numerical optimizationnumerical optimizationplato.asu.edu/apm523/crash_course.pdfoverview of methods...
TRANSCRIPT

Numerical OptimizationNumerical Optimization
Professor Horst Cerjak, 19.12.20051
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

Working Horse in Computer VisionWorking Horse in Computer Vision
Variational Methods Shape Analysis
Machine Learning
Markov Random Fields Geometry
Professor Horst Cerjak, 19.12.20052
Horst Bischof, Thomas Pock Mat Vis-Gra SS09
Common denominator: optimization problems

Overview of Methods
• Is the function smooth / non-smooth / semismooth?
• Are derivatives available?
• Is the problem convex / non-convex?
„The great watershed in optimization isn‘t between linearity and„The great watershed in optimization isn t between linearity and nonlinearity, but convexity and non-convexity“, T. Rockafellar, 1993
• Is the problem linear / nonlinear?p
• Is the problem constrained / unconstrained?
Professor Horst Cerjak, 19.12.20053
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

Optimization problems
Generic unconstrained minimization problem:
Optimization problems
h
Vector space is the search space
where
is a cost (or objective) function
A solution is the minimizer of
The value is the minimumThe value is the minimum
Finding the global minimum of general functions is as hard as
Professor Horst Cerjak, 19.12.20054
Horst Bischof, Thomas Pock Mat Vis-Gra SS09
finding a needle in a haystack …

L l l b l i iLocal vs. global minimum
Local minimum
Globalminimum
Professor Horst Cerjak, 19.12.20055
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

Local vs. global in real lifeLocal vs. global in real life
False summit
Main summit
8,030 m
Main summit8,047 m
Professor Horst Cerjak, 19.12.20056
Horst Bischof, Thomas Pock Mat Vis-Gra SS09
Broad Peak (K3), 12th highest mountain on Earth

Convex vs non-convex functionsConvex vs. non convex functions
A function defined on a convex set is called convex if
for any andfor any and
For convex function local minimum = global minimum
Professor Horst Cerjak, 19.12.20057
Horst Bischof, Thomas Pock Mat Vis-Gra SS09
Non-convexConvex

One-dimensional optimality conditionsOne dimensional optimality conditions
Point is the local minimizer of a -function if
.
Approximate a function around as a parabola using Taylor expansion
guarantees guaranteesguarantees the minimum at
guarantees the parabola is convex
Professor Horst Cerjak, 19.12.20058
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

GradientGradient
In multidimensional case, linearization of the function according to Taylor
gives a multidimensional analogy of the derivative.
The function , denoted as , is called the gradient of
In one-dimensional case, it reduces to standard definition of derivative
Professor Horst Cerjak, 19.12.20059
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

GradientGradient
In Euclidean space ( ), can be represented in standard basis
i th f ll iin the following way:
i-th place
Professor Horst Cerjak, 19.12.200510
Horst Bischof, Thomas Pock Mat Vis-Gra SS09
which gives

HessianHessian
Linearization of the gradient
gives a multidimensional analogy of the second-
order derivative.
The function denoted asThe function , denoted as
is called the Hessian ofLudwig Otto Hesse
(1811-1874)
In the standard basis, Hessian is a symmetric matrix of mixed second-order
derivatives
Professor Horst Cerjak, 19.12.200511
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

Multi-dimensional optimality conditions
Point is the local minimizer of a -function if
Multi dimensional optimality conditions
.
for all , i.e., the Hessian is a positive definite
matrix (denoted )
Approximate a function around as a parabola using Taylor expansionApproximate a function around as a parabola using Taylor expansion
guarantees the minimum at
guarantees the parabola is convex
Professor Horst Cerjak, 19.12.200512
Horst Bischof, Thomas Pock Mat Vis-Gra SS09
the minimum at the parabola is convex

