opendma - daten management solution
TRANSCRIPT


Open Data Management Automation (OpenDMA)
Eine moderne Datenmanagement Plattform für Ihr Data Warehouse
und Ihre Big Data Analysen
Torsten Glunde, Juni 2015

agenda
• Big Data
• OpenDMA Strategie
• OpenDMA – Automation, DataVault und Architektur

Industrie 4.0 Automation von Industrieprozessen, Vernetzung der Maschinen (Internet of Things)
Mobile Data Fitnessdaten, Apps, Shopping
Soziale Netzwerke & Co Facebook, Xing, LinkedIn, WhatsApp, Twitter, Tumblr, About.com, Blog
BigData Volume+Velocity+Variety, Strukturierte und Unstrukturierte Daten, MPP, Analytics
Datenstrategie, das daten-getriebene Unternehmen
RDBMS ist nicht für solche Datenmengen und nicht-strukturierte Daten ausgelegt
Prozesse müssen schneller werden, gleichzeitig aber auch flexibler und anpassungsfähiger
BigDataDatentreiber

BigDataImplementierung
• Roman Census Method, MPPwww.thedatascienceinstitute.com/big-data-and-the-roman-census-approach/
• MPP ermöglicht lineare Skalierung
• Prozessierung wandert zu den Daten (im Gegensatz zu ETL)
• Hadoop, HDFS• Speichert binäre Datenblöcke ohne interne Strukturen
• Kein ACID, kein UPDATE, INSERT ONLY
• Fail-over durch Duplizierung jedes Datenblockes
• Structure on Read (vs. Structure on Write)• Unstrukturierte oder semi-strukturierte Daten können gespeichert werden
• Ermöglicht die Speicherung von großen Datenmengen
• Dateninhalte müssen vor Verarbeitung geparsed werden
• Flexibel, da bestehende Datenstrukturen nicht angepasst werden müssen
Bill Inmon, Dan Linstedt, “Data Architecture: A Primer for the Data Scientist” ,
Elsevier, Morgan Kaufman 2015

BigDataLambda Architektur ist Bestandteil von OpenDMA
Die Lambda Architektur besteht aus 3 Komponenten
Batch layer
• Verwaltet den Master Datensatz, ein immutable, append-only Rohdaten Speicher
• persistente batch views zur Abfrage die vorberechnet werden
Serving layerDieser Layer indiziert die Batch Views, damit sie in niedriger Latenz abgefragt werden können
Speed layerReal-time bzw. Near-Realtime Anfragen werden hiermit Streaming Mitteln beantwortet. Schnelle, inkrementelle Algorithmen werden hier verwendet. Nur die aktuellsten Daten werden hier verarbeitet.
Michael Hausenblas, Chief Engeneer MapR, Lambda Architecture,
https://www.mapr.com/fr/developercentral/lambda-architecture
Nathan Marz – Big Data Principles and Practices of Scalable realtime data systems
http://www.manning.com/marz/

Verarbeitung geht zu den Daten
Distribution der Daten
MPP ist unabhängig von der Speicherhaltung der Daten
Strukturiert, Relational optimiertes, random Lesen per SQL ABER: modellierte, kontrollierte Daten Unstrukturiert, Ohne Schema optimiertes Schreiben, lesen per SQL, aber nur sequentiell optimiert Unstrukturierte Speicherung bedingt immer noch viel Programmierung – SQL ist aber zukünftig gesetzt
• Speicherung und Pflege der Daten ist strukturiert teurer als unstrukturiert• Automatisierung mittels DataVault vermindert die Kosten für strukturierte Datenhaltung• Sub-second Antwortzeiten nur mit schema-basierten Datenstrukturen möglich
BigDataMPP

