mpi in windows ee 8603: project reportcourses/ee8218/mpiwin.pdfmessage passing interface (mpi) is a...
TRANSCRIPT

MPI in Windows
EE 8603: Project Report
Submitted by:
Aaron Joseph Consebido (020675559)
Francis Fernandes (979070786)
Kiu Kwan Leung (031528300)
Instructor:
Prof. Nagi Mekhiel
Date:
December 17, 2007

M P I i n W i n d o w s | 1
Table of Contents
Introduction ..................................................................................................................................... 2
MPI Features ................................................................................................................................... 2
MPICH Architecture .......................................................................................................... 3
MPICH2 Characteristics.................................................................................................... 4
Current Work Done in MPI ............................................................................................................ 5
MPI forum .......................................................................................................................... 5
Adaptive Thread Management ........................................................................................... 5
Migration Technology ........................................................................................................ 6
Parallel Simulation to Evaluate MPI Programs ................................................................ 6
Broadcast and Pipeline Communication ............................................................................ 6
Future Work Required .................................................................................................................... 8
MPI Implementation Windows ....................................................................................................... 8
Windows MPI Procedure ................................................................................................................ 9
MPICH2 Microsoft Windows Installation .......................................................................... 9
Post-Installation Setup ..................................................................................................... 10
Windows Network Setup ................................................................................................... 12
MPI Network Setup .......................................................................................................... 14
Router Based Network MPI Program Execution ............................................................. 17
Wireless Network Setup Using Intel®PROSet/Wireless Software ................................... 18
Challenges ..................................................................................................................................... 19
Sample Application: Master/Slave ............................................................................................... 20
Program flow: .................................................................................................................. 21
Master Side: ............................................................................................................. 21
Slave side: ................................................................................................................ 21
Results ........................................................................................................................................... 22
Conclusion .................................................................................................................................... 24
References ..................................................................................................................................... 25
Appendix: Master/Slave Application Program Source Code ....................................................... 27

M P I i n W i n d o w s | 2
Introduction
Message Passing Interface (MPI) is a promising technology in parallel processing that can certainly help with various applications that requires a lot of processing power. Parallel processing conceptually, alleviates resource management in applications through proper partitioning among a number of processing elements that act more or less independently thus making more efficient use of resources available.
The rapid advances in computer technology over the last few years mean makes it possible to build supercomputer-class systems at commodity prices. The NASA Beowulf project has the way in developing this technology using MPI and open-source operating systems such as Linux. Previous work by others in this field has concentrated on low-level communication and application performance over 10Mbit/s Ethernet on IA32-base systems. The rapid development and deployment of MPI on NT means that it is now possible to compare the real-world performance of several different systems. WMPI was originally based on the MPICH implementation. MPICH’s architecture, though well fitted for portability and performance, is not flexible enough to allow the implementation of the new functionality introduced in the MPI-2 standard.
This report provides details on the MPI implementation to Windows platform. Several topics such as exploring the features of MPI, capabilities of Windows for its implementation, establishing the environment for hardware communication, and an implementation of a sample application in the established network.
MPI Features
MPI is used primarily to establish a network topology within various machines in order to function as a bigger entity for processing information for an application that may require increased processing power that could not be handled by a stand-alone computer. It is meant to make available a virtual topology, synchronization and communication functionality between the available resources, which are usually pertained to as processing elements. This topology consists of a set of various processes that are mapped into nodes of the network consisting of the resources being utilized. This essential part of parallel processing is made to constitute a relationship to perform tasks that are more dependent on the executable than the language used. Getting maximum performance from the resources, a one process per processor must be established in the mapping of during resource allocation. The resource allocation or mapping occurs during runtime. Agents normally pertained to as mpirun or mpiexec are responsible for initiating the MPI program.
MPI constitutes a multitude of functions that include:
• Point-to-point rendezvous-type send/receive operations
• Logical process topology
• Data exchange

M P I i n W i n d o w s | 3
• Gathering and reduction operations to combine partial results from networked processes
• Synchronization capabilities manifested in barrier and event operations
• Gathering network-related information for diagnostic purposes
o Number of processes in computing session
o Resource utilization mapping
o Network Topology, etc.
Point to point operations in MPI can be configured to be synchronous and asynchronous to suit semantics of the network being built. Most applications in MPI are made to be asynchronous.
The incarnations of MPI implementation, MPI-1 and MPI-2, are made to be capable of handling communication and computation issues through overlapping the former with the latter. The utilization of this feature is very dependent on the MPI software written for the application. Tread usage is also one key feature of MPI. Aside from this, built-in cohesion and coupling strategies help to manage and manipulate threads in order to make utilization of multithreaded point-to-point functionalities in MPI applications can be supported.
The current MPI implementation available is MPICH2 developed by Argonne National Labs (ANL).
MPICH Architecture
The construction of MPICH emphasizes its Unix origins. It uses only one thread per MPI process and works with one type of communication medium at a time. These design characteristics also helped the portability of the library, since not all platforms have threads. Although, some mechanisms were implemented to use more than one device, in fact they were very poor and hard to use. Since only one thread was available, the library had to make polling on the devices to get new messages. In addition, the message passing progress could only be possible when the user thread made a call to a MPI function. This architecture’s type is well fitted for super computers or dedicated clusters where there is only one process per CPU. However, the typical NT cluster is shared among several users, which may be executing interactive tasks.
Figure 1: Windows MPI Structure

M P I i n W i n d o w s | 4
The figure above presents the structure of the WMPI library. The upper layer implements the MPI interface. The WMPI Management Layer (WML) is responsible for managing the MPI environment. The WML interacts with the existing devices through a generic interface, called Multiple Device Interface (MDI). These devices implement the operations, whose implementation is dependent from the communication medium. The WML concentrates most of the features that allow the objectives of the design to be achieved. Thread safeness and performance were a constant concern during the design and implementation of the library’s architecture. Every structure and all the functions that manipulate its data were studied to verify if they have or not to be thread safe. The synchronization points were reduced to the minimum to improve the general performance of the library. However, one of the architecture goals is that it must easily support new communication technologies. Through an analysis of the library requirements, the operations that have to be performed by medium dependent code have been identified. To diminish the complexity of the communication medium dependent code (device), the set of operations that the WML requires is quite simple. The simplicity of the required functionality increases the number of technologies that can be used with WMPI. The implementation of a device does not require any knowledge of the library internals.
Figure 2: WMPI Processes world-view
MPICH2 Characteristics
MPICH2 is a freely available, portable implementation of MPI, the Standard for message-passing libraries. It implements both MPI-1 and MPI-2. MPICH2 is a high-performance and widely portable implementation of the MPI standard.
The goals of MPICH2 are to provide an MPI implementation that efficiently supports different computation and communication platforms including commodity clusters (desktop systems, shared-memory systems, multicore architectures), high-speed networks (10 Gigabit Ethernet, InfiniBand, Myrinet, Quadrics) and proprietary high-end computing systems (Blue Gene, Cray, SiCortex). Furthermore, it also aims to enable cutting-edge research in MPI through an easy-to-extend modular framework for other derived implementations.

