ncbi fieldguide ncbi molecular biology resources a field guide university of massachusettsaugust...
Post on 19-Dec-2015
216 views
TRANSCRIPT

NC
BI
Fie
ldG
uid
e
NCBI Molecular Biology Resources
A Field Guide
University of MassachusettsAugust 2-3, 2005

NC
BI
Fie
ldG
uid
e• The NCBI Entrez System
• NCBI Sequence Databases– Primary data: GenBank– Derivative data: RefSeq, Gene, Genome – Beyond Refseq: UniGene, Trace Archive
• NCBI Genomic Resources** Intermission **
• BLAST
• Protein Structure and Function
• Sequence polymorphisms and phenotypes
NCBI Resources
NC
BI
Fie
ldG
uid
eThe National Institutes of Health
Bethesda, MD

NC
BI
Fie
ldG
uid
eThe National Center for
Biotechnology Information
• Created as a part of NLM in 1988– Establish public databases– Perform research in computational biology– Develop software tools for sequence analysis– Disseminate biomedical information

NC
BI
Fie
ldG
uid
eWeb
Access
BLAST
VAST
Entrez
Text
Sequence
Structure

NC
BI
Fie
ldG
uid
e
NCBI Web Traffic
Christmas and New Year’s Day
User’s per day
NC
BI
Fie
ldG
uid
e
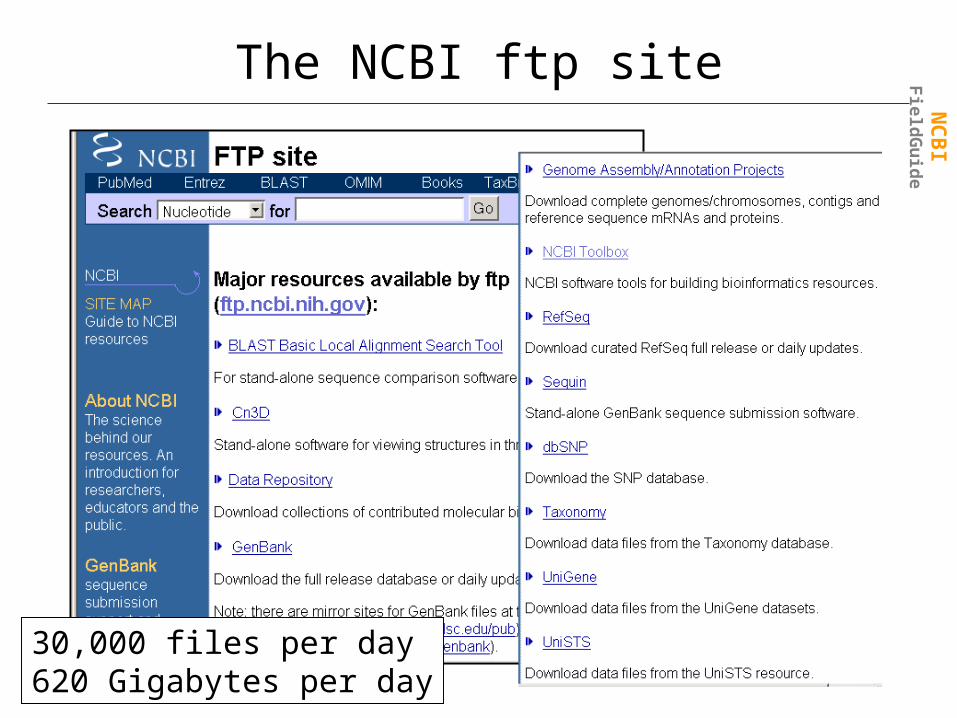
The NCBI ftp site
30,000 files per day620 Gigabytes per day

NC
BI
Fie
ldG
uid
e
What does NCBI do?
• NCBI accepts submissions of primary data
• NCBI develops tools to analyze these data
• NCBI uses these tools to create derivative databases based on the primary data
• NCBI provides free search, link, and retreival of these data, primarily through the Entrez system

NC
BI
Fie
ldG
uid
e
Types of Databases
• Primary Databases– Original submissions by experimentalists– Content controlled by the submitter
• Examples: GenBank, SNP, GEO, PubChem Substance
• Derivative Databases– Built from primary data– Content controlled by third party (NCBI)
• Examples: Refseq, TPA, RefSNP, UniGene, Protein, Structure, Conserved Domain, PubChem Compound

NC
BI
Fie
ldG
uid
e
Primary vs. Derivative Databases
ACGTGC
CG
TG
AATTGACTAACGTGCA
CG
TG
C
TTGACA
TATAGCCG
GenBank
SequencingCenters
GAGA
ATTC
C GAGA
ATTC
C UniGene
RefSeq:LocusLink andGenomes Pipelines
RefSeq:Annotation Pipeline
Labs
Curators
Algorithms
TATAGCCGAGCTCCGATACCGATGACAA
Updated ONLY by submitters
EST UniSTS
STS
GSS
HTG
Updated continuall
y by NCBI
PRI ROD PLN MAM BCT
INV VRT PHG VRL

