netflix open source meetup season 4 episode 2
TRANSCRIPT

High ThroughputLow Latency

https://github.com/Netflix/EVCache


User Request
The Hidden Microservice

Distributed Memcached
Tunable Replication
High Resilience
Topology Aware
Data Chunking
Additional Functionality
Ephemeral Volatile Cache

Architecture
Eureka(Service Discovery)
ServerMemcached
Prana (Sidecar)Monitoring & Other Processes
Client Application
Client Library
Client

Architecture
● Complete bipartite graph between clients and servers● Sets fan out, gets prefer closer servers● Multiple full copies of data
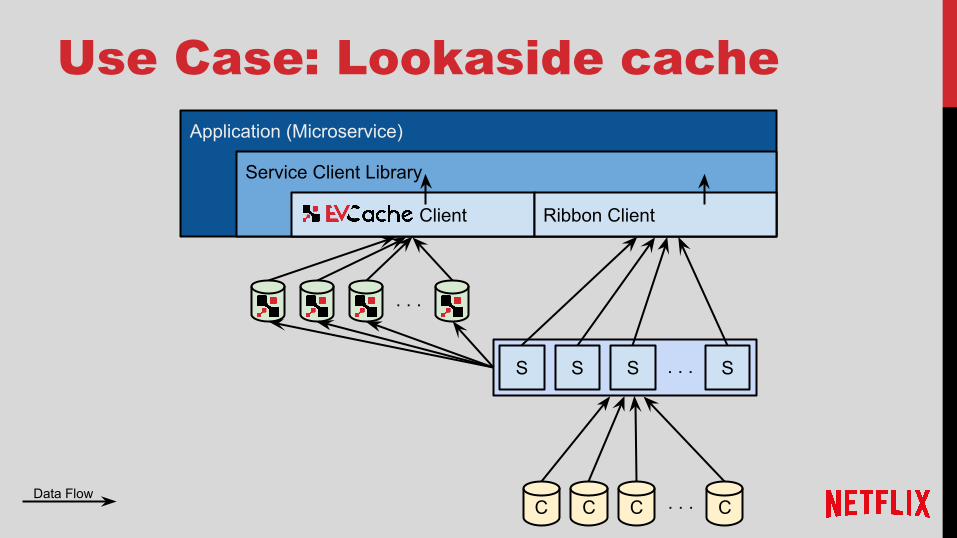
Use Case: Lookaside cacheApplication (Microservice)
Service Client Library
Client Ribbon Client
S S S S. . .
C C C C. . .
. . .
Data Flow
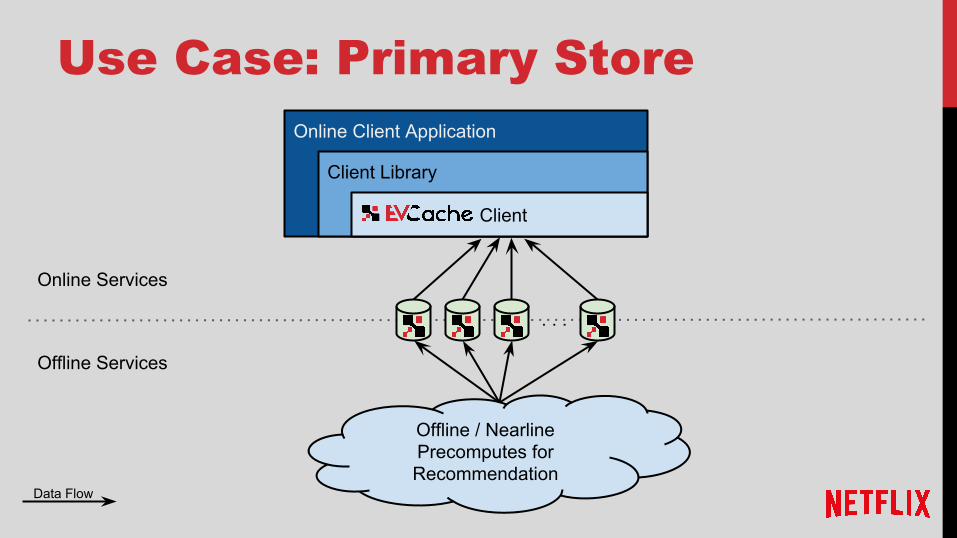
Use Case: Primary Store
Offline / Nearline Precomputes for Recommendation
Online Services
Offline Services
. . .
Online Client Application
Client Library
Client
Data Flow