M P I i n W i n d o w s | 5
According to ANL (2007), the current version of MPICH2 is 1.0.6p1, released on October 31, 2007. MPICH2 replaces MPICH1 and should be used instead of MPICH1 except for the case of clusters with heterogeneous data representations. MPICH2 is distributed as source (with an open-source, freely available license). It has been tested on several platforms, including Linux (on IA32 and x86-64), Mac OS/X (PowerPC and Intel), Solaris (32- and 64-bit), and Windows.
The current version of MPICH2 is 1.0.6p1, released on October 31, 2007. MPICH2 replaces MPICH1 and should be used instead of MPICH1 except for the case of clusters with heterogeneous data representations
WMPI II is an implementation of the complete Message Passing Interface (MPI) standard version 2.0. It is a software development kit, which enables the development and deployment of parallel applications for MS Windows and Linux platforms on x86 and x86_64 (AMD64).
The new features of WMPI II include dynamic process creation, parallel I/O, and one-sided communication that can be used on heterogeneous computations with processes running in MS Windows and Linux. Due to these advanced features the core of WMPI has been completely rewritten to offer superior performance and stability.
Current Work Done in MPI
MPI is a relatively new technology, however there have been much work done in various areas in order to make it a prominent part of the computing community and to fully utilize its capabilities in applications in order to improve efficiencies in computing at a much economical and portable manner. Listed below are several significant related work in MPI.
MPI forum
MPI forum started in April 1992. This forum became a model of how a broad community could work together to improve an important component of the high performance computing environment. The primary reason of the development of this group is to establish agreement and cooperation on development of a community standard for the message passing model of parallel computing. In more ways than one, the MPI forum is responsible on how MPI is defined and how it is adopted and implemented. Since its incarnation, the forum makes an effort to have new generation of applications for use of MPI technology and parallel computing in general. The leading development team, the Argonne National Laboratory developed and distributed MPICH—a portable, high performance implementation of MPI from the very beginning of the MPI effort. And later its improvement MPICH-2 has been released later.
Adaptive Thread Management
The thread handling capabilities of MPI is one of its key features so it is not surprising that effectively utilizing this characteristic is being worked on as well. In particular, adaptive thread management aims for performance portability of MPI code on multiprogrammed

M P I i n W i n d o w s | 6
shared memory machines. This method moves away from MPI implementations that map each MPI code to an OS process, which results in performance degradation an occurrence very prevalent in multiprogrammed environments. Application using the convention has been made to support multithreaded MPI execution by mapping MPI nodes to a kernel thread, but suffers context switch and synchronization issues that promotes overhead. Adaptive thread management has been proposed to alleviate this problem, which involves exposing thread scheduling information to the user-level and thus having event waiting much strategized based on application
Migration Technology
This aspect of MPI involves Group Communications which is a growing application for this technology. Existing migration mechanism does not support group communications rather it is essentially a single user using multiple platforms. This results in weaknesses in migration-based proactive fault tolerance to be applied in MPI applications. As a result, distributed migration protocols were proposed. This methodology is made to be able to have group membership management in order to support process migration with group changing. This essentially applying a more user-based network topology combined with hardware. Issues of security are also brought up as in this configuration, multiple users will be involved in the same MPI.
Parallel Simulation to Evaluate MPI Programs
Simulation is important in evaluating things before actual implementation. Efforts are made to have simulation to properly assess MPI programs as much as benchmarks are used to see how good an MPI configuration is. Simulators that are being proposed are based mainly on a couple of things: existing benchmarks suits such as NAS and statistics on existing MPI programs that are accepted by the community. This helps in preventing unnecessary implementation only to see that the MPI is not efficient.
Broadcast and Pipeline Communication
Communication is an important aspect of MPI. In actuality, it is the backbone of this technology. Two main methods of communication are currently used in MPI: broadcast and pipeline communication. Figure 3, as displayed below, provides a simplified visual representation of a broadcast communication. In broadcast communication, a main process transmits information to subordinate processes (as shown in part a) and combines partitioned data once they are processed and transmitted back (as shown in parts b, c, and d). This type of communication separates computation and communication times for the processes and thus takes a larger overhead. Ahmdal’s law is more prominent here. In the event that the partitioning of data is not done properly, wait time for the main process will over compensate for the computation, thus defeating the purpose of parallel processing capabilities in MPI. However, this constitutes a simple way of utilizing MPI for parallel processing provided that data partitioning is done correctly.

