nowe metodologiczne propozycje analiz w …demograf/publikacje/sad2.pdf · opisuj ących zjawiska i...
TRANSCRIPT

Sekcja Analiz Demograficznych Komitet Nauk Demograficznych PAN Al. Niepodległości 164 02-554 Warszawa tel/fax: 646-61-38 e-mail: [email protected]
2/2000
NOWE METODOLOGICZNE PROPOZYCJE ANALIZ W NAUKACH SPOŁECZNYCH ZE SZCZEGÓLNYM
UWZGLĘDNIENIEM DEMOGRAFII Spis treści
Przedmowa.
1. Ewa Frątczak – Nowe metodologiczne propozycje analiz w demografii.
2. Ewa Soja - Analiza historii zdarzeń grup. Rezultaty trwających badań.
3. Aneta Ptak-Chmielewska (SGH, Warszawa) - Analizy wielopoziomowe
w naukach społecznych.
4. Alicja Siwek, Małgorzata Kowalska, Małgorzata Szczyt - Analiza
tekstowa (statystyka tekstowa).
5. Maciej Rodzewicz - Metody mikrosymulacyjne w prognozowaniu
demograficznym.
Zeszyt nr 2. Sekcji Analiz Demograficznych (dokumentacja posiedzeń SAD).

2
Przedmowa
Sekcja Analiz Demograficznych KND PAN została powołana na posiedzeniu
Prezydium Komitetu Nauk Demograficznych Polskiej Akademii Nauk w dniu 23 września
1999 roku. Jest trzecią obok Sekcji Demografii Medycznej i Sekcji Demografii Historycznej
sekcją naukową działającą w ramach Komitetu Nauk Demograficznych Wydziału I. Nauk
Społecznych - Polskiej Akademii Nauk.
Sekcją Analiz Demograficznych SAD prowadzą : dr hab. Ewa Frątczak (kierownik
sekcji) i dr hab. Jolanta Kurkiewicz (z-ca kierownika sekcji).
Głównym zadaniem Sekcji Analiz Demograficznych jest organizowanie spotkań
merytorycznych poświęconych szeroko rozumianym metodom analiz demograficznych,
włączając najnowsze metody i techniki zarówno organizacji badań jak i metod analiz
opisujących zjawiska i procesy demograficzne ich uwarunkowania i konsekwencje. Podstawą
każdej prezentowanej metody w ramach spotkań SAD jest dokładny i gruntowny opis
teoretyczny metody (metod) oparty na możliwie wszechstronnej i najnowszej literaturze wraz
z prezentacją zastosowania teorii na danych empirycznych. Prezentacja nowych metod
wymagać będzie od referentów zapoznania się ze stosowną literaturą i niemałego nakładu
pracy. Dość często upowszechnienie nowej metody i jej zastosowanie wymagać będzie
nakładu pracy związanego z zapoznaniem się ze stosownym programem lub pakietem
komputerowym umożliwiającym dość sprawną aplikację modelu lub metody. Zatem działania
mające na celu informację o programach komputerowych i organizowanie w przyszłości
warsztatów szkoleniowych to jedno z kolejnych zadań SAD.
Ogranizatorom Sekcji i osobom prowadzącym SAD zależy na integracji środowiska
demograficznego, w tym głownie młodych adeptów nauki wokół zagadnień szeroko
rozumianych analiz demograficznych. Zebrania Sekcji Analiz Demograficznych mogą być
również poświęcone prezentacji nowych twórczych metod analiz lub zastosowań metod
(modeli) będących wynikami prac doktorskich lub habilitacyjnych ukończonych lub
znajdujących się w fazie przygotowywania, na odpowiednim etapie.
Drugie spotkanie Sekcji Analiz Demograficznych KND PAN miało miejsce 19
czerwca 2000 w sali 713, budynek F - Instytut Statystyki i Demografii Szkoły Głównej
Handlowej przy Al. Niepodległości 162 w Warszawie, miejsce w którym odbywają się
posiedzenia SAD. Wprowadzenie oraz referat na temat „Nowe metodologiczne propozycje
analiz w demografii” został wygłoszony przez Kierownika SAD dr hab. Ewę Frątczak.

3
Niniejszy, drugi numer Zeszytów Sekcji Analiz Demograficznych jest numerem,
zawierającym wystąpienia :
- Ewa Soja - Analiza historii zdarzeń grup. Rezultaty trwających badań.
-Aneta Ptak-Chmielewska (SGH, Warszawa) - Analizy wielopoziomowe w naukach
społecznych.
- Alicja Siwek - Analiza tekstowa (statystyka tekstowa).
- Maciej Rodzewicz - Metody mikrosymulacyjne w prognozowaniu demograficznym.
Zeszyty SAD przygotowywane są we własnym zakresie, za teksty odpowiedzialni są
Autorzy. Prace techniczne związane z końcową obróbką tekstu zostały wykonane przez mgr
Anetę Ptak-Chmielewską.
Z nadzieją na upowszechnianie informacji o działalności Sekcji Analiz
Demograficznych KND PAN oraz o formie dokumentacji spotkań w postaci serii Zeszytów
Naukowych Sekcji1.
Kierownik SAD
/ dr hab. Ewa Frątczak /
1Wobec faktu oczekiwania na uzyskanie formalnej zgody na publikowanie Zeszytów Naukowych SAD, mają one formę dokumentacji z kolejnych posiedzeń SAD.

4
SPIS TREŚCI str.
Nowe metodologiczne propozycje analiz w demografii............................................................ 6
Analiza historii zdarzeń grup - Rezultaty trwających badań. ..................................................7
1. Problemy badania wpływu otoczenia na zachowanie jednostki. ................................. 7
1.1 Model pseudojednostkowy ...................................................................................... 10
1.2 Model multijednostkowy ......................................................................................... 12
2. Modelowanie interakcji pomiędzy członkami grupy kontaktowej............................ 13
3. Rezultaty wstępnych badań empirycznych.................................................................. 15
4. Podsumowanie. ............................................................................................................... 20
Analizy wielopoziomowe w naukach społecznych.................................................................. 21
1. Informacje wprowadzające. .......................................................................................... 21
2. Model analizy wielopoziomowej – założenia ogólne.................................................... 23
3. Model analizy wielopoziomowej bez składnika losowego........................................... 24
3.1. Zastosowanie modelu do analizy migracji. ........................................................... 24
3.2. Analiza migracji uwzględniająca przepływy międzyregionalne......................... 25
4. Model analizy wielopoziomowej uwzględniający składnik losowy............................ 29
4.1. Zastosowanie modelu do analizy migracji. ........................................................... 31
5. Ograniczenia w zastosowaniu analizy wielopoziomowej do analizy historii zdarzeń.
.............................................................................................................................................. 33
6. Podsumowanie. ............................................................................................................... 34
7. Tabele i wykresy. ............................................................................................................ 35
Statystyczna analiza tekstu (Textual Statistics)...................................................................... 52
1. Wprowadzenie. ............................................................................................................... 52
2. Metodologia Statystycznej Analizy Tekstowej ............................................................ 53
3. Statystyka tekstowa dla celów analizy odpowiedzi na pytania otwarte .................... 55
4. Analiza długich tekstów................................................................................................. 62
4.1 Rozprawy naukowe i wywiady................................................................................ 62
4.2 Tekst specjalny: dziennik ........................................................................................ 63

5
5. Podsumowanie ................................................................................................................ 65
Metody mikrosymulacyjne w prognozowaniu demograficznym............................................ 67
1. Wstęp ............................................................................................................................... 67
2. Porównanie metody makro i mikro symulacyjnej ...................................................... 68
3. Zastosowanie mikrosymulacji w prognozowaniu demograficznym.......................... 71
4. Zastosowanie mikrosymulacji w prognozowaniu demograficznym.......................... 74
5. Losowość w mikrosymulacji.......................................................................................... 75
5.1 Losowość wewnętrzna (związana z metodą Monte Carlo). .................................. 75
5.2 Losowość populacji początkowej (próby) .............................................................. 76
5.3 Losowość sformułowania modelu (zakłócenia modelu). ....................................... 76
6. Inne właściwości charakterystyczne dla mikrosymulacji demograficznej .............. 78
6.1 Modele otwarte i zamknięte..................................................................................... 78
6.2 Modele ciągłe i dyskretne. ....................................................................................... 79
6.3 Ryzyko konkurencyjne i zdarzenia złożone........................................................... 80
6.4 Zdarzenia powiązane z kilkoma jednostkami ....................................................... 80
7. Przegląd istniejących demograficznych modeli mikrosymulacyjnych...................... 82
8. Omówienie modelu KIMSIM........................................................................................ 85
9. Wnioski............................................................................................................................ 88

6
Dr hab. Ewa Frątczak
Instytut Statystyki i Demografii,
Szkoła Główna Handlowa
Nowe metodologiczne propozycje analiz w demografii.

7
Mgr Ewa Soja
Zakład Demografii, Katedra Statystyki
Akademia Ekonomiczna w Krakowie
Analiza historii zdarzeń grup - Rezultaty trwających badań.1
1. Problemy badania wpływu otoczenia na zachowanie jednostki.
Klasyczna analiza historii zdarzeń w demografii pozwala badać przebieg życia
jednostki w czasie. Jednostka w ciągu życia doświadcza wielu zdarzeń, składających się na
różne kariery, tworzące jej biografię (rys.1).
Rysunek 1. Klasyczna analiza historii zdarzeń jednostki.
Kariery
rodzinna
migracyjna
zawodowa
tPrzebieg życia jednostki
(opisany za pomoc ą procesów stochastycznych)••••- zdarzenia
Pytanie:
Jak na ryzyko wystąpienia pewnegozdarzenia w życiu jednostkiwpływa zajście innego zdarzenia zjej życia (np. jak na pierwsząmigrację wpływa urodzeniedziecka)?
Metody klasycznej analizy historii zdarzeń, wykorzystujące procesy stochastyczne
umożliwiają badanie zjawisk i procesów demograficznych dotyczących jednostki. W
szczególności pozwalają badać w czasie interakcje jednego lub wielu zjawisk, biorąc
1 Opracowanie przygotowane na podstawie artykułu: Event history analysis of groups. The findings of an on-going research project. E.Lelievre, C. Bonvalet, X. Bry w Population vol. 10 No 1, 1998, str. 11-38. Prezentowany tekst był przedstawiony przez Autora i dyskutowany na posiedzeniu Sekcji Analiz Demograficznych w dniu 19.06.2000.

8
równocześnie pod uwagę dużą liczbę charakterystyk jednostki, które mogą być
modyfikowane w czasie.
Klasyczna analiza historii zdarzeń pozwoliła efektywnie rozwiązać kilka problemów
stawianych w tradycyjnej analizie wzdłużnej. Jednakże analiza historii zdarzeń jednostki nie
mogła dać odpowiedzi na pytanie jak zachowania wielu jednostek wpływają na zachowanie
wybranej jednostki (ego) i odwrotnie (rys.2).
Rysunek 2. Wzajemne oddziaływanie jednostek na siebie.
Jak grupa jako całość wpływana „ego”? (i odwrotnie)
ego
C K
BA
Jak poszczególne jednostki wpływają
na „ego”? (i odwrotnie)
t
ego
AAB
C
K
Trajektorie
Poniższe opracowanie przedstawia próbę przejścia z modelowania zdarzeń historii
dotyczących jednostki na jej grupę wpływów (grupę kontaktową). Proponowane modele są
tak budowane, aby wykorzystać narzędzia klasycznej analizy historii zdarzeń.
Próba definicji nowej jednostki - grupy kontaktowej
Jednym z pierwszych problemów pojawiających się w analizie historii zdarzeń grup jest
określenie tych jednostek, które rzeczywiście miałyby wpływ na wybraną jednostkę (ego) i
odwrotnie. Wydaje się iż tradycyjne grupy wpływów , takie jak: rodzina , rodzina nuklearna
czy też gospodarstwo domowe nie są już wystarczające z wielu względów. Głównie wynika
to z tego, iż:
⇒ tradycyjne grupy nie obejmują wszystkich osób bliskich (bierzemy pod uwagę związki
między osobami wynikają z pokrewieństwa, ze wspólnego mieszkania lub z przyjaźni),
⇒ tradycyjne grupy nie pozwalają na analizę ewolucji powiązań (sieci związków) między
wszystkimi jednostkami w czasie, np.: problem rozwodów – którą gałąź rodziny
śledzić, problem innych niż tradycyjne więzi rodzinne- np. wolne związki

9
Dlatego istnieje potrzeba powstania nowej jednostki statystycznej, która zastąpiłaby
dotychczasowe, tradycyjne jednostki (grupy wpływów) i równocześnie spełniłaby nowe
wymagania.
Zaproponowano następującą definicję grupy kontaktowej:
Grupa kontaktowa stanowi kombinację wszystkich członków różnych gospodarstw
domowych, do których należała jednostka (ego) w ciągu swojego życia wraz z kluczowymi
członkami rodziny, którzy nie mieszkali z jednostką i niekoniecznie związani byli
pokrewieństwem
Tak zdefiniowana grupa zachowuje dwie fundamentalne cechy rodziny: pokrewieństwo oraz
współzamieszkiwanie. Jest ona również wyznaczona jednoznacznie, co wynika ze
zorientowania grupy na „ego” (grupa ukonstytuowana na „ego” ).
Modelowanie grupy kontaktowej.
Dla potrzeb empirycznych badań oraz do budowania modeli użyteczne jest zdefiniowanie
następujących pojęć:
minimalna grupa kontaktowa – należą do niej:
• wszyscy członkowie gospodarstw domowych, do których należała jednostka,
• dzieci jednostki (nie mieszkające razem),
• współmieszkający partner.
pozycja jednostki - opisana przez fakt, że jest się:
• rodzicem,
• częścią pary,
• samotnym.
typy kohabitacji:
proste:
• mieszkanie z rodzicami
• mieszkanie z partnerem,
• mieszkanie z dziećmi,
• mieszkanie samemu.

10
złożone:
• kombinacje prostych typów z uwzględnieniem współzamieszkiwania z osobami
niespokrewnionymi
W modelowaniu grup kontaktowych są wykorzystane metody i miary klasycznej
analizy historii zdarzeń jednostki (procesy stochastyczne). Zaproponowano dwa uzupełniające
się modele: model pseudojednostkowy oraz model multijednostkowy. Opisują one wzajemne
oddziaływanie jednostki „ego” z jej grupą kontaktową (Rys.2).
1.1 Model pseudojednostkowy
W modelu pseudojednostkowym grupa traktowana jest jako złożona jednostka -
(pseudojednostka), charakteryzowana przez swoją struktur ę (skład), która zmienia się w
czasie.
Struktura opisana jest przez wektor charakterystyk reprezentujący:
1) egzogeniczne zmienne kolektywne np. typ kohabitacji (wyznaczony min. przez pozycję
jednostki „ego”), rozmiar grupy ,
2) zmienne endogeniczne opisujące poszczególnych członków grupy.
W przypadku zmiennych endogenicznych pojawia się problem "równowa żnych" członków
grupy, tj. osób mających równoważną pozycję (równoważność uwarunkowaną socjologicznie
i demograficznie). Osoby takie są reprezentowane przez tzw. "syntetycznego członka"
opisanego wspólną charakterystyką.
Przykład:
Badając determinanty migracji rodziny, można ją opisać jako:
(matka, ojciec, {dzieci}) lub ({rodzice},{dzieci}),
gdzie {dzieci} stanowią syntetycznego członka, reprezentującego poszczególne dzieci
(zostały one zagregowane i opisane wspólnymi charakterystykami takimi jak: liczba
dzieci, liczba dzieci przed migracją, piramida wieku dzieci...). Analogicznie w drugim
przypadku matka i ojciec zostali zastali zastąpieni wspólnym reprezentantem {rodzice}.
Struktura (skład) grupy w modelu pseudojednostkowym zmienia się w czasie. Zmiany te
zachodzą w czasie (t, t+1) i są obserwowane poprzez "wyjścia" i "wej ścia" członków
grupy („wejścia i wyjścia” są realizacjami zdarzeń doświadczanych przez jednostki).

11
Zdarzenia doświadczane przez poszczególne jednostki (indywidualne zdarzenia) w grupie są
traktowane jako warianty pewnego kolektywnego zdarzenia – w związku z tym badany jest
w czasie tzw. kolektywny proces np. dekohabitacja dzieci.
Obserwowane zmiany w strukturze opisuje wektor charakterystyk, reprezentujący
zmienne egzogeniczne i endogeniczne.
1) Zmiany w zmiennych kolektywnych (typ kohabitacji, rozmiar) dokonują się poprzez np.
zmianę pozycji „ego” np. urodzenie dziecka przez samotną matkę, odejście partnera
(zgon, rozwód, separacja),
2) W przypadku zmiennych endogenicznych opisujących poszczególnych członków grupy
pojawia się tzw. problem obcięcia (censoring) kolektywnego procesu przez jednostkowy
(indywidualny) proces.
Przykład:
Badając kolektywny proces dekohabitacji dzieci w grupie (matka, ojciec, {dzieci}),
powstaje problem „wyjścia” kolejnego dziecka. Można modelować go za pomocą ryzyk
konkurencyjnych (model ryzyk konkurencyjnych).
W modelu pseudoindywidualnym występuje również problem wyboru skali czasu.
Pamiętając o tym, iż zdarzenie kolektywne jest realizacją zdarzeń jednostkowych (kilku),
można wybrać:
• pojedynczą skalę czasu (wspólny kolektywny czas),
• kilka skal czasu
Najczęściej wybiera się pojedynczą skalę czasu, a specyficzne czasy członków grupy można
włączyć do zmiennych w modelu (np. w semiparametrycznym modelu)
Przykład: dekohabitacja dzieci
• kolektywny czas – liczony od momentu zawarcia małżeństwa przez parę
• specyficzne (jednostkowe) czasy - wiek dziecka w chwili odejścia
Wybierając więcej niż jedną skalę czasu, napotykamy na problem ograniczenia ilości skal
(„kilka” musi być ograniczone), aby była możliwość konstrukcji estymatorów. Jednakże z
góry nie wiadomo jaka jest wielkość grupy kontaktowej (dobierając jednostkę –„ego” do
próby nie możemy wykorzystywać wiadomości o niej –o rozmiarze jej grupy wpływów).

12
Podsumowując model pseudojednostkowy jest dobry we wstępnej fazie badań. Daje
"spojrzenie z góry" na grupę (rys.2) - pozwala zobaczyć ogólną strukturę grupy, jej zmiany w
czasie, przez co lepiej opisać badane zjawisko. Jednak aby analizować interakcje pomiędzy
jednostkami należy spojrzeć "od wewnątrz"- „do środka grupy” (rys.2). Prowadzi to do
modelowania multijednostkowego- do modelu multijednostkowego.
1.2 Model multijednostkowy
Model multijednostkowy angażuje do badania wszystkie trajektorie osób należących
do grupy kontaktowej i pozwala opisać relacje między nimi. Model opisany jest jako
wielowymiarowy proces stochastyczny, przy użyciu funkcji gęstości, przeżycia, dystrybuanty,
ryzyka oraz ich brzegowych i warunkowych wersji.
Kluczowym problemem w budowie tego modelu jest określenie zależności między
trajektoriami poszczególnych członków grupy wpływów. W przypadku klasycznej analizy
jednostki istnieje niezależność między jednostkami, jednak w analizie grupy zostaje utracona
stochastyczna niezależność. Problem niezależności próbuje się rozwiązać poprzez
odpowiednie uwarunkowanie zmiennych, aby otrzymać pewną lokalną niezależność. W tym
celu definiuje się zdarzenie brzegowe:
Zdarzenie brzegowe: zdarzenie zaobserwowane na jednostkowej (indywidualnej) trajektorii
członka grupy kontaktowej.
Rodzaje zależności pomiędzy procesami wywołującymi zdarzenia brzegowe wynikają ze
źródeł wywołujących te zdarzenia. Można wyodrębnić dwojakiego rodzaju zależności:
1) Zależność jawną - wywołaną przez obserwowalne źródła będące czynnikami, które
koduje się jako zmienne egzo i endogeniczne), np. odejście jednego
członka gospodarstwa domowego może zmienić ryzyko migracji
rodziny, czy ryzyko dekohabitacji innych członków, „odejście"- jest
obserwowalne.
2) Zależność niejawną - źródła wywołujące zależność są niejawne – czynników tych nie
można zidentyfikować, są zmiennymi ukrytymi nieobserwowalnymi,
np. wspólna tendencja do częstej migracji przez rodzinę.

13
2. Modelowanie interakcji pomiędzy członkami grupy kontaktowej
Hipoteza o lokalnej warunkowej niezależności.
Zależność jawna.
Jeżeli wszystkie źródła zależności zostaną zidentyfikowane i zakodowane w postaci
zmiennych, to wtedy warunkowo do tych zmiennych ryzyko pojawienia się indywidualnego
zdarzenia, można traktować jako czysto jednostkowy hazard, niezależny od pozostałych.
Przykład:
Fakt znalezienia zatrudnienia w czasie t przez dwóch bezrobotnych rodziców, jest traktowany
jako dwa zdarzenia, które podlegają niezależnym hazardom.
Ze względu na problem tzw. nieobserwowalnej heterogeniczności, powinno się jednak
testować zakładaną hipotezę. o lokalnej niezależności.
Zależność niejawna:
Jeżeli oprócz jawnych źródeł zależności istnieją źródła niejawne można wykorzystać
modele (Clayton,1978; Oakes,1989), bazujące na wspólnym dla różnych członków grupy
nieobserwowalnym czynniku ryzyka. W tym przypadku pojawiają się jednak pewne
problemy:
• model wymaga parametrycznego modelowania wspólnego czynnika, ale trudno jest
dobrać pasujący rozkład parametryczny, gdy nie znana jest natura źródła zależności,
• trudno twierdzić, że wspólny czynnik ryzyka odpowiada za podstawowy rodzaj
zależności.
W takiej sytuacji potrzeba bardziej ogólnego modelu. Wydaje się, iż rozwiązaniem jest
poszukiwanie sposobu rozdzielenia brzegów od ich struktury zależności (poszukiwanie
informacji o efektach brzegowych).
Modele wykorzystujące hipotezę o lokalnej warunkowej niezależności, pozwalają
badać interakcje pomiędzy jednostkami, tak jakby były one niezależne (zależność jest
uwzględniona poprzez zmienne). Do konstrukcji i estymacji tych modeli stosuje się narzędzia
analizy ekonometrycznej, w szczególności bazuje się na formule Jacod’a (Anderson (1993)):

14
Niech
X – oznacza proces stochastyczny, taki, że
]T,0[t)}t(X{X ∈= (1)
Niech
x - oznacza trajektorię grupy, będącą realizacją procesu:
],0[)}({ Tttxx ∈= (2)
Gęstość prawdopodobieństwa trajektorii, warunkową do punktu wyjścia można zapisać:
∏∈
====]T,0(t
)t,0[x)t,0[X|)t(X ))t(x(dP))0(x)0(X|xX(P (3)
Hipoteza lokalnej warunkowej niezależności prowadzi do grupy modeli „szoku”, wśród
których szczególnie użyteczne są modele semiparametryczne.
Przykład:
Rozważmy parę małżeńską, dla której możemy badać jak zmieni się ryzyko śmierci partnera
na skutek „szoku” wywołanego odejściem (śmiercią, rozwodem, separacją) drugiego partnera.
Dla każdej jednostki ryzyko to opiszemy używając modelu Coxa. Każdy indywidualny model
jest uwarunkowany w odniesieniu do objaśniających charakterystyk ryzyka (zmienne z, y).
Niech:
z - zmienna egzogeniczna opisująca jednego partnera
y – zmienna endogeniczna, będąca funkcją kodującą, czy partner doświadczył zdarzenia
Dla pierwszego partnera:
)yzexp()t(h)y,z|t(h 221101211 γ+β= (4)

15
gdzie:
)(01 th jest niewyspecyfikowaną parametrycznie funkcją czasu (tzw. baseline hazard)
Analogicznie dla drugiego partnera:
)yzexp()t(h)y,z|t(h 112202122 γ+β= (5)
Ryzyko śmierci pierwszego partnera przedstawia się następująco:
jeśli
02 =y co oznacza, że drugi partner „nie odszedł” (nie doświadczył zdarzenia)
to:
)zexp()t(h)0,z|t(h 110111 β= (6)
jeśli
12 =y co oznacza, że drugi partner „odszedł” (doświadczył zdarzenia), ryzyko
śmierci pierwszego partnera wzrosło, nastąpił efekt szoku
to
211012110111 γexp)zexp()t(h)zexp()t(h)1,z|t(h β=γ+β= (7)
3. Rezultaty wstępnych badań empirycznych.
Wydaje się, iż modele szoku są bardzo obiecujące, jednak metodologia zależy od
danych. Jednak do tego czasu nie zebrano zbioru danych, które zawierałyby informacje o
trajektoriach grup kontaktowych (zdefiniowanych tutaj). Niemniej dokonano prób
przybliżenia i rozjaśnienia koncepcji grupy kontaktowej wykorzystując dane z dwóch
francuskich badań retrospektywnych. Były to badania przeprowadzone przez INED.
Pierwsze z nich „Population and Depopulation of Paris” zostało przeprowadzone w
1986 roku i dotyczyło zaludnienia i wyludnienia Paryża. Wśród 2000 Paryżan w wieku 50 do
60 lat (generacje z 1926 do 1935 roku) zebrano informacje o strukturze gospodarstw
domowych, do których należały jednostki w ciągu swojego życia. Badanie to służyło do opisu
ewolucji grupy domowej (minimalnej grupy kontaktowej) w trakcie trwania życia jednostki.
Drugie z badań „Close friends and relatives” przeprowadzono w 1990 roku na
reprezentatywnej próbie dorosłej populacji Francuzów. Pozwoliło ono oszacować sieć
przyjaciół i krewnych jednostki w pewnym momencie jej życia.

