open source linkedin analytics pipeline - boss 2016 (vldb)
TRANSCRIPT

©2014 LinkedIn Corporation. All Rights Reserved.©2014 LinkedIn Corporation. All Rights Reserved.

Open Source Analytics Pipeline
at LinkedIn
Issac Buenrostro Jean-François ImBOSS Workshop, 2016

Outline
1 Overview of analytics at LinkedIn
2 Gobblin
3 Pinot
4 Demo
5 Operating an analytics pipeline in production
3
4

LinkedIn in Numbers
5
Members: 450m+
Number of datasets: 10k+
Data volume generated per day: 100TB+
Total accumulated data: 20PB+
Multiple datacenters
Thousands of nodes per Hadoop cluster
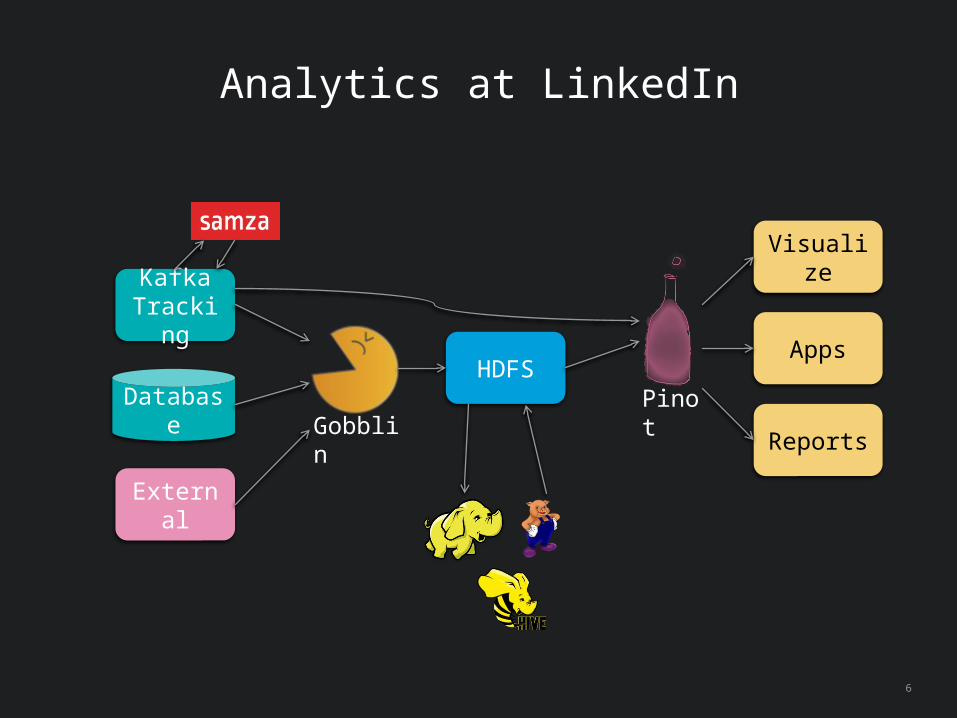
Analytics at LinkedIn
6
Kafka Tracking
External
Database Gobblin
HDFSPinot
Visualize
Apps
Reports
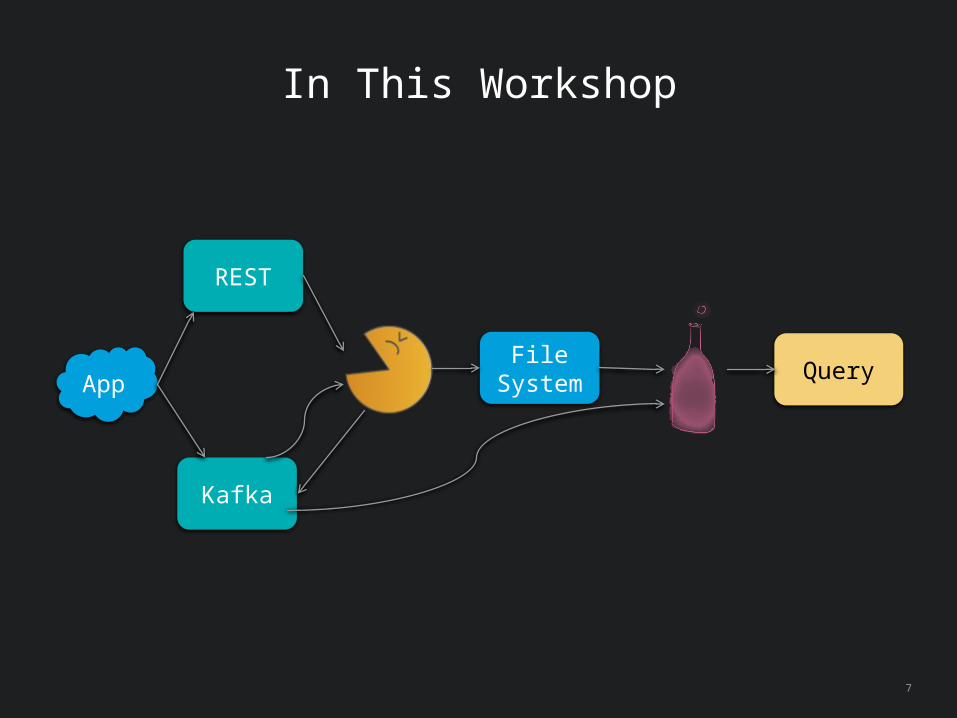
In This Workshop
7
Kafka
REST
FileSystem QueryApp

