ontology mapping needs context & approximation frank van harmelen vrije universiteit amsterdam
Post on 20-Dec-2015
217 views
TRANSCRIPT

Ontology mapping needs
context & approximation
Frank van HarmelenVrije Universiteit Amsterdam

2
Or:
andmore like a social conversation
How to make ontology-mapping less like data-base integration

3
Two obvious intuitions
Ontology mapping needs background knowledge
Ontology mapping needs approximation
The Semantic Web needs ontology mapping
Three

4
Which Semantic Web?Version 1:
"Semantic Web as Web of Data" (TBL)
recipe:expose databases on the web, use RDF, integrate
meta-data from: expressing DB schema semantics
in machine interpretable waysenable integration and unexpected re-
use

5
Which Semantic Web?Version 2:
“Enrichment of the current Web”
recipe:Annotate, classify, index
meta-data from: automatically producing markup:
named-entity recognition, concept extraction, tagging, etc.
enable personalisation, search, browse,..

6
Which Semantic Web?Version 1:
“Semantic Web as Web of Data”
Version 2:“Enrichment of the current Web”
Different use-cases Different techniques Different users
data-oriented
user-oriented

7between source & user
Which Semantic Web?Version 1:
“Semantic Web as Web of Data”
between sources
Version 2:“Enrichment of the current Web”
But both need ontologiesfor semantic agreement

8
Ontology research is almost done..we know what they are
“consensual, formalised models of a domain”we know how to make and maintain
them (methods, tools, experience)
we know how to deploy them(search, personalisation, data-integration, …)
Main remaining open questions Automatic construction (learning) Automatic mapping (integration)

9
Three obvious intuitions
Ontology mapping needs background knowledge
Ontology mapping needs approximation
The Semantic Web needs ontology mapping
Ph.D. student
young researcher
?=
?≈
AIO
post-doc

This work withZharko Aleksovski &
Michel Klein

Does context knowledge help mapping?

12
The general idea
source target
background knowledge
anchoring anchoring
mapping
inference

13
a realistic example Two Amsterdam hospitals (OLVG, AMC) Two Intensive Care Units, different vocab’s Want to compare quality of care OLVG-1400:
1400 terms in a flat list used in the first 24 hour of stay some implicit hierarchy e.g.6 types of Diabetes
Mellitus) some reduncy (spelling mistakes)
AMC: similar list, but from different hospital

14
Context ontology usedDICE:
2500 concepts (5000 terms), 4500 links Formalised in DL five main categories:
•tractus (e.g. nervous_system, respiratory_system)
•aetiology (e.g. virus, poising)
•abnormality (e.g. fracture, tumor)
•action (e.g. biopsy, observation, removal)
•anatomic_location (e.g. lungs, skin)

15
Baseline: Linguistic methods
Combine lexical analysis with hierarchical structure
313 suggested matches, around 70 % correct 209 suggested matches, around 90 % correct
High precision, low recall (“the easy cases”)

16
Now use background knowledge
OLVG (1400, flat)
AMC (1400, flat)
DICE(2500 concepts,
4500 links)
anchoring anchoring
mapping
inference

17
Example found with context knowledge (beyond lexical)

18
Example 2

19
Anchoring strengthAnchoring = substring + trivial
morphologyanchored on N aspects OLVG AMC
N=5N=4N=3N=2N=1
004
144401
2198711285208
total nr. of anchored termstotal nr. of anchorings
549129
8
39% 1404
5816
96%
21
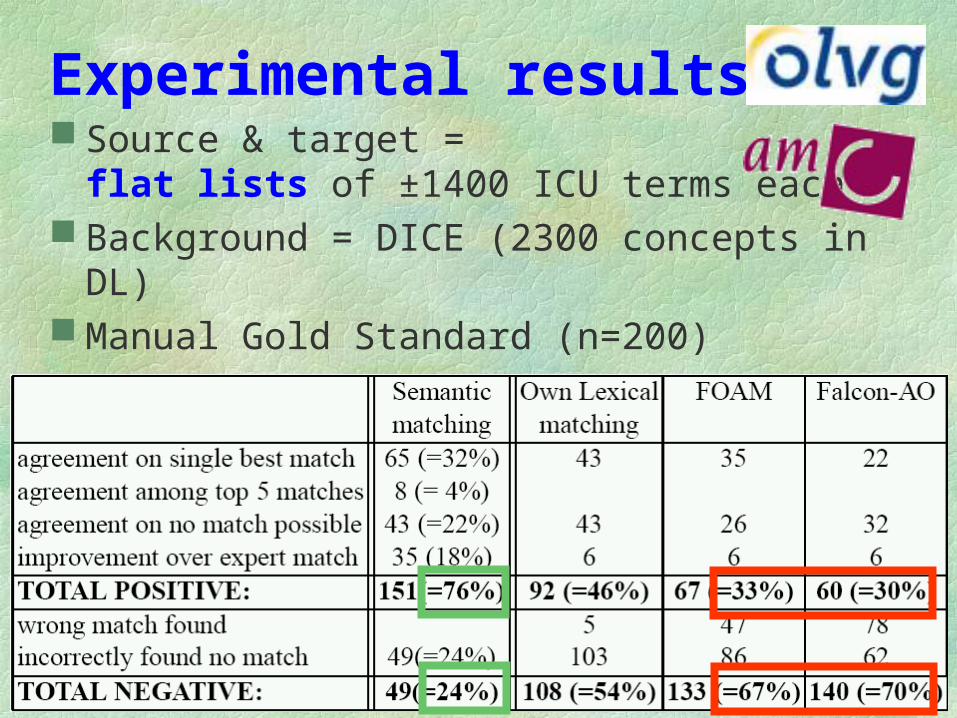
Experimental results Source & target =
flat lists of ±1400 ICU terms each Background = DICE (2300 concepts in DL) Manual Gold Standard (n=200)

Does more context knowledge help?