16
Badania te przyczyniły się do lepszego zrozumienia koncepcji grupy kontaktowej,
potwierdziły potrzebę porzucenia tradycyjnych grup wpływu (gospodarstwa domowego,
rodziny) do opisu ewolucji socjalno- demograficznych struktur. Tabele 1-3 dotyczą
pierwszego badania, a dane w tabeli 4 i 5 pochodzą z drugiego badania.
Tablica 1. Struktura gospodarstw domowych, do których należeli respondenci w czasie
swojego życia
Wiek respondenta (w latach) Typ gospodarstwa
25 35 45 55
Osoby mieszkające samotnie 18,7 10,1 10 16,1
Rodziny nuklearne:
• pary bez dzieci 16,8 9,4 11,6 34,2
• pary z dziećmi 29,8 65,3 65,5 38,4
Rodziny z jednym rodzicem 2,5 4,5 5,9 5,4
Rodziny złożone
• pary bez dzieci z dziadkami lub
rodzeństwem
2,9 0,7 0,8 1,4
• pary z dziećmi z dziadkami lub
rodzeństwem
5,9 5 3,3 2
• osoby samotne z rodzicami 21,9 4,4 2,4 1,7
• inne złożone rodziny 1,5 0,8 0,5 0,7
Razem 100 100 100 100
Źródło: Badania (Population and Depopulation of Paris)
Tablica 2. Przebywanie w różnych typach gospodarstw domowych do 50 roku życia
Typ gospodarstwa domowego Mężczyźni Kobiety Razem
Osoby mieszkające samotnie 55% 38% 46%
Pary bez dzieci 73% 73% 73%
Pary z dziećmi 80% 80% 80%
Rodziny niepełne 7% 24% 16%
Rodziny złożone 49% 43% 46%
Liczba osób 989 998 1987
Źródło: Badania (Population and Depopulation of Paris)

17
Przykładowo (Tab.2), zauważmy iż prawie połowa respondentów (46%) mieszkała
kiedyś w rodzinie złożonej, a w oficjalnych statystykach są to tylko marginalne udziały.
Widać, że ten typ kohabitacji był istotny dla badanej populacji. Jednak sam typ kohabitacji
nic nie informuje o rozmiarze grupy domowej (typ kohabitacji i rozmiar były zmiennymi
kolektywnymi opisującymi strukturę w modelu pseudojednostkowym).
Tablica 3. Średnia liczba osób w gospodarstwach domowych respondentów
Wiek (w latach) Liczba osób
25 3,0
30 3,4
35 3,7
40 3,8
45 3,6
50 3,1
55 1,9
Źródło: Badania (Population and Depopulation of Paris)
Dane w Tab.3 obrazują ewolucję w rozmiarze grupy domowej (gospodarstwa
domowego). Należy pamiętać że są to wielkości średnie. Ogólnie wywnioskowano, że średnia
liczba osób mieszkająca z respondentem w trakcie jego dorosłego życia wyniosła 4,9. Dla
osób, które nigdy nie wchodziły w związki małżeńskie wielkość ta wyniosła 3, a dla
małżeństw (w chwili badania) 5. Jak widać badania te pozwoliły wstępnie oszacować
wielkość minimalnej grupy kontaktowej oraz pokazały jej ewolucję w trakcie życia jednostki.
Drugie badanie (Bliscy i krewni) pokazuje znaczenie rodziny rozszerzonej. Składają się na nią
bezpośrednia rodzina „ego” i partnera „ego” (rodzice i dzieci) oraz krewni „ego” i
partnera„ego”. Oszacowano ,że średnia liczba poszerzonej rodziny (w danym punkcie czasu)
wyniosła dla młodych par 63 osoby, a dla starszych 46 osób, co sugeruje, że sieć powiązań
maleje z wiekiem jednostki. Rozmiar rodziny bezpośredniej waha się między10 a 20 osobami
bez względu na wiek, płeć i typ gospodarstwa domowego. Jednak liczba osób w sieci nie
informuje o naturze związków i powiązań (czy są one bliskie, przyjacielskie etc.).
Stwierdzono, że średnia liczba osób opisana jako bliscy (przyjaciele i krewni) wyniosła 8,1, w
tym 4,9 to krewni (związki pokrewieństwa), a 3,2 to niespokrewnieni przyjaciele. Dla par w
wieku 35-49 lat bezpośrednia rodzina stanowiła 86% grupy, dla samotnych mężczyzn w tym

18
samym wieku wielkość ta wyniosła 80%, a dla kobiet 73%. Wyniki te potwierdzają raz
jeszcze potrzebę skonstruowania nowej jednostki.
Tablica 4. Sieć powiązań według wieku i typu gospodarstwa domowego w badaniach
„Close friends and relatives” (podane liczby są wielkościami średnimi liczby
osób)
Sytuacja w czasie badania
Wiek (w latach) Pary Samotni
mężczyźni
Samotne
kobiety
Rodziny z jednym
rodzicem
Najbli ższa rodzina (rodzice, dzieci, rodzeństwo „ego” i „ego” partnera)
poniżej 35 17,7 10,0 8,6 14,4
35-49 18,5 11,1 9,0 15,3
50-64 18,0 10,5 12,7 15,9
powyżej 64 18,5 9,9 14,1 23,7
Członkowie rodziny opisani jako bliscy
poniżej 35 6,3 3,9 3,8 3,3
40-49 5,4 3,3 2,7 4,6
50-64 5,1 2,8 4,1 4,4
powyżej 64 4,9 2,8 3,5 5,2
Źródło: Bonvalet (1993)
Obserwując wyniki podane w Tab.5 wyraźnie widać demograficzną historię zdarzeń
grupy kontaktowej: dzieci zastępują dziadków, a potem wnuki rodziców. Na podstawie tych
danych można wyobrazić sobie, jak mogłaby wyglądać trajektoria grupy kontaktowej w
zależności od kariery małżeńskiej jednostki, np. kobiety. Rozważmy przypadek kobiety, która
wychodzi za mąż w wieku 35 lat, wychowuje dzieci, rozwodzi się w wieku 50 lat i zostaje
sama w domu w wieku 68 lat, gdy jej najmłodsze dziecko opuszcza dom. Wielkość jej grupy
kontaktowej zmienia się następująco: gdy jest niezamężna średnia liczba osób wynosi około
3.7, prawie że podwaja się (6.65) w wieku 35-50 wraz z dołączeniem do jej grupy wpływów
dzieci oraz jej partnera wraz z jego rodziną. W momencie rozwodu rozmiar (6.96) jej grupy
nie zmniejsza się, lecz z wiekiem wzrasta do około 10 osób. Podobnie można rozważać inne
ścieżki życia.

19
Tablica 5. Sieć powiązań według wieku i typu kohabitacji wyspecyfikowanej grupy
wpływów w badaniach „Close friends and relatives” (podane liczby są
wielkościami średnimi liczby osób)
Wiek respondentów w latach 20-34 35-49 50-64 powyżej 64
Najbli ższa rodzina pary Partner 1,0 1,0 1,0 1,0 Dzieci 1,17 2,22 2,5 2,69 Matka i ojciec ego 1,87 1,42 0,57 0,07 Dziadkowie „ego” 0,83 0,25 - - Matka i ojciec partnera 1,75 1,4 0,58 0,13 Dziadkowie partnera 0,77 0,23 0,03 0,02 Wnuki - 0,13 1,9 4,29 Razem 7,39 6,65 6,58 8,2 Najbli ższa rodzina mężczyzny mieszkającego samotnie Partner 0,24 0,62 0,52 0,06 Dzieci 0,03 0,85 1,58 1,32 Matka i ojciec ego 1,95 1,38 0,56 - Dziadkowie „ego” 0,85 0,25 - - Matka i ojciec partnera 0,38 0,7 0,51 - Dziadkowie partnera 0,13 0,03 - - Wnuki - - 1,09 2,49 Razem 3,58 3,83 4,26 3,87 Najbli ższa rodzina kobiety mieszkającej samotnie Partner 0,18 0,29 0,25 0,06 Dzieci 0,0 0,2 1,67 1,93 Matka i ojciec ego 2,03 1,36 0,54 0,02 Dziadkowie „ego” 1,29 0,22 - - Matka i ojciec partnera 0,22 0,24 0,32 0,04 Dziadkowie partnera 0,02 0,07 - - Wnuki - 0,05 2,22 3,98 Razem 3,74 2,43 5,0 6,03 Najbli ższa rodzina samotnego rodzica Partner 0,81 0,8 0,52 0,11 Dzieci 1,44 2,3 3,32 3,87 Matka i ojciec ego 1,96 1,5 0,66 0,15 Dziadkowie „ego” 1,01 0,14 - - Matka i ojciec partnera 1,2 0,96 0,4 - Dziadkowie partnera 0,25 0,06 2,06 - Wnuki - 0,06 - 5,9 Razem 6,67 5,82 6,96 10,03
Źródło: Badania (Close friends and relatives)

20
4. Podsumowanie.
Podsumowując można stwierdzić, że trudno zrozumieć fazy przebiegu życia jednostki
(takie jak opuszczenie domu rodzinnego, formowanie pary, rozpad rodziny) bez ich
odniesienia do rodziny i grupy osób bliskich, czyli do grupy kontaktowej jednostki. Prace
badawcze nad modelowaniem multijednostkowym i ich zastosowanie do dostępnych danych
powinny umożliwi ć pełną analizę informacji zebranych w przyszłych retrospektywnych
badaniach obejmujących już właściwą grupę kontaktową. Modele pozwolą opisać wpływ
grupy kontaktowej na socjalne, społeczne i demograficzne zachowanie jednostki, co ujawni
istniejące wzorce zachowań w społeczeństwie.
Streszczenie
Opracowanie poniższe przedstawia w skrócie najnowsze badania związane z modelowaniem
przebiegu życia grupy powiązanych ze sobą jednostek. Na wstępie omówiono niektóre
problemy związane z badaniem wpływu otoczenia na zachowanie jednostki. Następnie
zaproponowano definicję nowej jednostki statystycznej – grupy kontaktowej. W dalszej
części ogólnie przedstawiono dwa podejścia w modelowaniu tej grupy – model
pseudojednostkowy oraz model multijednostkowy. Na zakończenie zaprezentowane zostały
niektóre rezultaty wstępnych badań empirycznych związanych z koncepcją grupy wpływów
jednostki.

21
Mgr Aneta Ptak-Chmielewska
Instytut Statystyki i Demografii
Szkoła Główna Handlowa.
Analizy wielopoziomowe w naukach społecznych.1
1. Informacje wprowadzające.
W demografii jako dyscyplinie naukowej współpracującej z socjologią i innymi
dyscyplinami, popularne są analizy na poziomie zagregowanym. Przeprowadzanie tego typu
analiz jest możliwe przy założeniu jednorodności badanej zbiorowości pod względem
badanego zjawiska.
W przypadku analiz przeprowadzanych na zagregowanym poziomie uzasadnione jest
ograniczenie analizy do znalezienia zależności pomiędzy klasycznymi wskaźnikami
demograficznymi dotyczącymi rozpatrywanego zjawiska a średnimi charakterystykami
obliczanymi dla tych zbiorowości a nie do indywidualnych charakterystyk. W przypadku
migracji uzasadnione wydaje się powiązanie współczynników migracji dla regionów ze stopą
bezrobocia, średnimi dochodami itp. dla tych regionów.
Zagregowane charakterystyki które mogą być wyznaczone w takich przypadkach są
interpretowane jako ograniczenia wynikające z przynależności do danej zbiorowości i
wpływające na zachowania jej członków. Tego typu analizy mogą na przykład odkryć
pozytywne powiązania pomiędzy stopą bezrobocia a współczynnikiem emigracji.
Istnieje jednak bardzo duże ryzyko popełnienia błędu w interpretacji takich wyników.
Błąd określany jako „ecological fallacy” polega na błędnym zinterpretowaniu wyników w
odniesieniu do jednostki przy wykorzystaniu wyników uzyskanych na poziomie
zagregowanym. Dodatnia zależność pomiędzy stopą bezrobocia a współczynnikiem migracji
dla danego regionu nie oznacza, iż jednostki które są bezrobotne mają większe
1 Opracowanie przygotowane na podstawie artykułu: ”Multilevel anaysis in the social sciences”, D. Courgeau, B. Baccaiini w Population vol. 10 No 1, 1998, str. 39-72. Prezentowany tekst był przedstawiony przez Autora i dyskutowany na posiedzeniu Sekcji Analiz Demograficznych w dniu 19.06.2000.

22
prawdopodobieństwo wyemigrowania z danego regionu ale oznacza jedynie iż wysokiej
stopie bezrobocia w regionie towarzyszy wysoki współczynnik emigracji. Problemem tym
zajmował się m.in. Robinson, który w 1950 roku wykazał iż zależność pomiędzy dwoma
charakterystykami jest różna w zależności od poziomu agregacji. Dla przykładu (USA 1930)
zależność pomiędzy byciem czarnym i analfabetą wyznaczona dla dziewięciu regionów
geograficznym wykazała 0,95 natomiast na poziomie indywidualnym zależność ta wynosiła
zaledwie 0,20. Dalsze badania w tej dziedzinie wykorzystały liniową i logistyczną regresję ale
wyniki zawsze były takie same. Zagregowane analizy danych były odpowiedzialne za błędy
w próbach wnioskowania na ich podstawie o zachowaniach jednostki. Rozbieżności są tym
większe im bardziej wariancja wewnątrz grupowa przewyższa wariancję międzygrupową.
Wszystkie te nieścisłości spowodowały konieczność przeprowadzania analizy na
poziomie indywidualnym. Odpowiedzią był rozwój analizy historii zdarzeń oraz badań
zbierających dane, dotyczące wydarzeń z każdej dziedziny z życia jednostki, wykorzystywane
w tej analizie. Cykl życia jednostki jest traktowany jako proces stochastyczny: w ciągu życia
jednostka podlega procesowi który w dowolnym momencie jest zależny od dotychczasowego
przebiegu kariery do danego momentu, informacji zebranych w przeszłości oraz warunków
panujących w środowisku do którego przynależy dana jednostka. Celem tej analizy jest
powiązanie zachowania danej jednostki z charakterystykami jej odpowiadającymi.
Charakterystyki te mogą być stałe niezależne od czasu np. miejsce urodzenia, liczba
rodzeństwa itp., lub zależne od czasu które określają główne stany w jakich może znajdować
się jednostka w ciągu całego cyklu. Najważniejsze w tej analizie jest: niejednorodność
zbiorowości oraz zależności pomiędzy różnymi zjawiskami demograficznymi.
Dla przykładu analiza prawdopodobieństwa wyemigrowania z danego regionu
zawierać będzie fakt bycia bezrobotnym, wysokość dochodów itd. Dodatkowo można
uwzględnić zmienne stałe jak np. miejsce urodzenia dla sprawdzenia możliwości powrotu
jednostki która wcześniej wyemigrowała.
W analizie na poziomie jednostki istnieje jednak możliwość popełnienia błędu w
interpretacji wyników tzw. „atomic error”. Błąd ten jest związany z interpretacja wyników
dotyczących jednostki w oderwaniu od środowiska do którego dana jednostka przynależy.
Jednostka podlega ograniczeniom narzuconym przez środowisko i czas do którego
przynależy.
Poruszone powyżej dwa rodzaje błędów związanych z analizą na poziomie
zagregowanym i z analizą na poziomie jednostki narzucają konieczność podjęcia analiz na
wielu różnych poziomach agregacji równocześnie („Multilevel Analysis”).

23
Analiza wielopoziomowa pozwala na wyeliminowanie błędu „ecological fallacy”
ponieważ charakterystyki zagregowane są wykorzystywane do pomiaru konstrukcji
odmiennych od konstrukcji wykorzystywanych jako ich ekwiwalent na poziomie jednostki.
Błąd „atomic fallacy” jest również wyeliminowany ponieważ kontekst w jakim ujmowana jest
jednostka jest prawidłowo ujęty w analizie.
Rozwój bazy danych wykorzystywanych w analizie wielopoziomowej w ostatnich
latach pozwolił na zastosowanie tej analizy w wielu różnych dziedzinach jak np.:
epidemiologia, edukacja, geografia ludzkości, socjologia, ekonomia i demografia.
2. Model analizy wielopoziomowej – założenia ogólne.
Analizy wielopoziomowe mają na celu pokazanie na jakie różnorodne sposoby
charakterystyki: indywidualne i zagregowane, mogą wpływać na zachowanie jednostki
przynależnej do każdej ze stref.
Analiza skoncentrowana jest na jednostce ponieważ to jednostki tworzą różne stopnie
agregacji. Nie eliminuje to jednak wpływu zagregowanych zbiorowości (środowisk) na
jednostki, ponieważ jednostka zachowuje się jednak odmiennie niż zachowywałaby się gdyby
te ograniczenia nie istniały.
Podstawowe charakterystyki indywidualne wykorzystywane w tego typu analizach
mogą mieć charakter binarny: np. fakt bycia zamężnym lub nie; albo charakter ciągły: np.
dochód jednostki. Charakterystyki opisowe mogą być bardziej lub mniej złożone. Wychodząc
od charakterystyk prostych typu bycie zamężnym lub nie, można przejść do następnego
stopnia agregacji poprzez wyznaczanie charakterystyk średnich np. procent zamężnych w
danym regionie, lub zastosować bardziej skomplikowane procedury jak np. przy wyznaczaniu
dochodu i równocześnie wyznaczyć odchylenie standardowe dochodu.
Charakterystyki globalne dotyczą całościowych jednostek jak np. gęstość zaludnienia
lub liczba łóżek w szpitalach. Charakterystyki te nie są powiązane z charakterystykami
indywidualnymi nie dotyczą żadnej konkretnej jednostki indywidualnej. Mogą one być
agregowane w zależności od potrzeb według np. różnych jednostek administracyjnych.
Inna grupę stanowią charakterystyki, które są przypisane do konkretnego stopnia
agregacji i nie mogą być dowolnie agregowane np. polityczna orientacja środowiska
(commune).
Analizy wielopoziomowe wymagają zdefiniowania poziomów agregacji jak
również struktury zorganizowania tych poziomów. Do najprostszych i najczęściej

24
stosowanych należy struktura hierarchiczna w której każdy kolejny poziom powstaje ze
zgrupowania jednostek z poprzedniego poziomu. Innym typem agregacji jest agregacja
poprzeczna (cross-classyfication) który może tworzyć podział np. miast na miasta:
turystyczne i przemysłowe itp. Istnieje oczywiście możliwość utworzenia agregacji składanej
która zawiera zarówno podział hierarchiczny jak i poprzeczny równocześnie.
3. Model analizy wielopoziomowej bez składnika losowego.
Wyjściowa forma modelu zawiera analizę wpływu charakterystyk indywidualnych i na
różnych poziomach agregacji na zachowania jednostek bez uwzględnienia składnika
losowego. Jako przykład posłużyła analiza regionalnych migracji w Norwegii
przeprowadzona w 1996 roku przez B. Baccaini i D. Courgeau. W modelu wykorzystane były
dwa rodzaje analiz:
- regresja wykładnicza do modelowania współczynników migracji dla regionów,
- model logitowy i modele analizy historii zdarzeń do estymacji indywidualnych ryzyk
migracji w odniesieniu do charakterystyk regionalnych i indywidualnych.
3.1. Zastosowanie modelu do analizy migracji.
Dane wykorzystane do modelowania migracji prezentowane w artykule D. Cougeou
pochodziły z dwóch źródeł: rejestru bieżącego ludności który został w 1964 roku
scentralizowany i skomputeryzowany co umożliwiło zebranie danych do analizy historii
zdarzeń oraz dane zebrane podczas spisów w 1960, 1970 i 1980 roku.
Bazę danych stanowiły dane o 54 814 osobach urodzonych w 1958 roku którzy
mieszkali w 1991 roku w Norwegii i nie wyemigrowali za granicę. Sama analiza dotyczyła
zmian zamieszkania w odniesieniu regionalnym (Norwegia została podzielona na 19
regionów –(Figure 1.)) dla w.w. osób w ciągu krótkiego odcinka czasu tj. lat 1980 i 1981
(osoby te były wówczas w wieku 22-23 lata).
Dla poziomu indywidualnych jednostek do analizy zostały wybrane następujące
charakterystyki, które uznano jako mające potencjalny wpływ na możliwość wyemigrowania
z regionu:
- stan cywilny (zamężny(a)/ niezamężny(a)),
- aktywność zawodowa (aktywny(a) zawodowo/ nieaktywny(a) zawodowo),
- typ zatrudnienia (pracujący w rolnictwie/ pracujący poza rolnictwem),
- poziom wykształcenia (pełne 12 lat nauki/ mniej niż 13 lat nauki),

25
- potomstwo (co najmniej jedno dziecko/ bezdzietny(a)),
- poziom dochodów (wysokie dochody/ niskie dochody/ brak dochodów).
Jako charakterystyki zagregowane na poziomie wyznaczonych 19 regionów zostały
wyznaczone udziały procentowe w.w. cech tj. procent emigrujących z regionu w latach 1980-
1981, procentowy udział zamężnych, procentowy udział rolników itd.
Wyniki uzyskane dla trzech typów modeli: regresja wykładnicza wykorzystana do
modelowania współczynników migracji, model logitowy i analiza historii zdarzeń do
estymacji indywidualnych prawdopodobieństw wyemigrowania z danego regionu okazały się
podobne. Wyniki uzyskane dla analizy historii zdarzeń były dokładniejsze.
Wyniki uzyskane na poziomie indywidualnym i zagregowanym przy analizie
wielopoziomowej tj. przeprowadzonej na wielu poziomach równocześnie okazały się jednak
różne a w niektórych wypadkach nawet przeciwne. Dla przykładu wpływ faktu bycia
zamężnym dla mężczyzn zwiększa prawdopodobieństwo emigracji z regionu w wieku 22 lat
to prawdopodobieństwo to spada w miarę zwiększania się procentowego udziału mężczyzn w
danym regionie. (Tabela 9.)
Niezależność wyników na poziomie „makro” i na poziomie „ mikro” potwierdza niska
wartość wyznaczonego współczynnika korelacji wynoszącego zaledwie –0,10.
3.2. Analiza migracji uwzględniająca przepływy międzyregionalne.
W poszerzonej wersji modelu autorzy tj. D. Courgeau i B. Baccaini wykorzystali bazę
danych z poprzedniej wersji modelu z uwzględnieniem niewielkich zmian mających na celu
nadanie klarowności przeprowadzanej analizie. Model ten poddaje analizie nie tylko wypływy
z regionów ale również przepływy zwrotne czyli analizuje dodatkowo możliwość wyboru
tego a nie innego regionu jako miejsca docelowego lub powrotu do regionu wcześniej
opuszczonego.
Dla większej przejrzystości wyników model uwzględnia podział kraju analizowanego
tj. Norwegii na 5 dużych regionów. W tym modelu analiza obejmuje dwa lata 1981 i 1982.
Wprowadzono nowe charakterystyki na poziomie indywidualnym:
- wykształcenie (mniej niż 10 lat nauki lub więcej niż 12 lat nauki/ pomiędzy 10-12 lat
nauki),
- fakt zamieszkiwania wcześniejszego w regionie przeznaczenia,
- długość pobytu wcześniejszego w regionie przeznaczenia,
- czas jaki upłynął od opuszczenia regionu potencjalnego przeznaczenia,
- wiek w latach jeśli osoba wcześniej w tym regionie nie przebywała w ogóle.