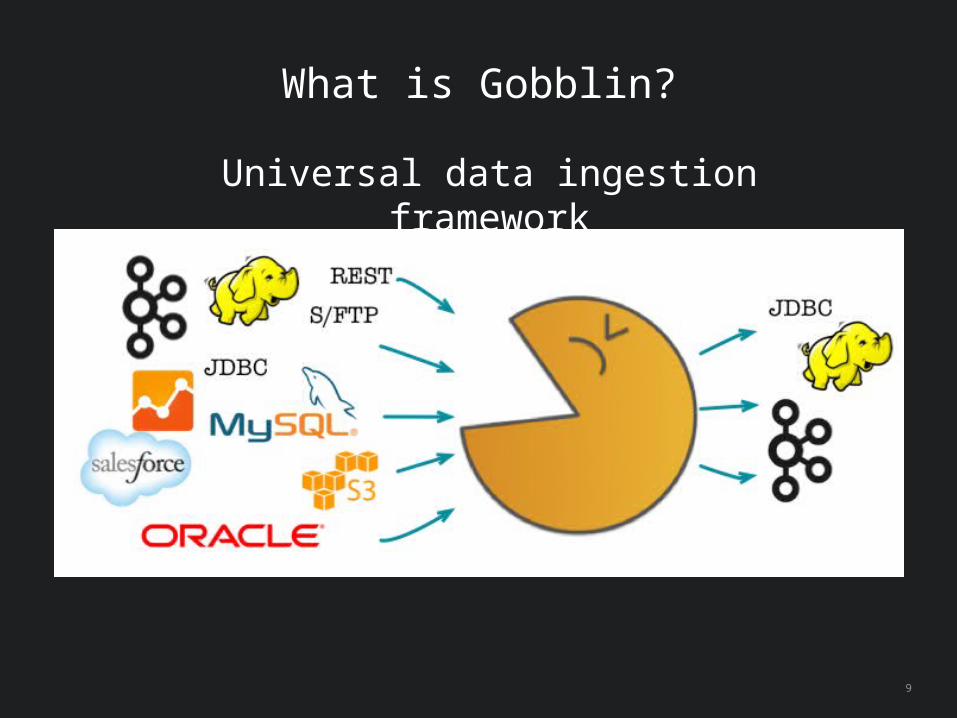
What is Gobblin?
Universal data ingestion framework
9

Gobblin Architecture
10

Sample Use Cases
1 Stream dumps (e.g. Kafka -> HDFS)
2 Snapshot dumps (e.g. Oracle, Salesforce -> HDFS)
3 Stream loading (e.g. HDFS -> Kafka)
4 Data cleaning (HDFS -> HDFS purging)
5 File download/copy (x-cluster replication, FTP/SFTP download)
11

Features
12
1. Pluggable sources, converters, quality checkers, writers.
2. Run on single node, Gobblin managed cluster, AWS, YARN (as MR or standalone YARN app).
3. Single Gobblin instance for multiple sources / sinks.
4. Quick start using templates for most common jobs.
5. Other Gobblin suite tools: metrics, retention, configuration management, data compaction.

Gobblin at LinkedIn
1 In production since 2014
2 ~20 different sources: Kafka, OLTP, HDFS, SFTP, Salesforce, MySQL, etc.
3 Process >100 TB per day
4 Process 10,000+ different datasets with custom configurations
5Configuration, retention, metrics, compaction handled by Gobblin suite
13

P not
14

What is Pinot?
15
• Distributed near-realtime OLAP datastore
• Horizontally scalable for larger data volumes and query rates
• Offers a SQL query interface
• Can index and combine data pushed from offline data sources (eg. Hadoop) and realtime data sources (eg. Kafka)
• Fault tolerant, no single point of failure

Pinot at LinkedIn
1 Over 50 different use cases (eg. “Who viewed my profile?”)
2 Several thousands of queries per second over billions of rows across multiple data centers
3 Operates 24x7 with no downtime for maintenance
4 The de facto data store for site-facing analytics at Linkedin
16
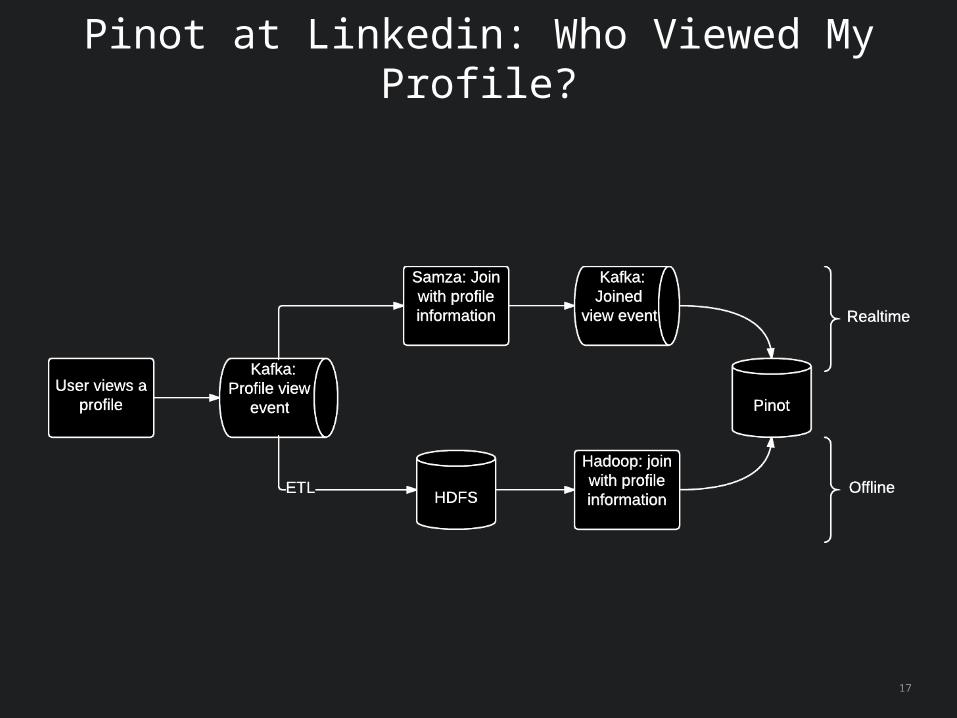
Pinot at Linkedin: Who Viewed My Profile?
17

