modern column stores for big data processingmodern column stores for big data processing k.t.sridhar...
TRANSCRIPT

Modern Column Storesfor
Big Data Processing
K.T.SridharXtremeData Technologies/XtremeData, Inc.
Bangalore, India/Schaumburg, USA

BDA 2017 2
Introduction
why did the MIGHTY fall?
what’s the churn?
can the fallen rise again?
process Big Data?
Internet/web, web 2.0,web scale mining, mobile,Big Data, IoT, Industry 4.0
20th & early 21st
Century Emperorof
Data Processing:row DBMS
The Emperor in21st Century:circa 2010
OLTP, EIS, OLAP..
Part 1:Background
Part 2:Modern Column Store
Part 3:Big Data & SQL

BDA 2017 3
♣ Big Data Era♣ Friends Foes♣ Lost in “Big Data”♣ Light in Tunnel?♣ Gates: Horn or Ivory?♣ NoSQL Wave Tsunami?
Part 1:Background

BDA 2017 4
Background: Big Data Era
Google’s MapReducedivide-and-conquer
distributed applications
programming framework
inspired by LISP
Map and Reduce on
key-value pairs
Big Data: noun in English; Oxford Dictionary, 2013“extremely large data sets that may be analyzed computationally to reveal patterns,trends, and associations, especially related to human behavior and interactions”
3Vs of Big Data: volume, velocity, variety
… and more Vs: veracity, variability, value
[5]: M.Chen, S.Mao, Y.Liu: Big Data: A Survey, Mobile Network Applications, 2014
Big Data: Impetus rise of the internet: processing
web-scale data and mining democratization of the web Web 2.0 technology location: GPS for civilian use ubiquitous mobile device IoT and Industry 4.0
NoSQL Systems … NewSQL[7]: J.Dean, S.Ghemawat: MapReduce: Simplified
Data Processing on Large Clusters, USENIXOSDI, San Francisco, USA, 2004
Apache’s Hadoopdistributed file system
availability, scalability and
performance
handled failures
open source infrastructure
for MapReduce
… and other related technology developments

BDA 2017 5
Background: Big Data Era
SQL DBMS: status quo ante
• row stores (System R, Ingres industry products)
• executor: tuple-at-a-time, iterator model (open, next, close)
[2]: G.Graeffe: Query Evaluation Techniques for LargeDatabases, Computing Surveys, 25(6), 1993
• products: DB2, Oracle, TeraData, SQL Server, MySQL, PostgreSQL,…
• enterprise OLTP applications (banking, EIS, reservations…)
• datawarehouses & OLAPMPP, shared nothing (TeraData, 1986)
• DB appliances: Netezza (2002), Oracle ExaData (2008), EMC DCA (2011)
fd(T2)
none
hash table
build left;probe right
fd(T1)
eof
eof
true
data
command

BDA 2017 6
Background: Big Data Era
NoSQL Products: status quo ante do not use relational model models: key/value pairs, columnar, document, graph abandon ACID conformance; emphasize availability horizontal scalability several are open source
Table from [11]
NoSQL (Not only SQL): Key Drivers relational schema: rigid, inflexible -- unstructured data? ACID properties of transactions performance degradation high availability? horizontal scalability? non-procedural SQL for applications programming?
[7]: C.Strauch: NoSQL Databases, StuttgartMedia University, Stuttgart, 2011
[5]: M.Chen, S.Mao, Y.Liu: Big Data: ASurvey, Mobile Network Applications,2014

BDA 2017 7
Background: Friends Foes
unlike HPC systems, poor gain from h/w advances incores, cache & memory
4 row DBMSs: 50% of query time in CPU stalls
[8]: A.Ailamaki, D.J.DeWitt, M.D.Hill, D.A.Wood: DBMSs on a Modern Processor:Where Does Time Go?, 25th VLDB, Edinburgh, UK, 1999
Memory Hierarchy
Fig. from [23]
main memory: bridges speeddifference CPU/disk
to bridge speed differencebetween CPU/Memory: cachehierarchy (L1/L2/…): 300 cyc
locality of reference/data L1: read only; instructions L2: read/write; (instr/data) more speed/less latency
diskmemoryL2L1registers
cache line: 32 to 128 cache hit & pre-fetching cache miss/misprediction CPU stall

BDA 2017 8
Background: Friends Foes
TC : useful computation time
TB : misprediction overheads
TR : resource related stall
TM : memory stall
TQ = TC + TB + TR + TM - TOVL
[8]: A.Ailamaki, D.J.DeWitt, M.D.Hill, D.A.Wood: DBMSs on a Modern Processor:Where Does Time Go?, 25th VLDB, Edinburgh, UK, 1999
CPU Stalls Figures from [8]