26
Charakterystyki te miały na celu dać odpowiedź na pytanie czy szanse na wybór
danego regionu jako regionu przeznaczenia są większe dla osób które w tym regionie
wcześniej mieszkały i wyemigrowały oraz mieszkały tam przez dłuższy czas i miało to
miejsce stosunkowo niedawno.
Jako nowe charakterystyki na poziomie zagregowanym wykorzystano:
- procentowy udział osób które mieszkały wcześniej w regionie potencjalnego
przeznaczenia,
- średni czas pobytu w różnych regionach przeznaczenia według osób mieszkających w
danym regionie (region wyjściowy),
- średni czas jaki upłynął od ostatniego pobytu w różnych regionach przeznaczenia
według osób mieszkających w danym regionie (region wyjściowy),
Przyjmując założenie iż osoby są bardziej związane z osobami o podobnych
charakterystykach przyjęto dodatkowo grupę charakterystyk o wymiarze zarówno „makro”
odnoszącym się do regionów jak i o wymiarze „mikro” odnoszącym się do jednostek:
- procentowy udział osób z tym samym stanem cywilnym,
- procentowy udział osób z tym samym wykonywanym zawodem,
- procentowy udział osób o tym samym wykształceniu,
Charakterystyki te mogą być więc wykorzystane do modelowania z użyciem analizy
historii zdarzeń do estymacji indywidualnych prawdopodobieństw migracji.
Dodatkowo możliwe jest uwzględnienie utrudnienia wynikającego z przeszkody jaką stanowi
geograficzna odległość pomiędzy regionami.
Pierwszym krokiem w analizie było wykorzystanie charakterystyk na poziomie
indywidualnym do analizy historii zdarzeń w celu zbadania wpływu poprzedniego pobytu na
wybór miejsca przeznaczenia w emigracji. Analiza składała się z pięciu modeli ryzyk
konkurencyjnych. Jeden model oddzielnie dla każdego regionu jako stanu wyjściowego z
czterema stanami przeznaczenia.
Niemożliwe okazało się wprowadzenie do modelu równocześnie zmiennych:
- fakt wcześniejszego pobytu w rejonie przeznaczenia,
- czas wcześniejszego pobytu w rejonie przeznaczenia,

27
- czas jaki upłynął od opuszczenia rejonu przeznaczenia.
Zmienne te były ze sobą silnie skorelowane więc model został wyestymowany dla każdej z
tych zmiennych oddzielnie.
(Tabela 1a. i Tabela 1b.)Wyniki okazały się jednoznaczne: fakt pobytu wcześniejszego
w rejonie przeznaczenia zdecydowanie zwiększa ryzyko wyjazdu do tego rejonu w przypadku
migracji. Podobnie jak czas wcześniejszego pobytu w tym rejonie: im dłuższy czas
wcześniejszego pobytu w rejonie przeznaczenia tym większe ryzyko wyboru tego rejonu jako
miejsca docelowego emigracji. Wskazuje to na przywiązanie osób do rejonu w którym
zamieszkiwali w młodości (dzieciństwie). Więzy te ulegają jednak osłabieniu w miarę
wydłużania się okresu czasu jaki upłynął od ostatniego pobytu w rejonie przeznaczenia.
Niezmiennie do poprzedniego modelu jednokierunkowych wypływów z rejonu i
niezależnie od rejonu wyjściowego i rejonu przeznaczenia pewne prawidłowości dla
charakterystyk indywidualnych nie zmieniają się. Prawdopodobieństwo zmiany miejsca
zamieszkania jest niskie dla mężczyzn, osób aktywnych zawodowo, osób zamężnych
posiadających dzieci, osób o niskim poziomie wykształcenia i osób o wysokich dochodach.
Jedynie fakt posiadania dzieci zwiększa ryzyko emigracji z dużego ośrodka jakim jest Oslo ze
względu na dekoncentrację rejonu zurbanizowanego. Wyjątek stanowi również fakt iż niski
poziom wykształcenia nie zniechęca ludzi do emigracji z rejonu Południowego od rejonu
określonego jako Wschodni. Zależnie również od rejonu zmienia się prawdopodobieństwo
migracji dla osób pracujących w rolnictwie.
Niektóre charakterystyki indywidualne mają przeciwne kierunki działania na migracje
w zależności od tego czy ruch następuje z rejonu i do rejonu j czy odwrotnie z rejonu j do
rejonu i.
Przechodząc do analizy charakterystyk na poziomie zagregowanym konieczne jest
rozważenie powodów migracji tj. czy opuszczenie danego rejonu jest następstwem czy
poprzedza wybór rejonu przeznaczenia. Co jest motywacją: czy chęć opuszczenia danego
zamieszkiwanego obecnie rejonu czy też chęć przeniesienia się do rejonu wybranego jako
rejon przeznaczenia. Oba te procesy są prawdopodobnie ze sobą ściśle związane. Podjęcie
decyzji zależy od rozpatrzenia dokładnego co przeważy: czy korzyści wynikające z
pozostania w rejonie obecnego pobytu czy też korzyści oferowane przez rejon przeznaczenia
w powiązaniu oczywiście z charakterystykami indywidualnymi osoby.
Pierwszym krokiem było podjęcie analizy modelu w zależności od rejonu
przeznaczenia w którym populacja zamieszkująca cztery pozostałe regiony była podmiotem
wystawionym na ryzyko przeniesienia się do tego rejonu. Zmienną na poziomie makro

28
służącą do wyjaśnienia efektu zależności pomiędzy osobami o takich samych
charakterystykach indywidualnych były wskaźniki pomiędzy procentowym udziałem osób o
tych samych charakterystykach w rejonie przeznaczenia a procentowym udziałem osób o tych
samych charakterystykach w rejonie dotychczasowego pobytu. (Tabela 2.)
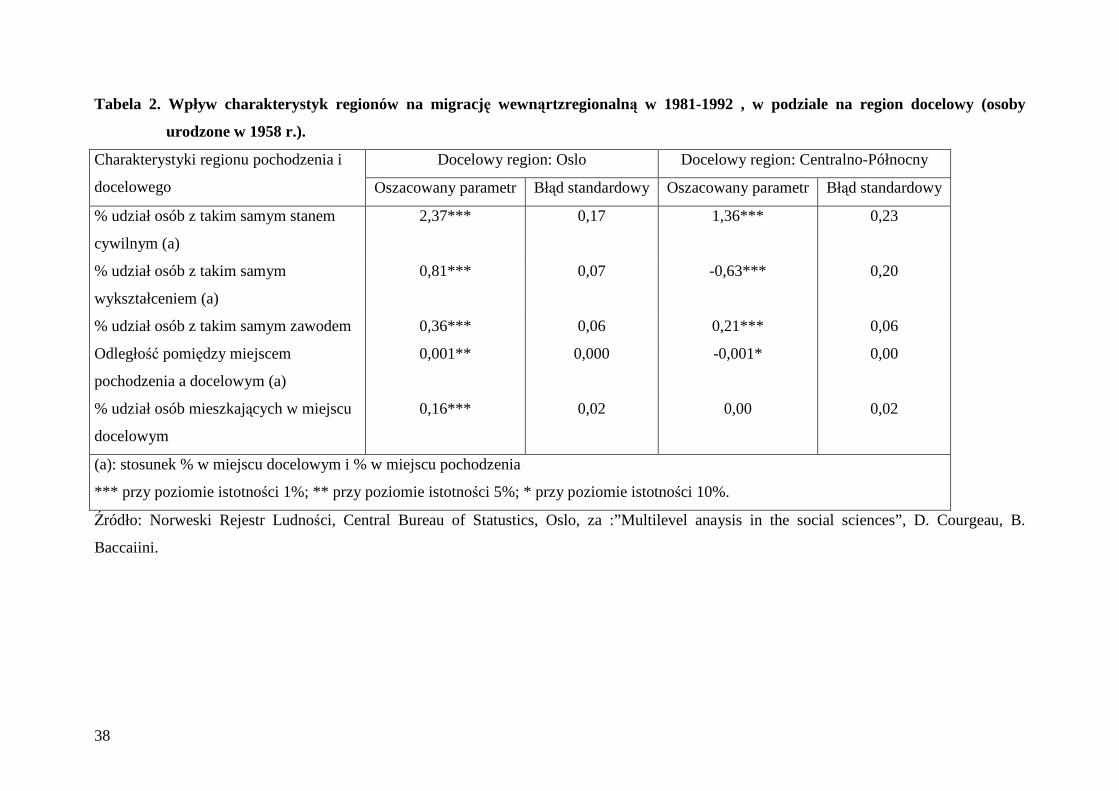
Jako przykład autorzy podali szanse migracji do dwóch wybranych regionów: Oslo i
Centralno-półnoncny. Wyniki okazały się podobne dla obu regionów: szanse migracji do tych
regionów zwiększają się w miarę jak proporcje osób z tym samym stanem cywilnym i z tym
samym zawodem zwiększają się w odniesieniu do rejonu pochodzenia tych osób.
Odwrotna sytuacja okazała się w przypadku proporcji osób z tym samym
wykształceniem. Oslo przyciąga osoby o wykształceniu odmiennym niż przeważające w
rejonach pochodzenia tych osób. Sytuacja w drugim z rozpatrywanych rejonów okazała się
odmienna ponieważ rejon Centralno-północny zachęca do przyjazdu osoby, których
przeważający w miejscu pochodzenia poziom wykształcenia jest taki sam jak w przypadku
rejonu przeznaczenia. Ogólnie osoby o wyższym poziomie wykształcenia są bardziej skłonne
do migracji.
Odległość geograficzna generalnie stanowi przeszkodę w przypadku rejonu Centralno-
północnego zachęcając do przyjazdu jedynie osoby z sąsiednich rejonów. W przypadku
natomiast rejonu Oslo odległość nie ma istotnego wpływu.
Fakt pobytu wcześniejszego w rejonie przeznaczenia oraz czas od ostatniego pobytu
(zamieszkiwania) w tym rejonie ma istotne znaczenie tylko w przypadku rejonu Oslo.
Jednocześnie fakt włączenia do modelu charakterystyk indywidualnych zmienia istotność
charakterystyk zagregowanych (Tabela 3.). Zmienia się znaczenie proporcji osób z
wykształceniem takim samym z miejsca pochodzenia i przeznaczenia.
Kolejnym krokiem w analizie było zastosowanie modelu ryzyk konkurencyjnych. Jako
cel postawiono zagadnienie: jak osoby mieszkające w danym rejonie mogą być zachęcone do
emigrowania do innego regionu poprzez korzyści oferowane przez region przeznaczenia.
Wyniki przedstawiono na podstawie dwóch wybranych regionów pochodzenia tj.
regionu Oslo i Centralno-północnego (Tabela 4. i Tabela 5.).
Wprowadzenie do modelu charakterystyk zagregownych zmienia znaczenie
niektórych charakterystyk indywidualnych wprowadzonych wcześniej w wersji modelu na
poziomie „mikro”. Przykładowo dla emigrantów z Oslo fakt bycia rolnikiem nie ma
znaczenia przy migracji do rejonu Zachodniego lub Centralno-północnego, a z kolei istotność

29
wykształcenia dla emigrantów z rejonu Centralno-północnego do rejonu Oslo zmieniła się z
pozytywnej na silnie ujemną.
Ogólnie znaczenie zagregowanych charakterystyk dla osób pochodzących z różnych
rejonów jest różne w zależności od rejonu przeznaczenia.
Analiza wprowadzająca równocześnie charakterystyki indywidualne jak i dotyczące
rejonów pochodzenia i przeznaczeni pozwala pełniej rozumieć proces migracji i wymaga w
związku z tym dalszych prac w tym kierunku.
4. Model analizy wielopoziomowej uwzględniający składnik losowy.
Jako podstawową formę modelu pozwalającą w pełni zrozumieć mechanizm działania
tego typu analizy autorzy podali szkoleniowy przykład wyprowadzony przez Woodhouse
(1996). Jest to przykład obserwacji wzdłużnej danych dotyczących kohorty uczniów od czasu
rozpoczęcia klasy wstępnej w wieku 8 lat do czasu opuszczenia szkoły czyli wieku lat 11.
Uczniowie pochodzili z pięćdziesięciu szkół wybranych z 650 szkół Londynu w sposób
losowy. Celem analizy było stwierdzenie czy są szkoły lepsze i gorsze w udoskonalaniu
postępu edukacyjnego uczniów. W celu pomiaru tego postępu przeprowadzono test z
matematyki na wstępie szkoły i na jej zakończenie. Analizę przeprowadzono na poziomie
indywidualnym i na poziomie szkół.
Wyjściowym modelem był model regresji liniowej dla indywidualnego ucznia:
yij = a0j + a1j x1ij + eij (1)
gdzie: yij – wyniki uzyskane w wieku 11 lat przez i-tego ucznia z j-tej szkoły,
xij – wyniki uzyskane na wstępie tj. w wieku 8 lat,
a0j , a1j – parametry funkcji regresji dla j-tej szkoły,
eij – składnik losowy (reszty modelu) o wartości oczekiwanej zero i wariancji 2ejσ .
Estymacja parametrów dla każdej ze szkół oddzielnie nie przyniosłaby żadnej informacji,
dopiero potraktowanie tych losowo wybranych 50 szkół jako próby losowej pobranej z
populacji 650 szkół londyńskich pozwoli na uzyskanie informacji statystycznej, która może
być podstawą do dalszego wnioskowania.
Następnym krokiem jest wyszczególnienie dwóch stopni agregacji: uczeń i szkoła.
Wprowadzenie poziomu szkół do wyjściowego równania regresji sprowadza się do
potraktowania parametrów a0j i a1j jako losowych różnicujących szkoły między sobą.

30
a0j = a0 + e0j (2)
a1j = a1 + e1j (3)
gdzie: a0 i a1 – to średnie parametry stałe dla wszystkich szkół,
e0j i e1j – to zmienne losowe o wartości oczekiwanej zero oraz wariancjach i kowariancjach:
01ej1j0
21ej1
20ej0
)e,ecov(
)evar(
)evar(
σ=
σ=
σ=
(4)
Stąd pełny zapis modelu jest następujący:
yij = a0 + a1 x1ij + (e0j +e1j x1ij +eij) (5)
W modelu tym wyodrębnione są dwie części: stały element niezależny od szkoły (a0 + a1 x1ij)
oraz element losowy, który zależy zarówno od ucznia jak i od szkoły.
Estymacja parametrów jak również wariancji i kowariancji przy użyciu metod
numerycznych a w tym przypadku programu MLn dało wyniki istotne dla wszystkich
rozpatrywanych efektów. (Tabela 6.)
Przede wszystkim okazało się że im wyższy wynik uczeń uzyskał wstępując do szkoły
tym wyższy wynik uzyskał na jej zakończeniu niezależnie od szkoły do której uczęszczał.
Jednocześnie jednak fakt iż kowariancja pomiędzy e0j i e1j jest ujemna wskazuje iż im wyższy
średni wynik dla szkoły tym mniej zależy wynik ucznia przy ukończeniu szkoły od wyniku
przy podjęciu nauki w wieku 8 lat. Oznacza to iż niektórym szkołom udało się doprowadzić
wszystkich uczniów do dobrego poziomu z matematyki niezależnie od wyjściowych wyników
tych uczniów a innych z kolei niestety nie udało się doprowadzić uczniów których wyniki są
już niskie do wyrównanego poziomu.
Różnice między szkołami są widoczne w przypadku ilustracji graficznej (Figure 2.)
prognozowanych zależności pomiędzy wynikami dla 8 latków i wynikami dla 11 latków w
każdej ze szkół wyestymowanej z wykorzystaniem modelu wielopoziomowego zapisanego
jako:
ij1j11j00ij x)ea(eay +++= (6)
gdzie: e0j i e1j – reszty odniesione do modelu, wyznaczone dla każdego regionu j.

31
Przedstawienie modelu regresji dla każdej ze szkół traktowanej oddzielnie daje wyniki
zdecydowanie mniej klarowne. (Wykres 3.) Spowodowane jest to faktem iż w wielu
przypadkach w szkole jest mała liczba uczniów stąd mało dokładna estymacja parametrów.
Dodatkowym uzupełnieniem modelu było wprowadzenie dodatkowej zmiennej
niezależnej od pierwszej o charakterze zero-jedynkowym. Zmienna ta x2ij również wpływa na
wynik końcowy ucznia. Zmienna oznaczająca pomoc ze strony rodziców: 1-oznacza istnienie
silnej pomocy ze strony rodziców w nauce matematyki a 0-brak tej pomocy. Zakłada się
również niezależności związku pomiędzy wynikiem końcowym oraz wynikiem początkowym
i pomocą ze strony rodziców a szkołą do której uczęszcza uczeń. Pozwala to na
wprowadzenie zmiennych losowych niezależnych od szkoły:
yij =a0 + e0ij + (a1 + e1ij )x1ij + (a2 +e2ij)x2ij +(a12 +e12ij)x1ij × x2ij + eij (7)
gdzie: e0ij , e1ij , e2ij , e12ij , eij – są zmiennymi losowymi o wartości oczekiwanej 0 i
wariancjach: 2e
212e
22e
21e
20e ,,,, σσσσσ dla których wszystkie kowariancje są równe 0 powodując
iż są niezależne od regionu i od siebie nawzajem.
Wyniki uzyskane z estymacji tego modelu okazały się bardzo zbliżone do wyników
uzyskanych dla poprzedniego modelu bez włączania zmiennej niezależnej: pomocy rodziców
w nauce. Włączenie zmiennej niezależnej typu: średnie wyniki uzyskane na wstępie dla
każdej ze szkół również nie zmienia modelu.
Istnieje jednak ryzyko doprowadzenia do błędnych wniosków przy modelowaniu
wielopoziomowym w przypadku wprowadzania do stałej części modelu wielu charakterystyk,
mających wpływ na omawiane zjawisko.
4.1. Zastosowanie modelu do analizy migracji.
Model służący do zilustrowania praktycznego zastosowania modelu uwzględniającego
składnik losowy został wyprowadzony wcześniej jako model bez składnika losowego.
Zastosowany został model logitowy prosty i model logitowy wielopoziomowy. (Tabela 9)
Przykładowe wyniki dla mężczyzn potwierdziły bez większych rozbieżności wyniki uzyskane
dla modelu bez składnika losowego w przypadku modelu prostego. Znaczne rozbieżności
pojawiają się w przypadku gdy efekty losowe nie są zerowe na poziomie regionalnym.
Pomimo tego większość efektów istotnych na poziomie indywidualnym jest również istotna
na poziomie modelu wielopoziomowego. Wyjątek stanowią dwie charakterystyki

32
zagregowane: fakt zamieszkiwania w rejonie o niskich dochodach zwiększający szanse
migracji w prostym modelu staje się na poziomie zagregowanym nieistotny, oraz w
przypadku regionów o wysokim poziomie wykształcenia w modelu wielopoziomowym
zmniejsza szanse na migracje o tyle w prostym modelu w ogóle nie jest istotny.
Dalszym krokiem w analizie jest uwzględnienie łącznego efektu parametrów stałych i
losowych na poziomie regionalnym. Model logitowy prawdopodobieństwa emigracji z
regionu j dla osób nie uwzględniający charakterystyk wcześniej opisywanych ma postać:
j00j0 ua +=∏ (8)
wariancja międzygrupowa dla tego modelu jest opisana: 20eσ
Model uwzględniający charakterystyki jest postaci:
j1j010j1 uuaa +++=∏ (9)
z wariancją międzygrupową o postaci: 21e01e
20e 2 σ+σ+σ .
Wyniki po wprowadzeniu charakterystyki jaką jest fakt pracy w rolnictwie wykazały
spadek wariancji międzygrupowej z 0,070 do 0,064. Kiedy procentowy udział rolników
zwiększa się to prawdopodobieństwo migracji zwiększa się zarówno dla rolników jak i dla
innych kategorii pomimo iż rolnicy jako jednostki charakteryzują się niską skłonnością do
migracji co potwierdza niebezpieczeństwo wyciągania wniosków o charakterystykach
zagregowanych na podstawie wyników na poziomie jednostek.
Wprowadzenie charakterystyki osób z przynajmniej jednym dzieckiem potwierdza
fakt iż osoby te maja mniejszą skłonność do migracji niż osoby bezdzietne bez względu na
fakt uwzględnienia czy też nie uwzględnienia procentowego udziału osób z przynajmniej
jednym dzieckiem. W tym przypadku w modelu nie uwzględniającym procentowego udziału
osób z co najmniej jednym dzieckiem wariancja międzygrupowa dla osób z co najmniej
jednym dzieckiem jest trzykrotnie większa (0,174) niż dla osób bezdzietnych (0,061).
Wprowadzenie charakterystyki zagregowanej tj. procentowego udziału osób z co najmniej
jednym dzieckiem powoduje spadek wariancji międzygrupowej o połowę.
Dla osób z wykształceniem więcej niż 12 lat dla których prawdopodobieństwo
migracji jest wyższe niż dla pozostałych korelacja zmiennych losowych na poziomie
regionalnym z osobami o wykształceniu mnie niż 12 lat jest bliska zeru.
Ostateczny model zawierający wszystkie rozpatrywane charakterystyki jako stałe czyli
nielosowe oraz charakterystykę wykształcenie rozpatrywaną jako losową pomiędzy regionami
dał podobne rezultaty zarówno przy wykorzystaniu prostego modelu logitowego jak i modelu
wielopoziomowego. Przykładowo potwierdziła się prawidłowość dotycząca faktu bycia