NC
BI
Fie
ldG
uid
e
What is Entrez?
• A system of 29 linked databases
• A text search engine
• A tool for finding biologically linked data
• A retrieval engine
• A virtual workspace for manipulating large datasets

NC
BI
Fie
ldG
uid
e
The Entrez System: Text Searches

NC
BI
Fie
ldG
uid
e
Entrez Databases
• Each record is assigned a UID– unique integer identifier for internal tracking– GI number for Nucleotide
• Each record is given a Document Summary– a summary of the record’s content (DocSum)
• Each record is assigned links to biologically related UIDs
• Each record is indexed by data fields– [author], [title], [organism], and many others

NC
BI
Fie
ldG
uid
e
Entrez Taxonomy
The backbone of NCBI
[organism]

NC
BI
Fie
ldG
uid
e
An Entrez Database - Nucleotide
• GenBank: Primary Data (97.9%)– original submissions by experimentalists– submitters retain editorial control of records– archival in nature
• RefSeq: Derivative Data (2.1%)– curated by NCBI staff– NCBI retains editorial control of records– record content is updated continually

NC
BI
Fie
ldG
uid
e
Entrez Nucleotide
Primary Data • DDBJ / EMBL / GenBank 56,865,268
Derivative Data• RefSeq 1,226,084
• PDB 5,973• Third Party Annotation 4,650
Total 58,101,975

NC
BI
Fie
ldG
uid
eWhat is GenBank? NCBI’s Primary Sequence
Database• Nucleotide only sequence database • Archival in nature• Each record is assigned a stable accession number• GenBank Data
– Direct submissions (traditional records )– Batch submissions (EST, GSS, STS)– ftp accounts (genome data)
• Three collaborating databases– GenBank– DNA Database of Japan (DDBJ) – European Molecular Biology Laboratory (EMBL)
Database

NC
BI
Fie
ldG
uid
e
EBI
GenBankGenBank
DDBJDDBJ
EMBLEMBL
EMBLEMBL
Entrez
SRS
getentry
NIGNIGCIB
NCBI
NIHNIH
•Submissions•Updates •Submissions
•Updates
•Submissions•Updates
The International Sequence Database Collaboration
SequinBankItftp

NC
BI
Fie
ldG
uid
e
• full release every two months• incremental and cumulative updates daily• available only through internet
ftp://ftp.ncbi.nih.gov/genbank/
Release 148 June 2005 45,236,251 Records 49,398,852,122 Nucleotides >140,000 Species 172 Gigabytes 785 files
GenBank Releases
NC
BI
Fie
ldG
uid
e
0
5
10
15
20
25
30
35
40
45
50
Jun
-82
Jun
-84
Jun
-86
Jun
-88
Jun
-90
Jun
-92
Jun
-94
Jun
-96
Jun
-98
Jun
-00
Jun
-02
Jun
-04
Date
Ba
se
Pa
irs
(b
illi
on
s)
0
5
10
15
20
25
30
35
40
45
Rec
ord
s (m
illio
ns)
BasepairsRecords
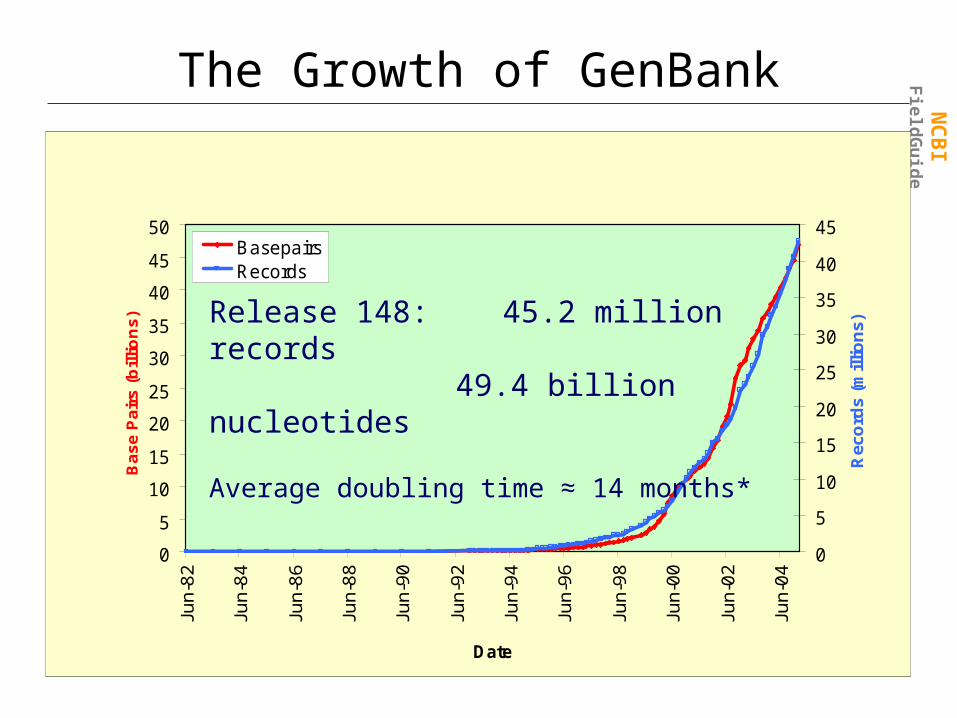
The Growth of GenBank
Release 148: 45.2 million records 49.4 billion nucleotides
Average doubling time ≈ 14 months*

