one tool to rule them all- seamless sql on mongodb, mysql ... · mongodb, mysql and redis with...
TRANSCRIPT

Tim Vaillancourt Sr. Technical Operations Architect
One Tool to Rule Them All: Seamless SQL on MongoDB, MySQL and Redis with Apache Spark

Staring..
as “the RDBMs”
as “the document-store”
as “the in-memory K/V store”

About Me• Joined Percona in January 2016• Sr Technical Operations Architect for MongoDB• Previous:
• EA DICE (MySQL DBA)• EA SPORTS (Sys/NoSQL DBA Ops)• Amazon/AbeBooks Inc (Sys/MySQL+NoSQL DBA Ops)
• Main techs: MySQL, MongoDB, Cassandra, Solr, Redis, queues, etc• 10+ years tuning Linux for database workloads (off and on) • NOT an Apache Spark expert

Apache Spark• “…is a fast and general engine for large-scale data processing” • Written in Scala, utilises Akka streaming framework and runs under Java JVM• Supports jobs written in Java, Scala, Python and R• Pluggable datasources for various file types, databases, SaaSs, etc• Fast and efficient: jobs work on datasources quickly in parallel• Optional clustering
• Master/Slave Spark cluster, Zookeeper for Master elections• Slave workers connect to master• Master distributes tasks evenly to available workers
• Streaming and Machine Learning (MLib) capabilities• Programatic and SQL(!) querying capabilities

Apache Spark: Software Architecture• Jobs go to Cluster Master or runs in the
client JVM directly• Cluster Master directs jobs to nodes
with available resources with messages• Cluster Master HA
• Slaves reconnect to Master• Apache Zookeeper for true HA

Apache Spark: Hadoop Comparison• Hadoop MapReduce
• Batch-based• Uses data less efficiently• Relatively hard to develop/maintain
• Spark• Stream Processing• Fast/Parallelism
• Prefers memory as much as possible in jobs• Divides work into many lightweight sub-tasks in threads
• Datasources• Uses datasource-awareness to scale (eg: indices, shard-awareness, etc)
• Spark allows processing and storage to scale separately

Apache Spark: RDDs and DataFrames• RDD: Resilient Distributed Dataset
• Original API to access data in Spark• Lazy: does not access data until a real action is performed• Spark’s optimiser cannot see inside• RDDs are slow on Python
• DataFrames API• Higher level API, focused on the “what” is being done• Has schemas / table-like• Interchangeable Programming and SQL APIs• Much easier to read and comprehend• Optimises execution plan

Apache Spark: Datasources• Provides a pluggable mechanism for accessing structured data though Spark SQL• At least these databases are supported in some way
• MySQL• MongoDB• Redis• Cassandra• Postgres• HBase• HDFS• File• S3
• In practice: search GitHub, find .jar file, deploy it!