33
rolnikiem, który na poziomie indywidualnym zdecydowanie zniechęca do migracji podczas
gdy im większy odsetek osób pracujących w rolnictwie w rejonie tym większe szanse na
migrację dla wszystkich bez względu na zawód. (Tabela 10)
W modelu o losowych charakterystykach w porównaniu do modelu gdzie losowa była
tylko charakterystyka wykształcenie, wyniki były następujące: wariancja międzygrupowa
została zredukowana do połowy, wzrosła zależność pomiędzy osobami o wykształceniu
poniżej i powyżej 12 lat.
Podsumowując okazało się iż zastosowanie wielopoziomowego modelu ze zmiennymi
losowymi nie podważa podstawowych wniosków uzyskanych przy zastosowaniu modelu
logitowego z charakterystykami na różnych poziomach agregacji. Zmienne losowe
dostarczają informacji o zależności pomiędzy prawdopodobieństwami migracji z różnych
regionów dla osób posiadających daną charakterystykę lub jej nie posiadających.
5. Ograniczenia w zastosowaniu analizy wielopoziomowej do analizy historii zdarzeń.
Zastosowanie analizy wielopoziomowej do analizy historii zdarzeń napotyka na
barierę dostępności danych wykorzystywanych w analizie historii zdarzeń. Na ogół są to dane
niekompletne ponieważ nie uwzględniają zdarzeń zaistniałych w całym życiu danych osób.
Dane wykorzystane w analizie migracji pochodziły z rejestru bieżącego zmian stanu
cywilnego jednostek jak również narodzin dzieci ale nie dostarczają informacji o ich
obecności na rynku pracy, dochodach. Informacje te zaczerpnięte ze spisu nie były jednak
kompletne na tyle by prowadzić analizę dłuższego okresu czasu.
Możliwą do zastosowania metodą analizy jest metoda częściowej wiarygodności (Cox
1972). Metoda ta pozwala na estymację parametrów od współczynników hazardu dla
jednostek, które doświadczają danego zdarzenia w danym czasie aż do sumy współczynników
hazardu dla całej populacji wystawionej na ryzyko doświadczenia zdarzenia. Metoda ta może
być maksymalnie uzupełniona poprzez wprowadzenie kilku poziomów agregacji (Goldstein
1995).
Utrudnieniem w zastosowaniu różnych poziomów agregacji jest fakt przemieszczania
się jednostek z jednego regionu do drugiego między wydarzeniami zaistniałymi w życiu
jednostek. W przypadku każdego przemieszczenia osoba musi być przywiązana do nowego
regionu więc poddana jest wpływowi zagregowanych charakterystyk z tego regionu. Według
hipotez Markowa zachowanie osób przemieszczających się do innego regionu podlega
automatycznie mechanizmom charakterystycznym dla nowego regionu zapominając swoje

34
wcześniejsze zachowanie. Hipotezy te traktowane są jako zbyt rygorystyczne i według D.
Courgeau powinny skłaniać się do pośrednich rozwiązań uwzględniających czas potrzebny na
zaadoptowanie się jednostek do nowych warunków. Zagadnienie to powinno być
uwzględnione w zastosowaniu modeli na wielu poziomach agregacji.
Zarówno utrudnienia w dostępie do danych jak i problemy w zastosowaniu
odpowiednich technik i problemy analityczne w modelach wielopoziomowych analizy historii
zdarzeń pozostają w dużej mierze nierozwiązane.
6. Podsumowanie.
Przedstawiony został w niniejszym opracowaniu przegląd modeli od najprostszych
które przedstawiają różne poziomy indywidualnych i zagregowanych charakterystyk do
bardziej skomplikowanych które wykorzystują zmienne losowe specyficzne dla każdego
poziomu kończąc na wielopoziomowych modelach analizy historii zdarzeń które pomimo iż
są najbardziej przydatne to napotykają na przeszkody w dostępie danych i problematyki
analitycznej.
Przedstawiona w powyższym opracowaniu metoda analizy jest jeszcze nowa w
demografii i wymaga jeszcze dopracowania zanim będzie powszechnie wykorzystywana.

35
7. Tabele i wykresy.
Tabela 1a. Wpływ charakterystyk indywidualnych na migrację regionalną w latach 1981-1982
(osoby urodzone w 1958 r., mieszkające w regionie Oslo w końcu roku 1980). Tabela 1b. Wpływ charakterystyk indywidualnych na migrację regionalną w latach
1981-1982 (osoby urodzone w 1958 r., mieszkające w regionie centralno-północnym w końcu roku 1980).
Tabela 2. Wpływ charakterystyk regionów na migrację wewnąrtzregionalną w 1981-1992 , w podziale na region docelowy (osoby urodzone w 1958 r.).
Tabela 3. Wpływ charakterystyk indywidualnych na migrację regionalną w latach 1981-1982 (osoby urodzone w 1958 r., mieszkające w regionie centralno-północnym w końcu roku 1980).
Tabela 4. Wpływ charakterystyk indywidualnych i zagregowanych na migrację regionalną w latach 1981-1982 (osoby urodzone w 1958 r., mieszkające w regionie Oslo w końcu roku 1980).
Tabela 5. Wpływ charakterystyk indywidualnych i zagregowanych na migrację regionalną w latach 1981-1982 (osoby urodzone w 1958 r., mieszkające w regionie Cebtralno-Północnym w końcu roku 1980).
Tabela 6. Parametry i błędy standardowe oszacowane w modelu wielopoziomowym w powiązaniu do 8- letnich i 11 letnich wyników uczniów.
Tabela 7. Parametry i błędy standardowe oszacowane w symulowanym modelu wielopoziomowym w powiązaniu do 8- letnich i 11 letnich wyników uczniów.
Tabela 8. Parametry i błędy standardowe oszacowane w symulowanym modelu wielopoziomowym w powiązaniu do 8 letnich i 11 letnich wyników uczniów w połączeniu z pomocą rodziców oraz w połączeniu interakcji pomiędzy pomocą.
Tabela 9. Wyestymowane parametry i ich błędy standardowe (w nawiasach) dla prostego i wielopoziomowego modelu logitowego włączającego równocześnie charakterystyki indywidualne i odpowiadające im charakterystyki zagregowane w 1980 r. (generacja mężczyzn urodzonych w 1958 r.)
Wykres 1. Podział Norwegii na regiony. Wykres 2. Wykres wyników prognozowanych dla 11 i 8 latków w każdej szkole, z
wykorzystaniem modelu wielopoziomowego dla próby londyńskich szkół. Wykres 3. Wykres wyników prognozowanych dla 11 i 8 latków w każdej szkole, z
wykorzystaniem modelu regresji liniowej dla każdej szkoły próby londyńskich szkół. Wykres 4. Wykres wyników prognozowanych dla 11 i 8 latków w każdej szkole, z
wykorzystaniem modelu wielopoziomowego dla symulowanej próby szkół. Wykres 5. Wykres wyników prognozowanych dla 11 i 8 latków w każdej szkole, z
wykorzystaniem modelu regresji liniowej dla każdej szkoły z symulowanej próby szkół. Wykres 6. Efekt trzech charakterystyk (bycie rolnikiem, posiadanie przynajmniej jednego
dziecka, więcej niż 12 lat wykształcenia) w logitowym modelu prawdopodobieństwa migracji w Norwegii, dla generacji 1958, (lata 1980-81).

Tabela 1a. Wpływ charakterystyk indywidualnych na migrację regionalną w latach 1981-1982 (osoby urodzone w 1958 r., mieszkające w
regionie Oslo w końcu roku 1980).
Rejon docelowy: wschodni Rejon docelowy: południowy Rejon docelowy: zachodni Rejon docelowy: północny Charakterystyki Oszacowany
parametr Błąd
standardowy Oszacowany
parametr Błąd
standardowy Oszacowany
parametr Błąd
standardowy Oszacowany
parametr Błąd
standardowy Mężczyźni -0,35*** 0,09 -0,04 0,20 -0,27 0,28 -0,11 0,14 Aktywni ekonomicznie
-0,10 0,12 -0,15 0,23 -0,15 0,22 -0,36** 0,16
Żonaci -0,06 0,12 -0,14 0,24 -0,11 0,22 0,08 0,17 Posiadający dzieci
0,11 0,16 -0,71 0,54 -0,04 0,36 -0,44 0,27
Rolnicy 0,83*** 0,25 -0,32 1,01 1,05*** 0,34 0,90*** 0,35 < 10 lat edukacji 0,02 0,12 -0,40 0,38 0,12 0,26 -0,15 0,20 >12 lat nauki -0,29 0,13 -0,30 0,24 0,24 0,21 -0,07 0,17 Bez dochodów -0,10 0,25 -0,34 0,63 -0,40 0,63 -0,41 0,31 Dochód < 20 000 koron
0,08 0,14 0,13 0,25 0,68*** 0,24 0,15 0,18
Dochód > 50 000 koron
0,15 0,11 -0,44* 0,24 0,15 0,22 -0,11 0,16
Poprzedno zamieszkały w regionie docelowym
1,65*** 0,14 3,24*** 0,27 2,58*** 0,22 2,26*** 0,19
*** przy poziomie istotności 1%; ** przy poziomie istotności 5%; * przy poziomie istotności 10%. Źródło: Norweski Rejestr Ludności, Central Bureau of Statustics, Oslo, za :”Multilevel anaysis in the social sciences”, D. Courgeau, B. Baccaiini.

37
Tabela 1b. Wpływ charakterystyk indywidualnych na migrację regionalną w latach 1981-1982 (osoby urodzone w 1958 r., mieszkające
w regionie centralno-północnym w końcu roku 1980).
Rejon docelowy: wschodni Rejon docelowy: południowy Rejon docelowy: zachodni Rejon docelowy: północny Charakterystyki Oszacowany
parametr Błąd
standardowy Oszacowany
parametr Błąd
standardowy Oszacowany
parametr Błąd
standardowy Oszacowany
parametr Błąd
standardowy Mężczyźni -0,26 0,11 -0,13 0,15 0,10 0,21 -0,16 0,16 Aktywni ekonomicznie
-0,35*** 0,12 -0,22 0,16 -0,22 0,23 -0,33* 0,18
Żonaci -0,25* 0,15 0,07 0,17 0,17 0,25 -0,19 0,21 Posiadający dzieci
-1,11*** 0,21 -0,41* 0,21 -0,32 0,29 -0,88*** 0,27
Rolnicy -0,06 0,25 0,27 0,29 -0,19 0,52 0,03 0,35 < 10 lat edukacji -0,43*** 0,15 -0,10 0,18 -0,47 0,30 -0,08 0,21 >12 lat nauki 0,32** 0,15 -0,09 0,23 -0,08 0,34 0,13 0,22 Bez dochodów -0,19 0,23 -0,29 0,34 -0,40 0,44 0,10 0,31 Dochód < 20 000 koron
0,05 0,14 0,13 0,19 -0,01 0,26 0,13 0,21
Dochód > 50 000 koron
-0,06 0,12 0,21 0,17 -0,21 0,24 -0,14 0,19
Poprzedno zamieszkały w regionie docelowym
1,26*** 0,18 1,73*** 0,21 2,32*** 0,28 1,93*** 0,23
*** przy poziomie istotności 1%; ** przy poziomie istotności 5%; * przy poziomie istotności 10%. Źródło: Norweski Rejestr Ludności, Central Bureau of Statustics, Oslo, za :”Multilevel anaysis in the social sciences”, D. Courgeau, B. Baccaiini.
38
Tabela 2. Wpływ charakterystyk regionów na migrację wewnąrtzregionalną w 1981-1992 , w podziale na region docelowy (osoby
urodzone w 1958 r.).
Docelowy region: Oslo Docelowy region: Centralno-Północny Charakterystyki regionu pochodzenia i
docelowego Oszacowany parametr Błąd standardowy Oszacowany parametr Błąd standardowy
% udział osób z takim samym stanem
cywilnym (a)
2,37*** 0,17 1,36*** 0,23
% udział osób z takim samym
wykształceniem (a)
0,81*** 0,07 -0,63*** 0,20
% udział osób z takim samym zawodem 0,36*** 0,06 0,21*** 0,06
Odległość pomiędzy miejscem
pochodzenia a docelowym (a)
0,001** 0,000 -0,001* 0,00
% udział osób mieszkających w miejscu
docelowym
0,16*** 0,02 0,00 0,02
(a): stosunek % w miejscu docelowym i % w miejscu pochodzenia
*** przy poziomie istotności 1%; ** przy poziomie istotności 5%; * przy poziomie istotności 10%.
Źródło: Norweski Rejestr Ludności, Central Bureau of Statustics, Oslo, za :”Multilevel anaysis in the social sciences”, D. Courgeau, B.
Baccaiini.

Tabela 3. Wpływ charakterystyk indywidualnych na migrację regionalną w latach 1981-1982 (osoby urodzone w 1958 r., mieszkające w
regionie centralno-północnym w końcu roku 1980).
Rejon docelowy: wschodni Rejon docelowy: południowy Charakterystyki
Oszacowany parametr Błąd standardowy Oszacowany parametr Błąd standardowy Mężczyźni -018*** 0,05 -0,04 0,08 Aktywni ekonomicznie -0,33*** 0,06 -0,37*** 0,08 Żonaci -0,36** 0,16 -0,24* 0,14 Posiadający dzieci -1,00*** 0,12 -0,59*** 0,15 Rolnicy -0,12 0,15 0,13 0,21 < 10 lat edukacji -0,57*** 0,09 -0,46*** 0,13 >12 lat nauki 0,78*** 0,20 0,59*** 0,19 Bez dochodów 0,00 0,12 0,29* 0,17 Dochód < 20 000 koron 0,39*** 0,06 0,64*** 0,10 Dochód > 50 000 koron -0,30*** 0,06 -0,14 0,10 Poprzedno zamieszkały w regionie docelowym
0,76*** 0,09 2,01*** 0,11
% udział osób z takim samym stanem cywilnym (a)
1,21*** 0,35 0,49 0,34
% udział osób z takim samym wykształceniem (a)
-0,55** 0,25 1,35*** 0,48
% udział osób z takim samym zawodem 0,36** 0,08 0,07 0,11 Odległość pomiędzy miejscem pochodzenia a docelowym (a)
0,001* 0,000 0,000 0,00
% udział osób mieszkających w miejscu docelowym
0,16*** 0,02 -0,01 0,02
(a): stosunek % w miejscu docelowym i % w miejscu pochodzenia *** przy poziomie istotności 1%; ** przy poziomie istotności 5%; * przy poziomie istotności 10%. Źródło: Norweski Rejestr Ludności, Central Bureau of Statustics, Oslo, za :”Multilevel anaysis in the social sciences”, D. Courgeau, B. Baccaiini.

40
Tabela 4. Wpływ charakterystyk indywidualnych i zagregowanych na migrację regionalną w latach 1981-1982 (osoby urodzone
w 1958 r., mieszkające w regionie Oslo w końcu roku 1980).
Rejon docelowy: wschodni Rejon docelowy: południowy Rejon docelowy: zachodni Rejon docelowy: północny Charakterystyki Oszacowany
parametr Błąd
standardowy Oszacowany
parametr Błąd
standardowy Oszacowany
parametr Błąd
standardowy Oszacowany
parametr Błąd
standardowy Mężczyźni -0,31*** 0,09 0,01 0,20 -0,36* 0,18 -0,12 0,13 Aktywni ekonomicznie -0,14 0,12 -0,24 0,25 -0,08 0,22 -0,43*** 0,16 Żonaci -0,17 0,14 -0,24 0,33 -0,15 0,27 0,05 0,20 Posiadający dzieci 0,18 0,16 -0,99* 0,54 -0,21 0,36 -0,45 0,27 Rolnicy 1,22*** 0,27 -0,41 1,05 0,91* 0,50 0,39 0,37 < 10 lat edukacji 0,01 0,12 -0,61 0,38 0,08 0,26 -0,18 0,20 >12 lat nauki 0,02 0,15 -0,32 0,34 0,27 0,27 -0,22 0,23 Bez dochodów 0,00 0,25 -0,48 0,63 -0,53 0,63 0,20 0,49 Dochód < 20 000 koron 0,08 0,14 0,26 0,25 0,60*** 0,24 0,11 0,19 Dochód > 50 000 koron 0,20* 0,11 -0,54** 0,23 0,13 0,22 -0,14 0,16 Poprzedno zamieszkały w regionie docelowym
0,43*** 0,09 0,37* 0,21 0,37* 0,18 0,47*** 0,14
% udział osób z takim samym stanem cywilnym (a)
0,40 0,30 1,18** 0,55 0,19 0,54 -0,72 0,48
% udział osób z takim samym wykształceniem (a)
1,54*** 0,50 -0,87 0,87 -0,18 0,71 -0,51 0,62
% udział osób z takim samym zawodem
-0,32* 0,17 -0,39 0,44 0,08 0,21 0,38*** 0,08
(a): stosunek % w miejscu docelowym i % w miejscu pochodzenia *** przy poziomie istotności 1%; ** przy poziomie istotności 5%; * przy poziomie istotności 10%. Źródło: Norweski Rejestr Ludności, Central Bureau of Statustics, Oslo, za :”Multilevel anaysis in the social sciences”, D. Courgeau, B.
Baccaiini.

41
Tabela 5. Wpływ charakterystyk indywidualnych i zagregowanych na migrację regionalną w latach 1981-1982 (osoby urodzone
w 1958 r., mieszkające w regionie Cebtralno-Północnym w końcu roku 1980).
Rejon docelowy: wschodni Rejon docelowy: południowy Rejon docelowy: zachodni Rejon docelowy: północny Charakterystyki Oszacowany
parametr Błąd
standardowy Oszacowany
parametr Błąd
standardowy Oszacowany
parametr Błąd
standardowy Oszacowany
parametr Błąd
standardowy Mężczyźni -0,40*** 0,11 -0,16 0,15 0,11 0,21 -0,11 0,16 Aktywni ekonomicznie -0,24** 0,12 -0,09 0,16 -0,26 0,24 -0,30 0,19 Żonaci -0,28* 0,17 0,19 0,19 0,16 0,30 0,08 0,22 Posiadający dzieci -1,11*** 0,21 -037* 0,21 -0,09 0,29 -0,08*** 0,27 Rolnicy -0,21 0,25 -0,01 0,31 -0,31 0,53 0,11 0,36 < 10 lat edukacji -0,37** 0,15 -0,15 0,19 -0,50 0,30 -0,12 0,21 >12 lat nauki -0,48** 0,24 0,30 0,28 -0,25 0,44 0,38 0,28 Bez dochodów -0,20 0,23 -0,34 0,34 -0,59 0,45 0,26 0,31 Dochód < 20 000 koron 0,01 0,14 0,05 0,19 -0,08 0,26 0,14 0,21 Dochód > 50 000 koron -0,08 0,12 0,23 0,17 -0,28 0,24 -0,13 0,19 Poprzedno zamieszkały w regionie docelowym
-0,88*** 0,13 -0,44*** 0,15 -0,91*** 0,23 -0,44*** 0,17
% udział osób z takim samym stanem cywilnym (a)
0,46 0,47 0,14 0,50 2,58*** 0,55 -1,37* 0,74
% udział osób z takim samym wykształceniem (a)
1,21*** 0,27 -1,38** 0,62 -0,66 0,88 -0,14 0,43
% udział osób z takim samym zawodem
-0,68** 0,34 -2,13*** 0,49 -0,18 0,70 0,29 0,49
(a): stosunek % w miejscu docelowym i % w miejscu pochodzenia *** przy poziomie istotności 1%; ** przy poziomie istotności 5%; * przy poziomie istotności 10%. Źródło: Norweski Rejestr Ludności, Central Bureau of Statustics, Oslo, za :”Multilevel anaysis in the social sciences”, D. Courgeau, B. Baccaiini.

Tabela 6. Parametry i błędy standardowe oszacowane w modelu wielopoziomowym w powiązaniu do 8- letnich i 11 letnich wyników uczniów.
Parametry Wartość Błąd standardowy Ustalone
Stała 15,040 1,318 Wynik z 8 lat 0,612 0,043
Losowe
Poziom szkoły σ2
e0 (konstanta) 44,990 16,360 σ2
e01 (kowarniancja) -1,231 0,521 σ2
e1 (wynik z 8 lat) 0,034 0,017 Poziom ucznia
σ2e 26,960 1,343
Źródło: ”Multilevel anaysis in the social sciences”, D. Courgeau, B. Baccaiini.
Tabela 7. Parametry i błędy standardowe oszacowane w symulowanym modelu wielopoziomowym w powiązaniu do 8- letnich i 11 letnich wyników uczniów.
Parametry Wartość Błąd standardowy Ustalone
Stała 16,720 1,189 Wynik z 8 lat 0,503 0,033
Losowe
Poziom szkoły σ2
e0 (konstanta) 57,000 14,080 σ2
e01 (kowarniancja) -1,298 0,373 σ2
e1 (wynik z 8 lat) 0,030 0,011 Poziom ucznia
σ2e 91.730 2,977
Źródło: ”Multilevel anaysis in the social sciences”, D. Courgeau, B. Baccaiini.
Tabela 8. Parametry i błędy standardowe oszacowane w symulowanym modelu wielopoziomowym w powiązaniu do 8 letnich i 11 letnich wyników uczniów w połączeniu z pomocą rodziców oraz w połączeniu interakcji pomiędzy pomocą.
Parametry Wartość Błąd standardowy Ustalone
Stała 4,410 0,545 Wynik z 8 lat 0,766 0,023 Pomoc rodziców 25,170 0,738 Interakcja -0529 0,033
Losowe
Poziom ucznia σ2
e 54,840 1,757 Źródło: ”Multilevel anaysis in the social sciences”, D. Courgeau, B. Baccaiini.

Tabela 9. Wyestymowane parametry i ich błędy standardowe (w nawiasach) dla prostego i wielopoziomowego modelu logitowego
włączającego równocześnie charakterystyki indywidualne i odpowiadające im charakterystyki zagregowane w 1980 r.
(generacja mężczyzn urodzonych w 1958 r.)
Parametry Żonaci Aktywni Rolnicy >12 lat nauki logitowy wielopoziomowy logitowy wielopoziomowy logitowy wielopoziomowy logitowy wielopoziomowy
Ustalone
Stała -1.465 (0,061)
-1,563 (0,114) 1,586 (0,684) 2,978 (1,625) -2,190 (0,043)
-2,291 (0,149) -2,216 (0,076)
-1,725 (0,217)
Charakterystyka 0,418 (0,054) 0,393 (0,079) -0,540 (0,042)
-0,588 (0,074) -0,401 (0,097)
-0,406 (0,096) 0,531 (0,058) 0,648 (0,117)
Zagregowana charakterystyka
-0,057 (0,005)
0,050 (0,008) -0,044 (0,009)
-0,062 (0,021) 0,028 (0,018) 0,028 (0,018) 0,002 (0,008) -0,058 (0,024)
Losowy poziom regionalny
σ2e0 (stała) 0,018 (0,015) 0,045 (0,032) 0,064 (0,029) 0,099 (0,055)
σ2e01 (kowariancja) 0,013 (0,012) -0,020 (0,027) 0,000 0,107 (0,072)
σ2e1 (charakterystyka) 0,056 (0,045) 0,060 (0,037) 0,000 0,178 (0,146)
Co najmniej 1 dziecko Niskie dochody Wysokie dochody Bez dochodów logitowy wielopoziomowy logitowy wielopoziomowy logitowy wielopoziomowy logitowy wielopoziomowy
Ustalone Stała -1,307 (0,077) -1,373 (0,180) -3,053 (0,150) -2,590 (0,382) 0,562 (0,306) -0,698 (0,670) -2,240 (0,083) -2,313 (0,290) Charakterystyka -0,133 (0,079) -0,165 (0,098) 0,096 (0,051) 0,125 (2,103) -0,195 (0,039) -0,256 (0,099) -0,065 (0,132) -0,074 (0,124) Zagregowana charakterystyka
-0,110 (0,080) -0,099 (0,026) 0,053 (0,009) 0,025 (0,021) -0,004 (0,005) -0,022 (0,011) 0,038 (0,029) 0,082 (0,099)
Losowy poziom regionalny
σ2e0 (stała) 0,033 (0,014) 0,100 (0,035) 0,035 (0,024) 0,067 (0,029)
σ2e01(kowariancja) 0,012 (0,022) -0,16 (0,034) -0,032 (0,038) 0,00
σ2e1 (charakterystyka) 0,055 (0,093) 0,156 (0,054) 0,152 (0,068) 0,00
Źródło: ”Multilevel anaysis in the social sciences”, D. Courgeau, B. Baccaiini.