Pinot Design Limitations
18
1. Pinot is designed for analytical workloads (OLAP), not transactional ones (OLTP)
2. Data in Pinot is immutable (eg. no UPDATE statement), though it can be overwritten in bulk
3. Realtime data is append-only (can only load new rows)
4. There is no support for JOINs or subselects
5. There are no UDFs for aggregation (work in progress)

Demo

How to run the demos back home
20
• Since we cover a lot of material during these demos, we’ll make the VM used for these demos available after the tutorial. This way you can focus on understanding what is demonstrated instead of trying to follow exactly what is being typed by the presenters.
• You can grab a copy of the VM after the tutorial at https://jean-francois.im/vldb/vldb-2016-gobblin-pinot-demo-vm.tar.gz or in person after the tutorial if you want to avoid downloading over the hotel Wi-Fi

Gobblin Demo Outline
21
1. Setting up Gobblin
2. Kafka to file system ingest
3. Wikipedia to Kafka ingest from scratch
4. Metrics and events
5. Other running modes

Gobblin Setup
22
Download binary: https://github.com/linkedin/gobblin/releases
Or download sources and build:
./gradlew assemble
Find tarball at build/gobblin-distribution/distributions
Untar, will generate a directory gobblin-dist

Gobblin Startup
23
cd gobblin-distexport JAVA_HOME=<java-home>
mkdir $HOME/gobblin-jobsmkdir $HOME/gobblin-workspace
bin/gobblin-standalone-v2.sh --conf $HOME/gobblin-jobs/ --workdir $HOME/gobblin-workspace/ start

Gobblin Directory Layout
24
gobblin-dist/ Gobblin binaries and scripts
|--- bin/ Startup scripts
|--- conf/ Global configuration files
|--- lib/ Classpath jars
|--- logs/ Execution log files
gobblin-workspace/ Workspace for Gobblin
|--- locks/ Locks for each job
|--- state-store/ Stores watermarks and failed work units
|--- task-output/ Staging area for job output
gobblin-jobs/ Place job configuration files here
|--- job.pull A job configuration
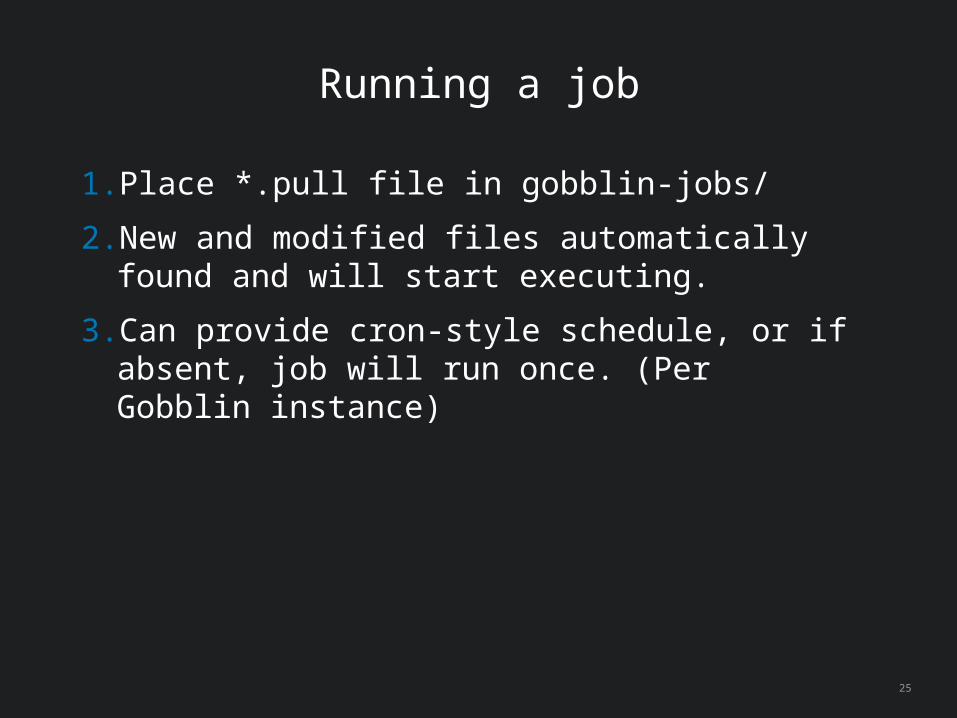
Running a job
25
1. Place *.pull file in gobblin-jobs/
2. New and modified files automatically found and will start executing.
3. Can provide cron-style schedule, or if absent, job will run once. (Per Gobblin instance)

Kafka Puller Job
26
gobblin-jobs/Kafka-puller.pull# Template to usejob.template=templates/gobblin-kafka.template
# Schedule in cron formatjob.schedule=0 0/15 * * * ? # every 15 minutes
# Job configurationjob.name=KafkaPulltopics=test
# Can override brokers# kafka.brokers="localhost:9092”
Pull records from Kafka topic (default at localhost), write them to gobblin-jobs/job-output in plain text.

