monitoraggio dell'inquinamento atmosferico in prossimità ... · • via marradi • incrocio...
TRANSCRIPT

Comune di Rimini Sezione di Rimini
Monitoraggio dell'inquinamento atmosferico
in prossimità di siti
influenzati da traffico autoveicolare.
Anno 2002
Rimini, novembre 2002
1

Responsabile del progetto: Gianna Sallese
Comune di Rimini: Riccardo Cola
A cura di
Arpa Emilia Romagna - Sezione di Rimini
Servizio Sistemi Ambientali: L. Ronchini, G. Sallese, G. Veschi
Dipartimento tecnico: M. Baldrocco, O. Peroni, S. Tiraferri
2

INDICE
INTRODUZIONE ....................................................................................................... 4
METODICA ANALITICA......................................................................................... 6
ELABORAZIONE DATI ........................................................................................... 8
CONCLUSIONI ........................................................................................................ 25
RIFERIMENTI BIBLIOGRAFICI......................................................................... 26
ALLEGATI ................................................................................................................ 27
3

Introduzione Arpa Sezione di Rimini ha condotto, su incarico dell'Assessorato alle Politiche Ambientali del
comune di Rimini, il monitoraggio di inquinanti atmosferici provenienti da traffico autoveicolare in
particolari siti nell'ambito del territorio comunale, di seguito individuati:
• Incrocio via Gambalunga – via Roma
• Incrocio via Tripoli – via Roma
• Rotatoria via Valturio – piazza Malatesta
• Incrocio viale Tolemaide - S.S. Adriatica 16
• Rotatoria viale Toscanelli - viale XXV Marzo
• Rotatoria via Marecchiese - via Caduti di Marzabotto
• Incrocio via Cardano - S.S. Adriatica 16
• Rotatoria via Panzini - via della Fiera
• Rotatoria via dei Mille - Ponte dei Mille
• Incrocio piazza Mazzini
• Incrocio S.S. Marecchiese 258 - S.S. Adriatica 16
• Incrocio S.S.72 Montescudo – S.S. Adriatica 16
• Centralina via Flaminia
• Centralina Parco Marecchia
• Via della Lama
• Via Marradi
• Incrocio via Marradi
Mediante l'uso di campionatori diffusivi, nel corso dell'anno 2002 sono stati raccolti dati relativi ad
inquinanti tipici del traffico autoveicolare (Benzene, Xilene, Toluene, Etilbenzene), per un periodo
di nove settimane distribuite in modo tale da rappresentare la stagionalità dei dati.
Il campionatore diffusivo è uno strumento capace di prendere campioni di gas dall’atmosfera ad un
tasso controllato dalla diffusione molecolare, senza richiedere il movimento di aria attraverso il
campionatore stesso.
Consiste di un tubo contenente un adsorbente che fissa l’inquinante. L’inquinante è raccolto
sull’adsorbente ad un tasso controllato dalla diffusione molecolare del gas inquinante nell’aria,
senza richiedere alcuna pompa o dispositivo elettrico.
4

Una piastra di supporto permette di posizionare il campionatore in un box di polipropilene che lo
ripara dalle intemperie e dall'irraggiamento solare diretto.
Dopo l’esposizione del campionatore per un determinato periodo di tempo, i tubi sono chiusi e
consegnati al laboratorio per l’analisi.
I dati sono stati successivamente elaborati mediante analisi statistica inferenziale, al fine di
riscontrare se:
• eventuali differenze tra due o più gruppi di dati, oppure di una serie di osservazioni possono
essere imputabili a fattori casuali specifici o a fattori casuali ignoti;
• le differenze riscontrate sono generate dalla naturale variabilità delle misure e del materiale
utilizzato, oppure esiste una causa specifica che le ha determinate.
5

Metodica analitica
Scopo
Il metodo consente la determinazione dei BTEX (Benzene, Toluene, Etilbenzene, o,m,p-Xilene), da
campionatori passivi (radielli®)posizionati in ambiente esterno, desorbiti con solfuro di carbonio.
Campo di applicazione
Il metodo descritto è applicabile a campioni di radiello® esposti in ambiente esterno.
Limite di rilevabilità:
Benzene = 0,5 μg/m3
Toluene = 0,5 μg/m3
Etilbenzene = 0,5 μg/m3
Xileni = 0,5 μg/m3
Principio del metodo
Il metodo si basa sul desorbimento con solfuro di carbonio contenente lo standard interno (2-
Fluorotoluene 400 μl/l) di radielli® posizionati in ambiente esterno per un tempo prefissato. Il
solfuro di carbonio viene analizzato mediante cromatografia.
Reagenti e prodotti per le prove
Solfuro di Carbonio (Aldrich cod. 34,227-0)
2-Fluorotoluene (purezza ≥ 99 %)
Benzene (purezza ≥ 99 %)
Toluene (purezza ≥ 99 %);
Etilbenzene (purezza ≥ 99 %);
o,m.p-Xilene (purezza ≥ 99 %);
Soluzione di standard interno: 2-Fluorotoluene 400 μl/l in solfuro di carbonio
Soluzione standard di BTEX in Solfuro di Carbonio a due livelli di concentrazione:
Benzene 4,40 – 8,80 mg/l
Toluene 8,67 – 17,34 mg/l
Etilbenzene 4,33 – 8,67 mg/l
p-Xilene 4,33 – 8,67 mg/l
m-Xilene 4,33 – 8,67 mg/l
o-Xilene 4,33 – 8,67 mg/l
6

Apparecchiature e attrezzature
Gascromatografo Perkin-Elmer 8420 con detector
Siringhe da 10 e 100 μl
Vetreria di classe A
Procedimento
Desorbimento delle cartucce
Senza togliere la cartuccia, introdurre nella provetta di radiello® 2,00 ml di Solfuro di Carbonio e
100 μl di standard interno.
Agitare di tanto in tanto per 30 minuti.
Conservare la provetta ben tappata in frigorifero (T < 4°C) fino al momento dell’analisi.
Determinazione cromatografica
Iniettare 2,0 μl del Solfuro di Carbonio desorbito dalla cartuccia nel gascromatografo alle seguenti
condizioni:
Temperatura Iniettore split/splitless 250 °C (iniettare in spitless aprire lo split dopo 0,8 min.)
Temperatura Detector FID 250 °C
Carrier gas He 5 psig
Temperatura Forno: iniziale 40 °C per 10 minuti, 8 °C/min fino 140 °C, isoterma finale 5 minuti
Calcolare i fattori di risposta dei BTEX, rispetto lo standard interno, iniettando 2,0 μl delle
soluzioni preparate utilizzando due cartucce vergini a cui vengono aggiunti rispettivamente 2,00 ml
delle soluzioni standard di BTEX e 100 μl di standard interno.
Espressione dei risultati
Dal report dell’integratore si ottiene la concentrazione dei singoli BTEX in mg/l.
Moltiplicando i singoli risultati per 2 si ottengono i μg (massa) presenti nella cartuccia.
La concentrazione C in aria si calcola applicando l’espressione seguente:
m [μg]
C [μg/m3] = --------------------------- · 10 6
Q [cm3/min] x t [min]
dove:
C = concentrazione in aria del singolo inquinante
m = massa in μg del singolo inquinante
Q = portata di campionamento indicata nel Manuale per l’uso del radiello®
T = tempo di esposizione in minuti
I risultati si esprimono in μg/m3 con una cifra decimale.
7