BDA 2017 9
Background: Friends Foes
CAP Theorem a network shared system can support only 2 of 3 desirable
properties, consistency (C), availability (A) and partitiontolerance (P)
a negative result that impacts transactions of parallel ordistributed DBMSs
give up 1-of-3 to build simpler and faster systems
[9]: Eric Brewer: Towards Robust Distributed Systems, 19th PODC, Portland, USA, 2000
consistency: how is “same” data perceived by all users in thepresence of concurrent read/write?
availability: what is the degree of availability in the presenceof failures?
partition tolerance: what happens when 1 or more nodesbecome inaccessible to other nodes?
“availability, graceful degradation & performance”greater importance to A and P stale data is OK; give up C simpler and faster

BDA 2017 10
Background: Friends Foes
atomic
consistent
isolation
durable
Distributed DBMS Transactions
ACID BASEbasically available
soft state
eventual consistency
SQL compliance needsACID; performance
overheads
compromised systemthat is simpler withbetter performance
[9]: Eric Brewer: Towards Robust Distributed Systems, 19th PODC, Portland, USA, 2000
CAP theorem was formally proved
NoSQL systems used CAP theorem to build A+Por C+A systems for transactions management
S.Gilbert, N.Lynch: Brewer’s Conjecture and the Feasibility of Consistent, Available,Partition-Tolerant Web Services, ACM SIGACT News, June, 2002
commodityh/w clusters
BDA 2017 11
Background: Friends Foes
is a row store DBMS an universal solution for data processing?
can it be used for data processing with different requirements?
One Size Fits All? financial feed, algorithmic trading, sensor networks, IoT
stream processing: low latency applications
OLAP, datawarehousing, analytics read optimized column stores
scientific databases in astronomy, particle physics… array processing
text data in library/medical/legal systems, web data mining,sentiment analysis custom solutions
[10]: M.Stonebraker, U.Centimel: One Size Fits All: An Idea whose Time has Comeand Gone, 21st ICDE, Tokyo, Japan, 2005

BDA 2017 12
Background: Friends Foes
[10]: M.Stonebraker, U.Centimel: One Size Fits All: An Idea whose Time has Comeand Gone, 21st ICDE, Tokyo, Japan, 2005
Soothsayers! “one size fits all” theme is unlikely to continue under these
circumstances advocate domain specific DB engines
always write process later
process first optional write
Figures from [10]
BDA 2017 13
Background: Lost in “Big Data”
Row Stores and 3Vs volume: horizontal vs vertical scalability velocity: low latency applications; outbound vs inbound variety: designed for structured data (numbers, char, etc.);
semi-structured data (XML, JSON,.. web data)?unstructured data (audio, video, tweets,…)?
Structured Big Data? high volume related performance issues knobs and pundits cost: DB appliances vs open source social factors

BDA 2017 14
Background: Light in Tunnel?
[20]: G.P.Copeland, S.N.Khoshafian: A Decomposition Storage Model, SIGMOD 1985
C-Store: MIT/Brandeis/UMass/Brown, USA
[23]: P.Boncz et al: Breaking the Memory Wall in MonetDB, CACM, 51(12), 2008[12]: S.Idreos et al: MonetDB: Two Decades of Research in Column Oriented
Architectures, IEEE Data Engg Bulletin, 35(1), 2012
[13]: M.Stonebraker et al: C-Store A Column Oriented Database, 31st VLDB,Trondheim, Norway, 2005
MonetDB: CWI, The Netherlands
Vertical Partitioning
DSM
NSM
N-ary Storage Model
Decomposition Storage Model
both outperformed SQL row stores & NoSQL several industry products

BDA 2017 15
Background: Gates -- Horn or Ivory?
Cloud Computing democratizes distributed computing: anyone, anywhere, pay-by-use IaaS, PaaS, SaaS, AaaS… no upfront high investment nice and easy browser based GUI for system configuration; QoS vendors: Amazon AWS, Microsoft Azure, Alibaba, CenturyLink, Internap INAP, …
SQL Column Stores MPP SQL Column Stores deploy on cloud
volume with horizontal scalability; even “elastic”scale-out
decouple compute & storage (EBS/ Premium IO)not 24x7
some from “archival” storage (AWS S3/Azure blob) application mobility: some are cloud “agnostic”;
even on private clouds

