open west 2015 talk ben coverston
TRANSCRIPT

Full Stack High Availability In an Eventually Consistent World
Ben Coverston @bcoverston DataStax Inc
OpenWest 2015

Who Am I?
• Ben Coverston
• Contributor: Apache Cassandra
• DSE Architect, DataStax Inc

Availability


“An analytics system based on Cassandra, for example, where there are no single points of failure might be
considered fault tolerant, but if application-level data migrations, software upgrades, or configuration changes take an hour or more of downtime to complete, then the
system is not highly available.”

Failure Before ~2010
• The website can fail
• We have a farm!


What About the Middleware?
• Make it stateless
• Spin up a bunch of app servers
• Who cares if one fails, we can recover.


How to Play Kick The Can!
Kick the Can is an old game that has been played through the generations. Not to mention lots of fun!

How about the Database?
• Build a massive database server
• Scale up

How about the Database?
• We can backup to tape!
• MTTR Hours, possibly days.
• We can mirror!
• Possible loss of data
• Some loss of availability during recovery
• What if we have multiple Availability Zones?
• Geographical distribution of master slave systems is not practical


No Good Option
• RDBMS Recovery is a Special Case
• RDBMS Was Not Built for Failure
• Once you shard it, you lose the benefits of an RDBMS anyway

The Problem
• Traditional databases don’t scale
• Because information is context sensitive
• When relationships matter, so does time
• When you guarantee consistency, something else has to give.

Eventual Consistency
“In an ideal world there would only be one consistency model . . . Many systems during this time took the
approach that it was better to fail the complete system than to break this transparency”[1]
— Werner Vogels
CTO amazon.com

The CAP Theorem
• Dr. Eric Brewer
• Consistency
• Availability
• Partition Tolerance

Tradeoffs!
• With Distribution we have to accept Partitioning
• If you want strong consistency, any failure of a master will result in a partial outage.

Banks Use BASE, not ACID
• Basically Available, Soft State, Eventually Consistent (BASE)
• Real time transactions are preferred, but ATMs fall back to partitioned mode when disconnected.

Why Does This Work?• Templars and Hospitiallars were some of the first modern
bankers [4]
• ATM Networks try to be fully consistent
• Banks lose money when ATMs are not working
• Partitioned State Fallback
• Operations are commutative
• Risk is an actuarial problem

Building On Eventual Consistency
• Eventual Consistency means . . .
• Two queries at the same time could get different results
• If that’s bad for your application:
• Change your application logic
• Change your business model
• OR
• Don’t use eventual consistency

Seat Inventory
• Airlines are eventually consistent too!
• Aircraft are routinely oversold (because booking flights is a distributed systems problem)
• People fail to show up, the airline makes money
• Too many people show up, the airline compensates a few, the airline makes money

But What If?
• I Need Global Distribution
• Strong Consistency
• At Scale


Remember, Tradeoffs

Other Problems
• Real Time Analytics is a Challenge
• MapReduce Helps
• But it’s too slow for a many things

Spark
• Not limited to MapReduce
• Directed Acyclical Graph
• Easy-To-Understand Paradigm
• Compared to Hadoop

What is Spark?• Apache Project Since 2010
• Fast
• 10-100x faster than Hadoop MapReduce
• Easy
• Scala, Java, Python APIs
• A lot less code (for you to write)
• Interactive Shell

Hadoop Mapreduce WordCount
package org.myorg; import java.io.IOException; import java.util.*; import org.apache.hadoop.fs.Path; import org.apache.hadoop.conf.*; import org.apache.hadoop.io.*; import org.apache.hadoop.mapreduce.*; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class WordCount { public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); context.write(word, one); } } } public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } context.write(key, new IntWritable(sum)); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = new Job(conf, "wordcount"); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true);

Spark MapReduce for WordCount
scala> sc.cassandraTable(“newyork”,"presidentlocations") .map( _.get[String](“location”) ) .flatMap( _.split(“ “)) .map( (_,1)) .reduceByKey( _ + _ ) .toArray res17: Array[(String, Int)] = Array((1,3), (House,4), (NYC,3), (Force,3), (White,4), (Air,3))
1 white house
white house
white, 1 house, 1
house, 1 house, 1
house, 2
cassandraTableget[String]
_.split()
(_,1)
_ + _