Elaborazione dati
È stata predisposta l'esecuzione di nove settimane di campionamento nei punti mostrati
nell'Allegato 1.
L'Allegato 2 riassume i codici dei punti prescelti, gli indirizzi, le settimane in cui sono stati raccolti
i dati, le concentrazioni rilevate relativamente agli inquinanti Benzene, Toluene, Xiloli totali,
Etilbenzene.
Quando si prendono in considerazione congiuntamente due o più variabili quantitative si possono
esaminare anche il tipo e le intensità delle relazioni che sussistono tra di loro ricorrendo all'analisi:
• della regressione;
• della correlazione.
L'analisi della regressione presuppone l'esistenza di un legame causa effetto tra due variabili.
Il campo di variazione comprende solo i valori osservati della X, usati per la stima della
regressione. Estrapolare i dati all'esterno del reale campo di osservazione è un errore di tecnica
statistica; per valori minori o maggiori non è assolutamente dimostrato che la relazione trovata tra le
due variabili persista e sia dello stesso tipo.
Nel Grafico 1 e nel Grafico 2 sono mostrate le rette di regressione rispettivamente di
Benzene/Toluene e Benzene/ Xileni.
Bisogna valutare la significatività delle rette di regressione cioè se il coefficiente angolare b si
discosta da zero in modo significativo. Il coefficiente angolare b è relativo al campione. La sua
generalizzazione nella popolazione è indicata con β e la sua significatività è saggiata mediante la
verifica dell'ipotesi nulla H0 : β = 0.
Rifiutando l'ipotesi nulla e senza altre e senza altre indicazioni si accetta l'ipotesi alternativa a due
code H1 : β ≠ 0.
Nel rifiutare l'ipotesi nulla si afferma che al variare di X si ha una variazione di Y e di conseguenza
si afferma che la regressione esiste perché conoscendo X si ha una informazione non nulla nel
valore di Y.
8
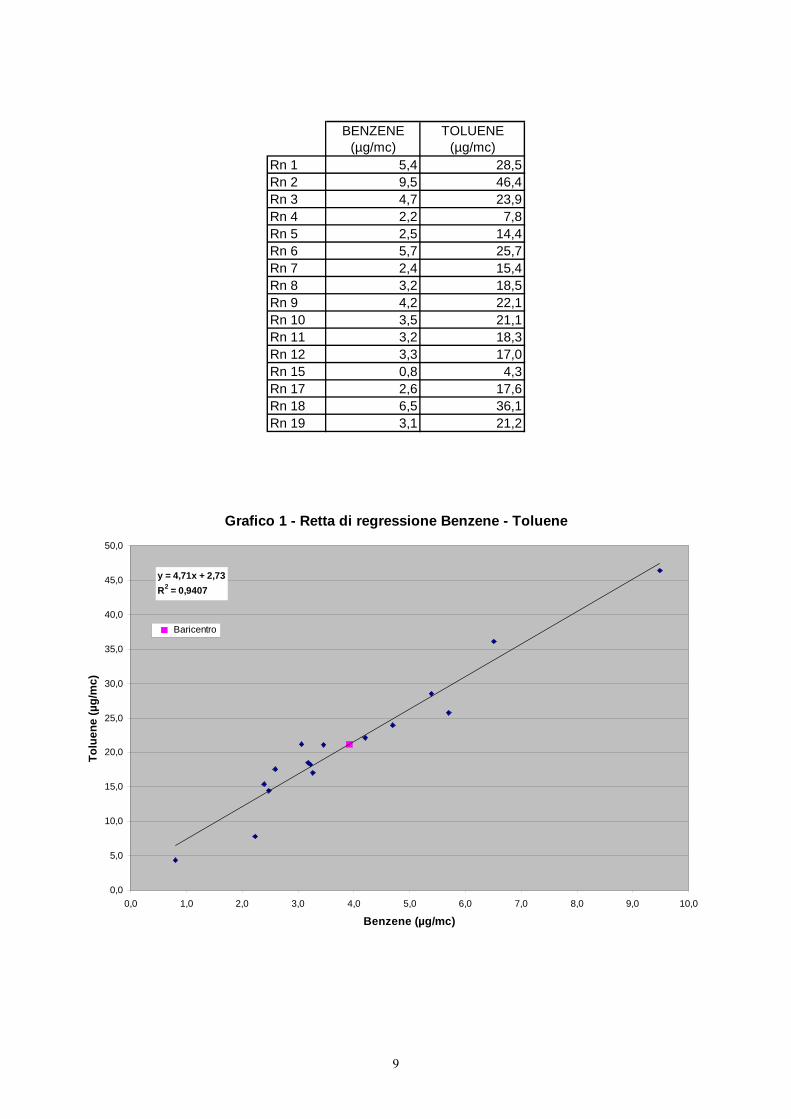
BENZENE (µg/mc)
TOLUENE (µg/mc)
Rn 1 5,4 28,5Rn 2 9,5 46,4Rn 3 4,7 23,9Rn 4 2,2 7,8Rn 5 2,5 14,4Rn 6 5,7 25,7Rn 7 2,4 15,4Rn 8 3,2 18,5Rn 9 4,2 22,1Rn 10 3,5 21,1Rn 11 3,2 18,3Rn 12 3,3 17,0Rn 15 0,8 4,3Rn 17 2,6 17,6Rn 18 6,5 36,1Rn 19 3,1 21,2
Grafico 1 - Retta di regressione Benzene - Toluene
y = 4,71x + 2,73R2 = 0,9407
0,0
5,0
10,0
15,0
20,0
25,0
30,0
35,0
40,0
45,0
50,0
0,0 1,0 2,0 3,0 4,0 5,0 6,0 7,0 8,0 9,0 10,0
Benzene (µg/mc)
Tolu
ene
(µg/
mc)
Baricentro
9
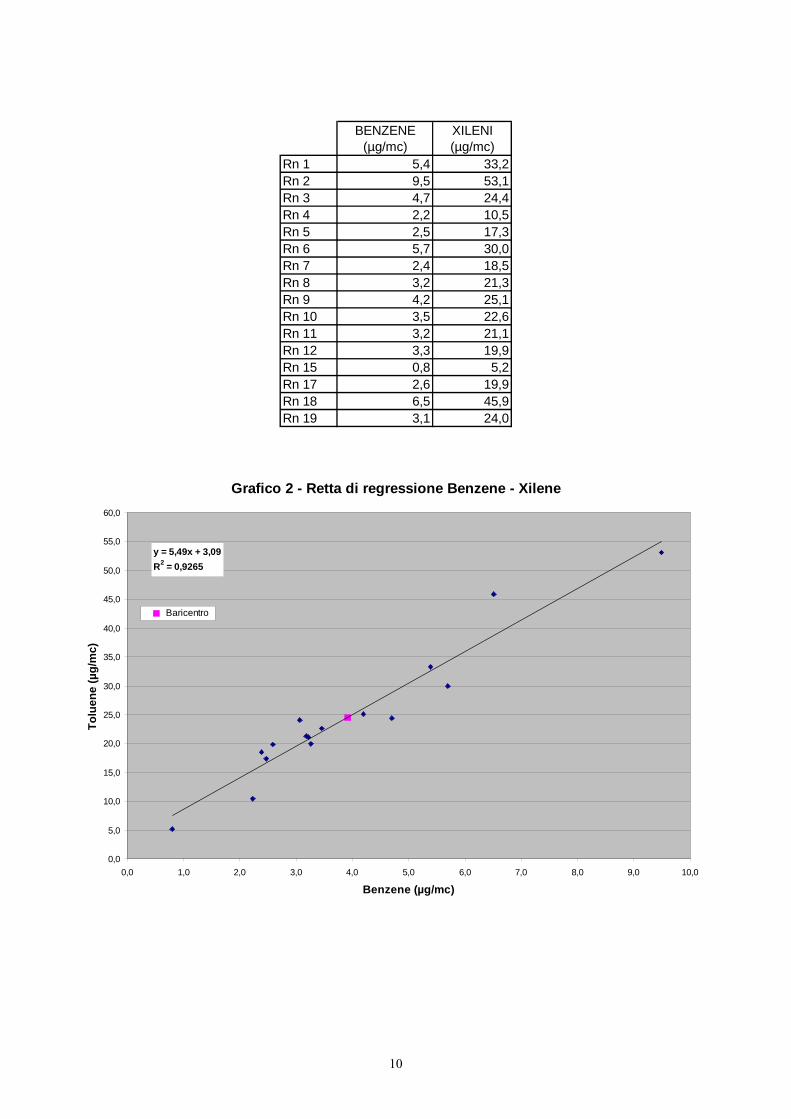
BENZENE (µg/mc)
XILENI (µg/mc)
Rn 1 5,4 33,2Rn 2 9,5 53,1Rn 3 4,7 24,4Rn 4 2,2 10,5Rn 5 2,5 17,3Rn 6 5,7 30,0Rn 7 2,4 18,5Rn 8 3,2 21,3Rn 9 4,2 25,1Rn 10 3,5 22,6Rn 11 3,2 21,1Rn 12 3,3 19,9Rn 15 0,8 5,2Rn 17 2,6 19,9Rn 18 6,5 45,9Rn 19 3,1 24,0
Grafico 2 - Retta di regressione Benzene - Xilene
y = 5,49x + 3,09R2 = 0,9265
0,0
5,0
10,0
15,0
20,0
25,0
30,0
35,0
40,0
45,0
50,0
55,0
60,0
0,0 1,0 2,0 3,0 4,0 5,0 6,0 7,0 8,0 9,0 10,0
Benzene (µg/mc)
Tolu
ene
(µg/
mc)
Baricentro
10

