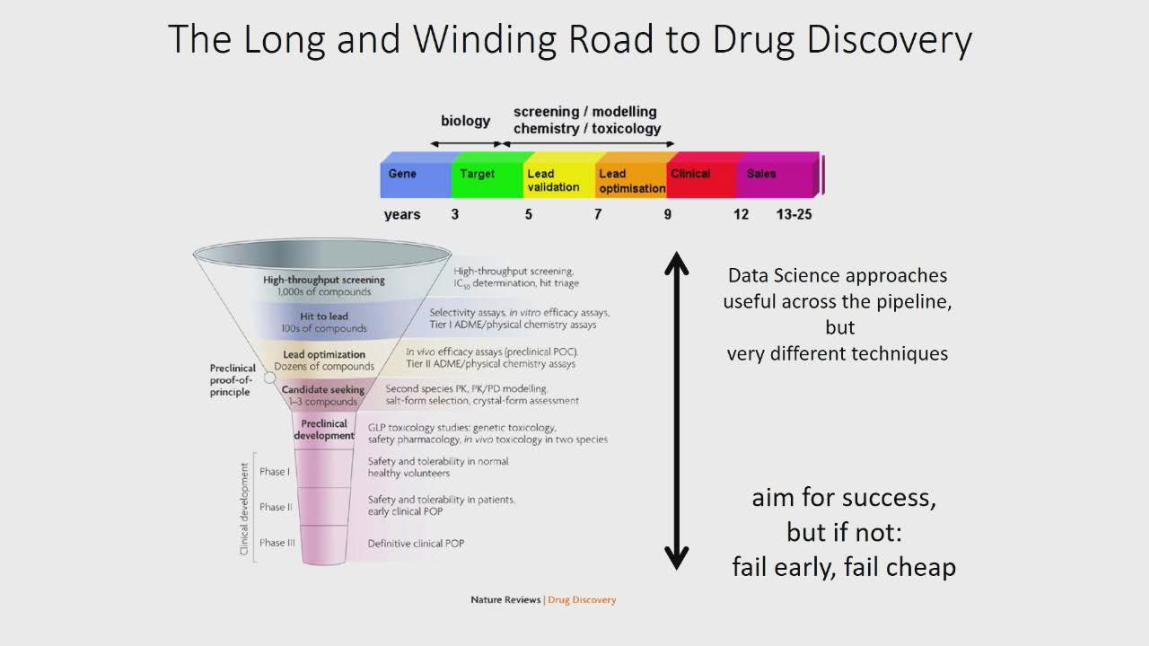
nvidia gpu...
TRANSCRIPT

井﨑 武士NVIDIA GPU ディープラーニング最新情報

Quanzheng Li Associate Professor, Massachusetts General Hospital
DEEP LEARNING ON METASTASIS DETECTION OF BREAST CANCER USING
DGX-1
SESSION 1

デジタルパソロジー
デジタルパソロジーはコンピュータテクノロジーにより可能となった画像を基にした情報環境で、デジタル標本から得られる情報の管理を可能とする
より良く、早く、より安価に癌やその他の病気の診断や予測を可能にする診療医学のもっとも有望な手段の一つ

研究の動機• リンパ節転移はほとんどの癌のタイプで発生する(e.g. 胸部、前立腺、結腸)
• リンパ節は小さな免疫細胞の塊でリンパ系のフィルターとして動作する
• 脇の下のリンパ節(腋下リンパ節)は乳がんが広がりやすい最初の箇所である
• リンパ節の状態は予後に大きく関連する、癌がリンパ節に広がっていると予後が悪くなる
• 病理検査医の診断の手順は単調で時間がかかる作業で、誤った解釈を引き起こす場合がある

• データセットはCamelyon16 Challengeのものを利用https://camelyon16.grand-challenge.org/
• データには2つの独立したデータセットから合計400の歩哨リンパ節のWSI(Whole-slide-image)が含まれている
• トレーニングデータ
• テストデータオランダのラドバウド大学メディカルセンター/ユトレヒト大学メディカルセンターから集めた130のWSI
データセット

データセット

データセット

TASK
スライドベースの評価
• 転移を含むスライドと正常なスライドの区別
• スライドレベルでのROC分析
• アルゴリズムの比較はROC曲線下面積(AUC)を用いる
病変ベースの評価
• 信頼スコアを伴う腫瘍領域の検出
• FROC曲線を使用
• 最終スコアはあらかじめ決められたFalse-Positive率の感度として決められる1/4,1/2,1,2,4,8

