no control in orientation search: the effects of instruction on oculomotor selection in visual...
TRANSCRIPT

Vision Research 51 (2011) 2156–2166
Contents lists available at SciVerse ScienceDirect
Vision Research
journal homepage: www.elsevier .com/locate /v isres
No control in orientation search: The effects of instruction on oculomotorselection in visual search
Mieke Donk ⇑, Wieske van ZoestVrije Universiteit, Amsterdam, The Netherlands
a r t i c l e i n f o
Article history:Received 17 March 2011Received in revised form 20 July 2011Available online 22 August 2011
Keywords:SalienceVisual selectionEye movementsTimeBottom upTop down
0042-6989/$ - see front matter � 2011 Elsevier Ltd. Adoi:10.1016/j.visres.2011.08.013
⇑ Corresponding author. Address: Department ofUniversiteit, Van der Boechorststraat 1, 1081 BT Ams
E-mail address: [email protected] (M. Donk).
a b s t r a c t
The present study aimed to investigate whether people can selectively use salience information in searchfor a target. Observers were presented with a display consisting of multiple homogeneously orientedbackground lines and two orientation singletons. The orientation singletons differed in salience, wheresalience was defined by their orientation contrast relative to the background lines. Observers had the taskto make a speeded eye movement towards a target, which was either the most or the least salient ele-ment of the two orientation singletons. The specific orientation of the target was either constant or var-iable over a block of trials such that observers had varying knowledge concerning the target identity. Theresults demonstrated that instruction – whether people were instructed to move to the most or the leastsalient item – only minimally affected the results. Short-latency eye movements were completely sal-ience driven; here it did not matter whether people were searching for the most or least salient element.Long-latency eye movements were marginally affected by instruction, in particular when observers knewthe target identity. These results suggest that even though people use salience information in oculomotorselection, they cannot use this information in a goal-driven manner. The results are discussed in terms ofcurrent models on visual selection.
� 2011 Elsevier Ltd. All rights reserved.
1. Introduction
Where do you look at when you open your eyes in the morning?Do you first move your eyes to the most conspicuous object in yourbedroom every single morning? Or do you ignore distracting infor-mation and move your eyes straight towards the alarm clock to in-spect whether or not you are able to stay in bed for a few moreminutes?
Both possibilities are conceivable thinking about the ways peopleselect visual information. On the one hand, visual selection can bestimulus driven completely determined by the stimulus propertiesin the visual field. On the other hand visual selection can be goal dri-ven in line with the intentions of the observer. In the former case,selection is assumed to be involuntary biased towards stimulusproperties that are visually salient, i.e., defined by a high localfeature contrast (Nothdurft, 2002; Theeuwes, 1991, 1992, 1994;Theeuwes et al., 1998; Yantis & Jonides, 1984, 1990), whereas inthe latter case selection is voluntarily driven towards those stimulusproperties that are relevant in the sense that they are in line with thegoals and intentions of an observer (Folk & Remington, 1998; Folk,Remington, & Johnston, 1992; Folk, Remington, & Wright, 1994).
ll rights reserved.
Cognitive Psychology, Vrijeterdam, The Netherlands.
Even though, both stimulus- and goal-driven control play a rolein visual selection, the question as to which type of control prevailshas been far from answered. Many studies have investigated the ex-tent to which goal-driven factors can override salience-driven ef-fects. On the one hand, the results of various studies advocate abottom-up view of visual selection stating that salient events inthe visual field inevitably attract the eyes and cannot be overriddenby goal-driven control (Mulckhuyse, van Zoest, & Theeuwes, 2008;Theeuwes et al., 1998, 1999). For instance, Theeuwes et al. (1998) re-quired observers to make an eye movement to an uniquely coloredobject presented simultaneously with a salient task-irrelevant on-set. The results demonstrated that eye movements were frequentlyerroneously directed towards the salient onset before they wereredirected towards the target. These results indeed show that peoplecannot prevent oculomotor capture by a salient event in the visualfield, even when they intentionally try to ignore the irrelevant infor-mation. On the other hand, there are also findings supporting a top-down view on visual selection arguing that oculomotor selection isin fact contingent upon the goal settings of an observer (Al-Aidroos& Pratt, 2010; Ludwig, Ranson, & Gilchrist, 2008; Wu & Remington,2003). For instance, Wu and Remington (2003) assessed the extentto which oculomotor capture was under voluntary control andfound that if observers were encouraged to use a feature-detectionmode (Bacon & Egeth, 1994), oculomotor capture was greatlyreduced relative to a condition in which observers used a singleton

M. Donk, W. van Zoest / Vision Research 51 (2011) 2156–2166 2157
detection mode. These results point to the idea that oculomotorcapture is predominantly contingent upon the goal settings of an ob-server. In this case, stimulus-driven capture occurs but is contingentupon the behavioral goals of the observer (e.g., Bacon & Egeth, 1994;Folk, Remington, & Johnston, 1992).
One major difficulty in interpreting the difference in results be-tween studies advocating a bottom-up view and those pointing toa dominant role for top-down control concerns the fact that tem-poral variations in behavior are often disregarded. Conclusionsare often based on averaged accuracy measures, ignoring possiblevariations in accuracy that may occur in time. There are severalstudies suggesting that the extent to which visual selection is un-der top-down control critically depends on the timing of behavior(Dombrowe, Olivers, & Donk, 2010; Donk & Soesman, 2010, 2011;Donk & van Zoest, 2008; Hunt, von Mühlenen, & Kingstone, 2007;van Zoest & Donk, 2004, 2005, 2006, 2008, 2010; van Zoest, Donk,& Theeuwes, 2004). For instance, Hunt, von Mühlenen, and King-stone (2007) investigated the time course of eye movements andmanual localization responses to targets in the presence of onsetdistractors. Their results demonstrated that both eye movementsand manual responses were often incorrectly directed towardsthe irrelevant onset distractor. However, this only occurred whenresponse latencies were short. When response latencies were long,observers were well able to ignore the irrelevant distractor.van Zoest, Donk, and Theeuwes (2004) required observers to makea speeded eye movement to a line tilted 45� towards the right orleft which was presented simultaneously with multiple verticallyoriented background lines and one distractor line which could beless salient (with a tilt of 22.5� relative to a vertical line), equallysalient (with a tilt of 45� relative to a vertical line), or more salient(67.5� relative to a vertical line). Their results also demonstratedthat the extent to which goal-driven processes played a role in ocu-lomotor selection was critically dependent on the saccade latency:when the saccade latency was short, oculomotor selection was sal-ience driven whereas when the response latency was long, selec-tion was no longer salience driven but primarily dependent onthe goal settings of the observer. Together these results suggestthat the extent to which people are able to exert top-down controlvaries as a function of time. Responses emitted immediately afterthe presentation of a display appear to be completely stimulus dri-ven, whereas long-latency responses are directed in line with thetask instructions. In other words, the quality of informationchanges over time and this depends in part on the to-be-processedinformation (de Vries et al., 2011; Hunt, von Mühlenen, & King-stone, 2007; van Zoest & Donk, 2008; van Zoest, Hunt, & Kingstone,2010). With time, visual representations become more complexthereby increasing the need for top-down control to resolve thecompetition between information. The question of the presentstudy is to what extent the later voluntary top-down processesare able to strategically tap into the processes that drive selectionearly on. That is, to what extent are early and late processing trulyindependent or not.