M P I i n W i n d o w s | 7
(a) (b) (c) (d)
Figure 3: Broadcast Communication
Pipeline communication is an increasingly used method of communication for MPI. It is modeled from the parallelism exemplified from parallel processors. In parallelism, there is no main processes, but instead all processes have basic copies of data. The only thing that is communicated are small instructions on what to do with a particular set of data. All data that the processes have will only be combined once the whole program has been run, as opposed to partitioning a small part of the code and transmitting it back and forth from processes as in broadcast. This makes the computation time overlap the communication time, thus reducing obvious overhead. The primary drawback of this method is the increased complexity that comes with it as communication is more inclined to instructions rather than data. Figure 4 provides a more visual perspective on pipelining communication between processes.
(a) (b) (c) (d)
Figure 4: Pipeline Communication
The multitude of current developments with MPI, it is apparent that this new technology has been taken into consideration by the community as a potentially useful tool in improving
Process Busy Process Busy
Process Busy
Process Busy
Process Busy Process busy
Process busy
Process idle
Process busy
Process Busy
Process Idle
Process Idle
Process Idle
Process Busy
Process Busy
Process Busy
Process Busy Process Idle
Process Busy
Process Busy
Process Busy
Process Idle
Process Idle
Process Busy
Process Busy

M P I i n W i n d o w s | 8
processing power in a more economical way through utilization of available resources. However, there are still more needed to be done.
Future Work Required
There are many areas in MPI that still need further improvements. One aspect that needs to be dealt with is MPICH2, which is becoming a close standard on how MPI is utilized and developed. Although MPICH2 is capable of many thing for the utilization of MPI on various platforms, it still does not support some features that can prove useful. Several of these features are:
• Explicit shared Memory operations
• Program construction tools, compilers, debugger
• Explicit support for threads
• Support for task management
• I/O support – important requirement still need work to be done
• Operations / Functions that are more linked within an operating system.
Aside from further research in the areas of exploration mentioned in the previous section, a possible hybrid communication method that harnesses the advantages and masks the disadvantages of broadcast and pipelining communication. This may prove useful particularly in the possibility of implementing neural network-based applications in MPI.
MPI Implementation Windows
Most Unix MPI implementations are derived from the MPICH code base from Mississippi State University and Argonne National Labs, thanks to its portable device abstraction layer. MPICH has also been ported to Windows NT, resulting in the three different implementations evaluated in this paper. WMPI is a TCP/IP port developed at the University of Coimbra, Portugal. It’s has now been commercialized by GENIAS Software GmbH as PaTENT MPI. For simplicity work at Mississippi State University on an SMP, TCP/IP and Myrinet port of MPICH to NT, It has resulted in MPI/Pro, a commercial implementation by MPI Software Technology Inc., supporting both TCP/IP and the VIA standard for system-area networks. Finally, the Fast Messages project provides HPVM, which supports MPI and other user-level protocols on top of TCP/IP and Myrinet.
The first version of the MPI standard only proposed a specification about how the processes communicate between each other. This decision was on purpose, since the standard tried to unify the functionality present in the several existent libraries and obtain a consensus in the high-performance computing community. MPI was well accepted by the community and became a de facto standard for parallel computing. Eager for more functionality, the users and developers presented several requests to the MPI Forum to increase the functionality of the MPI standard. Version 2.0 of the standard included several new types of functionality, from which one-sided communication and dynamic process creation are examples. Although the users and developers embraced these new chapters, they require deep changes in most of the existing MPI libraries.

M P I i n W i n d o w s | 9
The Argonne National Laboratory/Missisipi State University developed MPICH alongside with the standard’s first version. This library aimed to implement all the functionality specified by the standard in an efficient and portable fashion. Due to its characteristics, MPICH served as a development base for many other implementations, which addressed different operating systems and architectures. WMPI (Windows Message Passing Interface) was the first full implementation of the MPI standard for Windows operating systems. The first versions of WMPI were strongly based on the MPICH implementation. It used the Abstract Device Interface (ADI) to interact with the communication subsystem. A Win32 port of the p4 library was used to setup the environment and manage the communication between processes.
Windows MPI Procedure
This section is a step-by-step walkthrough from installing MPICH2 to running MPI programs on Microsoft Windows. Throughout the project, the group managed to execute MPI programs on one computer, two computers with direct network cable connection, three laptops with wireless ad hoc network connection and three computers with network router connection.
MPICH2 Microsoft Windows Installation
Figure 5. The MPICH2 Windows installation package.
M P I i n W i n d o w s | 10
Figure 6. The MPICH2 bin folder.
The software installation process began with downloading the MPICH2 installation package from the http://www.mcs.anl.gov/research/projects/mpich2/ website. Thanks to the user friendliness and easiness offered by Windows, the installation process was as easy as double clicking the installation package, accepting the end user agreements, choosing the installation directory and wait for the installer to install the software suite. Yet, the installation package does not perform all necessary setup steps for the package to operate correctly under Windows – this gives rise to the post-installation setup steps being discussed in the next subsection.
Note that MPICH2 requires all message passing workstation / computers to install the package in the same directory in order to launch the message passing programs; hence the group chose C:\Program Files\MPICH2 as the installation directory.
Post-Installation Setup

M P I i n W i n d o w s | 11
Figure 7. Windows Environment Variable setup.
Under linux and UNIX environment, software being successfully installed to the operating system can be executed by the command terminal regardless which directory the terminal is pointed to. Windows, on the other hand, does not aware what kind of software is intended to be a system-wide utility. That is, under Windows’ command prompt, user can only execute newly installed program within its installed directory and software development kits such as Microsoft Visual Studio would not recognize that the user has installed an API package for use with its compiler.
To notify Windows that the MPICH2 is a system-wide utility and API package, the group registered MPICH2 as a Windows environment variable. Environment variables, according to Microsoft’s definition, are the variables that controls the behaviour of various programs, such as the command prompt and Visual Studio. Under Windows XP and Windows Vista, the environment variables settings is located under System Properties’ Advanced tab > Environment Variables. Since the group’s interest was to add a new environment variable, the new button was clicked. By filling the variable name as PATH and the variable value as C:\Program Files\MPICH2\bin and click OK, the environment variable is stored to the Windows settings. Followed by the log off and log on action sequence, the new environment variable would then be activated and Windows now recognize MPICH2 as a system-wide utility.