FRAMEWORK

学習データ
Preprocessing

NNの詳細
ResNet101を用いて、Atrous畳み込み演算とAtrous Spatial pyramid pooling (ASPP)を使用
Atrous畳み込み演算とASPPは予測のための視野を拡大し、複数の倍率でオブジェクトとイメージコンテキストのキャプチャを可能とする
トレーニングはNVCAFFEを使用。パッチサイズは20xで512X512。ミニバッチサイズは10
ラーニングレートは2.5e-4から始め、0.9乗の多項式
重み減衰 0.0005 モーメンタム0.9
Tesla P100で40000イタレーション
約1日

分類タスク
Tumor Probability mapからもっとも大きな腫瘍を取り出すために高次の特徴を抽出(skimageの”regionprops”で異なる閾値を用いる)
分類にはランダムフォレストを使用
検出タスク
Tumor Probability mapにおいてヒートマップの領域を結合する(Connectivity=2、Threshold=0.95)

性能比較
推論性能
8*p100: DGX-1
計算性能

結果

Jiangye Yuan Research Scientist, Oak Ridge National Laboratory
LEARNING BUILDING EXTRACTION IN AERIAL SCENES WITH CONVOLUTIONAL
NETWORKS
SESSION 2

建物の航空写真

一般的なCNNは適さない典型的なネットワークは画面全体に対して、いくつかの情報を予測するが、高解像度下においては空間情報が失われてしまう
建物の抽出にはピクセルワイズでの分類が必要とされる

今回の手法
ピクセル分類のために複数のステージの特徴マップを統合する特別なネットワークを作成
ネットワークの学習には、符号付距離関数をラベルとして用いた
Original Boundary Region Signed Distance

学習・テストデータ
ワシントンDCをカバーするエリアで0.3mの解像度データを用いた
16万ビルを含むパブリックのデータベースを使用
トレーニングとテストに使う領域に分割
500x500のイメージ2000枚および対応するビルマスクデータをトレーニングに使用
テストセットは5000x5000のイメージ40枚

アライメント不整合対策
地図はしばしば画像との不整合がある地図とイメージの相互相関が最大になるようにマップの位置を調整
調整前 調整後

学習
7層で約50万パラメータのネットワークを用意。GPUで20時間の学習Theanoを使用。事前学習は無し学習はEnd-to-Endでプリ・ポスト処理は無しテスト時は生出力を評価。プリ・ポスト処理は無し1GPUで10K x 10Kピクセルの画像を1分以内で処理

結果

結果
他手法との比較 広大地域例

ソーラーパネルマッピング
サンフランシスコ

Joon Son Chung et al, Department of Engineering Science, University of Oxford. Google DeepMind
LIP READING SENTENCES IN THE WILD
SESSION 3
https://arxiv.org/pdf/1611.05358v1.pdf

LIP READING


CONVNET


学習

結果
WAS: Watch, Attend&SpellLAS: Listen, Attend & SpellWLAS: Watch, Listen, Attend & SpellCL: Curriculum LearningSS: Scheduled SamplingBS: Beam Search

