nvidia cuda - ohjelmistotekniikan laboratoriotlilja/multicore/slides/cuda.pdf · nvidia cuda...
TRANSCRIPT

NVIDIA CUDASeminar on Multi-core Programming
Feb 26, 2009

Hello, in parallel!
__global__voidfunctinttid=threadI__shared__floatif(tid<n){inttmp=tid
Outline
Introductionto CUDA
ProgrammingBasics
Planningfor CUDA

IntroductionGPGPU = General Purpose computing on GPU

“ (Gordon Moore)3 ”
2003 2004 2005 2006 2007 2008
GT200933 Gflops
G80
G703.0 GHz
Core2 Duo
3.2 GHzHarpertown
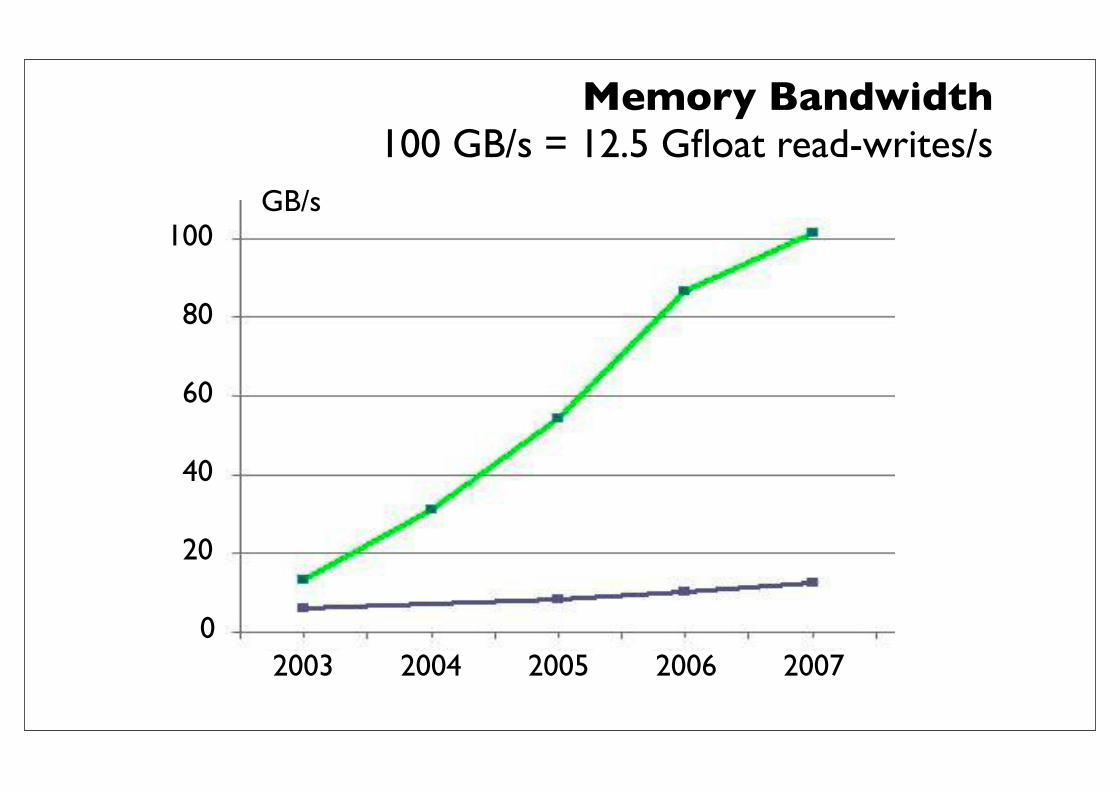
Memory Bandwidth100 GB/s = 12.5 Gfloat read-writes/s
100
02003 2004 2005 2006 2007
GB/s
80
60
40
20

First, there was just a graphics pipeline

What could they do with itby reading from textures and writing to others
?

