 typ.shown)
S
P
C
inner
conv.
codeJ
k systematic bits
IPG= SPC-CCS/P
Ibi
dj vm pm
bi
c(1)i
c(2)i
(c) TrellisWare Code

Mar. 2, 2009TrellisWare Technologies
TrellisWare Flexible S-SCP Examples• “FlexiCode”
- Outer Code: 4-state non-recursive (r=1/2)- Inner Code: 4-state recursive (r=1)- Very good floor properties
• Flexible LDPC (F-LDPC) Code- Outer Code: 2-state non-recursive (r=1/2)
‣ 1+D, 1+D- Inner Code: 2-state recursive (r=1)
‣ 1/(1+D) - same as Systematic RA- Extremely low complexity

Mar. 2, 2009TrellisWare Technologies
TW Code Properties
•Good performance over all code rates and block sizes-r=J/(J+2), flexible-finer rates by puncturing parity
•Uniform interleaver analysis:-Same as SCCCs-Unlike SCCCs, this can be achieved for very high
codes rates‣Can achieve low error probabilities, even at small block sizes
and high code rates
!max = !!
do,min + 1
2
"

Mar. 2, 2009TrellisWare Technologies
S-SCP References[8] S. Dolinar, D. Divsalar, and F. Pollara, “Code performance as a function
of block size,” Tech. Rep., JPL-TDA, May 1998, 42–133.[9] K.M. Chugg and P. Gray, “A simple measure of good modern code
perforamnce,” (in preparation).[10] S. Benedetto, D. Divsalar, G. Montorsi, and F. Pollara, “Serial concate-
nation of interleaved codes: performance analysis, design, and iterativedecoding,” IEEE Trans. Information Theory, vol. 44, no. 3, pp. 909–926,May 1998.
[11] D. Divsalar and F. Pollara, “Hybrid concatenated codes and iterativedecoding,” Tech. Rep., JPL-TDA, August 1997, 42–130.
[12] H. Jin, A. Khandekar, and R. McEliece, “Irregular repeataccumulatecodes,” in Turbo Code Conf., Brest, France, 2000.
[13] K. M. Chugg, “A new class of turbo-like code with desirable practicalproperties,” in IEEE Communication Theory Workshop (no proceedings),Capri Island, May 2004, (recent results session).
[14] “FlexiCodes: A highly flexible FEC solution,” 2004, TrellisWareTechnologies White Paper, available at http://www.trellisware.com.
[15] K.M. Chugg, P. Gray, and R. Ward, “Flexible coding for 802.11n MIMOsystems,” September 2004, IEEE 802.11-04/0953r3, (Berlin, Germany),available at http://www.trellisware.com.
[16] L. Ping, X. Huang, and N. Phamdo, “Zigzag codes and concatenatedzigzag codes,” IEEE Trans. Information Theory, vol. 47, pp. 800–807,Feb. 2001.
[17] S. Benedetto and G. Montorsi, “Design of parallel concatenatedconvolutional codes,” IEEE Trans. Commununication, vol. 44, pp. 591–600, May 1996.
[18] S. Benedetto and G. Montorsi, “Unveiling turbo codes: some resultson parallel concatenated coding schemes,” IEEE Trans. InformationTheory, vol. 42, no. 2, pp. 408–428, March 1996.
[19] A. Graell, i Amat, S. Benedetto, and G. Montorsi, “Optimal high-rateconvolutional codes for partial response channels,” in Proc. GlobecomConf., Taipei, Taiwan, 2002, pp. CTS–01–4.
[20] L. Ping, “The SPC technique and low complexity turbo codes,” inProc. Globecom Conf., Rio de Janeiro, Brazil, December 1999, pp.2592–2596.
[21] L. R. Bahl, J. Cocke, F. Jelinek, and J. Raviv, “Optimal decoding oflinear codes for minimizing symbol error rate,” IEEE Trans. InformationTheory, vol. IT-20, pp. 284–287, March 1974.
[22] K. M. Chugg, A. Anastasopoulos, and X. Chen, Iterative Detection:Adaptivity, Complexity Reduction, and Applications, Kluwer AcademicPublishers, 2001.
[23] A. Abbasfar, D. Divsalar, and K. Yao, “Accumulate repeat accumulatecodes,” in Proc. Globecom Conf., Dallas, Texas, December 2004, pp.509–513.
[24] A. Abbasfar, D. Divsalar, and K. Yao, “Maximum likelihood decodinganalysis of accumulate-repeat-accumulate codes,” in Proc. GlobecomConf., Dallas, Texas, December 2004, pp. 514–519.
[25] N. Wiberg, Codes and Decoding on General Graphs, Ph.D. thesis,Linkoping University (Sweden), 1996.
[26] S. M. Aji and R. J. McEliece, “The generalized distributive law,” IEEETrans. Information Theory, vol. 46, no. 2, pp. 325–343, March 2000.
[27] F.R. Kschischang, B.J. Frey, and H.-A. Loeliger, “Factor graphs and thesum-product algorithm,” IEEE Trans. Information Theory, vol. 47, pp.498–519, Feb. 2001.
[28] G. D. Forney, Jr., “Codes on graphs: Normal realizations,” IEEETrans. Information Theory, pp. 520–548, February 2001.
[29] J. Dielissen and J. Huisken, “State vector reduction for initialization ofsliding windows MAP,” in 2nd Internation Symposium on Turbo Codes& Related Topics, Brest, France, 2000, pp. 387 – 390.
[30] S. Yoon and Y. Bar-Ness, “A parallel MAP algorithm for low latencyturbo decoding,” IEEE Communications Letters, vol. 6, no. 7, pp. 288– 290, July 2002.
[31] A. Abbasfar and K. Yao, “An efficient and practical architecture for highspeed turbo decoders,” in IEEE 58th Vehicular Technology Conference,October 2003, pp. 337 – 341 Vol.1.
[32] L. Ping, W. K. Leung, and N. Phamdo, “Low density parity check codeswith semi-random parity check matrix,” IEE Electron. Lett., vol. 35, no.1, pp. 38–39, Jan. 1999.
[33] K. R. Narayanan, I. Altunbas, and R. Narayanaswami, “Design ofserial concatenated msk schemes based on density evolution,” IEEETrans. Commununication, vol. 51, pp. 1283 – 1295, Aug. 2003.
[34] D. J. C. MacKay, Information Theory, Inference, and Learning Algo-rithms, Cambridge University Press, 2003.
[35] P. E. McIllree, “Channel capacity calculations for M-ary N-dimensionalsignal sets,” M.S. thesis, The U. South Australia, School of ElectronicEng., Adelaide, February 1995.