Nel caso della retta di regressione Benzene/Toluene:
DEVIANZA GDL VARIANZA F P
TOTALE 1532,1 15 ---
REGRESSIONE 1442,5 1 1442,5 225,4 < 0,01
ERRORE 89,6 14 6,4
Nel caso della retta di regressione Benzene/ Xileni:
DEVIANZA GDL VARIANZA F P
TOTALE 2107,5 15 ---
REGRESSIONE 1950,5 1 1950,5 174,1 < 0,01
ERRORE 157 14 11,2
Pertanto, in entrambi i casi con probabilità inferiore a 0,01 di commettere errore di I tipo si rifiuta
l'ipotesi nulla e si accetta l'ipotesi alternativa: nella popolazione dalla quale è stato estratto il
campione esiste una relazione lineare tra la variabili prese in considerazione.
L'analisi della correlazione misura solo il grado di associazione spaziale o temporale dei due
fenomeni, ma lascia liberi nella scelta della motivazione logica nel rapporto tra i due fenomeni.
Il coefficiente r è la misura dell'intensità dell'associazione tra due variabili.
Dopo il calcolo del coefficiente di correlazione r, sempre valido come indice che misura la
relazione tra due variabili in quanto solo descrittivo, si pone il problema della sua significatività.
Per verificare l'ipotesi nulla H0 : ρ = 0 si ricorre alla distribuzione F.
CORRELAZIONE r F (1,17) P
BENZENE/TOLUENE 0,9690 269,7 < 0,01
BENZENE/XILENI 0,9626 214,4 < 0,01
Con probabilità inferiore a 0,01 di commettere errore di I° tipo si rifiuta l'ipotesi nulla: in entrambi i
casi esiste una correlazione di tipo lineare.
11

