optimizing mysql queries with indexes
TRANSCRIPT

Optimizing MySQL Queries With Indexes
Baron Schwartz, VividCortexMarch 17th, 2015 Webinar

Intro & Logistics
• Contact me at [email protected] or @xaprb
• Tweet questions to #vividcortex at any time
• Slides and video will be posted

What is an index?
• An index is a quick-lookup data structure for finding rows in a table.
• May be separate from the table, or may be a way of organizing the data itself.
• Common types of indexes:
• B-Tree
• Hash
• Log-Structured Merge
• Other (full-text, spatial, skiplist)
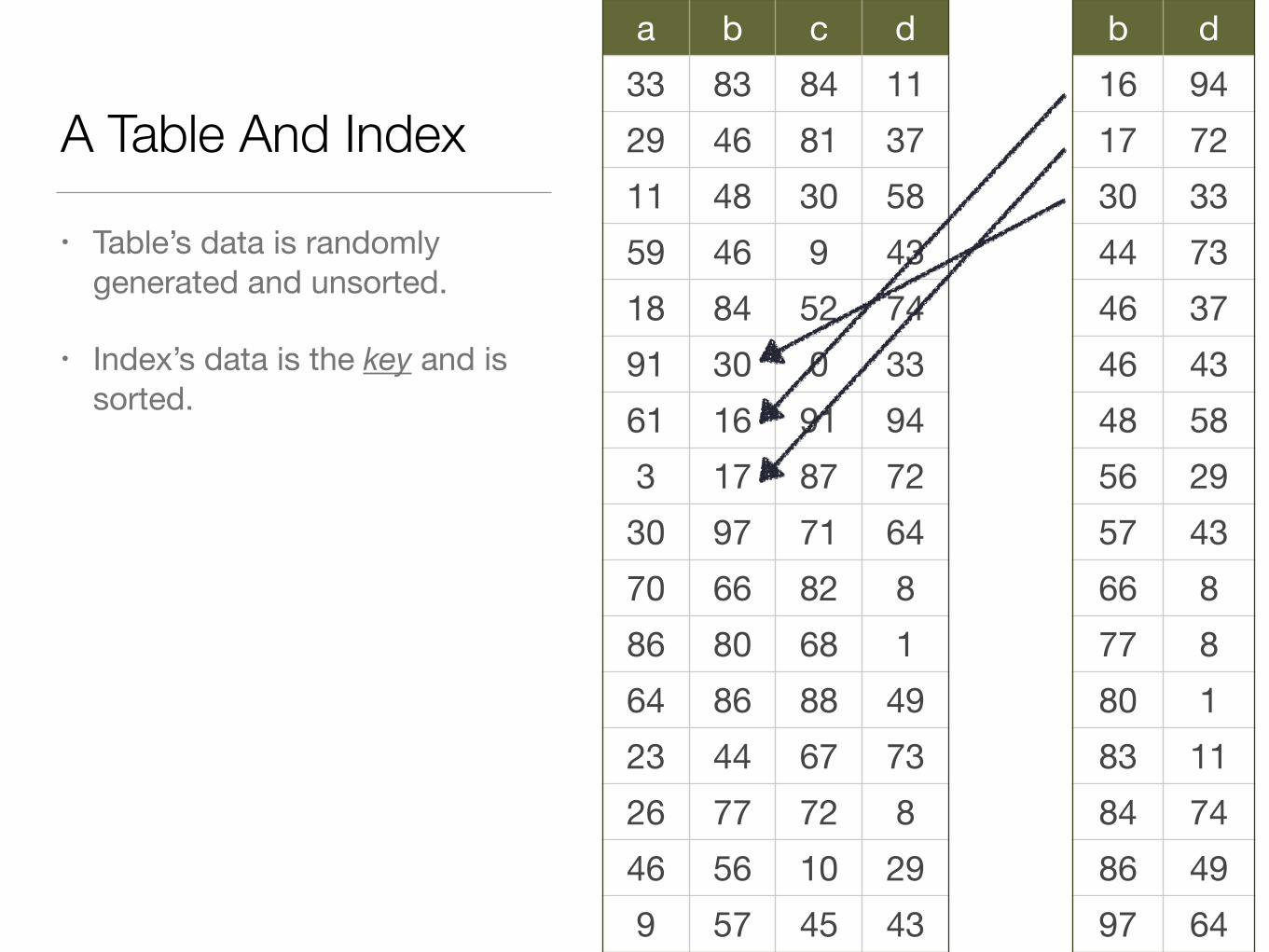
A Table And Index
• Table’s data is randomly generated and unsorted.
• Index’s data is the key and is sorted.
