oracle cloud developers meetup@東京
TRANSCRIPT

Tomoaki Uchimura 3-Jun-2016
データベースコンサルタントが語る!
活用の現場ワザ
Oracle Cloud Developers Meetup@東京

Program Agenda
はじめに
R活用例をとにかく見てもらう
Rという要素技術について
事例#1 randomForestパッケージ
事例#2 caretパッケージ
スキルアップに役立つ情報
Q&A
2
1
2
3
4
5
6
7
免責 本資料に記載された内容は、情報の提供のみを目的としています。したがって、本資料を用いた運用は、必ずお客様自身の責任と判断によって行ってください。これらの情報の運用の結果について、講演者はいかなる責任も負いません。本資料は Oracle Database の製品サポートとは無関係ですので、本資料を元に Oracleサポートに問い合わせることはご遠慮ください。また、本資料で紹介するパーティションやクラスタなどの応用的な機能を使用するためには、追加ライセンスなどが必要な場合があります。詳しくはオラクル社ホームページ(http://www.oracle.com/jp/index.html)を確認願います。なお、本資料において示されている見解は、講演者の見解であって、オラクル社の見解を必ずしも反映したものではありませんのでご了承ください。本資料記載の情報は、2016 年 6 月 3 日現在のものを掲載していますので、ご利用時には、変更されている場合もあります。また、ソフトウェアはバージョンアップされる場合があり、本資料での説明とは機能内容や画面図などが異なってしまうこともあり得ます。

はじめに 想定セッション参加者 自己紹介 スピーカーの立ち位置

•本セッションの対象者
–業務で機械学習を応用しようと考えているビジネスパーソン、または、これから触ろうとしているインフラエンジニアです。
•本セッションで目指すこと
–機械学習について漠然としたイメージしかないという方に、実例を紹介して、改めて使う人の視点から使い方を理解してもらうことを目指しています。
想定セッション参加者
学者
独法系研究機
関の統計家
私企業内の統計家
私企業内のエンジニア
コモディティ、メディア
このあたりが ターゲット 6月開催の
NTCIR-12 Conference へご参加ください!
4

自己紹介:内村 友亮(うちむら ともあき)
• ビジョン:テクノロジスト1000人集団
• 日本オラクル株式会社 クラウドテクノロジーコンサルティング統括本部 テクニカルアーキテクト本部 DBソリューション部 部長
• 2007年に中途入社後、DBアーキテクトとして大規模ミッションクリティカルシステムの マイグレーション/アップグレードに従事2013年からオラクルテクノロジー製品のサービスを展開するコンサルチームを担当
2016年の関心事はCloudとRとRDF • 拙著2冊刊行(技術評論社) 絶賛発売中 • オラクルBlog
– http://qiita.com/uchim
5

• データベースエンジニア
–出発点は、大規模データの扱いや可用性を得意とするデータベースエンジニアでして、統計的なデータ活用のための収集、変換、集計、可視化、などをやってくうちに徐々に統計解析の世界に足を踏み入れました。
• 最近のチーム活動はこんなこともやっています。
スピーカーの立ち位置
イタリア統計局のLOD視察(*1)
共通語彙基盤(*2)で発表頂いた統計LOD基盤(*3)の支援
BioHackathon2016 チャレンジ(*4)
GRADES2016 視察(*5)
SemStats2016 論文発表予定(*6)
*1 http://datiopen.istat.it/index.php *2 http://goikiban.ipa.go.jp/node1212 *3 http://data.e-stat.go.jp/lodw/ *4 http://2016.biohackathon.org/ *5 http://event.cwi.nl/grades/2016/ *6 http://semstats.org/2016/
• Column – 余談ではありますが、データベースのオプティマイザという機能は機械学習アルゴリズムといっても過言ではありません。オプティマイザが扱うサンプリング問題や、フィードバックの問題は、昨今の機械学習のテーマに通じるものがあると感じています。
6

R活用例をとにかく見てもらう なぜ、R活用例を見てもらいたいか? とある組織の業務改善

なぜ、R活用例を見てもらいたいか?
•とにかく使ってみるのが、一番の近道だと思います
–少し古いですが・・・「Bay Area R User Group 2009 Kickoff Video(*1)」 • 問い「統計の専門家ではない開発者がRを簡単に学ぶにはどうすればよいか?」に対して
• パネリスト(google/FB/Revolution Computingなど)の回答
– Phthon、Perl、その他の高次元スクリプト言語と相反して、Rは一定の資質に到達するに為には難しい言語のように感じている。
–しかしながら、パネリストもまた、統計の専門家ではない、と強調した。
–統計の専門家ではない我流のRユーザーとして、Rを学んだことの結果として、統計の価値を高められたと言えるだろう。
–統計を知ることは、データタイプからモデリングのシンタックスまで、Rの特徴を理解するための必要条件である。
*1 http://www.lecturemaker.com/2009/02/r-kickoff-video/
8

グラフによるスキルの相関を分析
コンサルレベルに相関するスキル Coherence WebLogic BIEE など
売上に相関するスキル
Parallel linux PaaS など
ノード「2」は 売上を表します
ノード「1」は コンサレベル を表します
9