BDA 2017 16
Background: NoSQL Wave Tsunami?
SQL and NoSQL comparison: 100 nodes; web-type data MapReduce/Hadoop vs row DBMS vs columnar Vertica 5 tasks: grep task + 4 DBMS tasks (selection, aggregation, join & UDF aggregation) both DBMSs outperformed MapReduce: row store (3.2x), column store (7.4x) data load: easier and faster in MapReduce repetititive, slow or no compression, pull model, no plan optimizer…
[16]: C.Mohan: History Repeats Itself: Sensible and NonsenseSQL Aspects ofthe NoSQL Hoopla, EBDT/IDBT, Genoa, Italy, 2013
[15]: A.Pavlo, E.Paulson, A.Rasin, D.J.Abadi, D.J.DeWitt, S.Madden, M.Stonebraker: A Comparison of Approaches toLarge Scale Analytics, SIGMOD, Providence, USA, 2009
M.Stonebraker, D.J.Abadi, D.J.DeWitt, S.Madden, E.Paulson, A.Pavlo, A.Rasin: MapReduce andParallel DBMS: Friends of Foes? CACM, 53(1), 2010
MapReduce “is more like an extract-transform-load (ETL) system” andhence “complementary” to SQL DBMSs
ignores history: not learning from the past expediency over rigor no support for an easy, interactive query interface ad-hoc solutions for inherently complex problems:
transactions, concurrency, etc. no standards
[7]

BDA 2017 17
Background: NoSQL Wave Tsunami?
“2 of 3 formulation was misleading as it tended to over-simplify the tension among properties” raison d’etere of NoSQL systems: applicable only in the context of failures! Neo4j is ACID; Google BigTable is C+A; HBase, Cassandra, Dynamo, MongoDB are A+P (BASE)
[16]: K.Grolinger, M.Hayes, W.A.Higashino, A.L’Heurex, D.S.Allison: Challengesfor MapReduce in Big Data, IEEE SERVICES, Anchorage, USA, 2014
[17]: E.Brewer: CAP Twelve Years Later: How the “Rules” have Changed, IEEE Computer, 45(2), 2012
D.J.Abadi: Consistency Tradeoffs in Modern Distributed Database System Design, IEEE Computer, 45(2), 2012“… CAP has become increasingly misunderstood and misapplied, potentially causing significant harm. In particular,many designers incorrectly conclude that the theorem imposes certain restrictions on a DDBS during normal systemoperation, and therefore implement an unnecessarily limited system. In reality, CAP only posits limitations in the faceof certain types of failure, and does not constrain any system capability during normal operation.”
schemaless world: data storage issues iterative analytics algorithims in MapReduce predictive modeling for correlated: performance overheads interactive data exploration: absence of SQL-like interface low latency applications: same issues as SQL DBMS lack of security & privacy: legal impact

BDA 2017 18
Background: NoSQL Wave Tsunami?
[16]: P.Wayner: Hard Truths about NoSQL Revolution, InfoWorld, July, 2012
informal style article discussing issues data: denormalization, schema-less world, consistency operational: no interactive querying, poor eco-system performance: data movement cost others: lack of standards
“We tear things down only to build them back again….The king is dead. Long live the king!”
NoSQL Evolution: Baroque as DBMSs? interactive querying support: SQL like Hive integrate with SQL engines (e.g. Oracle, Greenplum,…) iterative programming: Spark, HaLoop data mining: Mahout streaming data: Storm
D.Suciu: Big Data Begets Big Database Theory, BNCOD, LNCS 7968, 2013 database theoreticians questions 3Vs of Big Data alternative 3Vs: communication, iteration, failure

BDA 2017 19
♣ What is it?♣ Early Origins♣ Academia: MonetDB♣ Academia: C-Store♣ Industry: dbX
Part 2:Modern Column Store

BDA 2017 20
Modern Column Store: What is it?
NSM: n-arystorage model
DSM vs NSM inherent IO reduction better compression lesser IO columns-of-row: SQL is row driven
DSM
NSM
showing3 columns
persistent store: fixed size page or block page header + data values full table scan vs selected page read
row page header +(row data values)*
row size may vary high entropy
column page header+ (data values)*
size? lower entropy

BDA 2017 21
Modern Column Store: Early Origins
columns-of-row: surrogate key like row_id performance overheads
[20]: G.P.Copeland, S.N.Khoshafian: A Decomposition Storage Model, SIGMOD 1985
[21]: C.D.French: Teaching an OLTP Database Kernel Advanced Datawarehousing Techniques, ICDE, 1997[21]: R.MacNicol, B.French: Sybase IQ Multiplex – Designed for Analytics, 30th VLDB, Toronto, Canada, 2004
Sybase IQ product in 1996 (still in market!) not MPP, but good performance compression: page level, heavyweight method, LZ based gzip-like unlike MonetDB/C-Store, neither academia nor industry impact?
pre Big Data era?
?

