mysql cluster - files-cdn.cnblogs.com ·...
TRANSCRIPT

MySQL Cluster
数据服务中心 MySQL Cluster 应用
海南易建科技股份有限公司
李景帆
2013/3/15

1 .MySQL Cluster 的介绍
1.1 介绍(官方的)
MySQL 集群是一个写操作可扩展的、实时的、符合 ACID 规则的事务处理数据库,可用
性达 99.999%,且有开放源码,低 TCO 特点。
MySQL 集群的架构是分布式多主结构,无单点故障,通过 SQL和 NoSQL 接口访问,可以
在低成本硬件上横向扩展以支持大量读写工作量。
MySQL 集群的实时设计实现了可预计的毫秒级响应性能,每秒能支持数百万次操作。此
外,MySQL 集群还支持内存和磁盘数据存储,以及自动数据分区(分片),并带有负载平衡
和向正在运行的集群中添加注释(而不需停机)的功能,使线性数据库可以有效地扩展而处
理最难以预计的互联网工作量。
1.2 MYSQL 复制和 Cluster 集群的区别
在复制系统中,一个 MySQL 主服务器会更新一个或多个从服务器。事务是顺序地提交的,
因此一个慢事务就可能导致从服务器比主服务器落后一段时间。这也意味着如果主服务器出
错失败了,那么从服务器可能会缺少记录最后的那一小部分事务日志。
如果使用的是事务安全存储引擎的话,例如 InnoDB,那么事务日志则会完全记录到从
服务器上去或者完全不记录。但是复制不能保证主和从服务器上的数据总是保持一致性。
在 MySQL 集群中,所有的数据总是保持同步。在任何数据节点上提交的事务都同步到所
有其他的数据节点上了,如果有一个数据节点失败了,其他正常的数据节点照样能保持数据
的一致性。
1.2 使用集群的硬件要求
MySQL 集群可以运行在任何启用 NDB 的平台上。CPU 越快,内存越大,对集群性能提升
越明显。64 位的 CPU 也可能比 32 位的处理器更快。每个作为数据节点的机器都必须有足够
的内存来保存共享数据库,内存的使用量越大越好。
MySQL 集群适合用于高速带宽的环境中,它采用 TCP/IP 方式连接,它的性能跟主机间
的连接速率有直接关系,集群中的最小速率要求是常规的 100Mb 以太网或者等同的网络。

1.3 可扩展性
MySQL 集群自动将表格划分到不同节点上,使数据库可以在低成本的商业硬件上横向扩
展以支持读写量大的工作任务。另外由于有 active/active 的多主架构,更新可以在任何节
点上操作,而且可以立即用到访问集群的所有其它客户机上。
表可以自动分区到多个数据节点中,使数据库能够横向扩展以支持读写密集型的工作负
荷。最高支持255个节点,其中的48个可以是数据节点。
通过数据库层的自动分区表,MySQL集群无需在应用程序层面分片,因此大大简化了应
用程序的开发和维护。分片对应用程序来说是完全透明的,应用程序能够连接到集群中的任
何节点,并能在查询或事务处理时自动访问正确的分片。
默认情况下,分片是基于整个主键的散列而进行的,这种分片方法使数据和查询能在集
群中更加均匀地分布。需要注意的是,在MySQL集群下建表,必须要有主键ID。
另外,与其它分布式数据库不同,用户在不同片区间执行查询和事务处理时无需失去执
行 JOIN操作的能力或牺牲 ACID保证,这一点很重要。在 MySQL集群 7.2开发里程碑版本中,
适应性查询定位将 JOIN 操作推到数据节点层面,在那里以本地、平行的方式执行,从而大
大减少了网络跳跃,使网络吞吐量提高了 20-40 倍,并降低了延迟。这使用户可以在正在活
跃的 OLTP 数据集中执行复杂的查询,如实时分析性查询,从而为从用户行为和参数选择中
获得更大价值提供了无数可能。MYSQL 自动分区的示意图如下:
MySQL 集群允许用户通过在线添加应用程序和数据节点而扩展数据库性能和容量,使用
户可以从较小的集群开始而后按照具体需要进行扩展,且在扩展时无需停机。

在以下例子中,左边的集群配置有两个应用程序和数据节点以及一个管理服务器。随着
服务的增加,用户可以扩展数据库并添加管理备份——所有这些都以在线操作的方式进行。
扩展应用程序节点的另一个优势是这种方式提供了扩展灵活性,因此当对数据库的需求减少
时,可以返回到原先的状态。
1.4 高可用性
MySQL 集群的分布式无共享架构,能确保足够的自我恢复和故障恢复能力,详细描述如
下:
1,MySQL 集群即时地检测各种故障,并自动对集群中的其它活跃节点进行控制,而无
需中断客户端的服务。
2,在发生故障时,MySQL 集群的节点能通过自我重启、恢复和动态化的重新配置而自
我修复,且所有这些对应用程序来说都是完全透明的。
3,数据节点内的数据同步复制到节点组中的所有节点上。某个数据节点发生故障时,
至少有一个其他节点存储着相同的信息。
4,某个数据节点发生故障时,MySQL 服务器或应用程序节点可以使用节点组内的任何
其它数据节点来执行事务处理。此时,应用程序简单地重试这个事务处理请求,而其它数据
节点就会成功地满足这个请求。
5,可以部署复制管理服务器节点,这样,即使某个管理服务器发生故障,也不会丧失
任何管理或裁断功能。
用这种方式设计集群可以使系统具有更高的可靠性和可用性,因为消除了单点故障。任
何节点都可以发生故障而不会影响整个系统的功能。如下图所示,即使一个数据节点失效时,
只要该节点组中还有一个或多个有效节点,应用程序就可以继续执行。

从上图所见,MYSQL 集群提高数据库系统可靠性和可用性的技术包括:
1,数据在节点组中的所有数据节点之间复制。这能减少节点发生故障时的失效备援时间,
因为无需重新创建和查看日志文件。
2,节点在多个主机上执行,使 MySQL 集群在发生硬件故障时也能运行。
3,由于有无共享架构,每个数据节点都有自己的磁盘和内存存储器,因此在共享存储器中
的故障不会导致整个集群的停机。
4,消除了单点故障。即使多个节点发生故障,数据也不会丢失,使用数据库的应用程序也
无需停止。类似地,网络也可以用这种方式实现互连单元之间的无单点故障结构。
2 .MySQL Cluster 的安装
2.1 MYSQL Cluster 的准备
Mysql Cluster 的介绍:http://www.mysql.com/products/cluster/
Mysql Cluster 下载地址:http://www.mysql.com/downloads/cluster/
2.2 服务器的准备
10.21.11.81 管理节点服务器 Windows Server 2008