[8] S. Dolinar, D. Divsalar, and F. Pollara, “Code performance as a functionof block size,” Tech. Rep., JPL-TDA, May 1998, 42–133.
[9] K.M. Chugg and P. Gray, “A simple measure of good modern codeperforamnce,” (in preparation).
[10] S. Benedetto, D. Divsalar, G. Montorsi, and F. Pollara, “Serial concate-nation of interleaved codes: performance analysis, design, and iterativedecoding,” IEEE Trans. Information Theory, vol. 44, no. 3, pp. 909–926,May 1998.
[11] D. Divsalar and F. Pollara, “Hybrid concatenated codes and iterativedecoding,” Tech. Rep., JPL-TDA, August 1997, 42–130.
[12] H. Jin, A. Khandekar, and R. McEliece, “Irregular repeataccumulatecodes,” in Turbo Code Conf., Brest, France, 2000.
[13] K. M. Chugg, “A new class of turbo-like code with desirable practicalproperties,” in IEEE Communication Theory Workshop (no proceedings),Capri Island, May 2004, (recent results session).
[14] “FlexiCodes: A highly flexible FEC solution,” 2004, TrellisWareTechnologies White Paper, available at http://www.trellisware.com.
[15] K.M. Chugg, P. Gray, and R. Ward, “Flexible coding for 802.11n MIMOsystems,” September 2004, IEEE 802.11-04/0953r3, (Berlin, Germany),available at http://www.trellisware.com.
[16] L. Ping, X. Huang, and N. Phamdo, “Zigzag codes and concatenatedzigzag codes,” IEEE Trans. Information Theory, vol. 47, pp. 800–807,Feb. 2001.
[17] S. Benedetto and G. Montorsi, “Design of parallel concatenatedconvolutional codes,” IEEE Trans. Commununication, vol. 44, pp. 591–600, May 1996.
[18] S. Benedetto and G. Montorsi, “Unveiling turbo codes: some resultson parallel concatenated coding schemes,” IEEE Trans. InformationTheory, vol. 42, no. 2, pp. 408–428, March 1996.
[19] A. Graell, i Amat, S. Benedetto, and G. Montorsi, “Optimal high-rateconvolutional codes for partial response channels,” in Proc. GlobecomConf., Taipei, Taiwan, 2002, pp. CTS–01–4.
[20] L. Ping, “The SPC technique and low complexity turbo codes,” inProc. Globecom Conf., Rio de Janeiro, Brazil, December 1999, pp.2592–2596.
[21] L. R. Bahl, J. Cocke, F. Jelinek, and J. Raviv, “Optimal decoding oflinear codes for minimizing symbol error rate,” IEEE Trans. InformationTheory, vol. IT-20, pp. 284–287, March 1974.
[22] K. M. Chugg, A. Anastasopoulos, and X. Chen, Iterative Detection:Adaptivity, Complexity Reduction, and Applications, Kluwer AcademicPublishers, 2001.
[23] A. Abbasfar, D. Divsalar, and K. Yao, “Accumulate repeat accumulatecodes,” in Proc. Globecom Conf., Dallas, Texas, December 2004, pp.509–513.
[24] A. Abbasfar, D. Divsalar, and K. Yao, “Maximum likelihood decodinganalysis of accumulate-repeat-accumulate codes,” in Proc. GlobecomConf., Dallas, Texas, December 2004, pp. 514–519.
[25] N. Wiberg, Codes and Decoding on General Graphs, Ph.D. thesis,Linkoping University (Sweden), 1996.
[26] S. M. Aji and R. J. McEliece, “The generalized distributive law,” IEEETrans. Information Theory, vol. 46, no. 2, pp. 325–343, March 2000.
[27] F.R. Kschischang, B.J. Frey, and H.-A. Loeliger, “Factor graphs and thesum-product algorithm,” IEEE Trans. Information Theory, vol. 47, pp.498–519, Feb. 2001.
[28] G. D. Forney, Jr., “Codes on graphs: Normal realizations,” IEEETrans. Information Theory, pp. 520–548, February 2001.
[29] J. Dielissen and J. Huisken, “State vector reduction for initialization ofsliding windows MAP,” in 2nd Internation Symposium on Turbo Codes& Related Topics, Brest, France, 2000, pp. 387 – 390.
[30] S. Yoon and Y. Bar-Ness, “A parallel MAP algorithm for low latencyturbo decoding,” IEEE Communications Letters, vol. 6, no. 7, pp. 288– 290, July 2002.
[31] A. Abbasfar and K. Yao, “An efficient and practical architecture for highspeed turbo decoders,” in IEEE 58th Vehicular Technology Conference,October 2003, pp. 337 – 341 Vol.1.
[32] L. Ping, W. K. Leung, and N. Phamdo, “Low density parity check codeswith semi-random parity check matrix,” IEE Electron. Lett., vol. 35, no.1, pp. 38–39, Jan. 1999.
[33] K. R. Narayanan, I. Altunbas, and R. Narayanaswami, “Design ofserial concatenated msk schemes based on density evolution,” IEEETrans. Commununication, vol. 51, pp. 1283 – 1295, Aug. 2003.
[34] D. J. C. MacKay, Information Theory, Inference, and Learning Algo-rithms, Cambridge University Press, 2003.
[35] P. E. McIllree, “Channel capacity calculations for M-ary N-dimensionalsignal sets,” M.S. thesis, The U. South Australia, School of ElectronicEng., Adelaide, February 1995.
A New Class of Turbo-like Codes with Universally Good Performance and High-Speed Decoding
Keith M. Chugg1,2, Phunsak Thiennviboon2, Georgios D. Dimou2, Paul Gray2, and Jordan Melzer11Communication Sciences Institute 2TrellisWare Technologies, Inc.
Electrical Engineering Dept. 16516 Via Esprillo, Ste. 300University of Southern California San Diego, CA 92127–1708
Los Angeles, CA, 90089-2565 {phunsak,gdimou,pgray}{chugg,jmelzer}@usc.edu @trellisware.com