Apache Spark: SQLContext• ANSI SQL
• 30+ year old language..• Easy to understand• Everyone usually knows it
• Spark SQLContext• A Spark module for structured data processing, wrapping RDD API• Uses the same execution engine as the programatic APIs• Supports:
• JOINs/unions• EXPLAINs,• Subqueries,• ORDER/GROUP/SORT BYs• Most datatypes you’d expect
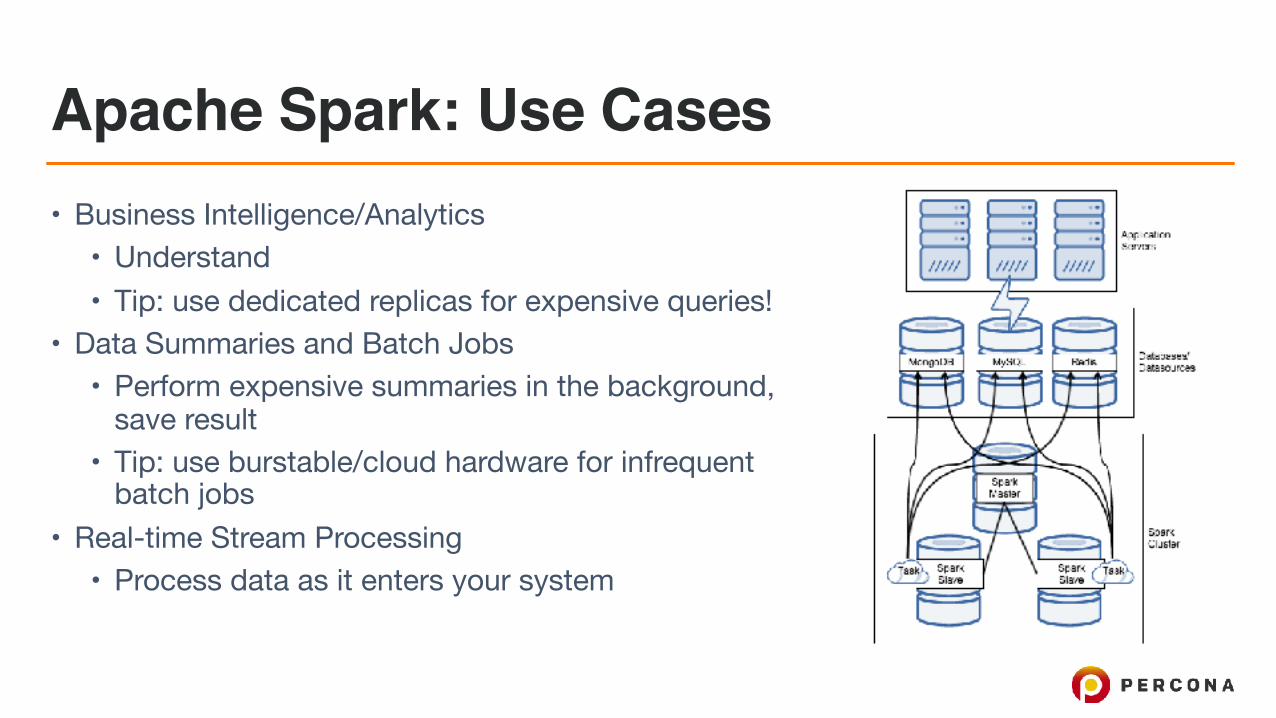
Apache Spark: Use Cases• Business Intelligence/Analytics
• Understand • Tip: use dedicated replicas for expensive queries!
• Data Summaries and Batch Jobs• Perform expensive summaries in the background,
save result• Tip: use burstable/cloud hardware for infrequent
batch jobs• Real-time Stream Processing
• Process data as it enters your system

So why not Apache Drill?• A schema-free SQL engine for Hadoop, NoSQL and Cloud Storage• Drill does not support / work with
• Relational databases (MySQL) or Redis• No programatic-level querying• No streaming/continuous query functionality
• I don’t know much about it

The Demo• Scenario: You run a Weather Station data app that stores data in both an
RDBMs and a document store• Goal: summarise weather station data stored in an RDBMs and a
Document store• Min Water Temperature• Avg Water Temperature• Max Water Temperature• Total Sample Count• Get Top-10 (based on avg water temp)

The Demo• RDBMs: Percona Server for MySQL 5.7
• Stores the Weather station metadata data (roughly 350 stations: ID, name, location, etc)
• Document-Store: Percona Server for MongoDB 3.2• Stores the Weather time-series sample data (roughly 80,000 samples:
various weather readings from stations)• In-Memory K/V Store: Redis 2.8
• Store summarised Top-10 data for fast querying of min, avg, max temperature and total sample counts

The Demo• Apache Spark 1.6.2
Cluster• 1 x Master• 2 x Worker/Slaves
• 1 x Pyspark Job• 1 x Macbook Pro• 3 x Virtualbox VMs• Job submitted on Master
The Demo
(Play Demo Video Now)

The Demo: The Pyspark Job
<- SparkContext and SQLContext
<- MySQL Table as SQLContext Temp Table

The Demo: The Pyspark Job
<- MongoDB Collection as SQLContext Temp Table
<- New Redis Hash Schema as SQLContext Temp Table

The Demo: The Pyspark Job
<- From Redis
<- Aggregation

The Demo: The Pyspark Job
<- Aggregation

The Demo

The Demo

The Demo

The Demo

Questions?

DATABASE PERFORMANCEMATTERS