Tabela 10. Parametry i błędy standardowe oszacowań w prostym i wielopoziomowym
modelu logitowym włączającym różne charakterystyki indywidualne
i zagregowane z istotnym efektem prawdopodobieństwa migracji w 1980-1981
r. (mężczyźni urodzeni w 1958 roku, Norwegia).
Parametry Prosty logitowy Wielopoziomowy
(>12 lat nauki)
Ustalone
Stała 2,467 (0,856) 1,711 (1,125)
Żonaci 0,641 (0,061) 0,653 (0,070)
Aktywni ekonomicznie -0,595 (0,046) -0,598 (0,085)
Rolnicy -0,226 (0,100) -0,208 (0,100)
>12 lat nauki 0,520 (0,063) 0,621 (0,082)
Co najmniej 1 dziecko -0,467 (0,089) -0,467 (0,102)
Niskie dochody -0,256 (0,063) -0,261 (0,067)
Wysokie dochody -0,107 (0,051) -0,102 (0,084)
Bez dochodów -0,610 (0,140) -0,619 (0,133)
Udział ekonomicznie aktywnych -0,042 (0,011) -0,034 (0,014)
Udział rolników 0,070 (0,007) 0,074 (0,010)
Udział osób z co najmniej 1 dzieckiem -0,155 (0,012) -0,138 (0,010)
Udział bez dochodów -0,087 (0,033) -0,100 (0,037)
Losowy poziom regionalny
σ2e0 (stała) 0,019 (0,009)
σ2e01 (kowariancja) -0,056 (0,030)
σ2e1 (>12 lat nauki) 0,150 (0,108)
Źródło: Norweski Rejestr Ludności, Central Bureau of Statustics, Oslo”.


Wykres 1. Podział Norwegii na regiony.
Źródło: ”Multilevel anaysis in the social sciences”, D. Courgeau, B. Baccaini, str 45.

48
Wykres 2. Wykres wyników prognozowanych dla 11 i 8 latków w każdej szkole,
z wykorzystaniem modelu wielopoziomowego dla próby londyńskich szkół.
Źródło: ”Multilevel anaysis in the social sciences”, D. Courgeau, B. Baccaini, str 56.
Wykres 3. Wykres wyników prognozowanych dla 11 i 8 latków w każdej szkole,
z wykorzystaniem modelu regresji liniowej dla każdej szkoły próby londyńskich
szkół.
Źródło: ”Multilevel anaysis in the social sciences”, D. Courgeau, B. Baccaini, str 56.

49
Wykres 4. Wykres wyników prognozowanych dla 11 i 8 latków w każdej szkole,
z wykorzystaniem modelu wielopoziomowego dla symulowanej próby szkół.
Źródło: ”Multilevel anaysis in the social sciences”, D. Courgeau, B. Baccaini, str 59.
Wykres 5. Wykres wyników prognozowanych dla 11 i 8 latków w każdej szkole,
z wykorzystaniem modelu regresji liniowej dla każdej szkoły z symulowanej
próby szkół.
Źródło: ”Multilevel anaysis in the social sciences”, D. Courgeau, B. Baccaini, str 59.

50
Wykres 6. Efekt trzech charakterystyk (bycie rolnikiem, posiadanie przynajmniej
jednego dziecka, więcej niż 12 lat wykształcenia) w logitowym modelu
prawdopodobieństwa migracji w Norwegii, dla generacji 1958, (lata 1980-81).

51
6. Bibliografia
1. Courgeau D., B. Baccaini, Multilevel Analysis in the Social Sciences, Population: An
English Selection, special issue New Methodological Approaches in the Social
Sciences, 1998, 39-71.
2. Goldstein H., G. Woodhouse, W. Browne, J. Rasbash, Multilevel models in the study
of population structures, Presented at 4 European Population Conferences, The Hague,
Seprt.1999.
3. Rivellini G., S. Zaccarin, Fertility behaviuor and context effect: how to take into
account? Some evidence from Italian FFS data.

52
Mgr Alicja Siwek
Mgr Małgorzata Kowalska
Mgr Małgorzata Szczyt
Katedra Statystyki i Demografii
Akademia Ekonomiczna, Poznań.
Statystyczna analiza tekstu1 (Textual Statistics).
1. Wprowadzenie.
Statystyczna analiza tekstu (w skrócie SAT) stanowi atrakcyjne narzędzie badawcze
dla studiów zawartości formalnej i merytorycznej tekstu jak i dla analizy porównawczej
tekstów.
Intensywny rozwój metodologii SAT miał miejsce na początku lat
dziewięćdziesiątych i był ściśle związany z ewolucją technologii informatycznych, a także z
badaniami z zakresu lingwistyki i statystyki2. Wypracowane wówczas metody zastosowano w
różnorodnych dziedzinach nauk społecznych i ekonomicznych: historii, psychologii,
socjologii, marketingu oraz w bardzo wyspecjalizowanych zagadnieniach jak na przykład
wywiad medyczny.
Zainteresowanie ilościowym badaniem tekstów pisemnych i ustnych ma jednak
zdecydowanie dłuższą historię. Opracowania z tego tematu można znaleźć w pracach z lat 30
i 40 XX stulecia3. Analizowano wówczas ilość wyrazów w badanym materiale, bogactwo
słownictwa, styl autora wypowiedzi. Obecnie metody SAT oparte są na podejściu
syntaktycznym oraz na technikach automatycznych4.
1 Opracowanie przygotowane na podstawie artykułu: „Textual Statistics. An exploratory tool for the social sciences”, Guerin-Pace F. w Population vol. 10 No 1, 1998, str. 11-38. Prezentowany tekst był przedstawiony przez Autora i dyskutowany na posiedzeniu Sekcji Analiz Demograficznych w dniu 12.09.2000. 2 Lebart L., Salem A., Statistique textuelle, Dunod, Paryż, 1994. 3 Zipf G.-K., The Psychobiology of Language, an Introduction to Dynamic Philology, Houston-Mifflin, Boston, 1935; Yule G.-U., The Statistical Study of Literary Vocabulary, Cambridge University Press, 1944, przedruk z 1968 Archons Books, Hamden, Connecticut. 4 Pecheux M., Analyse automatique du discours, Dunod, Paryż, 1969.

53
W ramach statystycznej analizy tekstu możemy wyróżnić dwa charakterystyczne
podejścia do materiału badawczego:
a) pierwsza grupa aplikacji dotyczy analiz statystyczno-stylistycznych ukierunkowanych na
ilościowe badanie tekstu z punktu widzenia jego formy. Do tej grupy należy badanie
tekstów: historycznych i literackich, porównywanie tekstów (stylów) różnych autorów,
badanie ewolucji stylu danego autora1.
b) drugą grupę stanowią analizy, które kładą nacisk na merytoryczną zawartość tekstu.
Metody należące do drugiej kategorii znajdują się w kręgu zainteresowań
demografów2. Ich efektywność została potwierdzona poprzez zastosowanie do badania
odpowiedzi na pytania otwarte. Są one również wygodnym instrumentem analizy historii
życia jednostek.
Poniższe opracowanie ma na celu próbę przedstawienia możliwości jakie stwarza SAT dla
badacza zagadnień o charakterze demograficznym. Szczególną uwagę zwrócimy na analizę
odpowiedzi na pytania otwarte.
2. Metodologia Statystycznej Analizy Tekstowej
Każdy tekst (zbiór słów) podlegający SAT nazywamy korpusem.
Rozmiary korpusu są uzależnione od charakteru tekstu, który podlega badaniu, a także od
właściwości autora wypowiedzi. W przypadku analizy historii życia jednostki korpus będzie
złożony z kilku słów; odpowiedzi na pytania otwarte oznaczają korpus w postaci zbioru
wypowiedzi złożonych z kilku zdań; korpus dotyczący wywiadów to wypowiedzi
kilkustronicowe. Możliwe jest także badanie opracowań stanowiących całe woluminy.
Pierwszy krok statystycznej analizy tekstu polega na identyfikacji bazy
leksykometrytcznej korpusu3. Na bazę tę składa się szereg form graficznych. Formę
graficzną definiujemy jako serię znaków, z reguły liter, otoczonych znakami
przestankowymi. Forma graficzna jest ściśle powiązana z określonym słowem. Zestawienie
form występujących w korpusie stanowi słownik korpusu.
W zależności od charakteru korpusu oraz od celu naszego badania formy graficzne
mogą pozostać w postaci surowej (nieprzetworzonej) lub mogą zostać poddane procesowi
1 Holmes D.-I., „The analysis of literary style A review”, J.R. Statisc. Soc., 148, część 4, 1985, str. 328-341; Beaudouin V., „Stylistique et analyse lexicale: Corneille et Racine”, JADT 1993, ENST, Paryż, 1993. 2 Lebart L., „Analyse statistique des données Textuelles: quelques problémes actuels et futurs”, w S. Bolasco, L. Lebart, A. Salem (eds), JADT 1995, vol. 1, CISU, Rzym, 1995, str. XVII-XXIV. 3 Lebart L., „Sur les analyses statistiques de textes”, Journal de la société statistique de Paris, vol. 134, nr 4, 1993, str. 17-36.

54
lematyzacji (lemmatization). Lematyzacja jest techniką umożliwiającą przypisanie do jednej
formy graficznej określonego słowa występującego w korpusie w różnych postaciach. Tzn. za
jedną formę uznamy czasownik zastosowany w różnych czasach lub trybach, rzeczownik w
liczbie mnogiej lub pojedynczej. W ten sposób grupujemy wyrazy, w ramach poszczególnych
części mowy, pochodzące z tego samego pnia słownego.
Proces lematyzacji posiada zarówno wady jak i zalety1.
Zastosowanie lematyzacji oznacza niebezpieczeństwo połączenia form, które co
prawda mają wspólny źródłosłów, ale różnią się znaczeniem. Ponadto każdy język cechuje się
pewną liczbą homonimów, które mogą znacznie utrudnić badania. Zwolennicy lematyzacji
zwracają z kolei uwagę na fakt, że rozpoznanie podobieństw semantycznych pozwala na
redukcję bazy leksykalnej co usprawnia dalsze analizy2.
Niezależnie od tego w jaki sposób dokonamy izolacji form graficznych w korpusie,
badany tekst musi być przekształcony w postać odpowiednią do analiz komputerowych.
Procedura ta, nazywana digityzacją (digitize), polega na rozdzieleniu korpusu na formy
graficzne i na przypisaniu każdej formie numeru porządkowego lub adresu. Podczas dalszych
analiz formy będą przechowywane w słowniku korpusu, a dla celów badania wykorzystywane
będą adresy lub numery form graficznych.
Badanie danych tekstowych, jakimi są formy graficzne należące do analizowanego
korpusu, wykorzystuje wielowymiarową analizę tekstu, przede wszystkim analizę
korespondencji, która pozwoli na klasyfikację danych dotyczących korpusu zgodnie z jego
właściwościami leksykalnymi3.
W opracowaniach z zastosowaniem metod SAT korzysta się z różnorodnego
oprogramowania komputerowego. Przykładem tego typu aplikacji są: ALCESTE (M. Reinert,
1995); HYPERBASE (E. Brunet, 1993), LEXICO (F. Leimdorfer i A. Salem, 1995), SPADT
(CISIA).
1 Bolasco S., „Choix de lemmatisation en vue des reconstructions syntagmatiques du texte par l’analyse de correspondances”, w JADT 1993, ENST, Paryż, 1993, str. 299-307; Salem A., „Les unités lexicométriques”, w S. Bolasco, L. Lebart, A. Salem (eds), JADT 1995, vol. 1, CISU, Rzym, 1995, str. 19-27. 2 Beaudouin V., Lahlou S., „L’analyse lexicale: outil d’exploration des représentations”, Cahiers de Recherche CREDOC, nr 48 i 48 b, Paris, 1993. 3 Lebart L., „Analyse…”, op. cit.

55
3. Statystyka tekstowa dla celów analizy odpowiedzi na pytania otwarte
Metody SAT mogą stanowić efektywne narzędzie badawcze dla demografa, który stoi
przed trudnym zadaniem analizy danych zawartych w ankiecie, w szczególności w przypadku
badania odpowiedzi na pytania otwarte. Statystyczna analiza tekstu oparta na metodach
automatycznych umożliwia studia dotyczące dużej liczby danych tekstowych; nie jest to
jednak technika wolna od wszelkich wad. W trakcie stosowania procedury następuje operacja
kodowania danych, która może spowodować utratę części informacji.
Opisany poniżej przykład ma na celu dokładniejsze przedstawienie metod
statystycznej analizy tekstu.
Klasyfikacja odpowiedzi w korpusie „Środowisko”
Wykorzystamy badanie przeprowadzone w 1992 r. na próbie 5000 osób wybranych
reprezentatywnie ze społeczeństwa francuskiego. Skoncentrujemy się na odpowiedzi na jedno
z pytań zawartych w badaniu: „Jakie skojarzenie wywołuje u Pani/Pana słowo środowisko?”.
Do analizy został użyty program Alceste, który bada strukturę formalną
współwystępowania słów w zdaniach. Innymi słowy zakłada, że każdy używa w swoich
wypowiedziach pewien zasób typowych dla siebie słów, tworzy własny słownik. Badanie
statystyczne przeprowadzone przez ten program dąży do odkrycia znaczenia obrazu, który
tworzy mówca poprzez swoje indywidualne słownictwo. W praktyce otrzymujemy
klasyfikację odpowiedzi opartą na podobieństwach lub na braku podobieństw w słownictwie.
Pierwszym krokiem w metodologii programu Alceste jest redukcja słownika oparta o
kryteria lingwistyczne. Program identyfikuje formy gramatyczne słów. Wyróżniane są
wówczas przyimki, spójniki, rzeczowniki, czasowniki, itd. Wtedy też następuje lematyzacja,
która sprowadza czasowniki do ich formy bezokolicznikowej, rzeczowniki do ich formy
podstawowej itp. Program używa w tym celu swojego wewnętrznego słownika. Na tym etapie
jest możliwe ingerowanie w działanie programu. Przykład lematyzacji pokazuje Tablica 1.

56
Tablica 1. Wyciąg z lematyzacji korpusu środowisko.
Kod Forma pierwotna
Częstotliwość Typ wyrazu Forma zlematyzowana
1440
1249
Móc
Mógł
19
3
Czasownik Móc
Móc
117
297
Zieleń
Zielenie
84
101
Kolor Zieleń
Zieleń
403
283
793
Przy
Obok
Na
80
22
21
wskaźnik
stosunku
przestrzennego
Przy
Obok
Na
398
24
639
Wiele
Trochę
Mało
27
97
18
wskaźnik
natężenia
Wiele
Trochę
Mało
269
153
280
488
122
Ja
Mnie
Nasz
Ktoś
Kogoś
268
232
26
148
28
wskaźnik osoby Ja
Mnie
Nasz
Ktoś
Kogoś
588
149
Ma
Jest
20
208
formy „być” i
„mieć”
Mieć
Być
Źródło: F. Guerin-Pace, Textual statistics. An exploratory tool for the social sciences, str 77.
Następnie program dokonuje klasyfikacji w wejściowej tabeli leksykalnej, której
wiersze odpowiadają zlematyzowanym przez program wyrazom, kolumny natomiast -
odpowiedziom na dane pytanie otwarte (w omawianym przypadku - dotyczące środowiska).
W komórki tabeli wpisywane są 1 lub 0 w zależności, czy dany wyraz występuje w
odpowiedzi, czy też nie. Metoda programu jest najbardziej skuteczna dla tablic zawierających
dużą liczbę 0 (ok. 95%). Umożliwia to automatyczną eliminację najbardziej specyficznych
odpowiedzi oraz ujrzenie odpowiedzi jako całości. Procedura programu w każdym kroku
dzieli tabelę na dwie najbardziej jednorodne klasy (to znaczy takie, dla których χ2 jest
maksymalne), aż do momentu uzyskania pożądanej liczby klas.
Stosując tę procedurę, odpowiedzi korpusu „środowisko” podzielono na 8 klas. Dwie
najbardziej zagregowane grupy odpowiadają dwóm skrajnie różnym podejściom w odbiorze
środowiska. Jedno jest bardzo bezpośrednie, drugie symboliczne (Diagram 1).

57
Diagram 1. Światy leksykalne w korpusie środowisko
Źródło: F. Guerin-Pace, Textual statistics. An exploratory tool for the social sciences, str 78.
W każdej klasie występuje specyficzne dla niej słownictwo i charakterystyczne odpowiedzi.
Typowe słownictwo użyte dla klasy nazwanej „jakość życia” przedstawia Tablica 2.
Tabela 2. Charakterystyczne słownictwo klasy 1 w korpusie „środowisko”
Kod Forma Liczba w klasie Ogólnie Częstotliwość Chi-2
41 Dzienny 37 48 77,08 99,25
43 Zdrowy 12 24 50,00 13,58
55 Przyjemny 5 7 71,43 11,58
78 Wybór 4 5 80,00 11,25
86 Warunki 19 25 76,00 49,35
128 Idea 3 3 100,00 12,00
132 Dzień 13 27 48,15 13,47
152 Niedogodność 10 23 43,48 7,97
174 Jakość 219 277 79,06 666,41
207 Wszechświat 3 4 75,00 7,56
213 Życie 565 758 75,54 1902,10
289 Krąg rodzinny 18 47 38,30 9,97
424 Wszyscy 13 28 46,43 12,31
Źródło: F. Guerin-Pace, Textual statistics. An exploratory tool for the social sciences, str 80.
Podejście abstrakcyjne Jakość życia
Przyroda i zanieczyszczenia
Podejście bezpośrednie Środowisko społeczne
Podejście konkretne Wszechświat lokalny
Przyjemne miejsce do życia
Wyobrażenia dotyczące przyrody
Otwarta przestrzeń i czyste powietrze
Przyroda i źródła dobrego samopoczucia
Podejście symboliczne

58
Analiza komplementarna przeprowadzona przy użyciu tego samego programu daje
interesujące wyniki. W wyniku analizy korespondencji przeprowadzonej na wielowariantowej
tabeli, zawierającej słowa i klasy otrzymane w poprzednim grupowaniu, otrzymujemy
prezentację graficzną, która w prosty sposób obrazuje relacje pomiędzy słowami i klasami.
Analiza ta upraszcza również samą ideę klasyfikacji. Diagram 2 ukazuje pozycje, jakie
zajmuje na wykresie osiem klas otrzymanych w grupowaniu oraz należące do nich słowa.
Patrząc na oś poziomą, na jej ujemnych wartościach znajdują się klasy, które opisują
środowisko w znaczeniu natury, otwartej przestrzeni, czystego powietrza…; przeciwieństwem
(wartości dodatnie osi poziomej) jest pojęcie środowiska zorientowanego na człowieka oraz
środowiska w kontekście jakości życia. Obserwując pozycje klas według osi pionowej można
zauważyć kontrast pomiędzy wysoce abstrakcyjnym przedstawieniem środowiska, jakości
życia, klimatu, czystego powietrza,… a bardziej bezpośrednim jego znaczeniem, opartym na
domu i jego otoczeniu.
Diagram 2. Położenie klas leksykalnych korpusu środowisko
MIEJSCE DO ŻYCIA życie znaleźć radość czuć lubić region przyjemność żyć środowiskowy ulica żyć miejsce miejsce ludzie praca przeszłość ktokolwiek droga rzecz słyszeć osiedle dom świat WSZECHŚWIAT LOKALNY miasto społeczeństwo krąg rodzinny PRZYRODA ogród rzeka roślina czysty pole rodzina naturalny słońce kwiat las morze jezioro ŚRODOWISKO SPOŁECZNE wieś dom przyjaciel wypoczynek sąsiad piękno geografia środowisko człowiek spokój czystość kultura równowaga harmonia woda zieleń dziki chronić utylizacja przyszłość pełny tlen miejski ludzki społeczny przestrzeń ochrona stan architektura polityczny powietrze wolność dobrobyt ekologia fizyczny OTWARTA PRZESTRZE Ń szacunek I CZYSTE POWIETRZE BEZPIECZE ŃSTWO I DOBROBYT zawód warunek codziennie JAKO ŚĆ ŻYCIA życie miejsce jakość
Źródło: F. Guerin-Pace, Textual statistics. An exploratory tool for the social sciences, str 81.

59
Struktura korpusu według cech respondentów
Odmiennym podejściem do analizy odpowiedzi na pytania otwarte jest badanie
słownictwa używanego w odpowiedziach respondentów należących do danych subpopulacji.
Wymaga to uporządkowania korpusu według indywidualnych charakterystyk podmiotu
badania.
Metodologia programu Spadt jest dostosowana przede wszystkim do badania
odpowiedzi na pytania o charakterze otwartym, w sytuacji kiedy dysponujemy
charakterystykami społeczno-demograficzymi respondenta lub jego odpowiedziami na
pytania zamknięte. Główna zaleta programu polega na określeniu zależności pomiędzy
charakterystykami jednostek i odpowiedziami na pytania otwarte.
Program nie przeprowadza lematyzacji, ale przy badaniu korpusu umożliwia grupowanie
ręczne. Następnie przeprowadzana jest analiza korespondencji wykorzystująca tabelę, która
zawiera słowa ze słownika i cechy populacji. Użycie tej analizy umożliwia obserwację
pozycji słów i cech społeczno-demograficznych oraz interpretację odległości pomiędzy nimi.
Analizując zbiór odpowiedzi dotyczących środowiska, dąży się do ustalenia zestawu
skojarzeń powiązanych z poszczególnymi subpopulacjami. W omawianym badaniu pod
uwagę brano następujące cechy jednostek: wiek respondenta, zawód, dochód gospodarstwa
domowego, wykształcenie, region i lokalizację mieszkaniową. Okazało się, że najbardziej
znaczące przeciwieństwa związane są z wiekiem i z wykształceniem1. Populacja z
niewielkimi lub bez kwalifikacji i niskim dochodem gospodarstwa domowego oraz jednostki
nieaktywne ekonomicznie, mają skojarzenia ze środowiskiem ograniczone do bezpośredniej
bliskości domu: „około”, „otoczenie”, „dom (budynek)”, „sąsiedztwo”, i skoncentrowane są
na jednostce: „mnie”, „ja”, „moje”; odmiennie jest w populacji charakteryzującej się
wysokimi kwalifikacjami, wśród jednostek o wysokim dochodzie i pracujących na
kierowniczych stanowiskach, które podając definicję słowa „środowisko” używają
słownictwa bogatszego i o dużo bardziej abstrakcyjnym znaczeniu: „równowaga”,
„naturalny”, „ekologia”, „przyszłość”,…2. Znaczny kontrast występuje również zależnie od
wiejskiego lub miejskiego charakteru miejsca zamieszkania. Mieszkający w miasteczkach i
miastach często pojmują środowisko w znaczeniu społecznym i opisują je poprzez:
„stosunki”, „dzielnica”, „atmosfera”, „sklepy”, „przyjemny”, „bezpieczeństwo”, „dzieci”;
1 Guérin-Pace F., Collomb Ph., „Les contours du mot environnement: enseignements de la statistique textuelle”, L’Espace Géographique, nr 1, 1998, str. 41-52. 2 Op. cit.