Abstract— Modern turbo-like codes (TLCs), including concate-nated convolutional codes and low density parity check (LDPC)codes, have been shown to approach the Shannon limit on theadditive white Gaussian noise (AWGN) channel. Many designaspects remain relatively unexplored, however, including TLCdesign for maximum flexibility, very low error rate performance,and amenability to simple or very high-speed hardware codecs.In this paper we address these design issues by suggesting a newclass of TLCs that we call Systematic with Serially ConcatenatedParity (S-SCP) codes. One example member of this family isthe Generalized (or Systematic) Repeat Accumulate code. Wedescribe two other members of this family that both exhibitgood performance over a wide range of block sizes, code rates,modulation, and target error probability. One of these provideserror floor performance not previously demonstrated with anyother TLC construction and the other is shown to offer verylow complexity decoding with good performance. These twocodes have been implemented in high-speed hardware codecsand performance curves based on these down to bit error ratesbelow 10!10 are provided.
I. INTRODUCTION
The introduction of turbo codes [1] and the rediscoveryof low density parity check (LDPC) codes [2], [3] has rev-olutionized coding theory and practice. Initially demonstratedfor relatively low code rates, large block sizes, and binarymodulation, these modern or Turbo-Like Codes (TLCs) havesince been shown to be capable of near-optimal performancefor nearly all practical operational scenarios. We use the termoperational scenario as a given target block error rate (BLER)or bit error rate (BER), input block size (k), code rate (r), andmodulation format.
While good TLCs have been demonstrated for most opera-tional scenarios of interest, no one simple code structure hasbeen shown to provide good performance over the entire rangeof practical interest. Also, some operational scenarios havebeen particularly challenging for TLC designers. An importantexample is the case of very high code rates (r > 0.9), moderateblock sizes (k < 4096), and very low error probabilities (BER< 10!10) which is of interest in data storage and high-speedfiber links.
In this paper we describe a new class of TLCs, called Sys-tematic with Serially Concatenated Parity (S-SCP) codes, thatprovide good performance over a wide range of operationalscenarios and are amenable to simple hardware implementa-tion. These codes were not designed to be the best performingcodes at a single operational scenario, but rather were designed
for this universally good performance, flexibility, and easeof implementation. This is in contrast to much of the recentTLC code design literature which has focused on performanceoptimization for a given operational scenario. In particular,optimizing the asymptotic signal-to-noise (SNR) threshold hasreceived a great deal of attention (e.g., [4], [5], [6], [7]).However, such optimizations typically yield highly irregularcode structures, which complicate implementation and rate-adaptation, especially for high-speed decoding.
Despite the fact that the S-SCP codes proposed have notbeen highly optimized for a particular operational scenario, theperformance achieved is near that of the best point designs.Specifically, the best performance for a particular opera-tional scenarios is readily estimated – providing a “theoreticalbound” on achievable performance [8], [9]. The best pointdesigns are typically within approximately 0.5 dB of SNR ofthis limit. The simple, flexible S-SCP codes presented typicallyperform within 0.3 dB of the best point design over a widerange of operational scenarios. In the case of high code rates,small block sizes, and low error probabilities, the new codepresented provides the best performance known to the authors.
The S-SCP code construction shares some common traitswith serially concatenated convolutional codes (SCCCs)[10],hybrid concatenated convolutional codes (HCCCs) [11], andthe structured LDPC codes that we refer to as Generalized Re-peat Accumulate (GRA) codes [12]. In fact, an effort has beenmade to combine the best traits of these constructions. Thenew TLC is a systematic code with parity bits generated usinga serial concatenation of an outer code, an interleaver and aninner recursive parity generator as illustrated in Fig. 1(a). Notethat a key feature of this code is that the inner parity generatoroutputs fewer bits than it takes in – this allows the code rateto be adjusted easily by adjusting this ratio.
In this paper we present two example S-SCP codes thatwere developed by TrellisWare Technologies in 2003 andare commercially available in various hardware codecs. Onecode, called the FlexiCode by TrellisWare, uses 4-state con-volutional codes and provides exceptional error floor perfor-mance [13], [14]. Another version is the Flexible LDPC (F-LDPC) code [15] which provides SNR threshold performancesimilar to that of the FlexiCode, but exhibits error floors typicalof well-designed LDPC codes (LDPCCs) – i.e., higher floorsthan that of the FlexiCode, but still acceptable for many appli-cations. The F-LDPC code uses two-state convolutional codes
(MILCOM 2005)
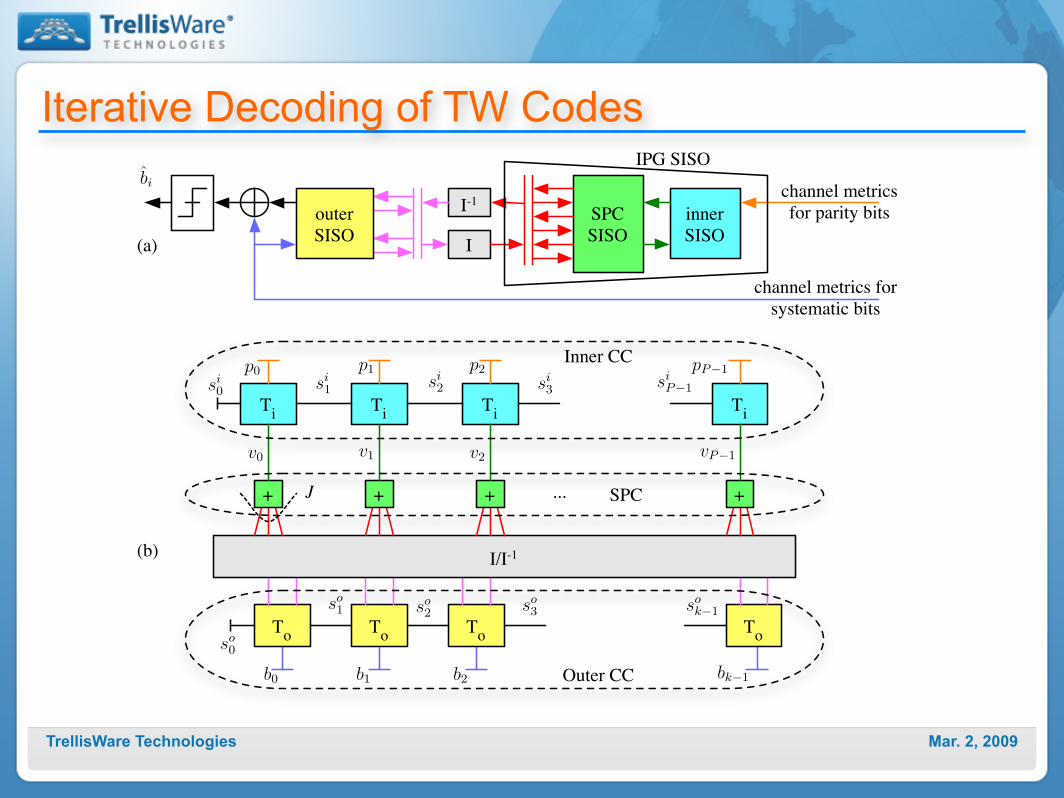
Mar. 2, 2009TrellisWare Technologies
Iterative Decoding of TW Codes
I
channel metrics for
systematic bits
bi
I-1
SPC
SISO
inner
SISO
outer
SISO
channel metrics
for parity bits
IPG SISO
b0 b1 b2 bk!1
To
To
To
Toso
0
I/I-1
Ti
Ti
Ti
Ti
+ + + +J ...
p0 p1 pP!1Inner CC
si0 si
1 si2 si
P!1
p2
SPC
Outer CC
v0 v1 v2 vP!1
sok!1so
1 so2 so
3
si3
(a)
(b)