BDA 2017 22
Modern Column Store: MonetDB
MonetDB DBMS architecture: radical departure from conventional systems vertical partitioning: DSM query executor: not the standard iterator model hardware conscious query processing algorithms not MPP; no compression (?) under development since 90s, targeting datawarehouse applications SQL:2003, ACID compliant; ODBC/JDBC; C/Python/Java/Ruby/Perl/PHP use cases: data mining, BI, OLAP, scientific databases, XML/text/multi-media… remains open source led to industry product Vectorwise
[23]: P.Boncz, M.L.Kersten, S.Manegold: Breaking the Memory Wall in MonetDB, CACM, 51(12), 2008[12]: S.Idreos F.Groffen, N.Nes, S.Manegold, S.Mullender, M.L..Kersten: MonetDB: Two Decades of Research in
Column Oriented Architectures, IEEE Data Engg Bulletin, 35(1), 2012[24]: S.Manegold, M.L.Kersten, P.Boncz: Database Architecture Evolution: Mammals Flourished long before
Dinosaurs became Extinct, 35th VLDB, Lyon, France, 2009[14]: D.J.Abadi, P.Boncz, S.Harizopoulous, S.Idreos, S.Madden: The Design and Implementation of Modern Column
Oriented Database Systems, Foundations and Trends in Database, 5(3), 2012

BDA 2017 23
Modern Column Store: MonetDB
Column Store each column is stored separately: Binary Association Table (BAT) BAT: pairs of <OID, data value> <head, tail> strings: in a heap/BLOB with its index as BAT data value; like dictionary encoding BAT: 2-part array for fixed width data types often head array is omitted; head value is index to tail array
columns-of-row: no surrogate key or OID in persistent BAT; zero overheads BAT is not compressed no difference between BAT on disk or in memory
Fig.from[23]
•facilitates tightly looped arrayprocessing•reduces cache misses for bothdata and instructions• better utilisation of cachehierarchy

BDA 2017 24
Query Execution: BAT Algebra no cost based planner generating a plan tree low level relational algebra: BAT algebra that works on BATs BAT algebra interpretation: virtual or abstract machine that runs MonetDB Assembly
Language (MAL) BAT algebra operators are simple; complex expressions sequence of simple BAT
algebra operators BAT algebra operations simple array operations
intermediate results are also BATs block level, not tuple level, processing: column at a time exploits bulk processing SQL query BAT algebra strategic optimizations MAL tactical optimizations at run-time, operational optimizations of MAL
Modern Column Store: MonetDB
• SQL select and projectoperators in BAT algebra•no context switch, branchmisprediction• coherent cache: instr/data• hardware conscious design

BDA 2017 25
Modern Column Store: MonetDB
Late Materialization postpone stitching of tuples into rows late
into query execution allows executor to work on columns rather
than rows performance gain inherent and natural to BAT algebra & MAL
not just for select/project: joins too leads to query execution performance gains
modifiedfigurefrom[14]

BDA 2017 26
Modern Column Store: MonetDB
Hardware Conscious Query Processing Algorithms partitioned hash join: access pattern is random cache miss performance drop Grace hash join partitions both relations better performance radix cluster: partition into clusters with multiple passes
reduces random access can generate a high number of clusters better L2 cache coherency and performance
SQL projection after a join and sort: radix decluster
Others less “knobs” Recycler: automatic materialized views by caching intermediate BATs Database Cracking: adapt and reorganize indexes based on workload vectorization: X100 Vectorwise