Optimization algorithmsOptimization algorithms
Descent directionStep sizeStep size
Professor Horst Cerjak, 19.12.200513
Horst Bischof, Thomas Pock Mat Vis-Gra SS09
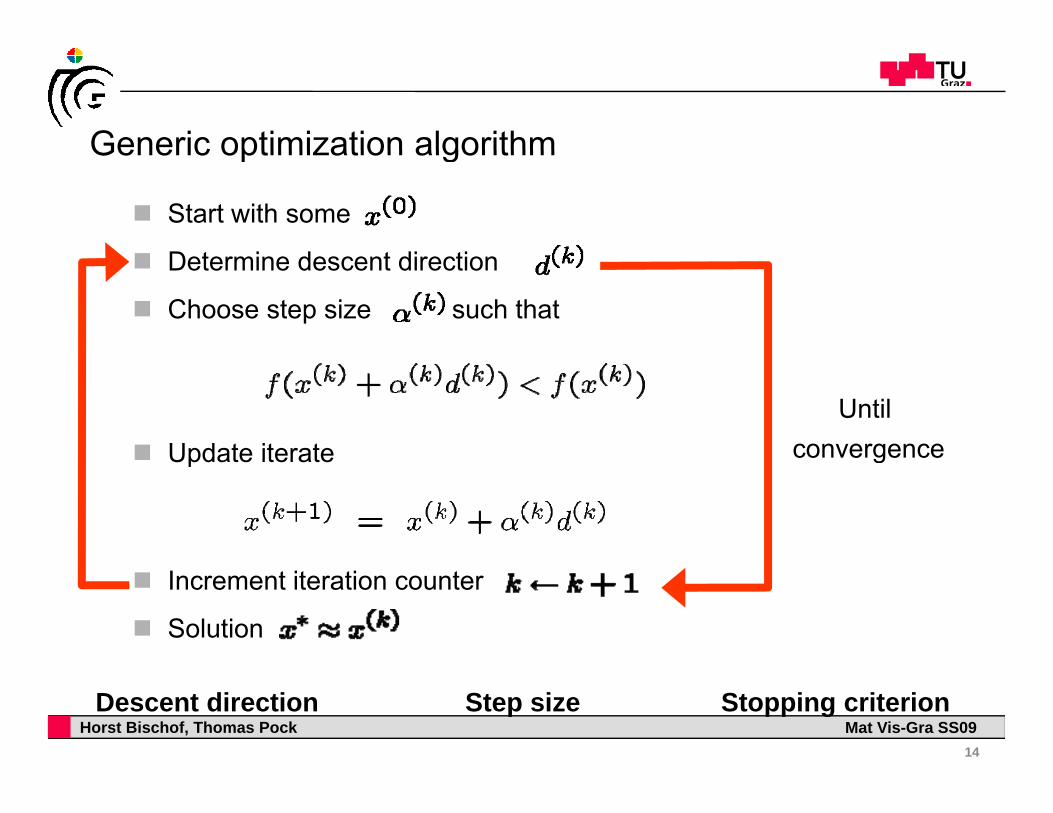
Generic optimization algorithmGeneric optimization algorithm
Start with some
D t i d t di tiDetermine descent direction
Choose step size such that
Update iterateUntil
convergenceUpdate iterate g
Increment iteration counter
Solution
Professor Horst Cerjak, 19.12.200514
Horst Bischof, Thomas Pock Mat Vis-Gra SS09Descent direction Step size Stopping criterion

Stopping criteriaStopping criteria
Near local minimum, (or equivalently )
St h di t b llStop when gradient norm becomes small
Stop when step size becomes small
Stop when relative objective change becomes small
Professor Horst Cerjak, 19.12.200515
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

Line searchLine search
Optimal step size can be found by solving a one-dimensional optimization
blproblem
One-dimensional optimization algorithms for finding the optimal step size
are generically called exact line search
Professor Horst Cerjak, 19.12.200516
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

Armijo ruleArmijo rule
The function sufficiently decreases if
Armijo rule (Larry Armijo, 1966): start with and decrease it by
multiplying by some until the function sufficiently decreases
Professor Horst Cerjak, 19.12.200517
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

Descent directionDescent directionHow to descend in the fastest way?
Go in the direction in which the height lines are the densestGo in the direction in which the height lines are the densest
Professor Horst Cerjak, 19.12.200518
Horst Bischof, Thomas Pock Mat Vis-Gra SS09
Devil’s Tower Topographic map