A completamento dell'analisi di correlazione tra le variabili, si applica il procedimento non
parametrico basato sui ranghi, denominato ρ (rho) di Spearman.
Il coefficiente di correlazione per ranghi di Spearman serve per verificare l'ipotesi di indipendenza
tra le variabili, nel senso che gli N valori della variabile Y hanno le stesse probabilità di associarsi
con ognuno degli N valori di X.
L'enunciazione dell'ipotesi bilaterale si esprime come:
• H0 : ρ = 0
• H1: ρ ≠ 0
In primo luogo consideriamo le variabili Benzene (X) e Toluene (Y)
Rappresentiamo, nella tabella successiva, le coppie di valori osservati nei punti di misura per le due
variabili
Benzene (X) 5,4 9,5 4,7 2,2 2,5 5,7 2,4 3,2 4,2 3,5 3,2 3,3 0,8 2,6 6,6 3,1
Toluene (Y) 28,5 46,4 23,9 7,8 14,4 25,7 15,4 18,5 22,1 21,1 18,3 17 4,3 17,6 36,1 21,2
Rn1 Rn2 RN3 RN4 RN5 RN6 RN7 RN8 RN9 RN10 RN11 RN12 RN15 RN17 RN18 RN19
Coppie di valori osservati
Successivamente si ordinano i ranghi delle variabili X ed Y(si assegna 1 al valore più piccolo e
progressivamente valori interi maggiori), naturalmente mantenendo inalterate le coppie.
Per quantificare il grado di correlazione o concordanza, Spearman ha proposto la distanza tra le
coppie dei ranghi (RI) elevate al quadrato (RI quadrato). Quando due o più valori sono identici e
pertanto hanno lo stesso rango, si calcola il fattore di correzione, attribuendo lo stesso valore medio
ai valori identici.
RANGHI X 13 16 12 2 4 14 3 7,5 11 10 7,5 9 1 5 15 6RANGHI Y 14 16 12 2 3 13 4 8 11 9 7 5 1 6 15 10RI 1 0 0 0 1 1 1 0,5 0 1 0,5 4 0 1 0 4RI QUADRATO 1 0 0 0 1 1 1 0,25 0 1 0,25 16 0 1 0 16
Rn1 Rn2 RN3 RN4 RN5 RN6 RN7 RN8 RN9 RN10 RN11 RN12 RN15 RN17 RN18 RN19
Ranghi Benzene - Toluene
Nel calcolo del coefficiente di correlazione tra ranghi (ρ) di Spearman si utilizza la sommatoria
delle distanze tra le coppie dei ranghi elevate al quadrato.
Nel caso di piccoli campioni (N < 20 - 25) la significatività di ρ è fornita dalla tabella dei valori
critici di Spearman. Alla probabilità α prefissata si rifiuta l'ipotesi nulla se il valore calcolato è
uguale o superiore a quello stimato.
12
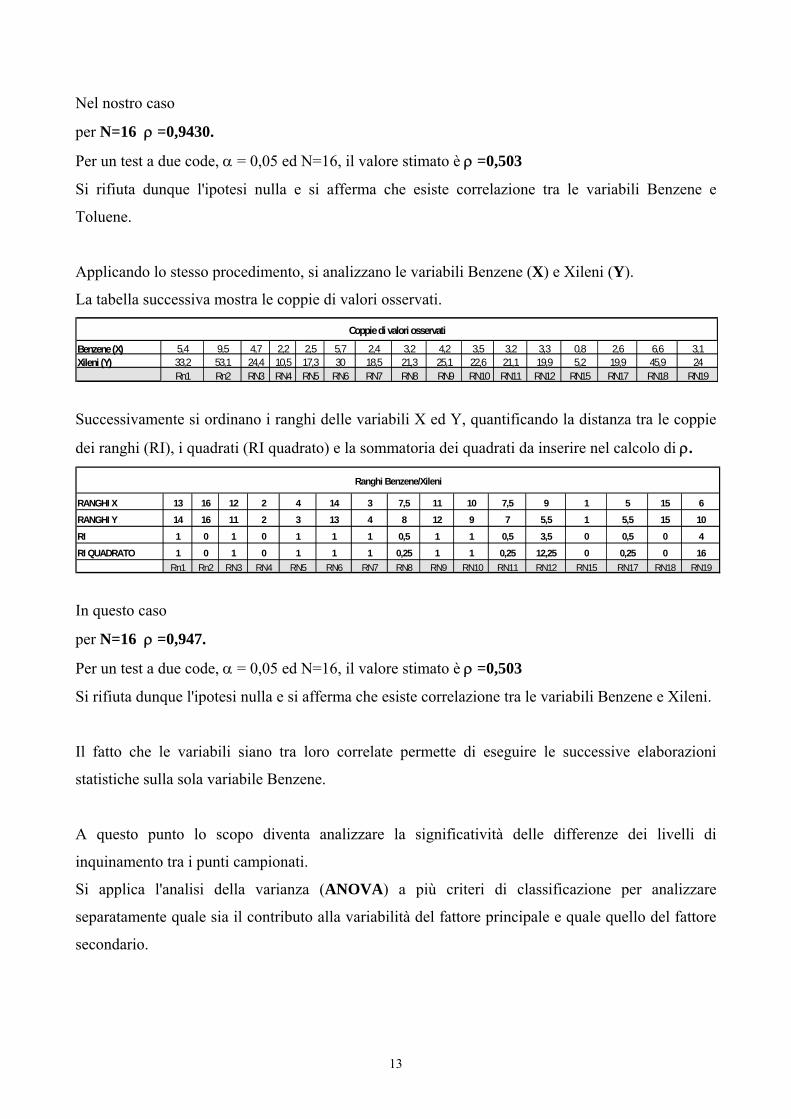
Nel nostro caso
per N=16 ρ =0,9430.
Per un test a due code, α = 0,05 ed N=16, il valore stimato è ρ =0,503
Si rifiuta dunque l'ipotesi nulla e si afferma che esiste correlazione tra le variabili Benzene e
Toluene.
Applicando lo stesso procedimento, si analizzano le variabili Benzene (X) e Xileni (Y).
La tabella successiva mostra le coppie di valori osservati.
Benzene (X) 5,4 9,5 4,7 2,2 2,5 5,7 2,4 3,2 4,2 3,5 3,2 3,3 0,8 2,6 6,6 3,1Xileni (Y) 33,2 53,1 24,4 10,5 17,3 30 18,5 21,3 25,1 22,6 21,1 19,9 5,2 19,9 45,9 24
Rn1 Rn2 RN3 RN4 RN5 RN6 RN7 RN8 RN9 RN10 RN11 RN12 RN15 RN17 RN18 RN19
Coppie di valori osservati
Successivamente si ordinano i ranghi delle variabili X ed Y, quantificando la distanza tra le coppie
dei ranghi (RI), i quadrati (RI quadrato) e la sommatoria dei quadrati da inserire nel calcolo di ρ.
RANGHI X 13 16 12 2 4 14 3 7,5 11 10 7,5 9 1 5 15 6RANGHI Y 14 16 11 2 3 13 4 8 12 9 7 5,5 1 5,5 15 10
RI 1 0 1 0 1 1 1 0,5 1 1 0,5 3,5 0 0,5 0 4
RI QUADRATO 1 0 1 0 1 1 1 0,25 1 1 0,25 12,25 0 0,25 0 16Rn1 Rn2 RN3 RN4 RN5 RN6 RN7 RN8 RN9 RN10 RN11 RN12 RN15 RN17 RN18 RN19
Ranghi Benzene/Xileni
In questo caso
per N=16 ρ =0,947.
Per un test a due code, α = 0,05 ed N=16, il valore stimato è ρ =0,503
Si rifiuta dunque l'ipotesi nulla e si afferma che esiste correlazione tra le variabili Benzene e Xileni.
Il fatto che le variabili siano tra loro correlate permette di eseguire le successive elaborazioni
statistiche sulla sola variabile Benzene.
A questo punto lo scopo diventa analizzare la significatività delle differenze dei livelli di
inquinamento tra i punti campionati.
Si applica l'analisi della varianza (ANOVA) a più criteri di classificazione per analizzare
separatamente quale sia il contributo alla variabilità del fattore principale e quale quello del fattore
secondario.
13
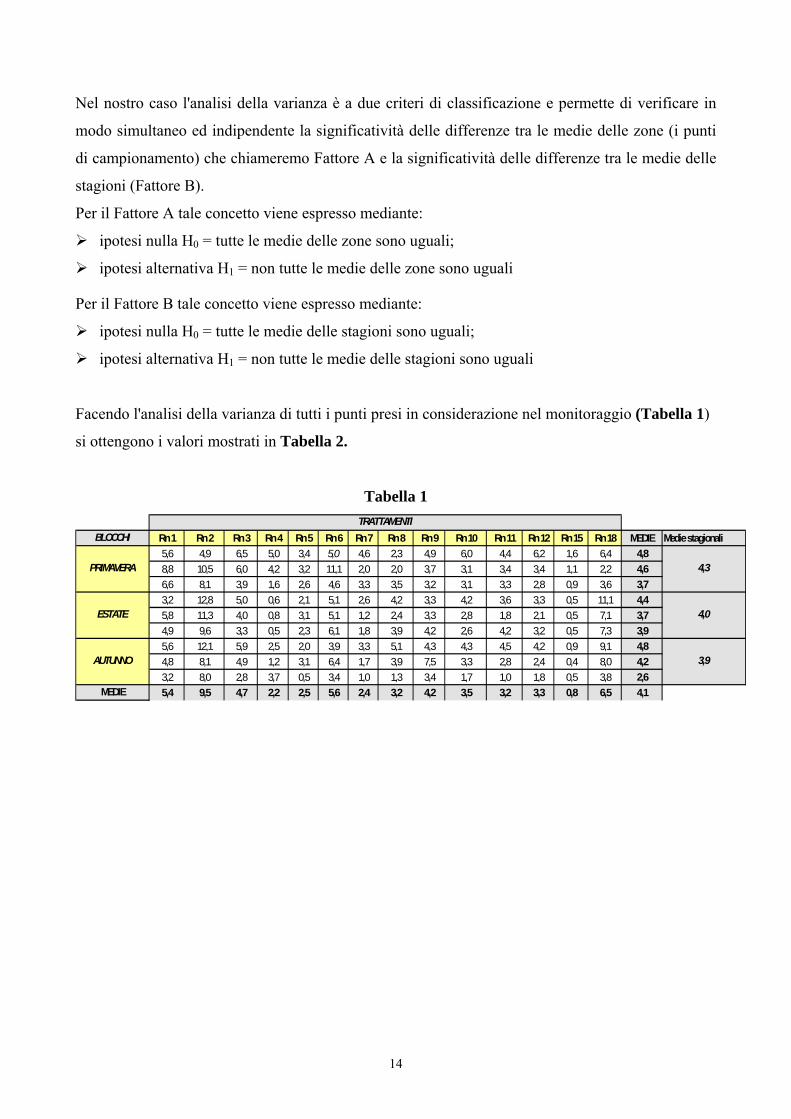
Nel nostro caso l'analisi della varianza è a due criteri di classificazione e permette di verificare in
modo simultaneo ed indipendente la significatività delle differenze tra le medie delle zone (i punti
di campionamento) che chiameremo Fattore A e la significatività delle differenze tra le medie delle
stagioni (Fattore B).
Per il Fattore A tale concetto viene espresso mediante:
ipotesi nulla H0 = tutte le medie delle zone sono uguali;
ipotesi alternativa H1 = non tutte le medie delle zone sono uguali
Per il Fattore B tale concetto viene espresso mediante:
ipotesi nulla H0 = tutte le medie delle stagioni sono uguali;
ipotesi alternativa H1 = non tutte le medie delle stagioni sono uguali
Facendo l'analisi della varianza di tutti i punti presi in considerazione nel monitoraggio (Tabella 1)
si ottengono i valori mostrati in Tabella 2.
Tabella 1
BLOCCHI Rn 1 Rn 2 Rn 3 Rn 4 Rn 5 Rn 6 Rn 7 Rn 8 Rn 9 Rn 10 Rn 11 Rn 12 Rn 15 Rn 18 MEDIE Medie stagionali5,6 4,9 6,5 5,0 3,4 5,0 4,6 2,3 4,9 6,0 4,4 6,2 1,6 6,4 4,88,8 10,5 6,0 4,2 3,2 11,1 2,0 2,0 3,7 3,1 3,4 3,4 1,1 2,2 4,66,6 8,1 3,9 1,6 2,6 4,6 3,3 3,5 3,2 3,1 3,3 2,8 0,9 3,6 3,73,2 12,8 5,0 0,6 2,1 5,1 2,6 4,2 3,3 4,2 3,6 3,3 0,5 11,1 4,45,8 11,3 4,0 0,8 3,1 5,1 1,2 2,4 3,3 2,8 1,8 2,1 0,5 7,1 3,74,9 9,6 3,3 0,5 2,3 6,1 1,8 3,9 4,2 2,6 4,2 3,2 0,5 7,3 3,95,6 12,1 5,9 2,5 2,0 3,9 3,3 5,1 4,3 4,3 4,5 4,2 0,9 9,1 4,84,8 8,1 4,9 1,2 3,1 6,4 1,7 3,9 7,5 3,3 2,8 2,4 0,4 8,0 4,23,2 8,0 2,8 3,7 0,5 3,4 1,0 1,3 3,4 1,7 1,0 1,8 0,5 3,8 2,6
MEDIE 5,4 9,5 4,7 2,2 2,5 5,6 2,4 3,2 4,2 3,5 3,2 3,3 0,8 6,5 4,1
4,3
4,0
3,9
TRATTAMENTI
PRIMAVERA
ESTATE
AUTUNNO
14