a b c d33 83 84 1129 46 81 3711 48 30 5859 46 9 4318 84 52 7491 30 0 3361 16 91 943 17 87 7230 97 71 6470 66 82 886 80 68 164 86 88 4923 44 67 7326 77 72 846 56 10 299 57 45 43
b d16 9417 7230 3344 7346 3746 4348 5856 2957 4366 877 880 183 1184 7486 4997 64
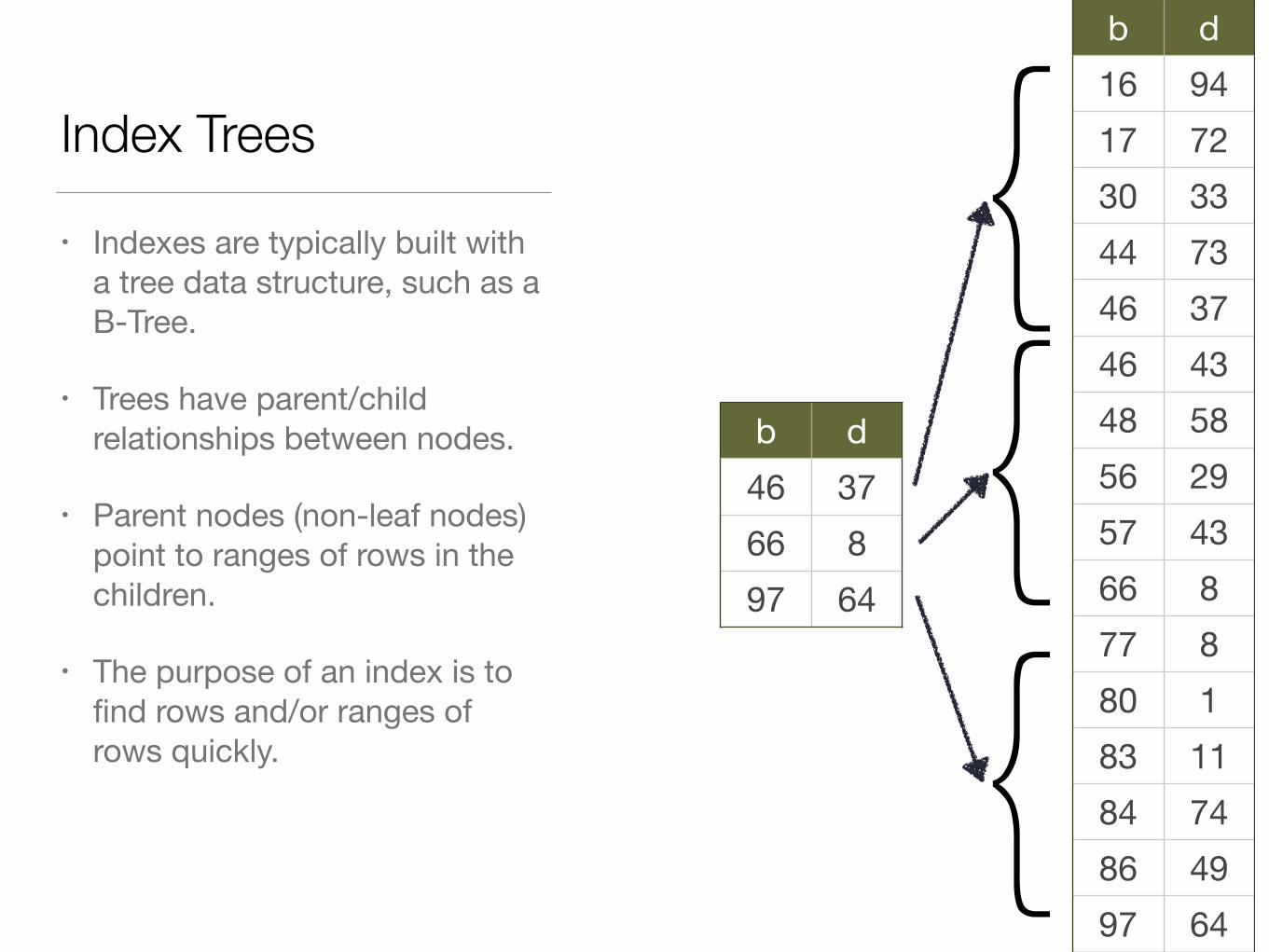
Index Trees
• Indexes are typically built with a tree data structure, such as a B-Tree.
• Trees have parent/child relationships between nodes.
• Parent nodes (non-leaf nodes) point to ranges of rows in the children.
• The purpose of an index is to find rows and/or ranges of rows quickly.
b d16 9417 7230 3344 7346 3746 4348 5856 2957 4366 877 880 183 1184 7486 4997 64
b d46 3766 897 64
{{{