BDA 2017 27
Modern Column Store: C-Store
C-Store read-optimized (ROS) DBMS: vertically partitioned, DSM compressed column store redundant and overlapped storage of columns no table indexes write store (WOS): update/insert oriented; also DSM; uncompressed MVCC-like snapshot isolation for ROS transactions a column oriented optimizer not MPP, but designed for it led to industry product Vertica that was shared nothing, MPP
[13]: M.Stonebraker, D.J.Abadi, A.Batkin, X.Chen, M.Cherniak, M.Ferreira, E.Lau, A.Lin, S.R.Madden, E.J.O’Neil,P.E.O’Neil, A.Rasin, N.Tran, S.B.Zdonik: C-Store: A Column Oriented DBMS, 31st VLDB, Trondheim, Norway, 2005
[26]: DJ.Abadi, S.Madden, M.C.Ferreira: Integrating Compression and Execution in Column Oriented DatabaseSystems, SIGMOD, Chicago, USA, 2006
[14]: D.J.Abadi, P.Boncz, S.Harizopoulous, S.Idreos, S.Madden: The Design and Implementation of Modern ColumnOriented Database Systems, Foundations and Trends in Database, 5(3), 2012
BDA 2017 28
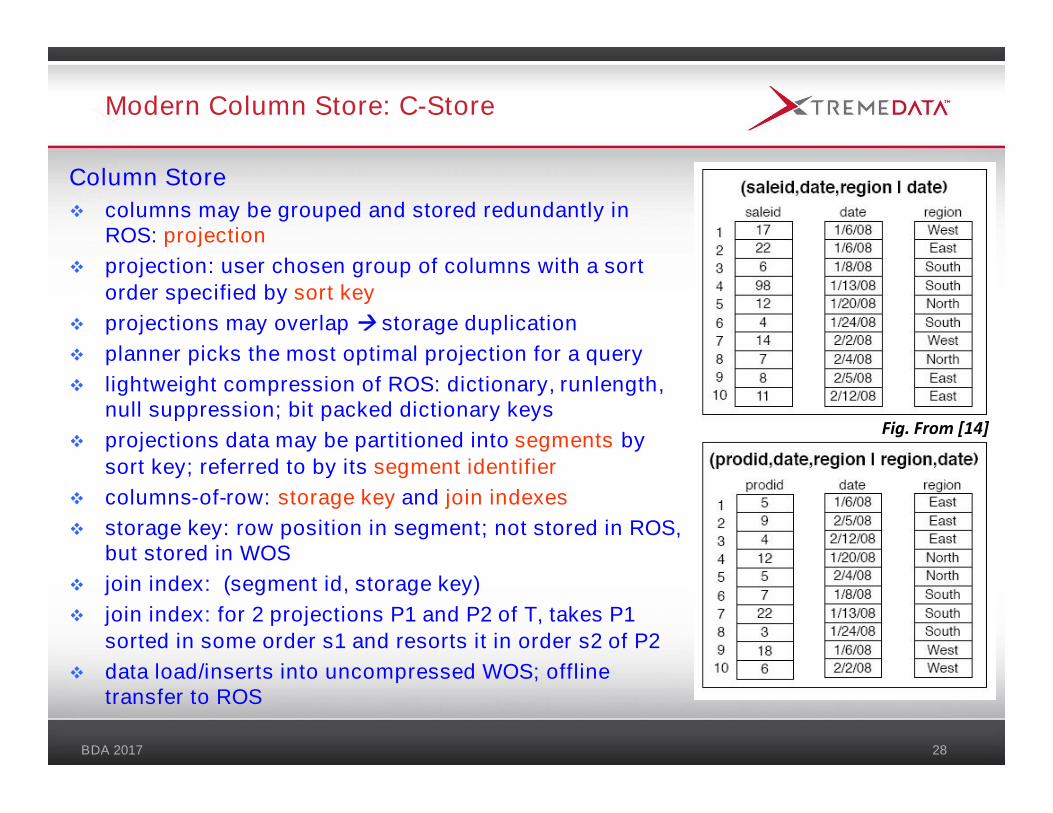
Modern Column Store: C-Store
Column Store columns may be grouped and stored redundantly in
ROS: projection projection: user chosen group of columns with a sort
order specified by sort key projections may overlap storage duplication planner picks the most optimal projection for a query lightweight compression of ROS: dictionary, runlength,
null suppression; bit packed dictionary keys projections data may be partitioned into segments by
sort key; referred to by its segment identifier columns-of-row: storage key and join indexes storage key: row position in segment; not stored in ROS,
but stored in WOS join index: (segment id, storage key) join index: for 2 projections P1 and P2 of T, takes P1
sorted in some order s1 and resorts it in order s2 of P2 data load/inserts into uncompressed WOS; offline
transfer to ROS
Fig. From [14]

BDA 2017 29
aggregate on compressed data
Modern Column Store: C-Store
Query Execution SQL query C-Store query operators
10 operators decompress, select, mask, project, sort, aggregate, concat, permute, join, bitstring ops
access data from both ROS & WOS and union results block level data processing: not tuple-at-a-time column oriented join processing no 2-phase locking for transaction management
Others extended to work directly on compressed data
compression block: compressed data + API API for query operators to use compressed data
extended with late materialization Tuple Mover
WOS to ROS transfer as a background task merge WOS segments with corresponding ROS
segments
Table From [26]
decompressed values
Pseudo-codeFrom [26]

BDA 2017 30
Modern Column Store: Industry
Industry Column Stores C-Store Vertica (HP to Micro Focus) MonetDB X100 Vectorwise (Ingres to Actian) Others: MPP and cloud deployed
modern/native column stores MPP for scale out option Software as a Service (SaaS) on Marketplace of public clouds cloud storage type: 24x7? cost impact? on-premise deployment? UDF support
[11]: K.T.Sridhar: Big Data Analytics using SQL: Quo Vadis? IFIP CONFENIS, Shanghai, China, 2017
• API interfaces toother data miningpackages: R,MADLIB