Usage @ Netflix
11,000+ AWS Server instances
30+ Million Ops/sec globally
Over 1.5 Million cross-region replications/sec
130+ Billion objects stored globally
70+ distinct caches
170+ Terabytes of data stored

MAPBruce WobbeSenior Software Engineer

What is Map?
● Merchandising Application Platform● It is the final aggregation point for the data before it
is sent to the device.● The Home page assembled here.


Why Map Uses EVCache?
● Map utilizes EVCache to cache the home page for each customer.
● The Home Page is cached from 1-10 hours depending on device (some rows updated more often).
● EVCache provides extremely quick and reliable access to data.

How Is The Data Stored?
● Map stores the data as individual records in EVCache. Each home page row is a record in EVCache.
● The normal access pattern is to request 1-6 rows at a time.
● Each record is given a TTL.

Advantages of EVCache For Map
● High hit rate: 99.99%● Clean up is automatic (Let the TTL handle it for you.) ● Solid (Map was using Cassandra as a backup for the
data, but EVCache proved so solid we removed the Cassandra backup)
● Super fast (Average latency under 1ms)

Confidence
● We’ve never have seen cases of data corruption.● When we have problems, EVCache is the last
place I'd look for a cause.

The Stats
Peak Per Region RPS:
● Total = Reads-Writes-Touches = 616K ● Reads = 275K ● Touches = 131K ● Writes = 210K● Peak Data Per Region● Total = 7.7 Tbytes

Future
● As a common use case is for devices to never hit the cache after initial load, MAP would like to see a cheaper way to store the data for infrequent accessing users.

MonetaScott Mansfield & Vu Nguyen

Moneta
Moneta: The Goddess of MemoryJuno Moneta: The Protectress of Funds for Juno
● Evolution of the EVCache server● EVCache on SSD● Cost optimization● Ongoing lower EVCache cost per stream● Takes advantage of global request patterns

Old Server
● Stock Memcached and Prana (Netflix sidecar)● Solid, worked for years● All data stored in RAM (Memcached)● Became more expensive with expansion / N+1 architecture

Optimization
● Global data means many copies● Access patterns are heavily region-oriented● In one region:
○ Hot data is used often○ Cold data is almost never touched
● Keep hot data in RAM, cold data on SSD● Size RAM for working set, SSD for overall dataset

Cost Savings
3 year heavy utilization reservations (list price)
r3.2xlarge x 100 nodes ≅ $204K / yr
Working set 30%
i2.xlarge x 60 nodes ≅ $111K / yr
~46% savings
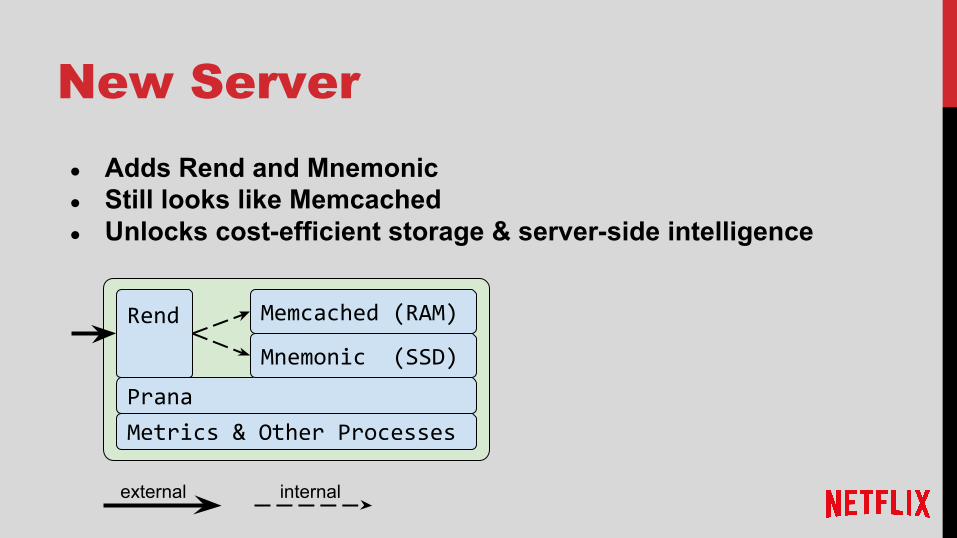
New Server
● Adds Rend and Mnemonic● Still looks like Memcached● Unlocks cost-efficient storage & server-side intelligence
external internal