In the studies discussed above, stimulus salience typically playsa passive role in determining visual selection. The potential effectsof stimulus salience are yoked to evidence for stimulus-driven con-trol, in such a way that stimulus salience resolves competition auto-matically or not. For example, finding an effect of stimulus saliencesuggests that stimulus-driven control influences performance;finding no effect of stimulus saliency implies that observers are ableto use goal-driven mechanisms to successfully ignore the irrelevantsalient information. One possibility that has not received muchattention in this discussion is the idea that stimulus salience maybe more actively exploited to benefit human performance. In otherwords, goal-driven control may actively and voluntary use informa-tion regarding stimulus salience to guide selection. More specifi-cally, it may be the case that observers benefit from knowing that
the target they are searching for is the most salient element inthe display. Thus, the question here is if people can voluntarilychoose to use salience information in visual search.
The present study consists of two parts. In the first part, guid-ance of salience is investigated in a modified visual search experi-ment measuring saccadic performance. In the second part, a formalmodel and its alternative are introduced and are fitted to the indi-vidual data sets. The motivation for testing these formal models isdriven by the limitation in the vincentizing procedure that is typ-ically used to look at temporal variations in oculomotor perfor-mance (e.g., Hunt, von Mühlenen, & Kingstone, 2007; van Zoest,Donk, & Theeuwes, 2004). In these studies, the proportions of cor-rect responses are calculated separately for different bins of theindividual saccade-latency distributions and subsequently aver-aged over subjects. One shortcoming of such an approach is thatthe averaged curves may delude the true variations in the relation-ship between saccade latency and accuracy. That is, individual sub-jects may show different relationships between the saccadelatency and the proportions of correct responses due to individualvariations in the saccadic latency distribution. Averaging bins oversubjects may subsequently mask the true relationship and limitthe validity of the inferences. By fitting formal models to the indi-vidual participant data, one takes into account between-subjectvariation, making it easier to draw conclusions regarding the twoalternative theoretical viewpoints that the models represent.
2. Experiment
Observers were presented with displays containing two differ-ent orientation singletons, one being more salient than the other,among multiple homogeneously oriented background lines.Observers had the task to make a speeded saccade towards eitherthe most salient singleton in one session and move to the least sali-ent singleton in another session. The specific orientation of the sin-gletons presented could be the same over a block of trials or haveone of two orientations, providing observers with varying knowl-edge concerning the exact target identity. Depending on whetherpeople are able to use salience information in a goal-driven manner,we expect to find differences as a function of whether people aresearching for the most or the least salient element in the display.
If people are unable to use salience information in a goal-drivenmanner, it should not matter whether people are instructed tosearch for the most or least salient item; people will saccade tothe same singleton in both instruction conditions. Bottom-up mod-els assume that salience-driven processes cannot be prevented toplay a role in visual selection unless people have prior informationconcerning the location of a target (Theeuwes, 1991). Conse-quently, observers are predicted to select the most salient single-ton as long as stimulus salience is represented, irrespective ofinstruction.
If people have control over the extent to which eye movementsare stimulus driven, it is predicted that saccadic target selectionvaries as a function of instruction. That is, top-down modelshypothesize that observers select a different target in the most-salient singleton instruction condition than in the least-salient sin-gleton instruction condition. Moreover, if the saccade target is con-stant across a block of trials, people might use feature informationinstead to select the target.
3. Methods
3.1. Subjects
Eight undergraduate students from the Vrije UniversiteitAmsterdam participated in two sessions of 2 h each in exchange

2158 M. Donk, W. van Zoest / Vision Research 51 (2011) 2156–2166
for money (28 Euro). Participants had normal or correct-to-normalvision and were naïve to the purpose of the study.
3.2. Apparatus
A Pentium II Dell computer with a 2100 SVGA color monitor (Phi-lips Brillance 201 P) controlled the timing of the events and gener-ated the stimuli. Eye movements were recorded by means of anEyelink tracker (SR Research Ltd.) with a 250 Hz temporal resolu-tion and a 0.2� spatial resolution. The system uses an infrared vi-deo-based tracking technology to compute the pupil center andpupil size of both eyes. An infrared head motion tracking systemtracked head motion. Display resolution was 1024 � 768 pixels.All subjects were tested in a sound-attenuated, dimly-lit roomwith their heads resting on a chinrest. The monitor was locatedat eye level 75 cm from the chinrest.
3.3. Stimuli and task
Participants performed a visual search task in which they wereinstructed to make a speeded saccade to a target. There were two
Fig. 1. Typical trial.
Fig. 2. An overview of the targets in all possible combinations of Singleton Set, Instructionthe actual displays). In each session participants completed three blocks.
different instructions. In the most-salient instruction condition,observers were required to make a speeded eye movement to-wards the most salient singleton in the display. In the least-salientinstruction condition, observers had to make a speeded eye move-ment towards the least salient singleton in the display. Instructionwas varied over different sessions.
Search displays always consisted of multiple vertical line seg-ments and two orientation singletons. There were two differentsingleton sets: singletons were either oriented +45� and �22.5�of arc relative to the vertical or +45� and �67.5� of arc relative tothe vertical.
All elements were arranged in a 9 � 13 rectangular matrix witha raster height of 15.9� of visual angle and width of 13.2� of visualangle. The orientation singletons could appear at six different loca-tions. These six potential locations were placed on an imaginarycircle in such a way that, both singletons were always presentedat equal eccentricity from fixation (4.3� of visual angle). The circu-lar angular distance between the two singletons was always 120�(see Fig. 1). Elements had an approximate height of 0.76� of visualangle and approximate width of 0.15� of visual angle. All stimuliwere white (CIE x, y, coordinates of 0.288/0.316; 93.14 cd/m2)and presented on a black background.
3.4. Design and procedure
A within-subject design was used. The two types of instructions(i.e., most-salient instruction condition and least-salient instruc-tion conditions) were tested in separate sessions.
Each singleton set was presented either blocked or mixedresulting in three different blocks of trials per session, i.e., blockedsingleton combination 45�/�22.5�, blocked singleton combination45�/�67.5�, and mixed singleton combinations 45�/�22.5� and45�/�67.5�. The order of block presentation was counterbalancedover participants. Fig. 2 depicts an overview of the targets in allpossible combinations of singleton set, instruction, and blocktype.
To start a trial, participants pressed the spacebar on a standardcomputer keyboard. Trial sequence was as follows: a fixation point
, and Block Type. The identity of the target is circled (the circle was not presented in

M. Donk, W. van Zoest / Vision Research 51 (2011) 2156–2166 2159
was presented for 1000 ms, followed by the stimulus array for1500 ms. Participants were instructed to remain fixated until thesearch display appeared, at which point they were instructed tomake a speeded saccade to the target. Participants were explicitlyinstructed to make a speeded eye movement and to maintain ahigh a level of accuracy in saccadic selection. After making aneye movement to the target, participants were instructed to re-main fixated on the saccadic target until the search display disap-peared. In this way we intended to prevent people from using thestrategy to make multiple eye movements to find the target. To en-sure that participants fully understood the task, both verbal andwritten instructions were provided. Participants were instructedthat the most salient singleton was the orientation singletonwhose orientation was most different from the surrounding non-targets; the least salient singleton being the element whose orien-tation contrast with the surrounding nontargets was smallest. Incase of the mixed condition, the two potential targets that wereconsidered most or least salient were pointed out to the partici-pant. In case of the blocked condition, the participants were toldexactly which orientation was considered the most or the leastsalient singleton.
