molecular data dna/rna protein expression interaction
Post on 21-Dec-2015
227 views
TRANSCRIPT
Molecular Data
DNA/RNAProteinExpressionInteraction

A sequence
A sequence is a linear set of characters (sequence elements) representing nucleotides or amino acids
http://www.cmu.edu/bio/education/courses/03310/LectureNotes/

Character representation of sequences
DNA or RNA use 1-letter codes (e.g., A,C,G,T)
protein use 1-letter codes
can convert to/from 3-letter codes
http://www.cmu.edu/bio/education/courses/03310/LectureNotes/

The I.U.B. Code proposed by International Union of Biochemistry
AA, , CC, , GG, , TT, , UURR = A, G (pu = A, G (puRRine)ine)YY = C, T (p = C, T (pYYrimidine)rimidine)SS = G, C ( = G, C (SStrong hydrogen bonds)trong hydrogen bonds)WW = A, T ( = A, T (WWeak hydrogen bonds)eak hydrogen bonds)MM = A, C (a = A, C (aMMino group)ino group)KK = G, T ( = G, T (KKeto group)eto group)BB = C, G, T (not A) = C, G, T (not A)DD = A, G, T (not C) = A, G, T (not C)HH = A, C, T (not G) = A, C, T (not G)VV = A, C, G (not T/U) = A, C, G (not T/U)NN = A, C, G, T/U (i = A, C, G, T/U (iNNdeterminate) determinate) XX or or - - are sometimes are sometimes usedused

DNA codeAmino Acid Abbreviation DNA Codons
Alanine Ala GCA, GCC, GCG, GCT
Cysteine Cys TGC, TGT
Aspartic Acid Asp GAC, GAT
Glutamic Acid Glu GAA, GAG
Phenylalanine Phe TTC, TTT
Glycine Gly GGA, GGC, GGG, GGT
Histidine His CAC, CAT
Isoleucine Ile ATA, ATC, ATT
Lysine Lys AAA, AAG
Leucine Leu TTA, TTG, CTA, CTC, CTG, CTT
Methionine Met ATG
Asparagine Asn AAC, AAT
Proline Pro CCA, CCC, CCG, CCT
Glutamine Gln CAA, CAG
Arginine Arg CGA, CGC, CGG, CGT
Serine Ser TCA, TCC, TCG, TCT, AGC, AGT
Threonine Thr ACA, ACC, ACG, ACT
Valine Val GTA, GTC, GTG, GTT
Tryptophan Trp TGG
Tyrosine Tyr TAC, TAT
Stop . TAA, TAG, TGA