NC
BI
Fie
ldG
uid
e
GenBank Divisions
PRI (28) Primate ROD (14) Rodent PLN (13) Plant and FungalBCT (10) Bacterial/ArchealINV (7) InvertebrateVRT (7) Other Vertebrate VRL (4) ViralMAM (2) MammalianPHG (1) PhageSYN (1) SyntheticUNA (1) Unannotated
•Direct Submissions (Sequin/Bankit)•Accurate (~1 error per 10,000 bp)•Well characterized•Organized by taxonomy
EST (349) Expressed Sequence Tag GSS (120) Genome Survey SequenceHTG (62) High Throughput GenomicHTC (6) High Throughput cDNA STS (5) Sequence Tagged Site
•From sequencing projects•Batch submissions (ftp/email) •Inaccurate•Poorly Characterized•Organized by sequence type
Traditional
Bulk

NC
BI
Fie
ldG
uid
e
A Traditional GenBank RecordLOCUS AY182241 1931 bp mRNA linear PLN 04-MAY-2004DEFINITION Malus x domestica (E,E)-alpha-farnesene synthase (AFS1) mRNA, complete cds.ACCESSION AY182241VERSION AY182241.2 GI:32265057KEYWORDS .SOURCE Malus x domestica (cultivated apple) ORGANISM Malus x domestica Eukaryota; Viridiplantae; Streptophyta; Embryophyta; Tracheophyta; Spermatophyta; Magnoliophyta; eudicotyledons; core eudicots; rosids; eurosids I; Rosales; Rosaceae; Maloideae; Malus.REFERENCE 1 (bases 1 to 1931) AUTHORS Pechous,S.W. and Whitaker,B.D. TITLE Cloning and functional expression of an (E,E)-alpha-farnesene synthase cDNA from peel tissue of apple fruit JOURNAL Planta 219, 84-94 (2004)REFERENCE 2 (bases 1 to 1931) AUTHORS Pechous,S.W. and Whitaker,B.D. TITLE Direct Submission JOURNAL Submitted (18-NOV-2002) PSI-Produce Quality and Safety Lab, USDA-ARS, 10300 Baltimore Ave. Bldg. 002, Rm. 205, Beltsville, MD 20705, USAREFERENCE 3 (bases 1 to 1931) AUTHORS Pechous,S.W. and Whitaker,B.D. TITLE Direct Submission JOURNAL Submitted (25-JUN-2003) PSI-Produce Quality and Safety Lab, USDA-ARS, 10300 Baltimore Ave. Bldg. 002, Rm. 205, Beltsville, MD 20705, USA REMARK Sequence update by submitterCOMMENT On Jun 26, 2003 this sequence version replaced gi:27804758.FEATURES Location/Qualifiers source 1..1931 /organism="Malus x domestica" /mol_type="mRNA" /cultivar="'Law Rome'" /db_xref="taxon:3750" /tissue_type="peel" gene 1..1931 /gene="AFS1" CDS 54..1784 /gene="AFS1" /note="terpene synthase" /codon_start=1 /product="(E,E)-alpha-farnesene synthase" /protein_id="AAO22848.2" /db_xref="GI:32265058" /translation="MEFRVHLQADNEQKIFQNQMKPEPEASYLINQRRSANYKPNIWK NDFLDQSLISKYDGDEYRKLSEKLIEEVKIYISAETMDLVAKLELIDSVRKLGLANLF EKEIKEALDSIAAIESDNLGTRDDLYGTALHFKILRQHGYKVSQDIFGRFMDEKGTLE NHHFAHLKGMLELFEASNLGFEGEDILDEAKASLTLALRDSGHICYPDSNLSRDVVHS LELPSHRRVQWFDVKWQINAYEKDICRVNATLLELAKLNFNVVQAQLQKNLREASRWW ANLGIADNLKFARDRLVECFACAVGVAFEPEHSSFRICLTKVINLVLIIDDVYDIYGS EEELKHFTNAVDRWDSRETEQLPECMKMCFQVLYNTTCEIAREIEEENGWNQVLPQLT KVWADFCKALLVEAEWYNKSHIPTLEEYLRNGCISSSVSVLLVHSFFSITHEGTKEMA DFLHKNEDLLYNISLIVRLNNDLGTSAAEQERGDSPSSIVCYMREVNASEETARKNIK GMIDNAWKKVNGKCFTTNQVPFLSSFMNNATNMARVAHSLYKDGDGFGDQEKGPRTHI LSLLFQPLVN"ORIGIN 1 ttcttgtatc ccaaacatct cgagcttctt gtacaccaaa ttaggtattc actatggaat 61 tcagagttca cttgcaagct gataatgagc agaaaatttt tcaaaaccag atgaaacccg 121 aacctgaagc ctcttacttg attaatcaaa gacggtctgc aaattacaag ccaaatattt 181 ggaagaacga tttcctagat caatctctta tcagcaaata cgatggagat gagtatcgga 241 agctgtctga gaagttaata gaagaagtta agatttatat atctgctgaa acaatggatt
1801 aataaatagc agcaaaagtt tgcggttcag ttcgtcatgg ataaattaat ctttacagtt 1861 tgtaacgttg ttgccaaaga ttatgaataa aaagttgtag tttgtcgttt aaaaaaaaaa 1921 aaaaaaaaaa a//
Header
Feature Table
Sequence
The Flatfile Format