Steepest descentSteepest descent
Directional derivative: how much changes in the direction (negative for a descent direction)
Find a unit length direction minimizing directional
( g )
Find a unit-length direction minimizing directional
derivative
Professor Horst Cerjak, 19.12.200519
Horst Bischof, Thomas Pock Mat Vis-Gra SS09
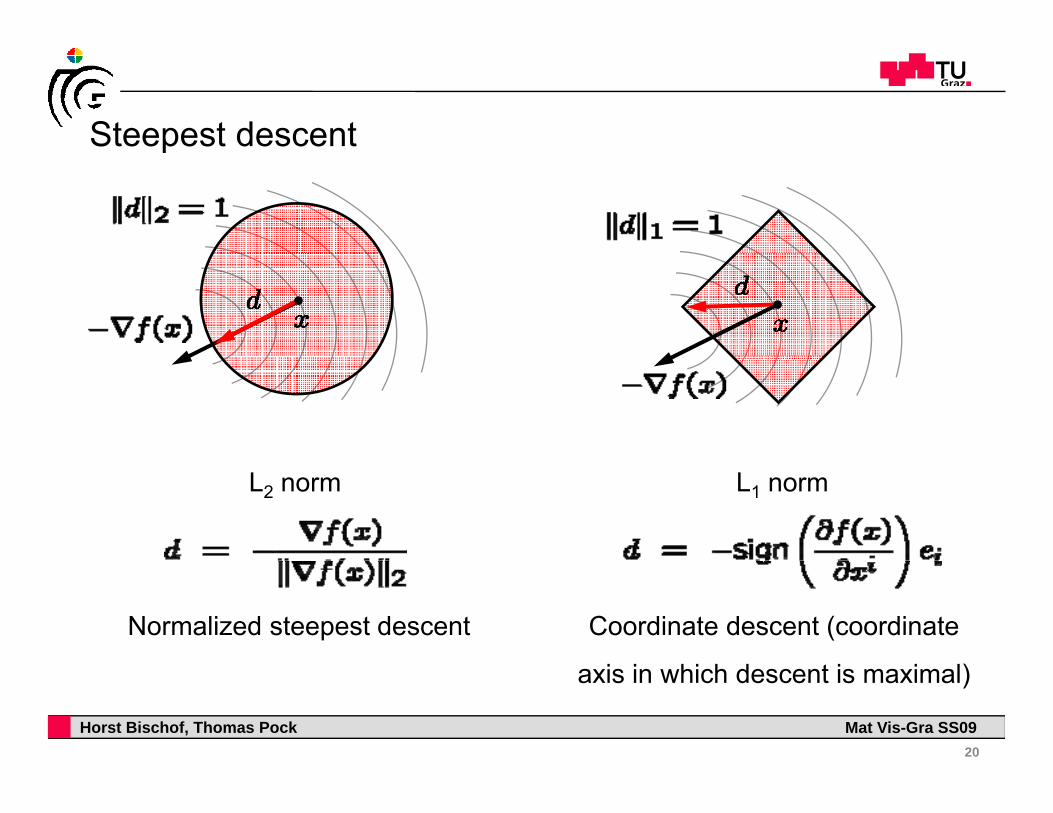
Steepest descentp
L1 normL2 norm
Coordinate descent (coordinate Normalized steepest descent
Professor Horst Cerjak, 19.12.200520
Horst Bischof, Thomas Pock Mat Vis-Gra SS09
axis in which descent is maximal)

Steepest descent algorithmSteepest descent algorithm
Start with some
C t t t d t di tiCompute steepest descent direction
Choose step size using line search Until convergence
Update iterate
g
p
Professor Horst Cerjak, 19.12.200521
Horst Bischof, Thomas Pock Mat Vis-Gra SS09
Increment iteration counter

E lExample
• Simple quadratic functionp q
• Matlab Example
Professor Horst Cerjak, 19.12.200522
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

Condition numberCondition numberCondition number is the ratio of maximal and minimal eigenvalues of the
Hessian ,
1 1
Hessian ,
0
0.5
0
0.5
-1
-0.5
-1
-0.5
-1 -0.5 0 0.5 11
-1 -0.5 0 0.5 11
Problem with large condition number is called ill-conditioned
Steepest descent convergence rate is slow for ill conditioned problems
Professor Horst Cerjak, 19.12.200523
Horst Bischof, Thomas Pock Mat Vis-Gra SS09
Steepest descent convergence rate is slow for ill-conditioned problems

Conjungate Gradient (CG-Method)Generates a sequence
Where the search directions have the property
(This property is known as conjugacy)( p p y j g y)
New search direction is given byNew search direction is given by
Professor Horst Cerjak, 19.12.200524
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

Conjungate Gradient (CG Method)Conjungate Gradient (CG-Method)
• Different choices of – Fletcher - Reeves
– Polak – Ribiere
– To ensure that d is a descend of Polak – RibiereTo ensure that d is a descend of Polak Ribiere ...
Professor Horst Cerjak, 19.12.200525
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

C j t G di t (CG M th d)
• Properties of the CG method:
Conjungate Gradient (CG-Method)
– In the linear case: At most n steps for n variables– Each iteration is very fast to computeEach iteration is very fast to compute– Needs little memory to store -> large problems– Global convergence is asured by line search
• Example
Professor Horst Cerjak, 19.12.200526
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

Preconditioningg
Perform steepest descent in a rescaled coordinate system, called
preconditioning.preconditioning.
Function:
P di i h ld b h i h di i b f
Gradient:
Preconditioner should be chosen to improve the condition number of
the Hessian in the proximity of the solution
In system of coordinates, the Hessian at the solution is
Professor Horst Cerjak, 19.12.200527
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