Just In Memory?
• Map Reduce Style Analytics
• Not Just In-Memory (though it is really good for ‘iteration’)

Cassandra + Spark
• Cassandra-Spark Driver
• Open source
• https://github.com/datastax/cassandra-driver-spark

That’s Great, But
• I still need real-time

Distributed Aggregation (A case study)
• Real time distributed counting is hard.
• At high volume, with geographic distribution.
• For most aggregations you only need sums and counts

Goals
• Provide near-real time counts for increments
• Updates are non-monotonic
• Historical windowing
• Real time

What about Streaming?
• Storm or Spark Streaming can help for some use cases
• But to do it right, you have to get acks from an external system (spark), or block until the items get processed by something you might have integrated (storm).
• Blocking for stream processing could cause back pressure, and loss of availability.
• Not “Real Time”

Distributed Counting
• Aggregate over time
• Per shard
• Save deltas
• Timestamps
• Because timestamps can come out of order
• Arrival time is important

Compromises
• Create a C* plugin to do aggregation (daemon, singleton)
• Do it locally, on each node (on the coordinator).
• Create a separate API to query for aggregation
• Create real-time aggregates on the fly
• Store snapshotted data in C* for windowed aggregation (1s, 1h, 1d, 1w, 1m).

Deltas
• Deltas are stored
• Aggregates have to be composed of commutative operations (because we cannot recalculate everything, every time)
• Cumulative Average is a good example of a compatible streaming operation.

Cassandra Counters
• Distributed Counting is Hard
• But a tractable problem
• In fact Cassandra already solved this problem

ARRIVED WINDOW DELTA COUNT
1 0 50 40
2 0 40 30
1 1 10 20
2 2 30 40

ARRIVED
WINDOW
DELTA
COUNT1 0 50 40
1 0 40 301 1 10 202 1 30 40
ARRIVED WINDOW DELTA COUNT
1 0 90 70
1 1 10 20
2 1 30 40

ARRIVED
TIMESTA
DELTA
COUNT1 0 50 40
1 0 40 301 1 10 202 1 30 40
ARRIVED TIME DELTA COUNT1 0 90 701 1 10 202 1 30 40
Aggregation Service Average T(1:1) -> 0.923

But Nodes Can Fail
• Snapshotted data is stored with RF > 1 (similar to RDDs)
• Aggregation is done by a ‘fat client’ running on each node.
• If a network partition happens, the real-time counts may be inconsistent.
• In case of a node failure, the counts may need to be repaired