B-Tree Characteristics
• Multi-purpose, most popular index data structure
• Leaf rows are sorted
• Supports single-row lookups
• Supports range lookups
• Supports scanning in order (sorted access)
Hash Index Characteristics
• Relatively special-purpose
• Supports single-row lookup
• Doesn’t support ordered access, bulk access, scanning

LSM Tree Index Characteristics
• A general-purpose family of algorithms and data structures; see also Fractal Tree (TokuDB)
• Supports single-row, bulk, and sorted access
• Avoids some problems with B-Tree indexes (e.g. read-before-write) but adds complexity
• See DZone guide for a recent article I wrote

Indexing Goals
1. Read less data
2. Read data in bulk
3. Exploit ordering
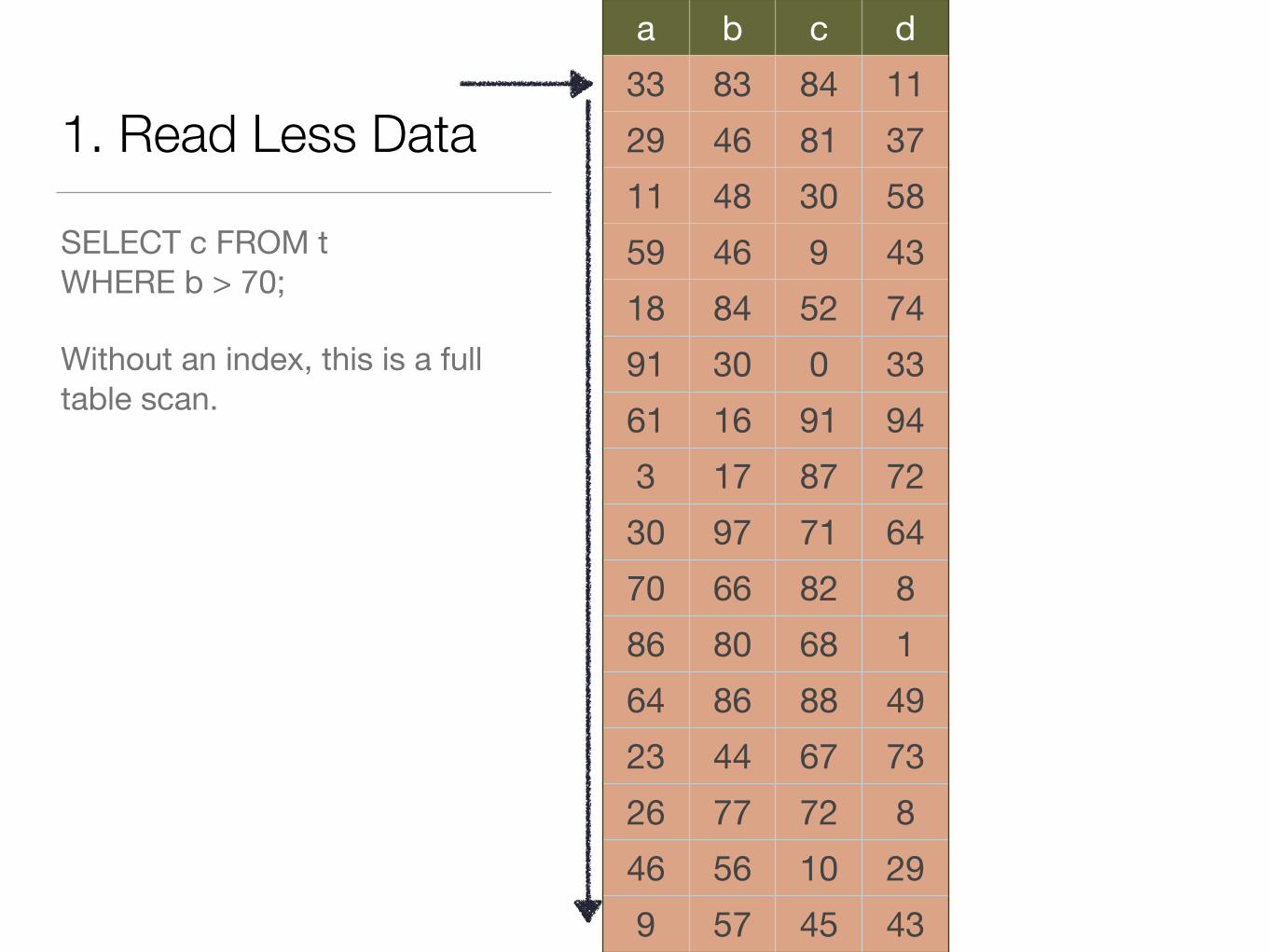
1. Read Less Data
SELECT c FROM tWHERE b > 70;
Without an index, this is a full table scan.
a b c d33 83 84 1129 46 81 3711 48 30 5859 46 9 4318 84 52 7491 30 0 3361 16 91 943 17 87 7230 97 71 6470 66 82 886 80 68 164 86 88 4923 44 67 7326 77 72 846 56 10 299 57 45 43
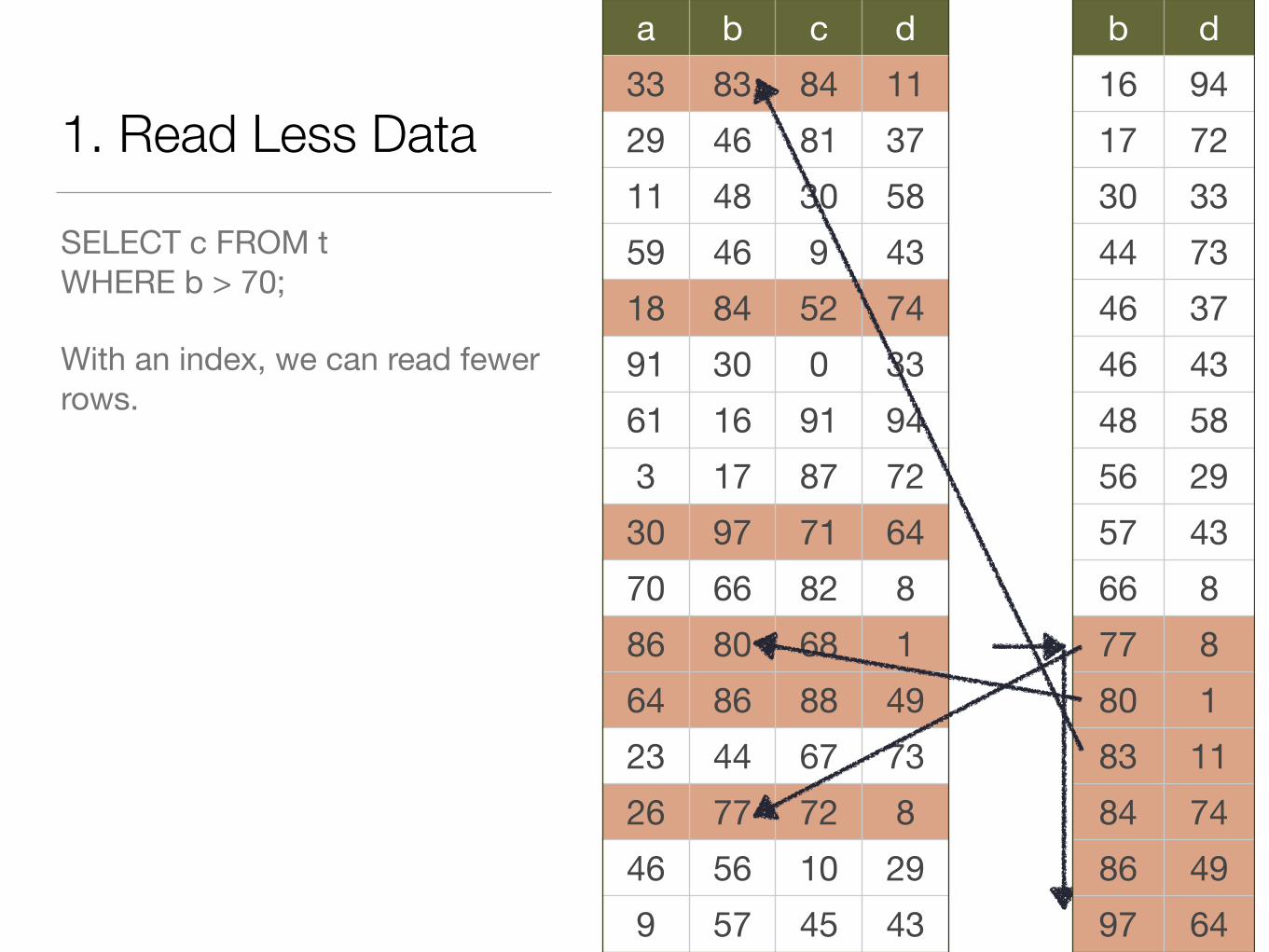
1. Read Less Data
SELECT c FROM tWHERE b > 70;
With an index, we can read fewer rows.