Newton method as optimal preconditionerNewton method as optimal preconditioner
Best theoretically possible preconditioner , giving descent
di tidirection
Ideal condition number
Problem: the solution is unknown in advance
Newton direction: use Hessian as a preconditioner at each iteration
Professor Horst Cerjak, 19.12.200528
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

Another derivation of the Newton methodAnother derivation of the Newton method
Approximate the function as a quadratic function using second-order Taylor
iexpansion
(quadratic function in )
Close to solution the function looks like a quadratic function; the Newton
method converges fast
Professor Horst Cerjak, 19.12.200529
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

Newton methodNewton method
Start with some
C t N t di tiCompute Newton direction
Choose step size using line search
Until
Update iterate
Until convergence
p
Professor Horst Cerjak, 19.12.200530
Horst Bischof, Thomas Pock Mat Vis-Gra SS09
Increment iteration counter

P ti f N t ‘ th dProperties of Newton‘s method• Fast convergence (at least locally)
– Quadratic convergence• Not always very robust• Each iterations amounts for solving a linear systemEach iterations amounts for solving a linear system• Overall performance depends on how fast can the system be
solved
Professor Horst Cerjak, 19.12.200531
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

E lExample
• Try again our simple quadratic exampley g p q p
• Needs one iteration to find the solution !
Professor Horst Cerjak, 19.12.200532
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

Frozen HessianFrozen Hessian
Observation: close to the optimum, the Hessian does not change
i ifi tlsignificantly
Reduce the number of Hessian inversions by keeping the Hessian from y p g
previous iterations and update it once in a few iterations
Such a method is called Newton with frozen Hessian
Professor Horst Cerjak, 19.12.200533
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

Cholesky factorizationCholesky factorization
Decompose the Hessian
where is a lower triangular matrix
Andre Louis Cholesky
Solve the Newton system
Andre Louis Cholesky(1875-1918)
Forward substitution
in two steps
Backward substitution
Professor Horst Cerjak, 19.12.200534
Horst Bischof, Thomas Pock Mat Vis-Gra SS09
Complexity: , better than straightforward matrix inversion

Truncated NewtonTruncated Newton
Solve the Newton system approximately (it’s a linear system)
A few iterations of conjugate gradients or other algorithm for the solution of j g g g
linear systems can be used
Such a method is called truncated or inexact Newton
Professor Horst Cerjak, 19.12.200535
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

Levenberg-Marquardt MethodgLevenberg:
– Combine Gradient with Newton
• Steepest Descent• Newton Method
τττ λdxx −=+1
ττττ dHxx 11
−+ −=
ττττ β dIHxx 11 )( −+ +−=
ττττ dHxx 11
−+ −=
1
0=β
Marquardt:– Take into account H also for large β– Better solution for „error valley“ Problem, Gradient is „bend“ towards
τττ βdxx 1
1 −=+β<<
quadratic
ττττ β dHdiagHxx 11 ])[( −+ +−=
Professor Horst Cerjak, 19.12.200536
Horst Bischof, Thomas Pock Mat Vis-Gra SS09
ττττ β g1 ])[(+

Levenberg-Marquardt Algorithmg q g
τττττ β dHdiagHxx 11 ))(( −+ +−=
Initalize β with small value e.g. 10-3
Calculate E(xז) and E(x1+ז)ז ז 1
If E(x1+ז) ≥ E(xז) Increase β (*10) and undo last If E(x ) < E(x ) Decrease β (/10)If E(x1+ז) < E(xז) Decrease β (/10)
If the error gets bigger, the quadratic approximation is not good more weight for gradient directionweight for gradient direction
Professor Horst Cerjak, 19.12.200537
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