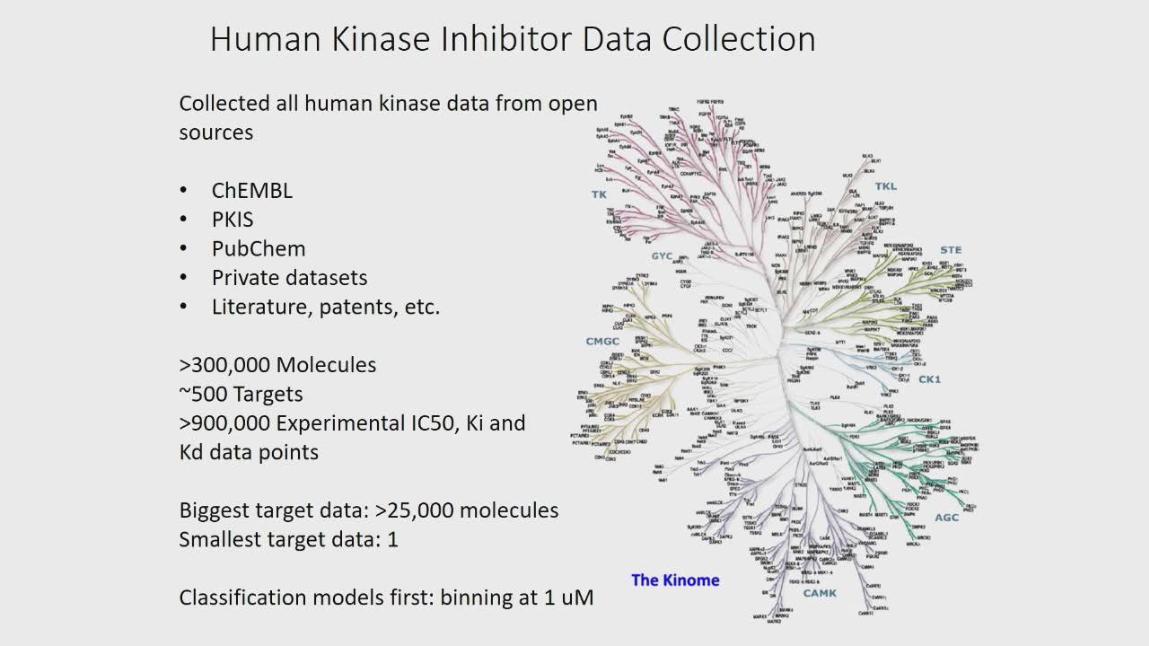
Olexandr Isayev Research Assistant Professor, University of North Carolina at Chapel Hill
ACCURATE PREDICTION OF PROTEIN KINASE INHIBITORS WITH DEEP
CONVOLUTIONAL NEURAL NETWORKS
SESSION 4









Han Zhang et al, Department of Computer Science, Rutgers University et al.
STACKGAN: TEXT TO PHOTO-REALISTIC IMAGE SYNTHESIS WITH STACKED
GENERATIVE ADVERSARIAL NETWORKS
SESSION 5
https://arxiv.org/pdf/1612.03242v1.pdf

GAN おさらい

GENERATIVE ADVERSARIAL TEXT TO IMAGE SYNTHESIS
文章から画像を生成するGAN
ψ:Text Encoder (今回128次元)
https://arxiv.org/pdf/1605.05396v2.pdf
Scott Reed et al, University of Michigan
https://arxiv.org/pdf/1605.05396.pdf


STACKGAN


Edward Raff Lead Scientist, Booz Allen Hamilton Jared Sylvester Senior Consultant , Booz Allen Hamilton
FIGHTING MALWARE WITH MACHINE LEARNING
SESSION 6

マルウェアに対するMLの必要性
• マルウェアの数は指数関数的に増加している• アンチウィルスや署名ベースのアプローチは受動的で最新のマルウェアには有効でない• 現在のアプローチは労働集約的で、優秀なアナリストを必要とする• 機械学習は能動的ソリューションの潜在的可能性を秘めているが、難しい

マルウェアの難しさデータに良いラベルをつけるのが困難
•領域の専門家が必要
•良性のデータの入手が特に困難
変数の長さと大きさ
•ひとつのバイナリは数KBから100MB以上にもなる
敵の行動は無限
データのモダリティ性
•ヘッダ、コード、データなどがそれぞれ異なる振る舞いをする
•バイトの意味は前後により変化する

MLによるマルウェア対策の現状
機械学習を使用し、専門知識が最小限でもマルウェアに対応していきたい
•高価で、マルウェアはいつも上手く動作するとは限らない
n-gramなどツールを使う前には多くの作業が発生し、多くの結果はデータ品質の問題に悩まされている
• Journal of Computer Virology and Hacking Techniques に載っている“An Investigation of Byte N-Gram Features for Malware Classification”を見よう
ディープラーニングは解決法を提供してくれそう
短期: より簡単なケースを手に入れ、より難しいものはMLを使ってアナリストを支援する

小規模な結果: PEヘッダを使用PEヘッダを使用して、ニューラルネットワークのアプローチと専門知識(DK)のアプローチを比較
•ニューラルネットワークはすべてのテストセットでよりよい性能を示した
•高いAUCは高いランキングになります
ニューラルネットワークが単なるバイトシーケンスから学習が可能かを検証する
アテンションLSTMで学習し、類似のアイテムが学習できているかの確認に使用
•TitanXを用いてモデルの学習に11日

アテンションとは?