10.21.4.166 数据节点服务器 / SQL 节点服务器 Windows Server 2008
10.21.4.177 数据节点服务器 / SQL 节点服务器 Windows Server 2008
10.21.11.252 SQL 节点服务器(暂时没用) CentOS Liunx
10.21.11.253 SQL 节点服务器(暂时没用) CentOS Liunx
当前的部署示意图:
在现有的结构下,当 CentOS的 MYSQL 设置完成之后,会将 SQL 节点换成 10.21.11.252
/ 10.21.11.253 两台服务器来承担。
2.3 MYSQL Cluster 在 Windows 下的安装
1,分别在三台服务器上解压 mysql-cluster-gpl-7.2.8-winx64 ,改名成 mysql-cluster,
并在每一个 data 目录下面创建子目录 ndbdata。
2,在 10.21.11.81 管理节点服务器上面设置 Config.ini,My.ini 文件不需要在管理节点中
配置,Config.ini 配置如下。
[NDBD DEFAULT]

# 定义集群中每个表保存在拷贝数, 另外还指定节点组的大小.
# 节点组指保存相同信息的节点集合.
# 通常情况下不需要为该参数指定值.
# NoOfReplicas 没有默认值, 最大的可能值为 4.
NoOfReplicas=2
#指定数据内存, 默认值为 80MB, 最小值 1MB, 无大小限制
DataMemory=600M
#指定索引内存, 默认值为 18MB, 最小值 1MB, 无大小限制
IndexMemory=100M
# # 该参数是 BackupDataBufferSize 和 BackupLogBufferSize 之和。默认值是 2MB + 2MB = 4MB
BackupMemory=64M
[MGM DEFAULT]
#端口号,其它节点通过这个端口通讯
PortNumber=1186
#管理服务器的数据目录
DataDir=D:\\mysql-cluster\\data\\ndbdata
[NDB_MGMD]
nodeid=1
#管理节点服务器的 IP 地址
HostName=10.21.11.81
[NDBD]
nodeid=2
#数据节点服务器
HostName=10.21.4.177
#数据节点服务器,数据文件存放地址。当数据节点连接上管理节点服务器后,可以自动创建该目录。
DataDir=D:\\mysql-cluster\\data\\ndbdata
[NDBD]
nodeid=3
HostName=10.21.4.166
DataDir=E:\\MySQL-Cluster\\data\\ndbdata
[MySQLD]

nodeid=4
#SQL 节点不需要数据目录
HostName=10.21.4.177
[MySQLD]
nodeid=5
HostName=10.21.4.166
3,在 10.21.4.166 和 10.21.4.177 上面设置 my.ini 文件,My.ini 可查看现有文件,My.ini
文件的重点就在于加上以下的配置节。
[MYSQL_CLUSTER]
#设置管理节点的地址及端口,这样就不需要在启动数据节点时输入 ndbd –c ipaddr:prot
ndb-connectstring=10.21.11.81:1186
[mysqld]
Ndbcluster
#连接管理服务器
ndb-connectstring=10.21.11.81:1186
#避免在建表的 sql 语句中还要加入 ENGINE=NDBCLUSTER。
default-storage-engine=NDBCLUSTER
4,安装 MySQL-Cluster,执行命令:
在 mysql\ bin 的 目 录 下 mysqld --install MySQL
--defaults-file="D:\mysql-cluster\my.ini"
5,启动 MySQL 进行下一步安装准备。
Net Start MySQL
6,配置 MYSQL 的访问信息。
Mysql\bin 下面 mysql -u root -p
mysql>use mysql;
mysql>desc user;
//设置权限,让 MYSQL 可以被外部访问
mysql>GRANT ALL PRIVILEGES ON *.* TO root@"%" IDENTIFIED BY "root";
//更新密码为 123456

mysql>update user set Password = password('123456') where User='root';
//立即生效
mysql>flush privileges;
mysql>exit;
7,关闭 MYSQL,等待 MySQL Cluster 集群的启动。
Net Stop MySQL
2.4 MYSQL Cluster 在 CentOS Liunx 下的安装
3 .MySQL Cluster 的启动及关闭
3.1 启动 MySQL Cluster 的顺序和方法
按照 管理节点 数据节点 SQL 节点的步骤启动 MySQL Cluster 集群,第一次启动需
要添加参数 --initial
1,启动管理节点,登陆 10.21.11.81 服务器。执行命令:
ndb_mgmd -f "D:/mysql-cluster/config.ini" --configdir="D:/mysql-cluster"
2,启动数据节点,分别登陆 10.21.4.166 和 10.21.4.177 两台服务器,执行命令:
ndbd --initial
3,启动 SQL 节点(windows),分别登陆 10.21.4.166和 10.21.4.177 两台服务器,执行命令:
Net start mysql
3.2 关闭 MySQL Cluster 的顺序和方法
按照 SQL 节点 数据节点 管理节点的步骤关闭 MySQL Cluster 集群。
1,关闭管理节点,登陆 10.21.11.81 服务器。执行命令:
ndb_mgm -e "SHUTDOWN"
2,关闭数据节点,分别登陆 10.21.4.166 和 10.21.4.177 两台服务器,执行命令:
ndb_mgm -e "SHUTDOWN"
3,启动 SQL 节点(windows),分别登陆 10.21.4.166和 10.21.4.177 两台服务器,执行命令:
Net Stop Mysql

4 .MySQL Cluster 的性能测试
4.1 测试方式
性能测试的目的是在多主服务器同时新增数据的场景下,数据同步的效率以
及应用程序的响应时间。
测试的部署结构图如下:
每一个 ASP.NET 的应用分别执行多个事务、更新、查询。如下图所示:

详细的 SQL 执行列表:
begin transaction with isolation level: Unspecified
INSERT INTO demo_role (RoleName) VALUES ('角色');
select SCOPE_IDENTITY()
INSERT INTO demo_user (UserName, Createtime, RoleId)
VALUES ('jadesun','2012-10-09T16:29:01.00', 2740970);
select SCOPE_IDENTITY()
commit transaction
begin transaction with isolation level: Unspecified
UPDATE demo_user
SET UserName = 'bincle' ,
Createtime = '2012-10-09T16:29:01.00',
RoleId = 2740970 WHERE Id = 2740970 /* @p3_0 */
commit transaction
SELECT TOP (1 /* @p0 */) this_.Id as Id14_0_,
this_.UserName as UserName14_0_,
this_.Createtime as Createtime14_0_,
this_.RoleId as RoleId14_0_
FROM demo_user this WHERE this_.UserName = 'bincle' /* @p1 */
SELECT demorole0_.Id as Id13_0_,
demorole0_.RoleName as RoleName13_0_
FROM demo_role demorole0_
WHERE demorole0_.Id = 1
4.2 测试结果
200 个并发虚拟用户响应时间
Transaction Name Minimum Average Maximum Std.
Deviation
90
Percent
Pass Fail Stop
Action_transaction 0 1.25 2.198 0.221 1.362 642,090 0 0
Minimum 最小。Average 平均。Maximum 最大。Std. Deviation 标准差,这值越小表明统计值越集中在某
个点。 90 Percent 90%的平均值,一般我们取这个值为平均响应时间,这 90%会在全部统计中去除共 10%
的最大、最小,以此降低统计偏差。Pass 事务成功次数。Fail 事务失败数。Stop 事务中止数。
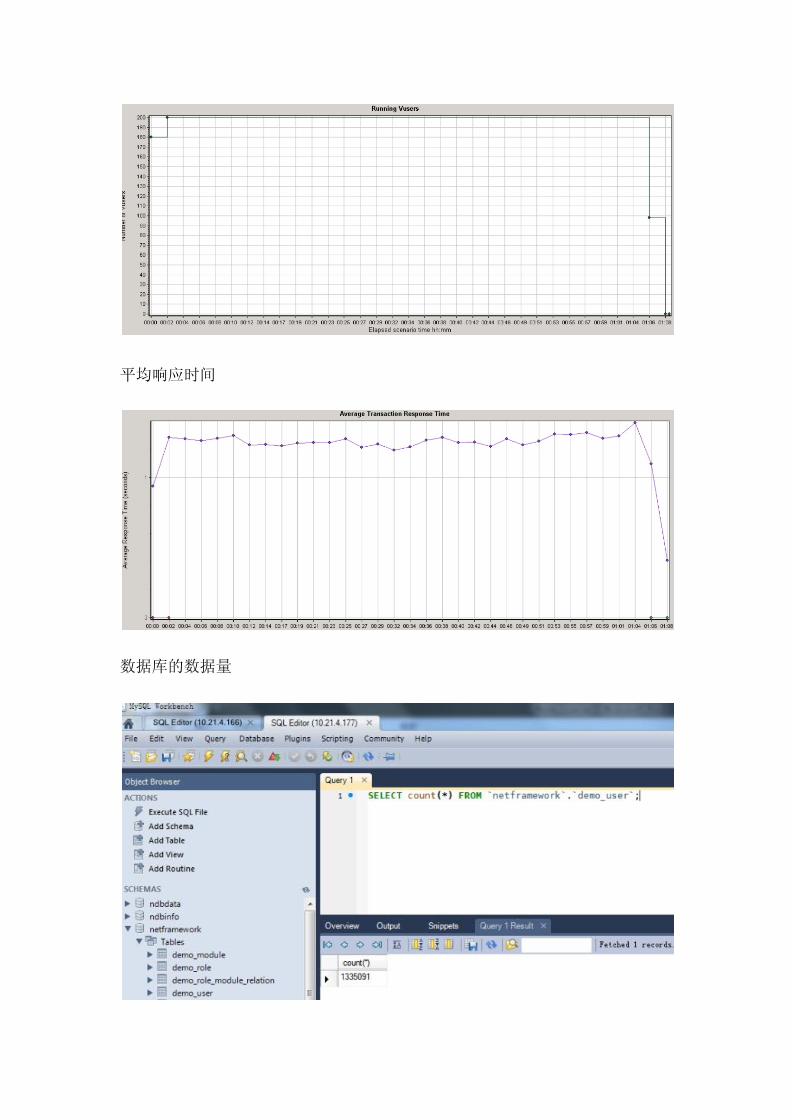
平均响应时间
数据库的数据量

5 .MySQL Cluster 的破坏性测试
5.1 模拟其中一个 SQL 节点宕机时,另一个 SQL 节点是否正常运行。
1,登陆 10.21.4.177,执行 net stop mysql;将 177 上面的 SQL 节点关闭。进行
查询时 177 报出了连接异常。
2,连接 10.21.4.166 的 MYSQL 服务器,可以继续进行查询。
5.2 模拟其中一个数据节点宕机时,集群是否正常。

1,登陆 10.21.4.177,将数据节点的进程强行杀掉,测试集群是否正常。
2,在 10.21.11.81 管理节点上面可以看到 177 的数据节点和管理节点都关闭。

3,启动 177 的 SQL 节点,看看此时查询是否正常。是否能用到 166 的数据节点
中的数据。
10.21.4.177 的 SQL 节点已经启动,但 ndbd(NDB)节点还是脱机的。
连接上 10.21.4.177 的 SQL 节点进行查询,是有结果返回的。说明使用了集
群中 166 的数据节点中的数据。
5.3 当宕机的数据节点恢复之后,是否能快速的同步恢复数据。
1,在当前有一个数据节点脱机的情况下新增数据,看看能不能同步到另一个数
据节点中。
INSERT INTO demo_user (username,roleid) values ('jadesun',2);
2,将 177 的数据节点恢复入集群,然后将 166 脱机。再查询一下数据总量是一
致的,说明数据已经进行了同步恢复。

3,更深入的破坏性测试后面再做。
6 .MySQL Cluster 应用注意事项
1:如果发现关闭一台机器的 ndbd 进程,另一台机器的 ndbd 的进程也关闭,则需要修改参
数 NoOfReplicas。
2:./ndbd --initial 不能同时在所有数据节点机器上执行,如执行,会删除所有数据。
3:可以像操作非簇类型的数据库那样,操作 mysqld 节点。
4:每次修改 config.ini 文件,重启 ndb_mgmd 时,需要删除 mysql-cluster 文件下的
ndb_1_config.bin.1 文件,因为 MySQL Cluster 默认调用此文件。
5:如果在相关节点服务器启动时,注意查看~/mysql/mysql-cluster 目录内的相关日志文件以获
取错误信息。
6:在管理节点的配置文件里各[mysqld],[ndbd]和[ndb_mgmd]配置的选项值顺序应该如下:
[mysqld]
nodeid=4
HostName=192.168.208.3
Id 在顶端紧跟其后的是 HostName,如果顺序错了,当 SQL 或数据节点连接管理节点时,管理
节点无法正确的定位到其对应的节点配置上。因为无法定位到对应的节点配置,当没有剩余
的[空节点]时,客户端节点启动时(./mysqld or ./ndbd)还会报:
Configuration error: Error : Could not alloc node id at 192.168.0.231 port 1186: No free
node id found for mysqld
(API).Failed to initialize consumers
7:[空节点]是没有指定 HostName 选项的节点配置均为空节点,空节点可以用来动态配置一
些动态 IP 的节点,一般管理节点的配置文件要预留 3 个以上的空节点,因为备份时需要连
接一个节点,如下:
[mysqld]
Id=6
8:配置集群的时候,正在加载的进程非正常中断了,并且报错信息如下,为什么会这样?
ERROR 1114: The table 'my_cluster_table' is full
原因很有可能是因为设置的内存不足以装下所有的数据表及其索引,包括 NDB 存储引