Mar. 2, 2009TrellisWare Technologies
Systematic RA & F-LDPC Code Graphs
Sys-RA
F-LDPC
same performance, but
Sys-RA uses 2x the interleaver size
(a)I/I-1
=
+ + + +
= = =
= = =Q
J
...
...
b0 b1 b2 bk!1
p0 p1 pP!1
I/I-1
=
+ + + +
= = =
= = =
J
...
...
b0 b1 b2 bk!1
p0 p1 pP!1RSPC
c0 c1 c2 ck!1
+ +
= =
+
=
+
=
so0
Outer Rep. Code
Outer Code
(b)
Mar. 2, 2009TrellisWare Technologies
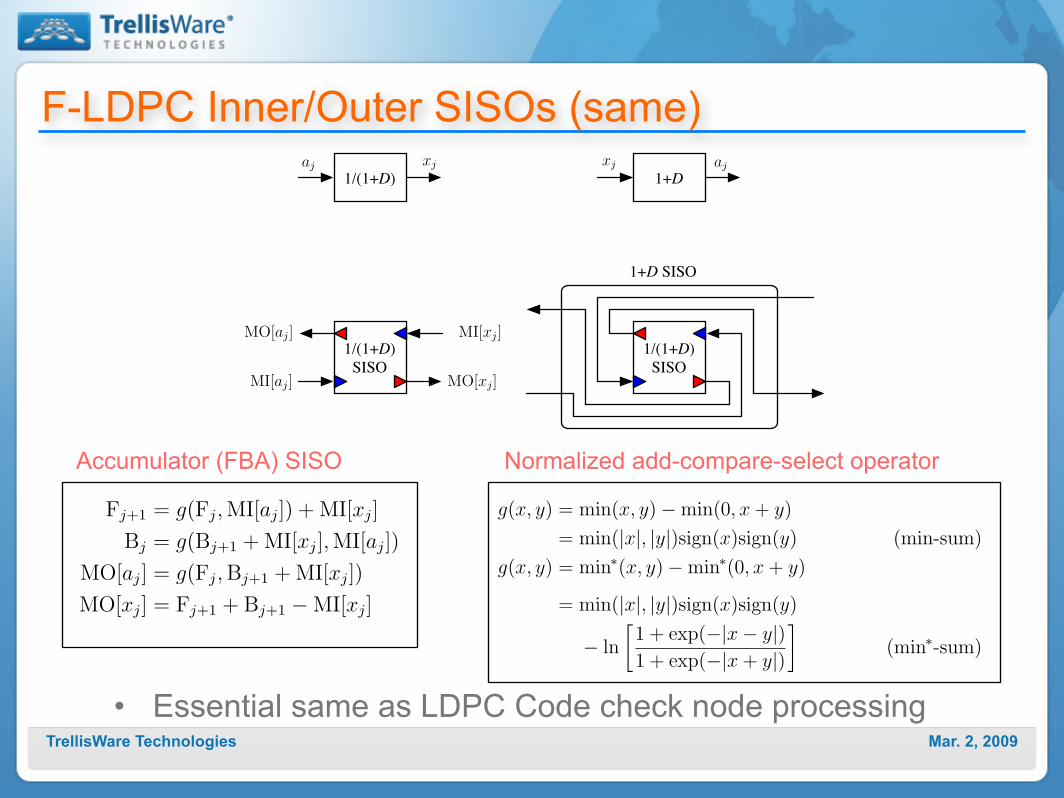
F-LDPC Inner/Outer SISOs (same)
• Essential same as LDPC Code check node processing
1/(1+D)aj xj
1+Dajxj
1/(1+D)
SISOMI[aj]
MO[aj]
MO[xj]
MI[xj]1/(1+D)
SISO
1+D SISO
Fj+1 = g(Fj, MI[aj]) + MI[xj]
Bj = g(Bj+1 + MI[xj], MI[aj])
MO[aj] = g(Fj, Bj+1 + MI[xj])
MO[xj] = Fj+1 + Bj+1 !MI[xj]
g(x, y) = min(x, y)!min(0, x + y)
= min(|x|, |y|)sign(x)sign(y) (min-sum)
g(x, y) = min!(x, y)!min!(0, x + y)
= min(|x|, |y|)sign(x)sign(y)
! ln
!1 + exp(!|x! y|)1 + exp(!|x + y|)
"(min!-sum)
Accumulator (FBA) SISO Normalized add-compare-select operator

