online supervised learning of non-understanding recovery policies dan bohus dbohus [email protected]...
Post on 20-Dec-2015
214 views
TRANSCRIPT

online supervised learning of non-understanding recovery policies
Dan Bohuswww.cs.cmu.edu/[email protected]
Computer Science DepartmentCarnegie Mellon UniversityPittsburgh, PA 15213
with thanks to:
Alex RudnickyBrian LangnerAntoine Raux
Alan BlackMaxine Eskenazi

2
•Sorry, I didn’t catch that …•Can you repeat that?•Can you rephrase that?•Where are you flying from?•Please tell me the name of the city you are leaving from …•Could you please go to a quieter
place?•Sorry, I didn’t catch that … tell me the state first …
S:
understanding-errors in spoken dialog
S: Where are you flying from?U: Birmingham [BERLIN PM]
System constructs an incorrect semantic representation of the user’s turn
MIS-understanding
S: Where are you flying from?U: Urbana Champaign [OKAY IN THAT SAME PAY]
System fails to construct a semantic representation of the user’s turn
NON-understanding
•Did you say Berlin?•from Berlin … where to?
S:
???

3
recovery strategies
large set of strategies (“strategy” = 1-step action)
tradeoffs not well understood some strategies are more appropriate at
certain times OOV -> ask repeat is not a good idea door slam -> ask repeat might work well
•Sorry, I didn’t catch that …•Can you repeat that?•Can you rephrase that?•Where are you flying from?•Please tell me the name of the city you are leaving from …•Could you please go to a quieter place?•Sorry, I didn’t catch that … tell me the state first …
S:

4
recovery policy
“policy” = method for choosing between strategies
difficult to handcraft especially over a large set of recovery strategies
common approaches heuristic “three strikes and you’re out” [Balentine]
1st non-understanding: ask user to repeat 2nd non-understanding: provide more help, including
examples 3rd non-understanding: transfer to an operator

5
this talk …
… an online, supervised method for learning a non-understanding recovery policy from data

6
overview
introduction
approach
experimental setup
results
discussion

7
overview
introduction
approach
experimental setup
results
discussion

8
intuition …
… if we knew the probability of success for each strategy in the current situation, we could easily construct a policy
S: Where are you flying from?U: [OKAY IN THAT SAME PAY] Urbana Champaign
•Sorry, I didn’t catch that …•Can you repeat that?•Can you rephrase that?•Where are you flying from?•Please tell me the name of the city you are leaving from …•Could you please go to a quieter place?•Sorry, I didn’t catch that … tell me the state first …
S: 32%15%20%30%45%25%43%

9
two step approach
step 1: learn to estimate probability of success for each strategy, in a given situation
step 2: use these estimates to choose between
strategies (and hence build a policy)

10
learning predictors for strategy success
supervised learning: logistic regression target: strategy recovery successfully or not
“success” = next turn is correctly understood labeled semi-automatically
features: describe current situation extracted from different knowledge sources
recognition features language understanding features dialog-level features [state, history]

11
logistic regression
well-calibrated class-posterior probabilities predictions reflect empirical probability of success
x% of cases where P(S|F)=x are indeed successful
sample efficient one model per strategy, so data will be sparse
stepwise construction automatic feature selection
provide confidence bounds very useful for online learning

12
two step approach
step 1: learn to estimate probability of success for each strategy, in a given situation
step 2: use these estimates to choose between
strategies (and hence build a policy)

13
policy learning
choose strategy most likely to succeed
BUT: we want to learn online we have to deal with the exploration /
exploitation tradeoff
S1 S2 S3 S4 0
1

14
highest-upper-bound learning choose strategy with highest-upper-bound
proposed by [Kaelbling 93] empirically shown to do well in various problems
intuition
S1 S2 S3 S4 0
1
S1 S2 S3 S4 0
1
exploitation exploration