Each block of the blocked singleton combination was composedof 180 trials, and participants completed 12 practice trials beforebeginning of each blocks. Each block of the mixed singletons con-dition consisted of two parts of 180 trials and 24 practice trials be-fore the beginning of each block. A short break was provided every180 trials, and participants were required to take a 15 min breakbetween blocks. Feedback concerning saccade latency was pro-vided every 30 trials. Calibration of the eye tracking equipmentwas conducted prior to recording.
4. Results
In 9.20% of all trials the initial saccade latency was below 80 ms.In 1.34% of all trials the saccade latency was above 600 ms. Thesetrials were excluded from further analyses. For the remainingtrials, the initial saccade was assigned to be directed towards the
Fig. 3. The proportions of correct saccades (i.e., saccades directed towards the target) anumber in each box represents the proportion correct, the lower number saccade latenc
target or the distractor if the endpoint of the initial saccade waswithin 3� of visual angle of the particular singleton position. On3.50% of all trials the initial saccades was neither directed to onenor the other singleton. These trials were also excluded from fur-ther analyses resulting in a total loss of 14.04% of all trials.
4.1. Means of proportion correct and saccadic latency
Fig. 3 depicts the proportions of correct saccades (i.e., saccadesdirected towards the target) and the mean saccade latencies as afunction of Block Type, Instruction and Singleton Set. An Analysisof Variance (ANOVA) on the mean saccade latencies with the vari-ables Block type (mixed and blocked), Instruction (most-salientinstruction condition and least-salient instruction condition), andSingleton Set (45�/�22.5� and 45�/�67.5�), did not show any sig-nificant results. The average saccade latency was 218 ms. An ANO-VA on the mean proportions of correct responses with the variablesBlock type (mixed and blocked), Instruction (most-salient instruc-tion condition and least-salient instruction condition), and Single-ton Set (45�/�22.5� and 45�/�67.5�) showed that people weremore accurate in blocked than in mixed trials (F(1,7) = 8.819,g2
p ¼ :898, p < .021). The proportion of correct responses was 0.53in the blocked conditions and 0.51 in the mixed conditions. Peoplewere more accurate to correctly saccade to the target when theywere instructed to make a saccade to the most salient singletoncompared to the least salient singleton (F(1,7) = 33.096,g2
p ¼ :971, p < .001). Finally, the effect of Instruction was largerfor the 45�/�22.5� singleton set than for the 45�/�67.5� singletonset (F(1,7) = 19.362, g2
p ¼ :951, p < .003). There were no other inter-action effects.
To closer examine how Instruction and Block Type affected per-formance, a separate ANOVA was performed on the mean propor-tions of eye movements towards the most salient singleton in thedisplay with the variables Singleton Set (45�/�22.5� and 45�/�67.5�), Instruction (most-salient instruction condition and least-salient instruction condition), and Block type (mixed and blocked).Note that these proportions are identical to the proportions ofcorrect responses in the most-salient instruction conditions and
nd the mean saccadic latencies per condition, matching those of Fig. 2. The uppery.
2160 M. Donk, W. van Zoest / Vision Research 51 (2011) 2156–2166
to 1 – the proportions of correct responses in the least-salientinstruction conditions. The results demonstrate that participantsmore often made an eye movements towards the most salient sin-gleton in the display in the 45�/�22.5� singleton set condition thanin the 45�/�67.5� singleton set condition (F(1,7) = 19.362,g2
p ¼ :951, p < .003). Moreover, the effect of Instruction was largerin blocked than in mixed trials, F(1,7) = 8.819, g2
p ¼ :898,p < .021). There were no other significant effects.
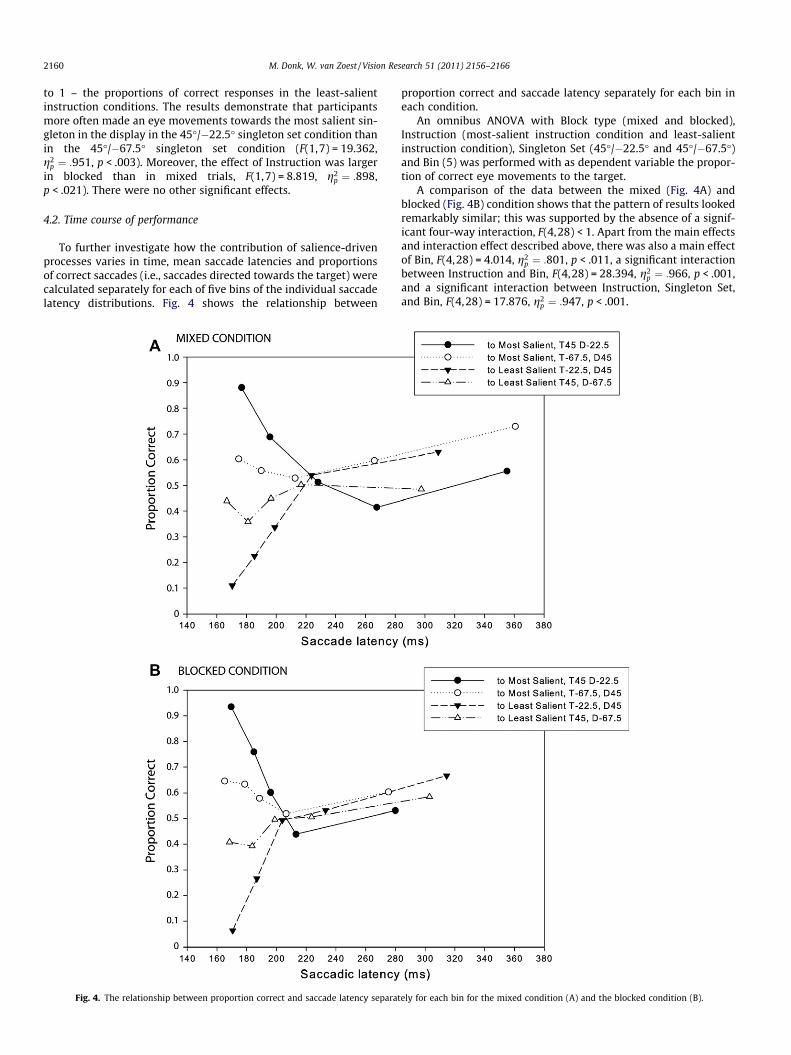
4.2. Time course of performance
To further investigate how the contribution of salience-drivenprocesses varies in time, mean saccade latencies and proportionsof correct saccades (i.e., saccades directed towards the target) werecalculated separately for each of five bins of the individual saccadelatency distributions. Fig. 4 shows the relationship between
Fig. 4. The relationship between proportion correct and saccade latency separat
proportion correct and saccade latency separately for each bin ineach condition.
An omnibus ANOVA with Block type (mixed and blocked),Instruction (most-salient instruction condition and least-salientinstruction condition), Singleton Set (45�/�22.5� and 45�/�67.5�)and Bin (5) was performed with as dependent variable the propor-tion of correct eye movements to the target.