Eignet sich zur Datenaufnahme im Datenmanagement, da es große Datenmengen sicher und redundant speichern kann
Eignet sich zur Transformation von großen Datenmengen, da über MPP linear skaliert werden kann - wie zu statistischen Analysen
ABER:
Transformationen werden in Hadoop programmiert (Java, Scala, …)
Reproduzierbarkeit schwierig zu gewährleisten, wenn Strukturen unbekannt und veränderlich sind
Ursprünglich ist Hadoop eine reine BATCH-Architektur – keine Adhoc-Abfragen
Häufig werden Daten in Hadoop verarbeitet, die mit MPP-fähigen RDBMS schneller verarbeitet werden können (In-Memory Technologie)
In RDBMS wird SQL verarbeitet, das eine hohe Akzeptanz und Verbreitung hat
BigData = MPP , BigData != NoSQL , BigData Maybe SQL
BigDataUnverzichtbare Komponente, aber kein Allheilmittel

agenda
• Big Data
• OpenDMA Strategie
• OpenDMA – Automation, DataVault und Architektur

Strategie
Ziele und Vorhaben
Datenmanagement
Systeme und Applikationen
Network / Infrastructure
Strategie
Ziele und Vorhaben
Systeme und Applikationen
Network / Infrastructure
Datenmanagement
Da
ten
ge
trie
be
nA
pplik
atio
nsgetrie
ben
OpenDMAStrategie

Personen und
Organisation
Geschäftsprozesse Ziele und
Vorhaben
Technologie
Technology Assets
Datenmanagement
Daten AssetsInformiert
ErstelltKontext
Datengetriebenes UnternehmenStrategie

Datengetriebene ArchitekturAnalogie zur Produktion

Informationen liefernProzesskette im Datenmanagement
Rohdaten
Geschäftsregeln
Historisierung
Standard
Regelwerk
Berechnung
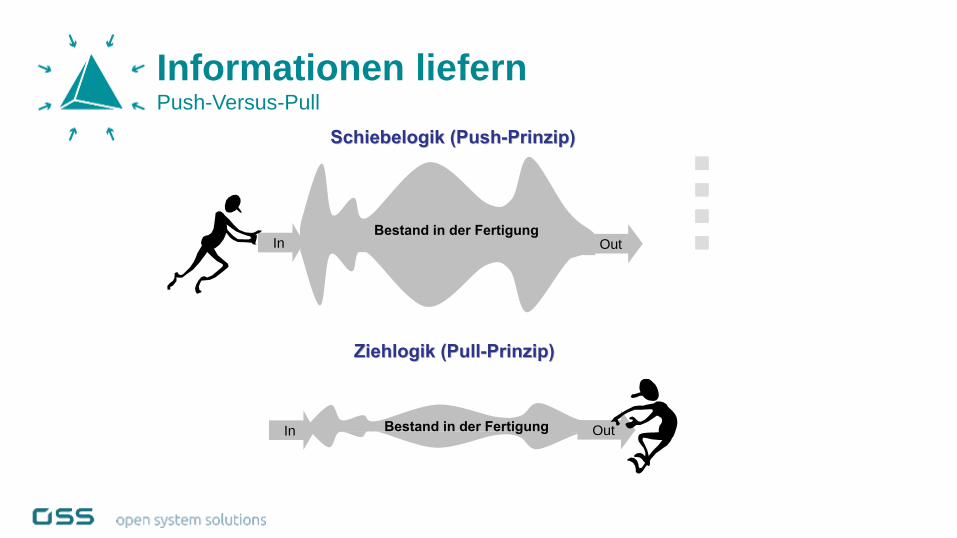
Informationen liefernPush-Versus-Pull
3FolieFolieAWF Arbeitsgemeinschaft “Pull-Systeme” – Dipl.-Ing. O. Völker und Dipl.-Ing. S. Binner
Einleitung „Push“ und „Pull“
In OutBestand in der Fertigung
Ziehlogik (PullZiehlogik (Pull--Prinzip)Prinzip)
Bestand in der FertigungIn Out
Schiebelogik (PushSchiebelogik (Push--Prinzip)Prinzip)

Bekannte Anforderungen
Geringe Personalisierung
Skaleneffekte
Gleichförmige Produktion
Geringe Änderungskosten
Geringe Vorbereitungszeit
Variable Anforderungen
Hohe Personalisierung
Geringer Verkaufsaufwand
Variabilität in der Produktion
Hohe Anpassungskosten
Größere Vorbereitungszeit
Push Pull
Informationen liefernPush-Versus-Pull