15
highest-upper-bound learning choose strategy with highest upper
bound proposed by [Kaelbling 93] empirically shown to do well in various
problems
intuition
S1 S2 S3 S4 0
1
S1 S2 S3 S4 0
1
exploitation exploration

16
highest-upper-bound learning choose strategy with highest upper
bound proposed by [Kaelbling 93] empirically shown to do well in various
problems
intuition
S1 S2 S3 S4 0
1
S1 S2 S3 S4 0
1
exploitation exploration

17
highest-upper-bound learning choose strategy with highest upper
bound proposed by [Kaelbling 93] empirically shown to do well in various
problems
intuition
S1 S2 S3 S4 0
1
S1 S2 S3 S4 0
1
exploitation exploration

18
highest-upper-bound learning choose strategy with highest upper
bound proposed by [Kaelbling 93] empirically shown to do well in various
problems
intuition
S1 S2 S3 S4 0
1
S1 S2 S3 S4 0
1
exploitation exploration

19
overview
introduction
approach
experimental setup
results
discussion

20
system
Let’s Go! Public bus information system
connected to PAT customer service line during non-business hours
~30-50 calls / night

21
strategiesName Example
HLP For instance, you can say ‘FORBES AND MURRAY’, or ‘DOWNTOWN’
HLP_RFor instance, you can say ‘FORBES AND MURRAY’, or ‘DOWNTOWN’, or say ‘START OVER’ to restart
RP Where are you leaving from? [repeats previous system prompt]
AREP Can you repeat what you just said?
ARPH Could you rephrase that?
MOVETell me first your departure neighborhood … [ignore the current non-understanding and back-off to an alternative dialog plan]
ASAPlease use shorter answers because I have trouble understanding long sentences …
SLL Sorry, I understand people best when they speak softer …
IT Give general interaction tips to the user
ASOI’m sorry but I’m still having trouble understanding you and I might do better if we restarted. Would you like to start over?
GUPI’m sorry, but it doesn’t seem like I’m able to help you. Please call back during regular business hours …

22
constraints
constraints don’t AREP more than twice in a row don’t ARPH if #words <= 3 don’t ASA unless #words > 5 don’t ASO unless (4 nonu in a row) and (ratio.nonu >
50%) don’t GUP unless (dialog > 30 turns) and (ratio.nonu >
80%)
capture expert knowledge; ensure system doesn’t use an unreasonable policy
4.2/11 strategies available on average min=1, max=9

23
features
current non-understanding recognition, lexical, grammar, timing info
current non-understanding segment length, which strategies already taken
current dialog state and history encoded dialog states
“how good things have been going”

24
learning
baseline period [2 weeks, 3/11 -> 3/25, 2006] system randomly chose a strategy, while obeying
constraints
in effect, a heuristic / stochastic policy
learning period [5 weeks, 3/26 -> 5/5, 2006] each morning labeled data from previous night
retrained likelihood of success predictors
installed in the system for the next night

25
2 strategies eliminatedName Example
HLP For instance, you can say ‘FORBES AND MURRAY’, or ‘DOWNTOWN’
HLP_RFor instance, you can say ‘FORBES AND MURRAY’, or ‘DOWNTOWN’, or say ‘START OVER’ to restart
RP Where are you leaving from? [repeats previous system prompt]
AREP Can you repeat what you just said?
ARPH Could you rephrase that?
MOVETell me first your departure neighborhood … [ignore the current non-understanding and back-off to an alternative dialog plan]
ASAPlease use shorter answers because I have trouble understanding long sentences …
SLL Sorry, I understand people best when they speak softer …
IT Give general interaction tips to the user
ASOI’m sorry but I’m still having trouble understanding you and I might do better if we restarted. Would you like to start over?
GUPI’m sorry, but it doesn’t seem like I’m able to help you. Please call back during regular business hours …