M P I i n W i n d o w s | 12
Windows Network Setup
Figure 8. Windows workgroup and computer name setup.
The first step of setting up a router based network is to setup the workgroup name and computer name. A workgroup, according to an article in Windows XP’s Help and Support Center, is “a peer-to-peer network where computers directly communicate with each other without a server to manage network resources. The computers in a workgroup are all equal and share resources among each other.” For this project, the group picked the word INTERWEIGH as the workgroup name.
Usually, it is unnecessary to setup a new computer name because during Windows installation, Windows would generate a random string as the name of the computer if the user does not provide any. Unfortunately, the Windows generated string is a meaningless word mixed with alphabets and numbers – this introduces a problem to the group when executing MPI programs since the computer name must be provided as an argument for the mpiexec program launcher. To tackle this problem, each of the group members gave their laptop a name – Aaron Consebido’s laptop is aaron_consebido, Francis Fernandes’s laptop is System_dev1 and Kiu Kwan Leung’s laptop is KenLaptop.
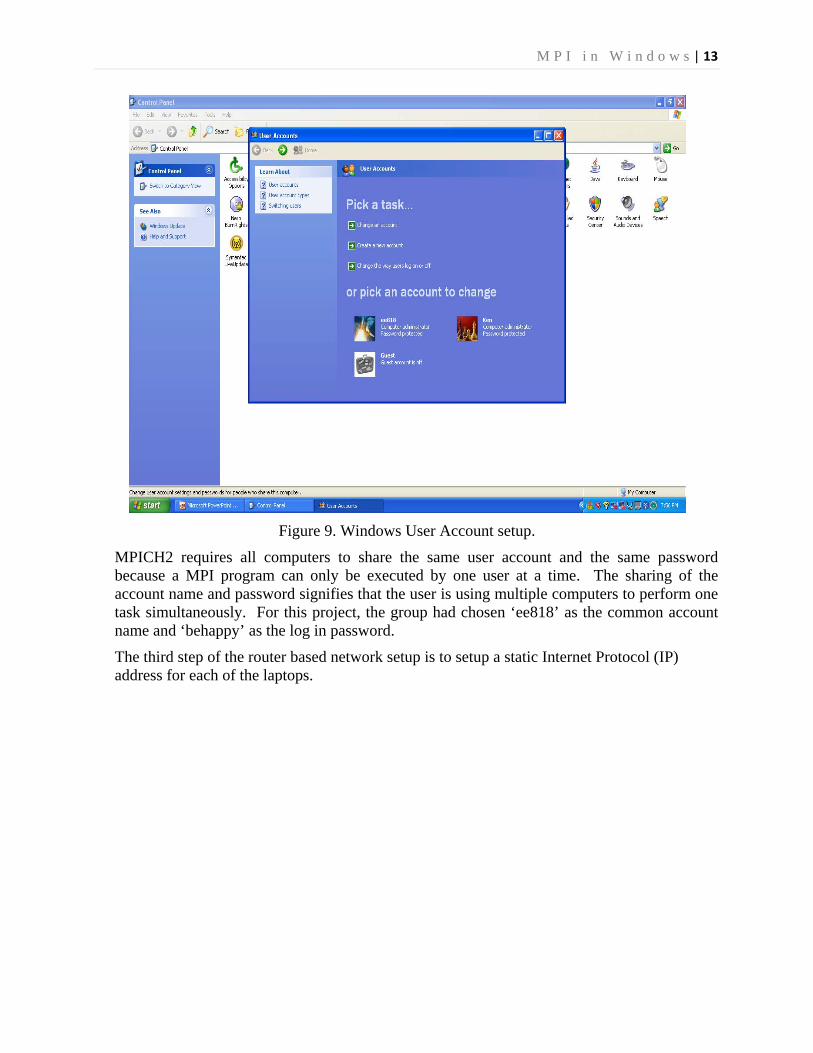
The second step of the router based network setup is to create a common user account across the three laptops.
M P I i n W i n d o w s | 13
Figure 9. Windows User Account setup.
MPICH2 requires all computers to share the same user account and the same password because a MPI program can only be executed by one user at a time. The sharing of the account name and password signifies that the user is using multiple computers to perform one task simultaneously. For this project, the group had chosen ‘ee818’ as the common account name and ‘behappy’ as the log in password.
The third step of the router based network setup is to setup a static Internet Protocol (IP) address for each of the laptops.

M P I i n W i n d o w s | 14
Figure 10. Windows static IP setup.
Under normal networked environment, the IP address of the workstation is unlikely to change unless the network/server is down and the IP address has to be redistributed. But for this project where three students’ laptop connects weekly to perform experiments, the only way to simulate a steady networked environment is to set a static IP address and subnet mask for each of the laptops’ network card TCP/IP properties. In Windows XP, the IP settings is under Control Panel > Network Connections. By opening the appropriate wired network card’s properties, the IP properties is in the check list as shown above. By double clicking the properties, the group were able to setup the IP address and subnet mask of each of the laptops. The group used IP address ranging form 192.168.0.100 to 192.168.0.102 with a subnet mask of 255.255.255.0.
The last step of the router based network is the simplest of all steps - to physically connect the laptops with a router provided by Francis Fernandes.
MPI Network Setup
There are two simple steps involved when setting up the MPICH2 network. The first step is to registry the laptop’s workgroup, account name and password using the wmpiregister.exe.

M P I i n W i n d o w s | 15
Figure 11. MPICH2 computer workgroup, account name and password registration.
MPICH2 requires the user to input the computer’s workgroup, account name and password using the wmpiregister.exe located at the bin folder of the MPICH2 directory. This process forms an encryption/ decryption key and network credential for security requirements and registers the encryption/ decryption key to the Windows’ registry for future use.
The second step of setting up the MPI network is to configure the host’s configuration and detect other hosts’ configuration with the wmpiconfig.exe.

M P I i n W i n d o w s | 16
Figure 12. MPICH2 host configuration.
The wmpiconfig.exe allows user to configure its host setting, scan the network domain/workgroup, search for other computers with MPICH2 installed and synchronize his settings with other hosts’. According to the screenshot provided above, on the left-hand side of the window is a Get Hosts button. By clicking on it, the laptop searches through the network for other hosts with MPICH2 installed and show them on the list below. These hosts should be highlighted in green if the laptop is able to communicate with other hosts through MPICH2, otherwise, they are highlighted in grey. On the right-hand side of the screen is a checkbox list of settings that allows the user to configure his laptop or view other host’s configuration. Simply clicking the Get Settings button allows the user to synchronize his setting with the selected host from the hosts list. For simplicity’s sake, the group used the default values given by the wmpiconfig.exe.