Kafka Puller Job – Json to Avro
27
gobblin-jobs/kafka-puller-jsontoavro.pull
job.template=templates/gobblin-kafka.template
job.schedule=0 0/1 * * * ?
job.name=KafkaPullAvrotopics=jsonDate
converter.classes=gobblin.converter.SchemaInjector,gobblin.converter.json.JsonStringToJsonIntermediateConverter,gobblin.converter.avro.JsonIntermediateToAvroConvertergobblin.converter.schemaInjector.schema=<schema>
writer.builder.class=gobblin.writer.AvroDataWriterBuilderwriter.output.format=AVRO
# Uncomment for partitioning by date# writer.partition.columns=timestamp# writer.partitioner.class=gobblin.writer.partitioner.TimeBasedAvroWriterPartitioner# writer.partition.pattern=yyyy/MM/dd/HH

Kafka Pusher Job
28
Push changes from Wikipedia to a Kafka topic.
https://gist.github.com/ibuenros/3cb4c9293edc7f43ab41c0d0d59cb586

Gobblin Metrics and Events
29
Gobblin emits operational metrics and events.
metrics.enabled=truemetrics.reporting.file.enabled=truemetrics.log.dir=/home/gobblin/metrics
Write metrics to file
metrics.enabled=truemetrics.reporting.kafka.enabled=truemetrics.reporting.kafka.brokers=localhost:9092metrics.reporting.kafka.topic.metrics=GobblinMetricsmetrics.reporting.kafka.topic.events=GobblinEventsmetrics.reporting.kafka.format=avrometrics.reporting.kafka.schemaVersionWriterType=NOOP
Write metrics to Kafka

Gobblin Metric Flattening for Pinot
30
gobblin-jobs/gobblin-metrics-flattener.pulljob.template=templates/kafka-to-kafka.template
job.schedule=0 0/5 * * * ?
job.name=MetricsFlattenerinputTopics=GobblinMetricsoutputTopic=FlatMetrics
gobblin.source.kafka.extractorType=AVRO_FIXED_SCHEMAgobblin.source.kafka.fixedSchema.GobblinMetrics=<schema>
converter.classes=gobblin.converter.GobblinMetricsFlattenerConverter,gobblin.converter.avro.AvroToJsonStringConverter,gobblin.converter.string.StringToBytesConverter

Distributed Gobblin
31
Hadoop / YARNAzkaban Mode
• AzkabanGobblinDaemon (multi-job)
• AzkabanJobLauncher (single job)
MR mode
• bin/gobblin-mapreduce.sh (single job)
YARN mode
• GobblinYarnAppLauncher (experimental)
AWSSet up Gobblin cluster on AWS nodes.
In development:Distributed job running for standalone Gobblin
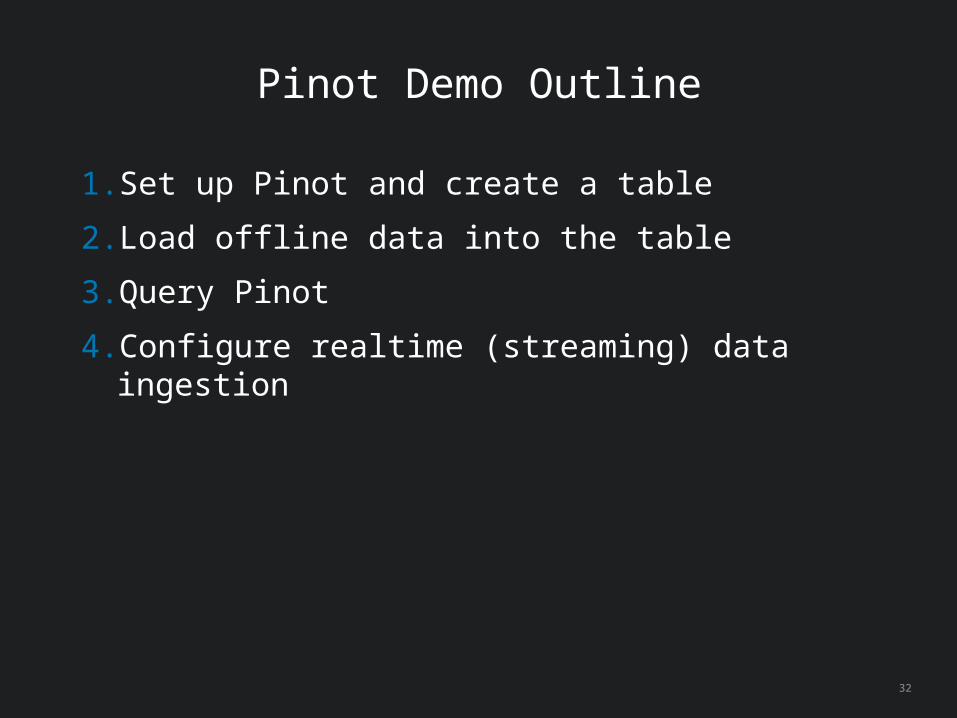
Pinot Demo Outline
32
1. Set up Pinot and create a table
2. Load offline data into the table
3. Query Pinot
4. Configure realtime (streaming) data ingestion