# R version 3.2.5 (2016-04-14) -- "Very, Very Secure Dishes“ # サンプルではデータ加工部分は省略 # ライブラリの読み込み library( mgm ) library( qgraph ) # データの読み込み setwd( "作業ディレクトリを指定" ) data <- read.table( "data.txt", sep = "¥t", header= FALSE ) data <- apply( data, 2, as.integer ) dif <- read.table( "dif.txt", sep = "¥t", header= FALSE ) data_colnames <- as.matrix( dif[1,] ) type <- as.matrix( dif[2,] ) lev <- apply( dif[3,], 1, as.integer ) # 混合グラフモデルの実行 fit <- mgmfit( data, type, lev, d = 1 ) groups_typeV <- list( "Gaussian"=which(type=='g' ), "Categorical"=which(type=='c' ), "Poisson"=which(type=='p' )) group_col <- c( "#ED3939", "#53B0CF", "#72CF53" )
# プロットする jpeg( "SkillGraph.jpg", height=2*1700, width=2*2000, unit='px' ) Q0 <- qgraph( fit$wadj, vsize=3.5, esize=2, layout="spring", edge.color = fit$edgecolor, color=group_col, border.width=1.5, border.color="black", groups=groups_typeV, nodeNames=data_colnames, legend=TRUE, legend.mode="style2", legend.cex=1.5 ) dev.off()
(サンプルコード) 37 Step
ライブラリの詳細は、以下のリンクをご参照ください。 http://arxiv.org/pdf/1510.06871v2.pdf
10

案件単価を分析
11

(サンプルコード)
# プロットする pirateplot(formula = FY ~ ConsLevel, data = data, xlab = "コンサルレベル", ylab = "案件別平均単価", main = "FYyy¥nコンサルレベル別案件別¥n平均単価", pal = "google", point.o = .2, line.o = 1, theme.o = 2, line.lwd = 10, point.pch = 16, point.cex = 1.5, jitter.val = .1, ylim = c(0, 35) )
axis( side = 1, labels = F )
axis( side = 2, labels = F )
26 Step
# R version 3.2.5 (2016-04-14) -- "Very, Very Secure Dishes" # サンプルではデータ加工部分は省略 # ライブラリの読み込み library( "devtools" ) install_github( "ndphillips/yarrr" ) library( "yarrr" ) # データの読み込み setwd("作業ディレクトリを指定") data <- read.table("data.txt", sep="¥t",header=T) data <- data[order(data$ConsLevel), ]
ライブラリの詳細は、以下のリンクをご参照ください。 http://nathanieldphillips.com/2016/04/pirateplot-2-0-the-rdi-plotting-choice-of-r-pirates/
12

統計解析環境「R」という要素技術について 私がRを使うことになった理由 コミュニティの偉大な貢献 機械学習について

Rを使うことになった理由
*1 http://www.kdnuggets.com/2015/05/poll-r-rapidminer-python-big-data-spark.html *2 http://redmonk.com/sogrady/2016/02/19/language-rankings-1-16/
kdnuggets によるアンケート結果(*1) RedMonk によるプログラミング言語のランキング(*2)
数ある統計解析ツールの中から、なぜRを選んだのかというと、2012年1月に、オラクルがディストリビューションを出し、当時担当していたお客様に使ってもらいやすかったというのが本音。とはいえ、当時はちゃんと調べていて、使っている人が多いということも調べた上で選択しました。
14

コミュニティの偉大な貢献
•実用化に向けてハードルが下がる
–ここ数年で、計算資源(HWリソース)×豊富なデータ×アルゴリズム進歩 = 機械学習がビジネスシーンに広がってきた
–十分な精度、コストが低く、入手しやすい、人間にできないことができる
•ユーザー会やコミュニティ、個人の貢献が偉大
User Groups and R Awareness(*1) Local R User Group Directory(*2)
*1: http://blog.revolutionanalytics.com/2016/05/user-groups-and-r-awareness.html *2: http://blog.revolutionanalytics.com/local-r-groups.html
15

機械学習とは?
•機械学習は、誤解を恐れずに一言で言えば、「与えられたデータの集まりから、分類・相関・特徴などの目的に応じた法則性を発見する技術手法」の一つです。
•機械学習のアルゴリズムは汎用性が高く、様々な種類のデータに対して適用できる点がメリットです。
•また、ルールベースとの違いにより、機械学習の良さが見えてきます。ルールベースの場合は、細かい調整によって人間が場合分けを考えて法則化する必要がありますが、機械学習ベースであれば、特徴ベクトルから法則化することができます。
16