Q i N t M th dQuasi-Newton Methods• Idea is to approximate the Hessian by some positive definite
matrix B
• and solve
• Most efficient method is the method of Broyden Fletcher• Most efficient method is the method of Broyden, Fletcher, Goldfarb and Shanno (BFGS)
• This method allows to iteratively update the inverse of BF l l bl• For large scale problems:– Limited memory BFGS (Nocedal)
Professor Horst Cerjak, 19.12.200538
Horst Bischof, Thomas Pock Mat Vis-Gra SS09
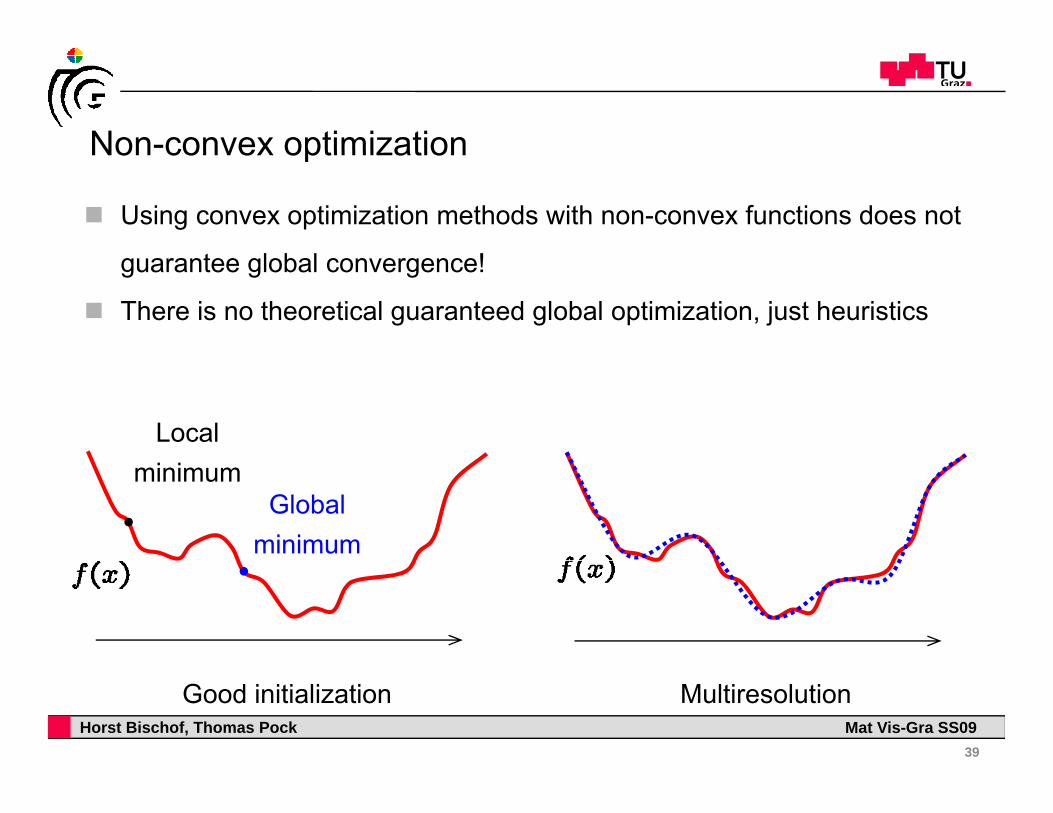
Non-convex optimizationNon convex optimization
Using convex optimization methods with non-convex functions does not
guarantee global convergence!
There is no theoretical guaranteed global optimization, just heuristics
Local minimum
Global minimum
Professor Horst Cerjak, 19.12.200539