Pinot Setup
33
git clone the latest version
mvn -DskipTests install

Pinot Startup
34
cd pinot-distribution/target/pinot-0.016-pkg bin/start-controller.sh -dataDir /data/pinot/controller-data &bin/start-broker.sh &bin/start-server.sh -dataDir /data/pinot/server-data &
After Zookeeper and Kafka started.
This will:• Start a controller listening on localhost:9000• Start a broker listening on localhost:8099• Start a server, although clients don’t connect to it
directly.

Pinot architecture
35
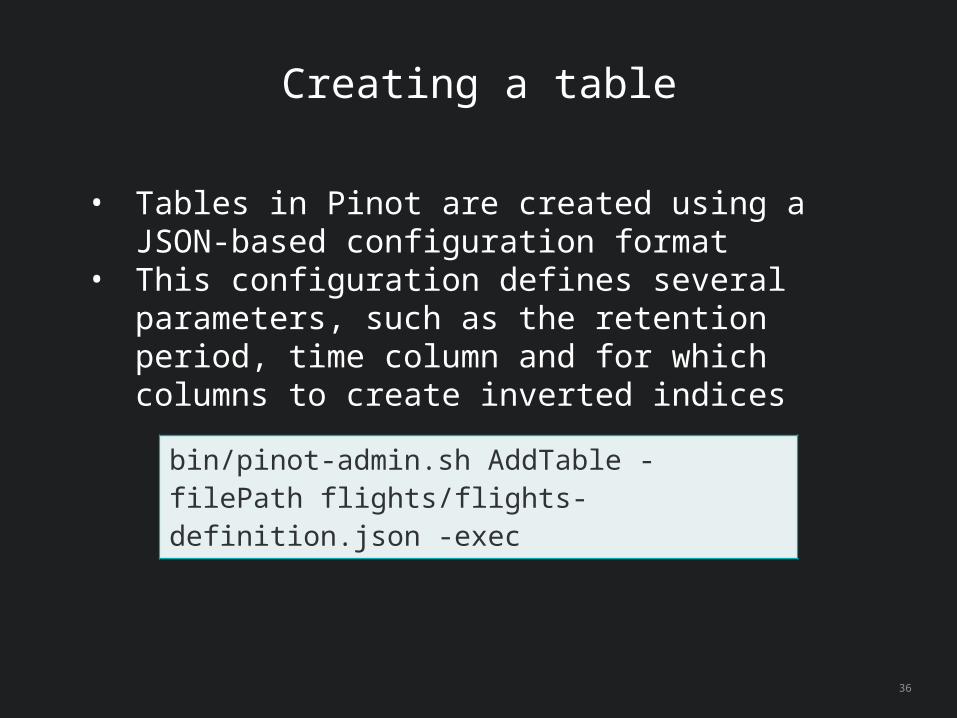
Creating a table
36
bin/pinot-admin.sh AddTable -filePath flights/flights-definition.json -exec
• Tables in Pinot are created using a JSON-based configuration format
• This configuration defines several parameters, such as the retention period, time column and for which columns to create inverted indices
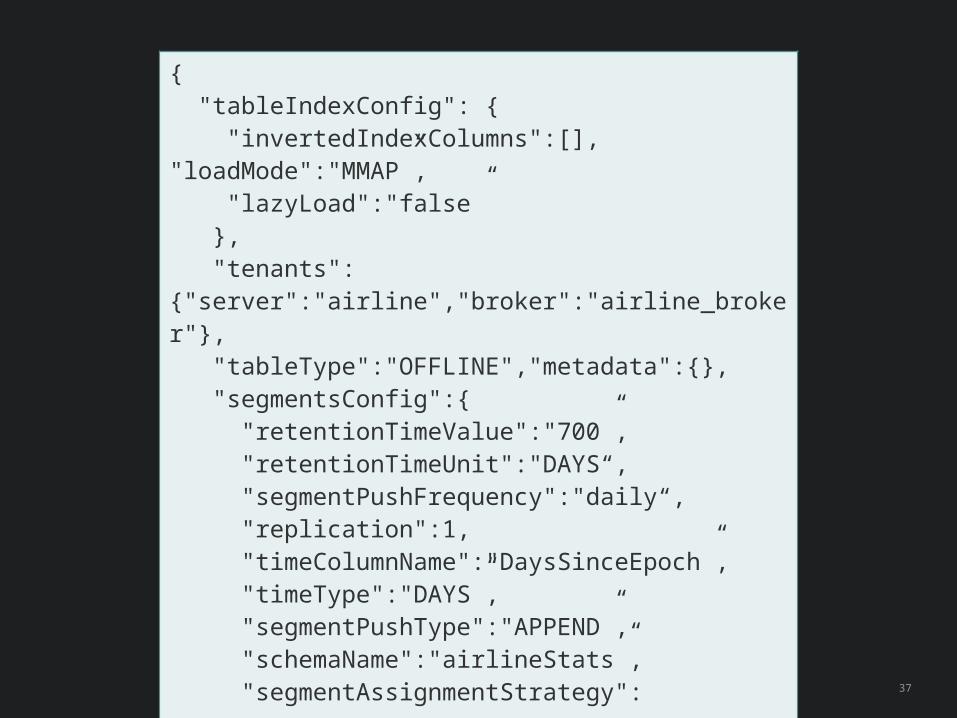
37
{ "tableIndexConfig": { "invertedIndexColumns":[], "loadMode":"MMAP”, "lazyLoad":"false” }, "tenants":{"server":"airline","broker":"airline_broker"}, "tableType":"OFFLINE","metadata":{}, "segmentsConfig":{ "retentionTimeValue":"700”, "retentionTimeUnit":"DAYS“, "segmentPushFrequency":"daily“, "replication":1, "timeColumnName":"DaysSinceEpoch”, "timeType":"DAYS”, "segmentPushType":"APPEND”, "schemaName":"airlineStats”, "segmentAssignmentStrategy": "BalanceNumSegmentAssignmentStrategy” }, "tableName":"airlineStats“}