BDA 2017 31
Modern Column Store: dbX
dbX shared nothing, MPP, analytics database 1 head + n data
nodes with own compute+memory+store; high speed NW hybrid: DSM and NSM pages; SQL: mix access to both stores data distribution: round robin, hash, single node not tuple level, iterator executor; block level data flow micro optimization: hardware conscious & query aware RTCG ACID compliant: MVCC transaction management high speed bulk data loading and extract memory: table cache & intermediate results stored procedures: plpgSQL, C/C++, Perl, Python standard SQL+extensions, ODBC/JDBC/libpq cloud agnostic: AWS, Azure, INAP, CenturyLink and VMware
based private clouds; deploy on attached/decoupled storage
[28]: K.T.Sridhar, M.A.Sakkeer: Optimizing Data Load and Extract for Big Data Era,DASFAA, Bali, Indonesia, 2014
[29]: K.T.Sridhar: Reliability Techniques for MPP SQL Database Product Engineering,IEEE ICSRS, Milan, Italy, 2017
Ravi Chandran, K.T.Sridhar, M.A.Sakkeer: Architectural Choices and theirImplications on Benchmarking, WBDB, San Jose, USA, 2013
Natively-parallel SQL Engine
Client Client
Overhead eliminated
True MPPSingle database with distributed
storage and SQL execution
Use: DW / Analytics
➤Scale by adding nodes ofmulti-threaded engines
➤Integration across nodes doneinside engine
dbX architecture

BDA 2017 32
Modern Column Store: dbX
Column Store each column is stored separately: like MonetDB, but no BAT columns-of-row: no surrogate key or OID; zero overheads sans physical schema: no projections or sort order column store compression: entropy aware and adaptive compression on-the-fly @load time; no off-line WOS ROS row header: runlength encoded column page JIT compilation for decompression range partitioning on column store; static & dynamic partitions gridded, thread based asynchronous IO scan for performance compressed column pages may be cached; scan from cache or persistent store
• adaptive: compressionmethod may vary across pagesof a column•compression ratio variesacross columns of a table
• block/page level• lightweight: DCT, DLT,RL, pRL• heavyweight: LZ•compression plannerchooses optimal methodautomatically

BDA 2017 33
Modern Column Store: dbX
Query Execution SQL query sequence of macroQ ops macroQ op executable in parallel microQ ops micro optimized: query aware, thread-safe RTCG
for modern h/w in C for microQ ops; not monolithic block level data flow between query ops 2-level intra-query parallelism
across MPP cluster nodes: macroQ ops run on distributed data in data node: microQ ops of macroQ op run in parallel as
threads pipelining block level data
generated JIT code optimized for machine generatedindustrial SQL by code pattern mining techniques
runtime stats & cost model: refine join distributionmethods and skew handling
RP columns: dynamic partition pruning• code pattern mining onmicroQ op RTCG code forSQL query• machine generatedindustry SQL

BDA 2017 34
Modern Column Store: dbX
Others exploits modern CPUs with multi-cores: highly threaded
microQ ops, Linux asynchronous IO (aio), communication layer
WOS to ROS overheads: none DELETE: status update in row header column page single row INSERT: to NSM page; off-line bulk transfer to DSM page UPDATE: (DELETE + single row INSERT) or (DELETE + DSM update)
agile bulk data loading and extract: several TBs/hr parallel IO, O_DIRECT, minimum locking, optimistic minWAL logging parallel at data node level; cloud tool: parallel load from S3 or blob
enhanced fault tolerance and reliability in a parallel framework If not sans knobsminimal knobs deployable on bare metal and virtualized environments use attached or decoupled storage (EBS, Premium IO)
• dbX load and extract ratesfor row store on commodityh/w and Amazon AWS cloud• 8x4 cloud load: 4.8 TB/h• 8x4 cloud extract: 5.9 tb/h
Fig.from[28]
fault tolerancedegrees: zero-fault,partial work, fullrecovery, degradedrecovery, fail-stoptermination levels:user-query, user-session, sys-restartbulk loading atpartial workproactive faultprediction: buddymonitors, loggerdistributedexception handler

BDA 2017 35
Modern Column Store: Key Differentiators
[27]: D.J.Abadi, S.R.Madden, M.Hachen: Column-Stores vs Row-Stores: How Different Are They Really? SIGMOD,Vancouver, Canada, 2008
Simulation: Row Store Column Store? vertical schema partitioning
columns-of-row: store a surrogate key in each column stich tuples: by equi-join of columns on surrogate key
materialized views: on each column of row table create indexes on each column
“elevator pitch…: column stores are more IO efficient”
Modern/Native Column Store not tuple-at-a-time execution: block level or vectorized compression late materialization join processing better utilization of modern hardware
[14]: D.J.Abadi, P.Boncz, S.Harizopoulous, S.Idreos, S.Madden: The Design and Implementation of Modern ColumnOriented Database Systems, Foundations and Trends in Database, 5(3), 2012
C-Storeoutperformed
modified row store