A comparison of the data between the mixed (Fig. 4A) andblocked (Fig. 4B) condition shows that the pattern of results lookedremarkably similar; this was supported by the absence of a signif-icant four-way interaction, F(4,28) < 1. Apart from the main effectsand interaction effect described above, there was also a main effectof Bin, F(4,28) = 4.014, g2
p ¼ :801, p < .011, a significant interactionbetween Instruction and Bin, F(4,28) = 28.394, g2
p ¼ :966, p < .001,and a significant interaction between Instruction, Singleton Set,and Bin, F(4,28) = 17.876, g2
p ¼ :947, p < .001.
ely for each bin for the mixed condition (A) and the blocked condition (B).

M. Donk, W. van Zoest / Vision Research 51 (2011) 2156–2166 2161
To further examine how Instruction, Block Type, Singleton Set,and Bin affected performance, a separate ANOVA was performedon the mean proportions of eye movements towards the most sali-ent singleton in the display. Apart from the main effect and inter-action effect reported above, there was a significant effect of Bin,F(4,28) = 28.394, g2
p ¼ :966, p < .001, Singleton Set and Bin,F(4,28) = 17.876, g2
p ¼ :947, p < .001, and Instruction and Bin,F(4,28) = 4.014, g2
p ¼ :801, p < .011.
5. Discussion
The results show that target selection can be determined by sal-ience-driven processes. However, salience-driven processes cannotbe used in a top-down manner. People do not substantially profitfrom knowledge concerning target salience. Instead, people tendto select the most salient singleton in the display irrespective ofwhether they are instructed to select the most or the least salientsingleton. Knowing the identity of the target contributes to bettersearch performance, however, the effect of block type was verymarginal: people correctly selected the target in 51% of all trialsin the mixed conditions and in 53% of all trials in the blockedconditions.
Inspection of the binned results shows that people initially tendto make an eye movement towards the most salient element, irre-spective of the instructions and irrespective of knowledge concern-ing the target identity. With increasing saccade latency peoplebecome more accurate in correctly selecting the target, however,performance does not reach its maximum, which is in line withthe findings of previous studies using similar types of displays(e.g., Donk & van Zoest, 2008; van Zoest & Donk, 2005, 2006,2008, 2010; van Zoest, Donk, & Theeuwes, 2004).
These results suggest that people are unable to use salienceinformation in a goal-driven manner. Two formal models were de-signed to test this claim computationally.
6. Two formal models
To compare the alternative theoretical notions of visual search,we constructed two alternative multinomial models (Batchelder &Riefer, 1986, 1990), one assuming that people do not have any top-down control over the extent to which salience-driven processesaffect oculomotor selection (bottom-up model) and the otherassuming that people have full control over the extent to whichsalience-driven processes affect selection (top-down model).According to a bottom-up model, the probability on a correct re-sponse is solely a function of S(a/b)(t) corresponding to the probabil-ity that an observer is biased towards the most salient element in adisplay with the singletons a and b on the basis of stimulus-drivenprocesses at time t. According to a top-down model, the probabilityon a correct response is in addition determined by G(i;a/b)(t) corre-sponding to the probability that an observer is biased towards thetarget in a display with the singletons a and b and the instruction ion the basis of goal-driven processes at time t.
Fig. 5 delineates eight tree diagrams per model depicting allpossible theoretical states and how they lead to correct and incor-rect eye movements. Note that both S(a/b)(t) and G(i;a/b)(t) are as-sumed to be different in dependency of the specific singleton setpresented in the display. G(i;a/b)(t) varies in addition in dependencyof instruction. On the basis of these tree diagrams the expectedproportion of a certain response (i.e., CR for Correct Responseand FR for False Response) is given by the sum of the paths corre-sponding to that response category. For example, in the mixedmost-salient instruction condition with the singleton combination45�/�22.5�, the predicted probability on a correct response at timet is given by
pCRðtÞ ¼ Sð45�=�22:5�ÞðtÞ þ 0:5ð1� Sð45�=�22:5�ÞðtÞÞ¼ 0:5þ 0:5Sð45�=�22:5�ÞðtÞ
in which S(45�/�22.5�)(t) corresponds to the probability that an obser-ver is biased towards the most salient element in the display withthe singleton combination 45�/�22.5� at time t. Both a modelassuming no control (bottom-up model) and a model assuming fullcontrol (top-down model) predict the same proportion of correctresponses in this condition, i.e., both models predict the proportionof correct responses to be a sole function of the probability that anobserver is biased towards the most salient element in this display.
In the mixed least-salient instruction condition with the single-ton combination 45�/�22.5�, the predicted probability on a correctresponse at time t differs between a bottom-up and a top-downmodel. According to a bottom-up model, people cannot controlthe extent to which performance is affected by stimulus-drivenprocesses. As a result, the probability on a correct response at timet is given by
pCRðtÞ ¼ 0:5ð1� Sð45�=�22:5�ÞðtÞÞ ¼ 0:5� 0:5Sð45�=�22:5�ÞðtÞ
Accordingly, the model predicts performance to be belowchance level as long as an observer is biased towards the most sali-ent singleton on the basis of salience-driven processes. In contrast,a top-down model assumes that people have influence on whetheror not stimulus-driven processes play a role. If people can freelydetermine whether or not they use stimulus-driven processes inoculomotor selection, they should refrain from using it in themixed least-salient instruction conditions because stimulus-drivenprocesses would always lead the eyes to the wrong singleton.Accordingly, a top-down model predicts oculomotor selection tobe independent of salience-driven processes:
pCRðtÞ ¼ 0:5
Finally, in the blocked conditions, the predictions of the twomodels further differentiate. A pure bottom-up model assumessaccadic target selection to be a sole function of salience-drivenprocesses, whereas a top-down model predicts that people mightin addition rely on feature-driven processes to select the target.For instance, in the blocked least-salient instruction condition withthe singleton combination 45�/�22.5�, a bottom-up model predictsperformance to be stimulus driven:
pCRðtÞ ¼ 0:5ð1� Sð45�=�22:5�ÞðtÞÞ ¼ 0:5� 0:5Sð45�=�22:5�ÞðtÞ
However, a top-down model predicts that performance should notdepend on stimulus-driven processes. Instead, it might be undergoal-driven control relying solely on identification processes:
pCRðtÞ ¼ Gðl;45�=�22:5�ÞðtÞ þ 0:5ð1� Gðl;45�=�22:5�ÞðtÞÞ¼ 0:5þ 0:5Gðl;45�=�22:5�ÞðtÞ
in which G(l;45�/�22.5�)(t) corresponds to the probability that an ob-server is biased towards the least-salient singleton (i.e., the target�22.5�) in the least-salient singleton instruction condition in thedisplay with the singletons 45� and �22.5� on the basis of goal-dri-ven processes at time t.