23
Adding more context Only lexical DICE (2500 concepts) MeSH (22000 concepts) ICD-10 (11000 concepts)
Anchoring strength:DICE MeSH ICD10
4 aspects 0 8 0
3 aspects 0 89 0
2 aspects 135 201 0
1 aspect 413 694 80
total 548 992 80

24
Results with multiple ontologies
Monotonic improvement Independent of order Linear increase of cost
Separate
Lexical ICD-10 DICE MeSH
RecallPrecision
64%95%
64%95%
76%94%
88%89%
Joint
0102030405060708090
100
Lexical ICD-10 DICE MeSH

does structured context knowledge help?

26
Exploiting structure CRISP: 700 concepts, broader-than MeSH: 1475 concepts, broader-than FMA: 75.000 concepts, 160 relation-types
(we used: is-a & part-of)
CRISP (738)
MeSH (1475)
FMA (75.000)
anchoring anchoring
mapping
inference

27
(S <a B) & (B < B’) & (B’ <a T) ! (S <i T)
a a
i
Using the structure or not ?

28
(S <a B) & (B < B’) & (B’ <a T) ! (S <i T)
No use of structure Only stated is-a & part-of Transitive chains of is-a, and
transitive chains of part-of Transitive chains of is-a and part-of One chain of part-of before
one chain of is-a
Using the structure or not ?

29
Examples

30
Examples

31
Matching results (CRISP to MeSH)
Recall = · ¸ total incr.
Exp.1:DirectExp.2:Indir. is-a + part-ofExp.3:Indir. separate closuresExp.4:Indir. mixed closuresExp.5:Indir. part-of before is-a
448
395
395
395
395
417516933151
1972
156405140
2222
8180
0
1021
1316
2730
4143
3167
-29%
167%306%210%
Precision = · ¸ total
correct
Exp.1:DirectExp.4:Indir. mixed closuresExp.5:Indir. part-of before is-a
171414
183937
35950
38112101
100%94%
100%
(Golden Standard n=30)

32
Three obvious intuitions
Ontology mapping needs background knowledge
Ontology mapping needs approximation
The Semantic Web needs ontology mapping
young researcher
?≈ post-doc

This work withZharko Aleksovski
Risto Gligorov Warner ten Kate

34
B
Approximating subsumptions(and hence mappings)
query: A v B ?
B = B1 u B2 u B3 A v B1, A v B2, A v
B3 ?
B1 B3
B2
A

35
Approximating subsumptions
Use “Google distance” to decide which subproblems are reasonable to focus on
Google distance
wheref(x) is the number of Google hits for xf(x,y) is the number of Google hits for
the tuple of search items x and yM is the number of web pages indexed by
)}(log),(min{loglog
),(log)}(log),(max{log),(
yfxfM
yxfyfxfyxNGD
≈ symmetric conditio
nal probability
of co-occurrence
≈ estimate of semantic distance
≈ estimate of “c
ontribution” to
B1 u B2 u B3
≈ symmetric conditio
nal probability
of co-occurrence
≈ estimate of semantic distance
≈ estimate of “c
ontribution” to
B1 u B2 u B3

37
Google distance
animal
sheep cow
madcow
vegeterian
plant

38
Google for sloppy matching
Algorithm for A v B (B=B1 u B2 u
B3)
determine NGD(B, Bi)=i, i=1,2,3
incrementally:
• increase sloppyness threshold • allow to ignore A v Bi with i ·
match if remaining A v Bj hold

39
Properties of sloppy matchingWhen sloppyness threshold goes up,
set of matches grows monotonically=0: classical matching=1: trivial matching
Ideally: compute i such that: desirable matches
become true at low undesirable matches
become true only at high Use random selection of Bi as baseline
?

40
CDNow (Amazon.com)
All Music Guide
MusicMoz
ArtistGigs
Artist Direct NetworkCD baby
YahooSize: 96 classesDepth: 2 levels
Size: 2410 classesDepth: 5 levels Size: 382 classes
Depth: 4 levels
Size: 222 classesDepth: 2 levels
Size: 1073 classesDepth: 7 levels
Size: 465 classesDepth: 2 levels
Size: 403 classesDepth: 3 levels
Experiments in music domain
very sloppy terms good

7 16-05-2006
Experimentpr
ecis
ion
recall
classical
randomNGD
Manual Gold Standard, N=50, random pairs
20
=0.5397
60 =0.5

wrapping up

43
Three obvious intuitions
Ontology mapping needs background knowledge
Ontology mapping needs approximation
The Semantic Web needs ontology mapping

44
So that shared context & approximation
make ontology-mapping a bit more like a social conversation

45
Future: Distributed/P2P setting
source target
background knowledge
anchoring anchoring
mapping
inference