Stream mapping
OP

Parallel reduction
OP OP

Gather input from textures
OP
Scatter output as vertices
OP
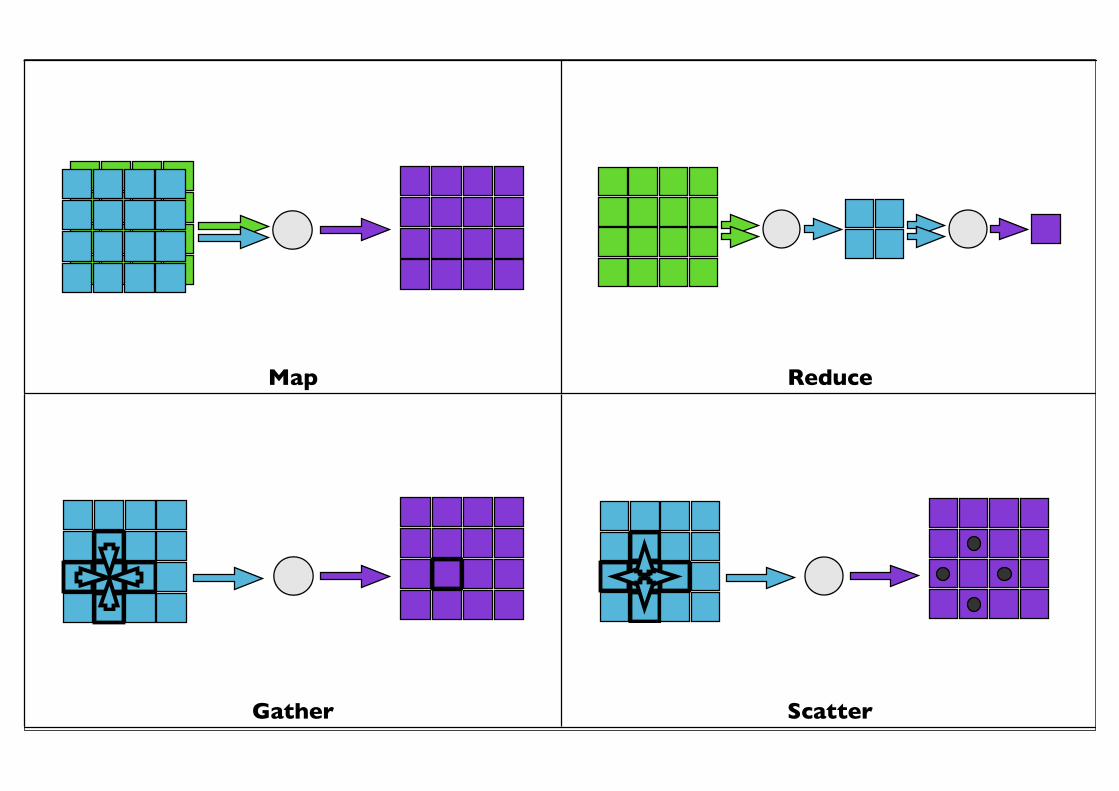
Map Reduce
Gather Scatter

Back to present…
What to use GPU for?

What to use GPU for?
Physics Simulations

What to use GPU for?
Linear Algebra
Finance Pattern Recognition…

What to use GPU for?
Biomedical Imaging

Do you have a casewhere CUDA could be used?