Rend
https://github.com/netflix/rend

Rend
● High-performance Memcached proxy & server● Written in Go
○ Powerful concurrency primitives○ Productive and fast
● Manages the L1/L2 relationship● Server-side data chunking● Tens of thousands of connections

Rend
● Modular to allow future changes / expansion of scope○ Set of libraries and a default
● Manages connections, request orchestration, and backing stores
● Low-overhead metrics library● Multiple orchestrators● Parallel locking for data integrity

Rend in Production
● Serving some of our most important personalization data● Two ports
○ One for regular users (read heavy or active management)○ Another for "batch" uses: Replication and Precompute
●● Maintains working set in RAM● Optimized for precomputes
○ Smartly replaces data in L1
external internal

Mnemonic

Mnemonic● Manages data storage to SSD
● Reuses Rend server libraries○ handle Memcached protocol
● Mnemonic core logic○ implements Memcached operations into
RocksDB
Mnemonic Stack

Why RocksDB for Moneta● Fast at medium to high write load
○ Goal: 99% read latency ~20-25ms
● LSM Tree Design minimizes random writes to SSD○ Data writes are buffered Record A Record B
...
memtables
● SST: Static Sorted Table

How we use RocksDB
● FIFO Compaction Style○ More suitable for our precompute use cases○ Level Compaction generated too much traffic to SSD
● Bloom Filters and Indices kept in-memory

How we use RocksDB
● Records sharded across many RocksDB’s on aws instance○ Reduces number of SST files checked--decreasing latency
...
Key: ABCKey: XYZ
RocksDB’s

FIFO Limitation● FIFO Style Compaction not suitable for all use cases
○ Very frequently updated records may prematurely push out other valid records
SST
Record A2
Record B1
Record B2
Record A3
Record A1
Record A2
Record B1
Record B2
Record A3
Record A1
Record B3Record B3
Record C
Record D
Record E
Record F
Record G
Record H
SST SST
time
● Future: Custom Compaction or Level Compaction

Moneta Perf Benchmark
● 1.7ms 99%ile read latency○ Server-side latency○ Not using batch port
● Load: 1K writes/sec, 3K reads/sec
● Instance type: i2.xlarge

Open Source
https://github.com/Netflix/EVCachehttps://github.com/Netflix/rend

https://github.com/Netflix/dynomite

Problems● Cassandra not a speed demon (reads)● Needed a data store:
o Scalable & highly availableo High throughput, low latencyo Active-active multi datacenter replicationo Advanced data structureso Polyglot client

ObservationsUsage of Redis increasing:
o Not fault toleranto Does not have bi-directional replicationo Cannot withstand a Monkey attack

What is Dynomite?
● A framework that makes non-distributed data stores, distributed.o Can be used with many key-value storage engines
Features: highly available, automatic failover, node warmup, tunable consistency, backups/restores.