Mar. 2, 2009TrellisWare Technologies
Systematic RA vs. TrellisWare F-LDPC
•Sys-RA with Q=4 has same performance as F-LDPC-Processing complexity
‣Sys-RA processes: Qk=4k trellis sections per iteration‣F-LDPC processes: k (outer) and 2k (inner) trellis sections per iteration
✓F-LDPC has 25% less processing complexity
-Memory complexity (interleaver only)‣Sys-RA: Qk = 4k storage elements‣F-LDPC: 2k storage elements
✓F-LDPC requires 50% less memory for messages exchanged

Mar. 2, 2009TrellisWare Technologies
Sys-RA, F-LDPC as Structured-LDPCs•Obtained by pulling all variable nodes to one side
see this note that (10) implies that
[ S | Hb ]!
pb
"= 0 (12)
S =
#
$$$$$%
1 0 0 · · · 01 1 0 00 1 1 0...
. . . 00 0 0 1 1
&
'''''((P ! P ) (13)
and Hb is a (k ! k) matrix with column weight Q and rowweight J . The vectors p (P ! 1) and b (k! 1) are vectors ofthe parity and systematic code bits, respectively. This can beseen graphically from Fig. 4(a) by pulling all variable (equalityconstraint) nodes to the bottom of the graph.
A similar approach can be used to show that the F-LDPCcode is an LDPC with some variables punctured (or hidden)from the channel. Specifically, the graph of Fig. 4(b) can bearranged so that all variable (equality constraint) nodes are atthe bottom of the graph and all check nodes (SPC constraints)are at the top. Note that the variable nodes are either bi, ci,or pm. Of these, only ci are not visible to the channel. It isstraightforward to write a check equation of the form
)S V 00 I G
*+
,pcb
-
. = 0 (14)
where c is the (k!1) vector of bits ci, S is the dual-diagonalmatrix in (13), G is (k ! k) and also dual-diagonal, and thematrix V accounts for the repetition by 2 at the outer code,interleaving and the SPC (see [15] for details).
Thus, both the GRA code and the F-LDPC code couldbe decoded using the variable-check node flooding scheduleusually assumed in the LDPC literature. This is not desirable,however, for either hardware of software implementation. Forsoftware, this converges at a much slower rate than the decoderschedule previously described. For hardware, this floodingschedule is impractical for memory design and routing. Ex-pressing the codes in this form does allow for high-levelcomparisons with LDPCCs in the literature. In particular, eachcheck message update is equivalent to running the accumulatorFBA-SISO over a number of trellis sections equal to the degreeof the check. Thus, the number of accumulator trellis sectionsprocessed by for each iteration is roughly the number ofedges in the LDPC code Tanner graph. For a regular (3,6)r = 1/2 LDPC code, this is 6k trellis sections. For highlyoptimized irregular LDPCCs, this is considerably higher –e.g., the LDPC code with best SNR threshold in [7, Table 1]has approximately 13k trellis sections to process per iteration.
In either case, the GRA code3 and, in particular, the F-LDPCcode compare favorably in terms of complexity – e.g., thecomplexity of the regular and irregular LDPC decoders areapproximately 100% and 433% greater than that of the F-LDPC decoder for each iteration.
V. PERFORMANCE CHARACTERISTICS
In this section we first briefly describe the theoretical limitsfor modulation-constrained, finite block size, finite BLERperformance that serves as a guideline for good moderncode performance. We then present representative performanceresults for TW’s FlexiCode and F-LDPC codes. Further per-formance results for these codes are available in [14] and [15],respectively, and available upon request.
A. Theoretical Guideline for Good TLC Performance
Channel capacity is the ultimate measure of achievableperformance. For the modulation constrained, AWGN channel,capacity is often well approximated by the upper bound of themutual information rate with a uniform a-priori distributionover the signal set. This is the so-called Symmetric Infor-mation Rate (SIR) and is readily computed as a function ofthe SNR [35], [9]. For a given rate (spectral efficiency) thisimplies a minimum required value of Es/N0 to operate, whereEs is the energy per modulation symbol. This value, denotedby
/EsN0
0
min,SIR, can be interpreted as the minimum value of
Es/N0 required to achieve zero BLER with infinite block sizeat the specified rate and modulation.
To account for the finite block size and non-zero errorrate, either the random coding bound (RCB) or the sphere-packing bound (SPB) for the constellation constrained AWGNchannel can be considered. These are upper and lower boundson the performance of the best finite block-length signalingscheme, respectively. The RCB can be computed for theconstellation constrained channel with some effort [9], butcomputation of the SPB is difficult. A SNR penalty canbe applied to the minimum SNR implied by capacity toapproximate the minimum Es/N0 required by the SPB for themodulation unconstrained AWGN channel [8]. It has also beenbe found empirically that applying this same penalty term to(Es/N0)min,SIR for the modulation constrained channel yieldsa finite block-size performance bound in close agreement withthe RCB over a wide range of operational scenarios [9].Thus, a good performance guideline for finite block-size, finite
3A subtle point in this comparison is that it is actually more computationallyefficient to decode the GRA code using an RSPC-SISO as described abovethan it is to decode on the standard Tanner graph neglecting the specialstructure. This is because the the two edges connecting each pm to the equalityconstraint in Fig. 4 are processed during the FBA without any additional g(·)operations since they represent the running partial parity values. If this RSPCstructure is ignored, these edges will require additional g(·) operations. TheF-LDPC code benefits from this both in processing the inner and outer codesince both bi and pm are partial parity state variables for the associatedaccumulator constraints.