M P I i n W i n d o w s | 17
Router Based Network MPI Program Execution
Figure 13. MPI program execution.
At this point, the router based network is ready to use and the sample MPI program – cpi.exe was executed.
All MPI programs are launched by using the mpiexec.exe launcher located at the bin folder. The launcher supports various input arguments, but for this project, the group only utilized the –n and –hosts arguments. The –n argument allows the user to control how many process/es MPICH2 should create throughout the runtime and the –hosts argument signifies how many MPICH2 hosts are responsible for the MPI program execution. In some situation, the user might be interested to execute a MPI program with multiple arguments and this can be achieved by using a color to separate two complete arguments, such as the following:
mpiexec –n 2 cpi : -hosts 2 KenLaptop Aaron_consebido cpi
The group had successfully executed the cpi program with the following conditions:
1. One laptop with single core processor running one process.
2. One laptop with dual core processor running two processes.
3. Two laptops with dual core processors running one process each in direct cable connection.
4. Two laptops with dual core processors running two processes each in direct cable connection.
M P I i n W i n d o w s | 18
5. Three laptops with dual core processors running one process each in router based network.
6. Three laptops with dual core processors running two processes each in router based network.
Wireless Network Setup Using Intel®PROSet/Wireless Software
Backed up by the successful result of the router based network test bed, the group had decided to extend the platform to a wireless ad hoc network. An ad hoc network refers to a basic wireless network that does not involve any wireless router. Instead, it is a device to device network such that each of the laptops is responsible for the packet routing and authentication process. Hence the ad hoc network is slower (an ad hoc wireless g network is upper bounded to 11Mbps although the wireless g specification states that it is capable of operating at 54Mbps) due to the stress introduced to each of the laptops.
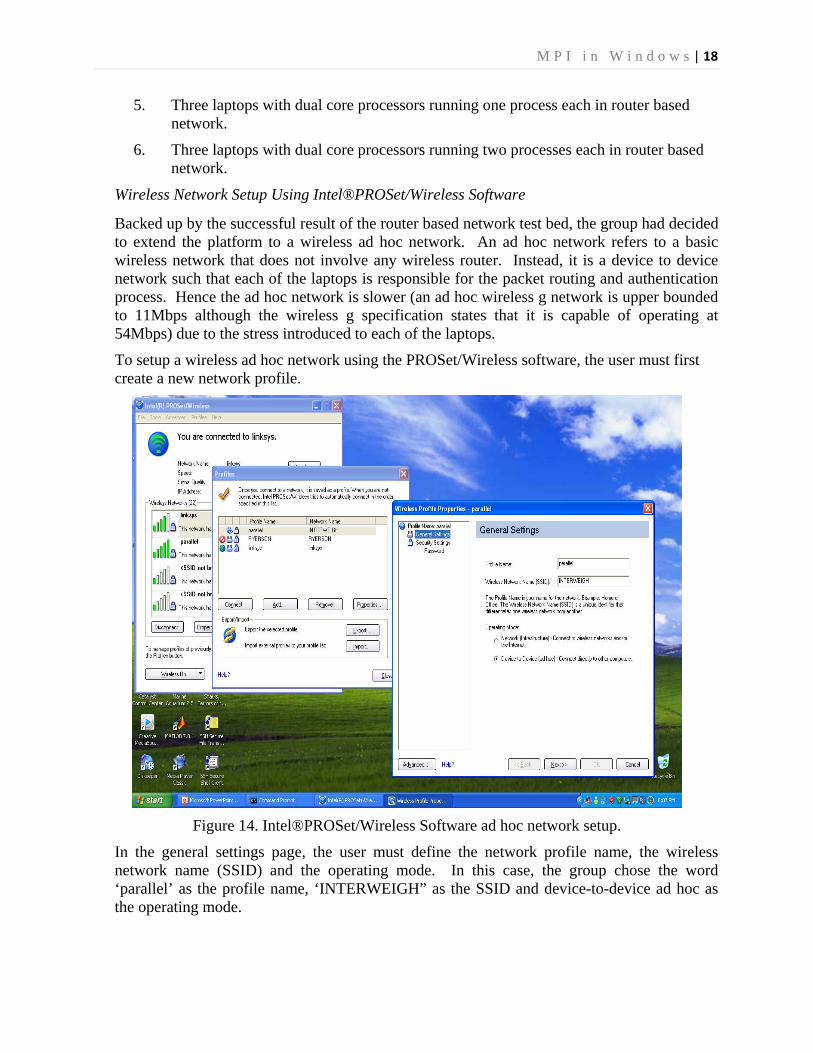
To setup a wireless ad hoc network using the PROSet/Wireless software, the user must first create a new network profile.
Figure 14. Intel®PROSet/Wireless Software ad hoc network setup.
In the general settings page, the user must define the network profile name, the wireless network name (SSID) and the operating mode. In this case, the group chose the word ‘parallel’ as the profile name, ‘INTERWEIGH” as the SSID and device-to-device ad hoc as the operating mode.
M P I i n W i n d o w s | 19
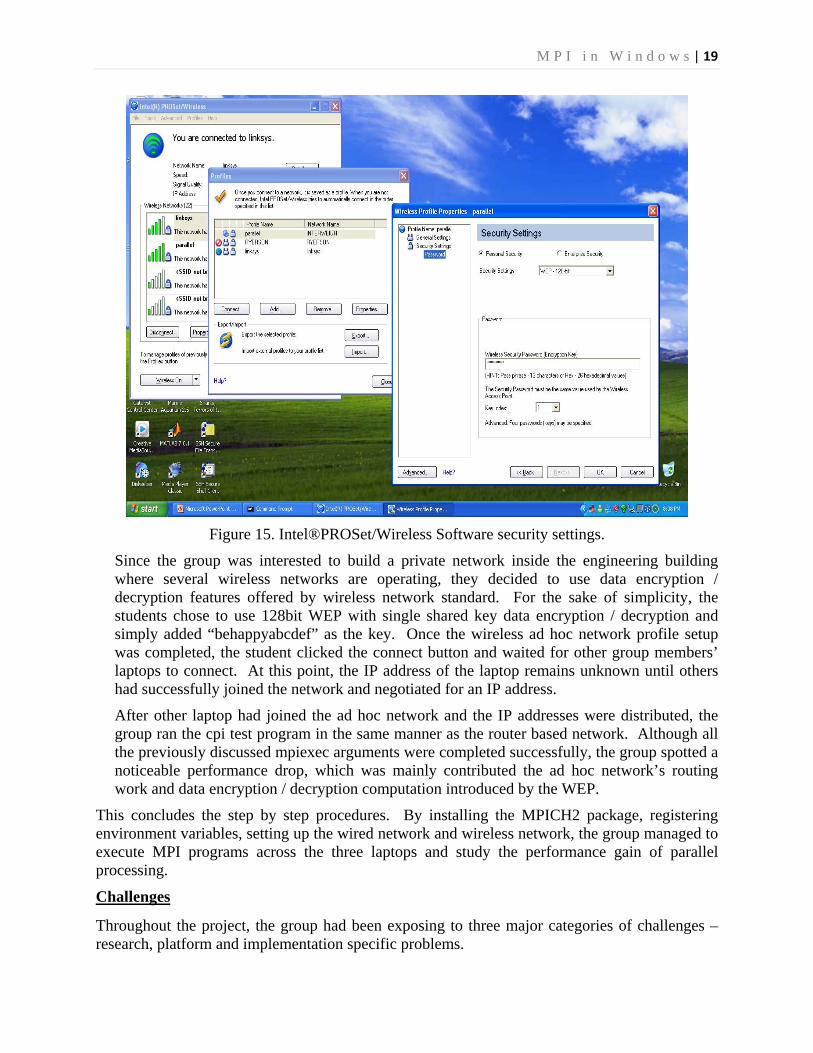
Figure 15. Intel®PROSet/Wireless Software security settings.
Since the group was interested to build a private network inside the engineering building where several wireless networks are operating, they decided to use data encryption / decryption features offered by wireless network standard. For the sake of simplicity, the students chose to use 128bit WEP with single shared key data encryption / decryption and simply added “behappyabcdef” as the key. Once the wireless ad hoc network profile setup was completed, the student clicked the connect button and waited for other group members’ laptops to connect. At this point, the IP address of the laptop remains unknown until others had successfully joined the network and negotiated for an IP address.
After other laptop had joined the ad hoc network and the IP addresses were distributed, the group ran the cpi test program in the same manner as the router based network. Although all the previously discussed mpiexec arguments were completed successfully, the group spotted a noticeable performance drop, which was mainly contributed the ad hoc network’s routing work and data encryption / decryption computation introduced by the WEP.
This concludes the step by step procedures. By installing the MPICH2 package, registering environment variables, setting up the wired network and wireless network, the group managed to execute MPI programs across the three laptops and study the performance gain of parallel processing.
Challenges
Throughout the project, the group had been exposing to three major categories of challenges – research, platform and implementation specific problems.