60
tymczasem populacje wiejskie mają tendencję określać środowisko w znaczeniu: „natura”,
„zewnętrze”, „wieś” a nawet „praca”.
Analiza ta może być dalej poszerzona przy pomocy innych narzędzi, np. badania
„powtarzających się segmentów” 1, to znaczy sekwencji słów, które powtarzają się w
odpowiedziach. tablica 3 przedstawia wyciąg powtarzających się segmentów uzyskanych w
odpowiedziach dotyczących środowiska.
Tablica 3. Wyciąg listy powtarzających się segmentów w korpusie „środowisko”.
Częstotliwość Segment Częstotliwość Segment
331 Warunki życia 92 Zielone przestrzenie
253 Jakość życia 85 Dookoła nas
190 Nasze otoczenie 66 To co jest dookoła nas
173 Moje otoczenie 60 Szacunek dla przyrody
172 Dookoła mnie 54 Czyste powietrze
168 Dobre samopoczucie 52 Wszystko dookoła
128 To co jest dookoła 50 Otwarta przestrzeń
100 Wszystko dookoła nas 40 Ochrona przyrody
Źródło: F. Guerin-Pace, Textual statistics. An exploratory tool for the social sciences, str 83.
Do grupowania charakterystycznych dla danej subpopulacji odpowiedzi bardzo
przydatna jest procedura oparta na wyliczaniu prawdopodobieństw. Porównuje ona
częstotliwość, z którą dany segment występuje w odpowiedziach danej subpopulacji, z jego
ogólną częstotliwością. Wynikiem jest zbiór słów, które są charakterystyczne dla danej
subpopulacji, ze względu na ich albo nadużywanie, albo używanie z częstością poniżej
przeciętnej. Tablica 4 przedstawia nadużywane formy w odpowiedziach na pytania dotyczące
środowiska według wieku respondentów. Można zauważyć, że ludzie młodzi znacznie
częściej kojarzą środowisko z naturą lub planetą (wysoka wartość statystyki testowej),
podczas gdy dla ludzi starszych środowisko ogranicza się do najbliższego otoczenia i do
jakości stosunków międzyludzkich. W ten sam sposób można wyszczególnić zbiór
odpowiedzi charakterystycznych dla każdej innej subpopulacji. Rozpatrując najbardziej
charakterystyczne odpowiedzi kobiet i mężczyzn, można zauważyć, że mężczyźni przeważnie
poruszają temat jakości życia, często w bezosobowej formie (takie słownictwo, jak: „styl 1 Lafon P., Salem A., „L’inventaire des segments répétés d’un texte”, Mots, nr 6, 1983, str. 161-177; Salem A., Pratique des segments répétés, Paryż, Klincksieck, INDLP, 1987, str. 333.

61
życia”, „miejsce, w którym się żyje”, „jakość życia”, „dobrobyt”), podczas gdy kobiety
chętniej mówią o otoczeniu oraz podkreślają, że są elementem natury lub swojego
społeczeństwa (np.: „ludzie wokół nas”, „nasze otoczenie”, „sąsiedzi”, „drzewa”).
Wyszczególniając subpopulacje według: miejsca zamieszkania, liczby posiadanych dzieci
oraz wysokości dochodów również można zauważyć istotne różnice pomiędzy
odpowiedziami respondentów.1
Tablica 4. Charakterystyczne formy według wieku
Częstotliwość Liczba Wartość Prawdopodo-
w klasie ogółem w klasie ogółem testowa bieństwo
25-35 lat
Przyroda 10,64 7,71 311 2125 5,988 0,000
Ekologia 1,33 0,54 39 148 5,308 0,000
Miejsce 0,92 0,5 27 138 3,029 0,001
Ochrona 0,62 0,29 18 80 2,962 0,002
Planeta 0,24 0,07 7 20 2,714 0,003
Zieleń 0,58 0,29 17 79 2,710 0,003
35-45 lat
Życie 4,21 3,25 266 895 4,771 0,000
Jakość 1,43 1,06 90 291 3,115 0,001
Zapachy 0,24 0,13 15 37 2,246 0,012
Wolność 0,3 0,19 19 53 2,009 0,022
Architektura 0,1 0,04 6 11 2,004 0,023
ponad 65 lat
Sąsiedztwo 0,95 0,61 73 168 4,220 0,000
Powiązania 0,1 0,04 8 11 2,789 0,003
Dobry 0,23 0,13 18 36 2,637 0,004
Średni 0,12 0,05 9 14 2,576 0,005
Źródło: F. Guerin-Pace, Textual statistics. An exploratory tool for the social sciences, str 85.
1 Inne zastosowania metod opracowywania odpowiedzi na otwarte pytania można znaleźć na przykład w pracach V. Beaudouin, S. Lahlou, op. cit. lub L. Clerc, A. Dufour, „Deux analyses lexicales: les améliorations á apporter au fonctionnement de la société, l’image du milieu professionnel”, Cahiers de recherche Crédoc, nr 22, Paryż, 1992.

62
Należy również zwrócić uwagę na wartość tej metodologii w opracowywaniu
odpowiedzi jednocześnie na pytania otwarte i zamknięte1. Pierwszym krokiem jest
utworzenie zbioru odpowiedzi na pytanie otwarte według indywidualnych cech
respondentów, a odpowiedzi na pytanie zamknięte dotyczące tego samego tematu należy
przedstawić jako charakterystykę uzupełniającą. Następnie należy zastosować podejście
przeciwne: utworzyć zbiór według odpowiedzi na zamknięte pytanie i zbadać cechy
respondentów. Te dwie procedury dopełniają się wzajemnie i znacznie pogłębiają analizę.
W podsumowaniu tego rozdziału należy podkreślić wkład wniesiony przez omawiane
metody statystyczne w zrozumienie czynników odpowiedzialnych za różnice w
odpowiedziach. Jednocześnie należy zwrócić uwagę na możliwość popełniania błędów i to
zarówno przy ręcznej, jak i automatycznej klasyfikacji. Krótkie odpowiedzi dobrze się
grupuje ręczne. Natomiast w przypadku rozbudowanych odpowiedzi skuteczniejsza jest
klasyfikacja automatyczna, gdyż pozwala ona uniknąć subiektywnych interpretacji
powodujących błędne skojarzenia. Jest to obszar, w którym nadal poszukuje się usprawnień.
4. Analiza długich tekstów
4.1 Rozprawy naukowe i wywiady
Znaczenie wywiadów (kwestionariuszowych) jako narzędzia badania w demografii
jest bardzo dobrze znane. Technika statystyki tekstowej może odgrywać wysoce efektywną
rolę w rozszyfrowywaniu i porównywaniu wywiadów. Do tego celu szczególnie przydatny
jest program Alceste.
Największym problemem, jaki pojawił się przy zastosowaniu tej metody, był
właściwy podział długich tekstów na jednostki. Jak długa powinna być taka jednostka?
Najlepiej, gdy długość jednostki wynika z kontekstu i jest proporcjonalna do długości
korpusu. Natomiast w przypadku analizy pojedynczego wywiadu lub zbioru prac bardziej
wskazana jest praca na podziale tekstu stworzonym przez samego autora (tzn. paragrafy,
rozdziały itp.)
Algorytm Alceste przebiega następująco: najpierw następuje podział początkowego
tekstu na podstawowe jednostki, które następnie są łączone w jednorodne klasy ze względu na
podobieństwa zawartego w nich słownictwa. Reinert pokazał optymalną długość i liczbę
1 Guérin-Pace F., Garnier B., „La statistique textuelle pour le traitement simultané de résponses á des questions ouvertes et fermées, sur le théme de l’environnement”, w S. Bolasco, L. Lebart, A. Salem (eds), JADT 1995, vol. 2, CISU, Rzym, 1995, str. 37-44.

63
jednostek, która pozwala na stabilną klasyfikację. Jest to około 14 jednostek, z których każda
odpowiada w przybliżeniu 10 liniom tekstu.
V. Beaudouin1 przeanalizował zbiór 580 opowiadań o doświadczeniach społecznych
młodych ludzi znajdujących się w trudnych sytuacjach, aby poznać okoliczności tych sytuacji
(stan emocjonalny badanego, jego sytuację materialną, zachowanie się). Do analizy tej autor
dokonał podziału opowiadań na klasy, odpowiadające różnym kategoriom zachowań.
Następnie klasy połączył w trzy grupy (pola): pole sytuacyjne, pole współdziałania, pole
autonomii. Pole sytuacyjne dotyczyło uwarunkowań społecznych sytuacji badanych osób
(niski poziom wykształcenia, niskie poczucie wartości, problemy rodzinne). Pole
współdziałania ukazywało współpracę pomiędzy strukturami wsparcia (pomoc społeczna) a
młodymi ludźmi i składało się z 4 stanów zdefiniowanych jako poszukiwanie pracy,
przekwalifikowanie, pomoc finansowa, pomoc socjalna. Pole autonomii odpowiadało
początkowi niezależności młodych ludzi i składało się ze szkolenia po którym następowało
zatrudnienie.
4.2 Tekst specjalny: dziennik
Metody statystycznej analizy tekstowej stosowane są z dużym powodzeniem do
badania dzienników i historii życia jednostek. Sekwencje stanów (zatrudnienie, status
zawodowy, ... ) traktuje się wówczas jako serie słów tworzących zdanie. Zaletą tej metody
jest możliwość porównywania dzienników i historii życia jednostek, które nie mają tej samej
liczby stanów (okresów).
W zależności od celu analizy możemy zastosować jedną z dwóch metod tworzenia
korpusu danych. Pierwsze podejście rozważa kolejne stany nie biorąc pod uwagę okresów
trwania tych stanów. Ważny jest tutaj typologiczny opis sytuacji w jakiej się znajduje
jednostka. Druga metoda bierze pod uwagę czas trwania, moment wystąpienia i liczbę
wystąpień danego stanu.
L. Haeusler zauważył, że w zależności od tego, czy czas jest uwzględniony w analizie,
czy nie, możemy uzyskać różne rezultaty2.
Metody te zastosowano do badania historii karier równoległych opierając się na pomiarze siły
roboczej (INSEE, 1990)3. Pomiar ten uzyskano w wyniku monitorowania statusu zatrudnienia
1 Beaudouin V., „Du récit au par cours: portrait de jeunes en difficulté” w S. Bolasco, L. Lebart, A. Salem (eds), JADT 1995, vol. 2, CISU, Rzym, 1995, str. 49-57. 2 Haeusler L., „Des phrases et des itin�raires”, w JADT 1993, ENST, Paryż, 1993, str. 249-256. 3 Courgeau D., Guerin-Pace F., „Lecture des parcours professionnels des couples”, w JADT 1998, Nice, 1998, str. 221-232.

64
członków gospodarstwa domowego co miesiąc przez okres trzech lat. Pozwoliło to na
odtworzenie ścieżki zawodowej par. Opierając się na 6 statusach siły roboczej (umowa o
pracę na czas określony (FC), umowa o pracę na czas nieokreślony (UC), bezrobocie (UN),
studenci i żołnierze (SS), pracujący na rachunek własny (SE) i nieaktywny ekonomicznie
(NA)), dla każdej historii karier równoległych skonstruowano zdania, w których każde słowo
odpowiada zestawieniu statusów zatrudnienia dwóch partnerów (możliwych jest 36
kombinacji). Okazało się, że najczęstsza jest sytuacja, gdy mężczyzna i kobieta mają umowę
o prace na czas nieokreślony (UCUC), a najrzadsza taka, kiedy mężczyzna jest nieaktywny
zawodowo, a kobieta studiuje (NASS). Tablica kontyngencji rozpatruje częstotliwości
przebywania badanych par w określonych statusach zawodowych. Wielowymiarowa analiza
korespondencji tej tablicy umożliwia identyfikację podobieństw w historiach karier
równoległych (Diagram 3). Stwierdzono, że najostrzejszy kontrast występuje pomiędzy
parami, w których jedna osoba pracuje na rachunek własny (SE) druga natomiast ma dowolny
status zawodowy, a wszystkimi innymi możliwymi kombinacjami statusów.
Diagram 3. Odległości między różnymi stanami i historiami karier.
Źródło: F. Guerin-Pace, Textual statistics. An exploratory tool for the social sciences, str 90.
SSSE
FCSE UNSE
NASE UCSE
SESE
SENA NANA
SEUC SEUN SESS
SEFC NANE
NAFC NASS
SSUC
FCNA
UNNA
UCNA
SSNA

65
Analizę tę można uzupełnić badaniem chronologii przejść par pomiędzy stanami.
W ten sposób możliwa jest identyfikacja prawidłowości występujących w historiach karier
równoległych dla par znajdujących się w określonym stanie. Analiza powtarzających się
segmentów zawierających dwa słowa (dwa stany) ukazuje większą niepewność zatrudnienia
kobiet. Najczęściej pojawiają się takie segmenty, w których mężczyzna jest bezrobotny (UN),
a kobieta jest albo zatrudniona na umowę o pracę na czas określony (FC), albo również
bezrobotna (UN). Badanie dłuższych segmentów ukazuje cykliczny charakter zmian statusu
siły roboczej dla par, na przykład historia kariery równoległej, w której mężczyzna cały czas
pozostaje zatrudniony na umowę o pracę na czas nieokreślony (UC), a status zawodowy
kobiety zmienia się z umowy o pracę na czas określony (FC) na bezrobocie (UN) i odwrotnie
(z UN na FC).
W innym podejściu do badania historii karier równoległych porządkuje się korpus
według cech socjo-demograficznych par. Tablica kontyngencji zawiera wtedy w wierszach
zbiór możliwych stanów, a w kolumnach socjo-demograficzne charakterystyki gospodarstw
domowych. Wynikiem analizy korespondencji są te cechy socjo-demograficzne, które mają
największy wpływ na charakter kariery zawodowej par, a także te, które najbardziej te kariery
różnicują.
Tego typu analiza jest bardzo dobrym uzupełnieniem dla technik analizy historii
zdarzeń1. Metody wywodzące się ze statystycznej analizy danych tekstowych mogą być
używane do badania skomplikowanych współzależności między różnymi sytuacjami
(stanami), które mają miejsce w historii zdarzeń par. Z drugiej strony metody te nie tworzą
objaśniających modeli statystycznych.
5. Podsumowanie
W czasie kiedy automatyczne tłumaczenie rozpraw naukowych (wykładów) rozwija
się, użycie techniki statystyki tekstowej jest nieocenioną pomocą w czytaniu i rozumieniu
tekstu. Metody SAT pozwalają na interpretację tekstu w oparciu o kryteria ilościowe, a nie
subiektywne. W demografii, w której opis i analiza są bardzo ważne, metody SAT są wysoce
efektywne.
Rozwój metod SAT związany jest z udoskonaleniem modeli zarówno pod względem
statystycznym jak i lingwistycznym. Wysiłki językoznawców są kierowane na udoskonalenie
1 Courgeau D., Meron M., „Mobilité résidentielle, activité et vie familiale des couples”, Économie et Statistique, nr 290, 1995, str. 1731.

66
słowników i zredukowanie liczby błędów podczas kodyfikacji korpusu. Automatyczne
kategoryzatory wykorzystywane są do rozdzielania form graficznych występujących w
korpusie według ich formy gramatycznej (czasownik, rzeczownik, przyimek) w porządku, w
którym występują one w korpusie.1 Skomputeryzowana analiza składni, rozbudowywane i
udoskonalane słowniki umożliwiają szczegółową lematyzację2, która obecnie jest wysoce (w
ponad 95%) wiarygodna. Jednocześnie statystycy udoskonalają modele, dostarczające coraz
bardziej wiarygodne wyniki. Szczególny wkład wnoszą tutaj nowoczesnych techniki
statystyczne (np.: Monte Carlo, Jackknife, Bootstrap).
Statystyka tekstowa jest dziedziną analizy, która rozwija się bardzo gwałtownie. S.
Lahlou3 w swojej teorii interpretacji wyników SAT podkreślał, że należy unikać nadużywania
i naciągania wyników oraz zbyt pochopnych interpretacji. Argumentował konieczność
odnalezienia powiązań pomiędzy tym, co jest obserwowalne (klasy uzyskane w analizie
czynnikowe) a modelami interpretacji wyników.
1 Salem A., „Les unités…”, op. cit. 2 Gross M., „On counting meaningful units in text”, w S. Bolasco, L. Lebart, A. Salem (eds), JADT 1995, vol. 1, CISU, Rzym, 1995, str. 5-18. 3 Lahlou S., „Vers une th�orie de l’interpr�tation en analyse statistique des donn�es textuelles”, w S. Bolasco, L. Lebart, A. Salem (eds), JADT 1995, vol. 1, CISU, Rzym, 1995, str. 221-229.

67
Mgr Maciej Rodzewicz
Katedra Statystyki
Uniwersytet Gdański
Metody mikrosymulacyjne w prognozowaniu demograficznym1
1. Wstęp
Na czym polegają prognozy demograficzne w ujęciu mikro i makro?
Prognozowanie liczby ludności z reguły jest przygotowywane przy zastosowaniu metody
czynnikowej. W swojej najprostszej formie, metoda ta wygląda następująco. Populacja jest
sklasyfikowana według płci (mężczyźni i kobiety) i grup wiekowych (kohorty). Dla każdej
kombinacji płci s i wieku x, populacja wyjściowa jest przekształcona na końcową
prognozowaną populację wg płci s i wieku x+1 poprzez przewidywane zmiany populacji,
determinowane przez czynniki. Typowymi czynnikami jest umieralność i płodność. Te
przekształcenia są powtarzane dla następujących po sobie okresach czasu, gdzie końcowa
populacja jednego okresu czasu służy jako początkowa dla następnego. Postępujemy tak,
dopóki nie osiągniemy okresu końcowego dla którego sporządzana jest prognoza.
Podstawowym założeniem modelu czynnikowego jest to, że populacja zmienia się
poprzez doświadczenie przez jednostki określonych zdarzeń demograficznych oraz to, że
mechanizm właściwy dla tych zdarzeń różnicuje płeć, grupy wiekowe i rodzaje zdarzeń.
Łączna liczba zdarzeń określonego typu, dla każdej kombinacji wieku i płci jest
projektowana jako rezultat dwóch czynników: rozmiaru populacji narażonej na działanie
zdarzenia; i poziomu nasilenia ryzyka dla indywidualnej osoby. Prawdopodobieństwo
wystąpienia określonego zdarzenia może być interpretowane jako miara zachowań
demograficznych.
1 1 Opracowanie przygotowane na podstawie artykułu: Microsimulation Methods for Population Projection, Evert Van Imhoff and Wendy Post, w Population vol. 10 No 1, 1998, str. 11-38. Prezentowany tekst był przedstawiony przez Autora i dyskutowany na posiedzeniu Sekcji Analiz Demograficznych w dniu 12.09.2000.

68
Przykład:
Przypuśćmy, że chcemy przewidzieć liczbę dzieci urodzonych w przeciągu roku przez 100
tys. kobiet w wieku 25 lat. Populacja składa się z 100 tys. kobiet w wieku 25 lat dla których
prawdopodobieństwo urodzenia dziecka w przeciągu roku na poziomie 0,1. (tj. współczynnik
płodności na 1000 kobiet w tej grupie wiekowej wynosi 100 promili). Zgodnie z tradycyjna
metodą prognozowania w demografii, którą możemy nazwać makrosymulacją, liczbę
urodzeń otrzymujemy poprzez odniesienie prawdopodobieństwa do liczebności kobiet w
danej grupie wiekowej: 0,10 x 100 tys. daje 10 tys. prognozowanych urodzeń.
W przypadku mikrosymulacji ta sama sytuacja wygląda następująco:
Losujemy z populacji próbę licząca np.: 1.000 kobiet, następnie przyjmujemy
założenie, że dla każdej kobiety w próbie prawdopodobieństwo wystąpienia zdarzenia
losowego (urodzenie dziecka) wynosi 0,1. Aby podjąć decyzję czy dana kobieta urodzi
dziecko, dla każde3j kobiety w próbie ciągniemy jedną liczbę rozkładu jednostajnego (0,1).
Jeżeli wartość ciągniona jest mniejsza od 0,1 uznaje się, że kobieta będzie miała dziecko. Tą
procedurę nazwano techniką Monte Carlo. Średnio, 1.000,- zdarzeń doje 100 sukcesów tj.
urodzeń. Jednakże w konkretnym zastosowaniu może być zarówno mniej jak i więcej niż 100
planowanych urodzeń. Następnie, liczba planowanych urodzeń w próbie jest przeliczana na
całą populację: 100 urodzeń w próbie 1000 elementowej daje 10 tys. urodzeń w populacji
liczącej 100 tys. jednostek.
A zatem, model mikrosymulacyjny wyróżnia to, że:
• model używa raczej próby niż całej populacji
• funkcjonuje raczej na poziomie danych jednostkowych niż zgrupowanych
• polega raczej na zdarzeniu losowym niż wartości przeciętnej
2. Porównanie metody makro i mikro symulacyjnej
Elementy wspólne mikro i makro symulacji:
• Obie symulacje oparte są na modelach, zdefiniowanych jako uproszczone, ilościowe
opisanie rzeczywistości. Modele są uproszczone w tym sensie, że nie wszystkie
zmienne oddziaływujące na strukturę ludności są uwzględnione w modelu (jest też

69
uproszczony w znaczeniu postaci funkcyjnej). Są też ilościowe, ponieważ ciąg liczb
wejściowych daje ciąg liczb wynikowych.
• Obie metody wymagają stosowania elementów zewnętrznych, dla których jest
wymagane sprecyzowanie hipotez co do ich przyszłej wartości. Takie elementy
zewnętrze w modelach prognostycznych pełnią rolę parametrów.
• Obie metody potrzebują jasno zdefiniowanego procesu, który będzie określał zmiany
wielkości zmiennych modelu.
• Oba modele są dynamiczne i zawierają w sobie element czasu.
• Są to dwie alternatywnymi metody służące do określania przyszłości.
Obie metody prezentują opis rzeczywistości („ liczba urodzeń jest zdeterminowana
liczbą kobiet i ich wiekiem umożliwiającym urodzenie dziecka”). Przyjmując hipotezy co
wartości parametrów w przyszłości („prawdopodobieństwo urodzenia dziecka będzie wynosił
0,10”), dwie metody dochodzą do tego samego przedstawienia przyszłości („ spodziewana
liczba urodzeń będzie wynosić 10 tys.). Oczywiście, nie oznacza to, że oba podejścia są
jednakowo właściwymi instrumentami we wszystkich możliwych sytuacjach. Jednakże,
pojęciowo te dwa podejścia mają istotną cechę wspólną bazującą na uproszczonym opisie
rzeczywistego świata. Samo pojęcie „symulacja” sugeruje metodę symulacyjną, czy to w
mikro czy w makro modelu, która to bazuje na pomyśle udawania procesów. Mimo że
model symulacyjny udaje rzeczywisty świat pozostaje tylko modelem i nie jest w zdolny
zastąpić rzeczywistości.
„To co robimy kiedy symulujemy nie jest podobne do działań w świecie, ale jest podobne do
pewnej grupy naszych własnych pomysłów dotyczących działań w świecie”1
Różnice występujące pomiędzy mikro i makro symulacją
1. Makrosymulacja nie zauważa losowego procesu w przeciwieństwie do
mikrosymulacji, która wyjaśnia go w procesie modelowania.
Zarówno mikro, jak i makro symulacja imituje procesy dynamiczne. Opisują one
zmiany systemu zdarzeń w czasie. Na poziomie populacji możemy mówić o średniej szansie
wystąpienia określonego typu zdarzenia, ale ta średnia zostaje oparta ostatecznie o
indywidualnie występujące zdarzenia. W takim razie zdarzenie jest zmienna losową i
1 Wachter K.W. (1987) „Microsimulation of household cycle”...