6.1. Temporal variations in performance
There have been various approaches to model the contributionsof stimulus-driven and goal-driven processes in visual search (e.g.Hwang, Higgins, & Pomplun, 2009; Navalpakkam & Itti, 2005;Zelinsky, 2008). However, these approaches do generally not takeinto account the idea that stimulus-driven and goal-driven contri-butions are subject to temporal variations (Nakayama & Mackeben,1989). In the present study we developed alternative models

Fig. 5. Sixteen tree diagrams corresponding to the eight conditions and two models (A. bottom-up model; B. top-down model). Each tree diagram depicts the outcome onevery trial as a function of the product of the probability that an observer is biased towards the most salient element in a display on the basis of salience-driven processes andthe probability that an observer is biased towards the target on the basis of goal-driven processes. S(45�/�22.5�)(t) corresponds to the probability that an observer is biasedtowards the most salient element in a display with the singletons 45� and �22.5� on the basis of stimulus-driven processes at time t; S(45�/�67.5�)(t) corresponds to theprobability that an observer is biased towards the most salient element in a display with the singletons 45� and �67.5� on the basis of stimulus-driven processes at time t;G(m;45�/�22.5�)(t) corresponds to the probability that an observer is biased towards the target in a display with the singletons 45� and �22.5� and with the instruction to searchfor the most salient singleton (m) in the display on the basis of goal-driven processes at time t; G(l;45�/�22.5�)(t) corresponds to the probability that an observer is biasedtowards the target in a display with the singletons 45� and �22.5� and with the instruction to search for the least salient singleton (l) in the display on the basis of goal-drivenprocesses at time t; G(m;45�/�67.5�)(t) corresponds to the probability that an observer is biased towards the target in a display with the singletons 45� and �67.5� and with theinstruction to search for the most salient singleton (m) in the display on the basis of goal-driven processes at time t; G(l;45�/�67.5�)(t) corresponds to the probability that anobserver is biased towards the target in a display with the singletons 45� and �67.5� and with the instruction to search for the least salient singleton (l) in the display on thebasis of goal-driven processes at time t; CR = correct response; FR = false response.
2162 M. Donk, W. van Zoest / Vision Research 51 (2011) 2156–2166
taking into account possible temporal variations in salience-drivenand goal-driven processes.
There are multiple studies demonstrating that the influence ofstimulus-driven processes on visual selection tends to be transient
(e.g., Nakayama & Mackeben, 1989). In our model, stimulus-drivenprocesses are assumed to be transient and their influence on ocu-lomotor selection is described by a decreasing function of timesince the presentation of a display:

Table 1Individual average saccade latencies, individual average proportions correct, individual parameter estimates from best-fitting models, and individual goodness-of-fit values (AIC,Akaike Information Criterion). The AIC values corresponding to the best-fitting model are printed in bold.
Participants
1 2 3 4 5 6 7 8
Saccade latency (ms) 243 213 191 174 267 212 212 227Proportion correct 0.51 0.51 0.53 0.51 0.58 0.56 0.47 0.49
Bottom-up modelS(45�/�22.5�)(t) kS(45�/�22.5�) 0.047 0.004 0.030 0.085 0.020 0.023 0.018 0.026
tS(45�/�22.5�) 172 0 147 144 145 133 145 140S(45�/�67.5�)(t) kS(45�/�67.5�) 2.428 0.030 0.018 0.094 0.016 0.021 0.055 0.144
tS(45�/�67.5�) 0 137 102 128 0 107 151 0AIC 292.24 242.57 285.51 251.80 442.84 232.91 283.40 268.59
Top-down modelS(45�/�22.5�)(t) kS(45�/�22.5�) 0.043 0.026 0.031 0.100 0.030 0.021 0.023 0.035
tS(45�/�22.5�) 169 164 154 148 143 127 146 140S(45�/�67.5�)(t) kS(45�/�67.5�) 9.091 0.023 0.006 0.017 4.803 0.007 0.113 0.017
tS(45�/�67.5�) 0 114 0 0 0 47 157 0G(m;45�/�22.5�) (t) kG(m;45�/�22.5�) 0.000 0.000 0.000 0.000 0.006 0.001 0.000 0.000
tG(m;45�/�22.5�) 0 0 0 0 247 0 0 0G(l;45�/�22.5�) (t) kG(l;45�/�22.5�) 0.005 0.000 0.000 0.000 0.005 0.000 0.000 0.000
tG(l;45�/�22.5�) 204 0 0 0 210 0 0 0G(m;45�/�67.5�) (t) kG(m;45�/�67.5�) 0.001 0.001 0.000 0.003 0.014 0.000 0.000 0.000
tG(m;45�/�67.5�) 0 0 0 169 214 0 0 1G(l;45�/�67.5�) (t) kG(l;45�/�67.5�) 0.007 0.000 0.000 0.000 0.018 0.001 0.000 0.000
tG(l;45�/�67.5�) 295 0 0 10 326 188 0 0AIC 313.42 339.84 431.29 314.47 440.61 274.43 412.89 330.84
Top-down model assumingG(t) = G(m;45�/�22.5�)(t) = G(l;45�/�22.5�)(t) = G(m;45�/�67.5�)(t) = G(l;45�/�67.5�)(t)S(45�/�22.5�)(t) kS(45�/�22.5�) 0.046 0.004 0.031 0.100 0.030 0.017 0.023 0.035
tS(45�/�22.5�) 169 0 154 148 143 125 146 140S(45�/�67.5�)(t) kS(45�/�67.5�) 14.505 0.016 0.006 0.119 3.847 0.013 0.113 0.016
tS(45�/�67.5�) 0 102 0 137 5 109 157 0G(t) kG 0.003 0.000 0.000 0.000 0.007 0.000 0.000 0.000
tG 207 0 0 0 244 0 0 0AIC 314.13 349.67 419.29 302.52 440.93 263.50 400.89 320.25
1 When t became smaller than tS(a/b) or tG(i;a/b) the corresponding values for S(a/b)(tor G(i;a/b)(t) became approximately 1 and 0, respectively. This was achieved by fixing(t � tS(a/b)) or (t � tG(i;a/b)) to 10�9 in case tS(a/b) or tG(i;a/b) became larger than t.
M. Donk, W. van Zoest / Vision Research 51 (2011) 2156–2166 2163
Sða=bÞðtÞ ¼ e�kSða=bÞðt�tSða=bÞð0ÞÞ
in which S(a/b)(t) corresponds to the probability that an observer isbiased towards the most salient element in a display with the sin-gletons a and b on the basis of stimulus-driven processes at timet; kS(a/b) is a rate parameter indicated the rate with which the stim-ulus-driven bias decreases; and tS(a/b)(0) corresponds to the timesince the presentation of the display at which the stimulus-drivenbias starts to decrease.
The influence of goal-driven processes on visual selection is as-sumed to be an increasing function of time since the presentationof a display:
Gði;a=bÞðtÞ ¼ 1� e�kGði;a=bÞðt�tGði;a=bÞð0ÞÞ
in which G(i;a/b)(t) corresponds to the probability that an observer isbiased towards the target in a display with the singletons a and band the Instruction i on the basis of goal-driven processes at timet; kG(i;a/b) is a rate parameter indicated the rate with which thegoal-driven bias increases; and tG(i;a/b)(0) corresponds to the timesince the presentation of the display at which the goal-driven biasstarts to increase.