M P I i n W i n d o w s | 20
Research-wise, due to the fact that MPICH2 for Windows is a relatively new subject, online resources regarding the subject are considerably harder to reach comparing to Linux’s and UNIX’s. For example, the installation guide for Windows is only a two pages PDF document covering Microsoft Windows XP; on the other hand, Linux/UNIX users are able to download a thirty five pages PDF document from the MPICH2 homepage.
In terms of problems regarding the implementation platform, unlike Linux/UNIX where the network topology is built into the MPICH2 package, the MPICH2 for Microsoft Windows package does not offer any built-in network topology support. Therefore, students must build, test and debug their network. In addition to shortage of built-in network features, the group was also exposed to cross-platform networking issues. Since Aaron Consebido’s laptop is a Windows Vista machine, the group had to work on two additional research topics, which are setting up MPICH2 in Windows Vista and learning ways of allow Windows XP and Windows Vista to communicate through Ethernet.
Last but not least, the group was facing an unexplainable problem during the implementation phase. When the group finished the physical network setup and setting the MPI host configurations with wmpiconfig.exe, error messages regarding the inability of acquiring queries with Francis Fernandes’ laptop appear occasionally with Aaron Consebido’s and Kiu Kwan Leung’s laptop. When this happens, the MPI network becomes unidirectional - only Francis’ laptop is able to launch MPI programs while the other laptops cannot.
To conclude the challenges section, it is inappropriate to state that the group had successfully solved all the above discussed issues. Yet, most of the issues were addressed by the group successfully and students were very pleased that they were able to proceed to program their own sample program for use with their Windows based MPI platform.
Sample Application: Master/Slave
Our implementation was based on Matrix [N X N] / Vector multiplication, and testing output results for various matrix sizes and number of processes.
Solution was based on the concept that master copy of matrix was kept with the master process, and a copy of vector to be multiplied was broadcast to each of the slave processes.
MPI_Bcast(b, COLS, MPI_INT, MASTER_RANK, MPI_COMM_WORLD);
Master process controls complete multiplication process, master assigns each process a ‘job’ at a time by broadcasting a single row at a time and waiting multiplication result to be received from each process, this way at any time number of parallel operation is directly proportional to number of processes, again once a row is broadcast to a process there is no more communication overhead required, memory sharing between master and slave for receiving results for other than waiting row X vector results. If our implementation with a matrix size of 400 X 400 and 8 processes, parallel operation improvement was eight times faster than achieving this by just using a single process loop, but we could not go any further than 400 X 400 and increasing the number of processes more than 8 to keep consistency in our results that as number of processes increases our execution increases in fact we could not expand our matrix size more than 400 X 400, only explanation I could see here was size of message passing buffer for broadcast between processes, also as we increased the number of processes beyond 8 our execution speed didn’t increased a lot, may be there is some sort of communication involved and starts to kick in as number of processes increases.