NC
BI
Fie
ldG
uid
e
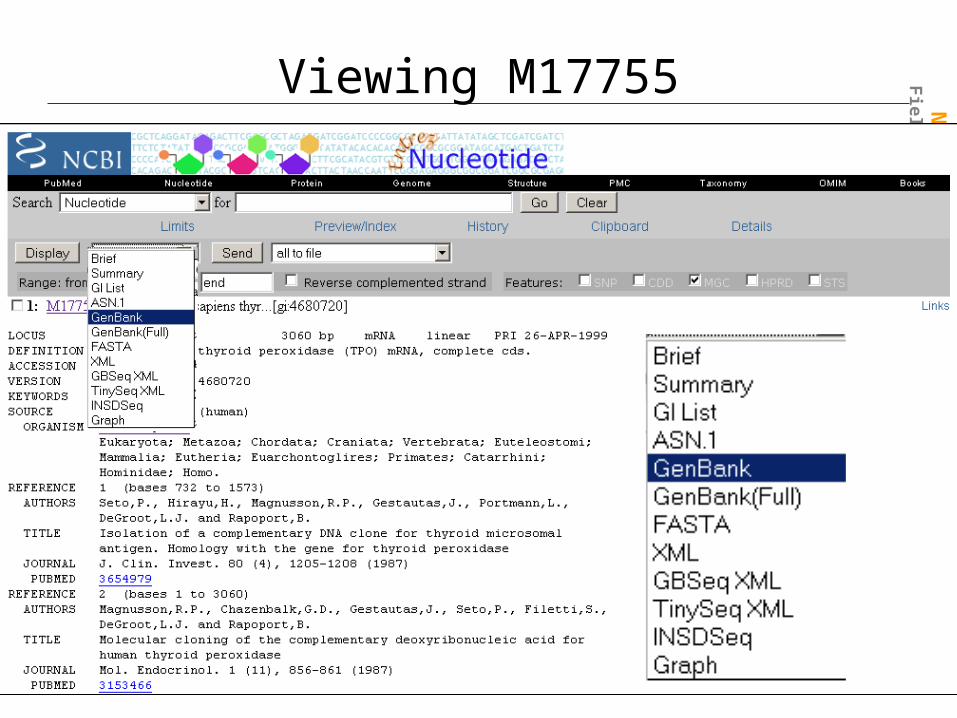
An Example Record – M17755
Field Indexed Terms
[primary accession] M17755[title] Homo sapiens thyroid peroxidase (TPO) mRNA…[organism] Homo sapiens[sequence length] 3060[modification date] 1999/04/26[properties] biomol mrna
gbdiv prisrcdb genbank
Indexing for Nucleotide UID 4680720

NC
BI
Fie
ldG
uid
e
M17755: Feature Table
CDS position in bp
TPO [gene name]
thyroiditis[text word]
thyroid peroxidase[protein name]
protein accession

NC
BI
Fie
ldG
uid
e
Sequence: 99.99% Accurate
The sequence itselfis not indexed…
Use BLAST for that!

NC
BI
Fie
ldG
uid
e
Entrez Protein
• GenPept (DDBJ, EMBL, GenBank) 4,444,405• RefSeq 1,753,167• PIR 222,395• Swiss Prot 189,005• PDB 68,621• PRF 12,079• Third Party Annotation 4,219 Total 6,693,891

NC
BI
Fie
ldG
uid
e
Protein Sources and Links
PIR
RefSeq
SWISS-PROT
GenPept
NM_000537
M17755
no mRNA!
no mRNA!

NC
BI
Fie
ldG
uid
e
Sequence Revisions
Version and GI change only if the sequence changes
The accession number always retrieves the most recent version
First seen at NCBI, not first seen at GenBank!

NC
BI
Fie
ldG
uid
eUpdate without a Sequence
Change
June 15, 1989!
GenBank cameto NCBI in 1992!