作業ステップ
No 概要 説明
1 観測データの収集 センサーデータなどの大量に溢れる生データの収集
2 利用可能な形式に変換 データ型、欠損値、次元、正規化、集計、加工、変換を行う
3 特徴ベクトルの抽出 専門家の経験に基づくドメイン知識を活用した特徴ベクトルの抽出
4 学習(訓練)データを基に、モデルを定義
モデルの構造やアルゴリズムの数式について事細かく理解する必要はありませんが、パラメータやロジックの理解は、モデル定義をうまくやるために有用な知識になると考えます
5 モデルのチューニングと検証
テストデータを基に、得られた法則性が意図したものになっているかを確認する 最良のモデルを得るため、同じ機械学習アルゴリズムを異なる設定や複数種類の特徴ベクトル形式で動作させたり、複数の機会学習アルゴリズムで学習したモデルを比較する事を行います。
6 モデルの適用
機械学習はすべて完ぺきに予測できると期待されることがありますが、現時点、ビジネスシーンでの実現では達成不可能です。 与えられたデータの集まりから法則性を導いているものであり、精度に限界があることを理解して使う事が必要です
17

事例#1 randomForestパッケージ

• 課題 – 新製品をシミュレーションするための実験計器の状態管理ができていなかった。故障が発生している状態に気付かずに実験を続けてしまい、後から報告書作成の段階で発覚しており、実験計器を交換して再実験する手間がかかっていた。
• 目的
– プロジェクトは、実験計器のデータを一か所に集めて、利用可能な形式に変換して可視化することを目的とした。課題からすると、実験計器のデータから、故障状態(いわゆるサイレント故障)を早期発見することを目的としたいところだが、観測データから特徴ベクトルを抽出できるとは限らないため、このような目標設定とした。
• 状況
– 実験前に全ての実験計器を交換することで故障を避けることができるが、必要のない交換を行うことになり、無駄なコストがかかっていた。
• 効果 – 実験計器データから特徴ベクトルを抽出し、故障を事前に検知するための兆候を発見する事ができた。統計解析の精度を向上するために必要な観測データの候補を挙げることができた。
PoCプロジェクトの概要
19
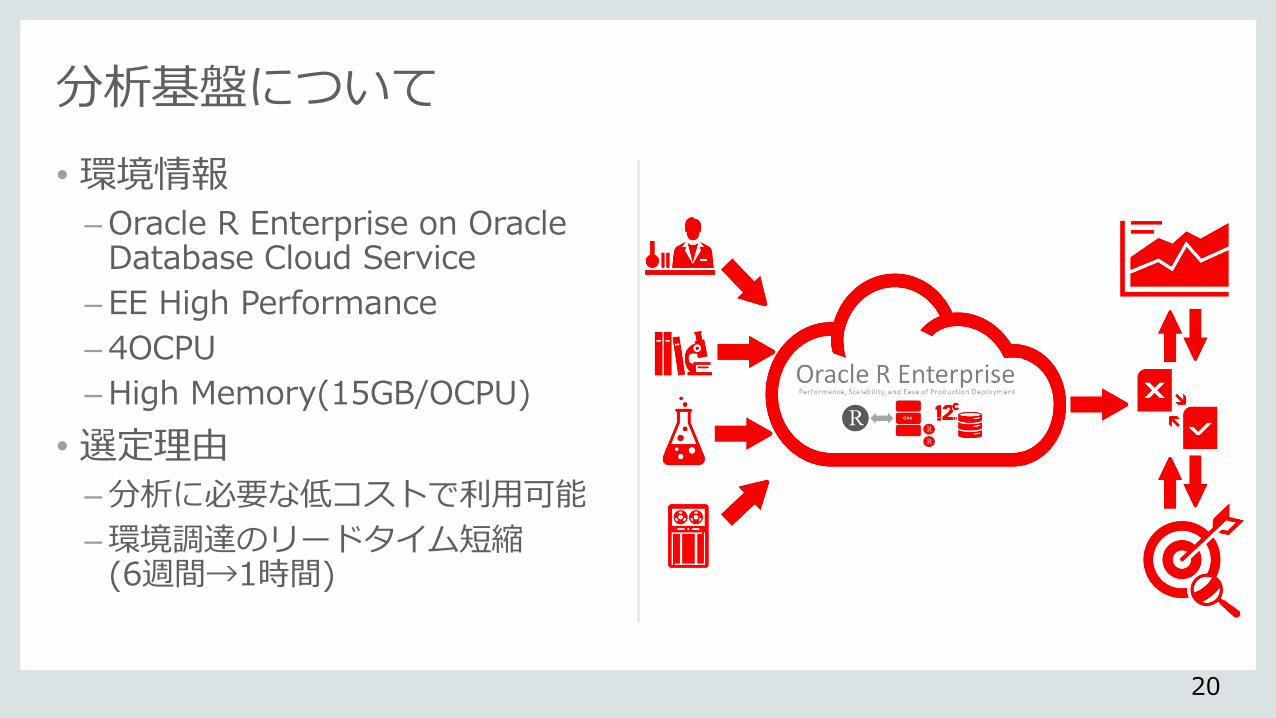
•環境情報
–Oracle R Enterprise on Oracle Database Cloud Service
– EE High Performance
– 4OCPU
–High Memory(15GB/OCPU)
•選定理由
–分析に必要な低コストで利用可能
–環境調達のリードタイム短縮 (6週間→1時間)
分析基盤について
20