M P I i n W i n d o w s | 21
Program flow:
The Program flow has been divided into two main parts: the Master side and the Slave side.
Master Side:
The first thing that the master process does is to initialize vector b and matrix A. Every entry in vector b is set to 1 and matrix A is set to Aij = i. This way it will be easy to check that the computation is correct, because
where N is the dimension of the matrix, in this case 100. So
To keep a tab of each job assigned to slave processes, the master maintains a counter, which is used as row number of matrix A sent to the slave processes, and sends the first batch of jobs to all slave process, as seen counter value is used as tag number.
MPI_Send(int_buffer, COLS, MPI_INT, destination, count, MPI_COMM_WORLD);
Int_buffer is a pointer to the matrix A to be multiplied by vector within the slave process. As seen in our implementation, the master does not participate in the computation. The master process waits for a message to arrive, from any process, and from any source.
for (i = 0; i < ROWS; i++) { MPI_Recv (int_buffer, BUFSIZ, MPI_INT, MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COMM_WORLD, &status);
Since our implementation of counter variable shown above master process need not worry, which slave process is going to be the first with an answer. Some may be slower and busier than others depending on what else runs on their CPUs. Once a message arrives, the master process checks where the message has come from by inspecting the status structure associated with the message, and inspects the tag number of the message to translate corresponding row number which this results belong.
sender = status.MPI_SOURCE; row = status.MPI_TAG; c[row] = int_buffer[0]; //c is the result matrix
If there is still some work left, then the master process transfers the corresponding row of matrix A to its send buffer, int_buffer, and sends its content to the slave process that has just delivered the answer until all rows within the matrix is multiplied.
Slave side:
MPI_Recv(int_buffer, COLS, MPI_INT, MASTER_RANK, MPI_ANY_TAG, MPI_COMM_WORLD, &status);
The row number is extracted from the tag of the message. Then the slave process evaluates

M P I i n W i n d o w s | 22
and sends it back to the master using the same tag. This way the master will know which row number the answer corresponds to. Finally, the slave process waits for another message from the master process.
Results
MPI Performance - varying number of processes
0102030405060708090
0 10 20 30 4
number of processes
time
in m
se
0
c
Figure 16: MPI Performance Results for Master/Slave Application for 300x300 Matrix
The figure above manifests the results of the performance of the Master/Slave MPI program with the following specifications:
• Master300X300
• Matrix size 300X300
• Multiplication of Matrix size 300X300 with a vector size 300
• MPI program tested on a dual core Intel Centrino with 2.5 GHz each CPU speed
As discussed in our implementation earlier in this report the best results obtained was when number of processes was around 6-8 on a dual core CPU system. When number of processes increases (n>9) execution time increases and almost doubles when n is around 20 processes. As number of processes increase, seems that the overhead required to broad cast messages to more processes increases. Overhead is defined to be:
“ the overhead, defined as the length of time that a processor is engaged in the
transmission or reception of each message; during this time, the processor cannot
perform other operations (Culler et al., 1993).” Application availability is defined to be the fraction of total transfer time that the application is free to perform non-MPI related work.
Application Availability = 1 – (overhead / transfer time)

M P I i n W i n d o w s | 23
MPI Performance - Multiple nodes
0
200
400
600
800
1000
1200
1400
0 5 10 15 20 25 30 35
Number of Processes
Tim
e in
mse
c
Figure 17: MPI Performance Results for Master/Slave Application for 300x300 Matrix
The figure above manifests the results of the performance of the Master/Slave MPI program with the following specifications:
• Master300X300
• Matrix size 300X300
• Multiplication of Matrix size 300X300 with a vector size 300
• Executed on three individual Intel dual core nodes (laptops) connected in a separate network with static IP’s.
Figure 18: Screenshot of MPI Network of 3 Computers

M P I i n W i n d o w s | 24
As seen in execution time increased (optimum value jumped from single node 22 milli seconds to around multi node 350 milli seconds) compare to execution the same program on a single node with dual core
Best performance was achieved for n=4 number of process and number of host=3 (six CPU cores), performance time around 350 milli seconds.
This clearly leads us to explanation in increase overhead time required for Master process to broadcast individual rows to each of the slave processes. One of the major reasons could be the type of send / receive commands use in our implementation, blocking / non-blocking, buffering / non-buffering. MPI_Send trends to buffer data it will not return until you can use the send buffer, it is allowed to buffer on the send or receive side or to wait for a matching receive. MPI_Send emphasize on buffering than performance, on system where multi nodes are involved MPI_Ssend may perform better and may help in lowering transmission / receiving over a lot to improve performance.
The results obtained from the application have opted to regard possible future work. Existing Master-Slave program can be optimized to change the way over all communication between master and slave processes are implemented. Replacing calls on codes involved with broadcast may be improved by using non blocking calls, such that application availability could be improved and wait time reduced.
Conclusion
MPI is one of the most promising technologies to be utilized for parallel processing. Throughout the duration of the project exploration of various current works have been explored as well as potential future development to make such a technology more efficient in order to accommodate a wide range of application that will require increased processing power in a more economical way. In addition to this exploration is the implementation of MPI in the Windows platform as well as using a program in the form of the Master/Slave application in order to utilize the parallel processing capabilities offered by the technology. Both the theoretical and the practical aspects revolving in this project were intended to explore and learn more about this new technology. Through various challenges faced in this project, the need for more research in this area has been exemplified. In essence, the learning experience acquired in implementing MPI in Windows proved to be a rewarding one as it had manifested many aspects of MPI topic, engineering and teamwork.

M P I i n W i n d o w s | 25
References
Argonne National Labs (2007). MPICH2 Retrieved October 3, 2007 from http://www.mcs.anl.gov/research/projects/mpich2/support/index.php?s=support
Banikazemi, M., Govihdaraju, R.K., Blackmore, R. & Panda, D.K. (Oct, 2001). MPI-LAPI: an efficient implementation of MPI for IBM RS/6000 SP systems. IEEE Transactions on Parallel and Distributed Systems 12 (10), 1081–1093
Cong Du, & Xian-He Sun Sun (May, 2006). MPI-Mitten: Enabling Migration Technology in MPI. Sixth IEEE International Symposium on Cluster Computing and the Grid 1, 11–18.
Culler, D., Karp, R., Patterson, D., Sahay, A., Schauser, K. E., Santos, E., Subramonian, R., & von Eicken., T. (1993). LogP: Towards a Realistic Model of Parallel Computation. In Fourth ACM SIGPLAN symposium on Principles and Practice of Parllel Programming, 262-273.
Gropp, W., Lusk, E., Doss, N., & Skejellum, A. (Sep, 1996). A high-performance, portable implementation of the MPI Message Passing Interface Standard. Parallel Computing 22 (6), 789-828.
Husbands, P.& Hoe, J.C.(Nov, 1998). MPI-StarT: Delivering Network Performance to Numerical Applications Supercomputing, IEEE/ACM Conference, 17-27.
Lawry, W., Wilson, C., Maccabe, A., & Brightwell, R. (2002). COMB: A Portable Benchmark Suite for Assessing MPI Overlap. Proceedings of the IEEE International Conference on Cluster Computing (CLUSTER 2002), 472-482.
Le, T.T. (Aug, 2005). Tuning system-dependent applications with alternative MPI calls: a case study Software Engineering Research, Management and Applications, 2005. Third ACIS International Conference, 137 – 143.
Lusk, E. (2002). MPI in 2002: has it been ten years already? Cluster Computing, 2002. Proceedings. 2002 IEEE International Conference, 435-444.
Marinho, J. & Silva, J.G. (Sep, 1998). WMPI – Message Passing Interface for Win32 Clusters. Proc. Of 5th European PVM/MPI User’s Group Meeting, 113-120.
Message Passing Interface Forum (1994). MPI: A message-passing interface standard. International Journal of Supercomputer Applications 8 (3/4), 165-414.
Microsoft (2002). Home or Small Office Networking Overview. Retrieved December 10, 2007, from Windows XP Help and Support Center.
Microsoft (2002). Windows XP Professional Product Documentation – Setting Environment Variables. Retrieved December 9, 2007, from http://www.microsoft.com/resources/documentation/windows/xp/all/proddocs/en-us/environment_variables.mspx?mfr=true