6.2. Model fits
To analyze the results, the bottom-up and the top-down modelwere separately fit to the individual binned data patterns of alleight conditions as depicted in Fig. 5. That is, estimates were ob-tained of S(a/b)(t) and G(i;a/b)(t) separately for each condition basedon the individual relationships between proportion correct andsaccade latency. For both models, maximum-likelihood estimateswere obtained via an iterative search procedure (Hu & Batchelder,
1994). The maximum-likelihood estimates are those parametervalues that minimize �ln(E) in which the likelihood E is given by
E ¼Y
j
nj
sj
� �ðpjÞ
sj ð1� pjÞnj�sj
in which nj corresponds to the total number of trials with a valid eyemovement in condition j, sj corresponds to the number of trials inwhich the eyes correctly selected the target in that condition, andpj corresponds to the probability of correctly moving the eyes tothe target in that condition given the model.
Both models were separately fit to the individual data. TheAkaike Information Criterion (AIC) was used to compare the good-ness of fit of the alternative models (Akaike, 1974).
AIC ¼ �2 lnðEÞ þ 2v
in which v corresponds to the number of free parameters. The bestmodel is the model with the smallest AIC value. Table 1 presents theindividual overall performance measures (saccadic latency andproportion correct), the maximum-likelihood estimates of the freeparameters of the bottom-up model, the top-down model, atop-down model assuming G(m;45�/�22.5�)(t) = G(l;45�/�22.5�)(t) =G(m;45�/�67.5�)(t) = G(l;45�/�67.5�)(t) = G(t) and the corresponding AICvalues.1 The bottom-up model provided the best fit for seven outof eight participants. In general, the data were better described bya bottom-up model when the individual average saccadic latencywas small: there was a significant correlation between individual
)

2164 M. Donk, W. van Zoest / Vision Research 51 (2011) 2156–2166
average saccadic latencies and the AIC values corresponding to thebottom up model (r = .73, p < .05). There was no such relationshipbetween the individual average saccadic latencies and the AIC valuescorresponding to the full top-down model (r = .23, p = .58) nor be-tween the individual average saccadic latencies and the AIC valuecorresponding to the constrained top-down model (r = .29, p = .48).
7. General discussion
The aim of the present study was to investigate whether peopleare able to control the extent to which salience plays a role in sacc-adic target selection. Guidance of salience was investigated in amodified visual search experiment measuring saccadic perfor-mance. Participants were asked to make a speeded eye movementtowards either the most or the least salient singleton. The averagedresults in the first part demonstrated that people were basicallyunable to control the extent to which saccadic selection was sal-ience driven. Short-latency eye movements were unaffected byinstruction and primarily directed towards the most salient single-ton in the display. Long-latency saccades were not specifically di-rected towards the most salient singleton in the display butneither primarily determined by instruction. The conclusions de-rived from the averaged results were substantiated by analysesof the individual data patterns in the second part. To examinethe extent to which overt visual selection is better described by abottom-up model or a top-down model, two formal multinomialmodels were developed corresponding to the alternative theoreti-cal views. The alternative models were separately fit to the individ-ual binned data patterns. The theoretical analyses revealed that thebottom-up model provided the best fit for seven out of eightobservers. The average saccade latency of these participants was210 ms. For Participant 5 the top-down model provided a betterfit of the data than the bottom-up model. The average saccade la-tency of Participant 5 was 267 ms which was well beyond the aver-age saccade latency of the other observers. The correlationsbetween de average individual saccadic latencies and the AIC val-ues derived from the bottom-up model fits revealed that therewas a significant relationship between the response latencies andthe goodness-of-fit of the bottom model. This shows that the fasterobservers were in emitting their responses, the better selectionbehavior was described by a bottom-up model.
Together the results demonstrate that people cannot freelydetermine whether or not they use salience information in control-ling their eye movements. More specifically, the results showedsome effects of Instruction but only when observers knew the tar-get identity (i.e., in the blocked trial conditions) and when saccadelatencies were long. This suggests that goal-driven guidance canonly be based on identity information. Salience information cannotbe used to guide goal-driven selection.
The present results are much in line with those previously re-ported by Hunt, von Mühlenen, and Kingstone (2007) who alsofound that short-latency response were salience driven whereaslong-latency responses were not (see also Donk & van Zoest,2008; van Zoest & Donk, 2005, 2006, 2008, 2010; van Zoest, Donk,& Theeuwes, 2004). The present results show in addition that thispattern of results cannot be changed when observers possess infor-mation concerning target salience. In fact, visual selection perfor-mance in the least-salient instruction condition was remarkablysimilar to that in the most-salient instruction condition, showingthat people are in essence incapable to exert goal-driven controlon the basis of salience information.
There are multiple studies demonstrating that people have con-trol over the extent to which salience-driven processes affect visualselection (Betz et al., 2010; Chen & Zelinsky, 2006; Einhäuser,Spain, & Perona, 2008; Foulsham & Underwood, 2007; Ludwig &
Gilchrist, 2002, 2003; Neider & Zelinsky, 2006; Wu & Remington,2003). For instance, Ludwig and Gilchrist (2002) had observerssearch for a no-onset color target among three distractors. Ontwo thirds of the trials, an additional distractor was presentedwhich could appear with or without abrupt onset and which couldbe similar or dissimilar to the target. Observers had to respondmanually or with an eye movement. The results demonstrated asubstantial amount of capture for both the manual and the oculo-motor responses which is in line with the present study. However,the results also indicated that the amount of capture was stronglymodulated by goal-driven factors. Eye movements were, for exam-ple, more often erroneously directed towards a similar onset dis-tractor than towards a dissimilar onset distractor. These resultssuggest that overt visual selection is at least partly under voluntarytop-down control, which seems to be inconsistent with the presentresults (see also Ludwig & Gilchrist, 2003). Critically, in Ludwig andGilchrist (2002) observers searched for a specific target identity andnot for a specific salience value like in the present study. Moreover,information concerning the target identity might have been moreinstantly available due to the use of low-density displays (4–5items). Finally, even though Ludwig and Gilchrist (2002, 2003)did find saccadic target selection to be under goal-driven control,their results also indicated that the prevalence of goal-driven con-trol strongly depended on response latency. For instance, the laten-cies of erroneous saccades towards similar onset distractors weregenerally about 70 ms faster than those correctly directed towardsthe target. These results suggest that when people are able to relyon information concerning identity, goal-driven selection may oc-cur and may even prevent the eyes from being captured by an irrel-evant distractor. However, the influence of goal-driven processeson saccadic target selection is limited to long-latency responses.Our results show, that irrespective of latency, goal-driven guidancecannot be based on salience information.