モデルのチューニングと検証
•予測モデルの構築では、テストデータを基に、得られた法則性が意図したものになっているかを確認します。最良のモデルを得るため、同じ機械学習アルゴリズムを異なる設定や複数種類の特徴ベクトル形式で動作させたり、複数の機会学習アルゴリズムで学習したモデルを比較する事を行います。本セッションではrandomForestパッケージのアプローチについてご紹介します。
•ご注意 – なお、事例のデータは公開できないため、カリフォルニア大学アーバイン校のセンサーデータのデータセット(*1)で代替している点をご了承ください。事前にデータセットをダウンロードして、zipファイルを展開します。
– https://archive.ics.uci.edu/ml/machine-learning-databases/00325/Sensorless_drive_diagnosis.txt *1 https://archive.ics.uci.edu/ml/datasets.html Citation Policy Lichman, M. (2013). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
21

(サンプルコード) 1 of 6
# R version 3.2.5 (2016-04-14) -- "Very, Very Secure Dishes" # ワーキングディレクトリの指定 setwd( "作業ディレクトリを指定" ) # ライブラリの読み込み library( randomForest ) # データの読み込み data <- "Sensorless_drive_diagnosis.txt" drive <- read.table( data ) head( drive ) ※実行結果
22

# 棒グラフで表示 barplot( table( drive$V49 )) ※実行結果
1~11まで分類されたデータが存在する事が確認できます
(サンプルコード) 2 of 6
23

# モデル作成のために、トレーニング用データセットを生成する # 元データの10%をトレーニングデータとしてサンプリング抽出 set.seed( 100 ) smpl <- sample( nrow( drive ), 0.1 * nrow( drive )) train <- drive[smpl, ] # 残りをテストデータ用データセットとする test <- drive[-smpl, ] # データセットを特徴量とラベルに分割する features <- train[1:48] labels <- train[49] # ラベルをファクターに変換する labels <- as.factor( labels[[1]] ) # モデルを作成する modelDrive <- randomForest( x=features, y=labels, importance=T, proximity=T )
モデルの汎化性能を向上させるために、クロスバリデーションを実行します
(サンプルコード) 3 of 6
24

# 説明変数の重要度を表示する print( importance( modelDrive )) ※実行結果 # 説明変数(分類に寄与した変数)の重要度をプロット varImpPlot( modelDrive ) ※実行結果
グラフから、V11のセンサーデータが寄与していることが分かります
#個体間の類似度を多次元尺度法で視覚化 MDSplot( modelDrive, drive$V49 ) ※実行結果
グラフから、一点に集中していないことが分かります
(サンプルコード) 4 of 6
25

# 学習の収束状況をプロットする plot( modelDrive ) ※実行結果
グラフから、300以下あたりで収束していることが分かります
# グリッドサーチを行う rfTuning <- tuneRF( x = features,y = labels, stepFactor = 2, improve = 0.05, trace = TRUE, plot = TRUE, doBest = TRUE ) ※実行結果
結果から、OOB error = 0.82% が最少であり、木の数は3が適していることが分かります
(サンプルコード) 5 of 6
26

# 木の数と特徴量の数を変えて再実行する modelDrive <- randomForest( x = features, y = labels, mtry = 3, ntree = 300, importance = T ) # テストデータにモデルを適用する prdct <- predict( modelDrive, newdata = test ) table( prdct, test$V49 ) ※実行結果
# 正確さの確認 correctAns <- 0 for ( i in 1:nrow( table( prdct, test$V49 ))) correctAns <- correctAns + table(prdct, test$V49)[i,i] correctAns / nrow( test ) ※実行結果
結果から、 99.5パーセントの精度を達成しました。ちなみに、再実行前のモデルの場合、[1] 0.9915684でした。
(サンプルコード) 6 of 6
27

部品4
勘所:次ステップ(データの高度活用)を描く
部品1 部品2 部品3
部品4 部品5
部品8 部品7 部品9
部品6
部品1 部品2
部品3
部品8
部品5
部品7
部品9
部品6
Semantic Data Layer
様々な種類の実験計器 データフォーマットも様々 保管している場所も様々
部品1 部品2 部品n
それぞれの領域が整合性を持った実験データを参照できると、最終実験にならないと明らかにならない問題が事前に分かってくると考えられる
完成品に必要な実験の種類の定義 意味的なメタデータ統合による領域横断的な実験結果の検索
28

事例#2 caretパッケージ

• 課題
– 約2500台ある通信機器のソフトウェアから出力される、温度、通信量、電圧などの機器のコンディションを表すログデータを、障害予兆検値などの高度なデータ活用ができていなかった。
• 目的 – 現状のログデータを使った予測モデルの精度が、既存の機械学習アルゴリズムでどの程度になるのかを検証することをプロジェクトの目的とした。
– そのために必要な、データ整理についても目的に含めた。
• 状況
– 通信機器の運用上、1カ月分のログデータが保持されていた。
– 通信機器は、ベースライン閾値監視がなされていた。
• 効果 – 機械学習アルゴリズムによる予測モデル精度を比較する事ができた
– 予測モデルを構築するステップの目途を立てることができた
PoCプロジェクトの概要
30