see this note that (10) implies that
[ S | Hb ]!
pb
"= 0 (12)
S =
#
$$$$$%
1 0 0 · · · 01 1 0 00 1 1 0...
. . . 00 0 0 1 1
&
'''''((P ! P ) (13)
and Hb is a (k ! k) matrix with column weight Q and rowweight J . The vectors p (P ! 1) and b (k! 1) are vectors ofthe parity and systematic code bits, respectively. This can beseen graphically from Fig. 4(a) by pulling all variable (equalityconstraint) nodes to the bottom of the graph.
A similar approach can be used to show that the F-LDPCcode is an LDPC with some variables punctured (or hidden)from the channel. Specifically, the graph of Fig. 4(b) can bearranged so that all variable (equality constraint) nodes are atthe bottom of the graph and all check nodes (SPC constraints)are at the top. Note that the variable nodes are either bi, ci,or pm. Of these, only ci are not visible to the channel. It isstraightforward to write a check equation of the form
)S V 00 I G
*+
,pcb
-
. = 0 (14)
where c is the (k!1) vector of bits ci, S is the dual-diagonalmatrix in (13), G is (k ! k) and also dual-diagonal, and thematrix V accounts for the repetition by 2 at the outer code,interleaving and the SPC (see [15] for details).
Thus, both the GRA code and the F-LDPC code couldbe decoded using the variable-check node flooding scheduleusually assumed in the LDPC literature. This is not desirable,however, for either hardware of software implementation. Forsoftware, this converges at a much slower rate than the decoderschedule previously described. For hardware, this floodingschedule is impractical for memory design and routing. Ex-pressing the codes in this form does allow for high-levelcomparisons with LDPCCs in the literature. In particular, eachcheck message update is equivalent to running the accumulatorFBA-SISO over a number of trellis sections equal to the degreeof the check. Thus, the number of accumulator trellis sectionsprocessed by for each iteration is roughly the number ofedges in the LDPC code Tanner graph. For a regular (3,6)r = 1/2 LDPC code, this is 6k trellis sections. For highlyoptimized irregular LDPCCs, this is considerably higher –e.g., the LDPC code with best SNR threshold in [7, Table 1]has approximately 13k trellis sections to process per iteration.
In either case, the GRA code3 and, in particular, the F-LDPCcode compare favorably in terms of complexity – e.g., thecomplexity of the regular and irregular LDPC decoders areapproximately 100% and 433% greater than that of the F-LDPC decoder for each iteration.
V. PERFORMANCE CHARACTERISTICS
In this section we first briefly describe the theoretical limitsfor modulation-constrained, finite block size, finite BLERperformance that serves as a guideline for good moderncode performance. We then present representative performanceresults for TW’s FlexiCode and F-LDPC codes. Further per-formance results for these codes are available in [14] and [15],respectively, and available upon request.
A. Theoretical Guideline for Good TLC Performance
Channel capacity is the ultimate measure of achievableperformance. For the modulation constrained, AWGN channel,capacity is often well approximated by the upper bound of themutual information rate with a uniform a-priori distributionover the signal set. This is the so-called Symmetric Infor-mation Rate (SIR) and is readily computed as a function ofthe SNR [35], [9]. For a given rate (spectral efficiency) thisimplies a minimum required value of Es/N0 to operate, whereEs is the energy per modulation symbol. This value, denotedby
/EsN0
0
min,SIR, can be interpreted as the minimum value of
Es/N0 required to achieve zero BLER with infinite block sizeat the specified rate and modulation.
To account for the finite block size and non-zero errorrate, either the random coding bound (RCB) or the sphere-packing bound (SPB) for the constellation constrained AWGNchannel can be considered. These are upper and lower boundson the performance of the best finite block-length signalingscheme, respectively. The RCB can be computed for theconstellation constrained channel with some effort [9], butcomputation of the SPB is difficult. A SNR penalty canbe applied to the minimum SNR implied by capacity toapproximate the minimum Es/N0 required by the SPB for themodulation unconstrained AWGN channel [8]. It has also beenbe found empirically that applying this same penalty term to(Es/N0)min,SIR for the modulation constrained channel yieldsa finite block-size performance bound in close agreement withthe RCB over a wide range of operational scenarios [9].Thus, a good performance guideline for finite block-size, finite
3A subtle point in this comparison is that it is actually more computationallyefficient to decode the GRA code using an RSPC-SISO as described abovethan it is to decode on the standard Tanner graph neglecting the specialstructure. This is because the the two edges connecting each pm to the equalityconstraint in Fig. 4 are processed during the FBA without any additional g(·)operations since they represent the running partial parity values. If this RSPCstructure is ignored, these edges will require additional g(·) operations. TheF-LDPC code benefits from this both in processing the inner and outer codesince both bi and pm are partial parity state variables for the associatedaccumulator constraints.
Sys-RA:
F-LDPC:
Mar. 2, 2009TrellisWare Technologies
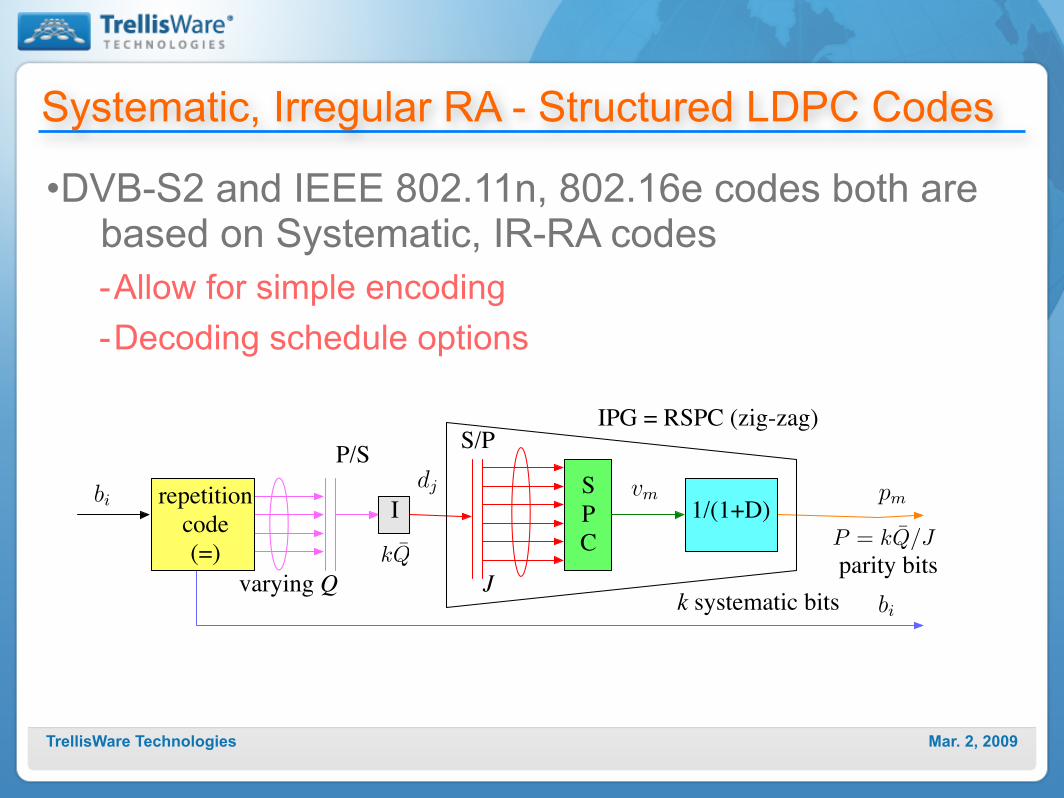
Systematic, Irregular RA - Structured LDPC Codes
•DVB-S2 and IEEE 802.11n, 802.16e codes both are based on Systematic, IR-RA codes-Allow for simple encoding-Decoding schedule options
parity bits
repetition
code
(=)
P/S
varying Q
S
P
C
1/(1+D)
Jk systematic bits
IPG = RSPC (zig-zag)S/P
Ibi
dj vm pm
bi
kQP = kQ/J