Fasta format>gi|17978494|ref|NM_078467.1| Homo sapiens cyclin-dependent kinase inhibitor AGCTGAGGTGTGAGCAGCTGCCGAAGTCAGTTCCTTGTGGAGCCGGAGCTGGGCGCGGATTCGCCGAGGC ACCGAGGCACTCAGAGGAGGTGAGAGAGCGGCGGCAGACAACAGGGGACCCCGGGCCGGCGGCCCAGAGC CGAGCCAAGCGTGCCCGCGTGTGTCCCTGCGTGTCCGCGAGGATGCGTGTTCGCGGGTGTGTGCTGCGTT CACAGGTGTTTCTGCGGCAGGCGCCATGTCAGAACCGGCTGGGGATGTCCGTCAGAACCCATGCGGCAGC AAGGCCTGCCGCCGCCTCTTCGGCCCAGTGGACAGCGAGCAGCTGAGCCGCGACTGTGATGCGCTAATGG CGGGCTGCATCCAGGAGGCCCGTGAGCGATGGAACTTCGACTTTGTCACCGAGACACCACTGGAGGGTGA CTTCGCCTGGGAGCGTGTGCGGGGCCTTGGCCTGCCCAAGCTCTACCTTCCCACGGGGCCCCGGCGAGGC CGGGATGAGTTGGGAGGAGGCAGGCGGCCTGGCACCTCACCTGCTCTGCTGCAGGGGACAGCAGAGGAAG ACCATGTGGACCTGTCACTGTCTTGTACCCTTGTGCCTCGCTCAGGGGAGCAGGCTGAAGGGTCCCCAGG TGGACCTGGAGACTCTCAGGGTCGAAAACGGCGGCAGACCAGCATGACAGATTTCTACCACTCCAAACGC CGGCTGATCTTCTCCAAGAGGAAGCCCTAATCCGCCCACAGGAAGCCTGCAGTCCTGGAAGCGCGAGGGC CTCAAAGGCCCGCTCTACATCTTCTGCCTTAGTCTCAGTTTGTGTGTCTTAATTATTATTTGTGTTTTAA TTTAAACACCTCCTCATGTACATACCCTGGCCGCCCCCTGCCCCCCAGCCTCTGGCATTAGAATTATTTA AACAAAAACTAGGCGGTTGAATGAGAGGTTCCTAAGAGTGCTGGGCATTTTTATTTTATGAAATACTATT TAAAGCCTCCTCATCCCGTGTTCTCCTTTTCCTCTCTCCCGGAGGTTGGGTGGGCCGGCTTCATGCCAGC TACTTCCTCCTCCCCACTTGTCCGCTGGGTGGTACCCTCTGGAGGGGTGTGGCTCCTTCCCATCGCTGTC ACAGGCGGTTATGAAATTCACCCCCTTTCCTGGACACTCAGACCTGAATTCTTTTTCATTTGAGAAGTAA ACAGATGGCACTTTGAAGGGGCCTCACCGAGTGGGGGCATCATCAAAAACTTTGGAGTCCCCTCACCTCC TCTAAGGTTGGGCAGGGTGACCCTGAAGTGAGCACAGCCTAGGGCTGAGCTGGGGACCTGGTACCCTCCT GGCTCTTGATACCCCCCTCTGTCTTGTGAAGGCAGGGGGAAGGTGGGGTCCTGGAGCAGACCACCCCGCC TGCCCTCATGGCCCCTCTGACCTGCACTGGGGAGCCCGTCTCAGTGTTGAGCCTTTTCCCTCTTTGGCTC CCCTGTACCTTTTGAGGAGCCCCAGCTACCCTTCTTCTCCAGCTGGGCTCTGCAATTCCCCTCTGCTGCT GTCCCTCCCCCTTGTCCTTTCCCTTCAGTACCCTCTCAGCTCCAGGTGGCTCTGAGGTGCCTGTCCCACC CCCACCCCCAGCTCAATGGACTGGAAGGGGAAGGGACACACAAGAAGAAGGGCACCCTAGTTCTACCTCA GGCAGCTCAAGCAGCGACCGCCCCCTCCTCTAGCTGTGGGGGTGAGGGTCCCATGTGGTGGCACAGGCCC CCTTGAGTGGGGTTATCTCTGTGTTAGGGGTATATGATGGGGGAGTAGATCTTTCTAGGAGGGAGACACT GGCCCCTCAAATCGTCCAGCGACCTTCCTCATCCACCCCATCCCTCCCCAGTTCATTGCACTTTGATTAG CAGCGGAACAAGGAGTCAGACATTTTAAGATGGTGGCAGTAGAGGCTATGGACAGGGCATGCCACGTGGG CTCATATGGGGCTGGGAGTAGTTGTCTTTCCTGGCACTAACGTTGAGCCCCTGGAGGCACTGAAGTGCTT AGTGTACTTGGAGTATTGGGGTCTGACCCCAAACACCTTCCAGCTCCTGTAACATACTGGCCTGGACTGT TTTCTCTCGGCTCCCCATGTGTCCTGGTTCCCGTTTCTCCACCTAGACTGTAAACCTCTCGAGGGCAGGG ACCACACCCTGTACTGTTCTGTGTCTTTCACAGCTCCTCCCACAATGCTGAATATACAGCAGGTGCTCAA TAAATGATTCTTAGTGACTTTAAAAAAAAAAAAAAAAAAAA

Sequence Content
Mononucleotide frequencies GC content
Dinucleotide frequencies CpG islands
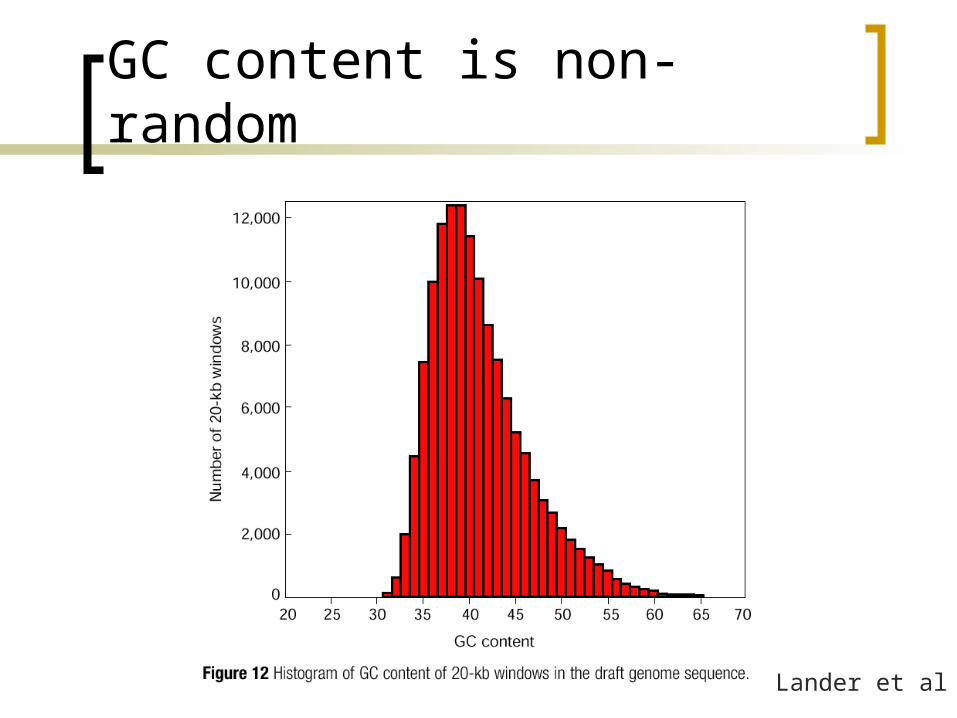
Lander et al
GC content is non-random