Horst Bischof, Thomas Pock Mat Vis-Gra SS09
Multiresolution Good initialization
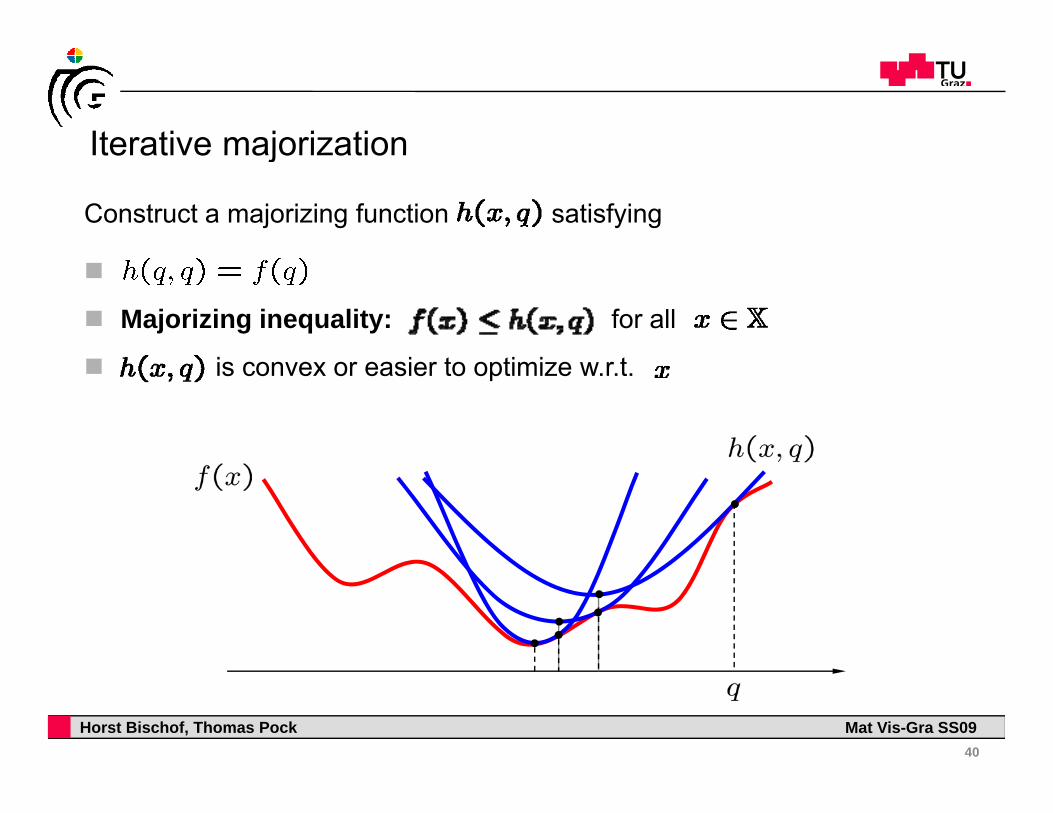
Iterative majorizationIterative majorization
Construct a majorizing function satisfying
Majorizing inequality: for all
is convex or easier to optimize w.r.t.
Professor Horst Cerjak, 19.12.200540
Horst Bischof, Thomas Pock Mat Vis-Gra SS09
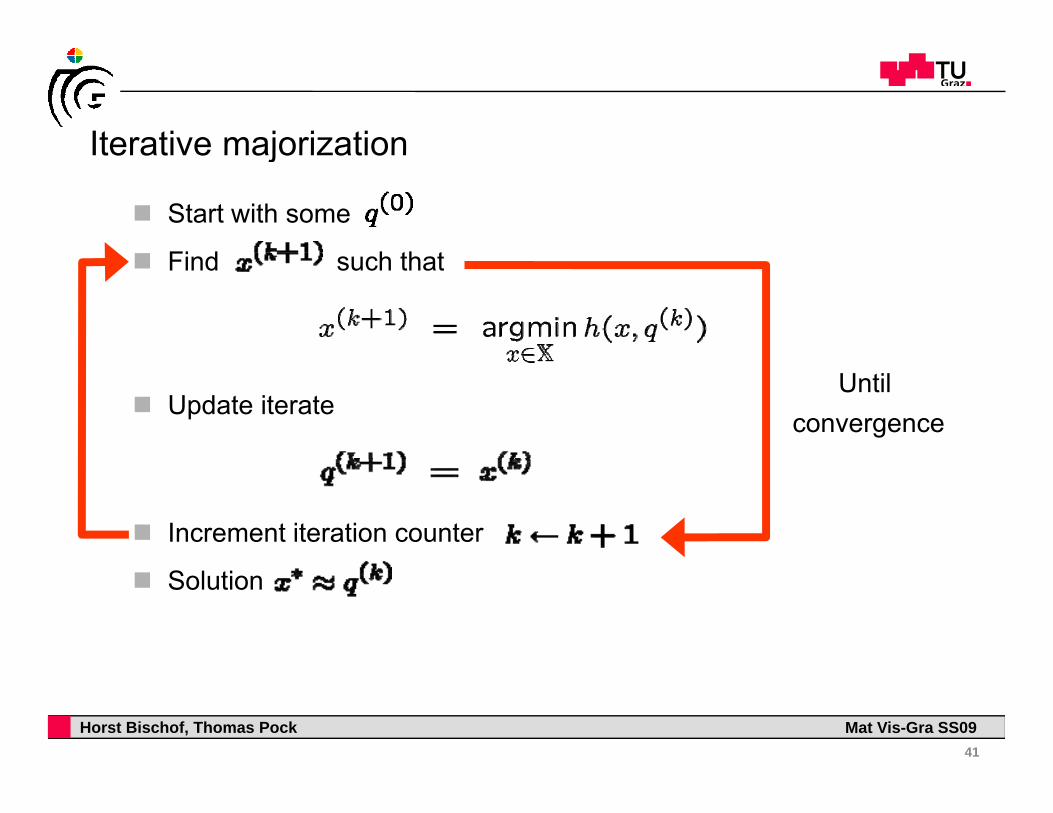
Iterative majorizationIterative majorization
Start with some
Fi d h th tFind such that
Update iterateUntil
convergence
Increment iteration counter
Solution
Professor Horst Cerjak, 19.12.200541
Horst Bischof, Thomas Pock Mat Vis-Gra SS09
Constrained optimizationConstrained optimization
MINEFIELDCLOSED ZONE
Professor Horst Cerjak, 19.12.200542
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