分析基盤について
•環境情報
–Oracle R Enterprise on Oracle Database Cloud Service
– EE High Performance
– 4OCPU
–High Memory(15GB/OCPU)
•選定理由
–分析に必要な低コストで利用可能
–環境調達のリードタイム短縮 (6週間→1時間)
31

モデルのチューニングと検証
• データが変わっても予測モデルの性能が大きく変わらないように、複数のアルゴリズムやクロスバリデーションなどのリサンプリング手法を用いた予測モデルを構築する必要があります。そのようなときは、caretパッケージやmlrパッケージを用いることで作業を効率化することができます。
• たとえば、以下のような作業の作業ステップを減らすことが可能です。 – グリッドサーチによってチューニングパラメータを変化させながら最適な予測モデルを構築する
– クロスバリデーションなどのリサンプリングを変化させながら最適な予測モデルを構築する
• 本セッションではcaretパッケージを使用したアプローチについてご紹介します。
• ご注意 – なお、事例のデータは公開できないため、カリフォルニア大学アーバイン校のセンサーデータのデータセット
(*1)で代替している点をご了承ください。事前にデータセットをダウンロードして、zipファイルを展開します。
– https://archive.ics.uci.edu/ml/machine-learning-databases/00325/Sensorless_drive_diagnosis.txt
*1 https://archive.ics.uci.edu/ml/datasets.html Citation Policy Lichman, M. (2013). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
32

(サンプルコード) 1 of 4
# R version 3.2.5 (2016-04-14) -- "Very, Very Secure Dishes" # ランダムフォレスト # ワーキングディレクトリの指定 setwd( "作業ディレクトリを指定" ) # ライブラリの読み込み library( caret ) # データの読み込み data <- "Sensorless_drive_diagnosis.txt" drive <- read.table( data )
# モデル作成のために、トレーニング用データセットを生成する # 元データの10%をトレーニングデータとしてサンプリング抽出 set.seed( 100 ) smpl <- sample( nrow( drive ), 0.1 * nrow( drive )) train <- drive[smpl, ] #データセットを特徴量とラベルに分割する features <- train[1:48] labels <- train[49] #ラベルをファクターに変換する labels <- as.factor( labels[[1]] ) # モデルを作成する fit.rf <- train(x=features, y=labels, method="rf", ntree = 100, importance = T, tuneGrid = NULL, tuneLength = 4)
33

(サンプルコード) 2 of 4
# 実行結果 > fit.rf Random Forest 5850 samples 48 predictor 11 classes: '1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11' No pre-processing Resampling: Bootstrapped (25 reps) Summary of sample sizes: 5850, 5850, 5850, 5850, 5850, 5850, ... Resampling results across tuning parameters: mtry Accuracy Kappa 2 0.9920029 0.9911994 17 0.9772760 0.9749927 32 0.9685406 0.9653798 48 0.9636917 0.9600440 Accuracy was used to select the optimal model using the largest value. The final value used for the model was mtry = 2.
# グラフの描画 plot(fit.rf)
正解率を確認できます
34