Tabella 2
Numero dati: 170Numero zone (o "trattamenti"): 19Numero blocchi (stagioni): 3
% GDLTOTALE 1096 100 169TRA ZONE 731 66 18TRA STAGIONI 5 2 2ERRORE 361 32 149
DEVIANZA VARIANZA-
40,612,362,42
È possibile ora calcolare i valori di F.
Per la differenza tra le zone F(18,149) =16,91
I valori critici corrispondenti
alla probabilità α = 0,05 F(18,149) è uguale a 1,83
alla probabilità α = 0,01 F(18,149) è uguale a 2,34
Con una probabilità αinferiore a 0,01 di commettere un errore di I tipo si rifiuta l'ipotesi nulla per
le medie tra le zone e si afferma che esiste una differenza significativa tra le medie delle zone.
Per la differenza tra le stagioni F(2,149) = 1,041
I valori critici corrispondenti
• alla probabilità α =0,05 F(18,149) è uguale a 3,07
• alla probabilità α =0,01 F(18,149) è uguale a 4,79
Con una probabilità α inferiore a 0,01 di commettere un errore di I tipo non si può rifiutare l'ipotesi
nulla per le medie tra le stagioni e si afferma che non esiste una differenza significativa tra le medie
delle stagioni.
È importante ricordare che in statistica "errore" non è sinonimo di sbaglio, ma indica l'effetto di uno
o più fattori sconosciuti, comunque non valutati o non controllati nell'esperimento.
Nel nostro caso l'analisi statistica ha evidenziato un errore del 32%. Ciò vuol dire che non state
prese in considerazione variabili importanti.
Quando con l'analisi della varianza si rifiuta l'ipotesi nulla, si può essere interessati a procedere
nell'indagine per individuare tra quali medie la differenza sia significativa.
15

Si creano due campioni, raggruppando i valori medi di Benzene raccolti agli incroci ed alle
rotatorie.
INCROCI ROTATORIE 5,4 4,7 9,5 2,5 2,2 5,6 2,4 3,2 3,5 4,2 3,3 3,2 0,8 - 6,5 -
Si applica il t di Student a due campioni indipendenti.
E' un test bilaterale in cui:
ipotesi nulla H0 = le medie delle due zone sono uguali;
ipotesi alternativa H1 = le medie delle zone sono diverse.
Per ognuno dei due campioni i dati possono essere riassunti come nella successiva Tabella 3
Tab.3
Campione INCROCI ROTATORIE Dimensione 8 6 Media 4,2 3,9 Varianza 7,87 1,34 Deviazione standard 2,80 1,16 Errore standard 1,25 0,52
Si calcola il valore di t con 12 gradi di libertà.
t(7+5) = 0,2447
Poiché il valore di t con 12 gradi di libertà per un test bilaterale
alla probabilità α = 0,05 è uguale a 2,179
alla probabilità α = 0,01 è uguale a 3,055
non si può rifiutare l'ipotesi nulla e si deve affermare che le medie tra incroci e rotatorie non hanno
differenze statisticamente significative
16