Mar. 2, 2009TrellisWare Technologies
Systematic, Irregular RA - Structured LDPC Codes
•Complexity varies linearly with Q-bar-irregular designs increase Q-bar
‣improved performance with software simulations (typical 0.1-0.3 dB)‣often not realized in practice due to limited hardware resources
H = [ Hb |S ]
J = (average) row weight of Hb
Q = average column weight of Hb

Mar. 2, 2009TrellisWare Technologies
F-LDPC Performance & Complexity

Mar. 2, 2009TrellisWare Technologies
Main Advantages of TW Codes (F-LDPC)
•Flexibility over rates >= 1/2•Flexibility over all block sizes•Simple/high-speed implementation•High code rates with low floors•Universally good performance
-Hardware performance‣typically within 1 dB of the pragmatic guideline over all code
rates and block sizes✓Recall best ‘academic’ point designs are 0.5 dB away

Mar. 2, 2009TrellisWare Technologies
F-LDPC as Compared to Sys-RA/LDPCs
CODE Comp. Complexity(# of accumulator trellis sections)
Memory Requirements (internal + channel)
Relative to F-LDPC(computation, memory)
F-LDPC 3k 2k + 4k 1, 1
Sys-RA (Q=4) 4k 4k+4k 1.3, 1.3
Sys, IR-RA (academic) 19.7 k 19.7k+4k 6.6, 4
LDPC (regular 3,6) 6k 6k + 4k 2, 1.6
Irregular LDPC (academic) 13k 13k+4k 4.3, 2.8
802.11n (Q-bar = 5.1) 5.1k 5.1k+4k 1.7, 1.5
DVB-S2 (Q-bar = 5) 5k 5k+4k 1.7, 1.5
per iteration comp. complexity, k=input block size, r=1/2(memory requirements depend on architecture details - typically, more memory
is required for decoder implementations not based on Sys.-RA structure)

Mar. 2, 2009TrellisWare Technologies
Relation to Hardware Performance
•Number of Trellis sections processed per iteration translates to throughput
•Memory requirements affect size •Characterize a codec by
-decoded info bits/sec per logic-Hz‣bps/logic-Hz
-performance at an achievable number of iterations‣best LDPC designs can perform slightly better in simulations, but gains
are lost with hardware constraints

Mar. 2, 2009TrellisWare Technologies
Why Add Complexity (irregularity)?
•Irregular designs have better asymptotic threshold-Typically small performance gains over F-LDPC at block
sizes of interest (<~ 0.2 dB)-Gains are often lost in practice due to
‣limited hardware resources✓15 iterations with F-LDPC vs. 9 iterations with DVB-S2
‣hardware approximations✓Highly irregular designs more sensitive to min*-sum processing
gains and hardware approximation errors
•Standards-based codes are selected based on academic-style simulations, not hardware testbeds
•TW has designed and implemented irregular F-LDPCs

Mar. 2, 2009TrellisWare Technologies
Example• Low-speed architecture
- 1 trellis section per clock cycle‣ F-LDPC: 1/(3i) bps/logic-Hz‣ 802.11n, DVB-S2: 1/(5i) bps/logic-Hz
- Assuming i=10 iterations, and 100 MHz clock‣ F-LDPC: 3.3 Mbps‣ 802.11n, DVB-S2: 2.0 Mbps
• May trade more logic for throughput...- Higher speeds require parallelism- Same proportional trade between codes

Mar. 2, 2009TrellisWare Technologies
Example F-LDPC Rate Flexibility
•k=8000 bits
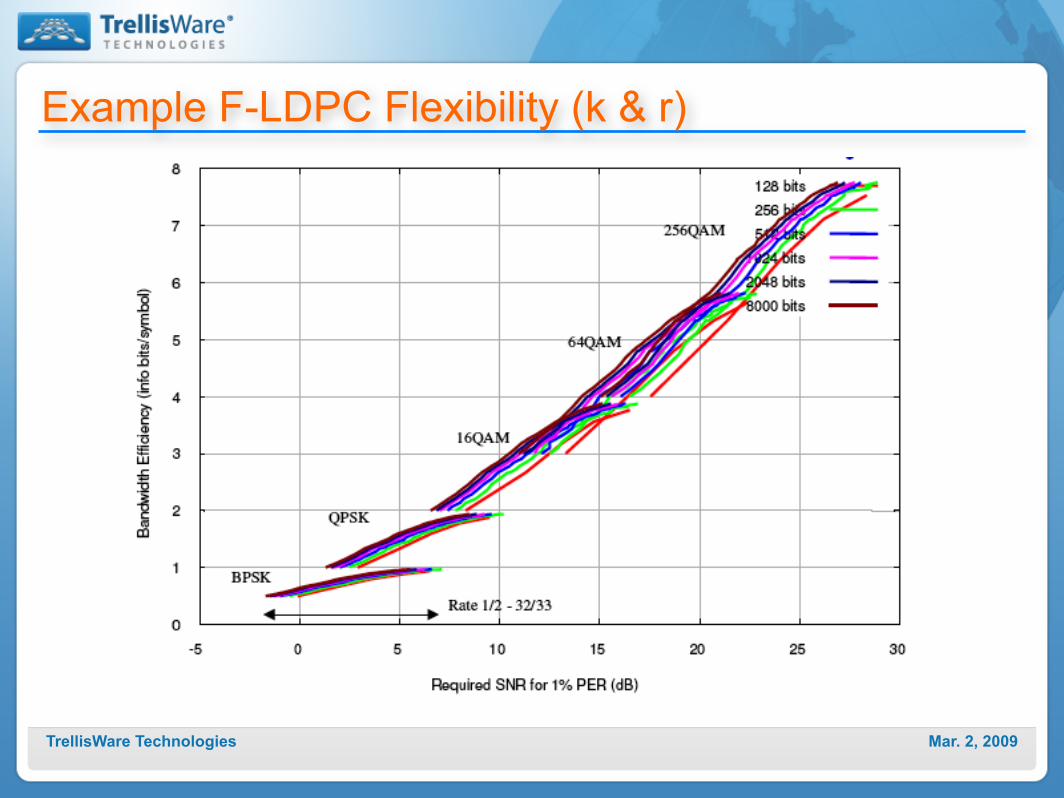
Mar. 2, 2009TrellisWare Technologies
Example F-LDPC Flexibility (k & r)
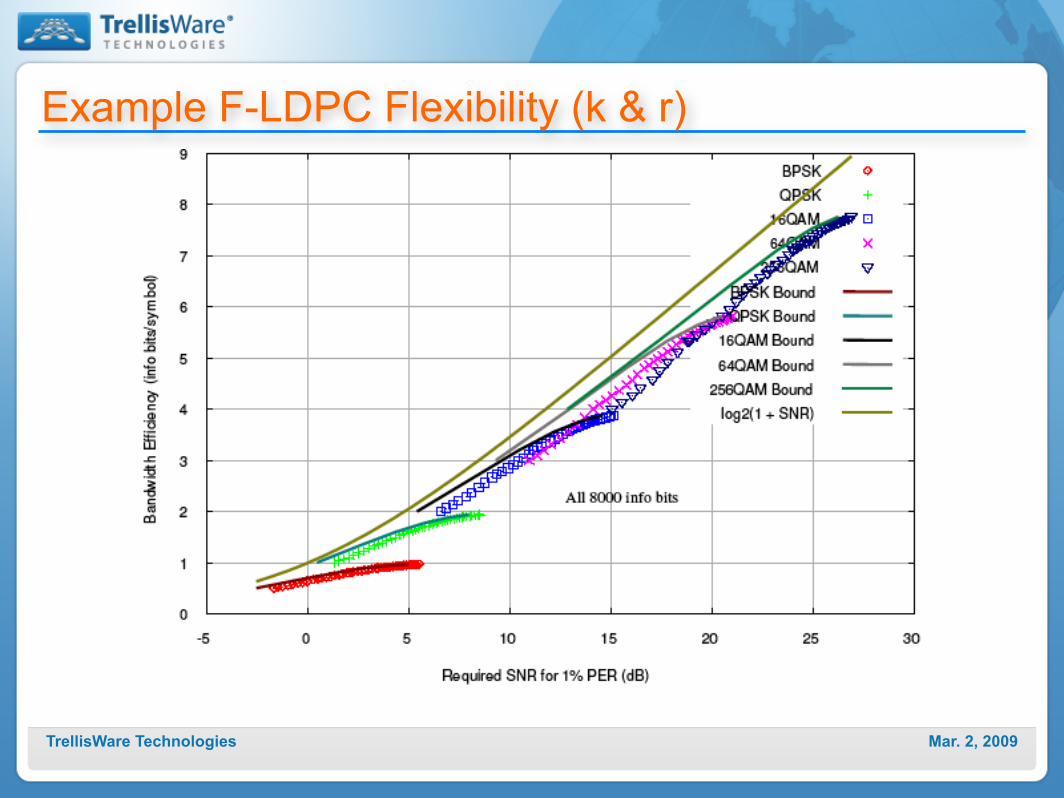
Mar. 2, 2009TrellisWare Technologies
Example F-LDPC Flexibility (k & r)