Loading data into Pinot
38
• Data in Pinot is stored in segments, which are pre-indexed units of data
• To load our Avro-formatted data into Pinot, we’ll run a segment conversion (which can either be run locally or on Hadoop) to turn our data into segments
• We’ll then upload our segments into Pinot
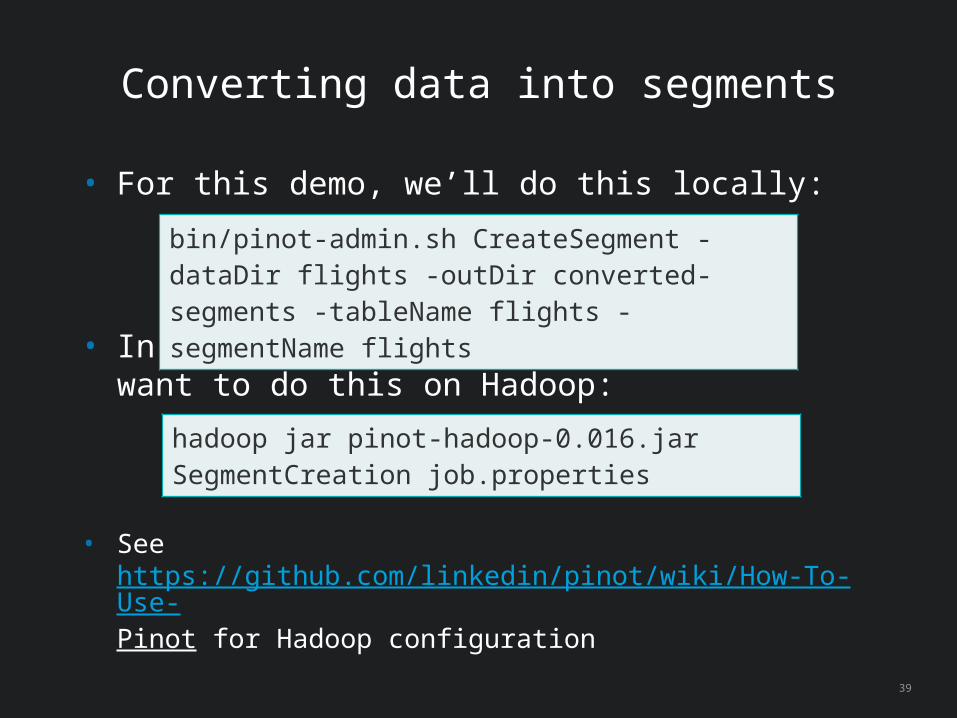
Converting data into segments
39
• For this demo, we’ll do this locally:
• In a production environment, you’ll want to do this on Hadoop:
• See https://github.com/linkedin/pinot/wiki/How-To-Use-Pinot for Hadoop configuration
bin/pinot-admin.sh CreateSegment -dataDir flights -outDir converted-segments -tableName flights -segmentName flights
hadoop jar pinot-hadoop-0.016.jar SegmentCreation job.properties
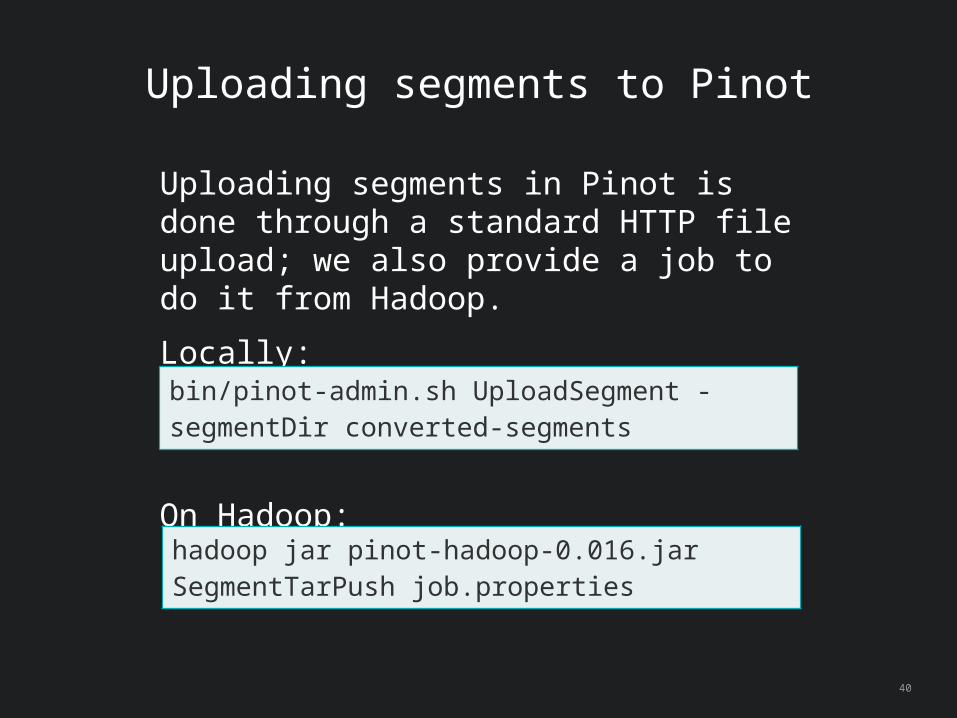
Uploading segments to Pinot
40
Uploading segments in Pinot is done through a standard HTTP file upload; we also provide a job to do it from Hadoop.
Locally:
On Hadoop:
bin/pinot-admin.sh UploadSegment -segmentDir converted-segments
hadoop jar pinot-hadoop-0.016.jar SegmentTarPush job.properties