Constrained optimization problemsConstrained optimization problems
Generic constrained minimization problem
where
are inequality constraints
are equality constraints
where
are equality constraints
A subset of the search space in which the constraints hold is called
feasible set
A point belonging to the feasible set is called a feasible solution
A minimi er of the problem ma be infeasible!
Professor Horst Cerjak, 19.12.200543
Horst Bischof, Thomas Pock Mat Vis-Gra SS09
A minimizer of the problem may be infeasible!

An exampleAn example
Inequality constraint
Equality constraint
Feasible setFeasible set
I lit t i t i ti t i t if i ti th iInequality constraint is active at point if , inactive otherwise
A point is regular if the gradients of equality constraints and of
Professor Horst Cerjak, 19.12.200544
Horst Bischof, Thomas Pock Mat Vis-Gra SS09
active inequality constraints are linearly independent

Lagrange multipliersLagrange multipliers
Main idea to solve constrained problems: arrange the objective and
t i t i t i l f ticonstraints into a single function
and minimize it as an unconstrained problem
is called Lagrangian
and are called Lagrange multipliers
Professor Horst Cerjak, 19.12.200545
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

KKT conditionsKKT conditions
If is a regular point and a local minimum, there exist Lagrange multipliers
d h th tand such that
for all and for all
such that for active constraints and zero for
inactive constraints
Known as Karush-Kuhn-Tucker conditionsKnown as Karush-Kuhn-Tucker conditions
Necessary but not sufficient!
Professor Horst Cerjak, 19.12.200546
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

KKT conditionsKKT conditions
Sufficient conditions:
If the objective is convex, the inequality constraints are convex
and the equality constraints are affine, and
for all and for all
such that for active constraints and zero forsuch that for active constraints and zero for
inactive constraints
then is the solution of the constrained problem (global constrained
Professor Horst Cerjak, 19.12.200547
Horst Bischof, Thomas Pock Mat Vis-Gra SS09
minimizer)
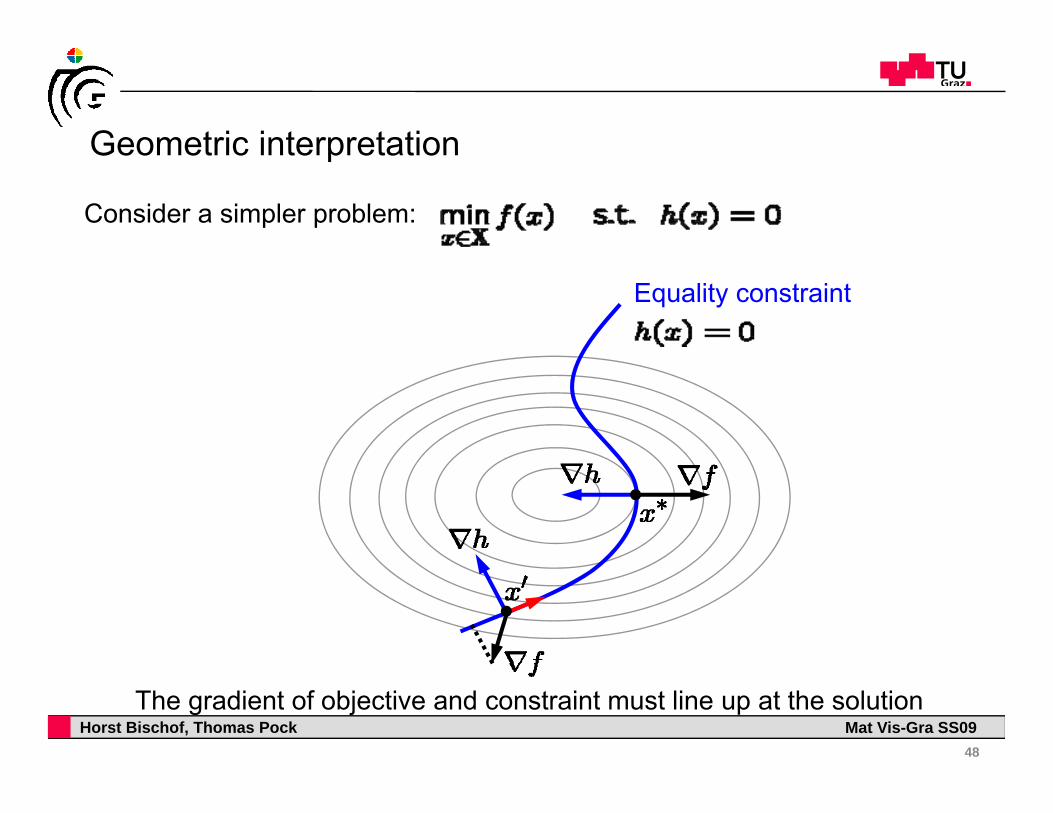
Geometric interpretationGeometric interpretation
Consider a simpler problem:
Equality constraint
Professor Horst Cerjak, 19.12.200548
Horst Bischof, Thomas Pock Mat Vis-Gra SS09The gradient of objective and constraint must line up at the solution