a b c d33 83 84 1129 46 81 3711 48 30 5859 46 9 4318 84 52 7491 30 0 3361 16 91 943 17 87 7230 97 71 6470 66 82 886 80 68 164 86 88 4923 44 67 7326 77 72 846 56 10 299 57 45 43
b d16 9417 7230 3344 7346 3746 4348 5856 2957 4366 877 880 183 1184 7486 4997 64
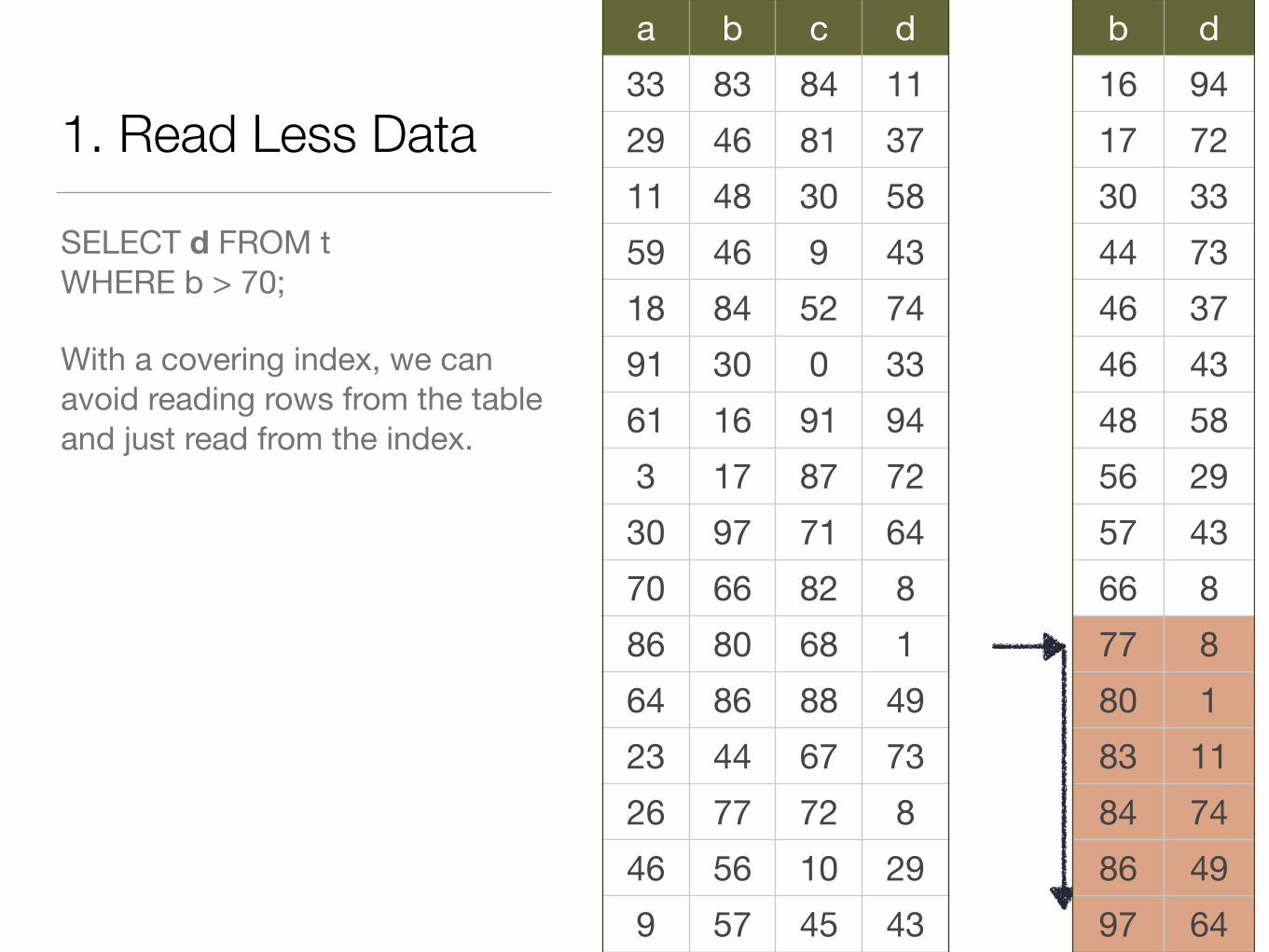
1. Read Less Data
SELECT d FROM tWHERE b > 70;
With a covering index, we can avoid reading rows from the table and just read from the index.
a b c d33 83 84 1129 46 81 3711 48 30 5859 46 9 4318 84 52 7491 30 0 3361 16 91 943 17 87 7230 97 71 6470 66 82 886 80 68 164 86 88 4923 44 67 7326 77 72 846 56 10 299 57 45 43
b d16 9417 7230 3344 7346 3746 4348 5856 2957 4366 877 880 183 1184 7486 4997 64