GC content and expression

Determining mononucleotide frequencies
Alphabet: A T C G Count how many times each nucleotide
appears in sequence Divide (normalize) by total number of
nucleotides fA mononucleotide frequency of A (frequency
that A is observed) pAmononucleotide probability that a
nucleotide will be an A
http://www.cmu.edu/bio/education/courses/03310/LectureNotes/

Determining dinucleotide frequencies
Make 4 x 4 matrix, one element for each ordered pair of nucleotides
Set all elements to zero Go through sequence linearly, adding one to matrix
entry corresponding to the pair of sequence elements observed at that position
Divide by total number of dinucleotides fAC dinucleotide frequency of AC (frequency that
AC is observed out of all dinucleotides)
http://www.cmu.edu/bio/education/courses/03310/LectureNotes/

Dinucleotide counts
A T C G
A 0 0 0 0
T 0 0 0 0
C 0 0 0 0
G 0 0 0 0
ATTCGACCAGAG
Create a 4 x 4 matrixSet all cells to zerosUse a window of size 2 and add 1 to each cell of the matrix when encountering the specified dinucleotide

Dinucleotide counts
A T C G
A 0 1 1 2
T 0 1 1 0
C 1 0 1 1
G 2 0 0 0
ATTCGACCAGAG

Observed and expected frequencies
http://www.maths.lth.se/bioinformatics/publications/BasicE_2005.pdf

Observed and expected frequencies
http://www.maths.lth.se/bioinformatics/publications/BasicE_2005.pdf

Dinucleotide frequencies in genome
http://www.lapcs.univ-lyon1.fr/~piau/mps/Poster-CpG.pdf

Sequence features
A sequence feature is a pattern that is observed to occur in more than one sequence and (usually) to be correlated with some function
http://www.cmu.edu/bio/education/courses/03310/LectureNotes/

Sequence features
promoters transcription initiation sites transcription termination sites polyadenylation sites ribosome binding sites protein features
http://www.cmu.edu/bio/education/courses/03310/LectureNotes/

Consensus sequences
A consensus sequence is a sequence that summarizes or approximates the pattern observed in a group of aligned sequences containing a sequence feature
Consensus sequences are regular expressions
http://www.cmu.edu/bio/education/courses/03310/LectureNotes/

Occurences
Example: recognition site for a restriction enzyme EcoRI recognizes GAATTC AccI recognizes GTMKAC
Basic Algorithm Start with first character of sequence to be searched See if enzyme site matches starting at that position Advance to next character of sequence to be searched Repeat previous two steps until all positions have been
tested
http://www.cmu.edu/bio/education/courses/03310/LectureNotes/

Statistics of pattern appearance
Goal: Determine the significance of observing a feature (pattern)
Method: Estimate the probability that a pattern would occur randomly in a given sequence. Three different methods Assume all nucleotides are equally frequent Use measured frequencies of each nucleotide
(mononucleotide frequencies) Use measured frequencies with which a given
nucleotide follows another (dinucleotide frequencies)
http://www.cmu.edu/bio/education/courses/03310/LectureNotes/

Example 1
What is the probability of observing the sequence feature ART (A followed by a purine, either A or G, followed by a T)?
Using observed mononucleotide frequencies: pART = pA (pA + pG) pT
Using equal mononucleotide frequencies pA = pC = pG = pT = 1/4 pART = 1/4 * (1/4 + 1/4) * 1/4 = 1/32
http://www.cmu.edu/bio/education/courses/03310/LectureNotes/

Example 1: using mononucleotide frequencies
Using equal mononucleotide frequencies pA = pC = pG = pT = 1/4 pART = 1/4 * (1/4 + 1/4) * 1/4 = 1/32
Using observed mononucleotide frequencies: pART = pA (pA + pG) pT

Example 1: using dinucleotide frequencies
pART=pA(p*AAp*
AT+p*AGp*
GT)

Example 2:
What is the probability of observing the sequence feature ARYT (A followed by a purine {either A or G}, followed by a pyrimidine {either C or T}, followed by a T)?
Using equal mononucleotide frequencies pA = pC = pG = pT = 1/4 pARYT = 1/4 * (1/4 + 1/4) * (1/4 + 1/4) * 1/4
= 1/64
http://www.cmu.edu/bio/education/courses/03310/LectureNotes/