NC
BI
Fie
ldG
uid
e
Update with a Sequence Change

NC
BI
Fie
ldG
uid
e
GenBank File Formats
ASN.1 – The Raw Data
XML (4 flavors)
FASTA
flat file

NC
BI
Fie
ldG
uid
e
/************************************************************************** asn2ff.c* convert an ASN.1 entry to flat file format, using the FFPrintArray. ***************************************************************************/#include <accentr.h>#include "asn2ff.h"#include "asn2ffp.h"#include "ffprint.h"#include <subutil.h>#include <objall.h>#include <objcode.h>#include <lsqfetch.h>#include <explore.h>
#ifdef ENABLE_ID1#include <accid1.h>#endif
FILE *fpl;
Args myargs[] = {{"Filename for asn.1 input","stdin",NULL,NULL,TRUE,'a',ARG_FILE_IN,0.0,0,NULL},{"Input is a Seq-entry","F", NULL ,NULL ,TRUE,'e',ARG_BOOLEAN,0.0,0,NULL},{"Input asnfile in binary mode","F",NULL,NULL,TRUE,'b',ARG_BOOLEAN,0.0,0,NULL},{"Output Filename","stdout", NULL,NULL,TRUE,'o',ARG_FILE_OUT,0.0,0,NULL},{"Show Sequence?","T", NULL ,NULL ,TRUE,'h',ARG_BOOLEAN,0.0,0,NULL},
Toolbox Sources
ftp> open ftp.ncbi.nih.gov..ftp> cd toolboxftp> cd ncbi_tools
ftp://ftp.ncbi.nlm.gov/toolbox/ncbi_tools
NCBI Toolbox

NC
BI
Fie
ldG
uid
e
Text Searches in Entrez
term1[limit] OP term2[limit] OP …
limit = Entrez indexing field (organism, author, …)
op = AND, OR, NOT
where
Organism? [ organism ]Journal? [ journal ]User compounds? search as phraseAuthor? [author]else [All Fields]
term1 term2
If no [limit] is specified…

NC
BI
Fie
ldG
uid
e
Entrez Tabs
Limits Provides a simple form for applying commonly used Entrez limits
Preview/Index Allows access to the full indexing of each Entrez database and aids in constructing complex queries
History Provides access to previous searches in the current Entrez database
Clipboard A temporary storage area for selected records
Details Displays the detailed parsing of the current Entrez query, and lists errors and terms without matches

NC
BI
Fie
ldG
uid
e
Programming Entrez: E-Utilities
ESearch
EPost
ESummary
Entrez query UID list or History
Document summaries
http://www.ncbi.nih.gov/entrez/query/static/eutils_help.html
History
UID list or History
UID list
EFetch Formatted dataUID list or History
ELinkUID list or History UID list or History

NC
BI
Fie
ldG
uid
e
Finding Primary Sequences
• Search Entrez Nucleotide– 97.9% GenBank (primary data)– 2.1% RefSeq (curated data)
M17755 [primary accession] TPO [gene name]thyroid peroxidase [title] thyroiditis [text word]Homo sapiens [organism] thyroid peroxidase [protein name]3060 [sequence length] 1999/04/26 [modification date]biomol mrna [properties] gbdiv pri [properties]srcdb genbank [properties]
Possible queries we’ve seen so far…

NC
BI
Fie
ldG
uid
e
A Starting Query
Find nucleotide records for human thyroid peroxidase
(("Homo sapiens“[Organism] OR human[All Fields]) AND thyroid peroxidase[All Fields])
human thyroid peroxidase
human[organism] AND thyroid peroxidase
("Homo sapiens“[Organism] AND thyroid peroxidase[All Fields])
309 records
298 records
Field Limit!
11 records aren’t human sequences!!

NC
BI
Fie
ldG
uid
e
Limit by Title and Database
#1: thyroid peroxidase AND human[orgn] 298#2: thyroid peroxidase[title] AND human[orgn] 169
#3: #2 AND srcdb refseq[properties] 5#4: #2 AND srcdb ddbj/embl/genbank[properties] 164
Entrez Nucleotide
GenBank srcdb ddbj/embl/genbank[properties]
RefSeq srcdb refseq[properties]
primary data

NC
BI
Fie
ldG
uid
e
Limit by Genbank Division
EST Division gbdiv est[prop]
Primate Division gbdiv pri[prop]
#1: thyroid peroxidase AND human[orgn] 298
#2: thyroid peroxidase[title] AND human[orgn] 169
#3: #2 AND srcdb refseq[properties] 5#4: #2 AND srcdb ddbj/embl/genbank[properties] 164
#5: #4 AND gbdiv est[prop] 20#6: #4 AND gbdiv pri[prop] 144
traditional GenBank records