2. Read In Bulk
• If the desired data is packed closely together, then bulk/contiguous reads are possible
• Sequential access is much more efficient than random
• Bulk/compact access is much more efficient than sparse/scattered (see goal #1, read less data)
a b c d33 83 84 1129 46 81 3711 48 30 5859 46 9 4318 84 52 7491 30 0 3361 16 91 943 17 87 7230 97 71 6470 66 82 886 80 68 164 86 88 4923 44 67 7326 77 72 846 56 10 299 57 45 43
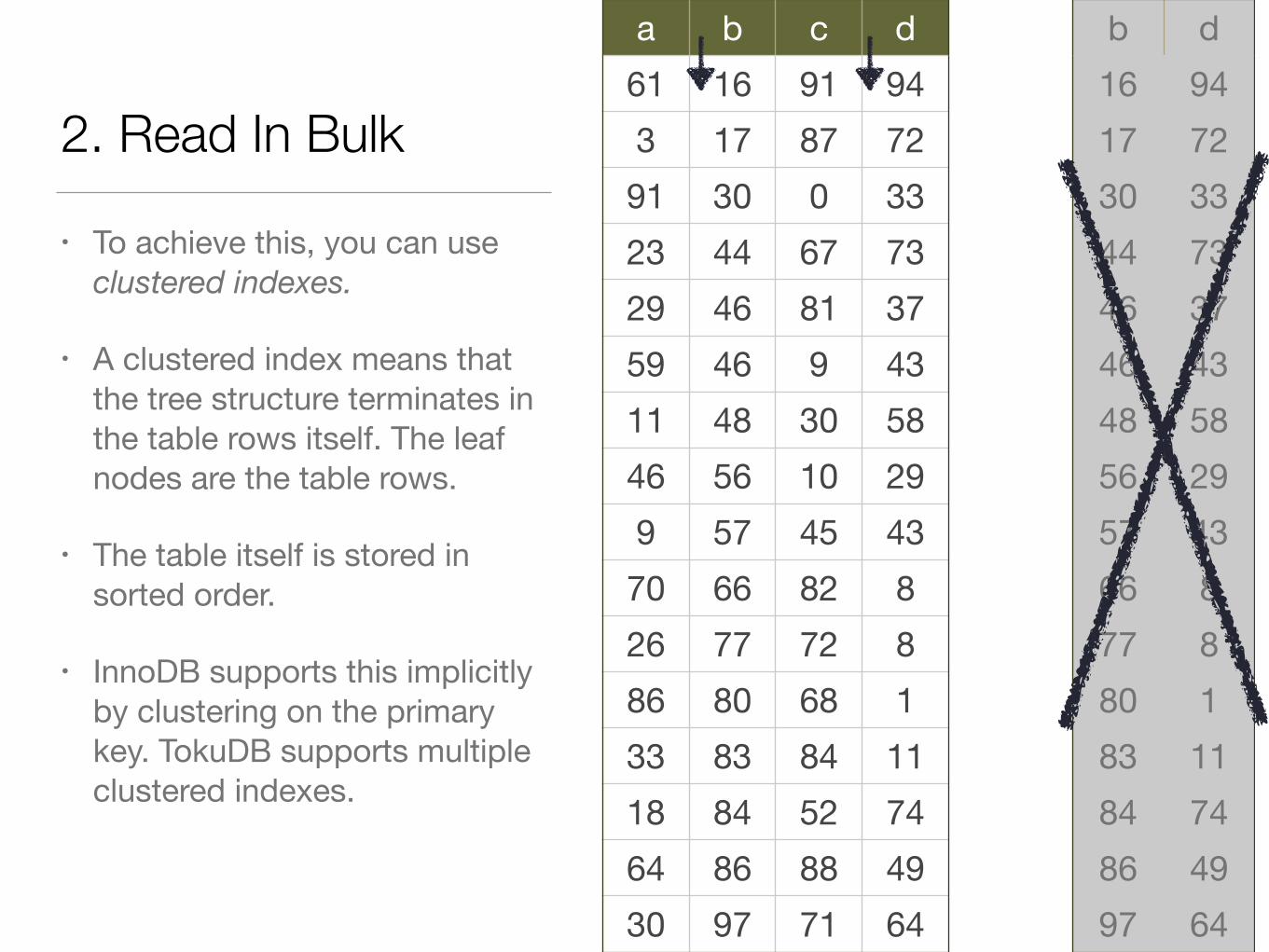
2. Read In Bulk
• To achieve this, you can use clustered indexes.
• A clustered index means that the tree structure terminates in the table rows itself. The leaf nodes are the table rows.
• The table itself is stored in sorted order.