(サンプルコード) 3 of 4 #サポートベクタマシン # ワーキングディレクトリの指定 setwd( "作業ディレクトリを指定" ) # ライブラリの読み込み library( caret ) # データの読み込み data <- "Sensorless_drive_diagnosis.txt" drive <- read.table( data ) # モデル作成のために、トレーニング用データセットを生成する # 元データの10%をトレーニングデータとしてサンプリング抽出 set.seed( 100 ) smpl <- sample( nrow( drive ), 0.1 * nrow( drive )) train <- drive[smpl, ] #データセットを特徴量とラベルに分割する features <- train[1:48] labels <- train[49]
#ラベルをファクターに変換する labels <- as.factor( labels[[1]] ) # 評価関数の作成 eval.summary <- function(data, lev=NULL, model=NULL){ conf <- table(data$pred, data$obs) correctAns <- sum(diag(conf))/sum(conf) out <- c(Accurancy=correctAns) out } # モデルを作成する fit.svm <- train(labels~., data=features, method="svmRadial", trace=T, tuneGrid=expand.grid(.C=c(0.5, 1.0), .sigma=c(0.05, 0.1)), trControl=trainControl (summaryFunction=eval.summary, method="cv", number=10) )
35
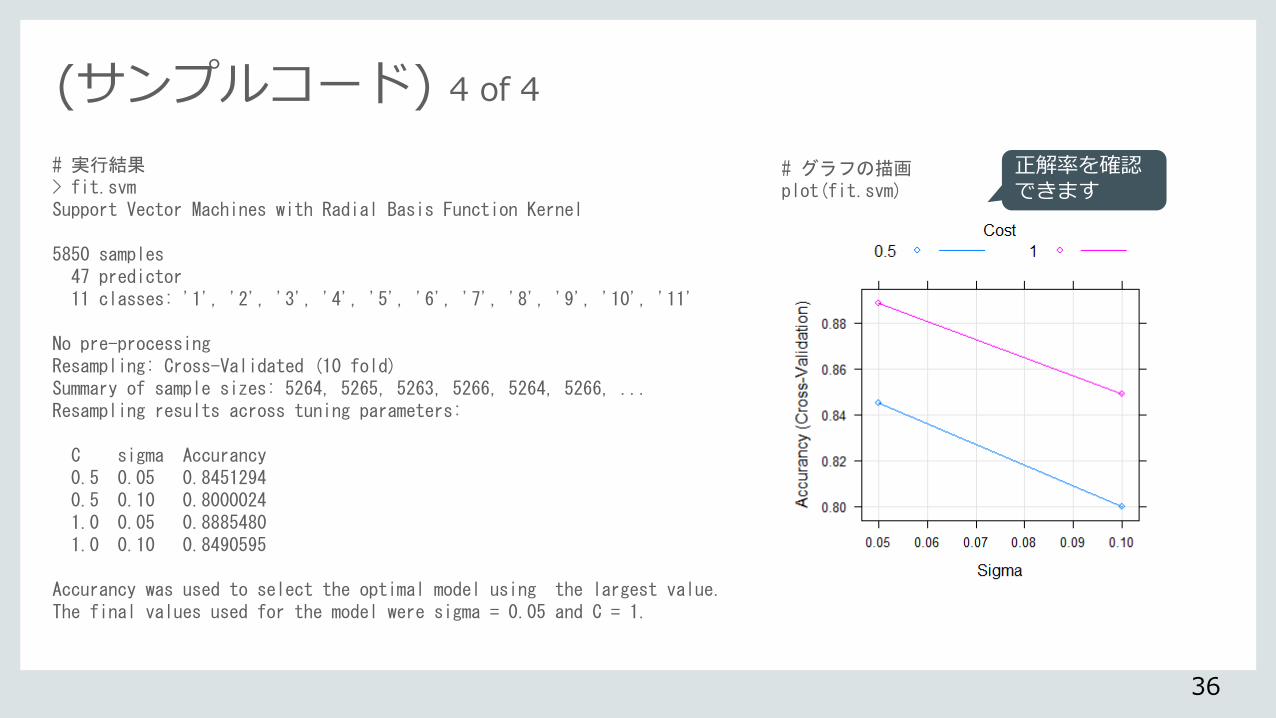
(サンプルコード) 4 of 4
# 実行結果 > fit.svm Support Vector Machines with Radial Basis Function Kernel 5850 samples 47 predictor 11 classes: '1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11' No pre-processing Resampling: Cross-Validated (10 fold) Summary of sample sizes: 5264, 5265, 5263, 5266, 5264, 5266, ... Resampling results across tuning parameters: C sigma Accurancy 0.5 0.05 0.8451294 0.5 0.10 0.8000024 1.0 0.05 0.8885480 1.0 0.10 0.8490595 Accurancy was used to select the optimal model using the largest value. The final values used for the model were sigma = 0.05 and C = 1.
# グラフの描画 plot(fit.svm)
正解率を確認できます
36
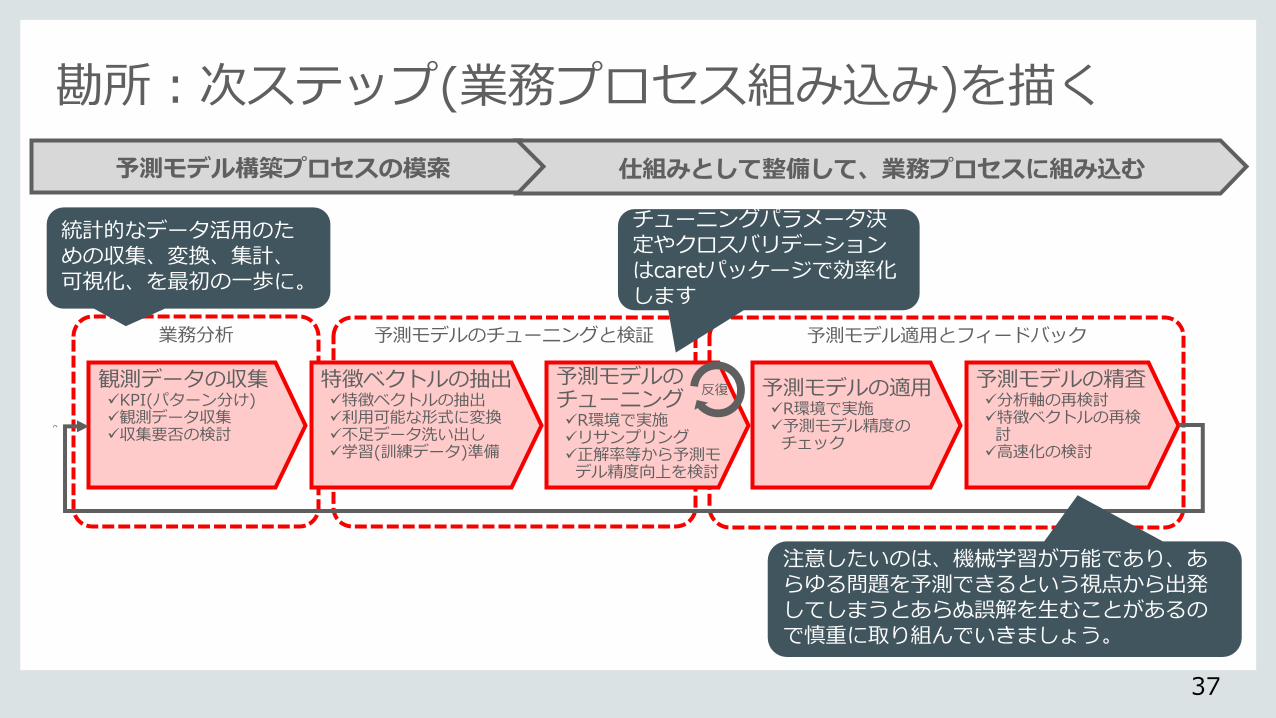
勘所:次ステップ(業務プロセス組み込み)を描く
予測モデル構築プロセスの模索 仕組みとして整備して、業務プロセスに組み込む
業務分析 予測モデルのチューニングと検証 予測モデル適用とフィードバック
観測データの収集 KPI(パターン分け) 観測データ収集 収集要否の検討
特徴ベクトルの抽出 特徴ベクトルの抽出 利用可能な形式に変換 不足データ洗い出し 学習(訓練データ)準備
予測モデルのチューニング R環境で実施 リサンプリング 正解率等から予測モデル精度向上を検討
予測モデルの適用 R環境で実施 予測モデル精度のチェック
予測モデルの精査 分析軸の再検討 特徴ベクトルの再検討 高速化の検討
反復
統計的なデータ活用のための収集、変換、集計、可視化、を最初の一歩に。
注意したいのは、機械学習が万能であり、あらゆる問題を予測できるという視点から出発してしまうとあらぬ誤解を生むことがあるので慎重に取り組んでいきましょう。
チューニングパラメータ決定やクロスバリデーションはcaretパッケージで効率化します
37