NC
BI
Fie
ldG
uid
e
Limit by Biomolecule Type
Genomic DNA biomol genomic[prop]
cDNA biomol mrna[prop]
#1: thyroid peroxidase AND human[orgn] 298#2: thyroid peroxidase[title] AND human[orgn] 169#3: #2 AND srcdb refseq[properties] 5#4: #2 AND srcdb ddbj/embl/genbank[properties] 164#5: #2 AND gbdiv est[prop] 20#6: #2 AND gbdiv pri[prop] 144
#7: #6 AND biomol genomic[prop] 26#8: #6 AND biomol mrna[prop] 118
mRNA / cDNA
genomic DNA

NC
BI
Fie
ldG
uid
e
Limit by Protein Namethyroid peroxidase[protein name] AND human[orgn] AND gbdiv pri[prop] AND biomol mrna[prop]
118 records [title] 4 records [protein name]

NC
BI
Fie
ldG
uid
e
Entrez Document Summaries
Click the accession to view the record
Links menu
Links to other Entrez databasescomputed for M17755

NC
BI
Fie
ldG
uid
e
Entrez Links for GI 4680720
Microarray datasets for M17755
Gene annotation based on M17755
DNA/RNA sequences similar to M17755
Human phenotypes involving TPO
Protein translation of M17755
Literature abstracts about M17755
Sequence polymorphisms in M17755
Source organism of M17755
STS markers in the TPO gene
TPO links beyond NCBI
Full text online articles about M17755
All polymorphisms in the TPO gene
Graphical view of TPO gene annotation
NC
BI
Fie
ldG
uid
e
Viewing M17755

NC
BI
Fie
ldG
uid
eGenBank Sequences for Human
TPO
Which one is the best sequence???

NC
BI
Fie
ldG
uid
e
• Non-redundant • Explicitly linked nucleotide and protein sequences• Updated to reflect current sequence data and biology• Validated by hand • Format consistency• Distinct accession series • Stewardship by NCBI staff and collaborators
ftp://ftp.ncbi.nih.gov/refseq/release
RefSeq: NCBI’s Derivative Sequence Database
RefSeq Benefits

NC
BI
Fie
ldG
uid
e
RefSeq: NCBI’s Derivative Sequence Database
• Curated transcripts and proteins– NM_123456 NP_123456– NR_123456 (non-coding RNA)
• Model transcripts and proteins– XM_123456 XP_123456
– XR_123456 (non-coding RNA)
• Assembled Genomic Regions (contigs)– NT_123456 (BAC clones)– NW_123456 (WGS)
• Other Genomic Sequence– NG_123456 (complex regions, pseudogenes)
– NZ_ABCD12345678 (WGS) ZP_123456
• Chromosome records in Entrez Genome– NC_123456 (chromosome; microbial or organelle genome)
Nucleotide
Protein

NC
BI
Fie
ldG
uid
e
Creating NM Records
Longest mRNA
NMs must have cDNA support
Genome annotation

NC
BI
Fie
ldG
uid
e
NM/NP Records in Entrez
COMMENT REVIEWED REFSEQ: This record has been curated by NCBI staff. The reference sequence was derived from M17755.2 and AW874082.1. On Feb 25, 2003 this sequence version replaced gi:21361188.
NM_000547: variant 1
COMMENT REVIEWED REFSEQ: This record has been curated by NCBI staff. The reference sequence was derived from J02970.1, AW874082.1 and M17755.2.
NM_175719: variant 2 EST that completes 3’ end
Nucleotide
Protein

NC
BI
Fie
ldG
uid
e
Genomic DNAGenomic DNA((NCNC, , NT, NWNT, NW))
Model mRNAModel mRNA (XM)(XM)(XR)(XR)
Curated mRNACurated mRNA (NM)(NM)(NR)(NR)
Model protein Model protein (XP)(XP)
Annotating the Gene
Curated ProteinCurated Protein (NP)(NP)
Scanning....
= ?= !
GenbankSequences
RefSeq

NC
BI
Fie
ldG
uid
e
Entrez Gene and RefSeq
• Entrez Gene is the central depository for information about a gene available at NCBI, and often provides links to sites beyond NCBI
• Entrez Gene includes records for organisms that have NCBI Reference Sequences (RefSeqs)
• Entrez Gene records contain RefSeq mRNAs, proteins, and genomic DNA (if known) for a gene locus, plus links to other Entrez databases • NCBI RefSeqs are based on primary sequence data in GenBank
GenBank RefSeq Gene
Nucleotide

NC
BI
Fie
ldG
uid
e
Entrez Gene: RefSeq Annotations

NC
BI
Fie
ldG
uid
e
NM/NP Records in Entrez Gene

NC
BI
Fie
ldG
uid
e
Entrez Gene RefSeq Graphics
NM NP

NC
BI
Fie
ldG
uid
e
What about LOC440844?
Entrez Gene

NC
BI
Fie
ldG
uid
e
BLAST Results for XM_496543Is there any GenBank support for this mRNA?
no full-length hit
srcdb ddbj/embl/genbank[prop] AND biomol mrna[prop]