26
overview
introduction
approach
experimental setup
results
discussion
27
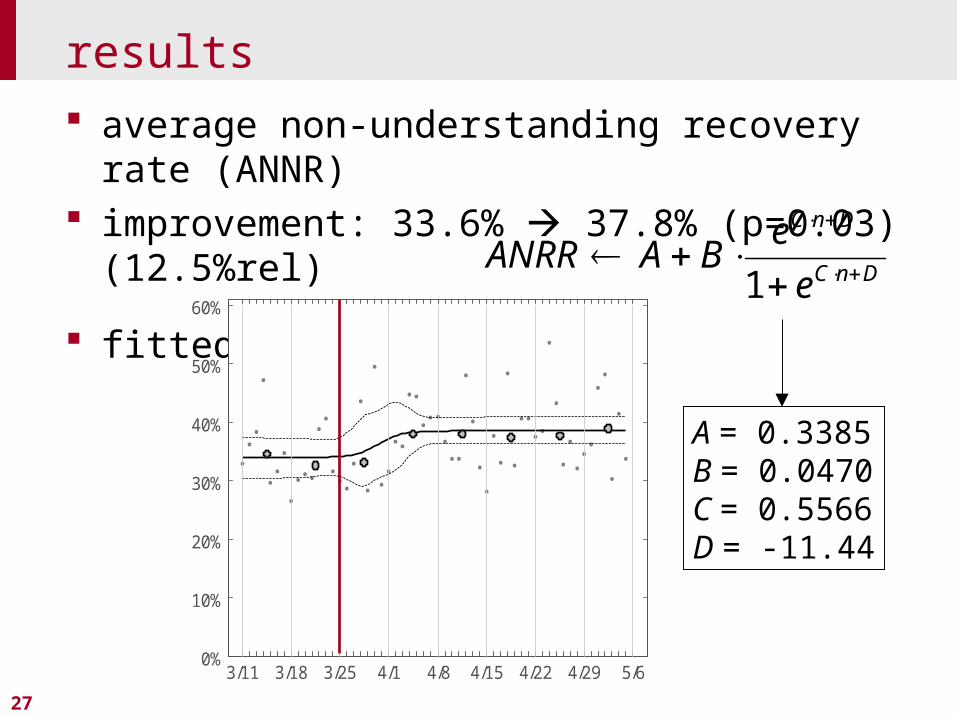
results average non-understanding recovery rate
(ANNR) improvement: 33.6% 37.8% (p=0.03)
(12.5%rel)
fitted learning curve:
3/11 3/18 3/25 4/1 4/8 4/15 4/22 4/29 5/60%
10%
20%
30%
40%
50%
60%
DnC
DnC
e
eBAANRR
1
A = 0.3385B = 0.0470C = 0.5566D = -11.44

28
policy evolution MOVE, HLP, ASA engaged more often AREP, ARPH engaged less often
3/11 3/18 3/25 4/1 4/8 4/15 4/22 4/29 5/60%
20%
40%
60%
80%
100%
MOVE
ASA
IT
SLL
ARPH
AREP
HLP
RP
HLP_R

29
overview
introduction
approach
experimental setup
results
discussion

30
are the predictors learning anything?
AREP(653), IT(273), SLL(300) no informative features
ARPH(674), MOVE(1514) 1 informative feature (#prev.nonu, #words)
ASA(637), RP(2532), HLP(3698), HLP_R(989) 4 or more informative features in the model
dialog state (especially explicit confirm states) dialog history

31
more features, more (specific) strategies
more features would be useful day-of-week clustered dialog states ? (any ideas?) ?
more strategies / variants approach might be able to filter out bad
versions more specific strategies, features
ask short answers worked well … speak less loud didn’t … (why?)

32
“noise” in the experiment
~15-20% of responses following non-understandings are non-user-responses transient noises secondary speech primary speech not directed to the system
this might affect training, in a future experiment we want to eliminate that

33
unsupervised learning
supervised version “success” = next turn is correctly understood
[i.e. no misunderstanding, no non-understanding]
unsupervised version “success” = next turn is not a non-
understanding “success” = confidence score of next turn training labels automatically available performance improvements might still be
possible

34
thank you!