M P I i n W i n d o w s | 26
Microsoft (2007). Microsoft Windows Retrieved October 31, 2007 from MS website www. microsoft.com
Pedroso, H., Silva, P., & Silva, J.G. (Sep, 2000). The WMPI Architecture for Dynamic Environments and Simultaneous Multiple Devices. Recent Advances in Parallel Virtual Machine and Message Passing Interface: 7th European PVM/MPI Users' Group Meeting, Balatonfüred, Hungary, September 2000. Proceedings, 184-192.
Prakash, S., & Bagrodia, R.L. (Dec, 1998). MPI-SIM: using parallel simulation to evaluate MPI programs. Simulation Conference Proceedings 1, 467 – 474.
Princeton University (Spring, 2007). Parallel Architecture and Programming Retrieved September 21, 2007 from PU website: http://www.cs.princeton.edu/courses/archive/spr07/cos598A/
University of California (Spring, 1999). Parallel Processors Retrieved September 19, 2007 from UoC website http://www.cs.berkeley.edu/~culler/cs258-s99/

M P I i n W i n d o w s | 27
Appendix: Master/Slave Application Program Source Code //Program title: Master Slave //Description: Multiplication of N X N matrix with M size vector //Development environment: VS2005 int main ( int argc, char **argv ) { int pool_size, my_rank, destination; int i_am_the_master = FALSE; int a[ROWS][COLS], b[COLS], c[ROWS], i, j; int int_buffer[BUFSIZ]; MPI_Status status; double startwtime = 0.0, endwtime; MPI_Init(&argc, &argv); MPI_Comm_size(MPI_COMM_WORLD, &pool_size); MPI_Comm_rank(MPI_COMM_WORLD, &my_rank); startwtime = MPI_Wtime(); if (my_rank == MASTER_RANK) i_am_the_master = TRUE; if (i_am_the_master) { int row, count, sender; for (j = 0; j < COLS; j++) { b[j] = 1; for (i = 0; i < ROWS; i++) a[i][j] = i; } MPI_Bcast(b, COLS, MPI_INT, MASTER_RANK, MPI_COMM_WORLD); count = 0; for (destination = 0; destination < pool_size; destination++) { if (destination != my_rank) { for (j = 0; j < COLS; j++) int_buffer[j] = a[count][j]; MPI_Send(int_buffer, COLS, MPI_INT, destination, count, MPI_COMM_WORLD); fprintf(stdout, "sent row %d to %d\n", count, destination); count = count + 1; } } for (i = 0; i < ROWS; i++) { MPI_Recv (int_buffer, BUFSIZ, MPI_INT, MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COMM_WORLD, &status); sender = status.MPI_SOURCE; row = status.MPI_TAG; c[row] = int_buffer[0]; fprintf(stdout, "\treceived row %d from %d\n", row, sender);

M P I i n W i n d o w s | 28
if (count < ROWS) { for (j = 0; j < COLS; j++) int_buffer[j] = a[count][j]; MPI_Send(int_buffer, COLS, MPI_INT, sender, count, MPI_COMM_WORLD); fprintf(stdout, "sent row %d to %d\n", count, sender); count = count + 1; } else { MPI_Send(NULL, 0, MPI_INT, sender, ROWS, MPI_COMM_WORLD); fprintf(stdout, "terminated process %d with tag %d\n", sender, ROWS); } } for (row = 0; row < ROWS; row++) printf("%d ", c[row]); printf("\n"); endwtime = MPI_Wtime(); printf("Process Time = %f\n", endwtime-startwtime); fflush( stdout ); } else { /* I am not the master */ int sum, row; startwtime = MPI_Wtime(); MPI_Bcast(b, COLS, MPI_INT, MASTER_RANK, MPI_COMM_WORLD); fprintf(stdout, "received broadcast from %d\n", MASTER_RANK); MPI_Recv(int_buffer, COLS, MPI_INT, MASTER_RANK, MPI_ANY_TAG, MPI_COMM_WORLD, &status); fprintf(stdout, "received a message from %d, tag %d\n", status.MPI_SOURCE, status.MPI_TAG); while (status.MPI_TAG != ROWS) { /* The job is not finished */ row = status.MPI_TAG; sum = 0; for (i = 0; i < COLS; i++) sum = sum + int_buffer[i] * b[i]; int_buffer[0] = sum; MPI_Send (int_buffer, 1, MPI_INT, MASTER_RANK, row, MPI_COMM_WORLD); fprintf(stdout, "sent row %d to %d\n", row, MASTER_RANK); MPI_Recv (int_buffer, COLS, MPI_INT, MASTER_RANK, MPI_ANY_TAG, MPI_COMM_WORLD, &status); fprintf(stdout, "received a message from %d, tag %d\n", status.MPI_SOURCE, status.MPI_TAG); } fprintf(stdout, "exiting on tag %d\n", status.MPI_TAG); } endwtime = MPI_Wtime(); printf("Process Time = %f\n", endwtime-startwtime); MPI_Finalize (); exit (0); }