擎中所需的主键以及如果没有定义主键时自动创建的索引。
所有的数据节点的内存大小都要一样,因为集群中任何数据节点都不能使用比其他数据
节点最小内存还多的内存。换句话,如果集群中有 4 台计算机,如果有 3 台计算机的内存都
是 3GB,另外一台只有 1GB,那么每个数据节点最多只能拿出 1GB 内存用于集群。
9:MySQL 集群使用 TCP/IP 协议,这是否意味着可以跨越 Internet 网,把某些节点放在远程,
来使用集群呢?
在这种条件下, MySQL 集群不大可能有稳定的表现,因为 MySQL 集群是设计和实现在良
好的高速连接速率环境下的。
同样地,要清楚地意识到 MySQL 集群的 2 个节点之间的通信是不安全的。它们没有经
过任何保护机制加密或者防护。
7.各种问题及解决办法
-- =============================================================================
【1】查看表空间数据文件大小
--
=============================================================================
mysql> SELECT TABLESPACE_NAME, FILE_NAME, EXTENT_SIZE*TOTAL_EXTENTS/1024/1024 AS
TOTAL_MB, EXTENT_SIZE*FREE_EXTENTS/1024/1024 AS FREE_MB, EXTRA FROM
information_schema.FILES WHERE FILE_TYPE="DATAFILE";
+-----------------+------------+----------------+----------------+----------------+
| TABLESPACE_NAME | FILE_NAME | TOTAL_MB | FREE_MB | EXTRA |
+-----------------+------------+----------------+----------------+----------------+
| ts_1 | data_2.dat | 10240.00000000 | 10146.00000000 | CLUSTER_NODE=4 |
| ts_1 | data_2.dat | 10240.00000000 | 10146.00000000 | CLUSTER_NODE=5 |
| ts_1 | data_2.dat | 10240.00000000 | 10146.00000000 | CLUSTER_NODE=6 |
| ts_1 | data_2.dat | 10240.00000000 | 10162.00000000 | CLUSTER_NODE=7 |
| ts_1 | data_1.dat | 512.00000000 | 19.00000000 | CLUSTER_NODE=4 |
| ts_1 | data_1.dat | 512.00000000 | 19.00000000 | CLUSTER_NODE=5 |
| ts_1 | data_1.dat | 512.00000000 | 16.00000000 | CLUSTER_NODE=6 |
| ts_1 | data_1.dat | 512.00000000 | 0.00000000 | CLUSTER_NODE=7 |
+-----------------+------------+----------------+----------------+----------------+
作者: mchdba 时间: 2012-8-16 19:45

-- ============================
【2】:建库报错
mysql> CREATE DATABASE zhang;
Query OK, 1 row affected, 2 warnings (0.01 sec)
mysql>
mysql>
mysql>
mysql> show warnings;
+---------+------+----------------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+----------------------------------------------------------------------------------+
| Warning | 1296 | Got error 4009 'Cluster Failure' from NDB. Could not acquire global schema
lock |
| Warning | 1296 | Got error 4009 'Cluster Failure' from Could not log query '%s' on other
mysqld's |
+---------+------+----------------------------------------------------------------------------------+
2 rows in set (0.00 sec)
【ok】安全模式启动
/usr/local/mysql/bin/mysqld_safe &
作者: mchdba 时间: 2012-8-16 19:45
-- ==============================
【3】ERROR 1296 (HY000): Got error 157 'Unknown error code' from NDBCLUSTER
-- ==============================
mysql> use bg;
Database changed
mysql>
mysql>
mysql> show create table bgt1;
ERROR 1296 (HY000): Got error 157 'Unknown error code' from NDBCLUSTER
mysql>
mysql>
mysql>
mysql>
mysql>
mysql> show create table bgt1;
ERROR 1296 (HY000): Got error 157 'Unknown error code' from NDBCLUSTER
mysql>
mysql>

mysql> create table bgt2(id int,name varchar(20))engine=ndb;
ERROR 1005 (HY000): Can't create table 'bg.bgt2' (errno: 157)
【ok】之后关闭 sql 节点,重新启动,搞定了!
[root@banggo data]# /etc/rc.d/init.d/mysqld stop
Shutting down MySQL.... [确定]
[root@banggo data]# /etc/rc.d/init.d/mysqld start
Starting MySQL... [确定]
[root@banggo data]# mysql
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.5.19-ndb-7.2.4-gpl MySQL Cluster Community Server (GPL)
Copyright (c) 2000, 2011, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> use bg;
Database changed
mysql> show tables;
+--------------+
| Tables_in_bg |
+--------------+
| bgt1 |
+--------------+
1 row in set (0.03 sec)
mysql> desc bgt1;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | 0 | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.02 sec)
作者: mchdba 时间: 2012-8-16 19:46

-- =============================================================================
【4】ERROR 1296 (HY000): Got error 157 'Unknown error code' from NDBCLUSTER
-- =============================================================================
2012-07-18 09:58:15 [MgmtSrvr] WARNING -- Failed to allocate nodeid for API at 10.100.200.41.
Returned eror: 'No free node id found for mysqld(API).'
2012-07-18 09:58:16 [MgmtSrvr] WARNING -- Failed to allocate nodeid for API at 10.100.200.39.
Returned eror: 'No free node id found for mysqld(API).'
2012-07-18 09:58:16 [MgmtSrvr] WARNING -- Failed to allocate nodeid for API at 10.100.200.39.
Returned eror: 'No free node id found for mysqld(API).'
2012-07-18 09:58:17 [MgmtSrvr] WARNING -- Failed to allocate nodeid for API at 10.100.200.41.
Returned eror: 'No free node id found for mysqld(API).'
2012-07-18 09:58:17 [MgmtSrvr] WARNING -- Failed to allocate nodeid for API at 10.100.200.41.
Returned eror: 'No free node id found for mysqld(API).'
2012-07-18 09:58:18 [MgmtSrvr] WARNING -- Failed to allocate nodeid for API at 10.100.200.39.
Returned eror: 'No free node id found for mysqld(API).'
2012-07-18 09:58:18 [MgmtSrvr] WARNING -- Failed to allocate nodeid for API at 10.100.200.39.
Returned eror: 'No free node id found for mysqld(API).'
2012-07-18 09:58:19 [MgmtSrvr] WARNING -- Failed to allocate nodeid for API at 10.100.200.41.
Returned eror: 'No free node id found for mysqld(API).'
2012-07-18 09:58:19 [MgmtSrvr] WARNING -- Failed to allocate nodeid for API at 10.100.200.41.
Returned eror: 'No free node id found for mysqld(API).'
2012-07-18 09:58:20 [MgmtSrvr] WARNING -- Failed to allocate nodeid for API at 10.100.200.39.
Returned eror: 'No free node id found for mysqld(API).'
【ok】:在 config.ini 里面加空的 sql 节点,以便自动扩展 s
[API]
[API]
作者: mchdba 时间: 2012-8-16 19:47
-- =============================================================================
【5】数据节点报错
-- =============================================================================
2012-07-18 23:34:48 [ndbd] INFO -- Start initiated (mysql-5.5.19 ndb-7.2.4)
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
Adding 7164Mb to ZONE_LO (32896,229247)
Adding 4301Mb to ZONE_LO (262145,137607)
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer

NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
WOPool::init(61, 9)
RWPool::init(22, 14)
2012-07-18 23:35:00 [ndbd] INFO -- timerHandlingLab now: 12658118985 sent: 12658118306
diff: 679
2012-07-18 23:36:09 [ndbd] WARNING -- Ndb kernel thread 0 is stuck in: Allocating memory
elapsed=60029
2012-07-18 23:36:09 [ndbd] INFO -- Watchdog: User time: 244 System time: 6855
2012-07-18 23:36:35 [ndbd] ALERT -- Node 4: Forced node shutdown completed. Occured
during startphase 0. Initiated by signal 9.
【ok】:调整参数值
调小参数,内存超过了。
作者: mchdba 时间: 2012-8-16 19:50
-- =============================================================================
【6】建立表空间报错
-- =============================================================================
mysql> CREATE LOGFILE GROUP lg_1 ADD UNDOFILE 'undo_1.log' INITIAL_SIZE 1024 M
UNDO_BUFFER_SIZE 128 M ENGINE NDBCLUSTER;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to
your MySQL server version for the right syntax to use near 'M UNDO_BUFFER_SIZE 128 M
ENGINE NDBCLUSTER' at line 1
mysql>
【ok】M 不识别
-- CREATE LOGFILE GROUP lg_1 ADD UNDOFILE 'undo_1.log' INITIAL_SIZE 536870912
UNDO_BUFFER_SIZE 67108864 ENGINE NDBCLUSTER;
mysql> CREATE LOGFILE GROUP lg_1 ADD UNDOFILE 'undo_1.log' INITIAL_SIZE 536870912
UNDO_BUFFER_SIZE 67108864 ENGINE NDBCLUSTER;
Query OK, 0 rows affected (27.95 sec)
-- CREATE TABLESPACE ts_1 ADD DATAFILE 'data_1.dat' USE LOGFILE GROUP lg_1 INITIAL_SIZE
536870912 ENGINE NDBCLUSTER;
mysql> CREATE TABLESPACE ts_1 ADD DATAFILE 'data_1.dat' USE LOGFILE GROUP lg_1
INITIAL_SIZE 536870912 ENGINE NDBCLUSTER;
Query OK, 0 rows affected (28.79 sec)

# 创建使用磁盘存储的表:
CREATE TABLE `bgtdisk` (
`Name` varchar(50) NOT NULL,
`ProviderName` varchar(200) NOT NULL,
PRIMARY KEY (`Name`)
) tablespace ts_1 storage disk ENGINE=ndbcluster DEFAULT CHARSET=utf8;
作者: mchdba 时间: 2012-8-16 19:51
-- =============================================================================
【7】配置报错
-- =============================================================================
Caused by error 2353: 'Insufficent nodes for system restart(Restart error). Temporary error,
restart node'.
【error】:没有解决,后来重新部署了 cluster。
作者: mchdba 时间: 2012-8-16 19:51
-- =============================================================================
【8】ERROR 1528 (HY000): Failed to create LOGFILE GROUP
-- =============================================================================
mysql> CREATE LOGFILE GROUP lg_02 ADD UNDOFILE 'undo_02.log' INITIAL_SIZE
5368709120 UNDO_BUFFER_SIZE 67108864 ENGINE NDBCLUSTER;
ERROR 1528 (HY000): Failed to create LOGFILE GROUP
mysql>
mysql>
mysql>
mysql> show errors;
+-------+------+--------------------------------+
| Level | Code | Message |
+-------+------+--------------------------------+
| Error | 1528 | Failed to create LOGFILE GROUP |
+-------+------+--------------------------------+
1 row in set (0.00 sec)
mysql>
解决办法:
原来现在的 MYSQL 只支持创建一个 LOGFILE GROUP 文件。
只有删掉原来的才可以创建新的。

作者: mchdba 时间: 2012-8-16 19:53
-- =============================================================================
【9】ERROR 1114 (HY000): The table 'UserMvpbak' is full
-- =============================================================================
mysql> insert into UserMvpbak select * from UserMvp limit 800000,200000;
ERROR 1114 (HY000): The table 'UserMvpbak' is full
mysql>
alter tablespace ts_1
add datafile 'data_3.dat'
initial_size 21474836480
engine ndb;
【ok】原有的数据文件空间满了,需要增加新的数据文件
mysql> alter tablespace ts_1
-> add datafile 'data_2.dat'
-> initial_size 10737418240
-> engine ndb;
Query OK, 0 rows affected (1 min 54.30 sec)
另外,也有可能是 DataMemory 满了的原因。解决办法如下:
ndb_mgm> all report memory; 查看使用量,然后修改相应的 config.ini 文件
Node 2: Data usage is 0%(22 32K pages of total 131072)
Node 2: Index usage is 0%(16 8K pages of total 102432)
Node 3: Data usage is 0%(22 32K pages of total 131072)
Node 3: Index usage is 0%(16 8K pages of total 102432)
作者: mchdba 时间: 2012-8-16 20:13
-- =============================================================================
【10】ERROR 1114 (HY000): The table 'UserMvpbak' is full
-- =============================================================================
mysql> insert into um select * from um limit 940000,3000000;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql>
[ok] 减少录入的数据量
mysql> replace into um select * from um limit 940000,800000;
Query OK, 755105 rows affected (2 min 44.54 sec)
Records: 755105 Duplicates: 0 Warnings: 0

作者: mchdba 时间: 2012-8-16 20:13
-- =============================================================================
【11】Node 4: Forced node shutdown completed. Occured during startphase 0. Initiated by signal
11.
-- =============================================================================
2012-08-15 12:35:38 [ndbd] INFO -- Start initiated (mysql-5.5.25 ndb-7.2.7)
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
2012-08-15 12:35:45 [ndbd] WARNING -- Ndb kernel thread 0 is stuck in: Polling for Receive
elapsed=159
2012-08-15 12:35:45 [ndbd] INFO -- timerHandlingLab now: 498814955 sent: 498814782 diff:
173
2012-08-15 12:35:45 [ndbd] INFO -- Watchdog: User time: 28 System time: 497
2012-08-15 12:35:47 [ndbd] INFO -- timerHandlingLab now: 498816970 sent: 498816803 diff:
167
2012-08-15 12:35:49 [ndbd] INFO -- Watchdog: User time: 39 System time: 741
2012-08-15 12:35:49 [ndbd] WARNING -- Watchdog: Warning overslept 262 ms, expected 100
ms.
2012-08-15 12:35:49 [ndbd] INFO -- timerHandlingLab now: 498818963 sent: 498818779 diff:
184
Adding 5201Mb to ZONE_LO (1152,166408)
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer

NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
NDBFS/AsyncFile: Allocating 310392 for In/Deflate buffer
2012-08-15 12:35:56 [ndbd] WARNING -- Ndb kernel thread 0 is stuck in: Allocating memory
elapsed=6002
2012-08-15 12:35:56 [ndbd] INFO -- Watchdog: User time: 61 System time: 1179
2012-08-15 12:36:02 [ndbd] WARNING -- Ndb kernel thread 0 is stuck in: Allocating memory
elapsed=12006
2012-08-15 12:36:02 [ndbd] INFO -- Watchdog: User time: 64 System time: 1763
2012-08-15 12:36:08 [ndbd] WARNING -- Ndb kernel thread 0 is stuck in: Allocating memory
elapsed=18030
2012-08-15 12:36:08 [ndbd] INFO -- Watchdog: User time: 70 System time: 1957
2012-08-15 12:36:12 [ndbd] ALERT -- Node 4: Forced node shutdown completed. Occured
during startphase 0. Initiated by signal 11.
[ok] 注释如下三个参数,启动 ok!
#MaxNoOfConcurrentTransactions=100000
#MaxNoOfConcurrentOperations=10000000
#MaxNoOfLocalOperations=11000000
作者: mchdba 时间: 2012-8-16 20:14
-- =============================================================================
【12】启动管理节点报错
-- =============================================================================
[root@banggo mysql-cluster]# ndb_mgmd -f /usr/local/mysql/cluster-conf/config.ini --reload
MySQL Cluster Management Server mysql-5.5.25 ndb-7.2.7
2012-08-15 21:36:54 [MgmtSrvr] ERROR -- at line 18: Illegal value 128 for parameter
LockPagesInMainMemory.
Legal values are between 0 and 2
2012-08-15 21:36:54 [MgmtSrvr] ERROR -- at line 18: Could not parse name-value pair in
config file.
2012-08-15 21:36:54 [MgmtSrvr] ERROR -- Could not load configuration from
'/usr/local/mysql/cluster-conf/config.ini'
2012-08-15 21:36:54 [MgmtSrvr] ERROR -- Could not determine which nodeid to use for this
node. Specify it with --ndb-nodeid=<nodeid> on command line
[root@banggo mysql-cluster]#
[root@banggo mysql-cluster]#
【ok】LockPagesInMainMemory 值设置太大了!改成默认的 1,搞定。

作者: mchdba 时间: 2012-8-16 20:15
-- =============================================================================
【13】 1528 错误
-- =============================================================================
mysql> CREATE LOGFILE GROUP lg_1
-> ADD UNDOFILE 'undo_2.log'
-> INITIAL_SIZE 634217728
-> UNDO_BUFFER_SIZE 134217728
-> ENGINE NDBCLUSTER;
ERROR 1528 (HY000): Failed to create LOGFILE GROUP
mysql>
mysql>
mysql>
mysql> show warnings;
+---------+------+---------------------------------------------------+
| Level | Code | Message |
+---------+------+---------------------------------------------------+
| Warning | 1296 | Got error 1504 'Out of logbuffer memory' from NDB |
| Error | 1528 | Failed to create LOGFILE GROUP |
+---------+------+---------------------------------------------------+
2 rows in set (0.00 sec)
【ok】
# UNDO_BUFFER_SIZE 不能超过 config.ini 的配置 RedoBuffer=32M 大小,否则创建失败,
CREATE LOGFILE GROUP lg_1
ADD UNDOFILE 'undo_2.log'
INITIAL_SIZE 634217728
UNDO_BUFFER_SIZE 33554432
ENGINE NDBCLUSTER;
CREATE TABLESPACE ts_1
ADD DATAFILE 'data_10.dat'
USE LOGFILE GROUP lg_1
INITIAL_SIZE 32212254720
EXTENT_SIZE 33554432
ENGINE NDBCLUSTER;
执行结束之后,需要去数据目录/var/lib/mysql-cluster/里面看看 undo 文件和 data 文件,
如果存在,那么就证明建立成功了。
可以建立 2 个表空间
CREATE TABLESPACE ts_2
ADD DATAFILE 'data_20.dat'
USE LOGFILE GROUP lg_1
INITIAL_SIZE 10737418240

EXTENT_SIZE 33554432
ENGINE NDBCLUSTER;
create table bguserdb.mcbak like test.mc;
alter table bguserdb.mcbak tablespace ts_1 storage disk ENGINE=ndbcluster DEFAULT
CHARSET=utf8;
insert into bguserdb.mcbak select * from test.mc;
CREATE TABLESPACE ts_1
ADD DATAFILE 'data_10.dat‘ USE LOGFILE GROUP lg_1 INITIAL_SIZE 32212254720
EXTENT_SIZE 33554432 ENGINE NDBCLUSTER;
作者: mchdba 时间: 2012-8-16 20:17
本帖最后由 mchdba 于 2012-8-16 20:17 编辑
-- =============================================================================
【14】 1528 错误
--
=============================================================================
mysql> insert into bguserdb.mv select * from test.mc;
ERROR 1297 (HY000): Got temporary error 410 'REDO log files overloaded (decrease
TimeBetweenLocalCheckpoints or increase NoOfFragmentLogFiles)' from NDBCLUSTER
mysql>
【】增加 2 个参数的值
TimeBetweenLocalCheckpoints=30
NoOfFragmentLogFiles=128
作者: mchdba 时间: 2012-8-16 20:19
本帖最后由 mchdba 于 2012-8-16 20:19 编辑
-- =============================================================================
【15】 1005 错误
-- =============================================================================
mysql> create table bu.mcbak like test.mc;
Query OK, 0 rows affected (0.07 sec)
mysql> alter table bu.mcbak tablespace ts_1 storage disk ENGINE=ndbcluster DEFAULT
CHARSET=utf8;
ERROR 1005 (HY000): Can't create table 'bu.#sql -14ab_2' (errno: 140)
mysql> show errors;
+-------+------+--------------------------------------------------------+

| Level | Code | Message |
+-------+------+--------------------------------------------------------+
| Error | 1005 | Can't create table 'bu.#sql-14ab_2' (errno: 140) |
+-------+------+--------------------------------------------------------+
1 row in set (0.00 sec)
mysql> show warnings;
+---------+------+--------------------------------------------------------+
| Level | Code | Message |
+---------+------+--------------------------------------------------------+
| Warning | 1296 | Got error 755 'Invalid tablespace' from NDB |
| Error | 1005 | Can't create table 'bu.#sql-14ab_2' (errno: 140) |
+---------+------+--------------------------------------------------------+
2 rows in set (0.00 sec)
mysql>
【ok】重新建立表空间:
CREATE LOGFILE GROUP lg_1
ADD UNDOFILE 'undo_1.log'
INITIAL_SIZE 334217728
UNDO_BUFFER_SIZE 33554432
ENGINE NDBCLUSTER;
CREATE TABLESPACE ts_1 ADD DATAFILE 'data_11.dat' USE LOGFILE GROUP lg_1 INITIAL_SIZE
4294967296 EXTENT_SIZE 33554432 ENGINE NDBCLUSTER;
alter table bu.mc tablespace ts_1 storage disk ENGINE=ndbcluster DEFAULT CHARSET=utf8;
insert into bu.mc select * from test.mc limit 0,100000;
作者: mchdba 时间: 2012-8-16 20:21
-- =============================================================================
【16】 1005 错误
-- =============================================================================
mysql> alter table oib TABLESPACE ts_1 STORAGE DISK ENGINE=ndbcluster DEFAULT
CHARSET=utf8;
ERROR 1005 (HY000): Can't create table 'os.#sql-711_3' (errno: 851)
mysql> show warnings;
+---------+------+-------------------------------------------------------------------------------------------------------------
--------+
| Level | Code |
Message |
+---------+------+-------------------------------------------------------------------------------------------------------------
--------+
| Warning | 1296 | Got error 851 'Maximum 8052 bytes of FIXED columns supported, use varchar
or COLUMN_FORMAT DYNMIC instead' from NDB |
| Error | 1005 | Can't create table 'os.#sql-711_3' (errno:

851) |
+---------+------+-------------------------------------------------------------------------------------------------------------
--------+
2 rows in set (0.00 sec)
[暂无解决方案]google 之,无果!
作者: mchdba 时间: 2012-8-16 20:22
-- =============================================================================
【17】 1297 错误
-- =============================================================================
mysql> alter table ebelkTABLESPACE ts_1 STORAGE DISK ENGINE=ndbcluster DEFAULT
CHARSET=utf8 comment '';
ERROR 1297 (HY000): Got temporary error 1501 'Out of undo space' from NDBCLUSTER
mysql>
mysql> show errors;
+-------+------+--------------------------------------------------------------+
| Level | Code | Message |
+-------+------+--------------------------------------------------------------+
| Error | 1297 | Got temporary error 1501 'Out of undo space' from NDBCLUSTER |
| Error | 1296 | Got error 4350 'Transaction already aborted' from NDBCLUSTER |
| Error | 1180 | Got error 4350 during COMMIT |
+-------+------+--------------------------------------------------------------+
3 rows in set (0.00 sec)
mysql>
[ok]增加数据文件,数据文件空间可能不够了。
alter tablespace ts_1 add datafile 'data_12.dat' initial_size 10737418240 engine NDBCLUSTER;
alter tablespace ts_1 add datafile 'data_13.dat' initial_size 10737418240 engine NDBCLUSTER;
alter tablespace ts_1 add datafile 'data_14.dat' initial_size 10737418240 engine NDBCLUSTER;
作者: mchdba 时间: 2012-8-16 20:23
-- =============================================================================
【18】 1297 错误
-- =============================================================================
mysql> alter table aau TABLESPACE ts_1 STORAGE DISK ENGINE=ndbcluster DEFAULT
CHARSET=utf8 comment '';
ERROR 1297 (HY000): Got temporary error 1501 'Out of undo space' from NDBCLUSTER
mysql> show warnings;

+---------+------+--------------------------------------------------------------+
| Level | Code | Message |
+---------+------+--------------------------------------------------------------+
| Warning | 1297 | Got temporary error 1501 'Out of undo space' from NDB |
| Error | 1297 | Got temporary error 1501 'Out of undo space' from NDBCLUSTER |
| Warning | 1296 | Got error 4350 'Transaction already aborted' from NDB |
| Error | 1296 | Got error 4350 'Transaction already aborted' from NDBCLUSTER |
| Error | 1180 | Got error 4350 during COMMIT |
+---------+------+--------------------------------------------------------------+
5 rows in set (0.00 sec)
mysql>
【】暂时未解决。
作者: mchdba 时间: 2012-8-16 20:24
-- =============================================================================
【19】 1297 错误
-- =============================================================================
ndb_mgm> Node 7: Forced node shutdown completed. Occured during startphase 4. Caused by
error 2303: 'System error, node killed during node restart by other node(Internal error,
programming error or missing error message, please report a bug). Temporary error, restart node'.
Node 4: Forced node shutdown completed. Occured during startphase 4. Caused by error 2308:
'Another node failed during system restart, please investigate error(s) on other node(s)(Restart
error). Temporary error, restart node'.
Node 5: Forced node shutdown completed. Occured during startphase 4. Caused by error 2308:
'Another node failed during system restart, please investigate error(s) on other node(s)(Restart
error). Temporary error, restart node'.
Node 6: Forced node shutdown completed. Occured during startphase 4. Caused by error 2308:
'Another node failed during system restart, please investigate error(s) on other node(s)(Restart
error). Temporary error, restart node'.
【ok】baidu,google 之,没有得到相似的案列,看到一个 emporary error, restart node 的提
示,不得已 restart node 节点
重新在 4 个 data 节点,执行 ndbd --initial,等待 2 分钟,搞定!oh,my god,不知道其中
的原理,但是 data node 确实是起来了。
ndb_mgm> Node 4: Started (version 7.2.7)
Node 7: Started (version 7.2.7)
Node 5: Started (version 7.2.7)
Node 6: Started (version 7.2.7)
启动 sql 节点,执行检查数据

mysql> SELECT TABLESPACE_NAME, FILE_NAME, EXTENT_SIZE*TOTAL_EXTENTS/1024/1024 AS
TOTAL_MB, EXTENT_SIZE*FREE_EXTENTS/1024/1024 AS FREE_MB, EXTRA FROM
information_schema.FILES WHERE FILE_TYPE="DATAFILE";
Empty set (0.00 sec)
mysql>
oh my god,原来的数据文件都无法显示了。简直是暴力破解啊,^_^!
作者: mchdba 时间: 2012-8-16 21:44
本帖最后由 mchdba 于 2012-8-16 21:51 编辑
-- =============================================================================
【20】 Out of undo space
-- =============================================================================
mysql> insert into mc select * from zzbak_mc limit 0,10000;
ERROR 1297 (HY000): Got temporary error 1501 'Out of undo space' from NDBCLUSTER
mysql> show warnings;
+---------+------+--------------------------------------------------------------+
| Level | Code | Message |
+---------+------+--------------------------------------------------------------+
| Warning | 1297 | Got temporary error 1501 'Out of undo space' from NDB |
| Error | 1297 | Got temporary error 1501 'Out of undo space' from NDBCLUSTER |
+---------+------+--------------------------------------------------------------+
2 rows in set (0.00 sec)
【ok】参考网址 http://forums.mysql.com/read.php?25,413217,413217
I add another undo log file ,it's ok now ,but counld some one tell me how can I know the usage of
my undo log file ? SELECT FILE_NAME FROM information_schema.files WHERE FILE_TYPE='UNDO
LOG'\G;
执行:alter LOGFILE GROUP lg_1 ADD UNDOFILE 'undo_21.log' UNDO_BUFFER_SIZE 33554432
ENGINE NDBCLUSTER;
mysql> alter LOGFILE GROUP lg_1 ADD UNDOFILE 'undo_21.log' ENGINE NDBCLUSTER;
Query OK, 0 rows affected (4.33 sec)
-- 查看系统已有的 undo 文件
mysql> SELECT FILE_NAME FROM information_schema.files WHERE FILE_TYPE='UNDO LOG';
+-------------+
| FILE_NAME |
+-------------+
| undo_2.log |
| undo_2.log |
| undo_2.log |
| undo_2.log |