Querying Pinot
41
• Pinot offers a REST API to send queries, which then return a JSON-formatted query response
• There is also a Java client, which provides a JDBC-like API to send queries
• For debugging purposes, it’s also possible to send queries to the controller through a web interface, which forwards the query to the appropriate broker
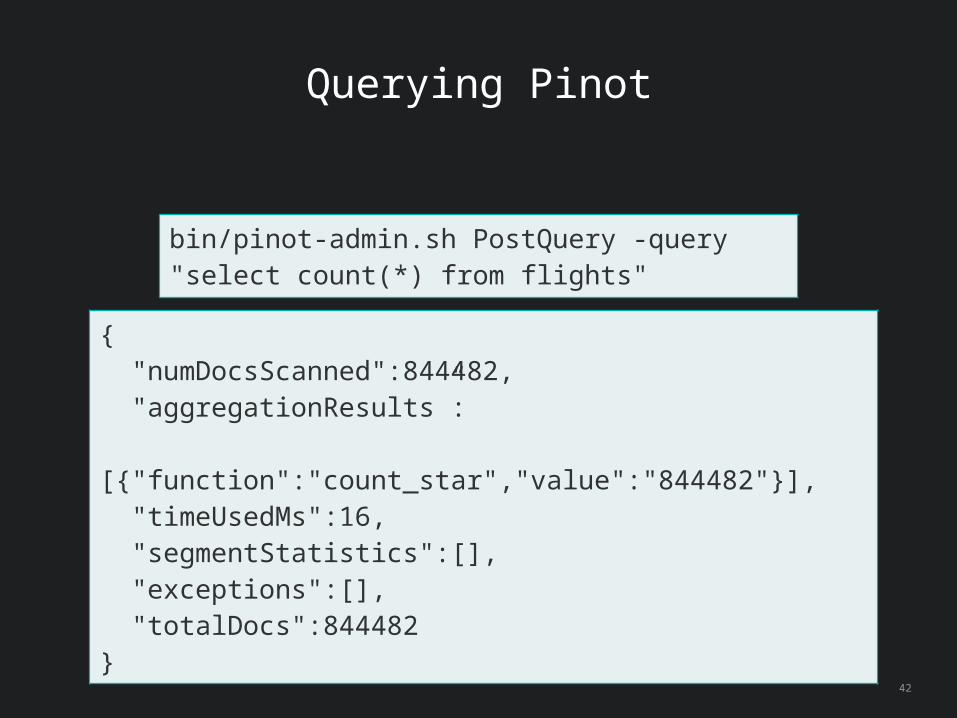
Querying Pinot
42
bin/pinot-admin.sh PostQuery -query "select count(*) from flights"
{ "numDocsScanned":844482, "aggregationResults”: [{"function":"count_star","value":"844482"}], "timeUsedMs":16, "segmentStatistics":[], "exceptions":[], "totalDocs":844482}

Adding realtime ingestion
43
• We could make our data fresher by running an offline push job more often, but there’s a limit as to how often we can do that
• In Pinot, there are two types of tables: offline and realtime (eg. streaming from Kafka)
• Pinot supports merging offline and realtime tables at runtime