Il t di Student è un test parametrico, applicabile di preferenza a dati tratti da una popolazione
distribuita normalmente.
Quando si dispone di piccoli campioni è difficile, se non praticamente impossibile, valutare con
attendibilità la forma della distribuzione e la non - normalità di una distribuzione ha conseguenze
rilevanti sulle probabilità calcolate con un test parametrico.
Applichiamo dunque anche un test non parametrico per due campioni indipendenti, ritenendo che il
confronto tra un test parametrico ed il corrispondente non parametrico permetta di ottenere le
informazioni più utili sulle probabilità stimate.
Il test U di Mann - Whitney o test dell'ordine robusto dei ranghi non richiede alcuna ipotesi
sulla simmetria dei due campioni e serve per verificare la significatività della differenza tra le
mediane.
L'enunciazione dell'ipotesi bilaterale si esprime come:
• H0 : Me1= Me2
• H1: Me1 ≠ Me2
La procedura del test è fondata sulle precedenze che rappresentano, nei test non parametrici,
l'alternativa ai ranghi. Essa utilizza non la somma dei ranghi, ma la somma delle differenze tra i
ranghi dei due gruppi.
Riproponiamo di seguito i due campioni utilizzati per il test t, che raggruppano i valori medi di
Benzene raccolti agli incroci ed alle rotatorie.
INCROCI ROTATORIE
A B 5,4 4,7 9,5 2,5 2,2 5,6 2,4 3,2 3,5 4,2 3,3 3,2 0,8 - 6,5 -
Si combinano i dati dei due gruppi in un insieme unico, disponendo i valori in ordine crescente,
secondo il valore algebrico e si conta quante volte ogni dato di A è preceduto dai dati di B .
0,8 2,2 2,4 2,5 3,2 3,2 3,3 3,5 4,2 4,7 5,4 5,6 6,5 9,5A A A B B B A A B B A B A A0 0 0 - - - 3 3 - - 5 - 6 6
17

La somma di queste precedenze è il valore di U che risulta uguale a 23.
Si sarebbe potuto calcolare quante volte il valore del gruppo B è preceduto da valori di A
0,8 2,2 2,4 2,5 3,2 3,2 3,3 3,5 4,2 4,7 5,4 5,6 6,5 9,5A A A B B B A A B B A B A A- - - 3 3 3 - - 5 5 - 6 -
ottenendo un valore uguale a 25.
Il valore corretto dell'indice U è quello minore.
Nel caso in cui sia vera l'ipotesi H1 , quindi un campione abbia una mediana nettamente minore
dell'altro, il valore di U tenderà a zero.
Per valutare la significatività del valore di U nel caso di campioni piccoli (n1 e n2 < 15), la tavola
dei valori critici fornisce il valore di U significativo. U calcolato è significativo quando è uguale o
minore del valore tabulato.
Nel nostro caso per un test a due code alla probabilità α ≤ 0,05, n1 = 6, n2 = 8, la tavola fornisce il
valore U = 8.
E' vera dunque l'ipotesi nulla di uguaglianza tra le mediane. Il test non parametrico conferma quindi
la non significatività tra i due campioni formati da incrodi e rotatorie.
Effettuiamo allora tutti i confronti tra le medie o loro combinazioni di incroci e rotatorie, alla
ricerca di quelle differenze che hanno determinato la significatività totale.
E' detta "procedura di dragaggio" e serve per individuare le differenze da studiare in modo più
approfondito.
Il metodo di confronti multipli più diffuso è il test HSD di Tukey.
Serve per confrontare tra loro k medie, escludendo loro somme, per cui il numero p di confronti da
effettuare è
p = k(k-1)/2
18

Nel nostro caso, nella Tabella 4 sono riassunti i dati utilizzati per l'esecuzione del test.
La Tabella 5 mostra i valori ottenuti.
La Tabella 6 riassume i confronti multipli.
Tabella 4
BLOCCHI Rn 1 Rn 2 Rn 3 Rn 4 Rn 5 Rn 6 Rn 7 Rn 8 Rn 9 Rn 10 Rn 11 Rn 12 Rn 15 Rn 18 MEDIE Medie stagionali5,6 4,9 6,5 5,0 3,4 5,0 4,6 2,3 4,9 6,0 4,4 6,2 1,6 6,4 4,88,8 10,5 6,0 4,2 3,2 11,1 2,0 2,0 3,7 3,1 3,4 3,4 1,1 2,2 4,66,6 8,1 3,9 1,6 2,6 4,6 3,3 3,5 3,2 3,1 3,3 2,8 0,9 3,6 3,73,2 12,8 5,0 0,6 2,1 5,1 2,6 4,2 3,3 4,2 3,6 3,3 0,5 11,1 4,45,8 11,3 4,0 0,8 3,1 5,1 1,2 2,4 3,3 2,8 1,8 2,1 0,5 7,1 3,74,9 9,6 3,3 0,5 2,3 6,1 1,8 3,9 4,2 2,6 4,2 3,2 0,5 7,3 3,95,6 12,1 5,9 2,5 2,0 3,9 3,3 5,1 4,3 4,3 4,5 4,2 0,9 9,1 4,84,8 8,1 4,9 1,2 3,1 6,4 1,7 3,9 7,5 3,3 2,8 2,4 0,4 8,0 4,23,2 8,0 2,8 3,7 0,5 3,4 1,0 1,3 3,4 1,7 1,0 1,8 0,5 3,8 2,6
MEDIE 5,4 9,5 4,7 2,2 2,5 5,6 2,4 3,2 4,2 3,5 3,2 3,3 0,8 6,5 4,1
4,3
4,0
3,9
TRATTAMENTI
PRIMAVERA
ESTATE
AUTUNNO
Tabella 5
Numero dati: 125Numero zone (o "trattamenti"): 14Numero blocchi (stagioni): 3
% GDLTOTALE 857 100 124TRA ZONE 559 66 13TRA STAGIONI 7 2 2ERRORE 291 32 109
DEVIANZA
2,67
VARIANZA-
43,003,61
19