| undo_21.log |
| undo_21.log |
| undo_21.log |
| undo_21.log |
| NULL |
+-------------+
9 rows in set (0.05 sec)
mysql>SELECT FILE_NAME FROM information_schema.files WHERE FILE_TYPE='UNDO LOG'\G;
搞定,OK。
mysql> insert into mc select * from zzbak_mc limit 0,10000;
Query OK, 10000 rows affected (0.80 sec)
Records: 10000 Duplicates: 0 Warnings: 0
mysql> insert into mc select * from zzbak_mc limit 810000,890000;
Query OK, 890000 rows affected (2 min 10.10 sec)
Records: 890000 Duplicates: 0 Warnings: 0
作者: mchdba 时间: 2012-8-17 12:33
-- =============================================================================
【21】 后台日志报错,批量 insert 数据
-- =============================================================================
2012-08-16 22:38:05 [ndbd] ERROR -- c_gcp_list.seize() failed: gci: 38285338476552 nodes:
0000000000000000000000000000000000000000000000000000000000016400
2012-08-16 22:38:05 [ndbd] WARNING -- ACK wo/ gcp record (gci: 8914/8) ref: 0fa2000e from:
0fa2000e
2012-08-16 22:38:05 [ndbd] WARNING -- ACK wo/ gcp record (gci: 8914/8) ref: 0fa2000a from:
0fa2000a
2012-08-16 22:38:05 [ndbd] WARNING -- ACK wo/ gcp record (gci: 8914/8) ref: 0fa20010 from:
0fa20010
2012-08-16 22:38:05 [ndbd] ERROR -- c_gcp_list.seize() failed: gci: 38285338476553 nodes:
0000000000000000000000000000000000000000000000000000000000016400
2012-08-16 22:38:05 [ndbd] WARNING -- ACK wo/ gcp record (gci: 8914/9) ref: 0fa2000e from:
0fa2000e
2012-08-16 22:38:05 [ndbd] WARNING -- ACK wo/ gcp record (gci: 8914/9) ref: 0fa2000a from:
0fa2000a
2012-08-16 22:38:05 [ndbd] ERROR -- c_gcp_list.seize() failed: gci: 38289633443840 nodes:
0000000000000000000000000000000000000000000000000000000000016400
2012-08-16 22:38:05 [ndbd] WARNING -- ACK wo/ gcp record (gci: 8914/9) ref: 0fa20010 from:
0fa20010
2012-08-16 22:38:05 [ndbd] WARNING -- ACK wo/ gcp record (gci: 8915/0) ref: 0fa2000a from:
0fa2000a

2012-08-16 22:38:05 [ndbd] WARNING -- ACK wo/ gcp record (gci: 8915/0) ref: 0fa20010 from:
0fa20010
2012-08-16 22:38:05 [ndbd] WARNING -- ACK wo/ gcp record (gci: 8915/0) ref: 0fa2000e from:
0fa2000e
【ok】减少 insert 的数量,一次批量从 100W 减少到 50W,ok,不会报异常信息了。
作者: mchdba 时间: 2012-8-17 12:33
-- =============================================================================
【22】 第 4 个 data 节点意外 down 了
-- =============================================================================
ndb_mgm> Node 7: Forced node shutdown completed. Caused by error 2305: 'Node lost
connection to other nodes and can not form a unpartitioned cluster, please investigate if there
are error(s) on other node(s)(Arbitration error). Temporary error, restart node'.
ndb_mgm>
【ok】执行 ndbd 重新启动起来
作者: arron 刘 时间: 2012-8-17 15:46
作者: mchdba 时间: 2012-8-18 23:12
arron 刘 发表于 2012-8-17 15:46
-- =============================================================================
【22】 管理台老是报警,诡异
-- =============================================================================
一次性批量录入了 100W 数据,管理节点控制台报如下信息:
ndb_mgm> Node 7: Data usage increased to 80%(64016 32K pages of total 80000)
Node 4: Data usage increased to 80%(64007 32K pages of total 80000)
Node 5: Data usage increased to 80%(64014 32K pages of total 80000)
Node 6: Data usage increased to 80%(64001 32K pages of total 80000)
Node 4: Data usage increased to 90%(72005 32K pages of total 80000)
Node 5: Data usage increased to 90%(72014 32K pages of total 80000)
Node 7: Data usage increased to 90%(72010 32K pages of total 80000)
Node 6: Data usage increased to 90%(72009 32K pages of total 80000)
Node 6: Data usage decreased to 89%(71772 32K pages of total 80000)

Node 7: Data usage decreased to 89%(71271 32K pages of total 80000)
Node 4: Data usage decreased to 89%(71215 32K pages of total 80000)
Node 5: Data usage decreased to 88%(70607 32K pages of total 80000)
Node 5: Data usage decreased to 79%(63850 32K pages of total 80000)
Node 7: Data usage decreased to 79%(63673 32K pages of total 80000)
Node 4: Data usage decreased to 78%(62947 32K pages of total 80000)
Node 6: Data usage decreased to 78%(62932 32K pages of total 80000)
没有搞懂这是什么情况呢?
作者: mchdba 时间: 2012-8-19 17:03
-- =============================================================================
【23】 ERROR 1297 (HY000)
-- =============================================================================
mysql> insert into bu.up_2012 select * from test.up_2012 limit 1200000,10000;
ERROR 1297 (HY000): Got temporary error 899 'Rowid already allocated' from NDBCLUSTER
mysql>
【ok】网上都说需要调大 datamemory,但是我的是磁盘表,应该不是这个原因,不得已只
有 restart cluster 了试试了,还好搞定了!
mysql> replace into bu.up_2012 select * from test.up_2012 limit 1200000,300000;
Query OK, 300000 rows affected (59.97 sec)
Records: 300000 Duplicates: 0 Warnings: 0
赞叹一句,网上关于 STORAGE DISK ndbcluster table 的测试的资料好少啊!
作者: mchdba 时间: 2012-8-19 20:05
-- =============================================================================
【25】 修改了 config.in 之后,data node 启动,需要 ndbd --initial 重新加载之后,
原有的*.dat 数据文件无效,启动不起来,sql 节点启动之后,show tables; 原来的磁盘表都
不见了,诡异啊!
-- =============================================================================
1 修改 config.inf
2 ndb_mgmd -f /usr/local/mysql/cluster-conf/config.ini --reload 重新加载管理节点
3 ndbd --initial 重新启动 data node
4 service mysqld start
5 use bu; show tables; 原来的表不存在了,丢失了。
看的文档是说,原有的数据文件加载不了,我想问的是:
1 如果我已经导入了很多数据,这个时候发现自己的配置参数不合理,我要修改配置参数,
能不能在线修改并生效。
2 如果 1 失败,我能否在重新启动管理节点之后,启动 data node 的时候,能加载进去以前

的数据呢?
作者: kerlion 时间: 2012-8-20 10:06
想修改配置,需要以--initial 或 reload 的方式重新启动 ndb_mgmd
ndbd 一般不需要--initial 启动,只有当有文件文件损坏的时候,它会删除所有本地文件,然
后从其他节点的 member 取回数据,如果其它都是 down 的,那数据库就丢失了
mysql cluster 很不稳定,启动很可能失败,修改场数据前最好备份一下,实在不行全部--initial
启动,恢复数据