Mar. 2, 2009TrellisWare Technologies
F-LDPC Hardware Codec Performance - QPSK
r=2/3 r=4/5 r=8/9
Mar. 2, 2009TrellisWare Technologies
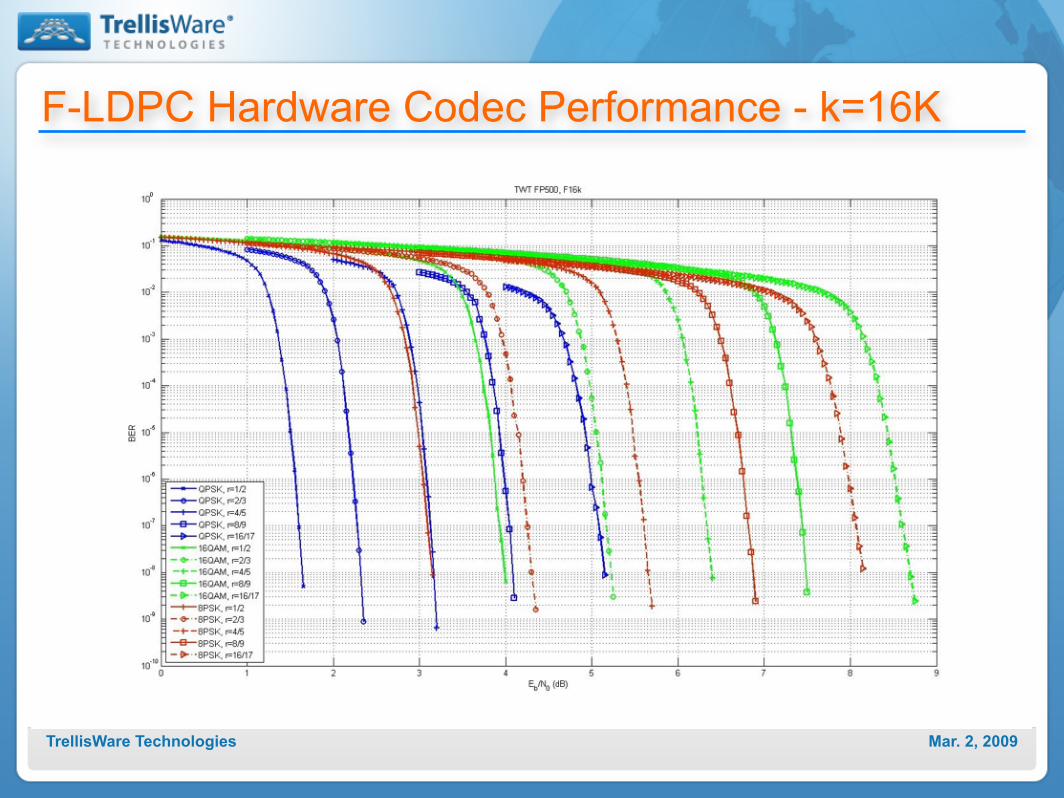
F-LDPC Hardware Codec Performance - k=16K

Mar. 2, 2009TrellisWare Technologies
Conclusions • Modern (turbo-like) codes
- Based on random-like code constructions- Iterative message-passing decoding (suboptimal)
• Many different constructions- Optimized for point designs
‣ Gains often come with increased complexity• Systematic with Serially Concatenated Parity (S-SCP)
- Yield flexible, universally good TLCs- TrellisWare’s F-LDPC
‣ Simplified version of Systematic Repeat Accumulate

Mar. 2, 2009TrellisWare Technologies
IEEE (802.11n, 802.16) LDPC Structure
July 16, 2007
Toy H Matrix Example
Sheet1
Page 1
V1 V2 V3 V4 V5 V6 V7 V8 V9 V10 V11 V12 P1 P2 P3 P4 P5 P6 P7 P8 P9 P10 P11 P12
C1 1 1 1 1 1
C2 1 1 1 1 1
C3 1 1 1 1 1
C4 1 1 1 1 1
C5 1 1 1 1 1
C6 1 1 1 1 1
C7 1 1 1 1 1 1
C8 1 1 1 1 1 1
C9 1 1 1 1 1 1
C10 1 1 1 1
C11 1 1 1 1
C12 1 1 1 1
Sheet1
Page 1
V1-3 V4-6 V7-9 V10-12 P1-3 P4-6 P7-9 P10-12
C1-3 1 2 - 0 1 0 - -
C4-6 - 0 2 1 - 0 0 -
C7-9 0 1 - 2 0 - 0 0
C10-12 2 - 0 - 1 - - 0
IEEE Cyclic Permutation Format, Z=3
Standard Format of IEEE Matrix Above
-’s represent the ZxZ all-zeros matrix
#’s represent permutations of the ZxZ identity matrix
(columns are cyclicly shifted # times to the right)
3