• InnoDB supports this implicitly by clustering on the primary key. TokuDB supports multiple clustered indexes.
a b c d61 16 91 943 17 87 7291 30 0 3323 44 67 7329 46 81 3759 46 9 4311 48 30 5846 56 10 299 57 45 4370 66 82 826 77 72 886 80 68 133 83 84 1118 84 52 7464 86 88 4930 97 71 64
b d16 9417 7230 3344 7346 3746 4348 5856 2957 4366 877 880 183 1184 7486 4997 64
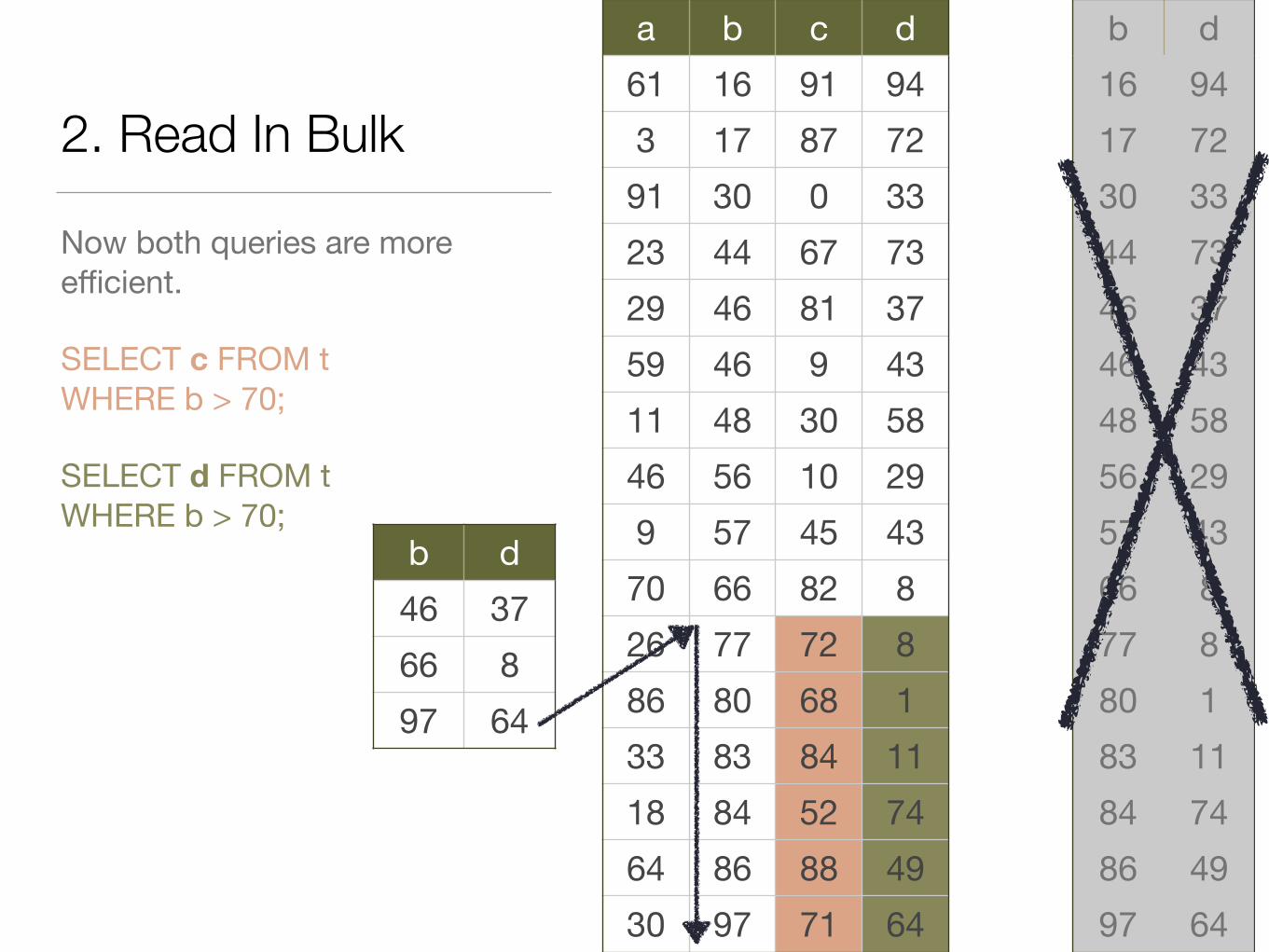
2. Read In Bulk
Now both queries are more efficient.
SELECT c FROM tWHERE b > 70;
SELECT d FROM tWHERE b > 70;
b d16 9417 7230 3344 7346 3746 4348 5856 2957 4366 877 880 183 1184 7486 4997 64
a b c d61 16 91 943 17 87 7291 30 0 3323 44 67 7329 46 81 3759 46 9 4311 48 30 5846 56 10 299 57 45 4370 66 82 826 77 72 886 80 68 133 83 84 1118 84 52 7464 86 88 4930 97 71 64
b d46 3766 897 64