Tabella 6
Rn 1 Rn 2 Rn 3 Rn 4 Rn 5 Rn 6 Rn 7 Rn 8 Rn 9 Rn 10 Rn 11 Rn 12 Rn 15 Rn 185,4 9,5 4,7 2,2 2,5 5,6 2,4 3,2 4,2 3,5 3,2 3,3 0,8 6,5
Rn 2 9,5 4,10Rn 3 4,7 0,69 4,79Rn 4 2,2 3,16 7,26 2,47Rn 5 2,5 2,91 7,01 2,22 0,24Rn 6 5,6 0,24 3,86 0,93 3,40 3,16Rn 7 2,4 3,00 7,10 2,31 0,16 0,09 3,24Rn 8 3,2 2,21 6,31 1,52 0,94 0,70 2,46 0,79Rn 9 4,2 1,19 5,29 0,50 1,97 1,72 1,43 1,81 1,02Rn 10 3,5 1,93 6,03 1,24 1,22 0,98 2,18 1,07 0,28 0,74Rn 11 3,2 2,17 6,27 1,48 0,99 0,74 2,41 0,83 0,04 0,98 0,23Rn 12 3,3 2,12 6,22 1,43 1,03 0,79 2,37 0,88 0,09 0,93 0,19 0,04Rn 15 0,8 4,62 8,72 3,93 1,47 1,71 4,87 1,62 2,41 3,43 2,69 2,46 2,50Rn 18 6,5 1,12 2,98 1,81 4,28 4,03 0,88 4,12 3,33 2,31 3,06 3,29 3,24 5,74
α = 0,05
α = 0,01
IncrocioRot at oria
Legenda
con:
k = 14 numero di medie a confronto
ν = 124 gradi di libertà della varianza d'errore
i valori critici del Q per il test di Tukey risultano:
α = 0,05 è uguale a 4,560
α = 0,01 è uguale a 5,299
La varianza d'errore ottenuta con l' ANOVA sui k gruppi risulta essere uguale a 2,67
Allora:
alla probabilità α ≤ 0,05
sono significative le differenze superiori a HDS = 2,50
alla probabilità α ≤ 0,01
sono significative le differenze superiori a HSD = 2,90
La Tabella 6 evidenzia che la maggioranza delle differenze è significativa ad una probabilità
α ≤ 0,01. Mostra, inoltre, come non sia corretto creare due gruppi formati da rotatorie ed incroci dal
momento che esistono differenze significative all'interno di questi due raggruppamenti.
20

In particolare si può notare che:
RN2 è statisticamente differente da tutti gli altri;
RN1 è statisticamente differente da RN2, RN4, RN7, RN15
RN10 è statisticamente differente da RN18.
Per quanto riguarda le rotatorie si nota una differenza significativa tra RN5 ed RN6, quindi il
gruppo delle rotatorie sembra presentarsi più omogeneo al suo interno.
Il test F ed il test t bidirezionale sono test parametrici, cioè richiedono la normalità della
distribuzione della popolazione.
In esperimenti nuovi e con pochi dati non è possibile dimostrare che la condizione di normalità sia
rispettata.
Dal momento che anche nostro caso i test sopra citati sono stati applicati senza dimostrare la
normalità della distribuzione della popolazione, ricorriamo alla applicazione di test non parametrici
al fine di verificare la concordanza dei risultati ottenuti.
I test non parametrici, non richiedendo la normalità della distribuzione della popolazione,
presentano un indubbio vantaggio sia quando la non - normalità è evidente, sia quando la normalità
dei dati è solo probabile.
Un test molto utile e diffuso è quello di Kruskal - Wallis.
È l'equivalente non parametrico dell'analisi della varianza ad un criterio di classificazione ed è uno
dei più potenti per verificare l'ipotesi nulla H0 secondo la quale k gruppi indipendenti provengono
dalla stessa popolazione.
Per verificare l'ipotesi nulla
H0 : tutti i campioni hanno la stessa mediana
oppure l'ipotesi alternativa
H1 : non tutte le mediane sono uguali
tutte le osservazioni dei k gruppi devono essere considerate come una serie unica e convertite in
ranghi.
Se i campioni provengono dalla stessa popolazione, queste medie aritmetiche dei ranghi di ogni
gruppo dovrebbero essere simili tra di loro e alla media generale.
21

22
Da questo concetto è possibile derivare la formula per il calcolo di un indice g che si distribuisce
approssimativamente come la distribuzione del χ 2 con k-1 gradi di libertà, dove k è il numero dei
gruppi a confronto ( la distribuzione del chi quadrato è tanto migliore quanto maggiore è il numero
dei gruppi a confronto ed il numero delle osservazioni entro ogni gruppo è alto, maggiore di 5).
Nel nostro caso i risultati dell'analisi sono riportati nelle successive tabelle.
Nella Tabella 7 sono riassunti i dati utilizzati per l'esecuzione del test.
Nella Tabella 8 le osservazioni sono state trasformate in ranghi.
Per13 gradi di libertà si ottiene un valore di g = 76,0106
Nella tabella dei valori critici del chi quadrato
alla probabilità α = 0,05 è uguale a 22,362
alla probabilità α = 0,01 è uguale a 27,688
alla probabilità α = 0,005 è uguale a 29,819
Pertanto si può rifiutare l'ipotesi nulla con probabilità di commettere errore di I tipo inferiore a 0,05
ed affermare con la stessa probabilità di commettere errore che esiste una differenza significativa tra
le mediane dei gruppi selezionati.
A questo punto si possono impostare i confronti multipli, mostrati in Tabella 9 la quale evidenzia
anche le differenze significative.
Il numero possibile dei confronti semplici tra 14 gruppi è 91.
Scegliamo una probabilità complessiva αT = 0,05 per 14 confronti simultanei.
Per un test bilaterale sulla tavola della distribuzione normale ad essa corrisponde un valore z = 3,75
Per ognuno dei k confronti il valore di α = 0,000549.
Di tutti i confronti, alla probabilità α; sono significativi quelli uguali o maggiori delle quantità D.
D = 64,043442 ( per tutti i confronti, tranne quelli della zona RN6)
D = 66,014469 (per tutti i confronti con la zona RN6 alla quale è associato un numero minore di
osservazioni)