Penalty methodsPenalty methods
Define a penalty aggregate
where and are parametric penalty functions
For larger values of the parameter the penalty on the constraint violationFor larger values of the parameter , the penalty on the constraint violation
is stronger
Professor Horst Cerjak, 19.12.200549
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

Penalty methodsPenalty methods
Inequality penalty Equality penalty
Professor Horst Cerjak, 19.12.200550
Horst Bischof, Thomas Pock Mat Vis-Gra SS09
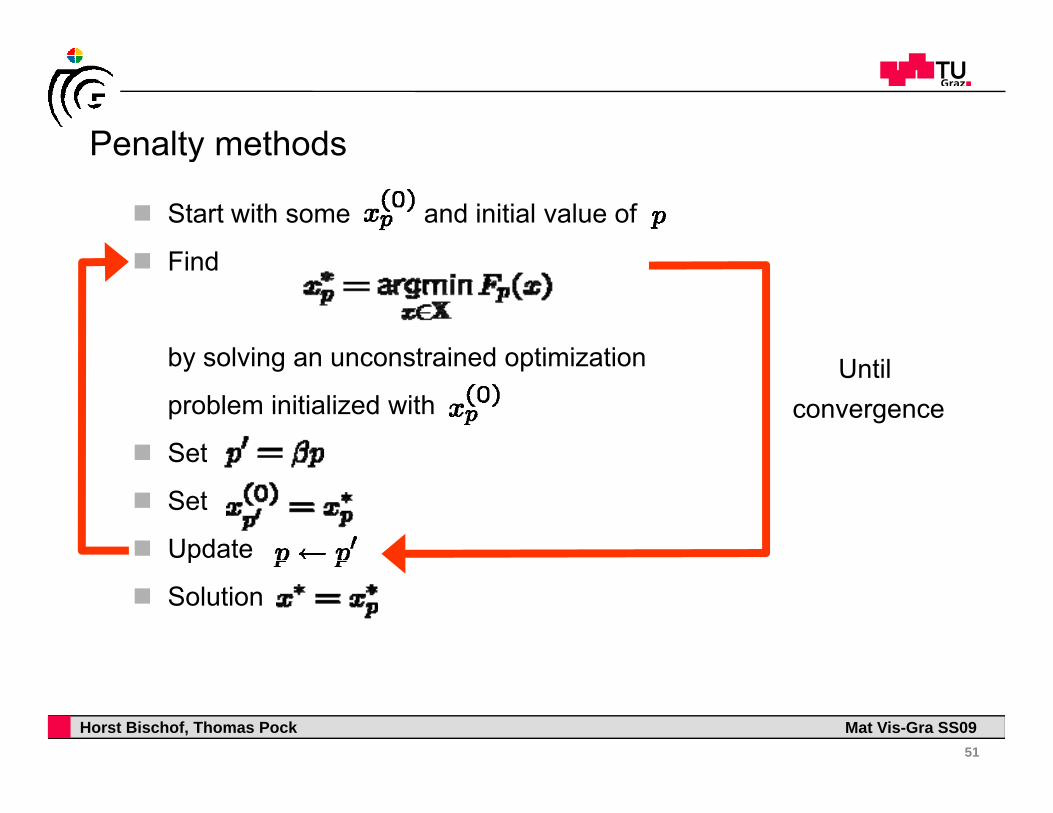
Penalty methodsPenalty methods
Start with some and initial value of
Fi dFind
by solving an unconstrained optimizationby solving an unconstrained optimization
problem initialized with
Set
Until convergence
Set
Set
Update p
Solution
Professor Horst Cerjak, 19.12.200551
Horst Bischof, Thomas Pock Mat Vis-Gra SS09

LiteratureLiterature• Bronstein, Bronstein, Kimmel, „Numerical Geometry of Non-Rigid
Shapes“ (Slides are taken from tosca.cs.technicon.ac.il/book)p ( )• Nocedal, Wright, „Numerical Optimization“
Professor Horst Cerjak, 19.12.200552
Horst Bischof, Thomas Pock Mat Vis-Gra SS09