3. Exploit Ordering
• Because indexes are sorted, post-retrieval work can be avoided
• Many “online” single-pass algorithms are possible
• ORDER BY
• GROUP BY
• DISTINCT

Top 6 Rules For Getting The Most From Indexes

1. Make it Sargable
• A “sarg” is a “search argument” that can be compared to the index’s key.
• Isolate columns in the WHERE clause to avoid defeating this.
• Good:d < NOW() - INTERVAL 30 DAY;
• Bad:d + INTERVAL 30 DAY < NOW();

2. Left Prefix Rule
• Multi-column indexes are sorted first by column 1, then sub-sorted by column 2, etc.
• Index prefixes (just some of the columns) can be used, starting from the left
• The index prefix stops being useful at the first non-equality comparison
• Create indexes with equality comparison columns first, range comparisons after
b d16 9417 7230 3344 7346 3746 4348 5856 2957 4366 877 880 183 1184 7486 4997 64
SELECT b, d FROM tWHERE b > 70 AND d = 11;
SELECT b, d FROM tWHERE d > 70;
SELECT b, d FROM tWHERE b = 46 AND d > 40;

2. Left Prefix Rule
• Sometimes you can do tricks to “fill in a gap,” such as:
• Convert a range to a list:b BETWEEN 5 AND 10=> b IN(5, 6, 7, 8, 9, 10)
• Supply missing equalities. If there are only a few values and you know them, you can specify them, e.g. searching for all sexes by omitting sex as a clause=> WHERE sex IN(‘m’, ‘f’, ‘’)
• Improved in MySQL 5.6: [1] [2]
b d16 9417 7230 3344 7346 3746 4348 5856 2957 4366 877 880 183 1184 7486 4997 64
SELECT b, d FROM tWHERE b > 70 AND d = 11;
SELECT b, d FROM tWHERE d > 70;
SELECT b, d FROM tWHERE b = 46 AND d > 40;

3. Index-Only Queries
• Create covering indexes for the most important queries. An index covers a query if it contains all mentioned columns.
• Particularly helpful for InnoDB, where secondary index lookups result in PK values that are then used for a PK lookup (two index lookups!)
• You need to know your servers, applications and the queries they run in order to do this effectively
• See “Using index” in EXPLAIN

4. Clustered Indexes
• Use clustered indexes!
• You can have only one (and only in InnoDB, in stock MySQL), so choose wisely
• Consider not using auto-increment surrogate keys if the data has a natural primary key that matches one or more of the most important access patterns
• You may have to fight your ORM to do this, but the wins can be huge

5. Column Order
• Order of columns matters a lot
• Can qualify or disqualify an index for optimizing an ORDER BY, GROUP BY, DISTINCT, or multi-column WHERE clause (leftmost prefix rule)
• If no preference for a specific WHERE clause or ordering, generally place most selective columns first to eliminate ranges of rows as fast as possible
• Try to make indexes serve several queries

6. Don’t Over-Index
• Indexes add cost to writes and planning/optimizing queries
• Avoid duplicate indexes
• Avoid redundant indexes with a shared prefix
• Drop unused indexes
• See Percona Toolkit for tools that can help with this (in the future VividCortex will offer tools for this too)

Questions
• Slides will be posted• Recording will be on YouTube• I’m [email protected]• Thankyouverymuch

Helpful Resources

More Resources
• Percona Toolkit
• MySQL Manual
• Relational Database Index Design and The Optimizers (Lahdenmaki and Leach)
• My DZone article on storage engines

Upcoming Webinar
6 Ways Ansible Can Improve Your WorkflowApril 28th, 2015 - Owen Zanzal
Registration >>
Credits• Structure https://www.flickr.com/photos/onkel_wart/4546379278/
• Dragon’s Blood Tree https://www.flickr.com/photos/rod_waddington/10941931846/
• Wine Glasses http://www.beveragefactory.com/
• Terrace https://www.flickr.com/photos/hmoong/10636076143/
• Goals https://www.flickr.com/photos/angietorres/4564135455/
• Sorting https://www.flickr.com/photos/13698839@N00/3001363490/
• Rulers https://www.flickr.com/photos/blmurch/795338143/
• Binoculars https://www.flickr.com/photos/gerlos/3119891607/
• Index cards https://www.flickr.com/photos/bean/3359500357/
• Bismuth crystal cluster https://www.flickr.com/photos/paulslab/4386663703/
• Temple https://www.flickr.com/photos/roger_ulrich/8177520403/
• Keys https://www.flickr.com/photos/popilop/331357312/
• Ladder https://www.flickr.com/photos/karamanis/1106389375/