スキルアップに役立つ情報 そのスキルセットによって提供できる価値 スキルアップに役立つ情報 お伝えしたかったこと 新たなスキルセットとしての機械学習
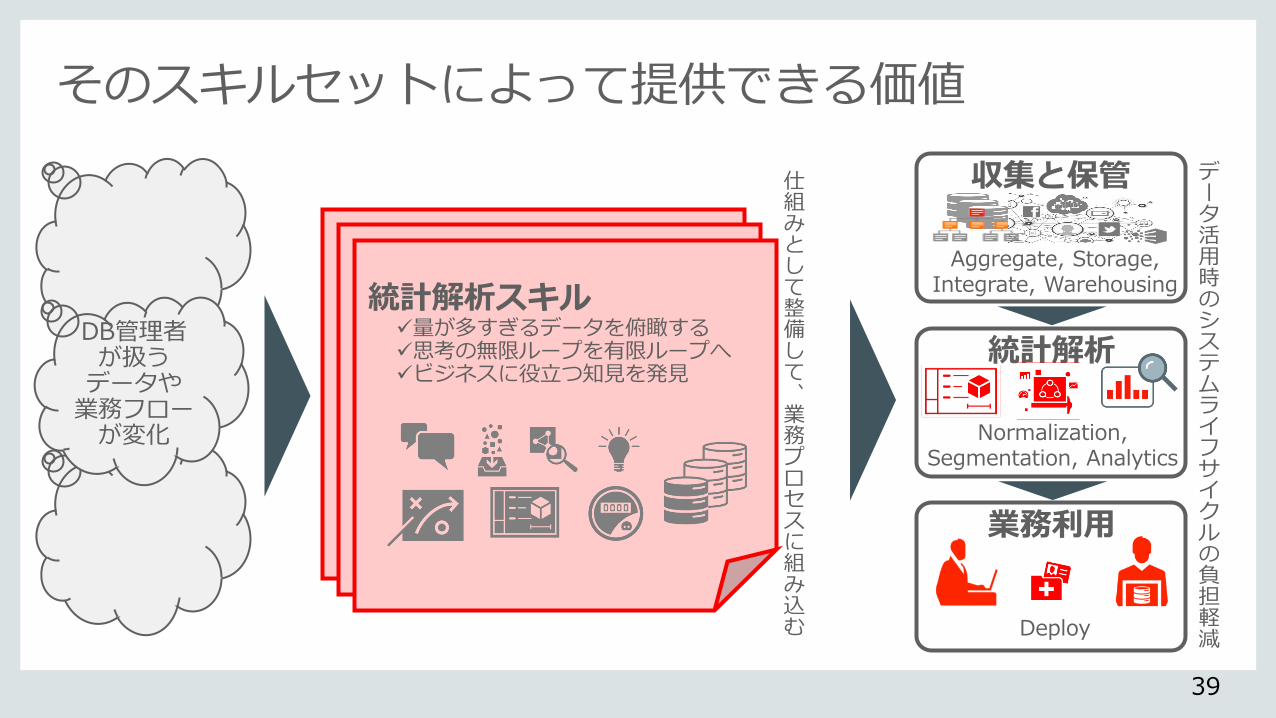
そのスキルセットによって提供できる価値
収集と保管
Aggregate, Storage, Integrate, Warehousing
業務利用
統計解析
Normalization, Segmentation, Analytics
Deploy
データ活用時のシステムライフサイクルの負担軽減
仕組みとして整備して、業務プロセスに組み込む
統計解析スキル 量が多すぎるデータを俯瞰する 思考の無限ループを有限ループへ ビジネスに役立つ知見を発見
DB管理者が扱う データや 業務フローが変化
39