BDA 2017 36
♣ Analytics♣ Bulk Loading♣ Security & Privacy
Part 3:Big Data & SQL

BDA 2017 37
Big Data & SQL: Analytics
IEEE KDD Top-10 Poll [37]: X.Wu, et al: Top 10 Algorithms in Data Mining, Knowledge InformationSystems, 14, 2008
[11]: K.T.Sridhar: Big Data Analyticsusing SQL: Quo Vadis? IFIPCONFENIS, Shanghai, China,2017
formulated on or before 2001: before Big Data Era based on math/stats and deal with numbers or categorical data:
both are structured data several are iterative: not too conducive for declarative SQL
external to DBMS: C/C++, Java, Python with ODBC/JDBC Stored procedures in imperative SQL: PL/SQL, T-SQL, plpgSQL User defined functions (UDF): C/C++, Java, Python product-native data mining packages
[33]: C.Ordonez: Can we Analyze BigData inside a DBMS?, DOLAP,San Francisco, USA, 2013
C.Ordonez: Can Parallel DatabaseSystems Help Big DataAnalytics? DEXA, France, 2017
parallel columnarDBs with UDF canhandle Big Dataanalytics in SQL

BDA 2017 38
Big Data & SQL: Analytics
Sufficient Statisticscluster j size; vector (k x 1)
cluster j sum; matrix (d x k)
cluster j quadratic sum;matrix (d x k)
• mining algorithm driver• smaller in size than data• decouple algorithm from data• better performance
k=3; random centroid cluster by centroid recompute centroid reassign to cluster
data of size n, d dimensions, k clusters
[32]: G.Graeffe, U.Fayyad, S.Chaudhari: On the EfficientGathering of Sufficient Statistics from Large SQLDatabases, KDD, 1998

BDA 2017 39
Big Data & SQL: k-Means
• unsupervised: no training set• partitioning by similarity• Euclidean distance• iterative: points move across clusters• termination: no movement• costly: similarity evaluation for full
data on each iteration + write/read• use of sufficient statistics
cluster j weight cluster j centroid
cluster j variance: iteration termination
• user defined functions (UDFs)• 4 nodes, parallel, row store, Teradata• data in millions
K-Means with Sufficient Statistics
data of size n, d dimensions, k clusters
[30]: C.Ordonez: Programming the K-means Clustering Algorithm in SQL, KDD, 2004P.S.Bradley, U.Fayyad, C.Reina: Scaling Clustering Algorithms to Large Databases, KDD, 1998

BDA 2017 40
Big Data & SQL: Naïve Bayes
• supervised classification• Gaussian classes and independence
across dimensions• sufficient statistics: g classes across d
dimensions for training set• non iterative• SQL implementation and comparison
with NoSQL MapReduce• SQL performs better than NoSQL
class variance
probability of xi for dimension hto belong to class g
joint probability of xi across alldimensions to belong to class g
final scoring for assignment to class g
class prior class means
C.Ordonez, S.K.Pitchaimalai: Bayesian ClassifiersProgrammed in SQL, IEEE TKDE, 22(1), 2010
S.K.Pitchaimalai, C.Ordonez, Garcia-Alvardo: ComparingSQL & MapReduce to Compute Naïve Bayes in aSingle Table Scan, ACM CloudDB, 2010

BDA 2017 41
Big Data & SQL: Graphs Mining
• 3 graphs mining algorithms: PageRank, SSSP& HCC for connected components
• real-life data: Twitter, Livejournal, YouTube• parallel, MPP column store Vertica with two
NoSQL systems: GraphLab & Giraph• mixed graph & relational queries• PageRank: SQL Vertica 17x over Giraph• SSSP on Twitter: SQL Vertica 4x over Giraph
[34]: A.Jindal, S.Madden, M.Castellanos, M.Hsu: Graph Analytics using the Vertica Relational Database, IEEEBig Data, Santa Clara, USA, 2015
Figuresfrom [34]

BDA 2017 42
Big Data & SQL: kNN and EM
• point z-value based Z-order: a SQL rangequery; mostly preserves spatial locality
• gamma neighborhood: theoreticalcorrectness; random shift + union + top k
• approximate/exact kNN, kNN joins, thetajoin
• enhance with ad-hoc conditions
multi-dimensional point to 1-dimension byinterleaving binary representation of point
Mahalanobis distance of xi to cluster j
kNN
• maximizes loglikelihood• determine probability of xi to belong to
cluster j• Cj: mean vector; Rj: covariance matrix• with and without sufficient statistics
Expectation Maximization
Probability of xi for cluster j
[36]: B.Yao, F.Li, B.Kumar: K Nearest Neighbor Queries and kNN-Joins in Large Relational Databases (Almost)for Free, IEEE ICDE, 2010
C.Ordonez, P.Cereghini: Fast Clustering in SQL using theEM Algorithm, SIGMOD, 2000
[31]: C.Ordonez: Statistical Model Computation with UDFs, IEEE TKDE,22(12), 2010
zp(2,6) = zp(010,110) = 011100 = 28