アテンションとは?

現在の研究とゴール
全バイナリ上でこれを再現できるか?
CNNとRNNの組み合わせ長さが変化するバイナリを扱うのにRNNを使用する
バイト単位での学習がとても大きくなるのが問題:200万以上のステップ
CNNは一度に多くのバイトを処理するのに使用する。
アテンションは入力の一部を無視するのに使用する粗いラベルのみで学習した場合、バイナリのどの部分に害があるかを推測するのに役立つ

最終的なアーキテクチャ

Associate Professor, Icahn School of Medicine at Mount Sinai, New York
DEEP PATIENT: PREDICT THE MEDICAL FUTURE OF PATIENTS WITH DEEP
LEARNING
SESSION 7

INTRODUCTION
• ヘルスケアに対するコストの上昇は、予防医学への動機となっている• 健康を促進し、維持し、疾病、障害、および死亡を予防するための予防的アプローチ
• 個別化医療(Precision Medicine)
• 個人の状態のすべての側面を考慮に入れた疾病の治療と予防の新たなアプローチ
• 適切な治療が適切な患者に適切なタイミングで提供されるようにする
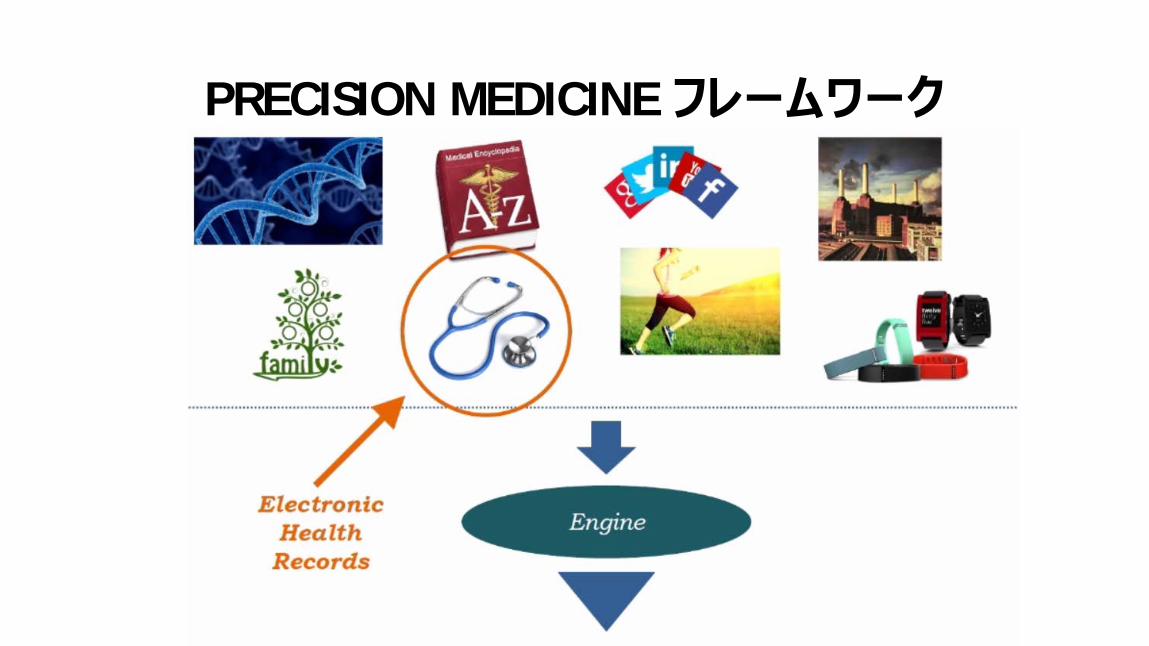
PRECISION MEDICINE フレームワーク

現状の問題点• EHRはその高い次元、ノイズ、異質性、希薄性、不完全性、ランダム誤差、および系統的バイアスによりモデル化が難しい
• モデルやシステムは特定の病気に焦点を当てている
• 臨床医によりアドホックな記述子が手作業で選ばれている
• スケーラブルでない
• 知らないパターンは無視される
• 病院内ではすべての臨床記述子で構成される生ベクトルが利用可能
• 希薄でノイズ交じりで繰り返し
• 単純な特徴学習アルゴリズムを用いた基本的な事前処理
• データに組み込まれた階層情報をモデル化することが出来ない