70
występuje z określonym prawdopodobieństwem. Kiedy robimy założenie co do przyszłej
liczby zdarzeń, faktycznie robimy założenie co do wartości oczekiwanej zmiennej losowej. W
ten sposób podejście mikro- i makro symulacji podlega Prawu Wielkich Liczb. Są jednak
pewne różnice. Makro model zakłada, że wielkość populacji 100.000,- kobiet jest tak duża, że
prognoza liczby zdarzeń (urodzeń) może być przyjęta jako równa wartości oczekiwanej (która
wynosi 10.000). Mikro model zakłada, że ilość elementów próby losowej (1000) jest na tyle
duża, że rezultaty prognozy w przybliżeniu równają się wartości oczekiwanej (100 w próbie;
10.000 po odniesieniu do poziomu populacji). Dopóki proces symulacji jest z natury losowy,
jakakolwiek prognoza przyszłości jest narażona na działanie zmienności losowej. Model
opisowy jest losowy, dlatego też odpowiedni model prognostyczny powinien, nie tylko
wyznaczyć wartość oczekiwaną ale określić również zróżnicowanie wokół wartości
oczekiwanej. W makrosymulacji losowa natura procesu jest zupełnie lekceważona.
Charakterystyki takie jak błąd standardowy mogą być liczone w makro modelach, ale w
praktyce są rzadko kiedy wyznaczane ze względu na potrzebę bardzo skomplikowanych
obliczeń.
Natomiast mikromodele ujmują losowa naturę procesu w formie powtarzanych
losowych eksperymentów (poprzez ciągnienie losowych liczb i na tej podstawie
podejmowanie decyzji czy dane zdarzenie powinno mieć miejsce). Tak przygotowana
prognoza podlega zmienności losowej. Efekty działania kilku modeli otrzymanych metodą
mikrosymulacji dostarczają różnych prognoz, dla których możemy dokładnie policzyć błąd
standardowy.
2. W mikro symulacji równania zachowań określające model opisowy powinny być
przystosowane do funkcjonowania na poziomie jednostki, natomiast w makro symulacji
funkcjonują na poziomie danych zagregowanych.
W makro symulacji, obliczenia wymagane podczas prognozowania są wykonane pod
kątem pól w zagregowanej tablicy klasyfikacyjnej; dla każdego pola tablicy model
prognostyczny powinien ocenić jak wartości w tym polu będą się zmieniać w czasie.
Mikrosymulacja natomiast przeprowadza obliczenia w kategoriach pojedynczych jednostek;
dla każdej jednostki wektor cech jest uaktualniany zgodnie z wymogami modelu i rezultatami
doświadczenia Monte Carlo.

71
Konsekwencją tego jest to, że:
3. Gromadzenie i przechowywanie danych w mikrosymulacji odbywa się w formie listy
jednostek z przypisanymi określonymi cechami, natomiast w makrosymulacji odbywa się
to w klasyfikacyjnej tablicy przekrojowej.
4. Makrosymulacja działa w warunkach populacji traktowanej jako całość, podczas gdy
mikrosymulacja funkcjonuje w warunkach próby. Byłoby bardzo niepraktyczne i
niewykonalne - nawet przy użyciu nowoczesnej technologii komputerowej - włączenie
informacji o każdej pojedynczej jednostce populacji. Model mikro symulacyjny zwykle
bierze pod uwagę relacje dużo większej liczby zmiennych niż macro model. Dane o
poszczególnych jednostkach, na których pracuje mikro model mogą być wprowadzone
bezpośrednio do bazy danych.
5. W mikro symulacji powiązanie pomiędzy danymi empirycznymi a parametrami modelu
jest bardzo ścisłe, podczas gdy w makro symulacji to połączenie nie jest tak silne.
6. Wadą makro modelu jest utrata pewnej ilości informacji. W przeciwieństwie do tego
mikrosymulacja stawia wysokie wymagania co do danych i podatna jest na wpływ
zakłóceń.
7. Ujednolicenie oprogramowania komputerowego jest dużo trudniejsze w przypadku
mikromodeli niż makromodeli. Istniejące komputerowe zastosowania mikrosymulacji są
prawie niemożliwe do zastosowania w innych realiach. Stąd też, makromodle są bardziej
dostępne z powodu dostępności doskonałego oprogramowania
3. Zastosowanie mikrosymulacji w prognozowaniu demograficznym.
Zalety mikrosymulacji:
1. Mikrosymulacja dobrze funkcjonuje w przestrzeni stanów o dużych rozmiarach
U podstaw każdego modelowania leży określenie przestrzeni stanów: reprezentacji
części składowych systemu oddziaływania. Na poziomie jednostek, przestrzeń stanów składa

72
się z charakterystyk lub cech, z których każda przyjmuje określoną wartość. Na poziomie
populacji przestrzeń stanów składa się, ze wszystkich możliwych kombinacji cechy. Jeżeli
mamy K cech w M wariantach dla każdej z cech i =1,...,K przestrzeń stanów w makro
modelach składa się z M1 x M2 x ... x MK pól. Macierz o takich rozmiarach jest potrzebna do
pełnego opisania populacji przez istotne cechy. Dla kontrastu, na poziomie mikro modelu
każda jednostka jest opisana przez wektor wartości cech długości K; cała populacja N
jednostek może być opisana przez macierz N x K pól.
Mikrosymulacja może funkcjonować w dużej przestrzeni stanów.
Jeżeli liczba cech jednostek włączonych do modelu i liczba wartości jakie te cechy mogą
osiągać staje się coraz większa, makromodel staje się nieporęczny: rozmiar przestrzeni
wzrasta w sposób wykładniczy wraz z cechami włączonymi do modelu.
Jako przykład, przedstawimy czysto demograficzny model dla Francji, w którym populacja
zastała określona przez:
płeć (mężczyźni, kobiety – 2 warianty)
parity (tylko kobiety: 0,....,5+, 6 wariantów)
obecny wiek (0,...,99+ 100 wariantów)
stan cywilny (panny i kawalerowie, żonaci i zamężne, wdowy i wdowcy, rozwiedzeni – 4
warianty)
okres trwania obecnego stanu cywilnego (0,....99+ - 100 wariantów)
region (96 regionów)
W makro modelu tablica zagregowana będzie składać się z
100x4x100x96 = 3.304.000 pól dla mężczyzn i
6x100x4x100x100x96 = 2.304.000.000- pól dla kobiet
W mikro modelu każda jednostka jest zapisana za pomocą 7 wartości. Nawet jeżeli
cała ludność Francji jest ujęta w próbie tablica dla makro modelu będzie i tak pięciokrotnie
większa niż lista mikro modelu. Dla mniejszych prób i dla większej liczby cech stosunek
rozmiarów tablicy do listy może łatwo stać się astronomiczny. Z punktu widzenia
przechowywania i uaktualniania danych, mikrosymulacja jest bez wątpienia bardziej wydajna
niż makrosymulacja.
Niezależność między zmiennymi ma znaczący wpływ na rozmiar przestrzeni stanów
Należy zastrzec, że jeżeli wszystkie cechy wzajemnie na siebie oddziaływają tj.
występuje pełna zależność pomiędzy zmiennymi w modelu, wtedy mikro symulacja

73
potrzebuje tak samo dużej liczby parametrów jak makrosymulacja. Dla przykładu, jeżeli w
przytoczonym przypadku wszystkie cechy mają równocześnie wpływ na współczynnik
płodności, model mikro symulacyjny wciąż wymaga 2.304.000.000 parametrów danych
wejściowych dla samej płodności. Tak więc w przypadku pełnego wzajemnego
oddziaływania, przechowywanie danych jest efektywniejsze w podejściu mikro ale wymogi
co do danych są równie duże. Jeżeli tylko możemy założyć kilka rodzajów zależności
pomiędzy cechami (np.: różnica pomiędzy zamężnymi i wolnymi kobietami jest taka sama
we wszystkich rejonach), liczba parametrów w tablicy jest znacznie zmniejszona. Musimy po
prostu założyć wysoki poziom niezależności, w przeciwnym razie w żaden sposób nie
będziemy w stanie szacować parametrów modelu i rezultaty prognozy mogły by być niczym
innym jak wynikiem czystego przypadku. Jednakże wraz z wprowadzeniem niezależności,
rozmiary tablicy maleją również w makro modelach. W powyższym przykładzie przy
założeniu całkowitej niezależności wszystkich cech, wektor wystarczający dla makro modelu
wymaga:
100+4+100+96 = 300 pól dla mężczyzn i 6+100+4+100+96=406 pól dla kobiet. Oczywiście,
w praktyce sytuacja znajduje się pomiędzy dwoma ekstremami – pełną zależnością i pełną
niezależnością.
2. Mikromodel może w znacznym stopniu uwzględnić wzajemne oddziaływanie między
zmiennymi
W mikro modelach możemy łatwiej ustalić zależności i wzajemne oddziaływanie
zmiennych ze względu na dostępność większej ilości danych o poszczególnych jednostkach.
3. Mikrosymulacja jest elastyczna w określeniu wzajemnego oddziaływania między
jednostkami
Mikrosymulacja jest bardziej elastyczna w definiowaniu wzajemnych oddziaływaniem
pomiędzy jednostkami. Szczególnie w modelach demograficznych wiele zdarzeń dotyczy
kilku osób. Na przykład: małżeństwa, rozwody, wdowieństwo, opuszczanie domu rodziców,
migracje całych gospodarstw domowych, itp. W makromodelach, gdzie w wyniku
sumowania, powiązania pomiędzy jednostkami zostały utracone, takie zdarzenia są
szczególnie problematyczne. W kontekście zawierania i rozpadu związków małżeńskich

74
trudności są znane jako problem dwóch płci, co jest specyficzną częścią bardziej ogólnego
problemu wewnętrznej zgodności. W makro modelach stosuje się procedury pomagające
spełnić zgodności w odniesieniu do rezultatów prognoz (np.: wymuszenie równej liczby
mężczyzn i kobiet zawierających związki małżeńskie). W przeciwieństwie do tego, w mikro
modelach łatwe jest utrzymywanie powiązań pomiędzy jednostkami, wprost poprzez
włączenie do bazy danych zapisu pewnych wskaźników odniesienia do innych osób w bazie
danych. W wyniku tego, konsekwencja zdarzenia planowanego dla jednej osoby może być
łatwo określona i uaktualniona dla innej powiązanej osoby.
4. Mikrosymulacja może uwzględniać zmienne o charakterze ciągłym w sposób poprawny.
Mikrosymulacja może uwzględniać zmienne o ciągłym charakterze. W modelach
demograficznych, zmienne takie jak dochody, czas godzin pracy mogą być całkiem istotnie
skorelowane z zachowaniami demograficznymi. W makro modelach, zmienne ciągle jeżeli są
traktowane właściwie wywołują tak olbrzymie problemy, że modelowanie jest praktycznie
niewykonalne. W mikromodelach, zmienne ciągłe nie wywołują żadnych szczególnych
problemów, które są zasadniczo rożne od tych kojarzonych ze zmiennymi dyskretnymi.
5. Zakres otrzymanych wyników przez mikrosymulację jest bogaty.
Wyniki modelu mikrsymulacyjnego niosą ze sobą dużo większą ilość informacji,
ponieważ składają się z bazy danych z danymi o poszczególnych jednostkach, które mogą być
agregowane w prawie nieskończona liczbę sposobów. W przeciwieństwie do sytuacji w
makromodelach, gdzie sposób agregacji jest raz ustalony na etapie definiowania modelu.
Poza zestawieniem przekrojowym, baza danych mikrosymualcji może być użyta do
konstruowania informacji wzdłużnych np.: w formie jednostkowych biografii.
4. Zastosowanie mikrosymulacji w prognozowaniu demograficznym
Mikrosymulacja jest szczególnie wygodna w wypadku, gdy zmienne ciągłe mają duże
znaczenie lub gdy problem wymaga dużej przestrzeni stanów. Jednakże, jeżeli przestrzeń jest
duża, to stopień niezależności pomiędzy zmiennymi powiązanymi powinien być duży.
Mikrosymulacja jest szczególnie przydatna w przypadku kiedy efekty badanego procesu są
złożone, ale siły kształtujące proces są proste.

75
W standardowym czynnikowym modelu w którym populacja jest określona przez wiek i płeć,
i w którym płodność i umieralność, migracje zewnętrze są funkcją tylko wieku i płci,
zastosowanie mikrosymulacji nie wnosi nic nowego. Przestrzeń modelu jest zbyt mała aby
inwestycja w mikro symulację przyniosła oczekiwane efekty.
Jeżeli model prognostyczny ludności zawierał by zmienne ciągłe to mikrosymylacja była by
jedynym możliwym do zastosowania w praktyce rozwiązaniem.Istnieje wiele modeli
mikrosymulacyjnych, w których zachowania demograficzne są przedstawiane jako funkcje
zarówno ciągłych i dyskretnych zmiennych, ale we wszystkich tych modelach prognoza
ludność jest produktem ubocznym bardziej pełnego modelu. (modele społeczno-
ekonomiczne)
W takich pełnych modelach, decyzja o zastosowaniu mikrosymulacji jest silnie
motywowane przez występowanie poza demograficznych zmiennych modelu (np.: dochody,
opieka socjalna, popyt konsumencki).
Dla prognoz ludnościowych gdzie występuje duża przestrzeń, mikrosymulacja jest
dobrym rozwiązaniem. Rozmiar przestrzeni w prognozach ludnościowych jest ustalany przez
dwa czynniki: poprzez liczbę cech populacji o których posiadamy informacje oraz liczbę
zmiennych pozademograficznych, które uważamy za istotnie powiązane z zachowaniami
demograficznymi.
Mikrosymulacja może być zastosowana w demografii do modelowania wzorca
pokrewieństwa. Modele pokrewieństwa kształtowane są przez płodność (dla relacji rodzice-
dzieci), łączenie się w pary i rozpad związków (dla małżonków i relacji rodzinnych),
umieralność (która determinuje czy określony krewny jest obecnie ciągle żywy).
5. Losowość w mikrosymulacji
Źródła losowości.
5.1 Losowość wewnętrzna (związana z metodą Monte Carlo).
Mikrosymulacja jest źródłem losowości sama w sobie. Ten rodzaj losowości
nazwiemy losowością wewnętrzną. Z powodu zastosowania Metody Monte Carlo w
konwencjonalnej mikrosymulacji, rezultaty prognozy mikrosymulacyjnej są podobne w

76
działaniu do zmiennej losowej: jeden model daje pewne wyniki, natomiast inny daje wyniki
różne od poprzedniego.
Możemy zmniejszyć, lecz nie zlikwidować ten rodzaj losowości poprzez:
• Zwiększenie bazy danych (liczba jednostek)
• Zastosowanie średnich wyników z kilku modeli
• Zastosowania metody sortowania (połączenie cech mikro i makro modelu)
5.2 Losowość populacji początkowej (próby)
Populacja wyjściowa używana w mikrosymulacji jest próbą wylosowaną z populacji
generalnej i dlatego też podlega działaniu czynnika losowego - rozkład zmiennych w bazie
danych początkowych jest losowy. Możemy zmniejszyć, lecz nie zlikwidować ten rodzaj
losowości poprzez zwiększenie bazy danych (liczby jednostek)
5.3 Losowość sformułowania modelu (zakłócenia modelu).
Błąd wynikający z niedostatecznego sprecyzowania modelu sprawia, że wyniki
prognozy mogą być obciążone. Zwiększenie ilości cech i parametrów nie powoduje
zwiększenia obciążenia, lecz powoduje zwiększenie zmienności wokół wartości oczekiwanej.
Są dwa źródła losowości sformułowania modelu:
Każde powiązanie pomiędzy zmiennymi objaśniającymi i parametrami wejściowymi
jest estymowane na podstawie danych empirycznych. Każde przybliżenie danych
empirycznych jest obciążone błędem pomiaru, zwykle wyrażonym jako błąd standardowy
estymacji.
Model mikrosymualacyjny generuje swoje własne zmienne objaśniające. Każda
dodatkowa cecha objaśniająca wymaga zastosowania eksperymentu Monte Carlo z
towarzyszącym jemu wzroście losowości Monte Carlo. Wraz ze wzrostem złożoności
modelu, moc przewidywania modelu maleje.

77
Zmniejszenie zmienności a zgodność zewnętrzna.
Metody zmniejszające zmienność wyników mikrosymulacji łączą własności
mikrosymulacji z makrosymulacją Podejście makro liczy ogólną liczbę zdarzeń jak i ich
wartość oczekiwaną, natomiast podejście mikro (używające eksperymentu Monte Carlo)
przypisuje tą liczbę zdarzeń do pojedynczych zapisów jednostkowych.
W omawianym przykładzie, było tysiąc dwudziestopięcioletnich kobiet każda z
prawdopodobieństwem 0,1 urodzenia dziecka w przeciągu jednego roku. Makro model
policzyłby ogólną liczbę urodzeń jako wartość oczekiwana: 1000 x 0,1 = 100. Tradycyjny
mikromodel przedstawiłby tysiąc eksperymentów Monte Carlo dających losową ogólną liczbę
urodzeń z wartością oczekiwaną 100 i błędem standardowym 9,5. Połączenie podejścia mikro
i makro narzuciło 100 makro liczb jako ogólną liczbę mikro zdarzeń. Dla każdej kobiety
eksperyment Monte Carlo został wykonany, aby określić czy jest ona jedną z tych stu. Jeżeli
makro liczba 100 jest traktowana jako stała, wariancja ogólnej liczby urodzeń w tym ostatnim
modelu wynosi zero. W metodzie tradycyjnej prawdopodobieństwo określające urodzenie
dziecka przez kobietę jest niezależne od urodzenia dziecka przez inne kobiety. W
alternatywnej metodzie większa liczba urodzeń u innych kobiet zmniejsza
prawdopodobieństwo urodzenia dziecka u określonej kobiety. Przykład ten odnosi się do
jednolitej grupy, gdzie wszystkie tysiąc kobiet jest identycznych jeżeli chodzi o ich płodność.
W praktyce, płodność będzie zależeć nie tylko od wieku ale od zmiennych takich jak stan
cywilny itd. W takiej sytuacji mamy tysiąc kobiet ze zróżnicowanym prawdopodobieństwem
urodzenia dziecka. Jeżeli ciągle chcemy uzyskać ogólną liczbę urodzeń 100 musielibyśmy
wybrać sto kobiet proporcjonalnie do ich współczynnika płodności (wyciągnąć jedną liczbę
losową dla każdej z kobiet i wybrać sto kobiet, dla których wynik losowania i ich
współczynnik płodności jest największy). Zmienność ogólnej liczby urodzeń jest wciąż równa
zero. Jednakże zmienność liczby urodzeń w podgrupach ( np. niezamężne kobiety, zamężne z
dwójką dzieci) jest w dalszym ciągu dodatnia. Aby zmniejszyć zmienność populację 1000
kobiet powinniśmy podzielić na mniejsze, bardziej jednorodne podgrupy a obliczenia
powinny się odnosić do każdej z grup osobno. Jeśli jednak podgrupy staną się zbyt małe
metoda przestaje być skuteczna ze względu na dyskretną naturę zdarzeń (w podgrupach
ogólna liczba urodzeń musi być liczbą całkowitą). Zatem każda podgrupa musi być tak
jednorodna jak to tylko możliwe, ale nie może być mniejsza od pewnej krytycznej wartości.
Budowa takich podgrup jest istotą metody sortowania.

78
Przykładem tej sytuacji niech będzie model mikrosymulacyjny dla płodności
względem stanu cywilnego i sytuacji na rynku pracy, dzięki któremu chcemy uzyskać dane na
temat ogólnej liczby urodzeń zgodnych z oficjalną prognozą ludności. W takim wypadku
liczba 100 pochodzi z zewnątrz, ale chcemy użyć jej jako ograniczenia dla mikromodelu.
Taka metoda zmniejszenia wariancji może skutecznie narzucać zewnętrzną zgodność.
6. Inne właściwości charakterystyczne dla mikrosymulacji demograficznej
6.1 Modele otwarte i zamknięte
Modelem zamkniętym nazywać będziemy model, w którym nowe jednostki powstają
tylko poprzez narodziny, zatem ich historia jest w pełni wyjaśniona przez model.
Model otwarty to model, w którym nowa jednostka jest tworzona w inny sposób niż
narodziny dziecka.
Występują dwa rodzaje wypadków kiedy nowe jednostki mogą powstać w inny
sposób niż narodziny. Pierwszy odnosi się do migracji zewnętrznych, drugi – do ustanowienia
powiązań między jednostkami. Jeżeli ktoś emigruje tj. opuszcza populację badania w inny
sposób niż poprzez śmierć, to taka osoba po prostu przestaje być związana z populacją
badania, a indywidualny zapis zawierający wszystkie cechy jest usuwany z bazy danych.
Odwrotnie dzieje się w przypadku imigracji, której zaistnienie sprawia, że nowy zapis o
jednostce powinien być dodany do bazy danych. Ze względu na to, że imigrant nie był
wcześniej w bazie danych, nie jest jasne jakie wartości dla różnych cech powinien zawierać
nowy zapis jednostkowy. Zatem nowa jednostka jest tworzona ex nihilo i pewne procedury
określenia jednostkowych cech demograficznych i innych istotnych zmiennych muszą być
uruchomione. W wielu mikrosymulacyjnych modelach demograficznych związki pomiędzy
poszczególnymi jednostkami odgrywają ważną rolę. Osiąga się to przez włączanie
określonych oznaczeń w jednostkowych zapisach danych tj. odniesienie do numerów
identyfikacyjnych innych zapisów jednostkowych. W przypadku urodzeń, numer
identyfikacyjny dziecka może być dodany do zapisu jednostkowego matki i numer
identyfikacyjny matki może być dodany do zapisu jednostkowego dziecka. W dodatku, jeżeli
zapis jednostkowy matki zawiera odniesienie do zapisu jednostkowego męża, powiązanie
pomiędzy ojcem i dzieckiem może być również ustanowione. Jednakże ustalenie takich
powiązań pomiędzy jednostkami nie zawsze jest łatwe. Na przykład dotyczy to kobiety w

79
próbie, co do której eksperyment Monte Carlo określił, że potencjalnie może ona zawrzeć
małżeństwo. W tej sytuacji połączenie musi być ustanowione z zapisem jednostkowym
mężczyzny. Jeżeli model jest modelem zamkniętym mąż powinien być istniejącym zapisem
jednostkowym w bazie danych. Odpowiedni zapis jednostkowy powinien zostać wówczas
określony. Z drugiej strony jest również możliwe stworzenie „nowego męża” ex nihilo
podobnie jak w przypadku imigranta.
Model otwarty jest łatwiejszy do stworzenia niż model zamknięty, w którym nie ma
potrzeby dopasowywania jednostek. Jednakże są dwa główne problemy z otwartą populacją:
• określenie historii charakterystyk nowo utworzonej jednostki jest bardzo trudne
• niezgodność pojawiająca się pomiędzy jednostkami „rdzennymi”, których obecna
sytuacja jest całkowicie określona przez dynamiczny model, a jednostkami których
stan jest określony przez statyczne procedury.
6.2 Modele ciągłe i dyskretne.
W teorii zdarzenia pojawiają się w ciągłym czasie. Mogą być one modelowane przez
określenie losowego czasu oczekiwania (dając stan obecny) aż do pojawienia się zdarzenia
opisanego odpowiednią funkcją rozkładu. Jeżeli jest kilka możliwych zdarzeń, jeden czas
oczekiwania jest przypisany każdemu z nich i zdarzenie z najkrótszym czasem oczekiwania
jest wtedy symulowane. Procedura jest powtarzana aż do pojawienia się zdarzenia „śmierć”.
Dla każdego momentu ciągłego czasu, stan jednostek może być określony z ich sekwencji
zdarzeń.
Z drugiej strony, w ramach dyskretnego czasu stan każdej jednostki jest modelowany
tylko dla dyskretnych punktów czasu. Pozwala to istotnie uprościć model. Natomiast z drugiej
strony muszą być wzięte pod uwagę możliwości wielu różnych zdarzeń w danym okresie
czasu. Upraszczając, modelowanie procesu w dyskretnym czasie równa się modelowaniu
zmian w stanie indywidualnych mikrojednostek pomiędzy następującymi po sobie punktami
czasu.
Modele ciągłe mają dwie zalety: są one obliczeniowo bardziej efektywne i są one
lepiej przygotowane do przedstawienia „ryzyk konkurencyjnych”. W modelach zamkniętych
dopasowywanie jednostek pomiędzy tymi, u których powinny być ustanowione powiązania,
jest pojęciowo skomplikowane oraz wymogi co do danych są olbrzymie w porównaniu do
tych z modelu dyskretnego. Z tych powodów większość istniejących modeli
mikrosymulacyjnych jest określonych w czasie dyskretnym.