CUDA Architecture

Yet Another...
S ingle I nstruction M ultiple T hreads
Warp = 32 threads, lock-step, masked
Chapter 2. Programming Model
!
10 CUDA Programming Guide Version 2.1!
Figure 2-1. Grid of Thread Blocks
2.3 Memory Hierarchy
"#$%!&'()*+,!-*.!*//),,!+*&*!0(1-!-23&453)!-)-1(.!,5*/),!+2(467!&')4(!)8)/2&416!*,!4332,&(*&)+!9.!:472()!;<;=!>*/'!&'()*+!'*,!*!5(4?*&)!31/*3!-)-1(.=!>*/'!&'()*+!931/@!'*,!*!,'*()+!-)-1(.!?4,493)!&1!*33!&'()*+,!10!&')!931/@!*6+!A4&'!&')!,*-)!340)&4-)!*,!&')!931/@=!:46*33.B!*33!&'()*+,!'*?)!*//),,!&1!&')!,*-)!7319*3!-)-1(.=!
C')()!*()!*3,1!&A1!*++4&416*3!()*+<163.!-)-1(.!,5*/),!*//),,493)!9.!*33!&'()*+,D!&')!/16,&*6&!*6+!&)8&2()!-)-1(.!,5*/),=!C')!7319*3B!/16,&*6&B!*6+!&)8&2()!-)-1(.!,5*/),!*()!15&4-4E)+!01(!+400)()6&!-)-1(.!2,*7),!F,))!G)/&416,!H=I=;=IB!H=I=;=JB!*6+!H=I=;=KL=!C)8&2()!-)-1(.!*3,1!100)(,!+400)()6&!*++(),,467!-1+),B!*,!A)33!*,!+*&*!043&)(467B!01(!,1-)!,5)/404/!+*&*!01(-*&,!F,))!G)/&416!K=J=KL=!
C')!7319*3B!/16,&*6&B!*6+!&)8&2()!-)-1(.!,5*/),!*()!5)(,4,&)6&!*/(1,,!@)(6)3!3*26/'),!9.!&')!,*-)!*5534/*&416=!
Grid
Block (1, 1)
Thread (0, 0) Thread (1, 0) Thread (2, 0) Thread (3, 0)
Thread (0, 1) Thread (1, 1) Thread (2, 1) Thread (3, 1)
Thread (0, 2) Thread (1, 2) Thread (2, 2) Thread (3, 2)
Block (2, 1) Block (1, 1) Block (0, 1)
Block (2, 0) Block (1, 0) Block (0, 0)

Abstraction
1) You won’t know which core or when.
2) You don’t care how many cores.
3) Forget synchronization if you can.

GeForce, Quadro or Tesla?

Compute Capability?
1.0 – 1st generation (Nov. 2006)
1.1 – Atomics & asynchronous memory transfers
1.2 – Relaxed alignment requirements, voting intrinsics
1.3 – Double support (on 1/8th float speed)

CUDA code can be compiled todifferent architectures,
including multi-core CPU’s.
PTX is an intermediate language between CUDA and CUBIN

IntroductionGPGPU = General Purpose computing on GPU

__global__voidfunctinttid=threadI__shared__floatif(tid<n){inttmp=tid
ProgrammingWhat’s needed to run GPGPU with CUDA?

CUDA is close to C or C++01enum{max_coeff=128;};02__constant__floatcoeff[max_coeff];0304__device__floateval(floatx,intorder){05floatr=0;06for(inti=order;i>=0;‐‐i)07r=(r+x)*coeff[i];08returnr;09}10__global__voidpolynomial(floatconst*x,float*y,11intn,intorder)//order<max_coeff12{13inti=threadIdx.x+blockIdx.x*blockDim.x;14if(i<n)15y[i]=eval(x[i],order);16}

But GPU ≠ CPU...

GPU ≠ CPUGPU isn’t independent. CPU takes the initiative:01voidcalculate_polynomial(floatconst*a,floatconst*x,02float*y,intn,intorder)03{04float*z=0;05cudaMalloc((void**)&z,n*sizeof(float));06cudaMemcpy(z,x,n*sizeof(float),cudaMemcpyHostToDevice);07cudaMemcpyToSymbol(coeff,a,order*sizeof(float),0,08cudaMemcpyHostToDevice);09unsignedblock=256;10unsignedgrid=(n+block‐1)/block;11polynomial<<<grid,block>>>(z,z,n,order);//kernellaunch12cudaMemcpy(y,z,n*sizeof(float),cudaMemcpyDeviceToHost);13cudaFree(z);14}

GPU ≠ CPU
GPU cannot access CPU memoryData must be explicitly transferred.