From a theoretical point of view, the present results are in linewith a bottom-up account of visual selection (e.g., Itti & Koch,2000, 2001; Theeuwes, 1991, 1992). According to a bottom-upview visual selection is primarily determined by the stimulus prop-erties in the visual field. As a result, salient objects will be priori-tized in selection over less salient objects. The results presentedhere fit this idea: observers prioritized the selection of the mostsalient singleton in the display, irrespective of instruction. To ac-count for salience-driven effects, most models have postulatedthe concept of a master map of locations or salience map, a topo-graphical representation of the relative distinctiveness of objectsin the visual field (Itti & Koch, 2000, 2001; Koch & Ullman, 1985;Treisman & Gelade, 1980; Wolfe, Cave, & Franzel, 1989). Visualselection is assumed to be guided by the distribution of activityin this salience map in such a way that at each moment in time vi-sual selection is biased towards that location in space that pos-sesses the greatest activity in the salience map (Itti & Koch, 2000,2001). Different accounts have been put forward for how the sal-ience map arises. Various authors have postulated that the saliencemap is produced by the summed output of separate feature maps(e.g., corresponding to red or vertical). The salience map is accord-ingly perceived as a ‘‘higher’’ brain structure, like the lateral intra-parietal area (Gottlieb, Kusunoki, & Goldberg, 1998) and the frontaleye fields (Schall & Thompson, 1999) receiving inputs from various‘‘lower’’ brain areas, including those concerned with featureextraction. Alternatively, it has been proposed that the saliencemap arises immediately at the level of V1 (Li, 2002; see also: Jin-gling & Zhaoping, 2008; Koene & Zhaoping, 2007; Zhaoping,2008; Zhaoping & Guyader, 2007; Zhaoping, Guyader, & Lewis,2009; Zhaoping & May, 2007). According to the V1 model of sal-ience proposed by Li (2002), there is no need to postulate the exis-tence of a separate satellite structure to account for salienceeffects. Instead, the neuronal responses in V1 can already create

M. Donk, W. van Zoest / Vision Research 51 (2011) 2156–2166 2165
a salience map that biases selection towards salient locations inspace. The results of the present study are much in line with thislatter account. Our results show that the effects of salience aretransient. It is plausible that the transience of salience effects di-rectly results from the differences in response latencies of individ-ual neurons in V1 in response to the presentation of a visual scene(Celebrini et al., 1993; Donk & van Zoest, 2008; Gawne, Kjaer, &Richmond, 1996).
A top-down account assumes selection to depend on the atten-tional control settings of an observer (Bacon & Egeth, 1994; Folk,Remington, & Johnston, 1992). This implies that if observers haveknowledge concerning a target, they should not be distracted bysingletons that are irrelevant to task performance. Our resultsshow substantial distraction, suggesting that people did not havemuch influence on selection behavior. However, observers in ourstudy were instructed to saccade to either the most or the leastsalient singleton in the display. It is quite well possible that thistype of instruction does not allow observers to employ a top-downset preventing distraction from an irrelevant singleton. Indeed, Ba-con and Egeth (1994) proposed that observers might be involved inone of two possible search modes. In a singleton-detection modepeople rely on a mode of processing in which salient visual stimuliare prioritized over non-salient ones. In a feature-search modepeople monitor a specific feature map for the presence of a relevantfeature. When a target feature is unknown, according to Bacon andEgeth, observers have to rely (by default) on a singleton-detectionmode. It is quite well possible that even though observers did haveforeknowledge concerning the relevant target feature in theblocked-trial conditions, they were unable to use this knowledgedue to the explicit instruction to search for either the most orthe least salient singleton in the display. Alternatively, it mighthave been that the goal-driven identity-based processes were justnot available fast enough to play a substantial role in the presentstudy. Indeed, the results of our previous studies (e.g., van Zoest& Donk, 2005, 2010; van Zoest, Donk, & Theeuwes, 2004) alsoshowed that if observers search for a specific target identity,goal-driven processes play no or only a subordinate role in the con-trol of saccadic target selection. This seems to be especially thecase when target and distractor have to be discriminated on thebasis of orientation. Previous studies have shown that when targetand distractors are defined in the orientation dimension, it takesabout 400 ms before accuracy in saccadic targeting reaches abouta 75% correct (van Zoest & Donk, 2006). In contrast, if a target is de-fined by color, this level can be reached much earlier in time at200 ms (van Zoest & Donk, 2008). These findings suggests thatsome features are processed faster than other features, influencingthe time course of selection (see also: de Vries et al., 2011).
Importantly, the present study aimed to investigate whetherobservers could use (or refrain from using) salience informationin a goal-driven manner. Despite the early availability of salienceinformation, later top-down processes were unable to rely on thisinformation. These results suggests that the later processing occursindependently of the early processing. People are not able to exertcontrol in overt visual selection when instructed to select an ele-ment on the basis of salience. This shows that salience-drivenselection cannot be determined by free will.
References
Akaike, H. (1974). A new look at the statistical model identification. IEEETransactions on Automatic Control, 19, 716–723.
Al-Aidroos, N., & Pratt, J. (2010). Top-down control in time and space: Evidence fromsaccadic latencies and trajectories. Visual Cognition, 18, 26–49.
Bacon, W. F., & Egeth, H. E. (1994). Overriding stimulus-driven attentional capture.Perception and Psychophysics, 55, 485–496.
Batchelder, W. H., & Riefer, D. M. (1986). The statistical analysis of a model forstorage and retrieval processes in human memory. British Journal ofMathematical and Statistical Psychology, 39, 129–149.
Batchelder, W. H., & Riefer, D. M. (1990). Multinomial processing model of sourcemonitoring. Psychological Review, 97, 548–564.
Betz, T., Kietzmann, T. C., Wilming, N., & König, P. (2010). Investigating task-dependent top-down effects on overt visual attention. Journal of Vision, 10(3),1–14 (article no. 15).
Celebrini, S., Thorpe, S., Trotter, Y., & Imbert, M. (1993). Dynamics of orientationcoding in area V1 of the awake primate. Visual Neuroscience, 10, 811–825.
Chen, X., & Zelinsky, G. J. (2006). Real-world search is dominated by top-downguidance. Vision Research, 46, 4118–4133.
de Vries, J. P., Hooge, I. T. C., Wiering, M. A., & Verstraten, F. A. J. (2011). How longersaccade latencies lead to a competition for salience. Psychological Science.doi:10.1177/0956797611410572 (published online 31.05.11).
Dombrowe, I. C., Olivers, C. N. L., & Donk, M. (2010). The time course of color- andluminance-based salience effects. Frontiers in Psychology, 1, 189. doi:10.3389/fpsyg.2010.00189.
Donk, M., & Soesman, L. (2010). Salience is only briefly represented: Evidence fromprobe-detection performance. Journal of Experimental Psychology: HumanPerception and Performance, 36, 286–302.
Donk, M., & Soesman, L. (2011). Object salience is transiently represented whereasobject presence is not: Evidence from temporal order judgment. Perception, 40,63–73.
Donk, M., & van Zoest, W. (2008). Effects of salience are short-lived. PsychologicalScience, 19, 733–739.
Einhäuser, W., Spain, M., & Perona, P. (2008). Objects predict fixations better thanearly saliency. Journal of Vision, 8(14), 1–26 (article no. 18).
Folk, C. M., & Remington, R. W. (1998). Selectivity in distraction by irrelevantfeatural singletons: Evidence for two forms of attentional capture. Journal ofExperimental Psychology: Human Perception and Performance, 24, 847–858.
Folk, C. M., Remington, R. W., & Johnston, J. C. (1992). Involuntary covert orienting iscontingent on attentional control settings. Journal of Experimental Psychology:Human Perception and Performance, 18, 1030–1044.
Folk, C. L., Remington, R. W., & Wright, J. H. (1994). The structure of attentionalcontrol: Contingent attentional capture by apparent motion, abrupt onset, andcolor. Journal of Experimental Psychology: Human Perception and Performance, 20,317–329.
Foulsham, T., & Underwood, G. (2007). How does the purpose of inspectioninfluence the potency of visual salience in scene perception? Perception, 36,1123–1138.
Gawne, T. J., Kjaer, T. W., & Richmond, B. J. (1996). Latency: Another potential codefor feature binding in striate cortex. Journal of Neurophysiology, 76, 1356–1360.