NC
BI
Fie
ldG
uid
e
The Perils of the XM
XM records are models based only on genomic sequence, and are subjectto revision or removal with each new build of that genome.
Query= gi|20850420|ref|XM_124429.1| Mus musculus expressed sequence AA553001 (AA553001), mRNA
gi|19527087|ref|NM_133873.1| Mus musculus DNA segment, Chr 4, Wayne State University 114, expressed (D4Wsu114e), mRNA Length=1898 Score = 3701.55 bits (1867), Expect = 0 Identities = 1870/1871 (99%), Gaps = 0/1871 (0%) Strand=Plus/Plus
BLAST the XM against the RefSeq database to look for a replacement:

NC
BI
Fie
ldG
uid
e
Eukaryotic NM/XM RecordsBos taurus: 37541Oryza sativa (japonica cultivar-group): 36836Danio rerio: 30577Homo sapiens: 29261Arabidopsis thaliana: 28953Mus musculus: 27033Rattus norvegicus: 23975Pan troglodytes: 21810Caenorhabditis elegans: 21124Drosophila melanogaster: 19412Aspergillus nidulans FGSC A4: 18951Gallus gallus: 18120Canis familiaris: 16891Anopheles gambiae str. PEST: 15328Plasmodium chabaudi: 14747Candida albicans SC5314: 13672Dictyostelium discoideum: 13570Ustilago maydis 521: 13044Plasmodium berghei: 11778Gibberella zeae PH-1: 11640Magnaporthe grisea 70-15: 11109Neurospora crassa: 10079Aspergillus fumigatus Af293: 9923Entamoeba histolytica HM-1:IMSS: 9772Cryptococcus neoformans var. neoformans JEC21: 6594
Giardia lamblia ATCC 50803: 6569Yarrowia lipolytica CLIB99: 6521Debaryomyces hansenii CBS767: 6318Apis mellifera: 6292Kluyveromyces lactis NRRL Y-1140: 5327Candida glabrata CBS138: 5181Schizosaccharomyces pombe 972h-: 5035Eremothecium gossypii: 4718Theileria parva: 4079Xenopus tropicalis: 4069Cryptosporidium hominis: 3886Cryptosporidium parvum: 3396Sus scrofa: 938Trypanosoma brucei: 599Ovis aries: 253Strongylocentrotus purpuratus: 215Felis catus: 162Plasmodium yoelii yoelii: 105Takifugu rubripes: 7Ciona intestinalis: 3Trypanosoma cruzi: 3

NC
BI
Fie
ldG
uid
e
Genome Annotation in Entrez Nucleotide
GenBank Components (clones, WGS) NT/NW Contigs NC
Assembly
Components
Genome
Components
NM/XMMaster
mRNA

NC
BI
Fie
ldG
uid
e
Genome Annotation Links
curated mRNA
genomic contig on human chromosome 2containing NM_000547
human chromosome 2
the 21 contigs of the chromosome 2 assembly

NC
BI
Fie
ldG
uid
e
Getting the Annotation Details
Genomic sequence
ACCESSION NC_000002 REGION: 1396242..1525502

NC
BI
Fie
ldG
uid
e
Getting the Annotation Details
exon-intron structure
These flat files contain all annotations in the gene and the full, explicit sequence
ACCESSION NC_000002 REGION: 1396242..1525502

NC
BI
Fie
ldG
uid
e
Searching Entrez Gene
RefSeq status and variants: Reviewed RefSeqs with transcript variants
srcdb refseq reviewed[prop] AND has transcript variants[prop]
Gene symbol: human thyroid peroxidase (TPO)
tpo [sym] AND human [organism]
Disease and Gene Ontology: Membrane proteins linked to cancer
integral to plasma membrane[gene ontology] AND cancer [dis]
Chromosome and Links: genes on human chromosome 2 with OMIM links
2 [chromosome] AND gene omim [filter] AND human [organism]
Protein name: topoisomerase genes from Archaea
topoisomerase[gene/protein name] AND archaea [organism]

NC
BI
Fie
ldG
uid
e
Gene Links in Entrez
Microarray datasets for TPO
Gene homologs for TPO
DNA and RNA sequences for TPO
Phenotypes involving TPO
Protein sequences for TPO
Literature abstracts about TPO
Sequence polymorphisms in TPO
Species whose genome has this TPO gene
STS markers in the TPO gene
ESTs aligned to the TPO gene

NC
BI
Fie
ldG
uid
e
Examples of sequences appropriate for TPA are:
Annotation of features on gene and/or mRNA sequences
Assembled “full length” genes and/or mRNAs
NCBI now accepts the submission of new annotationsof existing GenBank sequences.
• Submissions must be published in a peer-reviewed journal.
• Facilitates the annotation of sequences by experts.
What should not be submitted to TPA?
Synthetic constructs (such as cloning vectors) that use well-characterized, publicly available genes, promoters, or terminators
Updates or changes to existing sequence data
Sequence annotations without experimental evidence
Third Party Annotation(TPA) Database

NC
BI
Fie
ldG
uid
e
Beyond RefSeq
If your organism does not have RefSeqs…
• UniGene : gene-based clusters of cDNAs and ESTs
• WGS sequences in Entrez Nucleotide (wgs[prop])
• Trace Archive

NC
BI
Fie
ldG
uid
e
A gene-oriented view of sequence entries
•MegaBlast based automated sequence clustering
•Now informed by genome hits New!
•Nonredundant set of gene oriented clusters
•Each cluster a unique gene
•Information on tissue types and map locations
•Includes known genes and uncharacterized ESTs
•Useful for gene discovery and selection of
mapping reagents
What is UniGene?