There’s no...
stack
recursion
function pointers or calls
dynamic memory allocation (from device)
GPU ≠ CPU

thread: runs the kernel with given thread index
warp: 32 threads in lock-step
block: max. 512 threads with shared cache, block-level synchronization: __syncthreads()
grid: 100’s or 1000’s of blocks; no synchronization
device: kernel-level synchronizationhost: enqueues kernel calls for device
GPU ≠ CPU

There’s hardly any silicon spent on a GPU cache
GPU ≠ CPU
constant memorysame address for threads
textures2D, read-only
shared memoryread-write, within block
! Chapter 1. Introduction
!
CUDA Programming Guide Version 2.1 3!
!
!
Figure 1-2. The GPU Devotes More Transistors to Data Processing
!
"#$%!&'%()*)(+,,-.!/0%!123!)&!%&'%()+,,-!4%,,5&6)/%7!/#!+77$%&&!'$#8,%9&!/0+/!(+:!8%!%;'$%&&%7!+&!7+/+5'+$+,,%,!(#9'6/+/)#:&!<!/0%!&+9%!'$#=$+9!)&!%;%(6/%7!#:!9+:-!7+/+!%,%9%:/&!):!'+$+,,%,!<!4)/0!0)=0!+$)/09%/)(!):/%:&)/-!<!/0%!$+/)#!#*!+$)/09%/)(!#'%$+/)#:&!/#!9%9#$-!#'%$+/)#:&>!?%(+6&%!/0%!&+9%!'$#=$+9!)&!%;%(6/%7!*#$!%+(0!7+/+!%,%9%:/.!/0%$%!)&!+!,#4%$!$%@6)$%9%:/!*#$!&#'0)&/)(+/%7!*,#4!(#:/$#,A!+:7!8%(+6&%!)/!)&!%;%(6/%7!#:!9+:-!7+/+!%,%9%:/&!+:7!0+&!0)=0!+$)/09%/)(!):/%:&)/-.!/0%!9%9#$-!+((%&&!,+/%:(-!(+:!8%!0)77%:!4)/0!(+,(6,+/)#:&!):&/%+7!#*!8)=!7+/+!(+(0%&>!
B+/+5'+$+,,%,!'$#(%&&):=!9+'&!7+/+!%,%9%:/&!/#!'+$+,,%,!'$#(%&&):=!/0$%+7&>!"+:-!+'',)(+/)#:&!/0+/!'$#(%&&!,+$=%!7+/+!&%/&!(+:!6&%!+!7+/+5'+$+,,%,!'$#=$+99):=!9#7%,!/#!&'%%7!6'!/0%!(#9'6/+/)#:&>!C:!DB!$%:7%$):=.!,+$=%!&%/&!#*!');%,&!+:7!E%$/)(%&!+$%!9+''%7!/#!'+$+,,%,!/0$%+7&>!F)9),+$,-.!)9+=%!+:7!9%7)+!'$#(%&&):=!+'',)(+/)#:&!&6(0!+&!'#&/5'$#(%&&):=!#*!$%:7%$%7!)9+=%&.!E)7%#!%:(#7):=!+:7!7%(#7):=.!)9+=%!&(+,):=.!&/%$%#!E)&)#:.!+:7!'+//%$:!$%(#=:)/)#:!(+:!9+'!)9+=%!8,#(G&!+:7!');%,&!/#!'+$+,,%,!'$#(%&&):=!/0$%+7&>!C:!*+(/.!9+:-!+,=#$)/09&!#6/&)7%!/0%!*)%,7!#*!)9+=%!$%:7%$):=!+:7!'$#(%&&):=!+$%!+((%,%$+/%7!8-!7+/+5'+$+,,%,!'$#(%&&):=.!*$#9!=%:%$+,!&)=:+,!'$#(%&&):=!#$!'0-&)(&!&)96,+/)#:!/#!(#9'6/+/)#:+,!*):+:(%!#$!(#9'6/+/)#:+,!8)#,#=->!
1.2 CUDA™: a General-Purpose Parallel Computing Architecture
C:!H#E%98%$!IJJK.!HLCBCM!):/$#76(%7!N3BMO.!+!=%:%$+,!'6$'#&%!'+$+,,%,!(#9'6/):=!+$(0)/%(/6$%!<!4)/0!+!:%4!'+$+,,%,!'$#=$+99):=!9#7%,!+:7!):&/$6(/)#:!&%/!+$(0)/%(/6$%!<!/0+/!,%E%$+=%&!/0%!'+$+,,%,!(#9'6/%!%:=):%!):!HLCBCM!123&!/#!&#,E%!9+:-!(#9',%;!(#9'6/+/)#:+,!'$#8,%9&!):!+!9#$%!%**)()%:/!4+-!/0+:!#:!+!N23>!
N3BM!(#9%&!4)/0!+!&#*/4+$%!%:E)$#:9%:/!/0+/!+,,#4&!7%E%,#'%$&!/#!6&%!N!+&!+!0)=05,%E%,!'$#=$+99):=!,+:=6+=%>!M&!),,6&/$+/%7!8-!P)=6$%!Q5D.!#/0%$!,+:=6+=%&!#$!+'',)(+/)#:!'$#=$+99):=!):/%$*+(%&!4),,!8%!&6''#$/%7!):!/0%!*6/6$%.!&6(0!+&!PRSTSMH.!NUU.!R'%:NV.!+:7!B)$%(/DB!QQ!N#9'6/%>!
Cache
ALU Control
ALU
ALU
ALU
DRAM
CPU
DRAM
GPU