Informationen liefernProzessunterscheidung nach Entwicklungsstil
Systematisch
• Nutzer und Entwickler sind getrennt
• Fokus auf Kontrolle und Compliance
• Fokus auf Non-Functionals
• Zentrale, unternehmensweite Informationsobjekte
Opportunistisch
• Nutzer und Entwickler sind eng verbunden
• Offensive Governance – Fokus auf Agilität und Anpassbarkeit
• dezentralisierte Informationsobjekte
• Deployment direkt in Produktion
Development Style

I
• Facts
• Datenmodell
II
• Context
• Taxanomie
• Ad-Hoc Abfragen
• Geschäftsregel
III
• Shadow IT
• Incubation
• Ad-hoc
• Once off
IV
• Research
• Innovation
• Design
Pull / Demand / Product drivenPush / Supply / Source driven
Push/Pull Point
Development Style
Syste
matic
Opport
unis
tic
Informationen liefernDatenquadrant im Datenmanagement
Ronald Damhof, 4 Quadrant Model for Data Deployment, http://www.b-eye-network.com/blogs/damhof/archives/2013/08/4_quadrant_mode.php

I• Single Version of
Facts
II• Multiple Versions of
Truth
III
• Single Sources
IV
• All Data
MPP
Automatisierung
des DWH mit
DataVault
Enterprise Information
ProductsReports
Predictive Analytics
Adhoc-Queries
DWH Mart
MethodenDatenmanagement
Data LakeInput
ComplicatedSimple
ChaoticAnalytics, Innovations
Data Science
Data Mining
Machine Learning
Alle Daten
Complex

I• Single Version of
Facts
II• Multiple Versions of
Truth
III
• Single Sources
IV
• All Data
MPP
Enterprise Information
ProductsReports
Predictive Analytics
Adhoc-Queries
DWH Mart
Analytics, Innovations
Data Science
Data Mining
Machine Learning
Alle Daten
GovernanceIm Datenquadranten
Data Lake- Kontrolle und Verantwortung liegt beim
jeweiligen Anwender
- Hohe Freiheitsgrade ermöglichen Innovation
BI Governance
Metadaten

agenda
• Big Data
• OpenDMA Strategie
• OpenDMA – Automation, DataVault und Architektur

Datenmanagement PlattformDataVault Architektur und ModellierungMPP Datenhaltung für strukturierte und unstrukturierte DatenDatenverarbeitung mit linearer Skalierung
Werkzeug zur schnellen EntwicklungAutomatisierung der Data Warehouse Entwicklungbasierend auf Datenmodell und MetadatenErmöglicht Rapid Prototyping
ELT oder ETL Generatorgeneriert SQL und DDLoder auch ETL basierend auf Templatesunterstützt RDBMS und Hive (auf Hadoop)
ArchitekturvorgabenDie Einhaltung des Regelwerks gewährleistet eine lineare SkalierungSingle Version of Facts – Multiple Versions of the TruthMultiple Timelines - Temporalität
Open Data Management AutomationWas ist OpenDMA?

Nicht-Destruktive Datenmodellierung
Konsistente Kosten für Anpassungen
Automatisierung durch wiederholbare Muster
Implementierung in NoSQL, RDBMS und hybrid möglich
100% Tatsachen (anstatt von „Golden Record“, „One Version of The Truth“), ermöglicht:Gap Analyse, Auditing und Data Lineage
Separation of ConcernsKontext, Konzept, Logisch, Physisch
Bill Inmon sagt:
"the Data Vault is the optimal choice for modeling the EDW in the DW 2.0
framework."
OpenDMADataVault 2.0 Vorteile
Bill Inmon, Dan Linstedt, “Data Architecture: A Primer for the Data Scientist” ,
Elsevier, Morgan Kaufman 2015

http://LearnDataVault.com 6/3/2015
(C) Sam Bendayan and Mary Mink, DO NOT COPY OR DISTRIBUTE IN ANY WAY 22
43
Data Vault Benefits
Entire UDT DataVault Model
Typical OLTP Data Model
44
– Compression
– Indexes
– Table Partitioning
• By Date for Aging
• By # CPU cores, for parallelism
– Federated Configuration
• by subject area?
– DB Scale‐Out
…but how do
you sc a le it?
OpenDMADataVault 2.0 Vorteile
Bsam Bendayan and Mary Mink, Ultimate Software 2015, Presented at
WWDVC 2015