NC
BI
Fie
ldG
uid
e
Organisms in UniGene Top Ten1. Human2. Rice3. Mouse4. Cow5. Wheat6. Zebrafish7. Pig8. Chicken9. Frog (X. laevis)10. Frog (X. tropicalis)

NC
BI
Fie
ldG
uid
e
Finding UniGene Clusters
by link
by Entrez search

NC
BI
Fie
ldG
uid
e
UniGene Cluster for TPO

NC
BI
Fie
ldG
uid
e
GPLPlatform
descriptions
GSMRaw/processedspot intensities
from a singleslide/chip
GSEGrouping of
slide/chip data“a single experiment”
GDSGrouping ofexperiments
Curated byNCBI
Submitted byExperimentalistsSubmitted by
Manufacturer*
Entrez GEOEntrez
GEO Datasets

NC
BI
Fie
ldG
uid
e
Linking to GEO

NC
BI
Fie
ldG
uid
e
GEO Datasets

NC
BI
Fie
ldG
uid
e
Whole Genome Shotgun Projects
• Traditional GenBank Divisions• 300 + projects
– Viruses– Bacteria– Environmental sequences– Archaea– 73 Eukaryotes featuring:
• Cow, Chicken, Rat, Mouse, Dog, Chimpanzee, Human • Pufferfish (2), Zebrafish• Honeybee, Anopheles, Fruit Flies (4), Silkworm• Nematode (C. briggsae)• Yeasts (9), Aspergillus (3)• Rice

NC
BI
Fie
ldG
uid
e
Trace Archive
NC
BI
Fie
ldG
uid
e
Short-tailed opossum traces

NC
BI
Fie
ldG
uid
e
Viewing Simple Genomes
• Full chromosomal sequences are provided
• Genes are annotated
• The annotation can be shown graphically and linked to sequence records
All are RefSeq NC records in Entrez Genome

NC
BI
Fie
ldG
uid
e

NC
BI
Fie
ldG
uid
e
mutL

NC
BI
Fie
ldG
uid
e
Viewing Complex Genomes
• Map Viewer Home Page– Shows all supported organisms– Provides links to genomic BLAST
• Genome Overview Page– Provides links to individual chromosomes– Shows hits on a genome graphically
• Chromosome Viewing Page– Allows interactive views of annotation details– Provides numerous maps unique to each genome
NCBI Map Viewer

NC
BI
Fie
ldG
uid
eMap Viewer Home Page

NC
BI
Fie
ldG
uid
e
Genome Overview Page
Genomic BLAST
Species-specific help!
Search the maps

NC
BI
Fie
ldG
uid
e
Chromosome Viewing Page
Master Mapwith exploded content
Genes
UniGene
Contigs
Ideogram
Add or remove maps
ZoomingControls
Map Summary

NC
BI
Fie
ldG
uid
eMap Summary
TPO’s contig!

NC
BI
Fie
ldG
uid
e
Map ContentMap content varies greatly by species!
• Sequence Maps• Core assembly• Annotation evidence• Clones & Markers• Polymorphisms• Links & Features
• Genetic Maps• Cytogenetic maps• Linkage maps• Radiation hybrid maps
AssemblyContigComponentTranscriptGene

NC
BI
Fie
ldG
uid
e
View the Assembly near TPO

NC
BI
Fie
ldG
uid
eAssembly of Chr. 2
NT_033000
1255072
1563756

NC
BI
Fie
ldG
uid
e
Assembly of Chromosome 2

NC
BI
Fie
ldG
uid
eZooming

NC
BI
Fie
ldG
uid
eView of TPO
Links to Entrez Gene
Links to Entrez Nucleotide
Links to Tools and Data
Gap in assembly

NC
BI
Fie
ldG
uid
e
Map ContentMap content varies greatly by species!
• Sequence Maps• Core assembly• Annotation evidence• Clones & Markers• Polymorphisms• Links & Features
• Genetic Maps• Cytogenetic maps• Linkage maps• Radiation hybrid maps
Ab initio (model)GenBank DNAESTUniGeneGene

NC
BI
Fie
ldG
uid
e
Annotation Evidence
Ab initio models
UniGene Clusters
Aligned ESTs
GenBank records not used in assembly

NC
BI
Fie
ldG
uid
eEntrez Homologene
Homologs by protein BLAST