BDA 2017 43
Big Data & SQL: Others
• greedy, recursive & memory intensive• C4.5 and CART• using sufficient statistics (CC) and C++
middleware
• as Oracle PL/SQL stored procedure
Decision TreesApriori• market basket problems• earliest users of SQL for data mining• SQL with UDFs, stored procedures, or
plain; DB2
Others: not in KDD Top 10• regression, dimensionality reduction: PCA• standard SQL: regression functions over 2 variables• standard SQL OLAP: multi-dimensional cubes, rollup and grouping sets• standard SQL: windowing analysis with partitions, orders & frames
[35]: S.Sarawagi, S.Thomas, R.Agrawal: IntegratingAssociation Rule Mining with Relational DatabaseSystems, SIGMOD, Seattle, USA, 1998
R.Agrawal, K.Shim: Developing Tightly Coupled DataMining Applications on a Relational DatabaseSystem, KDD, 1996
[31]: C.Ordonez: Statistical Model Computation with UDFs, IEEE TKDE, 22(12), 2010[3]: S.Chaudhari, U.Dayal, V.Narasayya: An Overview of Business Intelligence Technology, CACM, 54(8), 2011
S.Chaudhari, U.Fayyad, J.Bernhardt: ScalableClassification over SQL Databases, 15th ICDE, 1999
K-U.Sattler, O.Dunemann: SQL Database Primitives forDecision Tree Classifiers, CIKM, 2001
D.Taniar, G.D’Cruz, J.W.Rahayu: Implementation ofClassification Rules using Oracle PL/SQL, FSKD, 2002

BDA 2017 44
Big Data & SQL: Bulk Loading
Data Loading SQL DBMS: data in-place
data integration cleansing and standardization ETL (extract-transform-load) Tools ELT (extract-load-transform) Tools
fault tolerant bulk data loaders agile loading of bulk data: several TBS/hr parallel data loaders cloud: load from archival storage S3, blob or data lakes incremental data loads: near real-time, IoT, Industry 4.0, The Edge
aggregators like Kafka Amazon AWS: IoT platform (2015), IoT Analytics (2017, GreenGrass (2016) Microsoft Azure: IoT Edge (2017)
[3]: S.Chaudhari, U.Dayal, V.Narasayya: AnOverview of Business IntelligenceTechnology, CACM, 54(8), 2011
T.J.Bitman: Maverick Research: The Edge will Eat the Cloud, Gartner Report, Id: G00338633, Sep, 2017
“Gartner predicts 1 million new IoT devices will be sold every hour by 2021, all needing toconnect, all with things to say.”
“The edge will flip the computing paradigm, pushing processing and storage to the edge.And over time, the edge will eat the cloud.”

BDA 2017 45
Big Data & SQL: Security & Privacy
authentication: login control what nodes/IP can connect to DB server: trusted or not? DB level password control LDAP (Lightweight Directory Access Protocol) authentication Kerebros or GSSAPI protocols RADIUS password control public/private key based access certificates PAM (Pluggable Access Module) access
object access control: SQL roles & groups database or schema table column
data encryption audit trails European Union’s GDPR
(General Data ProtectionRegulation) complianceby May 2018
August 2017: FTC fines Uber $20M andenforces 20-years of privacy audit forprivacy violations dating back to 2014-15;www.itbusinessedge.com
October 2017: AWS S3 data of Accenturenot protected; www.engadget.com
several Aadhaar data leaks in India
AWS S3 data access:single key for all
developers!also posted on github!!
unencrypted, plain text!!!
• data storage: where? who? whatprojects?• team compliance: no expediency• data subject requests: forget, accesshistory, personal data copy, algorithmicdata decisions• data governance: audits• penalty: 4% of global turnover; $20M

BDA 2017 46
METAMORPHOSIS
Conclusion
“although databases don’t solve all aspects of BigData problem, several tools – some based on
databases -- get part-way there”
Big Data: circa 2017, any SQL Users? Facebook: MySQL for social graph data Wikipedia: MariaDB derived from MySQL www.kdnuggets.com: 18th KDnuggets data
mining language poll, 2017; 2900 voters
R: 52.1%
C/C++: 6.3%
[27]: S.Madden: From Databases to Big Data, IEEE Internet Computing, 16(3), 2012
“all of the key systems in these groups will supportsome form of relational model and SQL”
[4]: A.Pavlo, M.Aslett: What’s Really New with NewSQL? ACM SIGMOD Record,45(2), 2016
Python 52.5% SQL: 34.9% One Third!! Java: 13.8%

BDA 2017 47
ThankYou
Acknowledgement: non-technical pictures/images/cartoons are courtesy of unknownand unsung artists who post their work on the web, and Google search that finds them
ANDtwo still pictures of Toshiro Mifune from Akira Kurosawa’s Shichinin no Samurai