NVCC separates,
compiles &
embeds GPU code
nvccmy_program.cu‐omy_program

NVCC separates,
compiles &
embeds GPU code
nvccmy_program.cu‐omy_program
host code(C or C++)
GPU functions(cu)

NVCC separates,
compiles &
embeds GPU code
nvccmy_program.cu‐omy_program
host code(C or C++)
GPU functions(cu)
GPU kernels(ptx)
GPU kernels(cubin)

NVCC separates,
compiles &
embeds GPU code
nvccmy_program.cu‐omy_program
host code(C or C++)
GPU functions(cu)
GPU kernels(ptx)
GPU kernels(cubin)

nvccmy_program.cu‐omy_program
host code(C or C++)
GPU functions(cu)
GPU kernels(ptx)
GPU kernels(cubin)
Runtime API vs. Driver API?

Where to feed input from CPU?CPU GPU
RAM
Global
Texture
Constant
KERNEL
uncached read/writealignment (coalescing)
2D spatial cache, read-only1D buffer texturing
read same address at a time

Where to feed input from CPU?GPU
Global
KERNEL
uncached read/writealignment (coalescing)
cudaMalloc(&dptr,n);cudaFree(dptr);cudaMemcpy(dptr,p,n,cudaMemcpyHostToDevice);

Threads have specialized memory
Global
Texture
Constant
KERNEL
registersthread-private,
usually only ~10’sper thread
local memorythread-privateglobal memory,
spilled-over registers
__shared__between block threads,limited size < 16 KB/MP,
16 banks (half-warp),broadcast function

__global__voidfunctinttid=threadI__shared__floatif(tid<n){inttmp=tid
ProgrammingWhat’s needed to run GPGPU with CUDA?

Four steps to CUDA performance
Planning
Four steps to performance
1. REDESIGNyour algorithm
2. RESTRUCTUREdata
3. COOPERATEwith block threads
4. SQUEEZEthe last juice out

1. Redesign
• redesign algorithm for GPU and big datamost C code won’t copy-paste to CUDA
• maximize parallel executiongo data parallel, with 10000’s threads
• find arithmetic intensity (flops / transfers)cache less, compute more; 1 global load ≈ 100 flops
• don’t leave the MP’s unemployed

2. Restructure
• strive for coherent global memory accessesit’s a matter of 100 GB/s vs. 10 GB/s
• access locality? could textures help?1D buffer textures read directly from global memory
• prevent CPU roundtripsGPU–CPU: ~5 GB/s; group transfers if possible

3. Cooperate• block threads talk through shared memory
save global memory loads when gathering
• use __syncthreads() if neededbut go lock-step within warps
• prevent cache bank conflictshalf-warp threads read different banks, or broadcast
• warp voting?

4. Squeeze
• parameterize your applicationauto-tuning algorithms?
• minimize registers and shared memory
• loop unrolling and template tricksthey help as long as GPU architecture differs from CPU’s

Four steps to performance
1. REDESIGNyour algorithm
2. RESTRUCTUREdata
3. COOPERATEwith block threads
4. SQUEEZEthe last juice out

Examples

Questions