スキルアップに役立つ情報 1 of 4
•統計解析の基本を、一般的な知識をWebから入手する
–社会人のためのデータサイエンス入門 • 第2弾が2016年4月19日に開講しています
• http://gacco.org/stat-japan/
–Kaggle R Tutorial on Machine Learning • Web上で、Rコンソールを使った演習ができます
• https://www.datacamp.com/courses/kaggle-tutorial-on-machine-learing-the-sinking-of-the-titanic
–初歩からの数学 • 微分、積分、三角関数など、数学の初歩を学べます
• http://ocw.ouj.ac.jp/tv/1234030/
40

スキルアップに役立つ情報 2 of 4
•試行錯誤するためのクリーンデータをWebから入手する
–国立情報学研究所 情報学研究データリポジトリ • yahoo!、楽天、リクルート、ニコニコデータセットなど
• http://www.nii.ac.jp/dsc/idr/
–政府統計の総合窓口 e-stat • 家計調査、国勢調査、経済センサス、人口動態など
• https://www.e-stat.go.jp/SG1/estat/eStatTopPortal.do
–カリフォルニア大学アーバイン校データセット • 本日のサンプルで使いました
• https://archive.ics.uci.edu/ml/datasets.html
41

スキルアップに役立つ情報 3 of 4
•コミュニティやニュースをチェックする
–コミュニティ • Japan.R
• Tokyo.R
–Data Science Central • http://www.datasciencecentral.com/
– inside-R • http://www.inside-r.org/
–R-bloggers • http://www.r-bloggers.com/
–東京で働くデータサイエンティストのブログ • http://tjo.hatenablog.com/
• Sapporo.R
• Tsukuba.R
• Kashiwa.R
• Nagoya.R
• Osaka.R
• Kobe.R
• Hiroshima.R
42

スキルアップに役立つ情報 4 of 4
•スキル定義を理解する –データサイエンティスト協会
• http://www.datascientist.or.jp/news/2014/pdf/1210.pdf
– THE DATA SCIENCE VENN DIAGRAM • http://drewconway.com/zia/2013/3/26/the-data-science-venn-diagram
– 5 Data Science Leaders Share their Predictions for 2016 and Beyond • http://www.datasciencecentral.com/profiles/blogs/7-data-science-leaders-share-
their-predictions-for-2016-and
–スキルを証明してみる • 統計検定の統計調査士や専門統計調査士
– http://www.toukei-kentei.jp/
• 統計力アセスメント(初心者向け) – http://www.stat.go.jp/ds
43

お伝えしたかったこと テクノロジストとしてのスキルセットの一つに、機械学習のスキルを追加することの優位性
ライフサイクル パフォーマンス
セキュリティ
アベイラビリティ
アクセシビリティ
開発リソース
グローバリゼーション
ロケーション
オペレーション
ユーザビリティ
44
keyValue、GraphDB、RDBMSなど、そうした大小のデータマネジメントプラットフォーム(狭義)が並存している時代、データ活用のシステムライフサイクルに費やされる費用と時間の浪費は避けたいと思いませんか? テクノロジストとしてのスキルセットの一つに、機械学習のスキルを追加することは、いまに時代に優位性のあることだと感じています。そういったスキルの積み重ねによって、広義の意味でのデータマネジメントプラットフォームとしての論点を理解して活用できる人になっていけば、すごい成長力を持つ事ができると考えています。
× Pig
Impala

データの活用度
データの多様さ
R C
C
C
C R R
②データ活用が可能に。
Analytics Data modeling
Structured Data (SoR)
Unstructured Data (SoE)
①データの範囲が広がり、 *SoR System of Record *SoE System of Engagement
45
• 私自身、機械学習について学んだのは、テクノロジストとして価値あるスキルセットを追加したかったからです
• スピーカの出発点は、大規模データの扱いや可用性を得意とするデータベースエンジニアで、統計的なデータ活用のための収集、変換、集計、可視化、などをやってくうちに徐々に統計解析の世界に足を踏み入れました
• 機械学習を使えることにより、新たなデータの価値を提供できることになり、結果としてお客様に感謝されるようになりました
新たなスキルセットとしての機械学習

ご清聴いただきまして誠にありがとうございました
46