80
6.3 Ryzyko konkurencyjne i zdarzenia złożone
Ryzyko konkurencyjne odnosi się nie tylko do ustalenia czasu wystąpienia
określonego zdarzenia ale do określenia, które zdarzenie będzie wynikiem procesu spośród
zdarzeń wykluczających się. Na przykład kobieta niezamężna jest narażona zarówno na
ryzyko małżeństwa jak i na ryzyko śmierci. Jednakże, jeżeli kobieta umrze małżeństwo
będzie niemożliwe do zrealizowania. Ryzyko konkurencyjne może być użyte również do
określenia powiązania pomiędzy dwoma procesami, które się nie wykluczają. Na przykład:
kobita niezamężna jest narażona na ryzyko małżeństwa jak i na ryzyko urodzenia dziecka.
Kiedy wyjdzie za mąż ryzyko urodzenia dziecka wzrasta. Ryzyko konkurencyjne jest łatwe
do uchwycenia w modelach ciągłych gdzie zdarzenie o najkrótszym czasie oczekiwania
realizuje się jako pierwsze. Jednak większość modeli mikrosymulacujnych jest określonych w
ramach czasu dyskretnego, gdzie występuje problem zdarzeń złożonych tj. pojawianie się
kilku zdarzeń w jednym odcinku czasu. W przypadku zdarzeń złożonych kolejność
pojawiania się zdarzeń elementarnych nie jest bez znaczenia. Na przykład: w tym samym
odcinku czasu kobieta jest symulowana do urodzenia dziecka i śmierci. Zatem o narodzinach
jej dziecka zdecyduje to, które ze zdarzeń pojawi się jako pierwsze.
W modelach dyskretnych z definicji nie jest znany moment zdarzenia w danym
odcinku czasu. Możemy to rozwiązać następująco:
• Zastosowanie ustalonego porządku zdarzeń np.: umieralność przed płodnością
• Ustalenie losowego porządku zdarzeń. Zdarzenie z największym
prawdopodobieństwem powinno mieć największe szanse zaistnienia jako pierwsze.
• Metoda dwuetapowa:
o wyznaczenie prawdopodobieństwa wszystkich zdarzeń złożonych.
o dzięki użyciu metody Monte Carlo określenie, które zdarzenie zaistnieje.
6.4 Zdarzenia powiązane z kilkoma jednostkami
Zdarzeniami powiązanymi z klilkoma jednostkami będziemy nazywali zdarzenia,
których konsekwencje dotyczą więcej niż jednej jednostki. Zdarzenia są bezpośrednio
związane z problemem zgodności (np. zdarzenie złożone małżeństwo, ilość zamężnych kobiet
musi się równać liczbie żonatych mężczyzn). W mikro symulacji konsekwencja jednego

81
zdarzenia może być łatwo wprowadzona do wszystkich jednostek powiązanych. Na przykład,
jeżeli kobieta jest wybrana do „rozwodu” jej stan cywilny jest zmieniony i stan jej (już
byłego) męża również.
Jeżeli chodzi o rozwiązanie powiązań (rozwód) mamy cztery rodzaje możliwych rozwiązań:
• Kobieta dominująca – zdarzenie „rozwód” jest symulowane dla kobiety na podstawie
prawdopodobieństwa rozwodu.
• Mężczyzna dominujący - zdarzenie „rozwód” jest symulowane dla mężczyzny.
• Na podstawie małżeństwa – jest jedno równanie określające prawdopodobieństwo
rozwodu, które zawiera dane obu małżonków (np.: wiek, czas trwania małżeństwa...).
symulując zdarzenie bierzemy pod uwagę zarówno kobietę, jak i mężczyznę
(rozwiązanie to zwiększa losowość i prowadzi do dużych wymagań co do danych).
• Oparty na jednostce - są dwa równania prawdopodobieństwa jedno dla mężczyzn i
jedno dla kobiet. Zdarzenie „rozwód” jest symulowane dwukrotnie: jeden raz biorąc
pod uwagę kobiety, drugi raz mężczyzn. Każde małżeństwo jest dwukrotnie narażone
na rozwód, z tego powodu tylko część prawdopodobieństw rozwodów danej płci może
być brana pod uwagę (zwykle jest to 50%).
Bardzo dobrze możemy obserwować powiązania na przykładzie małżeństw. Jeżeli
jednostka jest symulowana do małżeństwa należy znaleźć dla niej partnera. Jednym ze
sposobów jest stworzenie partnera ”ex nihilo” (model otwarty). W modelach zamkniętych
decyzja podejmowana jest podobnie jak przy rozwodach, a małżonka musimy dopasować,
korzystająć z jednego ze sposobów:
• Kobieta dominuje – małżeństwo planowane jest dla kobiety. Pożądane dane małżonka
są określone (np.: wylosowane z odpowiednich rozkładów) i poszukuje się następnie
pasującego partnera. Jeżeli nie znaleziono partnera również symulacja małżeństwa nie
dochodzi do skutku, lub poszukiwanie jest kontynuowane (złagodzenie oczekiwań).
• Mężczyzna dominuje – jak wyżej tylko odwrotnie.
• Wyczerpujące dopasowywanie: małżeństwa są symulowane dla mężczyzn i kobiet
oddzielnie. Wszystkie jednostki, dla których podjęto decyzję o małżeństwie są
dopasowywane z godnie z określonym algorytmem. Jednostki bez pary rezygnują z
planów małżeńskich.
• Oparty na jednostce - małżeństwa są symulowane dla mężczyzn i kobiet oddzielnie,
używając zmniejszonych o połowę prawdopodobieństw małżeństwa. Jednostka, która

82
przeszła przez te próbę jest dopasowywana do partnera, który nie przeszedł tego
egzaminu.
7. Przegląd istniejących demograficznych modeli mikrosymulacyjnych
Lata 50-te możemy uznać za okres pojawienia się mikrosymulacji. Osobą uważaną za
ojca mikrosymulacji jest Orcutt. Początkowo została ona stworzona jako narzędzie służące do
badań polityki społecznej. Następnie została rozwinięta przez wiele dyscyplin m in. przez
demografię.
Modele czysto demograficzne:
1964 – Hyrenius i Adolffson – symulacyjny model reprodukcji
1967 – Hyrenius – ogólny mikrosymulacyjny model demograficzny
1968 – Holmberg – opublikowanie rezultatów poprzedniego modelu
1966 – Ridley i Sheps – model REPSIM – badanie względnej ważności czynników
biologicznych i demograficznych
1967 – Jacquard i 1969 Barret – symulacyjny model płodności
1972 – ostatnia wersja REPSIM – uwzględniał kontrolę urodzeń przez kobietę
1971 – Horvitz – dynamiczny model Mikrosymulacyjny POPSIM – symulował główne
procesy demograficzne
1973 – Rao POPSIM został zastosowany do analizy alternatywnych metod planowania
rodziny i polityki
1976 – Hammel – SOCSIM – symulował procesy demograficzne związane ze strukturą
gospodarstw domowych
1978 – Wachter – zastosował model SOCSIM do modelowania składu gospodarstw
domowych angielskiej wioski okresu przed rewolucją przemysłową
1993 - Smith i Oeppen– model CASIM – symulacja grup pokrewieństwa i liczby
pokrewieństw podczas różnych etapów cyklu życia.
Modele społeczno – ekonomiczne:
1967-1975 (Orcutt 1976) DYNASIM – symulowanie szerokiego zakresu demograficznego i
społeczno-ekonomicznego i interakcji z polityką rządową
1986 - Wertheimer II - DYNASIM II – analiza zmian w polityce emerytalnej.

83
1974 – Hecheltjen – model Frankfuncki
1980 – Stager – włączył mobilność gospodarstw domowych do modelu Frankfurckiego
1990 – Galler – wytwarzanie więzów pokrewieństwa w modelu Frankfurckim
1988 – Heike - Darmstadt DPMS Model – z zakresu dziedzin: demografii, społeczno-
ekonomicznej i ekonomicznej.
1987 – Csicsman i Pappne – dynamiczny model mikrosymulacujny dla Węgier bazujący na
DPMS
1993 – Nelissen – NEDYMAS – dotyczył spraw związanych z bezpieczeństwem socjalnym
1995 – Brunborg i Keilman – norweski model MOSART- cel analiza ścieżki życia jednostki z
uwzględnieniem: edukacji, małżeństw, urodzeń, udziału w rynku pracy i opieki socjalnej w
Norwegii.
Przegląd wybranych istniejących dynamicznych modeli mikrosymulacyjnych:
Modele: DYNASIM, Frankfurcki, DPMS, NEDYMAS i MOSART są modelami
mikrosymulacyjnymi jednego typu: dynamiczne, przekrojowe, o dyskretnym czasie, ze
zmiennymi zarówno demograficznymi jak i społeczno - ekonomicznymi. Ze względu na
dobrze rozwinięty moduł demograficzny wszystkie wymienione modele są przydatne w
prognozach demograficznych. Tylko DPMS i MOSART mają w pełni samowystarczalny
moduł demograficzny. W modelu NEDYMAS zmienne pozademograficzne mają niewielki
wpływ (poprzez wykształcenie) na zachowania demograficzne. Podobnie sytuacja wygląda w
modelu Frankfurckim, gdzie przedstawiono wpływ „historii zdarzeń” na procesy
industrializacji. W model DYNASIM jest wiele interakcji pomiędzy zmiennymi
demograficznymi i pozademograficznymi i dlatego, jako konsekwencja model ten ma
znaczny zakres zmienności losowej.
Kiedy oceniamy plusy i minusy wybranych modeli musimy pamiętać do jakich celów
zostały pierwotnie stworzone . DYNASIM, DPMS i NEDYMAS nie są w pierwszym rzędzie
modelami demograficznymi. Z powodu silnego powiązania pomiędzy danymi a modelem
mikrosymulacyjnym, szczegółowe porównanie nie wnoszą nic istotnego.

84
DYNASIM Frankfurcki DPMS NEDYMAS MOSART Kraj USA Niemcy Niemcy Holandia Norwegia Główne źródło danych
Próba ze spisu ludności
Mikro spis ludności – próba wybrana do badań ciągłych budżetów
Badanie budżetów domowych
Spis ludności 1947 , rejestr ludności, badanie ankietowe
Próba spisowa Rejestry ludności
Porządek zdarzeń Stały Stały Losowy Stały Dwu-etapowy Samodzielny moduł demograficzny
Nie Prawie Tak Prawie Tak
Płodność Wiek, stan cywilny, parity, wykształcenie
Wiek, stan cywilny, parity, czas trwania małżeństwa
Wiek, pozycja godsp. domowego, parity
Wiek, stan cywilny, parity
Wiek, pozycja gospodarstwa domowego
Umieralność Wiek, płeć, stan cywilny, rasa, wykształcenie, parity
Wiek, płeć, Wiek, płeć, pozycja gospodarstwa domowego
Wiek, płeć, stan cywilny, institution
Wiek, płeć, pozycja gospodarstwa domowego
Opuszczanie domu
Wiek, płeć, rasa Wiek, płeć stan cywilny, dzieci, zawód
Wiek, płeć Wiek, płeć, wykształcenie
Wiek, płeć, pozycja gospodarstwa domowego
Małżeńskość Wiek, płeć, stan cywilny, rasa, wykształcenie, ekon
Wiek, płeć, stan cywilny, narodowość
Wiek, płeć, stan cywilny
Wiek , płeć, stan cywilny, institution
Wiek, płeć, pozycja gospodarstwa domowego
Dopasowanie Wyczerpujące wg. wieku, rasy
Kobieta dominująca wiek, stan cywilny
Kobieta dominująca wiek, stan cywilny
Kobieta dominująca wiek, stan cywilny
Wyczerpujące wg. wieku
Rozwody Na podstawie małżeństwa czas trwania , wiek małżeństwa, wykształcenie, rasa
Na podstawie małżeństwa Czas trwania małżeństwa, dzieci,
Na podstawie małżeństwa Czas trwania małżeństwa,
Kobieta dominująca Wiek, poprzedni stan cywilny, institution
Oparty na jednostce, wiek, pozycja gospodarstwa domowego
Migracje zewnętrzne
Scaling* _ _ Otwarty Wiek, płeć, skład gospodarstwa domowego
Otwarty Wiek, płeć, skład gospodarstwa domowego
Migracje wewnętrzne
Wiek, płeć, stan cywilny, rasa, region
_ _ _ _
Związki pozamałżeńskie
? Wiek, płeć, stan cywilny, zawód, dzieci
Wiek, płeć, Wiek, płeć, stan cywilny
Wiek, płeć, pozycja gospodarstwa domowego
* - w modelu DYNASIM migracje zewnętrze są brane pod uwagę przy użyciu wskaźnika łączącego dane mikro i makro (od skali mikro do skali całej populacji)

85
8. Omówienie modelu KIMSIM
cel modelu
Model powstał w celu zbadanie rozmiaru i struktury przyszłej sieci pokrewieństwa,
aby można określić dostępności wsparcia dla osób w podeszłym wieku w populacjach
starzejących się demograficznie.
Zakres zainteresowań:
• nie chcemy poznać tylko średnich, ale również rozkłady ( np.: ilość osób w podeszłym
wieku mających nieżyjące dzieci – rozkład tej liczby – ilu ma 1,2 ...)
• chcemy poznać różne typy relacji (np.: rodzeństwo, kuzyni, wnuki, partnerzy ...)
Proces kształtujący model jest prosty oparty tylko na kilku zdarzeniach: tworzenie
związków, rozpad związków, płodność i umieralność. Populacją początkową jest próbą ze
spisu ludności w 1947 r. i liczy 10 tys. jednostek. Zdarzenia demograficzne były w latach
1947 – 1994 symulowane zgodnie z zaobserwowanymi współczynnikami demograficznymi, a
od 1994 zgodnie z hipotetyczną wartością współczynników demograficznych.
Ogólna charakterystyka modelu
KINSIM jest dynamicznym modelem mikrosymulacyjnym o dyskretnym czasie.
Jednostką czasu jest jeden rok. Jest modelem zamknietym. Partnerzy w związkach są
dobierani przez proces dopasowywania.
Każda jednostka w bazie danych posiada następujące cechy:
• numer identyfikacyjny
• płeć
• rok urodzenia
• rok zgonu
• dla każdego związku:
o numer identyfikacyjny partnera
o rodzaj związku (formalny, nieformalny)
o rok utworzenia związku
o rok rozpadu związku
o powód rozpadu związku (śmierć partnera rozwód separacja

86
• numer identyfikacyjny dzieci
• numer identyfikacyjny rodziców
W populacji startowej w roku 1947 wiele z tych cech było niedostępnych, jednak wraz
z rozwojem modelu w czasie zdobywano coraz więcej informacji o cechach. Tak, że w 1994
roku można było otrzymać prawie kompletną bazę danych (obraz wzorca pokrewieństwa).
Dla każdej jednostki zdarzenia demograficzne symulowane są w stałej kolejności, w związku
z tym pewne zdarzenia nie mogą wystąpić w przeciągu jednego roku . Na przykład rozwody
są symulowane przed małżeństwami – nie może zaistnieć małżeństwo po rozwodzie w tym
samym roku. Jest tylko jeden wyjątek, jako jedyne może wystąpić zdarzenie złożone
polegające na zmianie stanu cywilnego i urodzeniu dziecka.
określenie modelu i szacowanie parametrów
Model KINSIM uwzględnia następujące zdarzenia demograficzne:
• Umieralność – na początku każdego roku , dla każdej jednostki jest przeprowadzany
eksperyment Monte Carlo, który decyduje czy dana jednostka umrze (ciągnione są
liczby losowe z przedziału (0,1) jeżeli liczba jest mniejsza niż jednostkowe
prawdopodobieństwo zgonu jednostka jest symulowana do śmierci). Jeżeli śmierć
pojawi się u osoby w związku, stan cywilny partnera jest zmieniany.
Prawdopodobieństwo zgonu zależy od wieku i płci.
• Płodność- metoda Monte Carlo decyduje czy kobieta urodzi dziecko, a następnie
decyduje o płci dziecka. Rok urodzenia dziecka jest rokiem dla którego
przeprowadzono symulacje, a stan cywilny – kawaler, panna. Kobieta staje się matką
dziecka, a jeżeli jest w związku jej partner staje się ojcem dziecka. Płodność jest
modelowana według stanu cywilnego, wieku i parity.
• Tworzenie związków – dla jednostek nie będących w żadnym związku małżeństwa i
związki pozamałżeńskie są symulowane jako dwa wykluczające się zdarzenia.
Nowy związek powstaje w dwóch etapach:
1. Wszystkie jednostki nie będące w żadnym związku klasyfikowane są w trzy
kategorie:
• Szukające aktywnie partnera do małżeństwa
• Szukające aktywnie partnera do związku poza małżeńskiego
• Wszystkie pozostałe mające prawo być w związku

87
2. Wszystkie jednostki aktywne są dopasowywane do nieaktywnych. Jednostki mogą
wejść w związek na dwa sposoby: wybrać partnera – jednostki aktywne, lub zostać
wybrane jednostki bierne. Brane jest pod uwagę 50% prawdopodobieństwa
zawarcia związku.
Prawdopodobieństwo zawarcia związku małżeńskiego zależy od: płci, wieku i
poprzedniego stanu cywilnego.
Procedura dopasowywania partnera bierze pod uwagę tylko wiek partnera. W tym celu
utworzono tablicę preferencji wiekowych partnera na postawie stosownych statystyk.. Ze
wszystkich wybranych kandydatów spełniających kryterium wieku losowany jest jeden.
• Rozwody – każda jednostka w związku małżeńskim ma pewne prawdopodobieństwo
rozwodu determinowane przez wiek i płeć. Jeżeli eksperyment Monte Carlo zdecyduje
o rozwodzie dla danej jednostki zarówno jednostka jak i jej partner osiągają nowy stan
cywilny „rozwiedzeni”
scenariusz modelu
Wszystkie parametry wejściowe są estymowane dla każdego roku w okresie 1947-
1994. W latach 1994 i dalszych (okres właściwej prognozy) zostały przyjęte założenia co do
prawdopodobieństw zdarzeń demograficznych. Hipotezy są następnie przetworzone dla
potrzeb modelu mikrosymulacyjnego.
wzorzec pokrewieństwa pomiędzy latami 1990 i 2050
Celem modelu jest ustalenie pokrewieństwa jako na wsparcie osób starszych. Zatem
skoncentrujemy się na grupach wiekowych 60-80 lat i 85 lat i więcej. Skupiając się na
starszych osobach możemy stwierdzić, iż wujek/ciotka nie są osobami mogącymi dać
wsparcie na grupę wiekową. Musimy ograniczyć się do następujących typów pokrewieństwa:
dzieci, wnuki, rodzeństwo, siostrzenica, bratanica, siostrzeniec, bratanek (dzieci rodzeństwa),
kuzynostwo (dzieci wujka lub ciotki).
Przeciętna liczba krewnych „rodzeństwa” dla osób w wieku 60-80 lat jest znacząco
większa niż dla osób w wieku 80 lat i więcej. Jeżeli chodzi o wnuki sytuacja jest odwrotna.
Jako, że różne typy pokrewieństwa dostarczają różnego typu wsparcia dla osób starszych,
zmiany w składzie krewnych maja wpływ na możliwość dostarczenia pomocy w przyszłości.

88
W przyszłości duża sieć pokrewieństwa będzie występowała u nielicznych osób.
Wykres przedstawia proporcję osób mających 10-cioro i więcej żyjących wnuków/wnuczek i
odpowiednio siostrzenic, siostrzeńców, bratanic, bratanków. W roku 1990 23% osób w wieku
80 lat i więcej miało więcej niż 10 żyjących wnuków, natomiast w roku 2010 udział ten
obniżył się o połowę aby w 2050 osiągnąć zaledwie 3%. Dla grupy wiekowej 60-80 lat
odpowiednie wskaźniki struktury obniżyły się z 10% w 1990 do 1% w roku 2050.
Podobnie dla osób powyżej 80 roku życia w roku 2015 więcej 40% ma powyżej 10-coro
żyjących siostrzenic, siostrzeńców, bratanic, bratanków ale w 2050 będzie ich tylko 5%. Dla
grupy wiekowej 60-80 lat odpowiednie wartości wskaźnika struktury wynoszą więcej niż
40% w 1990 i 3% w 2050.
9. Wnioski
Decyzja o zastosowaniu konkretnego rozwiązania (mikro- bądź makro- modelu)
powinna być podjęta stosownie do celem badania. Cel badania powinien determinować
sposób realizacji naszych zamierzeń. Mając na uwadze plusy i minusy obydwu metod
widzimy, że określone warunki skłaniają nas do wyboru jednej z metod. Metoda ta jest lepsza
w określonych warunkach od drugiej. Zatem nie możemy jednoznacznie określić wyższości
jednej metody nad drugą. Jednakże niewątpliwie mikrosymulacja ma wiele zalet i
możliwości, które musza być wzięte pod uwagę.