Realtime table and offline table
44

SELECT SUM(foo) rewrite
45
Configuring realtime ingestion
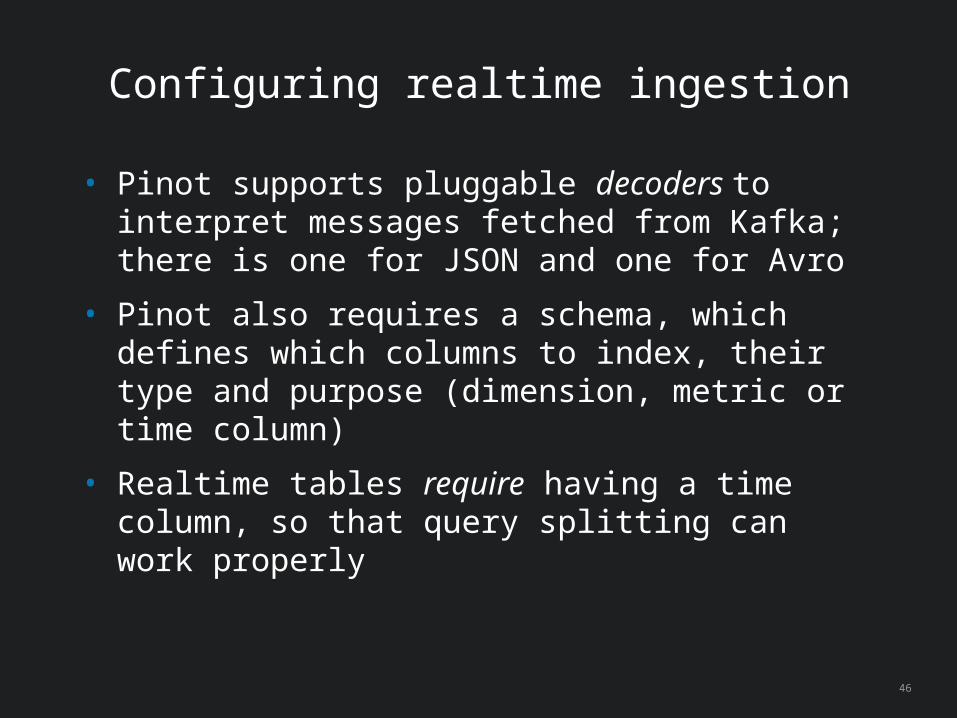
46
• Pinot supports pluggable decoders to interpret messages fetched from Kafka; there is one for JSON and one for Avro
• Pinot also requires a schema, which defines which columns to index, their type and purpose (dimension, metric or time column)
• Realtime tables require having a time column, so that query splitting can work properly

Configuring realtime ingestion
47
{ "schemaName" : "flights", "timeFieldSpec" : { "incomingGranularitySpec" : { "timeType" : "DAYS”, "dataType" : "INT”, "name" : "DaysSinceEpoch" } }, "metricFieldSpecs" : [ { "name" : "Delayed”, "dataType" : "INT”, "singleValueField" : true },
... ], "dimensionFieldSpecs" : [ { "name": "Year”, "dataType" : "INT”, "singleValueField" : true }, { "name": "DivAirports”, "dataType" : "STRING”, "singleValueField" : false },
... ],}

Operating in Production
48

Pipeline in production
1. Fault tolerance
2. Performance
3. Retention
4. Metrics
5. Offline and realtime
6. Indexing and sorting
49

Pipeline in production: Fault tolerance
Gobblin:
• Retry work units on failure
• Commit policies for isolating failures.
• Require external tool for daemon failures (cron, Azkaban)
Pinot:
• Supports replication data: fault tolerance and read scaling
• By design, no single point of failure; at Linkedin multiple controllers, servers and brokers, any one can fail without impacting availability.
50

Pipeline in production: Performance
Gobblin:
• Run in distributed mode.
• 1 or more tasks per container. Supports bin packing of tasks.
• Bottleneck at job driver (fix in progress).
Pinot:
• Offline clusters can be resized at runtime without service interruption: just add more nodes and rebalance the cluster.
• Realtime clusters can also be resized, although new replicas need to reconsume the contents of the Kafka topic (this limitation should be gone in Q4 2016).
51

Pipeline in production: Retention
Gobblin:
• Data retention job available in Gobblin suite.
• Supports common policies (time, newest K) as well as custom policies.
Pinot:
• Configurable retention feature: data expired and removed automatically without user intervention.
• Configurable independently for realtime and offline tables: for example, one might have 90 days of retention for offline data and 7 days of retention for realtime data.
52

Pipeline in production: Metrics
Gobblin:
• Metrics and events emitted by all jobs to any sink: timings, records processed per stage, etc.
• Can add custom instrumentation to pipeline.
Pinot:
• Emits metrics that can be used to monitor the system to make sure everything is running correctly.
• Key metrics: per table query latency and rate, GC rate, and number of available replicas.
• For debugging, it’s also possible to drill down into latency metrics for the various phases of the query.
53

Pipeline in production: Offline and real time
Gobblin:
• Mostly offline job. Can run frequently with small batches.
• More real time processing in progress.
Pinot:• For hybrid clusters (combined offline and real time), overlap between both
parts means fewer production issues:
• If Hadoop data push job fails, data is served from the real time part; increasing the retention can be done for extended offline data push job failures.
• If real time part has issues, offline data has precedence over real time data, thus ensuring that data can be replaced; only the latest data points will be unavailable.
54

Pipeline in production: Indexing and sorting
• Pinot supports per-table indexes; created at load time so there is no performance hit at runtime for re-indexing.
• Pinot optimizes queries where data is sorted on at least one of the filter predicates; for example “Who viewed my profile” data is sorted on viewerId.
• Pinot supports sorting data ingested from realtime when writing to disk.
55

Conclusions
56
1 Analytics pipeline collecting data from a variety of sources
2 Gobblin provides universal data ingestion and easy extensibility
3 Pinot provides offline and real time analytics querying
4 Easy, flexible setup of analytics pipeline
5 Production considerations around scale, fault tolerance, etc.

Who is using this?
57

Development Teams
58
P not

Find out more:
©2015 LinkedIn Corporation. All Rights Reserved.
Find out more:
©2015 LinkedIn Corporation. All Rights Reserved. 59
https://github.com/linkedin/gobblinhttp://gobblin.readthedocs.io/[email protected]
P nothttps://github.com/linkedin/[email protected]
https://engineering.linkedin.com/