OpenDMAUnser Stack

OpenDMA Automationbasiert auf OpenSource, beschleunigt die Entwicklung von Datenmanagement Prozessenbenötigt kein ETL-Werkzeug, unterstützt aber die gängigsten auf dem Markt
Methoden und Vorgehensweisenschnelle Implementierung neuer GeschäftsregelnBasis ist Data Vault 2.0 volle Nachvollziehbarkeit und Integration von strukturierten und unstrukturierten Daten
Lineare Skalierungläuft auf sogenannten Commodity-Hardware KnotenVerdopplung der Knoten halbiert die Laufzeitsowohl für unstrukturierte als auch strukturierte Daten
Cloud-fähigkeit steht an erster Stelleeinfache Implementierung und Unterstützung von DevOps
OpenDMADie wichtigsten Vorteile

Im Zeitalter von BigData und MPP gilt: ETL ist tot, es lebe SQLDie Verarbeitung der Daten wird mehr und mehr in der Datenbank stattfinden müssen, da die Datenmengen die für die Verarbeitung notwendig sind nicht mehr transportierbar sind. Die aktuellsten Entwicklungen in Hadoop setzen auf SQL als Schnittstelle zu Daten im HDFS.
Automatisierung ist der nächste große TrendDurch moderne Methoden der Datenmodellierung und Datenmodelltransformation lassen sich weite Teile des klassischen DWH automatisieren.
Das klassische DWH und BigData sind komplementäre InfrastrukturkomponentenData Lake, Enterprise Hub & Co. sind Bestandteile einer Dateninfrastruktur, können aber nicht die kompletten Architekturanforderungen abdecken. MPP gilt auch für klassisch modellierte RDBMS. Über DataVault 2.0 lässt sich das DWH mit unstrukturierten Daten verbinden.
OpenDMA: Cloud-First und Automatisierung der DatenintegrationNiedrige Einstiegsbarrierenschneller ROI
Takeaway

zentrale:marktplatz 382031 gru ̈nwaldtel: 089 939451- 0fax: 089 939451- 59www.oss.de
Vielen Dank

SQL
SQL
SQL in Hadoop minimiert die Programmierung
Lambda Architektur erhöht Reproduzierbarkeit durch Reduktion der Komplexität
Erweiterung um Real-Time Anforderung – allerdings auch mit API (Storm)
Caching durch Kylin OLAP-Komponente
In RDBMS wird SQL verarbeitet, das eine hohe Akzeptanz und Verbreitung hat
BigDataLambda im OpenDMA

HDP
OpenDMAEin Use Case
CSV-Strom
Postgres
XLOpenDMA
CSV
StreamingStundenprotokoll
Batch Vortagesaktuell
angereichert
DV Mart

OpenDMA verbindet die WeltenDataVault 2.0 Architektur
Bill Inmon, Dan Linstedt, “Data Architecture: A Primer for the Data Scientist” ,
Elsevier, Morgan Kaufman 2015

OpenDMALogical Data Warehouse Model – Separation of Concerns
- Corporate Overview: Context
- Top management view of the world, sketch environment
- What are the most important kinds of data
- Global things of significance, many-2-many relationships
- About dozen boxes
- “Environment Model”
- Conceptual
- complete, detailed description
- Business terms, concepts, one-to-many relationships represent assertions
- Moderate attributes
- Technology independent model
- Semantic
- Language as used, vehicle for identifying semantic conflicts
- divergent
- Architectural
- More abstract, convergent model
- Logical
- Particular data management technological
- Relational, hierarchical legs, network edges, object oriented, xml tags
- Implementation with technological twists
- Relational: foreign key and primary keys
- Path direction in object models
- Platform specific model
- Physical
- Physical storage
- Discrete physical databases
- Partitions
- Tablespaces
- Etc
- Vendor platform specific model