23
Tabella 7 - dati RN1 RN2 RN4 RN7 RN10 RN12 RN15 RN18 RN3 RN5 RN6 RN8 RN9 RN115,6 4,9 5,0 4,6 6,0 6,2 1,6 6,4 6,5 3,4 2,3 4,9 4,48,8 10,5 4,2 2,0 3,1 3,4 1,1 2,2 6,0 3,2 11,1 2,0 3,7 3,46,6 8,1 1,6 3,3 3,1 2,8 0,9 3,6 3,9 2,6 4,6 3,5 3,2 3,33,2 12,8 0,6 2,6 4,2 3,3 0,5 11,1 5,0 2,1 5,1 4,2 3,3 3,65,8 11,3 0,8 1,2 2,8 2,1 0,5 7,1 4,0 3,1 5,1 2,4 3,3 1,84,9 9,6 0,5 1,8 2,6 3,2 0,5 7,3 3,3 2,3 6,1 3,9 4,2 4,25,6 12,1 2,5 3,3 4,3 4,2 0,9 9,1 5,9 2,0 3,9 5,1 4,3 4,54,8 8,1 1,2 1,7 3,3 2,4 0,5 8,0 4,9 3,1 6,4 3,9 7,5 2,83,2 8,0 3,7 1,0 1,7 1,8 0,5 3,8 2,8 0,5 3,4 1,3 3,4 1,0
RN1 RN2 RN4 RN7 RN10 RN12 RN15 RN18 RN3 RN5 RN6 RN8 RN9 RN198,5 90,5 93,5 86,5 102,5 105,0 18,5 106,5 108,0 62,0 31,5 90,5 84,
117,0 120,0 78,5 26,0 44,5 62,0 14,0 30,0 102,5 49,0 121,5 26,0 68,5 62,109,0 115,5 18,5 55,5 44,5 40,5 10,5 66,5 72,5 37,0 86,5 65,0 49,0 55,49,0 125,0 8,0 37,0 78,5 55,5 4,0 121,5 93,5 28,5 96,0 78,5 55,5 66,
100,0 123,0 9,0 15,5 40,5 28,5 4,0 110,0 75,0 44,5 96,0 33,5 55,5 23,90,5 119,0 4,0 23,0 37,0 49,0 4,0 111,0 55,5 31,5 104,0 72,5 78,5 78,98,5 124,0 35,0 55,5 82,5 78,5 10,5 118,0 101,0 26,0 72,5 96,0 82,5 85,88,0 115,5 15,5 20,5 55,5 33,5 4,0 113,5 90,5 44,5 106,5 72,5 112,0 40,49,0 113,5 68,5 12,5 20,5 23,0 4,0 70,0 40,5 4,0 62,0 17,0 62,0 12,
Ri 800 1046 331 332 506 476 74 847 739 327 745 493 654 5ni 9 9 9 9 9 9 9 9 9 9 8 9 9
ri=Ri/ni 88,83 116,22 36,72 36,89 56,22 52,83 8,17 94,11 82,11 36,33 93,13 54,72 72,67 56,
1005505055
08939
RN1 RN2 RN4 RN7 RN10 RN12 RN15 RN18 RN3 RN5 RN6 RN8 RN9 RN1188,83 116,22 36,72 36,89 56,22 52,83 8,17 94,11 82,11 36,33 93,13 54,72 72,67 56,39
RN1 88,83RN2 116,22 27,39RN4 36,72 52,11 79,50RN7 36,89 51,94 79,33 0,17
RN10 56,22 32,61 60,00 19,50 19,33RN11 52,83 36,00 63,39 16,11 15,94 3,39RN15 8,17 80,67 108,06 28,56 28,72 48,06 44,67RN18 94,11 5,28 22,11 57,39 57,22 37,89 41,28 85,94RN3 82,11 6,72 34,11 45,39 45,22 25,89 29,28 73,94 12,00RN5 36,33 52,50 79,89 0,39 0,56 19,89 16,50 28,17 57,78 45,78RN6 93,13 4,29 23,10 56,40 56,24 36,90 40,29 84,96 0,99 11,01 56,79RN8 54,72 34,11 61,50 18,00 17,83 1,50 1,89 46,56 39,39 27,39 18,39 38,40RN9 72,67 16,17 43,56 35,94 35,78 16,44 19,83 64,50 21,44 9,44 36,33 20,46 17,94
RN11 56,39 32,44 59,83 19,67 19,50 0,17 3,56 48,22 37,72 25,72 20,06 36,74 1,67 16,28
Tabella 9 - Confronti multipli
Tabella 8 - Ranghi

Risulta evidente che il numero delle differenze significative risulta inferiore a quello stimato
mediante il test parametrico di Tukey (Tabella 6).
Ciò può essere ragionevolmente attribuito al fatto che i dati non siano distribuiti normalmente.
Analizzando gli istogrammi di frequenza (Grafico 3) dei dati, distinti nei due gruppi incroci e
rotatorie, si nota che l'andamento dei valori riferiti alle rotatorie segue un andamento normale, se si
esclude il valore maggiore rilevato in RN6 (tale valore non è stato comunque considerato anomalo e
pertanto è sempre stato incluso nelle elaborazioni effettuate).
Grafico 3 - Istogramma di frequenza dei dati di Benzene.
Classi di frequenza
0
5
10
15
20
25
0 - 1 1 - 2 2 - 3 3 - 4 4 - 5 5 - 6 6 - 7 7 - 8 8 - 9 9 - 10 10 - 11 11 - 12 > 12
Benzene (µg/mc)
Freq
uenz
a
IncrociRotatorie
(Valore iniziale = 0.5; Valore finale = 12.8; Passo = 1; Classi = 13)
Tale risultato dell'analisi è evidenziato anche dai dati presentati nella Tabella 3, in cui si può
osservare come la deviazione standard e l'errore standard calcolati sui dati relativi alle rotatorie
siano entrambi inferiori ai rispettivi valori relativamente agli incroci.
L'andamento dei dati riferiti agli incroci sembra seguire invece un andamento assimilabile ad una
distribuzione di Poisson.
Quanto sopra esposto ci induce ad ipotizzare che il livello di inquinamento registrato alle rotatorie
non sia influenzato dai fattori che determinano invece la variabilità registrata agli incroci ( direzione
e velocità del vento, traffico autoveicolare, altezza degli edifici adiacenti, etc.).
24

Conclusioni
I punti prescelti per l'indagine effettuata sono da considerarsi hot spots 3.
Non potendo pertanto realizzare una rappresentazione areale dei dati raccolti, si è scelto di
analizzarli mediante analisi statistica 2 , la quale ha inoltre permesso di giustificare l'esecuzione di
elaborazioni sul solo inquinante Benzene, l'unico al quale fa riferimento l'attuale normativa vigente.
Mediante l'analisi della varianza ANOVA su tutti i punti presi in considerazione nel monitoraggio,
si è dunque proceduto ad esaminare la significatività delle differenze dei livelli di inquinamento
secondo due criteri
• tra i punti campionati;
• tra le stagioni
potendo affermare con una certa probabilità di commettere errore, che esiste una differenza
significativa tra i punti campionati, ma non tra le stagioni, evidenziando un errore statistico molto
elevato (32%).
Poiché l'errore statistico indica l'effetto di uno o più fattori sconosciuti, comunque non valutati o
non controllati nell'esperimento, nel nostro caso si può ipotizzare che variabili importanti non
considerate possano essere individuate in valori di traffico, misure orarie/giornaliere di
inquinamento, parametri atmosferici. A posteriori risulta comunque impossibile stabilire il peso di
ognuna di esse.
La variabile stagionalità analizzata risulta essere ininfluente (2%).
Il test parametrico HSD di Tukey ed il test non parametrico di Kruskal - Wallis applicati al fine di
individuare differenze statisticamente significative tra i dati raccolti presso tutte le rotatorie e tutti
gli incroci, sembrano mostrare che i livelli di inquinamento registrati alle rotatorie non siano
influenzati dai fattori che determinano invece la variabilità registrata agli incroci (direzione e
velocità del vento, traffico autoveicolare altezza degli edifici adiacenti), potendo ritenere le rotatorie
un gruppo omogeneo.
Il test di Tukey inoltre mette in evidenza una differenza significativa del livello di inquinamento
nel punto RN2 (incrocio via Tripoli/ via Roma) rispetto a tutti gli altri incroci e rotatorie, peraltro
non confermata dal test non parametrico.
25

Riferimenti bibliografici
1. Manuale per l’uso di radiello® nel campionamento di Sostanze Organiche Volatili (SOV)
desorbite con Solfuro di Carbonio – Acquaria s.r.l.
2. Fondamenti di statistica applicata all'analisi e alla gestione dell'ambiente -L. Soliani,
Dipartimento di Scienze Ambientali, Parma. - http:/www.dsa.unipr.it/soliani.
3. Guidance report on preliminary assessment under EC air quality directives - Roel van Aalst et
altri - gennaio 1998.
26

ALLEGATI
27