DEEP PATIENT
Deep Learningで患者のデータを処理し、自由度が高く、高密度で、堅牢で低次元であり、患者の将来の出来事を予測するために効果的に使用できる表現を導き出す

構成
臨床データウェアハウスからEHRを取り出し患者ごとに集める
教師無しの深層特徴学習を用いて、患者ごとの深層表現を抽出
深層表現から患者の将来のイベントを予測する

データ事前処理
データウェアハウスの患者データ
臨床的に関連する表現型に正規化情報の分散を抑えるため、類似のコンセプトのものは、同じ臨床カテゴリにグループ化
患者ごとのデータをベクトル表現(Bag of phenotype)にまとめる

ネットワークアーキテクチャ

DENOISING AUTOENCODER

病気の予測:実験
病気の予測
患者の現在の臨床ステータスを下に、一定期間後の発病の確率を予測する
学習データセット
1980年~2013年の患者データ (約160万人)
テストセット
10万人の患者 2014年の新たな診断結果により評価
79種類の病気 腫瘍学、内分泌学、心臓学など

結果

結果

Aviv Tamar, Yi Wu, Garrett Thomas, Sergey Levine, and Pieter AbbeelDept. of Electrical Engineering and Computer Sciences, UC Berkeley
VALUE ITERATION NETWORKS
SESSION 8

アプリケーション例
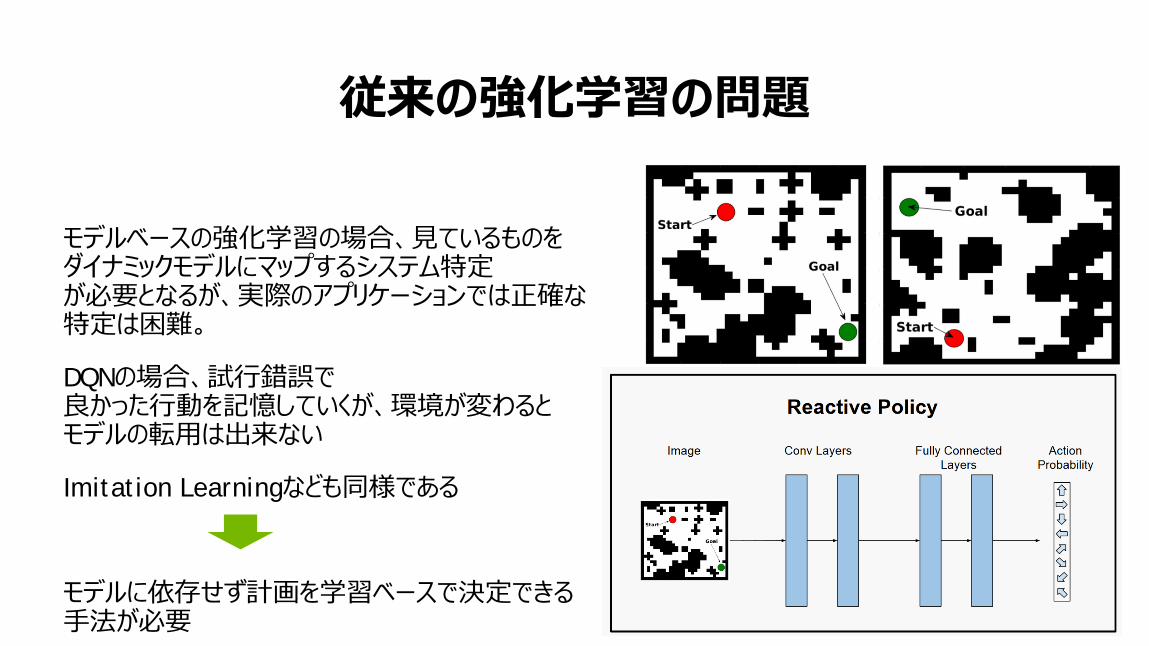
従来の強化学習の問題
モデルベースの強化学習の場合、見ているものをダイナミックモデルにマップするシステム特定が必要となるが、実際のアプリケーションでは正確な特定は困難。
DQNの場合、試行錯誤で良かった行動を記憶していくが、環境が変わるとモデルの転用は出来ない
Imitation Learningなども同様である
モデルに依存せず計画を学習ベースで決定できる手法が必要

ネットワークモデル(VIN)

結果