Gottlieb, J. P., Kusunoki, M., & Goldberg, M. E. (1998). The representation of visualsalience in monkey parietal cortex. Nature, 391, 481–484.
Hu, X., & Batchelder, W. H. (1994). The statistical analysis of general processing treemodels with the EM algorithm. Psychometrika, 59, 21–47.
Hunt, A. R., von Mühlenen, A., & Kingstone, A. (2007). The time course of attentionaland oculomotor capture reveals a common cause. Journal of ExperimentalPsychology: Human Perception and Performance, 33, 271–284.
Hwang, A. D., Higgins, E. C., & Pomplun, M. (2009). A model of top-down attentionalcontrol during visual search in complex scenes. Journal of Vision, 9(5), 1–18(article no. 25).
Itti, L., & Koch, C. (2000). A saliency-based search mechanism for overt and covertshifts of visual attention. Vision Research, 40, 1489–1506.
Itti, L., & Koch, C. (2001). Computational modelling of visual attention. NatureReviews Neuroscience, 2, 194–203.
Jingling, L., & Zhaoping, L. (2008). Change detection is easier at texture border barswhen they are parallel to the border: Evidence for V1 mechanisms of bottom upsalience. Perception, 37, 197–206.
Koch, C., & Ullman, S. (1985). Shifts in selective visual attention: Towards theunderlying neural circuitry. Human Neurobiology, 4, 219–227.
Koene, A. R., & Zhaoping, L. (2007). Feature-specific interactions in salience fromcombined feature contrasts: Evidence for a bottom-up saliency map in V1.Journal of Vision, 7(7), 1–14 (article no. 6).
Li, Z. (2002). A saliency map in primary visual cortex. Trends in Cognitive Sciences, 6,9–16.
Ludwig, C. J. H., & Gilchrist, I. D. (2002). Stimulus-driven and goal-driven controlover visual selection. Journal of Experimental Psychology: Human Perception andPerformance, 28, 902–912.
Ludwig, C. J. H., & Gilchrist, I. D. (2003). Goal-driven modulation of oculomotorcapture. Perception and Psychophysics, 65, 1243–1251.
Ludwig, C. J. H., Ranson, A., & Gilchrist, I. D. (2008). Oculomotor capture by transientevents: A comparison of abrupt onsets, offsets, motion, and flicker. Journal ofVision, 8(14), 1–16 (article no. 11).
Mulckhuyse, M., van Zoest, W., & Theeuwes, J. (2008). Capture of the eyes byrelevant and irrelevant onsets. Experimental Brain Research, 186, 225–235.
Nakayama, K., & Mackeben, M. (1989). Sustained and transient components of focalvisual attention. Vision Research, 29, 1631–1647.
Navalpakkam, V., & Itti, L. (2005). Modeling the influence of task on attention. VisionResearch, 45, 205–231.
Neider, M. B., & Zelinsky, G. J. (2006). Scene context guides eye movements duringvisual search. Vision Research, 46, 614–621.
Nothdurft, H. C. (2002). Attention shifts to salient targets. Vision Research, 42,1287–1306.
Schall, J. D., & Thompson, K. G. (1999). Neural selection and control of visuallyguided eye movements. Annual Review of Neuroscience, 22, 241–259.
Theeuwes, J. (1991). Exogenous and endogenous control of attention: The effect ofvisual onsets and offsets. Perception and Psychophysics, 49, 83–90.

2166 M. Donk, W. van Zoest / Vision Research 51 (2011) 2156–2166
Theeuwes, J. (1992). Perceptual selectivity for color and form. Perception andPsychophysics, 51, 599–606.
Theeuwes, J. (1994). Stimulus-driven capture and attentional set: Selective searchfor color and visual abrupt onsets. Journal of Experimental Psychology: HumanPerception and Performance, 20, 799–806.
Theeuwes, J., Kramer, A. F., Hahn, S., & Irwin, D. E. (1998). Our eyes do not always gowhere we want them to go: Capture of the eyes by new objects. PsychologicalScience, 9, 379–385.
Theeuwes, J., Kramer, A. F., Hahn, S., Irwin, D. E., & Zelinsky, G. J. (1999). Influence ofattentional capture on oculomotor control. Journal of Experimental Psychology:Human Perception and Performance, 25, 1595–1608.
Treisman, A. M., & Gelade, G. (1980). A feature-integration theory of attention.Cognitive Psychology, 12, 97–136.
van Zoest, W., & Donk, M. (2004). Bottom-up and top-down control in visual search.Perception, 33, 927–937.
van Zoest, W., & Donk, M. (2005). The effects of salience on saccadic target selection.Visual Cognition, 2, 353–375.
van Zoest, W., & Donk, M. (2006). Saccadic target selection as a function of time.Spatial Vision, 19, 61–76.
van Zoest, W., & Donk, M. (2008). Goal-driven modulation as a function of time insaccadic target selection. Quarterly Journal of Experimental Psychology, 61,1553–1572.
van Zoest, W., & Donk, M. (2010). Awareness of the saccade goal in oculomotorselection: Your eyes go before you know. Consciousness and Cognition, 19,861–871.
van Zoest, W., Donk, M., & Theeuwes, J. (2004). The role of stimulus-driven and goal-driven control in saccadic visual selection. Journal of Experimental Psychology:Human Perception and Performance, 30, 746–759.
van Zoest, W., Hunt, A. R., & Kingstone, A. (2010). Representations in visualcognition: It’s about time. Current Directions in Psychological Science, 19(2),116–120.
Wolfe, J. M., Cave, K. R., & Franzel, S. L. (1989). Guided search: An alternative to thefeature integration model for visual search. Journal of Experimental Psychology:Human Perception and Performance, 15, 419–433.
Wu, S.-C., & Remington, R. W. (2003). Characteristics of covert and overt visualorienting: Evidence from attentional and oculomotor capture. Journal ofExperimental Psychology: Human Perception and Performance, 29, 1050–1067.
Yantis, S., & Jonides, J. (1984). Abrupt visual onsets and selective attention: Evidencefrom visual search. Journal of Experimental Psychology: Human Perception andPerformance, 10, 601–621.
Yantis, S., & Jonides, J. (1990). Abrupt visual onsets and selective attention:Voluntary versus automatic allocation. Journal of Experimental Psychology:Human Perception and Performance, 16, 121–134.
Zelinsky, G. J. (2008). A theory of eye movements during target acquisition.Psychological Review, 115, 787–835.
Zhaoping, L. (2008). Attention capture by eye of origin singletons even withoutawareness – A hallmark of a bottom-up saliency map in the primary visualcortex. Journal of Vision, 8(5), 1–18 (article no. 1).
Zhaoping, L., & Guyader, N. (2007). Interference with bottom-up feature detectionby higher-level object recognition. Current Biology, 17, 26–31.
Zhaoping, L., Guyader, N., & Lewis, A. (2009). Relative contributions of 2D and 3Dcues in a texture segmentation task, implications for the roles of striate andextrastriate cortex in attentional selection. Journal of Vision, 9(11), 1–22 (articleno. 20).
Zhaoping, L., & May, K. A. (2007). Psychophysical tests of the hypothesis of a bottom-up saliency map in primary visual cortex. PLoS Computational Biology, 3, e62.