Dynomite @ Netflix
● Running >1 year in PROD● ~1000 nodes● 1M OPS at peak● Largest cluster: 6TB source of truth data
store.● Quarterly production upgrades

Completing the Puzzle
Dyno Dynomite-manager

Dynomite Ecosystem

Features
● Multi-layered Healthcheck of Dynomite node ● Token Management and Node configuration● Dynomite Cold Bootstrap (warm up)
o after AWS or Chaos Monkey terminations● Backups/Restores ● Exposes operational tasks through REST API● Integration with the Netflix OSS Ecosystem

Where can I find it?
https://github.com/Netflix/dynomite-manager
https://github.com/Netflix/dynomite
https://github.com/Netflix/dyno

Thomson Reuters

About us
Canadian Head of Architecture. SOA, Cloud, DevOps Practitioner. Drummer v1, Wine v0.5. Working on all aspects of NetflixOSS and AWS.
Brazilian Principal Software Architect, SOA Expert, DevOps Practitioner, Blogger, Terran SC2 Player. Working with Chaos / Perf Engineering and NetflixOSS.
@diego_pacheco
diegopacheco
http://diego-pacheco.blogspot.com.br/ilegra.com
@samsgro samsgro
https://www.linkedin.com/in/sam-sgro-4217845



2015
TechnologyPOC
2016
First Commercial Apps
“Project Neon”First Release
2017...
“Project Neon”
Platform

Business Use Case

Why Dynomite?
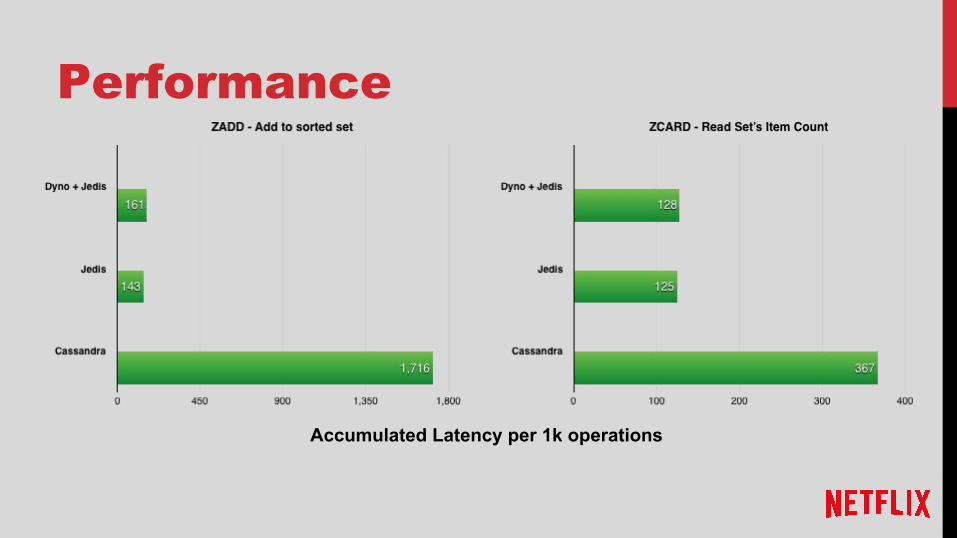
Performance
Accumulated Latency per 1k operations

Infrastructure Changes
Dynomite Manager ● Submitted 2 Dynomite PRs to Netflix to improve integration with the Dynomite Manager
Eiddo: TR’s git-based network property server● Converted this to talk to the Dynomite Manager
Ribbon: Eureka-integrated client load balancer● Cache service instrumentation around Dyno, observables
Docker: Fun with Containers● Simple image, ease of use, developer testing
Dynomite-manager

Issues and Challenges
Dynomite-manager
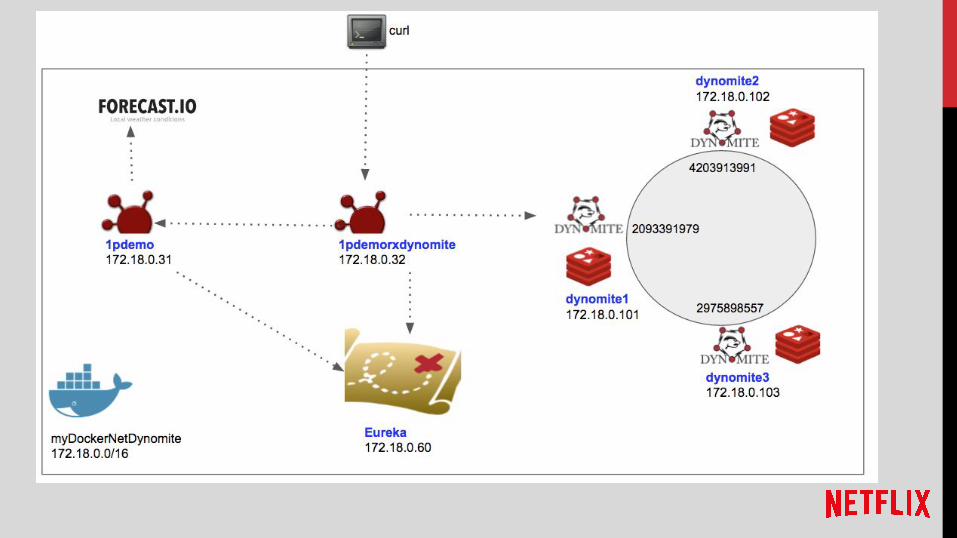
DEMO Architecture