Network Partition
C*
C*C*
C*
Average T(1:1) -> 0.923
Average T(1:1) -> 2.345


C1:3
Shard1
C1:4
Shard23+4 C1:7
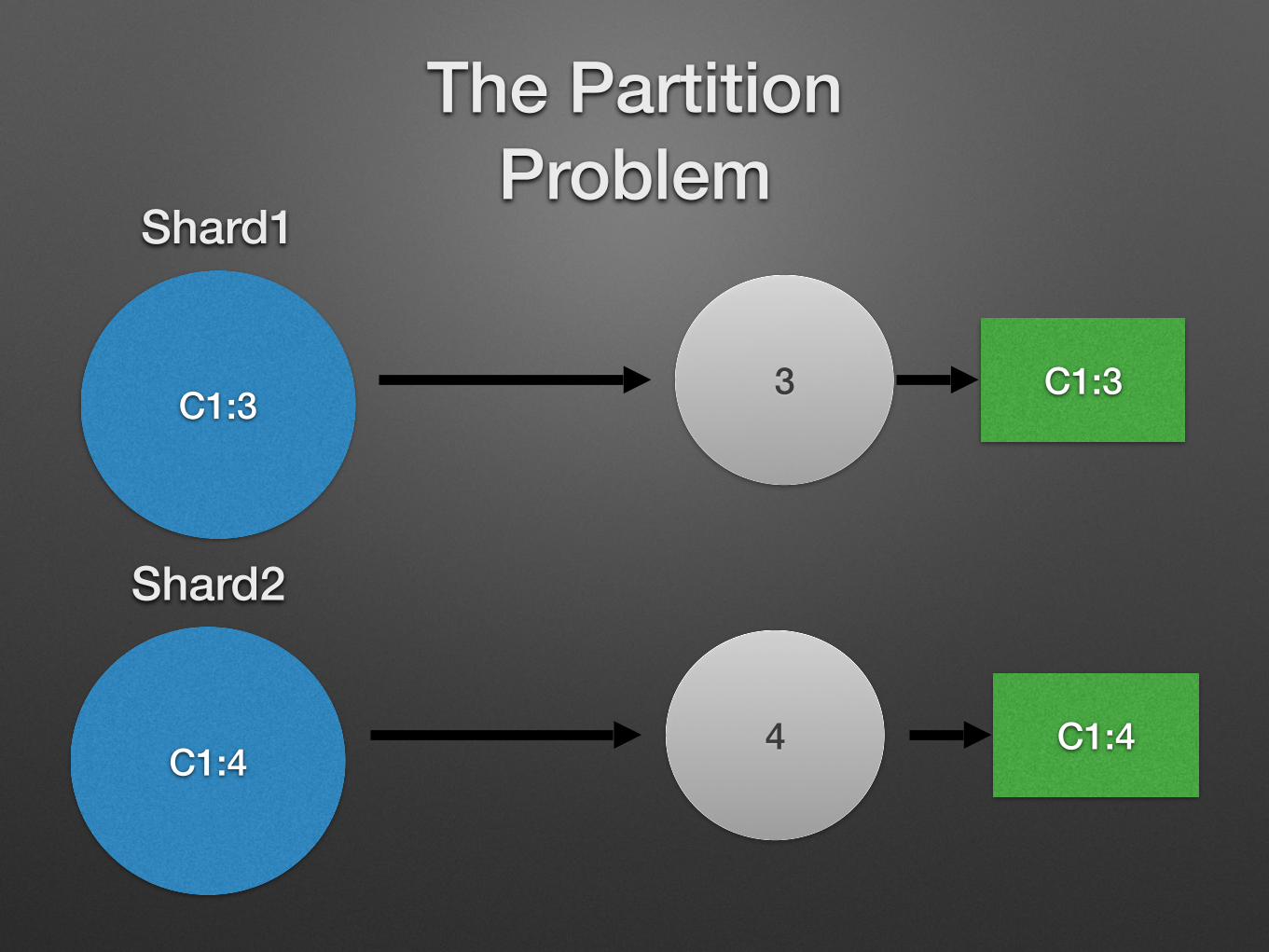
C1:3
Shard1
C1:4
Shard2
4 C1:4
The Partition Problem
3 C1:3

Lambda Architecture
• Real Time, should be Real Time
• Analytics is Batch
• Real time layer depends on processing incoming streams, or pre-aggregated data
• In a non-trivial system, CAP still affects the design

S1:C1:3 S2:C1:4
Shard1
S1:C1:3 S2:C1:4
Shard2
3+4 C1:7
The Partition Problem
3+4 C1:7

Design Compromises
• Counter Increment could fail
• Data Insert could fail
• Either could result in an over/under count

Counting Inconsistency
• Similar to Sharded Counters
• Background Task
• Watch for failed mutations
• Recalculate windows when failed mutations happen

The Partition Decision [3]
• Cancel the operation, and decrease availability
• Proceed with the operation, and risk inconsistency


If You Accept Eventual Consistency
• Real time aggregates may be inaccurate
• Due a network partition (may persist for hours)
• Due to latency (speed of light, network latency, small number of ms)
• In this system Historical aggregates are more reliable, because the deltas get written (and replicated) every second.

Designing for Eventual Consistency
• Partitions happen in the real world (not a myth)
• If you are building a distributed system, you have to account for possible failure.
• Define system behavior under failure conditions
• Make adjustments, set expectations

Call To Action• When building distributed systems
• Reason about concurrency
• Avoid Locking (if at all possible)
• Learn about Commutative Replicated Data Types (CRDTs)
• Learn about MultiVersion Concurrency Control (MVCC)
• Learn Functional Programming
• Scala, Clojure (lisp), whatever
• Functional programming makes distributed programming better

Things to Look At
• Cassandra (fully distributed database)
• Actor Pattern
• akka-cluster (fully distributed compute platform)

References
[1] http://www.allthingsdistributed.com/2007/12/eventually_consistent.html
[2] http://en.wikipedia.org/wiki/CAP_theorem
[3] http://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed
[4] http://en.wikipedia.org/wiki/History_of_banking