Acknowledgements
Diego PachecoMaksim LikharevYurgis BaykshtisSam Sgro


LatencyPerformance

2 to 3 years
Database Development

RESP server
Redis API
Hash Conf
Sharding
SnitchAnti-entropy
Dynomite
RESP API
Storage APIs / RESP Client
Redis Client
Gossip Telemetry
RESP protocol
RESP protocol
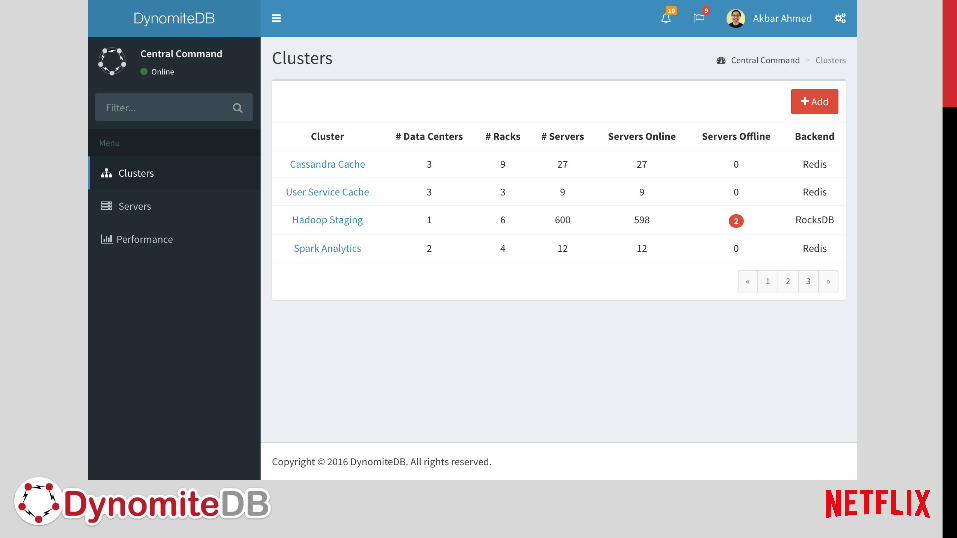
Central Command
Partitioning

2 to 3 yearsDatabase Development
3 weeksvs.

Dynomite + RocksDB

Dynomite + RocksDB


DevOps
RESP server
Redis API
Hash Conf
Sharding
SnitchAnti-entropy
Dynomite
RESP API
Storage API
Storage APIs / RESP Client
Redis Client
Gossip Telemetry
● Infrastructure● Tooling● Automation● Deployment
Central Command

Application Development
Redis APISimple, Composable, Powerful

Single Server Redis
Distributed Cache

Key/Value + Key/Data Structures
String
Integer
Float
List
Set
Sorted Set
Hash
Commands

Data model and query reuse

Function Benefits
Database engineers
● Order of magnitude faster development● Framework for rapid development
DevOps ● Efficiency gains● Common infrastructure● Reuse tools, scripts, and more
Application developers
● Increase development velocity● Single API for cache and database● Query and data model reuse

Beyond Key/Value
10 001 12 002
Smith 001 Jones 002
Joe 001 Mary 002

Thank you
@DynomiteDBwww.dynomitedb.com
